Mitigating Catastrophic Forgetting in Target Language Adaptation of LLMs via Source-Shielded Updates
📝 Original Info
- Title: Mitigating Catastrophic Forgetting in Target Language Adaptation of LLMs via Source-Shielded Updates
- ArXiv ID: 2512.04844
- Date: 2025-12-04
- Authors: Atsuki Yamaguchi, Terufumi Morishita, Aline Villavicencio, Nikolaos Aletras
📝 Abstract
Expanding the linguistic diversity of instruct large language models (LLMs) is crucial for global accessibility but is often hindered by the reliance on costly specialized target language labeled data and catastrophic forgetting during adaptation. We tackle this challenge under a realistic, low-resource constraint: adapting instruct LLMs using only unlabeled target language data. We introduce Source-Shielded Updates (SSU), a selective parameter update strategy that proactively preserves source knowledge. Using a small set of source data and a parameter importance scoring method, SSU identifies parameters critical to maintaining source abilities. It then applies a column-wise freezing strategy to protect these parameters before adaptation. Experiments across five typologically diverse languages and 7B and 13B models demonstrate that SSU successfully mitigates catastrophic forgetting. It reduces performance degradation on monolingual source tasks to just 3.4% (7B) and 2.8% (13B) on average, a stark contrast to the 20.3% and 22.3% from full fine-tuning. SSU also achieves target-language performance highly competitive with full fine-tuning, outperforming it on all benchmarks for 7B models and the majority for 13B models. 1📄 Full Content
Yet, adapting instruct models to these languages is uniquely challenging. Such models require specialized instruction-tuning data (Wei et al., 2022;Rafailov et al., 2023), which is often unavailable or prohibitively costly to create for underrepresented languages (Huang et al., 2024c). Furthermore, machine-translated data as a low-cost alternative is not consistently effective (Tao et al., 2024).
Consequently, unlabeled target language text is often the only viable data for adaptation. While this approach can improve target language proficiency, it often triggers catastrophic forgetting (Kirkpatrick et al., 2017;Tejaswi et al., 2024;Mundra et al., 2024;Yamaguchi et al., 2025a), where new training erases prior knowledge. This issue is particularly acute for instruct models, as it cripples the generalpurpose functionality of the model, which is primarily derived from core abilities like chat and instruction-following. In response, previous work has attempted post-hoc mitigation. For example, Yamaguchi et al. (2025a) merge the weights of the original instruct model with the corresponding adapted model, while Huang et al. (2024c) treat adaptation as a task vector, applying parameter changes from CPT on the base model to the instruct model. Nonetheless, these methods largely fail to mitigate catastrophic forgetting, substantially degrading these core functionalities. We therefore introduce Source-Shielded Updates (SSU), a novel source-focused approach that proactively shields source knowledge before adaptation begins (Figure 1). First, SSU identifies parameters critical to source abilities using a small set of source data and a parameter importance scoring method, such as those used in model pruning (e.g., Wanda (Sun et al., 2024)). Second, it uses these elementwise scores to construct a column-wise freezing mask. This structural design is crucial. Unlike naive element-wise freezing that corrupts feature transformations, our columnwise approach preserves them entirely. Finally, this mask is applied during CPT on unlabeled target language data, keeping the shielded structural units frozen. This process allows SSU to effectively preserve the general-purpose ability of the model while improving target language performance.
We verify the effectiveness of our approach through extensive experiments with five typologically diverse languages and two different model scales (7B and 13B). We evaluate performance on the source language (English) across multiple dimensions, including chat and instruction-following, safety, and general generation and classification abilities, alongside performance on the target language. We summarize our contributions as follows:
• A novel method for adapting instruct models to a target language without specialized target instruction-tuning data, addressing a key bottleneck to expand linguistic accessibility. • At two model scales, SSU consistently outperforms all baselines on all core instructionfollowing and safety tasks. It achieves leading target-language proficiency rivaling full fine-tuning while almost perfectly preserving general source-language performance. • Extensive analysis validates the efficacy of SSU, confirming the superiority of column-wise freezing and the importance of source data-driven parameter scoring. Qualitatively, we observe that SSU avoids the linguistic code-mixing that state-of-the-art methods suffer from, explaining its superior abilities across source chat and instruction-following tasks.
Language Adaptation. CPT on target language data is the standard method for adapting LLMs to target languages (Cui et al., 2024;Fujii et al., 2024;Da Dalt et al., 2024;Cahyawijaya et al., 2024;Nguyen et al., 2024;Yamaguchi et al., 2025b;Nag et al., 2025;Ji et al., 2025, inter alia.). While effective, CPT often leads to substantial degradation of the original capabilities of a model (Tejaswi et al., 2024;Mundra et al., 2024;Yamaguchi et al., 2025a), a phenomenon known as catastrophic forgetting. This trade-off presents a major obstacle, especially for instruct models where preserving core chat and instruction-following abilities is vital for their general-purpose functionality. While some research addresses tokenization overfragmentation, where words are split into inefficiently small units, via vocabulary adaptation (Tejaswi et al., 2024;Mundra et al., 2024;Yamaguchi et al., 2025a, inter alia.), we focus on catastrophic forgetting during parameter updates with a fixed architecture. We consider vocabulary adaptation orthogonal to our approach; combining it with SSU offers a promising avenue for future work.
