QKAN-LSTM: Quantum-inspired Kolmogorov-Arnold Long Short-term Memory
📝 Original Info
- Title: QKAN-LSTM: Quantum-inspired Kolmogorov-Arnold Long Short-term Memory
- ArXiv ID: 2512.05049
- Date: 2025-12-04
- Authors: Yu-Chao Hsu, Jiun-Cheng Jiang, Chun-Hua Lin, Kuo-Chung Peng, Nan-Yow Chen, Samuel Yen-Chi Chen, En-Jui Kuo, Hsi-Sheng Goan
📝 Abstract
Long short-term memory (LSTM) models are a particular type of recurrent neural networks (RNNs) that are central to sequential modeling tasks in domains such as urban telecommunication forecasting, where temporal correlations and nonlinear dependencies dominate. However, conventional LSTMs suffer from high parameter redundancy and limited nonlinear expressivity. In this work, we propose the Quantum-inspired Kolmogorov-Arnold Long Short-Term Memory (QKAN-LSTM), which integrates Data Re-Uploading Activation (DARUAN) modules into the gating structure of LSTMs. Each DARUAN acts as a quantum variational activation function (QVAF), enhancing frequency adaptability and enabling an exponentially enriched spectral representation without multi-qubit entanglement. The resulting architecture preserves quantum-level expressivity while remaining fully executable on classical hardware. Empirical evaluations on three datasets, Damped Simple Harmonic Motion, Bessel Function, and Urban Telecommunication, demonstrate that QKAN-LSTM achieves superior predictive accuracy and generalization with a 79% reduction in trainable parameters compared to classical LSTMs. We extend the framework to the Jiang-Huang-Chen-Goan Network (JHCG Net), which generalizes KAN to encoder-decoder structures, and then further use QKAN to realize the latent KAN, thereby creating a Hybrid QKAN (HQKAN) for hierarchical representation learning. The proposed HQKAN-LSTM thus provides a scalable and interpretable pathway toward quantum-inspired sequential modeling in real-world data environments.📄 Full Content
The views expressed in this article are those of the authors and do not represent the views of Wells Fargo. This article is for informational purposes only. Nothing contained in this article should be construed as investment advice. Wells Fargo makes no express or implied warranties and expressly disclaims all legal, tax, and accounting implications related to this article. * ycchen1989@ieee.org. † kuoenjui@nycu.edu.tw. ‡ goan@phys.ntu.edu.tw.
to capture nonlinear temporal dynamics and long-range dependencies, making them indispensable tools in modeling complex spatiotemporal systems, including those in telecommunication networks [6]- [8]. In urban telecommunication systems, LSTMs are particularly valuable for forecasting user activity patterns and network loads from historical time series, where data often exhibit irregular periodicity, bursty behavior, and strong spatial-temporal correlations [8]. Accurate telecommunication forecasting is crucial for real-time network resource allocation, traffic optimization, and anomaly detection in largescale urban environments [9].
Despite their success, conventional LSTMs face inherent challenges related to vanishing gradients, high computational overhead, and overparameterization, which limit scalability and interpretability when applied to high-frequency, highdimensional telecommunication data. Moreover, the reliance on static activation functions constrains their representational richness, particularly when modeling complex oscillatory patterns and nonlinear feedback prevalent in communication signals.
In parallel, quantum machine learning (QML) has emerged as a promising paradigm that utilizes the principles of quantum mechanics, such as superposition, interference, and entanglement, to enhance functional expressivity and parameter efficiency [10]- [17]. Some QML methods, such as the quantum kernel method [18]- [23], have also been developed and explored. However, current QML implementations remain limited by noisy intermediate-scale quantum (NISQ) hardware, constrained qubit counts, and insufficient two-qubit gate fidelities [24]- [28], restricting their scalability in real-world applications such as telecommunication signal prediction.
