The fast deployment of cognitive radar to counter jamming remains a critical challenge in modern warfare, where more efficient deployment leads to quicker detection of targets. Existing methods are primarily based on evolutionary algorithms, which are time-consuming and prone to falling into local optima. We tackle these drawbacks via the efficient inference of neural networks and propose a brand new framework: Fast Anti-Jamming Radar Deployment Algorithm (FARDA). We first model the radar deployment problem as an end-to-end task and design deep reinforcement learning algorithms to solve it, where we develop integrated neural modules to perceive heatmap information and a brand new reward format. Empirical results demonstrate that our method achieves coverage comparable to evolutionary algorithms while deploying radars approximately 7,000 times faster. Further ablation experiments confirm the necessity of each component of FARDA.
Cognitive radar systems have greatly enhanced environment adaptability and target recognition accuracy of radar systems, and have gradually gained attention in recent years. In modern warfare, where electronic countermeasures become increasingly intense, cognitive radars can crack the jamming strategies of enemies and control the electromagnetic network on the battlefield. Besides, in civilian sectors, such as autonomous driving and meteorological monitoring, the adaptive characteristics of cognitive radar can also significantly improve the ability to classify and track targets in complex scenarios. Therefore, developing cognitive radar technologies can considerably improve radar systems' anti-jamming capacities and information acquisition efficiency, manifesting the cutting-edge of radar development.
Currently, researchers mainly focus on evolutionary algorithms, for instance, Genetic Algorithms (GA) [1,2], Particle Swarm Optimization (PSO) [3,4], and Artificial Fish Swarm Algorithm [5] to deploy cognitive radars in the correct positions. However, since evolutionary algorithms require multiple rounds of iterative searches and independent fitness evaluation of the entire population in every round of iteration, they can not solve problems effectively. Furthermore, due to the limitations of the searching strategy, evolutionary algorithms often fail to fully explore the entire solution space, resulting in them easily falling into local optima. These disadvantages directly hinder the process of evolutionary algorithms in finding truly optimal solutions effectively.
Due to efficient inference and extraordinary performance, Deep Reinforcement Learning (DRL) [6] has recently gained attention. Agents trained by DRL showed superior skills in games like Atari [7], Go [8], and Starcraft II [9]. DRL is also used to tackle real-world scenarios, including autonomous driving [10], math problems [11], and machine translation [12]. Also, researchers use RL to solve combinatorial optimization problems [13], such as Traveling Salesman Problem [14] and Mixed Integer Linear Programming Problem [15].
Recently, combining DRL methods with radar problems has attracted increasing attention from researchers. Zhu et al. [16] used a hybrid action space RL to enhance the resource utilization of the Multiple-Input Multiple-Output (MIMO) radar system. Jiang et al. [17] formed a Markov Decision Process (MDP) and used a low complexity joint optimization algorithm to manage radars’ resources. Yang et al. [18] used Q-learning to solve the resource scheduling problem of radars. Hao et al. [19] used Q-learning and SARSA algorithm to select the radar’s anti-jamming policy method. Jiang et al. [20] and Wang et al. [21] applied Deep Deterministic Policy Gradient algorithm to select the radar’s anti-jamming policy. Zhu et al. [22] used Proximal Policy Optimization (PPO) algorithm to choose the location of antennas of an MIMO radar system in a jamming-free situation. To the best of our knowledge, no research has been conducted on the anti-jamming radar deployment problem using DRL.
In this paper, we innovatively introduce DRL method into the radar anti-jamming deployment problem: Fast Anti-Jamming Radar Deployment Algorithm (FARDA). We first model the deployment problem as a combinatorial optimization problem and propose the corresponding mathematical model. However, two factors impede us from solving this problem quickly and accurately. The first factor is the complicated optimization objective, while the second factor is the large search space. Therefore, we analyze the characteristics of the problem, extract inherent properties, and leverage them to optimize the problem’s modeling, including environment modification, dimensionality reduction, and constraint relaxation. These transformations reduce the computational complexity of the optimization functions and shrink the search space, making the problem easier to solve. Next, we formulate the Markov Decision Process (MDP) for the corresponding problem and propose a DRL framework, where we specifically design an encoder in our policy network. Not only can it extract the heatmap information of the detection probabilities, but it can also memorize the temporal features from previous states. In addition, we introduce a brand new reward shaping method: Constraint Violation Degree Penalty and EXPonential Function Reward (CVDP-EXPR), which can better guide the agent in the learning stage.
Finally, sufficient numerical experiments are conducted to show that our FARDA achieves coverage competitive to evolutionary algorithms while deploying radars approximately 7,000 times quicker. Also, our algorithm outperforms evolutionary algorithms by a factor of 120 in the efficiency metric we have designed. We also conduct a series of ablation tests to demonstrate the necessity of the encoder module in FARDA and the CVDP-EXPR we proposed.
Our contribution can be summarized as follows:
• We formulate the anti-jamming cognitive radar deployment problem as a combinatorial optimization problem, and point out some obstacles to solving the problem.
• We design a new framework, FARDA, to tackle the problem. We first explore the characteristics of the problem and modify it to make it easier to solve. Then, we specifically design a DRL framework to address the modified combinatorial optimization problem. We also devise CVDP-EXPR in FARDA, benefiting its training and deployment.
• Numerical experiments show that our method outperforms evolutionary algorithms in both speed, which is approximately 7000 times faster, and coverage area. Also, ablation experiments demonstrate the necessity of each part of our proposed encoder in FARDA and the design of CVDP-EXPR.
The main objective for the anti-jamming deployment of cognitive radar is as follows: Several jamming nodes deployed by the enemy will appear at discrete points set D J within a two-dimensional region S. We should deploy several cognitive radars at discrete points set D R within another area of S. Formally, region S is a 20km×120km area, to simplify the description, we place it in a rectangular coordinate system:
We should maximize the radars’ detection region S in S. However, it is difficult for a computer to calculate the region S for two reasons: first, the shape of S may be highly irregular; second, processing continuous data on computers is extremely difficult, so we need to discretize it. To match the precision of preceding tasks, we discretize the surveillance region S by sampling a point every 100 meters to obtain the discrete matrix D, where we denote the counts of rows and columns as n and m, respectively. Furthermore, we denote D the detected points by radars on D.
