Dynamic Content Moderation in Livestreams: Combining Supervised Classification with MLLM-Boosted Similarity Matching
📝 Original Info
- Title: Dynamic Content Moderation in Livestreams: Combining Supervised Classification with MLLM-Boosted Similarity Matching
- ArXiv ID: 2512.03553
- Date: 2025-12-03
- Authors: Wei Chee Yew, Hailun Xu, Sanjay Saha, Xiaotian Fan, Hiok Hian Ong, David Yuchen Wang, Kanchan Sarkar, Zhenheng Yang, Danhui Guan
📝 Abstract
Content moderation remains a critical yet challenging task for largescale user-generated video platforms, especially in livestreaming environments where moderation must be timely, multimodal, and robust to evolving forms of unwanted content. We present a hybrid moderation framework deployed at production scale that combines supervised classification for known violations with reference-based similarity matching for novel or subtle cases. This hybrid design enables robust detection of both explicit violations and novel edge cases that evade traditional classifiers. Multimodal inputs (text, audio, visual) are processed through both pipelines, with a multimodal large language model (MLLM) distilling knowledge into each to boost accuracy while keeping inference lightweight. In production, the classification pipeline achieves 67% recall at 80% precision, and the similarity pipeline achieves 76% recall at 80% precision. Large-scale A/B tests show a 6-8% reduction in user views of unwanted livestreams. These results demonstrate a scalable and adaptable approach to multimodal content governance, capable of addressing both explicit violations and emerging adversarial behaviors. CCS Concepts • General and reference → General conference proceedings.📄 Full Content
Although content moderation for pre-recorded short videos has been well studied in literature, research focusing specifically on live-streaming moderation remains scarce. The real-time, dynamic, and highly interactive nature of live streaming introduces unique technical and operational challenges that differ significantly from those of static video platforms. Livestreams are also much longer in duration, significantly increasing computational demands and requiring continuous, real-time monitoring. These constraints make it far more difficult to deploy large models directly in the online pipeline, necessitating lighter, optimized approaches. This paper seeks to address this gap by exploring effective content moderation strategies tailored to the demands of live-streaming platforms.
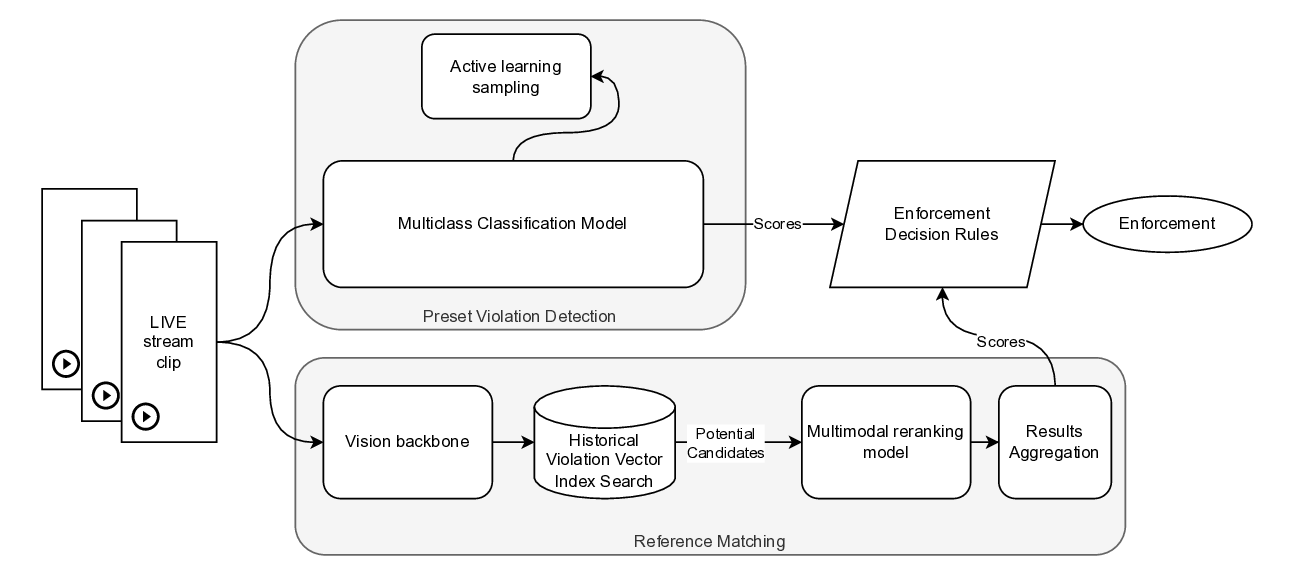
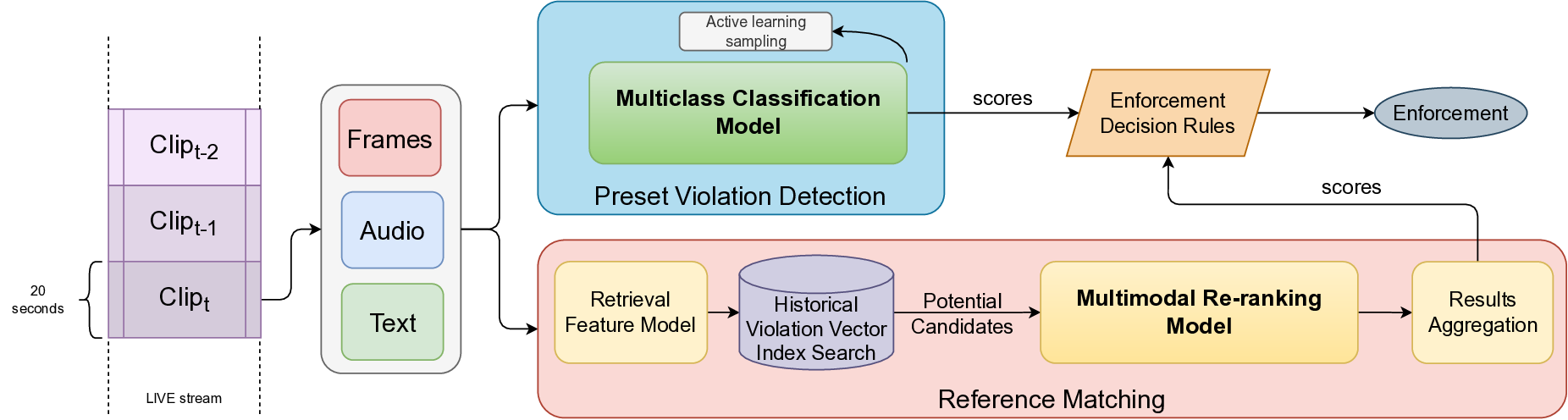
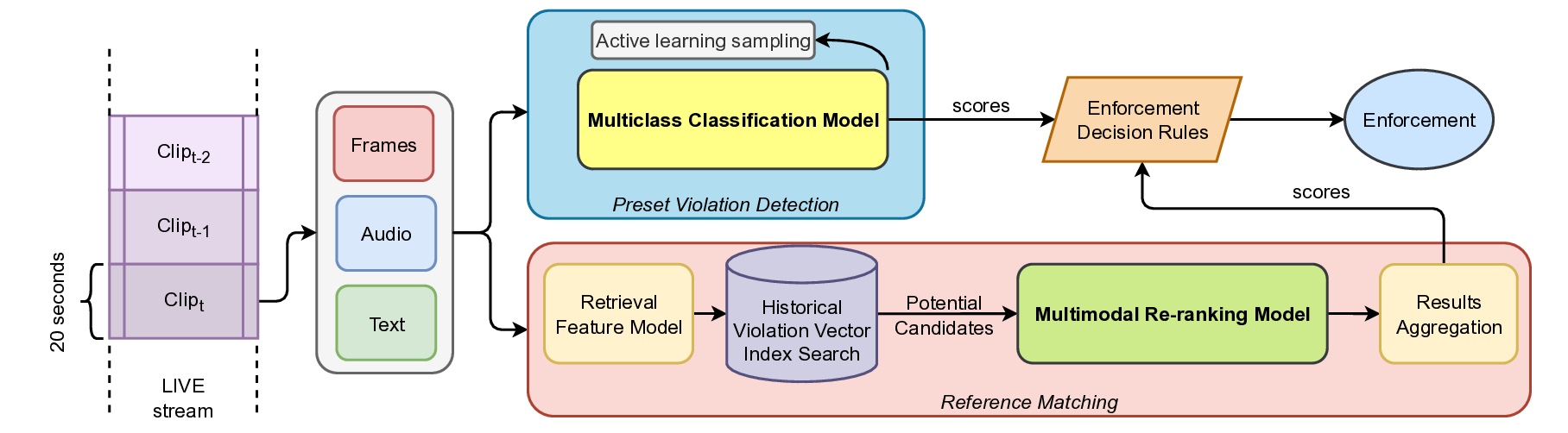
In this work, we propose a hybrid moderation framework that integrates two complementary paradigms: preset violation detection based on supervised multiclass classification and reference-based similarity matching based on video-clip retrieval and re-ranking.