To bridge the gap between classical and quantum paradigms, recent efforts have focused on quantum-inspired architectures that retain the expressive power of quantum models while remaining executable on classical hardware. The quantuminspired Kolmogorov-Arnold network (QKAN) [29] exemplifies this approach. QKAN reinterprets the Kolmogorov-Arnold network (KAN) [30] by employing single-qubit data reuploading circuits [12], [31] as quantum variational acti-vation functions (QVAFs), effectively forming a DatA Re-Uploading ActivatioN (DARUAN). Each DARUAN module encodes input features into parameterized rotations on a singlequbit Bloch sphere, with trainable pre-processing weights in each data-uploading block, enabling an exponentially rich Fourier representation without the need for multi-qubit entanglement. The method of adding trainable pre-processing weights has also been employed for multi-qubits data reuploading circuits [32], [33]. This design allows QKANs to preserve quantum-level expressivity while remaining computationally tractable from single CPU to multi-nodes highperformance computing (HPC) GPU clusters. While QKANs remain feasible for current real quantum devices, state-ofthe-art quantum devices have already empirically achieved single-qubit gate error rates at the 10 -5 -10 -7 scale, including superconducting devices [26], spin qubit devices [34], and trapped-ion devices [28].
Integrating QKANs into recurrent architectures such as LSTMs introduces a powerful new class of hybrid models-QKAN-LSTMs-that unify the temporal modeling strength of LSTMs with the spectral expressivity of quantuminspired activations. In this framework, QKANs replace the classical feedforward layers within the LSTM cell, acting as adaptive, quantum-enhanced feature extractors and parameter compressors. Recent studies have demonstrated that such hybrid quantum-classical architecture improves sequence modeling efficiency and generalization across time-series forecasting and natural language generation tasks [29], [35]- [37]. By leveraging the compact harmonic representation of DARUANbased QKANs, QKAN-LSTMs achieve enhanced trainability, reduced parameter counts, and robustness against gradient degradation-offering a scalable and physically interpretable pathway toward efficient sequential modeling.
Beyond temporal sequence modeling, the KAN framework has also been generalized to hierarchical architectures through the Jiang-Huang-Chen-Goan Network (JHCG Net) [29]. The JHCG Net extends the KAN paradigm into an encoder-KAN-decoder topology, where the latent KAN module serves as a nonlinear feature processor within an autoencoder-like structure. When the latent processor is realized using QKANs, the resulting hybrid quantum-inspired Kolmogorov-Arnold network (HQKAN) architecture integrates quantum-inspired transformations into the latent feature space, enabling exponential Fourier frequency spectral enrichment with less width and depth compared to classical KAN and MLP. Crucially, HQKANs function as scalable, drop-in replacements for multilayer perceptrons (MLPs) in deep architectures such as Transformers and Diffusion Models, maintaining classical differentiability and GPU compatibility while offering superior expressivity and efficiency.
In this work, we extend the QKAN framework to sequential modeling by integrating it into the LSTM architecture, forming the QKAN-LSTM. We further position this model within the broader hybrid paradigm defined by the HQKAN, which generalizes QKANs into hierarchical encoder-decoder architectures for representation learning. Together, QKAN-LSTMs and HQKANs establish a unified framework for quantum-inspired learning that spans both temporal modeling and hierarchical feature representation. We summarize our main contributions as follows:
- We introduce a novel QKAN-LSTM architecture that integrates quantum-inspired DARUAN modules within LSTM cells, replacing conventional affine transformations to enhance nonlinear expressivity and parameter efficiency. Furthermore, we extend this framework to its hybrid counterpart, HQKAN-LSTM, which embeds the JHCG Net mechanism for additional scalability and compression efficiency. 2) We achieve a substantial 99.5% reduction in trainable parameters compared to classical LSTMs while maintaining or improving predictive performance across multiple datasets. 3) We evaluate the proposed models on three representative benchmarks-damped harmonic motion, Bessel function regression, and urban telecommunication forecasting-demonstrating superior accuracy, stability, and generalization compared to both LSTM and QLSTM baselines.
