Title: SEAL: Self-Evolving Agentic Learning for Conversational Question Answering over Knowledge Graphs
ArXiv ID: 2512.04868
Date: 2025-12-04
Authors: Hao Wang, Jialun Zhong, Changcheng Wang, Zhujun Nie, Zheng Li, Shunyu Yao, Yanzeng Li, Xinchi Li
📝 Abstract
Knowledge-based conversational question answering (KBCQA) confronts persistent challenges in resolving coreference, modeling contextual dependencies, and executing complex logical reasoning. Existing approaches, whether end-to-end semantic parsing or stepwise agent-based reasoning, often suffer from structural inaccuracies and prohibitive computational costs, particularly when processing intricate queries over large knowledge graphs. To address these limitations, we introduce SEAL, a novel two-stage semantic parsing framework grounded in self-evolving agentic learning. In the first stage, a large language model (LLM) extracts a minimal S-expression core that captures the essential semantics of the input query. This core is then refined by an agentic calibration module, which corrects syntactic inconsistencies and aligns entities and relations precisely with the underlying knowledge graph. The second stage employs template-based completion, guided by question-type prediction and placeholder instantiation, to construct a fully executable S-expression. This decomposition not only simplifies logical form generation but also significantly enhances structural fidelity and linking efficiency. Crucially, SEAL incorporates a self-evolving mechanism that integrates local and global memory with a reflection module, enabling continuous adaptation from dialog history and execution feedback without explicit retraining. Extensive experiments on the SPICE benchmark demonstrate that SEAL achieves state-of-the-art performance, especially in multi-hop reasoning, comparison, and aggregation tasks. The results validate notable gains in both structural accuracy and computational efficiency, underscoring the framework's capacity for robust and scalable conversational reasoning.
📄 Full Content
A Knowledge Graph (KG) is a structured representation of knowledge, typically organized as triples (head entity, relation, tail entity) to encode factual information [1]. In recent years, KGs have gained widespread attention in both academia and industry [2,3]. Knowledge-based Question Answering (KBQA) systems are designed to query these structured KGs, using reasoning to provide accurate answers to natural language questions [4,5]. Among KBQA methods, Semantic Parsing (SP) based approaches translate questions into structured queries (e.g., SPARQL, Cypher, etc.) for execution against the KG, offering strong interpretability and high efficiency [6,7]. These systems are widely applied in fields such as healthcare and business, significantly reducing the technical threshold for accessing complex knowledge systems. Knowledge-based conversational QA (KBCQA) extends this paradigm to multi-turn interactive scenarios, requiring the system to conduct continuous reasoning and to address dialog understanding challenges such as coreference resolution [8,9]. For this task, SP remains a mainstream approach, where the goal is to convert contextual natural language queries into executable logical forms. With the emergence of large language models (LLMs) [10,11], SP increasingly leverages their advanced language understanding capabilities [12,13,14], primarily through two paradigms: end-to-end logical form generation and agent-based stepwise construction.
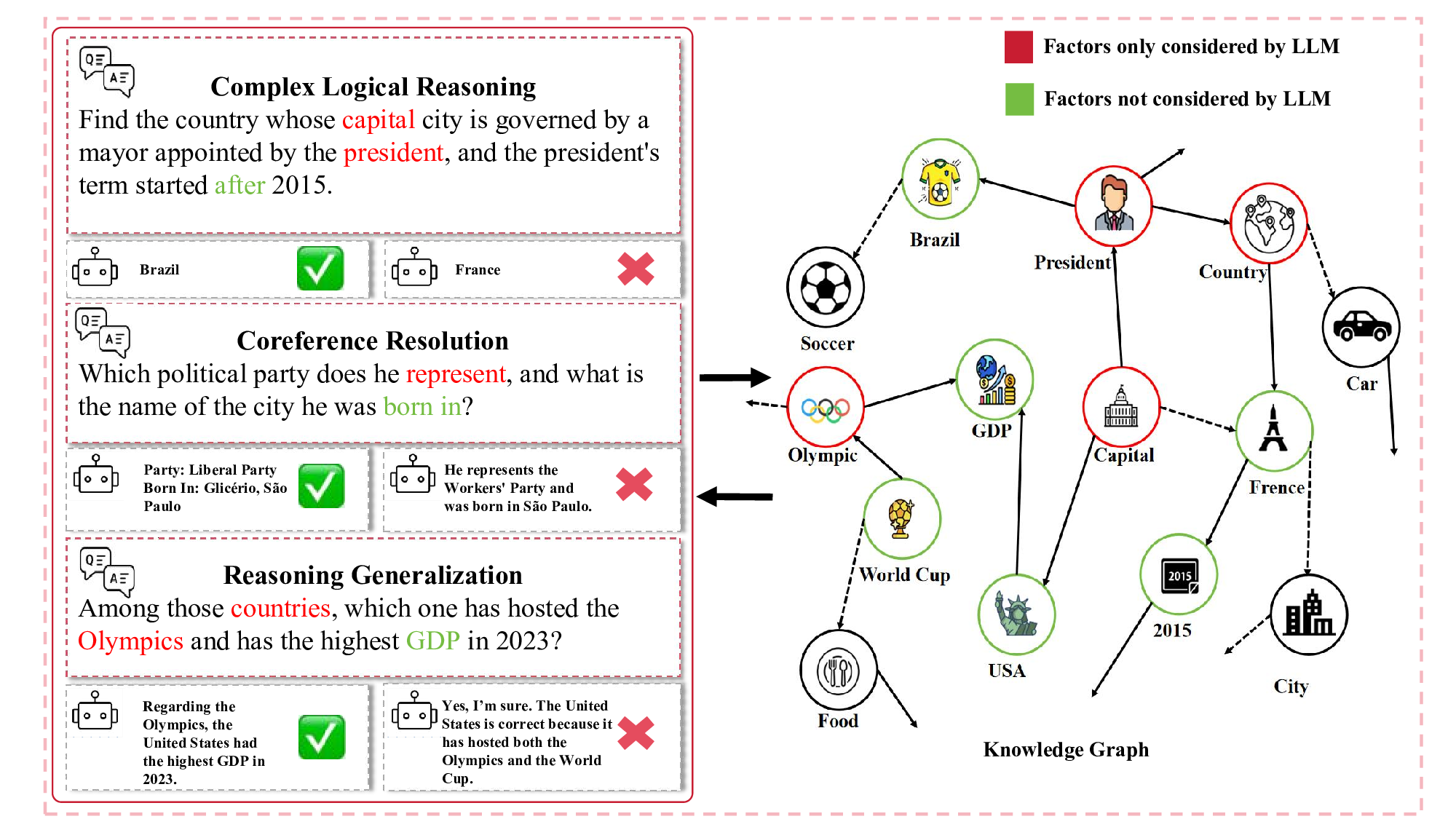
While LLMs offer significant opportunities for SP-based KBQA, and KBCQA tasks, current methods face substantial limitations in handling struc-turally complex questions [15]. Specifically, generated logical forms often fail to fully capture semantic intent in scenarios requiring multi-hop reasoning, comparison, or aggregation operations [16,17,18]. This limitation is particularly evident in complex logical reasoning, where LLMs tend to focus on surface-level concepts while overlooking critical structural constraints imposed by the knowledge graph .Furthermore, the entity and relation linking process suffers from an expansive candidate space due to linguistic ambiguity [19,20], leading to exponential growth in possible combinations and high computational overhead. This issue directly impacts reasoning generalization, LLMs often generate plausible but semantically invalid forms that ignore domain-specific validity constraints.These challenges hinder the scalability of SP-based KBQA systems, and are further exacerbated in the KBCQA setting, where the system must also manage dialog history to resolve coreferences and maintain contextual coherence.In particular,coreference resolution remains a major bottleneck that if but without aligning the resolved entity with its attributes in the knowledge graph , the final answer can still be inconsistent or incorrect. putational cost of entity linking, as shown in Figure 1. To this end, this article introduces Self-Evolving Agentic Learning (SEAL), a two-stage SP framework. SEAL leverages S-expressions, a structured logical form. This clear and readable structure is particularly advantageous for representing the complex and discrete operations required by the KBCQA task [7,6].
In the first stage, the LLM generates a preliminary S-expression core, which is then semantically calibrated by an agent to correct structural errors. In the second stage, the LLM completes the logical structure by integrating the validated core with predefined templates, producing an accurate and executable S-expression. Crucially, SEAL incorporates a self-evolving mechanism that establishes a continuously learning agent through the synergy of local memory, global memory, and a reflection module. This mechanism enables the system to adaptively learn from successful past dialogs and execution outcomes, transforming global memory from static storage into a dynamically updateable knowledge base without explicit retraining. This approach effectively combines the semantic understanding of LLMs with the structural rigor of templates, improving the accuracy of complex query generation in KBCQA while maintaining high efficiency.
