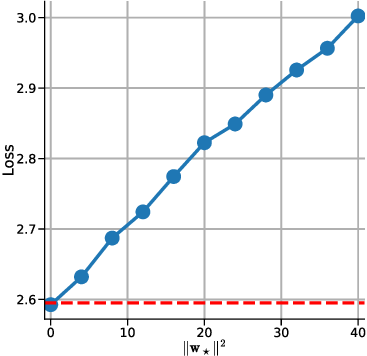The Initialization Determines Whether In-Context Learning Is Gradient Descent
📝 Original Info
- Title: The Initialization Determines Whether In-Context Learning Is Gradient Descent
- ArXiv ID: 2512.04268
- Date: 2025-12-03
- Authors: Shifeng Xie, Rui Yuan, Simone Rossi, Thomas Hannagan
📝 Abstract
In-context learning (ICL) in large language models (LLMs) is a striking phenomenon, yet its underlying mechanisms remain only partially understood. Previous work connects linear self-attention (LSA) to gradient descent (GD), this connection has primarily been established under simplified conditions with zero-mean Gaussian priors and zero initialization for GD. However, subsequent studies have challenged this simplified view by highlighting its overly restrictive assumptions, demonstrating instead that under conditions such as multi-layer or nonlinear attention, self-attention performs optimization-like inference, akin to but distinct from GD. We investigate how multi-head LSA approximates GD under more realistic conditions-specifically when incorporating non-zero Gaussian prior means in linear regression formulations of ICL. We first extend multi-head LSA embedding matrix by introducing an initial estimation of the query, referred to as the initial guess. We prove an upper bound on the number of heads needed for ICL linear regression setup. Our experiments confirm this result and further observe that a performance gap between one-step GD and multi-head LSA persists. To address this gap, we introduce y q -LSA, a simple generalization of single-head LSA with a trainable initial guess y q . We theoretically establish the capabilities of y q -LSA and provide experimental validation on linear regression tasks, thereby extending the theory that bridges ICL and GD. Finally, inspired by our findings in the case of linear regression, we consider widespread LLMs augmented with initial guess capabilities, and show that their performance is improved on a semantic similarity task.📄 Full Content
Theoretical studies on ICL have analyzed its mechanisms to understand how LLMs effectively learn from contextual examples (Brown et al., 2020). ICL can be framed as an implicit Bayesian process where the model performs posterior inference over a latent task structure based on contextual examples, performing a form of posterior updating (Xie et al., 2022;Falck et al., 2024;Panwar et al., 2024;Ye et al., 2024). Alternatively, a more recent perspective suggests that ICL in transformers is akin to gradient-based optimization occurring within their forward pass. Von Oswald et al. (2023) demonstrate that self-attention layers can approximate gradient descent by constructing task-specific updates to token representations. They provide a mechanistic explanation by showing how optimized transformers can implement gradient descent dynamics with a given learning rate (Rossi et al., 2024;Zhang et al., 2025). While this work provides a new perspective on ICL, it limits the analysis to simple regression tasks and it simplifies the transformer architecture by considering a single-head self-attention layer without applying the sfmx(•) function on the attention weights (also known as linear attention). Ahn et al. (2023) extend the work of Von Oswald et al. (2023) by showing how the in-context dynamics can learn to implement preconditioned gradient descent, where the preconditioner is implicitly optimized during pretraining. More recently, Mahankali et al. (2024) prove that a single self-attention layer converges to the global minimum of the squared error loss. Zhang et al. (2024b); Wang et al. (2025) also analyze a more complex transformer architecture with a (linear) multi-layer perceptron (MLP) or softmax after the linear self-attention layer, showing the importance of such block when pretraining for more complex tasks. In a related direction, Cheng et al. (2024) show that transformers can implement functional gradient descent to learn non-linear functions in context, further strengthening the view of ICL as gradient-based optimization.
Recent works have also raised important critiques of the ICL to GD hypothesis, questioning both its theoretical assumptions and empirical applicability. For example, Shen et al. (2023;2024) point out that many theoretical results-such as those in Von Oswald et al. (2023)-rely on overly simplified settings, including linearized attention mechanisms, handcrafted weights, or order-invariant assumptions not satisfied in real models. Giannou et al. (2024); Fu et al. (2024) demonstrated that in a multi-layer self-attention setting, the internal iterations of the Transformer conform more closely to the second-order convergence speed of Newton’s Method. Therefore, the interpretation of ICL needs to be examined under more realistic assumptions.
In this work, we extend the above lines of research by emphasizing more realistic priors, specifically, non-zero prior means. While Zhang et al. (2024a); Mahdavi et al. (2024) explore broader prior distributions by analyzing covariate structures or modify the distribution of input feature, our focus instead lies on the interplay between a non-zero prior mean and the capacity of LSA to emulate GD. We note that while Ahn et al. (2023); Mahankali et al. (2024); Zhang et al. (2024b) provide compelling theoretical analyses, their work does not include experimental validations. In doing so, our study builds upon and generalizes the prior-zero analyses found in Von Oswald et al. (2023); Ahn et al. (2023), illuminating new challenges and insights that arise when priors deviate from zero, both theoretically and empirically.
