Dynamic Correction of Erroneous State Estimates via Diffusion Bayesian Exploration
📝 Original Info
- Title: Dynamic Correction of Erroneous State Estimates via Diffusion Bayesian Exploration
- ArXiv ID: 2512.03102
- Date: 2025-12-01
- Authors: Yiwei Shi, Hongnan Ma, Mengyue Yang, Cunjia Liu, Weiru Liu
📝 Abstract
In emergency response and other high-stakes societal applications, early-stage state estimates critically shape downstream outcomes. Yet, these initial state estimates-often based on limited or biased information-can be severely misaligned with reality, constraining subsequent actions and potentially causing catastrophic delays, resource misallocation, and human harm. Under the stationary bootstrap baseline (zero transition and no rejuvenation), bootstrap particle filters exhibit Stationarity-Induced Posterior Support Invariance (S-PSI), wherein regions excluded by the initial prior remain permanently unexplorable, making corrections impossible even when new evidence contradicts current beliefs. While classical perturbations can in principle break this lock-in, they operate in an always-on fashion and may be inefficient. To overcome this, we propose a diffusion-driven Bayesian exploration framework that enables principled, real-time correction of early state estimation errors. Our method expands posterior support via entropyregularized sampling and covariance-scaled diffusion. A Metropolis-Hastings check validates proposals and keeps inference adaptive to unexpected evidence. Empirical evaluations on realistic hazardous-gas localization tasks show that our approach matches reinforcement learning and planning baselines when priors are correct. It substantially outperforms classical SMC perturbations and RL-based methods under misalignment, and we provide theoretical guarantees that DEPF resolves S-PSI while maintaining statistical rigor.📄 Full Content
One major source of initial state estimation error is the inherent uncertainty and bias in early-stage human assessments. When decision-makers narrow their focus based on incomplete or misleading information, they risk excluding the true state of the world from consideration. Once an erroneous initial state estimate anchors the process, it creates a path-dependent trap: monitoring systems and responders may remain fixated on the wrong location or strategy, even as contradictory evidence mounts. In practice, this means a search algorithm could ignore critical regions outside the presumed hazard zone, or resources might continue to be deployed ineffectively, compounding the crisis’s social and economic impacts. To avoid such outcomes, it is crucial to develop adaptive algorithms that revisit and revise early assumptions as new observations arrive.
From a robotics and Bayesian inference perspective, the above scenario is essentially a state estimation problem: an agent must form an initial belief (prior) about the latent state (e.g., the hazard’s location) and update this belief as new sensor data arrives. If the initial belief is mis-specified, the goal is to correct this incorrect state estimate in real time by incorporating incoming evidence. For clarity, we use the term initial policy error to denote such a mistaken initial state estimate under prior uncertainty, which our approach aims to correct. In recent years, particle filtering (PF) has become a go-to approach for sequential Bayesian state estimation in these settings Ristic (2013); Gordon et al. (1993b); Doucet et al. (2001a). PF offers a principled way to update beliefs by fusing sensor data with prior knowledge, making it a representative framework to tackle the problem of erroneous initial state estimates in emergency response and other high-stakes decision domains. However, existing Bayesian filtering methods Fox et al. (2003); Smidl & Quinn (2008) struggle with erroneous initial state estimates, often failing to recover when the true state lies outside the initial belief. 1) Bootstrap particle filters Candy (2007); Gordon et al. (1995) tend to remain confined to the support of the initial prior, hindering exploration beyond the originally assumed region when operated under a stationary bootstrap baseline with zero transition and no rejuvenation. We formalize this baseline-specific lock-in as Stationarity-Induced Posterior Support Invariance (S-PSI): under the zero-transition, no-rejuvenation baseline, the posterior cannot escape the initial support. Importantly, S-PSI is not an inherent limitation of PF; classical countermeasures (e.g., jittering, roughening) can in principle expand support (we include these as baselines in our experiments). 2) More advanced PF variants,such as auxiliary particle filters Mountney et al. (2009); Branchini & Elvira (2021) or filters with optimal proposal distributions, can partially mitigate bias when the true state has a small non-zero prior probability Fox (2001); Douc & Cappé (2005); Liu & Chen (1998); Doucet et al. (2000); Arulampalam et al. (2002), but they fundamentally cannot handle cases where the true state was assigned zero initial probability. Under the standard Bayesian update, any region with zero prior mass will remain at zero posterior mass indefinitely, meaning the algorithm can never discover a completely excluded possibility under this baseline. 3) Attempts to address these issues by augmenting particle filters have had limited success. Some works inject noise or broaden the prior artificially, and others integrate reinforcement learning (RL) with PF Shi et al. (2024); Zhao et al. (2022); Park et al. (2022) to actively guide sensor exploration. While such approaches can improve data collection, they may inherit the same blind spots from a mis-specified prior and often introduce significant complexity and resource demands. Without a new perspective, Bayesian trackers and decision methods remain at risk of locking onto an incorrect initial belief, especially under the S-PSI.
