RoCo: Role-Based LLMs Collaboration for Automatic Heuristic Design
📝 Original Info
- Title: RoCo: Role-Based LLMs Collaboration for Automatic Heuristic Design
- ArXiv ID: 2512.03762
- Date: 2025-12-03
- Authors: Jiawei Xu, Feng-Feng Wei, Wei-Neng Chen
📝 Abstract
Automatic Heuristic Design (AHD) has gained traction as a promising solution for solving combinatorial optimization problems (COPs). Large Language Models (LLMs) have emerged and become a promising approach to achieving AHD, but current LLM-based AHD research often only considers a single role. This paper proposes RoCo, a novel Multi-Agent Role-Based System, to enhance the diversity and quality of AHD through multi-role collaboration. RoCo coordinates four specialized LLM-guided agents-explorer, exploiter, critic, and integrator-to collaboratively generate high-quality heuristics. The explorer promotes long-term potential through creative, diversity-driven thinking, while the exploiter focuses on short-term improvements via conservative, efficiency-oriented refinements. The critic evaluates the effectiveness of each evolution step and provides targeted feedback and reflection. The integrator synthesizes proposals from the explorer and exploiter, balancing innovation and exploitation to drive overall progress. These agents interact in a structured multi-round process involving feedback, refinement, and elite mutations guided by both short-term and accumulated long-term reflections. We evaluate RoCo on five different COPs under both white-box and black-box settings. Experimental results demonstrate that RoCo achieves superior performance, consistently generating competitive heuristics that outperform existing methods including ReEvo and HSEvo, both in white-box and black-box scenarios. This role-based collaborative paradigm establishes a new standard for robust and high-performing AHD.📄 Full Content
In recent years, large language models (LLMs), such as GPT-4 (Achiam et al. 2023), have demonstrated impressive capabilities across various reasoning tasks (Hadi et al. 2023), leading to the development of LLM-based automatic heuristic design (AHD) methods that iteratively refine heuristics through evolutionary program search (Liu et al. 2024c;Chen, Dohan, and So 2023). Early works such as FunSearch (Romera-Paredes et al. 2024) and EoH (Liu et al. 2024a) adopt population-based frameworks that evolve heuristic functions using LLMs within fixed algorithmic templates. ReEvo (Ye et al. 2024) enhances heuristic quality through reflection-based reasoning (Shinn et al. 2023), while HSEvo (Dat, Doan, and Binh 2025) introduces diversity metrics and harmony search to improve population diversity. Recent work MCTS-AHD (Zheng et al. 2025) extends this line of research by organizing heuristics in a tree-based structure guided by Monte Carlo Tree Search, enabling structured refinement beyond conventional population-based methods. Together, these methods represent a growing family of LLM-EPS techniques that automate the design of high-quality heuristics for combinatorial and black-box optimization tasks.
Although recent LLM-based approaches to automatic heuristic design (AHD) have demonstrated success in evolving algorithms via population-level or iterative sampling methods, their performance remains unstable when applied to combinatorial optimization problems (COPs), especially in black-box scenarios. These approaches generally employ a single LLM with various prompt strategies, but do not explicitly model distinct agent roles or structured inter-agent coordination. Another relevant effort, LEO (Brahmachary et al. 2025), introduces separate explore and exploit pools to balance diversity and refinement in LLM-driven optimization. However, it lacks explicit role modeling or inter-agent communication, and its performance on complex COPs remains inconsistent. This ultimately limits their ability to adaptively decompose complex tasks or exploit diverse reasoning patterns.
