RoleMotion: A Large-Scale Dataset towards Robust Scene-Specific Role-Playing Motion Synthesis with Fine-grained Descriptions
📝 Original Info
- Title: RoleMotion: A Large-Scale Dataset towards Robust Scene-Specific Role-Playing Motion Synthesis with Fine-grained Descriptions
- ArXiv ID: 2512.01582
- Date: 2025-12-01
- Authors: Junran Peng, Yiheng Huang, Silei Shen, Zeji Wei, Jingwei Yang, Baojie Wang, Yonghao He, Chuanchen Luo, Man Zhang, Xucheng Yin, Wei Sui
📝 Abstract
In this paper, we introduce RoleMotion, a large-scale human motion dataset that encompasses a wealth of roleplaying and functional motion data tailored to fit various specific scenes. Existing text datasets are mainly constructed decentrally as amalgamation of assorted subsets that their data are nonfunctional and isolated to work together to cover social activities in various scenes. Also, the quality of motion data is inconsistent, and textual annotation lacks fine-grained details in these datasets. In contrast, RoleMotion is meticulously designed and collected with a particular focus on scenes and roles. The dataset features 25 classic scenes, 110 functional roles, over 500 behaviors, and 10296 high-quality human motion sequences of body and hands, annotated with 27831 fine-grained text descriptions. We build an evaluator stronger than existing counterparts, prove its reliability, and evaluate various text-tomotion methods on our dataset. Finally, we explore the interplay of motion generation of body and hands. Experimental results demonstrate the high-quality and functionality of our dataset on text-driven whole-body generation. The dataset and related codes will be released.📄 Full Content
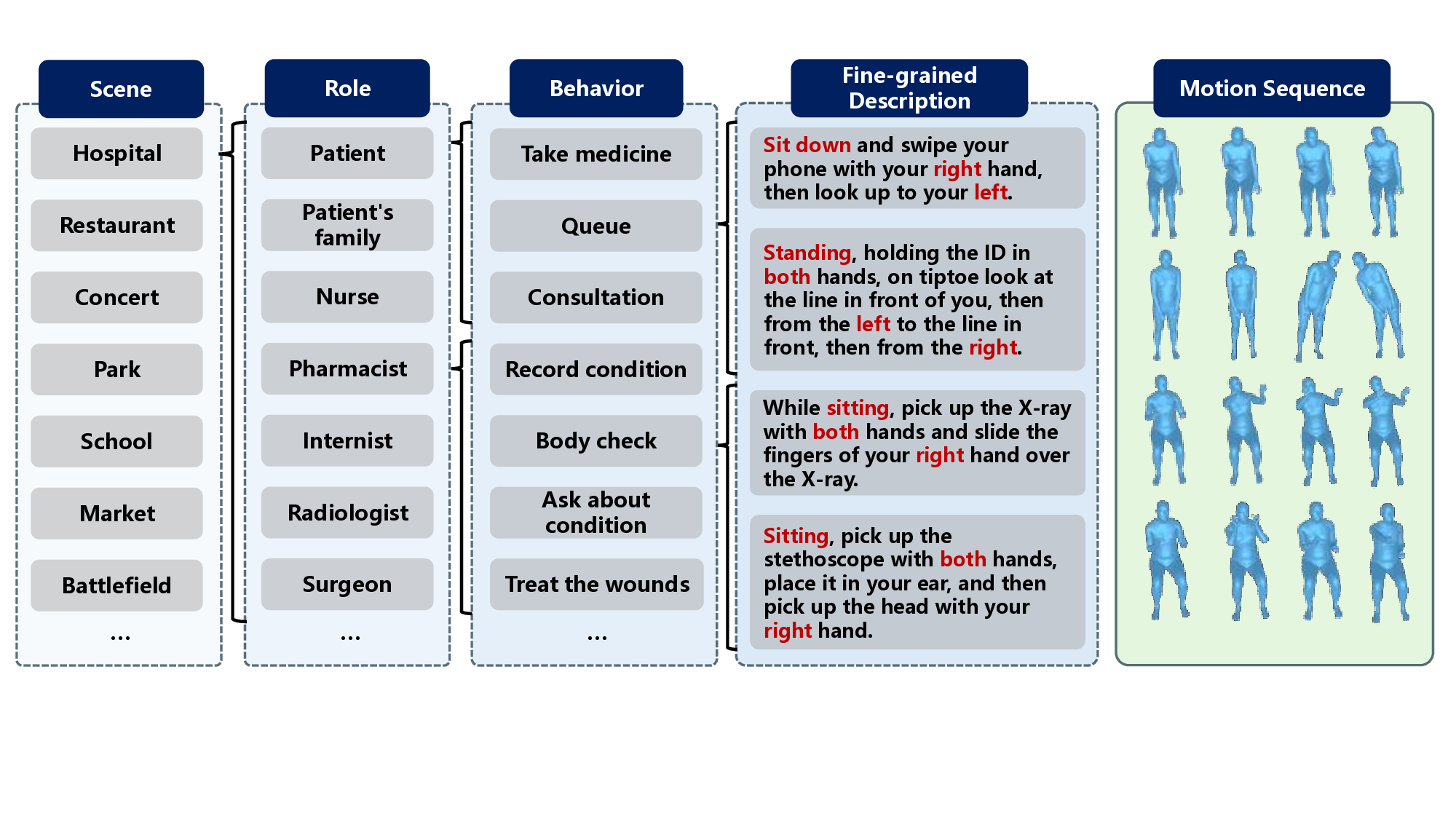
To tackle the aforementioned problems, we propose RoleMotion, a large-scale human motion dataset that contains scene-specific role-playing 3D motion sequences with fine-grained textual descriptions. We take scenes and roles into account when designing the dataset structure. Firstly, we collect commonly used scenes, such as hospital, school, restaurant, market, and enumerate all the essential roles within them. Subsequently, we thoroughly list possible behavior types of each role in the scene and expand these behavior types to numerous specific motion sequences with fine-grained descriptions. In total, there are 25 classic and common scenes, 110 roles, more than 500 meta behaviors, 10296 specific motion sequences, and 27831 text descriptions in RoleMotion. The data consists of both motion of body and hands while most existing text-to-motion datasets such as HumanML3D [11] and KIT-ML [39] only contain data of body motion. Besides, our text description is annotated precisely, including the body states, part-level actions, action directions, and even amplitude-related adjectives.
To demonstrate the effectiveness of our motion data and fine-grained textual annotation, we benchmark existing open-sourced text-to-motion generation methods on our datasets.
