Enhancing Cross Domain SAR Oil Spill Segmentation via Morphological Region Perturbation and Synthetic Label-to-SAR Generation
📝 Original Info
- Title: Enhancing Cross Domain SAR Oil Spill Segmentation via Morphological Region Perturbation and Synthetic Label-to-SAR Generation
- ArXiv ID: 2512.02290
- Date: 2025-12-02
- Authors: Andre Juarez, Luis Salsavilca, Frida Coaquira, Celso Gonzales
📝 Abstract
Deep learning models for SAR oil spill segmentation often fail to generalize across regions due to differences in sea-state, backscatter statistics, and slick morphology, a limitation that is particularly severe along the Peruvian coast where labeled Sentinel-1 data remain scarce. To address this problem, we propose MORP-Synth, a two-stage synthetic augmentation framework designed to improve transfer from Mediterranean to Peruvian conditions. Stage A applies Morphological Region Perturbation, a curvature guided label space method that generates realistic geometric variations of oil and look-alike regions. Stage B renders SAR-like textures from the edited masks using a conditional generative INADE model. We compile a Peruvian dataset of 2112 labeled 512×512 patches from 40 Sentinel-1 scenes (2014-2024), harmonized with the Mediterranean CleanSeaNet benchmark, and evaluate seven segmentation architectures. Models pretrained on Mediterranean data degrade from 67.8% to 51.8% mIoU on the Peruvian domain; MORP-Synth improves performance up to +6 mIoU and boosts minority-class IoU (+10.8 oil, +14.6 look-alike).📄 Full Content
Over the past decade, deep learning has transformed oil spill analysis, outperforming classical thresholding and texture based approaches. A major milestone was the release of a benchmark dataset containing 1,112 Sentinel-1 scenes with pixel-level labels for oil, look-alikes, sea, land, and ships [5,6]. This benchmark enabled systematic evaluation of convolutional architectures such as U-Net [7] and DeepLabV3+ [8]. Subsequent work introduced multiscale contextual modeling and attention mechanisms to further reduce false positives [9,10,11,12]. These studies consistently demonstrate that modern deep neural networks surpass traditional SAR-based oil detection algorithms.
Despite these advances, geographic domain shift remains a major obstacle. Most segmentation models are trained on regional datasets primarily from European waters and struggle to generalize to dis-Graphical Abstract. MORP-Synth framework overview. tinct environmental regimes [11,13,14]. The Southeast Pacific (Peruvian coast) illustrates this challenge: strong upwelling, the Humboldt Current, and unique wind conditions produce SAR backscatter textures and slick morphologies markedly different from those in the Mediterranean or North Atlantic (Table 1). This mismatch causes foreign-trained models to degrade when applied locally. Furthermore, annotated SAR datasets for South America remain scarce, limiting the applicability of state-of-the-art models. The 2022 Ventanilla/REPSOL spill underscored the urgent need for region specific monitoring tools [15].
Another limitation of these models is the scarcity of representative training data in the target domain. Variations in sea surface roughness, oil properties, and incidence angles significantly impact model transferability. In practice, models pretrained on Mediterranean data often confuse Peruvian lookalikes with oil and fail to recognize slicks exhibiting different shapes or scattering signatures. While small-scale fine-tuning can mitigate this [16,17], the limited amount of labeled Peruvian SAR data fails to capture the full variability required for robust generalization.
To overcome data scarcity, recent studies have explored generative augmentation. Approaches like diffusion-based models and conditional GANs [18,19,20,12] have been used to simulate SAR imagery.
However, these methods typically operate in image space or lack explicit control over object morphology. They often fail to generate the specific, irregular slick geometries such as thin, fragmented trails driven by the Humboldt Current that are critical for improving generalization under severe domain shift.
Our approach. To address cross-domain generalization, we combine transfer learning with synthetic data augmentation. First, we curate a new SAR dataset of 40 oil spill events along the Peruvian coast (2014-2024), annotated in full alignment with the Mediterranean benchmark. Second, we introduce MORP-Synth, a two-stage augmentation pipeline tailored for data-scarce domains. Stage A applies a Morphological Region Perturbation (MORP) algorithm that modifies oil and look-alike shapes via controlled geometric edits, shifting, rotating, and smoothly warping connected components (Figure 2). Stage B employs a employs a conditional Generative Adversarial Network (cGAN) based on Instance Adaptive De-Normalization (INADE) [21,22] to generate realistic SAR-like textures aligned with the edited labels (Figure 3). By conditioning feature normalization on instance-level statistics, the model achieves high-fidelity synthesis that preserves spatial coherence and label-image consistency. Synthetic samples are then mixed with real Peruvian patches using a controlled synthetic-to-real weighting strat-egy.
Additionally, we adopt a training strategy tailored for severe class imbalance, combining class balanced cross entropy, focal Tversky losses [23,24,25,26], confusion-aware penalties, hard negative mining, and multi scale patch sampling to improve robustness in operational monitoring scenarios.
Contributions. The main contributions of this work are:
• Cross-domain benchmark and analysis: A new Peruvian Sentinel-1 oil spill dataset harmonized with the Mediterranean benchmark.
• MORP-Synth augmentation: A geometryaware synthetic augmentation pipeline that generates diverse slick shapes and realistic SAR textures, improving mIoU by up to +6 percentage points and significantly boosting minority-class performance.
• Enhanced training under imbalance: A practical training regimen integrating composite losses, confusion penalties, hard negative mining, and multi-scale sampling, achieving state-of-theart segmentation performance in Peruvian waters.
This article is organized as follows. Section 2 (Materials and Methods) describes the study areas, datasets, preprocessing, MORP-Synth design, and model training. Section 3 (Results) shows quantitative evaluations and qualitative analyses. Section 4 (Discussion) outlines methodological insights and operational implications. Section 5 (Conclusions) summarizes the findings.
Mediterranean (Source) Dataset The source domain in this study corresponds to the Mediterranean Sea and is based on the publicly available dataset compiled by [5,6]. This dataset contains a total of 1,112 Sentinel-1 SAR images in Ground Range Detected (GRD) format with vertical-vertical (VV) polarization. Each image is centered around known oil spill incidents reported in the CleanSeaNet (CSN) service operated by EMSA (European Maritime Safety Agency), and covers a spatial extent of 1250×650 pixels at a 10-meter ground resolution natively.
