FlowEO: Generative Unsupervised Domain Adaptation for Earth Observation
📝 Original Info
- Title: FlowEO: Generative Unsupervised Domain Adaptation for Earth Observation
- ArXiv ID: 2512.05140
- Date: 2025-12-01
- Authors: Georges Le Bellier, Nicolas Audebert
📝 Abstract
The increasing availability of Earth observation data offers unprecedented opportunities for large-scale environmental monitoring and analysis. However, these datasets are inherently heterogeneous, stemming from diverse sensors, geographical regions, acquisition times, and atmospheric conditions. Distribution shifts between training and deployment domains severely limit the generalization of pretrained remote sensing models, making unsupervised domain adaptation (UDA) crucial for real-world applications. We introduce FlowEO, a novel framework that leverages generative models for image-space UDA in Earth observation. We leverage flow matching to learn a semantically preserving mapping that transports from the source to the target image distribution. This allows us to tackle challenging domain adaptation configurations for classification and semantic segmentation of Earth observation images. We conduct extensive experiments across four datasets covering adaptation scenarios such as SAR to optical translation and temporal and semantic shifts caused by natural disasters. Experimental results demonstrate that FlowEO outperforms existing image translation approaches for domain adaptation while achieving on-par or better perceptual image quality, highlighting the potential of flow-matching-based UDA for remote sensing.📄 Full Content
Emergency management of natural disasters requires rapid analysis of the ground-level situation to plan rescue operations and assess environmental consequences. However, the domain shift between post-disaster and ordinary satellite images degrades the performance of off-the-shelf deep models. The urgency of such events makes it impossible to annotate a dataset for supervised training in disaster-affected areas. Domain adaptation is therefore a promising solution to speed up image analysis for disaster management.
Similarly, robust remote sensing pipelines leverage the strengths of all available Earth observation sensors. For example, Synthetic Aperture Radar (SAR) provides all-weather day-and-night imaging capabilities, as its wavelength allows it to penetrate clouds and operate independently of illumination conditions. However, due to their speckle noise and sensitivity to terrain geometry, interpreting SAR images is harder for humans than optical images [56]. Therefore, crosssensor domain adaptation has been well-investigated in Earth observation. SAR-to-Optical translation (S2O) in particular can provide human-interpretable optical images in contexts where only SAR imagery is available [30,58,59], e.g. to fill in missing optical due to cloud cover. This provides higher frequency images by leveraging co-located multimodal SAR/optical acquisitions. In turn, this enables disaster monitoring and environmental surveillance in scenarios where acquiring cloud-free optical data is challenging.
Major efforts have been made in recent years to overcome distribution drift through domain adaptation [25,44,55]. Due to the low availability of labeled satellite image datasets, unsupervised domain adaptation methods have been preferred as they only require labels in the source domain. Unsupervised domain adaptation is mainly studied inside the feature space of a pretrained model [10,62]. Because of the lower dimensionality of the latent space, this favours classification tasks [16,31], although some approaches also have been proposed for dense tasks such as segmentation [8,15,64]. To overcome this limitation, domain adaptation can be applied in image-space [67]. It facilitates the transfer interpretation and improves explainability while disentangling transfer and downstream tasks. Such image translation approaches are orthogonal to future improvements in classifiers and can be used with any inference model without retraining. To this end, we employ flow matching models [1,33,43], a new family of models that have demonstrated high-quality generation across various modalities [13,60]. FlowEO. We propose FlowEO, a new model that leverages flow matching models for unsupervised domain adaptation in Earth Observation. We introduce a novel domain adaptation method in pixel-space, enabling visual interpretation, and test it extensively on four datasets covering classification and segmentation tasks, demonstrating its effectiveness for dense downstream tasks in challenging scenarios of post-disaster domain adaptation and sensor translation. In summary:
-
We introduce FlowEO, a new generative UDA method, downstream-task-agnostic that does not require modification or retraining of downstream predictive models.
-
We are the first to leverage latent flow matching for data-to-data translation, on multiple remote sensing modalities, including SAR, low-resolution, and highresolution optical data.
-
We introduce an application-driven evaluation protocol, going beyond standard image generation metrics to assess the impact of UDA on real-world Earth observation tasks: semantic segmentation and classification.
