Accurately predicting music popularity is a critical challenge in the music industry, offering benefits to artists, producers, and streaming platforms. Prior research has largely focused on audio features, social metadata, or model architectures. This work addresses the under-explored role of lyrics in predicting popularity. We present an automated pipeline that uses LLM to extract high-dimensional lyric embeddings, capturing semantic, syntactic, and sequential information. These features are integrated into HitMusicLyricNet, a multimodal architecture that combines audio, lyrics, and social metadata for popularity score prediction in the range 0-100. Our method outperforms existing baselines on the SpotGenTrack dataset, which contains over 100,000 tracks, achieving 9% and 20% improvements in MAE and MSE, respectively. Ablation confirms that gains arise from our LLM-driven lyrics feature pipeline (LyricsAENet), underscoring the value of dense lyric representations.
In 2023, the global recorded music market generated $28.6 billion 1 in revenue. With the advent of social media and streaming services, defining a single metric for music success has become increasingly challenging (Cosimato et al., 2019;Lee et al., 2020). Music popularity prediction can help the industry and artists forecast and optimize the potential success of newly composed songs.
Research in music popularity prediction has been driven by the advancements in machine learning with researchers applying classical ML approaches to predict popularity using acoustic features, and further with the growth of social networks, information about music consumers’ tastes capturing consumer response and their evolving music preferences (Seufitelli et al., 2023). Advancements in 1 IFPI Report ‘23 deep learning further sharpen the prediction model capability of capturing and learning complex patterns of evolving music taste, and researchers have worked on incorporating multiple modalities such as audio, lyrics and social metadata to predict song success (Zangerle et al., 2019;Martín-Gutiérrez et al., 2020). In all these works, the popularity score is typically defined as the time the song remains on the Billboard Top charts, and the evaluation metrics used include MAE, MSE, R 2 for regression, and accuracy, precision, recall, and F1 for classification. Recent developments in large language models have led to further research in music-related fields such as recommendation systems, sentiment/emotion analysis, data augmentation, understanding and composing song lyrics, using song lyrics text as the data source (Rossetto et al., 2023;Sable et al., 2024;Ma et al., 2024;Ding et al., 2024). Music Popularity Prediction research has still not fully exploited the power of lyrics in the models, while recent research have shown lyrics contributing significantly to song popularity (Yu et al., 2023). Through our work, we address the gap in the existing literature with the following main contributions:
-
A novel automated lyric feature extraction pipeline that uses LLMs to encode music lyrics into rich, learned representations. Details discussed in 3.4.2
-
An end to end multimodal deep learning architecture which predicts the popularity score in range (1,100) and outperformed current baseline by 9% and 20% in MAE and MSE metrics respectively. Details discussed in 3.4
The next section reviews related work. This is followed by a discussion of our methods, the dataset and our experiments. arXiv:2512.05508v1 [cs.SD] 5 Dec 2025 2 Related Work Music Popularity Prediction. Studied as a classification or regression problem in a supervised learning fashion, where a model learns to predict either binary class labels (hit or no-hit) or generate a continuous popularity score (Seufitelli et al., 2023). These predictions are derived using the song’s internal characteristics (audio and lyrics) and associated social factors like artist, genre, user demographics, etc. Song popularity is primarily measured using charts like Billboard 2 and UK Singles Charts 3 (Bischoff et al., 2009a;Askin and Mauskapf, 2017;Kim et al., 2014;Lee and Lee, 2018) , which rank songs based on sales, radio airplay, and streaming activity. Researchers determine success metrics based on these rankings, time on top charts, and other measures, including economic metrics like merchandise sales and user engagement metrics on social media and streaming services (Seufitelli et al., 2023).
Traditional research focused on using various machine learning techniques, including Logistic Regression, Decision Trees, Support Vector Machines (SVM), Bayesian Networks, Naive Bayes, Random Forest Ensemble, XGBoost, and K-Nearest Neighbors (KNN). These approaches advanced further to neural networks and deep learning techniques, building much stronger predictive models. A significant number of studies (Bischoff et al., 2009b;Dorien Herremans and Sörensen, 2014;Zangerle et al., 2019;Silva et al., 2022) focused on using acoustic characteristics of songs along with metadata that includes factors such as social influences. Other works such as (Dhanaraj and Logan, 2005;Singhi and Brown, 2015b;Martín-Gutiérrez et al., 2020) also emphasized the importance of song lyrics in determining song success using handcrafted text-based features that captured sentiment, emotions, and the syntactic structure of lyrics. These studies were often limited by their capabilities to capture central expressions of the song’s lyrics.
Multiple datasets have been released to drive research further and quench the thirst of data-heavy deep learning models. This includes Million Song Dataset 4 , SpotGenTrack 5 , and AcousticBrainz 6 sourced from different platforms like Spotify, Bill-2 Billboard Hot 100 3 Official Singles Chart Top 100 4 Million Song Dataset 5 SpotGenTrack 6 AcousticBrainz board, Genius7 , Youtube, and others. These datasets comprise a wide range of features, from low-level features like Mel-Frequency Cepstral Coefficients (MFCCs), lyrics text, and temporal features to high-level audio features such as danceability and loudness. Additionally, they include metadata on artists, albums, genres, demographics, and other relevant information.
Learned Representations of Lyrics. Lyrics form an integral part of music and carry a deep emotional meaning, which can strongly influence how listeners feel-sometimes even more than the song’s acoustic features alone (Singhi and Brown, 2015a). Yet, lyrics have often been overlooked as compared to acoustic attributes and social metrics of songs (Seufitelli et al., 2023). Earlier studies used methods like Probabilistic Latent Semantic Analysis (PLSA) (Hofmann, 1999) to capture the semantic content of lyrics, which helped researchers understand their role in defining a “hit” song (Dhanaraj and Logan, 2005). Later work moved beyond basic semantic analysis, focusing on more detailed features. For instance, (Hirjee and Brown, 2010) and (Singhi and Brown, 2014) relied on various rhyme and syllable characteristics to predict hit songs using only their lyrics, while other researchers applied Latent Dirichlet Allocation (LDA) (Blei et al., 2003) to discover thematic topics within lyrics (Ren et al., 2016).
Progress of deep learning techniques advanced the use of multimodal approaches that combine lyrics with audio and metadata, using stylometric analysis to extract lyric text features (Martín-Gutiérrez et al., 2020). Sentiment analysis also emerged as a way to glean emotional insights from lyrics when predicting popularity (Raza and Nanath, 2020). More recent research has turned to learned lyric representations, such as embeddings (Kamal et al., 2021;McVicar et al., 2022), which offer a more robust way to capture lyrical meaning. (Barman et al., 2019) demonstrated that these distributed representations can effectively predict both genre and popularity, reducing the need for handcrafted features. Datasets such as Music4All-Onion (Moscati et al., 2022) provide lyric embeddings that make it easier to study how lyrical content relates to a song’s success. Finally, a recent study found that a song’s lyrical uniqueness has a significant contribution towards its popularity (Yu et al., 2023), using TF-IDF for lyric vector representation; however, this approach inherently lacks the capacity to capture deeper sequential and contextual nuances, emphasizing the growing importance of learning robust, richer representations of lyrics to better understand what makes certain songs resonate with audiences.
To the best of our knowledge, there are limitations in existing literature for efficient automated lyrics feature extraction that are expressive and capture the underlying complexity of song lyrics. Thus, we have built a novel pipeline to exploit the power of Large Language Models. It has the potential to provide rich lyric representations that encapsulate both semantic and syntactic understanding, while preserving the sequential structure of the lyrics.
In this section, we provide the theoretical foundation of our approach. We begin by defining the problem of music popularity prediction in mathematical equations. This is followed by explaining the baseline approach and its implementation, including details of the dataset. Finally, we present a formal description of our proposed architecture.