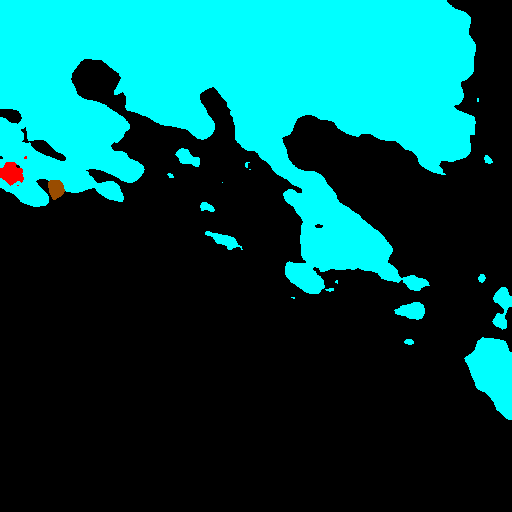
The dataset includes pixel-level segmentation masks distinguishing five semantic classes: open sea (0), oil spill (1), look-alike phenomena such as low wind or algae blooms (2), ships (3), and coastal land (4). Ground truth annotations were generated via visual inspection of SAR backscatter patterns in conjunction with metadata from CleanSeaNet alert records. This dataset provides a rich and balanced training ground for developing oil spill detection algorithms in a relatively stable marine environment.
Peruvian Coastal Dataset The Peruvian coastal dataset was developed to provide a representative target domain for oil spill detection under local environmental conditions. This region, located in the Southeast Pacific and influenced by the Humboldt Current, has oceanographic and meteorological characteristics that differ from those of the Mediterranean. These conditions make generalization harder, mainly because sea-surface roughness and slick dispersion behave differently along the Peruvian coast.
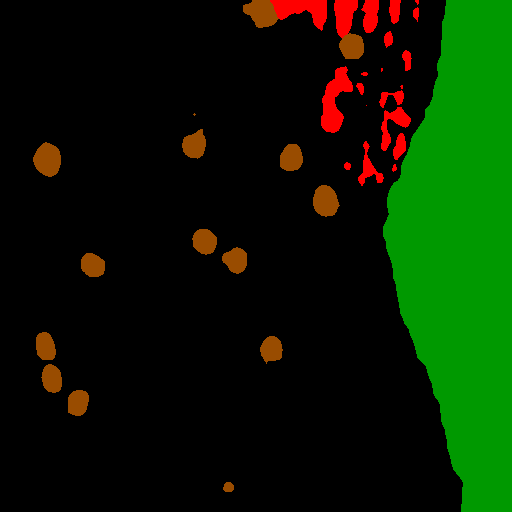
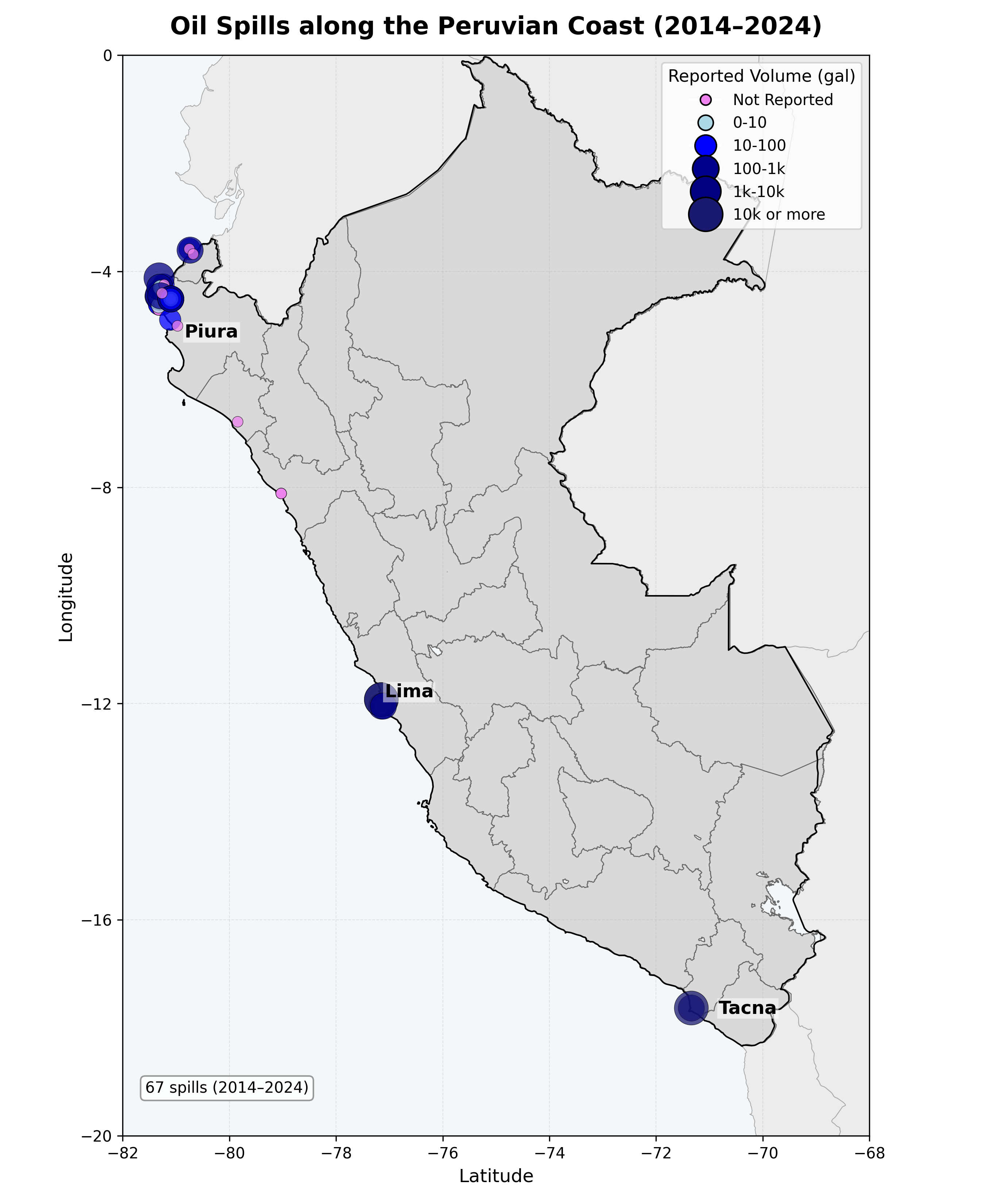
The initial stage of dataset construction involved compiling 66 documented oil spill incidents from 2014 to 2022, based on official records from Organismo de Evaluación y Fiscalización Ambiental (OEFA) and Organismo Supervisor de la Inversión en Energía y Minería (OSINERGMIN). Figure 1 visualizes the spatial distribution and estimated volumes of these incidents, which are mostly concentrated near Lima and the northern coast.
Figure 1 shows the spatial distribution of 67 reported oil spills (2012-2024) along the Peruvian coast, based on official records from OEFA and OSIN-ERGMIN. Bubble size represents reported discharge volume. Most incidents cluster around Talara-Piura in the north, Callao-Lima in the center, and the Ilo-Tacna corridor in the south.
