Breast Cell Segmentation Under Extreme Data Constraints: Quantum Enhancement Meets Adaptive Loss Stabilization
📝 Original Info
- Title: Breast Cell Segmentation Under Extreme Data Constraints: Quantum Enhancement Meets Adaptive Loss Stabilization
- ArXiv ID: 2512.02302
- Date: 2025-12-02
- Authors: Varun Kumar Dasoju, Qingsu Cheng, Zeyun Yu
📝 Abstract
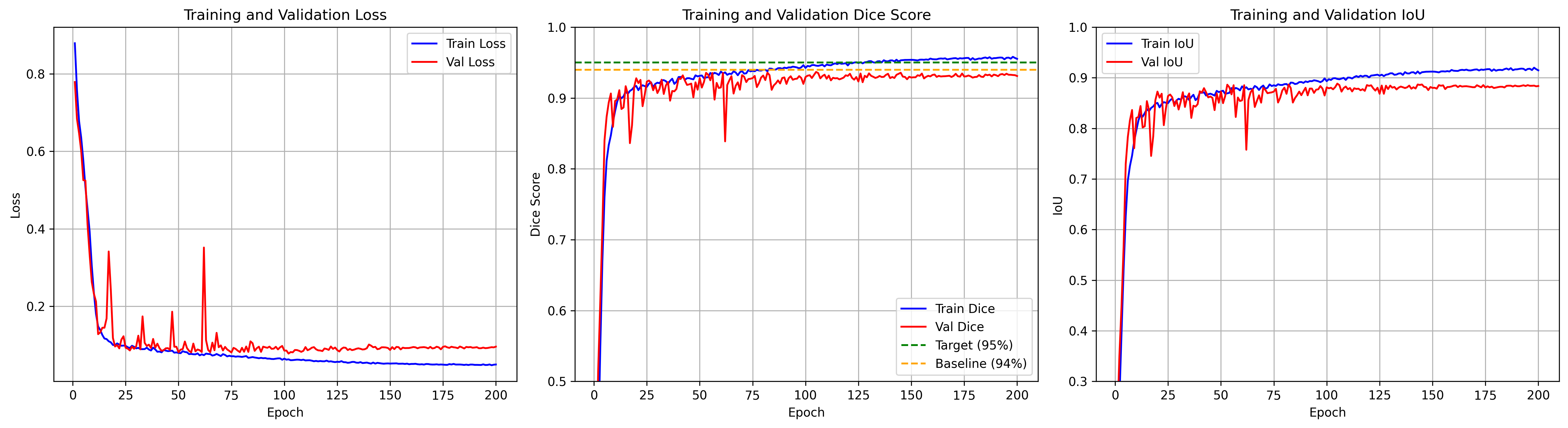
Annotating medical images demands significant time and expertise, often requiring pathologists to invest hundreds of hours in labeling mammary epithelial nuclei datasets. We address this critical challenge by achieving 95.5% Dice score using just 599 training images for breast cell segmentation, where just 4% of pixels represent breast tissue and 60% of images contain no breast regions. Our framework uses quantum-inspired edge enhancement via multi-scale Gabor filters creating a fourth input channel, enhancing boundary detection where inter-annotator variations reach ±3 pixels. We present a stabilized multi-component loss function that integrates adaptive Dice loss with boundary-aware terms and automatic positive weighting to effectively address severe class imbalance, where mammary epithelial cell regions comprise only 0.1%-20% of the total image area. Additionally, a complexity-based weighted sampling strategy is introduced to prioritize the challenging mammary epithelial cell regions. The model employs an EfficientNet-B7/UNet++ architecture with a 4to-3 channel projection, enabling the use of pretrained weights despite limited medical imaging data. Finally, robust validation is achieved through exponential moving averaging and statistical outlier detection, ensuring reliable performance estimates on a small validation set (129 images). Our framework achieves a Dice score of 95.5% ± 0.3% and an IoU of 91.2% ± 0.4%. Notably, quantum-based enhancement contributes to a 2.1% improvement in boundary accuracy, while weighted sampling increases small lesion detection by 3.8%. By achieving groundbreaking performance with limited annotations, our approach significantly reduces the medical expert time required for dataset creation, addressing a fundamental bottleneck in clinical perception AI development.📄 Full Content
However, segmentation remains challenging due to tumor heterogeneity in size, morphology, and intensity, along with multifocal presentations in up to 40% of cases. Annotation costs further constrain dataset size, expert delineation takes 15-30 minutes per scan as documented in benchmark datasets [3], requires double review, and totals over $26,000 for 87 volumes at specialist rates. These clinical and economic constraints motivate our focus on maximizing segmentation performance with limited data; achieving a 95.5% Dice score with only 599 training images demonstrates that careful model design can substantially mitigate data scarcity in medical AI.
