TokenPowerBench: Benchmarking the Power Consumption of LLM Inference
📝 Original Info
- Title: TokenPowerBench: Benchmarking the Power Consumption of LLM Inference
- ArXiv ID: 2512.03024
- Date: 2025-12-02
- Authors: Chenxu Niu, Wei Zhang, Jie Li, Yongjian Zhao, Tongyang Wang, Xi Wang, Yong Chen
📝 Abstract
Large language model (LLM) services now answer billions of queries per day, and industry reports show that inference, not training, accounts for more than 90% of total power consumption. However, existing benchmarks focus on either training/fine-tuning or performance of inference and provide little support for power consumption measurement and analysis of inference. We introduce TokenPowerBench, the first lightweight and extensible benchmark designed for LLMinference power consumption studies. The benchmark combines (i) a declarative configuration interface covering model choice, prompt set, and inference engine, (ii) a measurement layer that captures GPU-, node-, and system-level power without specialized power meters, and (iii) a phase-aligned metrics pipeline that attributes energy to the prefill and decode stages of every request. These elements make it straightforward to explore the power consumed by an LLM inference run; furthermore, by varying batch size, context length, parallelism strategy and quantization, users can quickly assess how each setting affects joules per token and other energyefficiency metrics. We evaluate TokenPowerBench on four of the most widely used model series (Llama, Falcon, Qwen, and Mistral). Our experiments cover from 1 billion parameters up to the frontier-scale Llama3-405B model. Furthermore, we release TokenPowerBench as open source to help users to measure power consumption, forecast operating expenses, and meet sustainability targets when deploying LLM services.📄 Full Content
Despite its importance, the community still lacks a comprehensive, reproducible, and scalable benchmarking methodology for measuring and analyzing the power and energy cost of LLM inference across model scales, hardware generations, software stacks, and deployment modes (from single-node to multi-node distributed inference). Existing efforts only partially address this need. For instance, MLPerf Inference benchmark (Reddi et al. 2020) standardizes performance benchmarking across a range of machine learning (ML) tasks but does not systematically capture end-to-end power or normalize energy to LLM-specific service units (e.g., Joules per generated token, per prompt). MLPerf Power benchmark (Tschand et al. 2025) extends inscope measurements, but its current workflows typically (i) emphasize single-node setups, (ii) focus on modest model sizes relative to frontier state-of-the-art (SOTA) LLMs (e.g., Llama 3 405B-class deployments remain largely uncharacterized), and (iii) often depend on external, high-precision metering equipment that is costly and difficult to replicate across institutional testbeds. Moreover, existing benchmark suites rarely explore the configuration space that practitioners routinely tune in production, such as batch sizing strategies, tensor/pipeline parallelism, context length and quantization levels. All of these configuration settings significantly impact both instantaneous power draw and energy per token in average.
To address this gap, we present TokenPowerBench, the first lightweight and extensible benchmark specifically designed to quantify the power consumption and energy cost of LLM inference. TokenPowerBench features a modular instrumentation layer that integrates vendor telemetry APIs (e.g., GPU/CPU/Memory power sensors), node-level energy sampling, and optional rack-or facility-level measurements when available. A single metrics pipeline lines up every power sample with the two main inference phases (prefill and decode) to allow us to pinpoint exactly where energy is spent. We conduct extensive experiments to systematically analyze the relationship between energy cost and inferencerelevant parameters, including batch size, maximum context length, parallelization strategy, and quantization. Our major contributions of this work are:
MLPerf Power (Tschand et al. 2025) is one of the most comprehensive benchmarks for measuring energy efficiency of machine learning systems. It integrates performance and power measurements using high-precision equipment across edge, datacenter, and cloud systems. However, it treats LLM inference as a generic machine learning inference task and does not account for LLM-specific characteristics such as parallelism techniques and memory optimization. Furthermore, its workflows often assume a static model and dataset configuration, and require expensive power instrumentation setups, limiting accessibility and extensibility for broader LLM deployments.
Green500 (Feng and Cameron 2007) evaluates the energy efficiency of supercomputers using the HPL benchmark. Although it ranks large-scale systems by FLOPS/Watt, it is not designed for ML or LLM-specific workloads. Other efforts propose power-aware profiling tools for general AI workloads, but they do not capture end-to-end inference flows in token-based generation models.
