When Forgetting Builds Reliability: LLM Unlearning for Reliable Hardware Code Generation
📝 Original Info
- Title: When Forgetting Builds Reliability: LLM Unlearning for Reliable Hardware Code Generation
- ArXiv ID: 2512.05341
- Date: 2025-12-05
- Authors: Yiwen Liang, Qiufeng Li, Shikai Wang, Weidong Cao
📝 Abstract
Large Language Models (LLMs) have shown strong potential in accelerating digital hardware design through automated code generation. Yet, ensuring their reliability remains a critical challenge, as existing LLMs trained on massive heterogeneous datasets often exhibit problematic memorization of proprietary intellectual property (IP), contaminated benchmarks, and unsafe coding patterns. To mitigate these risks, we propose a novel unlearning framework tailored for LLM-based hardware code generation. Our method combines (i) a syntax-preserving unlearning strategy that safeguards the structural integrity of hardware code during forgetting, and (ii) a fine-grained flooraware selective loss that enables precise and efficient removal of problematic knowledge. This integration achieves effective unlearning without degrading LLM code generation capabilities. Extensive experiments show that our framework supports forget sets up to 3× larger, typically requiring only a single training epoch, while preserving both syntactic correctness and functional integrity of register-transfer level (RTL) codes. Our work paves an avenue towards reliable LLM-assisted hardware design.📄 Full Content
Existing efforts to mitigate problematic memorization in general LLMs have primarily focused on retraining and machine unlearning. Retraining from scratch on sanitized datasets represents the most reliable way to achieve exact unlearning; yet, the prohibitive resource and time costs of training largescale models make this approach largely impractical in realworld settings. For instance, training the LLaMA 3.1 model (8B parameters) [8] from scratch requires approximately 1.46 million GPU hours on NVIDIA H100-80GB GPUs. Machine unlearning has emerged as a more practical alternative [9]- [15], which aims to selectively remove the influence of specific training data while preserving the utility of models. This ensures that the resulting model behaves as if the removed data had never been included in training. Specifically, existing efforts adopt post-training strategies for efficient unlearning without retraining [9]- [15], and have shown promise in natural language processing tasks, including harmful response removal, copyright erasure, and privacy protection. Yet, the application of unlearning to hardware code generation remains significantly underdeveloped. Recently, only SALAD [16] applied existing unlearning techniques to hardware design with limited domain adaptation, and therefore suffers from substantial utility degradation. This gap highlights the need to develop domainspecific unlearning strategies to ensure reliable hardware code generation without compromising utility.
This paper proposes the first-of-its-kind domain-specific unlearning framework tailored to reliable hardware code generation, which is capable of eliminating problematic knowledge while maintaining reliable hardware code synthesis. Specifically, by recognizing that RTL codes require strict syntax, precise dependency modeling, and faithful execution semantics, our strategies incorporate these factors into unlearning processes to strike a balance between forgetting effectiveness and hardware code generation reliability. Our key contributions are as follows:
• Novel unlearning framework for reliable hardware code generation. We pioneer the development of domainspecific unlearning frameworks to significantly improve the reliability of LLM-based hardware code generation with tailored strategies. • Syntax-preserving unlearning strategy. We introduce an RTL-specific mechanism that selectively excludes structural tokens from the forgetting process, ensuring that unlearning does not compromise the syntactic integrity of generated hardware code. • Fine-grained floor-aware selective loss (FiFSL). We develop a novel token-level objective that combines marginbased control with selective averaging, enabling precise and accelerated forgetting of undesired samples. A typical digital module is synchronous, consisting of two interacting components: combinational logic, which computes functions of the current inputs without memory, and sequential logic, which stores and updates states through registers or flip-flops at each clock edge. Register-Transfer Level (RTL) modeling captures this behavior by specifying data transfers between registers under clock control, together with the combinational logic that generates next-state values. In Verilog, for instance, sequential logic is commonly expressed using always @(posedge clk or negedge rst_n) blocks with nonblocking assignments (<=), while combinational logic is described with assign statements or always @( * ) blocks using blocking assignments (=). Consequently, Verilog code for digital designs frequently relies on recurring syntax patterns, particularly always blocks that encode both combinational and sequential behavior.
