ChipMind: Retrieval-Augmented Reasoning for Long-Context Circuit Design Specifications
📝 Original Info
- Title: ChipMind: Retrieval-Augmented Reasoning for Long-Context Circuit Design Specifications
- ArXiv ID: 2512.05371
- Date: 2025-12-05
- Authors: Changwen Xing, SamZaak Wong, Xinlai Wan, Yanfeng Lu, Mengli Zhang, Zebin Ma, Lei Qi, Zhengxiong Li, Nan Guan, Zhe Jiang, Xi Wang, Jun Yang
📝 Abstract
While Large Language Models (LLMs) demonstrate immense potential for automating integrated circuit (IC) development, their practical deployment is fundamentally limited by restricted context windows. Existing context-extension methods struggle to achieve effective semantic modeling and thorough multi-hop reasoning over extensive, intricate circuit specifications. To address this, we introduce ChipMind, a novel knowledge graph-augmented reasoning framework specifically designed for lengthy IC specifications. Chip-Mind first transforms circuit specifications into a domainspecific knowledge graph (ChipKG) through the Circuit Semantic-Aware Knowledge Graph Construction methodology. It then leverages the ChipKG-Augmented Reasoning mechanism, combining information-theoretic adaptive retrieval to dynamically trace logical dependencies with intentaware semantic filtering to prune irrelevant noise, effectively balancing retrieval completeness and precision. Evaluated on an industrial-scale specification reasoning benchmark, ChipMind significantly outperforms state-of-the-art baselines, achieving an average improvement of 34.59% (up to 72.73%). Our framework bridges a critical gap between academic research and practical industrial deployment of LLM-aided Hardware Design (LAD).📄 Full Content
To address this challenge, two dominant paradigms exist for extending the context window of LLMs: monolithic long-context models, which leverage techniques like RoPE (Ding et al. 2024) and fine-tuning (Chen et al. 2023); and Retrieval-Augmented Generation (RAG) (Wang et al. 2024) methods. However, both approaches commonly suffer from the “lost-in-the-middle” phenomenon (An et al. 2024): LLMs tend to over-rely on local context while neglecting the overall document structure and cross-module logical connections. This issue is particularly acute in chip design, since the very nature of a chip specification is a tightly-coupled logical chain that spans the entire document. Consequently, any fragmented understanding leads to significant inaccuracies or failures in downstream tasks.
Recently, Knowledge Graph (KG)-based RAG (Pan et al. 2024) has been explored to enhance global context perception by LLMs. However, we identify two fundamental limitations when applying these approaches to IC technical documentation: 1) Insufficient Semantic Modeling Capability for Complex IC Documentation: General-purpose KG construction techniques lack the domain-specific semantic precision required to accurately and comprehensively capture intricate interrelations of entities within IC documents. An incomplete and imprecise KG leads to reduced retrieval accuracy, thereby impairing subsequent reasoning performance. 2) Retrieval Completeness Bottleneck in Multi-Hop Reasoning: Tracing chip logic often requires following signal chains across modules, demanding complete contextual coverage. However, the commonly used fixed Top-K retrieval mechanism lacks the adaptability to support intermediate reasoning steps. As a result, critical information is often missed, a failure mode that becomes particularly pronounced in complex multi-hop reasoning tasks.
Ultimately, the core bottleneck in LAD has shifted from how to generate code to how to enable LLMs to perform deep comprehension and reasoning over vast specifications.