Catastrophic Forgetting. Mitigating catastrophic forgetting is a long-standing challenge in continual learning. Proposed solutions generally fall into five categories: (1) Regularization-based methods add a penalty term to the loss function to discourage significant changes to weights deemed important for previous tasks (Kirkpatrick et al., 2017;Chen et al., 2020;Zhang et al., 2022, inter alia.).
(2) Replay-based methods interleave old and new data (de Masson d’Autume et al., 2019;Rolnick et al., 2019;Huang et al., 2024b, inter alia.).
(3) Model merging methods interpolate between original and fine-tuned models (Wortsman et al., 2022;Yadav et al., 2023;Yu et al., 2024;Huang et al., 2024a, inter alia.). (4) Architecture-based methods like LoRA (Hu et al., 2022) add and train new parameters while freezing the original model (Houlsby et al., 2019;Hu et al., 2022;Zhang et al., 2023, inter alia.). (5) Selective parameter updates restrict which existing weights are modified during training (Zhang et al., 2024a;Hui et al., 2025). Our work belongs to this category. SSU also relates to foundational continual learning methods that protect critical parameters, such as HAT (Serra et al., 2018), CAT (Ke et al., 2020), and SPG (Konishi et al., 2023). See Appendix E for discussions.
Studies on multilingual CPT for LLMs similarly employ these strategies. Examples include mixing source (English) data (Category 2) (Zheng et al., 2024;Elhady et al., 2025), model merging (Category 3) (Alexandrov et al., 2024;Blevins et al., 2024), and concurrent work on architecture-based solutions (Category 4) (Owodunni & Kumar, 2025). Optimization strategies, such as controlling learning rates (Winata et al., 2023), are also utilized. These methods are largely orthogonal to our work. SSU, in contrast, focuses on selective parameter updates (Category 5), distinguished by a proactive, source-driven approach which we detail next.
Selective Parameter Updates. While often utilized for training efficiency (Liu et al., 2021;Lodha et al., 2023;Li et al., 2023a;Pan et al., 2024;Yang et al., 2024;Li et al., 2024;Ma et al., 2024;Li et al., 2025;He et al., 2025), selective parameter updates have also proven effective for mitigating catastrophic forgetting (Zhang et al., 2024a;Hui et al., 2025). These methods can be broadly categorized as dynamic or static. Dynamic approaches select a trainable parameter set that can change during training, based on random selection (Li et al., 2024;Pan et al., 2024) or target data signals like gradient magnitudes (Liu et al., 2021;Li et al., 2023a;Ma et al., 2024;Li et al., 2025).
In contrast, static methods define a fixed trainable parameter set before training or during warm-up. This allows for straightforward integration with existing pipelines, enabling the combination of orthogonal mitigation methods like regularization and replay more easily. For example, a method closest to our work (Hui et al., 2025) randomly freezes half of the components within each transformer sub-layer (i.e., self-attention, feed-forward, and layernorm), while others are data-driven based on target data (Lodha et al., 2023;Zhang et al., 2024a;Panda et al., 2024;He et al., 2025).
SSU: A Source-Focused Selective Parameter Update Approach. SSU is a static selective parameter update approach (Category 5) that introduces a new, source-focused paradigm for language adaptation. Unlike existing selective parameter update methods that rely on random choice or target data signals, SSU uses a small sample of source data (e.g., 500 samples) to identify and freeze parameters critical to the source knowledge within the model before adaptation. This also distinguishes it from previous importance-based methods in other categories. For instance, regularization methods (Category 1) are reactive, applying a penalty to weight changes (Jung et al., 2020). In contrast, SSU is proactive, using a static structural mask to prevent updates before adaptation. Similarly, SSU is not an architecture-based PEFT method (Category 4), which uses importance to insert new parameters (Yao et al., 2024). SSU instead operates on full, existing parameters to select and freeze structural columns.
We address the challenge of adapting an instruct model using only raw, unlabeled target language data. Unlike prior work that focuses on post-hoc mitigation (Huang et al., 2024c;Yamaguchi et al., 2025a), we introduce Source-Shielded Updates (SSU), a method that targets the CPT process itself.
The goal is to mitigate catastrophic forgetting during CPT, thereby maintaining the general-purpose functionality of an instruct model. Concurrently, SSU aims to achieve performance gains in the target language tasks comparable to those from full fine-tuning. Formally, given an instruct model M, calibration data D calib , unlabeled target language data D target , and a parameter freezing ratio k, SSU adapts M on D target in three stages (Figure 1).