In contrast, TokenPowerBench focuses specifically on LLM inference and provides phase-aware, token-level measurements aligned with model execution patterns. Our framework enables energy-normalized benchmarking (e.g., Joules per token) and supports reproducible multi-node configurations without requiring external metering hardware.
Recent studies begin to highlight the performance and energy cost of LLM inference. For example, LLM-Inferencebench (Chitty-Venkata et al. 2024) is a inference benchmark across diverse hardware but limits its power analysis to the accelerators themselves. Poddar et al. (Poddar et al. 2025) analyze the energy consumption of large transformer models during inference, often using cloud GPUs (e.g., A100, H100) and focusing on distillation or quantization strategies. However, these studies are typically limited to fixed setups, lack systematic benchmarking frameworks, and do not explore parameter space (e.g., batch size, context length) or cluster-wide energy variation. Samsi (Samsi et al. 2023) propose a more focused academic approach using direct hardware telemetry (nvidia-smi/DCGM (Corporation 2023)) to measure only the accelerator’s power consumption. Some works (Jegham et al. 2025) investigate the carbon footprint of foundation models, yet mostly focus on training-phase emissions rather than inference.
TokenPowerBench addresses this gap by offering a lightweight, extensible framework to benchmark and analyze energy efficiency across LLM sizes, hardware generations, and deployment modes. It introduces a normalized metric suite (Joules/token, power imbalance, energy-delay product) and automates parameter sweeps over key inference configuration dimensions.
A number of tools and frameworks exist for system-level power monitoring (Li et al. 2020;Stefanov et al. 2021). NVIDIA’s NVIDIA Management Library (NVML), Data Center GPU Manager (DCGM) and “nvidia-smi” provide GPU-level power telemetry, while Intel’s Running Average Power Limit (RAPL) (Intel Corporation 2023) interface supports package-level CPU/DRAM energy readings. Clusterwide monitoring systems like Intelligent Platform Management Interface (IPMI) (Corporation 2006), Redfish (DMTF 2023), and rack-level PDUs offer coarse-grained wall power data.
TokenPowerBench integrates vendor-native telemetry where available and aligns measurements with LLM inference phases. Our framework supports real-time sampling at multiple granularity levels (GPU, node, rack) and performs time-correlated breakdown across prefill, decode, and idle phases to enable fine-grained attribution of power consumption.
Table ?? contrasts TokenPowerBench with the main benchmark and measurement efforts proposed to date for LLM power analysis. TokenPowerBench is the first framework that combines LLM-specific coverage (dense and MoE models up to LLaMA-3-405B), component-level and power measurement without specialized meters, and a fully opensource implementation-thereby filling every gap highlighted in the comparison.
TokenPowerBenchis not a replacement for MLPerf Power or any other benchmark but rather a complementary, agile tool. While MLPerf answers the question “Which hardware is more efficient on a standard task?”, TokenPowerBench answers the question “What is the real-world energy cost of running my massive, distributed model with my specific configuration on my available hardware?”. Its lightweight nature makes it the ideal solution for this practical, operatorcentric measurement problem.
Benchmarking LLM inference power consumption is fundamentally different from benchmarking throughput or latency. Unlike traditional performance metrics, energy consumption is shaped by hardware heterogeneity, software stack complexity, and workload dynamics. All of the above settings vary significantly across deployments. Existing LLM benchmarks offer limited support for this variability, often assuming fixed configurations, static model sizes, and expensive instrumentation.
As shown in the Figure 1, TokenPowerBench overcomes these limitations through a three-layer architecture: Configuration, Execution & Measurement, and Report Generation. It offers a modular, configurable, fully reproducible, and scalable benchmarking methodology tailored to modern LLM inference.
The first task of TokenPowerBench is to help users set up the test environment by selecting the model to run, the inference engine to use, and prompts to feed into it. To keep this step lightweight, TokenPowerBench exposes three plug-and-play modules: a model pool (choose any supported LLM), a prompt-dataset menu (select from Alpaca, LongBench, or custom prompts), and an inference-engine selector (vLLM, TensorRT-LLM, Transformers, or DeepSpeed).
