Flowchart2Mermaid: A Vision-Language Model Powered System for Converting Flowcharts into Editable Diagram Code
📝 Original Info
- Title: Flowchart2Mermaid: A Vision-Language Model Powered System for Converting Flowcharts into Editable Diagram Code
- ArXiv ID: 2512.02170
- Date: 2025-12-01
- Authors: Pritam Deka, Barry Devereux
📝 Abstract
Flowcharts are common tools for communicating processes but are often shared as static images that cannot be easily edited or reused. We present FLOWCHART2MERMAID, a lightweight web system that converts flowchart images into editable Mermaid.js code which is a markup language for visual workflows, using a detailed system prompt and vision-language models. The interface supports mixed-initiative refinement through inline text editing, drag-and-drop node insertion, and natural-language commands interpreted by an integrated AI assistant. Unlike prior image-todiagram tools, our approach produces a structured, version-controllable textual representation that remains synchronized with the rendered diagram. We further introduce evaluation metrics to assess structural accuracy, flow correctness, syntax validity, and completeness across multiple models.📄 Full Content
We introduce FLOWCHART2MERMAID2 , an end-to-end web application that converts flowchart images into textual Mermaid.js3 (Sveidqvist and Jain, 2021) specifications and enables rich humanin-the-loop editing. After uploading an image, a vision-language model (VLM) produces an initial Mermaid program, which users can refine through three complementary interaction modes: (1) inline editing, by clicking labels directly on the rendered diagram; (2) visual editing, via drag-and-drop insertion of standard flowchart symbols that automatically synchronize with the underlying code; and
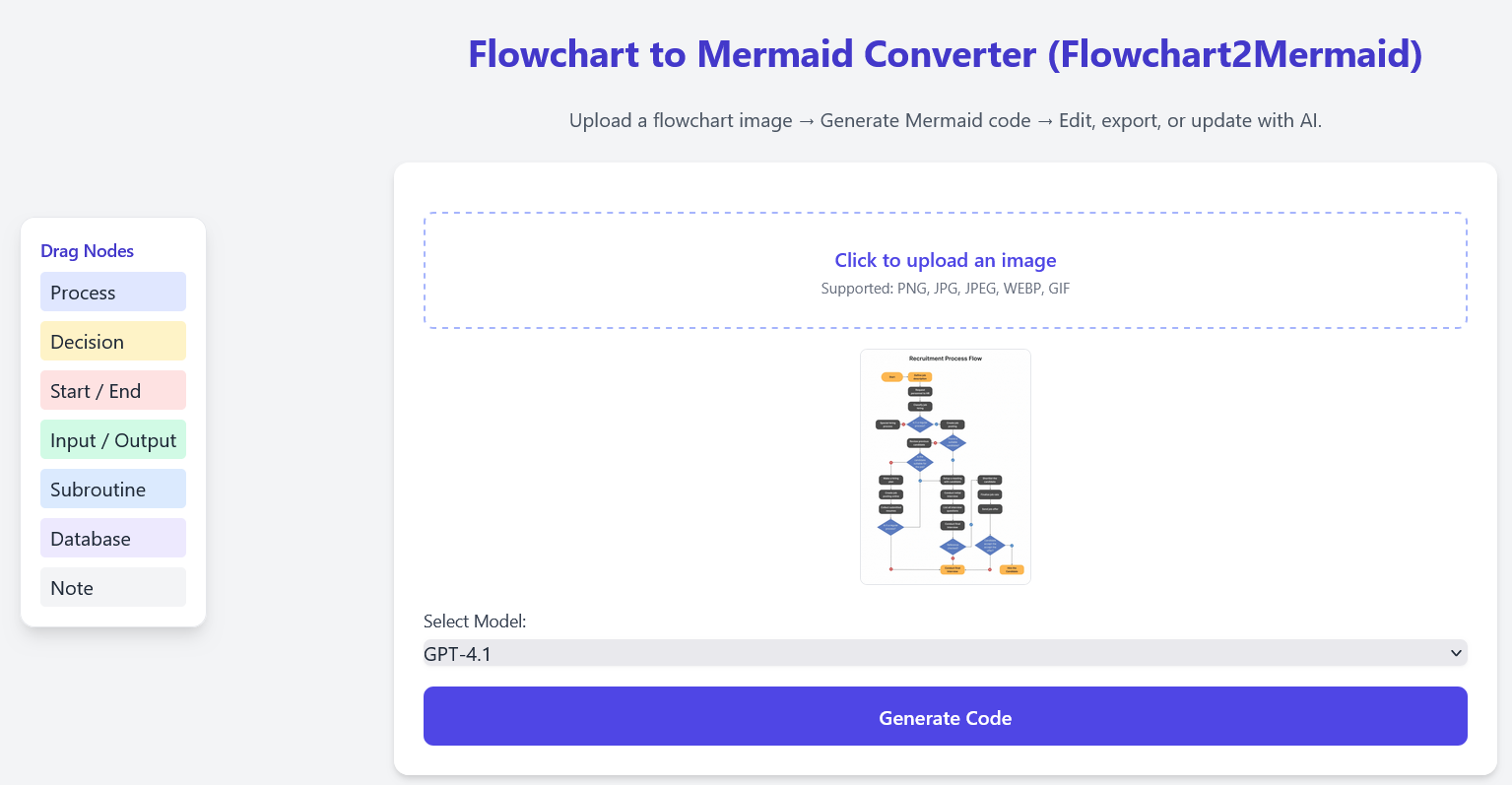
(3) natural-language edits, where free-form instructions trigger targeted LLM modifications to the diagram (e.g., “Connect A to B with a ‘Yes’ edge”). The system supports real-time rendering, export to SVG/MMD formats, and seamless handoff to the Mermaid Live Editor. The landing page of the application is shown in Figure 1.
This section reviews research relevant to transforming visual diagrams into structured, editable representations. We summarize prior work on diagram parsing, image-to-code translation, and interactive tools for programmatic diagram editing.
