ProAgent: Harnessing On-Demand Sensory Contexts for Proactive LLM Agent Systems
📝 Original Info
- Title: ProAgent: Harnessing On-Demand Sensory Contexts for Proactive LLM Agent Systems
- ArXiv ID: 2512.06721
- Date: 2025-12-07
- Authors: Bufang Yang, Lilin Xu, Liekang Zeng, Yunqi Guo, Siyang Jiang, Wenrui Lu, Kaiwei Liu, Hancheng Xiang, Xiaofan Jiang, Guoliang Xing, Zhenyu Yan
📝 Abstract
Large Language Model (LLM) agents are emerging to transform daily life. However, existing LLM agents primarily follow a reactive paradigm, relying on explicit user instructions to initiate services, which increases both physical and cognitive workload. In this paper, we propose ProAgent, the first end-to-end proactive agent system that harnesses massive sensory contexts and LLM reasoning to deliver proactive assistance. ProAgent first employs a proactive-oriented context extraction approach with on-demand tiered perception to continuously sense the environment and derive hierarchical contexts that incorporate both sensory and persona cues. ProAgent then adopts a context-aware proactive reasoner to map these contexts to user needs and tool calls, providing proactive assistance. We implement ProAgent on Augmented Reality (AR) glasses with an edge server and extensively evaluate it on a real-world testbed, a public dataset, and through a user study. Results show that ProAgent achieves up to 33.4% higher proactive prediction accuracy, 16.8% higher tool-calling F1 score, and notable improvements in user satisfaction over state-of-the-art baselines, marking a significant step toward proactive assistants. A video demonstration of ProAgent is available at https://youtu.be/pRXZuzvrcVs.📄 Full Content
Most existing LLM agent systems follow a reactive paradigm, relying on explicit user instructions to initiate their services [23,45,49,61]. Users must manually invoke the agent, typically by taking out the smartphone and issuing instructions, which requires excessive and repetitive human effort. This reactive nature of existing agents not only increases physical workload, but also elevates cognitive burden, † Equal Contribution. ‡ Corresponding author.
I want to buy the headphones. Can you find a cheaper price and some reviews?
Sure, I’ll help search online for prices and reviews…
As I talked with my friend, we want to plan a trip this weekend.
Can you suggest a good option?
Sure, to plan a trip, I’ll help check the weather and your agenda… as users risk missing timely information during live interactions or attention-intensive tasks. In contrast, proactive agents are designed to autonomously perceive environments, anticipate user needs, and deliver timely assistance, thereby reducing both physical and cognitive workload [36]. Shifting from reactive agents, which remain largely passive, to proactive agent systems with the autonomy to perceive, reason, and unobtrusively assist holds great potential.
Although earlier personal assistants with notification features exhibit basic proactivity, they are confined to rulebased workflows without agent reasoning, e.g., fall or abnormal heart rate alerts [5,25]. While recent work explores proactive LLM agents [36], it remains limited to perceiving enclosed desktop environments, offering assistance in computer-use scenarios such as coding. Some agents (e.g., Google’s Magic Cue [1]) can provide pre-defined assistance using text in specific Apps and functions. In contrast, humans are continuously immersed in massive “contexts” that can be sensed through wearable and mobile devices. Harnessing these contexts to enhance the proactivity of LLM agents holds great potential. Moreover, this seamless, handsfree perception closely aligns with the objective of proactive assistants: reducing both human physical and cognitive workloads. Though recent works [52,56] explore proactive agents with sensor data, they only focus on limited scenarios and ignore the system overhead in real-world deployments.
To bridge this research gap, we propose a proactive agent system that harnesses the rich contexts surrounding humans [49] Reactive ✔ ✔ ✘ ✘ AutoIoT [45] Reactive ✔ ✔ ✘ ✘ SocialMind [52] Proactive ✔ ✘ ✔ ✘ Proactive Agent [36] Proactive ✔ ✘ ✘ ✘ ContextLLM [41] N.A.
to proactively deliver unobtrusive assistance. As shown in Fig. 1, unlike reactive LLM agents, which only initiate tasks upon receiving explicit user instructions [33,45,49], proactive LLM agents must continuously perceive their environment to anticipate user intentions and provide unobtrusive assistance. We summarize the unique challenges as follows.
First, delivering timely and content-appropriate proactive assistance requires deriving intention-related cues from massive sensor data. However, while recent work has explored LLMs and visual LLMs (VLMs) [31] to interpret sensor readings for general purposes [17,50,59], extracting proactiveoriented cues from massive, multi-dimensional, and heterogeneous sensor data remains challenging. Second, unlike existing LLM agents that follow a reactive paradigm based on explicit text instructions [33,49], a context-aware proactive agent must map sensor contexts to user intentions, including the timing of proactive actions and required tool calls, posing challenges for LLM reasoning, especially for models running on edge platforms. Third, to avoid missing service opportunities, proactive agents must continuously sense in-situ contexts surrounding humans and perform ongoing LLM reasoning, creating significant system overhead, especially on resource-constrained mobile devices.