The first stage of SSU scores parameter importance to identify weights critical to source model capabilities. We posit that a source-data-driven score is suitable, as it directly aligns with the goal of preserving source knowledge. For this purpose, we adopt the importance score from Wanda (Sun et al., 2024), a popular pruning method.2 Using a small sample of source data D calib , Wanda computes an importance score s ij for each weight θ ij as the product of its magnitude and the L2-norm of its corresponding input activations X j :
This identifies weights that are both large and consistently active. Scores are computed for all parameters in M except for the embeddings and language modeling head, as all these are updated during training following Hui et al. (2025).
In the second stage, SSU converts element-wise importance scores into a structured freezing mask. A structured approach is crucial because naive, element-wise freezing disrupts feature transformations and causes catastrophic forgetting (Table 3). To avoid this, SSU operates at the column level. For instance, in a forward pass Y = W X, freezing an entire column of the weight matrix W leaves the corresponding output dimension of Y unchanged, ensuring a complete feature pathway. The approach is analogous to protecting the core structural columns of a building during renovation; the foundational support remains untouched while peripheral elements are modified.
Mask generation begins by aggregating scores for each column. For a weight matrix θ ∈ R dout×din , a column corresponds to all parameters associated with a single input feature. The total importance score S j for each column j is the sum of its individual importance scores: S j = i s ij . S j robustly measures the contribution of each input feature, identifying the core structural columns to be preserved. For 1D parameters, such as biases, each element is treated as its own column; thus, its per-weight score s i serves as its aggregated score S i .
The binary mask B for each weight matrix is generated by ranking columns by their S j and then selecting the top k% to freeze (50% by default following Hui et al. (2025)). The corresponding columns in the mask B are set to 0 (freeze), while all others are set to 1 (update).
In the third stage, the model M is continually pre-trained on unlabeled data D target using a standard causal language modeling objective, denoted as the loss L. During the backward pass, the static mask B is applied to the gradients, zeroing out updates for frozen columns. The gradient update rule for a weight θ ij is thus
Here, η is the learning rate, and b ij ∈ {0, 1} is the value from the mask B corresponding to the weight θ ij . This method preserves knowledge stored in the most critical input-feature pathways, thus mitigating catastrophic forgetting.
Following Hui et al. (2025) who used 7B and 13B models from the same family (i.e., Llama 2), we use the 7B and 13B OLMo 2 Instruct models (Walsh et al., 2025) for our experiments. The OLMo 2 models offer strong instruction-following capabilities and fully documented training data, allowing full control and transparency in our language adaptation experiments. We experiment with five typologically diverse languages (Table 1) that are significantly underrepresented in the training data of the source models but with wide availability of datasets with consistent task formulations (though data variations preclude direct performance comparisons between languages). These languages appear at least 840x less frequently than English in Common Crawl (CC),3 which accounts for over 95% of the OLMo 2 pre-training corpus (Walsh et al., 2025).
We use tulu-3-sft-olmo-2-mixture (Lambert et al., 2025), the original instruction-tuning data for OLMo 2, for calibration (i.e., choosing which parameters to freeze). We randomly select 500 samples with a sequence length of 2,048. For CPT, we use a clean subset of MADLAD-400 (Kudugunta et al., 2023), sampling 200M tokens per language as recommended by Tejaswi et al. (2024).4
We compare our approach against baselines from three categories: performance benchmarks, a reference approach from a related paradigm, and state-of-the-art methods.
Source: Off-the-shelf OLMo 2, reporting performance without any adaptation.
FFT: Full fine-tuning that updates all the parameters of the model via CPT on target language data, quantifying the extent to which a model suffers from catastrophic forgetting without any intervention.
AdaLoRA (Zhang et al., 2023): An architecture-based method to mitigate catastrophic forgetting. This achieves the best overall performance among LoRA-like methods in Hui et al. (2025).
HFT: A state-of-the-art static selective parameter update method (Hui et al., 2025). It updates 50% of parameters using a fine-grained, per-layer strategy by randomly freezing two out of the four self-attention matrices (W Q , W K , W V , W O ); and two out of three feed-forward matrices (W up , W down , W gate ) in a random half of the layers and one matrix in the remaining half. Since SSU is also a static method, HFT serves as a key baseline.
GMT: A state-of-the-art dynamic selective parameter update approach (Li et al., 2025) that drops gradients of a pre-defined ratio (50% in this study for fair comparison with HFT and SSU) with smaller absolute values on the target data.
To validate our use of source calibration data for scoring, we also introduce two calibration data-free ablation variants: (1) SSU-Rand that freezes an equal number of randomly-selected columns. This provides no principled way to preserve functionally important knowledge.
(2) SSU-Mag that freezes columns based only on the magnitude score (i.e.,
, isolating the effect of the activation term.
We report performance in the source and target languages across standard benchmarks.
Chat and Instruction-following: (1) IFEval (Zhou et al., 2023) Source Language (English): We evaluate target-to-English machine translation (MT) on FLORES-200 (NLLB Team et al., 2022), reporting three-shot chrF++ (Popović, 2017) on 500 samples, following previous work (Ahia et al., 2023;Yamaguchi et al., 2025a). For summarization (SUM) on XL-SUM (Hasan et al., 2021), we use zero-shot chrF++ on 500 samples. For machine reading comprehension (MRC) on Belebele (Bandarkar et al., 2024) and general reasoning on MMLU (Hendrycks et al., 2021), we report three-shot and five-shot accuracy, respectively, on their full test sets.
