MAR-FL: A Communication Efficient Peer-to-Peer Federated Learning System
📝 Original Info
- Title: MAR-FL: A Communication Efficient Peer-to-Peer Federated Learning System
- ArXiv ID: 2512.05234
- Date: 2025-12-04
- Authors: Felix Mulitze, Herbert Woisetschläger, Hans Arno Jacobsen
📝 Abstract
The convergence of next-generation wireless systems and distributed Machine Learning (ML) demands Federated Learning (FL) methods that remain efficient and robust with wireless connected peers and under network churn. Peer-topeer (P2P) FL removes the bottleneck of a central coordinator, but existing approaches suffer from excessive communication complexity, limiting their scalability in practice. We introduce MAR-FL, a novel P2P FL system that leverages iterative group-based aggregation to substantially reduce communication overhead while retaining resilience to churn. MAR-FL achieves communication costs that scale as O(N log N ), contrasting with the O(N 2 ) complexity of previously existing baselines, and thereby maintains effectiveness especially as the number of peers in an aggregation round grows. The system is robust towards unreliable FL clients and can integrate private computing.📄 Full Content
The promise of FL extends beyond privacy preservation to address a critical infrastructure challenge particularly relevant to next-generation wireless networks: the democratization of AI training capabilities at the network edge. Current AI development is increasingly dominated by regions with access to massive, centralized computing infrastructure and abundant power resources. However, many regions -particularly in Europe -face significant constraints in building comparable largescale AI data centers due to power grid limitations, environmental regulations, and infrastructure costs (EU Agency for the Cooperation of Energy Regulators, 2024). This disparity threatens to create a widening gap in AI capabilities between regions with different infrastructure capacities.
In the context of emerging wireless systems, where edge intelligence and distributed processing are fundamental design principles, FL offers a compelling alternative by enabling the orchestration of scattered computational resources -from mobile devices to small cell base stations -into a collective training infrastructure without requiring massive capital investments or power concentration (McMahan et al., 2017;Kairouz et al., 2021;Li et al., 2020).
Peer-to-peer (P2P) FL systems represent the natural evolution of this distributed paradigm, aligning perfectly with the vision of AI-native wireless networks where intelligence is embedded throughout the network and does not require a centralized coordination server. By eliminating the central coordinator, P2P FL removes the communication and memory bottleneck of client-server FL -where the server must coordinate massive numbers of unreliable devices in cross-device settings and shuttle large models in cross-silo settings -thereby throttling scalability and slowing training (Alqahtani and Demirbas, 2019;Huang et al., 2023). It also eliminates the single point of failure: progress no longer hinges on server-side compute or networking capacity, which can otherwise jeopardize training (Tang et al., 2020). Freed from these constraints, P2P FL can harness available computational resources wherever they exist-from idle GPUs in edge servers to distributed computing nodes in radio access networks-creating a resilient, fault-tolerant training infrastructure that adapts to the dynamic resource availability inherent in wireless environments. This decentralized approach is particularly valuable in scenarios where network topology changes rapidly, devices join and leave unpredictably, and no single entity can or should control the training process (e.g., multi-operator collaborations or community-driven deployments). These challenges create a fundamental research question: Can we design a communication-efficient P2P FL system that maintains training quality while handling the high peer churn rates and sudden training dropouts characteristic of wireless environments?
Contributions. In this paper, we present Moshpit All-Reduce FL (MAR-FL), a novel P2P FL system that builds on dynamic iterative group formation to significantly improve communication efficiency and tolerance towards unexpected peer churn. MAR-FL allows scalable decentralized learning by reducing the overall communication load and the required number of interactions between peers. Our system incorporates Knowledge Distillation (KD) to boost training performance and supports optional Differential Privacy (DP) to mitigate remaining risks of private information leakage. We conduct a comprehensive experimental evaluation that compares MAR-FL against client-server FL and P2P FL techniques, assessing communication efficiency, scalability, and robustness to network churn.
Despite compelling advantages over client-server FL, existing P2P FL systems face severe practical limitations preventing deployment in bandwidth-limited wireless networks (Table 1). The Galaxy Federated Learning system’s Ring Decentralized FL (RDFL) (Hu et al., 2020) incurs communication costs orders of magnitude higher than centralized FedAvg, making it economically infeasible for wireless environments. Moreover, RDFL’s closed ring topology cannot tolerate the dynamic participation and node failures characteristic of wireless networks due to mobility, channel fading, or varying signal conditions. Sparsification and Adaptive Peer Selection (SAPS) (Tang et al., 2020) improves communication efficiency through model sparsification and single high-throughput peer exchanges per round, but spreads information only locally with-out synchronized global aggregation, slowing convergence and making progress sensitive to churn. BrainTorrent (Roy et al., 2019) provides serverless P2P flexibility through dynamic model fetching and merging, but relies on uncoordinated gossip-based learning that suffers from inefficient global information propagation and vulnerability to node churn.
Structure. We introduce our new MAR-FL system in Section 2 and evaluate it in Section 3. We conclude in Section 4.
The overall objective of our P2P FL system is to reduce the communicational effort required to obtain globally averaged models, while retaining resilience to real-world network churn. Consequently, we deploy Moshpit All-Reduce (MAR) as fully decentralized aggregation mechanism.
We consider a P2P FL setting with N peers, each holding a private local dataset D i , which may be heterogeneous and non-i.i.d. across peers. Training proceeds over T iterations; in each iteration, peers perform local updates and exchange models over bandwidth-limited wireless links to conduct global aggregation. The system thereby faces the central FL challenge of communication costs: due to wireless links and connections operating at lower rates than intra-or inter-datacenter links, communication is costly and often by orders of magnitude slower than local computation (Kairouz et al., 2021;Li et al., 2020). Consequently, our objective is to minimize the communication cost of P2P FL systems.
Algorithm 1: MAR-FL (for i-th peer)
, to obtain a globally averaged state (θ t , m t ). This is done in multiple group formation rounds g ∈ G t per FL iteration t. KD is integrated if the use kd flag is set. After T iterations, each peer holds the final collaboratively trained global model θ T .
Coordinating FL peers. Synchronization of peers during group formation is coordinated through Distributed Hash Tables (DHT). Our system thereby relies on a Hivemind Kademlia DHT solely for lightweight coordination -barriers and group-formation metadata -while model and momentum weights never traverse the DHT. A single DHT get/store involves at most O(log N ) hops. In our implementation, coordination occasionally scans peer announcements (issuing O(N ) look-ups), so the control-plane cost per round is O(N log N ) and remains negligible compared to model-exchange traffic. To assemble into groups, each peer manages its own group key and forms groups with peers sharing the same key value in the DHT. To avoid redundant information exchange in consecutive MAR rounds, peers are prevented from revisiting one another within a single FL iteration by group key initialization and updates that leverage their chunk indices from d-1 previous MAR rounds. We therefore adopt techniques proposed by Ryabinin et al. (2021). In an optimal MAR-FL setup, exact global averaging can be achieved after d rounds of MAR when the group size is M and the group key dimension is d, so that the total number of peers N satisfies N = M d . With fixed MAR group size M , each round makes a peer talk to at most (M -1) others, and achieving (near-)global averaging needs G ≈ ⌈log M N ⌉ rounds (exactly G=d when N =M d ). Hence, each peer performs O(log M N ) exchanges per iteration and, over all peers, the system incurs O(N log M N ) = O(N log N ) communication per iteration, versus O(N 2 ) for P2P FL systems using all-to-all communication.
Algorithm 2: Moshpit-KD (for i-th peer in MKD round g of FL iteration t)
Our MAR-FL system allows the integration of KD to accelerate model convergence.
Let C g ⊆ A t be the candidate teacher peers in MKD round g with local models {θ g-1 c } c∈Cg , where A t refers to Algorithm 1. Candidate teachers are collected using the same procedure MAR uses for global model averaging; hence, we call this mechanism Moshpit-KD (MKD). The MKD process of an entire FL iteration proceeds over multiple MKD rounds g ∈ {1, . . . , G}, where each round g includes group formation and candidate teacher collection followed by the actual distilling of knowledge. To balance model utility and communication overhead, we use MKD only in the first K FL iterations. Algorithm 2 illustrates MKD round g in FL iteration t ∈ {1, . . . , K}, where K ≤ T denotes the number of FL iterations in which we actually apply MKD, with T being the total number of MAR-FL iterations in Algorithm 1. To account for data heterogeneity in FL (Shao et al., 2024), MKD selects a subset of top-ℓ teachers C top g ⊆ C g with the lowest Kullback-Leibler (KL) divergence, where ρ ℓ is the selection ratio (details in Section A.1). Student i then distills knowledge from these selected teachers: over E local epochs, starting from the previous MKD round’s state (θ g-1 i , m g-1 i
), the student updates on each available local mini-batch b ∈ B by computing a student loss L and applying Momentum-SGD (Reddi et al., 2020) with learning rate η and momentum µ to eventually obtain an updated state (θ g i , m g i ).
In MKD round g = 1, the previous state (θ 0 i , m 0 i ) refers to the student’s state before any MKD is applied (i.e., after local model update). The student loss L aligns to the loss term proposed by Hinton et al. (2015): L is the weighted sum of the KL divergence D KL between softened probability distributions over teacher-ensemble and student classes, rescaled by the squared temperature τ 2 , and a CE term L CE on hard labels y b . Averaged teacher-ensemble logits are hereby denoted as zb and student logits as ŝb . As we use MKD only in the first K FL iterations, we facilitate a gradual transition from the use of MKD to its complete omission by linearly reducing the weighting λ of the KL term L KL .
Privacy considerations. To allow privacy preserving training, we adapt the DP-FedAvg with adaptive clipping (Andrew et al., 2021) to fit our serverless P2P system (Algorithm 4, see Section A.2). In each FL iteration, every peer first computes the difference between its current local model and the previously aggregated global model. This update is then clipped to an adaptive bound and perturbed with Gaussian noise. The privatized update is used to compute a DP-safe local model and peers run MAR. After the final round of MAR, the clipping bound is updated to track a globally averaged clipping rate. This procedure fully decentralizes DP with adaptive clipping and renders it ready to use with MAR-FL: privacy loss accrues entirely from local computations, while MAR merely averages privatized models across groups.
The convergence of MAR-FL follows from the model mixing dynamics of MAR, analyzed by Ryabinin et al. (2021). In the optimal case where the total number of peers N forms a perfect d-dimensional grid N = M d and there are no peer dropouts, MAR computes the exact global average after exactly d rounds of communication -i.e., within a single FL iteration t when that iteration schedules d MAR rounds. For general settings, MAR exhibits exponential convergence to the global average θ. Specifically, if peers are randomly partitioned each iteration into r groups that average locally, the expected average distortion after T averaging iterations satisfies:
While this rate is derived for a simplified random-grouping model, our system’s MAR implementation avoids revisiting peers via deterministic key updates, which in practice accelerates mixing relative to purely random grouping. Crucially, the bound is independent of the spectral properties of the communication graph, avoiding the scaling limits typical of gossip-based decentralized FL.
3 Experiments This section presents our experimental setup and evaluates results in detail, while emphasizing communication cost, scalability, robustness and trade-offs concerning model utility.
In the following we delineate ML datasets and models, reference baselines, and parametrization used to evaluate and contextualize MAR-FL. Underlying objectives are described. We use a simulation environment for all of our experiments. Due to constraints of our simulation environment, model evaluation is conducted every fifth FL iteration. We simulate all experiments on a single node with 4×H100 GPUs, 768 GB of memory, and 96 CPU cores. Our code is publicly available.1 Additional details on the experimental setup can be found in the appendix.
Datasets and models. We evaluate MAR-FL on two widely used ML datasets, namely MNIST (LeCun et al., 2010) and 20 Newsgroups (20NG) (Lang, 1995). Local model aggregation. For peer-side local aggregation, we use SGD with momentum (Reddi et al., 2020), set the learning rate to η = 0.1 and the momentum to µ = 0.9. Across techniques, we use full peer participation if not specified otherwise (typical setup for cross-silo FL applications).