To overcome this core bottleneck, we introduce Chip-Mind: a knowledge graph-augmented reasoning framework tailored for long IC specifications. ChipMind explicitly parses intricate entity-semantic relationships within chip specifications, reconstructing them into a domainspecific knowledge graph (ChipKG), and employs a Graph-Augmented Reasoning mechanism with adaptive retrieval. This enables LLMs to iteratively query ChipKG, emulating human experts to accurately explore and verify deep dependency paths. Comprehensive experiments on a newly introduced benchmark for industrial-scale specification reasoning demonstrate significant and consistent advantages of ChipMind, achieving an average improvement of 34.59% over state-of-the-art baselines, with a maximum performance gain of 72.73% compared to GraphRAG (Edge et al. 2024). Our primary contributions are as follows:
- We are the first to systematically identify and address the core reasoning bottleneck for LLMs in industrial chip design. 2 Related Work
Large Language Models (LLMs) are increasingly being applied to automate IC development (Chang et al. 2024;Fu et al. 2023;Xu et al. 2025). Seminal works have demonstrated feasibility in generating HDL and HLS code (Pei et al. 2024;Wang et al. 2025a;Wong et al. 2024;Niu et al. 2025;Li et al. 2025a;Ye et al. 2025b;Wan et al. 2025b), creating SystemVerilog Assertions or testbenches (Ye et al. 2025a;Hu et al. 2024), and debugging (Xu et al. 2024;Wang et al. 2025b;Yao et al. 2024;Wan et al. 2025a). However, these methods typically operate on isolated, self-contained code snippets and have limited capability to comprehend the cross-document dependencies inherent in industrial-scale circuit specifications. In contrast, our work is specifically designed to enable reasoning across the entire design documentation.
RAG is the standard paradigm for grounding LLMs in external documents, but existing methodologies are ill-suited for the highly relational nature of circuit specifications.
Standard RAG. Conventional RAG, whether based on sparse (e.g., BM25 (Robertson, Zaragoza et al. 2009;Trotman, Puurula, and Burgess 2014)) or dense retrieval (Zhao et al. 2024;Zhan et al. 2021), relies on semantic similarity. This approach is effective for single-hop, fact-based queries but fundamentally fails to model the multi-hop logical dependencies in hardware design. Consequently, it often retrieves a mixture of relevant but functionally incongruous information, derailing the reasoning process.
Knowledge Graph-Augmented RAG (KG-RAG). To imbue retrieval with structural awareness, recent works augment RAG with KGs. However, existing methods still lack the requisite precision for the IC domain. For instance, GraphRAG (Edge et al. 2024;Han et al. 2024) relies on LLM-generated summaries, which risks abstracting away the fine-grained details essential for technical accuracy. To address this loss of granularity, HippoRAG 2 (Gutiérrez et al. 2025) innovatively incorporates raw document chunks as nodes directly into the graph. However, its reliance on generic OpenIE techniques yields entity triples that are too coarse to model the complex relationships between entities in circuit specifications. These collective limitations underscore the need for a new KG-RAG paradigm. To this end, we introduce a framework tailored to the unique semantics of chip design, one that constructs a semantically rich and structurally deep knowledge graph.
Frameworks like Chain-of-Thought (CoT) (Wei et al. 2022;Lyu et al. 2023) and Tree-of-Thought (ToT) (Yao et al. 2023a;Long 2023) improve LLM reasoning by decomposing problems into intermediate steps. Integrated approaches such as IRCoT (Trivedi et al. 2023) and ReAct (Yao et al.
{[“VSVertexDeq”, “is”, “active”],
[“VIVSBufCE”, “is”, “asserted”],
[“VIVSBufCE”, “when”, “VSVertexDeqisactive”],
[“VIVSBufCE”, “when”, “IncVIVSNumisactive”, [“VSVertexDeqisactive”, “relates”,“VSVertexDeq”] } {[“VSVertexDeq”, “is”, “active”],
[“VIVSBufCE”, “is”, “asserted”],
[“VIVSBufCE”, “when”, “VSVertexDeqisactive”],
[“VIVSBufCE”, “when”, “IncVIVSNumisactive”, [“VSVertexDeqisactive”, “relates”,“VSVertexDeq”] } ) require the reasoning paths to be explicitly predefined. This is incompatible with chip development, where crucial dependencies are often implicit and must be dynamically discovered through iterative exploration. Therefore, our framework departs from these static approaches by introducing a dynamic reasoning process where retrieval and reasoning are synergistically intertwined, allowing the model to actively uncover latent dependencies on-the-fly.