II. RELATED WORK a) Quantum-enhanced long short-term memory: Ref. [38] presents a fully quantum implementation of LSTM cells directly within quantum circuits. Quantum enhanced LSTM variants integrate LSTM cell with variational circuits [13], quantum kernels [20], [21] or quantum convolutional networks [39], while Quantum-Train LSTM replaces LSTM trainable parameters with quantum circuit outputs [40], [41]. Applications are also explored in telecommunication [8], weather prediction [17], [21], [41], cosmology [40], fraud detection [42], traffic [43], solar power [44], stress monitoring [45] and indoor localization [46]. b) Kolmogorov-Arnold network and its applications for time series forecasting: Liu et al. [30] introduced KANs, a neural architecture inspired by the Kolmogorov-Arnold representation theorem (KART) [47]. Refs. [30], [48] generalized KART to arbitrary widths and depths and showed that KANs are able to replace MLPs with better accuracy and interpretability. Subsequent studies have applied KANs to time series forecasting tasks [49]- [56], confirming their effectiveness in modeling temporal data.
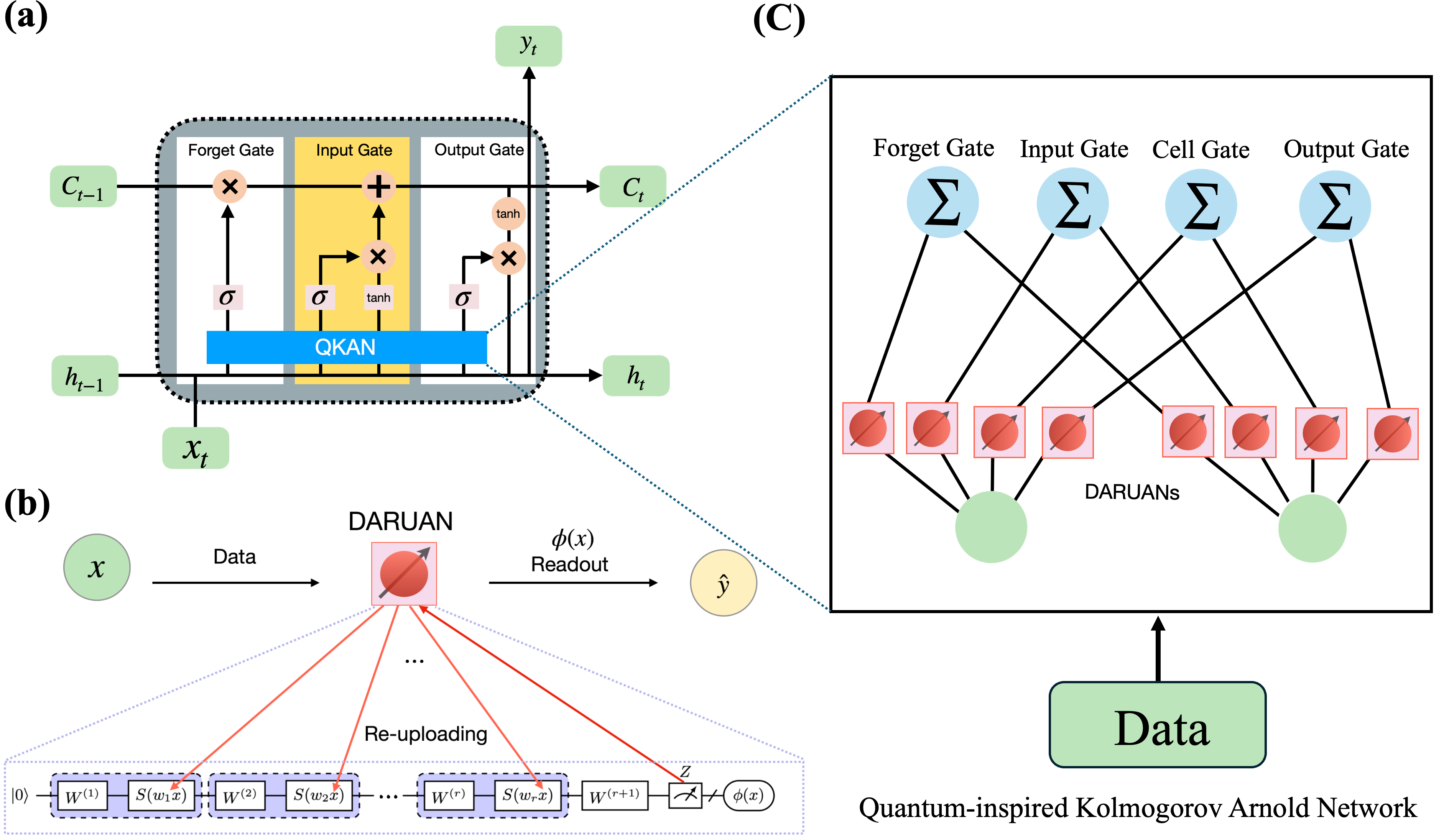
To further enhance the nonlinear modeling capability of LSTM networks, we propose the QKAN-LSTM model. This architecture replaces the conventional affine transformations in LSTM gates with quantum-inspired functional modules based on the KART. By constructing each gate as a composition of multiple variational quantum subfunctions acting on individual input dimensions, the QKAN-LSTM approximates complex high-dimensional nonlinear mappings through a structured aggregation of one-dimensional quantum transformations. This design enables stronger nonlinear expressivity and improved long-range dependency modeling in sequential data.
