The Erosion of LLM Signatures: Can We Still Distinguish Human and LLM-Generated Scientific Ideas After Iterative Paraphrasing?
📝 Original Info
- Title: The Erosion of LLM Signatures: Can We Still Distinguish Human and LLM-Generated Scientific Ideas After Iterative Paraphrasing?
- ArXiv ID: 2512.05311
- Date: 2025-12-04
- Authors: Sadat Shahriar, Navid Ayoobi, Arjun Mukherjee
📝 Abstract
With the increasing reliance on LLMs as research agents, distinguishing between LLM and human-generated ideas has become crucial for understanding the cognitive nuances of LLMs' research capabilities. While detecting LLM-generated text has been extensively studied, distinguishing human vs LLM-generated scientific ideas remains an unexplored area. In this work, we systematically evaluate the ability of state-of-the-art (SOTA) machine learning models to differentiate between human and LLM-generated ideas, particularly after successive paraphrasing stages. Our findings highlight the challenges SOTA models face in source attribution, with detection performance declining by an average of 25.4% after five consecutive paraphrasing stages. Additionally, we demonstrate that incorporating the research problem as contextual information improves detection performance by up to 2.97%. Notably, our analysis reveals that detection algorithms struggle significantly when ideas are paraphrased into a simplified, non-expert style, contributing the most to the erosion of distinguishable LLM signatures.📄 Full Content
While prior research on detecting LLMgenerated text has focused on watermarking (Zhao et al., 2023b), zero-shot methods (Yang et al., 2023;Mitchell et al., 2023), and fine-tuned classifiers (Hu et al., 2023), our study takes a fundamentally different approach. Rather than identifying LLMgenerated text, we examine the resilience of ideaswhich persist beyond surface-level writing styles. Unlike text, ideas are conceptually immutable; a human-conceived idea remains human in essence, even if heavily paraphrased by an LLM. We investigate whether these underlying origins: human or LLM-remain detectable after successive paraphrasing and stylistic transformations. To the best of our knowledge, this is the first study to explore scientific idea attribution in such a nuanced and dynamic setting.
Ideas manifest across diverse contexts, but in this research, we define an “idea” specifically as a proposed solution addressing a given research problem, using ‘scientific idea’ and ‘idea’ interchangeably. Scientific ideas inherently reflect nuanced thinking and careful planning, which distinguishes them from mere linguistic outputs. Formally, given a research problem RP , an idea can be represented as a response r = f (RP ), where f denotes either human or LLM generation. To evaluate whether the essence of human or LLMgenerated ideas persists through stylistic variations, we iteratively paraphrase these ideas through multiple stages. At each paraphrasing stage n, the idea transforms as r n = f pn (r n-1 , RP ). Paraphrasing serves two critical purposes: firstly, in real-world scenarios, ideas are communicated through varied expressions and settings-yet retain their core meaning; secondly, without paraphrasing, classifiers might easily identify the source due to stylistic cues specific to scientific paper writing, conflating stylistic detection with genuine idea detection.
In this research, We collect 846 papers from five top CS conferences to extract their main research problems. We then prompt LLMs to generate original ideas for each problem. Humangenerated (from papers) and LLM-generated ideas undergo systematic summarization and multi-stage paraphrasing using four strategies: general paraphrase, simplified summary, brief summary, and detailed technical paraphrase. Figure 1 illustrates this workflow.
We employ SOTA classifiers to assess detection performance across paraphrasing stages, revealing an average decline of 25.4% from Stage 1 to Stage 5. This deterioration suggests that characteristic “LLM signatures” initially present in earlier stagessuch as specific word choices, linguistic patterns, or stylistic markers-gradually diminish through successive paraphrasing. As these superficial markers fade, traditional text-based classifiers increasingly struggle to differentiate between human and LLM-generated ideas.
Our main contributions are as follows:
• We create and release a comprehensive dataset consisting of original and multi-stage paraphrased scientific ideas, systematically generated using cutting-edge LLMs.
• Through extensive evaluation using various classification algorithms, we empirically demonstrate the inherent challenges involved in identifying LLM-generated ideas, particularly as these ideas undergo iterative paraphrasing and stylistic transformations.
LLMLu et al. introduced AI Scientist, an end-toend framework designed for scientific discovery using LLMs. This framework autonomously generates novel research ideas, implements experimental code, executes experiments, visualizes results, composes scientific papers, and even simulates a peer-review process to evaluate its findings (Lu et al., 2024). Similarly, Baek et al. proposed a research agent capable of automatically formulating problems, suggesting methods, and designing experiments. Their approach iteratively refines these elements through feedback provided by collaborative LLM-powered reviewing agents (Baek et al., 2024).