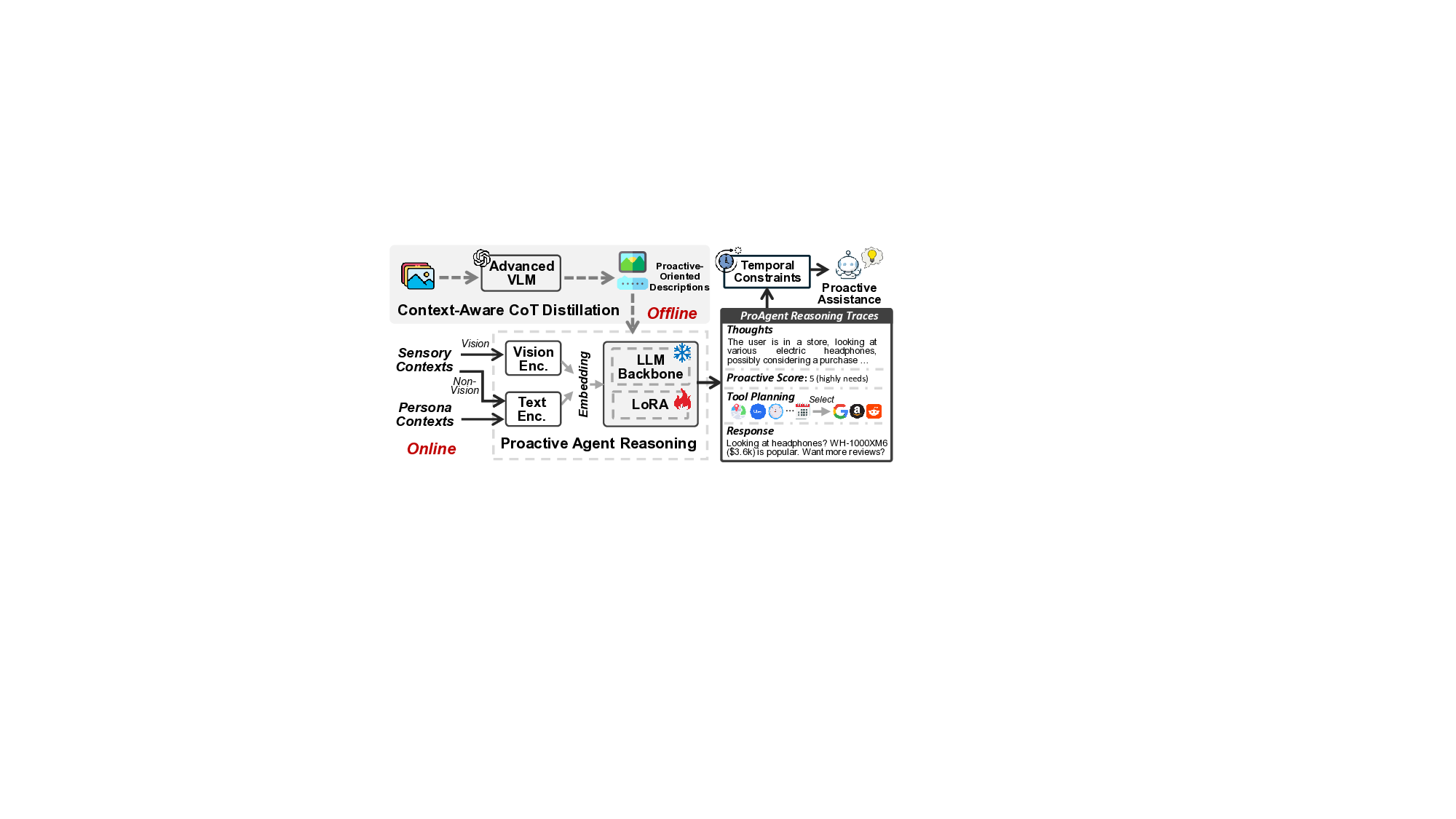
In this study, we introduce ProAgent, the first end-toend proactive agent system that integrates multisensory perception and LLM reasoning to deliver proactive assistance. ProAgent first adopts an on-demand tiered perception strategy that coordinates always-on, low-cost sensors with on-demand, higher-cost sensors to continuously capture proactive-relevant cues. ProAgent then employs a proactiveoriented context extraction approach to derive hierarchical contexts from the massive sensor data, incorporating both sensory and persona cues. Finally, it adopts a context-aware proactive reasoner using VLMs, mapping hierarchical contexts to user needs, including the timing and content of assistance, and the calling of external tools. To further reduce user disturbance, ProAgent also employs a temporal constraint strategy to avoid redundant proactive assistance.
We implement ProAgent on a testbed with AR glasses, a smartphone, and two edge servers (NVIDIA Jetson Orin and a personal laptop), and comprehensively evaluate it on both a real-world testbed and a public dataset. We deploy ProAgent on six VLMs of varying sizes (2/3/7/8/13/32 billion parameters). Experimental results illustrate that ProAgent achieves up to 33.4% higher accuracy in proactive prediction, 16.8% higher F1 score in tool calling, and 1.79x lower memory usage over state-of-the-art baselines. The user study demonstrates that ProAgent improves average satisfaction across five dimensions of proactive services by 38.9%. We summarize the contributions of this work as follows.
• We introduce ProAgent, the first end-to-end proactive agent system that considers proactive assistance in multisensory perception and LLM reasoning. • We develop a proactive-oriented context extraction approach with an on-demand tiered perception mechanism that continuously senses the environment on demand and derives proactive-relevant cues from massive sensor data. • We develop a context-aware proactive reasoner that maps hierarchical contexts to predictions of user needs and tool calling, delivering proactive and unobtrusive assistance under temporal constraints to avoid overload. • We implement ProAgent on AR glasses with an edge server and evaluate it on a real-world testbed, a public dataset, and through a user study, validating its effectiveness in delivering timely and unobtrusive proactive assistance.
LLM Agents for Mobile Systems. Recent studies have explored leveraging LLMs for task automation in mobile systems, including autonomous mobile UI operations [24,49,61], embedded programming [14,45,57], and sensor system coordination [11,15,33]. Several studies employ screenshots and multimodal LLMs (MLLMs) for UI understanding, enabling autonomous operations such as navigating and using various apps based on the user’s explicit instructions [47,61].
Studies also employ LLM agents to interpret user queries and control smart-home sensors [23,33]. However, these systems function as reactive LLM agents, relying on explicit user instructions and lacking the ability to proactively utilize sensory contexts to autonomously initiate assistance. Proactive Agents. Recent studies have explored proactive LLM systems [36,52,56]. Proactive Agent [36] and Social-Mind [52] offer users proactive assistance during computer usage and social communication, respectively. Other studies explore predicting teammates’ actions in multi-agent systems [60] and designing re-asking mechanisms to reduce ambiguity [62]. Previous personal assistants with notification features exhibit proactivity [5,25], such as health alerts [5], while these rule-based systems follow fixed and predefined workflows and specific sensing models to identify trigger events. However, existing work either relies on limited observations, such as computer desktops, or adopts a re-asking strategy to gather additional information, failing to fully leverage the rich sensory contexts surrounding humans and external tools to provide proactive assistance unobtrusively.
