HiMoE-VLA: Hierarchical Mixture-of-Experts for Generalist Vision-Language-Action Policies
📝 Original Info
- Title: HiMoE-VLA: Hierarchical Mixture-of-Experts for Generalist Vision-Language-Action Policies
- ArXiv ID: 2512.05693
- Date: 2025-12-05
- Authors: Zhiying Du, Bei Liu, Yaobo Liang, Yichao Shen, Haidong Cao, Xiangyu Zheng, Zhiyuan Feng, Zuxuan Wu, Jiaolong Yang, Yu-Gang Jiang
📝 Abstract
The development of foundation models for embodied intelligence critically depends on access to large-scale, high-quality robot demonstration data. Recent approaches have sought to address this challenge by training on large collections of heterogeneous robotic datasets. However, unlike vision or language data, robotic demonstrations exhibit substantial heterogeneity across embodiments and action spaces as well as other prominent variations such as senor configurations and action control frequencies. The lack of explicit designs for handling such heterogeneity causes existing methods to struggle with integrating diverse factors, thereby limiting their generalization and leading to degraded performance when transferred to new settings. In this paper, we present HiMoE-VLA, a novel vision-language-action (VLA) framework tailored to effectively handle diverse robotic data with heterogeneity. Specifically, we introduce a Hierarchical Mixtureof-Experts (HiMoE) architecture for the action module which adaptively handles multiple sources of heterogeneity across layers and gradually abstracts them into shared knowledge representations. Through extensive experimentation with simulation benchmarks and real-world robotic platforms, HiMoE-VLA demonstrates a consistent performance boost over existing VLA baselines, achieving higher accuracy and robust generalization across diverse robots and action spaces. The code and models are publicly available at https://github.com/ZhiyingDu/ HiMoE-VLA.📄 Full Content
Compared to the relative uniformity of textual and visual data in VLM, current VLA models face a fundamental challenge: large-scale robotic datasets are inherently heterogeneous from different aspects. Robots differ in embodiment, action space, state representation, and control frequency; observations vary across number of sensors, viewpoints, and environments; and even when identical tasks are collected in the same environment, variations in teleoperation styles, such as operator speed, can introduce additional heterogeneity. This diversity makes knowledge transfer across datasets and embodiments particularly difficult. As a result, a central and pressing question for the field is how to learn a generalizable foundation model for robotics from such highly heterogeneous robotic data.
Recent methods (Li et al., 2024;Qu et al., 2025;Kim et al., 2025;Liu et al., 2024) pre-train on large-scale datasets such as the Open X-Embodiment (OXE) dataset (O’Neill et al., 2024) and subsequently fine-tune on specific target domains in pursuit of robotic foundation models. Although this paradigm has yielded encouraging results, it still lacks principled designs to effectively handle data heterogeneity and diversity. As a result, they often struggle to integrate diverse data, leading to limited generalization and inefficient knowledge transfer.