A total of 40 Sentinel-1 SAR images were ultimately selected from this set of events based on three criteria: (1) visual observability of the oil slick in the SAR image, (2) temporal proximity to the reported spill date (within 3-20 days, following [15]), and (3) availability and quality of satellite acquisition. These images span the period from 2014 to 2024 and were acquired from the Copernicus Sentinel-1 GRD mission with a size of 5569 x 5569 pixel resolution size.
Table 8 in Appendix summarizes the 40 Sentinel-1 SAR scenes selected for the Peruvian coastal dataset, sorted chronologically by spill date. Each entry corresponds to a confirmed spill case, including its coordinates, SAR acquisition date, and delay in days between the incident and image capture.
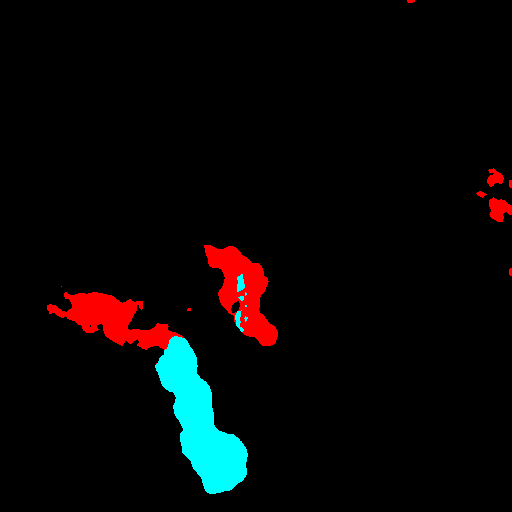
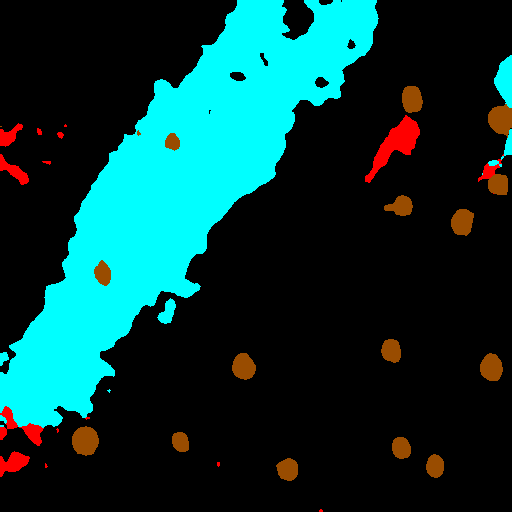
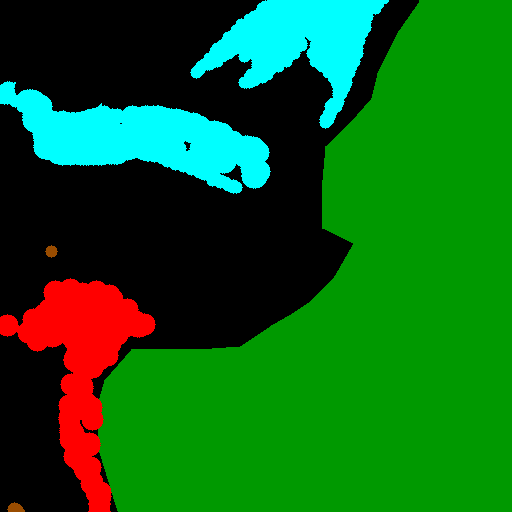
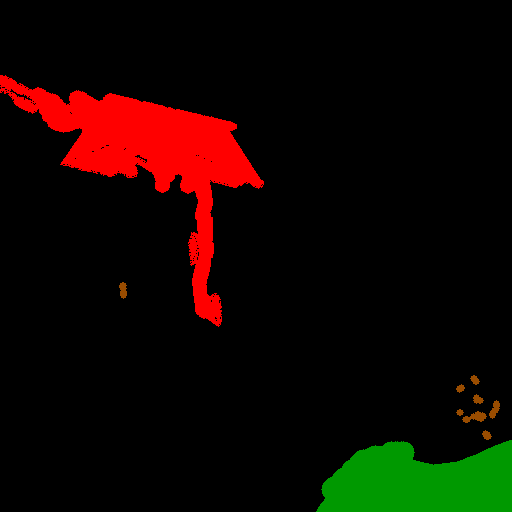
Color Coding for Visualizations. All segmentation maps in this work follow a consistent color scheme: oil (cyan), look-alike (red), land (green), ship (brown), and sea (black). Unless otherwise noted, this palette is used in all figures throughout the manuscript and Appendix.
All Sentinel-1 GRD images were radiometrically calibrated to σ 0 and resampled to 10 m/pixel. A 3 × 3 median filter was applied for mild speckle suppression; this choice preserves thin, elongated slick filaments that are easily oversmoothed by classical Leetype filters [27]. Only IW swath and VV polarization were retained. VV is known to be more sensitive to rough sea-state modulation, which amplifies textural domain shift between calm Mediterranean scenes and the rougher Peruvian background.
Despite relying on the same SAR sensor (Sentinel-1 GRD, VV polarization), the Mediterranean and Peruvian datasets exhibit distinct environmental and acquisition conditions that pose challenges for generalization and motivate the use of domain adaptation techniques (see Table 1). These domain shifts affect the visual appearance of oil slicks and background patterns in SAR images, which can degrade the performance of models trained in one region when applied to another. Therefore, domain adaptation becomes essential to improve generalization to new environmental conditions. ResNet-UNet (R34). A UNet-style architecture combining a ResNet-34 encoder with a symmetric decoder linked by skip connections. The residual backbone stabilizes gradient flow and enhances semantic abstraction, while the UNet decoder preserves spatial detail yielding a well-balanced baseline for remotesensing segmentation tasks [28,29].
ResNet-UNet + ASPP (R34+ASPP). A variant of ResNet-UNet where the bottleneck is replaced by an Atrous Spatial Pyramid Pooling (ASPP) TransUNet [34] module. Dilated convolutions enlarge the receptive field and improve capture of heterogeneous slick shapes and multi-scale structures, consistent with the DeepLab design [30].
A lightweight decoder-free model that aggregates features via ASPP and uses a shallow skip connection for boundary refinement. Its reduced computational cost makes it suitable for large-scale SAR inference and noisy sea-surface conditions [30].
EfficientNetV2-M + DeepLabV3. A fully convolutional encoder-decoder design pairing an Effi-cientNetV2 backbone a medium-capacity compound scaled CNN with a DeepLabV3 head. Progressive learning and fused-MBConv blocks improve speed accuracy efficiency, while ASPP provides robust multiscale contextual reasoning [31,32]. Swin-UNet. A pure Transformer-based model built upon the hierarchical Swin Transformer. Shifted-window self-attention captures long-range dependencies while maintaining local coherence, making it effective when oil spills or look-alikes span extended regions [33]. It serves as our Transformer-only benchmark.