Our architecture is designed to address the dual need for precision in known violation categories and flexibility in identifying emerging or ambiguous edge cases. The system ingests multimodal livestream inputs, processing them through a dual-path architecture. The first path employs a supervised classification model trained on labeled examples to detect explicit, high-confidence violations. The second path leverages a similarity matching engine that compares incoming content to a curated set of known policy violations using semantic and perceptual embeddings, enabling the system to generalize to previously unseen behaviors through nearest-neighbor retrieval. The two paths are complimentary as there is a large portion of detections are exclusive. Specifically, reference matching contributes approximately 22% additional coverage beyond the classification branch. While our offline benchmarks show that a finetuned multimodal large language-vision model (MLLM) would offer the strongest performance, it is not feasible to deploy such a model in production due to resource constraints. Instead, we adopt a knowledge distillation approach, using the MLLM as a teacher to guide and enhance the performance of preset violation detection model and the re-ranking model during training. We evaluate our system on a production-scale live streaming platform, operating in a real-world environment with millions of hours of content. Empirical results show that the hybrid framework significantly improves both coverage and precision, outperforming standalone classifiers or similarity systems by a wide margin. Our contributions can be summarized as follows:
• Hybrid Multimodal Moderation Architecture: We propose a novel dual-path system that unifies supervised multiclass classification with reference-based similarity retrieval, applied over text, audio, and visual modalities. This hybrid design enables highprecision detection of known violations while supporting flexible generalization to emerging and ambiguous policy breaches.
Pre-training for Real-Time Use: We leverage a distillation framework where a strong, large language-vision model (LLM) serves as a teacher to train a lightweight re-ranking model that is feasible for real-time deployment. Additionally, we employ MoCo-style contrastive pretraining with a memory bank and momentum encoder, using CLIP loss to align semantic and perceptual embeddings across modalities. • Production-Scale Deployment with Comprehensive Impact Evaluation: We deploy our system on a large-scale livestreaming platform processing millions of hours of content. Our empirical evaluation demonstrates substantial gains in coverage at high precision, and large scale online A/B experiments show a reduction of unwanted livestream views by 6% to 8%, demonstrating measurable impact in real-world production. Together, these results highlight the promise of hybrid, multimodal approaches for scalable and effective moderation in fast-evolving live-streaming ecosystems.
The prevalence of online video platforms have shifted the dynamics of business, entertainment, and information. Content moderation plays an important role to ensure quality and safety of online video platforms. Human moderation of such systems can incur significant costs, cause negative mental impact on human moderators [8,31], and be prone to inconsistencies and biases [24]. Machinemoderation systems arise as a solution for effective content moderation. Existing methods have applied neural networks towards such tasks, such as utilizing transformers or embedding models for hate speech detection [2,15], CNNs for detecting violative videos [6], and localization modules for video copy detection [11,14,21].
Live-streaming has become a popluar method for content creators to engage with audiences and platforms such as TikTok, Youtube, Twitch, and Red-Note have popularized live-streaming content. Live streaming platforms pose unique challenges for content moderation due to the real-time, dynamic, and multimodal nature of the content being broadcast. Unlike pre-recorded videos or static content, live streams require immediate detection and intervention to prevent harmful or policy-violating material from reaching viewers.