In this paper, we introduce HiMoE-VLA, a vision-language-action (VLA) framework grounded in a Hierarchical Mixture-of-Experts (HiMoE) architecture, designed to enable robust knowledge transfer across diverse robotic datasets. The framework integrates two complementary components: a pretrained vision-language model (VLM) that processes visual and text inputs, and a hierarchical MoE module that operates on robot states and noisy action signals. Considering that data from different action spaces are largely non-transferable, directly mixing this source of heterogeneity with other variations often leads to integration difficulties (as empirically demonstrated in Table 6 (b)).
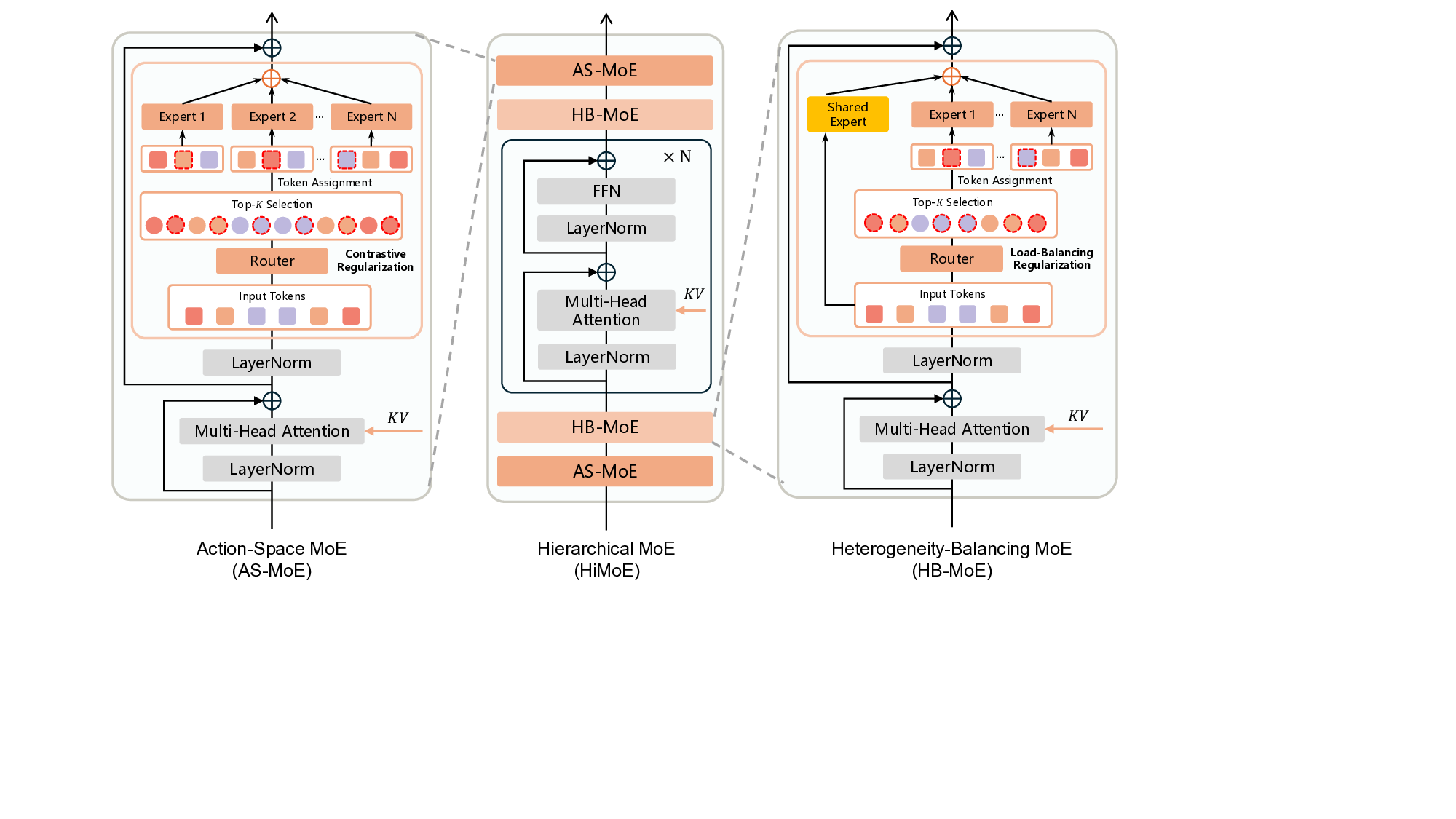
To address this challenge, we propose a hierarchical expert structure composed of three complementary components. At the boundary layers, the Action-Space MoE (AS-MoE) specializes in handling discrepancies between action spaces (e.g., joint-angle-space versus end-effector-space control). Adjacent to it, the Heterogeneity-Balancing MoE (HB-MoE) adaptively processes broader sources of variability, such as embodiment-specific kinematics and sensor configurations. At the middle layers, a dense transformer block consolidates these heterogeneous signals into shared representations, thereby enabling effective cross-domain generalization.
To further enhance this hierarchical abstraction process, we introduce two targeted regularizations. Action-Space Regularization (AS-Reg), implemented as a contrastive objective, sharpens expert specialization over different action spaces. Heterogeneity-Balancing Regularization (HB-Reg) guides experts to progressively abstract broader sources of variability into unified knowledge. Additionally, we employ a flow-matching loss to effectively model multimodal action distributions. Together, these objectives constitute the unified training signal of HiMoE-VLA, promoting both robust knowledge transfer and principled expert specialization within the framework.
We pre-train HiMoE-VLA on the OXE (O’Neill et al., 2024) dataset as well as the open-source ALOHA (Fu et al., 2024;Zhao et al., 2023;Liu et al., 2024) dataset, covering diverse embodiments, action spaces, state representations, and tasks. Building on this pre-training, we fine-tune and evaluate HiMoE-VLA across multiple challenging benchmarks, including CALVIN (Mees et al., 2022) and LIBERO (Liu et al., 2023a), as well as on two distinct robot platforms, xArm and ALOHA. Extensive experiments demonstrate that HiMoE-VLA achieves state-of-the-art performance, significantly surpassing existing VLA baselines in both success rates and generalization. Notably, our model exhibits strong generalization to unseen objects and environments, as well as robust adaptation to new robots and tasks, underscoring the effectiveness of our design.
Our contributions are summarized as follows:
• We propose a new Vision-Language-Action framework targeted at handling diverse robotic data with heterogeneity -ranging from action and state spaces to embodiments and sensor configurations -into shared knowledge representations, thus facilitating effective cross-domain transfer.
• We introduce a hierarchical Mixture-of-Expert architecture with an Action-Space MoE (AS-MoE) and a Heterogeneity-Balancing MoE (HB-MoE), supported by targeted regularizations. The AS-MoE addresses discrepancies across action spaces, while the HB-MoE abstracts broader variability into shared knowledge.