As illustrated in Figure 1, this design enriches the expressive capacity of the recurrent dynamics and improves the modeling of long-range temporal dependencies in sequential data.
- Classical LSTM Equations: The conventional LSTM cell consists of three primary gates-the forget gate (f t ), input gate (i t ), and output gate (o t )-along with a memory cell state (C t ). The evolution of these components over time is governed by the following equations:
where:
• σ(•) and tanh(•) are the sigmoid and hyperbolic tangent activation functions, respectively, • ⊙ denotes element-wise multiplication.
- Integration of Quantum-inspired Kolmogorov-Arnold Networks into LSTM: In QKAN-LSTM architecture, the conventional affine transformations W [h t-1 , x t ] + b in the LSTM gates are replaced by QKAN modules. Instead of a single linear mapping, each gate aggregates edge-wise quantum variational activation units, following the Kolmogorov-Arnold principle to approximate high-dimensional nonlinear functions through a sum of learnable one-dimensional mappings. This design enables each gate to process inputs through a set of QVAFs, effectively enriching the nonlinear mapping space without altering the classical neuron structure. Consequently, the QKAN-LSTM exhibits enhanced expressive capacity and spectral diversity in its recurrent dynamics.
Let the concatenated gate input vector be defined as
where [ •; • ] denotes vector concatenation. For each gate g ∈ {f, i, C, o}, a QKAN layer mapping is formulated as
where each quantum subnetwork ϕ g,p (•; θ g,p ) serves as a trainable nonlinear activation function realized by DARUAN.
The QVAF for each edge unit is defined as
where M is a fixed Hermitian observable (e.g., σ z ). The corresponding data re-uploading circuit U (u; θ) consists of a sequence of L parameterized quantum blocks:
Here H denotes a fixed Hermitian generator, a (ℓ) and b (ℓ) are scalar encoding parameters, and W (ℓ) (θ) represents a trainable single-qubit variational block. Stacking L such reuploading layers with the help of a (ℓ) and b (ℓ) endows the activation ϕ g,p with an exponentially enriched Fourier spectrum, enabling compact yet expressive nonlinear representations.
In our work, we initialize the quantum state using a Hadamard gate, preparing the system in a uniform superposition. The DURAUN operation is instantiated as
which corresponds to Eq. ( 4) with H = σ z , a (ℓ) = w ℓ , and b (ℓ) = 0. The trainable variational block is chosen as
where σ y is the Pauli-Y operator and σ z is the Pauli-Z operator.
Given the QKAN mappings Φ g (v t ; Θ g ), the LSTM gating dynamics remain structurally identical to the classical case:
Remarks.
• Eq. ( 2) follows the Kolmogorov-Arnold formulation, where node outputs are additive compositions of quantum nonlinear edge functions. • Eq. ( 3)-( 4) define the QVAF, implemented through data re-uploading circuits whose variational parameters θ are trained end-to-end. • Classical nonlinearities σ(•) and tanh(•) are preserved for gating stability, while quantum activations enrich the inner functional space of each gate. • The full trainable parameter set is Θ g = {θ g,p , a (ℓ) , b (ℓ) }, jointly optimized with other network weights.