Li et al. developed specialized LLM-driven agents, namely IdeaAgent and ExperimentAgent, tailored for research idea generation, experimental implementation, and execution within the machine learning domain (Li et al., 2024 (Si et al., 2024). Their results suggested that LLMs can generate ideas that surpass human-generated ideas in terms of novelty. However, their approach involved prompting-based idea generation across predefined NLP topics. In contrast, our research explicitly defines an idea as a response to a given research problem. This definition allows for a more unbiased comparison between human and LLM-generated ideas and reduces topic-related bias.
Unlike previous studies primarily focused on enabling research potential of LLMs, and comparing novelty, our work shifts attention toward the challenge of detection. Specifically, we investigate the inherent difficulty of distinguishing humangenerated ideas from those produced by LLMs, especially as these ideas undergo multiple stages of paraphrasing.
To generate research ideas, we first extract research problems from scientific papers and feed these into LLMs. Subsequently, we apply cascading paraphrasing to both human-written and LLM-generated ideas. Finally, we evaluate the distinguishability of these ideas at each paraphrasing stage using several SOTA classifiers. , 2025). This sample size was chosen primarily due to the substantial computational and financial resources required for large-scale generation and extensive cascading paraphrasing using SOTA LLM APIs. Table 1 summarizes the sampled dataset, while detailed statistics are available in our repository. 1 We include only papers published up to 2021 to ensure the integrity of our analysis, as this guarantees that the ideas originate purely from humans, predating the release of ChatGPT in 2022 (OpenAI, 2025a).
We extract the research problem from the first two pages of each paper, selecting five different LLMs at random for each extraction. In general, these pages encompass the abstract and introduction, where problem statements are typically presented either explicitly or implicitly. To minimize the risk of LLMs incorporating elements of the solution, we explicitly prompt them to focus solely on the problem itself (find the prompts in Appendix) 1 .
The extracted research problem is used as input to the LLM along with carefully designed instructions to generate potential research ideas. This process constitutes the core of LLM-driven idea generation. We employ two distinct prompting strategies. The first is a general prompting approach, where the LLM is simply instructed to provide a detailed research solution. The second approach, inspired by the idea generation technique outlined in (Si et al., 2024), involves a more structured prompt with stepby-step guidance on explaining the methodology, techniques employed, novelty, and contributions. While both approaches yielded comparable results, the latter tends to produce slightly more detailed and descriptive responses. To incorporate both prompting styles, we apply the general prompting method to half of the samples and the structured approach to the remaining half. A detailed description of both prompting strategies is provided in Appendix 1 .
Since we want to differentiate ideas generated by humans from those produced by LLMs, a direct comparison between LLM-generated ideas and research papers (first two pages) is not feasible. This is primarily due to the presence of stylistic cues that algorithms can easily detect, as well as inconsistencies in formatting across these two categories. Consequently, distinguishing ideas at this stage would not be reliable. Hence, we employ a multi-stage cascade of summarization and paraphrasing. In the first stage (Stage 1), we generate a three-paragraph summary of both the first two pages of each paper and the corresponding LLM-generated ideas. In the second stage, we apply four distinct paraphrasing strategies to each summary: (i) general paraphrasing, (ii) paraphrasing for a simplified non-expert audience, (iii) brief summarization, and (iv) detailed technical paraphrasing. This paraphrasing process continues in a cascaded manner across a total of five stages. To prevent excessive compression or the introduction of additional information, we avoid consecutive applications of the same paraphrasing type. Appendix C.3 shows the instruction prompts to generate these paraphrases.
Through this approach, we obtain 846 paraphrases in Stage 1. From Stages 2 to 5, this expands to 3,384 paraphrases for both LLM-generated and human-written ideas. In total, our process yields 28,764 paraphrased versions of research ideas. One of the authors also manually verified a 1% of the samples across all paraphrasing stages to ensure consistency.
We utilize six best-performing LLMs to generate data for research problem extraction, idea generation, and the five stages of idea paraphrasing. To ensure optimal performance, we conduct smallscale experiments and manual evaluations of the quality of generated outputs across different LLMs. Additionally, we consider the cost of API usage as a factor in model selection. Based on these tradeoffs, we selected three models from OpenAI (Ope-nAI, 2025c) and three from Anthropic (Anthropic, 2025).
From OpenAI’s suite of models, we use GPT-4o, GPT-4o-mini, and O3-mini. From Anthropic, we employ Claude-3.5-Haiku, Claude-3.5-Sonnet, and Claude-3-Opus. Across all stages of our study, 63% of the data was generated using OpenAI’s models, while the remaining 37% was produced using Anthropic’s models. Table 2 presents the exact distribution of data generation across the selected LLMs.
