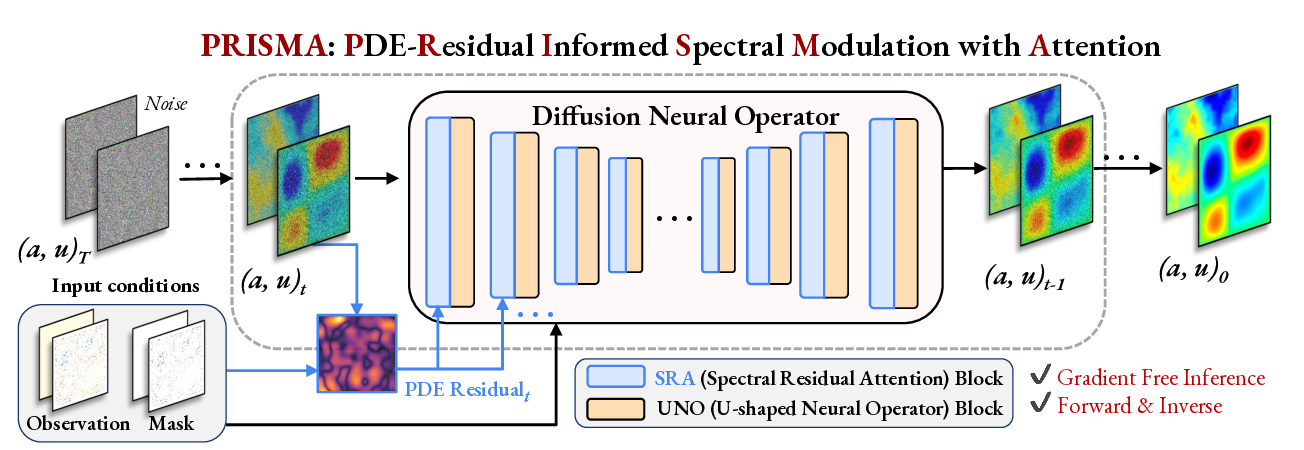
Beyond Loss Guidance: Using PDE Residuals as Spectral Attention in Diffusion Neural Operators
📝 Original Info
- Title: Beyond Loss Guidance: Using PDE Residuals as Spectral Attention in Diffusion Neural Operators
- ArXiv ID: 2512.01370
- Date: 2025-12-01
- Authors: Medha Sawhney, Abhilash Neog, Mridul Khurana, Anuj Karpatne
📝 Abstract
Diffusion-based solvers for partial differential equations (PDEs) are often bottlenecked by slow gradient-based test-time optimization routines that use PDE residuals for loss guidance. They additionally suffer from optimization instabilities and are unable to dynamically adapt their inference scheme in the presence of noisy PDE residuals. To address these limitations, we introduce PRISMA (PDE Residual Informed Spectral Modulation with Attention), a conditional diffusion neural operator that embeds PDE residuals directly into the model's architecture via attention mechanisms in the spectral domain, enabling gradient-descent free inference. In contrast to previous methods that use PDE loss solely as external optimization targets, PRISMA integrates PDE residuals as integral architectural features, making it inherently fast, robust, accurate, and free from sensitive hyperparameter tuning. We show that PRISMA has competitive accuracy, at substantially lower inference costs, compared to previous methods across five benchmark PDEs especially with noisy observations, while using 10x to 100x fewer denoising steps, leading to 15x to 250x faster inference.📄 Full Content
The rise of generative models has inspired another class of methods for solving PDEs by modeling the joint distribution of a and u using diffusion-based backbones (Huang et al., 2024;Yao et al., 2025;Lim et al., 2023;Shu et al., 2023;Bastek et al., 2024;Jacobsen et al., 2025). These methods offer two key advantages over operator learning methods: (i) they generate full posterior distributions of a and/or u, enabling principled uncertainty quantification crucial for ill-posed inverse problems, and (ii) they naturally accommodate sparse observations during inference using likelihood-based and PDE residual-based loss guidance, termed diffusion posterior sampling or test-time optimization. Despite these advances, current diffusion-based PDE solvers suffer from three major limitations. First, they are inherently slow during inference due to the large number of denoising steps required by their unconditional training paradigm, which is further burdened by expensive test-time optimization when PDE-residual loss is optimized. Second, the minimization of PDE residuals as external loss introduces optimization instabilities due to the sensitive nature of PDE loss gradients at different stages of inference, requiring careful hyperparameter tuning (Zhang & Zou, 2025;Cheng et al., 2024;Utkarsh et al., 2025). Third, when observations are corrupted by unknown noise structures (e.g., sensor failures or environmental interference), these methods cannot dynamically adapt their guided inference scheme to discount noisy PDE residuals, resulting in degraded performance. to iteratively refine estimates of a and u starting from noise (a, u) T to a clean solution (a, u) 0 . At each denoising step, PDE residuals are architecturally injected via a novel SRA block at every layer of the UNO, enabling fast, gradient-descent free inference for both forward and inverse problems.
At the heart of these limitations lies a fundamental bottleneck in existing generative frameworks for solving PDEs: “treating PDE constraints as external optimization targets rather than as integral architectural features.” Since previous methods employ PDE residuals solely as additional loss terms during training or inference, they face a challenging multi-objective optimization problem that is hard to stabilize and requires careful hyper-parameter tuning (Wang et al., 2021;Farea et al., 2025). Moreover, by reducing spatially-resolved PDE residual fields to scalar loss terms, existing methods discard the rich point-wise information that could otherwise provide local guidance for fine-grained steering. In contrast to using PDE residuals as loss guidance, we ask: “is it possible to incorporate the knowledge of PDE residuals directly in the architecture of diffusion-based models, avoiding slow and sensitive loss gradients during inference altogether?”
We introduce PRISMA (PDE Residual Informed Spectral Modulation with Attention), a conditional diffusion neural operator that embeds PDE residuals into the architecture via attention mechanisms instead of loss guidance, enabling gradient-descent free inference. A key innovation in PRISMA is a novel Spectral Residual Attention (SRA) block (Figure 1) that is injected at every layer of a U-shaped denoiser backbone to locally attend to the model’s generated outputs based on guidance from the PDE residual field, during both training and inference. By integrating PDE residuals as architectural features directly in the spectral domain, SRA is able to modulate and dynamically adapt to the local contributions of varying frequency modes in the PDE residual space, even in the presence of noise. Another innovation in PRISMA is the use of input masks in the architecture to regulate the generation of a and u under varying conditions of input observations, rather than training an unconditional model guided only at inference. This conditional design enables PRISMA to serve as a unified framework for solving PDEs: a single versatile model capable of addressing both forward and inverse problems under full, sparse, or noisy observations, without task-specific inference.
Our work makes four key contributions.
(1) We introduce a novel strategy for incorporating physical knowledge in diffusion models as architectural guidance, where the PDE residual is embedded directly as an internal feature in the model instead of a test-time guidance loss.
(2) A powerful outcome of this design is gradient-descent free inference, which fundamentally removes the need for costly and sensitive optimization of likelihood and PDE loss terms during inference, forming the basis of our method’s speed and robustness.
(3) We show 15x to 250x faster inference (time) compared to baselines across a diverse set of benchmark PDEs with varying problem configurations (forward and inverse), while achieving superior accuracy especially in the presence of noisy observations. (4) Our work also represents the first conditional design of a generative model trained to unify forward and inverse problems under varying configurations of input observations.
Neural PDE solvers: Deep learning methods such as Physics-Informed Neural Networks (PINNs) (Raissi et al., 2019b) offer a powerful alternative to classical methods for solving PDEs by mini-Table 1: Comparing PRISMA with previous methods for solving PDEs in terms of their strategy for integrating PDE residuals, their ability to solve forward and inverse problems using a single unified model, and their adaptability to the presence of noise in PDE residuals. PRISMA is unique from other works in terms of the use of PDE residuals in the spectral domain, with point-wise architectural guidance that is adaptive to noise, resulting in gradient-descent free inference. We also compare the forward error and inference time per sample for the Darcy equation.
mizing PDE residual loss during training. However, PINNs are prone to optimization and scaling challenges (Zhongkai et al., 2024;Liu et al., 2024a), motivating operator-learning methods such as FNO and DeepONet, which learn resolution-invariant mappings between functions of input parameters and solution fields for fast inference (Li et al., 2020;Rahman et al., 2022;Kovachki et al., 2023;Lu et al., 2019). To further enhance physics guidance in FNO architecture, PINO (Li et al., 2024) incorporates physics-based loss during training and inference optimization. However, similar to PINNs, PINO suffers from the same optimization issues due to the PDE loss-based training.
Another limitation with PINNs and operator learning methods is that they produce deterministic estimates for either the forward or inverse problem and typically assume clean, dense data, offering no native uncertainty.
Generative models for PDEs in Function Spaces: Diffusion models enable sampling from distributions over fields, providing uncertainty quantification and flexible conditioning. For example, DiffusionPDE Huang et al. (2024) learns the joint probability distribution of (a, u) using a diffusion model during training, and employs PDE-residual guidance as a loss term during inference to produce physically consistent solutions. By minimizing PDE residuals during inference, Dif-fusionPDE can work with arbitrary forms of sparsity in a and/or u that has not been seen during training. However, since DiffusionPDE operates directly in the native spatial domain, it remains tied to a fixed spatial resolution of a and u. Newer methods expand the design space by incorporating score-based or diffusion backbones for physics (Shu et al., 2023;Bastek et al., 2024;Jacobsen et al., 2025;Li et al., 2025). Because PDE states are functions, not images, several works lift generative modeling to function spaces for resolution independence: Denoising Diffusion Operators (DDOs) perturb Gaussian random fields and provide discretization robustness (Lim et al., 2023;Yao et al., 2025); and infinite-dimensional diffusion frameworks formalize well-posedness and dimension-free properties (Pidstrigach et al., 2023) Limitations of Diffusion-based PDE solvers: Existing diffusion-based methods mostly learn an unconditional distribution of (a, u) during training, and apply physics as external, spatial loss aggregating residuals rather than using their full point-wise structure. (Zhang & Zou, 2025;Cheng et al., 2024;Utkarsh et al., 2025). As a result, unconditional diffusion models with DPS-style guidance require multiple denoising steps and are sensitive to guidance hyper-parameter tuning (Chung et al., 2022;Huang et al., 2024). Training-time alternatives reduce this burden, e.g., conditioning on measurements (Shysheya et al., 2024;Zhang & Zou, 2025), yet still implement physics as an external objective. Moreover, optimizing PDE residuals during sampling introduces known instabilities and tuning overhead (Zhang & Zou, 2025;Cheng et al., 2024;Utkarsh et al., 2025).