Given a song S, its features are represented in a multi-dimensional space X ∈ R d , which comprises three key modalities: audio waveform w ∈ R k , lyrical text l ∈ R n , and metadata attributes m ∈ R p , where d = k + n + p represents the total dimensionality of our feature space. Our primary objective is to extract meaningful features from the song lyrics to effectively encode each song into a unique vector representation. Next, the prediction task is formulated as learning a mapping function f : X → Y, where we minimize the expected prediction error: E[(f (X) -Y ) 2 ] across the training distribution. Here, Y ∈ R represents the continuous popularity score.
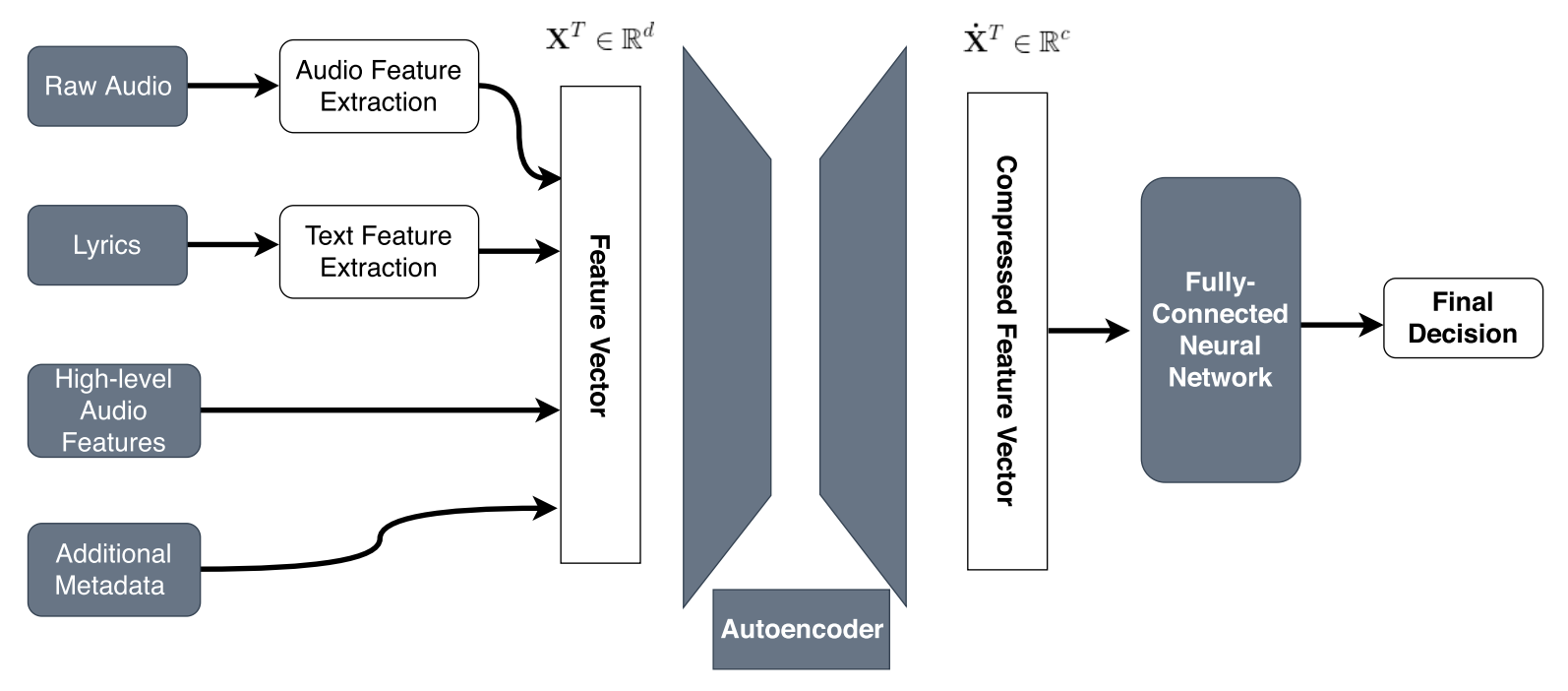
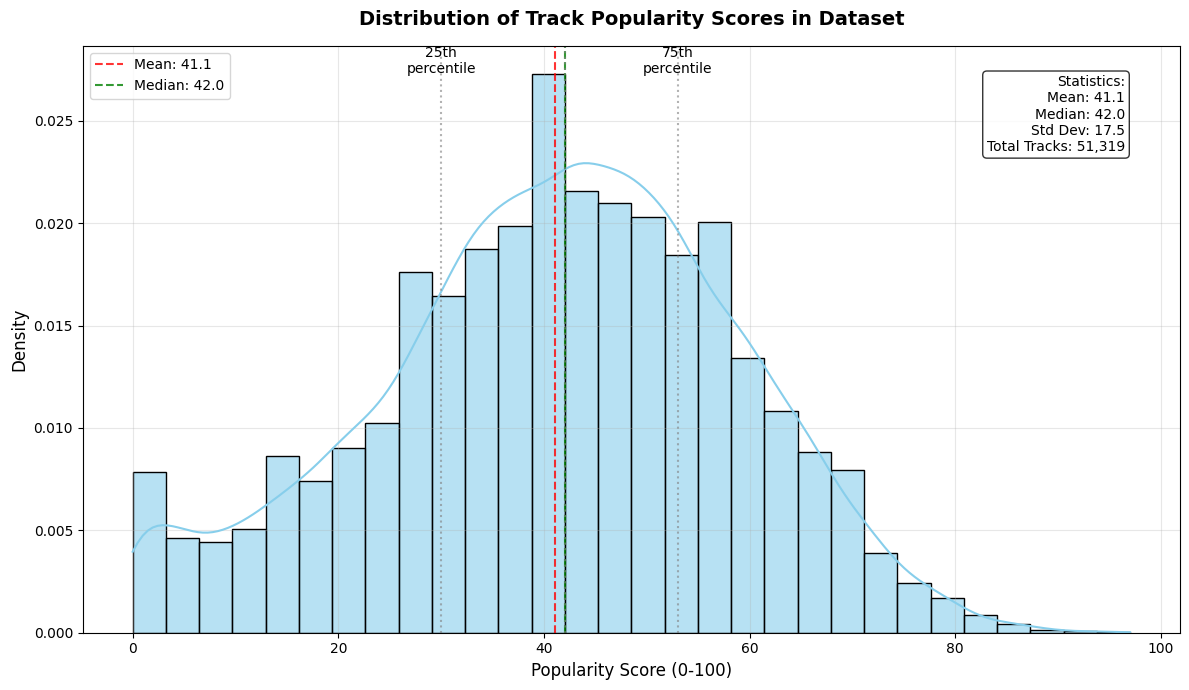
We trained HitMusicNet, a multimodal end-to-end Deep Learning architecture as proposed by (Martín-Gutiérrez et al., 2020) and validated the results using the SpotGenTrack Popularity Dataset (SPD). The model outputs a popularity score between 1 and 100, using audio features, text features, and metadata containing artist and demographic information as inputs. A complete description of the feature set used is provided in Table 1. HitMusicNet architecture as shown in Fig 1, employs an autoencoder for feature compression through two encoder layers with dimensions d/2 and d/3, followed by a bottleneck layer of d/5. Each layer uses ReLU activation, and the output layer employs a sigmoid activation for reconstruction. The autoencoder was trained using the Adam optimizer and an MSE loss function. The compressed features are then passed through a fully connected neural network with four layers, where the number of neurons in each layer is scaled by factors α = 1, β = 1/2, and γ = 1/4. The model is trained using an 80%-20% train-test split with stratified cross-validation (SCV) using k = 5. These settings helped us in effectively replicating the baseline results on the SPD dataset. 1 to 100. These scores follow a Gaussian distribution with µ = 40.02 and σ = 16.79. The dataset includes low-level audio features extracted from raw waveforms, high-level audio descriptors, stylometric text features derived from lyrics, and metadata such as artist popularity and market reach. To ensure data quality, we applied filtering steps to remove noisy lyric entries. Specifically, we excluded tracks with lyrics shorter than 100 or longer than 7,000 characters, which often contained placeholders or irrelevant content. Additionally, we restricted the dataset to five major languages: English, Spanish, Portuguese, French, and German-discarding other languages that constituted less than 1% of the data. This resulted in a cleaned corpus of 74,206 tracks, comprising 51,319 in English and 22,887 in the remaining languages. (Silva et al., 2019) included lyrics but lacked detailed audio-level features. Further, the LFM-2B dataset (Schedl et al., 2022), has copyright issues.
