Large Language Models (LLMs) demonstrate strong in-context learning abilities, yet their effectiveness in text classification depends heavily on prompt design and incurs substantial computational cost. Conformal In-Context Learning (CICLe) has been proposed as a resource-efficient framework that integrates a lightweight base classifier with Conformal Prediction to guide LLM prompting by adaptively reducing the set of candidate classes. However, its broader applicability and efficiency benefits beyond a single domain have not yet been systematically explored. In this paper, we present a comprehensive evaluation of CICLe across diverse NLP classification benchmarks. The results show that CICLe consistently improves over its base classifier and outperforms few-shot prompting baselines when the sample size is sufficient for training the base classifier, and performs comparably in low-data regimes. In terms of efficiency, CICLe reduces the number of shots and prompt length by up to 34.45% and 25.16%, respectively, and enables the use of smaller models with competitive performance. CICLe is furthermore particularly advantageous for text classification tasks with high class imbalance. These findings highlight CICLe as a practical and scalable approach for efficient text classification, combining the robustness of traditional classifiers with the adaptability of LLMs, and achieving substantial gains in data and computational efficiency.
Text classification is a fundamental task in Natural Language Processing (NLP) with applications ranging from sentiment and emotion analysis to news categorization and knowledge organization. Despite its long history, the task remains challenging when datasets are characterized by a large number of classes, highly imbalanced class distributions, or limited training data. Recent advances in Large Language Models (LLMs) have introduced new possibilities through in-context learning (Brown et al., 2020;Chowdhery et al., 2022), where models can adapt to unseen tasks from a small number of labeled examples, without further training. However, the effectiveness of few-shot prompting strongly depends on how examples are selected and presented (Liu et al., 2023), and the computational cost of querying large models remains substantial.
Conformal In-Context Learning (CICLe) was recently proposed as a resource-efficient approach that addresses these challenges (Randl et al., 2024). CICLe combines a traditional base classifier with Conformal Prediction (CP) to adaptively reduce the set of candidate classes and select corresponding few-shot examples to include in the prompt, where the LLM makes the final classification. This hybrid setup enables robust predictions while reducing the reliance on large context windows and bypassing the LLM entirely when the base classifier is sufficiently confident. Initial experiments on a food recall dataset (Randl et al., 2024) demonstrated that CICLe can outperform both traditional classifiers and regular few-shot prompting in terms of predictive performance and efficiency. However, its evaluation has so far been limited to a single domain, leaving open questions about CICLe’s generalizability and the conditions under which it provides the greatest benefit.
In this work, we conduct a systematic evaluation of CICLe across a diverse set of benchmark NLP datasets, including news categorization, ontology classification, community question answering, and fine-grained emotion detection. We also seek to understand in which kinds of situations CICLe performs well compared to its base classifier and regular few-shot prompting, focusing especially on efficiency aspects like sample size and model size, but also on the nature of the classification task, e.g. the number of classes and the class distribution. Our experiments build upon prior work in several ways: (i) we broaden the comparison between CICLe, its base classifier, and few-shot prompting by evaluating multiple selection strategies across diverse benchmark datasets; (ii) we analyze its robustness under varying training data sizes and LLM parameter scales; and (iii) we investigate its performance across class distributions ranging from balanced to highly imbalanced with class counts between 4 and 27. We frame our study around the following research question: under what conditions does CICLe provide advantages over traditional classification models and few-shot prompting strategies in text classification tasks with respect to sample size, the number of classes, and class imbalance.
By answering this question, we aim to provide a comprehensive empirical understanding of CICLe’s strengths and limitations, and to identify when it represents a practical alternative for efficient and reliable text classification. In summary, our systematic evaluation across four benchmark datasets demonstrates that CICLe consistently improves over its base classifier and outperforms the few-shot baselines when there is a sufficient amount of data for training the base classifier. In low-data regimes, CICLe on average performs on par with tradiational few-shot prompting methods. In terms of efficiency, CICLe reduces the number of shots and the prompt length in tokens by up to 34.45% and 25.16%, respectively. The results also demonstrate that CI-CLe allows for using smaller models that perform competitively with much larger models, underscoring its potential for resource-efficient deployment. Furthermore, CICLe shows clear advantages in highly imbalanced scenarios, where it achieves stronger and more stable performance compared to regular few-shot prompting.