We preferentially select methods that are stable and popular, including Motion Diffusion Model(MDM) [43], Motion Latent Diffusion(MLD) [6], MotionDiffuse [57] and StableMoFusion [18] as representatives of diffusion-based modelss, T2M-GPT [56], Mo- Mask [14] and Text-to-Motion Retrieval(TMR) [37] as representatives of auto-regressive methods. Experiments demonstrate the validity of our data, that various methods could be able to generate high-quality motion sequences well aligned with fine-grained textual descriptions. To validate the quality, expressiveness and effectiveness of human motion generators as well, a reliable evaluator is crucially needed. However, the existing evaluator that is most commonly used [10] is frequently challenged to be unconvincing and out-dated that the calculated scores could not reflect the real quality of generated motions for two possible reasons. In this work, we train a strong evaluator on our dataset and verify that it is much more convincing than its counterpart. All the metric scores in this work are calculated by our evaluator.
Whole-body motion generation involves the synthesis of
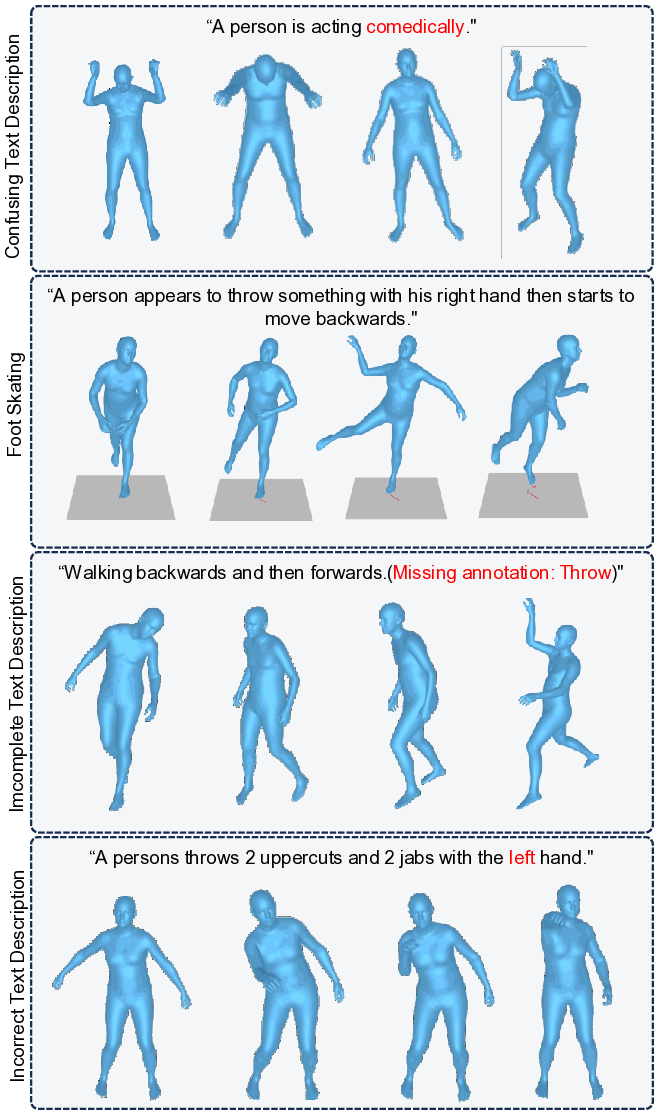
Human motion modeling is a long-standing problem in computer graphics. Early datasets [1,2,7,17,23,28,30,31,45,46,51,52] aims at action recognition and motion capture, with annotations of 3D joints collected through optical marker or IMU. These datasets apply a variety of skeleton standards that the number and location of markers for motion capture are different, and AMASS [27] unifies them by mapping into the common SMPL format. KIT Motion-Language(KIT-ML) [39] is the first motionlanguage datasets that each motion data is annotated with text description, enabling the task of text to motion generation. HumanML3D [11] combines the dataset of Hu-manAct12 [10] and the annotated AMASS, becoming the most popular text2motion dataset. MotionX [21], a recently proposed dataset, collects data from online video and annotates 3D joints based on the pseudo label generated by monocular motion capture method. These datasets have greatly advanced the development of human motion generation, spawning plenty of remarkable methods. However, since most existing datasets are amalgamations of assorted motion capture datasets, the overall data quality is far from satisfactory. The cases of footskate and distorted motions frequently occur, and text annotations are coarse-grained, ambiguous, and sometimes incorrect, especially when indicating which body parts are oriented in which specific directions. More importantly, data in these datasets is collected without a unified purpose or application motivation, making it difficult for these motions to adequately represent a specific scene or play. To address the issues, we develop a large-scale expressive human motion dataset from the perspective of covering all the role-playing in various scenes.
Thanks to these human motion datasets, tremendous progress has been witnessed recently in the field of 3D human motion generation. There are methods that could generate motion sequences based on action categories [22,29], audio [9,47,53,58] and text prompts [6,11,12,36,57]. [11] proposes to learn an aligned embedding space between natural language and human motions to enhance RNN model. In [4,13,35,54], GAN is applied to progressively expand the partial motion sequence to a complete action. Similarly, MotionCLIP [49] aligns text and motion embedding using CLIP [49] as the text encoder and rendered images as extra supervision. T2M [11] resorts to VAE to map the text prompt into a normal distribution of human motion. T2M-GPT [56] propose a 2-stage framework that combines VQVAE