Loss guidance vs. Architecture guidance: Table 1 summarizes how PRISMA is different from the baselines, specifically in the way it uses PDE residual as an architectural feature. Our work is related to the growing literature on enforcing constraints via architectural integration to provide stronger, more stable physics than soft penalties (Trask et al., 2022;Liu et al., 2024b). While shallow variants concatenate physics features to inputs (Shu et al., 2023;Takamoto et al., 2023), deeply integrating the PDE residual as a learnable architectural feature, especially in spectral domains where neural operators capture global behavior, remains largely unexplored, particularly for diffusion models.
3 PRISMA: PROPOSED UNIFIED FRAMEWORK FOR SOLVING PDES
We develop PRISMA as an all-purpose generative framework to model the joint distribution of PDE parameters and solutions conditioned on varying configurations of input observations. PRISMA is designed to be highly flexible for conditional generation of outputs in both forward and inverse problems, with complete, partial, or even noisy observations. In the following, we first describe the unified problem statement of PRISMA and provide a background on diffusion neural operators that we use as a backbone in our framework, before introducing the PRISMA model architecture.
Given a spatial domain Ω ⊂ R d , we are interested in solving parametric PDEs of the form
subject to some initial and boundary conditions where a ∈ A represents the parameter field of the PDE (e.g., material coefficients or source terms), u ∈ U denotes the solution field, and N is a non-linear differential operator. There are two main classes of problems when solving PDEs: (i) the forward problem, where we want to generate u given observations of parameters, a obs , and the inverse problem, where we want to generate a given observations of u obs . Optionally, we may have sparsity or noise in a obs , u obs , or both, arising from incomplete or inaccurate observations.
We consider a unified framework for solving both forward and inverse problems by training a single model to learn the joint probability of (a, u) conditioned on any partial set of observations, (a obs , u obs ). To encode varying configurations of input observations in the conditioning of the joint model, we introduce binary masks (M a , M u ) that serve two uses: (i) they indicate the sparsity patterns in a obs and u obs , and (ii) they specify whether we are solving the forward or inverse problem. A value of 1 in these masks indicates that an observation is present, while 0 indicates no observation. Table 2 summarizes the different configurations of input conditions that result in different problem settings, unifying forward and inverse problems as well as full and sparse observations. 2023). The forward process in DDO perturbs a clean function x 0 with progressively larger noise, yielding a noisy function x σ = x 0 + σϵ at noise level σ. To preserve the functional integrity of the data, the noise ϵ is sampled from a Gaussian Random Field (GRF), ϵ ∼ N (0, I).
The corresponding reverse diffusion process is learned by a denoiser network, D θ , parameterized as a neural operator to predict x 0 from x σ . We specifically instantiate D θ as a U-shaped Neural Operator (UNO) (Rahman et al., 2022) comprising of a multi-scale hierarchy of L layers, where the transformation of features from layer l to layer l + 1 is defined as:
where the global spectral path applies learnable weights W l in Fourier space using the Fast Fourier Transform (F) and its inverse (F -1 ), while the local spatial path is a local residual block ψ l .
We consider a conditional variant of UNO by augmenting the inputs to the denoiser network D θ with conditioning information y = {x obs = (a obs , u obs ), M = (M a , M u )}. We train D θ using the Elucidated Diffusion Model (EDM) (Karras et al., 2022) objective, defined as:
(3)
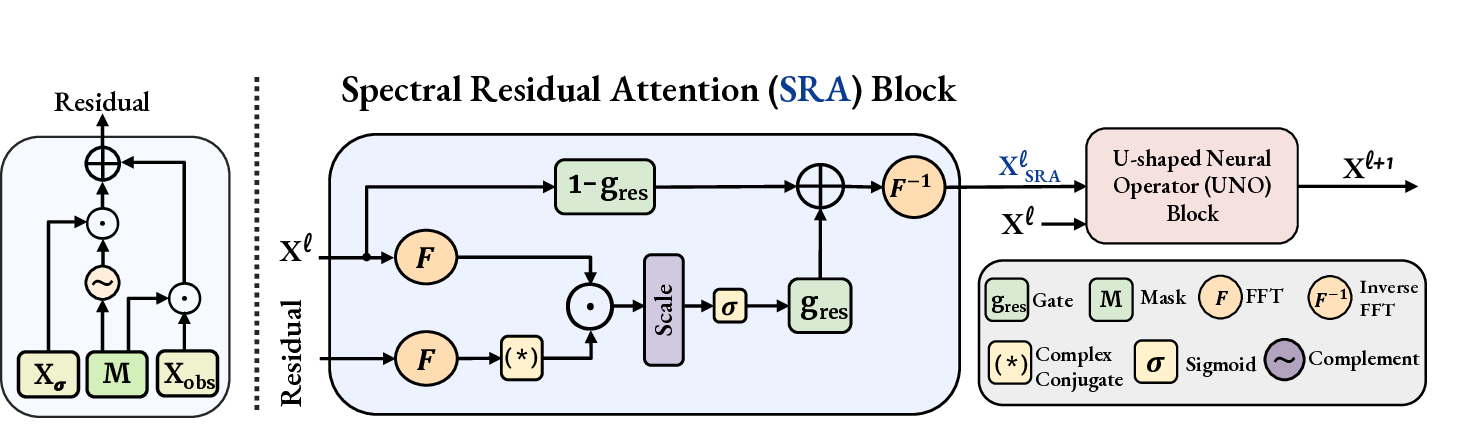
There are two key innovations that we introduce in our UNO backbone to arrive at PRISMA. First, we compute PDE residuals of x at every denoising step informed by observations, x obs = (a obs , u obs ). Second, we inject the residuals in the attention mechanism of a novel Spectral Residual Attention (SRA) block applied at every UNO layer. We describe both these innovations as follows:
Computing Observation-Informed PDE Residuals: Given some observations x obs and inputs to the denoiser network x = (a, u), we want to compute the physical consistency of x at unobserved locations (i.e., locations that are not part of x obs . To accomplish this, we first copy the information from x obs to x using masks M = (M a , M u ), obtaining mixed fields: x mix = (a mix , u mix ) as follows:
where x σ = (a σ , u σ ) is the input to the denoiser during training, which can be replaced with x t = (a t , u t ) during inference. We then compute PDE residuals, r = F(a mix , u mix ) (shown visually in Figure 2(left)). Note that r is computed once at every denoising step at the model’s native resolution and then progressively downsampled to provide a multi-resolution guidance signal at every layer of UNO.
Injecting PDE residuals in SRA: We adapt the UNO architecture by introducing a novel SRA block inside the global spectral path of every UNO layer The SRA block at layer l first modulates the input feature maps x l using the PDE residual r to produce an intermediate physics-informed state, x l SRA . This state is then passed through the global spectral path of the UNO block at layer l, while the original feature map x l is passed into the local spatial path as:
{Sample uncond/ for/inv masks} 5:
Set observations (a obs , u obs ) ← (a, u).
Sample GRF noise η ∼ N (0, σ 2 C).
Construct noisy sample
{Compute training loss} 11:
Update parameters θ by minimizing L. 12: until converged 13: return D θ Spectral Residual Attention (SRA) Block The SRA block operates in the Fourier domain to compute a physics-informed attention mask between the network state (x l t ) and the residual. This mask is applied in a gated skip-connection, controlled by a learned guidance strength (g res ), to produce a modulated state (x t SRA ) that is then passed to the UNO block.
Figure 2 shows the architecture of the SRA block that is the core mechanism for injecting physicsbased architectural guidance in PRISMA. The goal of SRA is to perform a dynamically adaptive cross-attention between the current feature map and the PDE residual, all within the spectral domain. By performing this physics-informed cross-attention, we aim to guide the denoising process toward physically consistent solutions by modulating the frequency spectrum without any loss guidance.
Let x l = F (x l ) and r = F (r) be the 2D Fourier transforms of the layer’s input feature maps and the corresponding PDE residuals, respectively. The SRA block performs a spectral cross-attention where the PDE residual r l is the key and the feature map x l is the query. First, a compatibility score S l measures the phase alignment between them at each 2D frequency mode k = (k 1 , k 2 ), via their complex inner product. This is calculated as the magnitude of their complex inner product across all channels C. This score is then used to create a physics-informed attention mask A l via learnable spectral gain weights w l gain , and passing it through a sigmoid activation as follows:
This allows the model to learn what frequency modes of the feature map are most informative for error correction based on guidance from PDE residuals. To dynamically control this process based on the relevance of PDE residuals in noisy settings, a scalar guidance strength g l res ∈ [0, 1] is learned by an MLP from the spatially-averaged residual r l avg and the diffusion noise embedding c σ . Finally, g res is used to modulate x via a skip-connection with the attention mask to produce SRA’s output:
When the noise level is high, r l avg is typically unreliable and the scalar gate g l res down-weights PDE residual correction. As the denoising trajectory progresses and the solution becomes cleaner, g l res increases, allowing stronger PDE-driven modulation through A l (k). During training, this entire process of forward propagation is incorporated into the EDM loss computation, teaching the denoiser to produce physically-consistent states. At inference, the model engages in a closed-loop, self-correcting process: it predicts a state, computes the residual based on that state, and then uses that residual to refine its own prediction in the next step of the reverse diffusion trajectory. The complete training loop is detailed in Algorithm 1 while the inference algorithm is in Appendix A.
We demonstrate the efficiency, robustness, and accuracy of PRISMA through a series of quantitative and qualitative experiments. We evaluate PRISMA on three distinct PDE problems, focusing on its performance in noisy, fully-observed, and sparsely-observed settings. Additional experiments and implementation details are provided in the Appendix (see sections B, D, E and I).
Dataset & Tasks: We validate our approach on three PDE problems from the dataset of Huang et al. (2024), which is characterized by multi-scale features, complex boundary conditions, and nonlinear dynamics. We evaluate both forward and inverse problems in three regimes: (1) Full Observation, with complete and clean data;
(2) Sparse Observation, where only 3% of the input field is known (e.g., initial condition or solution); and (3) a challenging Noisy setting, where the observed data is corrupted by additive Gaussian noise sampled from N (0, 1). For dataset details, see Appendix C.