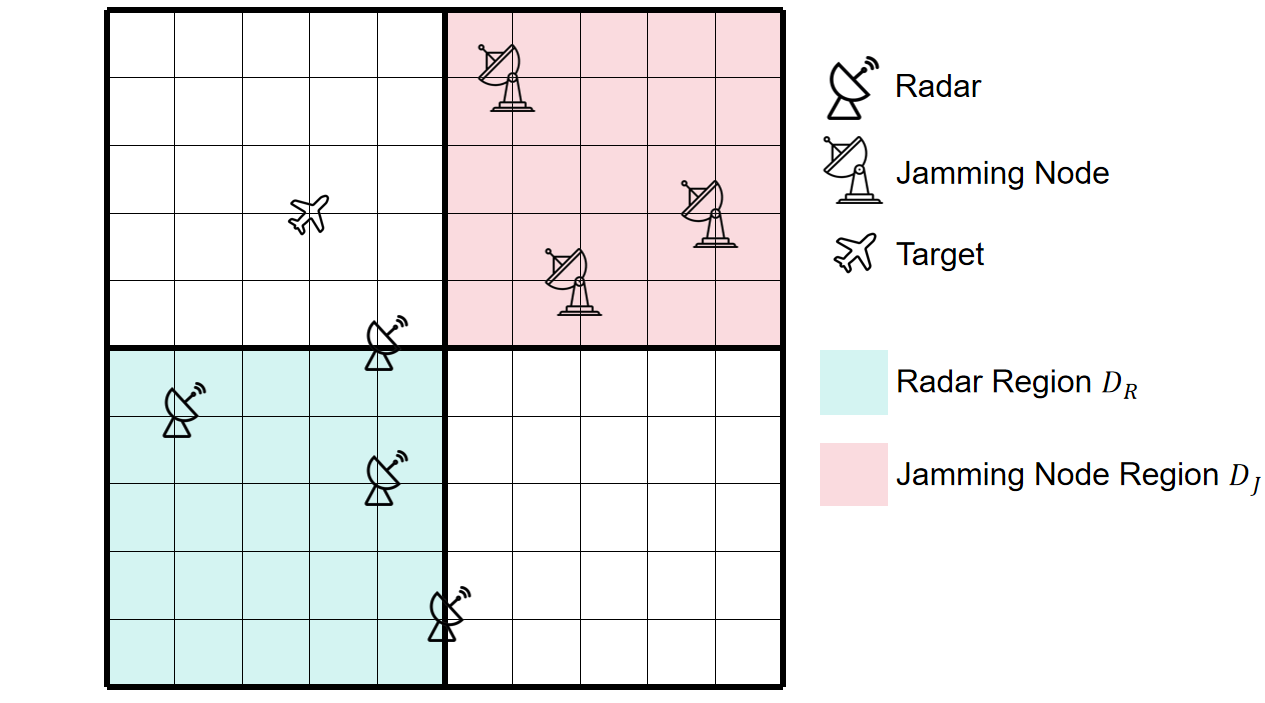
Figure 1 shows an example of the problem. The grid in light red represents D J , and the grid in light green represents D R . The three radars in D J are enemy jamming nodes, while the four radars in D R are our deployed radars. The aircraft represents a possible location of the target. Note that this figure has been scaled proportionally: the actual area is a rectangle. Furthermore, the grid in the figure is just an example; the actual grid will be denser.
In area D J , suppose the enemy has placed a jamming node combination J and its coordinates are described as follows:
Assume that we have deployed a radar combination R in area D R and denote the coordinates as follows:
We use four steps to calculate D. Note that we have omitted the superscripts and subscripts from some of the formulas where there is no ambiguity to simplify the formulas.
• Step 1: calculate the detection probability of a single radar countering a single jamming node at a certain point. For a radar r = (r x , r y ) T ∈ R, a jamming node j = (j x , j y ) T ∈ J and a certain point in discrete surveillance area d = (d x , d y ) T ∈ D. We can calculate relative coordinates δ j = (δ jx , δ jy ) T , distance R j and angle θ j of r relative to j:
Similarly, we can calculate relative coordinates δ d = (δ dx , δ dy ), distance R d and angle θ d of r relative to d:
Next, we calculate the effective power that can be received by radar r after the echoes of the signals emitted by the radar r and jamming node j at point d, which we denote as P r and P j respectively:
In (6), Pr and Pj are the power of transmit antenna of radar r and jamming j, G T and G R are the gain of the transmit and receive antennas of radar r, λ is the wavelength of the radar electromagnetic wave, K is the array element count in the radar antenna, B is the bandwidth of radar, and F r is the pulse repetition rate. Next, we give an angle threshold θ, and calculate whether there is a jamming node within the sector region centered at r with central angle [θ d -θ, θ d + θ], and thereby calculate the Signal to Interference Plus Noise Ratio (SINR):
P n denotes the power of noise in (7) and can be determined as follows:
where K e is the Boltzmann constant, T 0 is the room temperature, and F e is the noise factor. Finally, we set the false alarm rate P r f a ≪ 1, and the detection probability of radar r against jamming node j at point d is:
• Step 2: Calculate the detection probability of a single radar against a jamming combination at a certain point. Most of the calculating processes for the jamming node set J are similar to step 1, except for calculating the SINR in (7). Specifically, for each jamming node j i ∈ J, we can calculate its angle θ ji with the radar r and its power P ji at point d. We then calculate the interference set C that falls within the sector region:
Then SINR of radar against jamming combination at point d can be calculated using the following formula:
Then, using (9), we can calculate the detection probability of a radar r countering the jamming node combination J at point d, which we denote as P r J .
• Step 3: Calculate the detection probability of a radar combination against a jamming node combination at a certain point. For a radar combination R, we can calculate every single radar r i ∈ R as the procedure of step 2, and obtain a detection probability of radar r i against the jamming combination J, denoted as P r J i . Then, the detection of R against J can be calculated as:
• Step 4: calculate the detected set D of radar combination against jamming node combination in set D.
In the surveillance area set D, each point d corresponds to a detection probability P r R d calculated by step 3. Given a threshold τ , when the detection probability P r R d ≥ τ , we consider that if a target appears at point d, the radar combination can detect that point. Formally, the set of points detected by the radar combination under jamming nodes can be characterized as follows:
We aim to cover as much of the surveillance area D as possible. Therefore, we propose the following combinatorial optimization problem:
In ( 14), D is the detected discrete set, D is the discrete region set sampled in 100 meters, r i is the radar position, and D R is the radar deployable set.
As can be seen from the above modeling process, calculating the objective function in this combinatorial optimization problem is extremely complex. We summarize the detailed difficulties of this problem as follows:
• The optimization functions have some undesirable properties: First, compared to jamming-free conditions, our scenario contains the variables of jamming positions, resulting in a higher parameter dimension in the optimization function; Second, the function is highly sensitive and coupled in radar and jamming factors, a slight change in positions can cause significant fluctuation of the final value in the function. • Discontinuity property of the optimization function: The existence of the jamming nodes causes the (7) to change from continuous to discontinuous. Discontinuous functions have many undesirable properties compared to continuous functions, making the problem more challenging. • Large decision space: Since all possible combinations of radars can be represented by the combination number C(|D R |, |R|), when |R| is much smaller than |D R |, this combination number can be approximated by an exponential function. This indicates that the size of our decision space is exponential, with its base |D R | reaching the order of 10 8 . This means that the decision space for this problem is enormous, making it impossible to solve using traditional search algorithms. Additionally, using evolutionary algorithms will likely lead to local optima, causing the algorithm to converge to a suboptimal solution.
3 Methodology: FARDA
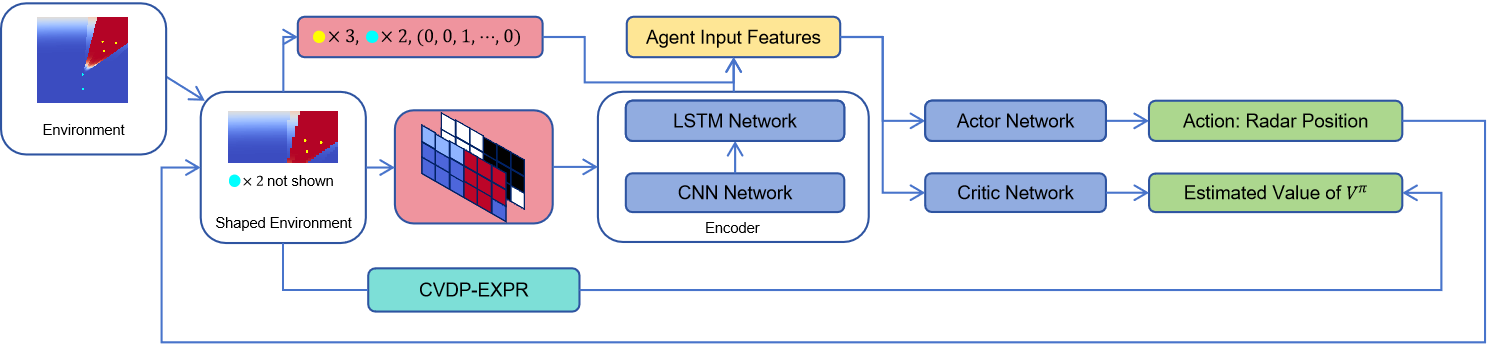
We have designed a new method, FARDA, to address this problem, which is summarized in Figure 2. We will introduce FARDA step by step in this section, starting with problem simplification, MDP modeling, policy network, and finally, our reward shaping method: CVDP-EXPR.