TransUNet. A hybrid architecture injecting CNN feature extraction into a ViT encoder to combine strong local texture modeling with global context reasoning. This fusion is especially effective for suppressing large look-alike structures while preserving fine boundaries [34]. It complements Swin-UNet by illustrating the benefits of mixing CNNs and Transformers.
We propose MORP-Synth, a two-stage pipeline that augments scarce SAR oil-spill training data by (1) perturbing object shape directly in label space via our Morphological Region Perturbation (MORP), and (2) rendering SAR-like appearance from the edited masks using an off-the-shelf conditional generator (INADE). Our novelty lies in Stage A; Stage B is an applied component selected for efficiency and controllability.
Let L ∈ {0, 1, 2, 3, 4} H×W denote a semantic label map with classes 0 sea, 1 oil, 2 look-alike, 3 ship, 4 land. We define C = {1, 2} as target classes for shape edits. MORP edits object geometry while preserving the surrounding context. Its pipeline has three mathematically grounded components: (i) flat-aware rigid placement, (ii) apex discovery by smoothed outward curvature peaks, and (iii) local apex edits that mirror inward radial profiles to create outward bulges (or the converse to carve wedges). The resulting augmented mask L ⋆ is then used to condition the appearance model (Stage B). The implementation code is provided in Appendix 1.
Connected components. For c ∈ C, let R ⊂ {1, . . . , H} × {1, . . . , W } be a connected component of 1 [L=c]. We denote by |R| its area in (1) Flat-Aware Region Placement. A region R is rigidly transformed by a rotation θ ∈ [-π, π) and a translation ∆ = (∆x, ∆y) with ∥∆∥ 2 ≤ S max , producing T θ,∆ (R). S max (the max_shift parameter) defines the maximum translation distance. Placement is accepted only if it does not intersect forbidden labels (e.g., land), expressed as a collision set Ω forbid . We allow a whitelist Ω allow for paste-over (e.g., sea, optionally ship). Flat-aware perturbations: when R exhibits long, near-linear boundary runs, small, localized bulges may be added before paste to avoid overly rectilinear silhouettes.
(2) Apex Detection via Smoothed Curvature. Parameterize ∂R as a periodic sequence of points P = {(x t , y t )} N t=1 in counter-clockwise (CCW) order. We smooth coordinates with a circular Savitzky-Golay filter (SG) [35]:
where w is an odd window, p a polynomial order (p < w). Discrete derivatives use step d s ≥ 1:
Signed curvature is discretized as:
We use positive curvature κ + t = max(0, κ t ). To emphasize distal lobes, we optionally apply a radial boost:
where (x, ȳ) is the centroid of (x, ỹ) and ρ is a scalar hyperparameter controlling the boost strength.
Apex indices are the peaks of κ + exceeding a quantile threshold τ = Quantile({κ + t }, q) with minimum arc-distance d:
Apex coordinates are A = {(x t , y t ) : t ∈ A}. The detailed steps for this process are shown in Algorithm 2.
(3) Apex-based Perturbation via Mirrored Radial Profiles. To select at most m well-spread apices, we cluster A by k-means (k = m) and pick in each cluster the point maximizing distance to the region centroid; denote the set by A m . Let D be the Euclidean Distance Transform (DT) computed on the background pixels (p / ∈ R), denoted as
, where ϕ k are evenly spaced in [-α, +α]. For each direction we measure the inward radial support length
and define an initial outward target length:
This length is then capped using a “soft easing” rule:
Here, R grow is the maximum growth radius (max_radius). The polygon with vertices {a + d out k u k } nrays k=1 , closed at a, defines a bulge mask B(a). In shrink mode, we reverse the normal (-n) and intersect the polygon with R to form a wedge S(a) ⊂ R. Multi-apex composition performs a union of all bulges and a union of all wedges, then writes (R ∪ B) \ S back into L ⋆ . The logic for a single apex edit is detailed in Algorithm 3
In the second stage, denoted Synth, we render SARlike backscatter onto the edited semantic masks L ⋆ produced by MORP (Stage A). We employ an IN-ADE generator [22], an instance-adaptive extension of SPADE [36]. SPADE injects spatially aligned normalization parameters derived from the semantic mask, preventing the semantic layout from being washed out during generation, while INADE introduces instance-specific modulation to diversify textures across objects belonging to the same class. This is important for SAR oil-spill data, where oil and look-alike regions can exhibit similar global darkness but distinct local texture. Unlike end-to-end diffusion models, INADE offers a favorable trade-off between controllability and compute efficiency: it preserves mask-level semantics and allows large batches of synthetic samples to be generated during training without prohibitively slow sampling [37,38]. The generator and discriminator architectures used in Synth follow the standard SPADE/INADE formulation, while training details (losses, hyperparameters, and TTUR schedule) are provided in Sec. 2.5.
Given a real mask L, MORP produces an augmented shape L ⋆ (Stage A), which conditions the Synth model (Stage B) to yield a synthetic SAR patch x ⋆ . We pair the synthetic samples {x ⋆ , L ⋆ } with real data {x, L} to train a segmentation model. The complete transformation process is visualized in Figure 2 (MORP) and Figure 3 (Synth).
All models were first trained from scratch on the Mediterranean dataset of [5] and subsequently finetuned on the Peruvian SAR dataset (1,795 training / 218 testing patches). Scene-level splits were used to prevent spatial or temporal leakage between domains (See Appendix Table 8). All models share identical preprocessing, augmentations, and loss formulation; differences in performance arise solely from backbone capacity and the inclusion of multi-scale and synthetic (MORP-Synth) data streams.
Patch extraction and normalization. Fixedsize 512×512 patches were sampled around annotated oil and look-alike regions using a sliding window and complemented by a limited number of background tiles (1.25:1 negative/positive ratio). Each patch was normalized by clipping backscatter values to the [0.5,97.5] percentile range per scene, preserving inter-scene contrast while mitigating illumination differences due to acquisition geometry or sea-state variability. Masks contained five semantic classes (sea, oil, look-alike, ship, land ), and augmentations included horizontal and vertical flips, Gaussian noise, and Coarse Dropout. This procedure produced a radiometrically standardized collection of Peruvian oilspill patches for subsequent fine-tuning.