We use x ∈ R d and y ∈ R to denote a feature vector and its label, respectively. We consider a fixed number of context examples, denoted by C > 0. We denote the context examples as (X, y) ∈ R C×d × R C , where each row represents a context example, denoted by (
To formalize an in-context learning (ICL) problem, the input of a model is an embedding matrix given by
where x q ∈ R d is a new query input and y q ∈ R is an initial guess of the prediction for the query x q . The model’s output corresponds to a prediction of y ∈ R. Notice that the embedding matrix in equation 2 is a slight extension to the commonly used embedding matrix, e.g. presented in Von Oswald et al. (2023), where y q is set to be zero by default. Its interpretation will be clearer in the next two sections.
Linear regression tasks. We formalize the linear regression tasks as follows. Assume that (X, y, x q , y) are generated by:
• First, a task parameter is independently generated by w ∼ N (w ⋆ , I d ) , where N (w ⋆ , I d ) is the prior, and w ⋆ is called the prior mean.
• The feature vectors are independently generated by x q , x 1 , . . .
∼ N (0, I d ).
• Then, the labels are generated by y = ⟨ w, x q ⟩, and
Here, w ⋆ ∈ R d is fixed but unknown and governs the data distribution.
A linear self-attention. We consider a linear self-attention (LSA) defined as
where d+1) are trainable parameters, [ • ] -1,-1 refers to the bottom right entry of a matrix, and W M def = I C 0 0 0 is a mask matrix. Our linearized self-attention removes softmax, LayerNorm, and nonlinear activations. Consequently, the update is an affine function of low-order context aggregates (e.g., X ⊤ X, X ⊤ y), which enables closed-form analysis of initialization effects while preserving the in-context learning setup.
ICL risk. We measure the ICL risk of a model f by the mean squared error,
where the input E is defined in equation 2 and the expectation is over E (equivalent to over X, y, and x q ) and y. The performance of different models are characterized by the ICL risk.
In order to improve the performance of linear self-attention (LSA), we consider the multi-head extension. Let H ∈ N be the number of heads. Similar to equation 3, we define the output of each transformer head as
where We emphasize that both the single-head LSA f LSA and the multi-head LSA f H-LSA share a common structural property: the bottom-right entry of the output matrix corresponds to the prediction for the query point x q , which can be interpreted as an initial guess y q refined by an attention-based update. In the special case of linear regression with zero prior mean, i.e., w ⋆ = 0, the choice y q = 0 introduces a non-trivial prior for the initial guess, as already observed by Von Oswald et al. (2023). The empirical role of this initial guess in the multi-head setting will be further analyzed in Section 5.1.3.
the hypothesis class associated with multi-head LSA models with H heads. Our first theoretical result establishes an invariance of the optimal in-context learning risk with respect to the number of heads once it exceeds the feature dimension.
Theorem 1. Let d ∈ N, and consider the hypothesis classes F (d+1)-LSA and F (d+2)-LSA corresponding to multi-head LSA models with H = d + 1 and H = d + 2 attention heads, respectively. Then
where R(f ) is the ICL risk defined in Eq. (4).
While the full proof of Theorem 1 is provided in Appendix A.1, we outline the key intuition here. Each attention head contributes a rank-one update to a set of (d + 1) matrices that fully describe the model. Collectively, these matrices live in a space of dimension (d + 1) 3 . A single head provides (d + 1)(d + 2) degrees of freedom, so once the number of heads reaches d + 1, the parameter space already has enough capacity to span the entire target space. In fact, with d + 1 heads one can explicitly construct any target configuration, which means the model is already maximally expressive. Since adding further heads simply amounts to appending zero-contributing heads, the hypothesis class does not grow beyond d + 1 heads, and the achievable risk remains unchanged. In Section 5, we provide empirical evidence supporting this theoretical result across a variety of model configurations.
Relation to concurrent work. Theorem 1 is a capacity statement for linear self-attention (LSA): once the number of heads reaches H = d+1, the hypothesis class and the attainable ICL risk no longer improve by adding heads. This contrasts with results for softmax attention, where (Cui et al., 2024) give exact risk formulas for single/multi-head ICL and show that as the number of in-context examples C grows, both risks scale as O(1/C) but multi-head achieves a smaller multiplicative constant when the embedding dimension is large-an improvement in performance constants rather than capacity. Complementarily, (Chen et al., 2024) study trained multi-layer transformers and find that multiple heads matter primarily in the first layer, proposing a preprocess-then-optimize mechanism; their conclusions concern learned utilization patterns (with softmax and multi-layer architectures), whereas Theorem 1 isolates an expressivity saturation specific to single-layer LSA.
Next, we explore the convergence of multi-head LSA. Inspired by the analysis of Ahn et al. (2023)
, except in the case where the prior mean vector vanishes, w ⋆ = 0.
Theorem 2 states that when the context size C → ∞, the gradient of the multi-head LSA’s ICL risk R(f H-LSA ) remains non-zero for the entire parameters space as long as w ⋆ ̸ = 0. This result highlights a fundamental limitation of multi-head LSA under non-zero priors: no choice of weights W K h , W Q h , W P h and W V h with h ∈ [H] can minimize the ICL risk in the infinite-context limit. See Appendix A.3 for a detailed discussion of how the results change when the context size C is finite.
