An Empirical Survey of Model Merging Algorithms for Social Bias Mitigation
📝 Original Info
- Title: An Empirical Survey of Model Merging Algorithms for Social Bias Mitigation
- ArXiv ID: 2512.02689
- Date: 2025-12-02
- Authors: Daiki Shirafuji, Tatsuhiko Saito, Yasutomo Kimura
📝 Abstract
Large language models (LLMs) are known to inherit and even amplify societal biases present in their pre-training corpora, threatening fairness and social trust. To address this issue, recent work has explored "editing" LLM parameters to mitigate social bias with model merging approaches; however, there is no empirical comparison. In this work, we empirically survey seven algorithms: Linear, Karcher Mean, SLERP, NuSLERP, TIES, DELLA, and Nearswap, applying 13 open weight models in the GPT, LLaMA, and Qwen families. We perform a comprehensive evaluation using three bias datasets (BBQ, BOLD, and HONEST) and measure the impact of these techniques on LLM performance in downstream tasks of the SuperGLUE benchmark. We find a tradeoff between bias reduction and downstream performance: methods achieving greater bias mitigation degrade accuracy, particularly on tasks requiring reading comprehension and commonsense and causal reasoning. Among the merging algorithms, Linear, SLERP, and Nearswap consistently reduce bias while maintaining overall performance, with SLERP at moderate interpolation weights emerging as the most balanced choice. These results highlight the potential of model merging algorithms for bias mitigation, while indicating that excessive debiasing or inappropriate merging methods may lead to the degradation of important linguistic abilities.📄 Full Content
Previous work on reducing social bias has explored various approaches, such as training LLMs with synthetic examples (Zmigrod et al., 2019;Ravfogel et al., 2020;Schick et al., 2021). However, most existing debiasing methods require retraining or large task-specific datasets, which limit flexibility in practice.
For this reason, model merging (Wortsman et al., 2022), which fuses multiple fine-tuned checkpoints originating from the same initialization directly in parameter space, has recently been explored to mitigate social bias, such as methods based on simple task arithmetic (Shirafuji et al., 2025) or parameter selective editing (Lutz et al., 2024).
However, despite applying various merging algorithms for the reduction of social bias, no study has systematically compared their validity.
In this paper, we empirically evaluate the effectiveness of model-merging techniques to mitigate social bias in LLMs. An overview of our pipeline is illustrated in Figure 1. According to Shirafuji et al. (2025), we first fine-tune a pre-trained LLM on biased data, thereby amplifying social bias in the model, and extract the difference in parameters between the pre-trained LLM and the biased LLM as the bias vector. Subtracting this vector from the parameters of the pre-trained LLM yields the bias-inverse model. We then merge with the original pre-trained model and the inverse model using various algorithms. Empirical experiments are conducted for seven merging techniques: Linear (Wortsman et al., 2022), Karcher Mean (Grove and Karcher, 1973), SLERP (Shoemake, 1985), NuSLERP (Goddard et al., 2024), TIES (Yadav et al., 2023), DELLA (Deep et al., 2024), and Nearswap (Goddard et al., 2024). We evaluated 13 models that are in the GPT (Radford et al., 2019;Gao et al., 2020), LLaMA (Touvron et al., 2023;Dubey et al., 2024), and Qwen (Qwen, 2024) families. Performances are measured in three bias datasets (BBQ (Parrish et al., 2022), BOLD (Dhamala et al., 2021), and HON-EST (Nozza et al., 2021)) and, to ensure downstream quality is preserved, on the SuperGLUE benchmark (Wang et al., 2019).
Our contributions are as follows:
• Conducting an empirical survey on seven model merging algorithms for social bias mitigation with three bias benchmarks and Super-GLUE across 13 LLMs.
• Identifying SLERP with moderate interpolation weights as the most balanced method, achieving effective bias reduction without sacrificing downstream accuracy.
• Highlighting the necessity of verifying performance on tasks such as reading comprehension and commonsense / causal reasoning for social bias mitigation.