Recent works have applied large language models (LLMs) and have shown they can be effective at content moderation for languagerelated tasks [16,26,39,40]. However, for online platforms, the challenge arises from the complexity of the media, which involve complex multi-modal signals including visual, auditory, and speech. Multi-modal LLMs (MLLMs) have explored techniques to integrate additional modalities, such as video or audio, from prevailing proprietary models such as GPT4o [36] and Gemini [35], to recent open-source models such as InternVL [4], QwenAudio [5], and Llava-One-Vision [19]. As such, MLLMs have began to be applied in the context of content moderation, by integrating image/video information [1,22], as well as audio [23]. The key challenge lies in effectively utilizing the MLLM to real-world use cases in a resourceefficient way.
Although multimodal large language models (MLLMs) deliver superior policy-understanding and cross-modal reasoning capabilities, their size and latency prohibit direct deployment in real-time moderation systems. Knowledge distillation [12] (KD) offers a principled solution by transferring the rich, multimodal knowledge of a teacher LLM into a compact student model optimized for low-latency inference [27,38]. Beyond logits, secondary KD techniques-such as aligning intermediate hidden representations or relational structures-have proven useful for preserving internal model semantics [34]. For instance, contrastive distillation approaches like CoDIR train the student to discriminate teacher-crafted embeddings from negative examples, improving compression efficacy [34]. These methods support knowledge transfer even when student architectures differ considerably from the teacher.
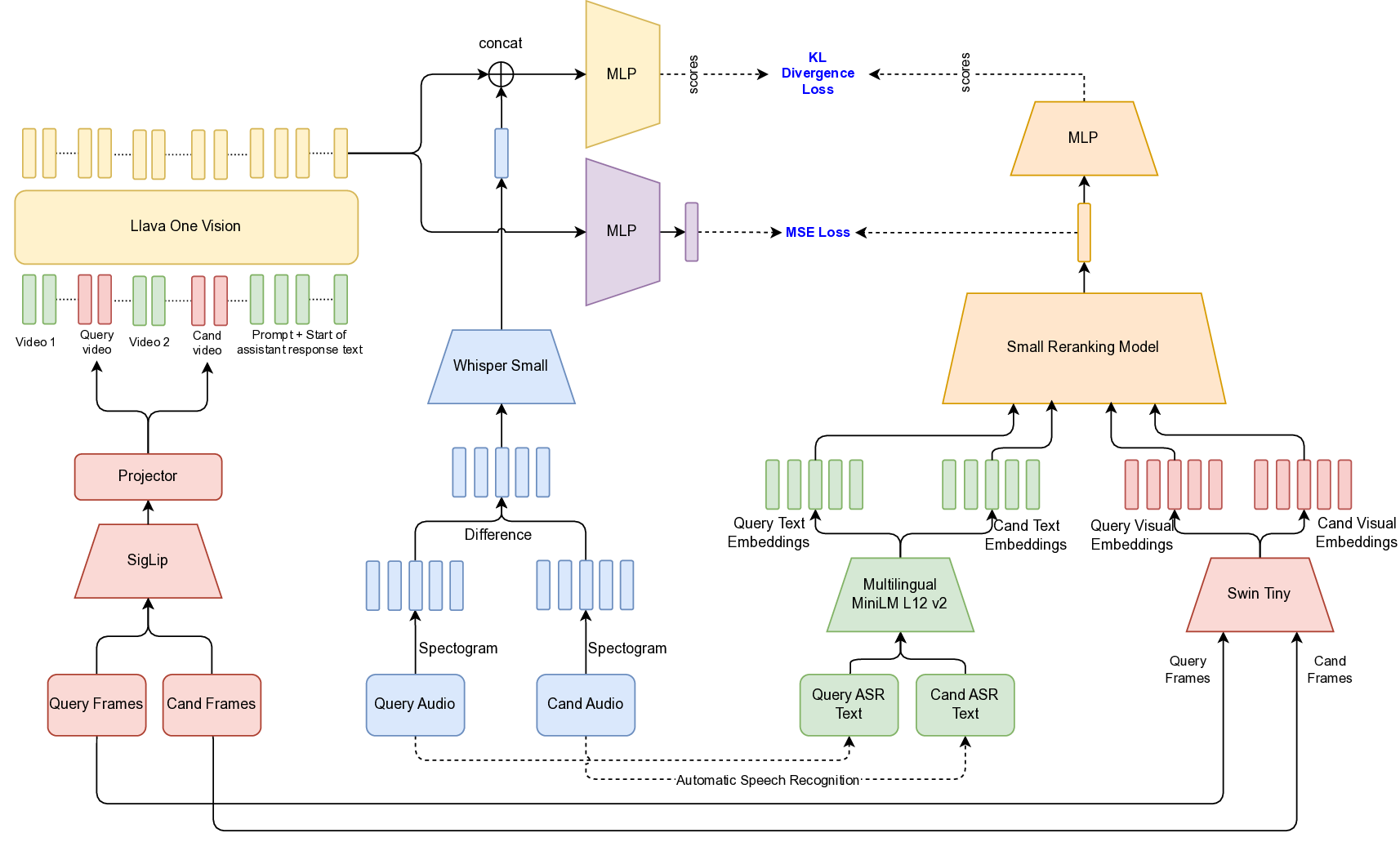
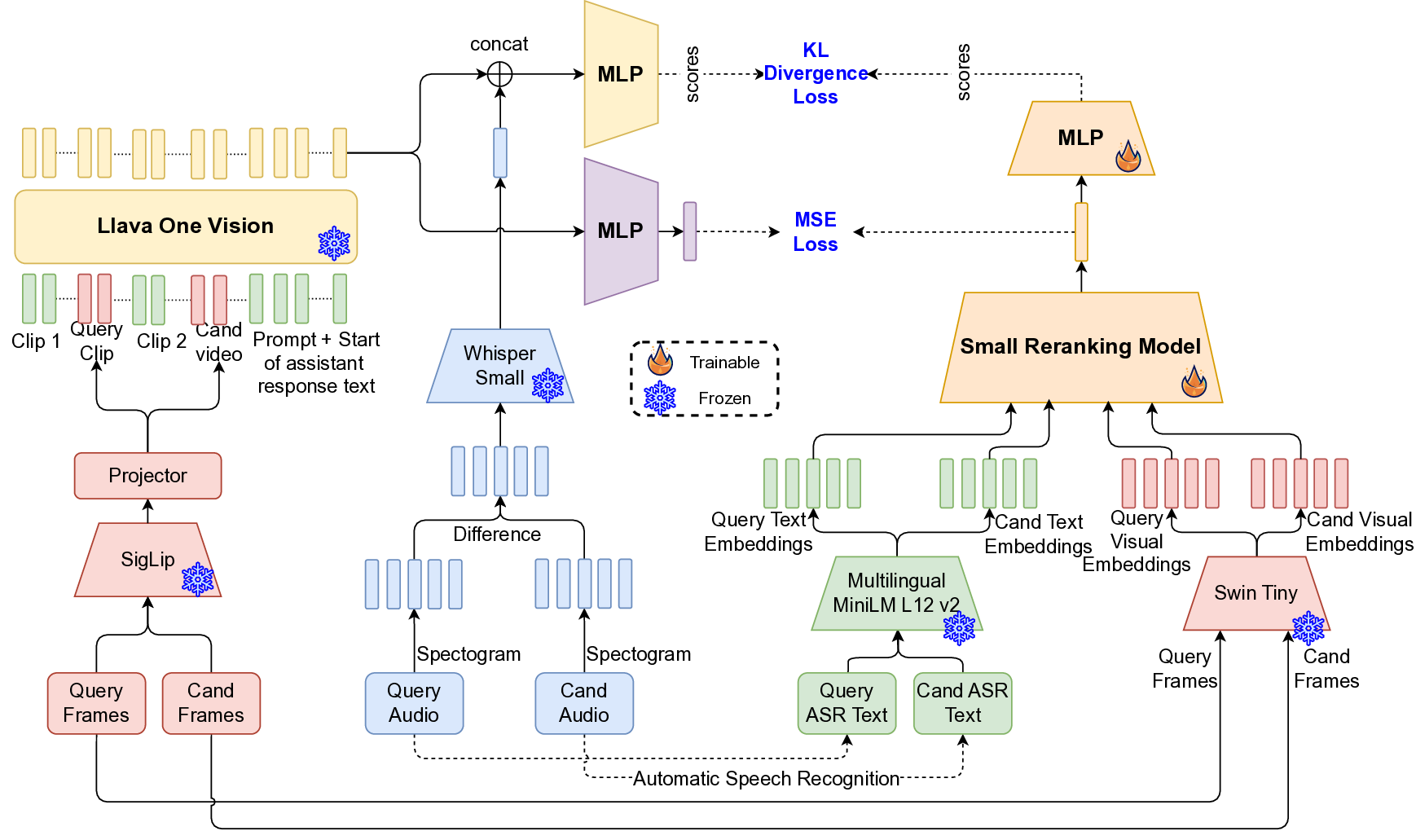
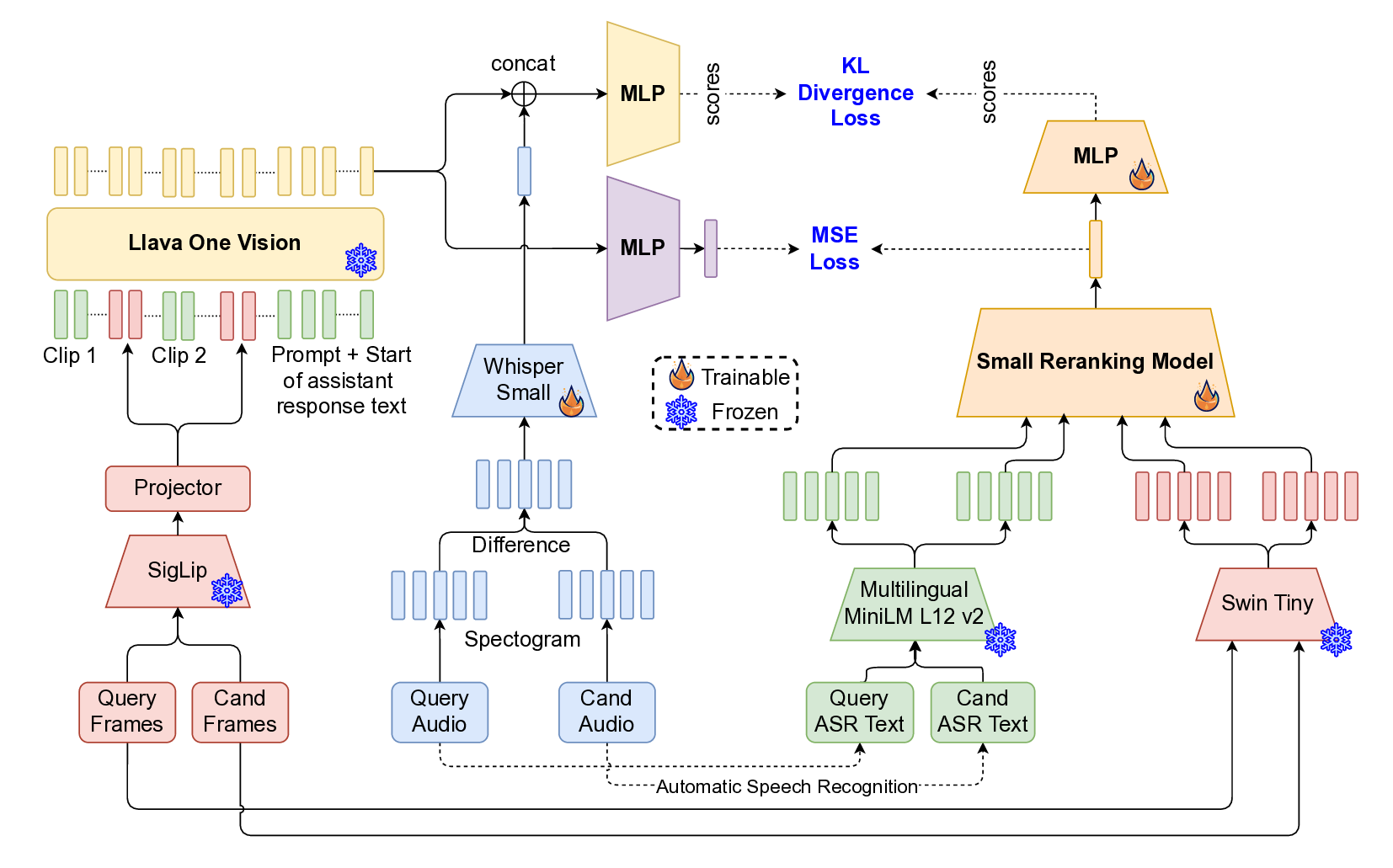
In application to content moderation, distilling from a frozen LLaVA-One-Vision [19] teacher enables a lightweight student reranking model to emulate multimodal decision boundaries learned by the full MLLM-providing strong semantic alignment and inference efficiency needed for live moderation tasks.
Live streaming platforms pose unique challenges for content moderation due to the continuous and transient nature of their data.
To enable real-time moderation, our system processes live streams by segmenting them into manageable temporal units. Specifically, each stream is split into 20-second clips, which we refer to as query clips. The goal is to analyze each query clip independently and eventually determine whether the live stream contains any content that violates platform policies.
Our content moderation framework follows a dual-path architecture, consisting of:
(1) Preset Violation Detection Pipeline: Designed to detect known categories of policy-violating content, such as official contents or paid contents (such as major sports events, TV shows, films, music videos etc.) broadcast on non-official livestreams.
(2) Reference-based Similarity Matching Pipeline: Complements the classifier by capturing emerging or subtle patterns of violations. This system computes feature embeddings for each query clip and retrieves semantically or perceptually similar content from pre-indexed historical clips known to have violated policies. These two pipelines work in parallel to maximize detection of both preset copyright violations (via supervised classification) and coverage of recent violation trends (via retrieval-based matching), allowing the system to respond to policy violations in real time.
Small Model Structure. The online Preset Violation Detection system (Figure 2) is powered by a lightweight multimodal model optimized for real-time inference. Visual features are extracted using a Swin-Tiny [20] visual encoder, while audio features are obtained using a Whisper-Base [30] audio encoder, followed by adaptive average pooling to reduce the number of feature embeddings. These visual and audio features are then passed to a METER [7] module for multimodal integration. The fused representation is pooled and fed into a multilayer perceptron (MLP) to produce the final prediction score. For supervised training on labeled data, crossentropy (CE) loss, L CE is applied to the logits produced by the MLP.
During knowledge distillation with unlabeled data, the model is trained using a combination of Kullback-Leibler (KL) divergence loss, L KL and mean squared error (MSE) loss, L MSE .
Where, 𝐶 is the number of classes, 𝑦 𝑖 is the ground truth, 𝑝 𝑖 is the predicted probability for class 𝑖.
Where, 𝑝 𝑖 is the true distribution, 𝑞 𝑖 is the predicted distribution, 𝐶 is the number of classes.