To make this highly complex combinatorial optimization problem easier to solve, we simplify it using a series of approaches, including dimension reduction, relaxation, and environment simplification.
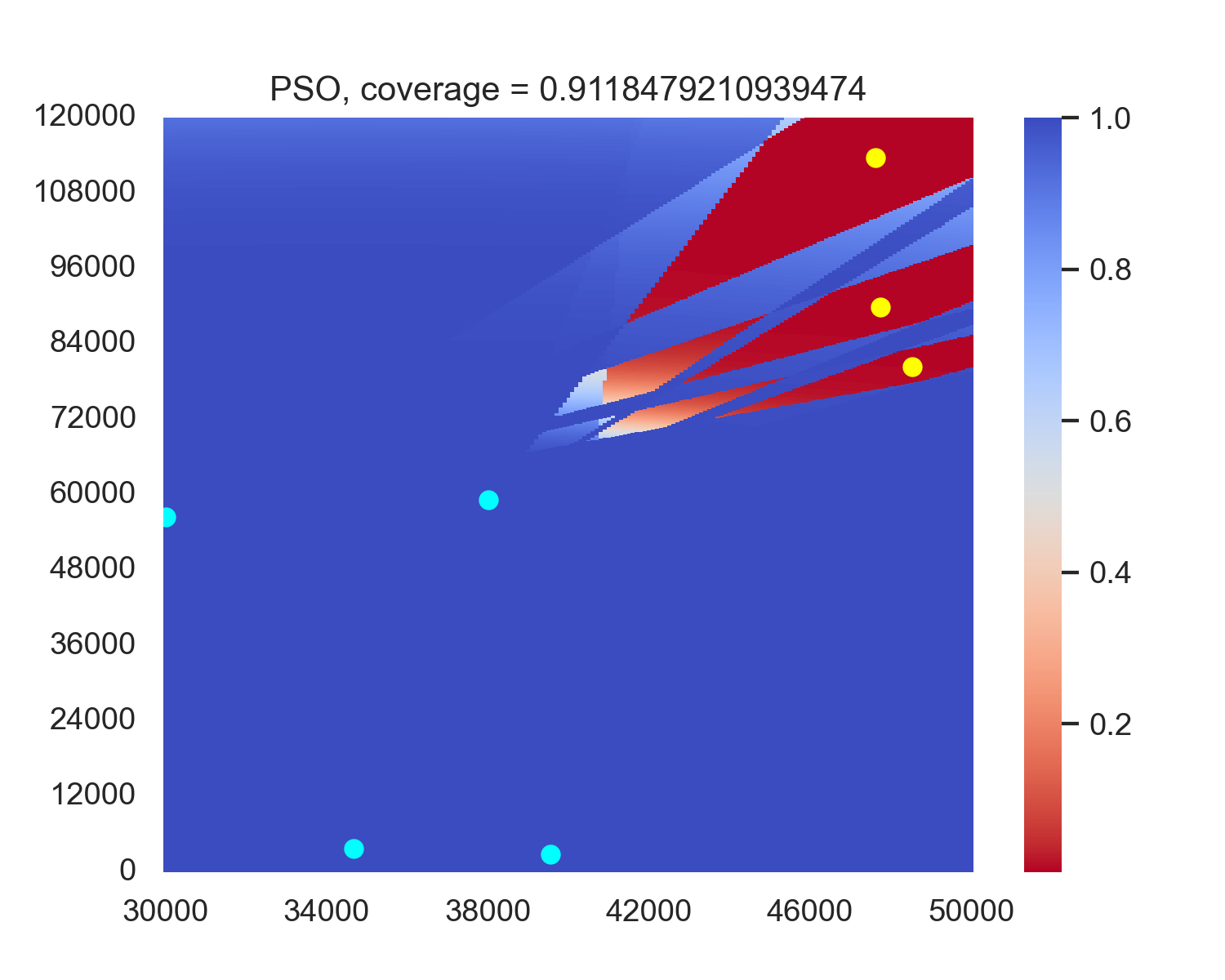
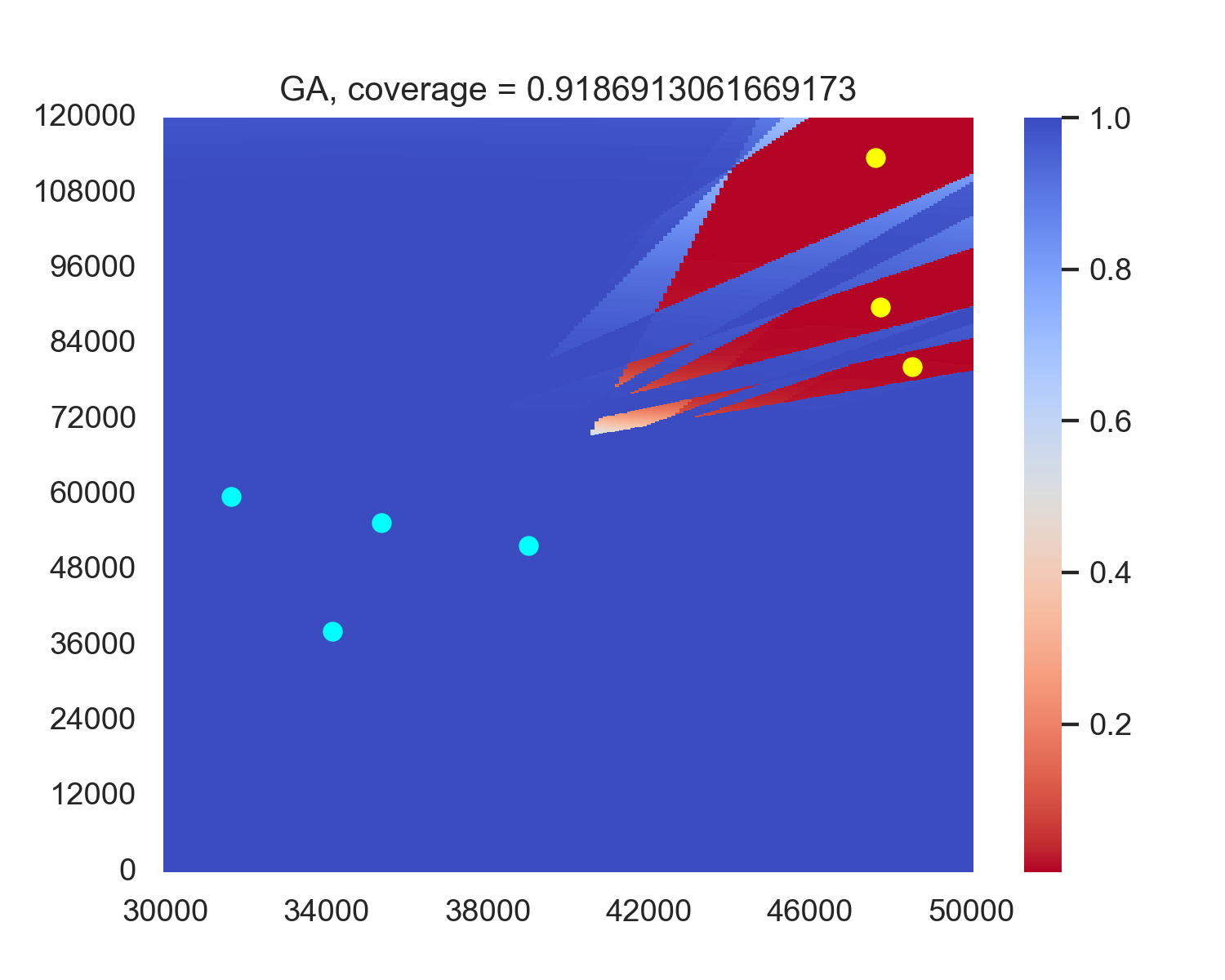
For the original problem, we first tried PSO and GA on it, and found that radars on the boundary of D R contribute most of the coverage. So we conceive the idea of trying to place radar only on the boundary, and conduct an experiment to see the coverage difference of placing radars only on the boundary and placing them in the region.
where, intuitively, B up and B right represent the upper and right boundaries of D R , while B R is the set of all points on the upper and right boundaries of the region D R .