Diagram Understanding and Diagram-to-Code. Early systems for flowchart interpretation focused on rule-based shape detection and template matching, enabling conversion of hand-drawn or scanned flowcharts into pseudocode or C programs (Wu et al., 2011;Herrera-Camara and Hammond, 2017;Carton et al., 2013). Educational environments such as Flowgorithm (Cook) or browser-based structured editors (Supaartagorn, 2017) support generating executable code from diagrams, but require users to construct diagrams within the tool itself and cannot process arbitrary images. More recent approaches incorporate deep-learning pipelines: Arrow-RCNN (Schäfer and Stuckenschmidt, 2019) and DrawnNet (Fang et al., 2022) use CNNs to detect shapes and connectors, while Montellano et al. (Montellano et al., 2022) reconstruct both the visual diagram and corresponding code from hand-drawn sketches5 . Although effective within controlled datasets, these systems lack generalization to diverse diagram styles and do not support interactive refinement.
Multimodal Models for Structured Visual Content. Advances in vision language models (VLMs) have enabled more flexible diagram parsing. The GenFlowchart system (Arbaz et al., 2024) combines SAM-based (Segment Anything Model) (Kirillov et al., 2023) segmentation with an LLM to assemble a unified symbolic representation from detected visual elements. Foundation models such as GPT-4 (Achiam et al., 2023) and Gemini (Team et al., 2023) can translate images into structured text or code, demonstrating strong priors about graphical layout and syntax. Recent work has ex-tended these capabilities to business process diagrams (Deka and Devereux, 2025) where the authors present a VLM-based pipeline for extracting structured JSON representations from BPMN images, enriched with OCR-based label recovery and alignment against XML ground truth. These multimodal systems enable diagram-to-text generation as a high-level translation task, moving beyond handcrafted rules. However, prior work typically treats generation as a one-shot inference problem and does not integrate downstream editing workflows.
Interactive Editing and Natural Languagedriven Diagram Manipulation. A growing ecosystem of AI-assisted diagram editors has recently emerged, including commercial platforms such as FlowchartAI6 , dAIgram7 , which convert uploaded images into editable flowcharts using shape detection and layout reconstruction. Tools such as DiagramGPT8 and Lucidchart AI9 provide natural-language (NL) driven diagram creation, while yEd Live10 integrates ChatGPT for modifying existing digital graphs (e.g., renaming or styling nodes). Although these systems demonstrate promising forms of AI-assisted editing, they cover only parts of the broader diagram-understanding space. As a result, existing tools rarely support semantic editing, versioncontrol-friendly outputs, or deep coupling between recognition, code generation, and iterative refinement. They further lack bidirectional synchronization between visual edits and a symbolic diagram representation, and their natural-language capabilities are typically limited to high-level prompting rather than fine-grained, code-level refinement.
