A Comprehensive Study of Supervised Machine Learning Models for Zero-Day Attack Detection: Analyzing Performance on Imbalanced Data
📝 Original Info
- Title: A Comprehensive Study of Supervised Machine Learning Models for Zero-Day Attack Detection: Analyzing Performance on Imbalanced Data
- ArXiv ID: 2512.07030
- Date: 2025-12-07
- Authors: Zahra Lotfi, Mostafa Lotfi
📝 Abstract
Among the various types of cyberattacks, identifying zero-day attacks is problematic because they are unknown to security systems as their pattern and characteristics do not match known blacklisted attacks. There are many Machine Learning (ML) models designed to analyze and detect network attacks, especially using supervised models. However, these models are designed to classify samples (normal and attacks) based on the patterns they learn during the training phase, so they perform inefficiently on unseen attacks. This research addresses this issue by evaluating five different supervised models to assess their performance and execution time in predicting zero-day attacks and find out which model performs accurately and quickly. The goal is to improve the performance of these supervised models by not only proposing a framework that applies grid search, dimensionality reduction and oversampling methods to overcome the imbalance problem, but also comparing the effectiveness of oversampling on ml model metrics, in particular the accuracy. To emulate attack detection in real life, this research applies a highly imbalanced data set and only exposes the classifiers to zero-day attacks during the testing phase, so the models are not trained to flag the zero-day attacks. Our results show that Random Forest (RF) performs best under both oversampling and non-oversampling conditions, this increased effectiveness comes at the cost of longer processing times. Therefore, we selected XG Boost (XGB) as the top model due to its fast and highly accurate performance in detecting zero-day attacks.📄 Full Content
To address these limitations, ML approaches and classification algorithms in particular are increasingly being used to improve the accuracy of intrusion detection systems. Some of these are described in the literature review section. However, these models are vulnerable to identifying the minority class of actual cyberattacks in a significant amount of normal network data. This challenge, known as the class imbalance problem, presents a training obstacle for models, as they often struggle to correctly classify the rare attacks into the vast majority of legitimate traffic. Consequently, significantly imbalanced data sets pose a frequent challenge for machine learning methods due to the model’s ability to generalize to the minority class [5].
Taking into account the mentioned factors, we developed a framework to address the class imbalance problem and study the performance of multiple supervised models in detecting zero-day attacks. These models are evaluated on a comprehensive benchmark data set containing 2,218,761 normal and 321,283 attack data sets, which makes them highly unbalanced. The data set contains a variety of features extracted from packet flows. During the selection of the data set and classification models, we considered the following crucial factors as in [6]:
- Selecting appropriate and effective ML models, 2. Leveraging special and informative features, 3. And collecting a comprehensive set of representative samples to train the model.
The research has three primary aims: i) investigate the effectiveness of various lightweight binary classification techniques on a specific benchmark data set, particularly in identifying zero-day attacks; ii) evaluate the influence of oversampling in addressing the data set’s imbalance issue; iii) and assess the execution time of each model to determine the feasibility of creating a high-performance yet fast model. The rationale behind the last objective is the distinction between merely identifying attacks and doing so efficiently. An intrusion detection system loses its efficacy if it takes an extended time to process incoming data and detect attacks while it’s distributed across a network, or halts traffic until classification is complete. The paper is organized as follows: Section 2 reviews the existing literature related to the application of ML techniques for recognizing network attacks and URL phishing. Section 3 outlines the framework designed for the study, including its development and implementation. Section 4 presents the implementation outcomes. Section 5 delves into the research findings, and Section 6 concludes the paper.
Although there are a variety of network security approaches, users continue to be affected by network attacks. Over the last ten years, ML models have been widely applied in detecting network intrusions; some include zero-day detection techniques. Table 1 provides a summary of the latest articles (published between 2018 and 2023) analyzed in this study, indicating the ML methods and data sets used in these articles. The complete model names are provided below the table .
As can be seen, all studies used supervised classification models, most of them (11 out of 15 papers) used Neural Networks (NN) and deep learning in their models. In addition to a study [13] that used visual data in their model, other works also used URLs and PCAP files in their work, and some of them used NLP-based feature extraction methods to extract structured data extract [11,14,15]. The table also shows that 10 out of 15 works are examined for the detection of zero-day attacks.