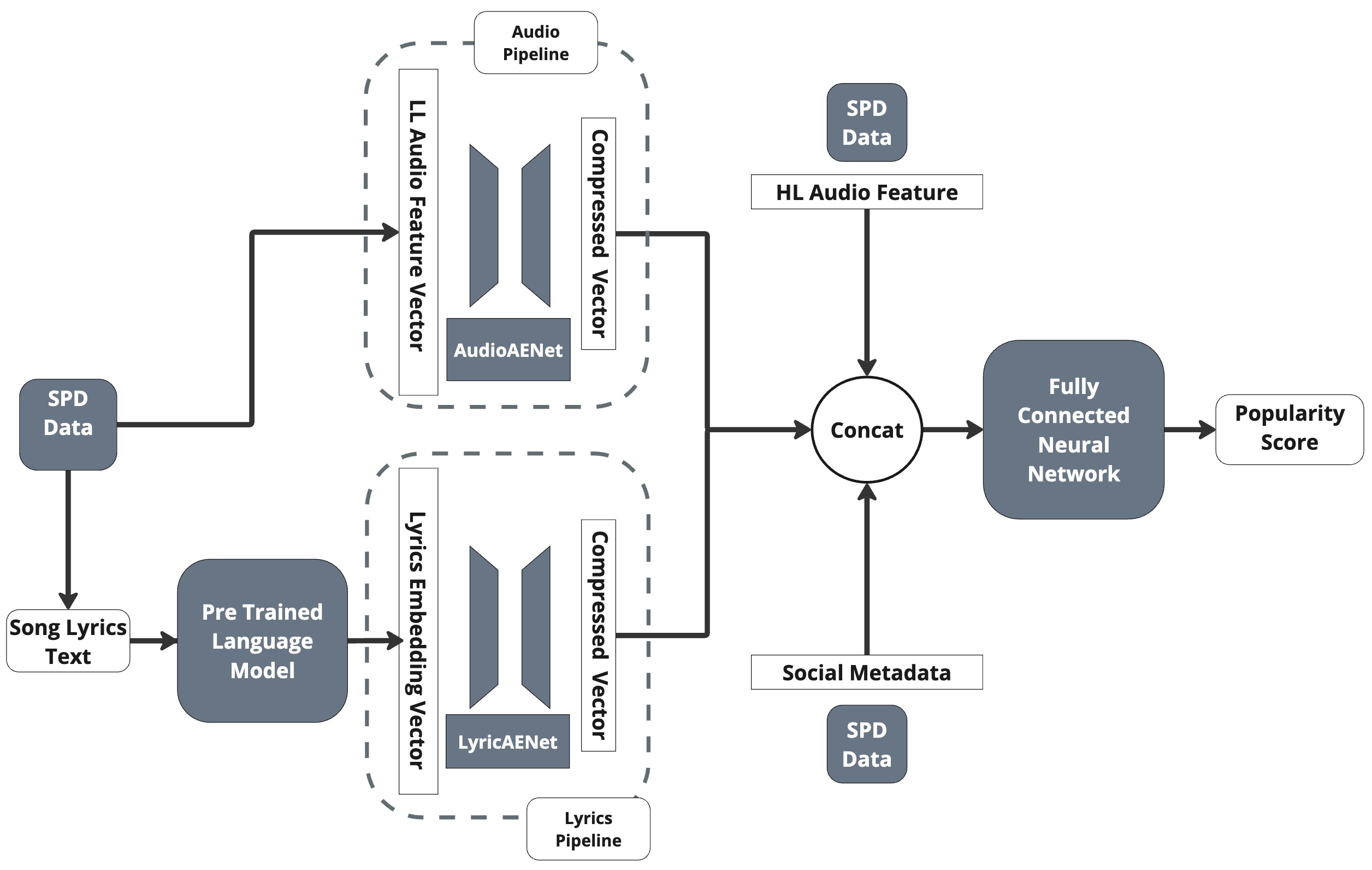
This section details our proposed HitMusicLyric-Net, an end-to-end multimodal deep learning ar-chitecture built upon the foundation of HitMusic-Net. HitMusicLyricNet comprises of three key components: AudioAENet, LyricsAENet, and Mu-sicFuseNet. AudioAENet compresses the low-level audio features. LyricsAENet compresses the lyric embeddings into a fixed-size representation using an Autoencoder, thereby encoding information while reducing noise. MusicFuseNet then combines these compressed audio and lyric representations with metadata and high-level audio features as described in Table 1.
In the HitMusicNet architecture, a single autoencoder compressed the combined feature vector of audio, lyrics, and metadata. We hypothesize that this can lead to information loss, particularly for the less abundant lyrics and metadata features. We believe that lyrics and metadata features should be fed directly into the popularity prediction network to retain their predictive power for song popularity. Furthermore, our reasoning behind the new approach of introducing distinct Autoencoders for audio and lyrics is based on the bipolar and directional nature of lyrics embeddings, requiring a different architecture for compression (Bałazy et al., 2021).
The Autoencoder used for compression has a similar architecture to that of MusicAENet in (Martín-Gutiérrez et al., 2020), but takes in only low-level audio features as described in Table 1 for compression. For input dimension d = 209, it gradually compresses the data to dimension d/2, d/3, and d/5. The output layer employs a sigmoid activation for reconstruction, whereas all remaining layers use ReLU activation functions. The model is trained using the Adam optimizer with a MSE loss function, achieving a loss value in the range of 1e-5, indicating negligible loss in compression.
LyricsAENet implements a tied-weights autoencoder architecture (Li and Nguyen, 2019) designed to reduce parameter size and risk of overfitting. Compressing lyric embeddings is susceptible to overfitting due to high dimensionality. The encoder follows a progressive compression with the following dimensions (d/2, d/4, d/8), followed by bottleneck layers (d/12 or d/16). The decoder mirrors the structure in reverse order, utilizing the transpose of the encoder weight. The progressive dimensional reduction is designed to minimize reconstruction losses in compressed embeddings extracted out of language models and LLMs such as BERT (Devlin et al., 2019), LLaMA 3 Herd (Grattafiori et al., 2024), and OpenAI’s embedding models 8 .
We use Scaled Exponential Linear Unit (SELU) (Klambauer et al., 2017) as the activation function for its self-normalizing characteristics and the ability to handle the bipolar nature of embeddings. Comparative analyses include alternate activation functions such as the Sigmoid Linear Unit (SiLU) (Elfwing et al., 2018) and the Gaussian Error Linear Unit (GELU) (Hendrycks and Gimpel, 2016). LyricsAENet was trained using the Adam optimizer with a MSE loss function, achieving loss values of approximately 1e-5. To further refine the training process, we incorporated a directional loss function inspired by (Bałazy et al., 2021) to preserve the directional characteristics of the embeddings during compression. This combined loss function is defined as:
where MSE(Y, Ȳ ) represents the Mean Squared Error. CD(Y, Ȳ ) denotes the Cosine Distance, which captures the angular similarity between the vectors Y and Ȳ . The constants α 1 and α 2 control the relative importance of the two loss terms. 8 Open AI text Embedding Model
We employ a similar architecture configuration as MusicPopNet by (Martín-Gutiérrez et al., 2020) for our MusicFuseNet. It uses a concatenation of compressed audio feature vectors from AudioAENet, compressed lyrics embeddings vectors from Lyric-sAENet, high-level audio features and metadata as mentioned in Table 1. The output of this neural net is a popularity score in the range [0, 1]. The architecture consists of a fully connected network with scaling parameters of (1, 1/2, 1/3) and ReLU activation functions, followed by a Sigmoid activation in the final layer, as empirically validated by (Martín-Gutiérrez et al., 2020). To train the model, we used the Adam optimizer with an MSE loss function and applied dropout regularization to mitigate overfitting.