and GPT. Following the trends in area of image and video generation, diffusion-based models become popular. MDM [50] and MotionDiffuse [57] both introduce versatile and controllable motion generation frameworks that could generate diverse motions with comprehensive texts. MLD [6] utilizes latent embeddings for efficient motion generation. In StableMoFusion [18], model architecture, training recipes, and sampling strategies are exhaustively analyzed, and a stable and efficient motion generator is introduced. MoMask [14] introduces a masked modeling framework to fill up missing tokens from empty sequence. In this paper, we train a stronger evaluator compared to the commonly used one [10], validate the reliability of our evaluator, and benchmark popular open-sourced human motion generation methods mentioned above on our dataset.
Creating believable agents and intellectual NPCs to craft immersive interactive experiences in animations or sophisticated game has always been a facinating dream for human. RoleLLM [55] exhibits strong ability of agent to imitate talking style of any role, requiring only role descriptions and catchphrases for effective adaptation. In [33], multiple agents of distinctive background and personality live and interact vividly in a small town driven by LLM. [41] introduces a framework for agents to collaborate to run a coding company. Nevertheless, these agent-based activities are only conducted conceptually and exist merely on textual level. Precisely for this reason, our dataset is proposed to concretize them into visual representations.
Since datasets like HumanML3D and KIT-ML originate from existing motion capture datasets, it is unable to determine the composition of data. Oppositely, RoleMotion is designed towards specific purpose of covering complete social activities across various scenes from the beginning. As shown in Tab. 1, the 10296 motion sequences in Role-Motion are collected from scratch through MoCap devices instead of amassing existing datasets or predicting pseudo labels from existing videos, without any concerns about license. In addition, there is no need to unify different skeleton standards [27] or obtain pseudo label from prediction [20], which inevitably harms the quality of motion data.
We take great consideration on scenes and roles when designing the structure of our dataset. Firstly, we list scenes that are commonly seen in animations, video games, metaverse, etc. Then we identify essential roles in these scenes and enumerate possible behaviors of each role. Ultimately, behaviors of each role are expanded to a variety of specific motion description. For instance, “A singer singing in vocal concert” is expanded to 88 specific motion entries like “Holding the microphone in the left hand close to the mouth, while slightly swaying the body from side to side and singing” or “Holding a microphone in one hand and spreading the other hand outward while performing a song”. Noticeably, all the text descriptions are fine-grained, that body states like sitting and standing, the side of part and the moving direction are required to be explicitly specified. Totally, there are 25 classic scenes, 110 functional roles, more than 500 behaviors, 10296 high-quality human motion sequences including body and hands, and 27831 fine-grained text descriptions in RoleMotion.