Consider two distinct domains, represented by two datasets D 0 and D 1 . Suppose that one contains annotations, i.e. D 1 = {X 1 , Y 1 }. This is the source domain, on which a predictive model S 1 has been trained, e.g. for segmentation, classification, regression, etc. Conversely, let D 0 = {X 0 , ∅} be the unlabeled target domain, on which we would like to infer new predictions. The absence of annotations on D 0 prevents us from training a predictive model on it. Instead, we intend to use the existing model S 1 for the new D 0 data. However, the underlying differences between the two domains will result in a drop in its performance if applied directly to the new domain. Its generalization capabilities do not allow direct transfer of segmentation scores. Domain adaptation aims to extend a model’s performance beyond its training domain by means of an adaptation procedure.
Domain adaptation techniques are split into two broad families. First, domain adaptation can be applied post-hoc on an existing predictive model. These approaches aim to align the features obtained from the predictive model, e.g. with optimal transport [10,16], or fine-tuning/adapting the weights of the model to the new domain [6,62]. However, every downstream model needs to be adapted, which can be costly and constrains usage of “off-the-shelf” models. Second, adaptation can take place directly in the data space, i.e. image space in our case. Instead of adapting the model to the target domain, the target data is altered to match the source domain. This approach, called image-to-image translation for domain adaptation [42], leverages conditional generative models derived from style transfer [23].
Image translation builds upon the seminal work of Pix2Pix [20], that trains an image-to-image model on paired datasets using a combination of supervised regression loss and an adversarial loss using a patch-wise GAN. It has been extended to the unpaired setting into CycleGAN [69], leveraging cycle consistency by training two GANs in symmetry. These models have been used for domain adaptation in multiple settings, including dehazing [47], tactile perception [22], and semantic segmentation [63]. More recent models include StegoGAN [61] that explicitly deals with features that are impossible to match between the two domains, and more recent generative model classes, e.g. diffusion models and Schrödinger bridges [11,49,68]. The Unpaired Neural Schrödinger Bridge [27], for example, has found success for domain adaptation of medical CT scans [53].
Image translation for Earth Observation Such approaches are also common in Earth Observation. For example, Ste-goGAN [61] performs style transfer from satellite images to maps and vice-versa. Natural disaster management is also the subject of domain adaptation research, via flood simulation using adversarial networks conditioned on physical measurements [38]. SAR to optical (S2O) image translation is especially popular because radar acquisitions can be carried out despite cloud cover, optical sensors suffer from cloud occultation. S2O imagery makes it possible to fill missing optical acquisitions based on SAR images from close dates. Research has leveraged various classes of generative models for S2O, e.g. [45] uses a conditional GAN, [65] uses Cycle-GAN, [28] uses diffusion bridges, and so on. FlowEO pushes forward this state-of-the-art by integrating flow matching models that deliver a better semantic-preserving transfer and higher quality generation.
Flow Matching Flow matching models (FMMs) have been introduced in the last years [1,33,43] and now represent the state of the art in generative models for various applications [13,39,60]. However, flow matching models also allow data-to-data transport between arbitrary distributions [2,34], and remain less well-studied. Contrary to diffusion bridges [1,68] and Schrödinger Bridges [5,11] that rely on stochastic differential equations to transport data, the flow is deterministic. Deterministic sampling processes [51,52], have been wildly used with diffusion models for image and video editing and composition as they better preserve semantic content than their stochastic counterparts [12,17,41,57]. This property is promising in domain adaptation contexts, where preserving semantics is critical. Moreover, unlike previously described image translation methods, such as Pix2Pix [20], CycleGAN [69], or UNSB [27], FMMs do not rely on adversarial learning to align the endpoint distributions, making them easier to train and less sensitive to hallucinations.
Our goal is to apply an existing classifier or segmenter S 1 trained on source domain D 1 on a new target domain D 0 . We assume that we have access to samples from D 0 , although we do not know their labels. To solve this unsupervised domain adaptation problem, we introduce FlowEO to perform domain adaptation in pixel space (see Fig. 1).