Generative AI is rapidly reshaping the landscape of hardware development [17]- [22]. In particular, the integration of Large Language Models (LLMs) into digital hardware design has shown remarkable progress, demonstrating strong capability in Verilog generation, assertion synthesis, testbench creation, and optimization of electronic design automation (EDA) workflows [23]- [26]. Early efforts such as ChipNemo [26] and ChipGPT [27], show that fine-tuning and prompt engineering can substantially improve RTL generation quality. More recent frameworks like HAVEN [28], CraftRTL [29], and MAGE [30] extend these capabilities through non-textual representations and multi-agent strategies. Complementary benchmarks such as VerilogEval [4] and Rtllm [5] further confirm that LLMs can produce syntactically correct and functionally reliable RTL, highlighting their promise to accelerate design workflows.
Despite these advances, fundamental challenges remain in ensuring the safety, legality, and reliability of LLM-based hardware code generation. Existing LLMs trained on massive public repositories risk propagating vulnerabilities and insecure coding practices through the memorization of buggy or outdated patterns. To address these risks, security-focused techniques have emerged, such as SafeCoder [6], which augments training with curated secure-code datasets, and VersiCode [31], a benchmark for evaluating robustness to Application Programming Interface (API) changes across releases. Yet, these approaches fall short of providing comprehensive guarantees. SafeCoder depends heavily on dataset quality and coverage, which cannot anticipate all insecure coding patterns or future vulnerabilities, leaving models susceptible to unseen exploits. VersiCode, by contrast, is limited to version-specific API robustness and does not address broader issues such as memorization of proprietary code, syntactic validity in hardware description languages, or broader security vulnerabilities. These limitations highlight the need for novel approaches that can suppress unsafe behaviors while preserving the utility of LLMs for code generation.
Machine unlearning, the process of eliminating the influence of specific data from a trained model without retraining from scratch, has recently emerged as a critical research field. In the context of LLMs, unlearning has been increasingly explored to address applications such as privacy preservation, removal of copyrighted material, and suppression of harmful content [14]. Early methods, such as Gradient Ascent (GA) [9], attempt to “reverse” prior learning by performing ascent on the next-token prediction loss of the forget set, but they often suffer from instability and collateral drift on the retain distribution due to the indiscriminate and unbounded optimization signal. To tackle these issues, Negative Preference Optimization (NPO) [11] introduces an alignment-inspired loss function embedded with a smooth bounded penalty to promote divergence from forgetset behavior while maintaining stability. More recently, Sim-NPO [12] refines this approach by removing the reliance on a teacher model and adopting a reference-free, length-normalized objective, thereby mitigating reference bias and enabling more balanced forgetting with stronger utility preservation.
While these advances have demonstrated the feasibility of unlearning in natural language processing (NLP), their applicability to hardware code generation remains largely unexplored. Unlike natural language, RTL code exhibits strict syntactic and structural constraints, where even minor inconsistencies can render outputs unsynthesizable. As a result, NLP-oriented unlearning methods cannot be directly transferred to hardware description languages-as shown by a recent work SALAD [16], ignoring domain-specific syntax significantly undermines the validity of code generation. These limitations highlight the need for domain-specific unlearning strategies that not only suppress undesired behaviors but also preserve the correctness and reliability of RTL code generation for hardware design.
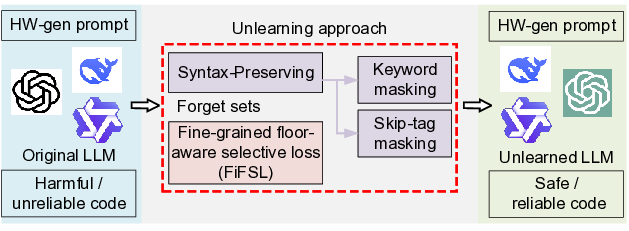
We propose a domain-specific unlearning framework for reliable LLM-based hardware code generation. Fig. 1 shows its overview, which leverages harmful data as a forget set, enabling the removal of problematic knowledge while preserving code utility. Our approach combines two major techniques: (1) syntax-preserving masking, which protects reserved keywords and code spans to maintain compilability, and (2) fine-grained floor-aware selective loss (FiFSL), which applies marginbased forgetting pressure while gating out already forgotten samples to focus updates on the hardest cases. Together, these strategies enable efficient, stable, and utility-preserving unlearning, yielding LLMs that generate reliable hardware codes.