• Model Pool: We include models with different underlying architectures to capture how design choices impact energy profiles. This includes standard decoder-only transformers (e.g., the LLaMA series) and Mixture-of-Experts (MoE) models (e.g., Mixtral), which exhibit distinct computational patterns, particularly in parameter activation and memory access. The benchmark covers a broad spectrum of model sizes, from smaller models with fewer than 1 billion parameters-suitable for a single consumer-grade GPU-to frontier-scale models like Llama 3-405B, which require multi-GPU and/or multinode distributed inference. This allows us to study how energy consumption sacles with increasing model size and hardware complexity. • Prompt-dataset memu: Prompt length and style can significantly affect energy consumption during inference. To capture this variability, TokenPowerBench provides built-in support for two representative datasets: Alpaca, featuring short, chat-style prompts, and Long-Bench, which includes extended contexts of up to 10k tokens. Users can also supply custom data in CSV or Beyond the choice of model, inference engine, and dataset, the specific configuration of the inference service is a primary determinant of power consumption. TokenPower-Bench is designed to explore the multi-dimensional configuration space that practitioners need to navigate. Instead of reporting a single performance number, it systematically varies key parameters to build a detailed power profile across different operational conditions. The primary axes of our benchmark scenarios are:
• -Quantization: We benchmark various numerical formats (e.g., FP16, FP8). While quantization reduces memory footprint and can accelerate computation, its overall impact on system-wide energy consumption remains a key question.
By sweeping through these scenarios, TokenPowerBench provides a holistic view of how operational choices, from hardware provisioning to software optimization, affect the energy efficiency of LLM inference.
-
Spatial view: where the power is spent. During each run, TokenPowerBench samples power consumption from all major node components: GPU, CPU, DRAM, andwhen sensors are available-the network interface and fan tray. GPU power is collected via NVML/DCGM; CPU and DRAM power via Intel RAPL; and full-node power via IPMI or a rack-mounted PDU. Storing these readings sideby-side enables insights such as GPUs typically account for over 60% of total energy use, while fans contribute only a few percent. Because all telemetry streams share the same timestamp, we can also sum them precisely to compute the total wall energy for each request.
-
Temporal view: when the power is spent. The same logger records two key stages of every inference: prefill, when the model reads the input tokens, and decode, when it produces new tokens. Each power sample is tagged with the stage that is active at that moment. After the run we integrate these tagged samples to obtain two clear numbers: energy consumed during prefill and energy consumed during decode. This separation reveals, for instance, that long prompts raise the prefill share, while large batch sizes increase the decode share. By combining spatial and temporal perspectives, we can determine both which component and
When an experiment ends, TokenPowerBench collects the log data and turns the raw time-stamped samples into a compact summary. First, it integrates the GPU, CPU, DRAM, and wall-plug traces over the two stages of inference including prefill and decode stages, so the user can see at a glance how many joules each component consumed in each part of the process. Users can get the data such as energy per token, energy per response, energy per second, peak powe, and energy consumed during prefill stage. Because every value is computed directly from the aligned samples, there is no need for post-hoc scaling or hand calculations.
The tool then writes the results in three complementary formats. A CSV file holds the numbers most people plot with Pandas or Excel; a matching JSON file fits easily into automated dashboards; If the user supplies electricity price and a regional carbon factor, the same pass also converts kilowatt-hours into dollar cost and CO 2 equivalents, so budget and sustainability discussions start from the same sheet as the technical metrics. Because every run follows the same pipeline, reports produced on different days or clusters line up without extra scripting, making it straightforward to track regressions or show savings after an optimization.
To demonstrate the utility and effectiveness of TokenPower-Bench, we conduct an in-depth case study on a representative Nvidia H100 GPU cluster. Our evaluation is designed to showcase how the benchmark can be used to derive actionable insights into the performance, energy consumption, and cost of deploying large-scale LLMs.
Hardware The experiments were performed on a 8-node GPU cluster, each node is equipment with 4 NVIDIA H100 GPUs (94 GB memory each), paired with two Intel Xeon Gold 6426Y CPUs (16 cores, 32 threads each) and 512 GB of RAM.
Prompt Datasets We evaluate our benchmark on two datasets: Alpaca (Taori et al. 2023) and LongBench (Bai et al. 2023b). Alpaca contains 52,002 prompts generated by OpenAI’s text-davinci-003 engine (OpenAI 2022). Long-Bench is an open-source benchmark and has longer prompts in average.