• Our model achieves better performance than previous VLA approaches across both simulation benchmarks and real-world single-arm and dual-arm robot platforms, exhibiting quick adaptation to new robots and tasks and effective generalization to unseen objects and environments
Vision-Language-Action Models. Rapid progress of large language models (LLMs) (Achiam et al., 2023;Touvron et al., 2023;Team et al., 2024a) and vision-language models (VLMs) (Abdin et al., 2024;Beyer et al., 2024) has spurred the development of vision-language-action (VLA) models that couple pretrained VLMs with robotic action generation. Representative approaches include RT-2 (Zitkovich et al., 2023) and OpenVLA (Kim et al., 2024), which discretize actions into tokens, RoboFlamingo (Li et al., 2023), which predicts continuous actions, and UniVLA (Bu et al., 2025) and Pi0 (Black et al., 2024), which incorporate action-aware objectives and multiview inputs. In parallel, video-pretrained policies (Wu et al., 2023;Cheang et al., 2024) exploit Internetscale videos to learn visuomotor representations without explicit action supervision. Despite these advances, most VLAs overlook the intrinsic heterogeneity of robotic data, including action spaces (e.g., joint-angle vs. end-effector control) and embodiments, which limits their robustness. Recent efforts attempt to address this: RDT-1B (Liu et al., 2024) introduces a unified action space for bimanual manipulation but lacks architectural mechanisms to handle heterogeneity within the same action space, while HPT (Wang et al., 2024a) employs dataset-specific stems and heads to align diverse inputs, at the cost of limiting transfer across datasets. Our work differs by introducing a hierarchical MoE design that explicitly disentangles action-space discrepancies and broader heterogeneity, while consolidating them into shared knowledge representations.
Mixture of Experts. Mixture-of-Experts (MoE) architectures were originally proposed to improve scalability by activating only a subset of parameters per input, achieving sparse computation without sacrificing model capacity. This idea has been widely adopted in LLMs (Fedus et al., 2022;Lepikhin et al., 2020), and later extended to vision (Riquelme et al., 2021) and diffusion models (Fei et al., 2024). The most common routing strategy is top-k token routing, where each input token is dynamically assigned to a subset of experts. Various extensions have been proposed to improve routing efficiency and load balancing, such as hashing-based routing (Roller et al., 2021), dynamic expert activation (Guo et al., 2024;Wang et al., 2024b), and regularization-based balancing losses (Dai et al., 2024). Compared with prior MoE designs, our hierarchical organization places action-space experts at shallow layers and heterogeneity-balancing experts at deeper layers, interleaved with Transformer blocks. This enables specialization over fine-grained action variations while progressively consolidating broader sources of heterogeneity into shared knowledge representations.
Our objective is to develop a generalist vision-language-action (VLA) model that enables robots with different embodiments (e.g., single-arm and dual-arm manipulators) to execute diverse tasks conditioned on multimodal inputs. Specifically, at each time step t, the model is given a language instruction l and multimodal observations consisting of robot proprioception q t and RGB images o t ,
where q t denotes the proprioceptive state of the robot (e.g., joint positions or end-effector states), and the language instruction l represents the task description expressed as a sequence of tokens. Visual observation o t is defined as: o t = [I 1 t , . . . , I n t ], where I i t denotes the i-th RGB image (normally i ranges from 1 to 3).
The action sequence A t is represented as a chunk of low-level robot control signals, where each a t can correspond to either end-effector deltas or joint angle commands, depending on the embodiment. This chunking formulation allows the model to generate temporally consistent actions that capture fine-grained manipulation dynamics.
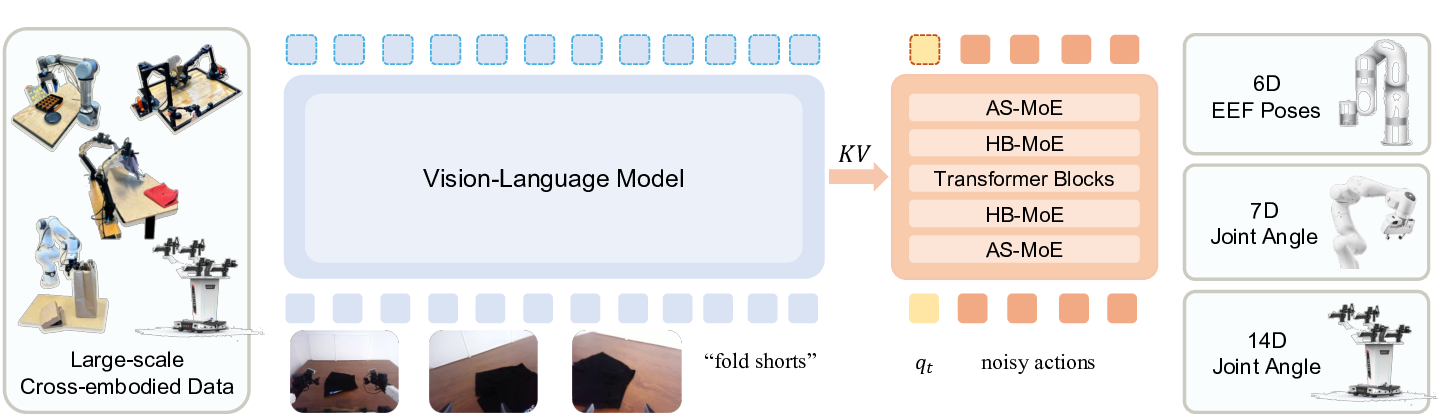
In this section, we describe the architecture of the HiMoE-VLA model, as illustrated in Fig. 1, which integrates a pre-trained vision-language backbone (Beyer et al., 2024)) with a dedicated action expert to enable policy learning from multimodal inputs. The model is trained with flowmatching (Lipman et al., 2022) loss for action generation, following recent advances in diffusionbased policy learning. At each time step, the policy takes as input the robot’s proprioceptive state, a noised action vector, and cross-attended image-text tokens from the VLM backbone, and produces a denoised sequence of future actions. In the following, we elaborate on each module in detail.