We summarize the contributions of this paper as follows:
• We introduce the concept of a minimal S-expression core to represent the essential semantics of a query. This core is calibrated by an agent for syntactic correctness and knowledge graph alignment, forming a robust foundation for the final query construction.
• We propose SEAL, a two-stage agentic learning framework for the KBCQA task, in which innovations are decomposition of SP into Sexpression core extraction followed by agent-driven calibration and template-based composition, significantly enhancing structural accuracy and computational efficiency in complex reasoning.
• We design a self-evolving mechanism that enables continuous performance enhancement through dynamic memory updates and reflection, allowing the system to adapt to novel expressions in real-world dialogs without retraining.
• Extensive experiments on the SPICE benchmark show that our method achieves state-of-the-art results, particularly in complex reasoning tasks, with the self-evolving mechanism demonstrating significant performance improvements as dialog progresses. The results validate significant improvement in both structural accuracy and efficiency.
The article is structured as follows: Section 2 reviews related works on SP in KBQA, KCBQA, and LLM-based agents. Section 3 provides preliminaries on knowledge graphs. Section 4 details our proposed method, including the reasoning, memory, and reflection modules. Section 5 presents the experimental setup, datasets, metrics, baselines, and main results. Section 6 concludes the article.
In this section, we introduce work related to our research, covering SPbased KBQA, KBCQA, and LLM-based Agents.
Early research on KBQA focused on SP to translate natural language questions into structured queries, ensuring interpretability and logical reasoning. In an early work, a staged framework [21] decomposes query generation into entity recognition, inference chain construction, and constraint aggregation, providing a foundation for NL2GQL. Graph embeddings and constraintbased path control [22] reduce the search space in multi-hop reasoning, emphasizing structural efficiency. Query construction as a state-transition process [23] employs node identification, connection, merging, and folding operations for dynamic semantic dependencies. With the rise of LLMs, KBQA shifted towards data-driven paradigms, with few-shot prompting [24] reducing reliance on annotated data and enhancing adaptability. Query generation aligned with code synthesis paradigms [25] leverages structured programming syntax. A generation and retrieval strategy [26] improves multi-hop reasoning, while external knowledge retrieval [27] enriches logic forms, addressing knowledge incompleteness. Agentic approaches facilitate dynamic query construction, with symbolic agents [28] improving the precision of relational inference.
Step-by-step reasoning within a thought action cycle [29] enables progressive refinement. A mechanism of observation, action, and reflection [30] enhances robustness. Planning, retrieval, and reasoning [31] support structured query generation on heterogeneous graphs.
KBCQA presents greater challenges than single-turn tasks, particularly in modeling dialog history and integrating heterogeneous knowledge. A comprehensive survey [32] traces the evolution of CQA, identifying context modeling issues. The Complex Sequential QA (CSQA) Dataset [33] incorporates dialog history into complex reasoning, while the CONVINSE framework and the ConvMix dataset [34] enable multi-source reasoning. Datasets with SPARQL annotations [35] support consistent logic parsing across turns.We choose the S-expression to represent the logical form of questions [36]. Proposed by Gu et al. [37], S-expressions are a Lisp-based format that uses functions to express logical relationships, widely applied in recent works such as KB-BINDER [24], KB-Coder [25], and Pangu [38]. Ambiguity resolution, including pronoun coreference and ellipsis, remains a challenge, with traditional and neural approaches [39] identifying limitations for rare entities. LLMdriven disambiguation strategies [40] address ellipsis and semantic ambiguity, while CoQA, SQuAD 2.0, and QuAC [41] reveal deficiencies in dynamic dialog. Question rewriting (QR) transforms context-dependent questions into self-contained forms, with a two-stage pipeline [42] improving retrieval. Reinforcement learning [43] optimizes rewriting via QA feedback. QR variants [44] enhance context representation. The REIGN framework [45] uses data augmentation and reinforcement learning. CornNet [46] integrates LLMbased rewriting with teacher-student architectures. Dialog history modeling integrates explicit memory and entity tracking, with Dialog-to-Action [47] resolving ellipsis via memory management. Graph neural networks [48] encode evolving subgraphs. LLMs with dynamic memory [49] synthesize diverse evidence. Reinforcement learning [50] tracks entities across multi-hop graphs. The Adaptive Context Management (ACM) framework [51] adjusts context windows for relevance. The KaFSP framework [52] integrates fuzzy reasoning, and LLM scalability [53] confirms effectiveness of few-shot prompting and fine-tuning.
Leveraging vast pre-training [54] on expansive corpora and subsequent instruction fine-tuning [55] across a diverse array of tasks, LLMs exhibit exceptional capabilities in representation, reasoning, and generation, facilitating their application across a broad spectrum of language-mediated challenges. This foundation has spurred significant interest in LLM-based agents [56], which have gained widespread attention [57,58] due to their intellectual proficiency, driving advancements in adaptive task execution. These agents integrate LLMs into sophisticated, human-like cognitive frameworks, incorporating key components such as perception [59,60], strategic planning [61,62], and actionable execution [63,64], enabling robust adaptation to dynamic and complex environments [65]. Furthermore, specialized modules tailored for long-term tasks enhance their efficacy: memory systems, encompassing symbolic [66] and textual [67] summaries of past interactions [68], support sustained contextual awareness, while reflection mechanisms [66] foster self-evolution and adaptability. Our approach aligns with this paradigm, harnessing these strengths to enable continuous performance enhancement in response to streaming data, without the need for retraining.
Let E, R denote the sets of entities and relations respectively. A knowledge graph can be represented as G = (E, R, T ) , where T ⊆ E × R × E is the set of facts stored in the KG. A fact in T can be represented as a triple (e h , r, e t ), indicating that a directed relation r ∈ R holds between a head entity e h ∈ E and a tail entity e t ∈ E.
For the KG-based conversational QA task, a dialogue d ∈ D consists of sequential turns of questions and answers d = (q 1 , a 1 , q 2 , a 2 , . . . , q n , a n ). The types of answers a i include sets of entities, Boolean values, aggregation quantities, etc., and need to be inferred based on the question q i , dialogue history H i = (q 1 , a 1 , . . . , q i-1 , a i-1 ), and the given knowledge graph G. This process is represented in Equation 1:
Moreover, some recent work parse the natural language question q i and map it onto an executable logic form f i ∈ F (e.g., SPARQL and S-expressions) on the KG, leading to an explicit reasoning process.