Partial participation and network churn. To assess the effect of partial participation and network churn, we vary participation rates and dropout likelihoods. Participation rates control how many peers participate in an entire FL iteration consisting of local updates and global aggregation, while dropout likelihoods simulate unreliable peer connectivity (i.e., peer has conducted local update but does not participate in global aggregation).
Privacy. To investigate privacy-preserving training and its effect on model utility, we vary the noise multiplier to control the extent of privatization. The peer sampling rate, where lower values reduce the privacy loss, is fixed at 100%. Results on scalability and partial participation will reveal whether our system can leverage this rate to enhance privacy without degrading training performance.
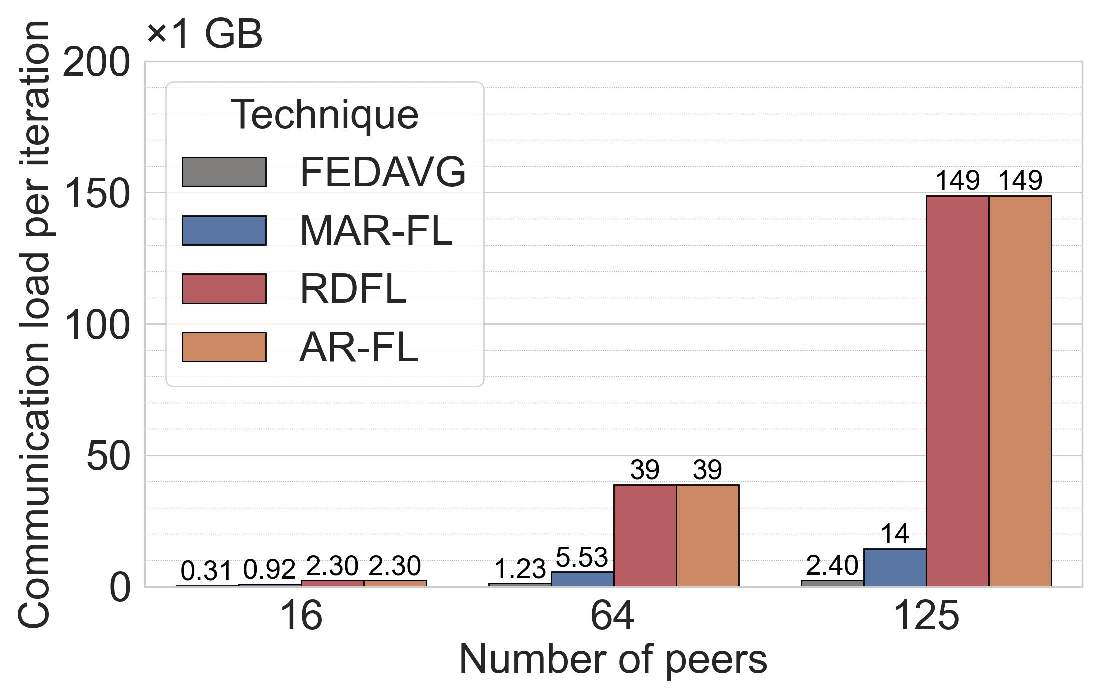
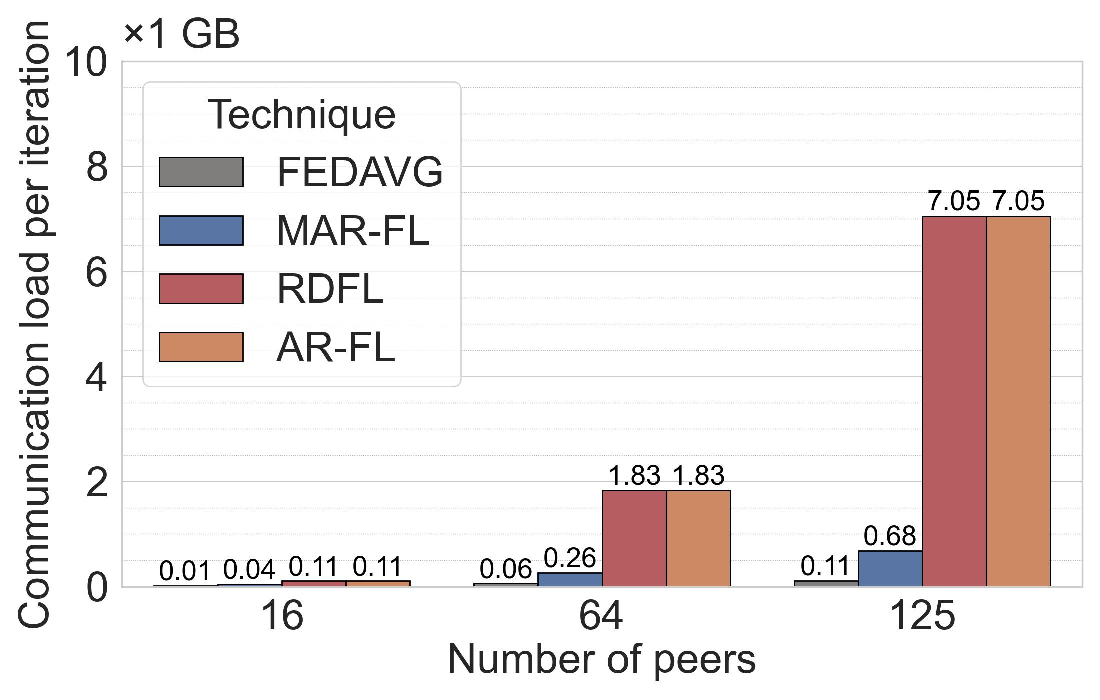
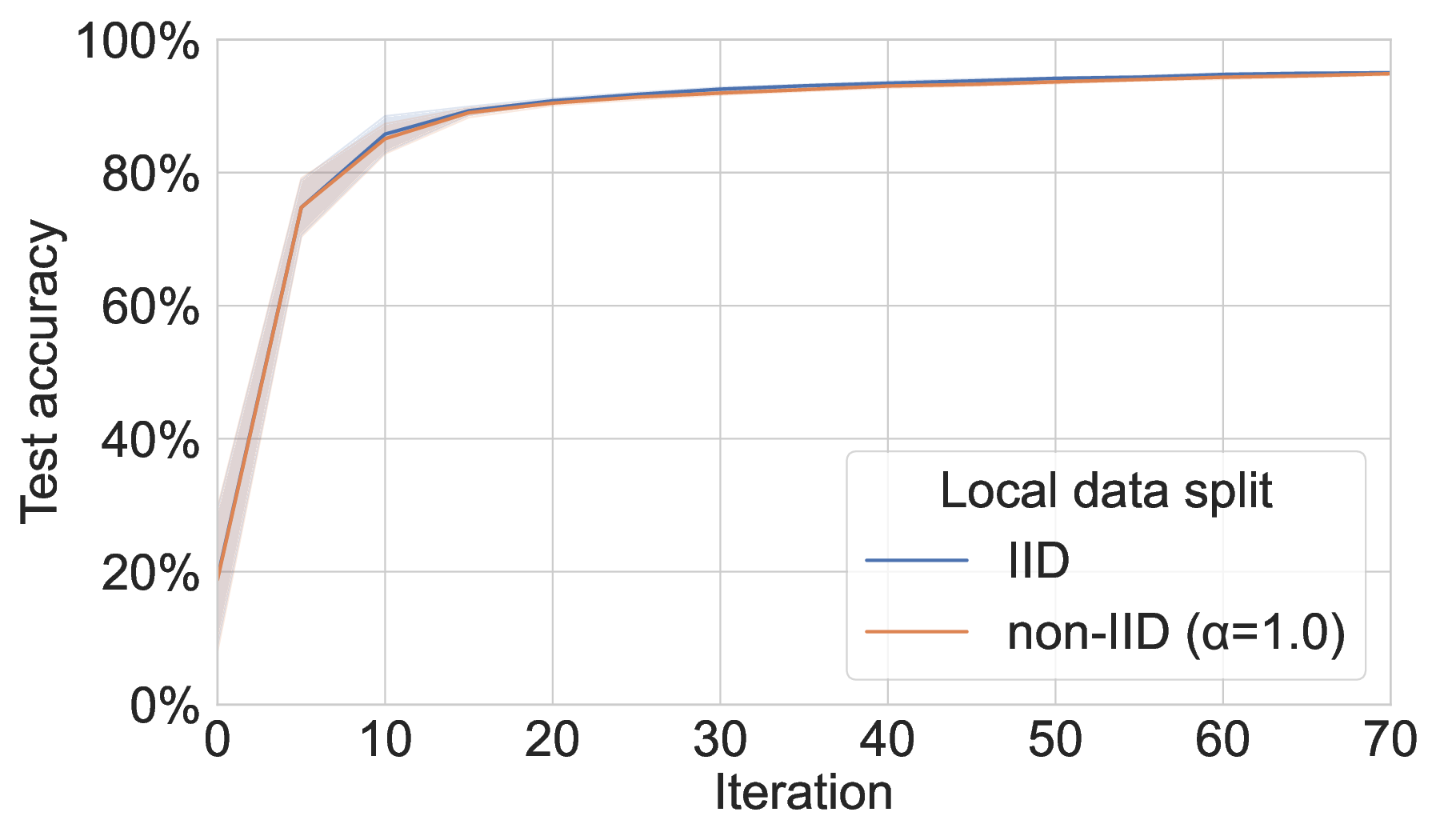
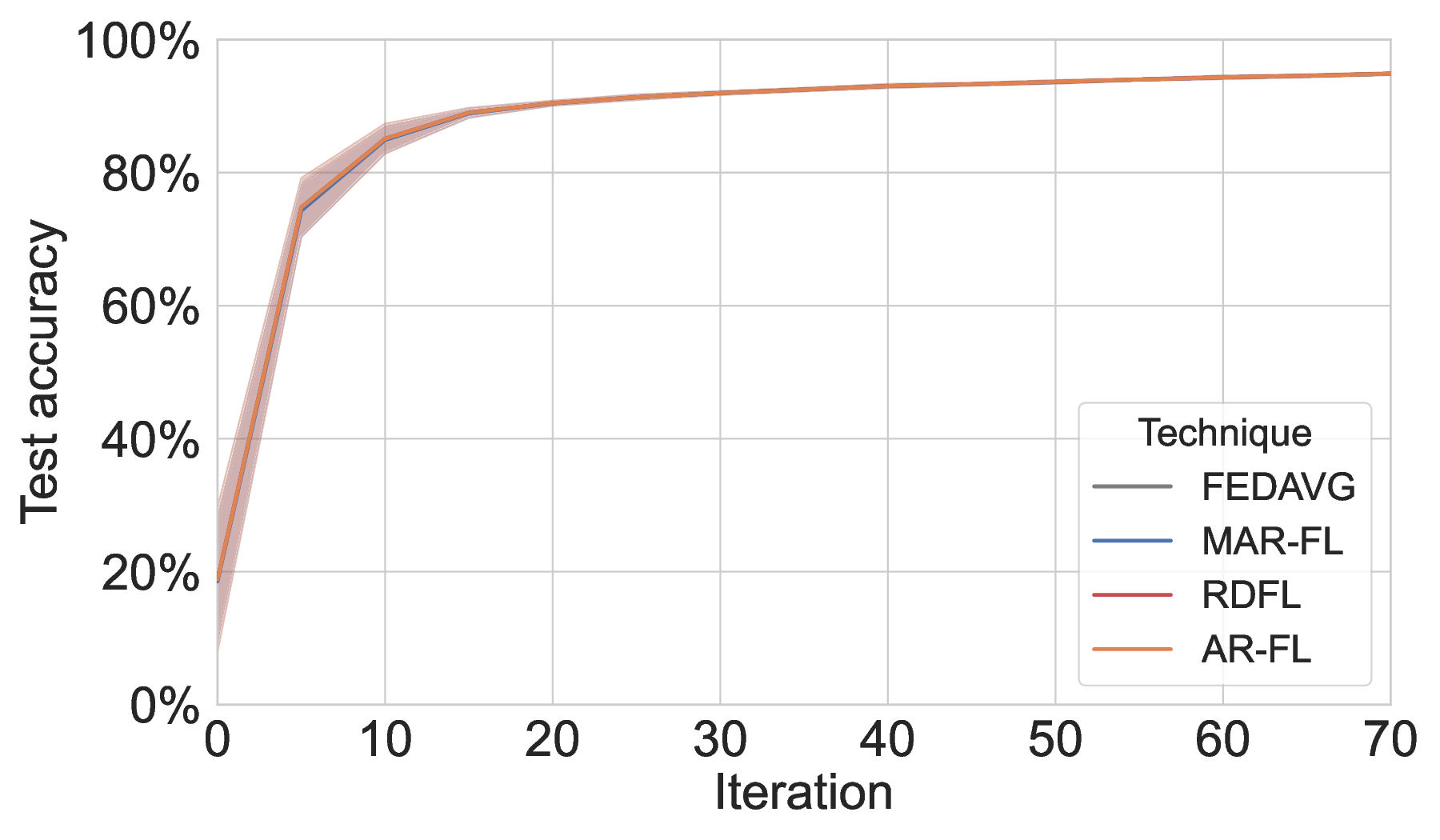
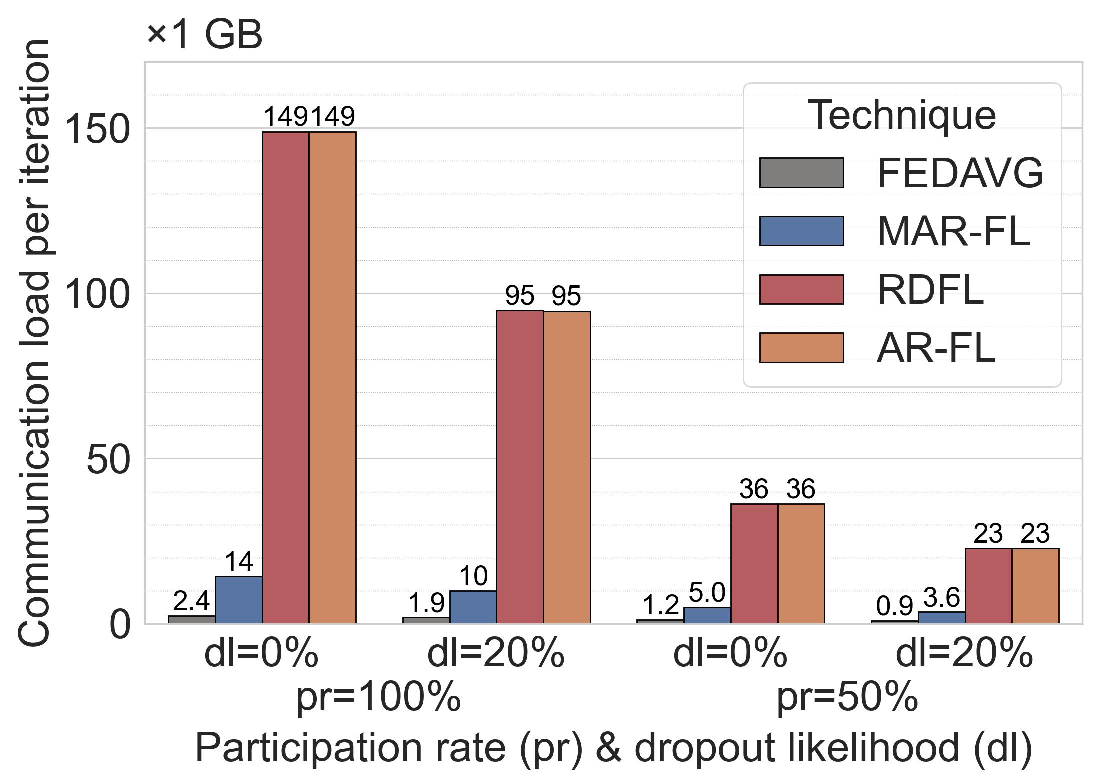
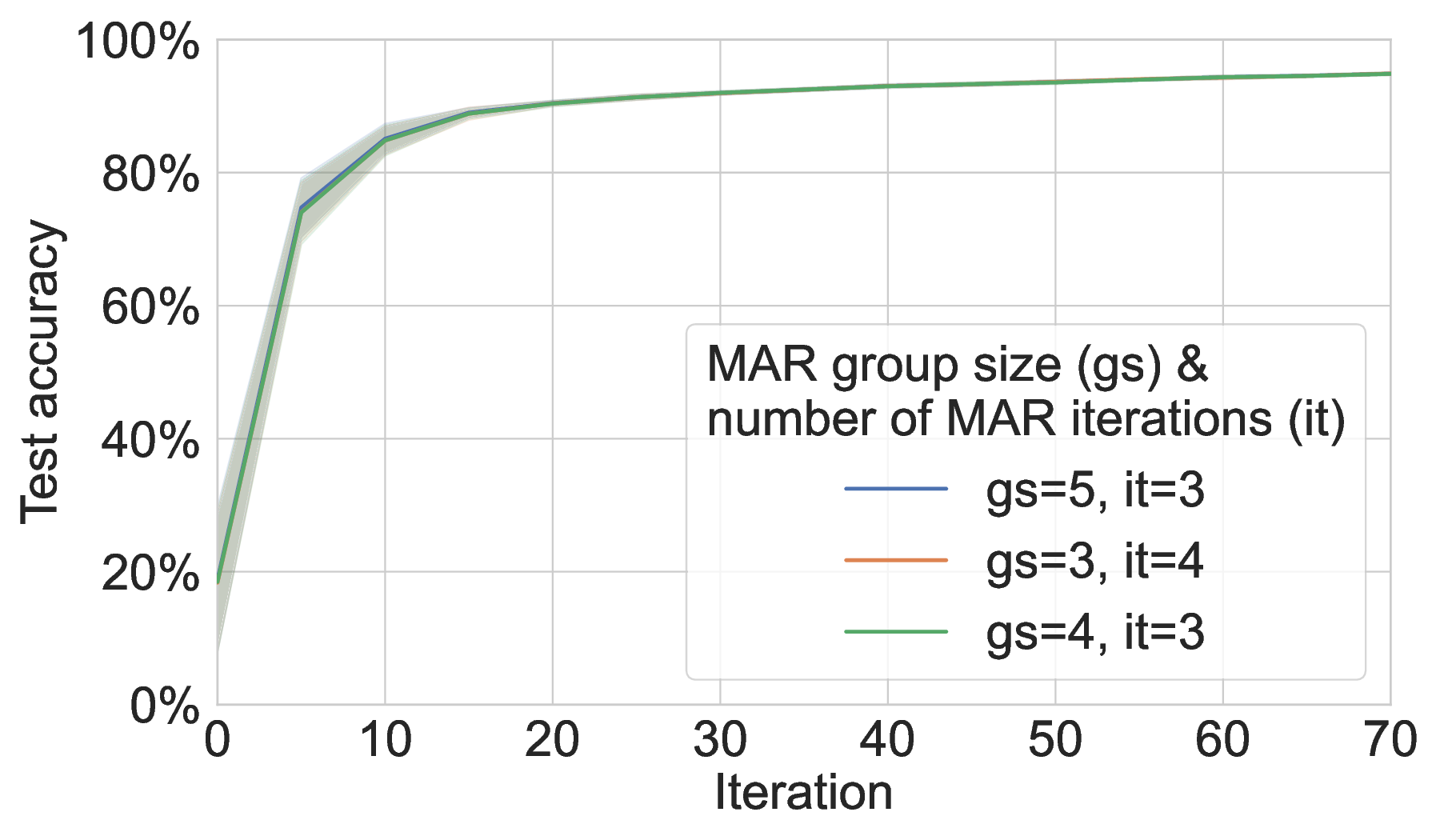
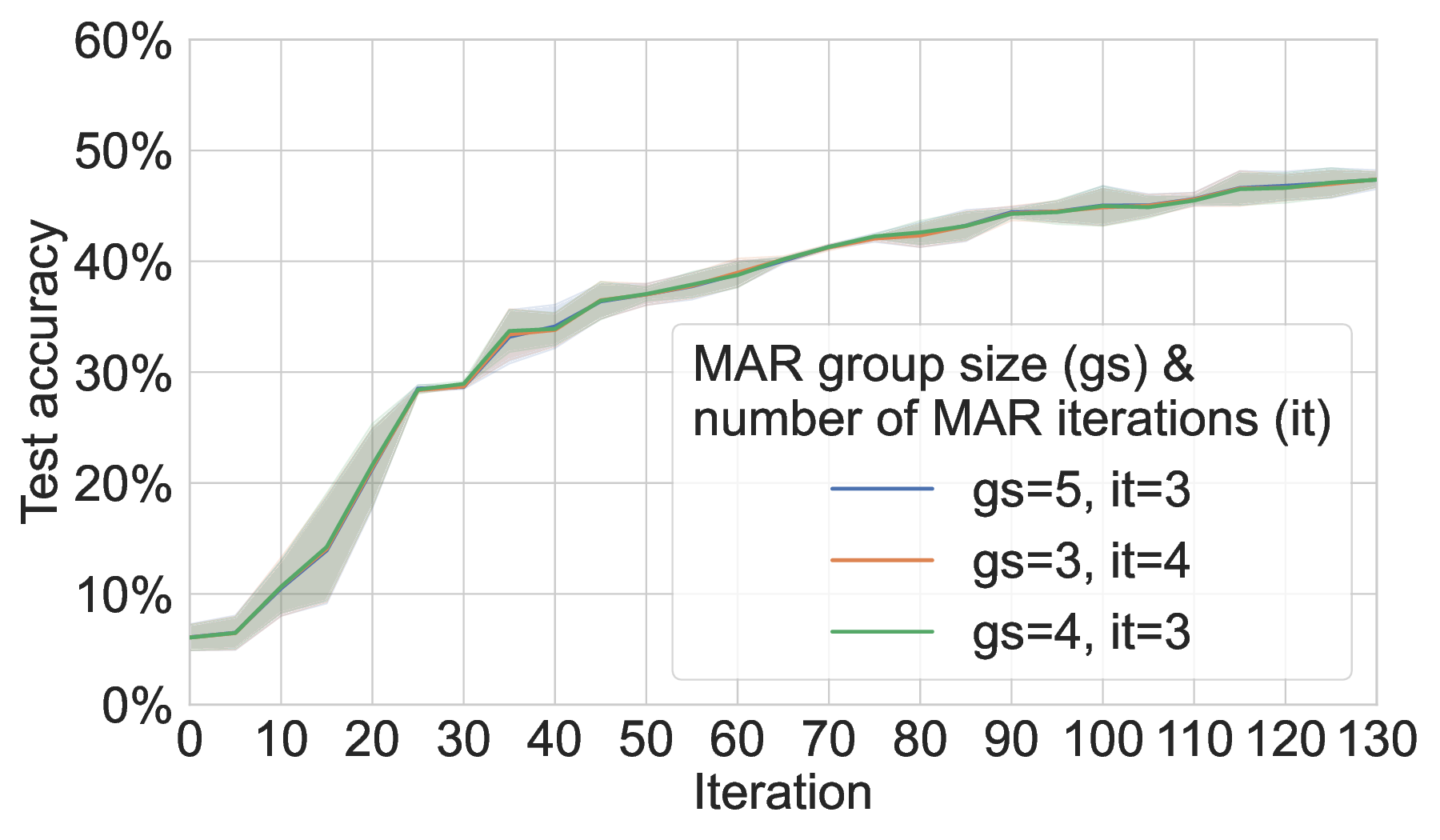
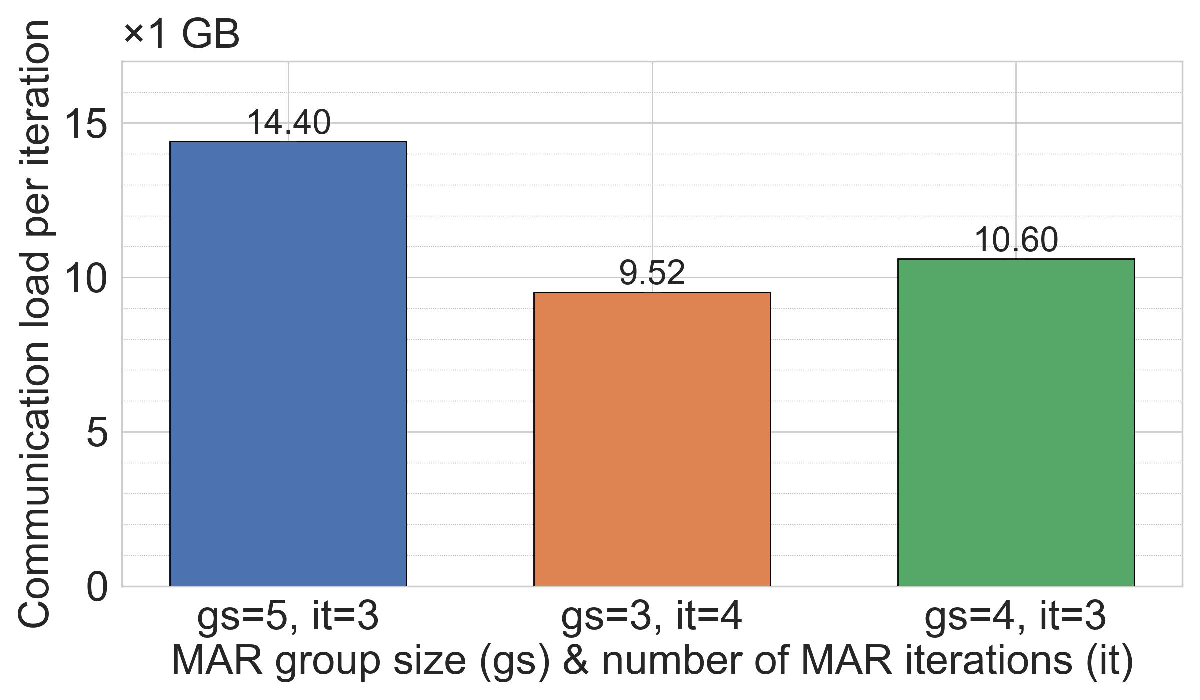
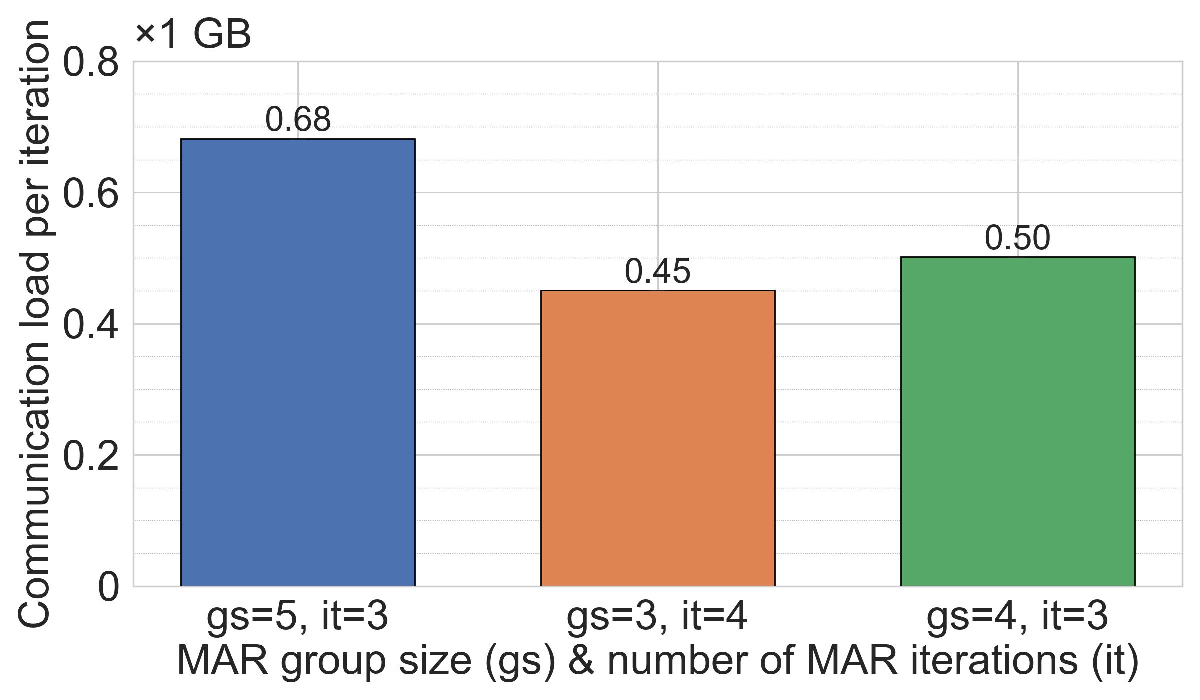
Communication efficiency and scalability. Across both ML tasks (MNIST and 20NG), MAR-FL matches the training performance of all three baselines (see Section C.1). This parity is expected because, with suitable MAR parameters, each iteration of MAR-FL attains an exact global average (e.g., group size 5 and 3 MAR rounds for 125 peers: 125 = 5 3 ). While obtaining identical model utility, MAR-FL requires far less communication per iteration, up