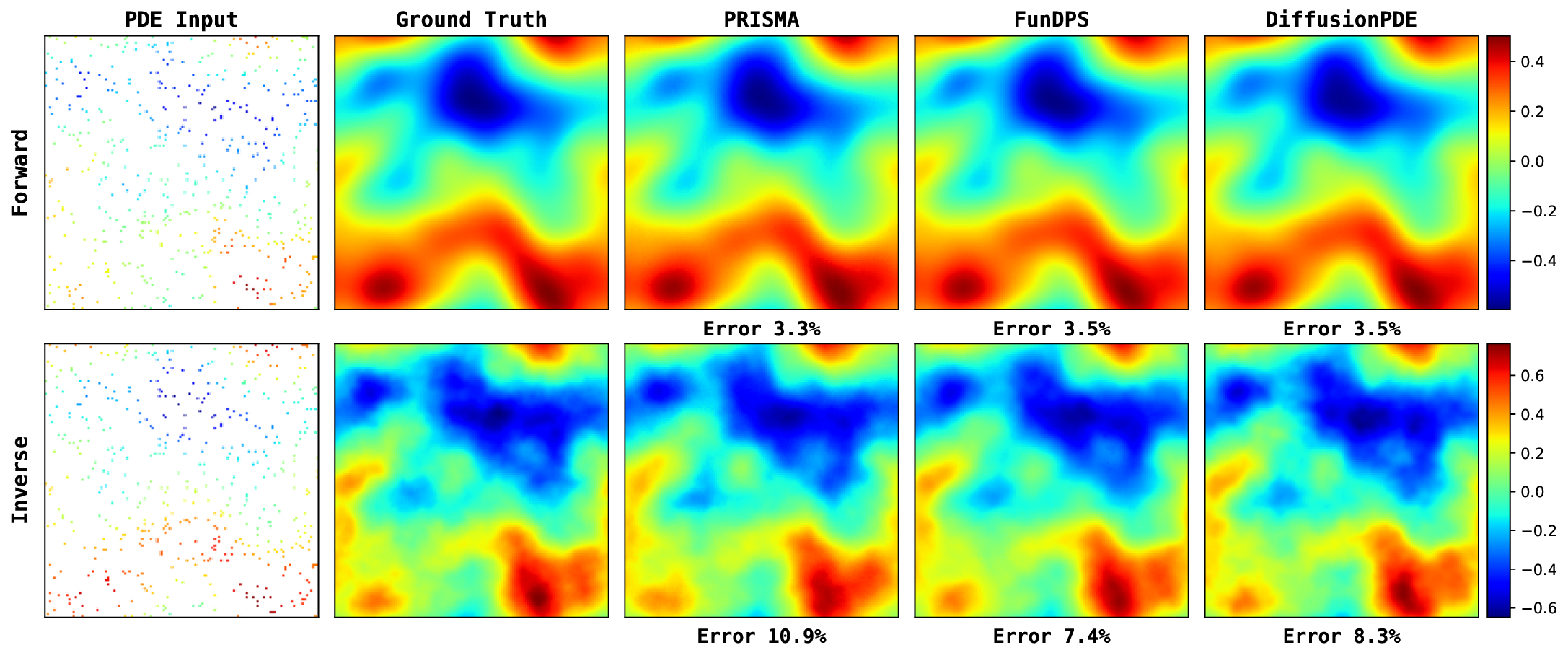
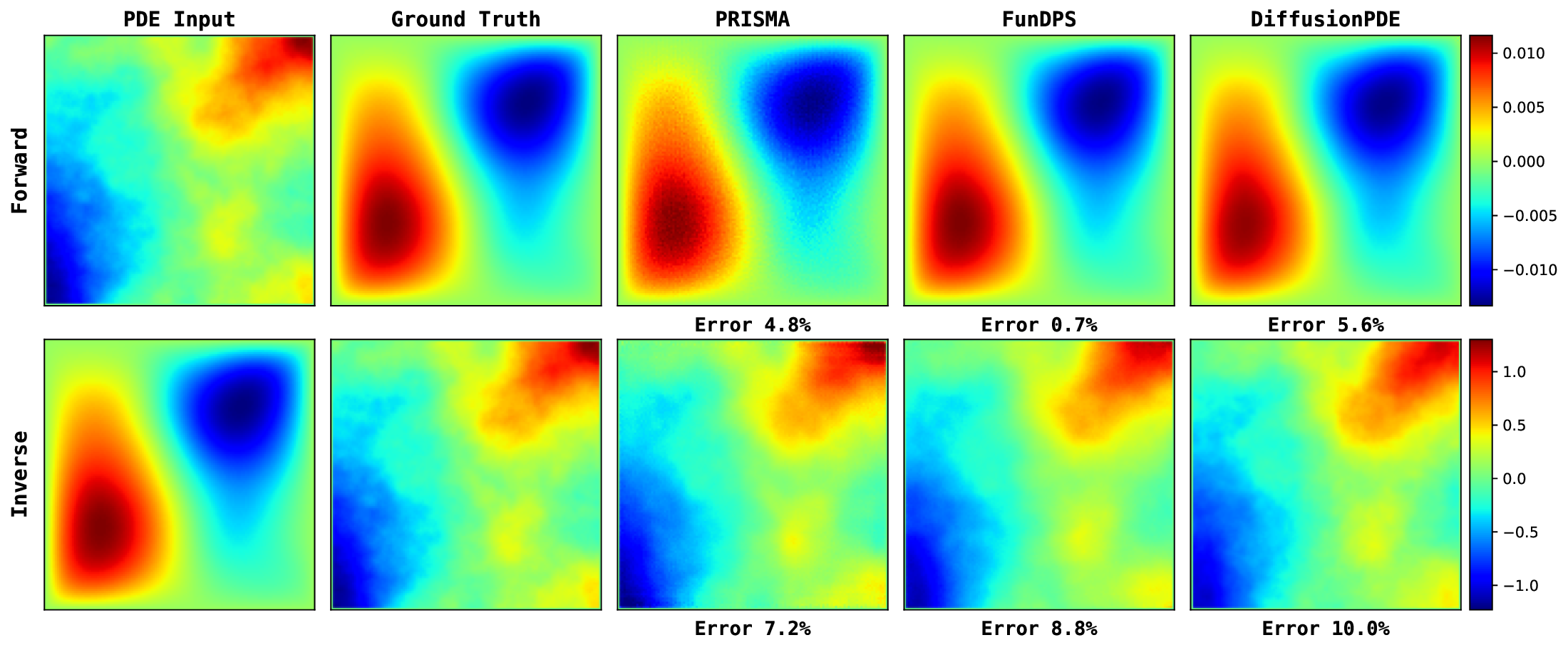
Training & Inference: Our implementation builds on the EDM-FS framework (Beckham, 2024) using a U-shaped neural operator (Rahman et al., 2022) as the denoiser D θ and adapting the process for functional noise. Our model’s parameter count is comparable to key baselines, with full implementation details provided in Appendix B. Baselines & Evaluation Metrics: We compare against deterministic solvers including FNO (Li et al., 2020), PINO (Li et al., 2024), and PINN (Raissi et al., 2019a), as well as state-of-the-art diffusion methods like DiffusionPDE (Huang et al., 2024) and FunDPS (Yao et al., 2025). Performance across all tasks is measured using the relative L 2 error. For the Darcy flow inverse problem, we report the classification error rate.
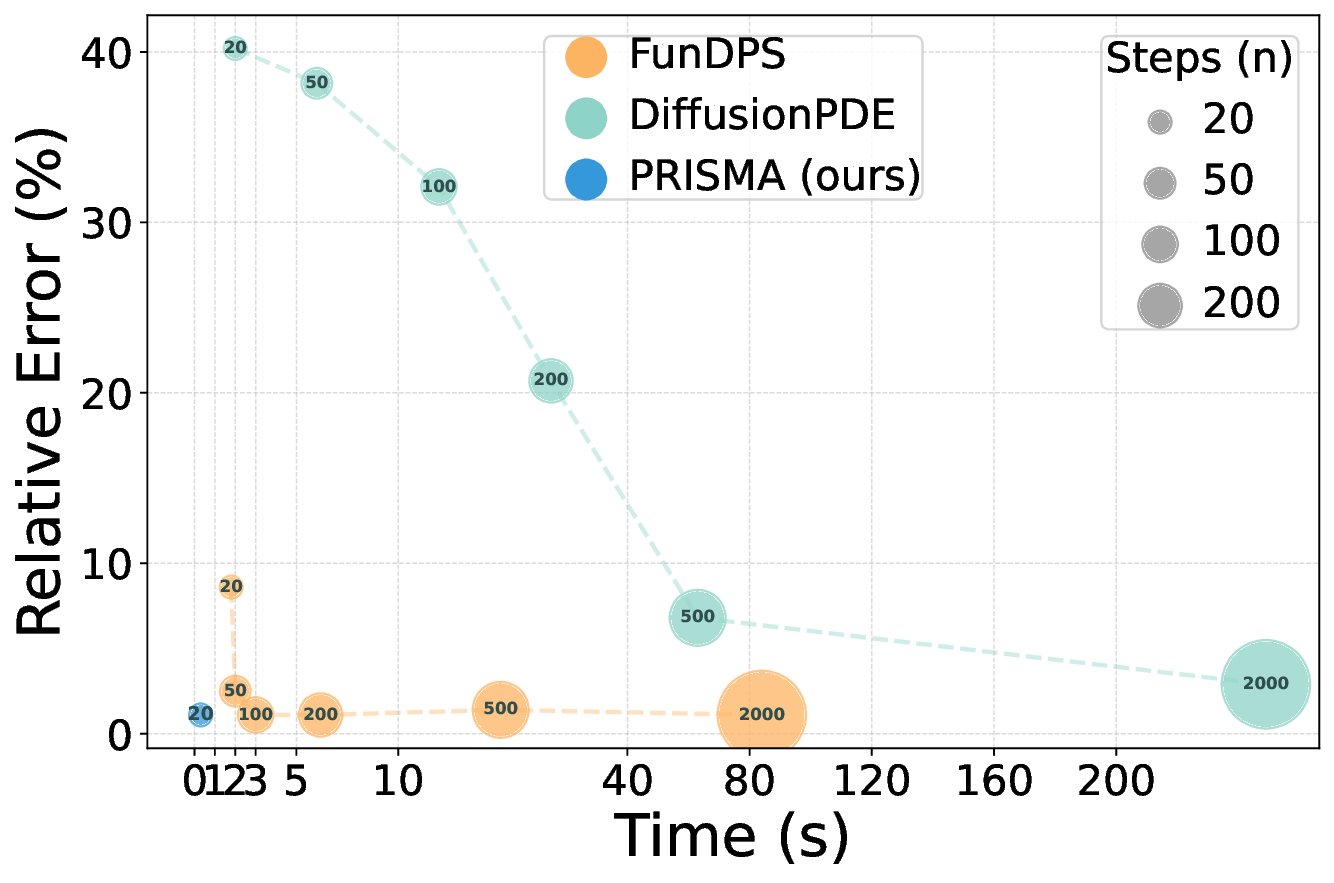
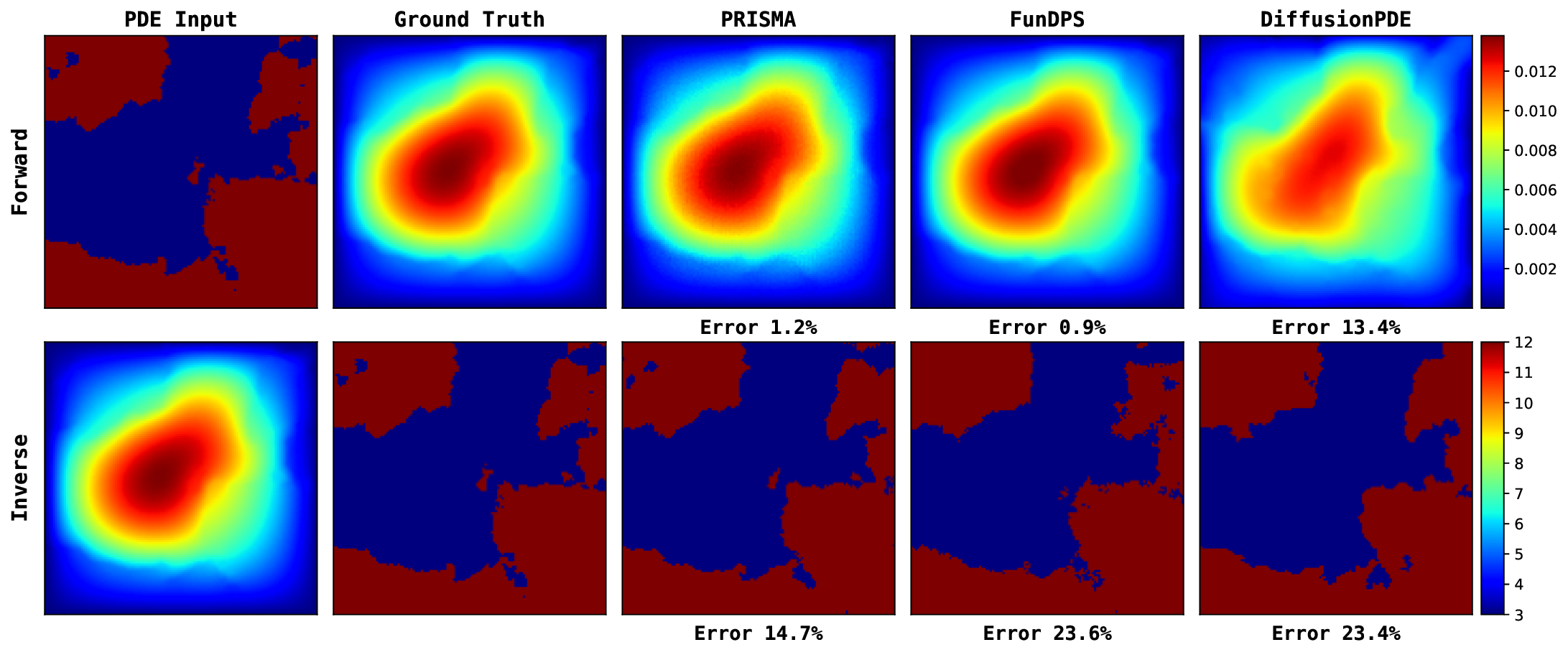
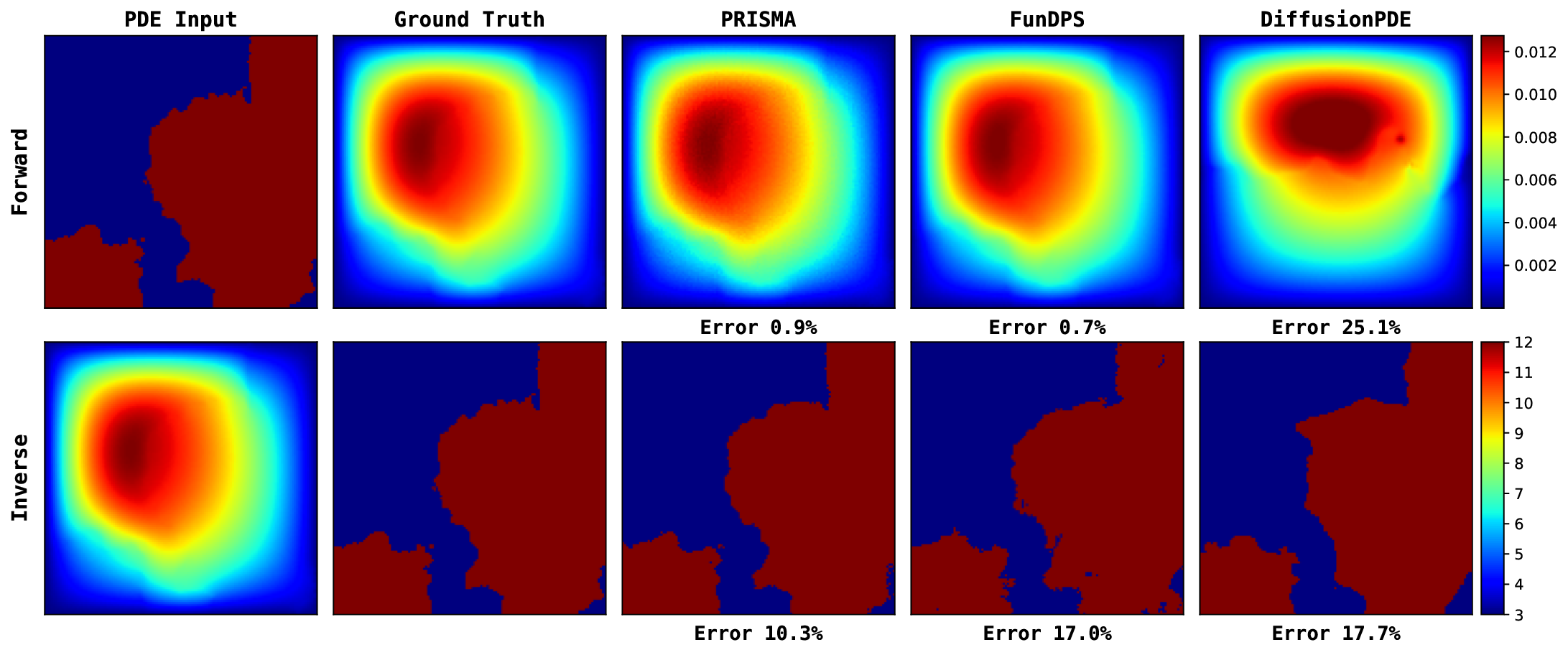
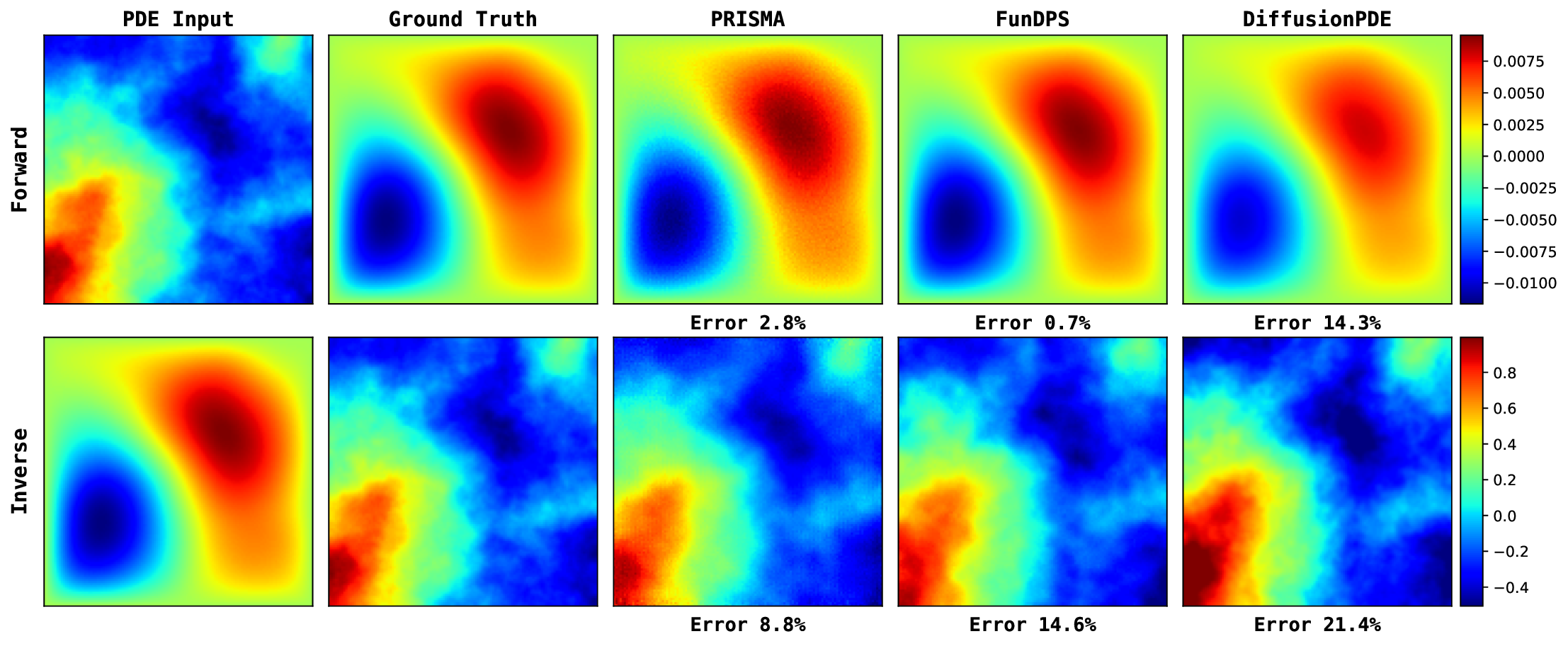
We first evaluate PRISMA’s robustness in the challenging noisy observation setting, mimicking real-world measurement noise. The results, summarized in Table 3, demonstrate that PRISMA achieves state-of-the-art performance across most of the equations. For instance, in the Darcy Flow forward problem, PRISMA with 50 steps achieves an L 2 relative error of 12.28%, outperforming the baselines (55.09% and 49.18%). We see a similar trend in other equations as well. While our primary focus is the challenging noisy setting, PRISMA also demonstrates competitive performance under full and sparse observation settings (Tables 6 and7), while requiring far fewer sampling steps. For a qualitative comparison, we provide key visualizations in Figure 3, with more extensive results available in Appendix I. A key advantage of PRISMA is its significant inference efficiency while having competitive accuracy, compared to the current state-of-the-art.
As shown in Table 3 and visualized in Figure 4, PRISMA occupies the optimal low-error, low-time quadrant. We attribute this inference speedup as a direct result of our unified conditioning framework and the strong physical guidance from the SRA block. This enables a gradientdescent free sampling process during inference, whereas DiffusionPDE and FunDPS rely on computationally expensive PDE-based inference sampling. By directly conditioning on the input, PRISMA converges in just 20-50 steps, while DiffusionPDE and FunDPS require 200 to 2000 steps. When they are also restricted to 20 steps, their performance degrades significantly as shown in Tables 10,11. PRISMA has an overall inference speed-up of 15x to 250x (seconds per sample) compared to competing diffusion-based PDE solvers.