During data collection, 6 actors are employed to perform motions strictly following the fine-grained descriptions. Motion clips that do not strictly conform to the textual descriptions or are performed unnaturally are removed and recaptured on the spot. Xsens motion capture suit and Manus gloves are adopted for body and hand capturing, respectively. The body data captured using Xsens suits is in the format of Filmbox (FBX) human skeletons of 23 joints, and hand skeleton has 30 joints.
The occurrence of footskate that foot move around while contacting the ground may happen in data captured through any devices, thus we manually refine the data with footskate to ensure the high-quality of the dataset. To contribute to both academic and industrial communities, we retarget all the motion sequences from Xsens standards(23+30 joints) to SMPL-H [34](22+30 joints) and Manny(24+30 joints) in Unreal5 [8]. In addition, each text description is augmented to multiple pieces via ChatGPT [3] to enhance the generalizability of data. Annotators would manually review the generated text and remove the pieces that could not ensure the integrity and accuracy of the original information.
Previous methods are evaluated following the setting proposed in Text2Motion [11], that a motion feature extractor and text feature extractor are trained under contrastive loss to align the two spaces. Frechet Inception Distance(FID) score is calculated between generated motions and the ground-truth motions to indicate the quality. R-Precision is calculated through a model trained to align text and motion, which demonstrates the matching rate between text and motion. Diversity and Multimodality are also applied following the metrics in [10]. However, this evaluator is challenged to be weak and out-dated recently that these scores could not reflect the real quality of generated motions for two possible reasons. The model is based on a small RNN network of limited capacity, and it is trained on HumanML3D dataset that the data diversity and quality are far from satisfactory. We follow the evaluation schema in TEMOS [36] and TMR [37], training a transformer-based motion and text encoders on our dataset of fine-grained textual annotation and high-quality motion sequences. The decoder part in TEMOS is abandoned in our implementation, because we find the supervision of Kullback-Leibler(KL) divergence loss reducing the disparity of data which greatly hinders the validity of FID.
Replacing the most commonly used and widespread evaluation methods needs to be down with caution. One convincing approach to prove the effectiveness of our proposed method is to compare the R-Precision of ground-truth data among evaluators. We compare performance of the original RNN-based evaluator [11] trained on RoleMotion, and our transformer-based evaluator trained on RoleMotion. Tab. 2 shows that our evaluator outperforms the others obviously, and is utilized for all our experiments in this paper.
StableMoFusion. utilizes Conv1D UNet with linear crossattention for diffusion-based generation. For our dataset, we specifically adjusted the sampling steps of the DPM-Solver [24] to optimize performance. MotionDiffuse. utilizes cross-modality linear transformer for diffusion-based generation. Instead of predicting noise, we adapt it to directly predict real samples. Motion Diffusion Model (MDM). utilizes Transformer encoder for diffusion-based generation. For our dataset, we incorporate a padding mask to make the Transformer independent of motion padding. Motion Latent Diffusion (MLD). utilizes VAE to obtain latent motion encodings, followed by a transformer with long skip connections for diffusion in the latent space. During VAE training, we use the joint positions inferred from SMPL-H to compute the joint reconstruction loss.
Text Motion Retrieval (TMR). utilizes a Transformerbased joint synthesis and retrieval framework. In line with this method, we apply DistilBERT [42] and MPNet [48] to our text data, extracting token and sentence embeddings.
MoMask and T2M-GPT. both employ discrete representations to process continuous human motion data. During VQVAE training, we use the representation difference between adjacent frames as velocity to calculate the velocity reconstruction loss, and adjust the window size according to our dataset. When training on our full-body data, the codebook size is set to double that used for body-only data.