In contrast to the systems above, our approach targets the full pipeline from raw diagram images to textual, semantically meaningful Mermaid code, supporting downstream reasoning and reproducible version control. While recent work (Deka and Devereux, 2025) demonstrates robust VLM-based extraction for BPMN, their focus is on faithful structured recovery rather than interactive editing. Beyond initial multimodal parsing, our interface enables iterative refinement through three coordinated
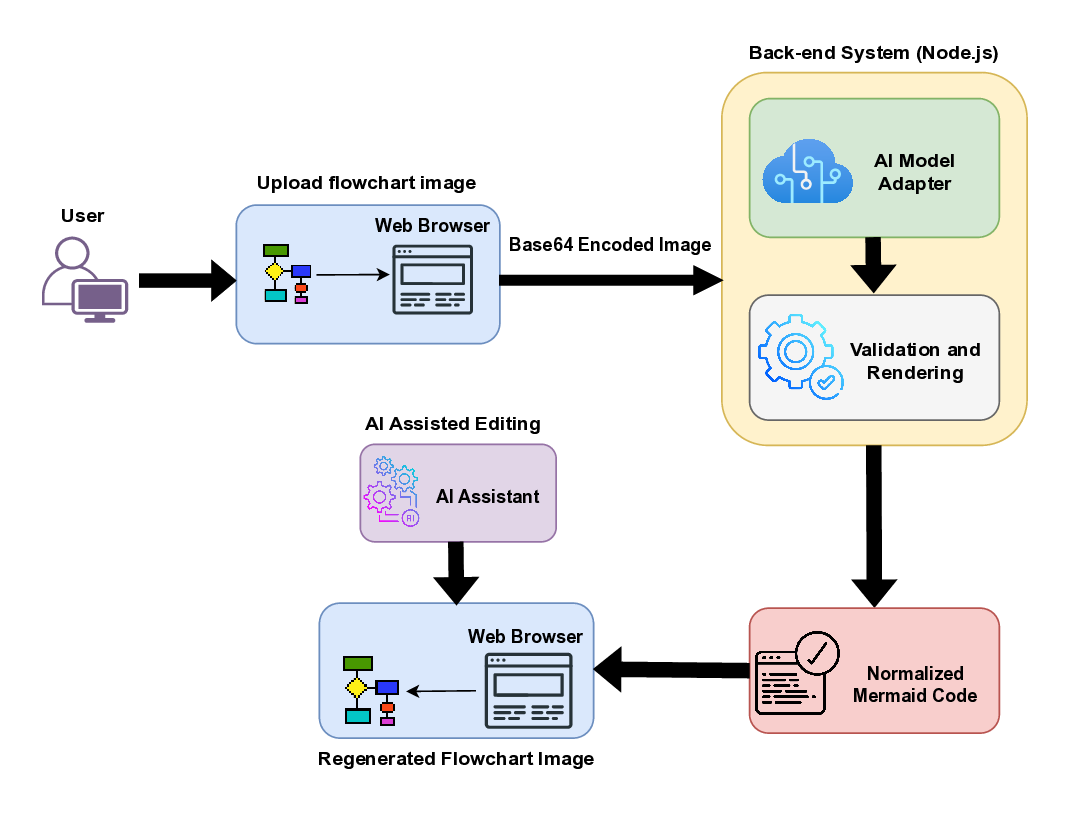
Figure 2 provides a high-level view of the FLOWCHART2MERMAID system. The application follows a lightweight client-server design in which the browser is responsible for visualization and user interaction, while a minimal server component mediates communication with external vision-language models (VLMs).
At a conceptual level, the system supports a mixed-initiative workflow: a user uploads a flowchart image, obtains an initial Mermaid representation generated by a multimodal model, and then iteratively refines it through direct manipulation, text editing, or natural-language commands. Throughout the workflow, the textual and visual representations remain tightly synchronized, supporting seamless switching between code-level and diagram-level editing.
The system is implemented as a lightweight web application integrating VLM inference with an in-teractive visualization layer. Its architecture balances modularity, responsiveness, and reproducibility across multiple model back ends.