To overcome these challenges, we propose a novel approach called Diffusion-Enhanced Particle Filtering (DEPF) that dynamically corrects erroneous initial state estimates via a diffusion-driven Bayesian exploration mechanism. The key insight of DEPF is to expand the particle filter’s support in response to observation feedback, allowing the algorithm to break out of the constraints imposed by a flawed initial prior. Instead of passively accepting the prior’s limits, our method systematically injects a small number of exploratory particles into regions outside the currently believed range. This injection is guided by indicators of model inconsistency when incoming sensor data strongly contradicts the filter’s predictions (e.g., high error or entropy). A controlled stochastic diffusion process then spreads these exploratory particles into previously neglected areas, effectively probing the hypothesis that the true state might lie beyond the old bounds. We incorporate a Bayesian validation step to ensure that the expanded support remains statistically coherent. Through this belief-triggered diffusion-and-validation cycle, DEPF augments the PF inference layer and mitigates S-PSI when it arises under the stationary bootstrap baseline.
The main contributions of this work are as follows: (1) We identify and formally define the Stationarity-Induced Posterior Support Invariance (S-PSI) under the zero-transition, no-rejuvenation bootstrap baseline, characterizing it as a diagnostic condition rather than a universal PF limitation ( §3.4). ( 2) We propose the DEPF framework, a particle filtering method that introduces a principled, belief-triggered technique to dynamically expand inference support beyond initial belief constraints ( §4). (3) We demonstrate via theory and experiments (hazardous gas leak scenarios) that DEPF can effectively correct initial state estimation errors across different scales and error severities, substantially improving localization and response efficiency over existing methods, including RL/planning baselines and classical perturbations ( §5).
In emergency localization scenarios Wu et al. (2021); Hite (2019), Bayesian filtering Fox et al. (2003); Smidl & Quinn (2008); Quinlan & Middleton (2009) methods such as the bootstrap particle filter leverage Bayesian inference to iteratively update state estimates but typically assume correctly-specified initial priors, thus may become ineffective under severely misaligned early assumptions when operated under a stationary bootstrap baseline (zero transition, no rejuvenation), due to Stationarity-Induced Posterior Support Invariance (S-PSI) Gordon et al. (1995);Candy (2007). S-PSI is a baseline-specific diagnostic rather than an inherent limitation of PF; classical countermeasures such as jittering/roughening or resample-move can, in principle, expand support, and we include them as baselines in §5. Advanced particle filter variants, including auxiliary particle filters Mountney et al. (2009); Branchini & Elvira (2021) and filters using optimal proposal distributions, improve proposal quality and sample efficiency but still fail when the initial belief assigns zero prior probability to the true state Fox (2001); Arulampalam et al. (2002), i.e., in the presence of a zero-prior barrier without explicit support expansion. Meanwhile, information-theoretic methods like Infotaxis Vergassola et al. (2007), Entrotaxis Hutchinson et al. (2018) and DCEE Chen et al. (2021) focus sensor motions on maximizing expected information gain or reducing entropy, yet they typically operate within the belief support induced by the initial prior and thus cannot systematically correct severe prior misalignment in real time without a support-expanding inference layer. More recently, integrated reinforcement learning and particle filtering (RL-PF) methods have emerged-e.g., AGDC and its variants using KL-divergence or entropy-based intrinsic rewards Shi et al. (2024), PC- DQN Zhao et al. (2022), and GMM-PFRL Park et al. (2022). While these RL-driven methods exhibit stronger adaptive exploration, they can still inherit the zero-prior barrier when the underlying filtering layer does not expand support (cf. the S-PSI baseline). In contrast, our proposed DEPF explicitly addresses this gap by introducing a belief-triggered, validated support-expansion mechanism that operates at the inference layer, making it complementary to proposal-improvement filters, classical perturbations (jittering/roughening/rejuvenation), and planning/RL controllers, and yielding superior robustness under severely misaligned early assumptions.