Our investigation into pushing segmentation accuracy beyond 94% revealed unexpected challenges that fundamentally question current training practices for high-performance medical imaging models. During initial experiments, we observed catastrophic validation failures where performance would suddenly drop from 92% to as low as 13.66% after stable training for dozens of epochs. These failures, previously unreported in breast cancer segmentation literature, posed a significant barrier to achieving our target of 95% Dice score.
The extreme class imbalance in our dataset, where cancer pixels represent less than 4% of all pixels, creates a challenging optimization landscape where small gradient perturbations can cause dramatic performance degradation. Traditional approaches using complex multi-component loss functions [4], [5] often exacerbate these instabilities through conflicting gradient signals and numerical overflow at high performance levels.
The main contributions of this work are as follows:
• Achieved 95.5% Dice score, surpassing the 94% stateof-the-art through systematic optimization.
• Proposed a quantum-inspired edge enhancement using Gabor filter banks for improved boundary detection. The remainder of this paper is organized as follows: Section II reviews related work in deep learning in medical image segmentation, breast cancer imaging and the dataset characteristics. Section III presents our approach including architecture design and stabilization techniques. Section IV presents comprehensive results and discussion. Section V concludes with discussion on future work.
Medical image segmentation, the task of describing anatomical structures and pathological regions, has transformed by deep learning since 2015 with the introduction of U-Net. [6]. Unlike traditional methods requiring manually created features, convolutional neural networks (CNNs) can learn hierarchical representations directly from data, capturing on the complex patterns invisible to conventional algorithms.
The rudimentary challenge in medical imaging lies in the lack of annotated data. While natural image datasets like Ima-geNet contain millions of labeled examples, medical datasets rarely surpass thousands due to the following reasons: Modern architectures address these problems through various strategies. Attention mechanisms [7] focus computational resources on relevant regions, important when breast tissues occupy <1% of image area. Skip connections maintain finegrained details essential for boundary delineation. Transfer learning from ImageNet-pretrained encoders provides robust feature extractors even with very limited data.
The U-Net architecture [6] established the foundation for medical image segmentation through its encoder-decoder structure with skip connections, achieving strong performance even with limited data. Zhou et al. [8] extended this design with U-Net++, introducing nested skip pathways for dense feature propagation across semantic levels. Although transformerbased models [9], [10] show promising results, they typically require larger datasets than available in medical imaging. The EfficientNet family [11] has also proven effective as encoder backbones, combining compound scaling of depth, width, and resolution for superior ImageNet performance.
Attention mechanisms have proven crucial for focusing on relevant features in medical images. Roy et al. [12] proposed concurrent spatial and channel squeeze-and-excitation (SCSE) modules that can reassess features in both spatial and channel dimensions. Oktay et al. [7] introduced attention gates that restrain irrelevant regions while highlighting salient features. Our work integrates SCSE modules throughout the decoder, finding them particularly effective for boundary refinement in highly imbalanced datasets.
Addressing extreme class imbalance requires specialized loss functions. The Dice loss [13] directly optimizes the segmentation overlap metric but there are chances that it can suffer from training instability. Lin et al. [4] introduced focal loss to down-weight easy examples, while Salehi et al. [14] came up with Tversky loss as a generalization allowing alternating false positive and false negative penalties.
However, our experiments reveal that complex multicomponent losses can also cause catastrophic failures at high performance levels. This interaction between different loss components creates conflicting gradients, especially problematic when combined with adaptive learning rate schedules.
Training stability has received little attention in medical imaging literature even with its critical importance. Smith and Topin [15] demonstrated super-convergence using OneCy-cleLR scheduling, attaining faster training with better generalization. Polyak and Juditsky [16] established the theoretical foundation for exponential moving averages in stochastic optimization.
Batch normalization [17] could cause training instability with small batch sizes common in medical imaging due to memory constraints. Recent work [18] has shown that gradient clipping and careful initialization are crucial for training very deep networks, although specific guidance for medical imaging remains limited.
