Semore: VLM-guided Enhanced Semantic Motion Representations for Visual Reinforcement Learning
📝 Original Info
- Title: Semore: VLM-guided Enhanced Semantic Motion Representations for Visual Reinforcement Learning
- ArXiv ID: 2512.05172
- Date: 2025-12-04
- Authors: Wentao Wang, Chunyang Liu, Kehua Sheng, Bo Zhang, Yan Wang
📝 Abstract
The growing exploration of Large Language Models (LLM) and Vision-Language Models (VLM) has opened avenues for enhancing the effectiveness of reinforcement learning (RL). However, existing LLM-based RL methods often focus on the guidance of control policy and encounter the challenge of limited representations of the backbone networks. To tackle this problem, we introduce Enhanced Semantic Motion Representations (Semore), a new VLM-based framework for visual RL, which can simultaneously extract semantic and motion representations through a dual-path backbone from the RGB flows. Semore utilizes VLM with commonsense knowledge to retrieve key information from observations, while using the pre-trained clip to achieve the textimage alignment, thereby embedding the ground-truth representations into the backbone. To efficiently fuse semantic and motion representations for decision-making, our method adopts a separately supervised approach to simultaneously guide the extraction of semantics and motion, while allowing them to interact spontaneously. Extensive experiments demonstrate that, under the guidance of VLM at the feature level, our method exhibits efficient and adaptive ability compared to state-of-art methods. All codes are released 1 .📄 Full Content
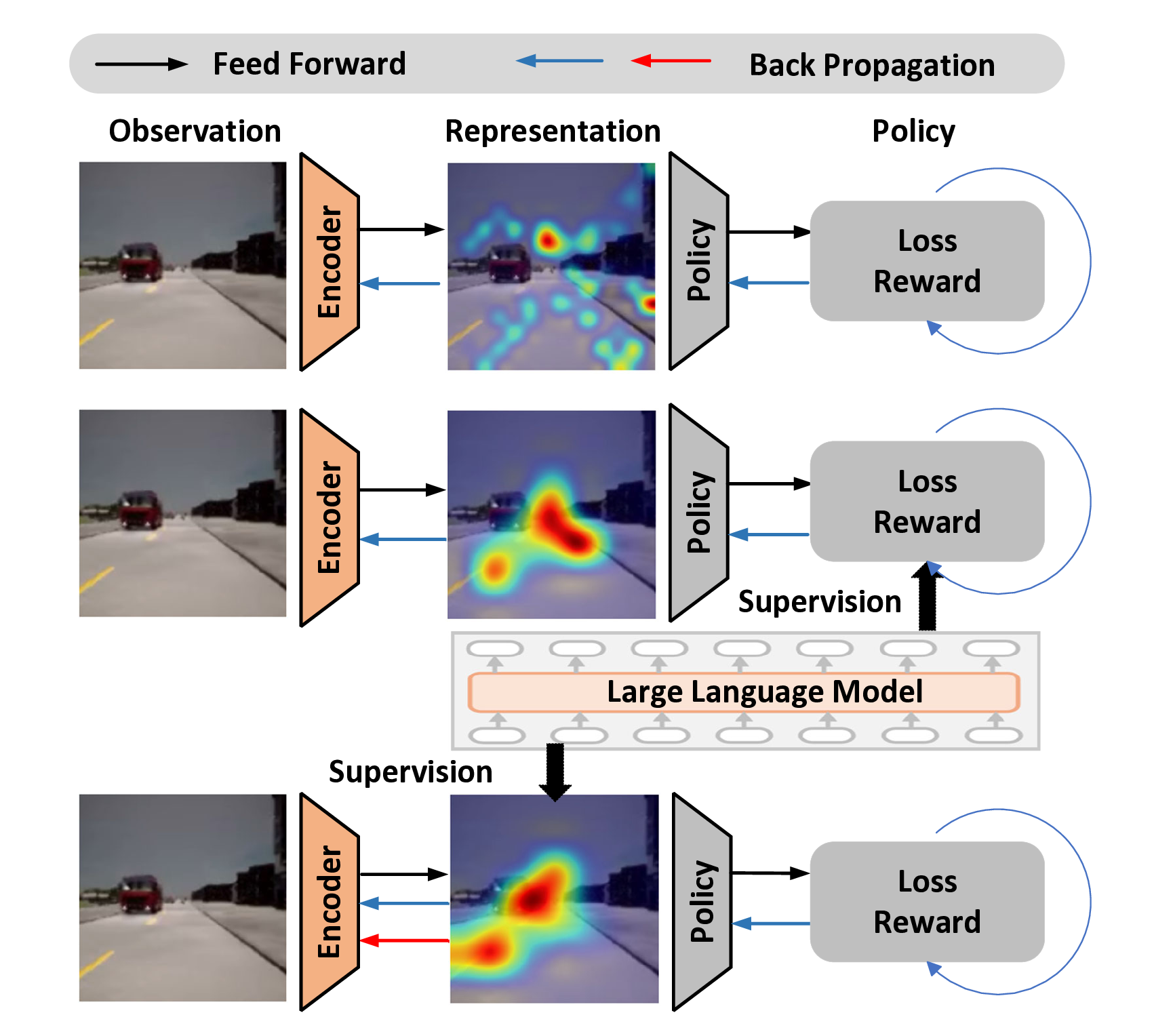
Previous researches leverage diverse state abstraction approaches including observation reconstruction (Vemprala,Figure 1: (a) In the first row, the overly large sampling space of RL leads to difficulty in capturing key objectives in extreme scenarios; (b) In the second row, due to the complex high-dimensional feature space and the back propagation, guidance at the policy level cannot ensure that the encoder extracts reliable features; (c) In contrast, our method can fully take advantage of the capability of VLMs to enhance the task-specific representations.