Recent works [52,56] explored proactive agents using sensor data, while they are either limited to understanding the necessity of proactive suggestions in a social context or predicting assistance from sensory inputs. In contrast, ProAgent focuses on-demand tiered perception for continuous sensing and an efficient reasoning pipeline for proactive assistance.
Understanding Sensor Contexts via LLMs. Recent studies have explored diverse approaches to leveraging LLMs for understanding sensor data. Several studies [20,50] prompt LLMs with domain expertise and raw sensor recordings as demonstrations to perform sensing tasks. Others employ LLMs to reason over predictions from specialized small models, enabling a comprehensive understanding of sensor data [39,41,51,52,55]. Studies also align large-scale text with sensor data in a unified embedding space, enabling natural language interaction [17,59,63]. However, existing studies primarily focus on interpreting sensor data, providing general-purpose descriptions. In contrast, ProAgent takes a step further by not only understanding the current sensory context, but actively anticipating users’ potential needs. In summary, existing studies primarily focus on developing reactive LLM agents for mobile automation or utilizing LLMs to understand diverse sensor signals. However, there remains a research gap in developing a context-aware agent system that can harness the massive sensory contexts surrounding humans to enhance the proactivity of LLM agents.
ProAgent is designed to offer proactive services to users with wearable devices and smartphones across a wide range of daily scenarios, such as commuting, shopping, and work. In these scenarios, ProAgent first performs human-like perception and derives sensory contexts from multi-modal signals, such as egocentric video, audio, and motion data. It then reasons over these contexts to identify the user’s needs, determine the appropriate timing and service content, which is delivered via smart glasses or audio cues to reduce both physical and cognitive workloads. For example, during a social conversation about travel plans, ProAgent can proactively prompt the user with weather updates or agenda conflicts to support in-situ decision-making. It can also provide relevant guidance in other scenarios, such as dietary health advice while eating, product comparisons and reviews while shopping, or transport information upon approaching a bus stop. ProAgent can also support applications such as assistive systems for visual impairments [54] and healthcare [22].
3.2.1 Limitations of Reactive Agents. Existing studies primarily focus on reactive LLM agents [24,45,49], which require explicit user instructions to initiate tasks. This passivity imposes both physical and cognitive workloads on users. Physical Workload. Prior to the advent of LLM agents, users relied on repeated interactions with services such as agenda and transit apps, resulting in a substantial physical burden. Although LLM agents can automate many of these tasks, existing systems remain primarily reactive, requiring explicit user instructions to initiate assistance. Users must still manually invoke agents whenever assistance is needed, such as unlocking a phone and navigating an interface before issuing a request. These actions are especially cumbersome during ongoing interactions, such as conversations, walking, or meetings, where attention is already occupied. Cognitive Workload. The reactive nature of these agents also raises cognitive demands on the user, as users may miss opportunities where agents or external tools could aid decision-making, particularly during tasks requiring sustained attention. In contrast, proactive agents anticipate user needs and provide timely assistance, such as reminders or relevant tips, reducing cognitive load and divided attention.
Context-Aware Proactive Agents. The limitations of existing reactive agents highlight the need for a paradigm shift toward proactive agents that can anticipate user needs and deliver timely support. Knob for Proactive Agents: Massive Sensory Contexts. Without explicit user instructions, environmental perception becomes the primary cue for determining whether to initiate services and what services to provide. While prior studies have explored predicting user needs from desktop [36] or mobile UI observations [1], we argue that proactive agents in open-world scenarios require richer and more diverse contexts, inferred from sensor data, to deliver seamless proactive assistance. First, the abundant and ubiquitous sensor data from mobile devices, such as smart glasses and smartphones, enable human-like perception, allowing for more accurate predictions of user needs. Second, their hands-free nature aligns closely with the fundamental goal of proactive agents: reducing both the physical and cognitive workload of users. Intention Understanding in Sensory Contexts. Without explicit user instructions, proactive agents must identify proactive-relevant cues from abundant sensor data. However, existing MLLMs and sensor LLMs mainly focus on understanding or captioning sensor recordings [17,41]. In contrast, proactive agents must take a step further by actively anticipating user needs, including timing, tools, and content.
The vision context shows that the user is walking down a staircase…
Reasoning of Proactive Agent
Assistance is not required, as I am just walking along on the road as usual.
Google Map (current location: current location, destination: park or scenic area) Tool Calling:
Response: I noticed that you might want a clear destination, there is a park 2 km away… (a) An example of a case that exhibits over-proactivity and tool-calling failures in proactive services.
The user is in a grocery store, looking at various bags of rice…
It would be helpful to have assistance in comparing different types of rice.
Tool Calling: Since the proactive prediction is false, there is no requirement to initiate tools for providing services.
Response: Since the proactive prediction is false, there is no response. We conduct experiments by adapting existing reactive LLMs and VLMs to context-aware proactive agent tasks on the public dataset CAB-Lite [56]. For LLM agents, we additionally employ a separate VLM for visual captioning. We employ prompts and in-context learning (ICL) [13] with ten examples to adapt them to proactive reasoning. We use Acc-P to measure the accuracy of user need prediction, and use F1 and Acc-Args to assess tool calling performance [56]. Fig. 3 illustrates that these adapted agents achieve limited performance in proactive predictions and tool calling. Fig. 2 further provides examples of their struggle to extract proactive cues and personal patterns from extensive sensor data, leading to both excessive proactivity and missed detections that limit practical usability. Additionally, existing reactive LLM agents are designed primarily for explicit user queries rather than mapping sensory contexts to intentions and tool calls. This knowledge gap often causes tool failures, severely degrading the quality of proactive assistance, as shown in Fig. 2.