Using the Code 9 to implement HitMusicNet and selecting the configuration details described in Section 3.2, we trained HitMusicNet on the SPD dataset with an 80-20 split. To replicate the results obtained by (Martín-Gutiérrez et al., 2020) To train HitMusicLyricNet, we extracted lyric embeddings from language models. For opensource models (BERT, Llama), we downloaded vanilla weights from Hugging Face 10 and loaded its vanilla configuration. We used Nvidia A100 GPU for compute requirements. After tokenizing lyrics, we forward-passed them through each model, extracted the last hidden-layer states, and applied max/mean pooling to obtain fixed-size vectors for our Autoencoder. Specifically for BERT, we considered mean pooling and concat (max + CLS token). To get embeddings from OpenAI text models, we used the API endpoint, costing $3 for the small model and $6 for the large. Obtaining embeddings via the OpenAI API took ∼5 hours due to rate limits, while the open-source took less than an hour. We then studied LLM model architecture and its training corpus effects on music popularity prediction with BERT, BERT Large, Llama 3.1 8B, Llama 3.2 1B, Llama 3.2 3B, and OpenAI text embeddings (small and large).
After extracting these embeddings, we examined different activation layers (Selu, Silu, Gelu) for embedding compression using LyricsAENet and introduced a directional loss function with α 1 = 0.5 and α 2 = 0.5 5 as suggested by (Bałazy et al., 2021), alongside our standard MSE loss for LyricsAENet, to see their impact on the HitMusicLyricNet perfor-10 Hugging Face mance metric MAE. As reported in Table 2, using SELU with the MSE loss function in LyricsAENet yielded the least MAE error while training HitMu-sicLyricNet on popularity prediction. Directional loss produced comparable metrics but not enough improvement to be included further. Other activation functions performed closely, but for simplicity and observing 1-2% randomness error, we proceeded with SELU and MSE.
Next, we compressed embeddings for different LLM models. While we experimented with two variants of BERT (small and large) and considered mean embeddings and concat (max + CLS token) embeddings, here we only report results for BERT large with mean embeddings, as it yielded the best results as seen in Table 3. All the Llama variants had very close performance metrics, whereas the OpenAI large text embedding model surpassed all of them. We attribute these small differences (∼ 2% variation) in HitMusicLyricNet’s performance to variations in each model’s training data and architecture, since none was specifically trained for our downstream task, leading to large differences in rich embedding representation.
Hence with HitMusicLyricNet, we used the Ope-nAI large text embeddings and the SELU activation with MSE loss function in lyricsAENet. Overall, we achieved close to a 9% improvement compared to the SOTA architecture. Dropping the lyrics feature pipeline and retraining and testing HitMu-sicLyricNet led to performance metrics comparable to that of HitMusicNet, validating the effectiveness of our proposed lyric feature extraction pipeline using LLMs and the overall enhancements in the music popularity prediction pipeline. A detailed ablation study for each feature set is provided in Appendix A.
While HitMusicLyricNet surpasses the state-of-theart baseline, an in-depth error analysis is necessary for real-world applications and future enhancements. In this section, we examine global residual errors, assess feature interpretability and impact via SHAP and LIME, and analyze social metadata to uncover any systematic biases and error patterns. All analyses are performed using the test set.
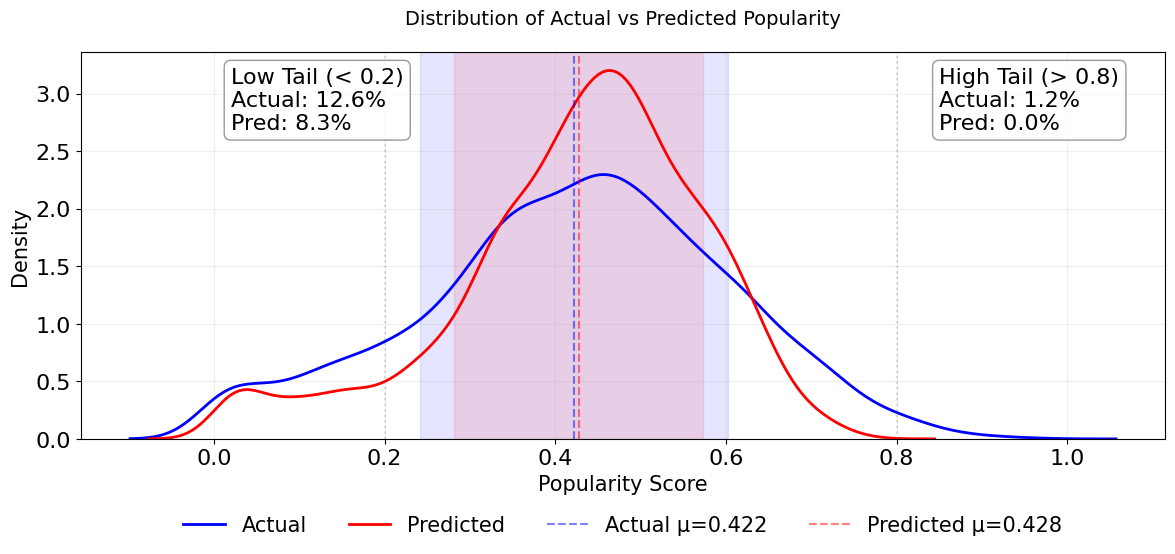
Figure 4 compares the actual and predicted music popularity distributions. Although the means are nearly identical (µ actual = 0.422, µ predicted = 0.428), the predicted distribution’s tails are compressed. The model predicts only 8.3% of songs with popularity below 0.2 (compared to 12.6% in the actual data) and fails to predict any songs with popularity above 0.8 (versus 1.2% in the actual data). This regression towards the mean reflects both the limited representation of extreme popularity cases in SPD dataset and also the model’s particular difficulty in capturing patterns of highly popular songs.
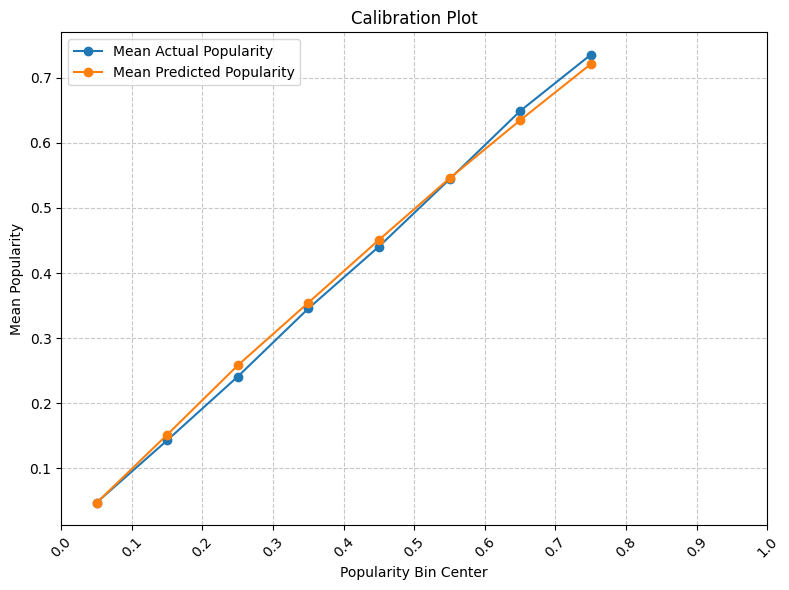
The calibration plot (Fig. 5) also indicates a strong alignment between predicted and actual music popularity within most bins, with the highest precision in the 0.4-0.6 range where data density peaks.