Relation to concurrent work. Although previous works such as Ahn et al. (2023) and Mahankali et al. (2024) provide analytical solutions corresponding to stationary points of the ICL risk, these results are derived under the assumption that the prior mean w ⋆ = 0. In this special case, the gradient of the ICL risk can vanish, allowing the existence of a stationary point. Our analysis generalizes this observation: we prove that when w ⋆ ̸ = 0, the gradient of the ICL risk remains strictly non-zero for all weights as context size C → ∞, thus precluding the existence of stationary points. We adopt C → ∞ as an asymptotic approach, as done by Zhang et al. (2024a); Huang & Ge (2024). Our analysis targets the asymptotic regime C → ∞, where finite-sample correlation terms vanish and the gradient remains strictly non-zero for w ⋆ ̸ = 0, hence no non-trivial stationary points exist. For fixed, finite C, an additional finite-sample correction-decaying inversely with C-can partially cancel the leading gradient, producing apparent stationary points or plateaus in practice. As C grows, these effects fade and the behavior converges to the asymptotic prediction, matching our experiments.
Finally, even though such a stationary point exists with finite context size, we still cannot imply that the stationary point is the global optimum, as the ICL risk of multi-head LSA R(f H-LSA ) is not convex, presented in the following lemma.
Lemma 1. For any H ∈ N, the in-context learning risk
Because R(f H-LSA ) is non-convex, any stationary point that arises, even at finite context sizes, does not guarantee a global optimum. In other words, one may encounter local minima or saddle points that satisfy the stationary condition without minimizing the overall ICL risk.
To address the performance gap between one-step GD and multi-head LSA, we introduce y q -LSA, a generalization of single-head LSA.
Our approach builds upon the GD-transformer developed by Von Oswald et al. (2023); Rossi et al. (2024), which implements one-step GD in a linear regression setup when the prior mean w ⋆ is zero. The original formulation is defined by the weight matrices
where η represents the GD step size. From the standard LSA formulation equation 3 with the given embedding equation 2, we derive
where the initial guess y q = 0 = w ⊤ ⋆ x q is fixed for any query x q , and the prior mean w ⋆ is zero. See the derivation of equation 8 in Section B for the completeness. Notably, we retain the terms for y q and w ⋆ to facilitate future extension to non-zero scenarios. Rewriting the equation equation 8 with
The red term represents the gradient of the least-squares loss in linear regression. Consequently, f LSA (E) becomes equivalent to a linear function f (x q ) = w ⊤ x q , where w is the one-step GD update initialized at the prior mean w ⋆ .
For the more general case with a non-zero prior mean w ⋆ , we relax the condition on the initial guess y q . By allowing y q to be a linear function of x q , specifically y q = w ⊤ ⋆ x q , we obtain the prediction of the linear regression task with a given query
which still implements the one-step GD update. Given this, we can now define y q -LSA.
Definition 3 (y q -LSA). We define y q -LSA with a flexible initial guess embedding matrix
where w ∈ R d is a trainable parameter and y q is the initial guess. The y q -LSA function is defined as
The y q -LSA extends the standard LSA by introducing an additional parameter w in the embedding, enabling better alignment with the query’s initial guess. The trainable parameters of y q -LSA now include W K , W Q , W P , W V and w, with inputs X, y and x q .
4.2 Analysis of y q -LSA Similar to the analysis of multi-head LSA, we first examine the stationary point of y q -LSA.
Theorem 4. For a y q -LSA function in equation 12 with a non-zero prior mean w ⋆ and contetxt size C → ∞, the weights
Theorem 4 is asymptotic in the context length C: when C → ∞, the gradient vanishes at the weights in Eq. ( 7) with w = w ⋆ . For finite C, each gradient component differs from its infinite-C value by a correction of order 1/C. Thus w = w ⋆ behaves as an approximate stationary point whose residual gradient (and the resulting bias) decays as C grows, explaining the small plateaus occasionally observed at finite C. Similar to multi-head LSA, we cannot conclusively determine that this stationary point represents the global optimum. This uncertainty comes from the non-convex nature of the y q -LSA ICL risk, as established in the following lemma.
Relation to concurrent work. Unlike Ahn et al. ( 2023)-who show that single-layer LSA attains one-step preconditioned GD under a zero-mean prior-Theorem 4 establishes that with a non-zero prior mean, one-step GD is still recovered without an MLP by introducing a trainable query initialization y q = w ⊤ x q . In contrast to Zhang et al. (2024b), where an LTB (LSA+MLP) realizes GD-β/near-Newton via the MLP, our result identifies input-side initialization as the minimal mechanism that closes the ICL-GD gap within LSA.
Lemma 2. The ICL risk of y q -LSA R(f yq-LSA ) is not convex.
While the non-convexity prevents a definitive proof of global optimality, our empirical investigations in Section 5.2 suggest an intriguing hypothesis. Notably, we conjecture that the stationary point identified in Theorem 4 may indeed be the global optimum. Empirical evidence indicates that the performance of one-step gradient descent serves as a lower bound for y q -LSA.
An additional noteworthy observation is y q -LSA’s relationship to the linear transformer block introduced by Zhang et al. (2024b). Unlike y q -LSA, LTB combines LSA with a linear multilayer perceptron (MLP) component. Critically, the global optimum of LTB implements a Newton step rather than one-step gradient descent. This approach fails to bridge the performance gap between one-step GD and single-head LSA and requires significantly more parameters through the additional MLP, in contrast to y q -LSA’s more parsimonious approach of introducing a single vector parameter w. See Lemma 3 in Section B for more details.