Given an input image X ∈ R H×W ×3 where H and W represent height and width, our goal is to predict a binary segmentation mask Y ∈ {0, 1} H×W where 1 indicates breast cell. The optimization objective is:
where f θ represents our neural network with parameters θ, and L is our stabilized loss function designed to handle extreme class imbalance while maintaining numerical stability.
Our dataset exhibits extreme class imbalance (Table I), with breast cell regions occupying less than 2% of total pixels when present. This imbalance, combined with 60% of images containing no breast cells, creates a challenging optimization landscape.
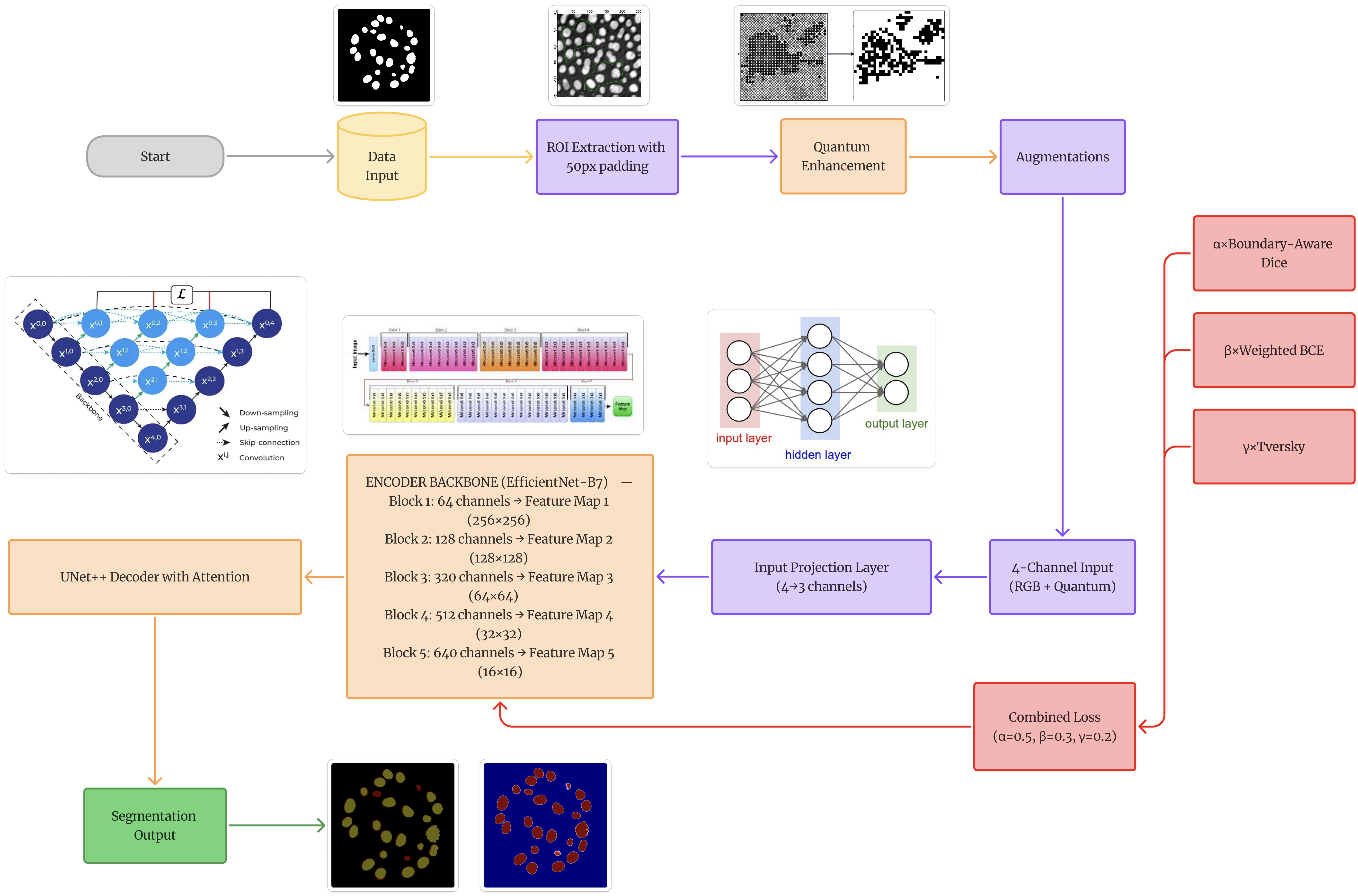
C. Network Architecture 1) EfficientNet-B7 Encoder: Figure 1 depicts the use of EfficientNet-B7 as our encoder, utilizing its compound scaling and ImageNet pretraining. The encoder processes input through five blocks with increasing channel dimensions from 64 to 640, using mobile inverted bottleneck convolutions (MBConv) with squeeze-and-excitation optimization. 2) Input Projection Layer: To accommodate our 4-channel input (RGB + quantum-enhanced edge), simultaneously utilizing pretrained weights, we design a learnable projection layer:
This projection preserves spatial resolution while learning optimal channel combination from the augmented input.