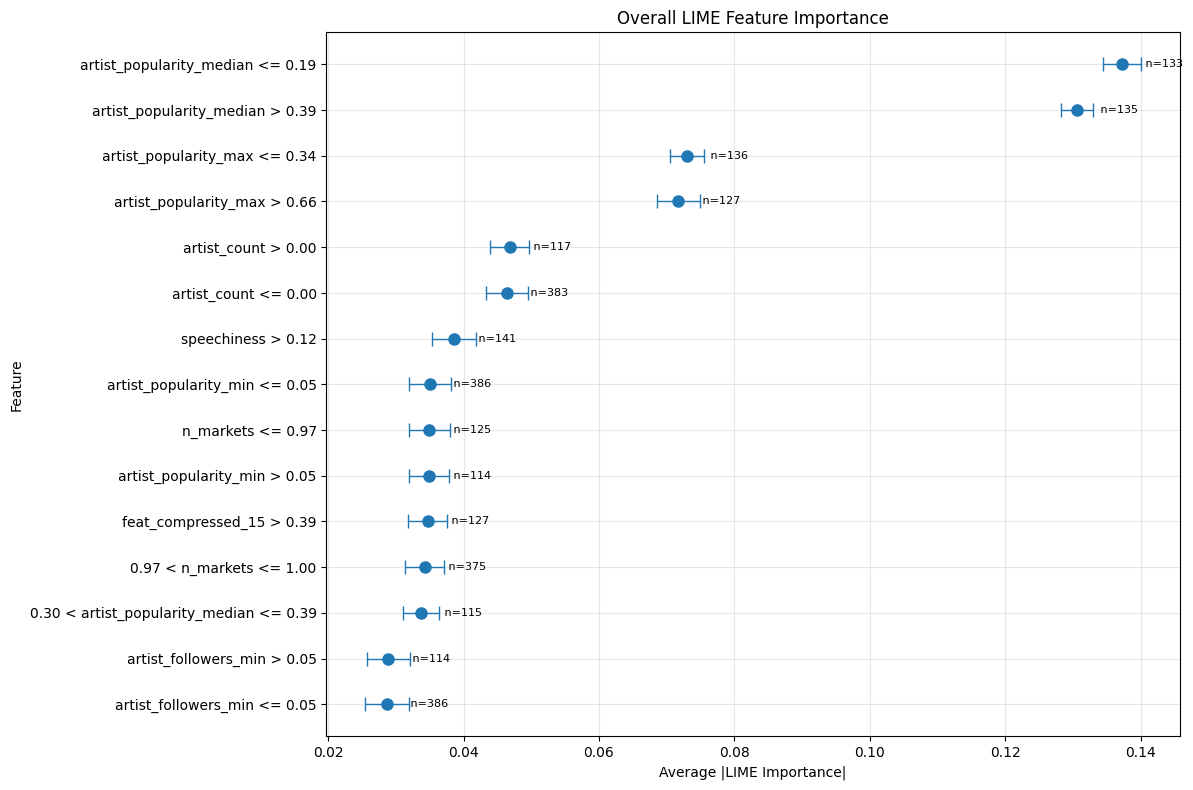
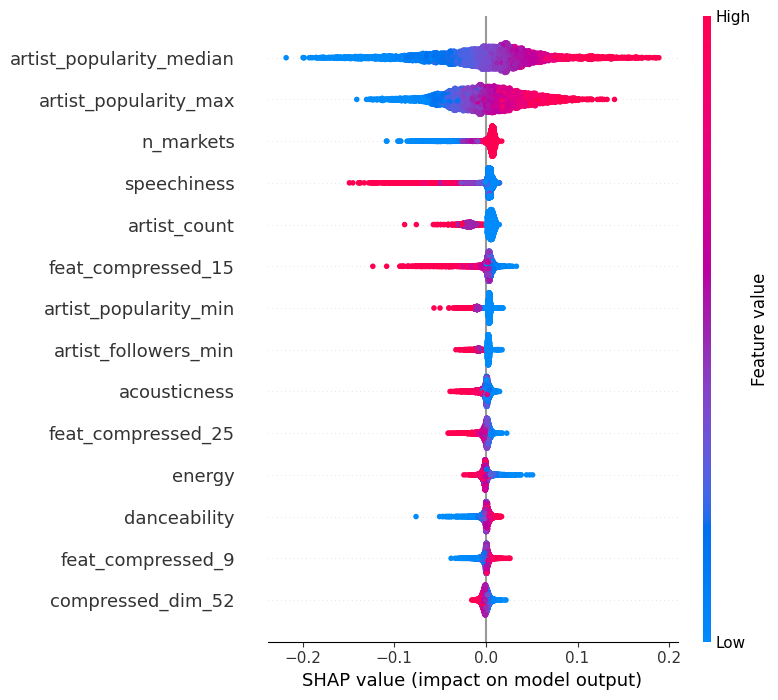
To understand the overall impact of noninterpretable latent representation of music audio On analyzing the outcome of SHAP (Fig 6), artist popularity was the strongest predictor of music popularity with SHAP values ranging from -0.2 to +0.2. The compressed audio features showed a decreasing impact across sequential layers, indicating that earlier layers captured more predictive patterns. Lyric embeddings showed a moderate but consistent impact unless there is a significant deviation from the typical pattern. LIME analysis supported these findings and substantiated detailed insights on decision boundaries within feature values as presented in Appendix B.
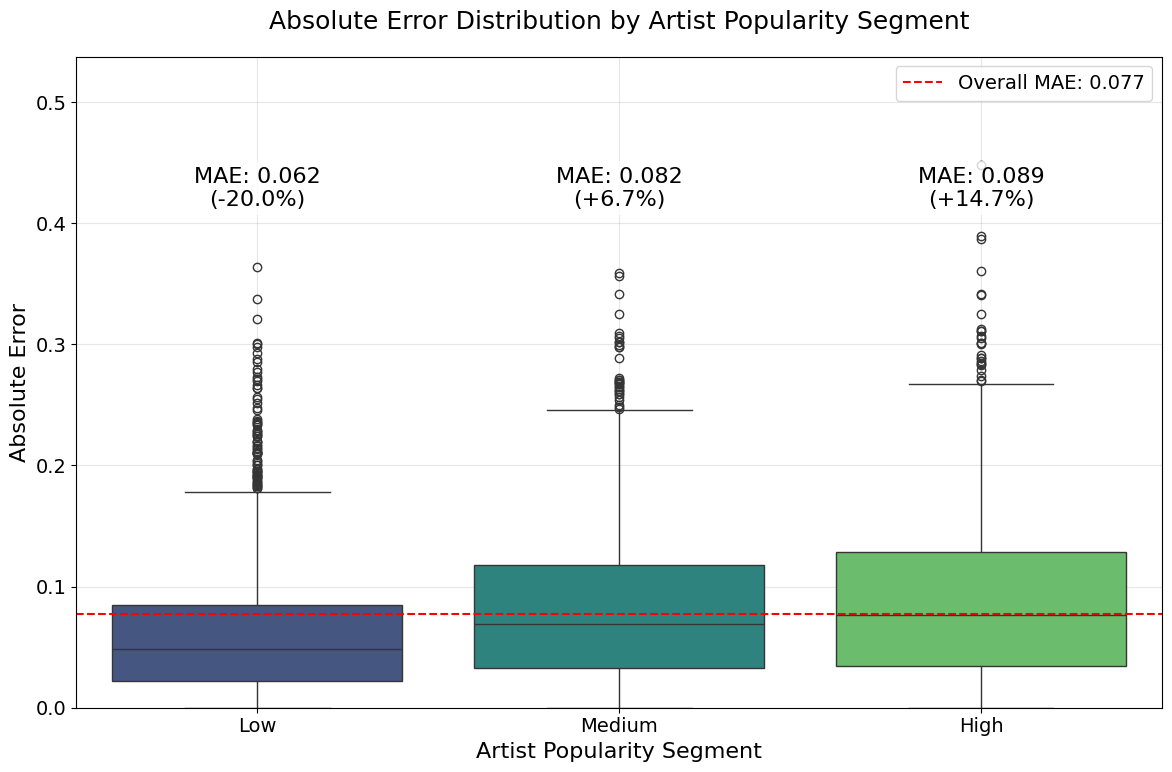
In the previous section, we observed that artist popularity is a dominant predictor of song popularity. To assess its impact and bias, we segmented the test set into three groups (low, medium, and high) based on artist popularity using quantiles. As shown in Fig. 7, songs composed by artists with low popularity have an MAE 20% below the global MAE, while those in the medium and high segments exhibit MAEs 6.7% and 14.7% above it, respectively. Furthermore, LIME analysis (appendix B) identified decision boundaries for artist popularity were at 0.19 and 0.39. Combined with the challenge of predicting the extreme right tail (Fig. 4), these findings indicate that while artist popularity is a strong predictor for low-and mid-popularity songs, it falls short for highly popular tracks. Therefore, identifying patterns and strong predictors for highly popular songs still remains a research challenge.