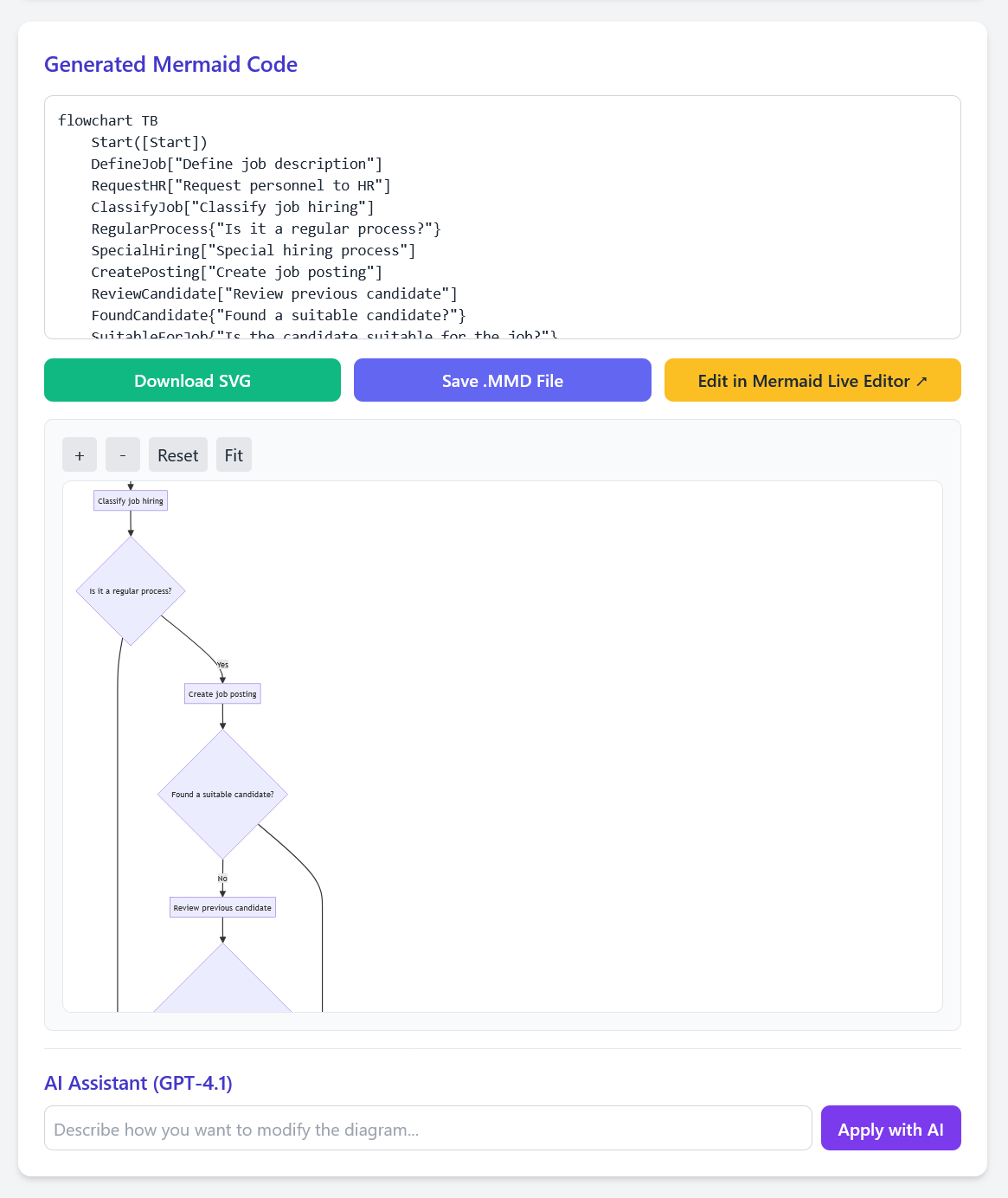
The system is composed of a browser-based front end for visualization and editing and a lightweight Node.js back end that handles multimodal model inference. This separation keeps user interactions responsive while delegating computationally intensive processing to the server. After a user uploads a diagram image as shown in Figure 3, the front end encodes it and forwards it, together with the chosen model identifier, to the back end. Inference is guided by a carefully engineered system prompt that specifies the expected flowchart elements, structural constraints, and output format of valid Mermaid code. This prompt serves as the core of the conversion process, drawing on insights from structured prompting and constrained generation (Liu et al., 2023;Cheng et al., 2024). The VLM produces a first-pass Mermaid program, which is lightly normalized before being returned to the browser as shown in Figure 4.