Some studies [8,10] present the results of ML accuracy for different types of attacks in tabular form. In particular, some attack types have lower accuracy compared to others because of the lack of suitable samples. [8] presents a novel application of Zero-Shot Learning (ZSL) within Network Intrusion Detection Systems (NIDS) to address the challenge of detecting novel cyberattacks, particularly zero-day network intrusions. By leveraging ZSL, the authors propose a method for training ML models using known attack data. These models can then extract and learn characteristic features (semantic attributes) that define different attack behaviors. During testing, the models use these learned attributes to classify entirely new classes of attacks, including previously unknown zero-day attacks. This data set is used in our research to apply multiple classifiers (RF, DT, LR, MLP, and XGB) along with dimensionality reduction and oversampling techniques to examine their performance in identifying zero-day attacks. Our goal is also to determine whether optimizing the hyper-parameters of the given models leads to a higher performance score. Among the articles discussed, [12] addresses the class imbalance problem and explores the use of ML to build an intrusion detection system (IDS) that can identify known and zero-day cyberattacks. To address this issue and improve the effectiveness of the ML models, the article explores under/oversampling techniques as methods to balance the data set. This approach ensures that models are trained on a more representative distribution of network traffic patterns, ultimately leading to better detection of malicious activity.
In detecting phishing attacks, [14] introduces VisualPhishNet, a similarity-based phishing detection framework that applies a CNN model. Using a similarity metric, this framework detects phishing websites, especially on pages with a new look. The authors also created the largest visual phishing detection data set by searching active phishing pages on the PhishTank website and collecting screenshots from the pages, resulting in 10,250 examples. The evaluation metrics they considered when detecting phishing samples were the size, color, location, and website languages of the elements.
CNN is also used in other research to detect phishing websites solely by analyzing URLs [13]. The authors explain that unlike other studies that split URLs into different parts and analyze each part to identify phishing attacks, their model only needs to encode URLs as character-level one-hot vectors. The vector is then passed to the CNN and the model can detect phishing samples with almost 100% accuracy. It is also suitable for detecting zero-day attacks.
PhishDet is another neural network-based framework for detecting zero-day phishing attacks. Developed based on Graph Convolutional Neural Networks (GCNN) and LRCN, this model can detect malicious websites by analyzing their URLs and HTML codes with an accuracy of 96.42%. To maintain its high performance, PhishDet requires frequent retraining over time [11]. Using a CAE [14] provides character-level URL functional modeling to detect zero-day phishing attacks. They used three real-world phishing data sets containing 222,541 URLs to examine their model and considered Receiver-Operating Characteristic (ROC) as a metric to compare their results with the results of other models in the literature.
Regarding non-NN models, four articles were written to study classification techniques. [2] proposes an ML-based classification algorithm that uses heuristic features such as URL, source code, session, security type, protocol and website type to detect phishing websites. The algorithm is evaluated using five ML models. The RF algorithm is considered the most effective, achieving an attack detection accuracy of 91.4%. Furthermore, [16] propose a real-time anti-phishing system that uses seven different classification algorithms and NLP-based functions. The system differs from other literature studies in its language independence, use of a large data set, execution in real time, detection of new websites and use of feature-rich classifiers. The experimental results show that the RF algorithm with only NLP-based features achieved the best performance in detecting phishing URLs.
One of the studies in which non-NN models have been applied is conducted with the main goal of creating a balanced benchmark data set containing an equal number of harmless and malicious URLs [6]. The collected URLs are processed and 87 features are extracted from URLs, web page content and external resources retrieved through third-party queries (such as Alexa and WHOIS). The authors then applied five different classification methods (RF, DT, LR, NB, and SVM) to see their performance on the created data set. However, they did not consider the issue of zero-day attacks in their work.