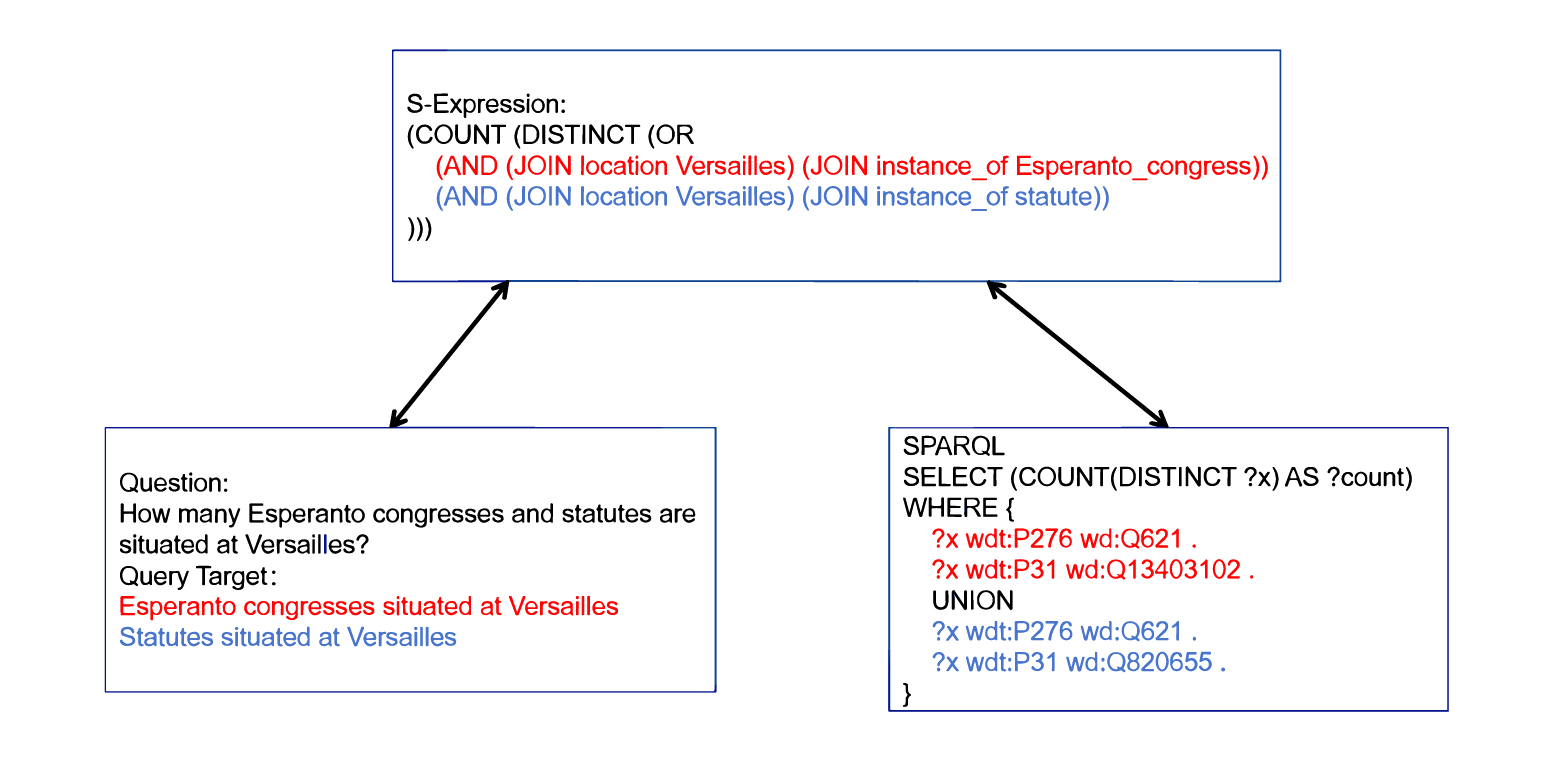
We propose a novel SP approach for KBCQA that uses LLMs to directly generate S-expressions. However, LLM outputs often contain ungrounded surface forms, and conventional entity and relation linking methods that rely on large candidate sets are computationally expensive. To enable efficient and accurate parsing, we introduce a lightweight calibration strategy that performs syntax correction and single-candidate KG alignment. In Table 1, we introduce a method to extract an S-expression core that captures the essential semantics of a natural language question. This decomposition simplifies the generation process by first extracting relatively independent substructures, which can then be combined by instantiating a predefined logical template (template composition).
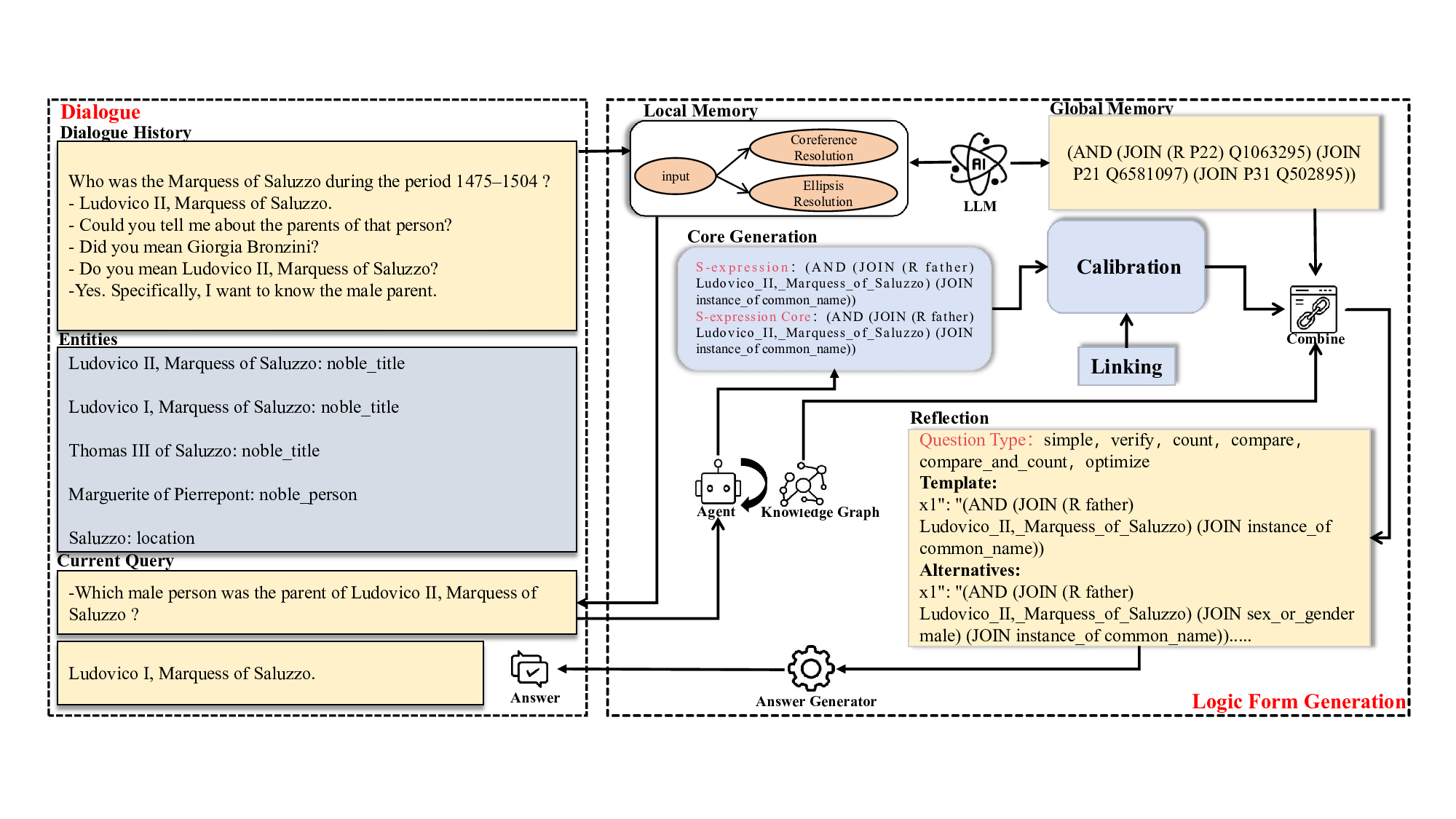
The generation process follows two stages as shown in Figure 2. First, the LLM generates candidate S-expression cores. An S-expression core is a simplified substructure of an S-expression which is composed of basic operations. These cores are calibrated by an agent interacting with the knowledge graph to produce refined variants. Second, the question type is predicted to select an appropriate template, and the LLM fills placeholders with functions, constants, or core expressions to produce the final S-expression.
The core extraction phase, the initial critical step of the proposed method, focuses on deriving the S-expression core that encapsulates the essential semantics of natural language questions. This phase comprises two key steps:
• S-expression Core Generation: LLM analyzes the question text to identify independent query objects, employing five fundamental func-tions: JOIN, R, AND, VALUES, and IS_TRUE to articulate their logical relationships, thereby generating the S-expression core.
• S-expression Core Calibration: An agent interfacing with the knowledge graph refines the generated S-expression core by correcting syntactic errors and aligning entities and relations with the knowledge graph, yielding candidate variants.
The key innovation of this phase lies in decomposing the complex task of S-expression generation into independent substructure extractions, establishing a foundation for subsequent template integration, for details regarding specific expressions, refer to Appendix B. Moreover, experimental validation confirms that this phased approach substantially reduces model learning complexity and enhances generation accuracy.
We introduce the concept of the S-expression core, referring to a simplified subclass of S-expression structures, the specific patterns that may appear in the core of S-expressions are shown in Appendix C. Such cores typically involve only basic logical functions, such as JOIN, R, AND, VALUES, and IS_TRUE. In the context of natural language questions, an S-expression core generally corresponds to the queried objects or targets within the question. In SPARQL queries, it maps to the graph patterns inside the WHERE{. . . } clause.
The entities and relations referenced in the S-expression core (e.g., as arguments in JOIN or AND) are elements of the underlying KG (G = (E, R, T )). While the LLM initially generates tokens, the subsequent calibration step aligns these with grounded entities e ∈ E and relations r ∈ R through KG linking, ensuring semantic consistency with the structured knowledge base.