Target Language: We evaluate English-to-target MT, SUM, and MRC on the same target-language subsets of respective datasets and settings. For reasoning, we use Global MMLU (Singh et al., 2025) and report five-shot accuracy on its full test set.
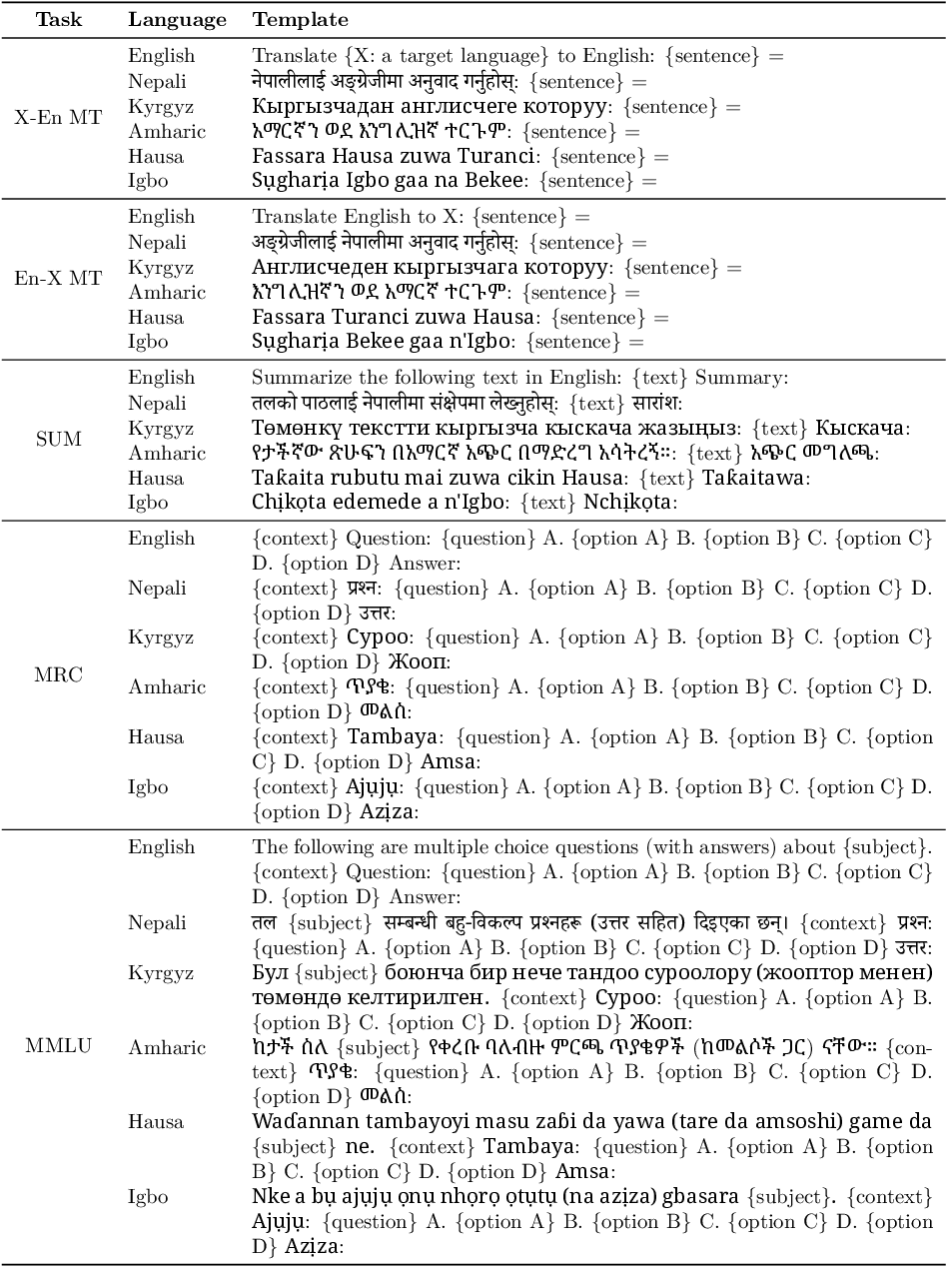
We report average scores over three runs for generative tasks (IFEval, AE2, MTB, GSM8K, MT, SUM) and use a single deterministic run with temperature zero for classification tasks. We use language-specific prompt templates for MT, SUM, MRC, and MMLU, listed in Table 7 in the Appendix. The rest use the default prompt templates.
Table 2 shows performance across the four task groups: chat and instruction-following, safety, source language, and target language for all methods.