We train a flow matching model to build a bridge between the image distribution p 0 of X 0 (target) and p 1 of X 1 (source) (see Fig. 2). Let φ be the learned transfer, i.e. our mapping from D 0 to D 1 . To apply our existing predictive model on data from the target domain, we first map it to the source domain, i.e. our model predicts S 1 (x 1 ) (Fig. 3, step 2). This prediction should be as close as possible to the (unknown) ground truth y 0 , i.e. we want φ to preserve the semantic information relevant to the task during transfer. By transferring the images rather than adapting the predictive model, FlowEO only depends on the datasets D 0 and D 1 , and neither on the task nor the model S 1 (Fig. 3,stage 2). This makes it applicable to a broad panel of tasks, and can benefit from better predictive models without retraining.
Mapping domains Flow matching models have been used extensively as generative models, mapping a normal distribution to the images’ latent distribution, similar to diffusion models [13,26,32,35]. However, flow matching can also bridge between arbitrary distributions [1,33]. Following this framework, we leverage a time-dependent flow φ : [0, 1] × R d guided by a velocity field u t describing the trajectories of samples z moving from p 0 to p 1 :
The flow φ t results in a transport between p 0 and p 1 when solving the Ordinary Differential Equation (ODE) defined by Eq. ( 1) from t = 0 to t = 1. Conversely, solving the same ODE with decreasing times t = 1 to t = 0 allows, by construction, to transport p 1 to p 0 . While the true velocity field u t is intractable, it is approximated with a neural network v θ (t, z t ) trained with a simple regression and simulation-free objective (Fig. 2):
where pairs (z 0 , z 1 ) are sampled from the joint distribution p(z 0 , z 1 ) also named coupling, that will be detailed later. From these endpoints, we can build z t using an interpolant [1]. We use linear interpolants, i.e. z t = (1-t)z 0 +tz 1 for which the conditional velocity field u t (z t | z 0 , z 1 ) equals z 1 -z 0 . At inference time (Fig. 3, Stage 1), we deploy ODE solvers to solve Eq. ( 1) by replacing the true velocity u t with its neural network approximation v θ (t, •). This way, we generate the transferred observation ẑ1 by integrating the ODE starting from z 0 using the mapping φ t following:
The properties of the transport learnt by the flow are greatly influenced by the choice of the image pairs (x 0 , x 1 ) used to compute the loss function Eq. ( 2). The most common setup relies on an independent coupling, i.e. (z 0 , z 1 ) is sampled uniformly across all possible pairings. Recent works [5,34,54] have introduced couplings inspired by optimal transport. However, their optimal transport coupling is defined with the L2-distance between images. In image space, there is no obvious reason that images with a small pixel-wise Euclidean distance would be semantically similar -an intuition we show to be true in Sec. 5.2. This contradicts our goal to obtain a transfer that preserves semantics. Because we leverage flow matching for image translation, i.e. conditional generation, we can turn towards a 1. Datasets used for domain adaptation. We evaluate post-flood to pre-flood adaptation and SAR-to-optical translation scenarios.
data-dependent coupling p(x 0 , x 1 ) = p(x 1 |x 0 )p(x 0 ) [2,50].
We therefore want to build image pairs of a semantically relevant x 1 in the p 1 distribution, given an image x 0 ∼ p 0 instead of defining a new ad hoc joint distribution. Finally, to sample latents from p(z 0 , z 1 ), we first sample from the image coupling p(x 0 , x 1 ) and then encode the images.
Post-flood Pre-flood We aim at building pairs of images (x 0 , x 1 ) that are semantically close. Because remote sensing data is geospatial, the coordinate metadata are available for each image. Thus, we consider spatially aligned datasets, which is possible to construct in most real-world applications, and leave geographical domain adaptation for future work. While coregistration provides pairs of images that have a common location, it does not ensure that the semantic information is shared between the two images. Thus, we distinguish between:
• Strong semantic alignment: the two images x 0 and x 1 share the same semantics, i.e. y 0 = y 1 . This is the ideal scenario, though impractical, as it needs synchronized acquisitions, or at least images of the same areas in a short timeframe, such that no significant semantic changes have occurred. This can be typically used to address sensor shift, e.g., SAR to optical translation.