To minimize topic bias, we ensured that the same LLM was used for both summarizing the research paper and generating the summary of the corresponding LLM-generated idea. This consistency was maintained throughout the paraphrasing process as well.
We evaluated four fine-tuned language models and four text embedding methods, each coupled with downstream classification layers. First, we employed BERT (bert-base-uncased) as our baseline, owing to its proven ability in capturing bidirectional contextual information (Devlin et al., 2019). RoBERTa (roberta-base), known for its more extensive pretraining, is included as a strong comparative choice (Liu et al., 2019). Additionally, BigBird (BigBird-RoBERTa-base) is selected due to its efficient handling of long sequences by employing a sparse attention mechanism, thus avoiding the quadratic complexity in traditional transformers (Zaheer et al., 2020). Finally, we incorporate T5 (t5-base), a text-to-text transformer featuring an encoder-decoder architecture that fundamentally differs from BERT-style models by translating input text into target text (Raffel et al., 2020).
For embedding-based representations, we use the sentence-transformers’ all-MiniLM-L6-v2 as our baseline, encoding text into 384-dimensional vectors (Wang et al., 2020). Additionally, we selected three advanced embedding models-GIST-Embedding-v0 (Solatorio, 2024), gte-base-en-v1.5 (Zhang et al., 2024), and stella en 400M v5 (Zhang et al., 2025), which consist of 109M, 137M, and 435M parameters respectively. These specific embedding models were chosen based on initial exploratory experiments and by carefully considering the trade-offs between model size and ranking performance (Face, 2025). Each embedding representation was subsequently coupled with a downstream two-layer Feed-Forward Neural Network (FFNN).
For the experiments, we prepare dataset using a systematic train-test splitting approach to ensure unbiased evaluation. Initially, we have 1,692 samples in Stage 1, comprising equal portions of LLMgenerated and human-generated ideas. For subsequent stages (Stage 2 to Stage 5), the dataset expanded to include 6,768 samples, incorporating four distinct paraphrasing styles for each original idea. To avoid data leakage, we perform splits such that there was no overlap between the original solution (and the research problem) in the training and test sets, meaning each problem-solution was exclusive to either the training or testing partition across all stages. This strategy ensures that all paraphrases derived from the same initial research problem statement remain consistently within the same partition, thus maintaining dataset integrity.
We conduct three random train-test splits and report the averaged results across these splits. From each training split, we further allocate 20% of the data as a validation set, specifically used for hyperparameter tuning. We perform tuning for batch size, number of epochs, dropout rate, and early stopping criteria.
For all our experiments, we use NVIDIA TITAN RTX (24 GB), Quadro RTX 8000 (48 GB), and NVIDIA GeForce RTX 2080 Ti (11 GB) GPUs. We report the macro F1-score to report the performances.
We evaluate the performance of various algorithms in idea-source detection (Table 3). Stage 1 achieves the highest F1-score (¿90% for BigBird, Stella) across many different models. We also find, even a simple logistic regression model attains 77%, suggesting strong lexical cues. Words like hybrid, transformer, adaptive, intelligently, dynamically, and advanced are highly correlated with LLMgenerated text.
To further analyze this, we apply Integrated Gradients (IG) Visualization with RoBERTa (Figure 2) Figure 2: Integrated Gradients Visualization: Green highlights words that contribute to classifying the text as human-written, while red highlights words that push the classification toward LLM-generated content. The overall text is LLM-idea-summarized (Sundararajan et al., 2017). IG attributes model predictions by integrating gradients from a baseline input to the actual input, quantifying feature importance. We find terms like adaptive, framework, regularized, and stability align with LLMs, likely due to their prevalence in structured academic writing, whereas domain-specific terms like federated and momentum are more indicative of human ideas.