Out of the above consideration, our work draws inspiration from LLM-based Multi-Agent Systems (MAS) (Zhang et al. 2023c;Li et al. 2024), introducing a collaborative agent framework, named RoCo(Role-based LLMs Collaboration), in which LLM-based agents assume specialized roles, such as explorer, exploiter, critic, and integrator, to collectively generate, critique, and refine algorithmic heuristics. Our method extends the population-based architecture of EoH, inheriting its advantages in maintaining heuristic diversity and leveraging population-level selection, while introducing an additional layer of role specialization to enable structured agent-level cooperation. Exploration and exploitation agents generate individuals, critics offer reflection and suggestions, and integrators consolidate the individual outputs of explorers and exploiters to generate new and improved heuristics, balancing exploration and exploitation. This design of critic and integrator is further inspired by multi-agent debate systems (Du et al. 2023a;Liang et al. 2023), where dialogic reasoning and reflective interaction support deep thinking and innovation. However, unlike adversarial debates, our agents engage in cooperative self-improvement, guided by critic feedback, and equipped with short-term (per round) and long-term (cross-round) reflection mechanisms. The longhorizon reflection mechanism is distilled from short-term feedback across rounds, capturing both successful patterns and failed heuristic attempts. Inspired by recent work that highlights the value of learning from exploration failures (An et al. 2023;Song et al. 2024), it enables agents to accumulate insight from both progress and missteps. Such a design leverages both the coordination potential of multi-agent collaboration and the iterative divergence-convergence dynamics of debate, fostering more robust and generalizable heuristic discovery.
In experiments, we apply our approach, RoCo, to five combinatorial optimization problems (COPs) under both white-box and black-box settings. RoCo consistently accelerates the convergence of heuristic search in white-box scenarios and enhances performance stability in black-box scenarios by evolving high-quality heuristics across diverse problem structures.
Our main contributions are as follows:
(1) We propose RoCo, a novel LLM-based automatic heuristic design (AHD) framework that introduces role-specialized agents:explorers, exploiters, critics, and integrators, for structured collaboration in generating and refining heuristics. (2) RoCo incorporates coordinated multi-agent interaction and a reflection process that captures both successful strategies and failed heuristic attempts, enabling agents to learn adaptively from mistakes and improve search quality over time.
A combinatorial optimization problem (COP) instance is defined as (Zheng et al. 2025):
where: • I P : the set of input instances (e.g., coordinates in TSP), • S P : the set of feasible solutions, • f : S P → R: the objective function to minimize. A heuristic h : I P → S P maps an input to a feasible solution. The goal of Automatic Heuristic Design (AHD) is to find the best heuristic h * in a heuristic space H, maximizing the expected performance:
LLM-based Evolutionary Program Search (LLM-EPS) integrates large language models into evolutionary computation frameworks to automate the design of heuristics. Representative methods include FunSearch (Romera-Paredes et al. 2024), which adopts an island-based strategy for evolving heuristics in mathematical problems; EoH (Liu et al. 2024a), which applies genetic algorithms with chain-ofthought prompting to improve solutions for tasks like TSP and bin packing ; and ReEvo (Ye et al. 2024), which introduces reflective evolution using paired LLMs. More recent approaches like HSEvo (Dat, Doan, and Binh 2025) and MEoh (Yao et al. 2025) explore diversity-driven harmony search with genetic algorithms and multi-objective strategies with dominance-dissimilarity mechanisms, respectively. MCTS-AHD (Zheng et al. 2025) mitigates this by using a tree-based structure to guide LLM exploration more flexibly, while RedAHD (Thach et al. 2025) further enables end-to-end heuristic design by prompting LLMs to construct and refine problem reductions without relying on fixed frameworks. To support the implementation and evaluation of such LLM-EPS methods, LLM4AD has been developed as a unified Python platform, integrating modularized blocks for search methods, algorithm design tasks, and LLM interfaces, along with a unified evaluation sandbox and comprehensive support resources (Liu et al. 2024b).
Recent work on LLM-based Multi-Agent Systems (MAS) has increasingly focused on collaboration mechanisms (Tran et al. 2025;Li et al. 2023;Pan et al. 2024) that facilitate interaction among agents, allowing them to coordinate actions, share information, and solve tasks collectively. Early methods explore fixed interaction patterns such as debate to enhance reasoning (Du et al. 2023b;Liang et al. 2023), while later approaches introduce adaptive communication protocols for multi-round decision-making (Liu et al. 2023).
Other frameworks support broader applications by organizing LLM agents to work jointly on complex problems (Hong et al. 2023;Wu et al. 2024).Our method follows a rolebased collaboration protocol (Chen et al. 2023;Talebirad and Nadiri 2023), where agents operate under distinct predefined roles to tackle subgoals modularly and cooperatively (Tran et al. 2025).