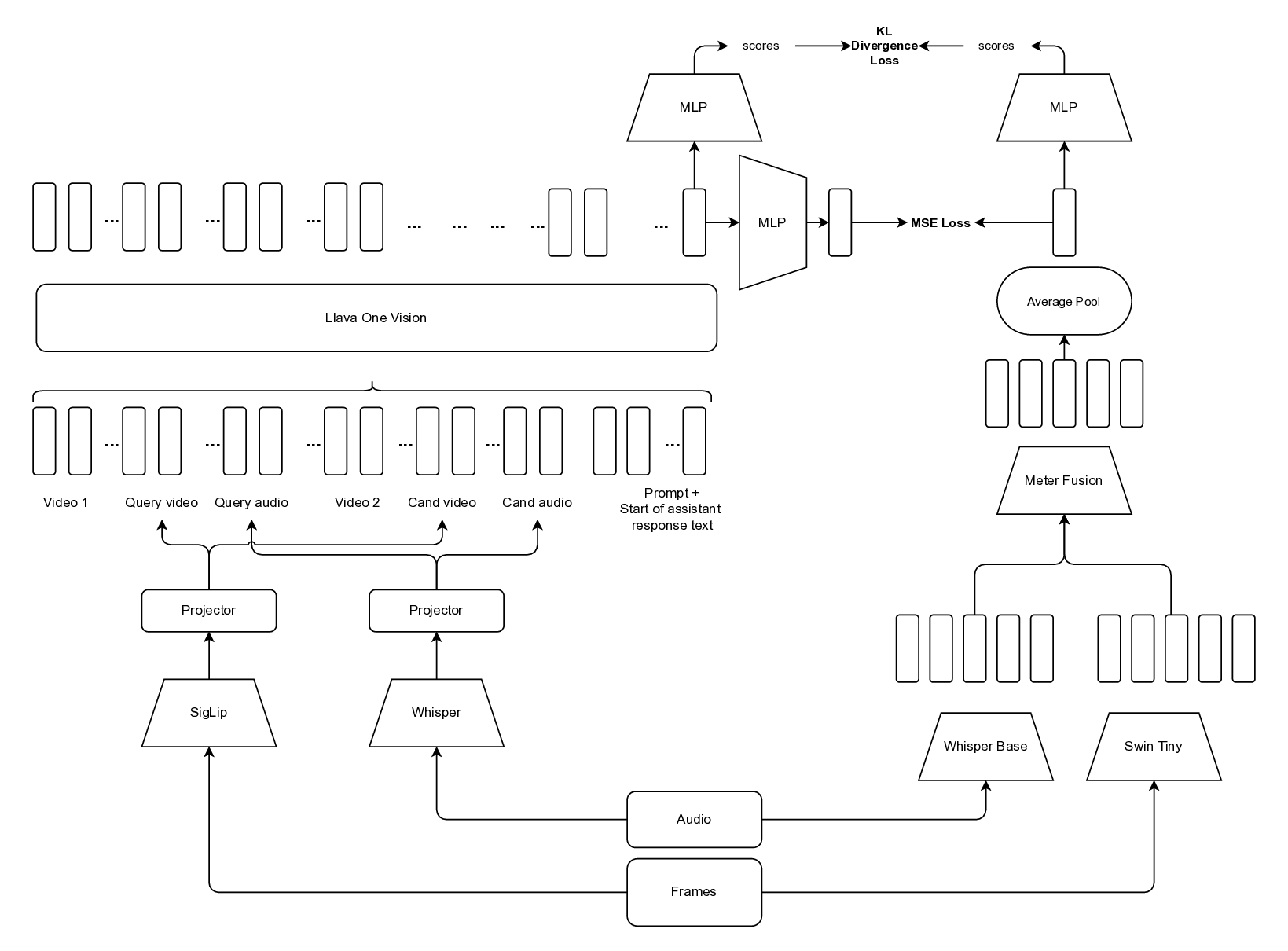
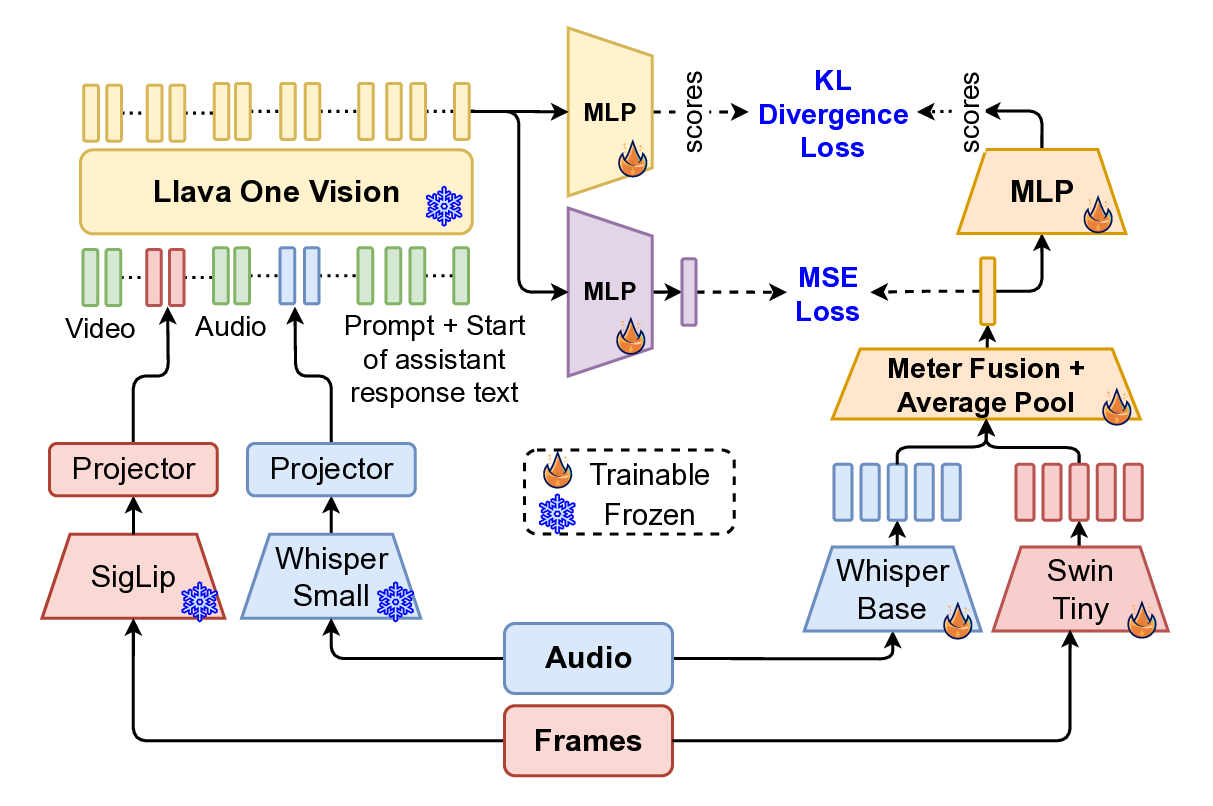
Where, 𝑛 is the number of data points, 𝑦 𝑖 is the true value, ŷ𝑖 is the predicted value. MLLM Model Structure. To enable improved performance and effective transfer learning, we adopt a modified version of LLaVA-One-Vision as the teacher model. While the original architecture supports vision-text inputs, we extend it to also accommodate audio embeddings, enabling true multimodal instruction. Specifically, we modify the model’s input pipeline to integrate audio features alongside visual features. Supervised fine-tuning (SFT) is then performed using our proprietary training dataset. During SFT, the SigLip visual encoder and Whisper-Small audio encoder are kept frozen, while the language model is fine-tuned using Low-Rank Adaptation [13] (LoRA) with a standard cross-entropy loss as the training objective.
To efficiently train the smaller model, we employ a dual-objective distillation strategy from the teacher MLLM, combining hidden state distillation and logit distillation. The hidden state distillation uses Mean Squared Error (MSE) loss between the final token hidden states of the teacher and student models, while the logit distillation applies Kullback-Leibler (KL) divergence between their predicted logits. This combined approach enables the student model to maintain the teacher’s generalization capabilities while meeting strict low-latency requirements, ensuring both performance and efficiency in deployment.
Active Learning. To continuously enhance model performance, we have deployed an active learning module based on the Info-Coevolution [28] framework introduced in recent research. This method enables the model to evolve alongside the data by actively identifying and sampling informative, edge-case, or difficult instances from production streams. Specifically, we use information loss as a selection criterion to prioritize samples that are expected to provide the highest learning value upon annotation. These highvalue samples are then sent for human annotation and added to the training set, facilitating targeted model refinement and improved generalization over time.
To detect novel, adversarial, or edge-case violations that may not yet be covered by standard classifiers, our system employs a referencebased similarity matching pipeline. This approach ensures robust detection of policy-violating content by comparing incoming clips against a curated database of known violations.