2 Related Works
Recently, model merging has emerged as an effective strategy for combining the strengths of multiple models without expensive retraining (Li et al., 2023;Yang et al., 2024). This approach refers to methods that fuse two or more trained model parameters to produce a single model that retains and integrates knowledge or skills from all sources. Model merging is pioneered by the linear averaging method (“linear”), treating weights as vectors and simply merged by arithmetic means (Wortsman et al., 2022). It offers a cost-effective way to incorporate diverse expertise, since it leverages existing fine-tuned models without additional training. Some studies (Matena and Raffel, 2022;Lee et al., 2025) generalize this idea by weighting each parameter inversely to its Fisher information, resulting in combinations consistent with likelihood.
Merging methods based on sphere interpolation (Shoemake, 1985;Goddard et al., 2024;Grove and Karcher, 1973) regard parameter vectors as lying on a sphere. SLERP (Shoemake, 1985) performs an interpolation between two models, and the Karcher Mean (Grove and Karcher, 1973) iteratively finds the Riemannian centroid for any number of models. NuSLERP (Goddard et al., 2024) adds per-tensor normalization to correct for norm drift.
Inspired by these model merging approaches, Ilharco et al. (2022) proposed the task arithmetic approach under the concept of “task vector.” Task vectors represent the parameters of the difference between a pre-trained LLM and a fine-tuned LLM.
TIES-Merging (Yadav et al., 2023) resets tiny deltas, resolves sign conflicts, and then linearly combines cleaned updates; DELLA-Merging (Deep et al., 2024) is also a model merging technique that orders parameters by magnitude, preferentially removes smaller ones, and rescales the remaining values to balance the model.
Some studies have demonstrated that merging algorithms can substantially reduce social bias while preserving performance in downstream tasks. Shirafuji et al. (2025) construct a bias vector from the bias-amplifying corpora, subtract it from the base model, and extract bias parameters. Dige et al. (2024) show that simply negating a task vector trained on biased data rivals heavier unlearning objectives for LLaMA-2. Gao et al. (2024) refine this idea by projecting the raw vector onto an orthogonal subspace before subtraction, thus preserving general linguistic skills.
Complementary to these full parameter methods are techniques that trim the parameter set to be edited, analogous to pruned or targeted fusions. Lutz et al. (2024) locate fewer than 0.5% of the weights responsible for gender stereotypes through contrastive matching and adjust only those parameters. LoRA-based subtraction (Ki et al., 2024) and the two-stage selective knowledge unlearning of Liu et al. (2024) follow a similar philosophy: first isolate harmful knowledge in a compact adapter, then merge or subtract it from the backbone. Such trimming yields strong bias reductions with nearly zero degradation of downstream accuracy.
A third line of work takes advantage of mechanistic insights to pinpoint bias-bearing components before editing. Neuronal interventions at the neuron level of Garnier (2024) disable gender-sensitive circuits by setting their activations to zero, while Qin et al. (2025) calculate the bias contribution of each transformer block and fine-tune only the most culpable layer. These interpretable edits modify the parameters ≪ 1% yet mitigate social bias in the Winogender (Rudinger et al., 2018) and StereoSet (Nadeem et al., 2021) datasets, confirming that social biases are often concentrated in identifiable substructures.
Impact on Downstream Tasks. Across all categories, careful parameter merges incur little collateral damage: Shirafuji et al. (2025) report a 3% drop on average in GLUE benchmarks (Wang et al., 2018), but they also observe over 50% declines in the COLA dataset. Dige et al. (2024) find no significant increase in perplexity and both Lutz et al. (2024) and Gao et al. (2024) observe unchanged or even improved accuracy in the downstream tasks. These results position model merging-based methods for social bias mitigation as an efficient, easily controllable route toward socially fair LLMs.
Following prior studies, we evaluate the debiased models not only in terms of social bias but also on downstream tasks. Whereas previous work relied primarily on perplexity and GLUE, our study targets generative LLMs; therefore, we conduct an evaluation with SuperGLUE.
3 Merging Experiments for Debiasing
In this section, we describe the preparations for applying model merging to mitigate social bias. Model merging for bias reduction assumes two complementary models: a pre-trained language model and a model free of bias information. How-ever, presuming the availability of such a predebiased model is a flawed premise.