Our VLM adopts the PaliGemma (Beyer et al., 2024) model, identical to that used in π 0 (Black et al., 2024). PaliGemma combines a SigLIP (Zhai et al., 2023) vision encoder with a Gemma (Team et al., 2024a) language model to produce semantically aligned vision-language representations from input images and language instructions. We extract intermediate key-value (KV) representations from the language model layers and feed them to the action expert for cross-attention with proprioception and action tokens (see Appendix B for details), which provides stronger conditioning than using only the final layer. At inference time, we employ a KV cache to reuse previously computed representations, substantially accelerating rollout without degrading performance.
On the action side, we propose a Hierarchical Mixture-of-Experts (HiMoE) architecture, referred to as the action expert, to process the robot’s proprioceptive state together with the noised action sequences. Both inputs are first projected into a unified vector representation, where different action spaces (e.g., joint-angle-based or end-effector-based control) are consistently assigned to fixed positions within the vector. These unified vectors are normalized to zero mean and unit variance across the dataset, and subsequently transformed by lightweight MLPs before being passed into the HiMoE.
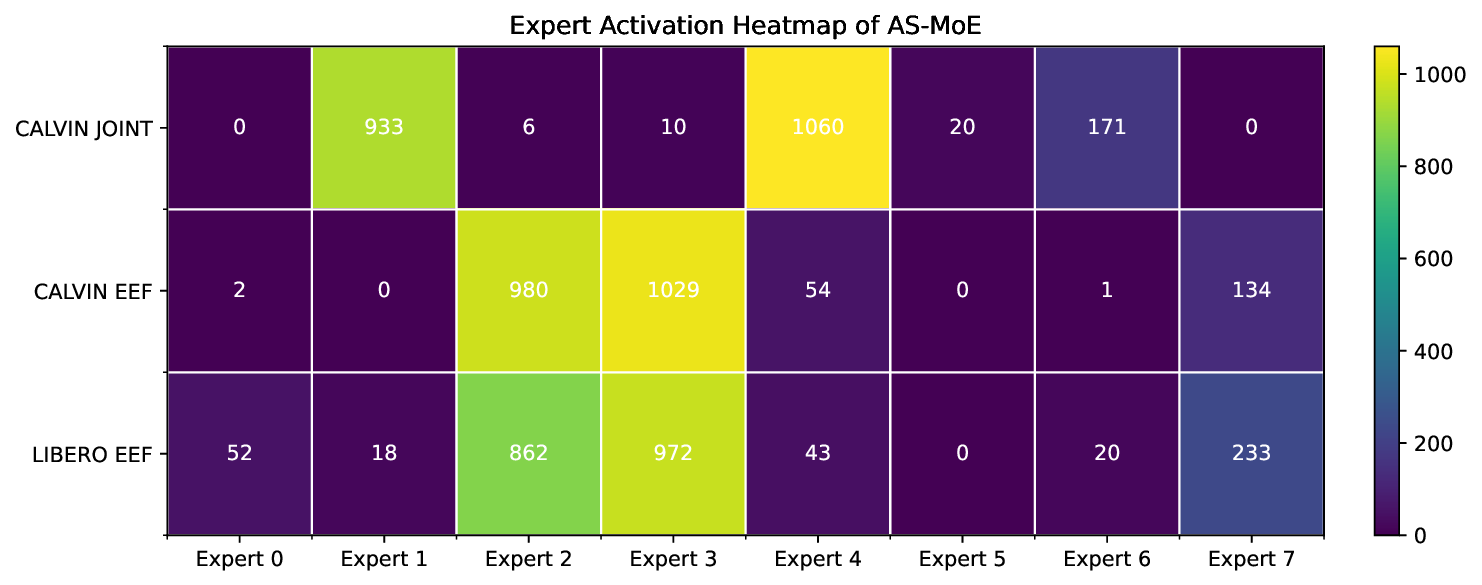
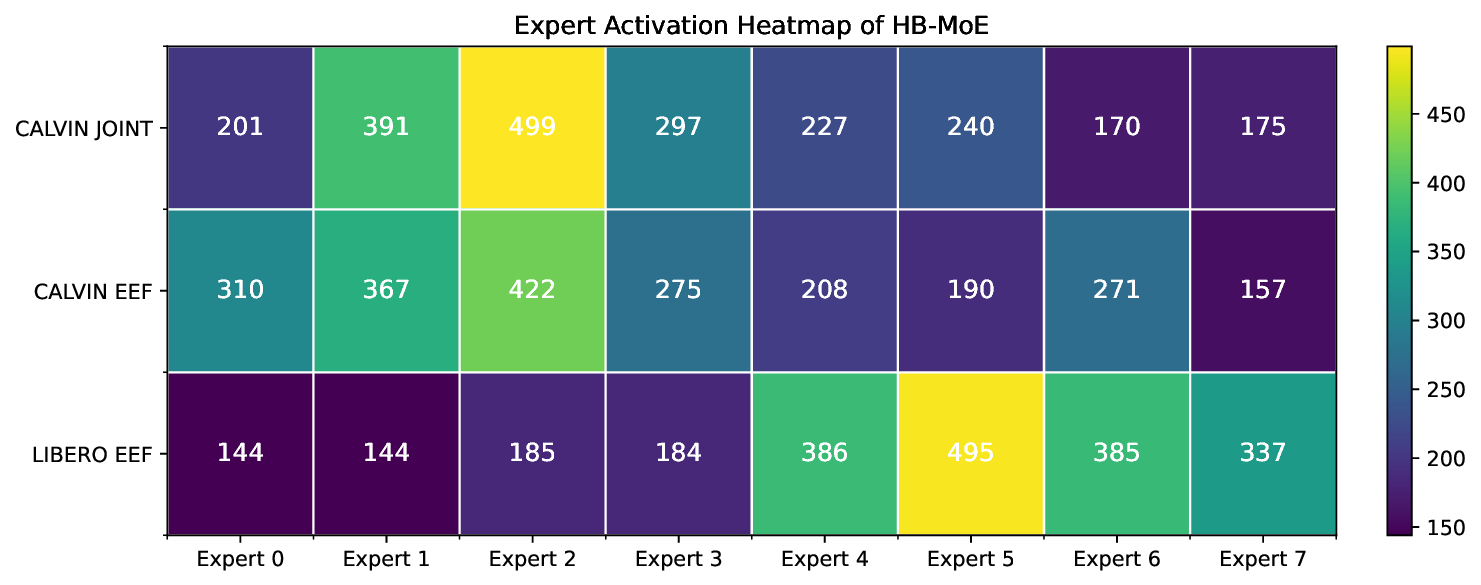
The HiMoE itself is composed of two key expert modules-Action-Space MoE (AS-MoE) and Heterogeneity-Balancing MoE (HB-MoE)-interleaved with standard Transformer blocks (see Fig. 2 for details). The AS-MoE operates at shallow layers to specialize in action-space-specific processing, ensuring that variations such as joint-based versus end-effector-based control are effectively captured. The HB-MoE, in contrast, functions at the adjacent layers to progressively abstract heterogeneous factors and balance representation learning across diverse embodiments, thereby consolidating the information into shared knowledge.
