Decoupling Template Bias in CLIP: Harnessing Empty Prompts for Enhanced Few-Shot Learning
Reading time: 2 minute
...
📝 Original Info
- Title: Decoupling Template Bias in CLIP: Harnessing Empty Prompts for Enhanced Few-Shot Learning
- ArXiv ID: 2512.08606
- Date: 2025-12-09
- Authors: Zhenyu Zhang, Guangyao Chen, Yixiong Zou, Zhimeng Huang, Yuhua Li
📝 Abstract
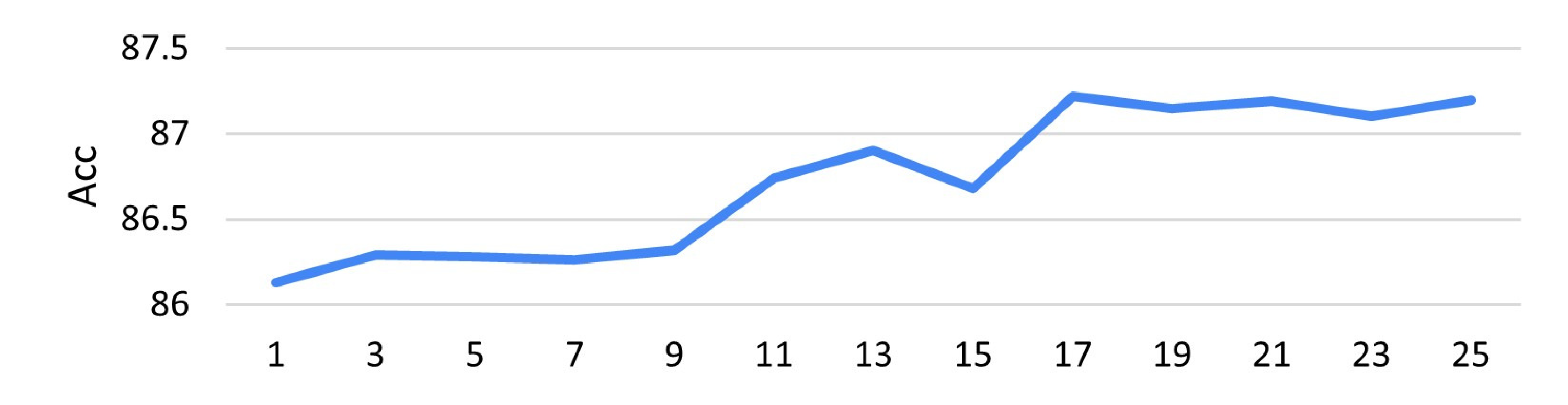
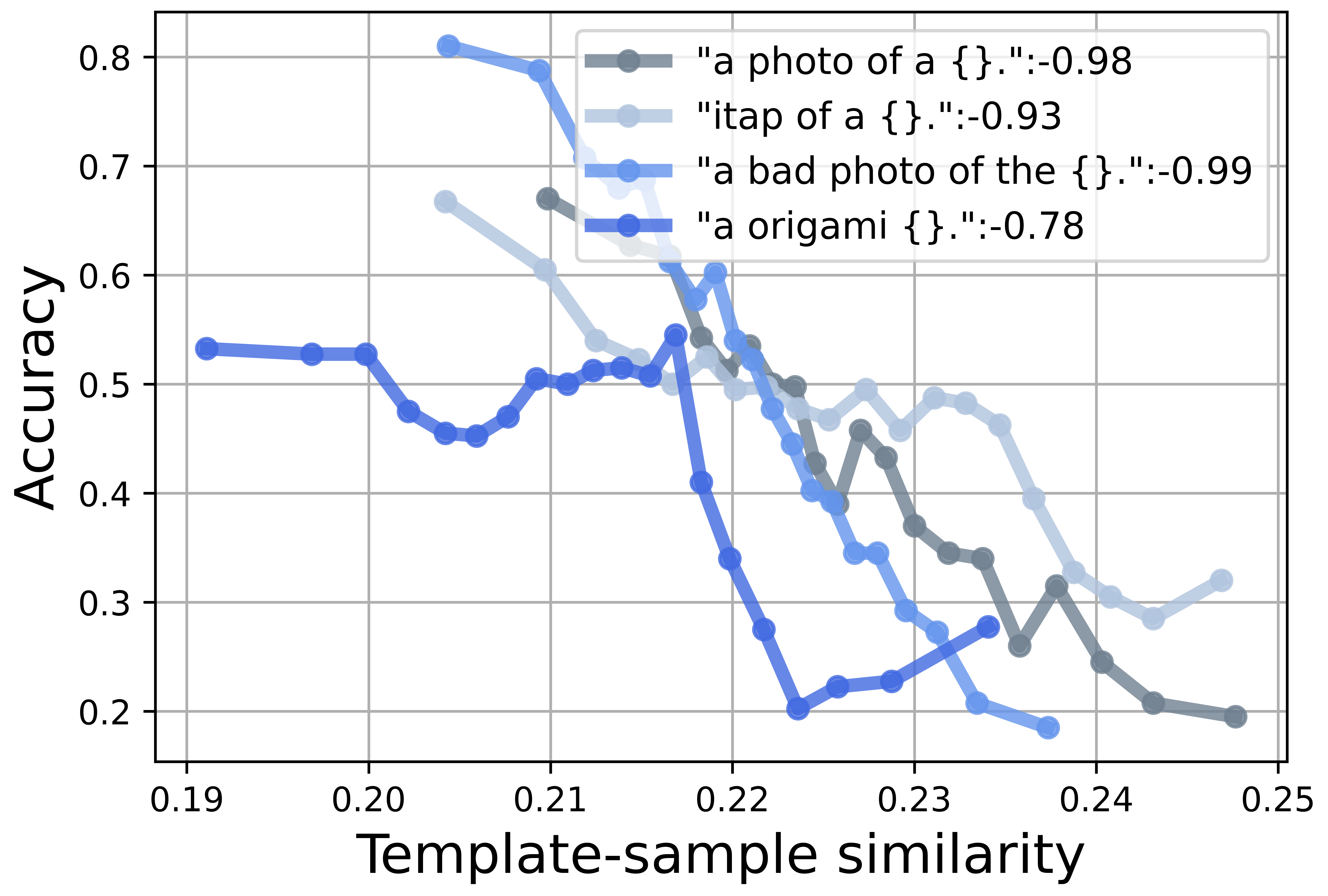