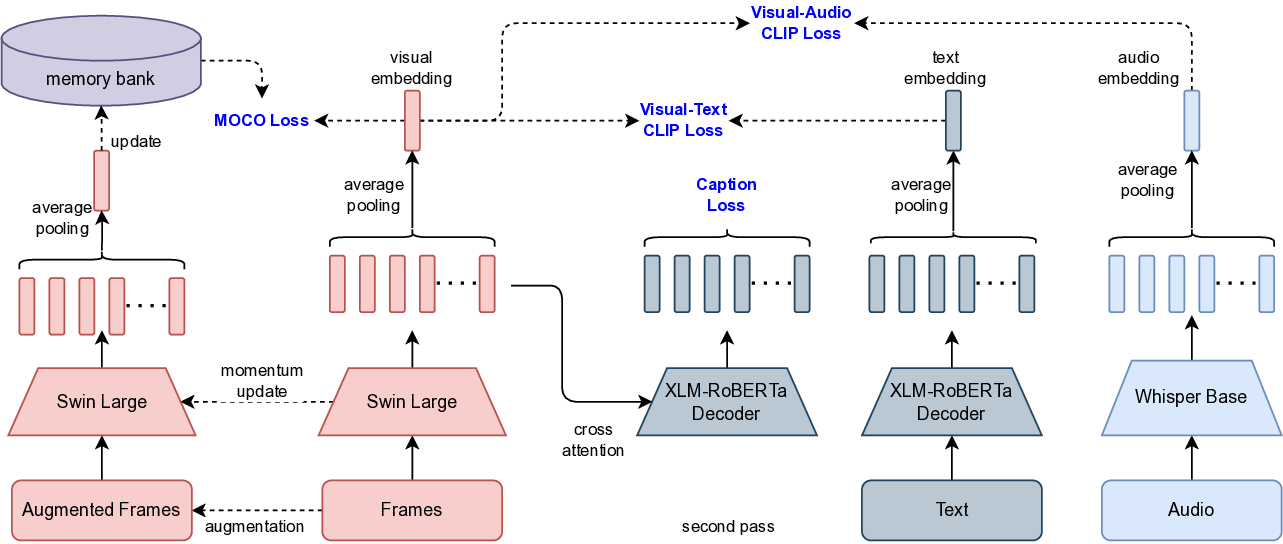
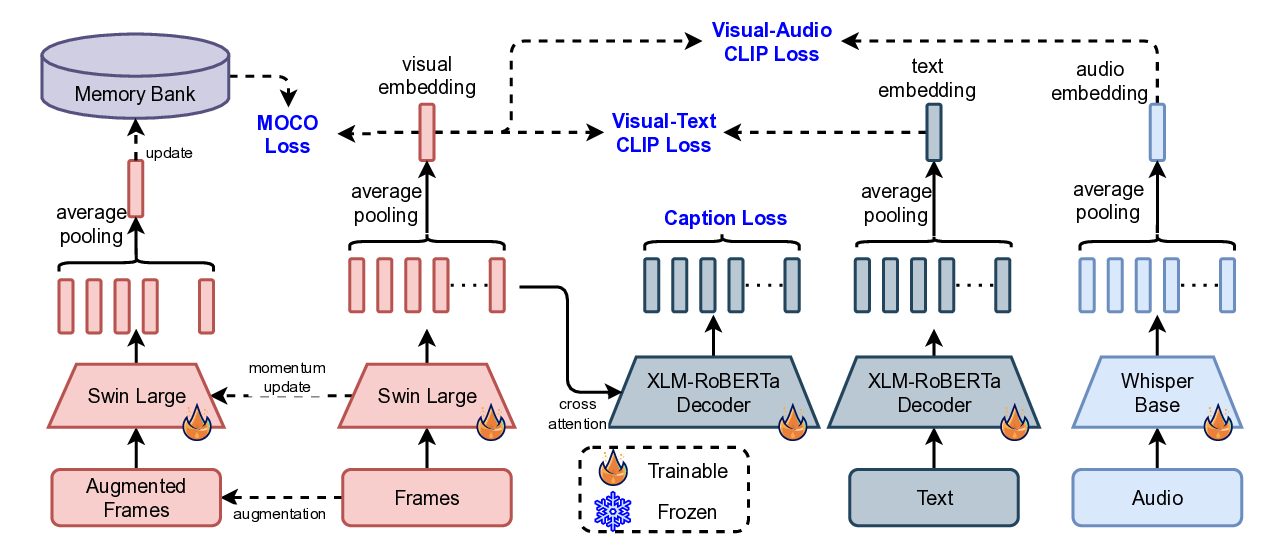
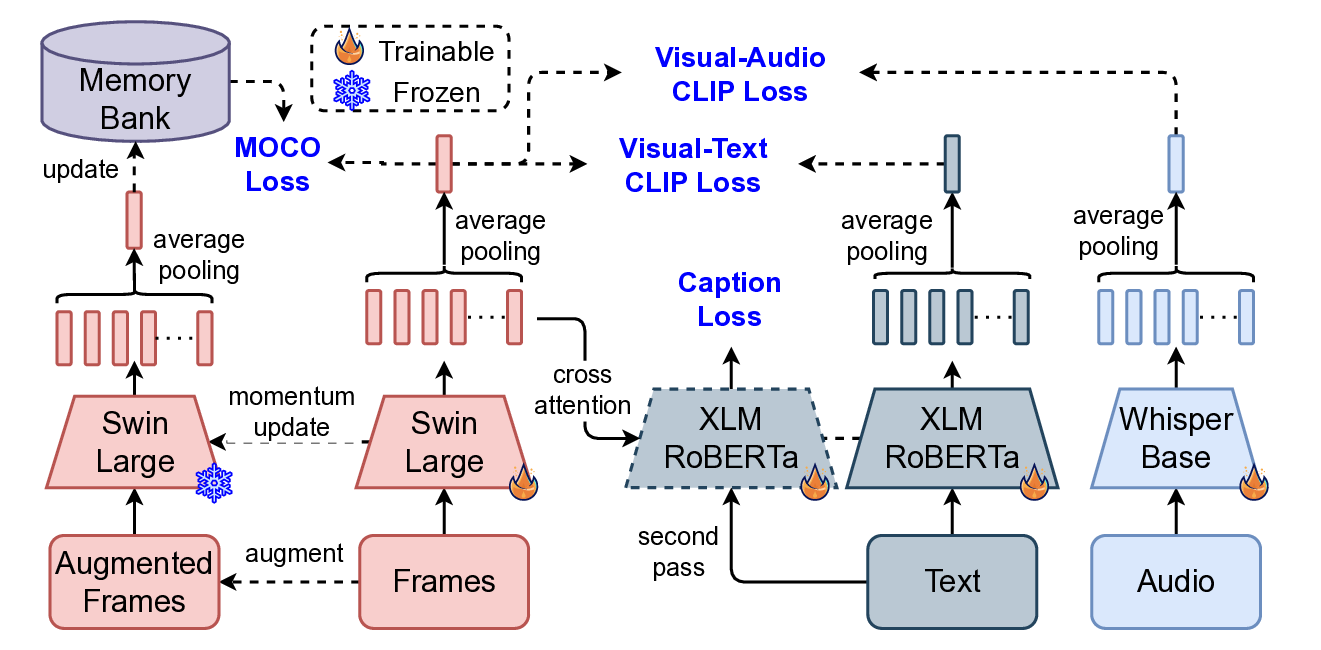
Video-Clip Retrieval Feature Model. The visual feature for candidate recall serves as a critical component in our video-clip analysis pipeline due to its efficiency and reliability in content representation. Extracted using a Swin-Large [20] proprietary data, these features capture rich visual semantics while maintaining computational tractability. We trained our visual retrieval embeddings using the MoCo[9] (Momentum Contrast) framework, which enables effective representation learning through contrastive learning with a dynamic memory bank by optimizing the multi-similarity loss function.
where: To enhance the semantic richness of these visual embeddings, we further incorporated CLIP [29] training using a learnable NT-Xent [3] (Normalized Temperature-scaled Cross Entropy) loss, aligning visual features for video clips with their corresponding textual descriptions and audio information. This multimodal training approach allows the model to capture both visual similarity and semantic meaning, resulting in improved generalization and more accurate similarity retrieval.
Where, 𝑣 𝑖 is the embedding of the 𝑖-th visual input, 𝑤 𝑖 is the embedding of the corresponding 𝑖-th text or audio input depending on the modality, 𝜏 > 0 is a temperature scaling hyperparameter, 𝑁 is the batch size (number of pairs).
By combining MoCo’s instance discrimination with CLIP’s crossmodal alignment, the learned embeddings are not only robust for visual retrieval but also semantically aware, bridging the gap between image content and textual concepts.
To optimize flexibility and efficiency, we leverage Matryoshka Representation Learning [17] (MRL), which enables a single model to generate embeddings of varying dimensions (e.g., 32, 64, 128, 512, 768, etc). This capability allows for dynamic resource allocation, lower-dimensional embeddings can be used for storage efficiency, while higher-dimensional embeddings are reserved for tasks demanding greater precision. This eliminates the need to train and maintain separate models for different resolution requirements.
Vector Index. For fast and scalable similarity searches, we utilize Hierarchical Navigable Small World [25] (HNSW) indices, which are particularly well-suited for high-dimensional vector spaces. HNSW provides low-latency query performance while maintaining high recall rates, making it ideal for real-time moderation applications. The system maintains separate HNSW indices for different violation categories, such as copyright infringement, duplicate content detection, and other policy-specific issues. This modular approach ensures that searches remain efficient and relevant to the specific moderation task at hand.