LLMs for few-shot classification has reshaped the landscape of text classification by enabling models to perform tasks with only a handful of labeled examples provided in natural language prompts (Brown et al., 2020). This in-context learning paradigm bypasses the need for task-specific fine-tuning and has been applied successfully to a variety of NLP tasks (Gao et al., 2021). However, performance depends heavily on the choice and ordering of examples (Liu et al., 2023), motivating strategies such as similarity-based retrieval (Rubin et al., 2022;Ahmed et al., 2023) or embeddingbased selection to improve reliability. Despite these advances, prompting remains sensitive to class imbalance, as LLMs may overpredict dominant classes while underpredicting others (Lin & You, 2024). While LLM prompting is powerful in lowdata settings, several studies show that fine-tuning smaller models still achieves superior performance on many text classification tasks, suggesting that LLMs are not yet universally state-of-the-art for classification (Edwards & Camacho-Collados, 2024;Bucher & Martini, 2024;Alizadeh et al., 2023). On the other hand, it allows for carrying out classification tasks without having to first curate a large manually labeled dataset, which can be prohibitively expensive. (Vovk et al., 2005, CP) provides a statistical framework for associating predictions with calibrated confidence sets, offering formal guarantees of coverage. In essence, CP estimates how uncertain a model is by constructing a set of plausible labels for each prediction, such that the true label lies within this set with a prede-fined probability. This allows CP-based methods to quantify prediction reliability and control error rates in a principled way. Building on this idea, Randl et al. (2024) proposed Conformal In-Context Learning (CICLe), which integrates CP with a base classifier to guide the selection of candidate classes for prompting. By adaptively reducing the number of classes passed to the LLM and bypassing the model when the base classifier is confident, CI-CLe addresses both reliability and efficiency. Initial results on food hazard classification showed that CICLe can outperform traditional classifiers and direct prompting while substantially lowering the computational cost. However, evaluation has so far been limited to a single dataset, leaving open questions about CICLe’s generalizability and the conditions under which it provides the greatest benefits.
As LLMs continue to grow in size and computational requirements, efficiency and accessibility in text classification have become increasingly important. Ideally, achieving strong classification performance should not depend solely on using the largest available models or extensive labeled datasets, as annotation remains costly and labor-intensive (Snow et al., 2008;Nie et al., 2019). Recent work has therefore emphasized approaches that balance effectiveness with practicality, aiming to reduce computational overhead while maintaining competitive results (Strubell et al., 2019;Henderson et al., 2020;Schick & Schütze, 2021;Min et al., 2023). However, most of these methods focus on efficient fine-tuning, or model compression rather than in-context classification, and are thus complementary to our evaluation. While Purohit et al. (2025) explore few-shot classification, they focus on reinforcement learning of optimal sample combinations which remains computationally costly. By contrast, CICLe contributes to the growing effort toward efficient and sustainable NLP by combining a lightweight base classifier with selective and adaptive LLM prompting, thereby reducing dependence on massive models while maintaining strong performance.
This section describes the methodological components of our study, comprising the TF-IDF-based base classifier, the few-shot prompting baselines used for comparison, and the CICLe framework, which extends the base classifier using conformal prediction for adaptive prompt construction.
Following Randl et al. (2024), we employ Logistic Regression trained on TF-IDF embeddings as our base classifier. This model provides a strong and efficient baseline against which we compare LLM-based methods. Notably, in the original CICLe study, this base classifier setup outperformed several BERT-family models, demonstrating that welloptimized traditional classifiers can remain highly competitive for text classification, particularly when computational efficiency is a priority. The base classifier also plays a central role in CICLe since its probability estimates are used for constructing conformal sets. While lightweight and competitive on well-represented classes, such linear models are known to degrade in low-data regimes and under strong class imbalance, motivating their integration with LLMs.
CICLe integrates a base classifier with Conformal Prediction (CP) to create a resource-efficient prompting pipeline. The base classifier first esti-mates a probability distribution over the label space, which is then used to construct a conformal set of candidate classes that includes the true label with a predefined confidence level controlled by CP’s α parameter. In other words, 1 -α represents the probability that the true class is contained in the conformal set. The LLM is prompted only with these candidate classes and with k = 2 few-shot examples from each, thereby reducing the context length and focusing the model on a smaller, more relevant subset of classes. In the limited case where the conformal set contains only one class, the system bypasses the LLM entirely and outputs the base classifier’s prediction directly. This hybrid mechanism not only reduces the computational cost of prompting but also improves robustness by adaptively balancing the strengths of traditional classifiers and LLMs.