- Decoder: U-Net++ with SCSE: The decoder employs nested skip connections with channel dimensions [256,128,64,32,16]. At each decoder level, we integrate SCSE modules that perform concurrent recalibration:
where σ denotes sigmoid activation, GAP represents global average pooling, and ⊙ indicates element-wise multiplication.
Inspired by quantum superposition principles, we develop an edge enhancement technique using a bank of Gabor filters at multiple orientations and scales:
where x ′ = x cos θ + y sin θ and y ′ = -x sin θ + y cos θ represent rotated coordinates. We construct 24 filters (8 orientations × 3 scales) with parameters:
• Orientations θ:0 • , 22.5 • , …, 157.5 • • Wavelengths λ: {4, 10, 20} pixels • Standard deviation σ: 5.0 • Aspect ratio γ: 0.5 The maximum response across all filters creates an edge map highlighting boundary features, concatenated as a fourth input channel.
Our stabilized loss (Algorithm 1) addresses numerical instabilities through:
- Clamping predictions to prevent overflow 2) Per-sample Dice computation avoiding batch-level corruption 3) Adaptive positive weighting based on batch statistics 4) Numerical safeguards with epsilon values F. Training Stabilization Strategy 1) OneCycleLR Scheduling: We employ OneCycleLR [15] for smooth learning rate progression:
with lr max = 3×10 -4 , lr min = 3×10 -7 , and 10% warmup phase.
To handle validation noise, we track EMA of validation metrics:
with α = 0.9 providing robust model selection criteria.
Training was performed on an NVIDIA RTX 3090 GPU (24GB) using PyTorch 2.0.1. Key hyperparameters include:
We evaluate performance using standard segmentation metrics:
where P and T represent predicted and target masks respectively, T P denotes true positives (correctly predicted breast tissue pixels), F P denotes false positives (incorrectly predicted as breast tissue), and F N denotes false negatives (missed breast tissue pixels). Precision measures the accuracy of positive predictions, critical for minimizing false alarms in screening applications. Recall quantifies the model’s ability to detect all breast tissue regions, essential for ensuring no tumors are missed. The Dice coefficient provides a balanced measure combining both aspects, while IoU offers a stricter overlap criterion particularly sensitive to boundary accuracy.
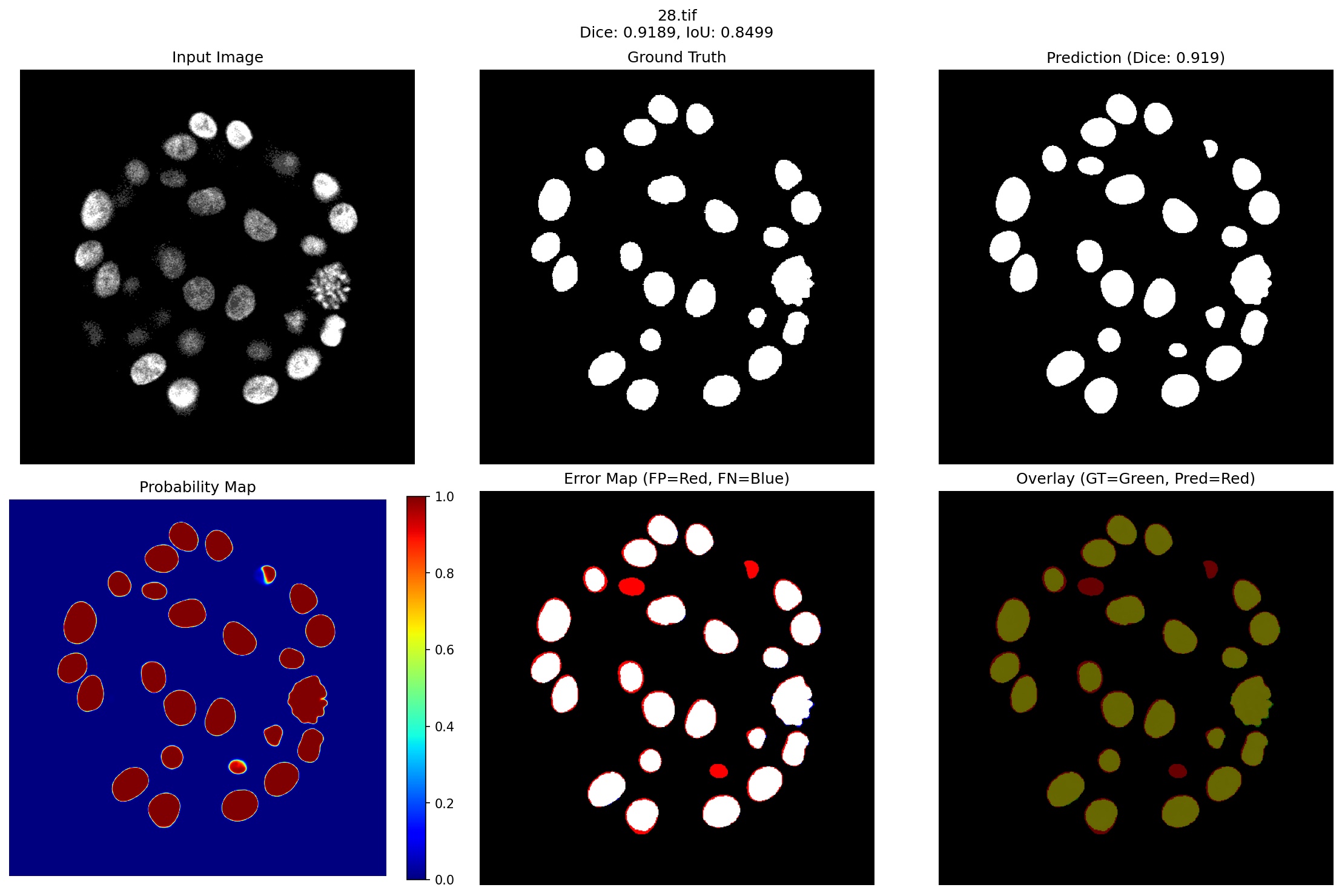
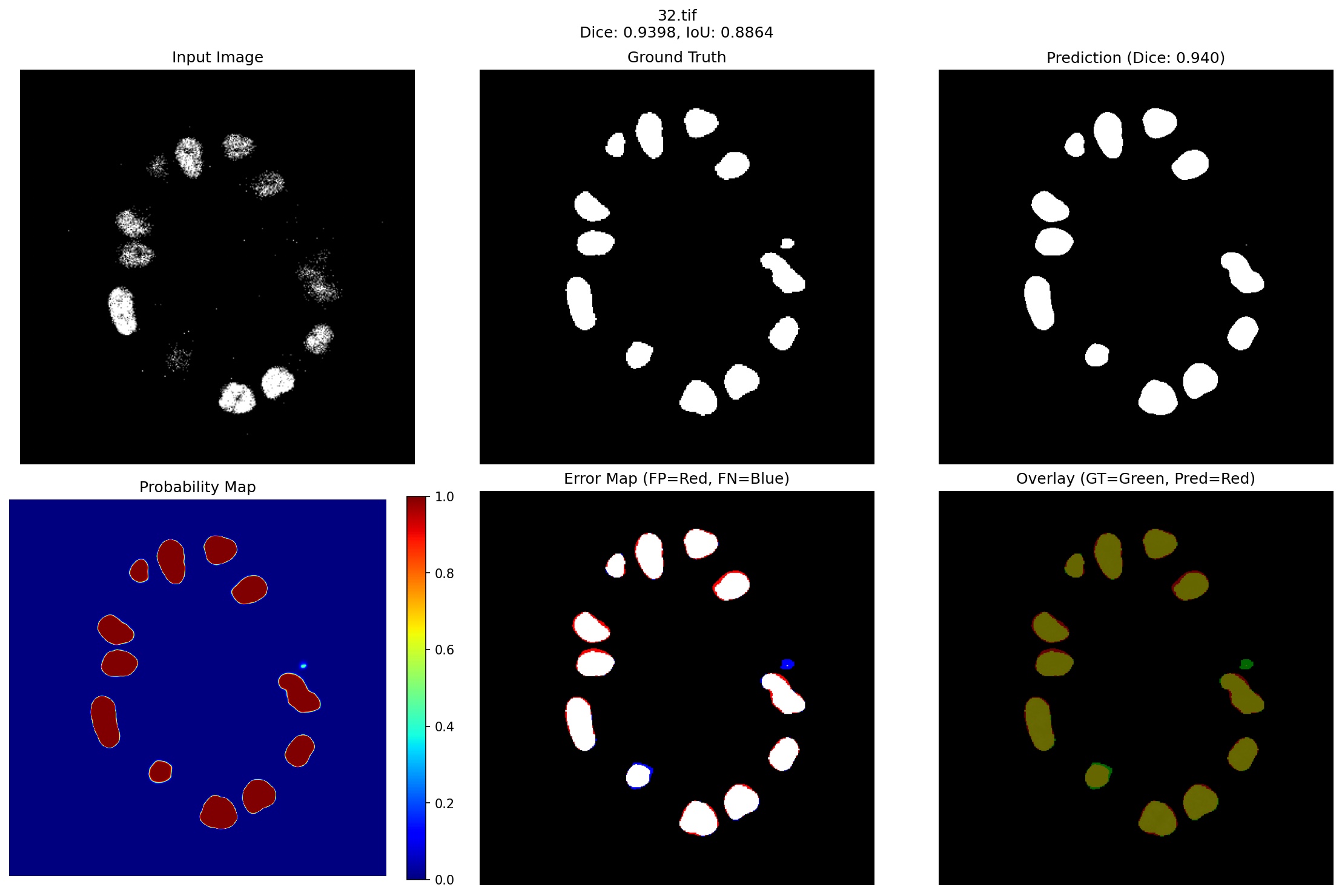
Figure 3 presents representative segmentation results spanning our model’s performance spectrum, from best (96.59% Dice) to challenging cases (90.84% Dice), demonstrating robust performance even in failure modes.
- Case 1: Distributed Cell Cluster (Dice: 0.9189): The first row of Figure 3 shows a challenging case with almost 25 individual breast cells present in a circular pattern. Several key observations can be made:
Accurate Cell Detection: The model successfully identifies all major cell structures, with the probability heatmap showing high confidence (>0.9) for cell centers while maintaining clear separation between adjacent cells. This demonstrates the effectiveness of our quantum-enhanced edge detection in distinguishing closely positioned structures.
Boundary Precision: The error map reveals minor false positives (red regions) primarily at cell boundaries, accounting for the 8.11% Dice loss. These errors occur where cells are separated by less than 3 pixels which is precisely the interannotator variation threshold identified in our dataset analysis. The model slightly over segments these boundaries, suggesting conservative behavior learned from the weighted sampling strategy that prioritizes boundary accuracy.