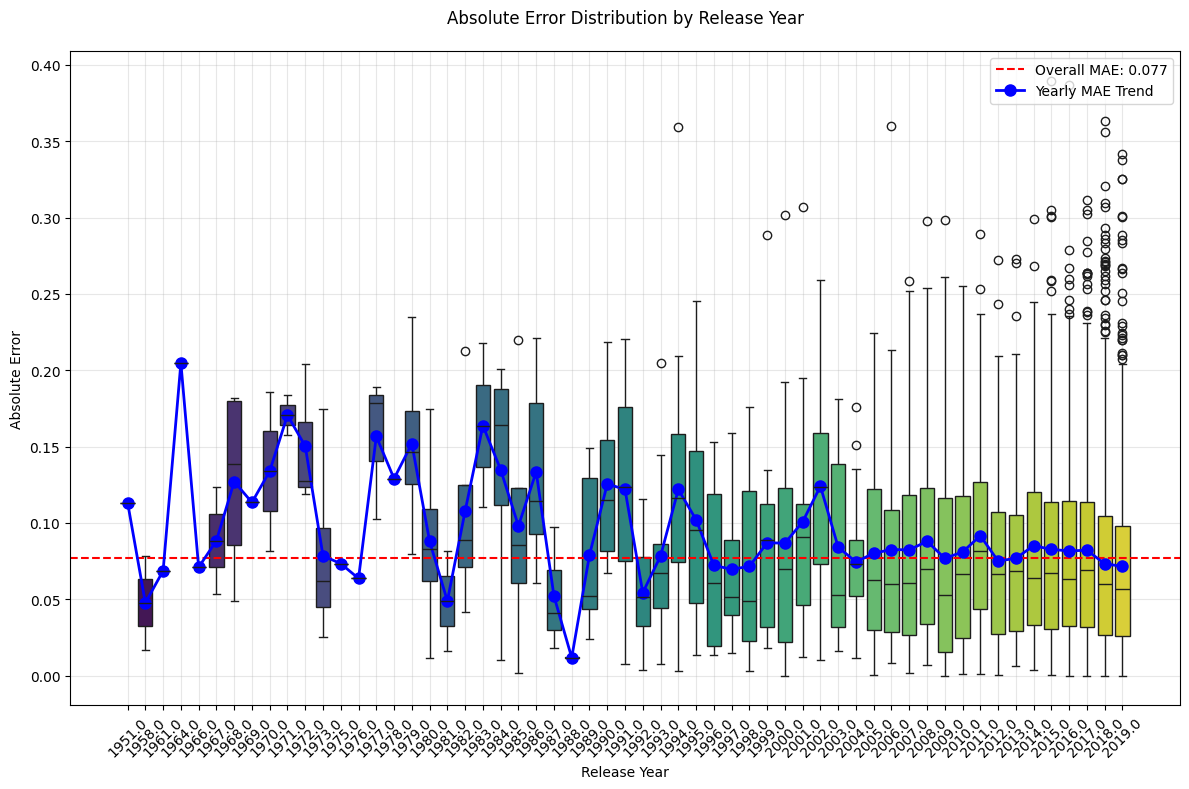
Additionally, a year-wise error analysis (Fig. 15) shows that both MAE and its variance were significantly higher in the 1990s and early 2000s. Since 2005, however, errors have stabilized-likely reflecting a training bias towards recent years and also aligning with Spotify’s song popularity score calculation, which emphasizes more on recent time metrics.
The work presented in this paper showcases the power of leveraging lyrics to predict the popularity of a song, with the help of LLMs with capabilities of capturing the deeper meaning of sentences using embeddings. We believe that advancements in music-aware language models will lead to more explainable and expressive lyric fea-tures based on domain-specific knowledge. This research presented a novel architecture, HitMu-sicLyricNet, along with an ablation study. Hit-MusicLyricNet beats the SOTA by 9% by incorporating lyric embeddings and improving upon the SOTA architecture. With advancements in compression techniques and multimodal learning architecture, we believe accuracy and commercial use can be improved. Furthermore, with advancements in audio representation learning using neural audio codecs, richer music audio representations can be scoped into the study. Current research aggregates features over an entire song. However, contemporary phenomena of virality suggest that local features within different musical segments need to be studied deeply and cannot be ignored given the micro-content consumption driven by platforms like Instagram and SnapChat.
Our findings may be constrained by genre, demographic, and cultural variability not fully captured in the current experimental setup. While LLMs such as BERT and LLaMA-3 enable deeper semantic modeling of lyrics, their general-purpose training limits their ability to capture music-specific linguistic patterns. Despite careful regularization, the high dimensionality of lyric embeddings presents inherent risks of overfitting. Moreover, as these embeddings are evaluated solely through downstream task performance, their intrinsic quality in representing lyrical content remains underexplored. Finally, the opacity of these feature vectors limits interpretability, pointing to a need for more explainable models of lyric representation.
In this section, we study how different modalities contribute to our model’s music popularity predictive strength. Table 5 shows model performance for each combination of our four feature types: highlevel audio (HH), low-level audio (LL), lyrics embeddings (LR), and metadata (M).
The model works best when it uses all modalities, with a test MAE of 0.0772. If we exclude lyrics embeddings, the test MAE increases by 10.4% to 0.0852, highlighting the usefulness of our proposed lyrics feature pipeline. Notably, using only highlevel features and metadata along with lyrics (HH, LR, M) gives comparable performance to using all the modalities features, indicating some redundancy in low-level audio features. The role of social context is apparent when we strip metadata by utilizing only audio and lyrics features (HH, LL, LR), which makes the test MAE rise by 40.2% to 0.1082. Performance suffers most significantly if we use only audio features (HH, LL) and obtain a test MAE of 0.1196.