This section details the experimental design used to evaluate CICLe and its baselines, including dataset selection, model configurations, prompt design, and implementation setup.
We evaluate our methods on four widely used text classification benchmarks that differ substantially in domain, text length, and label granularity: AG News (Zhang, 2015) for topic categorization of news articles (4 classes), DBpedia-14 (Zhang, 2015) for ontology-based classification of Wikipedia abstracts (14 classes), Yahoo Answers Topics (Zhang, 2015) for community question categorization (10 classes), and GoEmotions (Demszky et al., 2020) for fine-grained emotion detection from short Reddit comments (27 classes). Since the original dataset allows multiple emotion labels per sample, we follow prior work in using the main (primary) emotion as the single target label. These datasets collectively allow us to assess CICLe under a variety of linguistic and structural conditions, including short-text, multiclass, and imbalanced scenarios.
For each dataset, we experiment with varying numbers of available samples to simulate different data availability settings. Specifically, for training the base classifiers and constructing the few-shot example pool, we use subsets of 100, 200, 300, 400, 500, 1k, 2k, 3k, 4k, and 5k examples, employing identical random seeds to ensure consistency across models and runs. All single splits are stratified to maintain similar class distributions across training, calibration, and test sets. For the GoEmotions dataset, which is highly imbalanced, we conduct experiments only on subsets of 2k sam-ples and larger to ensure that all emotion categories are adequately represented. The evaluation is performed on a fixed test set of 1,000 examples for every dataset, providing a consistent and reproducible basis for comparison. A detailed overview of dataset statistics (average text length, class distribution, and total size) is provided in Table 1.
The base classifier is a Logistic Regression model trained on TF-IDF embeddings with an ℓ 2 penalty and a regularization strength of C = 1.0, corresponding to the default configuration in scikitlearn. This setup provides a simple and stable baseline while remaining fully consistent across datasets. The same configuration is used for the base classifier within the CICLe framework to ensure a fair and directly comparable evaluation. Unless otherwise specified, all experiments use α = 0.05, corresponding to a 95% confidence level for the conformal prediction step.
We evaluate CICLe and few-shot prompting using models from the LLaMA family, specifically the LLaMA-3.1-Instruct variants with 8 billion and 70 billion parameters. These two configurations allow us to examine how model size influences performance and efficiency within the same architecture. The smaller 8B model represents a resourcefriendly option suitable for most research environments, while the 70B model approximates the upper bound of commonly used open-weight models at the time of experimentation. While newer and larger open-weight LLMs (e.g., LLaMA-3.3 or Mixtral variants) have since been released, LLaMA-3.1 remains one of the best-performing and most widely benchmarked instruction-tuned models, making it a representative and well-established choice for evaluating the CICLe framework.
For generation, we use deterministic decoding without sampling and set max_new_tokens = 5 to ensure that only a single label is produced per instance. Each prompt explicitly instructs the model to output only the final label, and no postprocessing or filtering is applied. Predictions that do not match any valid class label are counted as incorrect, ensuring a strict and consistent evaluation across methods.
Both few-shot prompting and CICLe employ the same overall prompt structure: each prompt introduces the classification task, provides illustrative labeled examples, and finally includes the test instance to be classified. In all cases, the model is explicitly instructed to output only the final class label. The key difference lies in how class information is represented. In the few-shot setting, we include k = 2 labeled examples for each class, thereby enumerating all classes through the provided examples. In contrast, CICLe implicitly communicates the most relevant classes by presenting labeled examples ordered from most to least probable according to the base classifier’s confidence scores. This adaptive ordering allows CICLe to focus the prompt on a smaller, contextually relevant subset of classes, thereby reducing the number of few-shot examples required.
All experiments were conducted on a server equipped with 8 NVIDIA RTX A5500 GPUs, each with 24 GB of VRAM, allowing for efficient distribution of experiments across datasets and configurations. All models were implemented in Python using the scikit-learn library for traditional classifiers, the crepes library for CP, and the transformers framework for LLM-based experiments. Specifically, We use scikit-learn’s TfidfVectorizer for our sparse embeddings and all-MiniLM-L6-v2 (Reimers et al., 2024) embedding model from HuggingFace’s sentence transformers as our dense embeddings.