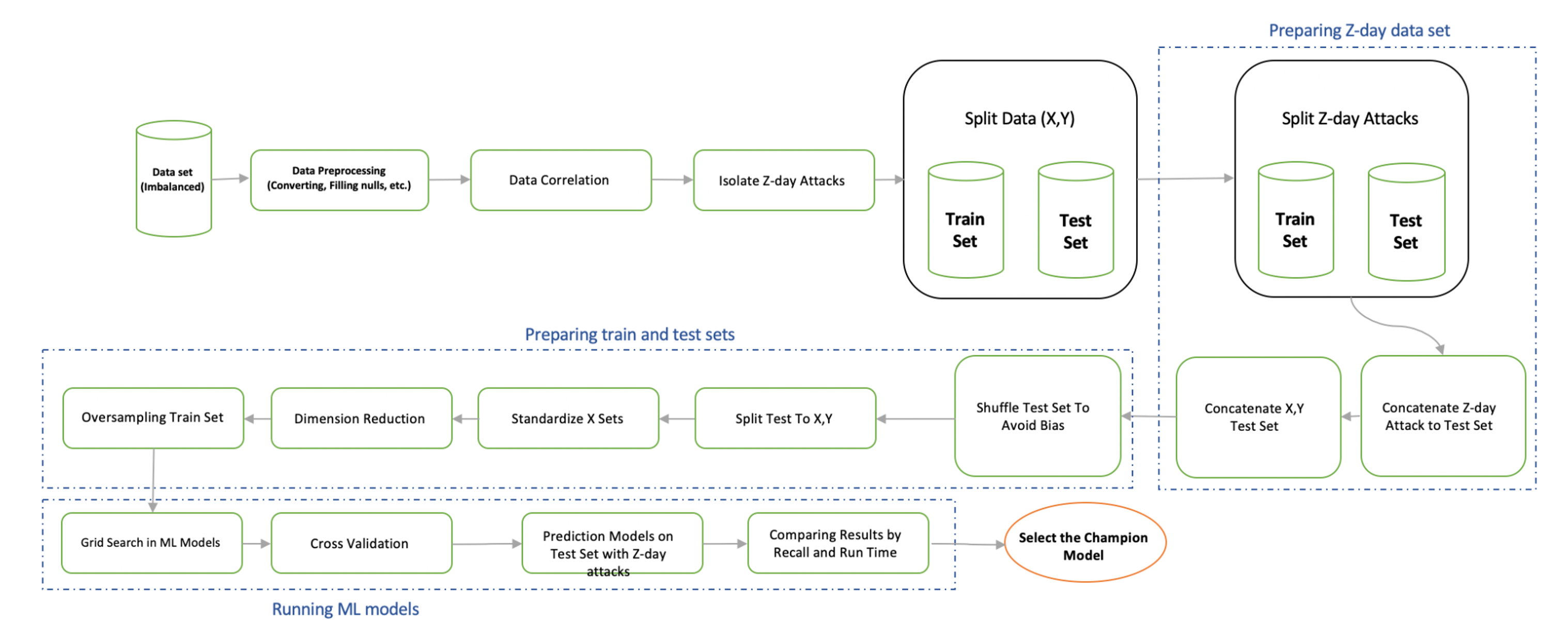
This section describes the zero-day attack detection framework with details of the data set and the ML models used in this work. The proposed framework aims to study the performance of several supervised algorithms on a popular Netflow data set to evaluate the models’ performance in detecting zero-day attacks. Two main differences characterize this framework: i) the application of a significantly imbalanced data set and ii) the implementation of zero-day attacks in a way that remains unknown to the classification models in order to emulate the real situation. As shown in Figure 1, most of the tasks performed in this framework are related to data preprocessing and feature engineering because the implementation of zero-day attacks is important. This type of attack should be isolated from ML models in the training phase and then presented in the testing phase. It is therefore important to implement the model in such a way that it reflects the real situation. To do this, we first split the data set into training and test sets (by 70% to 30%) and then added a zero-day attack set to the test set. The “shuffling” step plays a key role in randomizing the test data set. Otherwise, if the zero-day data set was appended to the test set, the data set would be biased, allowing models to falsely detect the attacks with significantly higher performance, as shown in Table 2. Before delving into the details of the framework, the next section describes the selected data set and the process of preparing the train and test sets.