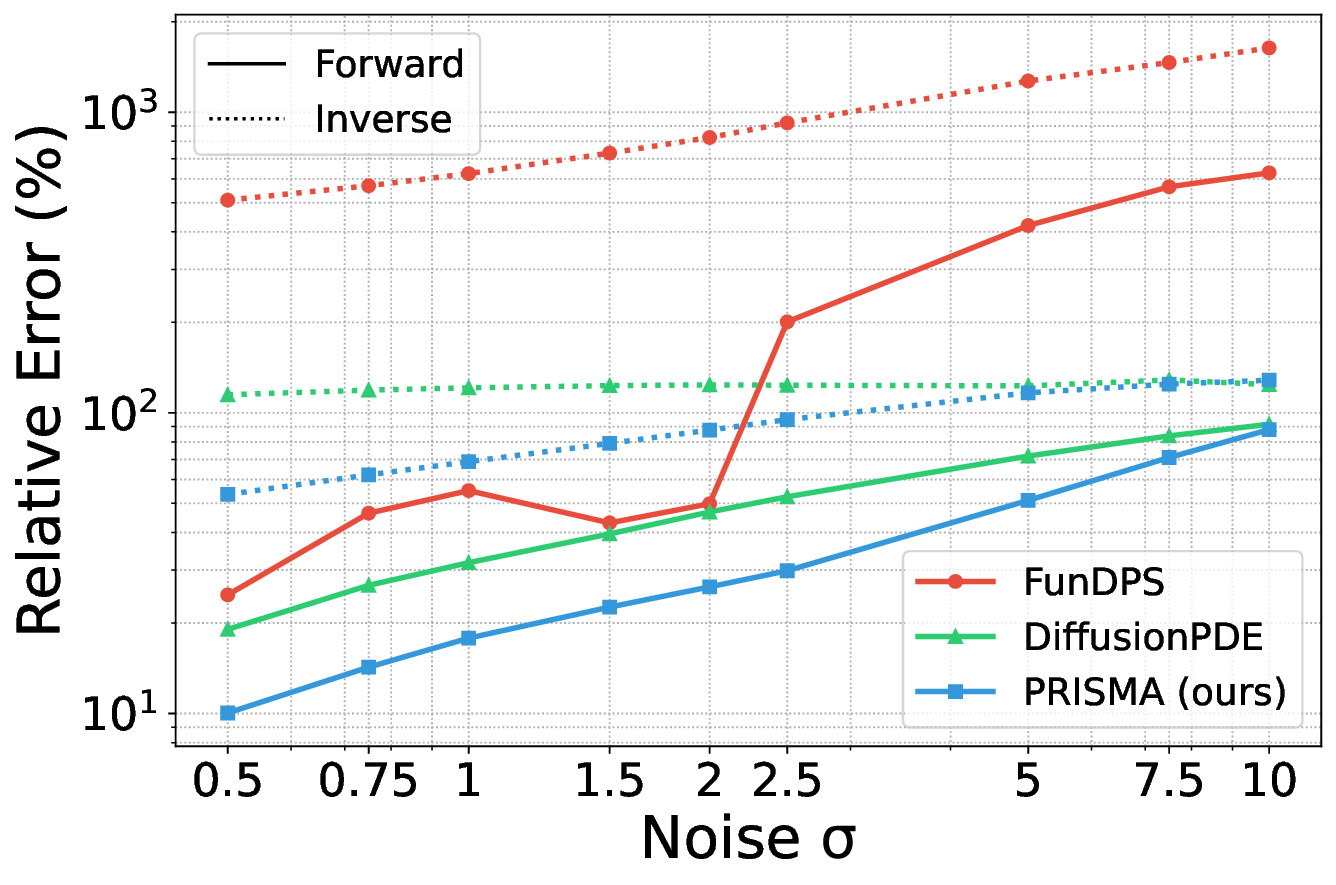
To further probe our model’s capabilities, we analyzed its performance under varying noise levels and examined the statistical properties of its PDE residuals. As plotted in Figure 6, PRISMA consistently maintains a lower error rate than FunDPS and DiffusionPDE across all noise levels for both forward and inverse tasks. Notably, while the error for baseline models increases sharply with noise, PRISMA’s performance degrades more gracefully, highlighting its enhanced stability in high-noise regimes.
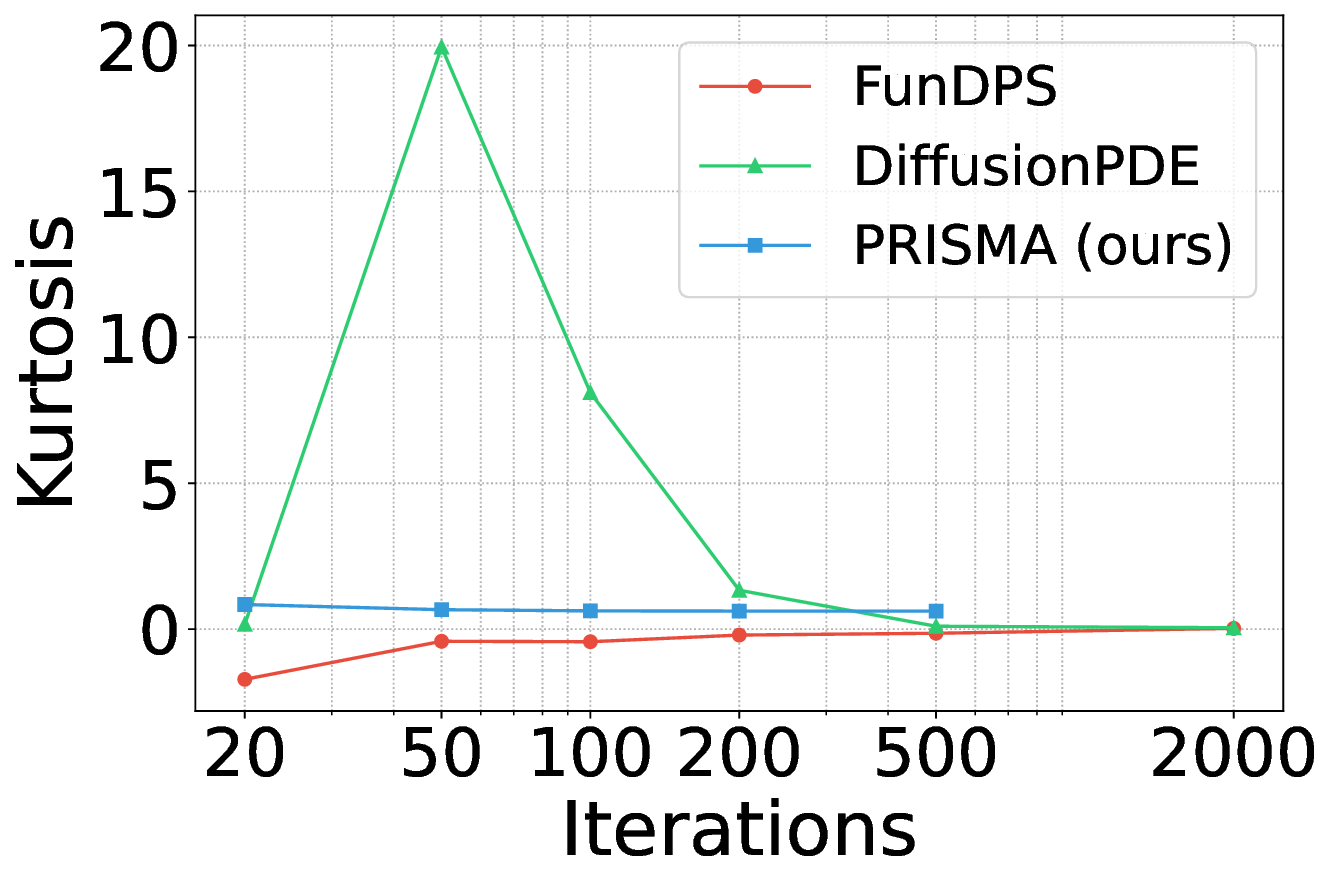
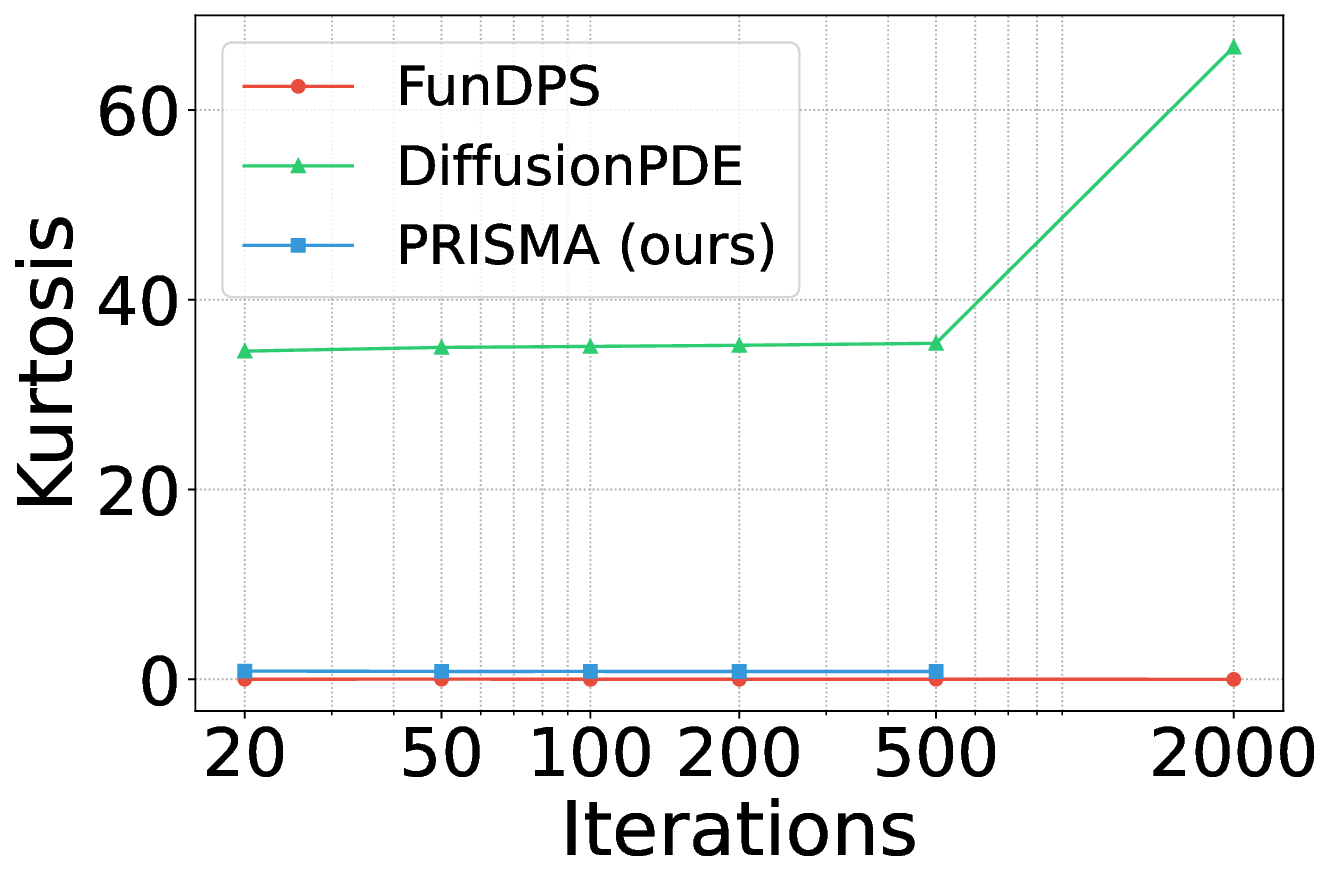
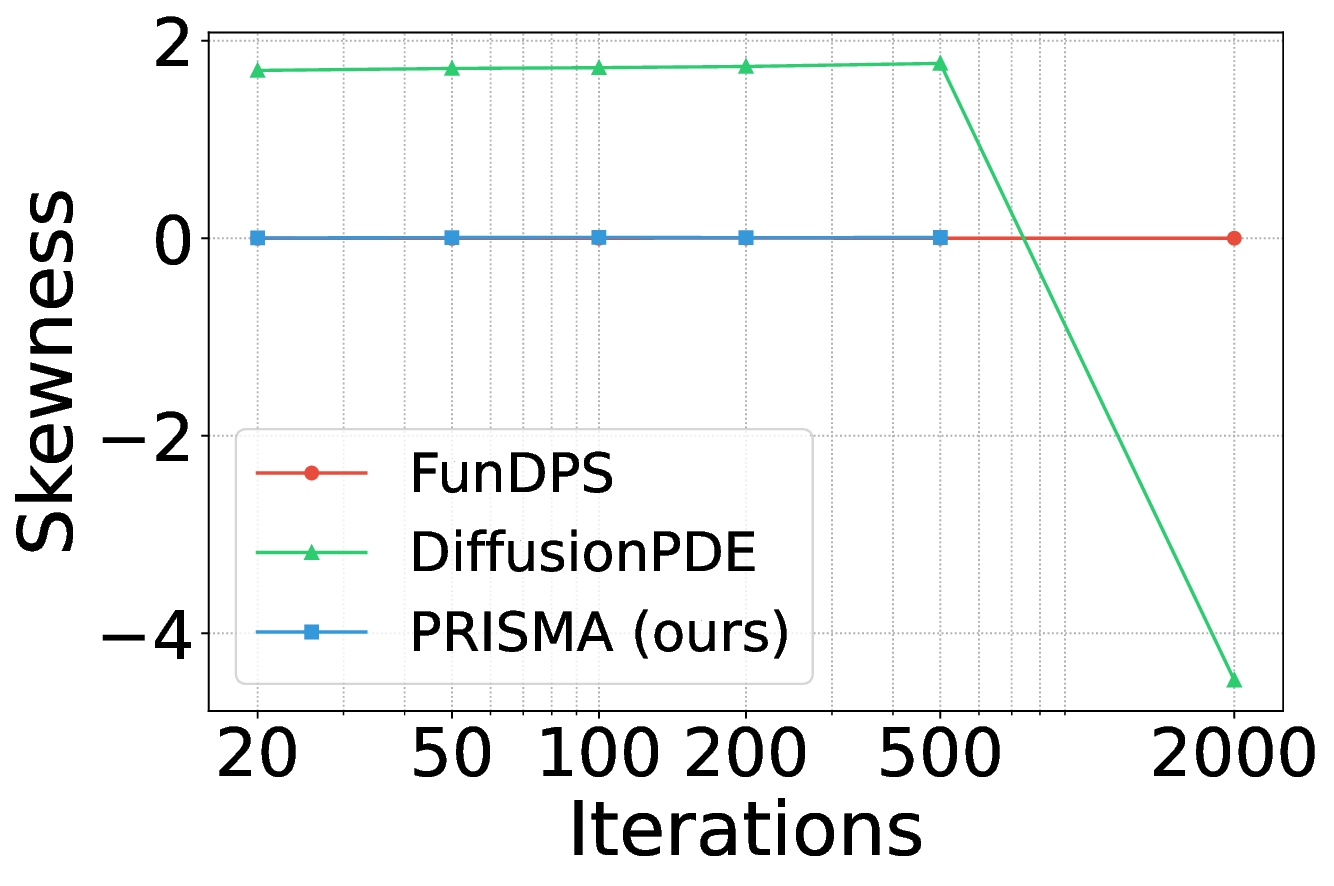
A welltrained model should produce PDE residuals with skewness and kurtosis values close to zero.
Figure 5 shows the skewness residual statistics for the Poisson problem. PRISMA’s residuals (blue) exhibit near-zero skewness across different inference sampling iterations. We observe a similar trend for kurtosis (see Appendix Figure 7).
In this work, we introduced PRISMA, a novel conditional diffusion neural operator that fundamentally challenges the prevailing paradigm of using PDE residuals as external loss terms for guidance.
Our approach centers on architectural guidance, embedding physical constraints directly into the model as learnable features via our novel Spectral Residual Attention (SRA) block. We condition the model with task & sparsity masks during training to perform both unconditional and conditional generation. This design enables two critical advantages: first, it facilitates an entirely gradient-descent free sampling process during inference, eliminating slow and unstable test-time optimization. Second, it allows the creation of a single, unified model capable of seamlessly solving both forward and inverse problems across the full spectrum of full, sparse, and noisy observation regimes. Our experiments validate the effectiveness of our approach, demonstrating inference speedups of 15x to 250x (seconds per sample) relative to state-of-the-art diffusion-based methods while delivering competitive or superior accuracy and robustness especially against noisy observations.
Our work opens several promising avenues for future research. A primary direction is the extension of PRISMA to spatio-temporal problems, which would involve adapting the architecture to handle time-dependent dynamics. Another key step is to generalize the model to operate on complex geometries and irregular meshes, moving beyond grid-based problems.
Algorithm 2 details the inference sampling procedure for PRISMA, which employs a 2nd-order solver to iteratively generate a physically consistent solution from a random field. A key innovation of this process is the use of an observation-guided PDE residual, which is re-computed and fed into the denoising model at every step of the sampling process.
The core of the algorithm lies in the guided self-correction step(Lines 4 and 9). At each iteration i, the PDE residual r is not computed on the model’s raw prediction alone. Instead, it is calculated on a composite field (1 -M ) ⊙ x i + M ⊙ x obs , where M is a binary mask. This formulation ensures that for the known parts of the domain (where M = 1), the residual calculation is grounded by the true observations x obs . For the unknown parts (where M = 0), it uses the model’s current estimate x i .
For instance, consider a forward problem with full observation, where the state x = [a, u] consists of the known input coefficients a and the unknown solution u. In this case, the mask M = [M a , M u ] would have M a as a matrix of ones (fully observed) and M u as a matrix of zeros (fully unobserved). Consequently, the composite field used to calculate the residual becomes [a obs , u i ]. This means the PDE residual operator R evaluates physical consistency based on the true input a and the model’s current prediction for the solution u i .