Reasoning. Since proactive agent systems must continuously perceive the environment to understand user intention, it is important yet challenging to handle the system overhead of computing and energy. Rich Yet High-Cost Continuous Perception. We first evaluate the impact of egocentric video on proactive agent reasoning using real-world data annotated with proactive service needs. Specifically, we evaluate proactive need detection and video caption quality with varying video sampling rates. Specifically, we use recall to measure whether frames requiring proactive service are captured, and two metrics (i.e., BLEU [40] and ROUGE [30]) to compare caption similarity between the 1-second interval and other intervals. Fig. 5a shows that reducing the sampling rate significantly lowers both recall and caption quality, highlighting the importance of egocentric video in proactive agent reasoning. However, always-on high-cost vision perception poses challenges for resource-constrained mobile devices such as smart glasses.
Opportunities of Low-Cost Modalities. Next, we analyze the impacts of vision sampling rates across scenarios where users remain still or move dynamically in changing scenes. Fig. 5b shows that low sampling rates have minimal impact when users are stationary but can miss critical events in dynamic environments. This highlights the potential of incorporating diverse low-cost sensor data, such as location and motion, to guide high-cost vision sampling, reducing system overhead while maintaining proactive service quality. Adaptive Perception. We further evaluate strategies for adaptive sampling of vision data. Specifically, we evaluate AdaSense [38] and SpeakerSense [35], which use always-on IMU and audio to trigger vision sampling when key events such as movement and conversation are detected. In addition to recall, we measure the sampling ratio relative to 10s periodic sampling to evaluate efficiency. We also present the performance of 20s periodic sampling (P-20s) and examine the vision-only input filtering strategy Reducto [28]. Fig. 4 shows that, although they can filter out unnecessary video data, they cannot capture the rich information in multimodal sensor data to provide proactive assistance correctly.
Results highlight the challenges of reducing continuous perception and reasoning overhead in proactive agent systems. In summary, existing reactive agents require users’ physical and cognitive effort, highlighting the need for proactive agents that can anticipate user needs and deliver unobtrusive assistance. However, the unique nature of proactive agents operating without explicit user instructions poses the following challenges: extracting proactive cues from massive sensor data to accurately anticipate user needs, and the system overhead of continuous perception and reasoning.
ProAgent is an end-to-end proactive agent system that harnesses sensory contexts to provide unobtrusive assistance. Fig. 6 illustrates the system overview of ProAgent. Specifically, ProAgent first employs an on-demand tiered perception strategy to continuously capture the user’s surrounding context via multi-modal sensors ( § 4.4). It coordinates multiple always-on low-cost sensors with on-demand high-cost sensors, adaptively adjusting their sampling rates to ensure efficient perception while capturing proactive-related cues.
Next, ProAgent uses a proactive-oriented context extraction approach that derives hierarchical contexts from the massive sensor data ( § 4.2). Finally, ProAgent employs a contextaware proactive reasoner using VLMs to integrate the derived sensory contexts and personas and determine whether proactive assistance is required ( § 4.3). When required, the reasoner identifies and calls the appropriate external tools to deliver assistance, while a temporal constraint strategy ensures the assistance remains unobtrusive.
Although existing studies have explored leveraging LLMs or VLMs to extract insights from sensor data [17,41], they primarily focus on general sensor data understanding rather than anticipating user intents and determining how to assist users, resulting in inaccurate need predictions in proactive agent systems. To address these challenges, ProAgent adopts a proactive-oriented context extraction approach that maps massive sensor data into hierarchical contexts, enabling a comprehensive understanding of user intent. Sensory Contexts. ProAgent perceives multi-modal sensor data, including egocentric video, audio, motion, and location, to capture user-surrounding contexts. Non-vision modalities are converted into text-based cues, generating location, motion, and audio contexts. Specifically, ProAgent uses GPS coordinates together with reverse geocoding to identify nearby points of interest such as bus stations and supermarkets, and obtain their proximity. They provide the location contexts. In addition, ProAgent uses the smartphone’s IMU to determine the user’s motion state, classifying into static or moving, and to generate motion contexts. ProAgent also captures audio to identify whether conversations occur [46], as such interactions are prone to necessitate proactive services, and transcribes the speech into dialogue as audio contexts. Persona Contexts. Since individuals vary in their reliance on and need for proactive services, the optimal timing and content of assistance can differ even under the same sensory context. To address this, ProAgent considers the diversity in users’ backgrounds and abilities. In particular, ProAgent allows users to input their personas in natural language. These persona contexts abstract the user’s profile and are expressed as textual descriptions of the user’s preferences and traits.
Retrieval. An individual may possess multiple personas. However, integrating all personas into agent reasoning can incur substantial system overhead and even reduce the accuracy of predicting user needs. Fig. 7 shows that as the number of personas irrelevant to the current scenario increases, relevant personas are overwhelmed in the lengthy prompt, reducing proactive prediction accuracy and leading to higher system overhead. To address this, we develop a context-aware persona retrieval approach that adaptively integrates personas into proactive reasoning. Fig. 8 shows the workflow. ProAgent first groups user personas by scenario in the offline stage. At runtime, it extracts coarse-grained visual context and then uses it to retrieve the corresponding scenario-relevant personas.
To obtain visual contexts, a straightforward approach is to employ VLMs to generate descriptions and use them to select appropriate personas for proactive reasoning. However, this is computationally expensive and would introduce significant latency. To address this, we develop a coarse-grained context extraction approach to retrieve personas efficiently. where 𝐷 𝑝𝑒𝑟𝑠𝑜𝑛𝑎 denotes the grouped persona database, and retrieval is performed via the scenario index. Only the personas 𝑷 𝒔 from the target scenario are incorporated into the reasoning process (see § 4.3). The scenario categories in this study follow those defined in the CAB-Lite dataset [56].