3 The Proposed RoCo
To enable effective and scalable AHD, we propose a rolebased collaborative system (RoCo) powered by multiple large language model (LLM) agents. This system leverages structured collaboration through clearly defined agent roles, shared memory, and multi-round interaction. Formally, our system is defined as (Tran et al. 2025):
i=1 : a set of n LLM-based agents. • R = {explorer, exploiter, critic, integrator}: the predefined set of agent roles. • E: the shared environment (e.g., population pool, reflection history). • C: a set of communication channels among agents. • x collab : the system input (e.g., selected individuals from EoH population). • y collab : the system output (e.g., improved heuristics via collaboration and reflection).
Each agent a i is further characterized by the tuple:
) • L i : the underlying language model (e.g., GPT-4).
• R i ∈ R: the agent’s role.
• S i : agent state, including current individuals and reflection buffer. • T i : tools (e.g., Python interpreter).
Finally, the entire system executes collaborative optimization as a function over its inputs and shared environment:
The heuristic representation in RoCo follows the structure of the EoH framework. Each heuristic h ∈ H is represented as a tuple:
- A natural language description desc(h) outlining the core idea of h. 2. A code implementation code(h), defined as a Python function that maps an input instance ins ∈ I P to a feasible solution h(ins) ∈ S P . 3. A fitness score g(h), measuring the expected performance of the heuristic across a distribution of instances, as defined in Equation 2. This structured representation enables seamless integration of newly generated heuristics into the EoH evaluation pipeline, while ensuring compatibility with standard analysis and benchmarking tools.
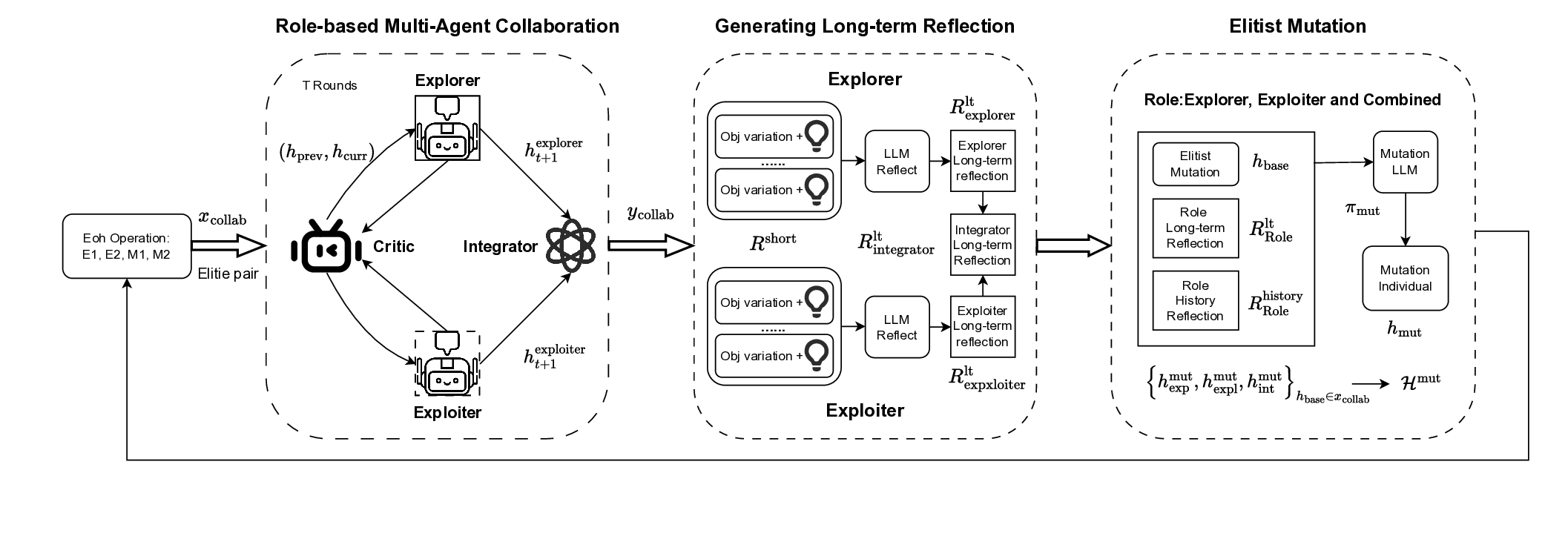
Our proposed RoCo system is a multi-agent collaboratereflection module designed to enhance heuristic generation in the evolutionary framework. As illustrated in Figure 1, RoCo operates as a plug-in system integrated within the Evolution of Heuristics (EoH) paradigm, extending the standard evolutionary loop with collaborative reasoning, structured role division, and multi-agent learning.