We consider the problem of machine unlearning in the context of LLMs for RTL code generation. Let π θ denote a pretrained LLM parameterized by θ, which generates RTL code y given an instruction or design intent x, i.e., π θ (y|x). In practice, not all training data should be retained indefinitely. Certain samples may correspond to privacy-sensitive hardware designs, erroneous code snippets, or legally restricted RTL modules [4]. Such cases can arise due to incomplete data cleaning, outdated versioned code, etc. We denote the set of data to be forgotten as D f = (x f , y f ). The objective of unlearning is to update the model into π * θ such that its dependence on D f is minimized. Specifically, given a prompt x f , the outputs of π * θ should diverge from the undesired targets y f . Meanwhile, the model must preserve its utility on the remaining distribution. We denote the validation set by D v = (x v , y v ), which reflects the task-relevant code generation capability to be preserved. Formally, the unlearning goal can be expressed as:
(1) This formulation captures the dual goal of unlearning: removing the influence of undesired data while retaining the model’s competence in hardware code generation. To address this dual goal in practice, our methodology consists of two key components: (i) syntax-preserving unlearning that ensures syntax structural correctness is not disrupted, and (ii) a finegrained floor-aware selective loss function that accelerates and strengthens the forgetting process.
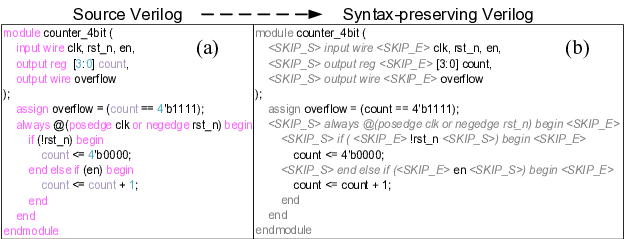
C. Proposed Unlearning Framework 1) Syntax-Preserving Unlearning: Unlike free-form natural languages, RTL codes follow a finite and well-defined grammar. Their tokens, such as reserved keywords, operators, delimiters, and numeric literals, recur systematically to capture combinational and sequential behaviors. While exact idioms differ across cases (e.g., continuous assignments or sensitivity lists for combinational logic vs. clocked processes for sequential logic), such tokens represent universal syntactic backbones rather than task-specific semantics. Thus, existing unlearning strategies [16] that indiscriminately suppress these high-frequency syntax tokens are harmful: they undermine grammaticality and compromise the compilability and synthesizability of RTL programs (i.e., treating every token in the toy example Verilog code of a 4-bit counter (Fig. 2(a)) as removable). Effective unlearning must be syntax-preserving, targeting semantic content while enforcing grammar constraints to maintain well-formed hardware description languages (HDLs).
To achieve this, we propose a syntax-preserving unlearning strategy that selectively protects structural elements while forgetting only task-specific tokens. As shown in Fig. 2(b), our approach integrates two complementary mechanisms to preserve structural correctness, grounded in the IEEE hardware code standard [32]- [34], and excludes them from the loss function. First, keyword masking is applied to a curated set of Verilog reserved words such as module, assign, wire, etc, ensuring that these essential tokens are not modified by forgetting operations. Second, skip-tag masking introduces special tokens <SKIP_S> and <SKIP_E> to mark spans of texts that should be ignored during loss computation, and all tokens appearing between these tags are excluded from the unlearning objective. To unify both operations, we assign each token x t in an input sequence x = (x 1 , . . . , x T ) with a binary mask value m t , where m t = 0 if x t falls within a skip-tag span or belongs to the reserved keyword set K, and m t = 1 otherwise. The loss for syntax-preserving unlearning is thus computed directly as
with ℓ •) denoting the token-level cross-entropy. By aligning the masking rule with the loss function, the model forgets undesired content while maintaining the universal syntactic backbone required for compilable RTL code. It is important to note that from the computational perspective, the proposed masking strategy introduces negligible overheads, since it only requires constructing a token-level binary mask during preprocessing and applying it element-wise to the loss function. This makes syntax-preserving unlearning highly efficient and scalable, enabling its deployment in large-scale Verilog LLMs without incurring noticeable computational or memory costs.
- FiFSL: Fine-grained Floor-aware Selective Loss: To further enhance the unlearning process, we introduce a finegrained floor-aware selective loss (FiFSL) that operates at the token level and combines margin-based control with a selective averaging mechanism. The key idea is to impose a lower bound on the loss to prevent excessive forgetting, while gradients are computed only for unmasked tokens and unforgotten samples.