This guided residual r acts as an explicit, spatially-varying map of physical inconsistency, which is then passed as a direct input to the denoising operator D θ (Lines 5 and 10). By providing this physical guidance at every step of the predictor-corrector solver, the model is continuously steered toward solutions that are not only consistent with the initial observations but also compliant with the governing PDE, enabling fast, gradient-descent free convergence.
Algorithm 2 PRISMA Inference with 2nd-Order Solver and Guided Residual
{Predictor Step}
Predict clean state x0 ← D θ (x i , σ i , x obs , M, r).
6:
{Evaluate derivative dx/dσ} 7:
{Take an Euler step} 8:
11:
12:
{Apply 2nd-order correction} 13: else 14:
end if 16: end for 17: return x 0
We adopt a 4-level U-shaped neural operator architecture (Rahman et al., 2022) as the denoiser D θ , which has 64M parameters, similar to DiffusionPDE’s and FunDPS’s network size. The network is trained using 50,000 training samples for 200 epochs on 2 NVIDIA A100 GPUs with a Batch size of 90 per GPU. The code-base is built upon Beckham (2024)’s implementation of Denoising Diffusion Operators (DDO). The hyperparameters we used for training and inference are listed in Table 5 and were taken from Beckham (2024)’s DDO implementation. We source the quantitative results of deterministic baselines for the full and noisy cases from DiffusionPDE’s (Huang et al., 2024) table. We faced reproducibility issues for DiffusionPDE, also observed by Yao et al. (2025). We had correspondence with DiffusionPDE’s authors about this and have rerun all their experiments for the Full and Sparse cases, and the tables 6 and 7 show our reproduced results for their method.
Residual-aware Guidance Strength MLP: Each SRA block uses a small two-layer MLP to predict the scalar guidance weight g res ∈ [0, 1]. The inputs to this MLP are: (i) the diffusion/timestep embedding c σ (of length E, e.g., E=256), and (ii) the spatial mean of the residual r avg (a scalar). We concatenate these to form a tensor of shape B × (E+1), where B is the batch size, and pass it through Linear(E+1 → E) → ReLU → Linear(E → 1) → Sigmoid, yielding a B × 1 output used as the skip-connected gating weight within the SRA block. Each SRA block contains its own distinct MLP.
All the experiments are conducted using a single NVIDIA A100 GPU. To determine per-sample inference time, we averaged batch inference time over 10 runs and divided by the batch size.
We evaluate our approach on three benchmark PDE problems: including Darcy Flow, Poisson and Helmholtz. Each PDE is considered in both forward (a → u) and Inverse (u → a) settings. We use the same data as used in DiffusionPDE (Huang et al., 2024) which consists of 50,000 training and 1000 test samples for each PDE, at both 64×64 and 128×128 resolution. All models are trained and evaluated at 128×128, and some ablations when stated are on the 64×64 resolution. For quantitative evaluation, we report the mean relative L 2 error between the predicted and true solutions, except for the inverse Darcy Flow problem, where we use the binary error rate.
where the domain is Ω = (0, 1) 2 , with g(x) = 1 (constant forcing) and zero Dirichlet boundary conditions. The coefficient function is sampled as a ∼ h # N 0, (-∆ + 9I) -2 , following (Huang et al., 2024;Yao et al., 2025). The mapping h is defined piecewise, taking the value 12 for positive inputs and 3 otherwise.