Therefore, in this study, we adopt the approach of Shirafuji et al. (2025), which inverts the information of bias within the LLM using task arithmetic (Ilharco et al., 2022). The overview of this process is shown in Figure 1. Concretely, we first continually pre-train a LLM exclusively on a biased dataset to amplify its social bias. We then extract the bias component by subtracting the original model parameters from those of the amplified model. Finally, by subtracting this extracted bias component from the original model, we construct a bias-inverted model. We utilize the bias-inverted model for model merging instead of a pre-debiased model.
In detail, this process is expressed by the following equation.
where θ LLM , θ bias , θ BV , and θ inv bias are the parameters of pre-trained LLMs, bias-amplified models, social bias components, and bias-inverted models, respectively.
In this section, we describe the way to construct debiased LLMs based on model merging approaches.
The formula of debiasing is described below:
where θ debias represents the debiased LLM parameter, and α denotes the scaling weight of θ inv bias . The merging of two models represented with + ⃝ in the above equation, and the seven model merging approaches detailed in Section 3.2.2 are applied to the merging process in our experiments.
If the norms of θ LLM and θ inv bias are different, we cannot examine the effect of the hyperparameter α. Therefore, we normalize the model weight θ inv bias to ensure that its norm is the same as that of θ LLM .
Our empirical experiments are conducted for seven merging techniques: Linear (Wortsman et al., 2022), Karcher Mean (Grove and Karcher, 1973), SLERP (Shoemake, 1985), NuSLERP (Goddard et al., 2024), TIES (Yadav et al., 2023), DELLA (Deep et al., 2024), and Nearswap (Goddard et al., 2024). Utilizing these methods, we merge a biasinverted model with a pre-trained LLM.
Linear (Model Soups). Wortsman et al. (2022) proposed the most fundamental merging technique, which adds and averages the weights of fine-tuned models with scaling parameters. Through simple summation, it compactly integrates knowledge from multiple models, yielding consistent performance at low cost.
Karcher Mean. Goddard et al. (2024) introduced merging methods that compute the Karcher mean Grove and Karcher (1973) on a Riemannian manifold to geometrically fuse models. Unlike Linear merging, the Karcher Mean considers the curved geometry of the parameter manifold, preserving performance in non-Euclidean structures.
SLERP. Goddard et al. (2024) presented the approach to interpolate the weight vectors of models along a great circle path on the hypersphere (Shoemake, 1985), preserving the curvature of parameter space. SLERP constrains the path to the unit hypersphere, performing pairwise spherical interpolation.
NuSLERP. Goddard et al. (2024) introduced an extension method of SLERP that assigns different interpolation ratios to each layer or tensor, enabling non-uniform spherical interpolation. By weighting critical layers more heavily, it balances local expertise with global stability, achieving strong performance with simple rule-based settings.
TIES. Yadav et al. (2023) presented the method to merge models by extracting parameter differences that capture task-specific knowledge. Sparsifying these differences, TIES is an algorithm to reduce interference and better preserve each model’s strengths. 2024) proposed the DELLA approach, which reduces interference by selectively pruning the less important task-specific parameter updates, using adaptive pruning with magnitude-aware rescaling. It assigns higher keep probabilities to larger-magnitude parameters within each row, improving retention of important weights and matching original model performance.
Nearswap. Goddard et al. (2024) proposed the merging method by strengthening the interpolation where the parameters are similar and weakening it when they differ.
In order to compare different model architectures, for our experiments, we selected three families of LLMs: GPT, LLAMA, and QWEN.
Specifically, the GPT family (Radford et al., 2019;Gao et al., 2020) includes GPT2-small, GPT2-medium, GPT2-large, GPT2-xl, and GPTneo-2.7B. The LLaMA family (Touvron et al., 2023;Dubey et al., 2024) includes LLAMA-2-7B, LLAMA-3-8B, LLAMA-3.1-8B, LLAMA-3.2-1B, and LLAMA-3.2-3B. Finally, the Qwen family (Qwen, 2024) consists of QWEN2-0.5B, QWEN2-1.5B, and QWEN2-7B.