At each generation g, the EoH framework maintains a population P g = {h g 1 , h g 2 , . . . , h g N } of heuristics. The population is evolved by applying four prompt-based operators, classified into two categories:
• Exploration Operators (E1, E2): generate heuristics by introducing diversity or combining conceptual patterns from multiple parents. • Modification Operators (M1, M2): refine or adjust existing heuristics via mutation or parameter tuning. The details of Eoh operators are exhibited in Appendix E. This results in a candidate pool of up to 4N new heuristics. Among these, a subset of heuristics is selected and passed to our multi-agent collaboration system S to undergo a structured refinement process.
Formally, two heuristics h (1) and h (2) are sampled from P g and passed as input:
The selection of elite individuals follows the strategy described in Appendix E.
The RoCo system then initiates a multi-round collaboration involving agents with distinct functional roles. The output is a set of improved heuristics directly produced from multi-round collaboration, covering different reasoning strategies:
To construct the next-generation population P g+1 , we first gather all heuristics generated by RoCo in generation g, including the collaborative outputs y collab produced during debate and the full set of elite-mutated individuals H mut . These together form the RoCo candidate set:
We then merge this set with the heuristic pool P g+1 eoh generated by standard EoH operators to obtain the full candidate set:
C g+1 full = C g+1 RoCo ∪ P g+1 eoh (9) From this combined set, we deterministically select the top N individuals with the best objective values to form the next population:
This approach ensures that high-quality heuristics, whether discovered through structured collaboration, memory-driven mutation, or standard evolutionary operators, are retained in the population. The details are shown in Algorithm 1.
Each agent in the RoCo system is assigned a specific role to facilitate decomposition of the overall heuristic optimization task into well-defined sub-tasks. The four main roles are: Explorer Responsible for generating diverse heuristics through conceptual exploration:
Exploiter Focuses on local improvement by refining promising candidates:
Critic Acts as an evaluator and reflective thinker, identifying strengths and limitations in heuristics and providing structured feedback. Evaluates pair (h prev , h curr ) and gives feedback and reflection:
Integrator Fuses two candidates with both exploration and exploitation based on their objective scores:
After all collaborative rounds, it performs elitist fusion of the best-performing explorer and exploiter heuristics. Details are exhibited in Algorithm 1 Each agent a i = (L i , R i , S i , T i ) operates with its own language model backend L i (e.g., GPT-4), a predefined role R i ∈ R such as explorer that governs its behavioral policy, an internal state S i containing its current candidate heuristics and optional reflection buffers, and a toolset T i that enables it to evaluate heuristics by executing them and obtaining objective values. The core behavior of each agent is determined by a role-specific policy function π role , which guides its reasoning and interactions within a multi-round collaborative loop.
RoCo introduces a multi-round collaborative debate process where agents iteratively refine heuristics over T steps. In each round, the critic agent plays a central role by evaluating the most recent heuristic pair and providing feedback, as described in Equation 13.
After T rounds, the accumulated critic reflections R short role are synthesized into long-term role-specific memory by incorporating not only the raw feedback but also the associated objective values and their changes:
) Here, g t-1 and g t are the objective values before and after the t-th reflection, with ∆g t = g t -g t-1 capturing per-round performance changes. This helps the model infer useful patterns by linking reflection to performance dynamics.
To enable continual learning, each role maintains its own historical memory R history role , formed by aggregating long-term reflections from previous generations. These role-specific historical reflections provide learning signals beyond the current population and enable richer generalization across diverse search states.