The training of QKAN-LSTM model involves optimizing both classical and quantum parameters that define the nonlinear mapping of each LSTM gate.
where y t and ŷt denote the true and predicted values at time step t. b) Gradient Computation: The model parameters Θ g = {α g,p , a (ℓ) , b (ℓ) , θ g,p } are optimized through hybrid quantum-classical backpropagation. Gradients of the classical parameters α g,p are computed using standard backpropagation through time (BPTT), while the gradients of quantum parameters θ g,p are obtained via the parameter-shift rule [57]:
where e k denotes the unit vector indicating the k-th parameter in θ, ensuring that only θ k is shifted while all other parameters remain fixed.
In our implementation, the QKAN modules operate in the exact solver mode, where all QVAF are represented by analytic, differentiable functions; therefore, gradients are computed directly using PyTorch’s autograd [58].
However, when executed on real quantum hardware or simulated quantum backends, the parameter-shift rule Eq. ( 9) is employed to estimate the derivatives of quantum observables.
c) Optimization Algorithm: A optimizer such as Adam [59] or RMSprop [60] is employed to jointly update both classical and quantum parameters. At each iteration, the optimizer computes the gradient of the loss with respect to all elements of Θ g , then updates them according to Θ g ← Θ g -η∇ Θg L, where η is the learning rate. This hybrid optimization loop iteratively refines both the quantum variational circuits and classical combination weights until convergence.
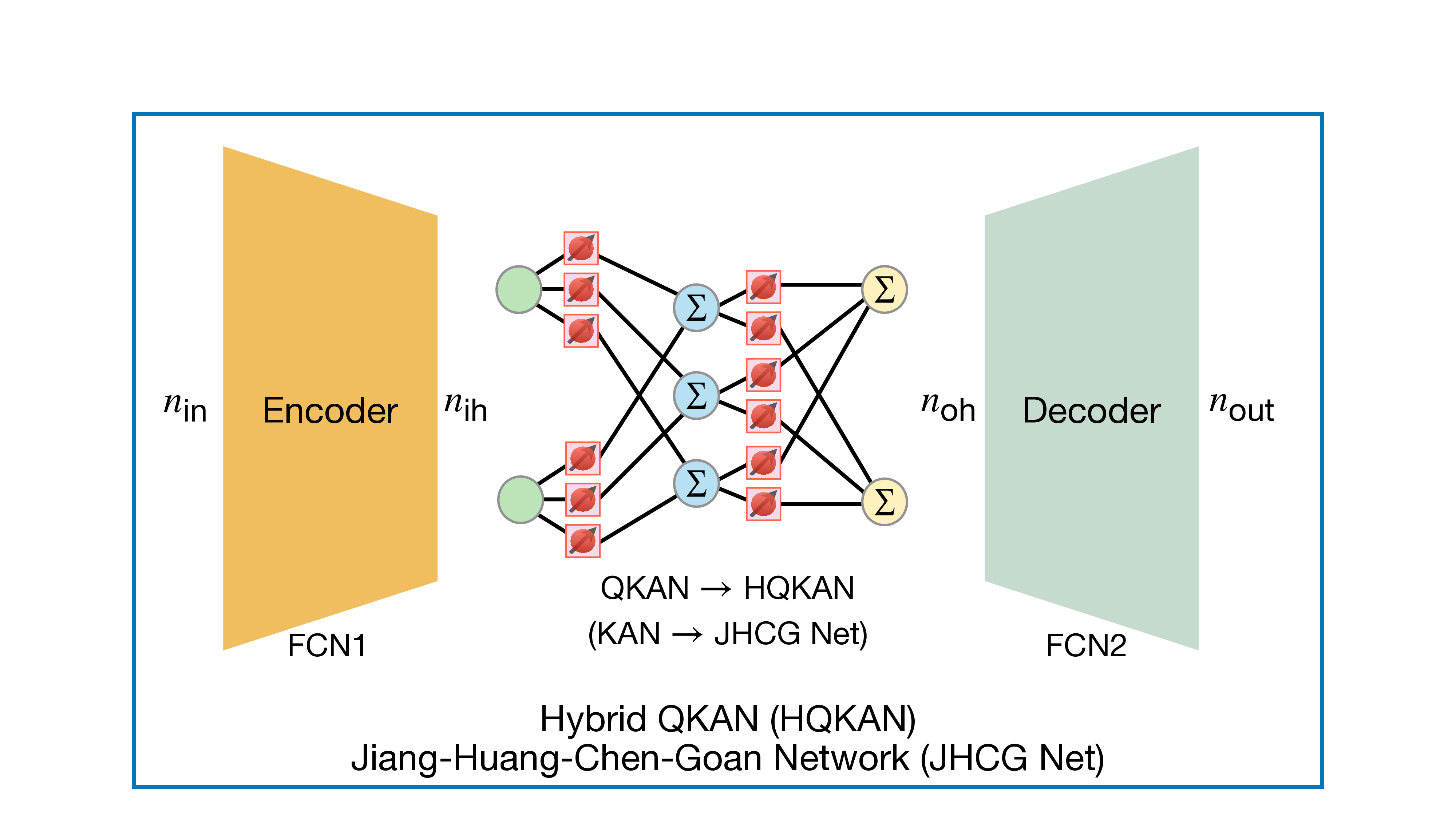
Ref. [29] further introduced the concept of HQKANs, representing a fusion of classical and quantum-inspired neural computation. Building upon this foundation, the JHCG Net generalizes the KAN paradigm into a scalable, autoencoder-like framework designed for hierarchical representation learning. The architecture comprises three principal modules: a fully connected encoder, a latent KAN processor, and a decoder. The encoder compresses high-dimensional input features into a compact latent space, where the KAN module performs nonlinear transformations through parameterized univariate functions. The decoder subsequently reconstructs the output Fig. 2. Architecture of the Jiang-Huang-Chen-Goan Network (JHCG Net) [29]. The JHCG Net comprises a fully connected encoder and