, a popular open source data set for evaluating NIDS, is used. With 49 fields and 2,540,044 records, including 2,218,761 benign and 321,283 attack records, this data set is accessible on Kaggle. The total number of attacks for each type is shown in Table 3. Two fields are used to label attacks: “Label” indicates whether the example is a normal (0) or an attack (1), and “attack-cat” indicates the type of attack. From the percentage of Total Attacks, it is obvious that the data set is highly imbalanced and causes the class imbalance problem in classification models. It can also be seen that the frequency of attacks varies and some are significantly smaller than others.
To prepare the data set for zero-day attacks, based on the approach proposed in [12], a group of attacks is selected, isolated from the training data set, and then inserted into the test set including newly collected and unseen samples, the number of which is smaller compared to known attacks. The selected group consists of four least common attack types, worms, shellcode, backdoor, and analysis. Therefore, the framework is designed to predict invisible zero-day attacks among other trained attacks by using the binary field “Label” that specifies normal and attack examples.
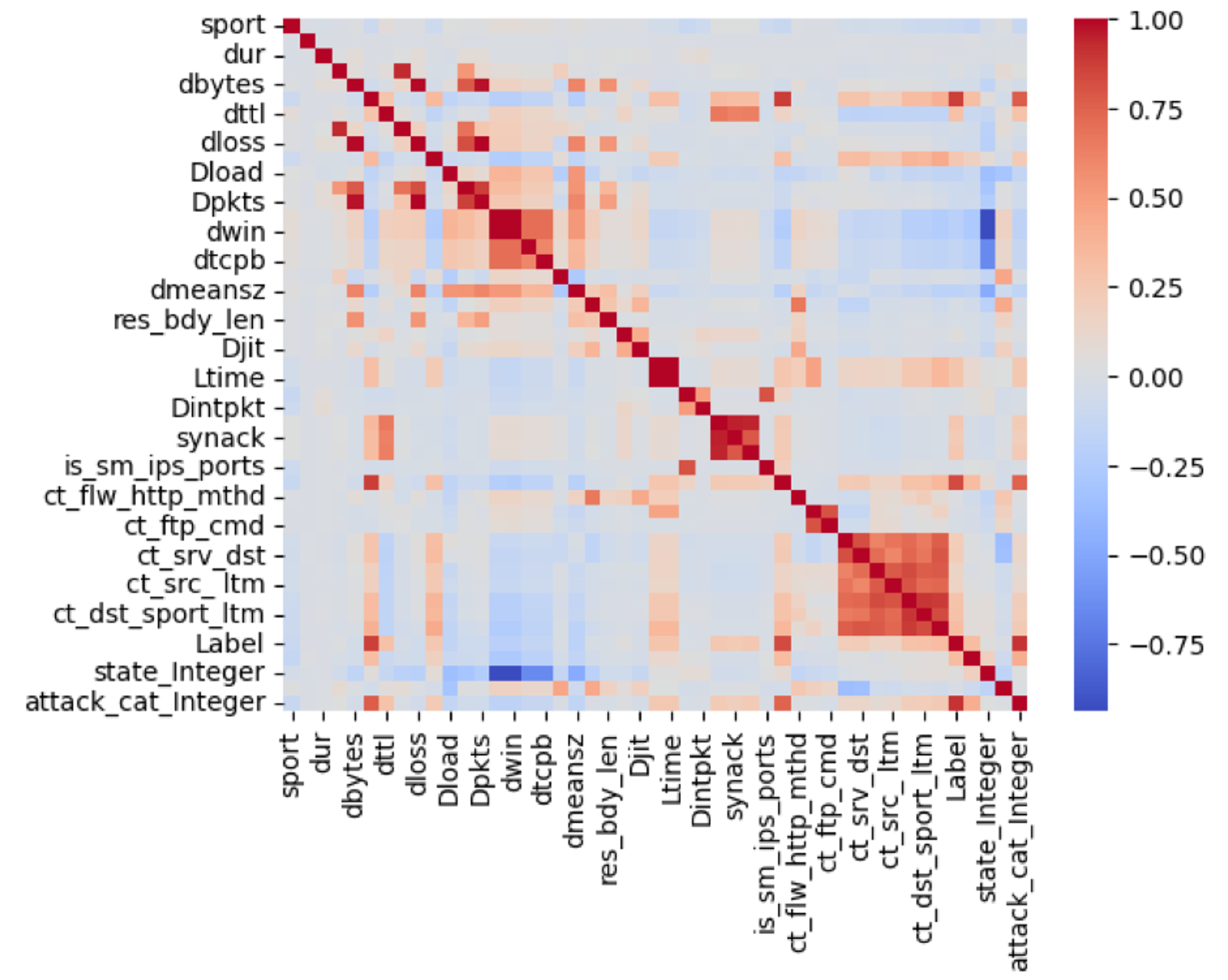
UNSW-NB15 is a relatively clean data set, but some types of cleansing and preprocessing were required to prepare the data for training and prediction. For the attack-cat field, non-attack records (with label = 0) were null and replaced with Normal. Most fields were numeric, but there were some object-like fields that converted to numeric values. The attack-cat field also required minor changes to standardize all category names. After managing the data type of the features, the null values, and the mismatched category labels, the next step was to examine the correlation between the features using a heat map chart (Figure 2). The features were then sorted according to their correlation with the target fields (label). This step resulted in the removal of the less relevant and less efficient features from the data set.