Mian, and Kapoor 2021; Yu et al. 2022), transition dynamics prediction (Gelada et al. 2019) and bisimulation (Zhang et al. 2020), resulting in the issue of high cost and data redundancy (Wang et al. 2024a). Consequently, a question arises regarding the existence of a more efficient method for explicitly extracting task-relevant representations.
Promisingly, Large Language Models (LLMs) have been actively developed in recent years, bridging human interaction and reasoning (Wang et al. 2024a;Gbagbe et al. 2024;Hu et al. 2024). Based on the advancements in LLMs, they can provide a more holistic understanding of the environment, allowing agents to respond more effectively to various scenarios with human-like logic (Han et al. 2024;Huang et al. 2024). Some works leverage LLM to guide the learning of RL at policy level (Chen et al. 2024;Ma et al. 2024;Hu et al. 2024) and indicate the enormous potential of LLMs. Due to the long forward propagation chain of the RL model, the guidance at the policy level cannot effectively enhance the extraction capability of representations, particular in complex visual input tasks (as shown in Fig. 1 (b)). This motivates the idea that the common-sense knowledge embedded in LLM can also be exploited to enhance the extraction capability of task-relevant representations at the feature level, which is shown in Fig. 1 (c).
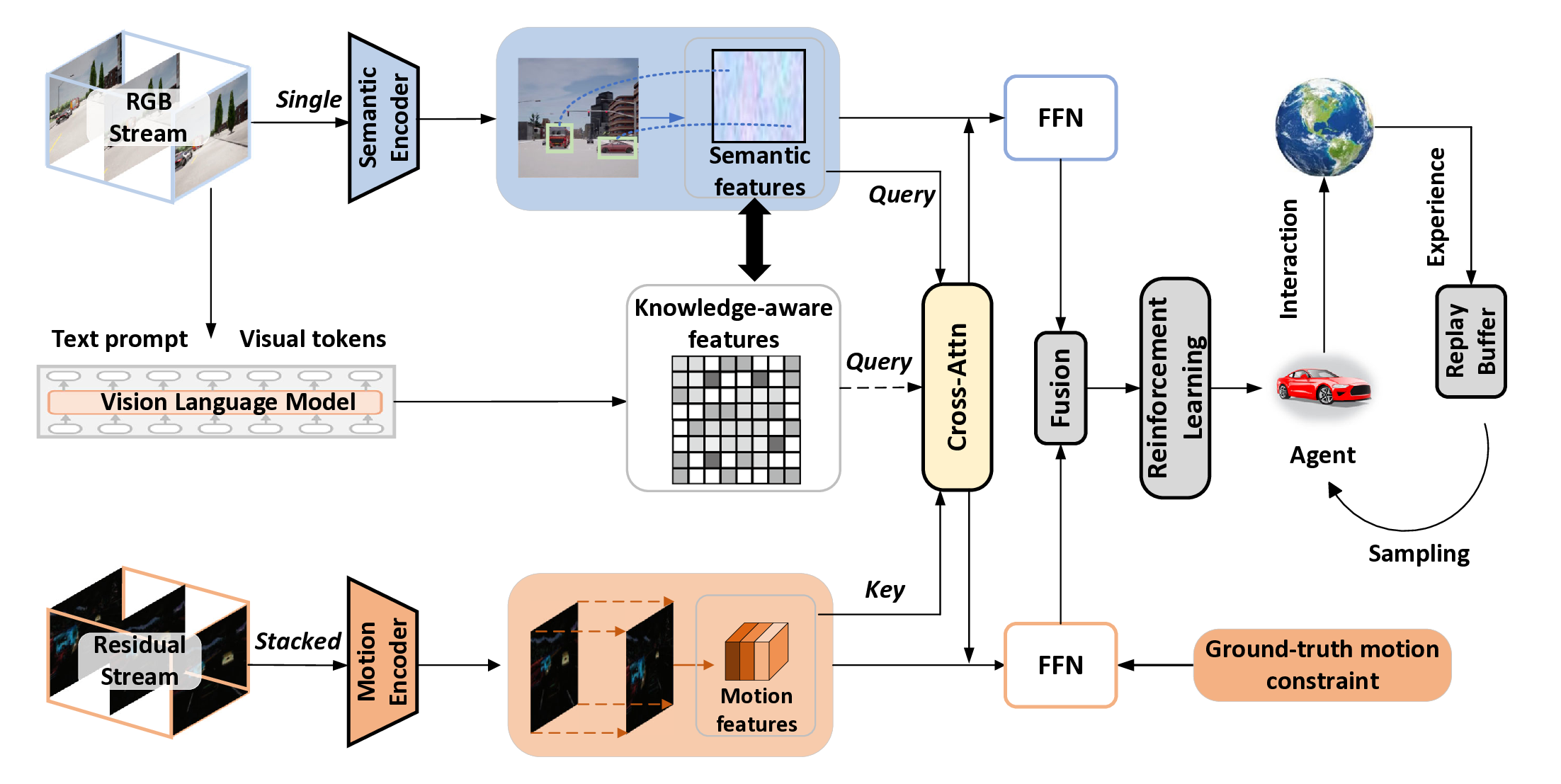
In order to address the aforementioned limitations, we introduce a novel Enhanced Semantic Motion Representation (Semore) Learning framework for visual RL, which employs a two-stream network to separately extract semantic and action representations. This design can decouple different features, thereby fully utilizing the LLM to guide the representation learning. Specifically, the semantic stream models the environmental semantics and can identify key objects in the scenario, while the motion stream models motion clues from the residual frame of adjacent frames. To align the extracted representations and the actual surrounding environment, we introduce a VLM-based feature-level supervision module. We utilize VLM to generate task-specific feature masks, highlighting key regions in the observations.
Semantic and motion representations have strong complementarity and therefore can be enhanced through interaction with each other. Unlike previous work that used transformerbased networks to fuse two specific feature maps, we inject the feature map generated by the VLM during the training process. Specifically, we adopt feature similarity loss to align the extracted semantic features to the VLM semantics for the semantic path. Meanwhile, we adopt cross-attention between motion features and VLM semantics to enhance the motion representation of key regions. Essentially, the supervision for both pathways can let encoders to focus on key regions. Note the interaction between semantics and motion is spontaneously achieved, with the knowledge-aware features provided by the VLM serving as a mediator in this process. Both semantic and motion representations are enhanced and fused for decision-making.
In summary, the contributions of this paper are three-fold:
• We propose Semore, a novel VLM-based visual reinforcement learning framework that can enhance representations by integrating VLM-based common-sense knowledge guidance at the feature level. • We designed a decoupled supervision module. For the semantic flow, we use explicit supervision for alignment, while for the motion flow, we use cross-attention to guide the focus areas. • We conduct comprehensive experiments using Carla benchmarks. Experimental results demonstrate the stateof-the-art performance of our proposed method and the effectiveness of the corresponding components.
Visual Reinforcement Learning. In vision-based RL, agents extract compact representations from lowdimensional visual observations to achieve decision-making. In this process, representation learning is the key to improving the performance of visual RL. Existing works can be roughly divided into three main approaches: (i) data augmentation technique (Huang et al. 2023b;Zhang et al. 2020); (ii) self-supervised representations (Castro 2020;Hansen et al. 2020); (iii) modeling environment dynamics (Pan et al. 2022;Fu et al. 2021;Lee et al. 2020). However, due to the extensive exploration required in the RL process, existing methods without any prior knowledge struggle to efficiently extract representations, especially in complex environments. The emergence of LLMs and VLMs brings new opportunities for addressing this issue.
Dual-stream Network. Dual-stream networks are particularly popular for extracting diverse representations (Gao et al. 2018;Simonyan and Zisserman 2014;Wang et al. 2024c). Generally, this structure is used for encoding heterogeneous modalities such as point cloud and text for feature fusion (Xiang, Xu, and Ma 2023;Liu et al. 2023;Liang et al. 2022). Some studies have demonstrated that separately extracting different representations containing specific information from images can achieve better performance than single-stream networks in extracting diverse representations (Kim, Jones, and Hager 2021;Liu et al. 2021;Huang, Zhao, and Wu 2023;Liu et al. 2022). Simoun (Huang et al. 2023b) adopts this design in visual RL learning and constructs a structure interaction module to leverage the correlations of the dual-stream features. We adopt a two-stream structure to decouple the semantic and motion representation learning, allowing the VLM to separately supervise the feature extraction and interaction.
VLM-based Learning. VLMs have shown significant potential in learning high-quality representations for diverse downstream tasks (Du et al. 2024;Singh et al. 2022;Chen et al. 2025). Their success largely stems from training transformer architectures on large-scale datasets of image-text pairs sourced from the web, using contrastive learning techniques. Notably, CLIP (Radford et al. 2021) proposed a promising alternative that directly learns transferable visual concepts from large-scale collected image-text pairs. In this paper, we first use the VLM to retrieve semantic information from the observations, such as relevant objects, and then use a clip-based approach to generate the corresponding visual features, thereby embedding common-sense knowledge into the representation learning.