Forward: In the forward pass, for each sample i in a batch of size b, let V i denote the set of all valid (unmasked) tokens after the syntax-preserving masking in Sec. III-C1. The tokennormalized negative log-likelihood for sample i is defined as
To impose forgetting, we shift this loss by a margin parameter γ and apply a smooth negative-preference mapping, yielding
where β > 0 controls the curvature and saturation rate (larger β gives a sharper transition), and softplus(z) = log(1 + e z ) is used to provide a smooth, bounded mapping. This construction exerts strong forgetting pressure when a sample is underforgotten (L i < γ), and gradually saturates once the margin is exceeded, thus preventing runaway gradients. To further prevent excessive forgetting and suppress outlier effects, we introduce a hard floor L min and average only over active samples whose penalties exceed this threshold (ϕ i > L min ), contributing both to the loss and to the gradient. Let α i = 1{ϕ i > L min } and N act = i α i , the mini-batch objective loss is expressed as
This is algebraically equivalent to first clamping ϕ i by L min , masking inactive samples, and then normalizing by the number of active ones. As a result, samples with ϕ i ≤ L min contribute no gradient and are effectively excluded from further updates. At the dataset level, FiFSL can be expressed as the expectation over the forget set D f :
Backpropagation: By establishing the forward objective, we now analyze the backward signal to show how our loss enforces forgetting stably and selectively. Recall Eqs. ( 3) and (4). Using softplus ′ (z) = σ(z) with the σ as logistic sigmoid, differentiating ϕ i with respect to the per-sample loss yields
Thus, the sensitivity lies strictly between -2 and 0: when L i < γ, the term -β L i -γ is positive, σ(•) ≈ 1, and the gradient magnitude approaches two, producing a strong negative push that increases L i and drives forgetting. Consequently, when L i > γ, the sigmoid gradually reduces the gradient, leading to milder updates and preventing overly large gradients that could cause excessive forgetting. At the token level, the derivative of L with respect to a logit at position t is 1 |Vi| m i,t p i,t -e(y i,t ) . Here, m i,t is the syntax mask, p i,t the softmax vector, and e(y i,t ) the one-hot target. The normalization by |V i | ensures that gradients are comparable across sequences of different lengths, while the mask guarantees that reserved keywords or skipped tokens never receive updates. Combining these results, the batch-level gradient becomes This expression shows that FiFSL rescales the standard crossentropy gradient by a bounded negative factor and suppresses it entirely when either the token is masked or the sample is already forgotten (α i = 0). The implications are twofold. First, FiFSL enforces forgetting with control: active samples below the margin receive strong forgetting pressure, but this pressure decays smoothly once the margin is passed, stabilizing optimization. Second, FiFSL avoids unnecessary updates by gating entire samples once they have been sufficiently forgotten, unlike conventional unlearning techniques [9], [11], [12], which continue to update all samples uniformly. In practice, as training proceeds, the number of active samples decreases, and optimization effort concentrates on the hard-to-forget tails of the distribution. This selective mechanism not only prevents collateral degradation of syntax tokens but also reduces the number of epochs required to achieve effective unlearning compared to conventional methods.
-
Summary of the Proposed Strategy: In summary, our framework combines syntax-preserving unlearning, which safeguards the structural correctness of RTL code, with FiFSL, a margin-based selective forgetting loss that ensures stable and efficient removal of undesired knowledge. This joint design enables effective forgetting while preserving syntactic and functional validity. The process is presented in Algorithm 1. metrics are widely adopted in the LLM unlearning domain and are adapted here to the context of hardware code generation. Forget quality. We employ two metrics to quantify the degree of forgetting: (1) PrivLeak [35], which quantifies the probability that the model regenerates HDL snippets or modules from the forget set. This corresponds to verbatim or nearverbatim leakage of RTL blocks (e.g., always blocks, state machines, or functional units). Lower values indicate stronger forgetting and reduced IP leakage risk. (2) MinK++ [36], which evaluates the average log-likelihood of the lowest-k% gold tokens in generated HDL codes. By calibrating against token distributions, it is sensitive to residual memorization of hardware coding patterns (e.g., signal naming conventions, pipeline templates) even when direct leakage does not occur. Lower scores suggest weaker memorization. For reference, untrained models typically yield scores around 0.5 [36]. Model utility. To ensure that forgetting does not degrade downstream performance, we evaluate model utility on hardware code generation tasks using: (1) Cross-entropy loss on held-out HDL test sets, measuring token-level predictive quality. (2) Pass@1 accuracy on functional hardware code generation benchmarks, assessing whether the generated Verilog/HDL compiles and passes simulation testbenches. (3) BLEU and chrF, which capture syntactic and stylistic fidelity. BLEU measures ngram overlap with reference RTL implementations, while chrF evaluates character-level similarity, useful for ensuring correct use of hardware-specific syntax.