At each layer, the expert outputs are fused with intermediate key-value (KV) representations extracted from the PaLI-Gemma backbone, enabling the model to integrate low-level visual cues with high-level semantic information throughout the hierarchy. This layer-wise fusion provides rich contextual conditioning: shallow layers achieve effective specialization, while deeper layers promote stronger generalization and transfer across tasks and embodiments. Finally, the fused representations are used to generate denoised action chunks under the flow-matching (Lipman et al., 2022) training objective.
The training objective of HiMoE-VLA consists of three components: a flow-matching loss for learning action distributions, an Action-Space Regularization (AS-Reg) to enhance expert specialization in the AS-MoE, and a Heterogeneity-Balancing Regularization (HB-Reg) to encourage balanced abstraction in the HB-MoE. The overall objective is given by:
where λ AS and λ HB control the relative contributions of the two regularization terms. Below, we elaborate on each loss in detail.
Flow-Matching Loss. We adopt the flow-matching objective (Lipman et al., 2022) to model the conditional distribution of action sequences, as it provides a more stable and efficient alternative to traditional diffusion training. Given an action chunk A t = [a t , a t+1 , . . . , a t+H-1 ], flow matching defines a continuous-time trajectory that transports a noise distribution to the target action distribution. Specifically, we define perturbed actions as:
where τ is the flow-matching timestep. The model then learns a vector field v θ that predicts the denoising direction:
where o t denotes the visual observation, l the language instruction, and q t the proprioceptive state.