to 10× less communication than RDFL or AR-FL. The communication complexity of MAR-FL, O(N log N ), yields stronger performance as systems scale (Figure 1). In contrast, RDFL and AR-FL exhibit a complexity of O(N 2 ).
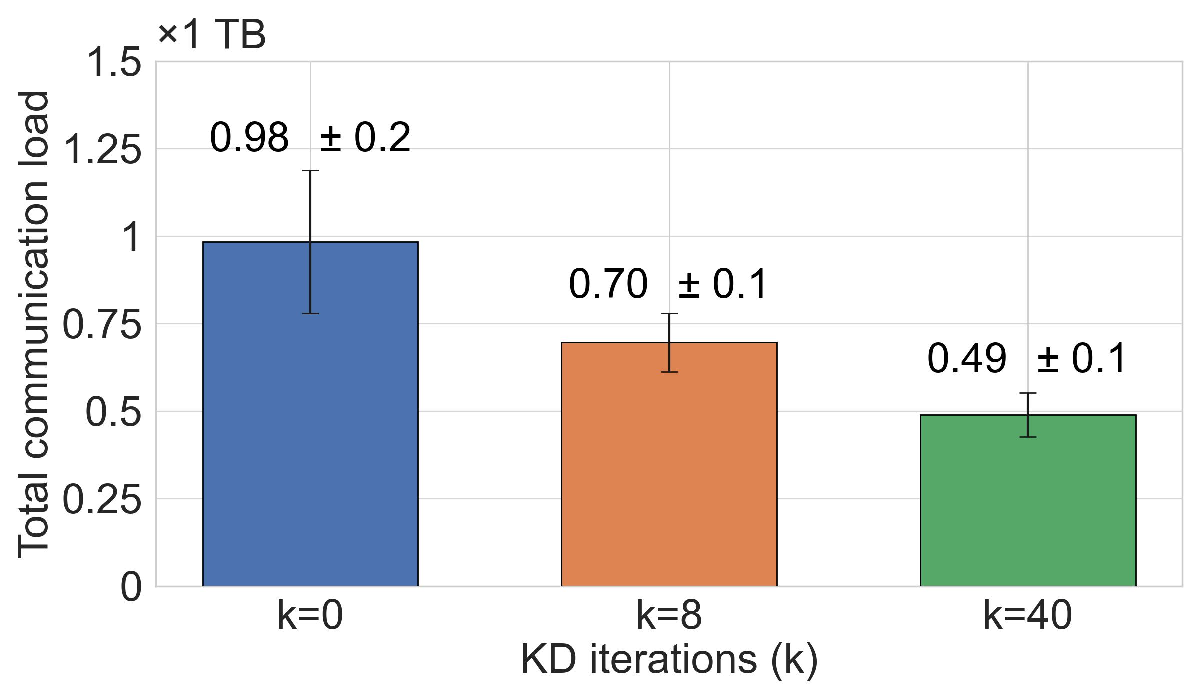
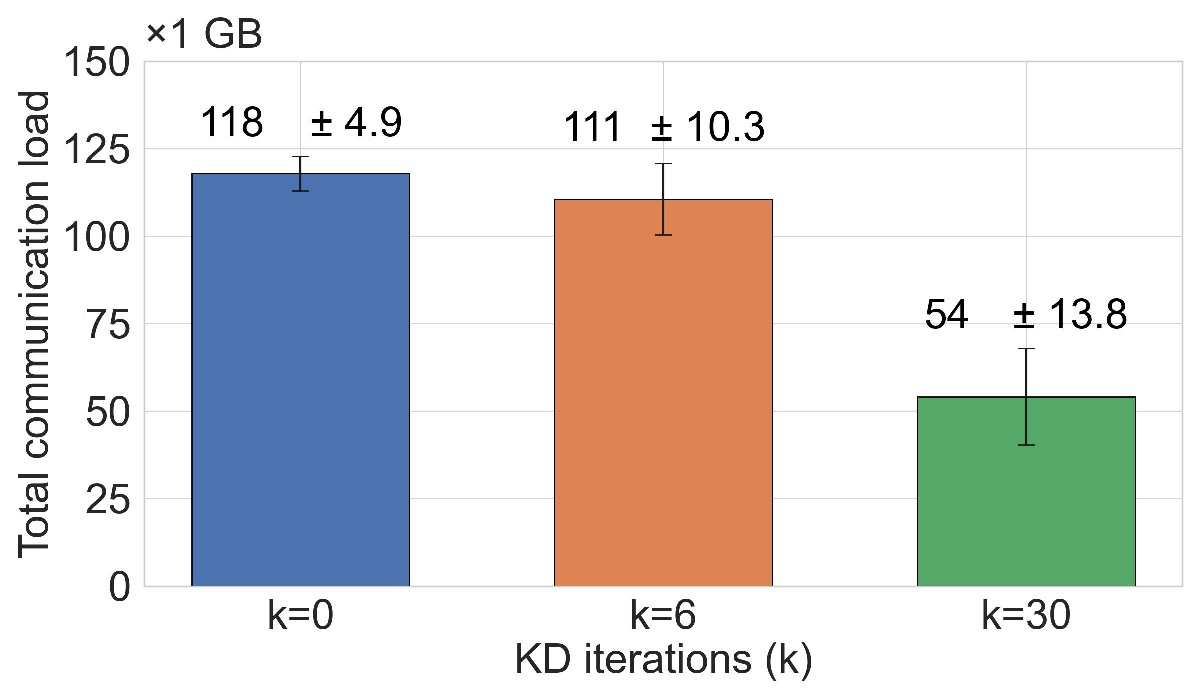
Improving communication efficiency with MKD. MAR-FL achieves substantially higher communication efficiency than our P2P FL baselines, narrowing the gap to the client-server FedAvg standard. To improve communication efficiency even further, MKD can be used. MKD accelerates model convergence so that a target accuracy can be reached with less total communication (Figure 2), although increasing the per-iteration load. The trade-off between communication costs and model utility can be controlled by the number of KD iterations.