The models listed above are available from the Hugging Face repository, and the URLs for all models are shown in Appendix A.
In merging models as described in Equation ( 2), we vary the scaling factor α from 0.1 to 0.5 in steps of 0.1. The range of the α value is determined on the basis of the results of preliminary experiments (described in Appendix B). Note that our model merging implementation is based on the mergekit toolkit2 , and the hyperparameters except for the scaling factor are set to the default values defined in the mergekit.
Continual Pre-Training Dataset. Following Shirafuji et al. (2025), we use the StereoSet intrasentence dataset (Nadeem et al., 2021) to construct bias-amplified models (θ bias ). Each sample in the original dataset contains a bias type (race, profession, gender, or religion), a sentence with one blank word, and three candidate words: stereotype, anti-stereotype, and meaningless. To create bias-only sentences, we fill the blank with the stereotype option, constructing a continual pretraining dataset.
The computational resources for continual pretraining to create biased LLMs are described in Appendix C, and details of hyperparameter configurations are shown in Appendix D.
We evaluate social bias in LLMs using three benchmarks: the Bias Benchmark for Question-Answering (BBQ) (Parrish et al., 2022), the Bias in Open-Ended Language Generation Dataset (BOLD) (Dhamala et al., 2021), and HONEST (Nozza et al., 2021). The URLs of these datasets are listed in Appendix E.
BBQ. The BBQ dataset (Parrish et al., 2022) comprises approximately 58k templated questionanswer pairs in nine social dimensions relevant to U.S. English speakers. By contrasting “underspecified” with “fully specified” versions of each question, it measures the extent to which models rely on stereotypical priors rather than explicit evidence.
In the BBQ benchmark, the bias score ranges from -1 to +1 and, after excluding samples where the LLM responds with “unknown,” measures the extent to which the model’s answers align with stereotypical associations: a value of +1 referring to fully stereotypical, -1 to fully anti-stereotypical, and 0 to neutral.
BOLD. The BOLD dataset (Dhamala et al., 2021) contains 23,679 prompts, organized into 43 demographic subgroups that cover occupation, gender, race, religion, and political ideology.
The generated text is classified by the regard library3 into positive (+1), neutral (0), or negative (-1), and the absolute mean of the scores for each group is calculated as the bias score. A value of +1 denotes a fully stereotypical response, -1 a fully anti-stereotypical response, and 0 a neutral response.
HONEST. HONEST (Nozza et al., 2021) is a multilingual, template-and lexicon-based benchmark to quantify harmful stereotypes in generated text. It comprises 420 identity-template prompts per language, and for each prompt, we collect the model’s top-K generated text and flag those containing HURTLEX (Bassignana et al., 2018) offensive terms 4 .
Following Nozza et al. (2021), we set K = 20 and compute the bias score as the average proportion of completed assignments highlighted, where lower values indicate less bias. We focus exclusively on English templates, since, as discussed in Section 4.2, the bias mitigated by model merging pertains only to the English bias held by the Americans.
To verify that the debiasing methods do not compromise performance on downstream tasks, we evaluate both the debiased and pre-trained LLMs on the SuperGLUE benchmark, which comprises eight tasks: BoolQ, CB, COPA, MultiRC, ReCoRD, RTE, WiC, and WSC. All evaluations are conducted using the Language Model Evaluation Harness 5 .
Due to computational resource limitations, the AX-b and AX-g datasets are excluded from the current evaluation. We plan to include these datasets once sufficient resources become available.