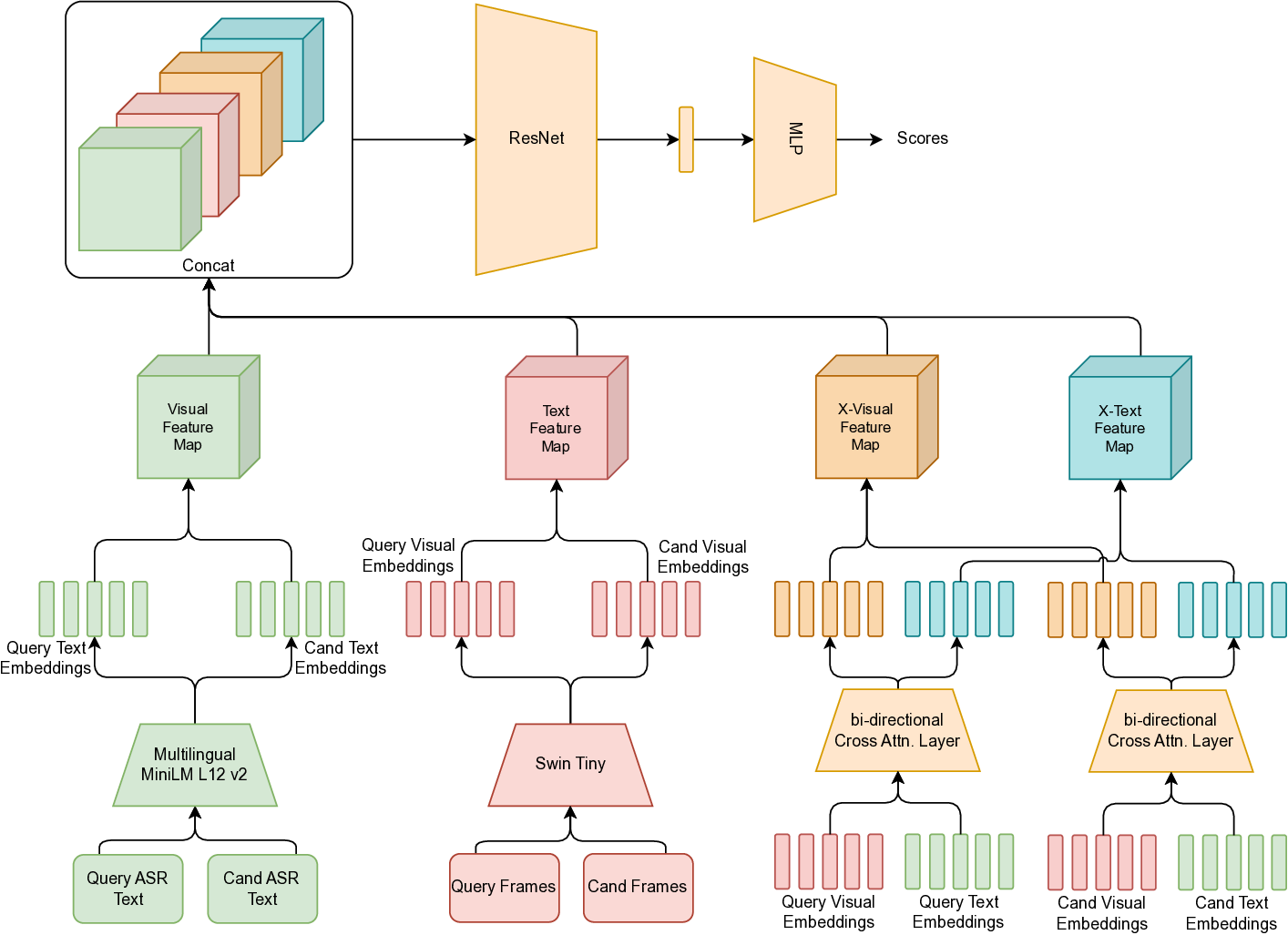
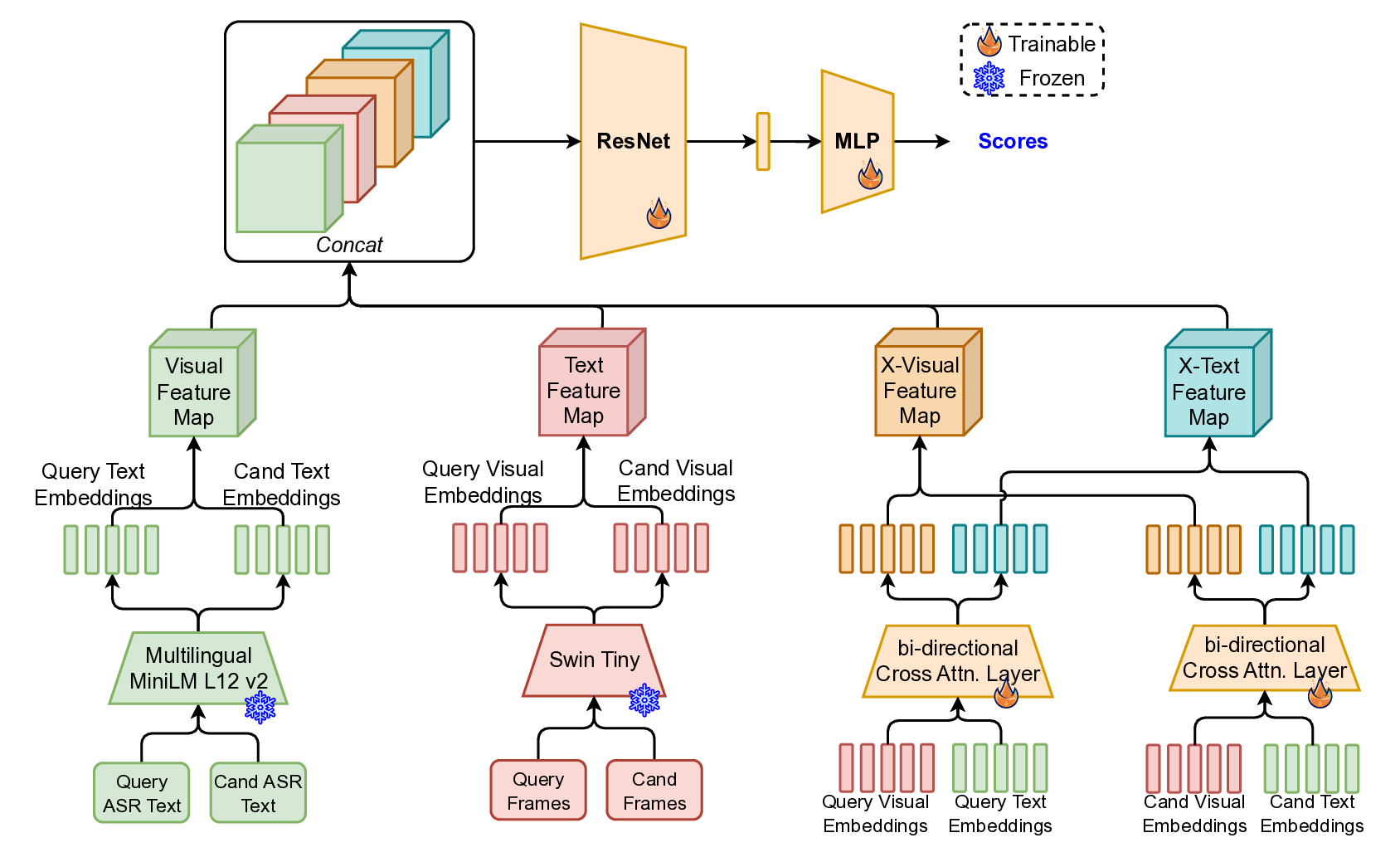
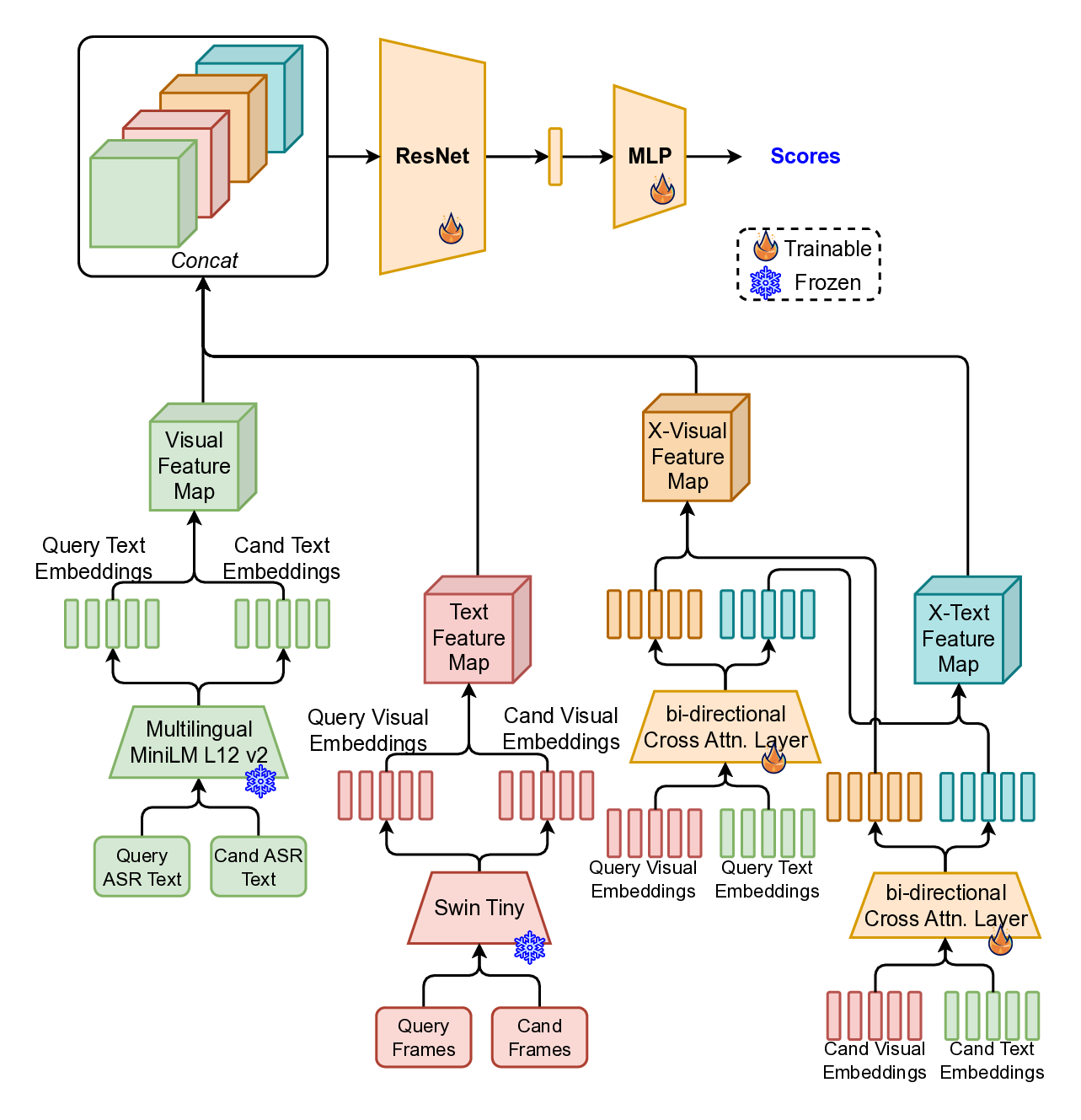
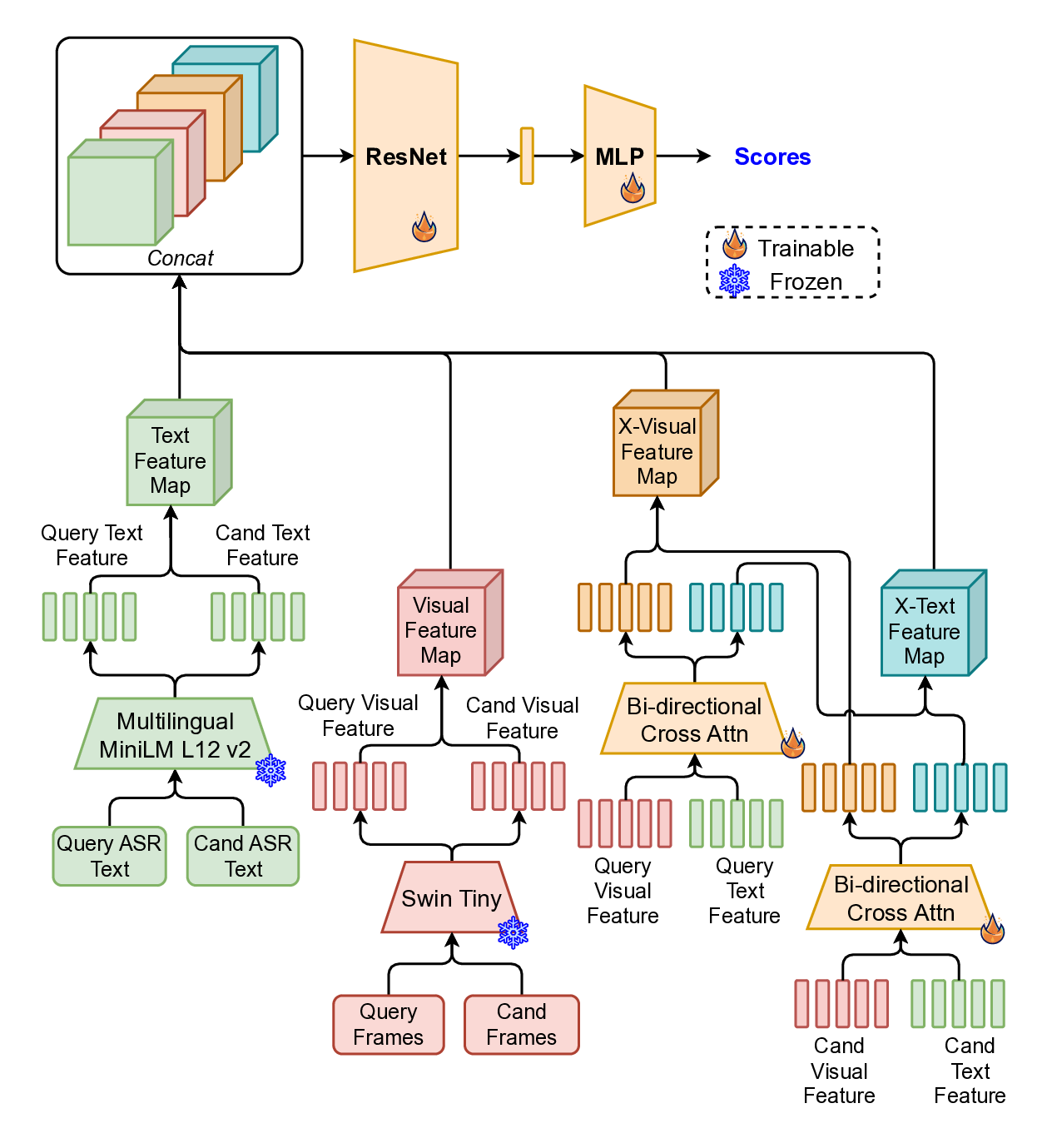
Re-ranking model. The re-ranking model (Figrue 4) refines query -candidate clip-pairs generated during the initial retrieval stage. Although visual similarity offers a strong baseline for identifying relevant content, it frequently leads to false positives in the context of livestreams. This is primarily due to the repetitive and visually similar elements common across different streams-such as shared backgrounds, user interfaces, or recurring patterns in host appearance and behavior. These similarities can mislead a purely visual retrieval system, necessitating a more nuanced re-ranking approach that can better distinguish truly matching content from visually similar but unrelated clips.
To overcome this, we adopt a multimodal re-ranking model that combines visual features and transcribed speech (ASR) to generate a fused similarity score. This multimodal approach enables more context-aware comparisons and significantly improves ranking accuracy in borderline or ambiguous cases by reducing over-reliance on visual features alone.
To further enhance learning, we apply knowledge distillation (Figrue 6 in Appendix) using a fine-tuned large language-vision model, the LLaVa-One-Vision [18], which provides richer semantic supervision. The student model (multimodal re-ranking model) is trained to align with the teacher’s outputs, enabling it to better capture nuanced cross-modal relationships.
The overall training objective includes Cross-Entropy Loss (L CE ) for direct supervision, KL Divergence Loss (L KL ) over predicted logits for distribution alignment, and Mean Squared Error Loss (L MSE ) on hidden states to promote representation consistency.
This setup enables robust re-ranking that integrates both semantic and perceptual signals to reduce false positives and improve moderation quality.
Aggregation Algorithm Matching a single query clip to a reference clip can be noisy and error-prone, especially in live-streaming environments where short clips may not fully capture the context of a policy violation. To improve robustness and reduce false positives, we employ a clip-match aggregation algorithm (Algorithm 1 in Appendix) that leverages temporal continuity across multiple query-reference matches. The core idea is to identify sequence-level matches between live room and a known violating room, based on the alignment of timestamps across matched clip pairs. By grouping matched clips and evaluating their temporal alignment within a tolerance window 𝜖, we can infer stronger matches at the session level rather than clip level. This strategy significantly improves accuracy by enforcing temporal consistency among detected matches.
Based on the classification scores and similarity match results, appropriate policy enforcement actions are applied.