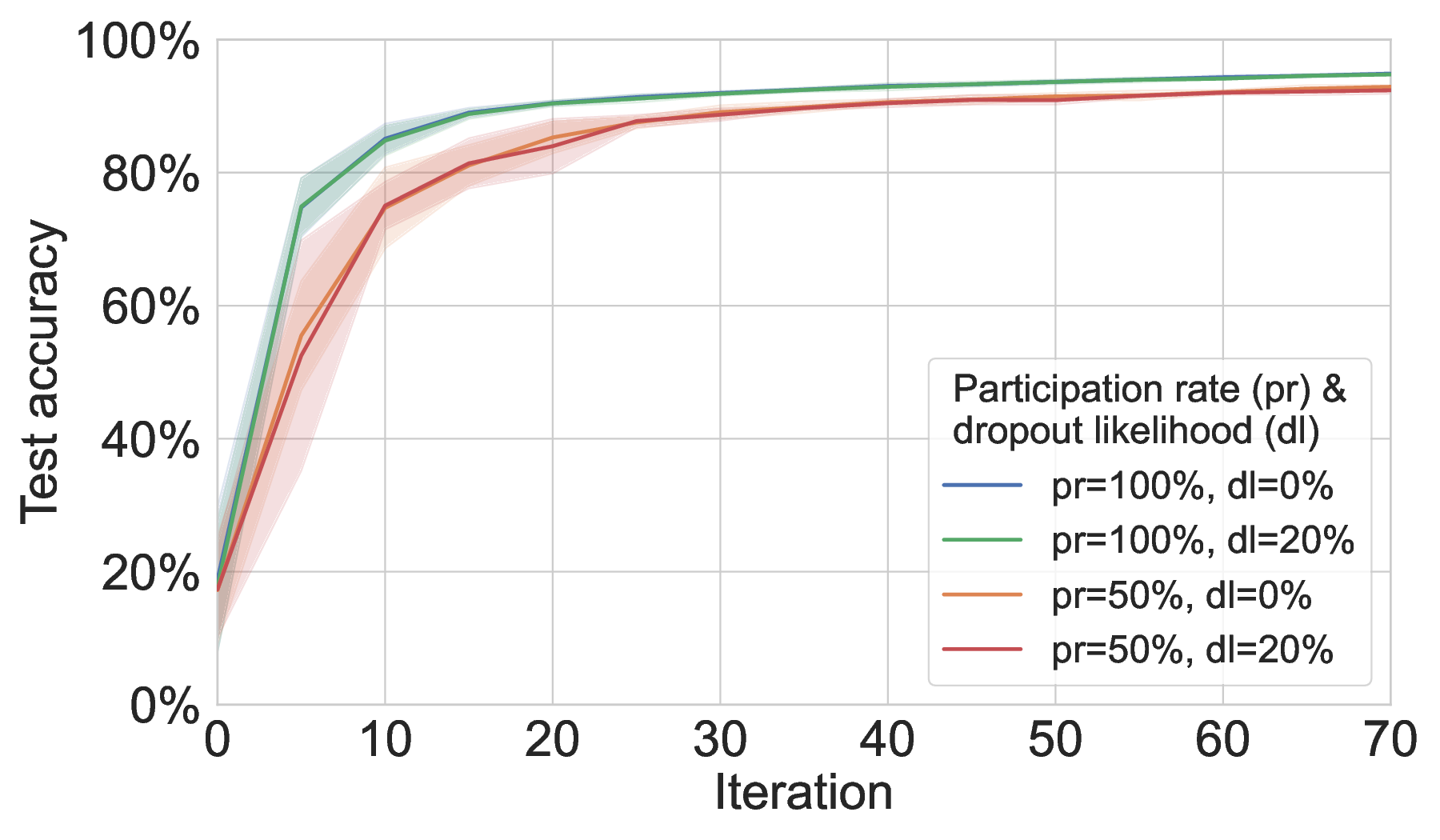
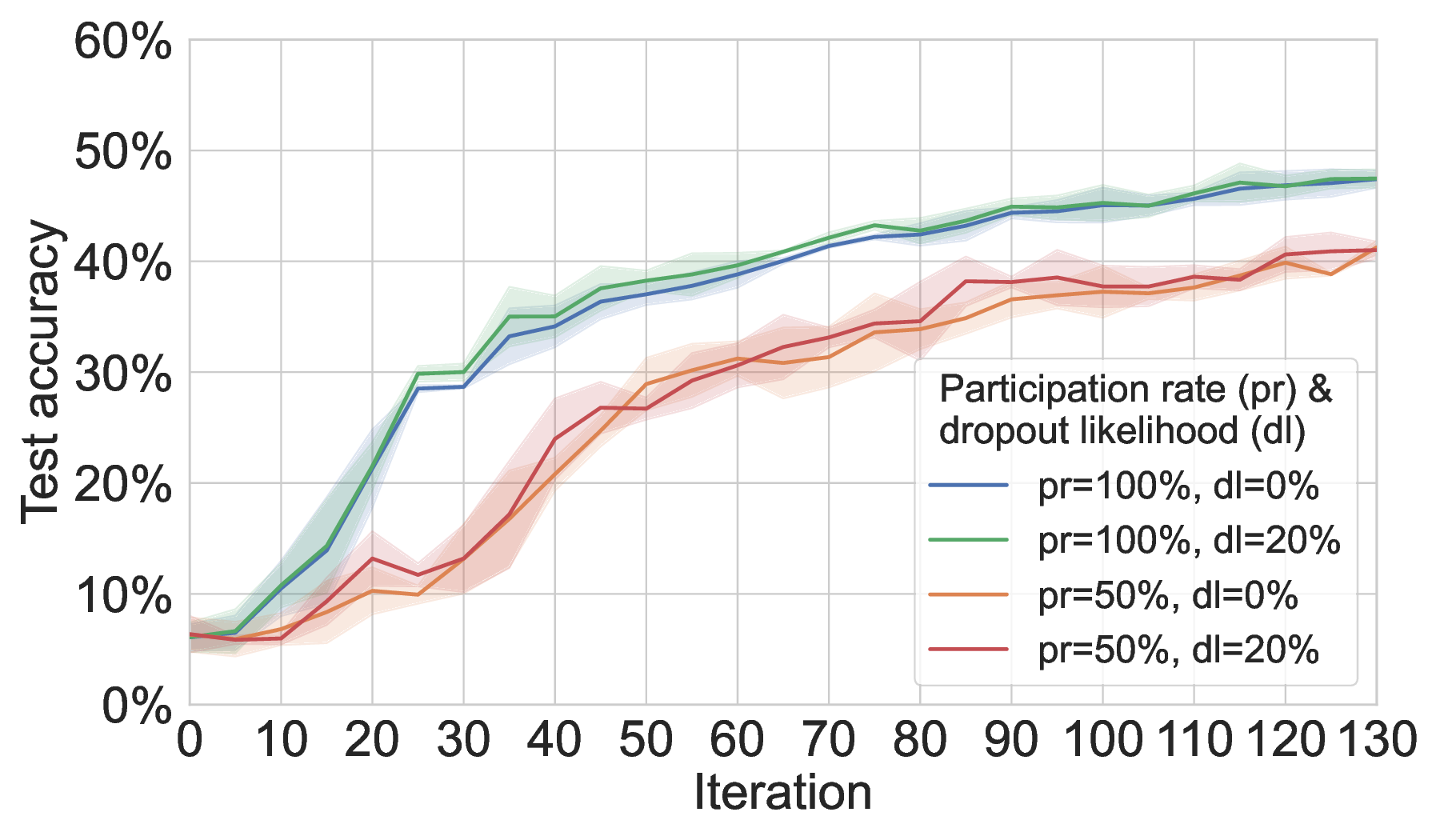
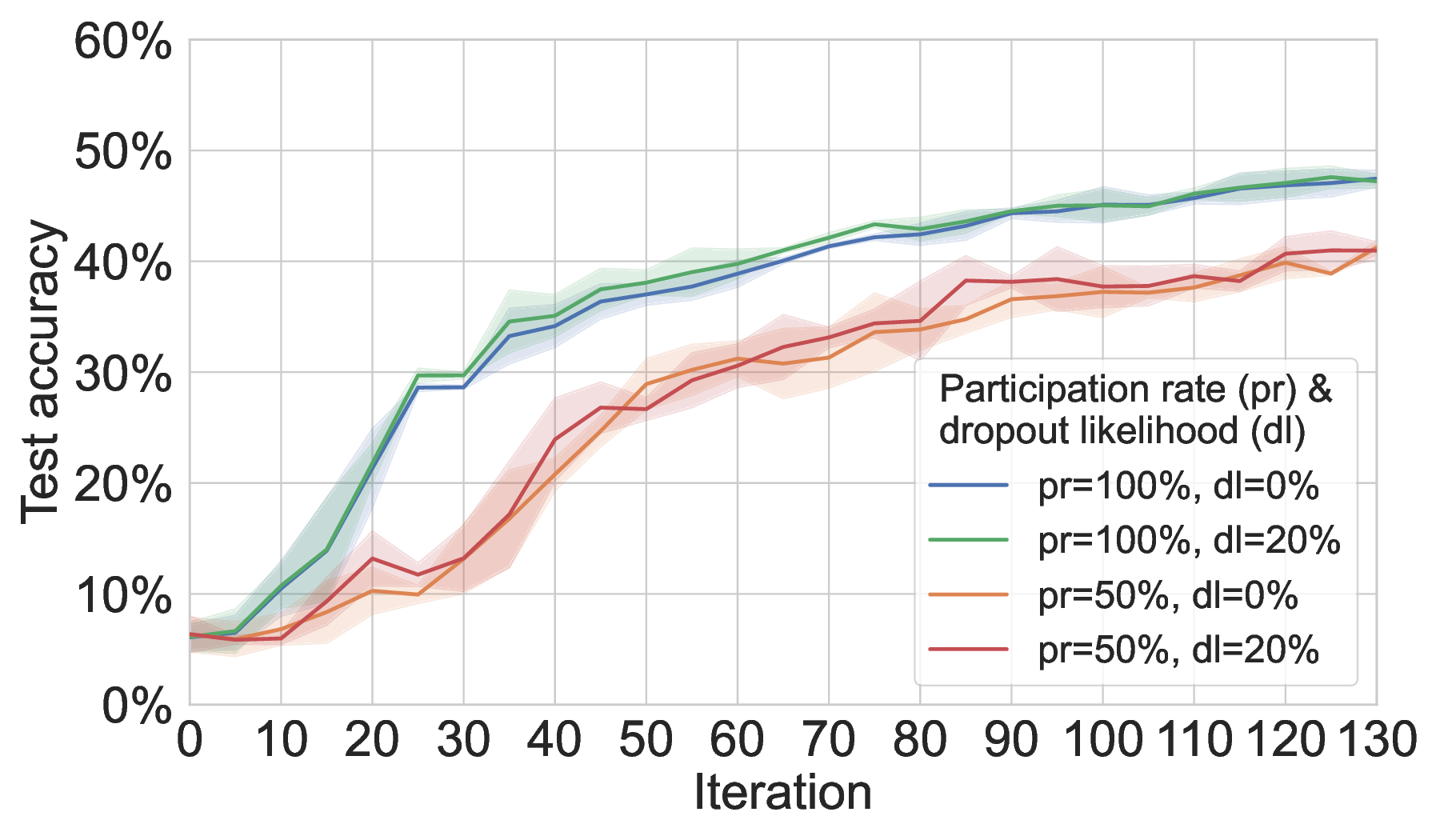
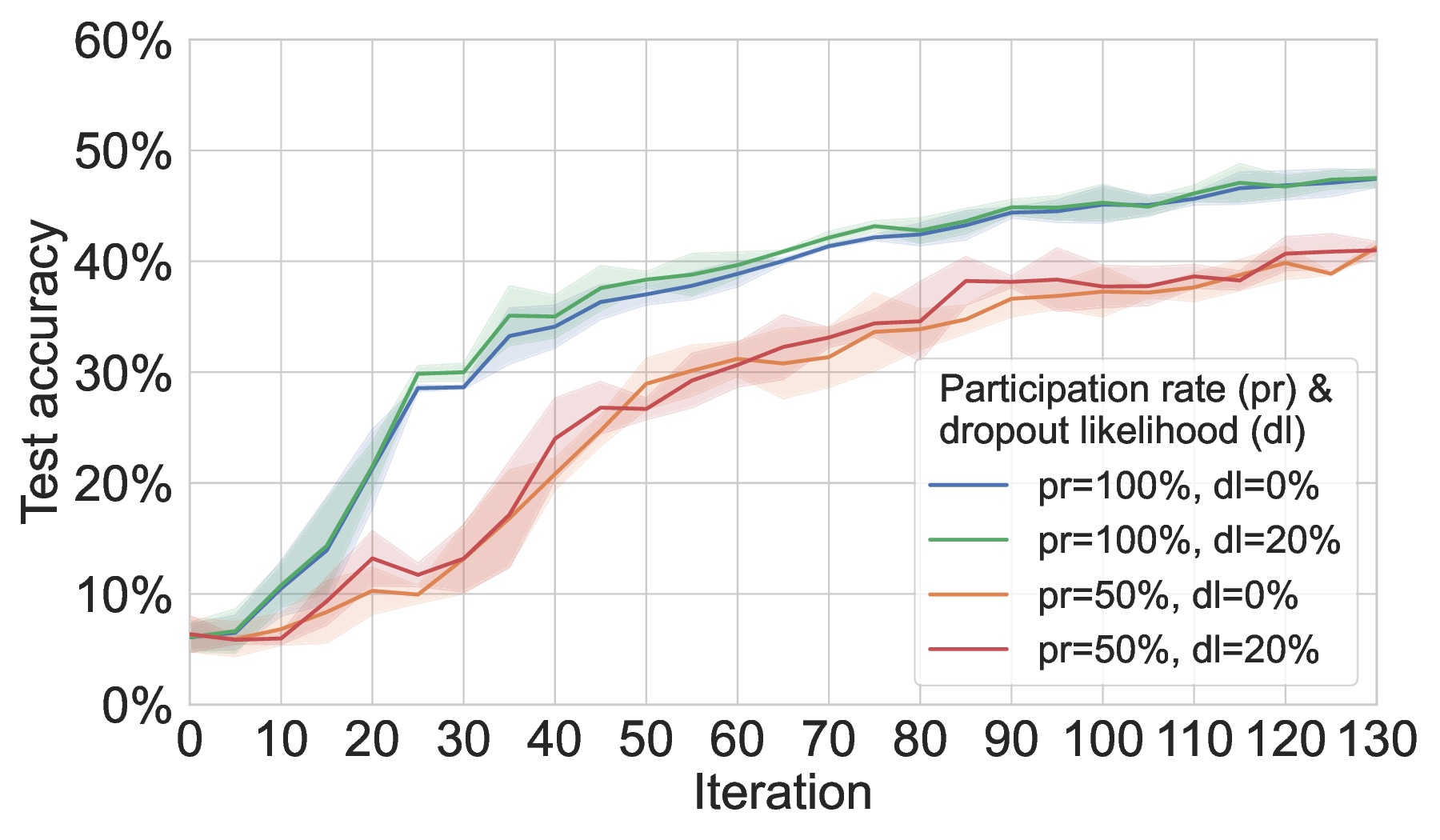
Partial participation and network churn. Partial participation leads to a substantial degradation of MAR-FL’s training performance, while configured network churn and unreliable connectivity do not cause additional accuracy drops (Figure 3); our three baselines show the same pattern. While the training performance of all three P2P techniques is equally affected by these real-world system disturbances, MAR-FL consistently preserves its net benefit over all baselines in communication efficiency, providing evidence for the enhanced practicality of our system. Even with 50% participation and 20% dropout likelihood, RDFL and AR-FL require more than 5× the communication of MAR-FL to reach the same model utility. The robustness towards unreliable connectivity (i.e., peer has conducted local update but does not participate in global aggregation) can be attributed to the fact that averaging incomplete global models over multiple FL iterations