Inference with the LLaMA-3.1 models was performed using the HuggingFace API without further fine-tuning. Random seeds were fixed across all runs to ensure full reproducibility. To promote transparency, the complete implementation, including code and configuration files, will be made publicly available on GitHub after the review phase and included in the camera-ready version.
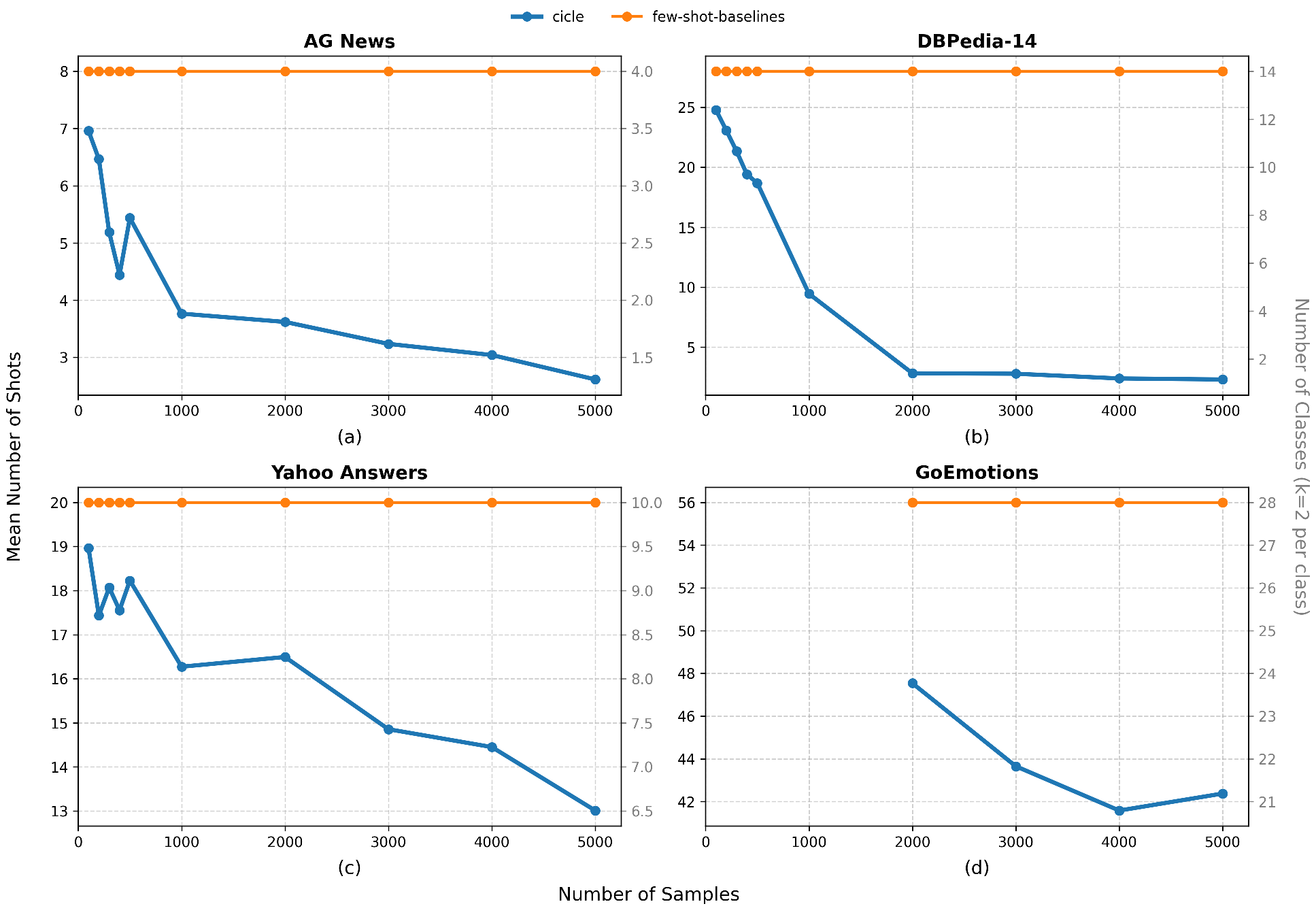
In this section, we present the results of our experiments across four benchmark datasets. Unless otherwise noted, the primary evaluation metric is the macro-averaged F 1 -score, which provides a balanced measure of performance across classes and is particularly informative under class imbalance. For each dataset, we plot the full learning curves for macro-F 1 across different training sample sizes, along with curves showing the reduction in the number of shots and candidate classes achieved by CICLe.