During training, τ is sampled from a Beta distribution, following practices in recent work such as Black et al. (2024), to emphasize noisier steps and thereby improve robustness. At inference time, future actions are generated by integrating the learned vector field from τ = 0 to τ = 1, starting from Gaussian noise. Action-Space Regularization (AS-Reg). The AS-MoE, located at shallow layers of the H-MoE, is designed to capture fine-grained variations in action spaces, such as differences between jointbased and end-effector-based control. To reinforce this specialization, we introduce an Action-Space Regularization (AS-Reg) based on a contrastive objective. Let u ∈ {1, . . . , U } index tokens in the input sequence. For each token u, we treat pairs of experts (i, j) assigned to the same action-space token as positive pairs, while pairs (i, k) with k ̸ = j are considered negatives. Denote by h i,u the score produced by expert i for token u. The loss is defined as
where τ is a temperature parameter, N is the number of experts, and sim(•, •) denotes cosine similarity. By encouraging agreement among experts routed to the same action-space tokens while reducing similarity to others, this objective guides AS-MoE experts toward targeted specialization, ensuring that action-space heterogeneity is effectively captured at shallow layers.
Heterogeneity-Balancing Regularization (HB-Reg). The HB-MoE, in contrast, functions in deeper layers to progressively abstract broader sources of heterogeneity-spanning robot embodiments, sensor configurations, and scene variations-and to consolidate them into shared knowledge.
To support this role, we introduce Heterogeneity-Balancing Regularization (HB-Reg).
Let N denote the number of experts, K the number of routed experts per token (top-K gating), U the number of tokens in the sequence, and s i,u ∈ [0, 1] the gating score assigned to expert i for the u-th token. After top-K selection, we define a binary routing indicator r i,u = 1{token u is routed to expert i}.
The (empirical) routing frequency and the expected routing probability for expert i are defined as
The heterogeneity-balancing loss is then defined as
This objective ensures that the expected routing probability (P i ) and the realized routing frequency (f i ) are aligned, thus distributing heterogeneous inputs more evenly across experts. In doing so, HB-Reg prevents expert underutilization and promotes balanced abstraction at deeper layers, enabling the HB-MoE to consolidate diverse information into generalizable shared representations.
In summary, AS-Reg drives specialization in the AS-MoE for capturing action-space differences at shallow layers, while HB-Reg enforces balancing in the HB-MoE for integrating heterogeneous factors at deeper layers. Together with the flow-matching loss, these objectives enable HiMoE-VLA to learn expressive and transferable policies from highly diverse robotic data. This combination provides diverse embodiments, action spaces, and tasks, enabling effective crossdomain learning. More details are provided in the Appendix A.1
Implementation Details. HiMoE-VLA (4B parameters) is trained end-to-end on 16 A100 GPUs with DeepSpeed optimization. The model consumes third-person and wrist-mounted camera views, along with unified state-action vectors for both single-and dual-arm settings. All heterogeneous actions and states are mapped into a fixed 24-dimensional vector, consisting of 8-dimensional endeffector actions and 16-dimensional joint angles. For states, a validity mask is concatenated to indicate which segments are active; actions are not masked but zero-padded if a particular type is absent. The MoE design uses N = 32 experts with top-k = 4, and the auxiliary regularization coefficients are set following best practices. For the MoE gating mechanism, each token’s hidden state is fed into a linear projection to compute the expert logits. These logits are normalized via a standard softmax without temperature scaling, producing a distribution over experts. The gate selects the top-k experts based on these scores, and the selected probabilities are renormalized so that their weights sum to one. This design ensures stable routing and well-scaled mixture coefficients throughout training. More details are provided in Appendix B.
Experiment setup. We evaluate HiMoE-VLA on two widely used simulation benchmarks: CALVIN (Mees et al., 2022) and LIBERO (Liu et al., 2023a). CALVIN benchmarks instructionconditioned, long-horizon tabletop manipulation with a Franka Panda arm. We adopt the challenging D→D setting, training on a limited subset of demonstrations and evaluating on held-out instructions, with comparisons against strong baselines including Octo, OpenVLA, RDT-1B, DeeR, MDT, and π 0 .
LIBERO is a simulation suite for lifelong learning and generalization, spanning four complementary task suites-Spatial, Object, Goal, and Long-each with 10 tasks. We follow standard preprocessing These results highlight HiMoE-VLA’s ability to maintain reliable performance as task sequences grow longer, validating its effectiveness for instruction-conditioned manipulation under limited data.
Table 2 presents results on the four LIBERO task suites. HiMoE-VLA achieves the highest overall average score of 97.8%, outperforming strong generalist baselines such as UniVLA (95.2%) and π 0 (94.2%). Compared to OpenVLA-OFT, the previous state-of-the-art (97.1%), HiMoE-VLA delivers consistent gains across all four suites: +0.6% on Spatial, +1.0% on Object, +0.7% on Goal, and +0.3% on Long. These results establish HiMoE-VLA as the new SOTA on LIBERO, demonstrating robust generalization across diverse manipulation tasks, including long-horizon planning.
We evaluate our model on two real-world robots: xArm7 single-arm and Aloha dual-arm robots.