eventually converges to almost exact global averages. In Section C.2, where we provide further results on partial participation, we outline how this phenomenon can be exploited to increase the communication efficiency of MAR-FL. The appendix also includes additional results for FedAvg, RDFL, and AR-FL.
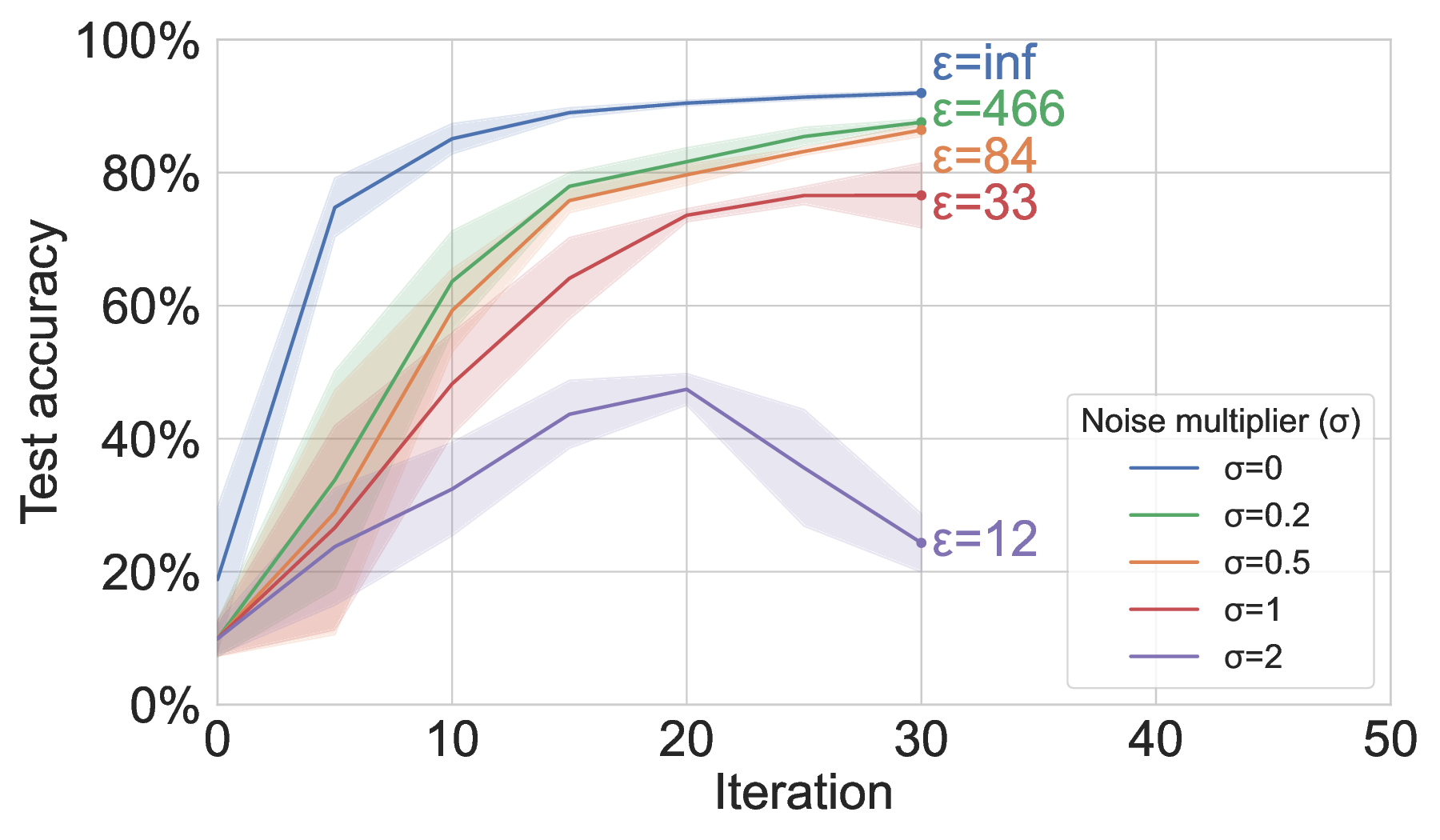
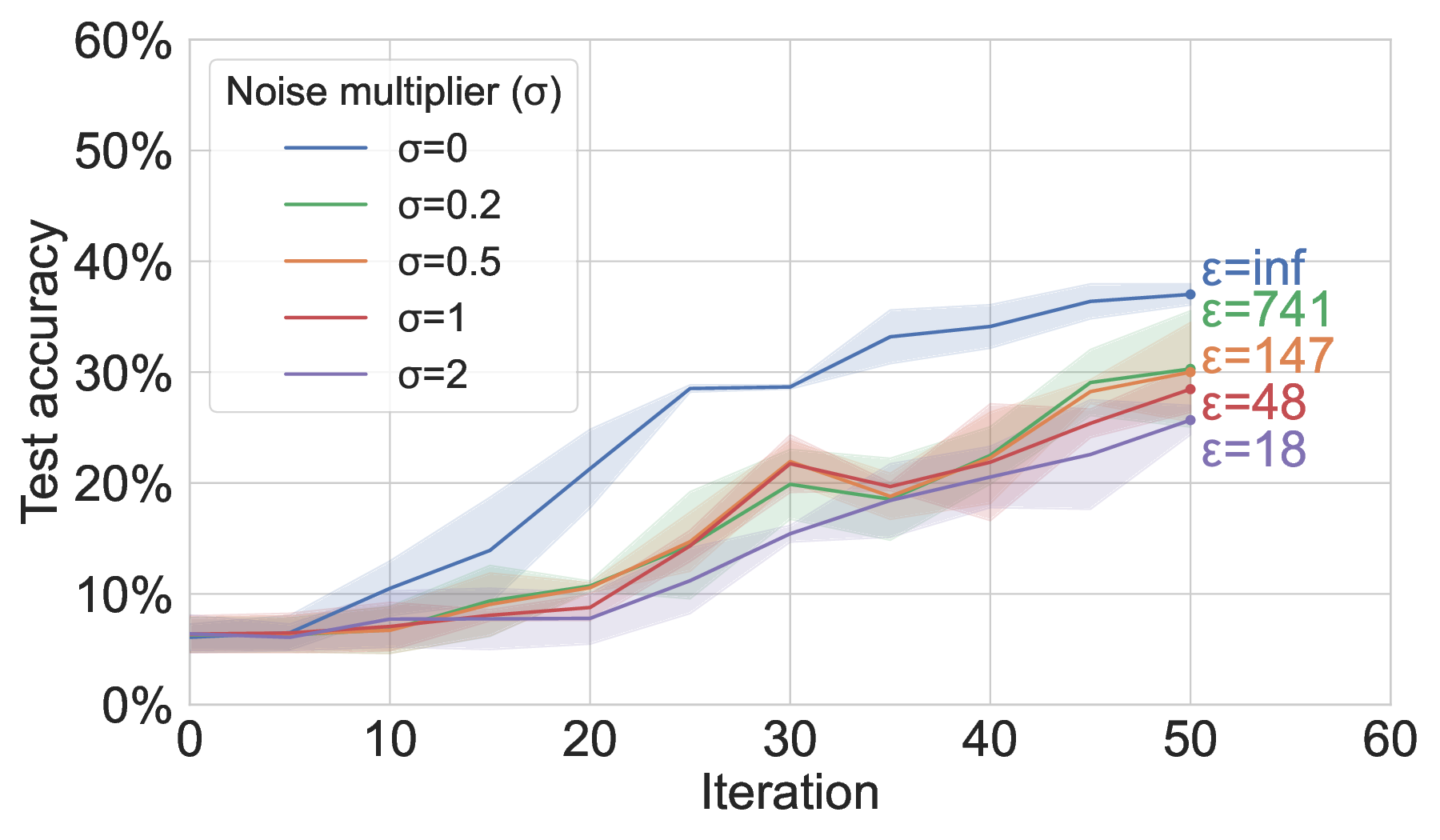
Differentially private training. When conducting DP-safe model aggregation in MAR-FL, increasing the strength of DP by raising the noise multiplier σ reduces the privacy loss ε but eventually degrades model utility (Figure 4). Since our observations align with the effect of DP on standard FedAvg (Andrew et al., 2021;Wei et al., 2020), this confirms that DP is readily supported within our fully decentralized system. We emphasize that the privacy loss ε can be substantially reduced by decreasing the peer-sampling rate (i.e., partial participation in local updates) (Wei et al., 2020;Mironov, 2017), so that our communication-efficient and scalable MAR-FL system provides a foundation for comprehensive privacy preservation.