• Weak semantic alignment: the two images x 0 and x 1 partially share their semantics, i.e. the ground truths are similar y 0 ≈ y 1 . For example, these may be acquisitions of the same geographical area but captured on different dates. As shown in Fig. 4,changes in semantics may be due to the construction of buildings between the two acquisitions, harvested crops, cloud coverage, natural disasters such as floods or fires, deforestation, moving objects, or any other event that can shift semantics. Note that x 1 in the dataset is not an accurate representation of the transferred x 0 because of the changes. Yet, in the absence of labels, this pair (x 0 , x 1 ) is the best available coupling. We then assume that the averaging of velocities in Eq. ( 2) is robust to moderate semantic changes and preserves the main transfer components between p 0 and p 1 . This can be used to address temporal shift, e.g. seasonal variations, and before/after an extreme event.
We evaluate FlowEO for domain adaptation on three segmentation and one classification datasets, listed in Tab. 1: SpaceNet 6 [48], Sen1floods11 [4], BigEarthNet2 (reBEN) [9] and SpaceNet 8 [19], split into Germany and Louisiana. These datasets are paired, i.e. have multiple acquisitions for the same area, allowing us to train image translation models with data dependent couplings. SpaceNet 8 contains before/after images of flood event, semantic differences exist in the images, making it “weakly aligned”. The others pair images from close dates, resulting in a “strong” alignment. We build 3-channels 256 × 256 images using RGB for color images, bands [4,3,2] for Sentinel-2, VV/HH/VH polarizations for SAR images from SpaceNet 6 and reBEN, and VV/VH/VH for Sen1Floods11. See Appendix B for details.
We use the DeepLabv3+ architecture [7] for semantic segmentation with a ResNet-34 backbone, ImageNet initialization, a batch size 512, and a learning rate of 0.001 with one-cycle cosine schedule. For classification, we follow the reBEN implementation [9] and train a ResNet-50 with ImageNet initialization for 100 000 training steps with a batch size of 512 and a linear-warmup-cosineannealing learning rate of 0.001. These models are trained once and used to evaluate all image translation methods.
Baselines We compare our FlowEO model against several commonly used image translation baselines: Pix2Pix [20 CycleGAN [69], StegoGAN [61], Diffusion Bridge [5], and Unpaired Neural Schrödinger Bridges (UNSB) [27]. For a fair comparison, we use data-dependent coupling for all methods, even those that could be trained using independent couplings (CycleGAN, StegoGAN, and UNSB), and train all models for 200 000 steps. We follow official implementations for hyperparameters (cf. Appendix C). Except CycleGAN, baselines are non-symmetric, thus we train two separate models from domain X 0 to X 1 and then from X 1 to X 0 when needed.
Hyperparameters We train our flow matching in the pretrained space of the VAE from Stable Diffusion 3 [13]. More precisely, we use a distilled model that is smaller and more compute efficient [3]. The flow is therefore performed on the latent codes of dimensions 16 × 32 × 32. Because flow matching is symmetrical, the same model can be used to transfer from X 0 to X 1 and vice versa, while baselines require two models. We use the classical U-Net backbone to train the flow [52] with 120 million parameters. The flow is trained for 200 000 steps using gradient clipping and exponential moving average. We use a learning rate of 1 × 10 -4 with 1000 steps of linear warmup and a batch size of 256.
At inference time, we integrate the flow from Eq. ( 1) with 50 steps of the Euler ODE sampler. We use the sigmoid time-scheduler introduced in [26] to focus on the times that are close to the image spaces. See Appendix A.3 for more insights and ablation studies about sampler design and Appendix A.4 for inference time and memory footprints.
Prediction metrics Because Earth observation tasks are often dense predictions, we focus on domain adaptation for semantic segmentation. For all methods, we first transfer the images from the test set of each dataset using the image translation model and then apply the same pretrained segmenter to obtain the semantic masks. We then compute mean Intersection over Union (mIoU) and mean Accuracy (mAcc) between the prediction on the transferred image x0 = φ(x 1 ) and the ground truth mask y 0 , that is only available for evaluation purposes. For reBEN, we use the standard multi-label classification metrics: Average Precision (AP) and F 1 -score (F 1 ), both micro and macro, i.e.
Image quality While it is not our main goal, we also evaluate the perceptual quality of the generated images as vi- sual artifacts can hinder downstream performances and interpretability. We compute both the Frechet Inception Distance (FID) [18] and LPIPS [66] similarity between the transferred images x0 and source images x 1 . Although commonly used, note that these are initially designed for natural images and not remote sensing imagery [21]. In addition, the size of our test sets is under the recommended size to compute FID. Despite the noise this might introduce, these metrics remain useful proxies to assess broad tendencies regarding the perceptual qualities of transferred images.