Optimization. All networks were trained using the AdamW optimizer (β 1 =0.9, β 2 =0.999, weight decay 10 -4 ) with a batch size of 32 (16 for heavier backbones). Mediterranean pretraining lasted 60 epochs at an initial learning rate of 1×10 -4 , while Peruvian Loss function. We minimize a composite objective that combines (i) class balanced cross entropy (CB-CE) to counter class imbalance [26,39], (ii) the Focal-Tversky loss [25,40] to emphasize difficult foreground regions, and (iii) targeted confusion penalties to discourage systematic misclassifications between visually similar categories (look-alike→oil and sea→look-alike). The total real-data objective is given by:
where (λ CE , λ FTL , λ 2→1 , λ 0→2 ) = (0.3, 0.7, 0.40, 0.30) and P = {(2, 1), (0, 2)}. The first term, L CB-CE , is the cross entropy loss weighted by:
where n c denotes the pixel count of class c, and µ controls the effective volume.
The Focal-Tversky term is computed only over the foreground classes (c > 0):
where TP c , FP c , FN c are computed from softmax probabilities p c,ij and one-hot labels y c,ij as usual.
We set (α, β, γ) = (0.65, 0.35, 1.33) to penalize false positives more strongly, with γ > 1 focusing learning on low-Tversky regions. Finally, each confusion penalty term takes the form:
averaging the model’s confidence for the wrong class b over all pixels whose true label is a. This term acts as a soft constraint to reduce confident false alarms between semantically related categories.
Hard negatives and multi-scale augmentation.
To increase robustness against false positives, we incorporated 210 hard-negative patches mined from the Peruvian training scenes [41,8]. These correspond to background regions where a previously fine-tuned model produced confident spill detections (overlap ≥ 80% with sea and area ≥ 0.5%). They were integrated via a weighted sampler contributing ∼10% of real batches. In addition, 959 multiscale patches (rescaled 1024-2048 pixel windows, resized to 512×512) were added to expand spatial context around slicks and coastal structures, representing roughly 20-25% of effective real batches.
Synthetic label-to-SAR augmentation (MORP-Synth). Synthetic samples were generated using the MORP-Synth pipeline, which integrates (i) label-space perturbations via MORP (Stage A) and (ii) conditional appearance synthesis via the Synth (INADE) generator trained on the Mediterranean domain [42]. The parameter morph controls the fraction of label maps undergoing MORP perturbation before synthesis, with morph00, morph50, and morph100 corresponding to 0%, 50%, and 100% edited masks, respectively. Synthetic batches were interleaved with real ones at a 2:1 ratio, and the training objective extended Eq. 9 as:
where λ synth ∈ {25, 50, 100, 150, 200} scales the contribution of synthetic gradients without changing sample counts. Small λ synth values limit exposure to synthetic features, while larger ones emphasize synthetic regularization.
The IN-ADE generators were trained for 60 epochs using Adam with TTUR-style learning rates [43] (D:G=1:1, λ feat =10, λ VGG =10, lr=5×10 -5 ) and a spectrally normalized discriminator with hinge loss [44]. The best checkpoint (epoch 42, FID ≈ 61) produced visually coherent SAR-like backscatter and was adopted for subsequent mixed-domain training.
Mean Intersection-over-Union (mIoU) We evaluate segmentation performance using the mean Intersection over Union (mIoU) over all C = 5 semantic classes. For each class c ∈ {0, . . . , 4}, the IoU is defined as:
where TP c , FP c , and FN c are the number of true positives, false positives, and false negatives for class c, respectively.
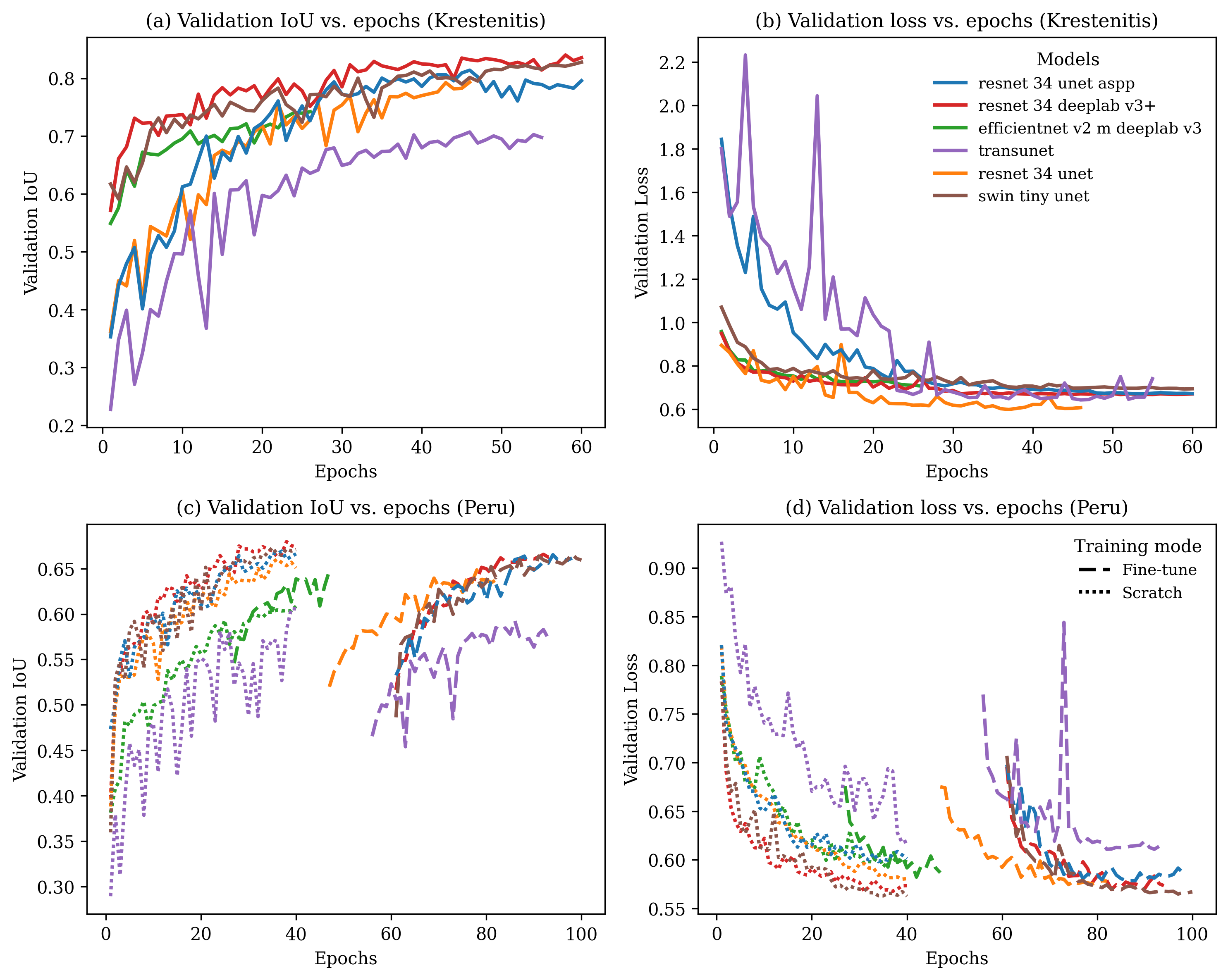
Baseline (Source-only) After pretraining on the Mediterranean source dataset [6,5], all seven architectures exhibited stable convergence within 60 epochs, reaching validation mIoUs between 0.75 and 0.85 with no evidence of overfitting. The learned features from this stage served as initialization for transfer to the Peruvian target domain, where models were either fine-tuned from their Krestinin checkpoints (dashed lines) or retrained from standard ImageNetpretrained weights (dotted lines). Fine-tuned runs started from the validation performance achieved on Krestinin and consistently converged faster and to higher mIoU and lower loss than ImageNet-initialized counterparts, confirming effective feature reuse across marine environments despite differences in sea-state and incidence-angle statistics. Table 3 summarizes the performance of all evaluated architectures on the unseen Krestinin test set (n=569 tiles of 512 × 512 pixels). Across all baselines, the newly introduced Swin-Tiny UNet achieved the highest mean IoU (68.66%), followed closely by the ResNet-34 DeepLabV3+ (67.82%) and ResNet-34 UNet+ASPP (66.05%). The transformer-based Swin backbone offered improved boundary delineation and spatial consistency, particularly on the oil spill (51.80%) and look-alike (53.76%) classes, where contextual attention across wide receptive fields reduces confusion with textured marine backgrounds [33,45].