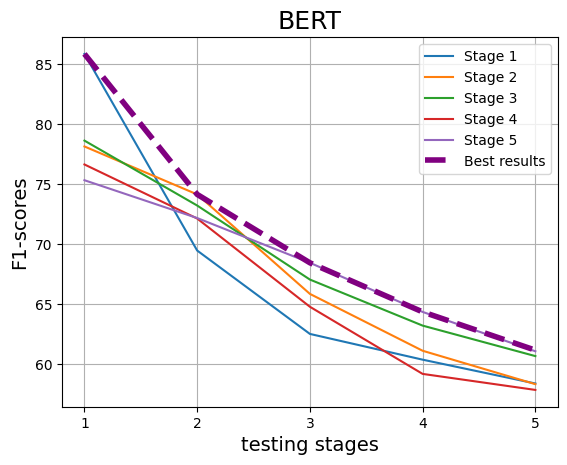
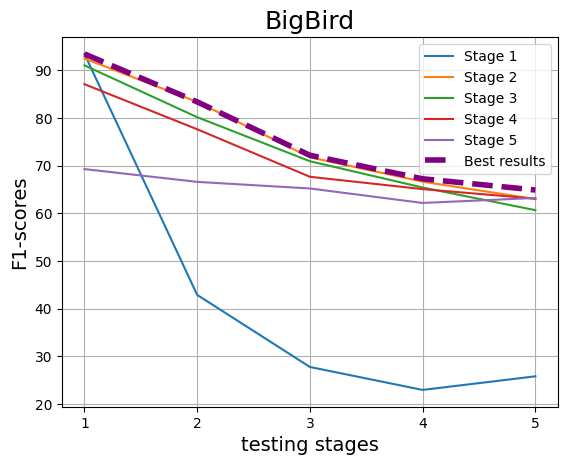
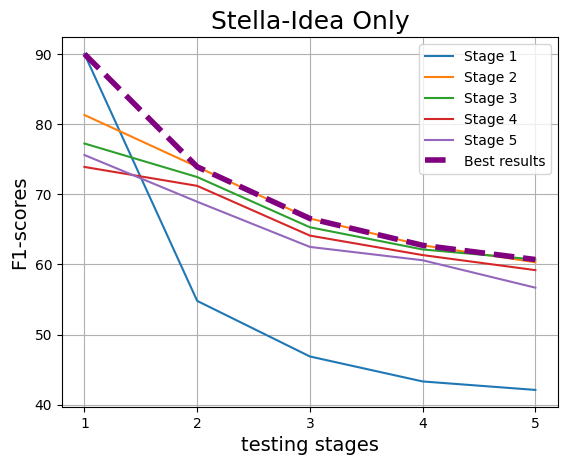
We observe, BigBird consistently outperforms all other models, leveraging its superior contextlength capability to capture both the research problem (RP) and idea representation effectively. Among fine-tuned models (BERT, RoBERTa, T5, BigBird), RoBERTa slightly outperforms BERT, while high-quality embeddings like Stella and GTE surpass idea-only models such as BERT, RoBERTa, and T5 in most stages, highlighting the advantage of robust embedding spaces.
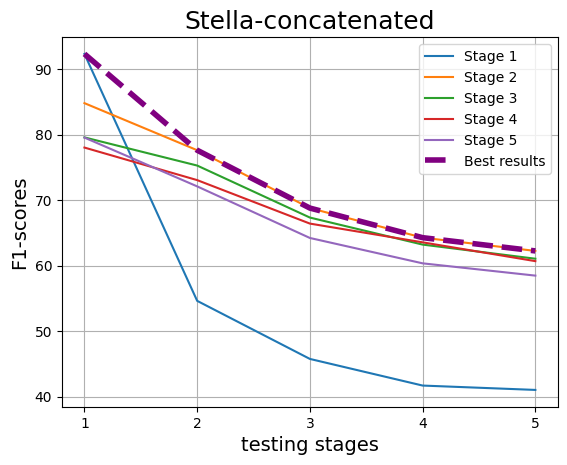
As training progresses across stages, a consistent decline in performance is observed, as depicted in Figure 3. their highest performance within the stage they were trained on, indicating a strong stage-specific learning effect. Nevertheless, irrespective of crossstage or within-stage, overall performance declines with the progression of stages. It also indicates that the earlier stages may still retain the “LLM signature”, which aids detection but gradually diminishes in later stages.
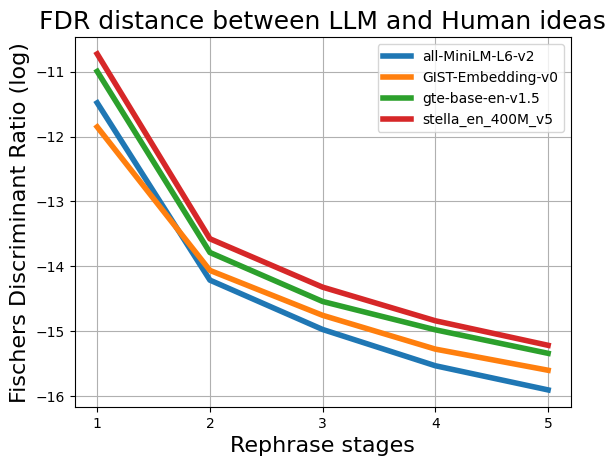
To further understand the issue, we investigate the Fisher’s Discriminant Ratio (FDR) between LLM and Human ideas acorss different stages (Li and Wang, 2014).
where µ 1 , µ 2 are the means of the feature (embedding representation) for Human and LLMgenerated ideas respectively, and σ 2 1 , σ 2 2 are the variances of them respectively. As illustrated in Figure 4(a), the FDR steadily declines across the stages, irrespective of the embedding representation used. It suggests that as ideas undergo iterative paraphrasing or transformation, their distinguishing characteristics erode, making human and LLMgenerated ideas increasingly indistinguishable.