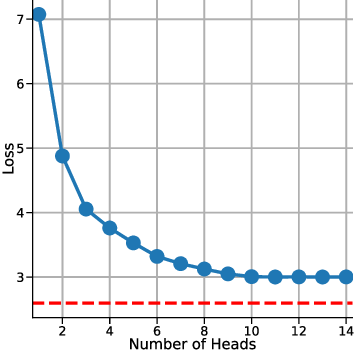
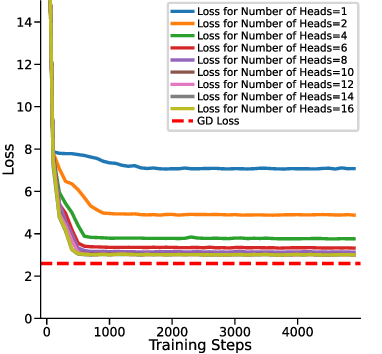
For experiments in Sections 5.1 and 5.2, we focus on a simplified setting where the LSA consists of a single linear self-attention layer without LayerNorm or softmax. We generate linear functions in a 10-dimensional input space (d = 10) and provide C = 10 context examples per task. We endow the LSA parameters with ICL capability by minimizing the expected ICL risk E[(f θ (E) -y) 2 ] over random tasks. Each training step is an Adam update of {W Q , W K , W V , W P } (and w for y q -LSA) using freshly sampled (X, y, x q , y); at test time, no parameter updates are performed. We train for 5000 gradient steps. Further implementation details are provided in Appendix C.1. We investigate the ICL risk (evaluation loss) of the multi-head LSA under different numbers of attention heads in the setting of a non-zero prior mean and y q is fixed at zero (details in Table 1). Fig. 2a illustrates the loss curves over the course of training for several head configurations, while Fig. 2b summarizes the final evaluation losses as a function of the number of heads. From these results, we observe that increasing the number of heads up to d + 1 (here d = 10, see Fig. 2b) substantially enhances the in-context learning capability of multi-head LSA, as reflected by a pronounced reduction in the final evaluation loss.
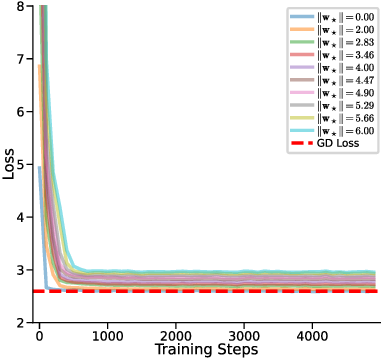
However, adding more than d + 1 heads yields negligible further improvement, indicating a saturation effect beyond this threshold. This confirms our results in Theorem 1. Notably, even at d + 1 heads, the multi-head LSA model does not converge to the one-step GD baseline loss, suggesting that while additional heads can capture richer in-context information (Crosbie & Shutova, 2024), they alone are insufficient for achieving full parity with the one-step GD performance in non-zero prior means setting. In other words, one-step GD loss serves as a strict lower bound of the ICL risk for multi-head LSA empirically. We investigate how the prior mean w ⋆ , which represents the mean weight of the generated linear function, affects the performance of multi-head LSA when the number of heads is fixed at or above d + 1 and y q is fixed at zero. Fig. 3a shows the loss curves for different values of ∥w ⋆ ∥, while Fig. 3b presents the final trained loss as a function of ∥w ⋆ ∥ 2 .
Our results demonstrate that even when the number of heads is sufficiently large (i.e., ≥ d + 1 , reaching the optimal multihead LSA configuration), multi-head LSA only matches the loss of one-step GD when the prior mean w ⋆ is zero. For non-zero prior means, a systematic gap remains between Multi-Head LSA and onestep GD. Furthermore, this gap increases linearly with the squared ℓ 2 norm of the prior mean, ∥w ⋆ ∥ 2 , indicating that the prior mean significantly impacts the optimal loss and that larger deviations from zero result in a larger discrepancy from the GD baseline. . Multi-head LSA reaches the GD loss only when both the linear guess component and the bias vanish (y q = w ⊤ ⋆ x q and no offset).