We tested all popular LLM models, including Llama3 -1B, 3B, 8B, 70B and 405B; Mistral 7B, 24B, 8×7B, 8×22B; Qwen 8B, 32B and 480B; Falcon 7B, 10B and 180B. The representative results as shown in the following table. Please check the total results in the supplementary material.
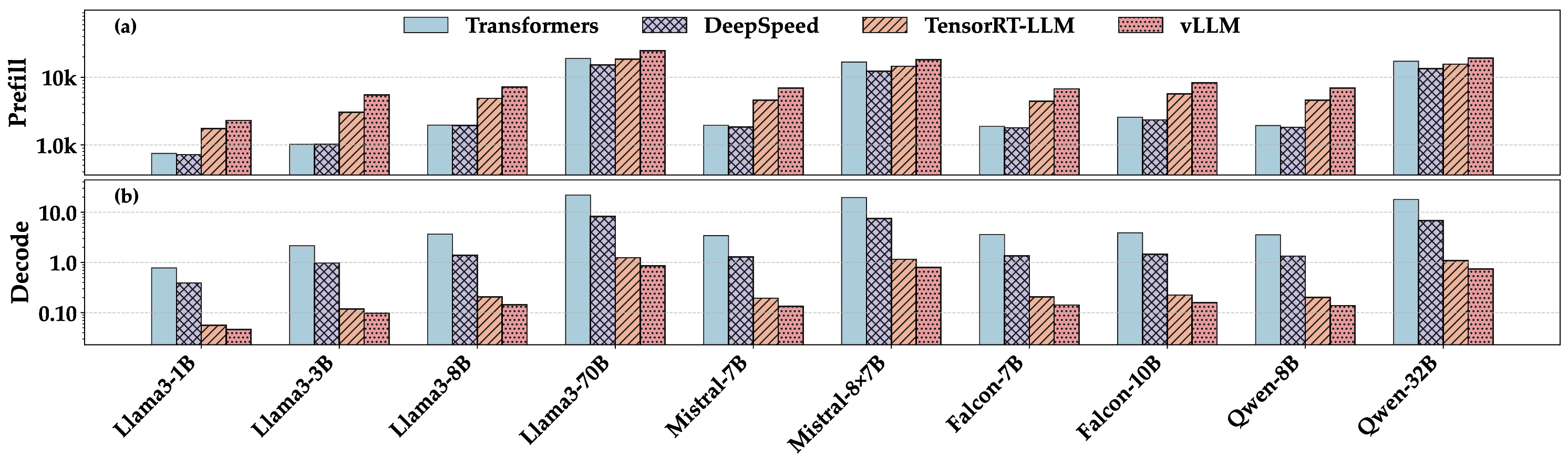
Figure 2 compares energy consumed by prefill stage and total energy per token for 10 open-source models (dense and MoE) served by four mainstream engines: Transformers, DeepSpeed-Inference, TensorRT-LLM, and vLLM on a single node with 4 H100 GPUs. Within each LLM family, energy rises faster than the parameter count. For LLaMA-3, moving from 1 B to 70 B parameters increases energy per token by 7.3×, even though parameter count grows 70×. This super-linear trend confirms that larger models pay an extra cache-bandwidth and memory-traffic penalty beyond pure FLOPs.
Dense versus MoE. Mixtral-8×7B consumes roughly the same energy per token as a dense 8B model while delivering quality closer to a 56 B dense model. The sparse routing that activates only two experts per token cuts token energy by 2-3× compared with dense models of similar emergent accuracy.