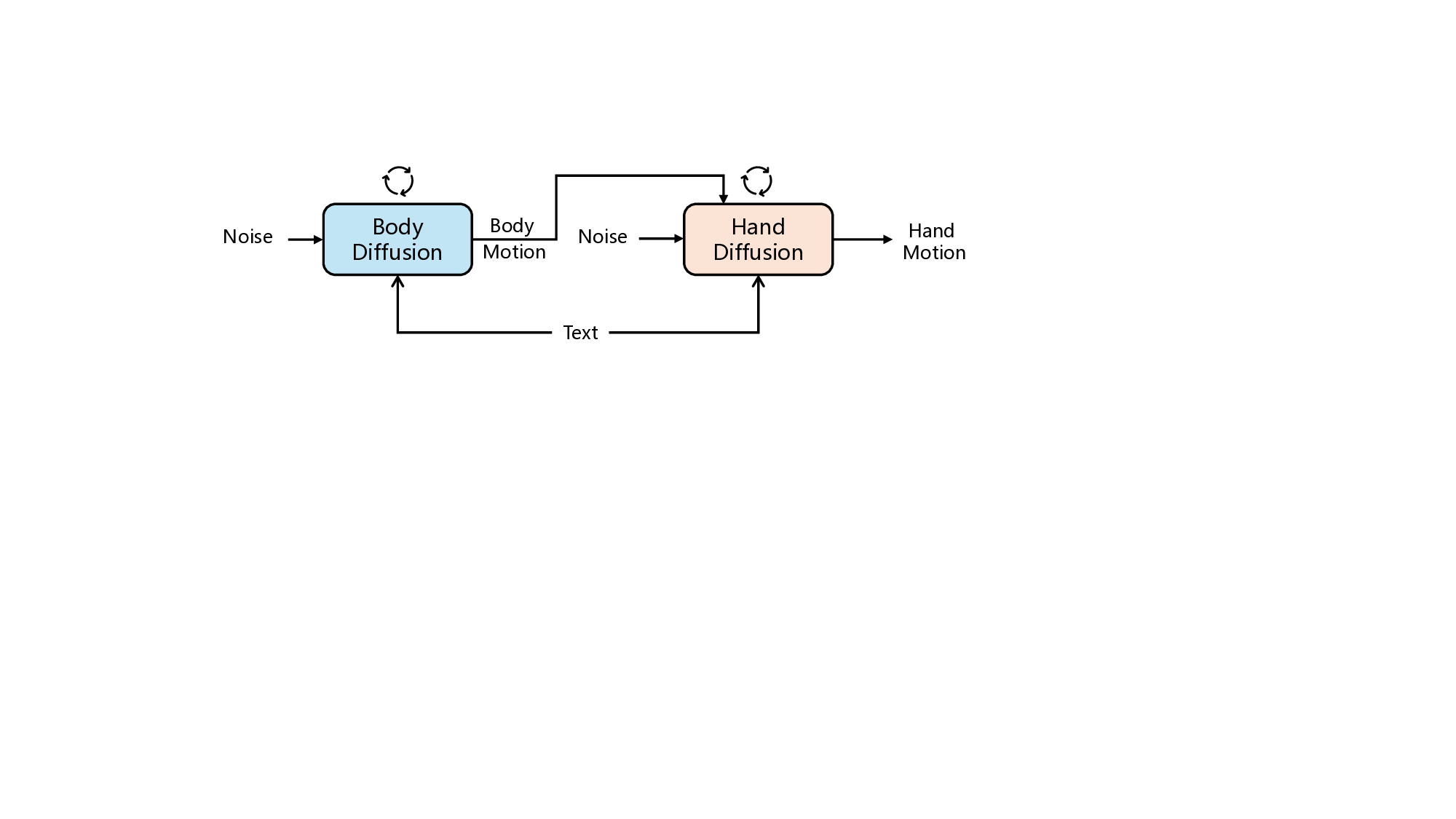
Whole-body motion generation involves the synthesis of temporal movement of the body and hands. The body movement generally dominates the motion semantics described by text instructions in our setting. In comparison, the hands are more dexterous and keep almost idle in many cases. Their movement should be coordinated with body movement and mainly make effects in interaction scenarios. Due to such a discrepancy, it is suboptimal to synthe-size the motion of the body and hands by a single generator. In light of this observation, we propose to disentangle the generation of body and hand motion. We employ efficient StableMofusion as the baseline and adapt it to two-stage generation. The first stage focuses on generating body motion according to the text instruction, which is the same as the original setting of StableMofusion. We therefore directly invoke StableMofusion and train it on our dataset variant that excludes hand motions. The second stage concentrates on the generation of hand motion. Considering the dependency between hands and body, we condition the denoising network on the body motion. We concatenate the ground-truth body motion with noisy hand motion as the input of the network during training. Such ideal conditioning suffers from somewhat inconsistency between training and inference, which may lead to inferior synthesis quality of hand motion. To enhance the robustness of generation, we follow the practice in cascade diffusion [15] and manually distort the body motion by Gaussian noise before conditioning. During inference, we invoke the first stage to generate the body motion. The outcome acts as the condition of the second stage for the synthesis of hand motion. The outputs of both stages are combined to form the final results.
Dataset Split. We follow HumanML3D [11] and Mo-tionX [21] to split the dataset into training, validation, and test sets with an 0.80 : 0.15 : 0.05 ratio. This division resulted in 8,236 samples for the training set, 515 samples for the validation set, and 1,545 samples for the test set.