3.1 PROBLEM SETUP Consider a two-dimensional spatial domain Ω ⊂ R 2 with a stationary hazardous gas source. We describe the unknown source term by the parameter vector at time step k: Θ k = [x s , y s , q s , u s , ϕ s , d s , τ s ] ⊤ ∈ R 7 where p s = (x s , y s ) ∈ Ω ⊂ R 2 represent the Cartesian coordinates of the source, q s ∈ R + denotes the scaled release strength, representing the true emission rate adjusted by an unknown sensor calibration factor, u s ∈ R + and ϕ s ∈ [0, 2π) represent the wind speed and wind direction respectively, d s ∈ R + describes the diffusivity of the gas in air, τ s ∈ R + indicates the effective lifetime of the gas. At each discrete time step k, a mobile robot equipped with a gas sensor occupies position p k = (x k , y k ) ∈ Ω and records a scalar sensor output z k ∈ R + , which represents the raw voltage signal from the gas sensor. This signal serves as the observation in the Bayesian filtering model, linking sensor data to the hidden source state Θ. The cumulative sensor readings up to step k are denoted as z 1:k = {z 1 , z 2 , . . . , z k }. Our objective is to estimate the posterior distribution p(Θ k | z 1:k ) given the observed sensor signals z 1:k (i.e., raw voltage measurements), and robot locations, under the assumption of source stationarity, i.e., Θ k+1 = Θ k . To handle nonlinearities and intermittency in sensor readings, a particle filter is adopted to iteratively approximate this posterior.
We adopt a simplified analytical plume model derived from the advection-diffusion equation to represent gas transport from the source to the sensor location. The expected sensor output at location p k under source parameters Θ is given by: h
Since we use a low-cost metal oxide (MOX) sensor, the sensor output is not a calibrated concentration but a voltage value subject to significant uncertainty and miss-detection. Thus, the final measurement model is:
encodes whether the sensor successfully detects the gas, P d is the probability of detection, reflecting turbulence, dilution, or sensor failure. The resulting Gaussian mixture likelihood function becomes:
Particle filtering offers a non-parametric, sequential Bayes estimator of the posterior p(Θ k | z 1:k ).
We represent that posterior by a set of N weighted particles { Θ
k = 1, with δ(•) the Dirac delta. In general, particles propagate via a transition kernel p(Θ k | Θ k-1 ) and are sampled from a proposal q(Θ k | Θ k-1 , z k ). The importance weights then update as
w(j) k , with the likelihood p(z k | Θ) given in §3.2. We trigger resampling when the effective sample size
k ) 2 falls below a threshold η. In the widely used bootstrap filter, the proposal equals the transition,
k . In our setting the source term Θ is assumed static during the response horizon. Without a natural dynamical law, a common and widely used reference method is the bootstrap filter, where particles are simply carried forward and only their weights are updated by the likelihood of new sensor data.
The simplicity of the bootstrap filter, while natural under static parameters, reveals a structural vulnerability: particles remain fixed in parameter space and can never leave the initial prior region. Even when new observations strongly contradict the prior, the filter cannot escape this confinement. We formalize this lock-in effect as Stationarity-Induced Posterior Support Invariance (S-PSI).