The final step of preprocessing is to apply dimensionality reduction methods to the selected data set to make it suitable for ML models. To do this, all values of the original data set (X set) converted into numbers should be normalized and transformed on a similar scale and made comparable using the dimension reduction process. In addition, standardization leads to improvement in the performance of ML algorithms.
There are various methods to reduce the dimension of a data set. One of the most popular is Principal Component Analysis (PCA). PCA analyzes complex data sets with multiple variables to extract important information while minimizing the loss of relevant data by reducing dimensionality and retaining the maximum possible variation [17]. The reason why PCA was chosen for this research is that PCA is not sensitive to noise, requires less memory and computational units, and is sufficiently efficient when working on data sets that are not very high dimensional [18]. . Due to the large size of our data set and the lack of hardware capacity, PCA was the best choice to reduce the size of the data set.
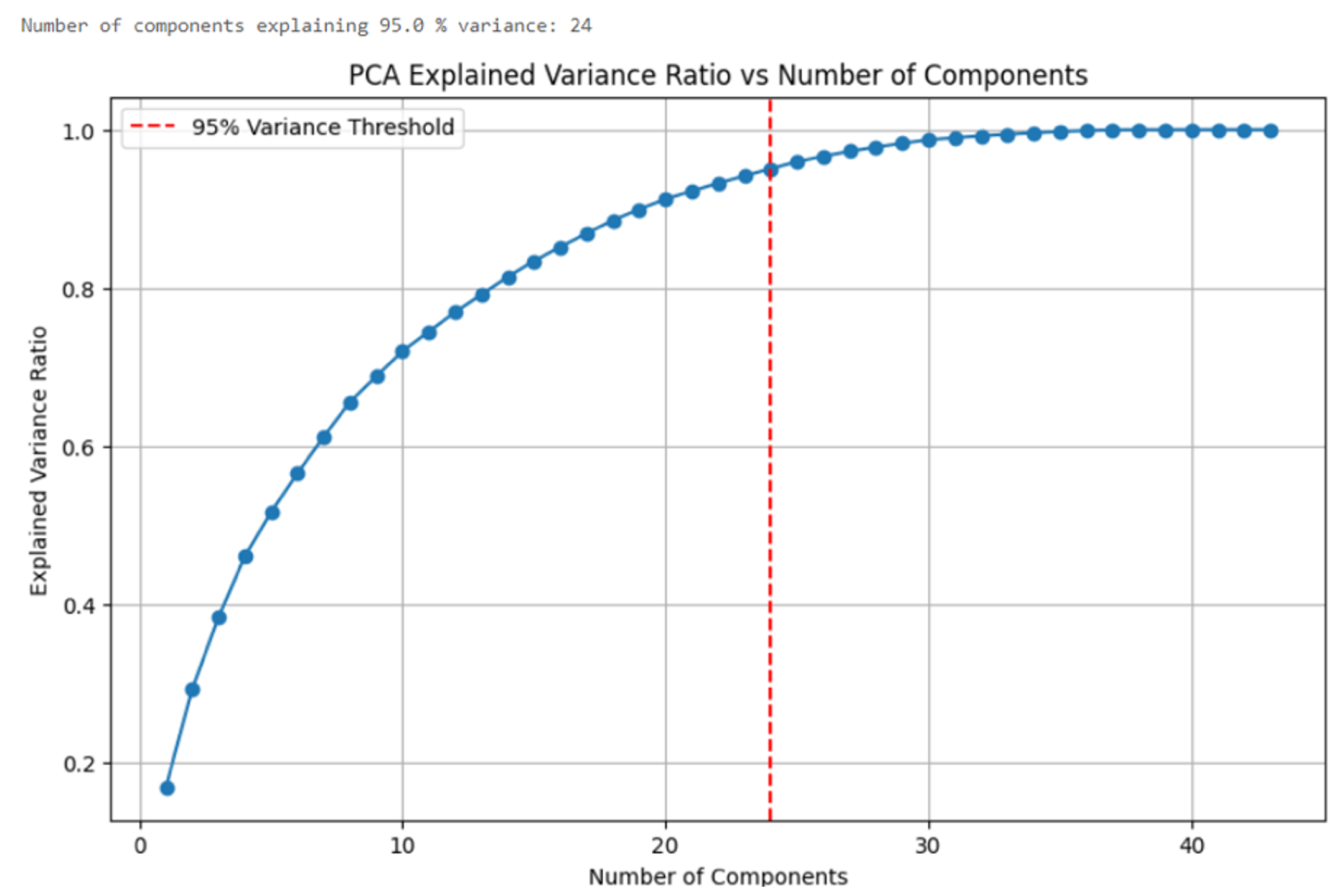
Applying PCA to the data set and then examining the output of the classification models shows how relevant and important the removed features are for prediction. To find the best number of components to use in PCA, we gave PCA a range of (1, data set.Shape + 1) and graphed the results to find the number of components that result in a variance threshold of more than 95%. The results show that 24 components should be selected for the X set (Figure 3). As mentioned previously, the UNSW-NB15 data set is highly imbalanced, which means that it includes minority classes with significantly fewer samples compared to the majority class. This problem causes the classification models to be inefficient at detecting attacks, despite having considerably high accuracy (Table 5).
To address this issue, resampling techniques should be applied to balance the proportion of anomalies compared to normal samples in the training set. In this research, the Synthetic Minority Over-sampling Technique (SMOTE) addresses the imbalance problem by creating new data points in a similar path to existing ones. This is done by interpolating between existing data