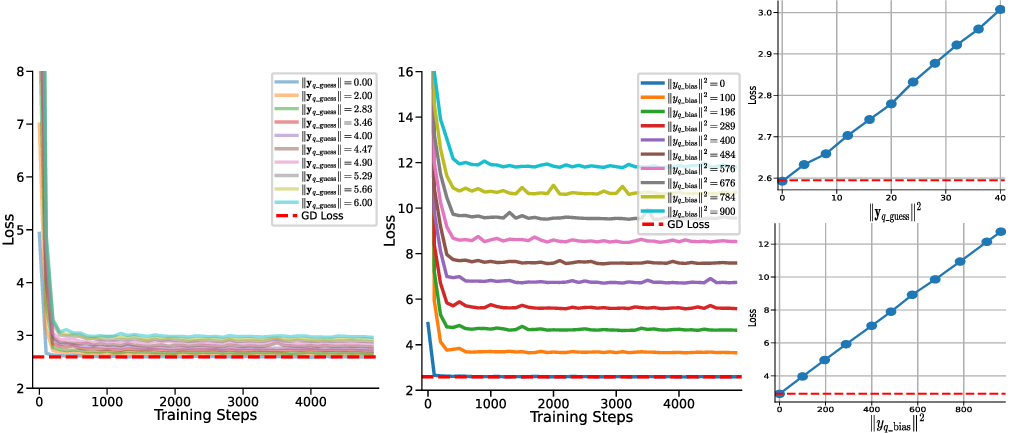
To investigate the effect of the initial guess y q , contained in the embedding matrix equation 2 on the in-context learning ability of multi-head LSA, we decompose y q into two components: We set the prior mean w ⋆ to zero and number of head is d + 1, then conduct two separate experiments:
(1) varying y q_guess while fixing y q_bias = 0, and (2) varying y q_bias while fixing y q_guess = 0. This allows us to isolate the contribution of each component to the model’s behavior.
As shown in Fig. 4, multi-head LSA only converges to the same loss as one-step GD when y q_guess = 0 (i.e., equal to the prior mean) and y q_bias = 0. In all other cases, a systematic gap remains between the loss of multi-head LSA and onestep GD. Moreover, this gap is directly proportional to ∥y q_guess ∥ 2 (the squared ℓ 2 -norm of the guessed component) and ∥y q_bias ∥ 2 (the squared bias term). These findings suggest that deviations in y q from the optimal initialization introduce a persistent discrepancy in multi-head LSA’s performance relative to one-step GD, regardless of the training of multi-head LSA.
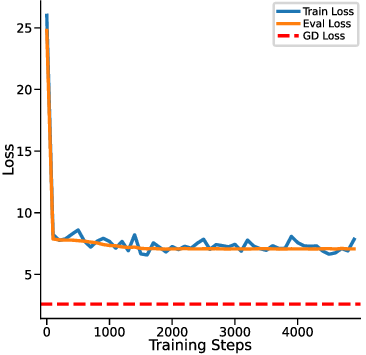
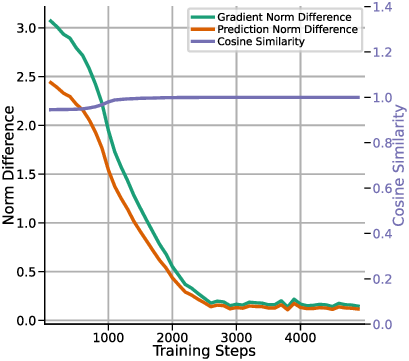
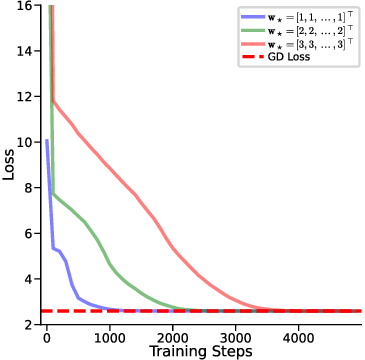
In this section, we aim to empirically validate whether y q -LSA, introduced in Section 4, aligns with one-step GD across different prior settings. Fig. 5 presents the training loss of y q -LSA. Throughout Fig. 5a the dashed “GD Loss” curve is the in-context risk of the predictor obtained by one GD step initialized at the prior mean w 0 = w ⋆ : w 1 = w 0 -η C X ⊤ (Xw 0 -y), ŷGD (x q ) = x ⊤ q w 1 , and the plotted baseline is
In Fig. 5a, we compare the convergence of y q -LSA to one-step GD, demonstrating that regardless of the prior configuration, y q -LSA effectively matches the GD solution. Fig. 5b provides a detailed evaluation of prediction norm differences, gradient norm differences (defined in Section C.2), and cosine similarity between the models. The results confirm that y q -LSA exhibits strong alignment with one-step GD in both loss convergence and gradient analysis.
Through theoretical and experimental analysis, we hypothesize that providing an initial guess for the target output during the ICL significantly improves the model’s ability to refine its predictions. Specifically, we posit that initial guesses act as a prior for optimization, guiding the model to more accurately. To validate this hypothesis, we conduct experiments leveraging widespread LLMs, demonstrating the efficacy of initial guesses in improving prediction accuracy.
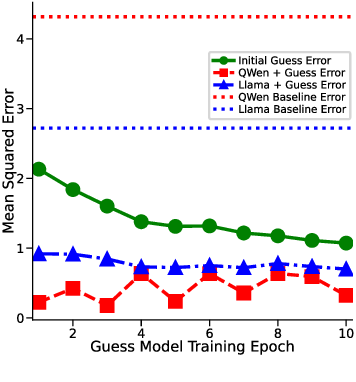
Figure 6: Error Comparison Two pre-trained models show consistently improved ICL performance on a sentence similarity task when prompted with a non-trivial initial guess.