Chat and Instruction-following. Our SSU-Wanda achieves the best performance on all chat and instruction-following benchmarks, exhibiting the smallest average relative performance drops from Source of just 5.9% and 4.7% for the 7B and 13B models, respectively. This result is particularly Preprint important as these tasks directly measure core instruct model capabilities, such as multi-step reasoning and following complex constraints. The performance of SSU-Wanda demonstrates its efficacy in retaining source knowledge and abilities. The architecture-based method, AdaLoRA, performs second best with average degradations of 9.0% (7B) and 6.1% (13B). This aligns with previous findings that LoRA-style adaptations tend to forget less. However, as we discuss later, they also learn less from target data (Biderman et al., 2024;Hui et al., 2025).
In contrast, other methods exhibit more substantial performance drops. The state-of-the-art selective parameter update baselines lag considerably behind SSU-Wanda. For instance, the performance of HFT drops by 18.0% (7B) and 15.1% (13B), while the target-data-driven GMT degrades by 27.7% (7B) and 26.3% (13B). Notably, the static HFT method preserves source capabilities more effectively than the dynamic GMT method, supporting our main hypothesis that optimizing on signals from unstructured target data risks corrupting the foundational abilities of an instruct model ( §1). The risk of standard adaptation is starkly illustrated by the overall performance of full fine-tuning (FFT). FFT suffers a drastic average performance loss of 34.1% (7B) and 32.3% (13B).
Finally, the low performance of baseline SSU variants (SSU-Rand and SSU-Mag) highlights the importance of the source-data-driven scoring. While both freezing random columns (SSU-Rand) and columns selected by magnitude alone (SSU-Mag) outperform FFT, they substantially underperform SSU-Wanda. SSU-Rand performance is 18.2% (7B) and 16.0% (13B) lower than Source, while SSU-Mag causes even greater drops of 23.0% (7B) and 21.7% (13B). The substantial underperformance of these calibration data-free approaches underscores the critical need for a source-data-informed importance scoring method for preserving the core capabilities of an instruct model in the source language. As we demonstrate in §6, this principle is not limited to Wanda; other source-data-driven scoring methods are also highly effective, confirming the versatility of the SSU framework.
Safety. SSU-Wanda also best preserves the safety alignment of the source, with small performance drops of only 0.1% (7B) and 2.0% (13B) compared to Source. In contrast, FFT and the target-datadriven GMT cause large drops, with safety scores dropping by up to 10.2%. While other selective methods partially preserve source performance, they still lag behind SSU-Wanda.
Source Language. SSU-Wanda not only preserves source language capabilities but also enhances them in the cross-lingual translation task. For the 7B model, SSU-Wanda is the top performer across all source benchmarks. For the 13B model, it ranks top in MT and MMLU and is a close second in SUM and MRC. Notably, its performance on MT (target-to-English) improves substantially by up to 52.3% relative to Source. For monolingual tasks (SUM, MRC, and MMLU), performance is almost perfectly maintained, with relative drops never exceeding 2.0% (7B) and 1.0% (13B). AdaLoRA is the second-best performer overall, also showing strong preservation across monolingual tasks. However, its gains in the MT task are substantially smaller, the worst among all approaches. This suggests that while LoRA-based methods effectively prevent forgetting, the structural isolation of their updates may be less adept at integrating new linguistic knowledge for complex cross-lingual tasks. The remaining adaptation methods generally exhibit greater performance degradation than SSU-Wanda, consistent with instruction-following and safety results.
Target Language. Finally, SSU-Wanda demonstrates exceptional performance on target language tasks, securing the best results across all benchmarks for both model scales in the majority of cases. Crucially, its performance is highly competitive with FFT, even surpassing it on all benchmarks for 7B models and on half for 13B models. The performance difference between SSU and FFT is consistently minimal, confirming that SSU-Wanda achieves the target-language gains of a full update with drastically smaller catastrophic forgetting. This aligns with observations from optimization theory, arguing that freezing parameters acts as a regularization term that stabilizes training and enables a sparse fine-tuned model to match or exceed the performance of its dense counterpart (Fu et al., 2023;Zhang et al., 2024b;Hui et al., 2025). All the other selective parameter update methods also yield solid improvements, though typically smaller than those of SSU-Wanda. In contrast, AdaLoRA shows the smallest improvement and often fails to surpass the source model. This confirms that LoRA-based methods have a smaller inductive bias from the target data (Biderman et al., 2024;Hui et al., 2025). This highlights the unique effectiveness of SSU-Wanda, which successfully masters tasks in the target language while preserving its original knowledge and abilities in the source. Figure 2: Model performance (SSU-Wanda, HFT, GMT) on Igbo as target language across freezing ratios. The dashed red line indicates Source performance (omitted for MT and SUM due to very low scores). Some data points for HFT and GMT are also omitted due to extremely low performance.
Overall, SSU-Wanda demonstrates the benefits of full fine-tuning without the associated catastrophic forgetting, consistently outperforming all other evaluated methods.
This section evaluates the robustness of the SSU framework by isolating the impact of core design choices and hyperparameters. Due to resource constraints, we use the 7B model with our primary method, SSU-Wanda. We select Igbo as the target language, as it is the most underrepresented language among our target languages (Table 1).