To formally describe this generation process, we denote a natural language question as q in Equation 2. Through a constructed prompt P q = Prompt(q), the input is provided to a LLM. Under the parameter space Θ LLM , the LLM generates an S-expression core sequence Core * = (s 1 , s 2 , . . . , s L ) by maximizing the conditional likelihood:
Where q represents the original natural language question, P q is the prompt constructed from q for LLM inference, Core denotes a candidate sequence of S-expression tokens, and Core * is the optimal core sequence selected by the model. The parameter Θ LLM represents all learnable parameters of the LLM, optimized during pretraining and fine-tuning to capture statistical patterns in natural language. Each s l in the sequence (s 1 , s 2 , . . . , s L ) corresponds to a token in the S-expression core, such as a function, an entity, a relation, or a constant. L is the length of the sequence.
The output of this generation process, denoted as Core * , is a preliminary representation of the question’s intent. However, due to the inherent ambiguity of natural language and potential hallucinations in LLM outputs, this raw core may contain syntactic errors, unlinked surface forms, or incorrect function compositions. To address these issues, we decompose the overall core generation into two key phases. First, the LLM analyzes the question to identify independent query objects and synthesizes a preliminary core expression. Second, an agent refines this candidate by calibrating the syntactic structure and aligning its entities and relations with the underlying knowledge graph, producing multiple valid variants.
Targeting KBCQA tasks [36], we implement conversions between extended S-expressions and SPARQL, enabling the transformation of SPARQL queries into corresponding S-expressions in the context of KBCQA tasks. Testing confirms that all SPARQL queries in the dataset can be successfully converted to S-expressions, which can then be converted back to SPARQL while maintaining consistency with the original query results.
The proposed method employs a LLM to generate an initial S-expression draft based on the input question and annotated examples. As the LLM lacks access to the underlying knowledge graph, it produces element representations using surface names rather than canonical entity or relation identifiers. Consequently, the draft cannot be directly executed as a SPARQL query and requires a subsequent linking process. A lightweight linking strategy is adopted, which first maps each surface-named element to the most semantically similar entity or relation in the knowledge graph. Corrections are then applied to address two common error types which are relationship inversion and type constraint errors. After completing the linking, the final S-expression is obtained and translated into an executable SPARQL query via a custom conversion function, enabling retrieval of the final answer from the knowledge graph.
In the entity and relation linking phase, this method discards the traditional entity candidate approach, retaining only the single candidate with the highest semantic similarity. Specifically, the embedding model encodes knowledge graph elements into vectors, retrieving the best match via cosine similarity. Given that LLM-generated S-expressions are semantically precise, single entity candidate suffices without degrading linking performance. In contrast, the entity candidate approach which keeps three entities can produce non-empty but semantically incorrect queries, masking linking errors and leading to wrong answers. The single entity candidate strategy, by comparison, enforces stricter semantic alignment and thus ensures higher consistency.
After the LLM generates an S-expression core Core j , a calibration phase ensures both syntactic correctness and semantic grounding within the knowledge graph. This process consists of two key steps.
The first step performs syntactic correction. The agent parses the initially generated S-expression core Core j and corrects any syntactic errors to produce a structurally valid variant Core ′ j . The correction function Corr syn (•) detects mismatched parentheses, function argument errors, or illegal nesting structures, returning a syntactically well-formed expression:
In Equation 3, Core j denotes the initial S-expression core generated by the LLM, and Core ′ j represents the corrected output. The correction function Corr syn (•) performs rule-based structural validation to fix mismatched parentheses, incorrect function arity, or illegal nesting patterns.
The second step conducts knowledge graph linking to replace each surface name s within Core ′ j , such as entity or relation names, with the most semantically similar element x * selected from the candidate set C s , which is retrieved from the knowledge graph G = (E, R, F ). The optimal match is determined by computing cosine similarity over vector embeddings in Equation 4:
The embedding function Embed(•) converts surface names or knowledge graph elements into vector representations, typically implemented via pre-trained language models such as an embedding model. The similarity function Cos(•, •) measures alignment between vectors, with higher values indicating stronger semantic similarity. The candidate set C s consists of entities or relations from G potentially corresponding to the surface form s. Each x * is the best-matching element from C s according to embedding similarity. Each surface element s m in Core ′ j is substituted with its optimal match x * m to form calibrated candidates. The final set Calibrated_Core j retains the candidate variants whose query executions return non-empty results. In this study, the candidate variants are preserved.
This calibration strategy enhances alignment between LLM-generated symbolic structures and the underlying knowledge graph by building directly upon the core-wise linking mechanism described earlier. Rather than treating the entire S-expression as a monolithic unit, calibration operates on decomposed cores, leveraging the linking strategy to ground each component’s entities and relations into the knowledge graph. This design not only ensures syntactic well-formedness but also enforces semantic validity through query executability: only those variants that yield non-empty SPARQL results are retained as plausible candidates. By integrating linking as a foundational step within calibration, SEAL achieves a tighter coupling between symbolic reasoning and knowledge graph interaction, enabling robust and scalable semantic parsing in conversational settings.
We divide memory into local and global components to capture different types of information in dialog understanding. The local memory focuses on short-term contextual dependencies within the current conversation, such as coreference resolution and intent tracking. In contrast, the global memory stores structured knowledge accumulated over past interactions, enabling generalization and long-term reasoning.
For KBCQA tasks, coreference and ellipsis phenomena present key challenges. To ensure accurate interpretation of user intent by the LLM, our method employs the LLM for coreference resolution. Specifically, historical dialog records are provided to the LLM, enabling it to complete the user’s latest question into a fully specified form based on contextual information. Specific examples of input and output can be found in Appendix A. While simply concatenating historical dialogs can also complete semantics, redundant information may degrade the accuracy of keyword matching in the subsequent question type prediction phase. Moreover, regardless of the approach, the LLM is ultimately required to resolve coreferences and ellipses. Therefore, performing semantic completion using the LLM in advance shifts critical parsing steps earlier in the pipeline, thereby enhancing overall processing efficiency.
The template composition stage serves as a pivotal component of the proposed framework, aiming to synthesize calibrated S-expression cores with predefined templates to construct complete and executable S-expressions. This stage comprises three primary steps: question type prediction, template selection, and replacement plan generation.
Question type prediction employs intent analysis and keyword matching to categorize questions into predefined types such as “simple” or “verify.” This categorization constrains the search space to appropriate templates retrieved from a curated template library, which is organized according to common reasoning patterns. All generated templates are listed in Appendix D.
Template selection further refines the candidate space by analyzing the logical structure of the question and selecting a suitable template T emplate * compatible with the calibrated S-expression core. Following this selection, a replacement plan is constructed to determine the correspondence between placeholders and concrete values. The replacement plan is formally defined as:
In Equation 5, P j denotes placeholders in the template, while V alue j represents the substitution elements drawn from {Constants} ∪ {F unctions} ∪ {Calibrated_Core k }. M is the number of placeholder-value pairs in the replacement plan. These elements consist of calibrated cores, functions, and constants.
The generation of the final S-expression is achieved by applying the replacement plan to the selected template, as expressed by: S-expression final = T ransf orm(T emplate * , P lan * )
In Equation 6, T ransf orm(•) is a recursive function that replaces each placeholder in T emplate * according to P lan * to produce the final S-expression.
The recursive transformation procedure can be further formalized as:
Where the function F corresponds to the operation associated with node N within the template, and N 1 , . . . , N k denote its child nodes, each recursively transformed based on the plan in Equation 7.
The design of S-expression templates is grounded in a detailed analysis of the training corpus. Expression cores, specific functions , and constants are abstracted into placeholders , resulting in a versatile and reusable template library. These templates encapsulate typical logical operations such as set union, difference, deduplication, grouping, counting, and extremum computation, effectively reducing syntactic and semantic errors in LLM-generated outputs.
Adopting a template-based strategy facilitates generalization and reduces reliance on exhaustive learning by encouraging consistency through reusable syntactic patterns. In KBCQA tasks, certain equality comparison queries in SPARQL references often omit necessary FILTER components, resulting in structurally incomplete S-expressions. This observation highlights the importance of ensuring query completeness during template design to enhance the robustness of generated expressions in practical scenarios.
Each S-expression template is associated with a predefined question type, allowing efficient type-based filtering during inference. Question type prediction is performed by prompting the LLM with three examples per type. Although the task appears straightforward, semantic overlap frequently causes confusion, particularly among types involving numerical reasoning. To address this issue, a hybrid strategy is employed that integrates keyword-based heuristics to refine ambiguous type predictions-for example, reclassifying certain comparison-oriented questions as count-augmented variants when numerical quantification cues are detected in the utterance.