Among convolutional models, integrating multiscale contextual modules such as ASPP or DeepLab’s atrous encoders enhanced discrimination of elongated and low-contrast spill regions, confirming prior observations for SAR segmentation [46,11]. While Tran-sUNet reached 62.93% mIoU, it underperformed relative to purely convolutional and Swin-based models, likely due to its heavier hybrid encoder and limited training data for learning long-range dependencies. The EfficientNetV2-M DeepLabV3 yielded comparable overall accuracy (62.09%) but weaker results for the ship class (23.24%), consistent with the over-smoothing effect of compound scaling in compact maritime targets. Overall, the Swin-Tiny UNet emerged as the most balanced and data-efficient architecture, delivering top mIoU and per-class consistency across both dominant (sea, land ) and minority (oil, look-alike, ship) categories. Given its strong baseline performance, it was subsequently used to examine the generalization limits of the proposed MORP-Synth augmentation framework under arXiv:2501.12345v1 [cs.CV] December 3, 2025 a higher-capacity setting (See Table 10 . Cross-domain Testing Modern segmentation pipelines increasingly rely on large pre-trained models, yet direct deployment to out-of-domain imagery often leads to degraded performance due to domain shift [17]. To assess cross-domain transferability, each architecture was fine-tuned on the Peruvian training split for 40 epochs using the composite loss defined in Eq. 9. As summarized in Table 4, fine-tuning improved mean IoU for most architectures while preserving or enhancing class-wise balance. Among convolutional networks, ResNet-34 UNet achieved the strongest recovery, improving mean IoU by +4.9 pp and showing the largest per-class gains on oil (+6.9 pp) and look-alike (+9.3 pp), indicating better boundary delineation and reduced confusion between low-contrast slicks and sea background. Tran-sUNet and EfficientNetV2-M + DeepLabV3 also benefited from adaptation (+2.9 pp and +2.3 pp, respectively), reflecting partial reuse of spectral-textural priors learned in the source domain.
ResNet 34 DeepLabV3 remained stable (+0.3 pp) while slightly improving ship detection (+4.7 pp). In contrast, UNet+ASPP exhibited a small decrease (-2.1 pp), mainly from degraded segmentation of the look-alike class (-14.3 pp), consistent with ASPP’s known sensitivity to heterogeneous marine textures. This decline suggests that the strong contextual filters optimized on the Mediterranean domain overspecialized to its smoother sea clutter, leading to feature drift when exposed to the higher speckle and coastline variability of Peruvian SAR imagery.
The transformer-based Swin-Tiny UNet-already the strongest source-only model showed marginal overall improvement (+0.1 pp) yet achieved the highest adapted IoUs for oil (52.42%). This limited gain suggests that global attention priors in Swin architectures already capture robust scene context, leaving less room for improvement from local fine-tuning alone. Overall, these results confirm that modest domain-specific retraining effectively bridges crossdomain gaps for convolutional backbones, whereas transformer-based models may require more sophisticated augmentation or loss weighting to further exploit their representation capacity. Synthetic label-to-SAR augmentation (MORP-Synth) with scale weighting We assess the quantitative impact of synthetic augmentation using ResNet-34 DeepLabV3+ as the primary analysis backbone (Tables 3,4). Synthetic sets were generated with the INADE checkpoint described in Sec. 2.5. Three pool sizes were tested (N synth ∈ {902, 1804, 3608}), with real:synthetic batches interleaved at 2:1 and synthetic gradients scaled by λ synth ∈ {25, 50, 100, 150, 200}. For the base pool (N synth =902, matching the available positive seed patches), we compared four edit regimes: nomove (no geometric change), m00 (movement only), m50 (movement+MORP on 50% of masks), and m100 (movement+MORP on 100% of masks). However, for the expanded pools (N synth =1804 and 3608), we exclusively employed the m100 regime. Since the number of source seed patches is fixed (≈ 902), simply repeating the nomove generation would result in exact duplicates. Instead, we leveraged the stochastic nature of MORP (randomized apices, rays, and placement) to generate distinct geometric variations of the same source instances. The N =1804 and N =3608 sets represent 2× and 4× stochastic expansions, respectively, where every synthetic mask possesses a unique geometry. Full results appear in Table 5 (N =902) and Table 6 (Expanded Pools).
The strongest configuration reached 60.07% mIoU at N synth =1804, λ synth =150, and m50, outperforming the fine-tuned baseline on Peruvian data (54.07% mIoU) by +6.00 pp. Class-wise improvements were concentrated in minority categories: oil increased from 38.56% to 49.37% (+10.81 pp) and look-alike from 23.37% to 37.96% (+14.59 pp), while dominant classes such as sea and land varied within ±1 pp.
For the smallest synthetic pool (N synth =902), performance generally rose with higher λ synth , peaking near 58.15% mIoU for m50 at λ synth =200. Interestingly, the nomove control remained competitive even at low weights (58.20% at λ synth =25), indicating that additional synthetic supervision improves stability across the scale range. Expanding to N synth =1804 further stabilized minority-class IoUs and yielded the best overall means across mid-high weighting factors. Doubling again to N synth =3608 did not uniformly enhance accuracy: while strong oil scores were preserved, ship IoU tended to decrease, suggesting limited benefit from excessively large synthetic exposure when the underlying semantic diversity (number of unique seeds) remains constant.