Parameter Freezing Ratio. While we use a default 50% freezing ratio for fair comparison with baselines following Hui et al. (2025), this hyperparameter can impact performance. We therefore evaluate freezing ratios from 0% (defaulting to FFT) to 87.5% in 12.5% increments. As shown in Figure 2, performance on source language capabilities, such as chat and safety, generally improves as the freezing ratio increases. In contrast, performance on target language tasks often shows an opposite trend, degrading as more parameters are frozen, with a particularly sharp drop in MMLU after reaching a 37.5% ratio. Target-to-English MT is a notable exception. Although the models generate English text, performance declines as the freezing ratio increases, particularly after 37.5%. This trend contradicts other source tasks. This occurs because MT requires knowledge of both source and target languages.
Our results show a trade-off between source knowledge retention and target language acquisition. Therefore, we recommend practitioners tailor the freezing ratio based on their specific goals: General purpose: A default 50% ratio offers a robust and balanced performance. Source-capability priority: A higher ratio (e.g., ∼ 60% or higher) is optimal, as performance on tasks like IFEval, MRC, and MMLU plateaus around this point. Target-language priority: A lower ratio (e.g., ∼ 40% or lower) is preferable, given the performance drops observed in MT and MMLU beyond this threshold.
Impact of Freezing Ratio on Baselines. We extend this analysis to state-of-the-art selective parameter update baselines (Figure 2). The closest baseline, the static method HFT, follows a trend similar to SSU but fails to surpass the performance of SSU across tasks and freezing ratios.
In contrast, the dynamic method GMT exhibits a different trend. While it often achieves strong target language and MT performance at ratios above 60%, it consistently yields low performance on monolingual source tasks regardless of the freezing ratio. We attribute this to the dynamic nature of GMT, which allows updates to any parameter over time, leading to cumulative corruption from unstructured target data optimization ( §1 and §5). Ultimately, this confirms SSU as the optimal method for simultaneously achieving strong source preservation and high target language gains.
Alternative Freezing Methods. SSU employs column-wise freezing to preserve the entire processing pathway of critical source features ( §3.2). To validate this design choice, we compare its effectiveness against row-wise and element-wise freezing. As shown in Table 3, the results demonstrate a clear advantage for our column-wise approach. Column-wise freezing consistently achieves Preprint .371
+14.9
the best performance on chat, safety, and source language tasks.6 On target language tasks, it remains highly competitive, with only a 1.2 point drop on MT compared to element-wise freezing. These results validate the guiding hypothesis for the design of SSU: preserving entire feature pathways is a critical strategy to safeguard source knowledge while enabling effective target-language adaptation.
Alternative Importance Scoring Methods. SSU is compatible with alternative importance scoring methods beyond Wanda. To demonstrate this, we evaluate two different source-data-driven methods: SparseGPT (Frantar & Alistarh, 2023) and the diagonal of the Fisher Information Matrix (Kirkpatrick et al., 2017, FIM); see Appendix B for details. In monolingual source tasks, SSU-SparseGPT and SSU-FIM show comparable average performance drops (4.3% and 3.5%, respectively) to SSU-Wanda (4.0%), as detailed in Table 4. This contrasts sharply with the larger drops of data-free variants like SSU-Rand (13.5%) and SSU-Mag (17.9%). These findings demonstrate the versatility of SSU, offering strong performance across various source-data-driven scoring methods.
Calibration Data for Parameter Importance Scoring. SSU-Wanda requires source calibration data to identify critical model weights since it relies on Wanda for parameter importance scoring. While we use the original instruction-tuning data for OLMo 2 in our main experiments, this is often unavailable for other frontier models. We therefore investigate the efficacy of using an alternative, publicly available dataset. Specifically, we use Alpaca (Taori et al., 2023) as the calibration dataset and follow the exact same preprocessing and training procedures as the original data. Table 5 shows that performance with Alpaca is highly comparable to that with the original data, with a maximum difference of only 1.0, demonstrating the robustness of SSU-Wanda to the choice of calibration data.
Calibration Data Size for Parameter Importance Scoring. SSU uses 500 source calibration examples by default to compute parameter importance scores ( §4.3). To assess sensitivity to this hyperparameter, we compare the default (500 examples, ∼1M tokens) with a smaller 128-example set (∼0.26M tokens), a size common in model pruning literature (Williams & Aletras, 2024). The results in Table 5 show minimal changes across tasks; the maximum performance difference observed is only 1.2 points on IFEval. This confirms the robustness of SSU to calibration data size, demonstrating that a small sample set suffices for effective importance scoring.