Given the predicted type, the optimal template and its corresponding replacement plan are determined by maximizing the conditional probability over the candidate space :
(Tem * , Plan * ) = arg max (T,P )∈Tc×P (T )
In Equation 8, the candidate template set T c , comprising templates Tem m , is determined through filtering based on the predicted question type. For a given template T , P (T ) denotes the set of all possible replacement plans compatible with T . Each P ∈ P (T ) represents a specific assignment of values to the placeholders in T , and the pair (T, P ) denotes a candidate templateplan combination considered during selection. Q com is the complete form of the current question, C_Core k denotes the set of calibrated S-expression cores from the current dialog, Exa represents the set of in-context examples, and Θ ref LLM denotes the parameters of the LLM used in the reflection phase. Examples of related inputs and outputs can be found in Appendix F.
To resolve potential ambiguity among compare_and_count, compare, and count, heuristic-based adjustment rules are introduced. In Equation 9, Type final is the corrected question type after heuristic adjustment, H(•) is a rule-based function that refines the initial prediction by analyzing keyword patterns and syntactic cues in Q com , Type pre denotes the initially predicted type, and Q com is the complete natural language form of the current question:
The LLM is provided with up to four examples per candidate template to facilitate accurate template selection. This structured methodology simplifies the selection process while leveraging the semantic transparency of S-expressions.
Most existing methods rely on fixed KG and static parsing rules. Such systems struggle to effectively adapt to the novel expressions continuously emerging in real-world dialog. To overcome this limitation, we introduce a self-evolving mechanism. It establishes a continuously learning agent through the close synergy of local memory, global memory, and a reflection module. In each dialog turn, the local memory module maintains the current context state, which includes resolved entities and completed semantic intent. This maintenance ensures precise input comprehension and semantic consistency, particularly when handling multi-turn dependencies. The global memory module structurally stores knowledge distilled from successful past dialogs. Knowledge is typically organized as question type to relevant question sample pairs. This mechanism supports the long-term reuse of historically validated logical forms for frequent queries. It guides S-expression generation, significantly boosting parsing accuracy and query efficiency. Following Sexpression execution, the reflection module performs post-analysis. Analysis includes syntactic validation, predicate-relation alignment checks, and result non-nullity tests. If this module detects errors, such as entity linking failure or structural invalidity, it logs the cause. It then triggers a correction loop to generate an alternative logical form.
The reflection module validates a generated S-expression to check if it is syntactically well-formed, exhibits consistent alignment between natural language predicates and knowledge graph relations, and executes to produce a non-empty result. Upon such validation, the S-expression, along with its question type and surface-form pattern, is serialized and incorporated into the global memory as a new template instance. This update is performed incrementally and selectively: only execution-verified logical forms with high confidence are retained, ensuring that the global memory evolves through the accumulation of reliable and reusable knowledge rather than unverified or noisy hypotheses.
The self-evolving mechanism transforms global memory from static storage into a dynamically updateable KG. Validated knowledge is incrementally written through reflection. This closed-loop process, which involves perceiving the current input, retrieving relevant historical patterns, reflecting on execution outcomes, and updating the KG, enables adaptive learning without explicit retraining. As dialog progresses, the system’s capacity to handle similar or complex queries progressively strengthens. This demonstrates sustained evolutionary performance.
In this section, we first introduce the datasets and evaluation metrics used for evaluation. Then, we present baseline methods for comparison and finally explain the implementation details.
Datasets. We conduct the experiments on SPICE [36], a conversational semantic parsing dataset over Wikidata [69] derived from CSQA [33] benchmark. Each conversation instance in the SPICE dataset is a natural language user-system QA sequence. Additionally, SPARQL parsing for mapping natural language to KG query statements is also provided, exploring the paths and entities on the underlying KG. For experiments, we select nine of the ten types of questions from SPICE, covering simple questions, logical reasoning, and comparative reasoning. We discard the “Clarification” subset as it lacks corresponding SPARQL queries. To reduce cost, we randomly sample conversation instances from the complete conversation, meanwhile ensuring that each subtype of questions contains at least 50 samples.
Evaluation Metrics. Following previous works [36], we choose marco-F1 and Accuracy score as the execution-based evaluation metrics for the experiments, which are used to evaluate the questions with answer types of entity sets and numerical values (boolean values), respectively. The marco-F1 metric averages the F1 score of each question subset to prevent the evaluation bias caused by imbalanced instance amount.
Baselines. We compare SEAL with two types of baselines: For supervised methods, we utilize BertSP [36] and DCG [70] for comparison. These approaches use the AllenNLP tool1 for NER and global look-up (denoted as GL) for type linking. For the unsupervised type, we adapt KB-Binder [24], a strong single-turn semantic parsing-based KBCQA baseline to the conversational question answering setting. Additionally, we follow [71] to utilize LLMs to generate logic forms directly by providing them linked entities and relations. The details of the baselines can be found in Sec 2.
Implementation Details. The question taxonomy consists of six types: simple, verify, count, compare, compare_and_count, and optimize, following the annotation schema of the SPICE dataset. For question type prediction, we employ the Qwen2.5-32B-Instruct model prompted with three incontext examples per type. All other components-coreference resolution, S-expression core generation, template selection, and replacement plan generation-are implemented using the DeepSeek-V3 model.
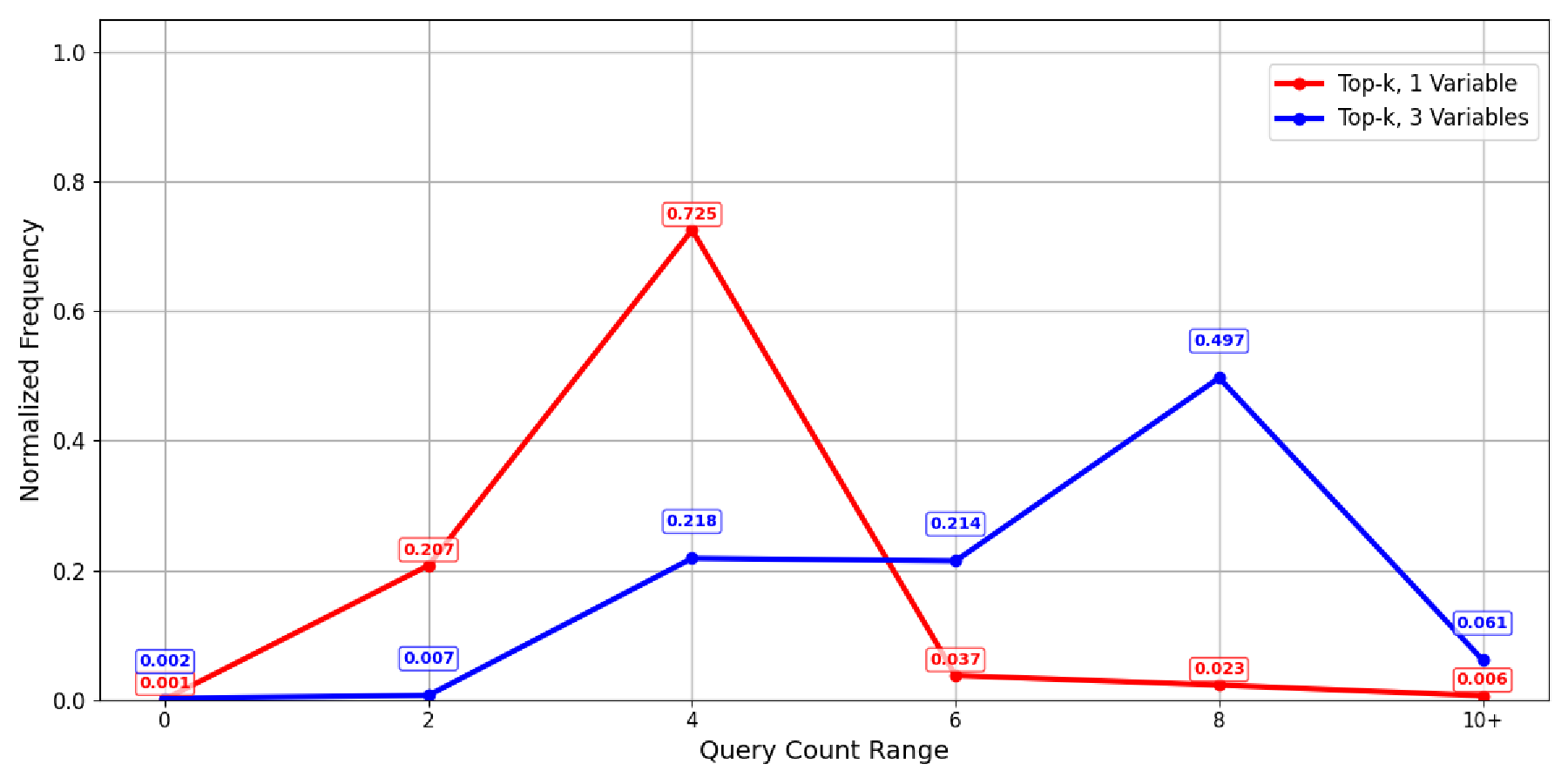
Two key parameters are explored in the experiment. The first concerns the linking strategy during the binding of surface forms to knowledge graph elements: we compare a top-1 approach (retaining only the highest-similarity candidate) against a top-k strategy (retaining k=3 entity or relation candidates per mention, as commonly used in prior work). The second parameter is the number of candidate variants preserved during calibration (either the first variant yielding a non-empty query result or the top three variants). These retention strategies influence both the accuracy and efficiency of the linking process.