The overall framework is illustrated in Fig. 2. We start by formalizing the task of visual RL and then discuss the details of Semore.
Visual RL can be normally formulated as a Partially Observable Markov Decision Process (POMDP), denoted as a tuple M =< O, S, A, P, R, γ >, where O denotes the observation space containing RGB frames o t at different time step and A denotes the action space. The interaction process of the agent in a POMDP can be defined as follows: (i) the agent perceives visual observations o t ; (ii) the agent then selects an action a t ∈ A based on a stochastic policy π(a t |o t ). P(o t , a t ) is the observation transition, R(o t , a t ) is the reward funciton, and γ denotes the discount factor. The goal of this formulation is to find an optimal policy that maximizes the expected cumulative reward based on the visual observations across the entire traversal of MDPs:
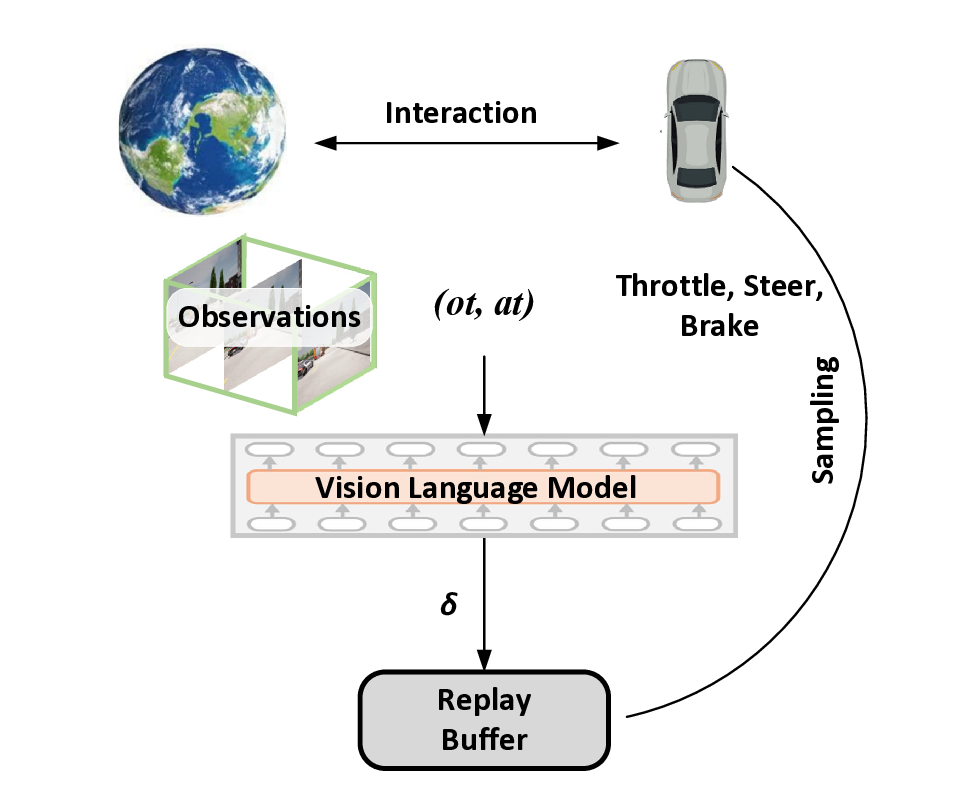
During training, π is used to interact with the environment and the generated experience is stored in a replay buffer B.
Semantic Encoding. Semantic information is vital for visual representations as it can provide environmental understanding for the agent. Specifically speaking, the agent can identify objects or events relevant to its control based on visual representations from observations, thereby improving the decision-making capabilities. Semantic encoding aims to extract the visual semantic representations of the surrounding environment from the observed frames. Semantic encoder adopts a four-layer convolutional structure with 3 × 3 kernel size and ReLU non-linearity. And the output feature map of the last convolution layer is represented as
Then we use a fully connected layer with layer normalization to reduce the dimension of F t s and output compact feature vector f t s . Motion Encoding Motion information is critical for vision-based agents to understand the dynamics of the surrounding scenarios. In other words, motion features enable the agent to have predictive capabilities, allowing it to make more reasonable decisions. The goal of motion encoding is to extract the motion features at the pixel level (such as the movement of objects within the perception range) from multiple adjacent visual frames. Given a sequence of 3 adjacent observation frames [o t-2 , o t-1 , o t ] sampled from the replay buffer, we can obtain the motion input by residual of adjacent frames
. Similar to semantic encoding, the motion encoder adopts a four-layer convolutional encoder with a different number of first-layer’s input channels to extract feature map F t m ∈ R C×H×W .