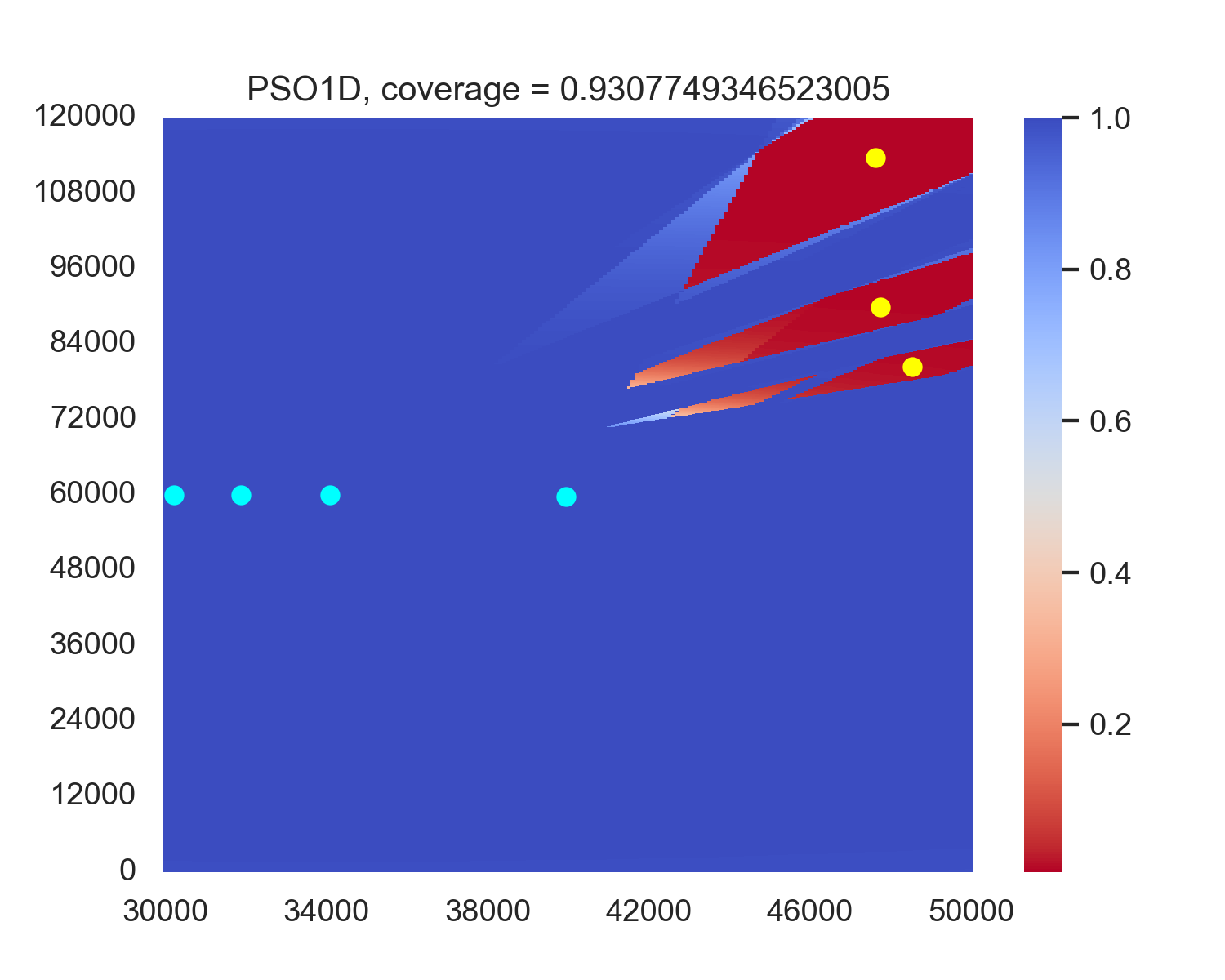
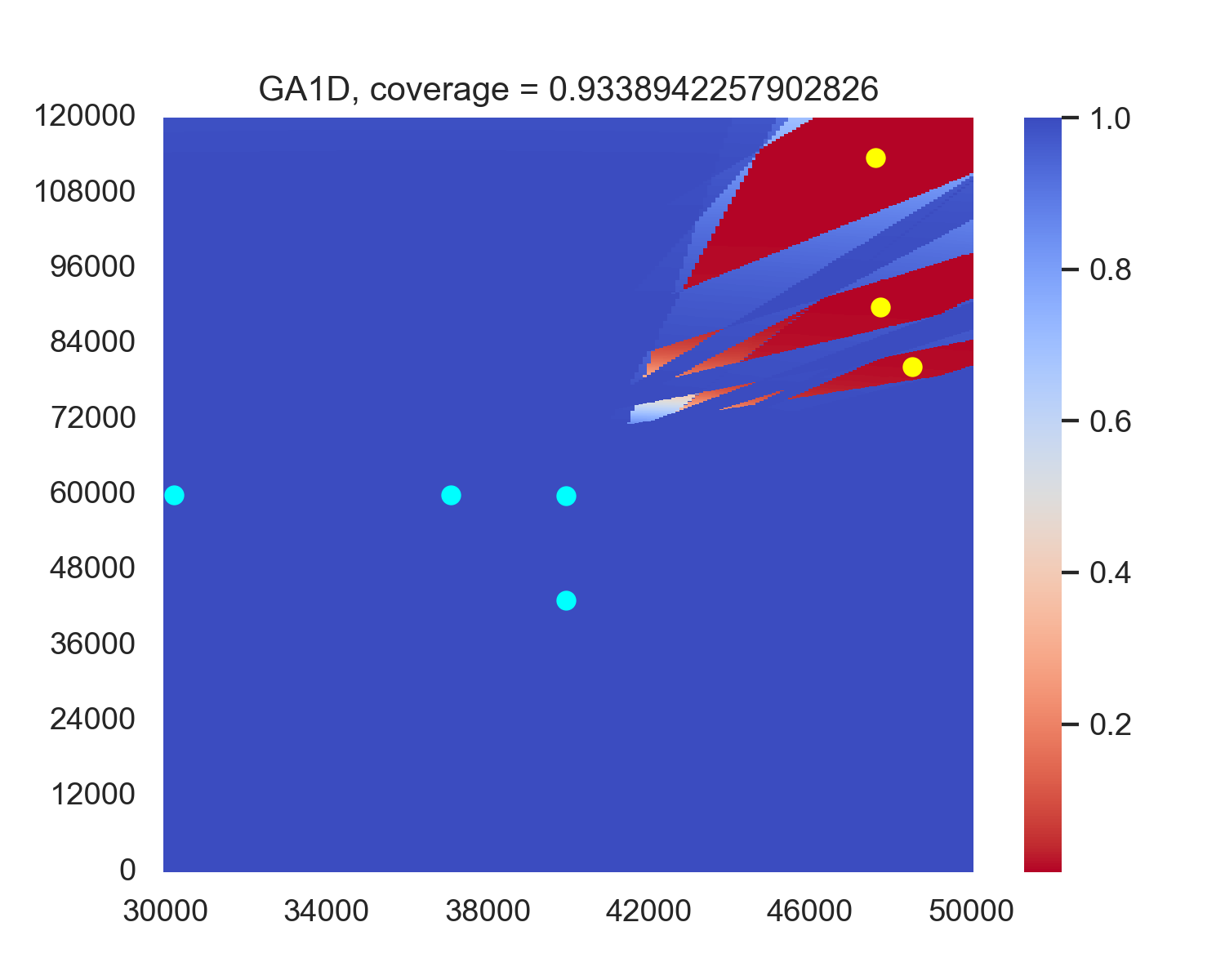
For the original optimization problem (14), we attempted to deploy radars using GA and PSO in regions D R and B R . Descriptions of the GA and PSO are provided in Appendix A and B, while the hyperparameters are detailed in Section 4.1. To simplify our descriptions, we denote the particle swarm and genetic algorithms deployed on B R as PSO1D and GA1D, respectively, and denote the algorithms deployed on D R as PSO and GA. We randomly select 100 sets of jamming node combination locations, run these algorithms, and record the average coverage of radar combinations of different algorithms on these 100 sets. The results are shown in Table 1.