Let the prior be p 0 (Θ) with support S prior := supp p 0 (Θ) = { Θ :
) and no rejuvenation step (e.g., jittering, roughening, resample-move) is applied. Proposition 3.2 (S-PSI under M.1). If particles are initialized within S prior , then for all k, supp p(Θ | z 1:k ) ⊆ S prior . In words, the posterior support remains permanently trapped inside the initial prior region. As a direct consequence, if the true source Θ * lies outside the prior, then Θ * / ∈ S prior ⇒ p(Θ * | z 1:k ) = 0, ∀k, i.e., the filter fundamentally cannot discover it, not due to likelihood mismatch, but simply because no particles ever enter that excluded region. The interaction between the mobile robot and the unknown gas plume can be framed as a partially observableMarkov decision process (POMDP) M = (S, A, Ω, T, O, R, γ), where S is the latent state space containing the stationary source vector Θ = (x s , y s , q s , u s , ϕ s , d s , τ s ) ⊤ ; A is the set of motion commands that move the robot in the plane; Ω is the observation space, where an observation at time
where the likelihood p(z k | p k , Θ) is the mixture-Gaussian plume sensor model of §3.2. At decision time the agent cannot access Θ directly, so it reasons with the belief b k = p(Θ | z 1:k ) supplied by the particle filter. We therefore feed the RL policy with the augmented information state
The reward is chosen as the expected one-step information gain
encouraging actions that shrink posterior uncertainty, and future rewards are discounted by γ ∈ (0, 1). The objective is to learn a policy π * that maximises the expected discounted return J = E[ ∞ t=0 γ t R k+t ], thereby steering the robot along paths that are most informative about the hidden source. The details are provided in Appendix § N.
Particle filtering provides a sequential Bayesian framework with weighted particles approximating the posterior. Under the S-PSI baseline introduced in §B-i.e., a zero-transition, no-rejuvenation bootstrap setting-the posterior support cannot escape the initial prior support S prior . We treat this as a didactic baseline, not an inherent limitation of PF. To mitigate S-PSI when it arises, we propose a diffusion-enhanced correction module (Fig. 1) that (i) injects a small fraction of exploratory particles, (ii) applies covariance-scaled stochastic diffusion, and (iii) validates proposals via Metropolis-Hastings (MH), thereby enabling minimal-bias, data-triggered support expansion.
Adaptive Diffusion via Exploratory Particles: At each time step, a subset of particles is designated as exploratory particles, which introduce a uniform diffusion process into the framework. These particles are sampled from an adaptively extended bounding region B k , dynamically adjusted according to the current particle distribution to cover regions beyond the initial prior boundary S prior :
where x max and y max denote the current maximum particle positions along each spatial dimension and δ is an adaptively determined margin parameter. Exploratory particles are then uniformly sampled from this expanded bounding region:
, where E represents the indices of exploratory particles. The exploratory particles are initialised with small weights: w
This mechanism enables the bootstrap filter to sample states outside the original support range S prior , thereby increasing the likelihood of reaching states Θ * / ∈ S prior .
To ensure that the exploratory diffusion does not collapse prematurely, an entropy regularisation term is added during the weight update step. This regularisation diffuses the weights across all particles, encouraging exploration of low-probability regions:
, where H(w k ) is the entropy of the weight distribution, defined as:
The regularisation parameter β is adaptively chosen based on the discrepancy between the current entropy and a predefined target entropy
, where β min and β max represent the predefined minimum and maximum regularisation strengths, respectively. By penalising weight distributions that become overly concentrated, this adaptive entropy-based mechanism promotes balanced diffusion across the state space. The diffusion of weights helps exploratory particles retain influence, thus effectively encouraging the discovery and sustained exploration of regions beyond S prior .
Kernel-Induced Stochastic Diffusion: To further expand the particle support range dynamically, we introduce a stochastic diffusion mechanism based on kernel perturbations. Each particle Θ (i) k is perturbed by a Gaussian kernel that models diffusion within the local neighbourhood:
n+4 is the optimal kernel bandwidth dynamically adjusted to balance exploration and precision L is the lower triangular matrix obtained from the Cholesky decomposition of the covariance matrix Σ, ensuring diffusion adapts to the local particle distribution. The covariance matrix Σ is computed dynamically:
k is the weighted mean, and λ > 0 ensures positive definiteness of Σ. This perturbation mechanism expands the effective support range by introducing stochastic diffusion, allowing particles to explore new regions iteratively:
Diffusion-Driven Validation via MCMC: To ensure consistency with the target posterior distribution, a Metropolis-Hastings acceptance criterion Hastings (1970) validates the diffused particles. For each perturbed particle Θ (i) k , the acceptance probability is:
.