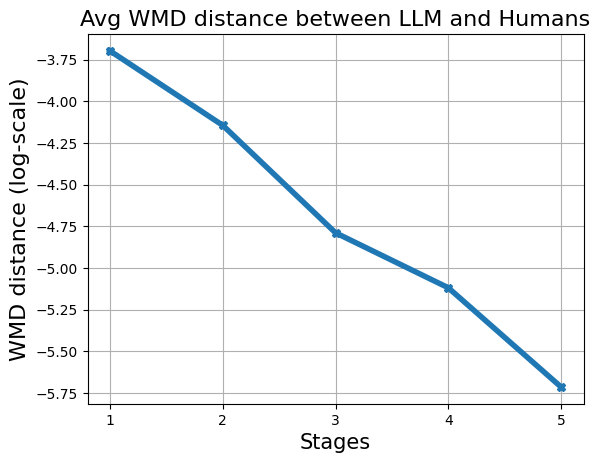
In addition, we examine Word Mover’s Distance (WMD), a metric that quantifies the effort required to change one document’s word embeddings into another’s, serving as a measure for textual dissimilarity (Kusner et al., 2015). We employ the GloVe-wiki-gigaword-50 embedding model to compute WMD at each stage. Figure 4(b) reveals a progressive decline in WMD, further reinforcing the notion that the iterative modifications reduce the distinctiveness of LLM-generated content. As the transformation stages accumulate, the ‘LLM signature’ becomes increasingly elusive, making it more challenging to establish a clear boundary between human and LLM-generated ideas.
Finally, we investigate the “learning difficulty” through the analysis of the loss curves, focusing on the MiniLM + FFNN architecture trained on concatenated (RP + idea) inputs (Figure 5). Computing the average slope of the validation loss across the initial five epochs, given by (L(t+n-1)-L(t))/n, reveals progressively decreasing slopes of 0.029, 0.014, 0.007, 0.003, and 0.002 from stages 1 to 5. Intuitively, as the cascaded paraphrasing stages progress, this indicates that while early stages rapidly achieve a stable, low-loss plateau, the higher stages quickly plateau at higher losses, followed by an upward drift in validation loss, clearly reflecting increased learning difficulty and poorer generalization .
We investigate whether combining training examples from different paraphrase stages can improve detection performance, and Figure 6(a) reveals that this strategy unexpectedly degrades performance in earlier stages (stages 1 and 2). For stage 1 and 2, combined training declines the average performance by 6.07 and 1.08 points respectively. However, for stage 3, 4, 5, combined training imrpoves the performance by an average of 0.6, 1.4, and 2.4 points respectively, likely due to the increased volume of training data improving generalization.
In stage 1, even smaller datasets suffice to achieve high accuracy because the LLM’s distinctive “signature” remains relatively intact, making it straightforward to distinguish from humangenerated content. However, as we progress to later stages (stages 4 and5), repeated paraphrasing gradually erodes these features, creating a more challenging detection task. Under these conditions, adding data from earlier stages proves beneficial because it provides subtle patterns and cues that help the model better learn residual LLM signatures.
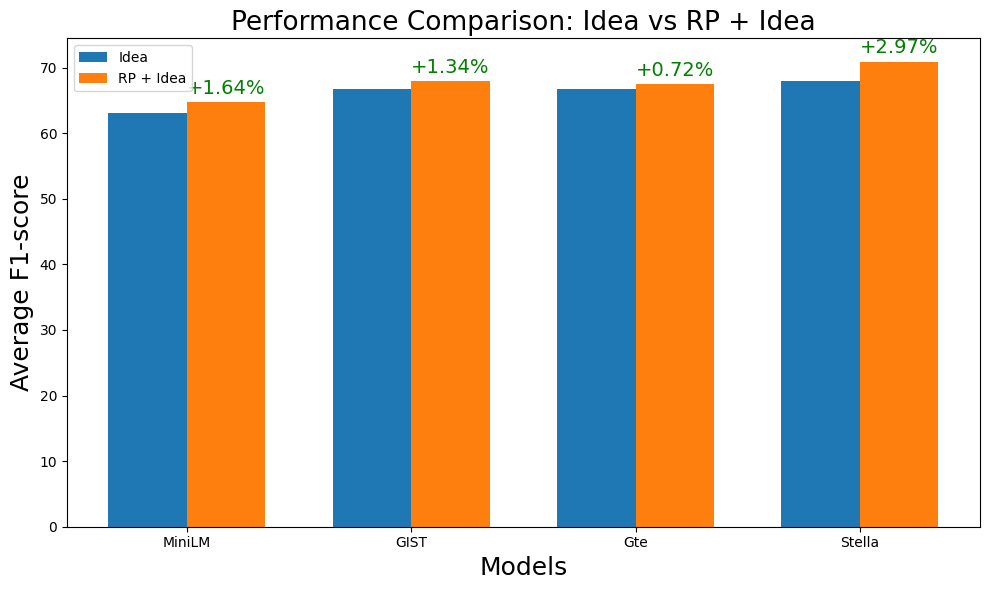
Through the embedding + FFNN models, we observe that RP + idea versions of training significantly outperform their idea-only counterparts 6(b), with observed performance gains of +1.64 (p=0.00) for MiniLM, +1.34 (p=0.04) for GIST, +0.72 (p=0.02) for GTE, and +2.97 (p=0.00) for Stella.