points for minority classes, resulting in a more balanced representation of the training data. This allows the model to learn the characteristics of the minority class more effectively and potentially improve classification performance for this underrepresented group [19]. The following lines show the number of attacks (1s) added to the training set after performing the SMOTE oversampling technique:
Each classification model used in our framework has several hyper-parameters (or Hparams for short) that affect the process and time of learning in the training phase. To achieve optimal performance in the classification models, Hparams should be tuned with the most likely values. Various methods can be used to optimize Hparams, including grid search.
Grid search is one of the simplest search algorithms and provides extremely accurate predictions if sufficient resources are available. This approach allows users to consistently identify the optimal parameter combinations [20]. In contrast to Bayesian optimization and Bayesian search, grid search can be carried out in parallel relatively easily because each trial runs independently and is not influenced by timing. This flexibility in resource allocation makes grid search particularly beneficial for distributed systems.
A comparative analysis by [21] highlights the superior performance of grid search over random search, regardless of whether oversampling and normalization techniques are applied. Still, grid search is not without its challenges. It is significantly affected by the curse of dimensionality, which leads to an exponential increase in resource consumption as the number of Hparams to be optimized grows [20]. To address this issue, we used principal component analysis (PCA), a well-established dimensionality reduction method.
Grid search is a method for generating different model configurations by analyzing a range of values for each Hparam of interest. The approach involves training and testing models across all combinations of values for all Hparams. Although the technique is easy to use, it can be expensive due to the large number of Hparams and levels of each one and as a result, the computational cost increases exponentially [22]. To use grid search, the Hparams are given a range of values as shown in Figure 4.