In the absence of supervision on the feature level in previous visual RL models, the extracted representation of observations is not guaranteed to align with the expressive nature of the real environment. In particular, the long propagation chain and the vast sampling space of RL make it difficult to learn ground-truth representations through the mere supervision of the policy level. The difference from the true representation imposes inherent limitations on the model. To mitigate this shortfall, we introduce VLM-guided representations by using the pretrained VLM and clip-based image segmentation model CRIS (Wang et al. 2022), as illustrated in Fig. 3. The core objective is to align the extracted representations with the ground-truth as possible, thereby enhancing the agent’s understanding of the environment. We first employ the pretrained VLM to extract comprehensive semantic information from raw visual observations. The VLM takes a single frame o as input and uses a visual encoder g V to extract the visual features, which are then converted into language embedding tokens. Meanwhile, the prompt P m is fed into the text encoder g T to obtain text tokens. This can be formulated as:
where H V , H T are the visual and text tokens, respectively. Then the visual tokens H V and the text tokens H T are fed into the VLM f for generating responses:
where Y is the output of task-specific prompts, as the text semantics.
Given the text semantics, we need to generate a semantic feature map of the observations for representation learning. Although CLIP (Radford et al. 2021) learns powerful imagelevel visual concepts by aligning the textual representation with the image-level representation, this type of knowledge is suboptimal for referring image segmentation, due to the lack of more fine-grained visual concepts. Hence, we apply CRIS (Wang et al. 2022), a clip-driven image segmentation framework to accurately generate more discriminative visual representations through the alignment of text and visual features at the pixel-level. Specifically, given image o and text sequence Y = y 1 , …, y n , CRIS can compute and output a similarity map. Then we use the sigmoid function (Cybenko 1989) to segment specific objects in the image, thereby generating corresponding high-confidence masks. We add the feature masks of different objects together to obtain the complete mask map. This process can be described as:
where o, Y is the input observed frame and text semantics. Sigmoid denotes the Sigmoid function.
To impose effective supervision on semantics, we employ a similarity loss (Zhao et al. 2016) between extracted and knowledge-aware representations, which is denoted as:
where Ĥka is obtained by input H ka into the semantic encoder, thus having the same dimension as F s . Based on this process, VLM can leverage common-sense information to provide explicit guidance for semantics extraction. This guidance enables the visual encoder to focus on critical factors from the observations, thereby allowing it to detect objects that are key to control.
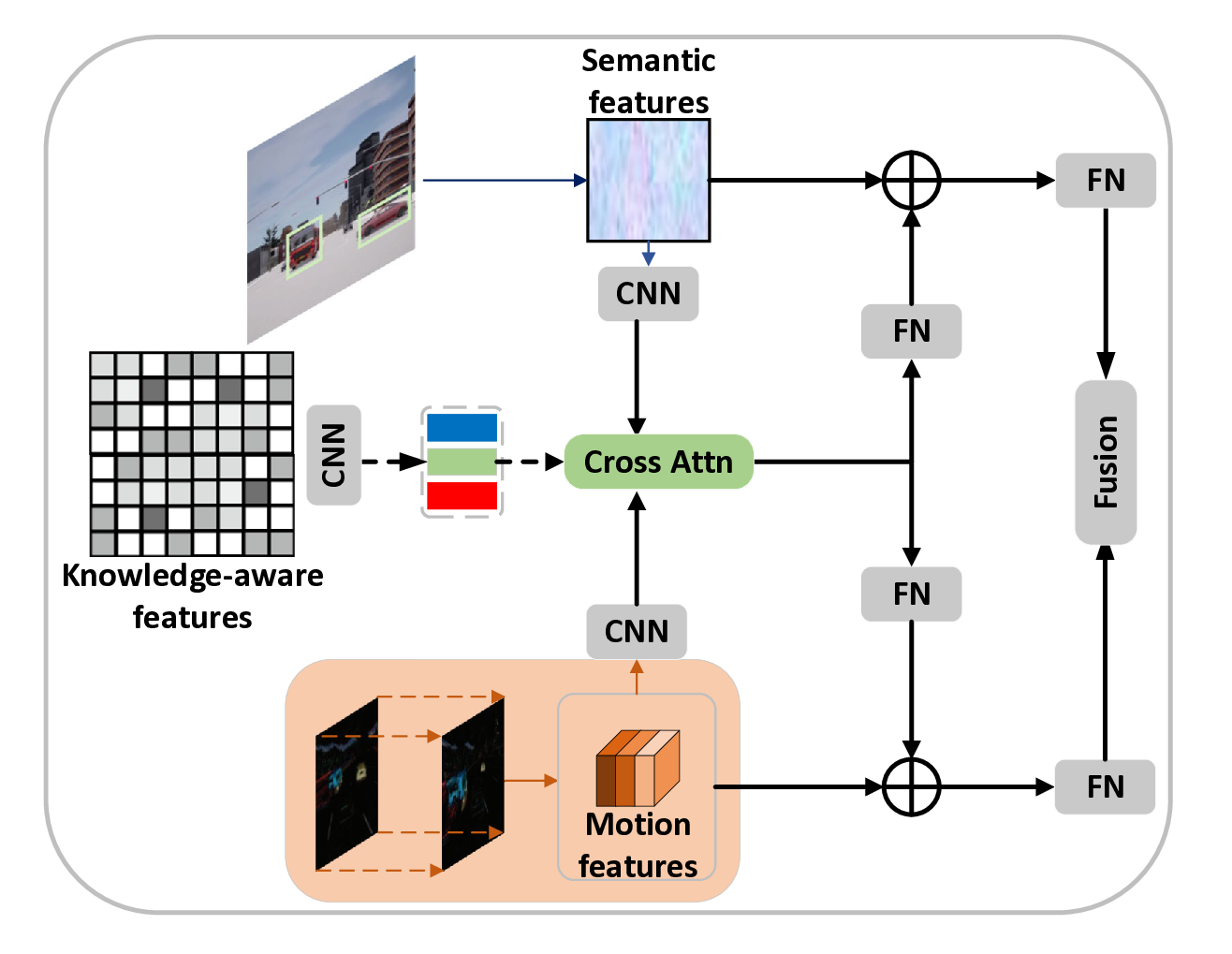
In previous work, popular approaches to handling different features were to use attention mechanisms for interaction, thereby outputting fused features. However, this process is a black-box operation, and supervision exists only at the end-point, thus lacking a comprehensive understanding. In particular, when processing motion and semantic features, attention-based fusion essentially aggregates them from different spaces into a common space. However, due to the impact of sampling efficiency, the learned fusion space is prone to overfitting and has low interpretability. To address this issue, we use VLM to enhance the motion features and guide the interaction between semantics. Since motion information is extracted using frame differences, which is sparse. This makes it difficult to apply feature alignment for supervision. Therefore, during the training phase, we employ bidirectional cross-attention to guide the motion encoder in focusing on key areas using VLMgenerated features. Specifically, as shown in Fig. 4, during the training, the input of the interaction module are knowledge-aware feature map H ka and a motion feature map F m . Then an interactive attention map X can be obtained:
where Hka is obtained by inputting to a convolution layer for reducing the spatial complexity, Fm is as well. σ denotes the Softmax function. Then we use the interactive feature map containing both semantic and motion information to simultaneously enhance original representations. Specifically, we separately use a fully connected layer to process the interaction and then add them to the feature maps of the semantic and motion feature maps:
where F N denotes the fully connected layer. In this way, the semantic and motion representations complement each other, thereby enhancing understanding. Note that the semantics generated by VLM are only used to compute attention weights during training, while in reality, it is the semantic features and motion features that interact.
To ensure the motion encoder can effectively extract sufficient features and remove noise to prevent redundancy, we adopt a transition constraint via an MLP predictor P m . Specifically, the obtained feature vector f m t and action a t at time step t is input into the motion predictor. And the predictor can predict future features, thereby enhancing the encoder’s ability to extract motion information. Then the transition loss can be defined as:
where P m represents the motion predictor and |||| 2 is the L2-norm.
After completing the interaction, we use fully connected layers to reduce the dimensions of F s t and F m t , obtaining compact features f s t and f m t . Then we concatenate them and the final representation is
To reduce noise, we use a prediction head to further purify the information related to RL rewards. Motivated by DeepMDP (Gelada et al. 2019), we utilize a reward predictive head by incorporating the tractable reward and state head from DeepMDP (Gelada et al. 2019) to predict the reward value of each observationaction pair: where r t+1 is the actual reward value at the next time step, which is returned from the interaction with the environment.
We adopt the baseline RL algorithm SAC (Haarnoja et al. 2018) to maximize the expected cumulative reward to find the optimal policy via approximating the action-value Q and a stochastic policy π based on an α-discounted maximum entropy H(•). The action-value function Q is learned by minimizing the soft Bellman error and the soft state value V can be estimated by sampling an action under the current policy. The above process can be formulated as:
(10) where Q denotes the exponential moving average of the parameters of Q. And the policy is optimized by decreasing the difference between the exponential of the soft-Q function and the policy: Selective Replay Buffer RL agents are very likely to perform ineffective exploration in the initial stage due to the lack of prior knowledge. To alleviate the low exploration efficiency for large continuous action space in visual RL that often prohibits the use of challenging tasks, we design the selective replay buffer to provide better exploration. The intuition is that if the agent is provided with some positive training data such as expert supervision at the beginning, it can acquire a certain level of initial execution capability, thus avoiding the high cost of excessive random sampling. Specifically, our RL framework will be first warmed up by learning knowledge via the observation-action pairs that are deemed qualified by the LLM to initialize the action exploin a reasonable space. LLM is not able to make precise decision signals, but can offer macro-level guidance, such as braking, turning left, or turning right. Therefore, it can be fully leveraged to evaluate the reasonableness of observation-action pairs. As illustrated in Fig. 5, the generated pair (o t , a t ) is fed into the image LLM and we can obtain the output that is reasonable or unreasonable. We additionally adopted a decay factor δ to represent the probability of adding the observation-action pair to the replay buffer. Its initial value is set to 1, and it decreases along the training process. When its value reaches 0.5, it indicates that no further selective additions will be made, and instead, all interactions with the environment will be added to the replay buffer.