3 Methodology
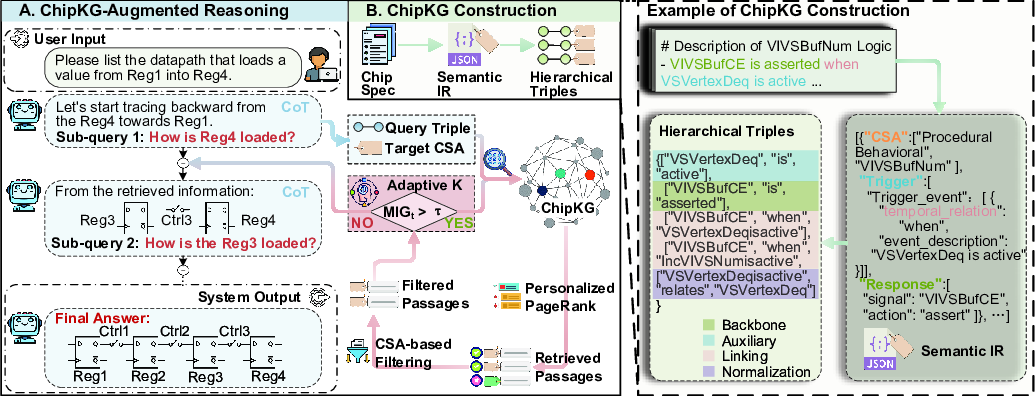
To enable deep, multi-hop reasoning over complex Integrated Circuit (IC) design specifications, we propose Chip-Mind, a two-stage framework (shown in Figure 2):
In the first stage, the Circuit Semantic-Aware Knowledge Graph construction methodology is employed. Specifically, semantic content is transformed into a semantic intermediate representation (IR) by functional categorization, and Circuit Semantic Anchors (CSAs) are extracted to identify design intents. Based on semantic IR, structured triples are derived through the Hierarchical Triple Extraction schema, forming a domain-specific Chip Knowledge Graph (ChipKG).
In the second stage, reasoning proceeds through dynamic interactions with ChipKG. When encountering incomplete knowledge during reasoning, the system generates targeted sub-queries, retrieves relevant knowledge graph nodes via vector-similarity matching, and refines their relevance through Personalized PageRank (PPR). Retrieval precision and completeness are further enhanced by employing the adaptive Top-K retrieval strategy based on marginal information gain, along with a CSA-guided semantic filtering layer to eliminate semantic noise from lexically similar yet irrelevant nodes. This structured integration of knowledge and adaptive reasoning systematically decomposes intricate IC reasoning tasks into transparent, traceable steps.
Accurate reasoning over chip specifications requires precise modeling of chip design semantics. However, as discussed in the introduction, generic methods fall short in capturing complex, hierarchical semantic relations within IC documents. Therefore, we propose the Circuit Semantic-Aware Knowledge Graph Construction methodology, which explicitly deconstructs and reconnects semantic relationships within circuit documents via a tailored paradigm, enabling comprehensive and robust IC domain-specific knowledge graph (ChipKG) construction. A detailed illustration of this methodology is provided in Figure 2.
Circuit Semantic Anchoring and Categorization. We observe that sentences in IC specifications serve two primary functions:
• Declarative Functional Description: Describes static properties and definitions, such as module composition, register fields, and signal functions. • Procedural Behavioral Description: Delineates dynamic logic and behavior, such as state transitions, conditional triggers, and signal assignments.
Based on this classification, we utilize specialized parsing templates: declarative descriptions are parsed into central entities and their attributes, while procedural descriptions yield structured “trigger-condition-action” logic. Each sentence is first deconstructed into a concise JSON-based semantic intermediate representation (IR) and distilled into a Circuit Semantic Anchor (CSA). While the IR provides finegrained details for subsequent triple extraction, the CSA acts as a high-level semantic filter to facilitate efficient downstream reasoning.
To trace complex multi-hop dependencies inherent in chip specifications, we propose ChipKG-Augmented Reasoning, enabling the LLM to iteratively query ChipKG. This dynamic interaction is driven by two novel components: (1) Adaptive Top-K Retrieval for comprehensive evidence collection, and (2) Semantic Anchor-Guided Filtering for precise noise reduction. This synergy improves the signal-tonoise ratio for more reliable and interpretable reasoning.