decoder with a Kolmogorov-Arnold Network (KAN) serving as the latent feature processor, forming an autoencoder-like architecture. When the latent KAN module is implemented using Quantum Kolmogorov-Arnold Networks (QKANs), the framework is referred to as the Hybrid QKAN (HQKAN), integrating quantum-inspired nonlinear transformations within the latent representation space.
from the processed latent representation. By integrating the functional decomposition capability of KANs with the hierarchical abstraction mechanisms of deep neural networks, the JHCG Net achieves interpretable and parameter-efficient feature compression, transformation, and reconstruction.
Replacing the latent KAN processor with a QKAN yields the HQKAN architecture, which inherits quantum-inspired expressivity and frequency adaptability from the DARUAN activation framework while retaining the differentiability and scalability of classical optimization pipelines. The structural composition of HQKAN is illustrated in Figure 2, emphasizing its encoder-KAN-decoder topology and the inclusion of a QKAN module within the latent layer. Unlike conventional QKANs that operate primarily as direct function approximators, HQKANs act as compositional operators embedded within classical architectures, integrating quantum-inspired nonlinear transformations into the latent feature space. Thus, this design enables an exponential enhancement in spectral capacity without increasing network width or depth, and facilitates high-fidelity, cross-modal representation learning with improved computational efficiency.
Crucially, HQKANs function as a scalable, drop-in substitute for MLPs within modern deep architectures such as Transformers and Diffusion Models [29]. They can replace conventional feed-forward layers in large-scale generative frameworks, providing superior expressivity, reduced parameterization, and enhanced convergence stability-while maintaining compatibility with classical GPU-based training pipelines.
Overall, the JHCG Net establishes a cohesive bridge between classical and quantum-inspired learning paradigms. While KANs offer interpretable and smooth functional decomposition, QKANs introduce exponentially compact yet expressive nonlinear mappings. The resulting HQKAN architecture thereby defines a unified, interpretable, and hardware-efficient foundation for scalable hybrid learning systems.