Training Objective. Based on the fused semantic motion representations, Semore learns from visual to control signals in an end-to-end manner via optimizing the following equation:
where the objective jointly considers the semantic and motion representations, as well as the purification of rewardrelated information for RL learning.
To evaluate our approach under realistic and challenging vision-based environments, we employ the CARLA simulator (Dosovitskiy et al. 2017), which is a widely used open-source simulator for autonomous driving (Liang et al. 2018;Xu et al. 2024;Huang et al. 2023a). CARLA provides a rich and realistic urban environment to evaluate autonomous driving agents in various traffic scenarios. As shown in Fig. 6, we evaluate our method in three traffic scenarios: the HighBeam (HB) scenario, where the ego-vehicle encounters a cyclist, JayWalk (JW) scenario, where the egovehicle encounters both stationary and moving pedestrians intermediately and HighWay (HW) scenario, where the egovehicle is driving on an eight-lane highway with numerous vehicles traveling in the same direction. Similar to (Zhang et al. 2020;Fan et al. 2021), the reward function can encourage the agent to avoid crashes with other moving and static objects and travel as long as possible. We set the single camera on the ego-vehicle’s roof with a view of 60-degree.
Our method is implemented based on SAC (Haarnoja et al. 2018) and DeepMDP (Gelada et al. 2019). The same encoder network architecture and training hyperparameters are adopted for all comparative methods. The spatial resolution of the input RGB images is 128 × 128 × 3. All methods are trained for 110k frames using 5 random seeds to report the mean and standard deviation of the rewards. And more details can be found in the attached supplementary material.
We adopt Qwen2-VL-7B-Instruct (Wang et al. 2024b) in the experiments and Fig. 7 shows the input prompts for the VLM.
Methods Compared: We consider the following baseline methods for comparison: 1) SAC (Haarnoja et al. 2018), a widely-used RL algorithm based on α-discounted maximum entropy; 2) Flare (Shang et al. 2021), a multi-frame visual RL method that utilizes temporal information through latent Figure 6: Visulization of the CARLA scenarios, where the left column is JW, the middle column is HB, and the right column is HW. vector differences. 3) CURL (Laskin, Srinivas, and Abbeel 2020), which integrates contrastive learning with modelfree RL with minimal changes to the architecture and training pipeline. 4) DrQ (Yarats, Kostrikov, and Fergus 2021), built upon the SAC by adding a convolutional encoder and data augmentation in the form of random shifts. 5) Deep-MDP (Gelada et al. 2019), a latent model of an MDP and has been trained to minimize two tractable losses: predicting the rewards and predicting the distribution of the next latent states. 6) Simoun (Huang et al. 2023b), a dual-stream visual RL method that simultaneously extracts appearance and motion information, and enhances representations through interaction and intrinsic rewards. This is a first-person view image from an autonomous driving scenario. Please list the objects in the image that are relevant to the driving of the ego vehicle. The driving goal of the ego vehicle is to move forward without changing lanes. List objects such as vehicles, obstacles, buildings, etc., using the format: position + color + object (e.g., “front-left white car”). This is a first-person view image from an autonomous driving scenario. The ego vehicle’s driving goal is to go straight without changing lanes, but the current driving control signal is {turn right}. Is this reasonable? Please respond with yes, no, or unable to determine.