These gains indicate how incorporating RP helps models learn structured semantic dependencies between RP and their corresponding research idea solutions, thus, leading to richer conceptual representations and reducing ambiguity. In FFNN classifiers, this additional context strengthens decision boundary formation by providing clearer distinctions between different idea categories. However, in the embedding models, RP and ideas are only concatenated at the representation level. To further enhance contextual integration, we plan to explore a cross-attention modeling structure in future work, which may better capture problem-idea interactions and improve the model’s understanding of idea patterns.
Across all stages and classifiers, we observe a consistent pattern: simplified paraphrasing intended for non-expert audiences leads to the most substantial reduction in detection performance (Figure 7). The average F1-score across all algorithms and paraphrasing stages is 64.5%, while simplified nonexpert paraphrasing underperforms this benchmark significantly by 2.98% (p-value = 0.03). This phenomenon likely occurs because nonexpert paraphrasing deliberately omits technical nuances, replacing them with simpler, more general language. Such simplification further diminishes the research domain specific linguistic signatures used by models to distinguish between human and LLM-generated ideas. These findings also illus-trate critical limitations in current detection algorithms, suggesting they rely heavily on superficial linguistic patterns and struggle to capture deeper ‘Idea Signature’ when technical complexity is removed.
This paper examines the ability of SOTA textual ML models to differentiate between human and LLM-generated research ideas, revealing the challenges posed by iterative paraphrasing. Unlike direct text-based detection, idea detection is significantly harder as paraphrasing progressively erodes distinctive LLM signatures, making idea attribution increasingly unreliable. By constructing a systematic dataset from top CS conferences and leveraging advanced LLMs for idea generation and rephrasing, we find that even the best detection models struggle once ideas undergo multiple paraphrasing stages. Our results emphasize that existing classifiers rely heavily on surface-level linguistic features rather than deeply understanding the underlying idea structures, leading to substantial performance declines as paraphrasing progresses.
In future, we aim to extend this study beyond CS to other scientific disciplines, exploring whether similar challenges persist across diverse knowledge domains. A key direction for improvement involves incorporating the reasoning trajectory of LLMs during idea generation, as tracing the thought process may provide a more robust signal for detection. Additionally, integrating structured knowledge-based embeddings could help models capture deeper conceptual patterns, reducing their dependence on linguistic artifacts and enhancing their ability to differentiate between human and LLM-generated ideas.
Our work investigates the diminishing detectability of LLM-generated ideas using SOTA models. Below are the key limitations of our study:
• Limited Domain Research: We focus on five A* conferences in the Computer Science domain, primarily covering AI and NLP. While these conferences are highly regarded, we do not include other major CS conferences such as CVPR, AAAI, ICSE, or ISSP. Additionally, we exclude papers from other disciplines like Electrical Engineering, Economics, and Psychology. This limits our ability to assess LLMs’ idea-generation capacity across a broader range of fields.
• Limited Explainability: While our detection models are state-of-the-art, they lack strong interpretability. Although we incorporate visualizations to analyze their impact, a more explainable approach could provide deeper insights into how these models distinguish human and LLM-generated ideas.
• Limited Paraphrasing Stages: We paraphrase ideas up to stage 5, observing continuous degradation in detectability. However, we do not determine the exact point at which performance drops to chance levels, making LLM-generated ideas entirely indistinguishable.