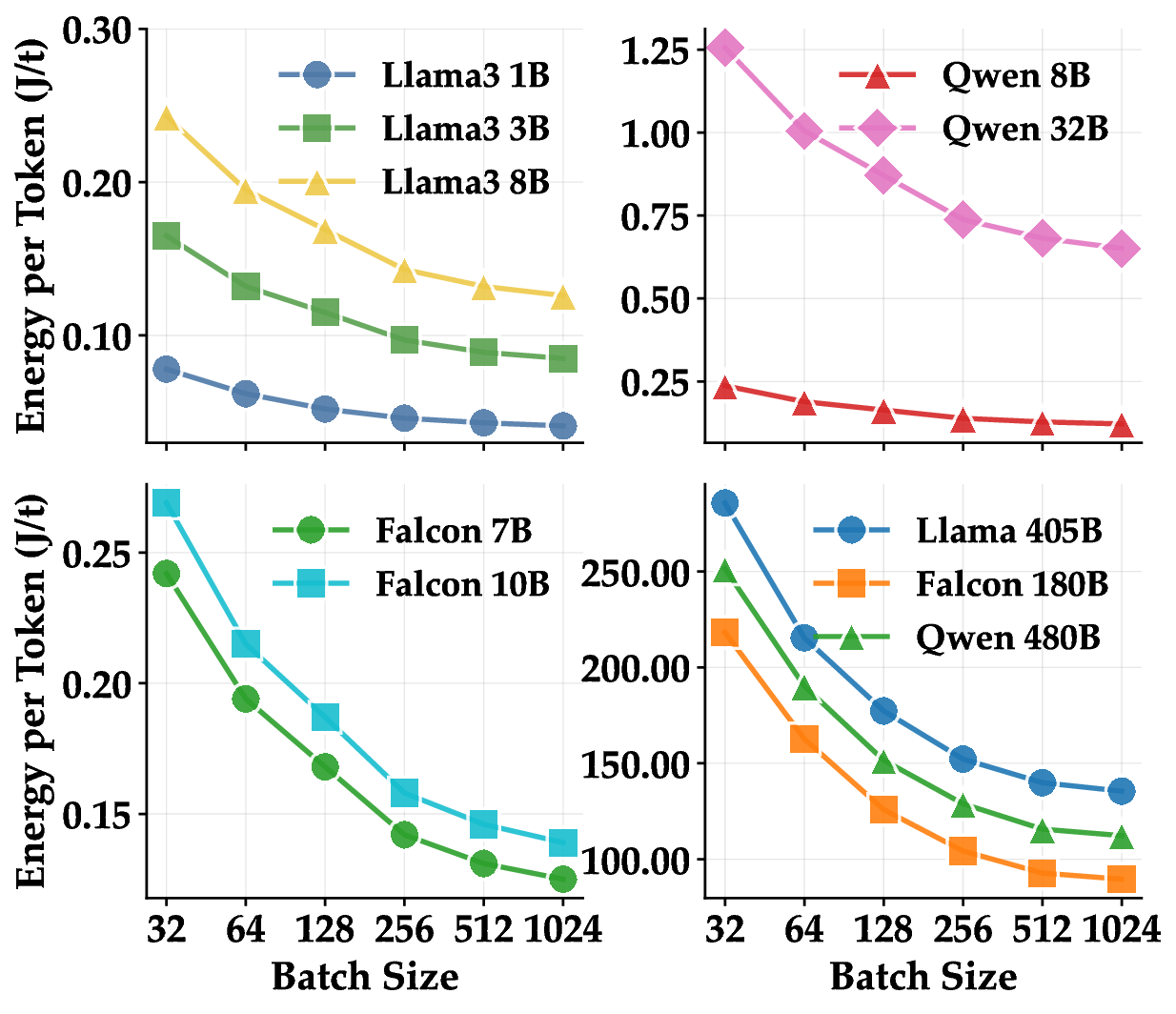
Engine impact. Across all models, TensorRT-LLM and vLLM consume 3 times more than DeepSpeed and Transformers in the prefill stage. However, TensorRT-LLM and vLLM reduce energy per token by 25-40% relative to Transformers engine due to the optimization techniques Beyond batch 256 the curve flattens: power draw stays roughly constant while additional tokens add proportionally less work, so further efficiency gains are modest. Here batch sizes up to 1024 still fit in memory, so energy per token continues to fall, though at a slower rate, giving an overall two-to-three-fold spread between the smallest and largest batches.