The experiment results indicate that when using evolutionary algorithms, the average performance along the boundary B R consistently outperforms performance in the deploy area D R . A possible factor is that although deploying along B R may discard some more optimal solutions than deploying in D R , the corresponding reduction in search space facilitates algorithm convergence. Moreover, the performance loss from the discarded solutions is outweighed by the efficiency gains in convergence achieved through the reduced search space. Therefore, we will also deploy the radar along B R in our subsequent reinforcement learning algorithms. Figure 3 shows an example case of the performance in PSO and GA versus PSO1D and GA1D, showing that PSO1D and GA1D outperform PSO and GA by around 0.015 of coverage in this example. An intuitive sense is in PSO and GA, only the radars near the boundary contribute most of the coverage, while every radar in PSO1D and GA1D contributes to the final coverage. A possible reason for the non-boundary radars of PSO and GA is that this position combination becomes a local optimum, and non-boundary radars are stuck in this position and cannot get out.
In this problem, we try to set the action space on discrete point set B R and find it hard for the agent in learning and converge. A further analysis shows that this action space may be enormous in our training environment. Therefore, we relax the problem by transforming the agent’s action space into a continuous region boundary.
Specifically, we define the following continuous boundary B ′ R and set the agent’s action space as the coordinates of B ′ R . After the agent selects a radar deployment location, we move the position nearest to B R as the final radar location for agent-environment interaction. This transformation converts the agent’s action space from discrete to continuous. Agents will make decisions on coordinates instead of a set of specific points, significantly reducing the dimensionality of the action space, making it easier to deploy.
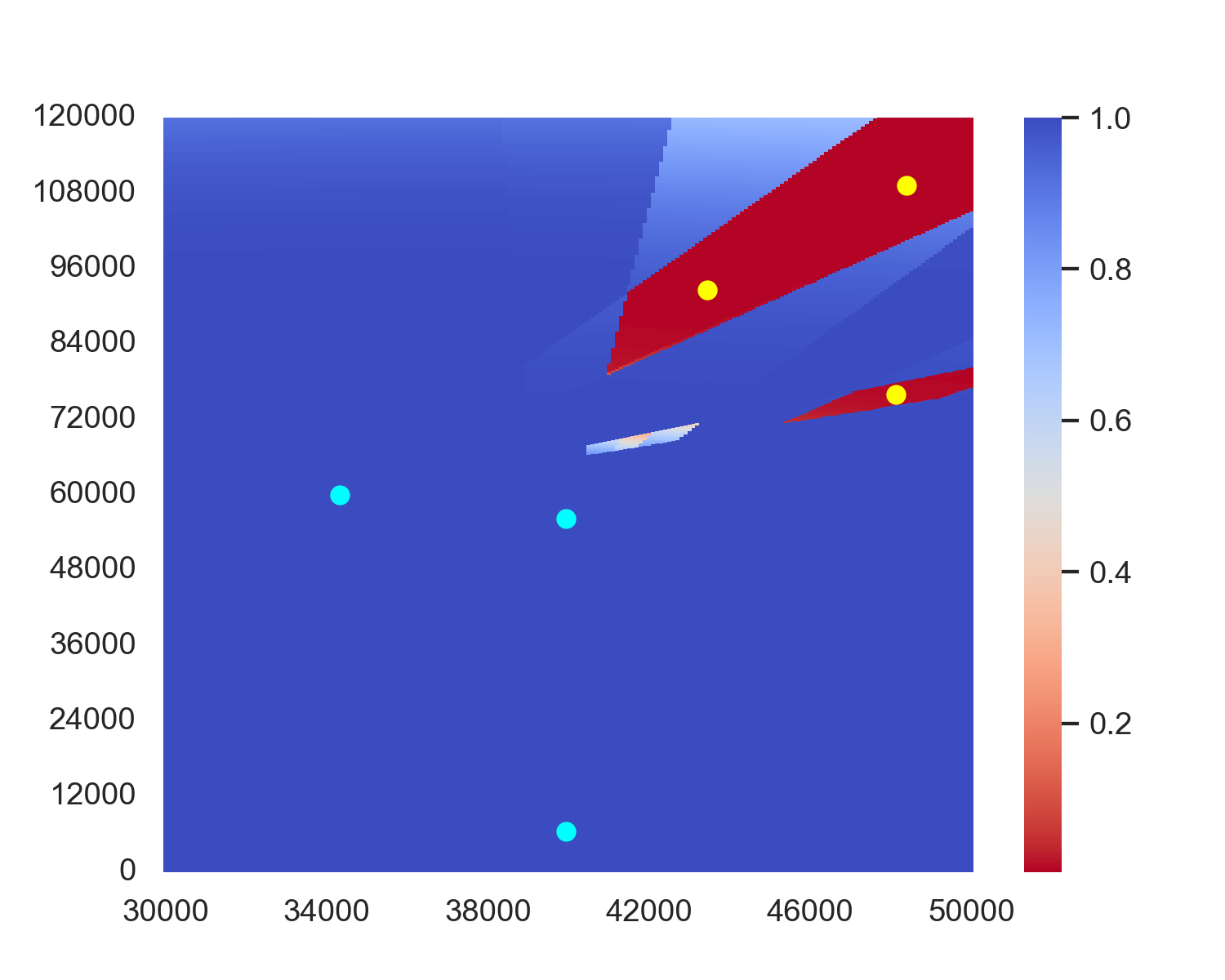
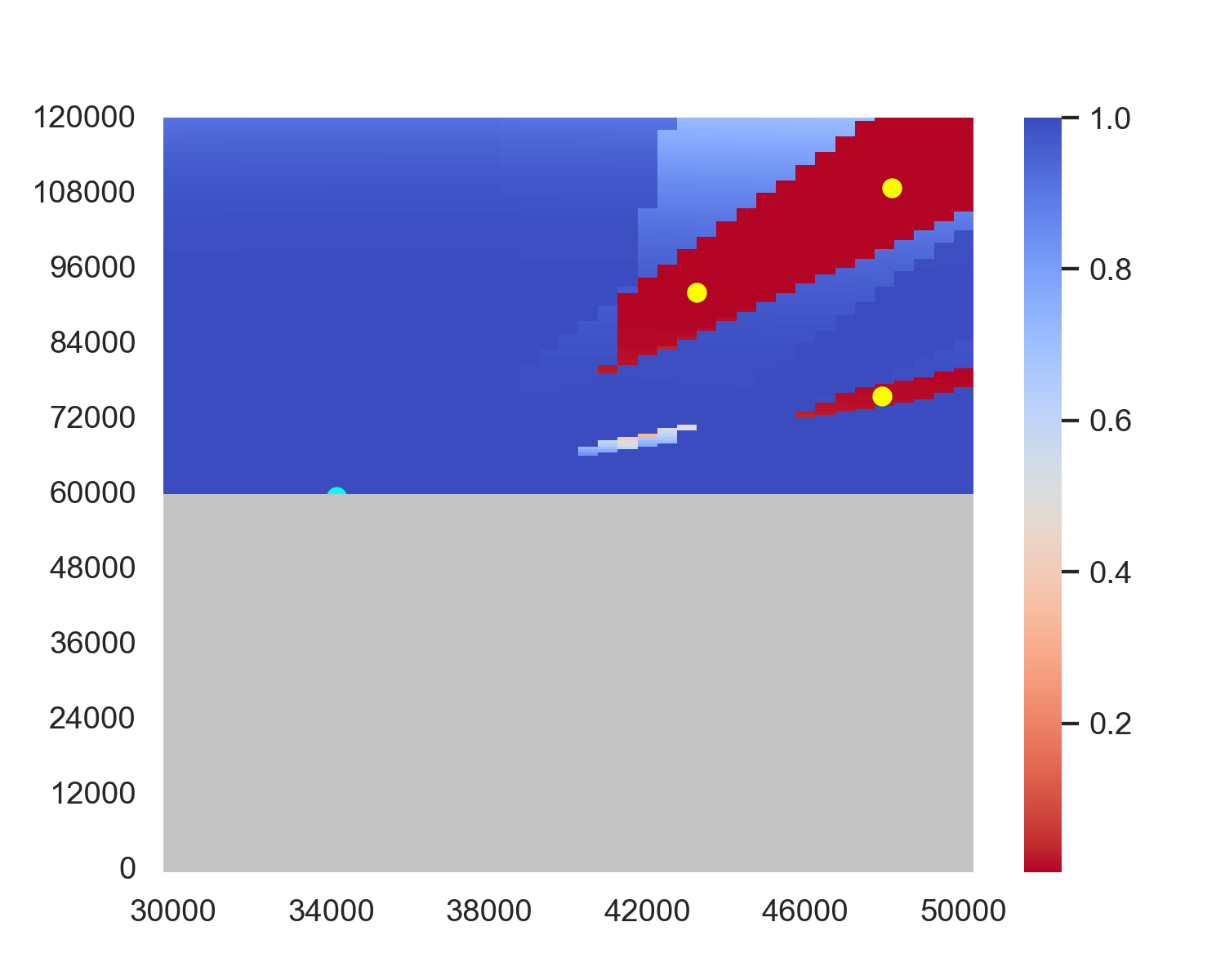
During the implementation of the optimization function, we found that the calculation speed of this function is extremely slow, taking about 15 seconds. Our further analysis reveals some possible reasons. The first is that in the optimization function, we need to calculate the detection probability on approximately 200 × 1200 = 2.4 × 10 5 points, which is numerous and redundant for the problem. Second, the detection function contains a lot of calculations of trigonometric functions, which may further decrease the speed of calculation.