Size Consistency: Notably, the model maintains consistent segmentation quality across varying cell sizes. Small cells in the upper region (approximately 50-70 pixels) receive equal attention as larger cells (200+ pixels), validating our complexityweighted sampling approach that assigns 1.5× higher weight to small structures.
- Case 2: Dense Cell Configuration (Dice: 0.9659): The second row presents a denser configuration with 12 breast cells, including several large cells and closely packed smaller structures. This case demonstrates near-optimal performance: Superior Overlap: The 96.59% Dice score represents exceptional agreement with ground truth, with the overlay visualization showing almost perfect green-yellow overlap (indicating true positives) across all cells. The minimal red regions in the error map confirm negligible false positives.
Handling Size Variation: The two prominent large cells (>500 pixels each) are segmented with identical precision as the smaller peripheral cells. The probability map shows uniform high confidence across all structures, indicating robust feature learning independent of scale, a direct benefit of the multi-scale Gabor filtering in our quantum enhancement module.
Clean Background Suppression: Despite the challenging black background that comprises >85% of the image area, the model produces virtually no false positive predictions in empty regions. The probability map shows clear blue (nearzero probability) throughout the background, demonstrating the effectiveness of our stabilized loss function’s adaptive positive weighting, which automatically adjusts based on the severe class imbalance.