We evaluate the proposed QKAN-LSTM and HQKAN-LSTM model on three representative datasets: Damped Simple Harmonic Motion, Bessel Function, and Urban Telecommunication time-series data for real-world testing.
where x(t) denotes the displacement at time t, ω = 2πf is the angular frequency of oscillation, and ζ = c 2mk represents the damping ratio. We constructed a time-series dataset of damped SHM systems, where each sample includes the temporal variable t and the corresponding displacement x(t). This dataset serves as a benchmark for evaluating the model’s capability to learn and predict harmonic oscillatory dynamics.
b) Bessel Function: The Bessel Function dataset represents a class of nonlinear oscillatory dynamics that frequently arises in the solutions of wave propagation and diffusion problems under cylindrical or spherical coordinate systems. It is governed by Bessel’s differential equation:
where y(x) denotes the displacement (or amplitude) at position x, and α is the order of the Bessel function. The solution is given by the Bessel function of the first kind: where Γ(x) is the Gamma function. In this work, we constructed a time-series dataset based on the second-order Bessel function J 2 (x), where each sample includes the variable x and its corresponding amplitude J 2 (x). c) Urban Telecommunication: The Urban Telecommunication dataset is derived from the Milan Telecommunication Activity Dataset [9], which records telecommunication activities sampled every 10 minutes across a spatial grid of the city. To mitigate data sparsity and modality imbalance present in the original dataset, we focus exclusively on the univariate SMSin channel, which provides higher completeness and reliability across grid cells. Follwing Ref. [8], We preprocess the dataset by selecting grid cells that exhibit sufficient temporal continuity and normalize all SMS-in activity values to the interval [0, 1]. Each training instance is constructed from a fixed-length input sequence X = [x t-T +1 , . . . , x t ], with the subsequent value x t+1 used as the prediction target. To assess the model’s capability of capturing temporal dependencies across different horizons, we experiment with multiple sequence lengths T ∈ {4, 8, 12, 16, 32, 64}. The dataset is divided into 70% for training, 15% for validation, and 15% for testing.
In our experiment, we evaluate the performance of LSTM, QLSTM, QKAN-LSTM, and HQKAN-LSTM models on three datasets: Damped SHM, Bessel Function, and Urban Telecommunication. Experiments are simulated with PennyLane [61], PyTorch [58], and QKAN adapted from the open-sourced library on GitHub [62] 1 . For implementations of LSTM and QLSTM, we followed the setup in ref. [8].
For training, the learning rate is set to 10 -2 for the Damped SHM and Bessel Function datasets, and 10 -3 for the Urban Telecommunication dataset, except for HQKAN-LSTM, which uses a slightly higher rate of 2 × 10 -3 to facilitate faster convergence.
For the LSTM model, the hidden unit size is set to 5 for the Damped SHM and Bessel Function datasets, and 4 for the Urban Telecommunication dataset. Similarly, for the QLSTM model, the hidden unit size is set to 5 for the Damped SHM and Bessel Function datasets, and 4 for the Urban Telecommunication dataset. In contrast, for the QKAN-LSTM and HQKAN-LSTM model, the hidden unit size is set to 1 for both the Bessel Function and Urban Telecommunication datasets, and 2 for the Damped SHM dataset. The input and output dimensions for all models are both set to 1, as these hyperparameter configurations are chosen to balance model expressivity and parameter efficiency, while ensuring a fair performance comparison across all architectures and properly reflecting their differences in representational capacity.
Regarding the quantum components, the QLSTM model utilizes 6 qubits for Damped SHM and Bessel Function, and 5 qubits for Urban Telecommunication. The quantum gates are parameterized with RY encoding, defined as RY (x) = e -i x 2 σy , where σ y is the Pauli-Y operator and x denotes the input data. Following the encoding stage, the circuit applies repeated CNOT + trainable RY (θ) blocks as the RealAmplitudes Anstaz [8], [63] and performs Pauli-Z measurements to generate the quantum outputs. In contrast, both QKAN-LSTM and HQKAN-LSTM models employ a single-qubit DARUAN layer across all datasets.