Based on the results obtained from Grid Search, the classification models are set with the resulting values, shown Below:
The next step after training the model using the cross-validation technique is to examine them against the test set, including the zero-day attack set that the models are not exposed to. To evaluate the proposed framework, various metrics are considered, including recall, which quantifies the proportion of true positive cases correctly identified by a model [27]; Precision, which reflects the model’s ability to accurately identify true positives [28]; F1 score, which eliminates the limitations of relying solely on precision or recall by providing a harmonious mean between the two [27]; False Positive Rate (FPR), i.e. the proportion of negative cases that were incorrectly classified as positive by the model [28]; AUC ROC, which quantifies the performance of a classification model at different classification thresholds. It reflects the model’s ability to distinguish between positive and negative cases [28]; And accuracy, which represents the overall proportion of correctly classified instances within the data set [27].
Unlike other studies that do not consider the time it takes for models to classify the test set, we considered the running time as an evaluation metric, not for the model’s prediction performance, but as a measure of whether the model is a suitable candidate in intrusion Detection systems can be used without the detection of attacks taking a lot of time. It is worth noting that to identify anomalies (in our research attacks), Recall, Precision and F1-Score are mostly used instead of Accuracy. This is because the accuracy is usually high even if the model cannot accurately classify attacks due to the high number of normal cases, while other metrics mentioned show the performance of the models based on the number of attacks correctly labeled.
In our framework, the number of zero-day attacks in the test set is significantly lower than other attacks and normal samples (only 0.63%). Therefore, the performance of the models is expected to decrease dramatically. Hence, it is important to apply methods to improve prediction performance. Thus, in addition to techniques such as standardization, dimensionality reduction, and cross-validation, we equipped the framework with the oversampling method (SMOTE) to balance the train set. To determine how oversampling affects prediction performance, we applied two parallel approaches when running the classification models: one without oversampling and one with oversampling. Table 7 shows how the classification models affect the sentence before the SMOTE method is applied. As shown in the table, running time is also added to the evaluation metrics.
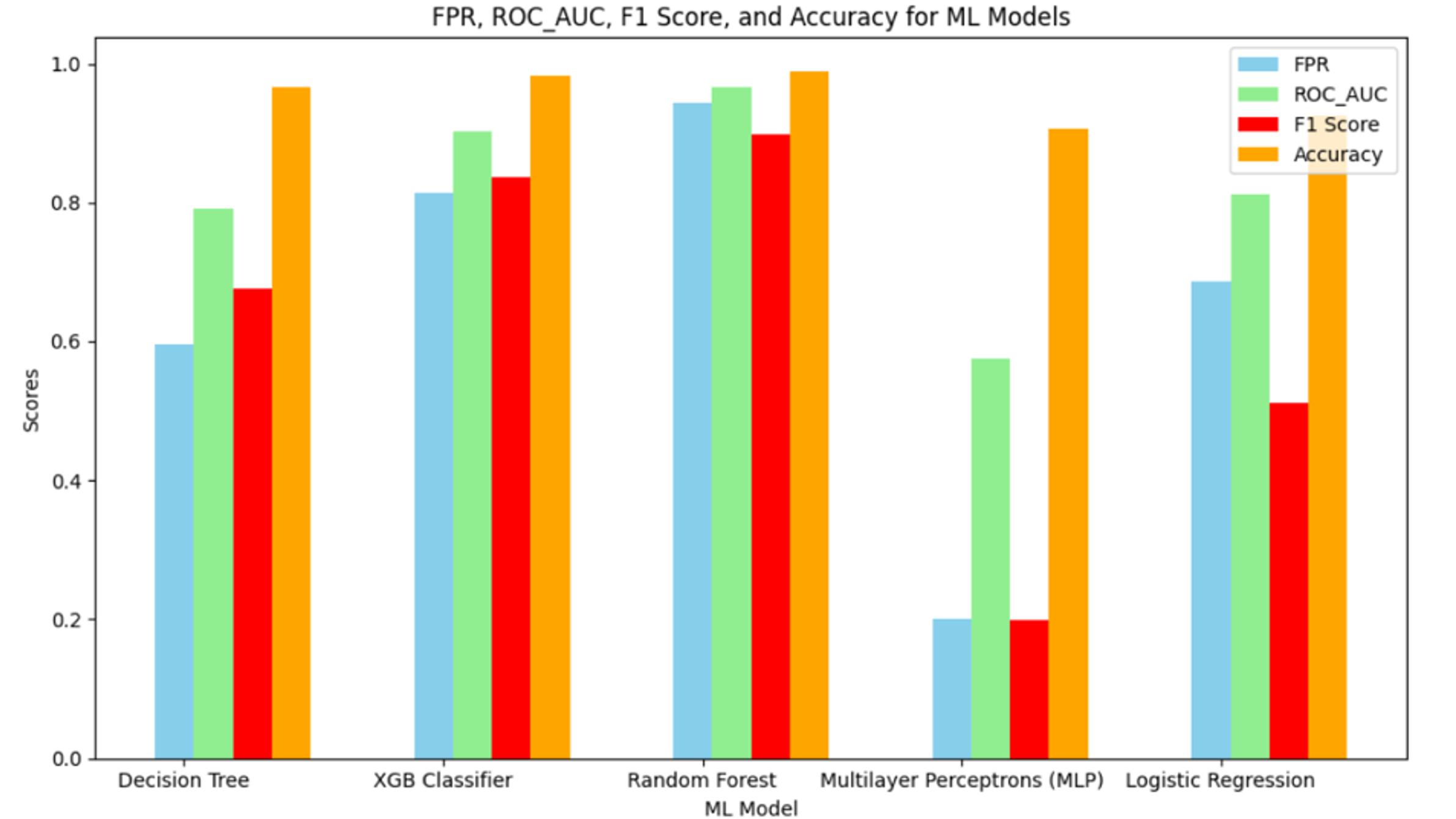