• Black-box LLM: We generated and paraphrased ideas using SOTA black-box LLMs. However, the field is rapidly evolving, and we could not incorporate some of the latest models, such as GPT-4.5 or Claude-3.7. We also couldnot include LLMs from other platforms like Llama, Mistral, and Gemma. Furthermore, the reliance on black-box models limits interpretability, as we lack insight into their internal mechanisms, decision-making processes, and biases. This restricts our ability to analyze why certain ideas are generated or transformed in specific ways, making it harder to attribute detectability degradation to intrinsic model behaviors versus external linguistic shifts.
We collected a total of 18,581 papers in total as shown in table 4 Guidelines:
• Focus solely on articulating the main problem, providing only the context necessary to understand the issue.
• Provide a concise and clear explanation of the problem in exactly one paragraph.
• Do not summarize, hint at, or include any aspects of the solution provided in the paper.
• Avoid using phrases such as ẗhis paperör referring to the document itself.
We used two types of prompting for LLM idea generation. Both approaches take the research problem statement and the instructions as input.
Approach 1 (General): Act as an experienced researcher. Read the problem statement and devise your idea to solve the problem in a detailed manner.Present the research solution in the first person plural (i.e., ‘we’), as if we are the authors of the idea.
Approach 2 (Detailed):Assume the role of an experienced researcher. You are presented with a problem statement. Your task is to devise a detailed research solution to address the problem. Present the solution as if we are the authors of the idea, using the first-person plural (“we”). Your response should include the following elements:
• Clarify the problem clearly to provide proper context.
• Outline the core idea or approach we propose to solve the problem. Clearly explain the methodology, frameworks, or techniques involved.
• Provide a step-by-step plan for how we would execute the solution, including any data, tools, or experimental setup required.
• Highlight the expected results or impact of the solution.
• Explain why our proposed solution is novel and how it contributes to the field.
• If there are risks or potential limitation state that briefly
Ensure the response is detailed, logical, and well-structured, with researchers in your field as a target audience.
General Prompting:
Given the research problem statement, extract only the main idea from the following research document. Focus solely on the core problem being addressed and the key idea proposed to solve it. Do not include discussions about previous works, results, or any extrapolation. Ensure absolute fidelity to the research document-do not add, remove, or alter any idea.
For Non-expert Audience: Assume you have a non-expert general audience, who wants to lsiten to your research summary. Now, given the research problem statement, Extract only the main idea from the following research document, and avoid technical jargons. Focus solely on the core problem being addressed and the key idea proposed to solve it. Do not include discussions about previous works, results, or any extrapolation. Ensure absolute fidelity to the research document-do not add, remove, or alter any idea.
Brief Summary: Assume you are in a conference and you have an extremely short time to explain your research. Extract only the main idea from the following research document. Focus solely on the core problem being addressed and the key idea proposed to solve it. Do not include discussions about previous works, results, or any extrapolation. Ensure absolute fidelity to the research document-do not add, remove, or alter any idea.
Assume you are explaining this research to a highly technical audience, such as engineers or scientists. Given the research problem statement, provide a deep, step-by-step breakdown of the research while maintaining a clear and structured explanation. Do not discuss previous work, results, or make any extrapolations. Ensure absolute fidelity to the research document-do not add, remove, or alter any idea.
The paper: Alet, F., Lopez-Contreras, J., Koppel, J., Nye, M., Solar-Lezama, A., Lozano-Perez, T., … & Tenenbaum, J. (2021, July). A large-scale benchmark for few-shot program induction and synthesis. In International Conference on Machine Learning (pp. 175-186). PMLR.
The primary problem being addressed is the lack of a substantial, real-world dataset for few-shot program induction and synthesis, which is crucial for training machine learning models to generalize effectively from limited examples. While existing methods often rely on synthetic datasets generated from Domain Specific Languages (DSLs), they fail to capture the complexities and nuances of meaningful programs in generalpurpose programming languages like C++. The challenge lies in generating a large collection of program induction tasks that satisfy the necessary properties for effective learning, including well-defined inputoutput examples that are representative of the real-world contexts in which these programs operate. In our research, we address a significant challenge in the field of AI: the need for few-shot program induction and synthesis. Traditional machine learning methods often require vast amounts of data to perform effectively, which is not feasible for the task of program synthesis. The lack of a large-scale benchmark for analyzing few-shot program induction has created a gap in exploring how to train algorithms to generalize from limited examples effectively. By leveraging existing human-generated code and associated unit tests, we aim to dramatically expand the dataset for program induction tasks, thus facilitating more robust learning and generalization for AI systems.
To tackle this issue, we introduce a novel benchmarking dataset named PROG RES. This dataset synthesizes a large collection of program induction tasks by extracting subprograms from real-world codebases (specifically those from competitive programming platforms) and associating them with meaningful input-output examples derived from their unit tests. Our approach focuses on using real programs instead of synthetic data, which significantly enhances the relevance and quality of the training examples. By deriving input-output pairs from subprograms, we provide a structured learning curriculum that reflects the complexities present in practical programming scenarios while keeping the tasks manageable for current machine learning models.