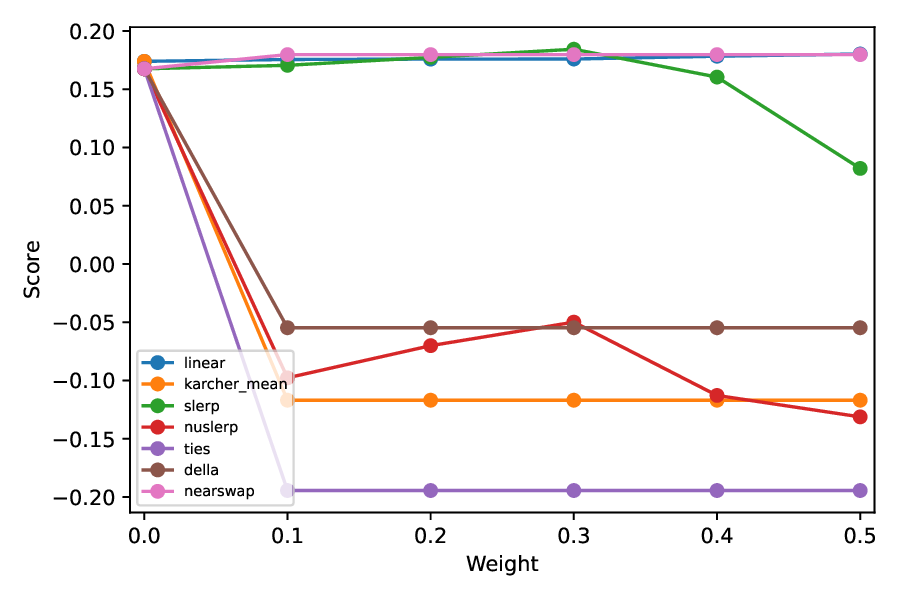
The results of the bias scores on the BBQ, BOLD and HONEST datasets are shown in Figure 2, 3, and4, respectively. The detailed results are described in Appendix F.
Overall Tendencies. Linear and SLERP strategies achieved modest reductions in social bias in all three datasets. Nearswap further lowered the scores in most settings, with the notable exception of Qwen models in HONEST.
In contrast, Karcher Mean, NuSLERP, and TIES occasionally over-mitigated social biases, leading to anti-stereotypical outputs (e.g. -1.0 in GPT and Qwen in BBQ). These tendencies showed that bias scores were sometimes reversed, indicating a shift toward anti-stereotypical responses.
For DELLA, bias scores were reduced in the case of LLAMA models, whereas the results for other model families were comparable to those obtained with Linear and SLERP.
Impact of Model Architecture. Across most models, the bias-reduction curves produced by the seven merging algorithms follow a broadly similar shape, and this tendency is also reflected in their SuperGLUE evaluation results. In general, most methods produce an approximately linear decrease as the mixing factor varies (λ ∈ [0, 0.5]).
However, some methods, such as NuSLERP, Karcher Mean, and occasionally Nearswap, exhibit irregular behavior in certain cases. Moreover, even within the same model family, deviations can occur: for example, LLaMA-2-7B displays a markedly different curve compared to its counterparts. This 5 https://github.com/EleutherAI/ lm-evaluation-harness. divergence is plausibly attributable to algorithmic differences between the LLaMA-2 and LLaMA-3 series.
Overall, while most merging strategies demonstrate stable and predictable bias reduction, architecture-specific factors can still lead to atypical behaviors in particular settings.
Model Parameters. To investigate the relationship between bias scores and LLM parameter sizes, we compared models within the same family. Bias scores in BBQ for individual models are provided in the Appendix F.
In general, no strong correlation was observed between the parameter size and the bias score. Although some models (e.g., GPT-2-medium, LLaMA-2-7B, Qwen2-0.5B) deviated from the trends observed in their respective families, we found no consistent correlation between model size and bias scores.
The aggregated SuperGLUE results are shown in Figure 5.
Two main observations emerge from the results: (i) increasing the scaling factor consistently decreases SuperGLUE scores in most cases; and (ii) Linear, SLERP, and Nearswap preserve downstream performance, and the remaining four techniques reduce average scores by more than 10%.
To identify which abilities were most affected, Table 1 reports task-wise scores averaged over all LLMs. Relative to the three stable methods, the other approaches substantially impair performance on ReCoRD (↓ 50-60%), BoolQ (↓ 15-20%), COPA (↓ 15-20%), and CB (↓ 10-20%), while leaving the other SuperGLUE tasks largely unaffected.