Across all scales, moderate edits (m50) with mid high λ synth provided the most consistent gains, while heavier modifications (m100) performed variably depending on pool size. Lighter regimes (nomove/m00) often remained competitive at smaller λ synth , confirming their effectiveness as stable baselines. These quantitative patterns are examined in detail in the Discussion.
Finally, running the same experiments on a highercapacity Swin-Tiny UNet yielded smaller or neutral changes (improvements in 3/12 settings; full results in Appendix 10). This highlights architecturedependent sensitivity to synthetic augmentation See Discussion 4.
Visual Comparisons Figure 5 presents qualitative outputs on representative Peruvian Sentinel-1 patches for (c) DeepLabV3+, (d) Swin-Tiny UNet, and their synthetically fine-tuned counterparts with N =902 and N =1804 real samples (e-f). At patch scale, both baselines delineate the main slick bodies but occasionally fragment diffuse perimeters and over-respond to textured sea. Synthetic fine-tuning smooths contours and suppresses small spurious islands, with the N =902 variant giving the most complete outlines on thin, wispy edges, and the N =1804 variant favoring more cautious responses near complex background. We therefore use N =1804 for fullscene panels below to emphasize low oil false positives, and N =902 in patch panels to illustrate boundary completeness. 17,19,21), reflecting wind-slick bands, biogenic films, internal-wave striations, and rain-cell signatures typical of the Peruvian coast. Under this variability, FT-Synth 1804 maintains low oil false positives in half the scenes (FPoil ≤ 0.31 km 2 in 17, 18, 21, 25; zero in 18), while higher FP-oil concentrates in cluttered nearshore or frontal zones (14,19,26,28). IoU co-varies with footprint size and background complexity (e.g., 28: 0.713; 19: 0.620; 14: 0.579), consistent with larger, wellcontrasted slicks being easier to segment than thin filaments embedded in structured sea state. These perscene numbers ground the qualitative panels by quantifying the operationally relevant trade-off: strong boundary adherence where contrast supports it, and restrained oil alarms where background phenomena dominate.
Full-Scene Qualitative Panels Figure 6 shows full image segmentations of four test scenes using FT-Synth 1804. (a) Img 18, small offshore sheen with weak contrast amid low-wind background; the model avoids spurious oil, consistent with FP-oil ≈ 0 km 2 . (b) Img 19, broad look-alike bands (likely wind/internal-wave structure) with embedded slick fragments; predictions follow the main cyan plume while limiting coastal false alarms (IoU ≈ 0.62). (c) Img 26, nearshore edge with bright backscatter from breaking waves and possible layover/foreshortening; the model retains the along-shelf slick but is conservative against shoreline-adjacent patches where rain cells and surf texture increase confusion. (d) Img 14, large, high-contrast event with complex coastline; segmentation recovers the dominant extent and preserves land boundaries, with residual false positives appearing in frontal zones where sea-state transitions are sharp (IoU ≈ 0.58). Across these scenes the outputs remain spatially coherent: continuous slick axes align with ambient texture gradients, vessel wakes are not mislabelled as slicks, and dark streaks from environmental modulation are largely filtered. Together with Table 7, these panels illustrate that the model scales from patch-level detail to full-scene mapping under heterogeneous sea states while keeping oil false positives operationally low.
events in peruvian coast.
Two high-impact events were examined to assess the temporal stability of the fine-tuned MORP-Synth model. Although included in training, the Lobitos offshore spill sequence (26 Dec 2024-10 Jan 2025; Fig. 7) and the Repsol/Ventanilla event (25 Jan-02 Feb 2022; Fig. 9,8) serve as temporal plausibility checks.
Lobitos sequence. The Lobitos sequence (26 Dec 2024-10 Jan 2025; Fig. 7). evaluates the model’s ability to track the same spill through time. On 26 December, the segmentation captures a compact slick of about 5.2 km 2 near the source, although part of the adjacent elongated anomaly is labelled as lookalike rather than oil. Its dark, coherent appearance suggests a thin sheen, indicating a likely false negative arising from the model’s conservative treatment of low-contrast filaments. By 29 December, the detected oil area increases to roughly 40 km 2 , accompanied by about 76 km 2 of look-alike surface modulation. The 7 January scene shows northward transport and fragmentation, reaching an estimated 86 km 2 of oil with limited look-alike interference. By 10 January, only faint streaks remain (<1 km 2 of oil against 144 km 2 of look-alike), consistent with dispersion and thinning below SAR detectability. Overall, the sequence illustrates coherent temporal evolution, initial localization, spreading, and eventual decay-with the early false negative reflecting the inherent difficulty of segmenting marginal slicks under low contrast.
Repsol/Ventanilla sequence. The Repsol/Ventanilla event (25 January-02 February 2022; Figs. 8 and9) provides a second test of temporal behavior over a much larger spatial domain than the Lobitos case.
Each mosaic spans roughly 1.3 × 10 4 km 2 , with complex radiometric structure from surf, shallow-water roughness and cloud shadowing. On 25 January (Fig. 8), the model detects an elongated slick of 2.93 × 10 3 km 2 over the full mosaic, extending northward from the reported discharge location. South of the yellow reference point, however, large areas are labelled as oil despite official assessments indicating that the spill did not propagate into this sector; these southern detections should therefore be interpreted as false positives linked to coastal darkening and wave shadow effects.
By 2 February (Fig. 9), the model identifies a coherent plume displaced northward toward Ancón, with the oil-labelled area decreasing to about 1 143 km 2 , consistent with surface transport and thinning documented in hydrodynamic reconstructions of the event [15]. In this second frame, a compact red patch near the coast appears to be a false negative (oil misclassified as look-alike), as its geometry and tonal contrast resemble the main slick rather than a natural surfactant feature. Despite these local misclassifications, the model preserves the alongshore continuity of the plume, avoids severe fragmentation, and follows a realistic northward drift between the two dates. As in the Lobitos sequence, the temporal evolution of the predicted slicks remains smooth and physically plausible.
Overview of Main Findings Our research demonstrates that geometrically diversified synthetic augmentation (MORP-Synth) substantially reduces the cross-domain performance gap between Mediterranean source data and the Peruvian target environment. While standard fine-tuning provides initial adaptation, it struggles with the severe class imbalance inherent to oil spill datasets. The proposed augmentation strategy specifically targeted this limitation.