When retaining only one variant, a comparison between selecting the single best candidate and selecting multiple candidates shows that the multiple candidate strategy issues slightly more SPARQL queries, though the difference is minimal. This result supports the earlier observation that Sexpression cores generated by LLMs are generally semantically accurate.
We present the main experimental results in Table 2, comparing our method SEAL with state-of-the-art supervised and unsupervised approaches across various question types. The bold values indicate the best performance for each task category. As shown, SEAL achieves competitive results in both supervised and unsupervised settings, particularly excelling in complex reasoning tasks. Specifically, in Logical Reasoning, SEAL obtains a m-F1 of 73.08, surpassing all baselines and demonstrating strong capability in handling multi-hop logic. In Quantitative Reasoning, it achieves 64.45, outperforming KB-Binder by a large margin despite lacking supervision. For Comparative Reasoning, SEAL reaches 41.06, significantly higher than KB-Binder’s 12.17, indicating its robustness in comparative queries. On simple questions, SEAL performs well across variants, achieving 78.49 on direct questions and 70.03 on ellipsis-based ones, showing effective coreference resolution. In the verification tasks, SEAL also achieves the highest accuracy at 85.97 for boolean verification and 70.12 for count-based comparison, further validating its generalization ability. Overall, SEAL achieves an AC of 66.83, significantly outperforming KB-Binder (36.66) and approaching the performance of supervised models like LLM GT (65.65), while requiring no labeled data.
Under the setting of retaining three candidate variants, the total number of SPARQL queries remains low despite a slight increase. Compared to KB-BINDER, our method mitigates the long-tail issue of high query counts, demonstrating improved efficiency. This advantage stems from two key factors: (1) decomposing the full S-expression linking task into multiple corelevel subtasks reduces the base of exponential growth, and (2) core expressions are semantically simpler and easier to link, making it more likely to find non-empty results early and avoid unnecessary queries, thereby further reducing SPARQL overhead. As shown in Figure 3, compared to the approach of retaining a single best candidate, the method of retaining multiple candidates (k=3) improves recall by considering a broader set of options, though it slightly reduces precision due to increased noise. It performs better overall on complex questions. Building on this, retaining multiple variants further enhances recall, especially for questions involving multiple conditions or complex relations, by reducing semantic drift during the calibration phase. However, for simple questions with clear intent, retaining too many variants introduces noise, complicating the selection of the correct answer and thus lowering overall performance. Although our framework relies on a library of predefined S-expression templates, we observe that the LLM can generalize beyond these constraints when necessary. For instance, in questions requiring logical disjunction over three or more independent query cores, the model autonomously constructs nested expressions such as (OR (OR x1 x2) x3) , which are not explicitly covered by any single template in the global memory. This behavior demonstrates the LLM’s capacity for compositional synthesis and robust generalization in out-of-template scenarios. Additional examples are provided in Appendix E.
As shown in Table 3, the core extraction method consistently outperforms direct generation in structural accuracy. For all question types beyond Simple Questions, it achieves higher structural overlap and parsing success rates. This is because complex S-expression structures are harder to learn directly, whereas the two-stage approach helps reduce syntax and structural errors. This leads to outputs more closely aligned with the correct expressions.
Table 4 presents the results of an ablation study on the SEAL model, evaluating performance through F1 score, accuracy (AC), and overall per- , where each removed module is replaced by a default method to ensure fair comparison. The omission of entity candidate generation affects precision, possibly due to compensatory effects in candidate selection. Calibration removal reduces output reliability, highlighting its optimization role, while the absence of local memory slightly diminishes performance stability, though less than calibration.The reliability is measured through three independent runs, referred to as the reliability experiment, to assess consistency across trials. Comparative analysis indicates a hierarchical dependency, with core extraction and entity candidate generation exerting the greatest influence due to their core functions, while calibration and local memory enhance robustness through synergy. The results affirm the interdependent nature of these components, as their individual removal consistently degrades performance, validating their collective importance to the SEAL framework.
Table 5 presents the results of an ablation study for zero-shot and fewshot settings, with evaluation metrics F1 score, accuracy (AC), and overall performance score. KB-Binder, in the few-shot setting, shows an F1 score of 32.61, an AC of 36.82, and an overall score of 34.02, serving as the baseline reference. SEAL-base, also in the few-shot setting, shows an F1 of 41.34, an AC of 35.39, and an overall score of 39.36, indicating superior performance compared to few-shot KB-Binder. KB-Binder lacks data in the zero-shot setting, while SEAL-self-evolving, under zero-shot, shows an F1 of 34.42, an AC of 34.10, and an overall score of 34.32, demonstrating performance improvement through the self-improvement mechanism. Comparative analysis reveals that SEAL-base excels in the few-shot task, whereas SEAL-selfimprovement shows potential enhancement in the zero-shot task, validating the efficacy of the self-improvement mechanism in data-scarce scenarios.
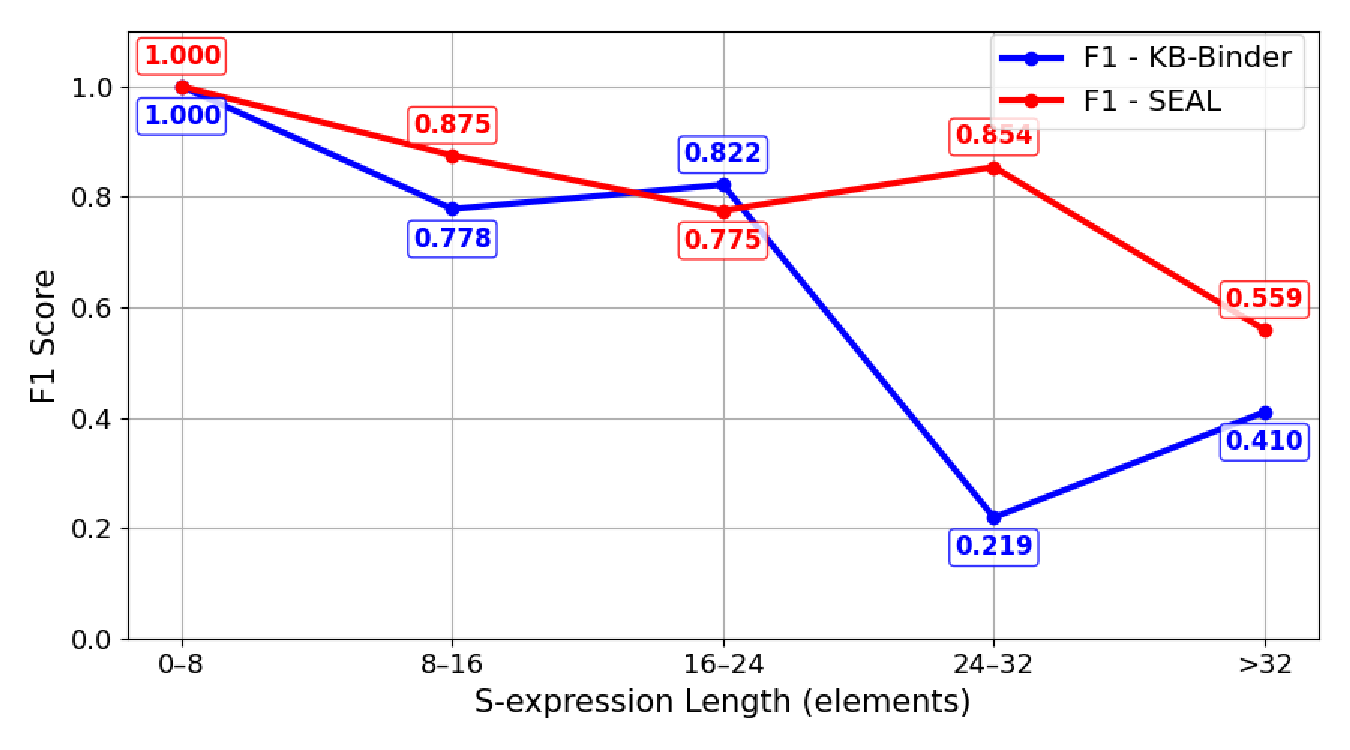
To measure the effectiveness of the self-evolving mechanism, we conducted a series of experiments. The experimental results are shown in Figure 4. In the first experiment, we segmented all test samples into intervals based on the length of S-expressions (0-8, 8-16, …, >32) and calculated the F1 scores for SEAL and KB-Binder for each interval. The results are shown in Figure 4 (a). The query length refers to the number of elements in the target S-expression, serving as a metric for semantic logic complexity. SEAL demonstrated superior stability and adaptability across varying complexities. While both models performed well in the short query stage (<16 elements) , KB-Binder’s performance dropped sharply as complexity increased. Specifically, in the 24-32 element interval, its F1 score decreased from 0.822 to 0.219, indicating a high susceptibility to long-range dependencies and error accumulation. In contrast, F1 score of SEAL avoided this decline, maintaining 0.854 in the same range, showcasing robust parsing for complex structures. Even with extremely long expressions (>32 elements), SEAL scored 0.559, outperforming KB-Binder’s 0.410 (a relative improvement of 36.3%). This validates the S-expression core extraction mechanism of SEAL and its modular two-stage design, which prevents the performance collapse common in end-to-end long sequence generation.