Information-Theoretic Adaptive Top-K Retrieval. As discussed in Section 1, a fundamental challenge in RAG is the static retrieval number, K: a small K misses crucial information, while a large K introduces noise. We thus propose adaptively expanding the retrieval set until marginal utility diminishes.
Formalism. We model the LLM’s belief state as a posterior probability distribution P (A|C t ) over the answer space A, conditioned on context C t = (Q, S t ), where Q is the query and S t is the current document set. The value of new information ∆S, is measured by its impact on this belief state. We quantify this impact using the Kullback-Leibler (KL) divergence and define the Marginal Information Gain (M IG) as:
A significant M IG indicates that ∆S provides novel, decision-relevant evidence, whereas a near-zero value implies redundancy and signals retrieval termination.
Iterative Retrieval Algorithm. As detailed in Algorithm 1, the context set S is iteratively expanded with evidence nodes retrieved from the ChipKG. Since directly computing P (A|C) is infeasible, we approximate Marginal Information Gain (MIG) by prompting the LLM to summarize contexts with (A ′ new ) and without (A ′ base ) new nodes. The MIG at each iteration is then estimated as the cosine distance between their embeddings:
We terminate the retrieval once M IG t drops below a threshold τ , indicating diminishing returns. end if 14: end for CSA-based Semantic Filtering. While adaptive retrieval ensures evidence completeness, it can also introduce functionally irrelevant information. To maintain retrieval precision, we introduce a semantic filtering layer guided by Circuit Semantic Anchors (CSAs). Specifically, for each query or sub-task Q, we prompt the LLM to infer the query’s intent by generating a target anchor CSA target = (type target , entity target ).
The candidate set S cand is pruned to form the final context S f inal by retaining only nodes whose anchors exactly match the target anchor CSA target :
This precise filtering removes irrelevant information, enhancing signal-to-noise ratio for downstream reasoning.
ChipKG-Augmented Reasoning Workflow. We integrate the preceding components into our ChipKG-Augmented Reasoning framework (Algorithm 2).
An iterative loop begins by reasoning on the current context and introspectively detecting knowledge gaps. Once a gap is identified, ChipMind formulates a targeted sub-query, retrieves relevant evidence from ChipKG, and integrates refined evidence back into reasoning. This loop repeats until sufficient context is collected to synthesize a final, grounded answer.
Our framework advances existing multi-step retrieval methods in two key aspects: we replace static, fixed-K retrieval with a dynamic, information-theoretic strategy to optimize context size, and elevate filtering from shallow semantic matching to intent-level precision using CSA-guided functional alignment. This synergy improves the signal-tonoise ratio for more reliable and interpretable reasoning.
Traditional n-gram overlap metrics (e.g., ROUGE) struggle with semantic variations, while modern metrics like BERTScore improve semantic matching but still fail to reliably evaluate factual correctness-often misled by plausible hallucinations or partially correct statements. The core of our approach is a two-part decomposition: first, human experts decompose the reference answer y into a set of minimal, self-contained semantic “atomic facts” A ref = {a 1 , a 2 , …, a n }. In parallel, a powerful LLM similarly decomposes the generated answer ŷ to produce the set A gen . An LLM semantic judge then identifies correct matches A matched via semantic equivalence:
Finally, drawing from classic information retrieval, precision, recall, and F1-score quantify factual correctness, completeness, and balanced semantic fidelity, respectively:
To rigorously evaluate ChipMind, we introduce a challenging benchmark specifically designed for industrial-scale Integrated Circuit (IC) specifications. We systematically compare our framework against strong baselines, evaluating performance using our proposed Atomic-ROUGE metric. Furthermore, we also validate the effectiveness and reliability of Atomic-ROUGE itself.
Benchmark. Current benchmarks for LLM-aided hardware design (LAD) fall short of reflecting the scale and complexity of real-world chip specifications. To address this limitation, we propose SpecEval-QA, a novel question-answering benchmark derived from a comprehensive, industrial-grade specification of a High-Performance Compute and Interconnect Macro-block (51k tokens). 1) designed to test long circuit specification comprehension and reasoning over 1∼12 reasoning hops. Critically, each question is rigorously annotated with a gold answer, associated atomic facts, and corresponding ground-truth supporting passages. Such detailed annotations enable a fine-grained verification of factual correctness and reasoning pathways, forming the basis for our new metrics.