Unlike existing reactive LLM agents [34,49] that require explicit user instructions, we develop a context-aware proactive reasoner that interprets sensor data while simultaneously inferring users’ potential needs. We first introduce the runtime workflow of the reasoner, followed by its training strategies. vision data and the hierarchical contexts from § 4.2, including both sensory and persona contexts. The reasoner generates structured outputs that include thoughts, proactive score, tool calls, and the final assistance delivered to the user. Sensory Contexts Inputs. A straightforward approach to building a proactive agent is to first employ MLLMs for sensor data interpretation, followed by utilizing an LLM agent for reasoning and tool calling [56]. However, this twostage pipeline introduces significant system overhead as it requires running two large models for each inference. To address this, ProAgent employs a VLM that integrates visual context extraction and agent reasoning into a unified process, as illustrated in Fig. 9. Specifically, the raw vision data is sent to the visual encoder, and the remaining hierarchical contexts obtained in Sec. 4.2, including location, motion, audio contexts, and personas, are sent to the text encoder. Context-Aware CoT Reasoning. The reasoner first generates an explicit description of the current vision inputs using Chain-of-Thoughts (CoT) [48], e.g., “The user is in a store, looking at various headphones, possibly considering. . . “. Our experimental results demonstrate that this step allows the reasoner to better understand the current situation than directly mapping inputs to outputs via supervised learning, and improves proactive prediction performance. Proactive Predictions. Next, the reasoner generates a proactive score based on the current contexts. This score indicates the predicted level of user need for proactive assistance, ranging from 1 for the lowest to 5 for the highest. The proactive assistance is initiated only when the prediction exceeds a threshold. Otherwise, the user remains undisturbed. Users can adjust this threshold to align with their preferred level of agent proactivity, e.g., individuals with visual impairment may lower it to receive assistance more frequently. Tool Calling for Proactive Agent. Once ProAgent identifies that the user requires proactive assistance, it calls external tools [27,56], such as agendas and weather, to assist the user. Note that we categorize these tools into retrievalbased and execution-based tools. ProAgent can directly use retrieval-based tools, (e.g., weather updates and bus schedules), while for execution-based tools (e.g., Uber and email), the agent only reasons about their use and prompts the user for confirmation, rather than executing them directly. Finally, ProAgent integrates sensory and persona contexts, thoughts, and tool results to generate the final assistance. The following is a high-level view of the prompt’s structure.
Task Instructions: Instruct the VLM on the task, including receiving sensory and persona contexts, generating a thought, deciding whether to initiate a proactive service, and calling external tools if needed. Tool Set: Tool functions, descriptions, and arguments. Personas: Retrieved user personas:
Although in-context learning (ICL) [13] can adapt MLLMs to proactive reasoning tasks, integrated examples incur additional inference overhead. Additionally, directly applying supervised fine-tuning (SFT) [6] on sensor data and proactive labels leads to limited understanding of the current situation and user intent.
To address this, we develop a context-aware CoT distillation approach to fine-tune the VLM. Specifically, we use the paired data <img, sen, personas, thoughts, score, tools > with SFT for fine-tuning, where img, sen, and persona are the inputs, indicating raw images, non-visual sensory contexts (location, motion, and audio), and personas, respectively. score and tools are the corresponding annotations for each sample, indicating the proactive score and tool calls. thoughts is the description of the current vision inputs, which are used to enable the VLM to learn to first generate explicit thoughts about the current context rather than directly generating proactive score and tool calls. We employ an additional advanced VLM with a proactive-oriented prompt to generate a description for each image, and it is used solely for training data generation. Details of the prompt see the Appendix. Finally, we train the VLM on the paired datasets and apply Low-Rank Adaptation (LoRA) [19] to reduce training cost. 4.3.3 Temporal Constraints on Proactivity. Since individuals often remain in similar environments for a while, such as waiting at a station or examining a product in a store, a proactive agent may repeatedly provide similar assistance, causing unnecessary disturbances. To address this, ProAgent employs a temporal constraint mechanism to avoid prompting users repeatedly within a period of time. Specifically, ProAgent calculates the semantic similarity between consecutive outputs using BERT [12] and delivers the output to the user only when the similarity falls below a threshold. Users can also adjust this threshold to align with personal preferences in temporal sensitivity to proactive assistance.
Compared to reactive LLM agents, proactive agent systems must continuously perceive sensory contexts, posing additional challenges for mobile devices such as smart glasses, particularly in capturing high-cost vision data, as shown in 5b. However, prior work on adaptive sampling strategies can only work on predefined tasks using heuristic approaches like fixed rules [35,38], failing to support LLM reasoning over open-world contexts (as shown in Fig. 4).
To address these challenges, ProAgent employs an ondemand tiered perception strategy, as illustrated in Fig. 10. Specifically, it keeps multiple low-cost sensors always on while only activating high-cost sensors on demand, based on patterns from the low-cost sensors and the agent’s internal reflections. This enables ProAgent to continuously capture proactive cues with minimal overhead.
4.4.1 On-Demand Context Perception. Our preliminary results in Fig. 5b illustrate that egocentric vision data is crucial for proactive agent systems, while costly to capture continuously on edge devices. Therefore, ProAgent employs an adaptive strategy for on-demand visual context perception.
Specifically, ProAgent first employs always-on low-cost sensors to continuously capture the environment cues and human states at minimal cost, using the location, motion, and audio contexts ( § 4.2.1). ProAgent then uses a dual-mode sampling strategy for visual perception, dynamically switching between low-and high-rate sampling. By default, ProAgent operates in a low-rate mode to reduce system overhead, while it switches to a high-rate mode when patterns detected by the low-cost sensors indicate the need for finer perception. These patterns include user motion, proximity to POIs, and active conversations. Our preliminary results in Fig. 5b show that movement requires more frequent perception to avoid missing proactive services. Therefore, ProAgent switches to a higher visual sampling rate when the user is moving, near POIs within a certain range, or engaged in conversation, since these moments either involve rapid environmental changes or present higher opportunities for proactive assistance. We set the high-and low-rate sampling intervals in ProAgent to 5 s and 60 s, respectively, based on our preliminary results in Fig. 5b. Sampling rate can also be adapted based on device cues (e.g., battery and resource usage). 4.4.2 Periodic Agent Reflection. Relying solely on alwayson patterns to determine visual sampling rates handles only limited scenarios and risks misinterpreting user intents or missing proactive needs. For example, movement occurs both when a user casually walks down the street without needing assistance and when browsing in a store where timely assistance could benefit decision-making. Accurately determining the appropriate sampling rate thus requires reasoning over the user’s surrounding contexts.