To further understand individual modality performance, we conducted isolated training experiments as shown in Table 6. Single-modality tests ascertain that metadata features (M) alone achieve the highest single-modality performance with a test MAE of 0.0968, verifying our initial observation about
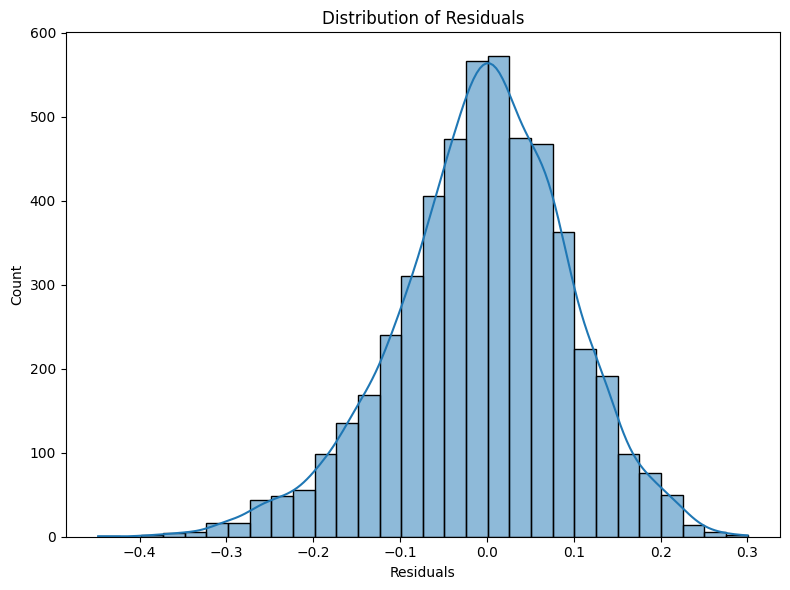
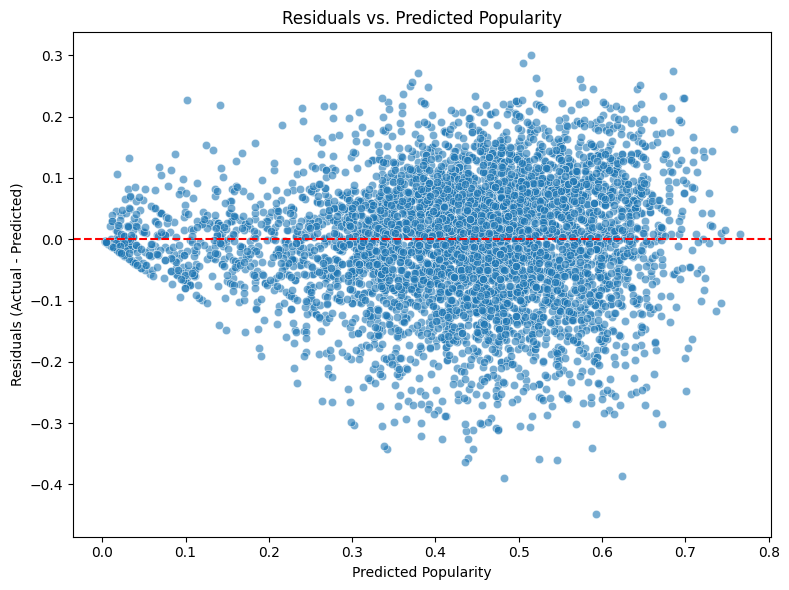
To supplement our error analysis discussed in Section 5, we conducted a detailed investigation of model behavior through two complementary approaches: (1) analysis of prediction residuals and their distribution patterns, and (2) assessment of feature importance across different modalities using SHAP and LIME techniques. Analysis of the residual distribution (Figure 8) shows a quasi-normal pattern centered at zero, with about 95% of forecasts falling within ±0.2 of actual values. The distribution shows minimal negative skewness, suggesting a small inclination toward underestimating in extreme conditions. With variance amplification in the mid-popularity range (0.3-0.6) and more limited errors at the extremes, the residual scatter plot against predicted popularity (Figure 9) shows heteroscedastic behavior.
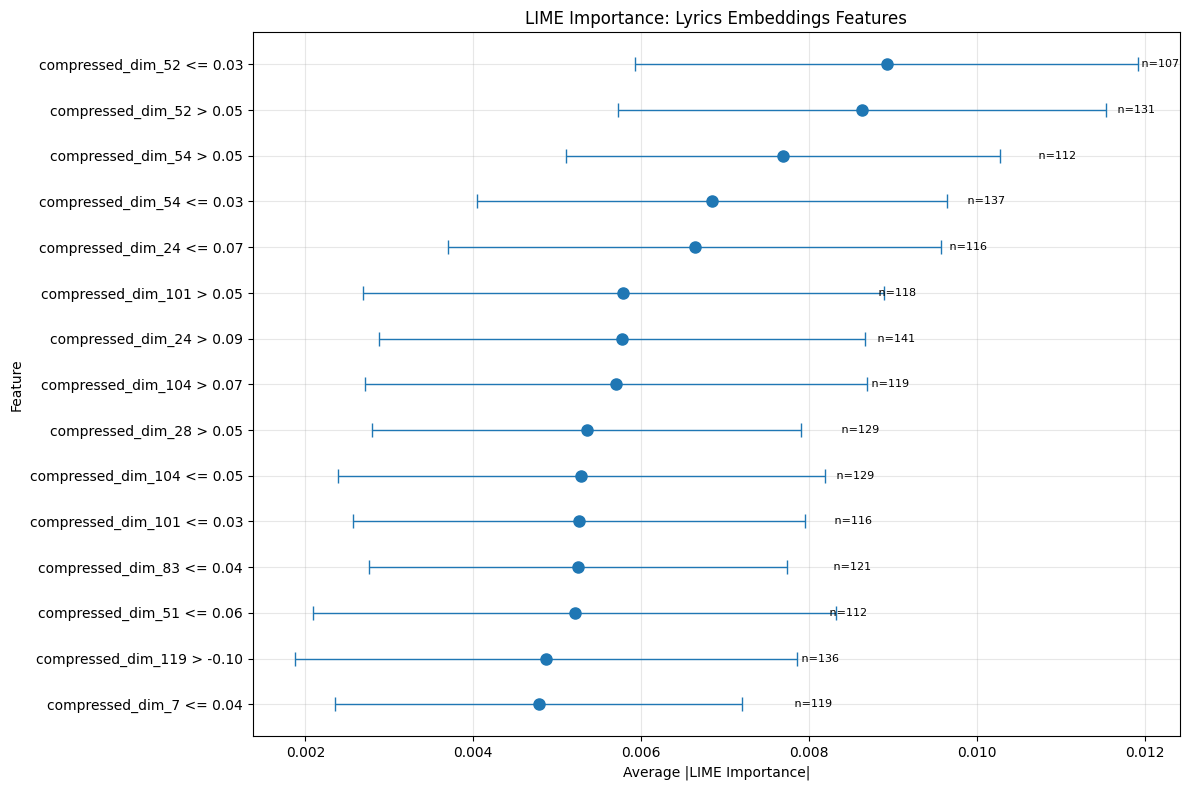
The LIME study shows varied trends in feature . relevance over multiple modalities. With artist popularity thresholds (≤ 0.19 and > 0.39) displaying the highest importance scores (∼0.13), artistrelated metadata dominates the prediction process in the general feature landscape (Figure 10). This division implies that the algorithm has learnt different behavioral patterns for artists at various degrees of popularity.