A uniformly sampled random variable u i ∼ U(0, 1) determines whether the particle is accepted:
where I(α i < u i ) is the indicator function, which equals 1 when α i < u i is true, and 0 otherwise. This step ensures that the diffusion-driven expansion aligns with the posterior distribution, preserving the accuracy of the particle filter.
Diffusion-Enhanced Particle Filtering: By integrating exploratory particles, entropy-driven diffusion regularisation, and kernel-induced stochastic perturbations, the proposed framework creates a dynamic diffusion process that iteratively expands the effective support range. The recursive relationship for the support range becomes: S k+1 = (S k ∪ B) ⊕ h opt , where ⊕h opt represents kernel-induced stochastic diffusion. This diffusion framework effectively mitigates the posterior support invariance by continuously extending the particle filter’s exploration capability, enabling robust state estimation for target states Θ * / ∈ S prior . The detailed theoretical analysis and justification of the effectiveness of our proposed method are provided in Appendix §C.
To evaluate the ability of our method to dynamically recover from severe prior misalignment, we conduct experiments using the ISLC environments (ISLCenv), a simulation suite designed for emergency gas leak localization under varying levels of initial policy error. As detailed in §F, ISLCenv models a multi-source Gaussian plume and simulates noisy sensor observations without explicit reward signals. This setup allows us to rigorously assess the capacity of DEPF and competing baselines to overcome posterior support limitations and adaptively infer the full 7-D parameter vector Θ in real time under realistic operational constraints, rather than only the source coordinates.
To evaluate our proposed approach and compare it against baseline algorithms, we use four distinct metrics: Operational Completion Efficacy (OCE), which measures how frequently emergency response missions meet their goals, with higher scores indicating better deployment effectiveness; Average Deployment Efficiency (ADE), representing the average distance traveled by response units, where shorter distances imply more efficient routing; Response Execution Velocity (REV), quantifying the time duration from deployment to task completion, with faster times signifying more efficient operations; and Localization Precision Score (LPS), assessing the accuracy of source localization by computing the average discrepancy between estimated and actual source locations, with smaller values denoting higher accuracy. Our proposed method is evaluated alongside various baseline algorithms, grouped according to their methodological foundations. The first group merges reinforcement learning with Bayesian inference and includes a single representative, AGDC Shi et al. ( 2024 (2000), PF+Roughening Gordon et al. (1993b;1995), andPF+Rejuvenation Hastings (1970); Doucet et al. (2000). Implementation details and hyperparameter grids are given in §H and I. We evaluate our proposed approach under three distinct scenarios representing different levels of initial policy error made by emergency response planners. In all scenarios, the agents operate in a 30 × 30 spatial domain, and the gas source location, wind speed, and wind direction are sampled according to the distributions specified in Table 7 of Appendix §F. Each training and testing instance uses entirely different plume parameters, with 1000 training and 500 testing instances. Agents start uniformly distributed within the initial subregion (0, 5) × (0, 5) and move with unit-length steps.