The novelty of our idea lies in its dual focus: not only do we construct a rich benchmark from actual code, but we also innovate by isolating subprograms that can streamline the learning process. This allows for the development of more efficient algorithms capable of tackling complex programming problems with fewer examples. By ensuring that our dataset includes comprehensive tests that cover potential edge cases, we maximize the utility of each task, preparing algorithms to perform robustly in varied real-world programming contexts. Our approach not only enriches the landscape of few-shot learning in program synthesis but also lays a foundational framework for future research in the field, aiming to bridge the gap between human-like programming skills and machine learning capabilities.
We are addressing a significant shortcoming in the field of few-shot program induction and synthesis-namely, the lack of diverse and rich real-world datasets. Existing synthetic datasets often fall short when it comes to capturing the complexities and variabilities of programming tasks as they exist in actual software projects. Our goal is to bridge this gap by collecting, curating, and augmenting a comprehensive dataset of programming tasks from various real-world contexts. This initiative is particularly focused on programs written in C++, a widely utilized general-purpose programming language that presents unique challenges due to its diverse applications and intricate syntax.
To achieve this, we have developed a systematic approach that includes the rigorous exploration of open-source code repositories such as GitHub and Bitbucket. Using APIs and advanced web scraping techniques, we aim to compile a substantial and varied collection of existing C++ projects that reflect real-world applications ranging from game development to embedded systems. This foundational data collection step is crucial, as it allows us to extract meaningful programming tasks, complete with detailed input-output specifications, constraints, and contextual information-something most current datasets lack. By sourcing these tasks directly from practical coding scenarios, we ensure their relevance and potential for real-world applicability.
What sets our project apart is not only the breadth of our data collection but also the meticulous methodology we employ for task definition, annotation, and validation. We plan to engage domain experts to review our extracted tasks, alongside crowdsourcing efforts to enhance diversity in the dataset. Each task will be carefully structured to include essential details such as example input-output pairs and metadata that highlights the challenges posed in real-world coding scenarios. Furthermore, we aim to enhance our model’s fewshot learning capabilities through controlled data augmentation strategies-introducing variability and complexity that better mirrors the real-world coding environment. This unique combination of rigorous data collection, expert validation, and innovative augmentation methodologies positions our approach as a novel and impactful contribution to the landscape of machine learning for program synthesis.
The research addresses the lack of a substantial, real-world dataset for few-shot program induction and synthesis by introducing PROG RES, a novel benchmarking dataset that extracts subprograms from real-world codebases with associated unit tests, providing meaningful input-output examples to facilitate more effective machine learning training with limited examples.
The research focuses on improving how artificial intelligence learns to write computer programs by creating a new, large collection of real-world programming tasks. Instead of using simple, artificially created examples, the researchers gathered actual code and its corresponding tests from competitive programming platforms. This approach provides meaningful and complex examples, allowing AI models to better understand and generate programs even when they have only a few examples to learn from.
The core problem being addressed is the lack of a substantial, real-world dataset for few-shot program induction and synthesis, which is essential for training machine learning models to generalize from limited examples. The key idea proposed to solve this problem is the introduction of a novel benchmarking dataset named PROG RES, which This research establishes a structured approach to creating a robust dataset for few-shot program induction, emphasizing real-world applicability while maintaining technical rigor in the extraction and validation processes.
Click to add a cell.
The research aims to address the lack of diverse, real-world datasets for few-shot program induction and synthesis by systematically collecting and curating a comprehensive dataset of C++ programming tasks from open-source repositories. The approach involves using APIs and web scraping to extract meaningful programming tasks, followed by expert validation and data augmentation to create a rich, contextually representative dataset that captures the complexities of real-world coding scenarios.
The main idea of this research is to create a large and diverse collection of real-world C++ programming tasks. This collection will help train machine learning models to better understand and generate programs by using examples that reflect actual coding scenarios, rather than simplified or artificial ones.
The core problem being addressed is the lack of a substantial, real-world dataset for few-shot program induction and synthesis, which is essential for training effective machine learning models. The key idea proposed to solve this problem is to collect, curate, and augment a comprehensive dataset of programming tasks from various real-world con-
When cross-stage train-test is performed, Stage 1 shows a larger degradation, since it contains only 25% of the data compared to the later stages. In Stages 2 to 5, models generally achieve
Check the Appendix of the full paper: https: //github.com/sadat1971/Erosion_LLM_ Signatures/blob/main/Paper/RANLP_ _LLMErosion_cameraReady.pdf
📸 Image Gallery