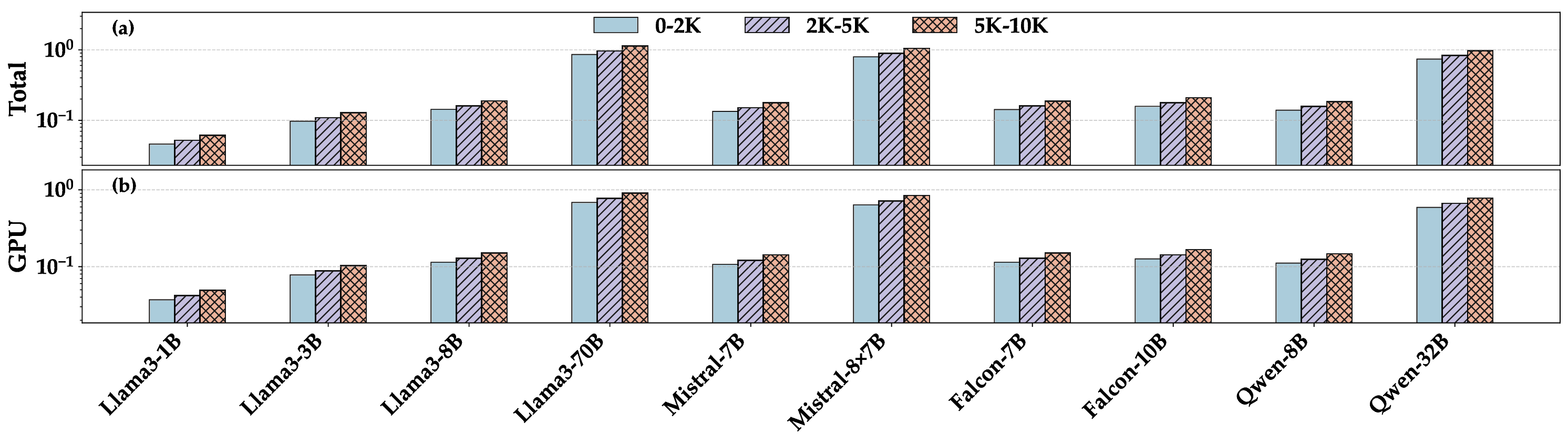
Context Length Figure 3 reports energy (total and gpu) per token for ten models at three prompt length range : 0-2K, 2K to 5K, and 5K to 10K tokens. Across all models, energy grows steadily as the prompt gets longer because the prefill stage must process every input token while the compute cost of each new output token stays the same.
For the largest dense model we tested (Llama3 70B), the jump from 2K to 10 K tokens raises energy per token by roughly a factor of three; medium models (e.g., Llama 3 8B, Mistral 7B) see a smaller but still clear rise. The pattern is nearly identical in the GPU-only trace and in the node-level trace, confirming that most of the extra power is drawn by the accelerators rather than by the host CPU or memory.
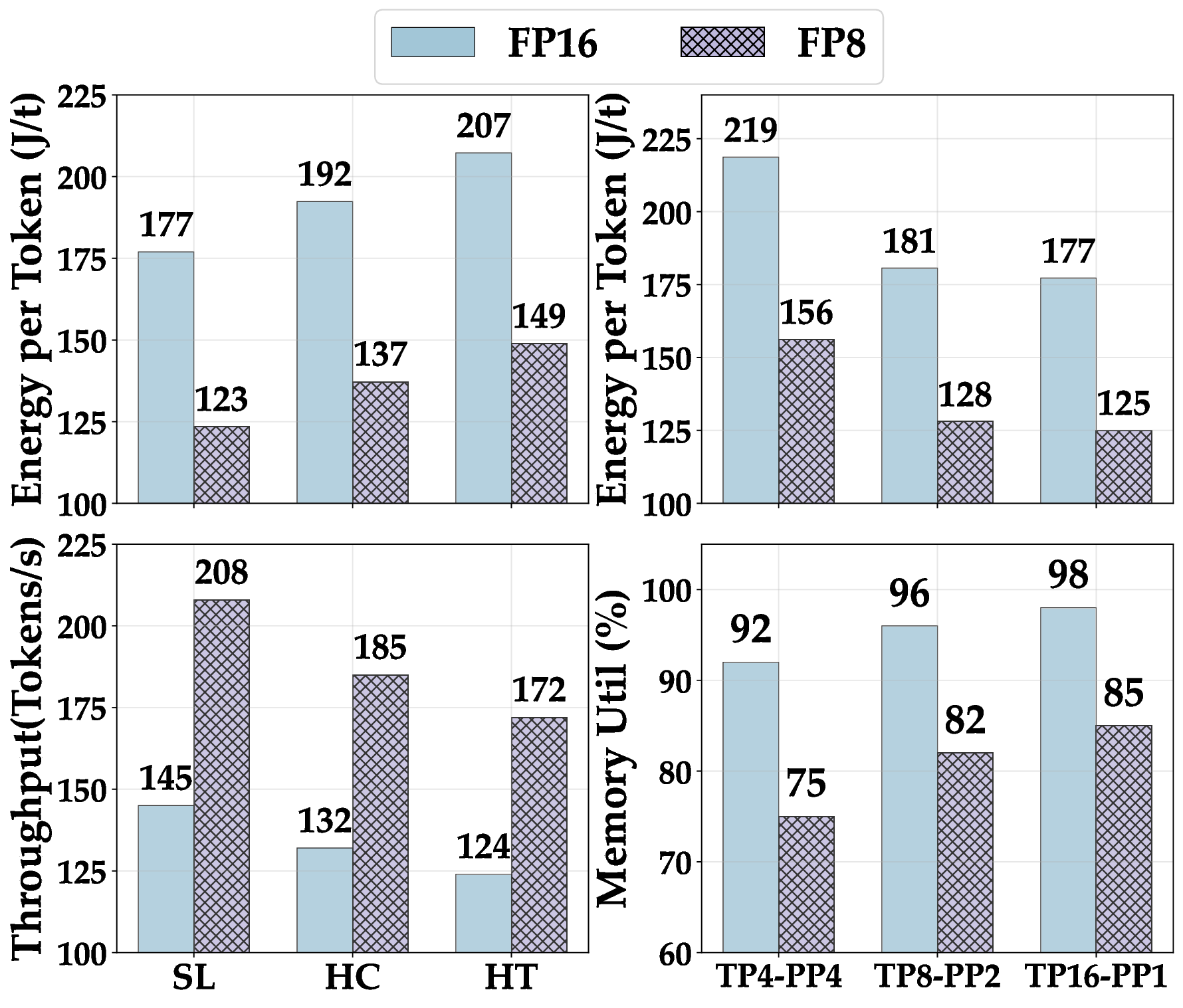
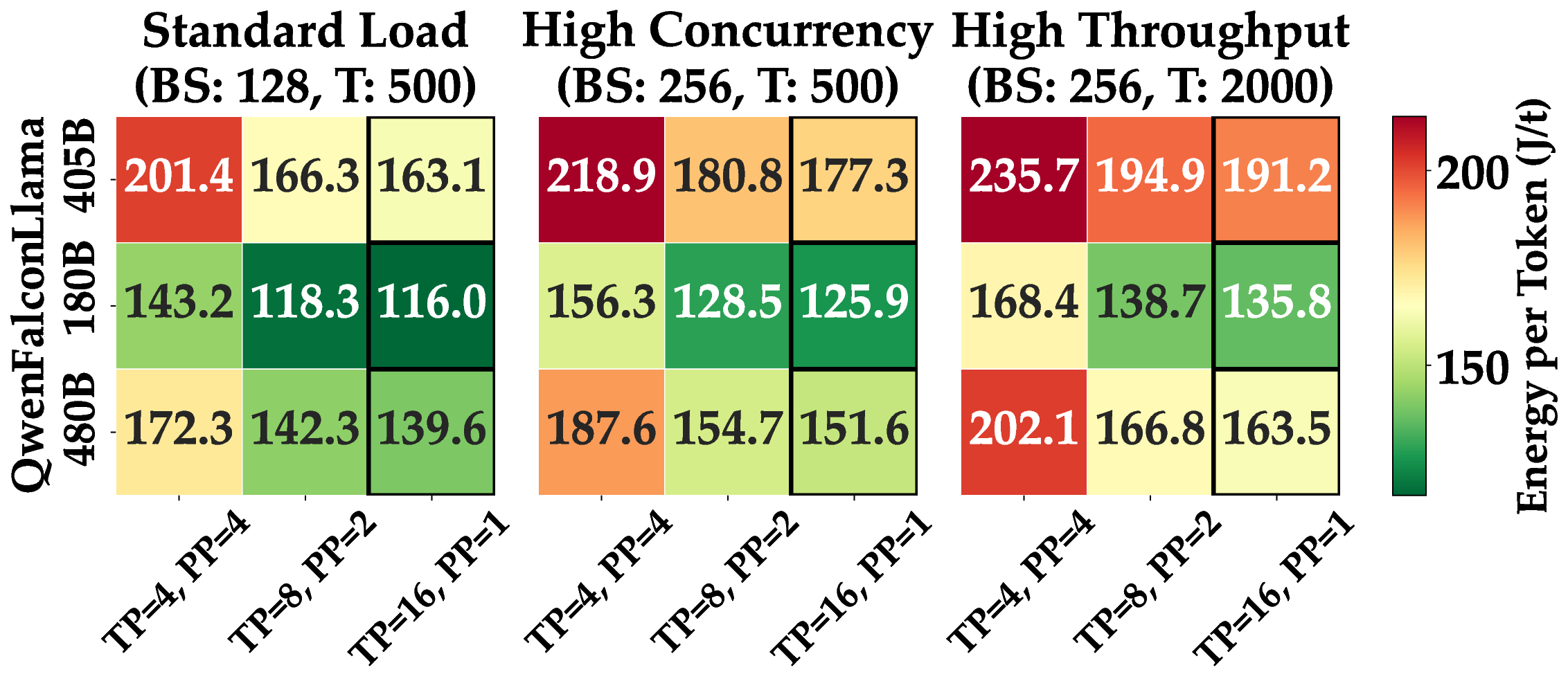
Longer prompts therefore hurt energy efficiency in two ways: they increase the joules spent before the first output token appears, and they lower overall throughput because GPUs stay busy on attention over a larger context window. The heatmap figure presents a heatmap for three SOTA models: Llama 3 405B, Falcon180B, and Qwen 480B on 16 H100 GPUs under three workload profiles. For each model we tested three ways to split work across the GPUs: a balanced mix of tensor and pipeline parallelism with TP 4 and PP 4, a tensor-heavy mix with TP 8 and PP 2, and pure tensor parallelism with TP 16 and PP 1. Green cells in the figure mark lower energy use.