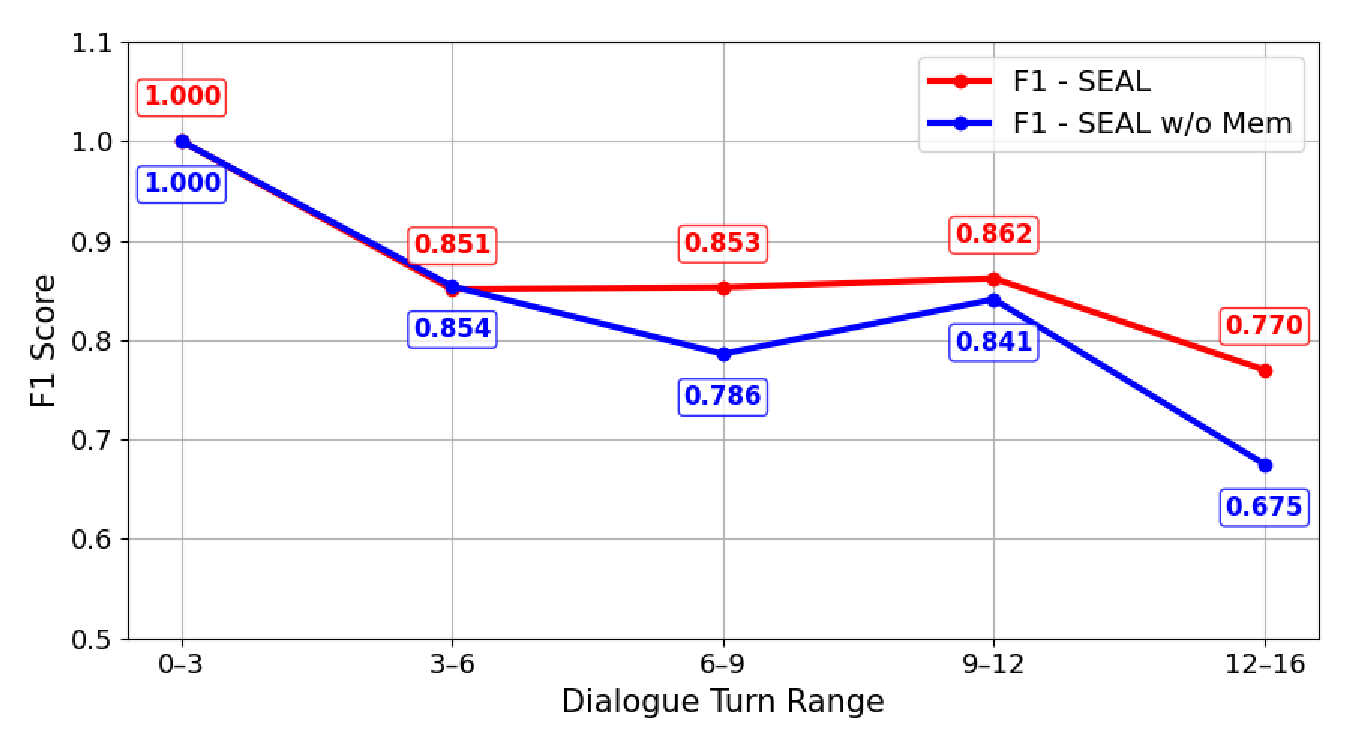
In the second experiment, to verify whether the self-evolving method possesses the ability to continually optimize performance as the dialog progresses, we segmented the entire sequence of dialog turns into several ranges (0-3, 3-6, . . . , 12-16 turns) and evaluated the F1 performance within each interval. Here, dialog turn refers to the position of the current question within the multi-turn dialog. The experimental results are shown in Figure 4(b).
In the early phase (0-3 turns), the F1 of both SEAL and the ablation model (SEAL w/o memory) achieved 1.0. However, SEAL’s advantage became evident from the 6th turn. In the 6-9 turn range, SEAL maintained stability (0.853), while the memory-ablated version dropped to 0.786. SEAL then peaked at 0.862 in the 9-12 turn range, contrasting sharply with the ablation model’s limited rebound (0.841). In the final stage (12-16 turns), SEAL’s F1 (0.770) remained superior to the ablated version’s 0.675 (14% gap). This trend confirms that SEAL achieves self-evolving behavior by using local memory for contextual consistency and global memory to retrieve successful patterns, thereby continuously enhancing semantic parsing capability during complex dialogs.
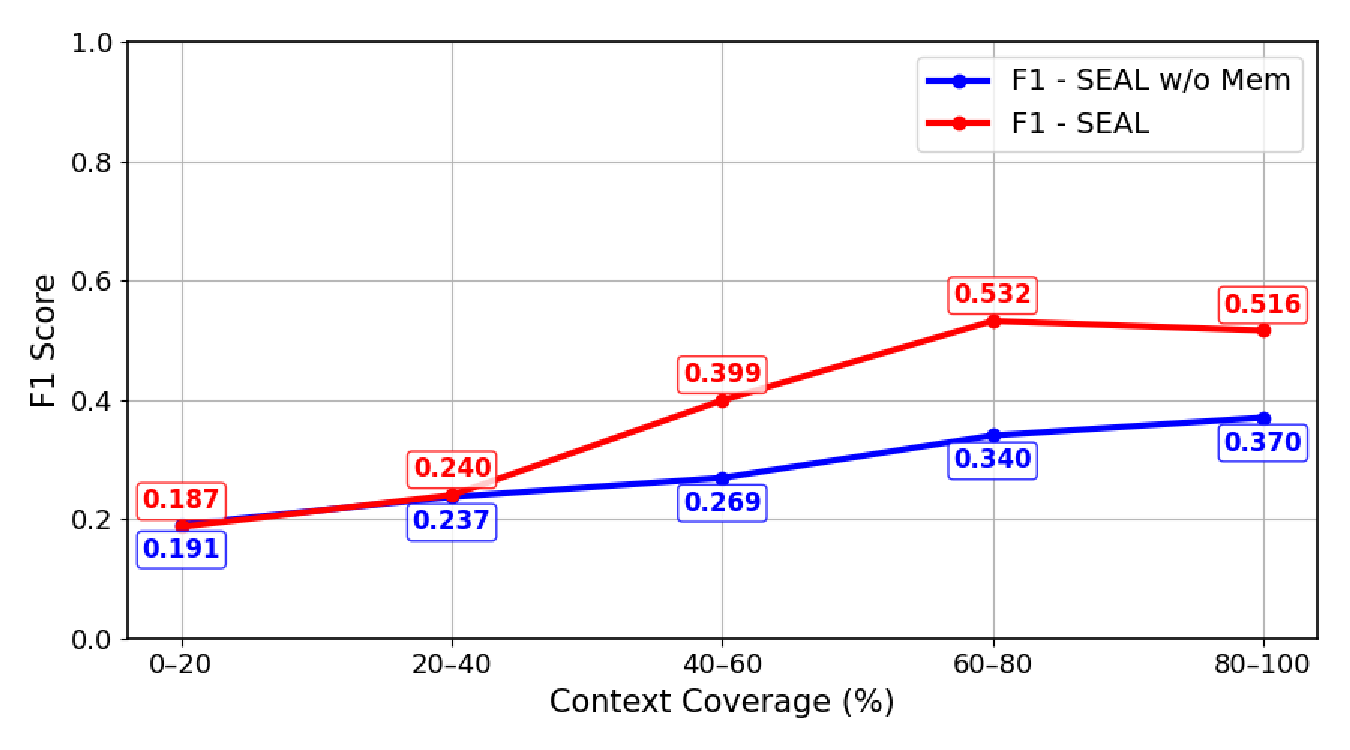
In the third experiment, to measure the impact of the available proportion of cumulative dialog history data (data stream) on F1 performance in multi-turn dialogs and to quantify the contribution of memory, we segmented the entire dialog dataset into several intervals based on the proportion of visible context (0-20%, 20-40%, 40-60%, 60-80%, 80-100%). The model’s F1 performance was then evaluated within each interval. The results are shown in Figure 4(c). The system’s performance changes based on the amount of historical dialog observed. The results show that in the early stages (<40% data stream), the performance of both versions (with and without memory) is similar, indicating that the memory mechanism is not yet influential during the initial dialog turns. However, starting from 40%, SEAL (with memory) shows a performance leap, while SEAL w/o memory exhibits gradual growth. In the 60-80% interval, SEAL’s F1 peaks at 0.532, surpassing the memory-ablated version (0.340) by 56%. Even in the final stage (80-100% interval), where F1 values slightly decrease, likely due to noise accumulation from long dialogs, SEAL maintains a clear advantage.