Motion Representation. In our work, we use the translation of the root joint and the rotation of all joints to represent the human body pose. Specifically, the i-th pose in the human motion sequence m i is defined by a tuple (r x , r y , r z , j r ), where (r x , r z ) ∈ R are root translation on horizontal XZ-plane; r y ∈ R is root height; j r ∈ R 6N are 6D continuous rotations of all joints relative to their parent in a hierarchical structure, N denoting the number of joints. Our data follows the skeleton structure of SMPL-H [34] with 22 joints for the body and 30 joints for the hand.
Data Pre-processing. We adjust the root xz-translations (r x , r z ) for each pose to be relative to the 0-th pose and reset the root y-translation r y to place the motion on the ground by aligning the motion sequence’s lowest joint ytranslation to zero based on SMPL-H kinematics. All motions are scaled to 20 FPS.
Training and Inference Details. For training, we normalize the motion data by calculating the mean and variance, then average the variances within translation and rotation dimensions separately to achieve two unified scales: one unit variance for translation, and another for rotation.
In our experiments, we largely follow the original method’s training and inference settings. All experiments are conducted on NVIDIA A40 GPUs. More implementation details are provided in the appendix file.
To validate the quality, expressiveness and effectiveness of human motion generators and datasets as well, it is essential to provide a reliable evaluator. As introduced in Sec. 3.3, we compare our evaluator with the most widely used one proposed in Text2Motion [11], based on the R-Precision of ground-truth. Similar to TMR [37] and HumanTomato [25], we train a text encoder and a motion encoder for evaluation but discard the motion decoder, and the comparative loss of InfoNCE [32] with negative samples is utilized to better construct the latent space. Token embeddings and sentence embeddings are extracted using distilbert-baseuncased and all-mpnet-base-v2 from our text annotations. To evaluate motion of body and body with hands respectively, we train evaluators on data of both settings. As shown in Tab. 2, our evaluators outperforms the counterpart in every settings. Given this, all the FID and R-Precision in this paper are calculated by our evaluators instead. As illustrated in Tab. 3, the RoleMotion dataset demonstrates significantly superior text-motion alignment compared to the HumanML3D dataset.
Here we focus on two objectives: i) building a benchmark that shows how different methods perform on RoleMotion; ii) exploring the influence of generating hand motion while generating body motion. We train 4 diffusion-based methods [6,18,50,57], VAE-based TMR [37], VQVAEbased methods MoMask [14] and T2M-GPT [19] on our datasets. All the diffusion-based methods, MDM, Motion-Diffuse, MLD, StableMoFusion, and the VAE-based TMR are trained well and converge easily, following the setting in Sec. 4.1. However, when it comes to the VQVAE-based methods, models perform badly in the first stage of training VQVAE, and the reconstruction results on our test set are Table 2. R-Precision of ground-truth from RoleMotion tested by different evaluators. B and H denote Body and Hand. The higher matching score of texts and motions is achieved by our evaluator indicating that our evaluator is more reliable.
Text2Motion(B) 0.820 ±.003 0.931 ±.001 0.964 ±.001 0.509 ±.005 0.680 ±.004 0.768 ±.005 Ours(B) 0.939 ±.001 0.978 ±.001 0.987 ±.001 0.802 ±.005 0.902 ±.002 0.931 ±.001
Text2Motion(B&H) 0.867 ±.004 0.950 ±.002 0.974 ±.001 0.608 ±.005 0.770 ±.002 0.838 ±.004 Ours(B&H) 0.954 ±.002 0.988 ±.001 0.995 ±.001 0.828 ±.004 0.926 ±.002 0.950 ±.001 Second, we evaluate the models trained with whole-body data, including hands, on generating both body and hand motion. As listed in Tab. 6, the performance of TMR has greatly deteriorated. StableMoFusion keeps to be stable that the version of DDPM1000 and the two-stage version rank first and second in terms of FID and R-Precision. Influence of training body and hands together. To explore the influence of training with body and hands together on body motion generation, we train models on concatenated body and hand data and evaluate only body track in 1 All the diversities are calculated by our evaluator. generated output. The results in Tab. 5 reveal some interesting insights. Compared with models trained only with body data, it could be found that performance is universally impacted. While diffusion-based methods generally maintain the ranking, the performance of TMR deteriorates even harder than in Tab. 6. Meanwhile, the model trained using two-stage schema achieves the finest results. We infer that the numerous joints of hands squeeze the learning space of body joints, models like TMR trained with contrastive loss are greatly influenced compared to diffusion-based models. Another insight is that results evaluated on both body and hand seem to be more decent, and this implies that the numerous joints of hands are also suppressing body during evaluation. The result that two-stage model has weaker FID and R-Precision than the one-stage model also verifies this. Thus it is unreasonable to evaluate the body&hand motion generation with a single evaluator trained with body&hand. It is essential to train an evaluator of body and evaluate the body, and train an evaluator of body&hand and evaluate body&hand as an indicator of hand motion.