Additionally, for integrative reasoning, the long-term reflections from explorer and exploiter can be merged to support integrative generation strategies: R lt integrator = Merge R lt explorer , R lt exploiter (16) To complement collaboration-based generation, RoCo supports a memory-guided elite mutation strategy. For each elite individual h base , three types of memory-augmented mutations are performed:
All resulting mutated individuals from all elite bases are collected into a unified set:
This mechanism mimics a memory-augmented exploitation strategy and supports lifelong learning across generations through diverse role-informed mutations.
This section first introduces the experimental setup, including baseline algorithms and implementation details. We then evaluate the proposed method under two metaheuristic frameworks: Ant Colony Optimization (ACO) (Dorigo, Birattari, and Stutzle 2007) and Guided Local Search (GLS) (Arnold and Sörensen 2019), covering a range of combinatorial optimization problems (COPs). Under the ACO framework, we conduct both white-box and black-box evaluations to assess the method’s generalization and robustness. In the GLS framework, we further demonstrate the effectiveness of our approach on the Traveling Salesman Problem instances. Finally, ablation studies are presented to analyze the contribution of each system component.
Benchmarks: To evaluate the generality and robustness of our approach, we conduct experiments across a suite of combinatorial optimization problems (COPs) spanning multiple structural categories. Specifically, we include: the Traveling Salesman Problem (TSP), Capacitated Vehicle Routing Problem (CVRP), and Orienteering Problem (OP) as representative routing tasks; the Multiple Knapsack Problem (MKP) for subset selection; and the Bin Packing Problem (BPP) for grouping-based challenges. These benchmarks are widely adopted in the COP literature and collectively cover a broad spectrum of algorithmic patterns and difficulty profiles.
Baselines: To assess the effectiveness of our system in generating high-quality heuristics, we compare it against a set of strong baselines. These include several representative LLM-based automatic heuristic design (AHD) approaches such as EoH, ReEvo, and HSEvo, as well as the most recent MCTS-AHD framework. Additionally, we include Deep-ACO (Ye et al. 2023), a neural combinatorial optimization method tailored for ACO frameworks, along with manually designed heuristics, ACO (Dorigo, Birattari, and Stutzle 2007).
Settings: In our RoCo multi-agent system, the number of collaboration rounds is fixed to 3, with a total LLM API budget capped at 400 calls per generation. The underlying EoH framework uses a population size of 10. All experiments are conducted using GPT-4o-mini as the language model. Rolespecific temperatures are set as follows: explorer with 1.3, exploiter with 0.8, and default 1.0 for all other roles. Detailed dataset configurations and general framework settings are provided in Appendix D.
We first evaluate our RoCo-based heuristic generation system under the Ant Colony Optimization (ACO) framework, a widely adopted paradigm that integrates stochastic solution sampling with pheromone-guided search. Within this framework, our method focuses on designing heuristic functions that estimate the potential of solution components, which are then used to bias the construction of solutions across iterations. We apply this approach to five classic and diverse NP-hard combinatorial optimization problems: TSP, CVRP, OP, MKP, and offline BPP.
Under the white-box prompt setting , we evaluate LLMbased Automatic Heuristic Design (AHD) methods across five COPs. As shown in Table 1, experiments conducted on 64 instances per problem demonstrate that our RoCo method achieves competitive performance. Notably, RoCo outperforms traditional ACO across all problems and surpasses DeepACO in most cases. Compared to other LLM-AHD approaches, RoCo attains the highest scores in 10 out of 15 problem-size combinations, demonstrating its effectiveness for heuristic design in white-box optimization.
As visualized in Figure 2, which plots the evolution of alltime best objective values across diverse problem types and scales, RoCo not only achieves strong final performance but also demonstrates faster convergence across most problem types beyond TSP, where all methods converge similarly. Specifically, in CVRP, MKP, BPP, and OP, RoCo reaches near-optimal performance within fewer iterations compared to baselines, indicating superior sample efficiency. Furthermore, RoCo exhibits robust scalability across problem sizes, consistently maintaining leading or near-leading performance as the instance scale increases-from small to large sizes-across all five combinatorial optimization problems. This highlights RoCo’s capacity to generalize its heuristic design abilities across both simple and complex scenarios under white-box prompting conditions.