Experiment setup. For the xArm7 (single-arm, 7-DoF with a 1-DoF gripper), we evaluate three manipulation tasks: (1) Fruit-to-Plate -placing fruits (apple, orange) onto colored plates (blue, pink);
(2) Cup-in-Cup -inserting one colored cup (red, yellow, blue) into another; and (3) Block-on-Block -stacking one colored block onto another of a different color. Each task is further decomposed into sub-stages (e.g., Pick/Place, Pick/Insert, Pick/Stack). We collect a total of 320 teleoperated demonstrations: 80 for Fruit-to-Plate, 120 for Cup-in-Cup, and 120 for Block-on-Block, with 20 demonstrations per configuration. For evaluation, Fruit-to-Plate uses 4 settings with 4 trials each, while Cup-in-Cup and Block-on-Block each use 6 settings with 3 trials each. We additionally assess generalization with two tests: (1) introducing distractor objects such as an unseen pomegranate or green cup, and (2) novel-object tasks such as placing fruit on a purple plate not seen during training.
For the Aloha (dual-arm, 14-DoF), we evaluate three tasks: (1) Fold-Shorts -folding a pair of shorts with 50 teleoperated demonstrations; (2) Cup-Handover -the right arm grasps a colored cup (red, yellow, blue) and hands it to the left arm, which places it on a plate (180 demonstrations total); and (3) Scoop -the left arm positions a bowl and the right arm scoops materials (mung beans, black rice, sticky rice) into it (120 demonstrations total). Altogether, 350 demonstrations are collected. Evaluation includes 15 trials for Fold-Shorts, 5 trials per color for Cup-Handover, and 5 trials per material type for Scoop. For generalization, we test ( 1) distractor objects such as bananas or green apples in Scoop, and ( 2) novel shorts in Fold-Shorts.
Put the yellow cup into the red cup.
Place the yellow block on top of the red block.
Pick up the blue cup, switch hands, and place it on the plate.
Place the bowl in the middle of the table, then scoop the glutinous rice with a spoon. Results. On the xArm7, HiMoE-VLA achieves the best overall average success rate of 75.0%, outperforming strong baselines such as π 0 (62.5%) and CogACT (61.5%). Gains are consistent across sub-stages, with particularly notable improvements on the challenging Block-on-Block task, where HiMoE-VLA reaches 50.0% success in the stacking stage compared to 33.3% for π 0 and CogACT. In the generalization tests (Table 5), HiMoE-VLA achieves 67.6% average success, again outperforming π 0 (55.9%) and CogACT (51.5%), demonstrating robustness to unseen distractors (e.g., pomegranate, green cup) and novel objects (e.g., purple plate).
On the Aloha, HiMoE-VLA consistently surpasses π 0 and RDT-1B across all three tasks (Table 4), with particularly large improvements on Fold-Shorts and Scoop, highlighting the strength of hierarchical experts in coordinated bimanual manipulation. In generalization evaluations (Table 5), HiMoE-VLA achieves the best overall performance, demonstrating resilience to unseen distractors (e.g., banana, green apple) in Scoop and novel shorts in Fold-Shorts.
We perform a set of experiments and ablations on the CALVIN benchmark to analyze the contributions of different components in HiMoE-VLA and assess its ability to handle heterogeneous data.
Effect of Initialization and Pretraining. Table 6 (a) compares models fine-tuned on CALVIN-D with different initialization strategies. Removing MoE re-initialization during fine-tuning (w/o init) slightly degrades performance compared to the full model, while training from scratch without pretrained weights (w/o pretrain) leads to a more notable drop. These results highlight the importance of leveraging pretrained representations and carefully initialized experts for effective adaptation in data-scarce regimes. Aloha datasets. To complement OXE, we incorporate demonstrations from three high-quality, publicly available Aloha datasets (Liu et al., 2024;Zhao et al., 2023;Fu et al., 2024), contributing 36.28M frames in total. Compared to OXE, they emphasize coordinated bimanual actions and higher-fidelity manipulation skills, substantially enriching the diversity of our training corpus.
CALVIN benchmark. CALVIN (Mees et al., 2022) is a benchmark for evaluating instructionconditioned policies in long-horizon tabletop manipulation tasks using a Franka Panda arm. It comprises 34 tasks spanning from simple pick-and-place to articulated object manipulation. In our experiments, we adopt the challenging D → D setting, where policies are trained on a limited subset of demonstrations from environment D and evaluated on held-out instruction sequences in the same block, e.g., “Place the yellow block on top of the red block.” Each task is decomposed into sub-stages (e.g., Pick/Place, Pick/Insert, Pick/Stack) for fine-grained evaluation. We collect 320 teleoperated demonstrations in total: 80 (Fruit-to-Plate), 120 (Cup-in-Cup), and 120 (Block-on-Block), with 20 demonstrations per configuration.