Our experiments utilize Meta-LLaMA-3.1-8B-Instruct (Grattafiori et al., 2024), Qwen/Qwen2.5-7B-Instruct (Yang et al., 2024;Team, 2024) and the STS-Benchmark dataset (English subset) (May, 2021). Each prompt is presented in conjunction with a context comprising 10 labelled examples, where each example included a pair of sentences and its correct similarity score. A lightweight guess model is used to generate initial guesses for both the query and context examples. These guesses are included in the prompts provided to the LLM model, framed as prior guess. The model’s task is to predict a similarity score for the query pair, explicitly improving upon the initial guess. For evaluation, we calculate the mean squared error (MSE) between the predicted and true similarity scores, comparing the models with and without initial guesses. More details are in Section C.3.
The results demonstrate that the inclusion of initial guesses significantly enhances the performance of LLMs in ICL tasks. As shown in Fig. 6, incorporating initial guesses into the context reduce MSE under all experimental conditions. Comparative analysis of the LLaMA and QWen models further underscores the generality of this approach, as both models consistently benefit from the inclusion of initial guesses. These findings follow our hypothesis that initial guesses enhance ICL by providing an initial guess for refinement.
In this work, we have theoretically and empirically studied the extent to which multi-head LSA approximates GD in ICL, under more realistic assumptions of non-zero prior means. Our analysis establishes that while increasing the number of attention heads to d + 1 suffices to reach the minimal ICL risk in the linear setting, the model fundamentally fails to reach a stationary point when the prior mean is non-zero and context size grows. This limitation is further connected with the initial guess y q , whose misalignment with the prior induces a persistent optimality gap, even when the number of heads is sufficient. To solve this, we introduce y q -LSA, an LSA variant with a trainable initial guess, and show both theoretically and empirically that it bridges the gap between LSA and one-step GD in linear regression. Finally, we illustrate that incorporating an initial guess also benefits ICL in large language models, showing how this approach can be also used in more common settings.
Limitations. While our analysis is limited to linear regression tasks and simplified architectures without nonlinearities, normalization, or softmax, these assumptions are standard across much of the theoretical literature on in-context learning and mechanistic interpretation of transformers. The theoretical results rely on the infinite-context limit, which, although analytically tractable, diverges from practical settings where context size is finite. Additionally, while y q -LSA closes the gap with one-step GD in controlled experiments, its applicability to complex real-world tasks remains contingent on effective mechanisms for estimating or learning initial guesses. The LLM experiments suggest empirical benefits, but further exploration is required to assess generalizability across diverse tasks, model families, and training regimes.
Published in Transactions on Machine Learning Research (12/2025)
First, let’s redefine the notations used in Theorem 1 and restate the theorem. We write the input of a model as an embedding matrix given by
where X, y, x q , y q are defined in Section 2. The multi-head linear-self attention (LSA) function is defined as
where the output of each transformer head is defined as
The trainable parameters W K h , W Q h , W P h and W V h are specific to the h-th head, and W M def = I C 0 0 0 is a mask matrix, to ignore the query token when computing the attention scores. Let’s define by
the hypothesis class associated with multi-head LSA models with H heads. Finally, we measure the ICL risk of a model f by the mean squared error,
where the expectation is taken over the data distribution (and effectively over the embedding matrix E defined in equation 13).
Now we are ready to restate and prove Theorem 1.
Theorem 1. Let d ∈ N, and consider the hypothesis classes F (d+1)-LSA and F (d+2)-LSA corresponding to multi-head LSA models with H = d + 1 and H = d + 2 attention heads, respectively. Then
where R(f ) is the ICL risk defined in Eq. (4).
Proof. To simplify the notation, let’s introduce a couple of additional definitions. For each head h ∈ [H], the product of the output projection W P h and the value projection W V h can be written without loss of generality as
where b h ∈ R d+1 is the last row of the matrix, and the block * denotes entries that have no influence on the ICL risk. Then, let’s rewrite the product of the key and query matrices as
and denote its column decomposition by
where
With this notation, the contribution of all heads to the attention mechanism can be expressed in terms of the matrices
Each M i is a (d + 1) × (d + 1) real matrix. The space of such matrices, R (d+1)×(d+1) , has dimension (d + 1) 2 .
The collection
is thus an element of the Cartesian product
with dimension dim R (d+1)×(d+1) d+1 = (d + 1) 3 . Hence, the set of all possible tuples (M 1 , . . . , M d+1 ) can be identified with a vector space of dimension (d + 1) 3 .
We now compute the number of parameters available per head. For a fixed head h, the parameters that influence the construction of M i are (1) the vector b h which contributes (d + 1) free parameters, (2) the family of vectors a h 1 , . . . , a h d+1 , which contributes (d + 1)(d + 1) free parameters. Therefore, in total one head contributes (d + 1) + (d + 1)(d + 1) = (d + 1)(d + 2) degrees of freedom. With H heads in total, the dimension of the parameter space
This inequality shows that, when H ≥ d + 1, the parameter space has dimension at least as large as the target space. In particular, there is no dimensional obstruction to surjectivity of the mapping from parameters (b h , a h i ) to matrices (M 1 , . . . , M d+1 ). To demonstrate that the mapping is indeed surjective once H ≥ d + 1, we now construct explicitly any desired collection of matrices (M 1 , . . . , M d+1 ).
where M i [h] denotes the h-th row of the matrix M i . For h > d + 1, we may set b h = 0 and a h i = 0, so that those heads contribute nothing. With this choice of parameters,
Thus, every M i is exactly reproduced, and therefore every tuple (M 1 , . . . , M d+1 ) is realizable when
We have shown that with H = d + 1 heads, the model can realize any element of the target space, and therefore the hypothesis class is saturated. Adding additional heads H > d + 1 cannot enlarge the class of realizable functions. For this reason, for any
Finally, observe that F (d+1)-LSA ⊆ F (d+2)-LSA , since a (d + 1)-head model can be viewed as a (d + 2)-head model with the additional head parameters set to zero. Consequently, it follows that the only possibility is that inf
which concludes the proof.