-
Benchmarks and Experiment Setup: We evaluate our approach on four LLMs fine-tuned for RTL code generation: Llama-3-8B-Instruct [8], CodeLlama-7B-Instruct [37], DeepSeek-Coder-7B-Instruct [38], and Qwen2.5-Coder-7B-Instruct [39]. Among them, Llama-3-8B-Instruct is a generalpurpose model, while others are explicitly optimized for code understanding and generation. As the fine-tuned corpus, we adopt the open-source RTLCoder dataset [1], which provides instruction-response pairs comprising natural language design specifications and their corresponding RTL code implementations. Each model is fine-tuned on 1,000 samples for six epochs using the Adam optimizer with a learning rate of 1 × 10 -5 , a maximum sequence length of 2,048 tokens, and a batch size of 2 on 4×A6000 GPUs. For inference, we set the sampling temperature to 0.5 and top-p to 0.9. Table I reports the performance of these benchmark models after fine-tuning. All models exhibit strong memorization tendencies (PrivLeak and MinK++ > 0.8), which provides a baseline reference for subsequent unlearning evaluations.
Since there are no publicly available domain-specific datasets for proprietary or contaminated RTL designs, we follow prior works [9]- [16] to emulate realistic unlearning scenarios by subsampling 100, 200, and 300 examples from the training corpus (i.e., about 10%, 20%, and 30%). These forget sets emulate practical cases where LLMs may memorize proprietary IP, contaminated benchmarks, or unsafe coding patterns that must be forgotten. The downstream utility is assessed on the held-out RTLCoder test set, consistent with the benchmark evaluation protocol.
- Unlearning Baselines and Configurations: We compare our method against two of the most recent and representative LLM unlearning approaches, which SALAD [16] used. Gradient Ascent (GA) [9] maximizes the cross-entropy loss on forget samples:
SimNPO [12] introduces a smooth penalty function to improve stability and avoid collapse of GA:
) To ensure fairness, we follow the reward-margin settings in [12] to set β = 2.5 and γ = 0. Our FiFSL further introduces an adaptive floor parameter (L min ), chosen as 0.35, which corresponds to the validation loss after the first fine-tuning epoch. In addition, we explore a broader hyperparameter space by using Llama-7B as an example, varying β between 1.5 and 4 and γ from 0 to 2.5. Consistent with the findings of [12], the configuration β = 2.5, γ = 0 achieves the best performance. We build our syntax-preserving dataset guided by [32]- [34].
Unlearning is performed using a learning rate of 2 × 10 -6 until MinK++ converges near 0.5, ensuring effective forgetting without excessive utility degradation.