Front left Gray Sedan
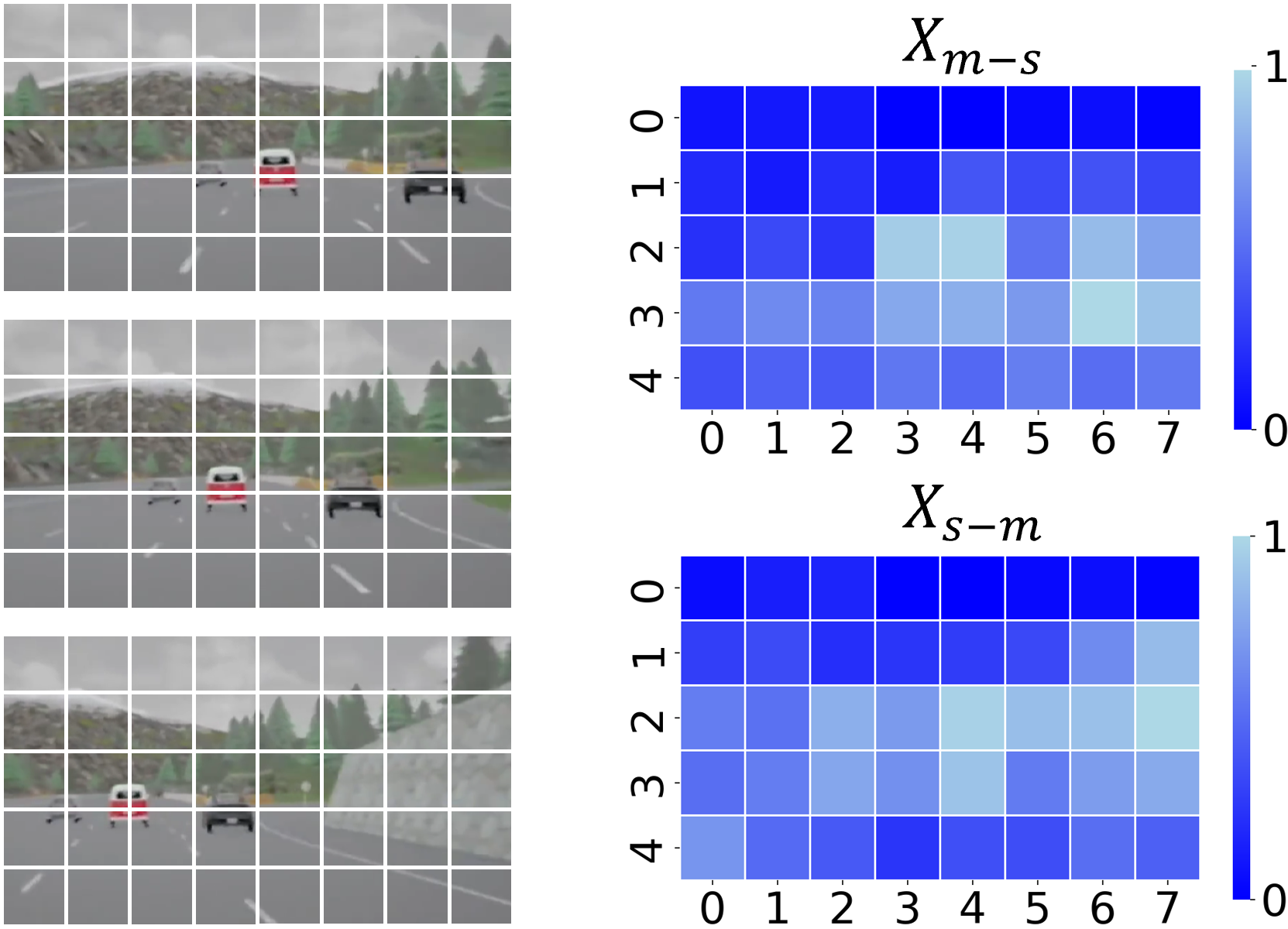
We compare Semore with benchmarks and the results are shown in Tab. 1. It can be observed that our method outperforms all other methods in terms of the episode reward. And the average driving distance is farther than other methods and the average crash intensity is lower. In particular, the observed improvements over Simoun emphasize the effectiveness of VLM in guiding representation learning. Note that our method did not achieve the best driving smoothness with a higher average brake and steer value. Combining the driving distance and crash intensity, this is likely because the comparative methods did not make appropriate obstacle avoidance decisions based on specific objectives. This is particularly evident in scenarios with higher traffic density. When the number of objects on the road increases, the egovehicle must take action to alter its current state for obstacle avoidance. Fig. 8 visualizes the computed interaction feature masks using the Equation. 7 of the HW scenario.
Effectiveness of Semore Components. To validate the contribution of each component, we incrementally incorporate individual components of the framework and obtain a series of models labeled M1 to M4. Specifically, M1 utilizes solely the semantic-stream branch for decision-making without the supervision of explicit similarity loss; In M2, the semantic and motion branches are employed, and the features from both streams are directly concatenated to feed into the policy learning. Both M3 and M4 utilize VLM-generated features as explicit supervision of semantic representation. M3 leverages semantic supervision to align to the knowledge-aware representations in terms of Eq. 5. M4 builds upon M3 by incorporating motion supervision and interaction. Tab. 2 shows the performance of each model. It is clear that M1 degrades to a conventional multi-frame input visual RL, while M2, by decoupling semantic and motion information, enhances the representation extraction capability. This demonstrates the effectiveness of dual-stream design. With the guidance of the VLM, M3 achieves significant perfor-mance improvements. However, due to its inability to effectively integrate motion information, and considering the highly dynamic nature of the scenes, its obstacle avoidance capability improves only marginally compared to M2.
In this paper, we propose Semore, a novel framework aimed at addressing the issue of limited representation learning capability in visual RL. Semore can leverage knowledgeaware supervision in both semantic and motion representation learning under the guidance of VLM. Based on the decoupled two-stream network architecture, semantic extraction can be enhanced through feature alignment under explicit supervision. Simultaneously, a bidirectional crossattention mechanism is used to enhance motion extraction while achieving semantic-motion interaction. Thus, the knowledge of the VLM is distilled into our encoders, thereby enhancing the representations. Extensive experiments in different challenging scenarios demonstrate the efficacy and superiority.
Figure 8: Visualization of the feature masks.
📸 Image Gallery