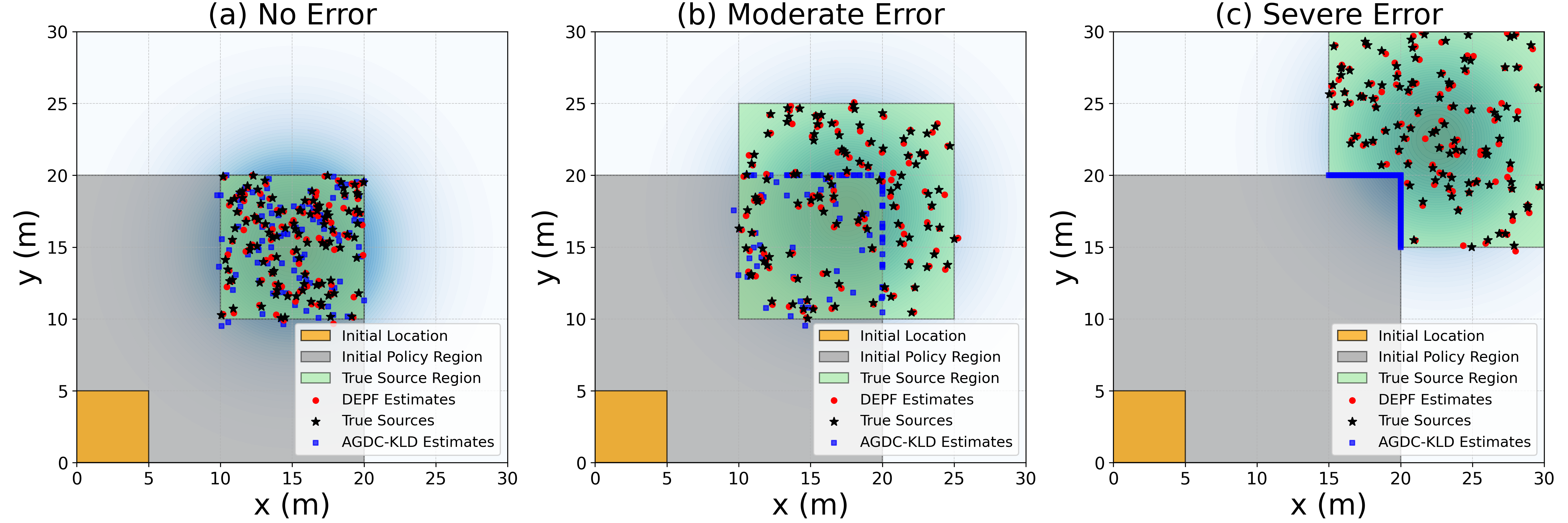
The three initial estimation error scenarios in Figure 2 represent increasing levels of prior misalignment between the initial belief and the true disaster source.
(1) No Error (Ideal) corresponds to an ideal case where the initial particle distribution fully covers the true source region, providing a best-case baseline without decision uncertainty.
(2) Moderate Error (Partial Misalignment) models a realistic situation where the initial assumed region partially overlaps with the true source area, testing whether each method can adapt to moderate initial mistakes.
(3) Severe Error (Complete Misalignment, PSI) is the most challenging case, where the initial prior support is entirely disjoint from the true source location, creating a strict zero-prior barrier. This PSI scenario explicitly probes whether an algorithm can expand its posterior support and recover from severely misaligned initial state estimates, a setting in which standard bootstrap particle filters typically fail. The exact spatial layouts and parameter ranges for these three scenarios are provided in the appendix E.
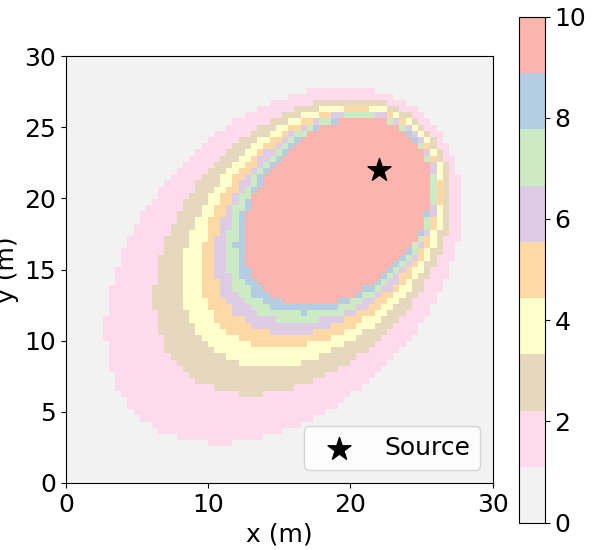
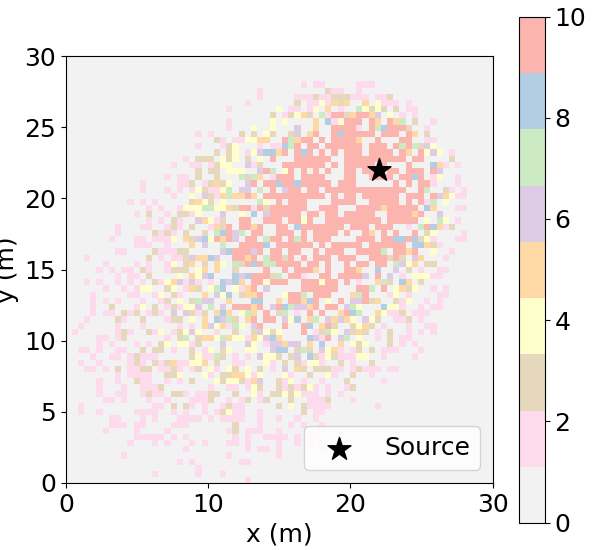
We conduct a detailed evaluation of DEPF and nine baseline algorithms under varying levels of initial policy error-No Error, Moderate Error, and Severe Error-each tested in both small-scale (agent-domain ratio 1:30) and large-scale (1:300) environments. Performance is assessed using four metrics: OCE, ADE, LPS, and REV. Quantitative results are presented in Table 1, with spatial illustrations provided in Figure 3, which visualizes the posterior estimates from 100 test trials of DEPF and AGDC under each policy error condition.
No Error (Ideal). When the initial prior support fully covers the true source region, all methods perform well. DEPF attains OCE = 0.90, LPS = 0.20, ADE = 19 (small-scale) and ADE = 167 (large-scale), with REV = 0.10 in both scales. AGDC closely matches DEPF on all metrics (OCE = 0.90/0.87, LPS = 0.20, ADE = 18/168). RL baselines PC-DQN and GMM-PFRL also converge (OCE ≈ 0.80), while information-theoretic planners show varying success (e.g., Infotaxis achieves OCE 0.85 in small-scale but degrades in large-scale). The three classical SMC perturbation