We present domain adaptation and image quality metrics obtained by the compared image translation methods in Tab. 2 (weakly aligned) and Tab. 3 (strongly aligned). In addition to the results obtained by state-of-the-art models and FlowEO, we include two comparison points:
• No adaptation: classification/segmentation metrics of the pretrained model applied directly on the nontransferred target data, i.e. the performance of S 1 on x 0 . This represents a lower bound of the expected performance. Image quality metrics (FID and LPIPS) are computed directly between images from D 0 and D 1 and show an estimate of how far away the two image distributions are.
• Upper bound: classification/segmentation metrics of the pretrained model on its source domain, i.e. the performance of S 1 on x 1 . This represents the performance of an ideal semantic-preserving transfer from p 0 to p 1 , for which S 1 is as accurate on x 0 transferred as on x 1 .
Semantic preservation FlowEO consistently demonstrates superior semantic preservation compared to existing image translation models. It ranks first in the weakly aligned setting (Tab. 2), significantly outperforming both the second-best state-of-the-art transfer method (+4 mIoU points compared to CycleGAN) and the no-transfer baseline by a large margin (44.65 mIoU vs. 40.05 mIoU) on SpaceNet 8. Domain adaptation for pre/post-flood imagery is a particularly challenging task considering the significant changes that impact the images, as shown in Fig. 5. Note that only FlowEO and CycleGAN successfully increase segmentation performance over the no-adaptation baseline. FlowEO consistently achieves the highest mIoU and mean accuracy across both regions (Germany and Louisiana), demonstrating its effectiveness in handling real-world geographic variations, even when trained on smaller datasets (<10 000 samples).
For strongly aligned datasets (Tab. 3), FlowEO achieves the best segmentation metrics on both Sen1Floods11 and SpaceNet 6 datasets with respectively +3.42 and +8.59 in mIoU compared to the second best transfer models. Somewhat surprisingly, Pix2Pix constitutes a strong baseline for paired image translation and achieves the second-best performance in this setting despite being the oldest model evaluated. On the ReBEN multi-label classification dataset, the flow model and Pix2Pix perform competitively, trading first and second places depending on the metric considered. Despite their training with data-dependent coupling, adversarialbased methods struggle to offer semantic-preserving transport. This suggests that adversarial objectives may be unaligned with semantic preservation by hallucinating new instances e.g. clouds, that can reduce segmentation performances (as shown for Sen1Floods11 in Fig. 5
Transferred image quality In addition to better preserving the semantics, FlowEO generates consistent high-quality images. It ranks first in LPIPS and first or second in FID on all datasets, both in weakly aligned RGB→RGB transfer on SpaceNet 8 (Tab. 2) and strongly aligned SAR-to-optical translation (SpaceNet 6, Sen1Floods11 and reBEN in Tab. 3). Unlike previous methods, FlowEO does not rely on adversarial loss functions explicitly designed to enhance perceptual quality. Despite that, generated images remain of high quality and do not show hallucinations commonly attributed to adversarial training. This trend holds for both weakly and strongly aligned datasets. In particular, we observe that FlowEO learns complex texture transfer on the post-to-predisaster scenario, correctly mapping turbulent and murky flood water to the usual river state (Fig. 5, third row).
We report in Tab. 4 ablation results on SpaceNet 6 and SpaceNet 8 domain adaptation and image generation using the three couplings: independent, minibatch-OT [54], and data-dependent. Minibatch-OT coupling outperforms the independent coupling on the two datasets in segmentation accuracy after domain adaptation and image quality. Yet, data-dependent coupling outperforms them by a large margin for domain adaptation (+17% mIoU on SpaceNet 6, +7% mIoU on SpaceNet 8) and image quality (30% decrease in FID on both datasets). This is expected since OT pairs images based on Euclidean distance in pixel space, which is irrelevant to semantics e.g. in SpaceNet 6 where it compares SAR and RGB modalities. Yet, OT is also far behind the data-dependent coupling in the favourable case of RGB to RGB transport on SpaceNet 8. This confirms the importance of data-dependent coupling -thus dataset alignment -to preserve semantic information during flow-based transfer, and motivates our focus on aligned datasets, even weakly.