To address this, we extend ProAgent with a dedicated tool for adapting the visual sampling rate. Specifically, the tool converts the VLM reasoner’s output (e.g., whether assistance is needed) into the next visual sampling interval. Since a high need for proactive assistance at the current moment often indicates a higher chance in subsequent periods, ProAgent switches the sampling rate to high mode when proactive assistance is currently predicted and lowered otherwise to conserve resources. This adjustment is produced naturally during its reasoning process in § 4.3, without incurring additional overhead. ProAgent then employs an adaptive sampling scheduler that coordinates low-cost cues with agent reflection to determine vision sampling mode. They can override each other. For instance, when low-cost cues suggest a low rate but the agent infers that a high rate is required, the system promptly switches to high-rate vision perception.
5.1.1 Testbed Setup. We implement ProAgent on Ray-Neo X3 Pro [4] smart glasses with a back-end server as our hardware testbed for real-world evaluation. The glasses are powered by Qualcomm’s Snapdragon AR1 Gen-1 wearable platform and feature a binocular full-color micro-LED waveguide display, 4 GB LPDDR4X RAM, and 32 GB eMMC storage. The Android client, implemented in Kotlin and Java (≈1.2 K LOC), packages sensor data with contextual metadata (timestamp, request type) and renders results in the AR overlay.
On the server side, we implement the system on heterogeneous platforms for evaluation, including two edge servers (an NVIDIA Jetson Orin and a laptop with RTX 1660 Ti) and two high-performance servers (one with an NVIDIA 4090 GPU and another with 8× NVIDIA RTX A6000 GPUs). Unless noted, all results are from the NVIDIA Jetson AGX Orin. LLM/VLM inference runs on the Ollama framework [3] via Python wrappers, and the smart glasses communicate with the server via WiFi and cellular networks over HTTPS.
We fine-tune the VLMs using LoRA with a rank of 8, training for 10 epochs at a learning rate of 5 × 10 -4 . For coarse-grained context extraction, we employ YOLO-v5 [21], pretrained on the Objects365 dataset [44]. In addition, we set 𝑘 = 30, and use all-MiniLM-L6-v2 [43] for semantic similarity comparison. We use Google’s Geocoding and Places APIs for reverse geocoding and nearby PoI identification. The advanced VLM used in context-aware CoT distillation is Qwen2.5-VL-32B [7]. We implement the agent with an API-based function calling framework [27], with a
Figure 11: Our real-world testbed. We implement ProAgent on AR glasses with a smartphone. Data collection uses both the glasses and a chest-mounted camera, with participants providing in-situ annotations via the app.
tool set from [56], containing 20 tools. In our experiments, the threshold for the proactive score and temporal constraint are set to 3 and 0.5, respectively. Evaluation on Real-World Testbed. We also evaluate ProAgent using data collected from the real-world testbed. We recruited 20 volunteers for real-world data collection (12 males, 8 females), with an average age of 24.3. Participants varied in personality traits and education. As shown in Fig. 11, each participant wore devices with egocentric cameras, such as smartglasses or a chest-mounted camera, and used a Google Pixel 7 smartphone to capture sensor data, including audio, IMU, and GPS. Ten participants wore the Ray-Neo X3 Pro, while the other ten used the Insta360 [2]. Participants recorded sensor data during daily routines across nine common scenarios defined in CAB-Lite, with each session lasting an average of 25.1 minutes. Participants were required to annotate the collected data, identifying moments requiring proactive services and specifying the intended tools. Participants used a mobile app, as shown in Fig. 11, to immediately record any moments when they believed proactive services might be needed, thereby preventing potential omissions. They could either specify the intended tools manually or select them from a candidate set provided in the app.
Each participant maintains an average of 20 personas. Each data collection session contains an average of 28 proactive assistance events, each labeled within a 5-second window, producing 6,025 samples. The agent’s toolset included 20 tools defined in CAB-Lite, with general tools like GetDate-Time used most and specialized ones like GetHealthData less often. The study was approved by the author institution’s IRB, and all participants provided informed consent.
We extensively evaluate ProAgent’s performance from the following perspectives: trigger accuracy, content quality, and system overhead. Trigger Accuracy. This dimension evaluates whether proactive services are initiated at appropriate moments. First, following prior studies [36,56], we use Acc-P (Proactive Accuracy) and MD (Missed Detection) to evaluate the system’s accuracy in identifying moments that require proactive services and its miss detection rate. To assess on-demand tiered perception in ProAgent, we use recall to assess whether vision sampling is triggered when needed, and use sampling ratio relative to 1s interval sampling to evaluate efficiency. Content Quality. This aspect evaluates the relevance and usefulness of proactive responses. Since the response content is closely related to the agent’s use of external tools, we assess whether ProAgent calls the user-intended tools for proactive assistance. Following prior works [8,56], we adopt F1-score to compare tool names between the predicted and ground-truth tool sets and Acc-Args (Arguments Accuracy) to determine whether the agent correctly parses the tools’ arguments. Any errors in the tool name, API call format, or incorrect parameters are treated as incorrect for Acc-Args. System Overhead. We also evaluate the system overhead of ProAgent, including the inference latency, communication time, token consumption, and memory consumption.
To the best of our knowledge, no prior work has developed proactive agent systems with long-term sensor perception. To comprehensively evaluate ProAgent, we implemented strong baselines by adapting them to this setting. Since a proactive agent system requires both user-need prediction and continuous perception, we adopted strong approaches for each when building baselines, including: 1) a proactive agent and 2) an efficient perception strategy. ContextLLM-P. The original ContextLLM [41] is designed to transform sensor data to descriptive contexts. We adapt its system prompt to enable it for proactive reasoning, using its intrinsic knowledge to assist users proactively. Moreover, we equip it with periodic visual sampling strategies set at 10s intervals, and use a VLM to generate visual sensory context. ContextAgent-Ada. It extends ContextLLM with tool-calling capabilities, enabling it to leverage external tools for user assistance. Moreover, it uses AdaSense [38] to adaptively sample vision data according to IMU-derived motion states.