Baselines. Since no existing end-to-end frameworks directly address this task, we comprehensively evaluate Chip-Mind against three categories of strong baselines:
• Vector RAG: The standard vector-based retrieval methods (BGE-M3 (Chen et al. 2024)) with state-of-the-art (SOTA) LLMs (see Model Selection and Fairness for details), representing the conventional RAG approach. • KG-RAG: Advanced KG-enhanced methods, including GraphRAG (Edge et al. 2024), HippoRAG 2 (Gutiérrez et al. 2025), and LightRAG (Guo et al. 2024), to assess our domain-specific ChipKG against generic graphbased solutions. • Reasoning-Augmented Framework: Advanced reasoning-driven approaches like ReAct (Yao et al. 2023b), IRCoT (Trivedi et al. 2023), and Search-o1 (Li et al. 2025b), specifically benchmarking the effectiveness of ChipMind’s KG-augmented reasoning against contemporary reasoning strategies.
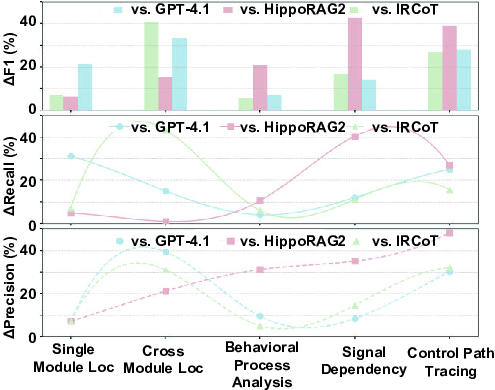
Model Selection and Fairness. We select several toptier LLMs, including: SOTA closed-source models, GPT-4.1 (OpenAI 2025) and Claude-4 (Anthropic 2025); a strong open-source baseline Llama-4-scout (Meta 2025); and a reasoning-optimized open-source model DeepSeek-R1 (Guo et al. 2025). Because experimental results (Table 2) show that GPT-4.1 achieves the highest performance, we adopt it as the backbone across all KG-RAG and reasoningaugmented frameworks. This standardization ensures observed performance differences reflect framework design rather than LLM capability. The sole exception is Search-o1, whose reasoning process is tightly coupled with its native QwQ-32B-Preview (Qwen Team 2024) model. Addition- Prototyping and Implementation. ChipMind is designed as a model-agnostic framework, compatible with various capable LLMs. In our implementation, we selected DeepSeek-R1 as the core reasoning engine, given its proven effectiveness in logic-intensive tasks and open accessibility that ensures reproducibility. Tasks demanding strong instructionfollowing capabilities, such as ChipKG construction and Atomic-ROUGE evaluation, leveraged GPT-4.1. We set the sampling temperature to 0.7 for generative tasks and 0.2 for evaluation to improve stability and reproducibility. All experiments were performed on a server with dual Intel Xeon Platinum 8480+ CPUs and eight NVIDIA H20 GPUs (96 GB each). Overall Performance. To ensure robust evaluation, each method was executed 5 times, with each run assessed 20 times using Atomic-ROUGE. Outliers were removed via the 2σ rule before averaging. As summarized in Table 2, ChipMind achieves a SOTA mean F1-score of 0.95, outperforming all baselines by an average of 34.59% and a maximum gain of 72.73% compared to GraphRAG. Chip-Mind consistently surpasses the strongest baselines within each category, with improvements of 20.25% over GPT-4.1 (F1=0.79), 25% over HippoRAG 2 (F1=0.76), and 17.28% over IRCoT (F1=0.81).
Performance by Task Type. CoT, which rely on unstructured RAG. This advantage stems from ChipMind’s KG-enhanced retrieval for greater precision, coupled with adaptive iterative retrieval that ensures comprehensive context coverage and improved recall.