Poisson Equation .We consider the Poisson equation on the unit square Ω = (0, 1) 2 which describes steady-state diffusion processes:
subject to homogeneous Dirichlet boundary conditions:
The source term a(x) is a binary field, obtained by thresholding a Gaussian random field at zero:
where 1 • is the indicator function. The PDE residual, which serves as a physical constraint for the model, is defined as,
Helmholtz Equation. We consider the static inhomogeneous Helmholtz equation on the domain
subject to homogeneous Dirichlet boundary conditions:
where k = 1. This equation describes wave propagation in heterogeneous media. The coefficient function a(x) is generated as a piecewise-constant field sampled from a Gaussian random field. Unlike the Poisson case, where the source term is thresholded to a binary field, the Helmholtz coefficients can take a range of values across different regions, giving heterogeneous variation. The solution u(x) is computed using second-order finite differences, with zero boundary enforced via the same mollifier as in (Huang et al., 2024).
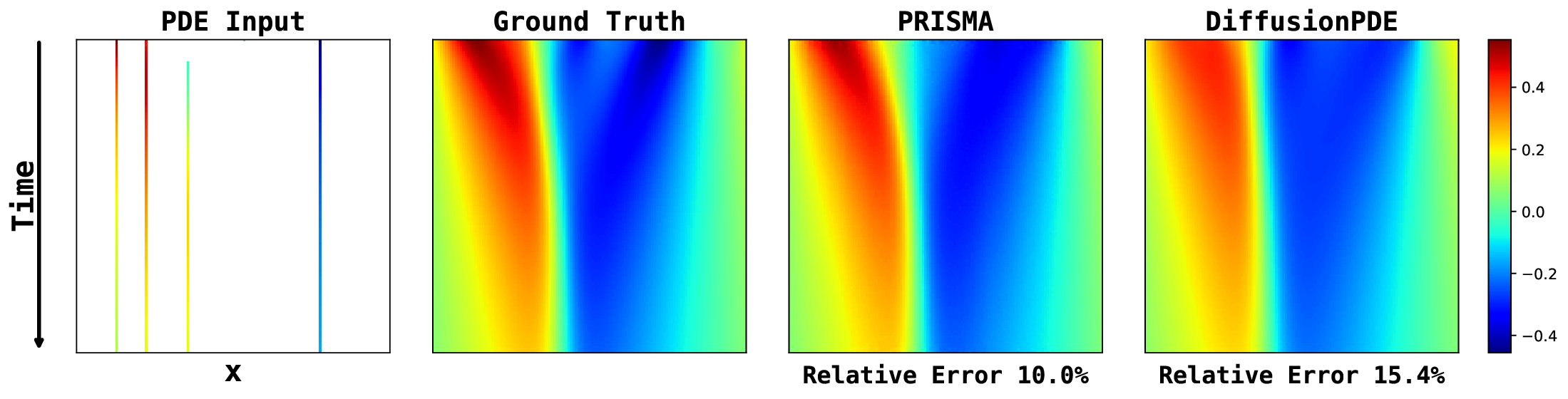
Navier-Stokes Equation (non-bounded). We consider the 2D incompressible Navier-Stokes equations in vorticity-streamfunction form: with periodic boundary conditions. Here ω = ∂ x v y -∂ y v x is the vorticity, ψ the streamfunction, v the velocity, and ν = 10 -3 (Re = 1000). Initial vorticity ω 0 is sampled from a Gaussian random field.
For our experiments, we use the dataset provided by DiffusionPDE (Huang et al., 2024), which contains pairs (ω 0 (x), ω T (x)) corresponding to the solution at final time T = 1 s. We deviate from their final-frame prediction setup and instead predict the next time step with a small interval ∆t = 0.1 to enable a physically meaningful residual. DiffusionPDE exploits the identity ∇• (∇ × v) = 0 and uses a simplified residual written as f (x) = ∇• ω(x, t), however this is not physically valid in 2D because ω is a scalar field and ∇• ω is not a well-defined divergence (nor a meaningful physics residual).
Residual used for guidance: Given ω t and a candidate ωt+∆t , we first recover the velocity at t+∆t via a streamfunction solve:
The one-step vorticity-transport residual is
D RESULTS
Table 6 compares different models across three PDE problems for the full observation setting.
Our method achieves competitive performance, achieving the best average rank of 2.75 across all tasks. In addition to accuracy, our approach demonstrates significant efficiency: compared to other diffusion-based models, it is 15x to 250x (seconds per sample) faster during inference. Note that the baseline values for DiffusionPDE are taken from the original paper. Reproduced results for DiffusionPDE are reported here due to reproducibility issues, as also noted in FunDPS.
Table 7 presents a comparison of PRISMA against deterministic and generative baselines under the challenging sparse observation setting. While FunDPS (at 500 steps) achieves the highest accuracy, PRISMA demonstrates a superior balance of performance and efficiency. Our model delivers competitive accuracy, comparable to the top-performing generative methods, but at a fraction of the computational cost. Notably, PRISMA at 20 steps is over 65 times faster than the most accurate FunDPS configuration and over 1000 times faster than DiffusionPDE. This highlights PRISMA’s significant advantage in inference speed, making it a practical and efficient choice for applications where rapid predictions are critical. To analyze the convergence behavior of PRISMA, we evaluate its performance across a range of inference steps (N ) from 20 to 500. This sensitivity analysis is conducted for both the challenging noisy observation setting (Table 8) and the ideal full observation setting (Table 9). The results clearly demonstrate that PRISMA converges remarkably quickly. In both scenarios, performance saturates early, with minimal to no improvement observed beyond 20-50 steps. This rapid convergence justifies our use of a small number of steps for inference, as it provides an optimal balance between computational efficiency and accuracy. To highlight the inference efficiency of our method, we conduct a direct comparison where all models are restricted to just 20 sampling steps, a regime where PRISMA excels. While the optimal performance for FunDPS and DiffusionPDE is achieved at much higher step counts (200-500 and 2000 steps, respectively), this analysis serves as a stress test to evaluate per-step convergence speed.