Table 5: Performance of SSU-Wanda with different calibration data sources and sizes, using Igbo as the target language. Comparison to Additional Baselines. We also compare SSU-Wanda to other selective parameter update methods: LoTA (Panda et al., 2024) and S2FT (Yang et al., 2024). We evaluate LoTA at its default 90% sparsity and at 50% sparsity to match the freezing ratio of SSU. For S2FT, we test its default down projection-focused adaptation. As shown in Table 6, LoTA at 90% sparsity exhibits inferior source preservation compared to SSU-Wanda (e.g., 7.6% vs. 4.0% average drop on monolingual source tasks) and lower target gains (23.9% vs. 30.7%). While LoTA at 50% sparsity achieves substantial target gains (31.7%), it suffers severe catastrophic forgetting on monolingual source tasks (19.9% drop). S2FT effectively preserves source capabilities (3.3% drop) but yields minimal target gains (2.3%). These results underscore that only SSU-Wanda achieves both strong source preservation and high target language gains comparable to FFT. This trend holds across different sparsity levels (see Appendix D).
Qualitative Analysis. SSU-Wanda surpasses other state-of-the-art selective parameter update baselines across all chat and instruction-following benchmarks (Table 2). This performance gap arises partly because baseline methods are prone to code-mixing (i.e., the unintentional blending of multiple languages in responses) or generating responses entirely in the target language, despite English instructions. A typical example of this behavior for models trained on Igbo is as below: Analyzing the language ratio in generated responses on AE2 shows that SSU produces codemixed text in only 1.0% of its responses on average for the 7B models. In contrast, HFT and GMT generate code-mixed text in 6. 4% and 16.9%, respectively. 7 This substantial reduction in the occurrence of code-mixing reflects the more robust retention of the source language abilities and superior chat and instruction-following performance of SSU.
Theoretical Analysis. SSU addresses the stability-plasticity dilemma in neural systems (Grossberg, 1982), balancing plasticity for new knowledge with stability for prior knowledge. SSU mitigates catastrophic forgetting by identifying and freezing a source-critical subnetwork, extending the Lottery Preprint Ticket Hypothesis (Frankle & Carbin, 2019) to transfer learning. Using an importance score to shield crucial parameters, SSU proactively preserves source capabilities by enforcing a hard constraint that confines updates to a subspace that avoids interfering with the source language knowledge. This approach aligns with findings on spurious forgetting (Zheng et al., 2025), which suggest that performance drops can stem from task misalignment caused by nearly orthogonal weight updates. Furthermore, SSU employs structured, column-wise masking, motivated by the need to preserve entire learned features. Unlike unstructured pruning which can degrade learned representations, pruning entire columns of a weight matrix corresponds to removing specific neurons or feature detectors (Voita et al., 2019). This structural preservation ensures that the core feature space of the source model remains intact, enabling effective adaptation to the target language.
We introduced Source-Shielded Updates (SSU) for language adaptation of instruct models using only unlabeled target language data. SSU is a framework that proactively identifies critical source knowledge using an importance scoring method and a small set of source calibration data. It then shields this knowledge via a column-wise freezing strategy before adaptation, effectively preventing catastrophic forgetting in the source language. Extensive experiments across five languages and two model scales show that SSU best preserves crucial source capabilities, such as instruction-following and safety, over strong baselines while achieving target language proficiency matching or surpassing full fine-tuning. This work provides an effective and scalable pathway to expand the linguistic reach of instruct models without costly, specialized data, opening avenues for robust model adaptation.
The authors acknowledge the use of Large Language Models (LLMs) during the preparation of this work. Gemini 2.5 Pro was utilized to find related work and to improve the grammar and clarity of the draft. Additionally, GPT-5 served as a coding assistant for implementation and debugging.
Our code and a step-by-step guide for preprocessing, training, evaluation, and analysis for both the proposed method and all baselines are available on GitHub: https://github.com/gucci-j/ssu . Full details on hyperparameters, software, and hardware, including specific versions used, are provided in Appendix B.
Table 8: Hyperparameters for continual pre-training. Values for GMT and AdaLoRA were selected based on our setup, as they were not provided in their respective original papers (Li et al., 2025;Hui et al., 2025). Table 13: Performance on target language tasks. Scores that are better than Source are highlighted in green . The best and second-best adaptation approaches for each model scale are indicated in bold and underlined, respectively.
In §6, we use the default sparsity levels for additional baselines: LoTA and S2FT. To ensure a comprehensive evaluation, we extend this with a fine-grained sparsity-level ablation study (Table 14).
LoTA. We examine LoTA across sparsity ratios in 12.5% increments, consistent with our analysis of SSU, HFT, and GMT. High sparsity ratios (e.g., 90% and 87.5%) preserve source performance reasonably well while improving target performance. Despite these gains, these configurations consistently underperform SSU-Wanda. At 90% sparsity, LoTA shows lower target gains (e.g., 23.9% relative average gain vs. 30.7% for SSU-Wanda) and weaker source preservation (e.g., 7.6% average drop in monolingual source tasks vs. 4.0%). Conversely, lower sparsity allows for more adaptation and leads to better target performance. For instance, LoTA at 50% achieves a 31.7% average target gain, surpassing the 30.7% gain of SSU-Wanda. However, this improvement triggers substantial catastrophic forgetting: the average drop in monolingual source tasks reaches 19.9%, substantially worse than the 7.6% drop at 90% sparsity. This degradation intensifies at 37.5% sparsity, reaching a 25.4% drop. These results indicate that while the default high-sparsity setting mitigates catastrophic forgetting in LoTA, the approach fails to match the balance of source preservation and target language acquisition achieved by SSU-Wanda.