For complex reasoning tasks (behavioral processes, signal dependencies, control paths), ChipMind markedly surpasses HippoRAG 2’s single-round static retrieval by decomposing tasks into iterative, verifiable reasoning steps, capturing deep dependencies overlooked by single-step retrieval.
To isolate the source of ChipMind’s performance gains, we compare the retrieval completeness of vector-based RAG (BGE-M3), KG-RAG (HippoRAG 2), and ChipMind using System Recall@K, defined as the fraction of ground-truth passages retrieved during the entire reasoning process.
As shown in Fig. 4, ChipMind achieves near-perfect System Recall@20 of 99.2%, significantly outperforming single-pass methods HippoRAG 2 (86.8%) and BGE-M3 (70.5%). This confirms that the baselines’ lower performance primarily stems from incomplete evidence retrieval.
The performance gap arises from semantic mismatches in multi-hop queries, as initial queries are often semantically distant from intermediate evidence, causing single-pass retrieval to rank critical passages poorly. ChipMind bridges this gap via iterative sub-query generation, progressively aligning with intermediate evidence and elevating essential passages to top-ranked positions for complete retrieval.
To validate that Atomic-ROUGE aligns with human judgments, we compared its scores against expert ratings. Three senior chip engineers independently rated ChipMind outputs on 10-point scales for Semantic Fidelity and Answer
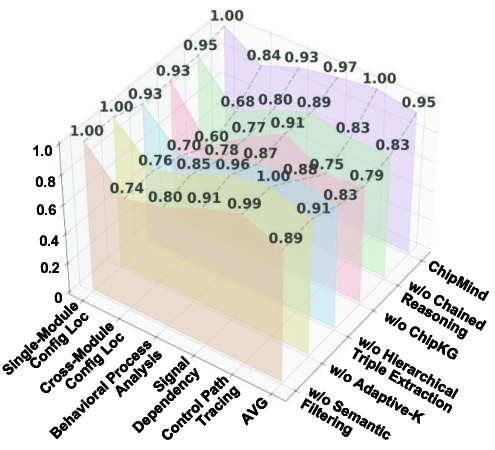
To quantify the contribution of each key component, we conducted four ablation studies, systematically disabling modules from the full ChipMind framework (Figure 5).
Contribution of ChipKG-Augmented Reasoning. Replacing the multi-turn loop with single-pass reasoning sharply decreases performance on multi-hop tasks, confirming the necessity of dynamic sub-query generation for complete evidence retrieval (Section 4.3). Notably, even the degraded single-pass variant (F1=0.83) surpasses KG-RAG baselines such as HippoRAG 2 (0.76), underscoring the inherent schema advantage of our domain-specific ChipKG.
Contribution of ChipKG. Replacing ChipKG with standard Vector RAG severely reduces precision on localization tasks. Further substituting our triple-extraction schema with OpenIE, although outperforming Vector RAG, remains inferior to the full system. This highlights our ChipKG schema’s crucial role in modeling the logic of chip specifications.
Contribution of Adaptive-K Retrieval. The adaptive-K mechanism is the most critical for cross-module configuration localization tasks, as dynamically expanding the search scope ensures comprehensive information coverage.
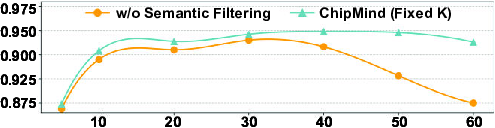
Contribution of Semantic Filtering. The CSA-guided filter mitigates context pollution, with performance sharply degrading as K increases without it, due to noise from irrelevant documents (Figure 6). In contrast, ChipMind maintains robust performance even at K = 50, highlighting the filter’s role in preserving signal-to-noise ratios and supporting larger retrieval budgets.
This paper introduced ChipMind, a graph-enhanced reasoning framework designed for the unique complexities of hardware specifications. ChipMind deconstructs implicit logic from specification text into an explicit Chip Knowledge Graph (ChipKG), and its graph-augmented engine enables an LLM to perform verifiable, multi-hop reasoning with high contextual sufficiency and precision. This work sheds light on how structured reasoning can enhance the viability of LLMs for industrial LLM-aided hardware design challenges.
📸 Image Gallery