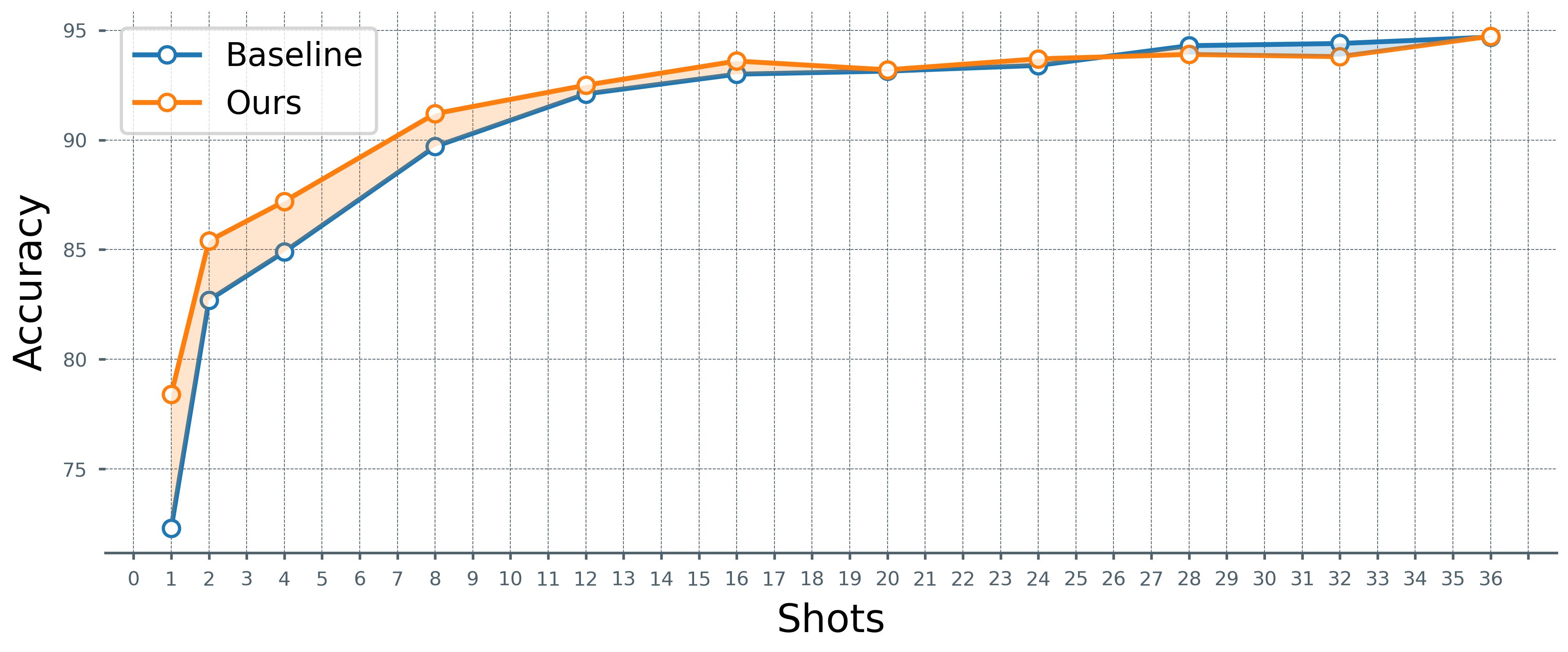
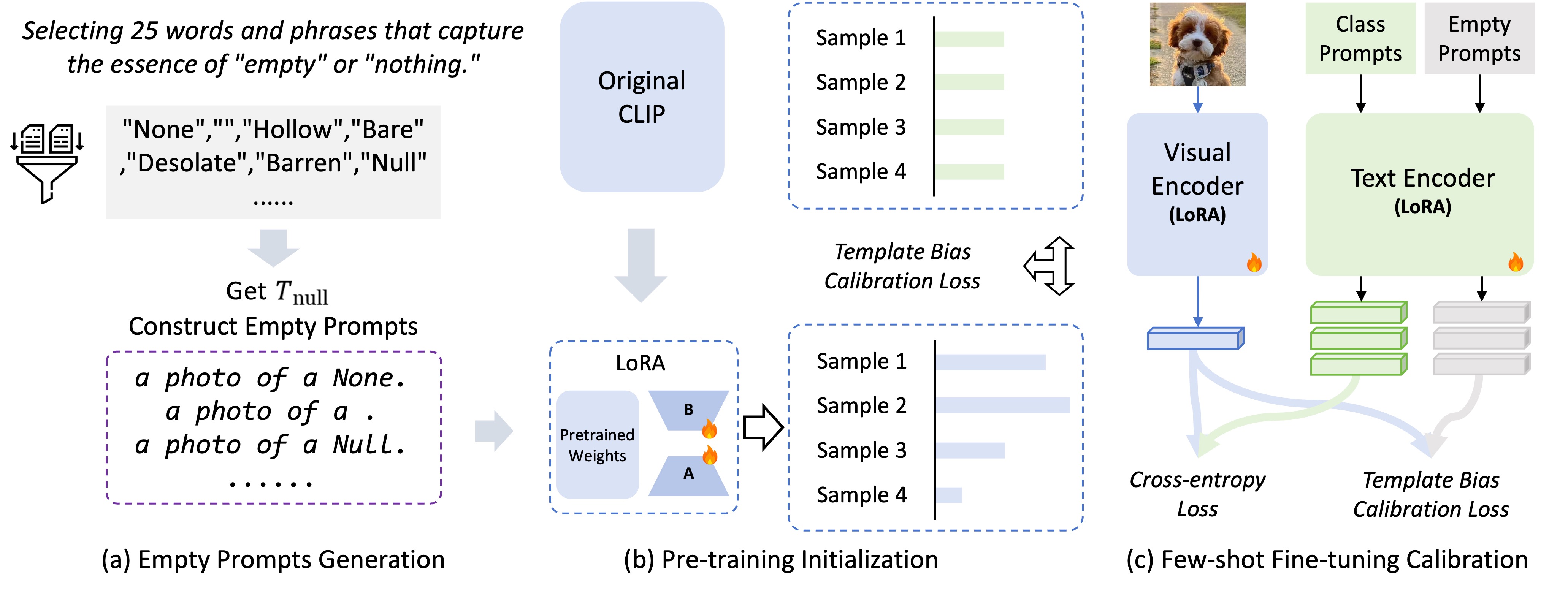
The Contrastive Language-Image Pre-Training (CLIP) model excels in few-shot learning by aligning visual and textual representations. Our study shows that template-sample similarity (TSS), defined as the resemblance between a text template and an image sample, introduces bias. This bias leads the model to rely on template proximity rather than true sample-to-category alignment, reducing both accuracy and robustness in classification. We present a framework that uses empty prompts, textual inputs that convey the idea of "emptiness" without category information. These prompts capture unbiased template features and offset TSS bias. The framework employs two stages. During pre-training, empty prompts reveal and reduce template-induced bias withi...📄 Full Content
📸 Image Gallery

Reference
This content is AI-processed based on open access ArXiv data.