Table 8 shows the performance of models in a parallel approach after performing oversampling. This table also contains the runtime. Comparison of the results in Tables 7 and8 leads to valuable conclusions. RF shows the best performance under both conditions with a recall of 83.1% on an unbalanced data set and 94.3% for a data set balanced using an oversampling method. However, the second and third places differ for balanced and unbalanced data sets. According to RF, DT performs better than other models in an unbalanced set (recall = 65.6%), while XGB shows a good performance of (81.3%) in a balanced set. Furthermore, MLP performs poorly under both conditions, with recall below 30%, while its running time is second only to RF, showing that this model is very slow and inefficient in detecting attacks.
Overall, it is evident that oversampling (SMOTE) significantly increases the performance of the models, especially for RF and XGB, which are ensemble algorithms. However, the important point that should not be overlooked is the incredibly long run time of RF. It took 15 to 25 minutes to run RF on the test device, which is significant for use in cybersecurity systems. Systems of this type are designed to detect attacks in near real time. Therefore, it makes no sense to equip them with slow classifiers. XGB, on the other hand, required the shortest execution time in the test set (less than 10 seconds) with relatively high recall and precision. This shows that XGB can be chosen as the top model due to its extremely fast and precise performance.
To create the data set, the tcpdump tool is used to capture 100GB of network packets, which are stored in 4 different CSV files to facilitate downloading and working with data. Since the entire data set is very large and requires huge computing and storage resources, half of it is selected for this research, which contains 1,400,002 data sets, including 1,325,038 benign and 75,063 attack examples. Table4shows the total number of attacks per type in the selected data set.
To create the data set, the tcpdump tool is used to capture 100GB of network packets, which are stored in 4 different CSV files to facilitate downloading and working with data. Since the entire data set is very large and requires huge computing and storage resources, half of it is selected for this research, which contains 1,400,002 data sets, including 1,325,038 benign and 75,063 attack examples. Table4
To create the data set, the tcpdump tool is used to capture 100GB of network packets, which are stored in 4 different CSV files to facilitate downloading and working with data. Since the entire data set is very large and requires huge computing and storage resources, half of it is selected for this research, which contains 1,400,002 data sets, including 1,325,038 benign and 75,063 attack examples. Table
📸 Image Gallery