(a) User’s trajectory in daily life. ContextAgent-SFT. This baseline [56] extends ContextLLM with both tool-calling capabilities and SFT-based fine-tuning of the LLM agent to enhance its reasoning abilities. It adopts periodic sampling strategies at 10s for perceiving vision data. The three baselines above use a two-stage pipeline, where a VLM first generates visual contexts, followed by an LLM agent for proactive reasoning. Besides, we use two singlestage baselines, which unify the two stages into a VLM agent. VLM-ICL-R. This approach utilizes a VLM with few-shot examples for proactive reasoning. Additionally, it employs Reducto [28] to eliminate redundant video frames. VLM-CoT-R. This approach employs a VLM with CoT [48] for proactive reasoning. It also leverages Reducto to filter out redundant video frames.
Note that for all baselines that employ ICL or CoT strategies, we integrated ten demonstrations from CAB-Lite [56] into the VLM/LLM’s system prompt for task adaptation.
We deploy ProAgent on six VLMs of different scales, including Qwen2.5-VL-3B/7B/32B [7], InternVL2.5-2B/8B [10], and LLaVA-1.5 [32]. By default, experiments use Qwen2.5-VL-3B, while baselines are evaluated on models of the same size (Qwen2.5-3B or Qwen2.5-VL-3B) for fairness.
We evaluate the end-to-end performance of ProAgent in delivering proactive assistance during daily routines. Fig. 12a shows a user’s real-world trajectory, where several moments are marked to display egocentric images and the corresponding outputs of ProAgent. Red points mark the moments where ProAgent delivers proactive assistance, while the blue points indicate decisions not to disturb the user. Results in Fig. 12b show that ProAgent can proactively provide valuable assistance to users in their daily routines. For example, it can provide real-time bus schedules when it detects that a bus is departing from a stop, and offer real-time suggestions during conversations to help users make informed decisions. Additionally, ProAgent remains silent when its reasoning indicates that assistance is unnecessary. We also measure the
ConLLM-P ConAgent-Ada ConAgent-SFT VLM-ICL-R VLM-CoT-R ProAgent end-to-end latency on Nvidia Jetson Orin, with ProAgent averaging 4.5s, showing its capability to operate in real-world scenarios and deliver continuous, timely proactive support.
5.4.1 Quantitative Results. We first evaluate the overall performance of ProAgent on the real-world testbed. Fig. 13 demonstrates that ProAgent consistently outperforms baselines, achieving up to 33.4% higher Acc-P, 16.8% higher F1, and 15.5% higher Acc-Args, validating its effectiveness in triggering timely proactive services and delivering informative assistance. Since ContextLLM-P relies solely on intrinsic knowledge without tool calling, its F1 and Acc-Args remain minimal. We also assess the system overhead of ProAgent during continuous proactive assistance. Fig. 13 to proactive predictions and lacks tool-calling capabilities, leading to less useful content in proactive assistance. Coarse-grained Context Extraction. We first evaluate the coarse-grained vision context extraction. We compare ProAgent with four baselines: (i) a rule-based approach that uses the same detection model as ours and predefined rules specifying which objects are indicative of a particular scene; and (ii) three VLM-based baselines, where a VLM is prompted to identify the scene. Specifically, we employ SmolVLM [37], Qwen2.5-VL-3B [7], and InternVL3-1B [64]. Fig. 16 shows that ProAgent achieves 18.3% higher accuracy while using 6.0x less memory than Qwen2.5-VL-3B. Moreover, ProAgent achieves a latency of 118.4ms for coarse-grained vision context extraction, significantly lower than most baselines. Adaptive Persona Retrieval. We then evaluate the adaptive persona retrieval of ProAgent on CAB-Lite. We compare its performance with using all personas from CAB-Lite and with random subsets of the same size. Fig. 15 shows that adaptive retrieval achieves up to 13.9% higher Acc-P, 4.4% higher F1, and 3.8% higher Acc-Args. It can also reduce input length by 6.5x, greatly lowering system overhead for agent reasoning. 5.5.2 Effectiveness of Context-Aware CoT Distillation. We evaluate the context-aware CoT distillation in ProAgent. Specifically, we assess the impact of removing thoughts during SFT on the VLM agent’s performance (denoted as w/o C). Fig. 17 shows that ProAgent achieves 3.6% higher Acc-P, 6.0% higher F1, and 10.1% higher Acc-Args. This is because prompting the VLM reasoner to first generate a description of the current vision data enables it to better interpret the situation and infer the user’s intent, thereby improving performance. 5.5.3 Effectiveness of On-Demand Tiered Perception. We evaluate the performance of on-demand tiered perception. Specifically, we compare ProAgent with several strong baselines: (i) Periodic vision sampling at fixed intervals of 𝑥 seconds (denoted as P-x); (ii) Reducto [28]; (iii) AdaSense [38]; (iv) SpeakerSense [35]. Fig. 20 shows that ProAgent achieves the best trade-off between sampling ratio and recall, validating the effectiveness of on-demand tiered perception. We further provide examples of different approaches performing on-demand visual perception and always-on sampling over time, along with their predicted proactive scores and ground truth. Fig. 22 shows that the timing of visual sampling initiated by ProAgent aligns better with the moments when the user requires proactive services and more accurately predicts higher proactive scores at those moments. Further, Fig. 21 shows the semantic similarity of agent outputs across time intervals, with outputs with higher similarity not presented to the user. This temporal constraint mechanism prevents ProAgent from repeatedly disturbing users with identical outputs in consecutive periods. We also observe that the data traces in Fig 22 show several false positives and false negatives. The reason is that although ProAgent already considers personas for personalized assistance, there are still corner cases such as user requests exceeding the tool set or VLM capabilities. However, ProAgent still achieves 83.3% Acc-P, demonstrating its effectiveness in the real world. 5.5.4 Impact of Base VLMs. Next, we evaluate the performance of ProAgent using different VLMs as the base agent. Fig. 23 shows that increasing the base VLM size leads to improved proactive reasoning performance. Notably, scaling up the model produces larger gains in Acc-Args and F1 compared to Acc-P. For example, scaling up from 7B to 32B leads to a 3.1% increase in F1, while Acc-P increases by only 1.1%. This is because F1 and Acc-Args reflect agent planning, which is inherently more complex than the discriminative task of proactive need prediction, especially for smaller VLMs.