S2FT. Following the original paper (Yang et al., 2024), we sparsely tune the down projection layers using a parameter count equivalent to LoRA with a rank of 8 (Table 8). We additionally evaluate larger parameter budgets equivalent to ranks of 16, 32, and 64. We also test the combination of “Down and Output” projection tuning to determine if the poor performance reported for Mistral and Llama3 (attributed to inflexible selection in multi-query attention) applies to OLMo 2.
First, as noted in §6, the default setting preserves source capabilities effectively (3.3% average drop vs. 4.0% for SSU-Wanda) but yields minimal target gains (2.3% vs. 30.7%). Increasing the trainable parameter budget (i.e., reducing sparsity) improves target performance but erodes source capabilities. At the equivalent of rank 64, S2FT exhibits a larger source drop (8.2%) than SSU-Wanda (4.0%) while still achieving lower target gains (15.0% vs. 30.7%). As larger capacities progressively degrade source performance without matching the target gains of SSU-Wanda, we conclude that no optimal S2FT configuration exists to surpass SSU in our problem setup. Finally, we confirm that tuning “Down and Output” projections yields suboptimal results, causing severe relative drops of up to 23.1% in monolingual source tasks and 9.25% in target tasks. In summary, regardless of sparsity-level adjustments, only SSU provides robust source preservation while elevating target language abilities to levels comparable to FFT.
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024), with judgments fromGPT-4.1 nano (2025-04-14); (3) MT-Bench(Zheng et al., 2023, MTB), using the mean Likert-5 score over two turns, judged by Flow-Judge-v0.1 per the Hugging Face LightEval protocol(Fourrier Preprint et al., 2023); and (4) GSM8K for multi-turn, few-shot mathematical reasoning(Cobbe et al., 2021), reporting the five-shot exact match score.
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024), with judgments fromGPT-4.1 nano (2025-04-14); (3) MT-Bench(Zheng et al., 2023, MTB), using the mean Likert-5 score over two turns, judged by Flow-Judge-v0.1 per the Hugging Face LightEval protocol(Fourrier Preprint et al., 2023); and (4) GSM8K for multi-turn, few-shot mathematical reasoning(Cobbe et al., 2021)
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024), with judgments fromGPT-4.1 nano (2025-04-14); (3) MT-Bench(Zheng et al., 2023, MTB), using the mean Likert-5 score over two turns, judged by Flow-Judge-v0.1 per the Hugging Face LightEval protocol(Fourrier Preprint et al., 2023); and (4) GSM8K for multi-turn, few-shot mathematical reasoning
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024), with judgments fromGPT-4.1 nano (2025-04-14); (3) MT-Bench(Zheng et al., 2023, MTB), using the mean Likert-5 score over two turns, judged by Flow-Judge-v0.1 per the Hugging Face LightEval protocol(Fourrier Preprint et al., 2023)
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024), with judgments fromGPT-4.1 nano (2025-04-14); (3) MT-Bench(Zheng et al., 2023, MTB), using the mean Likert-5 score over two turns, judged by Flow-Judge-v0.1 per the Hugging Face LightEval protocol
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024), with judgments fromGPT-4.1 nano (2025-04-14); (3) MT-Bench(Zheng et al., 2023, MTB)
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024), with judgments fromGPT-4.1 nano (2025-04-14); (3) MT-Bench
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024), with judgments fromGPT-4.1 nano (2025-04-14)
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024), with judgments from
length-controlled win-rate againstGPT-4 (1106-preview) (OpenAI et al., 2024)
length-controlled win-rate against
Our code and models are available via https://github.com/gucci-j/ssu .
While we use Wanda for its simplicity and popularity, the SSU framework is agnostic to the importance metric. To demonstrate this, we also evaluate two alternative source-driven scoring methods ( §6).
CC Ratio is based on https://commoncrawl.github.io/cc-crawl-statistics/plots/languages .
During CPT, we remove the chat template to support unlabeled data lacking role annotations (e.g., user).
As instruct models typically undergo extensive safety alignment(Gemma Team et al., 2025; Lambert et al., 2025, inter alia.), verifying that this is not compromised during adaptation is a crucial aspect of our analysis.
While row-wise freezing preserves all connections from a single input neuron, it fails to protect any single, complete output feature. This explains its weaker performance across chat, safety, and source language tasks.
We use GlotLID(Kargaran et al., 2023, Commit 28d4264) to compute the language ratio of each response. If the normalized confidence for English is less than 0.9, it is regarded as code-mixed.
Following Lambert et al. (2025), we use their forked version: https://github.com/nouhadziri/ safety-eval-fork (Commit 2920bb8).
📸 Image Gallery