The strongest configuration (N =1804, λ synth =150, moderate edits) delivered a 6.00 pp improvement in overall mIoU compared to the fine-tuned baseline. Most critically, this gain was driven by a substantial recovery of minority classes: Oil Spill IoU increased by +10.81 pp and Look-alike IoU by +14.59 pp. This indicates that synthetic diversity is particularly effective at resolving the confusion between low-contrast slicks and naturally occurring dark formations (wind shadows) [4,3]. We also observed an architecture-dependent response: mid capacity CNNs (ResNet-DeepLabv3+) benefited significantly from synthetic regularization, whereas the Swin-Tiny UNet, which already had strong baseline performance, showed smaller or neutral gains under MORP-Synth. Beyond these immediate performance gains, the recursive nature of the mask-based perturbations establishes a scalable framework for continuous data generation, offering a systematic solution to the chronic data scarcity that typically bottlenecks 8.
By systematically discovering and perturbing boundary apices and shifting object placement (Stage A of MORP), we decoupled the slick’s geometry from its radiometric texture. Since the GAN generator (INADE) maintains the spectral properties of SAR backscatter while the mask geometry changes, the network is forced to learn robust textural features (dampening ratios, gradient boundaries) rather than overfitting to specific spill contours. This explains why the nomove baseline (which adds texture diversity but no shape diversity) was less effective than the m50 regime: geometry appearance decoupling appears particularly effective in our experiments to break the semantic confusion between oil and look-alikes [47]. Conversely, the performance drop at m100 consistent with the idea that overly aggressive curvature edits may produce shapes that are less physically plausible for wind and current driven slicks, which in practice acts as label noise.
The observed cross-domain gap and its partial closure through fine-tuning are consistent with prior SAR segmentation studies that emphasize local adaptation before operational deployment [46,11,13]. The faster convergence and better endpoints of fine-tuned models relative to ImageNet-initialized runs align with the view that marine backscatter statistics learned on one region offer transferable midlevel priors even under shifted incidence-angle distributions and sea-state regimes [17,14]. Regarding augmentation, our results suggest that the proposed pipeline improves generalization by decoupling geometric priors from textural signatures. In standard training, CNNs often overfit to the specific elongation or smooth boundaries typical of oil slicks (geometric priors). MORP (Stage A) disrupts this correlation by introducing high-variance, stochastically perturbed shapes via curvature driven mask editing, since the conditional generator (Stage B) consistently fills these varied geometries with realistic SAR backscatter, the downstream segmentation model is forced to reduce its reliance on shape heuristics and instead prioritize local radiometric features (e.g., dampening contrast, texture gradients) to identify the class. This explains the significant reduction in Look-alike false positives: the model learns that “dark texture” is a more reliable predictor than elongated shape. Finally, the smaller deltas on Swinbased models echo reports that transformer backbones encode strong global priors and multi-scale 8 for reference).
context [33], leaving less headroom for gains unless synthetic realism and weighting are tuned with care.
• The Synthetic Scale “Sweet Spot”: Contrary to the assumption that “more data is better,” we observed diminishing returns when quadrupling the synthetic pool to N =3608. While Oil IoU remained high, Ship detection degraded. This suggests that simply repeating the stochastic generation process without increasing the diversity of the underlying seed patches leads to redundancy. A pool size of N =1804 (roughly 2× the available real training seeds) provided the optimal balance between diversity and class distribution.
• Architecture-Specific Sensitivity: The contrast between the ResNet-DeepLabV3+ (sensitive to augmentation) and Swin-Tiny UNet (robust/insensitive) highlights a fundamental difference in inductive biases. The Swin Transformer’s hierarchical attention windows capture long-range dependencies natively [33], rendering it less dependent on synthetic context expansion.
For CNNs, however, MORP-Synth acts as a critical “context regularizer,” bringing their performance on par with Transformers for minority classes.
• Training Dynamics: The use of a composite Focal Tversky loss was essential. By penalizing False Negatives and specifically weighting the confusion between Oil and Look-alikes, the loss function allowed the optimizer to exploit the subtle boundary cues provided by the synthetic samples, rather than collapsing into the majority “Sea” class. See Appendix 9.
Operational Implications and Methodological Recommendations For Peruvian enforcement agencies such as OEFA, the reduction of False Positives (look-alikes) is the metric of highest strategic value. Given the prevalence of biogenic lookalikes in the Humboldt Current, a low False Positive Rate is essential to prevent “alert fatigue” and ensure interdiction resources are not wasted on false alarms [1,2]. The practical viability of this precisionoriented approach is validated by the model’s temporal stability on major historical events. In the Lobitos sequence (2024-2025), the model success- [18,48,49]; our choice trades ultimate fidelity for efficiency and larger spatial contexts [22]. Finally, the 8).
physical detection limits of C-band SAR impose an inherent ceiling on performance. The False Negatives present in the dataset likely reflects thin-sheen annotation uncertainty under low wind speeds, suggesting that future work should incorporate boundary-aware metrics (e.g., contour F-score) or multi-modal data to better quantify perceptual accuracy in these marginal regimes.
This work addressed the challenge of cross-domain oil spill segmentation by adapting deep models from Mediterranean source data to the Peruvian coast using the proposed MORP-Synth augmentation.
Our results confirm that while standard fine-tuning bridges the initial domain gap, geometrically diversified synthetic data is essential for resolving the severe class imbalance typical of coastal monitoring. The MORP-Synth framework improved the ResNet-34 DeepLabV3+ baseline by 6.00 percentage points in mean IoU on the unseen test set. Most critically, it achieved a +14.59 pp gain in the discrimination of Look-alikes, validating our hypothesis that decoupling geometric priors from radiometric texture forces the model to learn more robust, physically grounded features. We observed an architecture dependent response: mid-capacity CNNs benefited substantially from synthetic regularization (acting as a context regularizer), whereas Transformer-based backbones (Swin-UNet) exhibited intrinsic robust-ness to spatial variations, leaving less headroom for synthetic gains.
In summary, MORP-Synth offers a data-efficient pathway to enhance SAR oil-spill detection in data scarce regions. By generating diverse, label consistent training samples, it reduces the dependency on extensive local annotation, reinforcing both the scientific understanding of marine pattern recognition and practical environmental response capacity.
Scene ID mIoU Pred. oil (km 2 ) Pred. look-alike (km 2 ) FP oil (km 2 ) FP look-alike (km 2 )
).fully tracked the slick’s expansion from ≈ 5 km 2 to 86 km 2 over 15 days. This temporal coherence
).
5:B ← RadialFanPolygon(a, ⃗ n, α, n rays , s exp , r exp max , …) 6: else ▷ shrink 7:S ← exp Probability of performing an “expand” operation
5:B ← RadialFanPolygon(a, ⃗ n, α, n rays , s exp , r exp max , …) 6: else ▷ shrink 7:
5:
arXiv:2501.12345v1 [cs.CV] December 3, 2025
Appendix
📸 Image Gallery