Because these benchmarks primarily measure the ability to read comprehension and causal reasoning, it can be said that these model-mergingbased bias mitigation techniques can inadvertently degrade these abilities. Even the more stable methods (Linear, NuSLERP, and Nearswap) show minor decreases of ↓ 2-3%, ↓ 2-10%, and ↓ 7%, respectively. Furthermore, in all methods, the larger α becomes, i.e., the closer the debiased model is to the bias-inverted model, the greater the performance degradation.
Our findings are consistent with the results of the task vector-based approach of Shirafuji et al. (2025), which also reported that the debiased mod-els maintain the general precision of the GLUE, but suffer substantial losses in CoLA (over ↓ 50%), a task that evaluates grammatical acceptability.
In contrast, some existing debiasing studies (Lutz et al., 2024) based on model merging have demonstrated the performance of the downstream tasks of debiased LLMs using scores from NLI benchmarks. Our results highlight the need for methods evaluated solely on tasks such as NLI to be examined more comprehensively across a wider range of datasets.
Accurate for Social Bias Mitigation?
SuperGLUE results indicate that, except for Linear, SLERP, and Nearswap, the other merging techniques substantially degrade the causal reasoning capabilities of LLMs (Section 5.2). Consequently, these methods are unsuitable for reliable bias mitigation.
Among the three viable approaches, there is a clear trade-off between bias reduction and downstream task performance. SLERP and Nearswap achieve the largest reductions in bias but incur an average SuperGLUE decline of approximately 5%. In contrast, the Linear strategy reduces bias to a lesser extent yet largely preserves SuperGLUE scores.
In particular, SLERP with moderate interpolation weights (α = 0.2-0.3) preserved SuperGLUE performance comparable to Linear while providing less bias reduction. Therefore, we recommend SLERP at α = 0.2 -0.3 as the most effective compromise.
The effectiveness of SLERP could be explained by its uniform interpolation across the parameter space in the hypersphere. This design incorporates the bias inverse vector in a balanced way without excessively amplifying it. In contrast, the other interpolating approach (NuSLERP) performed normalization at the layer or tensor level, substantially affecting its SuperGLUE scores.
This difference in accuracy arises from the fact that SLERP merges parameters across all layers as a whole, while NuSLERP performs the merging at the level of individual layers. In other words, SLERP preserves the global balance of interpolation and maintains a consistent meaning of α throughout the model, while NuSLERP rescales each layer separately, which amplifies local variations and leads to unstable behavior when all layers are merged simultaneously. These findings suggest that, unlike SLERP, most recent model-merging methods cannot be directly applied for bias mitigation without risking substantial losses in reasoning performance.
This work presented the first comprehensive study of how seven model-merging algorithms influence social bias in LLM. By evaluating 13 models spanning the GPT, LLaMA, and Qwen families on three social bias datasets and the SuperGLUE benchmark, we revealed a trade-off between fairness and utility.
Linear, SLERP, and Nearswap consistently mitigated stereotypical tendencies across all architectures, whereas Karcher Mean, NuSLERP, TIES, and DELLA often reduced social bias excessively, resulting in LLMs that exhibit anti-stereotypical behavior. Among the seven methods, SLERP with moderate interpolation weights (α = 0.2-0.3) proved to be the most balanced approach, achieving a greater bias reduction than Linear while maintaining downstream accuracy.
Our analysis also revealed that bias reduction patterns were broadly consistent across architectures, with the notable exception of LLaMA2-7B. Trends with respect to the scaling factor α also remained stable regardless of model size, suggesting that parameter scale alone does not alter the fundamental dynamics of merging.
In addition, the four methods (Karcher Mean, NuSLERP, TIES, and DELLA) substantially degraded performance on tasks requiring reading comprehension and commonsense or causal reasoning, such as ReCoRD, COPA, CB, and BoolQ in the SuperGLUE benchmark. Some existing debiasing methods based on model merging have demonstrated their debiased LLMs’ downstreamtask performance using scores from NLI benchmarks. However, we revealed that it is also essential to verify accuracy on tasks for reading comprehension and commonsense / causal reasoning.
In future work, to preserve these capabilities of debiased LLMs, we plan to jointly merge models specialized for these tasks during bias mitigation via model merging.