On the balanced AG News benchmark, CICLe achieves strong performance in terms of macro-F 1 , confirming its effectiveness: Figure 1a more than 500 labeled texts. With less than 500 samples, dense-70B slightly outperforms CICLe-70B, but CICLe quickly closes this gap as data increases. Notably, CICLe-8B not only surpasses all 8B few-shot variants but also performs comparably to larger models such as sparse-70B. Overall, we see very similar performance for all non-random tested strategies on this dataset.
On the balanced DBpedia-14 dataset (see Figure 1b), CICLe achieves consistently strong results across all sample sizes. Both CICLe variants outperform their base classifiers and random sample selection baselines, but perform minimally worse than dense or sparse strategies with the same LLM. Again we see largely comparable performance of the non-random prompting strategies.
The Yahoo Answers Topics dataset, while still be-ing balanced, presents a more challenging, longertext classification task with higher topical variability.
Figure 1c shows that for this dataset the LLM size makes a clear difference, as the strategies leveraging Llama-70B consistently outperform Llama-8B. CICLe consistently shows top performance for strategies based on the same LLM, and clearly outperforms its base classifier independent of the size of the training set.
GoEmotions, with its 27 imbalanced emotion categories, provides a challenging benchmark for finegrained emotion classification. Here, CICLe-70B clearly achieves the highest macro-F 1 across all data sizes, while CICLe-8B remains competitive and often surpasses the 70B few-shot prompting variants. Overall, CICLe demonstrates stable and superior performance especially in this highly im-balanced setting as illustrated in Figure 1d.
While CICLe overall receives comparable or better F 1 scores than the baselines it needs consistently less few-shot samples to do so, as shown in Figure 2. Even for small sizes of training sets, we see a reduction of the number of classes included in the prompt compared to prompting with the full set of classes for each dataset. Furthermore, we see the number of classes decreasing drastically with increasing size of the training set.
Across datasets, several consistent trends emerge. First, CICLe shows stable performance across number of training samples that is either comparable (for balanced datasets) or (in the case of class imbalance) better than the tested dense or sparse few-shot selection strategies. Second, we find that CICLe is able to deliver its competitive performance with considerably fewer few-shot samples than its competition. Third, on the highly imbalanced GoEmotions dataset, CICLe attains the best overall performance, indicating its effectiveness in handling uneven label distributions. Finally, CICLe also reliably outperforms its base classifier, reflecting the additional reasoning capabilities contributed by the LLM.
Regarding few-shot prompting, dense and sparse strategies perform overall comparably, with the sparse strategy often slightly outperforming dense few-shot selection. Random selection remains consistently unstable. Overall, CICLe combines the efficiency of classical models with the adaptability of LLMs, achieving robust and resource-efficient text classification across diverse linguistic and structural conditions.
To provide an overall comparison of model performance across datasets, we report the average macro-F 1 scores of each method computed over all sample sizes for each dataset separately in Table 2. This aggregation captures the general behavior of each model while smoothing out small fluctuations caused by random sampling or data scarcity.
Both CICLe strategies achieve the best performance overall compared to sparse and dense strategies using the same size LLM, ranking first on three of the four datasets (AG News, Yahoo Answers, and GoEmotions) for the 8B variant and two out of four (AG News, GoEmotions) for the 70B variant. The smaller CICLe-8B model remains highly competitive, sometimes even closely matching several 70B prompting variants. Among the few-shot baselines, we again see no clear winner between dense and sparse strategies. The base classifier remains strong on AG News and DBpedia but drops substantially on the more complex and imbalanced datasets, highlighting the role of CP in CICLe’s steady performance in those settings.
To further examine CICLe’s data efficiency, we analyze performance across three data availability regimes by aggregating results over comparable sample sizes. Specifically, we categorize training set sizes into three groups: low-data (100-400 samples), medium-data (500-2,000 samples), and large-data (3,000-5,000 samples). For each group, we compute average macro-F 1 scores across the AG News and Yahoo Answers datasets, enabling us to study how each method scales with increasing amounts of training data across multiple datasets.