To address this trouble, we define a new area D ′ for training the agent: in this area, we remove the lower half of D and change the sampling interval to 500 meters. We remove the lower half of the heatmap because radars can consistently detect these parts, so this region carries much less information than the upper half. We then use this D ′ to calculate the detected point set D′ by the radar combination, and obtain a detected area | D′ |/|D ′ | for the reward given by the Figure 4 shows a three-radar example of the heatmap before and after environment simplification. From the figure, it is evident that the shape of the undetected area remains similar. Besides, the detection probability in the lower half is essentially 100% and does not carry much information. Therefore, our operation is reasonable.
Suppose the size of D ′ is n ′ × m ′ , the relationship of shape between D and D ′ will be: n ′ = 1/10n, m ′ = 1/5m. So we reduce 50 times fewer points when calculating the coverage area by sacrificing a small amount of heatmap information, significantly decreasing computation time and accelerating training speed.
We transformed the radar deployment problem into a sequential decision-making problem. Specifically, at time step t, we determine the deployment location of the tth radar based on the positions of already deployed radars, jamming node locations, and environmental information. We further formulate it as an MDP M = (S, A, T , R, γ, µ 0 ):
• State space S: At time step t, the state comprises: the current detection probability heatmap of D ′ , the location of jamming nodes, historical actions (i.e., positions of radars already deployed), and a one-hot vector indicating which radar should be deployed next. That is:
Formally, M t := {P r R d,t } d∈D ′ represents the heatmap of detection probabilities in D ′ given the combination of radar positions output by the agent before time t. J represents the jamming node combination. R t is a vector with 2 × |R| dimensions, where the first 2 × (t -1) dimensions are the radar’s historical positions, and the remaining dimensions are set to zero. v t denotes the one-hot vector with dimension |R|, with the tth dimension is set to one.
• Action space A: At time step t, the agent outputs an action a t as a two-dimensional coordinate a t = (a x,t , a y,t ), indicating the position of the tth radar placement.
• State transition T : After the agent takes action a t at time step t, a deterministic transition occurs. First, the environment computes the new detection probabilities for each point, generating a new probability heatmap M t+1 , along with a new action history R t+1 and a new one-hot vector v t+1 . These form a new state
The parameters of convolutional kernels and pooling layers.
• Reward function R: Our goal is to maximize the detected area as shown in equation ( 14). After each interaction with the environment, the environment provides a reward equal to the coverage ratio | D′ |/|D ′ | calculated from all deployed radars. • Discount factor γ: We set γ = 1 in this MDP due to the limited horizon length in the environment of this problem. • Initial distribution µ 0 : Before each episode starts, we randomly sample jamming nodes’ location J from the environment. Since no radar is initially deployed, we initialize the probability matrix M 0 as a zero matrix. Then, we initialize H 0 as a zero vector and v 0 as a one-hot vector where the first dimension is set to 1. Based on this, we can obtain the initial state s 0 = (M 0 , J, R 0 , v 0 ).
The policy network in FARDA is based on an encoder network, along with an actor and a critic network. We will describe these networks in detail in this section.
Due to the presence of the detection probability heatmap, it is necessary to extract its features. Furthermore, as we need to deploy radars sequentially, the network needs to remember the newly gained area between two consecutive radar deployments.
To deal with these two problems, we have designed our encoder network, incorporating a Deep Convolutional Neural Network (DCNN) and a Long-Short Term Memory (LSTM) block. The primary purpose of the encoder is to abstract the heatmap information into a feature vector using DCNN, then employing LSTM to remember the area changes by the newest deployed radar. We will introduce these two networks separately:
• The DCNN block:
In the state set (18), the DCNN block only uses the heatmap information M t as input. The primary objective of this DCNN block is to extract heatmap information into a latent space and learn a favorable embedding. First, we add a new channel to the heatmap. Formally, for every P r R d,t ∈ M t , we perform the following operation and add the derived
This new channel aims to amplify the influence of τ while enabling the network to learn the threshold τ we have set.
Next, we put M t and M ′ t as two channels, denoted as X C t,0 , into the CNN, which can be concretely expressed as follows:
For the convolutional layer and pooling layer, we can use the following formula to represent the forward propagation at time step t:
where K C j denotes convolutional kernel, σ denotes the sigmoid activate function. The parameters of convolutional kernels and pooling layers are given in Table 2. After the convolutional and pooling operations, we can obtain a two-dimensional embedding X C t,3 . We flatten the embedding to one dimension, denoted as X C t,4 . Then we use a multilayer perception (MLP) to obtain the final embedding vector H C t by DCNN, where the hidden sizes of the three fully connected layers are 128, 64, and 64, respectively, and the activation function is the sigmoid function. We can use the following formula to present this process more formally:
• The LSTM block: Before every episode starts, the LSTM block initializes two zero vectors h 0 and c 0 as the hidden vectors, which can be formalized as follows:
At time step t, when the embedding vector of the DCNN block H C t passes through the LSTM block, the hidden vectors obtained from the last time step h t-1 and c t-1 will become the input hidden vectors for the LSTM block. After these three vectors pass through the LSTM block, three more vectors X L t , h t , c t will be obtained. We will then feed X L t to an MLP with one hidden layer of size 64 to get the output vector H L t . The formula below shows the detailed process of the LSTM block:
We use the LSTM block to remember which areas each newly deployed radar covers during the deployment process. The vector H L t is then used to guide the actor network in radar placement decisions and the critic network in obtaining rewards.