These results collectively demonstrate that SEAL’s global memory effectively utilizes structured knowledge from the dialog history, significantly improving semantic parsing in mid-to-late turns. As visible context increases, the results show a clear benefit from self-evolving functionality as SEAL continuously improves its inference capability through accumulated experience. Conversely, lacking the memory module, the ablated model cannot sustain this learning, reflected in slower performance growth. This directly validates the proposed self-evolving architecture, showing system performance improves with increasing dialog turns.
To validate the effectiveness of the SEAL framework in complex dialogue scenarios, we conducted an analysis of a typical multi turn question answering case. This case involves identifying implicit semantic constraints, resolving cross turn coreference, and integrating user feedback. Successfully handling such scenarios requires dynamic dialogue state tracking and iterative refinement of the reasoning path. Traditional methods based on static templates, such as KB Binder, often fail in such situations due to their lack of contextual awareness. In contrast, SEAL achieves more robust reasoning through its self-evolving mechanism, which integrates global memory, local memory, and semantic calibration.
Which male person was the parent of Ludovico II? SEAL: 1)Input: “male person” → detected as implicit constraint 2)Template Matching: Matches to (JOIN P21 Q6581097) 3)Predicted S-expression: (AND (JOIN (R P22) Q1063295) « (JOIN P21 Q6581097) » (JOIN P31 Q502895)) 4)Reasoning: Explicitly models “male” as a constraint on the parent entity. 5)Calibrated S-expression:(AND (JOIN (R P22) Q1063295) (JOIN P21 Q6581097) (JOIN P31 Q502895)) KB-Binder: 1)Input: “male person” → ignored (no calibration) 2)Template Matching: Uses default “parent” template → P40 3)Predicted S-expression:(AND (JOIN (R «P40 ») Q1063295) (JOIN P31 Q502895)) 4)Reasoning:Uses incorrect relation (P40 = has child),and omits the gender constraint.
User:“Who are the children of Ludovico II? → System lists: Gian Gabriele I, Francesco, Giovanni Ludovico User:Who are siblings of that one? System (implicitly) Did you mean Francesco? User:No, I meant Giovanni Ludovico. Could you tell me the answer for that?” Global memory: 1)“results”: [“Q3750875”, “Q3756712”, “Q3767600”, “Q3856501”] 2)“coreference_resolved_question”: “Who are the children of Ludovico II, Marquess of Saluzzo?” KB-Binder: As illustrated in Figure 5, the dialogue begins with a seemingly simple query: “Who are the children of II, Marquess of Saluzzo?” However, the user’s actual intent is to identify his male offspring, as all subsequent references and reasoning revolve around male heirs. This query involves two key semantic components: retrieving the “child” relationship and imposing an implicit constraint that the result must be a male person. KB-Binder ignores this gender constraint during initial parsing, defaulting to a generic “parent” template (P40) without modeling the gender restriction, which may return non-target entities such as female relatives or individuals of unknown sex, thereby contaminating the candidate set for later coreference resolution. In contrast, SEAL detects “male person” as an implicit constraint through calibration, explicitly models it as a type restriction (e.g., P31: Q502895), and incorporates it into the S-expression, ensuring that only the four male children, namely Gian Gabriele I, Francesco, Giovanni Ludovico, and Michele Antonio, are returned. This calibrated result is then stored in global memory, providing a clean and semantically consistent foundation for subsequent multi-turn reasoning.
In the following turn, the user asks, “Who are siblings of that one?” The system initially infers the referent as Francesco, but the user corrects it explicitly: “No, I meant Giovanni Ludovico.” In particular, “Giovanni Ludovico” does not appear in the user’s input but was listed in the previous answer. KB-Binder lacks cross-turn memory and relies solely on surfaceform entity linking, making it prone to incorrectly bind “that one” to the first-mentioned entity or the system’s prior guess, such as Francesco, and does not respond to explicit user correction. In contrast, SEAL resolves the coreference by leveraging global memory to access the previously retrieved list of children and their corresponding QIDs, including Q3767600 for Giovanni Ludovico, thereby constraining the search space to a reliable candidate set. Local memory records the negative feedback (“No, I meant…”), and reflection enables dynamic elimination of incorrect options, confirming Giovanni Ludovico as the intended subject. Based on this accurate entity identification, SEAL generates a correctly oriented SPARQL query: SELECT ?x WHERE { wd:Q3767600 wdt:P7 ?x . ?x wdt:P31 wd:Q502895 }, retrieving all siblings including Michele Antonio, who was never mentioned by the user. Meanwhile, KB-Binder either fails to resolve the correct entity or produces a query with reversed relation direction (?x wdt:P7 wd:Q3767600), resulting in incomplete or logically inconsistent results. This case demonstrates how SEAL achieves robust multi-turn understanding through a synergistic pipeline of implicit constraint calibration, memory-augmented coreference resolution, and feedback-driven refinement.
This case study demonstrates how SEAL evolves its reasoning continuously across multiple turns of dialogue. It starts with single turn semantic calibration, then coordinates global memory, local memory, and a reflection mechanism. This multilayered architecture for memory and calibration allows the system to genuinely comprehend the user’s implicit intentions within the flow of conversation. This capability enables SEAL to outperform baselines like KB-Binder, which lack mechanisms for cross-turn context integration and feedback-driven refinement.
By decomposing complex logical form generation into core extraction and template composition, and leveraging agent-based calibration to address syntactic and linking limitations of LLMs, SEAL’s two-stage framework based on S-expression core extraction markedly enhances the accuracy of complex logical form generation. SEAL improves structure overlap and parsing success rates by 22.6% and 22.1%, respectively compared to KB-BINDER.
The S-expression core extraction method for semantic parsing shows robust experimental performance, yet several avenues warrant further exploration. To enhance scalability, the current S-expression to SPARQL transformation, constrained by specific syntactic patterns and datasets, could be generalized through versatile transformation functions validated across diverse benchmarks. Additionally, the calibration strategy, which targets nonempty query outputs, may inadvertently revise valid empty queries, reducing precision; refining the agent’s semantic understanding to accurately distinguish such cases could improve robustness. Furthermore, the LLM’s reliance on prompts for S-expression comprehension could be strengthened through targeted training on S-expression generation tasks to deepen syntactic and semantic proficiency. Finally, the computational overhead from multiple LLM invocations during core extraction could be mitigated by employing smaller models for subtasks like coreference resolution or question type classification, thereby improving efficiency.