Navigli et al. ( 2023) define bias in natural language processing as “prejudices, stereotypes, and discriminatory attitudes against certain groups of people.” We adopt this definition throughout this paper.
For simplicity, we use the term “bias” to refer to both stereotypes and biases, while acknowledging that they are distinct concepts. We also recognize that the stereotypical data (StereoSet) used in our experiments reflect the biases of U.S. residents (Nadeem et al., 2021).
Our work specifically addressed bias mitigation in LLMs by leveraging stereotypes. Biases arise when concepts that should not be associated with particular social groups are unfairly linked. If LLM systems exhibit such biases, they may leave a negative impression on users. Our study examines the applicability of a task-arithmetic approach to mitigate bias, with the aim of reducing LM bias using the proposed methods.
We recognize the importance of maintaining an objective position. Therefore, we emphasize that the content of this study is not influenced by any political positions, stereotypes, or biases of the authors. Our research is guided by the ethical principle of fairness in scientific inquiry and seeks to make constructive and responsible contributions to the development of AI technologies. Methods cola avg. GPT2-small 0.449 0.760 w/ Bias Vector (α = 0.1) 0.396 0.754 w/ Bias Vector (α = 0.2) 0.440 0.759 w/ Bias Vector (α = 0.5) 0.362 0.754 w/ Bias Vector (α = 1) 0.050 0.702 w/ Bias Vector (α = 2) 0.012 0.705 w/ Bias Vector (α = 5) 0.000 0.669 w/ Bias Vector (α = 10) 0.016 0.590 evaluation of GPT2-small in GLUE are presented in Table 2. From the evaluation, we found that for values of α around 5, bias was nearly eliminated for all models. However, in certain downstream tasks (COLA), performance began to gradually degrade from α = 0.5 and dropped to almost zero at α = 1.
Based on these results, the main experiments in this paper restrict α to the range of 0.1 to 0.5.
All LLM training for the stereotypical bias experiments was performed on AWS p4d.24xlarge instances, each equipped with eight NVIDIA H100 GPUs. Models with up to 3 billion parameters were trained on four H100 GPUs, while larger models used all eight.
For the evaluation experiments on SuperGLUE, BBQ, BOLD, and HONEST, all runs -except those for the GPT-based model family -were conducted on NVIDIA H100 GPUs: models with up to 3 billion parameters used a single GPU for inference and scoring, and larger models were allocated two GPUs. GPT-based models were evaluated on an Model lr scheduler GPT2-small 3e-5 linear GPT2-medium 3e-5 linear GPT2-large 2e-5 linear
1e-5 cosine
The experimental setup for continual learning is designed as follows. We utilize the HuggingFace AutoModelForCausalLM library for model training. To reduce GPU memory consumption, the maximum sequence length (max_length) is set to 512, the batch size is set to 64. Training is carried out for 30 epochs with a weight decay of 0.01 and a warm-up ratio of 0.1. The hyperparameters specific to each model, namely the learning rate and the learning rate scheduler, are described in Table 3.
Note that the scheduler was set to linear for the GPT family but cosine for the other models, since we followed the configuration of Shirafuji et al. (2025), which established the linear scheduler as the default choice for GPT.
The URLs of the social bias evaluation datasets are listed as follows:
• BBQ: https://huggingface.co/ datasets/heegyu/bbq; Figure 7: The SuperGLUE evaluation results in GPT models. The blue, orange, green, red, purple, brown, and pink lines correspond to the results for Linear, Karcher Mean, SLERP, NuSLERP, TIES, DELLA, and Nearswap, respectively. The scores of setting the weight α to zero are resulted using the pre-trained LLMs.
NVIDIA Quadro RTX 8000.
Navigli et al. (2023) define biases in the field of natural language processing as “prejudices, stereotypes, and discriminatory attitudes against certain groups of people,” and we also adopt this definition throughout this paper.
https://github.com/arcee-ai/mergekit .
https://huggingface.co/spaces/ evaluate-measurement/regard.
https://huggingface.co/spaces/ evaluate-measurement/honest.
📸 Image Gallery