Fine-grained language driven human motion synthesis.
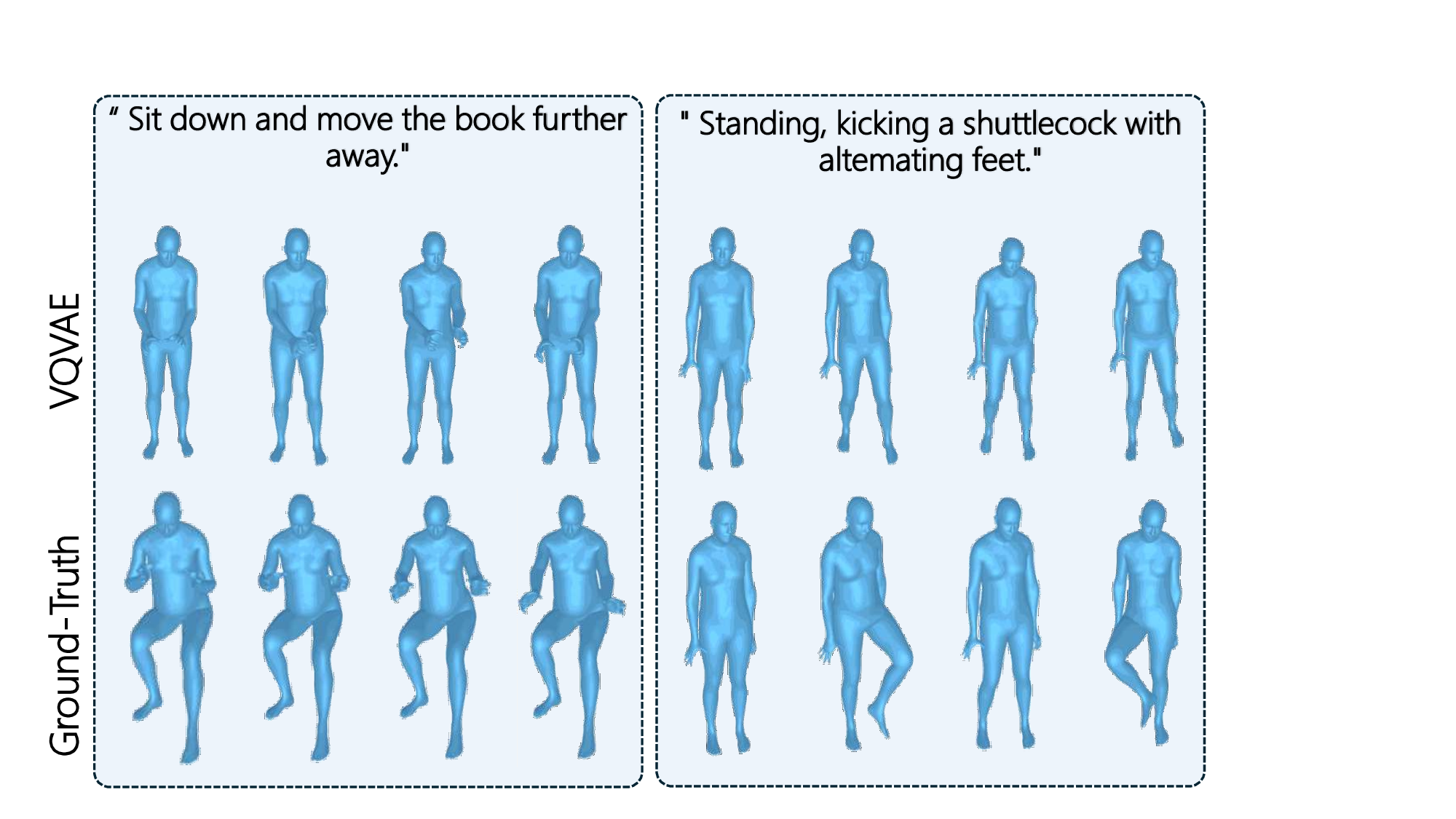
To display the quality of data and annotation, we compare models trained on HumanML3D and RoleMotion. We randomly create motion descriptions that need to specify the motion details while keeping all the action categories included in both datasets for fairness. As illustrated in Fig. 3, almost all the action details specified in the text are accurately conducted by model trained on RoleMotion, while motions of model trained on HumanML3D tend to be unnatural and contain many errors regarding body states, side of part and direction. This implies that the quality of motion data and granularity of annotation are extremely important for accurate motion generation. 1.871 ±.016 0.809 ±.006 0.905 ±.002 0.938 ±.003 19.200 ±.035 0.201 ±.024 MLD(DDIM50) [6] 5.244 ±.118 0.709 ±.003 0.833 ±.006 0.875 ±.007 19.066 ±.021 1.471 ±.120 MotionDiffuse(DDPM1000) [57] 1.859 ±.015 0.852 ±.004 0.935 ±.002 0.957 ±.002 19.160 ±.038 0.177 ±.022 TMR [37] 1.772 ±.006 0.865 ±.004 0.948 ±.001 0.970 ±.002 19.193 ±.051 0.063 ±.025 MMM [38] 7.558 ±.041 0.573 ±.005 0.682 ±.005 0.734 ±.004 19.100 ±.050 BAD [16] 7.430 ±.092 0.575 ±.004 0.682 ±.005 0.731 ±.004 19.110 ±.048 StableMoFusion(DPMSolver50) [18] 2.140 ±.011 0.843 ±.003 0.933 ±.003 0.959 ±.002 19.175 ±.049 0.202 ±.022 StableMoFusion(DDPM1000) [18] 1.709 2.236 ±.022 0.781 ±.003 0.884 ±.004 0.917 ±.002 19.151 ±.049 0.330 ±.041 MLD(DDIM50) [6] 9.016 ±.117 0.595 ±.004 0.722 ±.007 0.770 ±.007 19.011 ±.043 2.129 ±.138 MotionDiffuse(DDPM1000) [57] 2.985 ±.017 0.807 ±.002 0.905 ±.003 0.936 ±.001 19.129 ±.051 0.144 ±.019 TMR [37] 2.497 ±.009 0.838 ±.003 0.932 ±.002 0.958 ±.001 19.148 ±.049 1.450 ±.058 MMM [38] 7.951 ±.070 0.392 ±.003 0.480 ±.002 0.539 ±.003 19.087 ±.057 BAD [16] 8.474 ±.073 0.535 ±.003 0.631 ±.004 0.677 ±.005 19.046 ±.063 StableMoFusion(DPMSolver50) [18] 2.454 ±.014 0.813 ±.005 0.920 ±.002 0.949 ±.002 19.072 ±.040 0.190 ±.025 StableMoFusion(DDPM1000) [18] 2.042 ±.012 0.820 ±.004 0.928 ±.002 0.956 ±.002 19.097 ±.041 0.188 ±.024