The experiment on the Urban Telecommunication dataset, the models are trained for 50 epochs, with sequence lengths
Table I summarizes the number of classical and quantum parameters across all models. Compared with QLSTM, both QKAN-LSTM and HQKAN-LSTM achieve a notable reduction in quantum parameters on the Urban Telecommunication dataset-approximately 50-70% fewer-while utilizing the single qubit DARUAN layer, yet maintaining comparable or superior predictive performance. In addition, compared with LSTM, both QKAN-LSTM and HQKAN-LSTM exhibit a substantial decrease in the total number of parameters on the same dataset. For the Damped SHM task, however, the relative simplicity of the sequence pattern limits the learning capacity of QKAN-LSTM when using a single hidden unit. Therefore, two hidden units are adopted in this case to ensure sufficient expressive power, which leads to a higher parameter count compared to the same model applied to other datasets. These results collectively highlight the parameter efficiency and scalability of the QKAN-based architecture, enabling effective sequence modeling with limited quantum resources.
The evaluation on the Damped SHM and Bessel Function datasets is presented in Table II, Table III, and Figure 3, respectively. Across both datasets, all quantum-enhanced models exhibit steady convergence and high predictive accuracy as training progresses.
In the Damped SHM task, QKAN-LSTM exhibits slower convergence during the early training stage, which can be attributed to the relatively simple oscillatory dynamics of the dataset. As training progresses, however, the model rapidly stabilizes and achieves superior accuracy, reflecting its adaptability even in low-complexity temporal patterns. As shown in Table II, QKAN-LSTM attains a final testing loss of 1.02 × 10 -3 and an R 2 score of 0.9771 after 30 epochs, surpassing LSTM baselines. Similarly, HQKAN-LSTM achieves comparable convergence with an R 2 of 0.9903, confirming the hybrid model’s ability to sustain high predictive accuracy while maintaining a reduced number of quantum parameters.
For the Bessel Function dataset, QKAN-LSTM and HQKAN-LSTM demonstrate more robust and stable performance than LSTM and QLSTM, achieving testing losses of 3.27×10 -4 and 3.21×10 -4 , respectively, with corresponding R 2 scores exceeding 0.986, as shown in Table III.
For the Urban Telecommunication dataset, Table IV presents the comparison of mean absolute error (MAE) and MSE values across different sequence lengths. Overall, QKAN-LSTM and HQKAN-LSTM exhibit consistently lower error metrics than LSTM and QLSTM, demonstrating superior stability and adaptability across varying temporal dependencies. Notably, from Table I, both QKAN-based models employ substantially fewer quantum parameters than QLSTM and significantly fewer classical parameters than LSTM, highlighting their efficiency in balancing representational capacity with computational economy. As the sequence length increases, both models maintain clear performance advantages, indicating scalability and the ability to capture long-range temporal correlations without significant degradation in accuracy. In particular, HQKAN-LSTM achieves the lowest MAE from short to long sequence lengths across the experiments, confirming the robustness of the hybrid quantum-classical design. Collectively, these results validate that the QKANbased architectures not only enhance predictive precision but also achieve efficient parameter utilization, demonstrating their practicality for complex real-world temporal datasets.
This study has demonstrated that incorporating the QKAN framework into LSTM architectures substantially enhances temporal sequence modeling capabilities across both synthetic and real-world datasets. The proposed QKAN-LSTM and HQKAN-LSTM models utilize the expressive power of quantum mappings to enrich classical recurrent representations, creating a compact yet powerful feature encoding for temporal dependencies. This is achieved by enhancing frequency adaptability and enabling an exponentially enriched spectral representation without requiring complex multi-qubit entanglement. This integration allows the models to deliver higher predictive accuracy and faster convergence while requiring far fewer trainable parameters and quantum resources, fundamentally boosting computational efficiency and scalability.
Looking ahead, the proposed QKAN-based LSTM models hold great potential to bridge the gap between classical and quantum computing paradigms, enabling efficient deployment in edge computing environments and resource-limited quantum devices. This advancement highlights the versatility and scalability of QKAN-enhanced architectures, positioning them as a key solution for both large-scale, complex, and high-dimensional datasets and low-resource quantum machine learning implementations in real-world settings.
Available at https://github.com/Jim137/qkan .
📸 Image Gallery