Theorem 2. Let H ∈ N and consider the hypothesis class F H-LSA of multi-head LSA models with context size C → ∞. Then the in-context learning risk R(f ) admits no non-trivial stationary point in parameter space. More precisely,
for every choice of parameters
, except in the case where the prior mean vector vanishes, w ⋆ = 0.
The proof of Theorem 2 is based on the analysis of Ahn et al. (2023).
We first derive explicitly the expression of multi-head LSA’s ICL risk and simplify it. The key idea is to decompose the ICL risk into components. That is,
Since the prediction of f H-LSA is the bottom right entry of the output matrix, only the last row of the product W P h W V h contributes to the prediction. Therefore, we write
where b h ∈ R d+1 for all h ∈ [H], and * denotes entries that do not affect the ICL risk.
To simplify the computation, we also rewrite the product (W K h ) ⊤ W Q h and the embedding matrix E as
where
We define d+1) and
where ϵ ∈ R d ∼ N (0, I d ) is the noise.
Then the ICL risk can be written as
where x q [i] is the i-th coordinate of the vector x q .
Furthermore, we know that, for all h ∈ [H] and i ∈
where ⟨U , V ⟩ def = Tr U V ⊤ is the Frobenius inner product for any squared matrices U and V .
Hence, by using the linearity of the Frobenius inner product, we rewrite the ICL risk as
where w[i] is the i-th coordinate of the vector w.
By reparametrizing the ICL risk, using a composite function, we have
where
Recall x q ∼ N (0, I d ). Thus, both G and w are independent to x q [i] for all i ∈ [d], and x q [i] ∼ N (0, 1) are i.i.d.
Expanding equation 17 yields
where
Thus, the ICL risk equation 18 is decomposed into (d + 1) separated components
To compute the gradient of R(f H-LSA ), we can first compute the gradient of each component with respect to
Step
Recall that w ∼ N (w ⋆ , I d ) and x j i.i.d.
∼ N (0, I d ) are independent for all j ∈ [C], y j = w ⊤ x j , and
.
In particular, for each block of the above matrix, we have
where e i denotes the standard basis vector with zeros in all coordinates except the i-th position, where the value is 1.
Combining the above three components, we have
We start by calculating the expected value of the product of elements in matrix G. That is, for all m, n, p, q
where G mn is the value of matrix G in m-th row and n-th column position for all m, n ∈ [d + 1]. By expanding the summation, we have
To compute
where δ is the Kronecker delta.
We denote
By using equation 22, when C -→ ∞, we have
By linearity of the Frobenius inner product, we have
Combining the above equation with equation 21, equation 19 becomes
where
.
Notice that M is full rank and the rank of N is smaller or equal to 2. Thus, for any M i ∈ R (d+1)×(d+1) , we have
In the proof of Theorem 2 we work in the infinite-context limit C → ∞ and use
where G ∈ R (d+1)×(d+1) defined in equations ( 22)-( 24). For completeness, we now make explicit how equation 26 is obtained from the finite-C expression and how the resulting gradients are modified when C is finite.
Recall that
For any indices m, n, p, q ∈ [d + 1] we have
and therefore
Taking expectation and separating the cases j ̸ = k and j = k yields
where we introduced the fourth-order tensor
Equivalently,
so that in tensor form
Using the linearity of the Frobenius inner product, the quantity that appears in equation ( 19) can be written as
for some matrix U i ∈ R (d+1)×(d+1) whose entries are linear combinations of the tensor coefficients ∆ mnpq . Substituting this expression into equation 28 and combining with equation ( 21) gives the finite-C gradient
Equation ( 25) corresponds exactly to the leading term in equation 29 when C → ∞, since in that regime U i is bounded while the 1 C U i correction vanishes. For any fixed finite C, however, the additional term 2 C U i provides an O(1/C) perturbation of the gradient. This perturbation can partially cancel the leading term (2⟨M, M i ⟩ -2w ⋆ [i])M -2N and may create (non-global) stationary points in parameter space, which is consistent with the non-convexity discussion.
Implications for Theorem 4. The same finite-C decomposition is also relevant for the proof of Theorem 4 in Section B.3. There, the gradients with respect to the parameters b, a j , a d+1 and v[j] are expressed in terms of expectations of products involving G (see the expressions preceding the verification that b = -w ⋆ 1 , a j = e j 0 , a d+1 = 0, v = w ⋆ form a stationary point in the C → ∞ limit). Using equation 27-equation 28, each such expectation can be written as its infinite-context value plus an O(1/C) correction. Consequently, for finite C every first-order derivative at w = w ⋆ takes the form
where R ∞ denotes the risk in the limit C → ∞. Thus, w = w ⋆ is an approximate stationary point whose residual gradient decays at rate O(1/C) as the context size grows. This clarifies how the exact correspondence with one-step gradient descent established in Theorem 4 is approached as C increases, and how small but non-zero biases may appear in practice when C is finite.