We introduce FlowEO, a flow matching-based framework for unsupervised domain adaptation in Earth Observation. By learning a semantically consistent mapping between source and target distributions, FlowEO consistently outperforms existing image translation methods for domain adaptation in five segmentation and classification tasks across multiple challenging scenarios ranging from post-disaster monitoring to SAR-to-Optical translation, while achieving on-par or better image generation quality. FlowEO opens the door to generic unsupervised domain adaptation with possible extensions to semantic-based couplings based on image similarity or image metadata embeddings to fare with unpaired image translation scenarios in Earth observation.
A.1. Couplings The choice of the coupling has been of prime importance to improve generation capabilities for flow matching models [5,34,54]. Figure 6 shows the pairing matrices M obtained with each coupling i.e. M ij = 1 iff latents x i 0 and x j 1 are paired. The training batches are built by stacking strongly or weakly aligned x 0 and x 1 images in order. Because the data-dependent coupling matches x i 0 with x i 1 , its pairing matrix is diagonal. We observe that the optimal transport-based coupling (left) is poorly aligned with the data-dependent coupling (center), suggesting that semantic information matching cannot be solely recovered through optimal transport.
In addition, we provide visual ablation results in Fig. 7, which illustrate the necessity to use data-dependent couplings to train FlowEO.
We use a distilled version of the VAE from StableDiffusion 3 [13] to speed up training and inference. The encoder is trained to reconstruct the latents produced by the original encoder to preserve the latent space structure of the full model. As shown in the main paper, our experiments show that the reconstructions D(E(x)) of Sentinel-2 images are of poor quality because the range and distribution of multispectral images deviates from the pretraining dataset used for Stable Diffusion. For the reBEN and Sen1Floods11 datasets that use Sentinel-2 as source data, we finetune the decoder of the distilled VAE on each dataset for 5000 iterations with a learning rate of 10 -4 , 250 warmup steps, and cosine decay learning rate scheduler. The decoder remains frozen when training the flow. The remaining datasets use the original pretrained decoder. Generation We report in Tab. 5 metrics for flow models trained with and without a fine-tuned VAE decoder. We observe that fine-tuning the VAE decoder prior to learning the flow matching has a positive impact when the final domain differs from usual RGB imagery. Indeed, fine-tuning the decoder is beneficial for Sen11Floods11 and ReBEN, for which the images are transferred in the Sentinel-2 color bands. Because Sentinel-2 imagery uses the [0, 10 000] range instead of the usual [0, 255], the pretrained decoder is less effective, which reflects in image quality. Yet, on SpaceNet 6 and 8, which use both standard RGB images, there is no advantage of fine-tuning the decoder. It is even detrimental, as we hypothesize that the decoder overfits to the small training set, compared to the original dataset used for StableDiffusion.
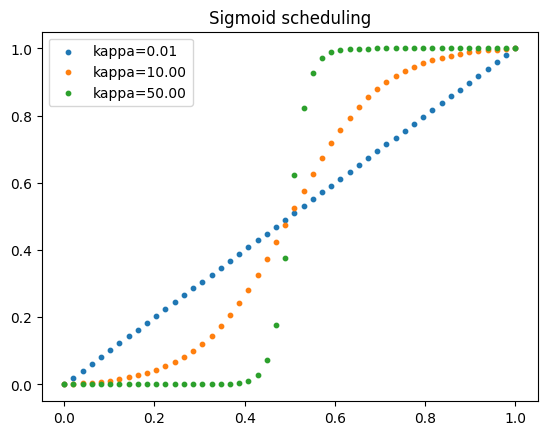
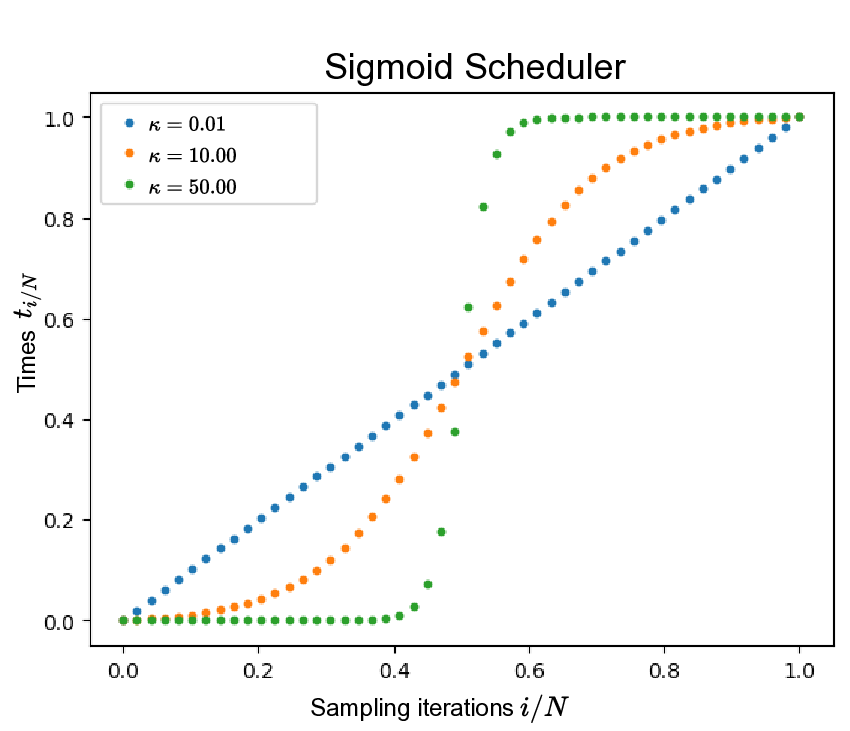