Our models were trained on a comprehensive dataset combining large-scale in-house annotated livestream content and publicly available open-source data. The in-house data comprises extensive human annotations of policy-violating clips, curated via both random sampling and high-traffic livestream streams to capture diverse and real-world violations. Complementing this, open-source datasets, primarily LAION-2B [32] (both English-only and multilingual subsets), provide a rich source of image-text pairs to support robust generalization in our retrieval models.
• Preset Violation Classification model: 2 million human -annotated clips from in-house livestream data, with preset violations as labels. This rich multi-modal and multi-source data foundation helps ensure our models maintain robustness across highly dynamic and diverse livestream scenarios.
Livestream videos were segmented into fixed-length 20-second clips to standardize input units for model processing. From each clip, we extracted and synchronized three complementary modalities: audio waveform, automatic speech recognition (ASR) transcripts, and key representative visual frames. These multimodal inputs harness complementary signals vital for effective moderation.
Training utilized NVIDIA H100 GPUs, enabling efficient handling of the massive datasets and supporting computationally intensive models, including knowledge distillation from large-scale language and vision models. To prepare the models for real-time deployment, we applied model tracing, post-training quantization (PTQ) and quantization aware training (QAT), optimizing inference speed and reducing memory and computational footprint with minimal accuracy sacrifice.
Table 1 summarizes the performance of our supervised preset violation detection model. The model attains a strong Average Precision (AP) score of 75.84% and an F1 score of 73.61%, reflecting its balanced precision and recall. It is important for the online pipeline to have high precision, while we try to achieve higher recall in gradual iterations of the model. This strong performance demonstrates that direct supervised classification remains a highly effective strategy for known policy violations, providing rapid and reliable detection.
Effective candidate retrieval is crucial to guarantee that potential violations are included for detailed analysis in the later ranking stage. Table 2 reports recall rates of the video retrieval model at various “Top k” values.
The model achieves exceptionally high Recall@Top-5 (90.53%) and Recall@Top-100 (98.99%) for retrieving at least one relevant match, indicating that the system confidently surfaces appropriate candidate clips from billions of video segments. This search breadth ensures the reference matching path effectively captures diverse forms of violations that might be semantically or visually nuanced, even if unseen during training. Overall, the retrieval model’s high recall supports strong downstream verification performance.