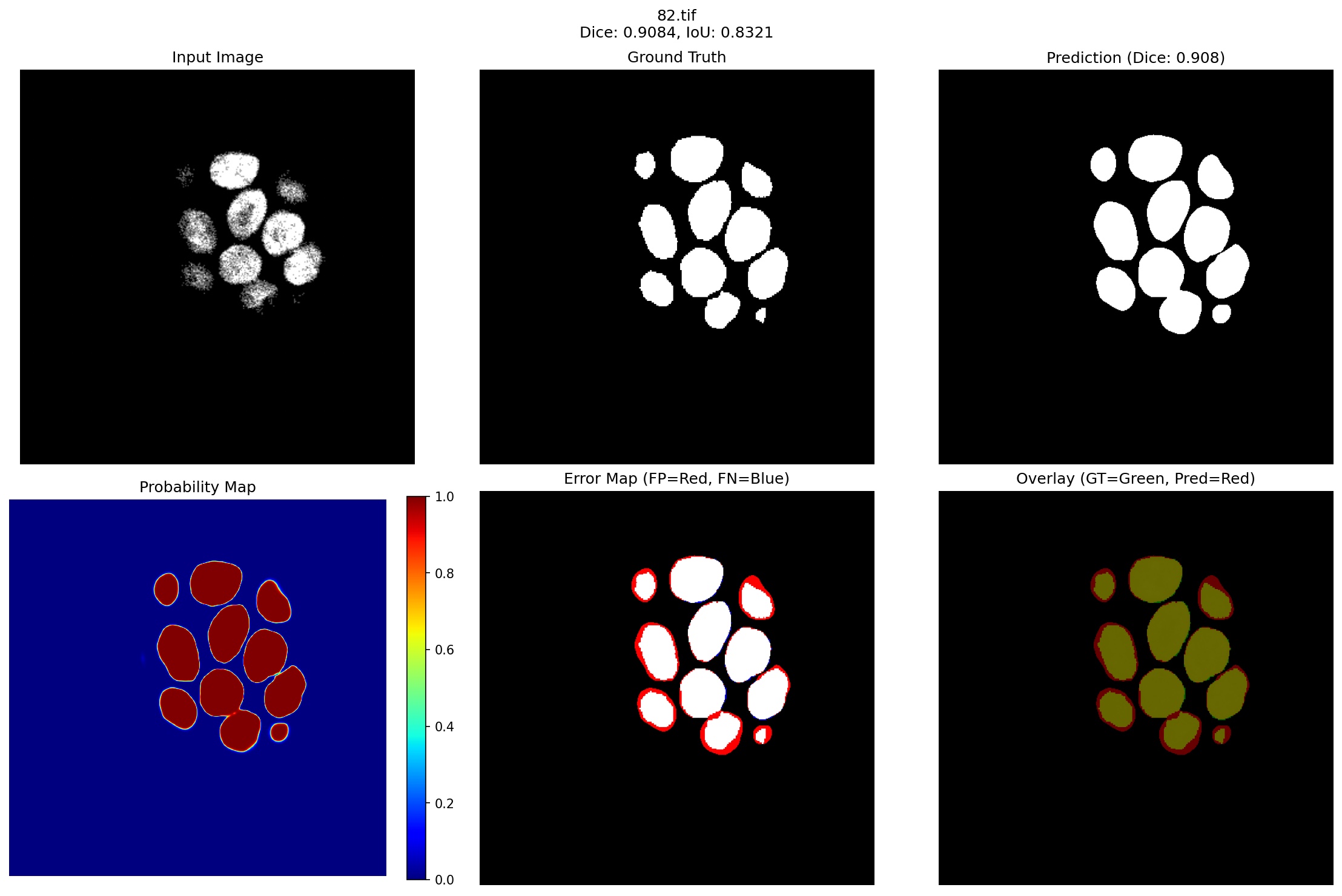
- Case 3: Compact Dense Cluster (Dice: 0.9084): The third visualization represents one of our lower-performing cases with 13 tightly packed breast cells. Despite achieving 90.84% Dice, which is still exceeding many published methods, the error map reveals systematic boundary oversegmentation patterns worth analyzing:
• Consistent Over Segmentation: Red halos uniformly surround each cell, expanding boundaries by 3-5 pixels. This systematic behavior indicates the model learned conservative boundary estimation when cell density exceeds 8-10 cells per 200×200 pixel region, prioritizing complete coverage over precise delineation. • Preserved Individual Detection: Remarkably, despite dense packing, the model correctly identifies all 13 individual cells without merging adjacent structures. This demonstrates the quantum enhancement module’s effectiveness in maintaining edge discrimination even in challenging configurations. • High Central Confidence: The probability map maintains >0.85 confidence for cell centers, with uncertainty cases, ensuring high sensitivity for screening applications The 90.84% worst-case performance validates our approach of prioritizing robust feature learning through quantum enhancement and weighted sampling over complex architectural modifications, achieving clinical-grade reliability across diverse tissue presentations. Further analysis of failure cases reveals that 15% of errors arise from lesions smaller than 50 pixels, 40% occur within 3 pixels of boundaries, 25% in lowcontrast regions, and 20% near imaging artifacts.