Proof. From equation 25, we can compute the Hessian of the function L i (M i ), that is,
We verify that M is positive semi-definite. Indeed, let u ∈ R d and u ∈ R. We have
Since M is positive semi-definite, we have the function L i is convex with respect to M i .
From equation 18, we know that
Each function L i is a function of M i . We denote
Then the Hessian of the function f with respect to variables M 1 , • • • , M d+1 is a block diagonal matrix, each block on the diagonal is
Lastly,
To simplify it, we can consider only one head. That is, M i = b 1 (a 1 i ) ⊤ , a bilinear function, which is known to be not convex with respect to b 1 and a 1 i . To conclude, the ICL risk R(f H-LSA ) is a composite function with a convex function and non convex functions, which implies that R(f H-LSA ) is not convex.
Here we provide the derivation of equation 8. Recall
From the standard LSA formulation equation 3 with the given embedding in equation 2, we have
So we get the LSA simplified as
.
In this case, we have
and LSA recovers the result in Von Oswald et al. ( 2023), which performs one-step GD on the update of the linear regression parameter initialized at w ⋆ = 0 with y q = 0 = w ⊤ ⋆ x q :
that yields equation 8.
In this section, we show that y q -LSA defined in equation 12 is a special case of linear transformer block (LTB) presented in Zhang et al. (2024b), which is mentioned in Section 4.
LTB combines LSA with a linear multilayer perceptron (MLP) component. That is,
where W 1 , W 2 , W P , W V , W K and W Q are trainable parameters for f LTB , and
for X ∈ R C×d , y ∈ R C and x q ∈ R d . Notice that there is no initial guess y q involved in this embedding matrix E.
We denote the hypothesis class formed by LTB models as
where f LTB is defined in equation 30. Then we have the following lemma.
Lemma 3. Consider f yq-LSA defined in equation 12. We have C+1) .
We aim to find (W
Let choose W 2 = I d+1 and
From u + uw = 0, we have u = -uw. Plugging it into w ⊤ u + cu = 0, we obtain (c -∥w∥ 2 )u = 0.
Since c ̸ = ∥w∥ 2 , we obtain u = 0. Thus, u = -uw = 0. This implies that W 1 is invertible.
Next, we consider the following matrix
We show that f yq-LSA (X, y, x q ) = f LTB (E). Indeed, by using Xw = y, we have
Thus, we conclude f yq-LSA ∈ F LTB .
The risk (loss) function with learnable vector v is given by:
Similar as Section A, we rewrite the risk:
We define, for each j:
Step 1: Gradient for parameters
We list the first-order partial derivatives with respect to b, a j , a d+1 , and v
Only the j-th term depends on a j , so
We have
Step 2: Plug in One Step GD we verify when b = -w ⋆ 1 , a j = e j 0 , a d+1 = 0 , v = w ⋆ , the gradients equal to zero we define w = ww ⋆ , We have the following intermediate formula:
Calculate each part:
if we have very large C, we have: Taking expectation:
Case 1: i ̸ = k Since x i and x k are independent:
Given x i ∼ N (0, I d ):
where e j is the j-th standard basis vector. There are C such terms, contributing: C(2w j w + ∥w∥ 2 e j ).
Adding contributions from both cases:
x k x T k w = C(C -1)w j ∥w∥ 2 + C(2w j w + ∥w∥ 2 e j ).
= C(C + 1)w j w + C∥w∥ 2 e j .
Thus, the expectation is: Proof. Based on the proof of Lemma 3, we consider the following matrix d+1) . Now for any f yq-LSA ’s inputs (X, y, x q ), by using Xw = y, we have
x q w ⊤ X ⊤ w ⊤ x q = E w .
Team, 2024). The model’s generation parameters included a maximum of 150 new tokens and deterministic decoding.
The guess model was trained to generate initial similarity score guesses. It consisted of a two-layer feedforward architecture, taking as input the concatenated embeddings of two sentences computed by the Sentence-Transformer model all-MiniLM-L6-v2 (Reimers & Gurevych, 2020). The first layer mapped the concatenated embeddings to a 16-dimensional space with ReLU activation, followed by a second layer that outputs a single scalar value as the predicted similarity score. The model was trained using Adam Optimizer(Kingma, 2014) with a learning rate of 1e-3 and a mean squared error loss function. Training was performed over 10 epochs, with a batch size of 8. Sentence embeddings were dynamically computed during training. The loss for training the guess model was computed as the MSE between the predicted and ground truth scores.
For each prompt, a context was constructed by randomly sampling 10 labelled examples from the dataset.
Each labelled example included two sentences, a ground truth similarity score, and an initial guess for the similarity score generated by a lightweight guess model. The query example included two sentences and its guessed similarity score and an explicit instruction for the LLM to refine the guess and provide a similarity score between 0 and 5.
To evaluate the effectiveness of the initial guess, we calculated the MSE between the LLM’s predicted similarity scores and the ground truth scores across 100 experimental runs. The baseline performance, derived from the initial guesses provided was compared to the refined predictions generated by the LLM.
Published in Transactions on Machine LearningResearch (12/2025)
📸 Image Gallery