On the client side, the code is rendered immediately and remains fully editable. Users may refine the diagram through direct manipulation (dragging nodes, adding connections, modifying labels), through text-based editing of the Mermaid program, or via natural-language commands handled by an integrated AI assistant consisting of the GPT-4.1 model. All edits maintain bidirectional synchronization between the textual and visual representations. This architecture supports rapid iteration while remaining model-agnostic and easily extensible. We showcase the complete working demo for the example flowchart image in video. This unified design abstracts away API-specific differences between providers, offering a consistent interface to the front end while enabling easy extension to future multimodal models.
Strict validation routines ensure that all inputs conform to supported image types and that generated outputs compile successfully in Mermaid.js. The architecture emphasizes modular extensibility and low-latency feedback, making it suitable for both research exploration and pedagogical use cases involving diagrammatic reasoning.
We evaluate our flowchart-to-Mermaid pipeline using a subset of the FLOWVQA dataset (Singh et al., 2024), which contains diverse, real-world flowcharts annotated with step-level semantics. Although intended for visual question answering, its Mermaid annotations for each image allow us to construct the gold-standard (image, code) pairs for our task.
Because Mermaid code admits multiple semantically equivalent surface forms, direct string matching is unreliable: models may emit different node identifiers, paraphrased labels, or alternate arrow styles while still producing a fully correct diagram. These variations make rigid token-or rule-based evaluation brittle. Following recent work on LLMas-a-judge evaluation (Zheng et al., 2023;Li et al., 2025), we therefore use a structured evaluator implemented within the DeepEval framework (AI, 2025). 11 . A GPT-based judge model (GPT-4.1) is prompted to parse both predicted and gold Mermaid diagrams, normalize node labels, identify directed relations, and compute symbolic precision, recall, and F1-score for nodes and edges. The full evaluation prompts are provided in Appendix A.
We evaluated five vision-language models integrated into our system: GPT-4.1, GPT-4.1-mini, GPT-4o, GPT-4o-mini, and Gemini-2.5-Flash. All models used the same structured instruction template and were tasked with generating Mermaid flowcharts for 200 input diagrams. Predicted Mermaid code was parsed automatically, normalized, and compared against gold-standard annotations.
These metrics quantify symbolic alignment and graph-topological similarity. We compute: Entity extraction accuracy: precision (P), recall (R), and F1-score between predicted and gold node labels.
Relationship extraction accuracy: P, R, and F1score for directed edges. Semantic similarity: Cosine similarity between the predicted and gold Mermaid code using SBERT embeddings (Reimers and Gurevych, 2019).
To evaluate global diagram quality beyond exact node-edge matching, we use five complementary structural metrics assessed by . Each metric captures a distinct aspect of diagram-level fidelity: Structural Accuracy (0-1): high-level alignment of node-edge organization. Flow Accuracy (0-1): preservation of control-flow and execution paths. Syntax Validity (0-1): conformance to Mermaid syntax and renderability. Semantic Fidelity (0-1): retention of the workflow’s intended meaning. Completeness (0-1): inclusion of essential elements and relations from the gold diagram.
A reconstructability override is applied when the judge model determines that the predicted diagram could be transformed into the gold version through minor structure-preserving edits, granting full credit across metrics. Each metric is originally 11 https://github.com/confident-ai/deepeval scored on its native bounded scale (0-5, 0-3, or 0 -2) and subsequently normalized to the range [0, 1] for comparability. While these metrics are conceptually formalized, their implementation relies on GPT-4.1’s implicit reasoning rather than explicit numerical computation.