In-distribution evaluation. Fruit-to-Plate: 4 settings × 4 trials/setting = 16 trials in total, where each “setting” is a fruit-plate pairing from {apple, orange} × {blue, pink}. Cup-in-Cup: 6 settings × 3 trials/setting = 18 trials, where each “setting” is an ordered inner→outer color pair from {red, yellow, blue} with distinct colors (i.e., 3 × 2 = 6 ordered pairs). Block-on-Block: 6 settings × 3 trials/setting = 18 trials, where each “setting” is an ordered top→bottom color pair (distinct) from {red, yellow, blue}.
(1) Distractors in Cup-in-Cup: 6 settings (the 6 inner→outer color pairs as above) × 3 trials/setting = 18 trials, with an unseen distractor (e.g., a pomegranate or a green cup) placed in the scene. ( 2) Novel objects in Fruit-to-Plate: 4 settings × 4 trials/setting = 16 trials.
Here, “4×4” means that we test four novel configurations -placing a pomegranate onto a blue plate, a pomegranate onto a pink plate, an apple onto a purple plate, and an orange onto a purple plate -with each configuration repeated for 4 trials.
Real-world Aloha benchmark. We further evaluate on the Aloha robot (dual-arm, 14-DoF) with three tasks: (1) Fold-Shorts -folding a pair of shorts (50 teleoperated demonstrations), e.g., “Fold black shorts through multiple bimanual folds”; (2) Cup-Handover -the right arm grasps a colored cup (red, yellow, blue) and hands it to the left arm to place on a plate (60 demos per color; 180 total), e.g., “Pick up the blue cup, switch hands, and place it on the plate”; (3) Scoop -the left arm places a bowl centrally, then the right arm uses a spoon to scoop materials (mung beans, black rice, sticky rice) into the bowl (40 demos per material; 120 total), e.g., “Place the bowl in the middle of the table, then scoop the glutinous rice with a spoon.” Altogether, 350 demonstrations are collected.
In-distribution evaluation. Input modalities. The visual encoder consumes one third-person camera view together with two wrist-mounted views. When a view is unavailable in a dataset, the corresponding channel is zeropadded and masked using attention masks, ensuring a consistent input format. For state and action inputs, we construct a unified vector representation that jointly accommodates both joint-angle and end-effector signals. In single-arm demonstrations, the available arm is mapped to the right-arm channel, while the left-arm channel is zero-padded with masks to preserve compatibility with dualarm settings.
Mixture-of-Experts design. We set the number of experts to N = 32 with a top-k routing of 8. As shown in Table 6, this configuration consistently outperforms alternative settings in terms of both average performance and stability, striking a favorable balance between model capacity and computational efficiency. To encourage effective expert utilization and hierarchical abstraction, we introduce two auxiliary regularizations: an Action-Space regularization term with coefficient λ AS = 0.002, and a Heterogeneity-Balancing regularization term with coefficient λ HB = 0.001. These choices follow best practices for balancing specialization and generalization in MoE architectures.
The virtualization of all tasks are shown in Fig. 6 and Fig. 7.
Pre-training Dataset. We pre-train HiMoE-VLA on a large-scale mixture of the Open X-Embodiment (OXE) subset (O’Neill et al., 2024) (22.5M frames) and publicly available Aloha datasets(Liu et al., 2024;Zhao et al., 2023;Fu et al., 2024) (1.6M frames), totaling 24.1M frames.
Pre-training Dataset. We pre-train HiMoE-VLA on a large-scale mixture of the Open X-Embodiment (OXE) subset (O’Neill et al., 2024) (22.5M frames) and publicly available Aloha datasets(Liu et al., 2024;Zhao et al., 2023;Fu et al., 2024)
Pre-training Dataset. We pre-train HiMoE-VLA on a large-scale mixture of the Open X-Embodiment (OXE) subset (O’Neill et al., 2024) (22.5M frames) and publicly available Aloha datasets
bustness in long-horizon execution. Compared to π 0 (3.76), which is among the strongest baselines, HiMoE-VLA improves by +0.18, and compared to MDT (3.72), by + 0.21. The gap is even larger against earlier methods such as DeeR (2.83), RDT-1B (2.04), Octo(1.97), and OpenVLA (1.41).
bustness in long-horizon execution. Compared to π 0 (3.76), which is among the strongest baselines, HiMoE-VLA improves by +0.18, and compared to MDT (3.72), by + 0.21. The gap is even larger against earlier methods such as DeeR (2.83), RDT-1B (2.04), Octo(1.97), and OpenVLA (1.41)
bustness in long-horizon execution. Compared to π 0 (3.76), which is among the strongest baselines, HiMoE-VLA improves by +0.18, and compared to MDT (3.72), by + 0.21. The gap is even larger against earlier methods such as DeeR (2.83), RDT-1B (2.04), Octo
out architectural changes. To further validate the efficiency of HiMoE, we co-train models from scratch on CALVIN-ABC-EEF and CALVIN-D-Joint. As shown in the table, both variants underperform our method, demonstrating the effectiveness of HiMoE in modeling heterogeneous action data. Such entangled heterogeneity makes it difficult for the gating network to learn consistent routing patterns and negatively affects the convergence of the MoE.
📸 Image Gallery