EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Reading time: 2 minute
...
📝 Original Info
- Title: EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
- ArXiv ID: 2512.08868
- Date: 2025-12-09
- Authors: Rui Min, Zile Qiao, Ze Xu, Jiawen Zhai, Wenyu Gao, Xuanzhong Chen, Haozhen Sun, Zhen Zhang, Xinyu Wang, Hong Zhou, Wenbiao Yin, Bo Zhang, Xuan Zhou, Ming Yan, Yong Jiang, Haicheng Liu, Liang Ding, Ling Zou, Yi R. Fung, Yalong Li, Pengjun Xie
📝 Abstract
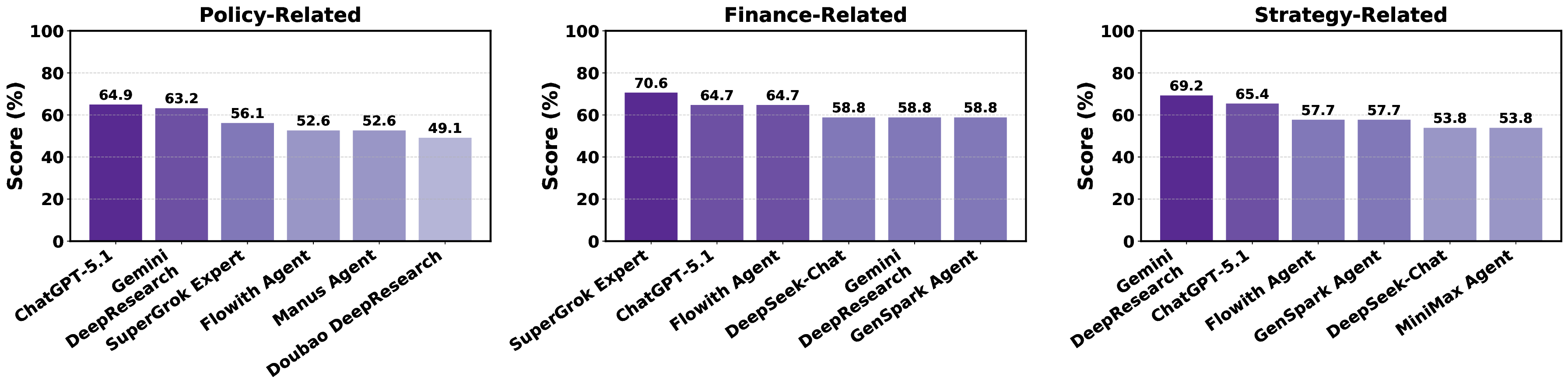
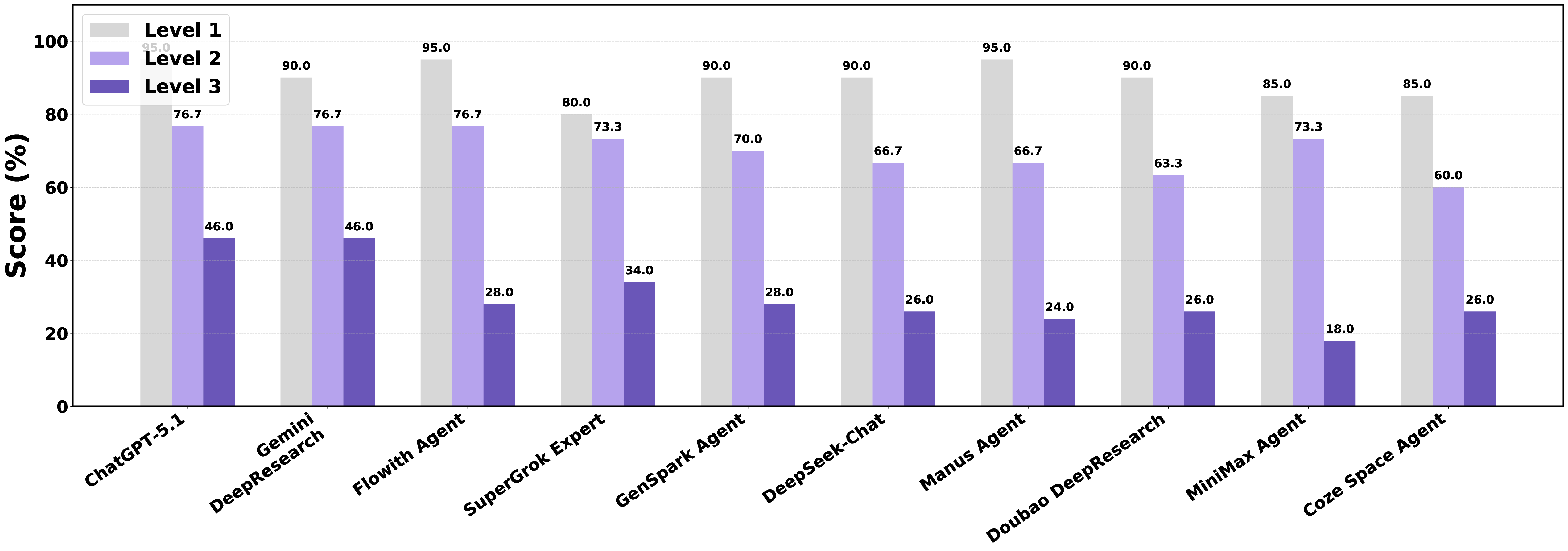
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic...📄 Full Content
📸 Image Gallery



Reference
This content is AI-processed based on open access ArXiv data.