We introduce MAR-FL, a P2P FL system that leverages iterative group-based aggregation to substantially reduce communication costs compared to existing P2P FL techniques. On 125 peers, MAR-FL requires about 10× less total communication than RDFL or AR-FL while achieving identical model utility. MAR-FL scales with O(N log N ), enabling efficient training as the number of peers grows. Moreover, our system remains robust under unreliable peers, supports KD to further reduce communication, and integrates DP. Our findings position MAR-FL as a practical foundation for scalable, communication-efficient P2P FL in next-generation wireless settings.
Limitations. While MAR-FL improves the communication efficiency of P2P FL, there is still a performance gap towards client-server FL. Such performance penalties cause higher operating costs, which typically hinders practical adoption. We offer a starting point for using DP with MAR-FL but analyzing the impact of group-based aggregation in combination with momentum on DP dynamics remains open.
Future work. Future work includes a thorough analysis of partial participation and network churnbringing our system even closer to real-world applicability. Exploring approximate aggregation and adaptive group-based information propagation could further improve communication efficiency and narrow the gap to client-server FedAvg. Experimental evaluations of integrating DP into MAR-FL should exploit our system’s scalability to compress peer-sampling rates; maintaining model utility while reducing the privacy loss. Finally, we emphasize the importance of P2P FL: by omitting a centralized server, MAR-FL avoids communication and memory bottlenecks inherent in client-server FL and moves FL closer to its promising applications.
(θ t i , m t i ), the peer’s last obtained global model θt-1 i , and the peer’s last obtained smoothed delta ∆t-1 i are all denoted as if peer i had participated in the previous local update and aggregation. This is not necessarily the case, since our system allows for partial participation and network churn. The last global model θt-1 i could, for example, date back to the penultimate aggregation step (i.e., to FL iteration (t -2)). To clarify that the last global model and last obtained smoothed delta might differ among peers, both are denoted using the peer indicator i. After initializing the noise-calibrating parameters σ b and σ ∆ using the number of participating aggregation peers n t and noise multiplier σ mult , peer i prepares its DP-safe local model θt,0 i . This is done by computing the local model update vector ∆ i , clipping, blurring, and smoothing it with factor β to obtain ∆t,0 i , and then finally deriving θt,0 i , where η u denotes the stepsize (we set β = 0.9 and η u = 0.1). The noisy clipped local delta is denoted by ∆ i . A binary indicator b t,0 i reveals whether peer i has clipped its ∆ i to the clipping bound C t . The squared noise calibration σ 2 ∆ is rescaled by n t to account for noising local model deltas instead of their aggregated sum as Andrew et al. (2021) do.
Algorithm 4: DP-safe model aggregation in MAR-FL (for i-th peer in FL iteration t)
Over G rounds of MAR, each groupbased MAR aggregation step MAR g iteratively averages relevant peer information P t from the set of participating aggregation peers A t until each peer i ∈ A t obtains: (i) a global state (θ t , m t ), (ii) a global clipping indicator bt , and (iii) a global smoothed delta ∆t . The information peer i has so far aggregated up to MAR round g ∈ {1, 2, …, G} of the current FL iteration t is denoted as ( θt,g i , m t,g i , b t,g i , ∆t,g i ). A simple aggregation of binary indicators is not DP-safe as it reveals whether a peer i has clipped its model update vector ∆ i . To prevent this sensitive information leakage, a privacypreserving mechanism (e.g., Secure Aggregation) has to be deployed for global binary indicator computation. When blurring the averaged binary indicator, sampled noise N (0, σ 2 b ) is rescaled by the number of participating peers n t , because we add noise to an average value and not to a sum as Andrew et al. (2021) do. The global averaging of smoothed deltas from all participating peers i ∈ A t ensures that during global model aggregation of the next FL iteration (t + 1), the privatized local delta ∆ i is mixed with a privatized global momentum delta ∆t i before being applied to the last global model θt i . This yields variance reduction and global alignment when computing a DP-safe local model. Eventually, the clipping bound is updated to C t+1 , tracking a target quantile γ of globally averaged clipping, where η C denotes the stepsize (we set γ = 0.5 and η C = 0.2). After each aggregation, the DP-safe global model θ t is stored as the peer’s last global model θt i , to be used in its next global aggregation iteration; analogously for ∆t . We note that the local momentum vectors m t i are not private as noise is applied only when each peer communicates their final model update for an aggregation round.
We run all experiments on a high-performance computing (HPC) cluster using Slurm as the job scheduler. Each experiment runs on a single node with 4×H100 GPUs, 768 GB memory, and 96 CPU cores, reserving the entire node. After resource allocation, the job launches an Enroot runtime inside the allocation. The runtime is built from an Enroot SquashFS image created by im-porting the NGC container nvcr.io/nvidia/pytorch:22.04-py3. Inside the container we use Python 3.8, PyTorch, and our MAR-FL and baseline implementations.
Process model.