5.5.5 Impact of Scenarios. We also evaluate the cross-scenario generalizability of ProAgent. Specifically, we tested ProAgent on real-world data from commuting and shopping scenarios, while the VLM was trained on a CAB-Lite dataset with these scenarios removed. We then evaluate the VLM trained on partial data (denoted as partial) and on the full dataset (denoted as full). Fig. 18 shows that ProAgent still achieves 81.6% Acc-P, validating its generalization capability.
5.5.6 Impact of Contexts. This section presents an ablation study on the effect of different contexts in ProAgent. Impact of Modalities. We first evaluate the impact of different sensor modalities on ProAgent. Fig. 19a shows the performance of on-demand tiered perception when motion, location, audio, or agent reflection is removed individually. Results indicate that removing any input reduces performance. LLM reasoning has the largest effect, with recall dropping by 33.7%, while audio has the smallest impact, with only a 6.7% decrease. Fig. 19b shows that removing vision or audio substantially degrades proactive prediction, with vision removal causing a 26.6% drop in Acc-P. Impact of Personas. We also evaluate the effect of personas. Specifically, we assess the performance of ProAgent without personas (denoted as w/o P) on CAB-Lite. Fig. 17 illustrates that removing personas causes a significant performance
QwVL-3B QwVL-7B QwVL-32B
(a) QwenVL-2.5 series. drop for ProAgent with Qwen2.5-VL-7B, resulting in 20.2% and 17.0% decreases in Acc-P and F1, respectively.
We evaluate ProAgent’s overhead in submodule inference time and communication latency across multiple hardware platforms and outdoor scenarios. Fig. 24 shows that ProAgent achieves reasoning times of 0.52 s on the A6000 and 3.89 s on the Jetson Orin. Notably, the Time-To-First-Token (TTFT) on both Jetson Orin and laptop (RTX 1660 Ti GPU) is under 300ms, showing that ProAgent can deliver timely proactive assistance when deployed on edge servers. The personas occupy 86.1KB of storage. Additionally, coarse-grained context extraction (CE) and temporal constraints (TC) incur 118.5ms and 58.6ms on Jetson Orin, respectively. ProAgent achieves average communication latencies of 321.2ms, 434.1ms, and 726.5ms in office, store, and subway scenarios, validating real-world usability. ProAgent consumes 4.2% and 12.1% more battery per hour than idle on the Google Pixel 7 and RayNeo X3 Pro, respectively, indicating it does not impose significantly more power overhead than regular use.
We conducted a user study with 20 participants to evaluate whether ProAgent meets their expectations as a proactive assistant. Each participant rated the proactive assistance on a 0-5 scale across five dimensions, with the questionnaire administered once. These dimensions include: Timeliness, which asks participants whether assistance is delivered at appropriate moments. Relevance asks participants how well the assistance matches the user’s current context. Usefulness asks the practical value of proactive support in assisting reallife tasks. Intrusiveness asks participants whether proactive assistance causes disturbance. Finally, Satisfaction represents the user’s overall impression and acceptance of the system. Fig. 25 shows that ProAgent significantly outperforms the baseline in all dimensions, especially the Timeliness and Relevance. The main reasons are its on-demand sampling strategy, which reduces missed cues compared with the baseline, and its ability to extract proactive-related cues for accurate triggering. Results also show that ProAgent provides notably higher Usefulness, since it accurately maps contexts to user-intended tool calls, delivering informative proactive assistance. Additionally, the intrusiveness score averaged 4 out of 5, showing broad acceptance but also sensitivity differences across users, highlighting opportunities to further align assistance with individual habits. We further analyzed user feedback to understand both what users found helpful and where gaps remained. Most participants valued the dining suggestions, noting they often struggle to decide what to eat, while some found calorie or health tips unnecessary, likely due to personal preferences not being fully specified at setup time. Most participants also appreciated online pricecomparison assistance, while a few felt it was only useful for high-value items such as headphones and unnecessary for everyday low-cost goods. Overall, results demonstrate the practicality of ProAgent as a proactive assistant system.
Understanding Proactive Behaviors. Although the results validate ProAgent’s practicality in real-world use, the data traces in Fig. 22 reveal several false positives and negatives. They may arise from requests that exceed tool or model capabilities and from incomplete persona descriptions. We also observe that larger models (32B) could improve accuracy (Fig. 23). Incorporating user feedback and scaling the size of the VLM and the tool set can further mitigate these gaps. Scalability of ProAgent. ProAgent is implemented with an API-based solution for agent tool calling. Other techniques, such as enhancing reasoning abilities [58], Model Context Protocol (MCP) [18], and efficient inference [16,26,53] are orthogonal to this work and can be integrated into ProAgent to further improve system capabilities and efficiency. Privacy Concerns. ProAgent can be run on personal devices or edge servers like laptops without cloud access, ensuring user data remains local and preserving privacy. It can also use hardware-based cues, such as visible lights, flashes, or sound alerts, to notify others during environmental capture.
We introduce ProAgent, the first end-to-end proactive agent system that harnesses rich human-surrounding sensory contexts and LLM reasoning to deliver seamless and unobtrusive proactive assistance. Extensive evaluations show that ProAgent significantly improves the accuracy of proactive prediction and overall quality of assistance in the real world.
📸 Image Gallery