Two-stage(DDPM1000) 1.719 ±.007 0.849 ±.004 0.938 ±.003 0.962 ±.001 19.133 ±.036 0.197 ±.022 Table 6. Quantitative results of models trained with body and hand data, and evaluated on body and hand track.
Method FID ↓ R-Precision↑ Diversity → Multi-modality ↑ top1 top2 top3 Real -0.828 ±.004 0.926 ±.002 0.950 ±.001 19.157 ±.035 -MDM(DDPM1000) [50] 1.786 ±.023 0.805 ±.004 0.904 ±.002 0.934 ±.002 19.134 ±.051 0.498 ±.051 MLD(DDIM50) [6] 4.941 ±.145 0.690 ±.009 0.807 ±.007 0.846 ±.006 19.081 ±.045 3.990 ±.210 MotionDiffuse(DDPM1000) [57] 1.760 ±.012 0.849 ±.003 0.935 ±.002 0.960 ±.002 19.151 ±.051 0.269 ±.042 TMR [37] 1.762 ±.013 0.848 ±.003 0.935 ±.002 0.960 ±.001 19.159 ±.057 0.267 ±.030 MMM [38] 6.533 ±.095 0.561 ±.007 0.663 ±.004 0.713 ±.004 19.152 ±.027 BAD [16] 6.524 ±.062 0.560 ±.004 0.664 ±.004 0.713 ±.004 19.073 ±.036 StableMoFusion(DPMSolver50) [18] 1.690 ±.009 0.864 ±.005 0.952 ±.002 0.973 ±.001 19.122 ±.053 0.316 ±.032 StableMoFusion(DDPM1000) [18] 1.532 ±.008 0.867 ±.004 0.952 ±.003 0.973 ±.002 19.133 ±.050 0.311 ±.031
Two-stage(DDPM1000) 1.426 ±.006 0.872 ±.003 0.953 ±.002 0.970 ±.001 19.168 ±.037 0.747 ±.046
This paper presents RoleMotion, a large-scale human motion dataset featuring extensive role-playing motions across diverse scenarios. The data is meticulously designed, collected, and annotated with fine-grained textual descriptions.
Experiments show that models trained on RoleMotion generate higher-quality motions with better textual alignment compared to existing datasets. We further establish a reliable evaluation benchmark for text-to-motion tasks. Finally, we explore the interplay between body and hand motion synthesis, advocating separate training and evaluation for each modality. Nevertheless, convincingly evaluating hand motion remains challenging, as it requires simultaneous alignment with both text and body movement.
📸 Image Gallery