Under the black-box setting, where LLMs receive only the textual prompt without access to the internal solver state, we evaluate five AHD methods across TSP, OP, CVRP, MKP, and offline BPP. As shown in Table 2, RoCo achieves strong and stable performance across all problem types and sizes. Notably, RoCo yields the best average results in numerous cases, and performs on par with the best-performing method (ReEvo) in terms of overall heuristic quality. Complementing these results, Figure 3 illustrates the distribution of objective values across multiple runs. RoCo consistently demonstrates smaller standard deviations, indicating enhanced robustness and stability under prompt-only settings. These findings highlight the generality and reliability of RoCo in automatic heuristic design, even under limitedaccess black-box conditions. Guided Local Search (GLS). We further evaluate RoCo in the GLS framework by evolving penalty heuristics that guide local search in escaping local optima. Specifically, we embed the best heuristics produced by RoCo into KGLS, a state-of-the-art GLS baseline, and compare its performance (denoted as KGLS-RoCo) against several competitive methods, including NeuOpt (Ma, Cao, and Chee 2023), GN-NGLS (Hudson et al. 2021), EoH (Liu et al. 2024a), and KGLS-ReEvo (Arnold and Sörensen 2019). As shown in Table 4, KGLS-RoCo achieves the lowest average optimality gap on TSP200 and remains highly competitive across other sizes. These results indicate that RoCo can effectively enhance GLS by producing generalizable and high-quality penalty heuristics.
To better understand the contribution of each core component in the RoCo framework, we conduct a comprehensive ablation study on the TSP dataset under both white-box and black-box prompting scenarios. The ablations target the functional roles of key agents (explorer, exploiter, integrator) as well as the elite mutation mechanism and the multiagent synergy (MAS), comparing each variant against the full RoCo system and the baseline Evolution of Heuristics (EoH). The results are shown in Table 3. Specifically, we disable each role or component individually: the explorer agent responsible for conceptual diversity, the exploiter agent focusing on local refinement, the integra- Figure 3: Heuristic performance evaluation (mean and standard deviation) across diverse datasets (TSP200, OP200, CVRP200, MKP500, BPP1000) under black-box setting, with results aggregated from four independent runs per dataset, using LLM-based AHD.
tor agent for solution fusion, the elite mutation strategy that leverages historical memory, and the MAS mechanism that coordinates collaborative interactions. Each ablated variant is evaluated over multiple runs, and results are reported as mean ± standard deviation of objective values. Notably, the performance drop under the black-box setting is generally more pronounced, indicating that the absence of any single component hampers the system’s ability to compensate for limited internal feedback. An additional ablation on MAS further shows that while the memory-guided elite mutation alone can outperform the baseline, it still falls short of the full RoCo system. This demonstrates that role-based collaboration provides additional stability and exploration benefits beyond what is achievable through memory alone, especially in black-box scenarios. This underscores the importance of each role and the necessity of structured role-based collaboration in achieving robust heuristic evolution.
We further investigate the effect of the number of collaboration rounds in RoCo. As shown in Table 3, increasing the number of rounds from 1 to 3 consistently improves performance, particularly under black-box prompting where the gap between single-round and multi-round variants is more pronounced. Extending the ablation to 4 and 5 rounds reveals only marginal gains beyond 3 rounds, confirming that three collaboration rounds achieve an optimal balance between performance and efficiency. This highlights the importance of iterative role interactions for refining heuristic candidates and confirms that multi-round collaboration enhances both robustness and generalization in the RoCo framework.
This paper presents RoCo, a novel multi-agent role-based system for Automatic Heuristic Design (AHD) that leverages structured collaboration among four specialized LLMguided agents-explorer, exploiter, critic, and integrator. Integrated into the Evolution of Heuristics (EoH) framework, RoCo enhances heuristic generation through multi-round reasoning, elite mutations, and role-based refinement. Experiments across five combinatorial optimization problems under both white-box and black-box settings demonstrate that RoCo achieves competitive or superior performance compared to state-of-the-art methods. RoCo exhibits faster convergence, better generalization across problem scales, and greater robustness under limited-feedback conditions, setting a new standard for collaborative LLM-based AHD.