Table 3 presents results of the re-ranking stage, which refines the initial candidates retrieved by the visual similarity model by integrating multimodal features. The re-ranking model achieves an AP of 74.82% and F1 of 73.49%, demonstrating strong performance in filtering out false positives while promoting semantically aligned matches. This re-ranking step is critical in production environments where high recall alone is insufficient, initial retrieval may surface visually or textually similar content that is contextually irrelevant or benign. By leveraging a fusion of audio, visual, and text features, the re-ranking model enhances precision by verifying the semantic and policy-relevant correspondence between retrieved clips and reference violations. The strong results validate the importance of this multimodal re-ranking model, ensuring that downstream moderation decisions are based on accurate, policy-grounded matches rather than superficial similarity. 4 compares variants of the preset violation classification model to assess the impact of modality inclusion and knowledge distillation. Using only visual inputs yields lower performances on both small model (AP=64.70%) and MLLM (AP=77.35%). Incorporating audio modality boosts AP by 6.3% on small model and 2.7% on MLLM, underscoring the importance of multimodal signals in ambiguous scenarios.
The MLLM-based model attains the highest AP (80.03%), demonstrating the power of large multimodal language models. However, its computational cost makes it impractical for real-time production. Our distilled Small+KD model strikes a strong balance,
Feature AP F1 R@P70 R@P75 R@P80 R@P85 R@P90 achieving 75.84% AP by transferring knowledge from the MLLM into a resource-efficient architecture. This knowledge distillation proves critical for maintaining high accuracy under tight latency constraints.
In the ablation study focusing on small-scale preset-violation detection models, several trends emerge from scaling the backbone sizes and applying adaptive mean pooling (AMP) as shown in Table 5. In the heaviest multimodal setup, with Swin Large visual backbone, Whisper Small audio backbone, XLM-RoBERTa text backbone and 12-layered METER fusion, the model achieves its best performance (AP=77.35%) but with notably low throughput of only 14 QPS on a A10 GPU. Scaling down backbone sizes, trimming the fusion layers, and dropping the text branch accelerates inference substantially, yet each simplification brings a predictable dip in effectiveness. Adding adaptive mean pooling before METER fusion module increases model throughput and helps to slightly recover model performance, especially at higher precision level (R@P90 +9%).
While leaner models offer impressive speed, their lower performances can be effectively countered via knowledge distillation. In the smallest student model setting, the AP jumped from around 71% to 75.8%, bringing it much closer to the performance of the largest model setting above, while maintaining much higher throughput suitable for online deployment. This demonstrates that distillation enables lean architectures to serve traffic at scale with minimal loss in effectiveness relative to the largest multimodal configuration. 4.6.2 Candidate Recall. Table 6 studies architecture and feature dimension for the retrieval model. Reducing feature dimensionality from 768 down to 128 has negligible impact on recall. This suggests that compressed embeddings effectively retain semantic information, enabling faster retrieval and ranking without sacrificing accuracy-a practical consideration for production scalability.
Introducing 7: Performance comparison of the re-ranking model across variations. The full MLLM achieves the highest accuracy but is impractical for real-time deployment due to resource constraints. The Small model offers higher efficiency but lower accuracy, while the knowledge-distilled Small+KD model significantly recovers performance, narrowing the gap to the MLLM while remaining lightweight for production. benefits from richer semantic supervision beyond MoCo’s visualonly contrastive training. This performance gap is substantially huge especially at lower top-K (e.g. at RecallOne@Top-5, MoCo + CLIP achieves over 90%, whereas MoCo alone achieves only around 60%). The gap narrows at higher top-K thresholds, but remains non-negligible. 4.6.3 Re-ranking and Aggregation. Table 7 evaluates the re-ranking model with and without knowledge distillation. The Small+KD model achieves a compelling AP of 74.82%, significantly outperforming the non-distilled Small baseline (71.05%) while remaining more efficient than the full MLLM (77.60%). This validates the effectiveness of knowledge distillation in transferring rich multimodal semantics into lighter architectures, crucial for scalable real-time moderation.
A key objective of our moderation pipeline is to effectively reduce user exposure to unwanted or policy-violating live streams on the platform. To evaluate real-world impact, we conducted rigorous online A/B tests following the deployment of each pipeline upgrade. These experiments measured critical business metrics related to the consumption of undesirable content, demonstrating meaningful gains over previous baselines.
The online A/B experiment was conducted over a few weeks with 10% traffic assigned to each of the experiment groups. The evaluation was performed using a two-sample z-test for proportions to measure the change in view rate of violated live streams.
• Metric: 1.2% decrease in violation-related user views.
• Standard deviation: 0.055 over the sampled population.
• Confidence interval (95%): [-0.1476%, -0.087%].
• P-value: ∼ 0.
• Minimum Detectable Effect (MDE): 0.04%.
Preset Violation Detection Pipeline: The baseline in this experiment was an older moderation system that relied solely on visual features for detection. Our upgraded pipeline, which incorporates multimodal inputs (visual, audio, and ASR text) alongside knowledge distillation techniques, led to a statistically significant reduction in user views of preset violation-based live streams by 1.2%. Additionally, there was a 2.7% decrease in the total duration users spent watching these flagged streams. These improvements highlight how leveraging richer multimodal signals in classification enhances the precision and effectiveness of direct violation detection in a live-streaming context.
Reference Matching Pipeline: The previous version of this pipeline employed an outdated recall model and a re-ranking module based exclusively on visual features. The updated pipeline integrates multimodal learning in both retrieval and re-ranking stages, accompanied by knowledge distillation from large multimodal language models. This upgrade yielded several notable outcomes: To monitor the impact and effectiveness of our pipeline, a longterm A/B backtest experiment is carried out to monitor the performances of the preset violation detection pipeline and reference matching pipeline. The preset violation detection pipeline alone leads to about 4% reduction in user views of unwanted live streams. Introducing reference matching pipeline further reduces the user views of unwanted live streams down by about 2% to 4%, demonstrating how the enhanced reference matching pipeline could effectively complement the preset violation detection pipeline to improve overall moderation efficacy.
To minimize false positives and over-moderation, the system employs several safeguards:
• Model thresholds are tuned at P90 precision to minimize overkill in automated moderation. • Human moderators review detections in lower precision bands (P70-P85) for verification before enforcement. • For affected creators, an appeal mechanism routes disputed cases directly to the human moderation team, where decisions are re-evaluated based on both model outputs and contextual review. Overall, the online performance evaluation confirms that our unified dual-path moderation framework not only advances detection accuracy in offline metrics but also delivers tangible business value by reducing exposure to harmful and duplicative live streams in a production environment. The multimodal, knowledgedistilled models enable more precise and scalable content governance, thereby enhancing platform health and user experience.
In this work we present a unified, multimodal content moderation framework tailored for the unique demands of real-time livestreaming platforms. By integrating supervised classification with a reference-based similarity matching pipeline enhanced through knowledge distillation from large language-vision models, our approach effectively balances precision and recall to govern a rapidly evolving content ecosystem.
Our experiments demonstrate that supervised classification excels at detecting known, preset categories of policy violations with high precision and balanced recall. The inclusion of multimodal signals-visual frames, audio features, and ASR transcription-notably improved detection accuracy compared to visual-only baselines. This underscores the importance of leveraging complementary modalities to address the ambiguity and complexity often inherent in live stream content.
At the same time, the reference matching pipeline extends the system’s capability to identify novel or subtle violations beyond the reach of supervised models. Leveraging a large-scale retrieval model followed by a multimodal re-ranking step guided by distillation from a large language-vision model, this pipeline achieves outstanding recall while maintaining precise verification of candidates. The ability to compress embeddings without significant recall loss further enhances retrieval efficiency and scalability, crucial for handling billions of retrospective and live clips.
The dual-path architecture offers compelling synergy: highconfidence classification enforces known policies reliably, while similarity-based retrieval generalizes to emerging violation forms and adversarial behavior. This complementarity is reflected in both offline benchmarks and online A/B testing, where pipeline upgrades led to substantial reductions in unwanted live stream views, flagged content, and duplicate stream consumption. These real-world gains translate directly into improved platform integrity and user experience.
Knowledge distillation emerges as a pivotal technique, enabling compact student models to approach the rich semantic awareness of large language-vision teachers. This transfer of multimodal contextual understanding permits efficient real-time inference, meeting tight latency constraints without sacrificing predictive power. Such scalability is imperative for production deployment in large live streaming ecosystems.
Looking ahead, this framework lays the foundation for continued innovation in multimodal moderation. Future research could explore expanding modality coverage (e.g., integrating chat signals or user interaction metadata), incorporating temporal modeling for more holistic stream-level analysis, and adapting knowledge distillation strategies to evolving LLM architectures. Additionally, enhanced active learning loops to incorporate feedback from human moderators and user reports can drive continual refinement and robustness against adversarial attempts. Table 11: Comparison with a pretrained MLLM (Gemini-2.5-Pro) on the classification branch. The pretrained model exhibits extremely low precision and F1 when applied directly to the moderation domain, likely due to hallucination tendencies and a lack of task-specific grounding.
Gemini-2.5-Pro 30.28% 35.84% Our Approach 74.82% 73.49%
Table 12: Comparison with a pretrained MLLM (Gemini-2.5-Pro) on the reference-matching branch. While the pretrained model performs better than in the classification setting, it still significantly underperforms our approach, highlighting the importance of task-specific modeling and grounding for reliable moderation. A.
📸 Image Gallery