We exclude DBpedia-14 from this analysis due to indications of potential data contamination, reflected in unusually high F 1 scores for the sparse and dense few-shot baselines. Since DBpedia-14 consists of Wikipedia abstracts, which overlap with the pretraining data of many large language models, this dataset may not provide a fully independent evaluation of in-context classification performance. Similarly, we exclude GoEmotions, as it is evaluated only for sample sizes above 2k (see Section 4.1) to ensure adequate class representation. This selection ensures direct comparability across regimes, with all remaining datasets contributing uniformly.
Table 3 reports the resulting averages, illustrating how CICLe and few-shot prompting methods behave under different data regimes. CICLe-70B achieves the highest overall macro-F 1 scores across data regimes, ranking first in the medium and large settings and and achieving comparably to top performances in low-data conditions. The smaller CICLe-8B model also performs best among the 8B variants, matching or slightly surpassing the larger few-shot models as the amount of training data increases. These findings confirm that CICLe maintains strong generalization and delivers substantial efficiency gains, allowing smaller models to approach the performance of much larger LLMs.
While most methods improve with more data, the gains are not uniform: for example, few-shot dense prompting with the 70B model slightly decreases in the large-data regime, suggesting diminishing returns from additional examples. The base classifier also benefits from more data but continues to lag behind CICLe, particularly in low-data scenarios where conformal calibration and LLM reasoning provide the greatest advantage. Overall, CICLe demonstrates robustness and scalability, maintaining competitive performance while requiring fewer computational resources.
This study set out to examine under what conditions CICLe provides advantages over traditional classifiers and few-shot prompting strategies in text classification. Our systematic evaluation across four diverse benchmarks shows that CICLe consistently improves over its base classifier and performs competitively with few-shot prompting methods. The results across datasets highlight several consistent insights about the behavior and applicability of CI-CLe. First, our experiments on a diverse set of datasets and tasks largely support the findings of Randl et al. (2024): we find that CICLe performs on par or better than other few-shot selection approaches at substantially shorter prompt length, up to 50% in some cases. This reduced prompt length leads to lower runtime and memory requirements because of the causal masking mechanism in transformer models and by extension LLMs: although these models have a fixed context length, attention weights are only computed for tokens in the input prompt (Vaswani et al., 2017;Touvron et al., 2023).
Second, as also shown by Randl et al. (2024), the framework provides a robust and data-efficient improvement over its base classifier. This advantage is particularly evident in imbalanced settings, where CICLe maintains reliable performance by effectively combining the strengths of lightweight traditional models and LLM-based reasoning. It thereby bridges the gap between traditional classifiers and large-scale prompting methods, achieving competitive results without requiring extensive finetuning or large labeled datasets.
Nevertheless, our findings also include previously unpublished insights. In very low-data regimes (less than 500 training samples), CICLe and fewshot prompting exhibit comparable performance, with minor differences likely arising from how examples are selected and ordered. In these cases, the base classifier’s limited confidence only leads to a small reduction of the candidate label set, resulting in a similar number of shots to standard few-shot prompting. Consequently, performance mainly depends on the quality and ordering of the examples rather than on the framework itself. Although CI-CLe relies on sparse embeddings for similarity estimation, the few-shot sparse and dense baselines occasionally show marginal variation, possibly influenced by the different ordering of examples. This aspect is not systematically evaluated in this work and left for future investigation. Importantly, there is no theoretical reason for CICLe to perform worse than regular few-shot prompting, as both rely on the same underlying model behavior and differ only in how examples and candidate labels are selected.
Furthermore, our experiments reveal that CICLe often outperforms other strategies for training datasets with more than 500 samples. This is especially true for imbalanced datasets, where CI-CLe’s ability to balance between the computationally cheap but weaker base classifier and the computationally costly but more powerful LLM ensures optimal handling of each class independently of its support. Beyond these observations, our results confirm that smaller instruction-tuned models can reach nearly the same performance as much larger ones when used within the CICLe framework, reinforcing its value as a practical and sustainable approach to efficient text classification.
Future work will focus on a deeper examination of the α parameter, which controls the confidence level in CICLe and thus governs the trade-off between prediction certainty and label coverage. Another important direction is to more thoroughly experiment with CICLe using dense embeddings, as well as to study the impact of example ordering in the prompt, while may also influence performance. Finally, we plan to extend CICLe to more complex tasks such as multi-label or hierarchical classification, where managing uncertainty across overlapping categories remains a key challenge.
Overall
⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆
This content is AI-processed based on open access ArXiv data.