Future directions include applying RoCo to more NPhard problems and other frameworks, beyond combinatorial optimization (e.g., continuous, mixed-integer). Exploring RoCo’s potential in real-world applications, such as logistics and scheduling, remains an exciting avenue for practical impact.
The following pseudocode details the core evolutionary framework of RoCo, including key processes such as population initialization, agent-based heuristic collaboration, memory-guided mutation, and candidate selection for next-generation evolution.
Algorithm 1 RoCo’s Evolutionary Framework for Heuristic Population Optimization Require: Initial population P 0 of size N 1: for generation g = 1 to G do 2:
Apply standard EoH operators (E1-M2) to generate P g eoh 3:
Sample elite pair (h (1) , h (2) ) ⊂ P g 4:
Initial critic comparison between elites:
5:
Initialize agent states from h (2) with critic feedback:
7:
for round t = 1 to T do 10:
Critic evaluates current heuristics:
11:
) 12:
Explorer proposes new heuristic:
13:
Exploiter refines current heuristic:
15:
Integrator fuses both heuristics:
The Traveling Salesman Problem (TSP) is a classic optimization challenge that seeks the shortest possible route for a salesman to visit each city in a list exactly once and return to the origin city. As one of the most representative combinatorial optimization problems (COPs) , synthetic TSP instances for our experiments are constructed by sampling nodes uniformly from the [0, 1] 2 unit square, following the dataset generation protocol described in ReEvo (Ye et al. 2024).
The Capacitated Vehicle Routing Problem (CVRP) extends the Traveling Salesman Problem (TSP) by introducing capacity constraints on vehicles. It aims to plan routes for multiple capacity-limited vehicles (starting and ending at a depot) to satisfy customer demands while minimizing total travel distance. For experimental instances: Across experiments, the depot is fixed at the unit square center (0.5, 0.5), following the dataset generation protocol of ReEvo (Ye et al. 2024).
The Orienteering Problem (OP) aims to maximize the total collected score by visiting a subset of nodes within a limited tour length constraint. Following the dataset generation strategy of Ye et al. (2024Ye et al. ( , 2023)), we uniformly sample all nodes, including the depot, from the unit square [0, 1] 2 . The prize p i associated with each node i is set according to a challenging distribution:
where d 0i denotes the Euclidean distance from the depot to node i, and k is a fixed scaling parameter. The tour length constraint is also designed to be challenging, with the maximum length set to 3, 4, 5, 8, and 12 for OP50, OP100, OP200, OP500, and OP1000, respectively.
The Multiple Knapsack Problem (MKP) involves assigning items (each with a weight and value) to multiple knapsacks to maximize total value, without exceeding any knapsack’s capacity. For instance generation, we follow ReEvo (Ye et al. 2024): item values v i and weights w ij (for item j and knapsack i) are uniformly sampled from [0, 1], and each knapsack’s capacity C i is drawn from (max j w ij , j w ij ) to ensure valid instances.
The Offline Bin Packing Problem (Offline BPP) aims to pack a set of items with known sizes into the minimum number of bins of fixed capacity W , where all items are available for assignment upfront. For instance generation, we follow ReEvo (Ye et al. 2024): bin capacity is set to W = 150, and item sizes are uniformly sampled from [20,100].
Guided Local Search (GLS) explores the solution space via local search operations, where heuristics guide the exploration process. Following the setup in ReEvo (Ye et al. 2024), we adopt a modified GLS algorithm that incorporates perturbation phases: edges with higher heuristic values are prioritized for generalization (Arnold and Sörensen 2019).
In the training phase, we evaluate candidate heuristics on the TSP200 instance using 1200 GLS iterations. For generating results in our experiments (e.g., Table 4), we use the GLS parameters specified in Table 5 (consistent with ReEvo). Iterations terminate when a predefined threshold is reached or the optimality gap is reduced to zero.
§
📸 Image Gallery