The choice of time discretization and inference-time sampling strategy plays a crucial role in improving the performance of diffusion models [24,36,37]. Recently, [26] introduced a sigmoid time-scheduler tailored for flow matching models (see Eq. ( 4)). This scheduler is parametrized by κ which controls the distribution of sampling steps across time. Higher values of κ concentrate computational effort near the endpoints (t ≈ 0 and t ≈ 1), whereas κ → 0 corresponds to the linear time schedule (see Figure 8).
Despite originally designed for generative modeling with flow matching models, i.e. mapping a Gaussian prior distribution to the data distribution, this time scheduling is well-motivated in our setting where increasing the number of sampling steps near the data distributions p 0 and p 1 is beneficial. Tab. 6 presents a comparison between sigmoid and linear time discretization, demonstrating consistent improvements in segmentation metrics across all datasets and for all numbers of inference steps. Image quality metrics exhibit only marginal improvements and, in some cases-such as on the Sen1Floods11 dataset-even show slight deterioration. Nevertheless, the performance gains in segmentation metrics from using a sigmoid rather than a linear schedule diminish as the number of inference steps increases. Also observe that more sampling steps might not be beneficial for domain adaptation. On the two datasets used for validation, 25 sampling steps tends to perform on-par or better than 50 and 100 steps. We attribute this to slightly better preservations of semantics with a low number of steps, which reduce small but accumulating errors in the Euler integration. In practice, we set κ = 10 and use 50 sampling steps for all experiments.
We report memory and times in Tab. 7. We agree that inference time is an issue, as flow matching is slower than GANs. This is why we use a lighter distilled version of SD3’s VAE (0.24s vs. 2.11s for encoding-decoding). Despite relying on ODE integration, FlowEO transfers a batch of 256 images in 7.79s on a single A100 with 50 NFE (≈30 ms/image).
For all datasets, we define three distinct splits: train, validation, and test. The training set is used to train both domain adaptation methods and predictive models. To reflect realworld scenarios -where retraining a generative model on new data batches is impractical -we restrict the training of image translation models to the training set. The validation set is used for hyperparameter tuning and model selection based on performance metrics, while the final reported metrics are computed on the test set.
Pix2Pix We train two Pix2Pix models, one translating images from p 0 to p 1 and vice versa. We use the reference PyTorch implementation available1 and train the models with the data-dependent coupling. We train the models with a batch size of 1 for 200 000 training steps with a learning rate of 2 × 10 -4 and learning rate linear decay. Following the reference implementation, we use the LSGAN [40] adversarial loss. We deviate from the default hyperparameters for λ L1 , which we decrease from 100 to 10 to fix blurry image generation issues on ours datasets. The generator is a 9blocks ResNet and we use the PatchGAN discriminator [20] with instance normalization.