Tables 1 and2 summarize performance on the FLOWVQA subset. Table 1 focuses on symbolic extraction quality (entities, relations, SBERT cosine similarity), while Table 2 captures higher-level structural properties of the generated diagrams. For SBERT cosine similarity, we use a fine-tuned MiniLM (Wang et al., 2020) model from Huggingface 12 . Symbolic extraction performance. All large models achieve strong entity extraction, with entity F1-scores above 0.94 for GPT-4.1, GPT-4o, and Gemini-2.5-Flash. Relationship extraction is consistently more difficult: relation F1 scores are typically 1-3 points lower than entity F1 scores, indicating that recovering the full edge structure is the primary source of error. GPT-4.1-mini and Gemini-2.5-Flash yield the strongest overall symbolic performance for both entity and relation F1-score. GPT-4o produces slightly lower relation F1-score, suggesting occasional omissions in branching structure while GPT-4o-mini is the weakest model overall. Cosine similarity scores are uniformly high, showing that label semantics are well preserved. Interestingly, GPT-4o-mini attains one of the highest cosine similarities despite poor structural F1-score, highlighting that embedding similarity alone cannot identify missing or misrouted transitions.
High-level structural behaviour. The high-level Mermaid metrics in Table 2 reveal how these symbolic errors translate into perceived diagram quality. For the strongest models, structural accuracy (SA), flow accuracy (FA), semantic fidelity (SF), and completeness (C) are all close to 1.0, indicating that the judge model regards the predicted diagrams as near-perfect reconstructions of the gold workflows. Gemini-2.5-Flash achieves the highest scores across these metrics, followed closely by GPT-4.1-mini. This suggests that on this dataset, the smaller GPT-4.1-mini is able to preserve the global process semantics almost as well as the largest models.
GPT-4o maintains perfect syntax validity (SV = 1.000) but shows slightly lower SA and FA (0.954), mirroring its lower relation F1-score. This pattern is consistent with a model that produces wellformed Mermaid code but sometimes simplifies omits less salient branches. GPT-4o-mini again stands out: although its syntax validity is almost perfect (0.998), its SA, FA, SF, and C are substantially lower (around 0.83-0.86), confirming that it tends to generate syntactically correct but structurally incomplete diagrams.
Taken together, the two metric families highlight complementary aspects of model behaviour. High entity and relation F1-score scores show that the best models recover the vast majority of symbolic content, while high SA, FA, SF, and C indicate that this content is arranged into globally coherent, semantically faithful workflows. The small but consistent gap between entity and relation performance confirms that edge reconstruction is more challenging than node labeling, and the discrepancy between cosine similarity and structural metrics for GPT-4o-mini illustrates that text-level similarity can mask important structural errors.
Practically, these results suggest that large multimodal models such as GPT-4.1 and Gemini-2.5-Flash already support near-lossless flowchart-to-Mermaid translation on realistic diagrams, while smaller variants offer a controllable quality-latency trade-off. The complementary nature of symbolic and judge-based metrics is essential: symbolic metrics capture fine-grained correctness, whereas high-level structural metrics reveal whether a diagram remains interpretable as a coherent workflow.
We introduced a lightweight web application that converts flowchart images into structured Mermaid code and supports mixed-initiative refinement through visual editing, code manipulation, and natural-language commands. Using a carefully engineered system prompt together with state-of-theart VLMs, the system transforms static diagrams into editable, version-controllable representations. Future work includes expanding evaluation beyond the small FLOWVQA subset, extending coverage to additional diagram types such as UML diagrams, exploring fine-tuned models specialized for diagram parsing, and enhancing interaction features such as intelligent autocompletion, collaborative editing, and cross-diagram consistency checking.
Flowchart2Mermaid converts flowchart images into editable Mermaid code through structured prompting and careful post-processing to ensure syntactic validity. However, as with all AI-based systems, the underlying vision-language models may occasionally hallucinate or misinterpret diagram elements. While the generated output typically provides a strong starting point, it may not exactly match the original diagram’s layout or semantics. The system is therefore intended as an assistive tool that complements human expertise, requiring user review and refinement to ensure correctness and completeness.
https://flowchart-to-mermaid.vercel.app/
https://www.dropbox.com/scl/fi/ wzoidww81ccqvw2pmwxn8/flowchart2mermaid_demo_ pritam.mkv?rlkey=li9d3jliwvqf40kvjdm9r7tgk&st= 651lnjfa&dl=0.
https://github.com/dbetm/ handwritten-flowchart-with-cnn
https://www.daigram.app/?utm_source=eliteai . tools&ref=eliteai.tools
https://www.eraser.io/diagramgpt
https://www.lucidchart.com/pages/use-cases/ diagram-with-AI
https://www.yworks.com/products/yed-live
https://huggingface.co/sentence-transformers/ all-MiniLM-L12-v2
📸 Image Gallery