Across every workload the pure tensor parallelism setting delivers the best energy efficiency because long pipelines leave some GPUs idle. The gap between the best and worst split widens as the workload grows from about 40 J/token under Standard Load to more than 60 J/token under High Throughput. The results show that parallelism tuning matters most in heavy, batch-oriented jobs. Performance also benefits by the quantization. FP16 increases effective memory-bandwidth utilization by 13-17 percentage, but FP8 raises end-to-end throughput from about 48-63 tokens/s in the largest batch setting, without noticeable accuracy loss in our prompt set. Together, these results confirm that low-precision formats can deliver a double dividend lower power and higherspeed, when the underlying hardware and kernels fully support them.
TokenPowerBench’s core contribution is a lightweight, extensible, and reproducible framework for benchmarking the power and energy consumption of LLM inference across diverse hardware configurations, model families, and workload patterns. We briefly summarize the core aspects of our benchmark design here.
Energy-normalized inference metrics. To enable meaningful comparison of inference systems, TokenPowerBench introduces a set of energy-centric metrics including Joules per token, Joules per response and instantaneous power draw. These metrics are aligned with the internal execution phases of transformer-based LLMs (prefill and decode), enabling fine-grained attribution of energy costs. Unlike traditional performance metrics like latency or throughput, these energy metrics directly reflect sustainability and costefficiency, which are critical concerns in modern AI infrastructure.
Reproducible measurement methodology. Power measurement in LLM inference is highly sensitive to hardware access level and instrumentation fidelity. TokenPowerBench defines a three-level measurement model-from GPU-only telemetry to full-system power monitoring using IPMI and rack-level PDUs-allowing users to adopt the benchmark in environments ranging from user-space workstations to institutional testbeds. We pair this with a declarative configuration harness that ensures repeatability across experiments.
Scalable scenario design. LLM inference workloads vary widely based on system scale, model size, and deployment constraints. TokenPowerBench systematically explores key configuration dimensions, including batch size, context length, quantization format, parallelism strategy to expose how each factor impacts energy usage. We support scaling from single-GPU inference to multi-node distributed serving, capturing both component-level breakdowns and cluster-wide energy imbalances.
The landscape of LLM inference is rapidly evolving, and TokenPowerBench is designed to evolve with it. We will extend coverage beyond our current H100 testbed to other GPU architectures, including the next NVIDIA generations and AMD accelerators, as well as emerging AI chips and DPUs. We will also polish the benchmark and extend the functionality to quantify the trade-off between inference accuracy and energy efficiency, providing users with guidance on where energy savings begin to erode model quality.
📸 Image Gallery