After the LSTM network outputs the embedding vector H L t , we concatenate it with the remaining information from the MDP state vector, which contains J, H t , v t , and can be detailed as follows:
The concatenated vector X P t serves as the input to the actor and critic networks. We use an MLP for both actor and critic network to obtain the action and the value function. The hidden layer size for both the actor and critic networks is 64, and the activation function is the sigmoid function. We use the following formulas to describe the outputs of the actor and critic networks:
V π (X P t ) = M LP v (X P t ).
Finally, the parameterized policies can be detailed as follows:
We use PPO algorithm [23] to train and Adam optimizer [24] to optimize our model. The detailed information of PPO algorithm can be found in Appendix C.
At time step t, when the agent receives a reward r t ∈ R, we perform two operations (namely CVDP-EXPR) to enable more efficient learning (since B ′ R is a broken line, which will be inconvenient for further discussion, we straighten B ′ R into a segment):
• Constraint Violation Degree Penalty (CVDP): An intuitive idea is that uniformly deploying radars means each radar can cover the target area more evenly. Therefore, we designed CVDP based on the constraint violation. First, suppose radars are uniformly placed on B R , with their position set denoted as
Next, we define a threshold set U = {u 1 , • • • , u |R| } and guide the agent to deploy the radar within the set B(l t , u t ) ∩ B ′ R at time step t, where B(x, r) denotes a line segment centered at x with length 2r. Formally, assume the agent takes action a t , we designed the following constraint violation degree penalty:
• Exponential Function Reward (EXPR): We found that after deploying the first few radars, they could cover the vast majority of jamming-free areas. This resulted in diminishing returns when placing new radars, as the additional coverage gain became smaller. Consequently, reward fluctuations became less pronounced, leading to inefficient learning by the agent in subsequent time steps.
To address this, we designed the EXPR: Given that the environment provides a reward r t at time step t and a reward r t-1 at the previous time step, we formulate the exponential-like reward as follows:
Finally, the reward rt guiding the agent’s update is defined by the following equation:
We can chain all the networks together and obtain a pseudocode for network training in FARDA, represented by Algorithm 1.
Algorithm
To validate the effectiveness of FARDA, we design numerical experiments tailored to specific environments. We compare FARDA with the PSO1D and GA1D algorithms on the test dataset. The results demonstrate that FARDA achieves coverage comparable to PSO1D and GA1D while operating nearly 7,000 times faster. Additionally, we conduct a series of ablation tests, whose outcomes confirm the essential role of each component within FARDA.
We display the necessary setups of the experiment, detailed as follows:
• Test Dataset: Due to the high computational cost of evolutionary algorithms, we randomly select 500 jamming node combinations from our environment as our test set. During training, we also select jamming node combinations randomly from the environment. This ensured the test and training datasets were sampled from the same distribution.
• Baselines: We use PSO1D algorithm and GA1D as our baselines. These two algorithms are based on PSO and GA, which are thoroughly introduced in Appendix A and B. GPU. We utilize a 12th Gen Intel® Core™ i9-12900 CPU for evolutionary algorithms to get the result. • The number of jamming nodes and radars: In the environment, the number of enemy jamming nodes is 3, and we need to deploy four radars, i.e., |J| = 3, |R| = 4. • Hyperparameters: Our experiment contains three parts of hyperparameters: environment, evolutionary algorithms, and policy network in FARDA.
- For the environment after simplification: We set Pr = 450W, Pt = 30W, λ = 0.3m, K = 32, B = 10 6 Hz, F r = 2 × 10 3 , T 0 = 270K, P r f a = 10 -3 , F e = 10 3/10 . Besides, we set the number of pulses accumulated during the phase-correlation period N = 16, and we set θ = 2 × 0.886/N, G T = 2πd E (N -1)/λ, and G R = 2πd E /λ. The Boltzmann constant is K e = 1.38 × 10 -23 . Finally, we set the detection probability threshold τ to 0.5. 2. For evolutionary algorithms: For GA1D, we set P r c = 0.9, P r m = 0.1, T G = 100, and N G = 50. For PSO1D, we set T P = 100, N P = 20, ω = 1, c 1 = c 2 = 2. 3. For policy network in FARDA: The training rates are set to η ψ = 10 -4 , η θ = 10 -4 , η ϕ = 5 × 10 -4 , the number of episodes E = 2 × 10 5 , the number of training steps in each iteration T train = 10, and the clip ratio ϵ in PPO is set to 0.2.
For the dataset we have obtained, we compared FARDA with GA1D and PSO1D algorithms.
To better compare the efficiency of these algorithms, we specially designed an efficiency metric to measure the detected coverage in every log unit of time:
where we consider the impact of the scale of time becomes less significant as the deployment takes longer.
Table 3 shows the main testing results. It can be demonstrated that, compared to the evolutionary algorithms GA1D and PSO1D, our FARDA exhibits superior performance in all metrics. The most significant improvement is in the time metric, where FARDA is approximately 7000 times faster than evolutionary algorithms, reducing the computation time from about half an hour to less than half a second. Also, FARDA significantly enhances the efficiency metric from 0.13 to 4.21. As for the least improved metric coverage, FARDA still outperforms evolutionary algorithms.
Additionally, we divide the instances in the test dataset into three categories: Bad, Normal, and Good. The dividing standard is the coverage of evolutionary algorithms: we define bad data as coverage lower than 0.9 when using both GA1D and PSO1D. For the normal data, the coverage threshold is set to be greater than 0.9 but lower than 0.95, while the rest of the data in the test dataset is considered as good data. We test FARDA on these three categories and compare with evolutionary algorithms. The results are shown in Table 4.
We found that in these three categories, FARDA outperforms evolutionary algorithms in all three datasets. Furthermore, higher improvements are shown in bad data and normal data. In real-world military scenarios, the enemy tends to make the jamming node combination more difficult to detect targets, making our method more useful in real-life applications.
To demonstrate the effectiveness of each part of FARDA, we designed two parts of ablation tests focused on network design and reward design, respectively. Since the forward propagation time of the following networks is approximately the same, as reported in 3, we do not record time and efficiency metrics. It can be observed that our proposed encoder in FARDA performs best. In addition, removing either the CNN or the LSTM leads to a decrease in performance, and removing the entire Encoder results in a significant drop in average coverage. Upon analysis, we found that without the encoder, all the high-dimensional heatmap information is fed directly to the actor network, while the hidden size of the actor is relatively small compared with the dimension of the heatmap. This may prevent the actor from extracting the necessary and correct information from the heatmap, leading to incorrect decision-making.