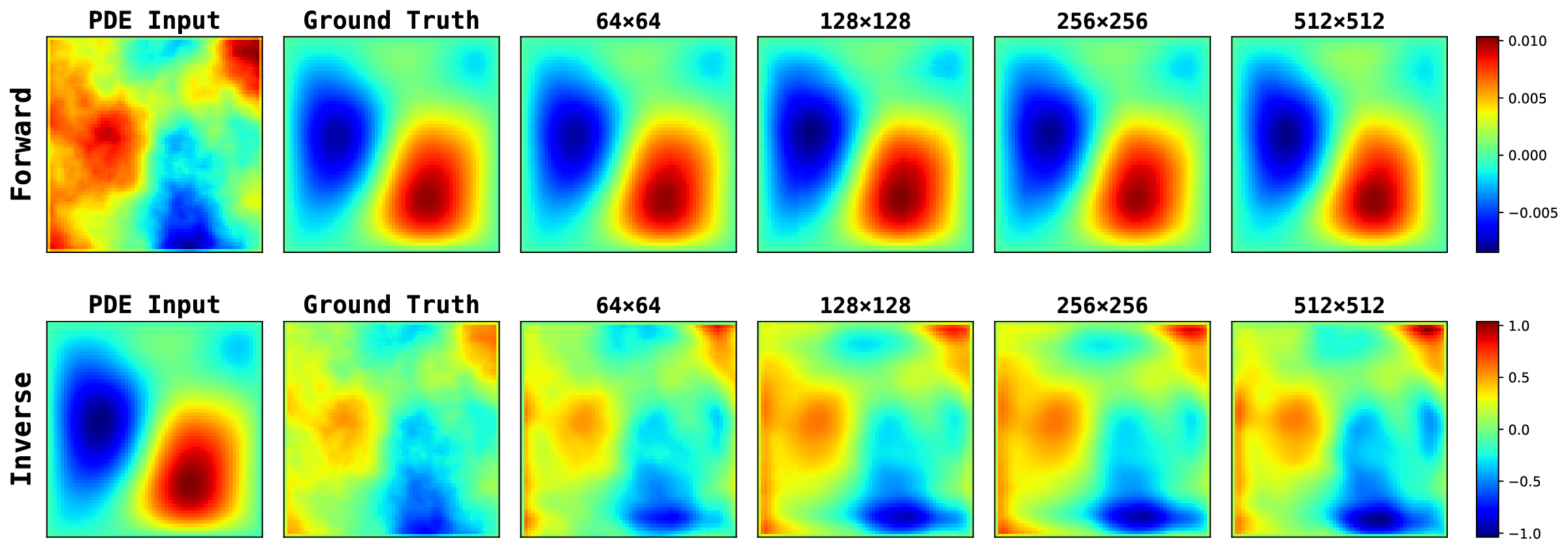
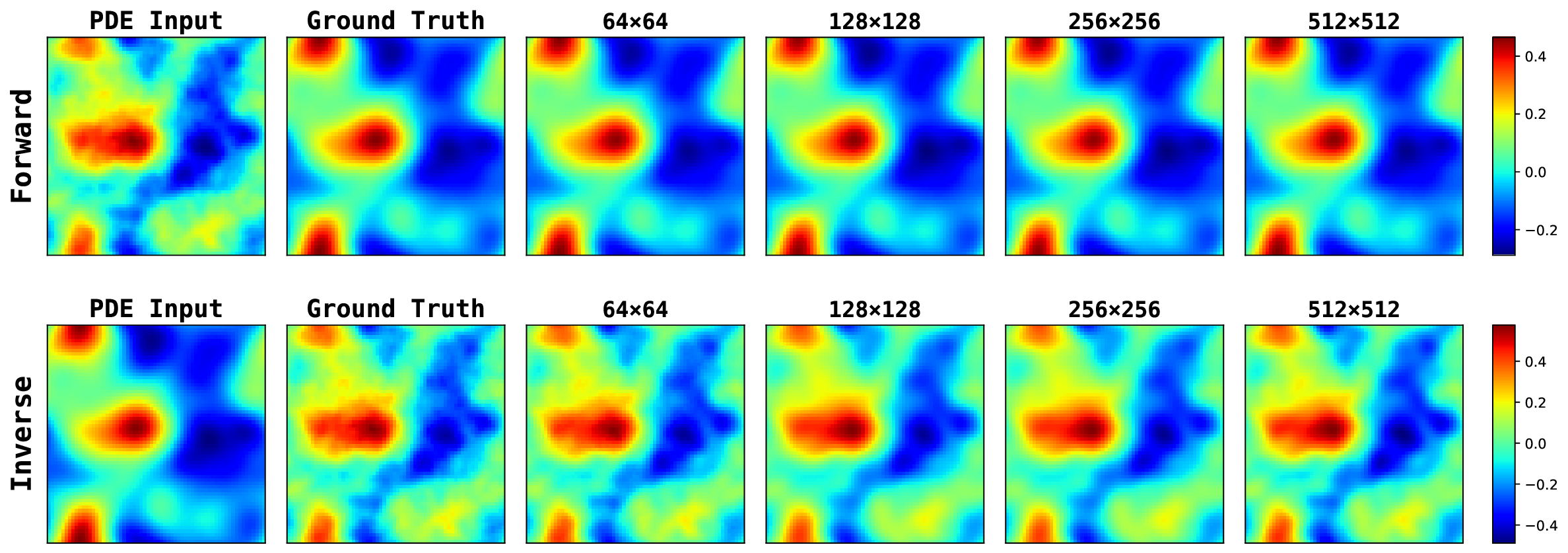
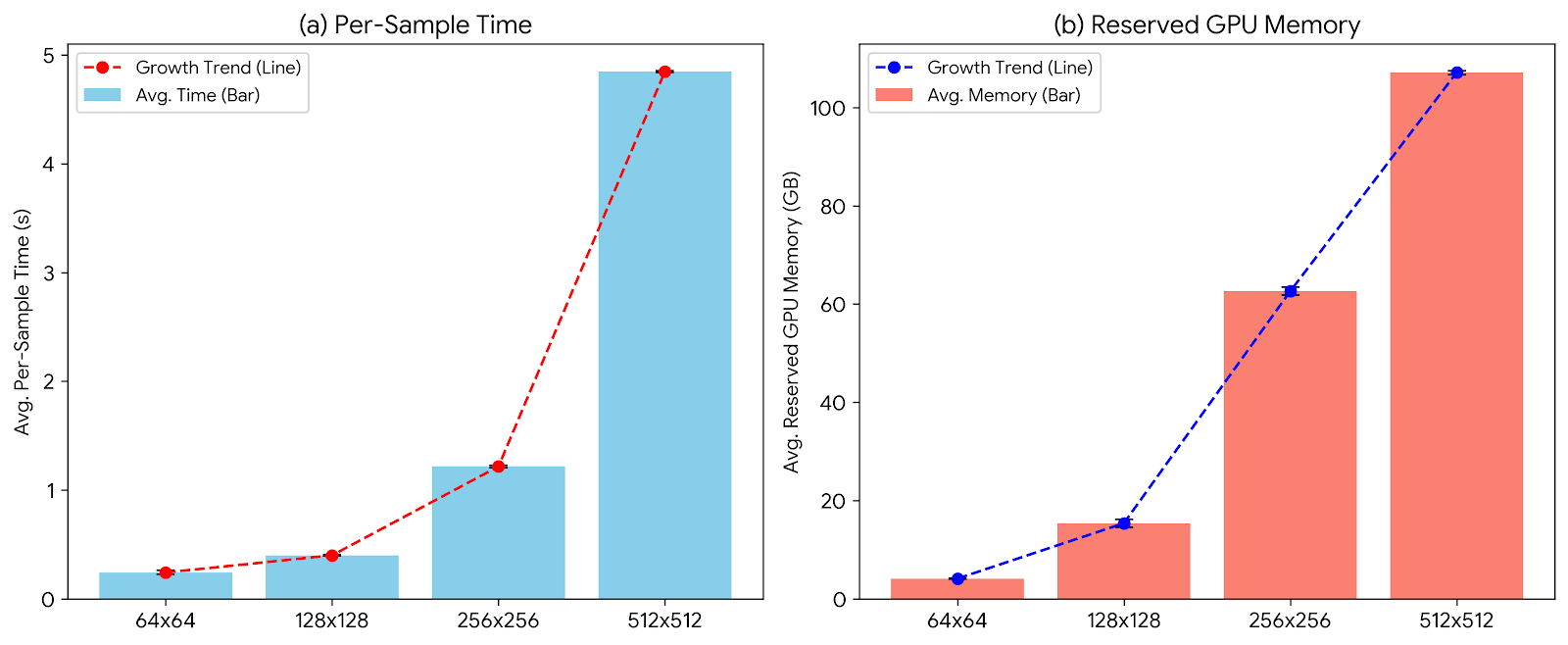
As shown in Table 10, PRISMA consistently achieves low error rates across all tasks in the noisy setting. In contrast, the baseline models produce significantly higher errors, with FunDPS often failing to converge entirely. We see a similar trend for the full observation case in Table 11. This demonstrates that PRISMA’s architectural guidance enables a much more rapid convergence to accurate, physically consistent solutions. (5) Without guided PDE residual where we do not guide the PDE residual as described in Appendix Section A , and Ours (PDE Res SRA). We observe that the choice of gating matters, the skip-connected scalar gate stabilizes residual injection and helps notably in noisy inverse settings. Furthermore, we see that phase-aware spectral attention outperforms magnitude-only/phase-blind variants, indicating that per-mode phase alignment provides useful physics signal and lastly residual guidance helps SRA consistently improve over no-guidance on inverse tasks while remaining competitive on forward tasks, more so in noisy observation settings. 13. Figure 9 visualizes how inference cost grows with resolution, specifically the per-sample time increases smoothly from 0.24s → 4.85s, and reserved GPU memory rises from 4 GB → 107 GB. While the 512×512 case incurs a significantly higher memory footprint, PRISMA remains stable across all resolutions tested.
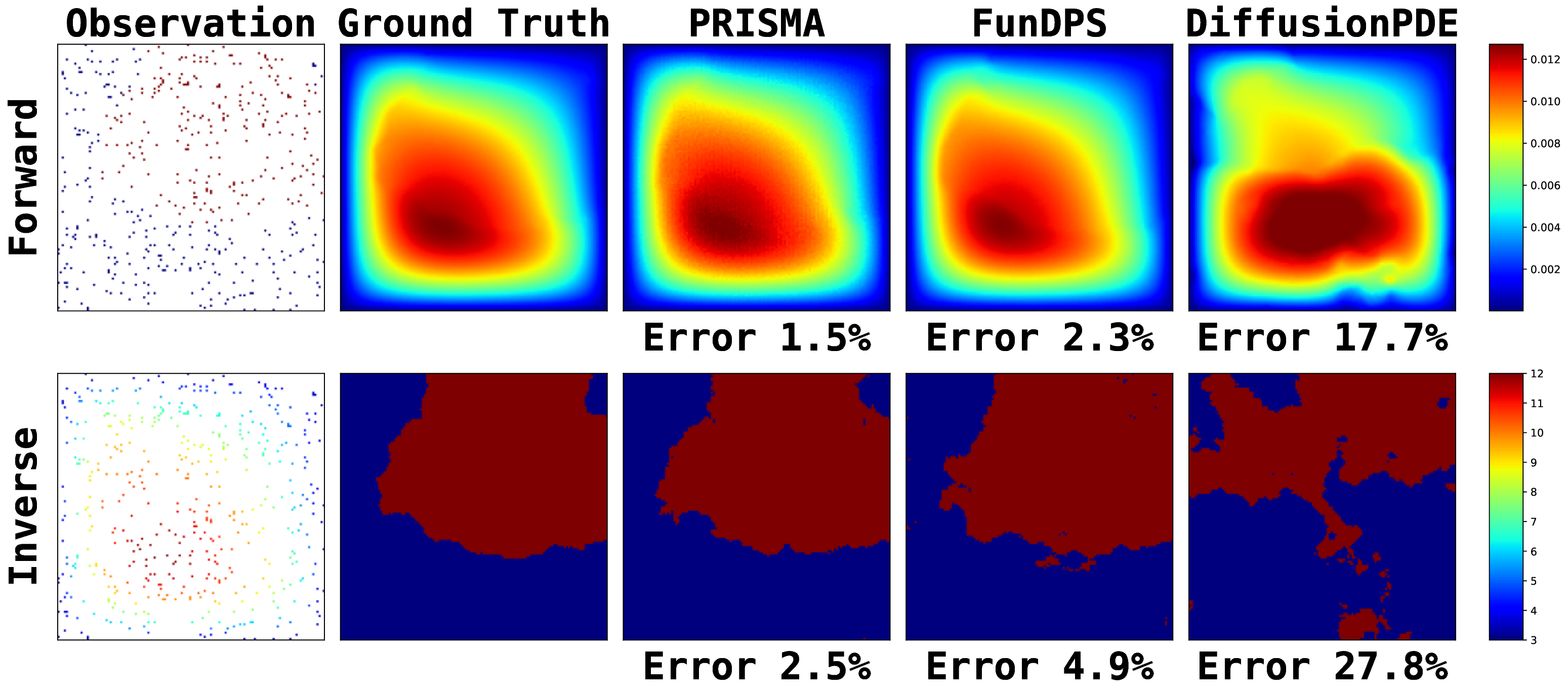
We evaluate PRISMA and all baselines under varying levels of additive measurement noise. For each sample, we corrupt a fixed percentage of pixels (90%, 50%, 30%, 10%) with unit-variance Gaussian noise, keeping the remaining pixels clean. This setup simulates real-world sensor degradation where only part of the field is corrupted. The diffusion models (including PRISMA) are not trained with any noise augmentation beyond the intrinsic diffusion noising, all methods are evaluated out-ofdistribution. Tables 14-17 report results across five PDEs in forward and inverse settings. Across all noise levels, classical operator-based models (FNO/PINO) degrade sharply, while diffusion models remain substantially more stable. FunDPS benefits from per-sample DPS optimization but becomes sensitive at high noise levels and in inverse regimes. PRISMA shows consistent performance across all noise ratios, even when a large majority of pixels are corrupted.
Figure 13 provides a qualitative comparison of the solutions generated by PRISMA and the baseline models under the challenging noisy observation setting. Across both problems: Poisson and Darcy Flow, PRISMA’s predictions are visually faithful to the ground truth solutions. The corresponding error maps are consistently darker, and the reported error values are significantly lower compared to the baselines. In contrast, solutions from FunDPS often appear corrupted by noise, while those from DiffusionPDE can be blurry or inaccurate, particularly in complex inverse problems. These visualizations provide strong qualitative evidence of PRISMA’s robustness and superior performance when dealing with imperfect data. Figures 14, 15, 16 presents qualitative comparison of the solutions generated by PRISMA and the baseline models under Full observation setting. Figure 17 compare PRISMA predictions against the baseline models on Navier-Stokes Equation under Sparse observation settings.
Characterizing varying configurations of input conditions in our framework for solving different settings of PDE problems. A value of True (False) in masks indicate a tensor of all 1s (0s).
E.1 Ablation on the Number of Inference Steps . . . . . . . . . . . . . . . . . . . . . 16 E.2 Comparison at 20 steps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 E.3 Fidelity to Physical Constraints . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 E.4 SRA Ablations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
📸 Image Gallery