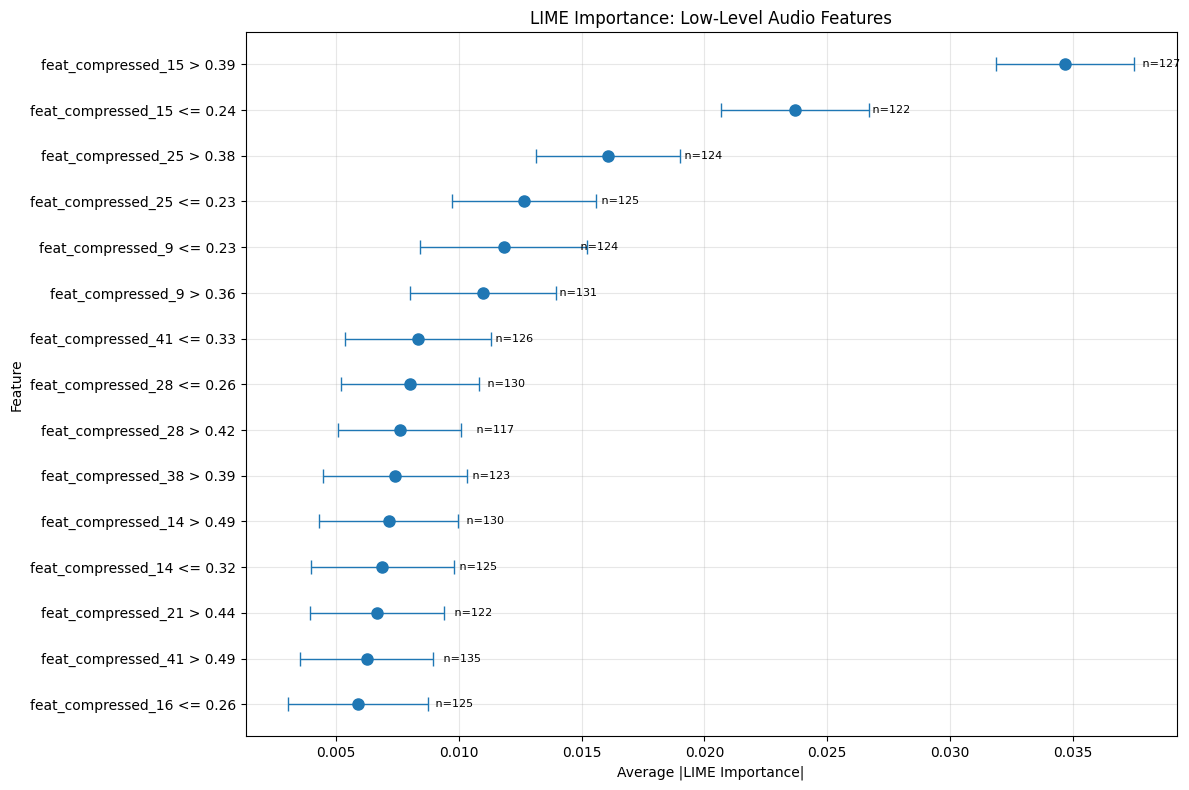
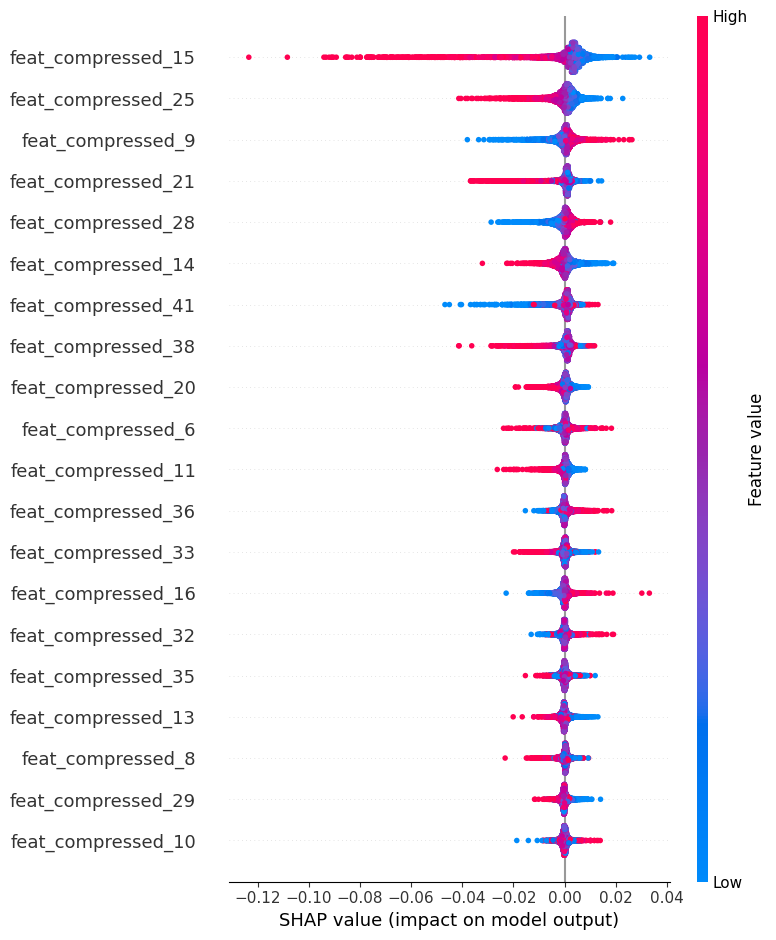
Early compressed dimensions (especially feat_compressed_15) have higher predictive weight than later ones, therefore displaying a hierarchical importance structure in the low-level audio characteristics (Figure 11). This trend shows that in its first compression layers, our AudioAENet efficiently retains fundamental acoustic information.
A deeper interpretation of the LIME results for lyric-embedding characteristics shows that although some compressed dimensions (such as 52 and 54) often show themselves as most essential, their impact on the prediction is not consistent across all samples. Particularly several threshold splits for these dimensions (e.g., compressed_dim_52 > 0.05 vs. ≤ 0.03) point to a non-linear or boundary-based relationship: the model may be using these latent factors to distinguish between songs that surpass certain “lyrical thresholds” (perhaps tied to vocabulary, theme, or semantic content) and those that do not.
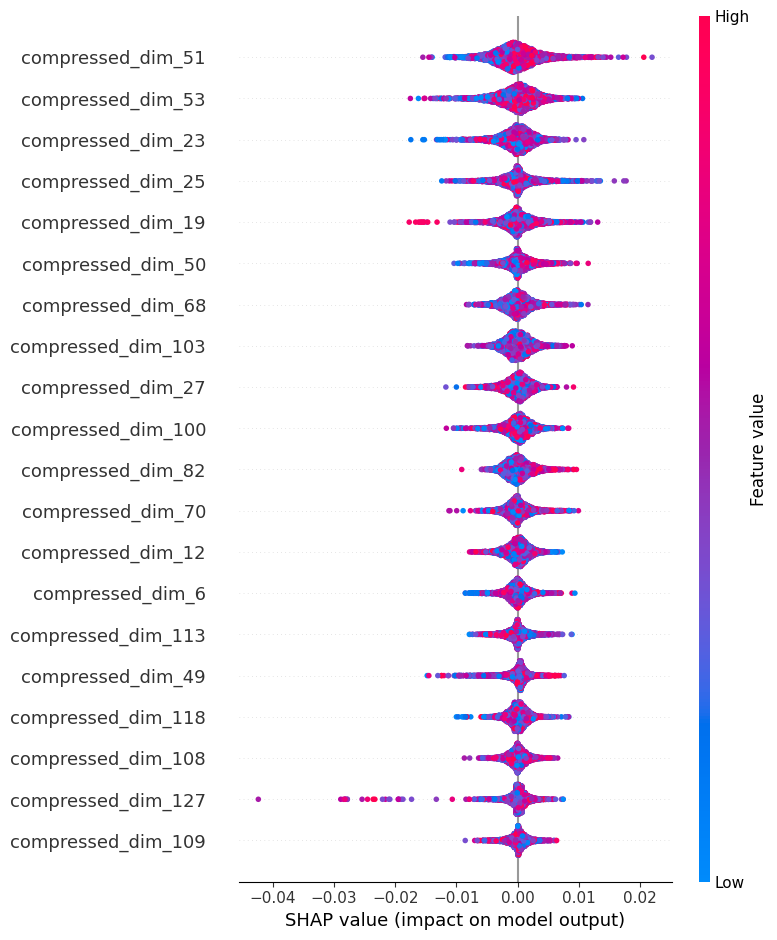
The SHAP analysis shows complex patterns in how lyrical elements influence popularity predictions spond with greater feature values (red) and negative with lower values (blue). This implies that these measures reflect poetic aspects that, either highly present or missing, always affect popularity in particular directions. With scarce but considerable negative effects (reaching -0.04) and a mixed color distribution, Compressed_dim_127 exhibits a distinctive pattern that indicates it captures complicated lyrical features that influence popularity irrespective of their size.
By contrast, the audio features (Figure 13) exhibit more asymmetric impact distributions, especially in feat_compressed_15 with the highest magnitude of impact (-0.12 to 0.04). Early compressed audio characteristics (15, 25, 9) show significantly higher SHAP values than later dimensions, therefore confirming the capacity of our autoencoder to retain important acoustic information in its first layers. Notably, while audio features tend to have larger absolute SHAP values than lyrics features, they also show more defined directionality in their effects, suggesting more deterministic relationships with popularity predictions.
text features proposed by(Martín-Gutiérrez et al., 2020) did not degrade the metrics, so we dropped those features for further experiments.
text features proposed by(Martín-Gutiérrez et al., 2020)
text features proposed by
Genius.com
This content is AI-processed based on open access ArXiv data.