-
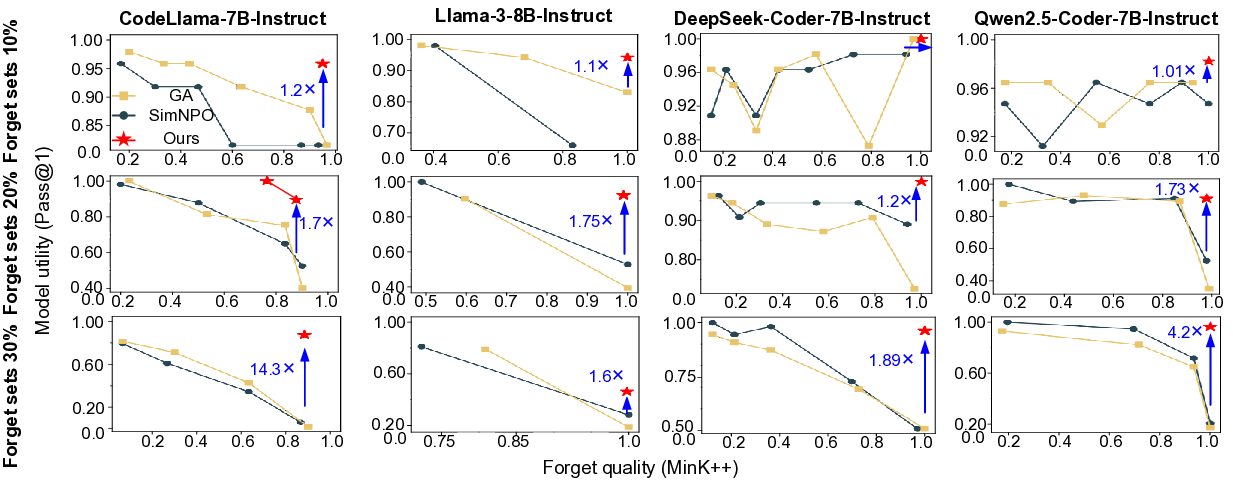
Forgetting Effectiveness vs. Utility Preservation: We compare our approach against GA and SimNPO in terms of forget quality and model utility. Fig. 3 shows results across different forget sets and benchmark models. We adopt MinK++ as the indicator of forget quality and Pass@1 as the measure of model utility, since they directly capture the trade-off between eliminating memorized knowledge and retaining downstream RTL code generation reliability. Both values are normalized for comparability. An ideal unlearning method aspires to the point (1.0, 1.0) in the forget-utility space, denoting perfect forgetting without utility loss. Our method consistently lies closest to this ultimate goal across all models and forget-set sizes. particular, it forgetting up to 30% of the training corpus across coder LLMs, while conventional methods fail beyond 10% (i.e., a 3× larger forget set). For Llama-3-8B, our method achieves up to 20% forgetting, which we attribute to model-specific architectural constraints, as this model is not explicitly optimized for code understanding and generation. Nevertheless, this still outperforms conventional methods, demonstrating the robustness and broad applicability of our approach. Importantly, our method preserves the highest model utility among all methods: at 30% forgetting, it retains up to 14.3× higher Pass@1 than baselines, whereas GA and SimNPO exhibit sharp utility degradation. Concrete values across all metrics are reported in Table II. Moreover, our method accomplishes nearcomplete forgetting within a single epoch, drastically reducing unlearning cost, while GA and SimNPO require 4∼7 epochs and underperform, particularly on larger forget sets.
-
Generalization Ability and Scalability: Table II reports all evaluation metrics, where “epoch” denotes the number of training epochs required to reach ideal forget quality, with ↓ (↑) indicating that lower (higher) values are better. Our method surpasses in all metrics. We further assess generalization on unseen, simple code generation tasks, shown as generalization ability columns. The shaded rows highlight that the unlearned models maintain Pass@1 close to their fine-tuned baselines, confirming that forgetting does not compromise general-purpose generation ability. In addition, the proposed ap- proach sustains high BLEU and chrF scores across these tasks, demonstrating that effective unlearning can be achieved without sacrificing broad code generation performance. To further validate domain-level utility preservation, we additionally evaluate our method on VerilogEval [4] and Rtllm [5] before and after unlearning. As shown in Table III, the unlearned models retain competitive performance across both benchmarks, confirming that the proposed method does not compromise downstream RTL generation utility.
-
Summarization: Overall, our domain-specific method supports up to 3× larger forget sets than existing methods (i.e., GA and SimNPO used by SALAD [16] without domain adaptation), achieves effective forgetting in only one epoch, and sustains both validation and generalization performance (Table IV). These results show that it offers near-ideal unlearning: strong forgetting quality, preserved model utility, broad generalization, and exceptional efficiency, making it a scalable and practical solution for reliable code-specialized LLMs.
We present the first domain-specific unlearning framework for RTL code generation, addressing critical reliability challenges in hardware design automation. By combining a syntaxpreserving strategy with the proposed FiFSL objective, our approach enables precise and efficient forgetting while maintaining syntactic validity and functional reliability. Experiments show that it supports up to 3× larger forget sets with only one training epoch, significantly outperforming prior methods. This work demonstrates a practical and scalable path toward reliable hardware code generation with LLMs.
• Scalable and robust unlearning for hardware code generation.
t p i,t -e(y i,t ) .Input:
t p i,t -e(y i,t ) .
📸 Image Gallery