Next, we explored the impact of CVDP-EXPR. We conducted ablation experiments by removing CVDP, EXPR, and CVDP-EXPR. The results are shown in Table 6:
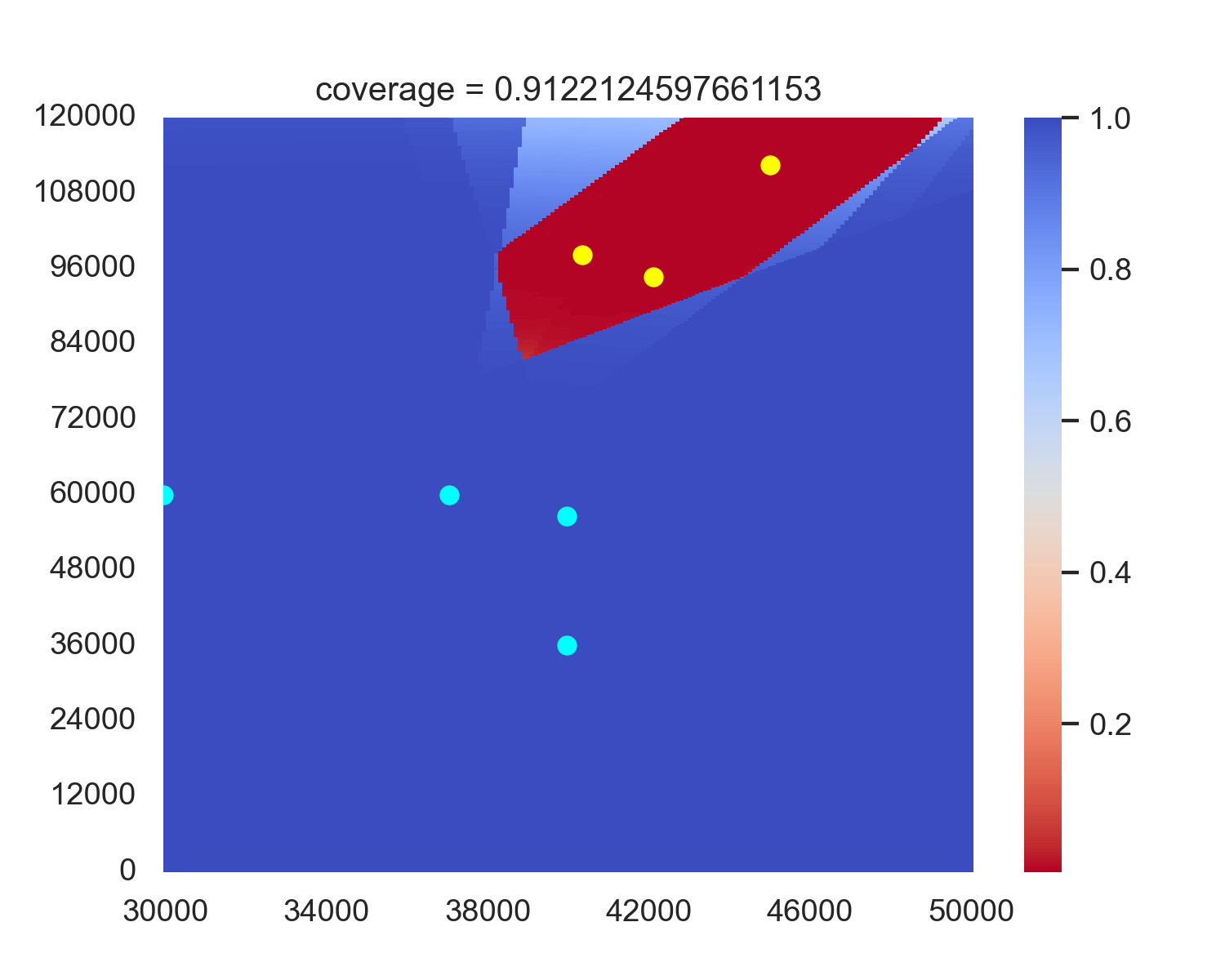
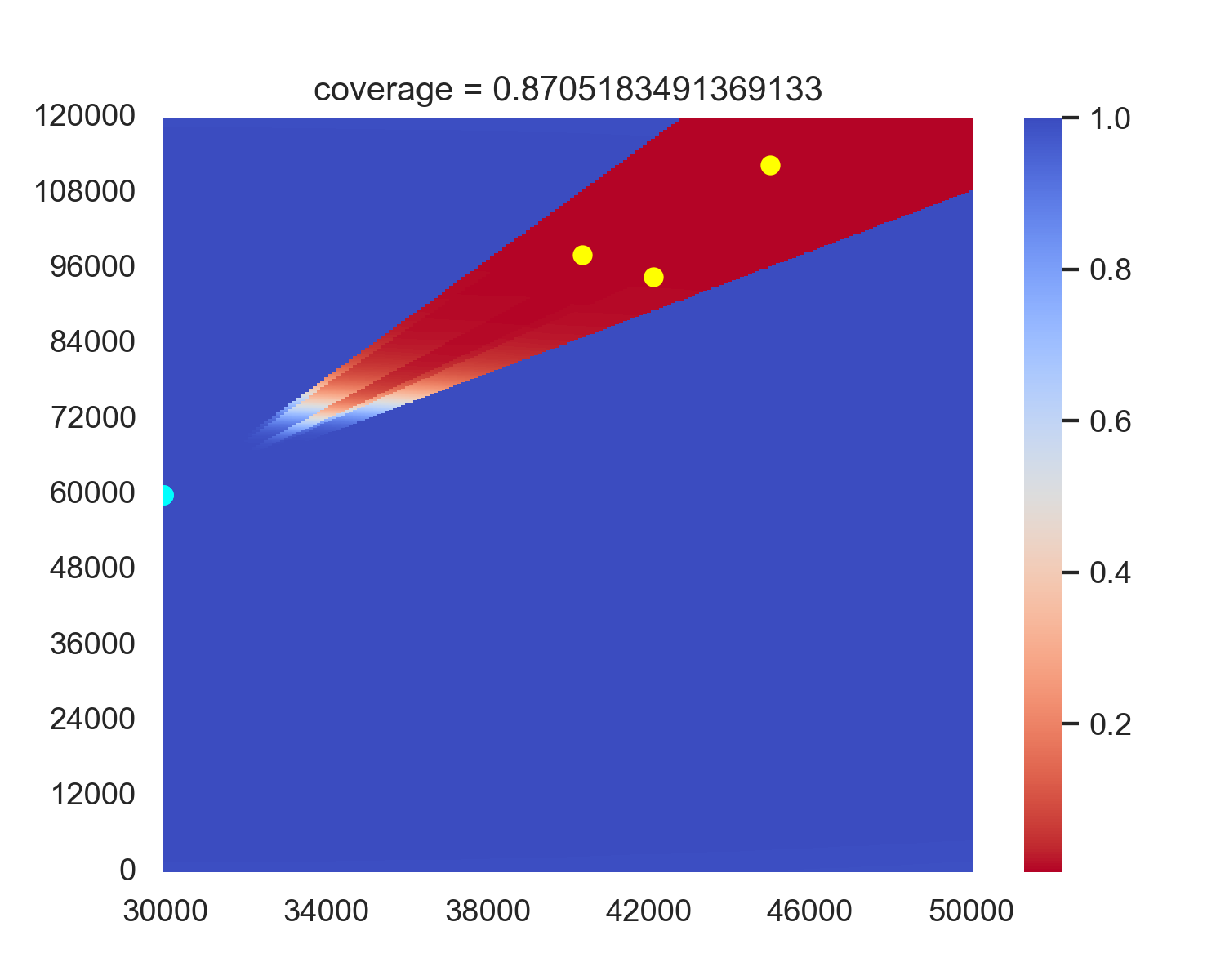
It can be seen that FARDA shows the best performance, and deleting any other part leads to varying degrees of decline in coverage. Notably, the removal of the CVDP results in a significant performance drop. Our analysis revealed that without CVDP, the training collapses: As shown in Figure 5, all radars tend to move in the same direction and get stuck. This phenomenon also occurs when removing CVDP-EXPR, as it involves the removal of CVDP. Further analysis indicates that removing CVDP causes the agent to consistently receive positive rewards, which gradually increases the probability of selecting incorrect actions, and the agent is unable to learn the correct way to place radars. However, with CVDP, if the agent deviates too far from the specified position, it receives punishment, which means the reward can be negative, reducing the probability of the agent selecting those actions and thus preventing training collapse.
We introduced a brand new approach, FARDA, in the anti-jamming situation of cognitive radar deployment: a novel pipeline combining the encoder network and reinforcement learning. We have shown that FARDA has significantly improved deployment time, while coverage also outperforms evolutionary algorithms. The improvement in time shows the prospect of utilizing our approach in real-world scenarios, where fast deployment is as important as coverage.
Our subsequent research will focus on two aspects: more complex static environments and dynamic environments. In the more complex static environment section, the number of radars and jamming nodes will be adjusted accordingly, while the size of region S and the shape of the deployable area will also change. In the dynamic environment section, the positions of jamming nodes may shift over time, requiring a dynamic response of radars to their positions. However, unlike the static scenario, each radar position at any given moment cannot deviate too far from its previous position. Additionally, the evaluation metrics will also change.
We first define the boundary B R of the deploy region as follows:
This content is AI-processed based on open access ArXiv data.