We simulate peers as separate Python multiprocessing processes, each spawned by a dispatcher. Processes are created under a spawn context, assigned a unique peer ID, and pinned to specific CPU cores to simulate vCPUs.
A shared multiprocessing.Manager() exposes two queues (task/results) and a shared dictionary for model exchange between the dispatcher and peers.
Dispatcher. A central dispatcher loop orchestrates FL iterations by: (i) selecting participating peers for local updates and aggregation (modeling partial participation and churn), (ii) enqueueing perpeer tasks (update, aggregate, skip, shutdown) on the task queue, (iii) collecting results, logging timings, and monitoring communication volume, (iv) performing early-stopping and robustness checks, and (v) periodically clearing stale entries from the shared dictionary. Peer lifecycle. Each peer process follows three steps: (i) initialize a Hivemind DHT node to synchronize lightweight barriers and group-formation metadata (note that no model tensors are sent over the DHT), (ii) load its local data partition (MNIST or 20NG) and the ML model (CNN or DistilBERT head), and (iii) repeatedly execute tasks pulled from the task queue.
Group formation and synchronization (MAR-FL). At the beginning of the first MAR round, every peer initializes its group key. In each MAR round, peers then: (i) publish their presence via the DHT and collect peers with the same key, (ii) enforce group symmetry by cross-checking gathered group members through DHT keys, (iii) perform communication and aggregation within that group, and (iv) update the group key via a deterministic schedule before the next round. To prevent repeatedly matching with the same peers, group key updates leverage each peer’s chunk index. This procedure aligns with the MAR algorithm of Ryabinin et al. (2021).
Datasets and models. To evaluate MAR-FL and all baselines on two distinct learning problems, we use one vision task (image classification) and one language task (text classification). For handwritten-digit recognition we employ a small two-block convolutional network with a compact multilayer-perceptron head that outputs class logits. MNIST images are loaded via torchvision and normalized in the usual way. For topic classification we use a lightweight classifier head on top of a frozen DistilBERT encoder (Sanh et al., 2019); the sequence representation is obtained from the classification token’s (CLS token) hidden state, and the head produces 20-way logits. Text is tokenized with a BERT-base uncased tokenizer and sequences are padded to a fixed length. The 20 Newsgroups dataset is loaded from Hugging Face Datasets (SetFit/20 newsgroups).
FL baselines. We do not utilize Butterfly All-Reduce (BAR) as an additional P2P FL baseline. BAR aims to reduce total communication load by assigning disjoint parameter chunks to different peers and only partially aggregating at each node. Under heterogeneous participation or network churn this yields incomplete/partially aggregated models, where the network might be stalled waiting for entire chunks of the model architecture. BAR consequently requires peers to be totally reliable. Hence we compare MAR-FL against FedAvg, RDFL, and AR-FL, which better reflect the characteristics of aggregation relevant to FL.
C.1 Qualitative Results between MAR-FL and our Baselines Qualitative identity. On MNIST and 20NG, MAR-FL achieves the same training performance as client-server FedAvg and the two P2P FL baselines (see Figure 5), as all four techniques yield identical global model averages under the given configurations.
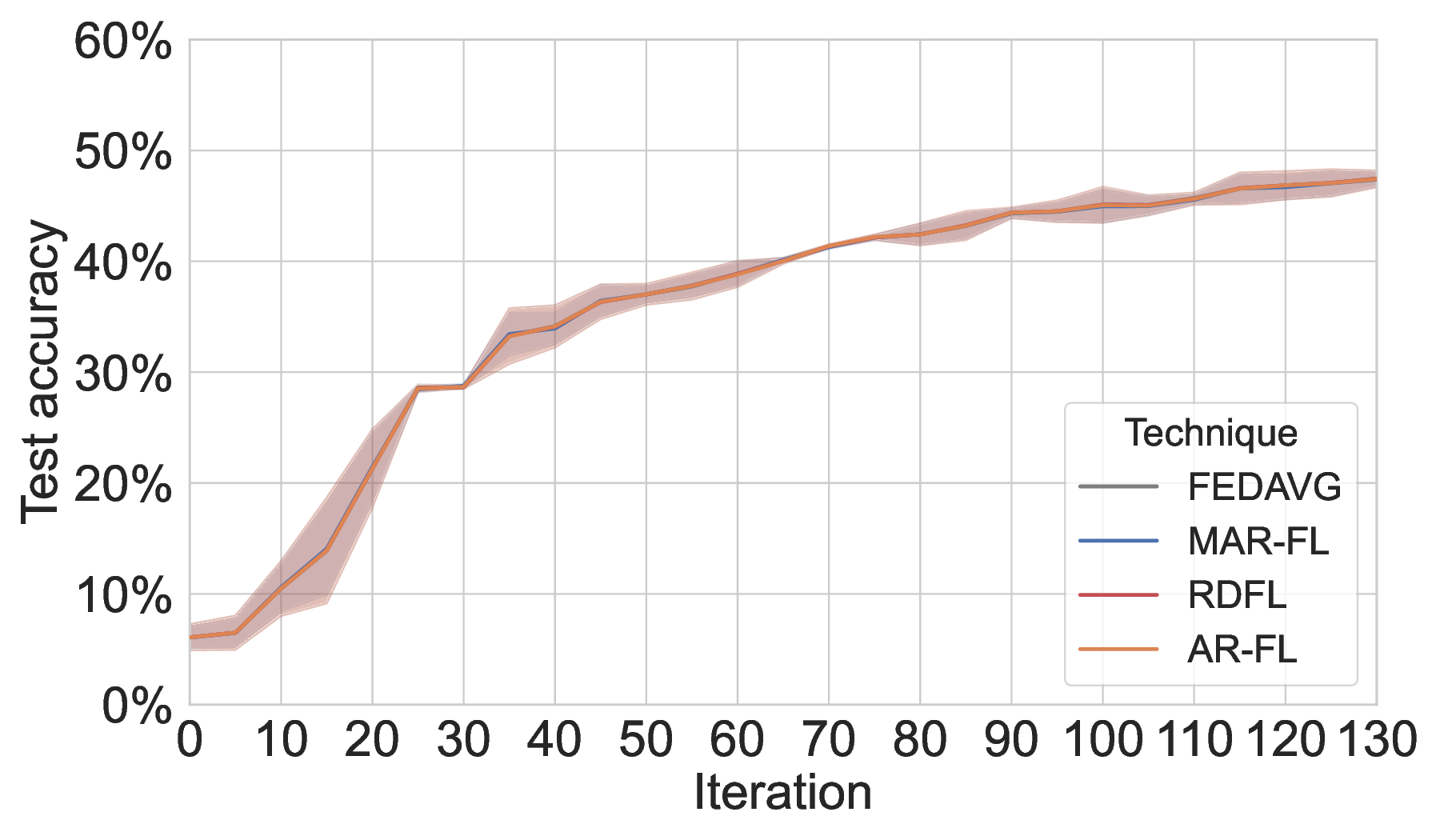
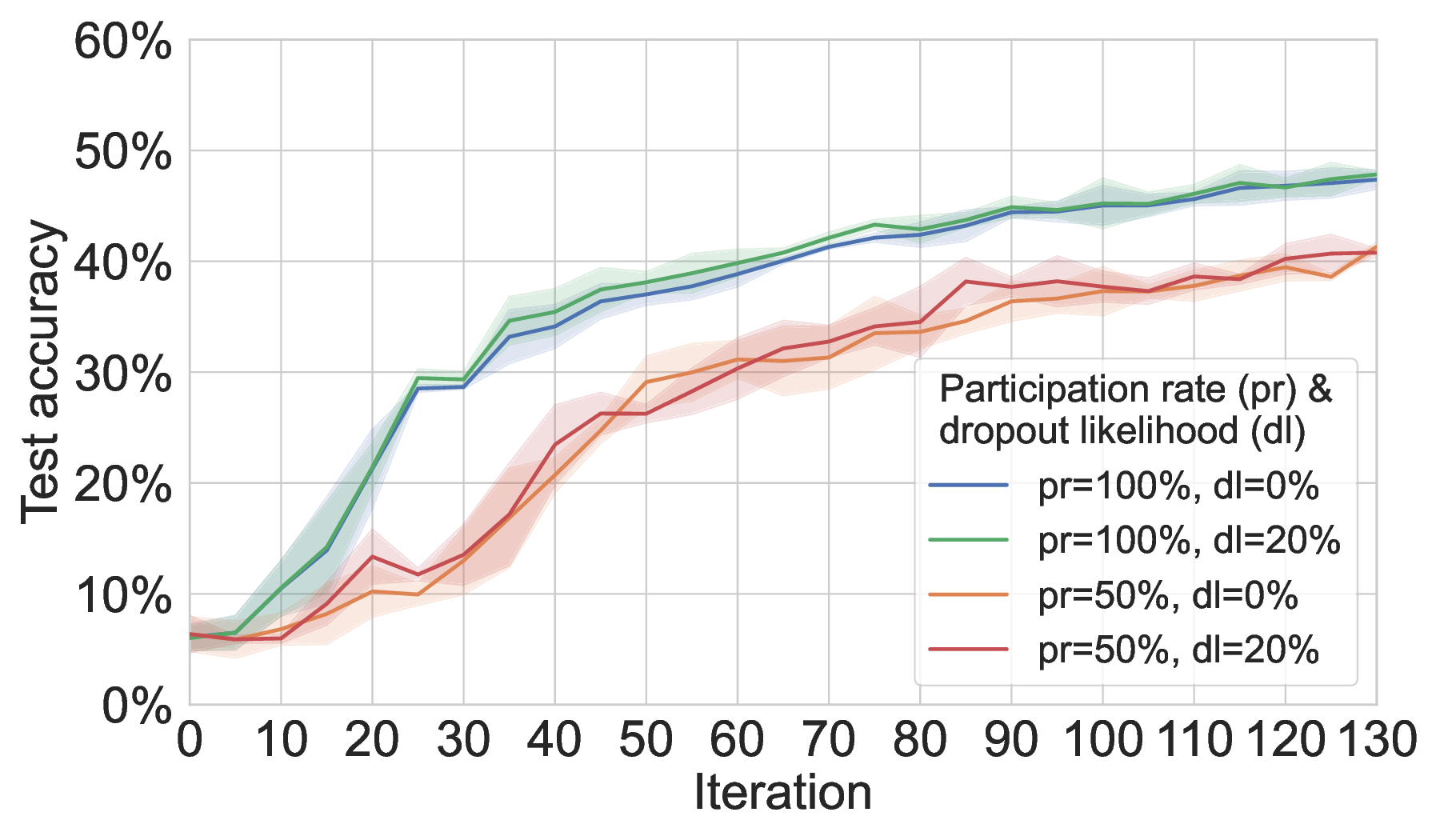
Partial participation. On MNIST, MAR-FL incurs some loss in model utility under partial participation (see Figure 6), though the degradation is milder than on 20NG. However, even with only 50% peer participation and a 20% dropout likelihood, MAR-FL remains more than 5× as communication-efficient as our two P2P FL baselines. On 20NG, Figure 7 shows that FedAvg and both P2P baselines degrade to a similar extent, consistent with the behavior observed for MAR-FL (see Figure 3).
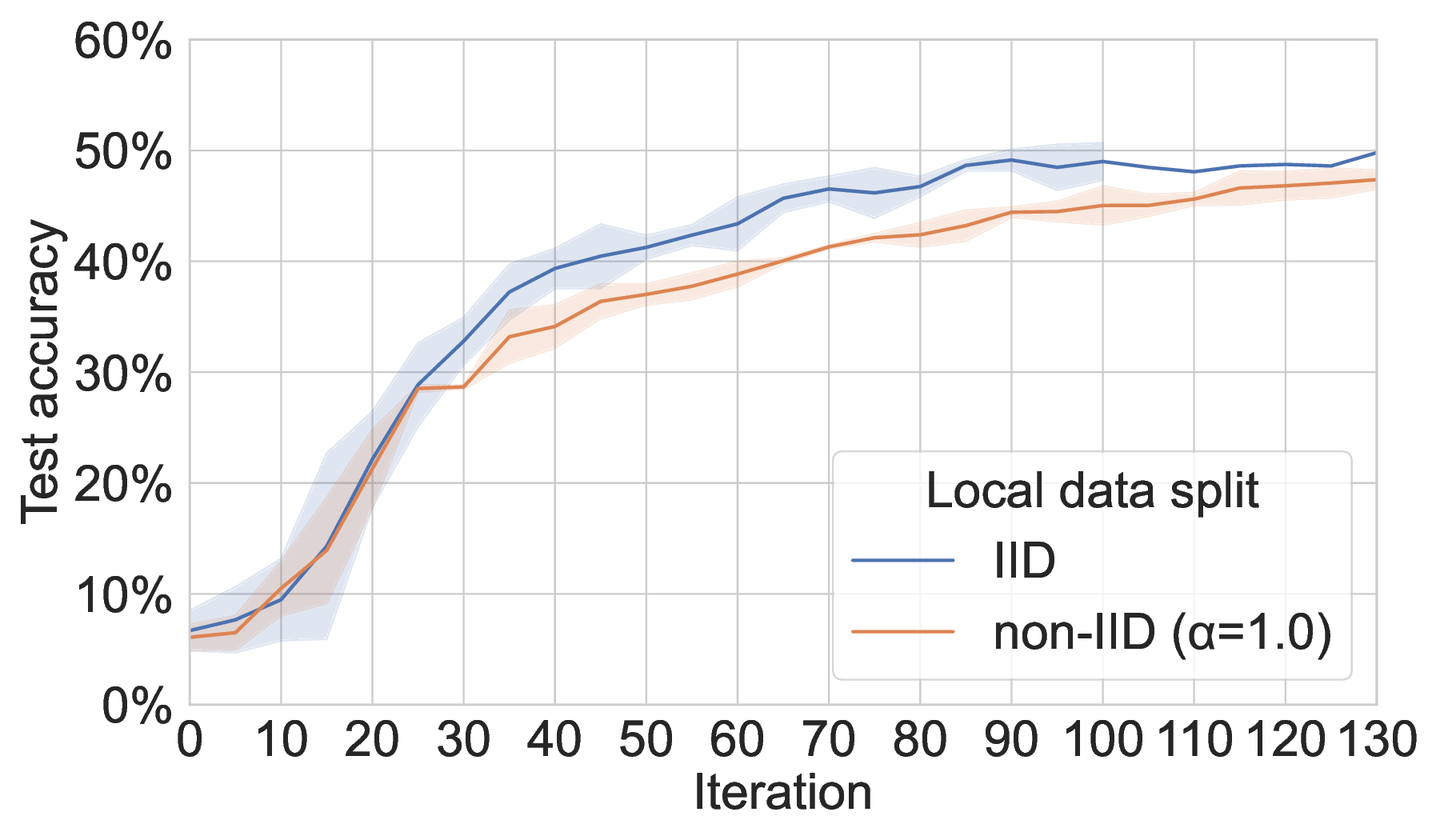
Heterogeneous peer data. We employ Latent Dirichlet Allocation (α = 1.0) to create non-i.i.d. local data splits among participating peers. While our simulation of real-world heterogeneous data distributions has no significant effect when training MAR-FL on MNIST, performance on 20NG is noticeably impaired compared to training with nearly i.i.d. local data splits (see Figure 8).
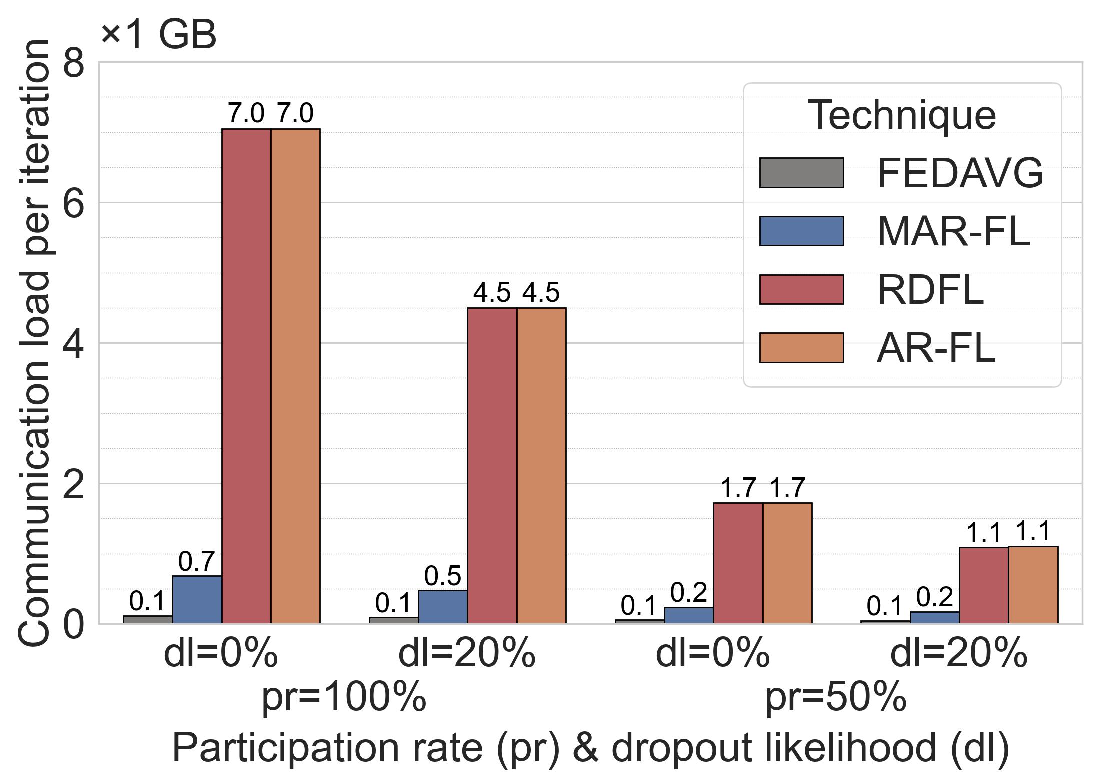
Improving communication efficiency with MKD. As on 20NG, MKD also accelerates convergence for MAR-FL on MNIST, enabling a target accuracy of 95% to be reached with up to 3× lower total communication (see Figure 9), despite the increased per-iteration load from global aggregation. The number of KD iterations k is chosen such that -without data loader shuffling -for k = 8 on MNIST and k = 6 on 20NG each peer processes its entire local dataset twice, while for k = 40 on MNIST and k = 30 on 20NG it is seen ten times.
39th Conference on Neural Information Processing Systems (NeurIPS 2025) Workshop: AI and ML for Next-Generation Wireless Communications and Networking (AI4NextG).
Github: https://github.com/felix-fjm/mar-fl
We do not compare against Galaxy Federated Learning as a whole since the framework largely depends on a distributed ledger/blockchain for training verification. Verification is beyond the scope of our work.
📸 Image Gallery