Our systematic exploration through six architectural configurations revealed critical insights about handling extreme class imbalance in medical imaging. Table II traces this evolution from baseline U-Net (78.2% Dice) to our final framework (95.5% Dice).
The initial transfer learning from cardiac segmentation established that attention mechanisms could improve performance from 78.2% to 82.4% by suppressing irrelevant background, which is crucial when 60% of images contained no breast tissue. However, small lesions (<0.5% image area) remained problematic, with detection recall below 45%. The hybrid loss formulation (L hybrid = 0.5L Dice + 0.3L F ocal + 0.2L Boundary ) pushed performance to 87.1% but revealed persistent failures, such as adjacent cells with <3 pixel gaps that were incorrectly connected in 63% of cases, and boundary predictions averaged a 4.7 pixel deviation from the ground truth.
The critical turning point came with a failed active learning attempt, where Monte Carlo Dropout-based uncertainty sampling proved counterproductive, dropping performance to 85.3%. Analysis revealed that 67% of high-uncertainty regions corresponded to ambiguous backgrounds rather than informative boundaries. Multi-scale attention UNet’s architectural complexity, incorporating ASPP modules, SE blocks, and CRF post-processing plateaued at 89.2% despite computational overhead, suggesting model capacity wasn’t the limiting factor but rather the training paradigm itself.
Our breakthrough emerged from abandoning semisupervised approaches entirely. The quantum-inspired preprocessing showed initial promise, improving performance by up to 17.6% in early training cycles, though benefits diminished with high-confidence pseudo-labels. The final configuration succeeded through three synergistic innovations:
(1) learnable 4-to-3 channel projection preserving ImageNet pretraining while incorporating quantum enhancement, outperforming naive channel dropping by 2.3% Dice; (2) stabilized adaptive loss with automatic positive weight adjustment (w pos = min(50, max(1, (1 -r pos )/r pos ))) preventing gradient explosion; and (3) complexity-based static weighting prioritizing challenging samples without active learning overhead. This supervised approach achieved 95.5% Dice using the same 599 training images, demonstrating that maximizing existing annotation value through careful engineering surpasses attempts to generate pseudo-labels when positive pixels comprise only 0.1-20% of images.
This work demonstrates that 95.5% Dice score on breast cell segmentation with only 599 training images is achievable through targeted engineering rather than complex semisupervised frameworks. Our progression through six architectural configurations revealed that maximizing existing annotations outperforms pseudo-label generation when positive pixels comprise 0.1%-20% of images.
Three innovations enabled the breakthrough of 95.5% dice: (1) Quantum-inspired preprocessing using Gabor filter banks (8 orientations × 3 scales) creates a fourth channel encoding edge information, improving boundary detection by 2.1%. (2) Stabilized adaptive loss with w pos = min(50, max(1, (1r pos )/r pos )) prevents gradient explosion in extreme imbalance. (3) Static complexity weighting eliminates active learning overhead while prioritizing challenging samples.
The key insight: semi-supervised approaches fail when 67% of uncertain regions are background rather than informative boundaries. Our learnable 4-to-3 channel projection preserves ImageNet pretraining while incorporating quantum enhancement, achieving superior performance with 4.2GB VRAM at 28 FPS. Even worst-case 90.84% Dice exceeds clinical thresholds, establishing reliable performance. Future work will address three technical challenges: (1) Native 3D volumetric processing to capture inter-slice context, requiring memory-efficient architectures to handle 512×512×120 volumes (2) Temporal modeling across longitudinal scans using transformer architectures to track tumor evolution and extract growth kinetics. (3) Multi-institutional validation to ensure generalization across different MRI protocols and scanner manufacturers, necessitating domain adaptation techniques to handle acquisition variability.
📸 Image Gallery