CycleGAN The implementation of CycleGAN follows the same hyperparameters set as the Pix2Pix mentioned above. We train the models with a batch size of 1 for 200 000 training steps with a learning rate of 2 × 10 -4 and learning rate linear decay. We keep λ L1 = 100 since it does not negatively impact the training or the generated images’ quality. We used the same network architectures as for Pix2Pix.
StegoGAN While the StegoGAN models use two generators, translating respectively from domain X 0 to X 1 and vice versa, the training process is asymmetrical. Thus, we trained two different models for each dataset, using the of-ficial implementation 2 . We use LSGAN adversarial loss, instance normalization, and train the model for 200 000 iterations with a learning rate of 2 × 10 -4 . We select the set of loss weightings used for the GoogleMismatch dataset in the original paper: λ A = 10, λ B = 10,λ A = 10, λ id = 0.5, λ cycle = 0.5 and λ reg = 0.3 for the mask regularization loss. Note that this last value is similar for all remote sensing datasets used in StegoGAN: λ cycle = 0.5 for GoogleMismatch and λ cycle = 0.3 for PlanIGN. The generator is a 9blocks-Resnet and we use the PatchGAN discriminator [20] with instance normalization.
UNSB Schrödinger bridges map two arbitrary distributions with forward and backward stochastic processes. Nevertheless, UNSB leverages an adversarial loss on p 1 making the training asymmetrical. Thus we train two different models, translating respectively from domain X 0 to X 1 and vice versa. We use the official implementation 3 and train the models for 200 000 iterations with a learning rate of 2 × 10 -4 . We use the proposed set of hyperparameters: λ GAN = 1, λ NCE = 1, λ SB = 1. We use the same architectures as the other methods, namely 9-blocks-Resnet and PatchGAN discriminator with instance normalization. We use 5 sampling steps at inference, following original paper guidelines.
Diffusion Bridges Diffusion bridges establish mappings between arbitrary distributions via forward and backward stochastic processes. We adopt the formulation of [5] and train the models for 200 000 iterations using an x 1 -prediction objective, with a batch size of 32 and a learning rate of 2 × 10 -4 . The UNet backbone follows the same design as FlowEO, but is adapted to operate directly on image inputs rather than latent representations. Inference is performed with 50 sampling steps, consistent with FlowEO.
CycleGAN is a data-to-data translation framework originally designed to handle unaligned datasets through its cyclical loss. However, in the context of pre-and post-disaster datasets, we observe that CycleGAN benefits from the availability of co-registered pairs (data-dependent coupling improves segmentation metrics) (Table 8). For SAR-to-optical translation, the use of unpaired datasets can offer certain advantages, though the performance gains are marginal and do not alter its relative ranking compared to our method (Table 9).
We include in Table 10
We provide here qualitative domain adaptation results for reBEN, with transferred images for baselines and FlowEO and predicted labels shown in Figure 9. As for the segmentation tasks, this underlines both the visual quality of the generated images by FlowEO and the accuracy of the predictions by the pre-trained classification model on the adapted images. In addition to the generated optical images, we show the top-3 predicted classes, i.e. the 3 classes with the highest probabilities predicted by the classification model C * 1 .
We provide in Figure 10 additional image generation results for a more exhaustive assessment of our image translation approach. We can observe that FlowEO tends to better capture the color range of the reference images, avoid hallucinations, and better reconstruct the scene geometry. In particular, note that FlowEO is robust to changes between the source and target images, e.g. clouds and boats that have moved. Interestingly, this shows the potential of flow matching for inverse problems in Earth observation, such as cloud removal.
. Quantitative results on domain adaptation for strongly aligned datasets. We report both segmentation (mIoU, mAcc) or classification (AP/F1) and image quality metrics (FID, LPIPS). FlowEO preserves achieves the best UDA segmentation performances, and on-par classification performances with Pix2Pix.
bands[4,3,2] for optical data and VV/HH/VH polarization for SAR data. We resize the original 120 × 120 patches with bilinear interpolation to match the 256 × 256 used for the other datasets.
bands[4,3,2]
bands
https : / / github . com / junyanz / pytorch -CycleGANand-pix2pix
📸 Image Gallery