baselines (PF+Jittering/Roughening/Rejuvenation) behave similarly or slightly worse than DEPF due to always-on diffusion incurring mild over-exploration cost in ideal conditions. Moderate Error (Partial misalignment). With partial overlap between prior support and ground truth, DEPF maintains high performance: OCE = 0.90, LPS = 0.20, ADE = 22 (small) and ADE = 200, REV = 0.10 (large). AGDC degrades substantially (OCE = 0.45/0.42, LPS = 2.60, ADE = 59/235) with increased timeouts at larger scale. PC-DQN and GMM-PFRL show similar or worse drops (OCE ≈ 0.40). Among planners, Infotaxis/Entrotaxis/DCEE underperform markedly (see Table ). Notably, the classical PF perturbation baselines recover part of the gap relative to RL/planning baselines: PF+Rejuvenation > PF+Roughening > PF+Jittering in OCE/LPS, consistent with resample-move providing the strongest rejuvenation. However, all three remain well below DEPF in both accuracy and efficiency, especially in the large-scale setting where path lengths and timeouts increase. Severe Error (Complete misalignment; S-PSI test). This scenario creates a strict zero-prior barrier: the initial prior support is disjoint from the true source region. DEPF remains stable with OCE = 0.89 (small) and 0.88 (large), LPS = 0.20, and ADE = 27/255-all below the 100/300 step timeout thresholds and with REV = 0.10. In contrast, bootstrap PF under the S-PSI baseline (zero transition, no rejuvenation) cannot escape the prior support; accordingly, AGDC, PC-DQN, GMM-PFRL, and information-theoretic planners collapse (OCE < 0.05, LPS > 12.5; frequent timeouts). The classical SMC perturbation baselines alleviate this limitation to a degree: PF+Rejuvenation achieves the highest non-zero success among the three (occasionally localizing in the small-scale severe case), followed by PF+Roughening and then PF+Jittering; nevertheless, their success rates remain low and many runs still timeout-especially in the large-scale severe case-highlighting the cost of always-on diffusion and the absence of belief-triggered control.
We perform a series of ablations and sensitivity studies to understand how different components and hyperparameters of DEPF affect performance under the Severe Error setting, where the true source lies entirely outside the initial prior support.
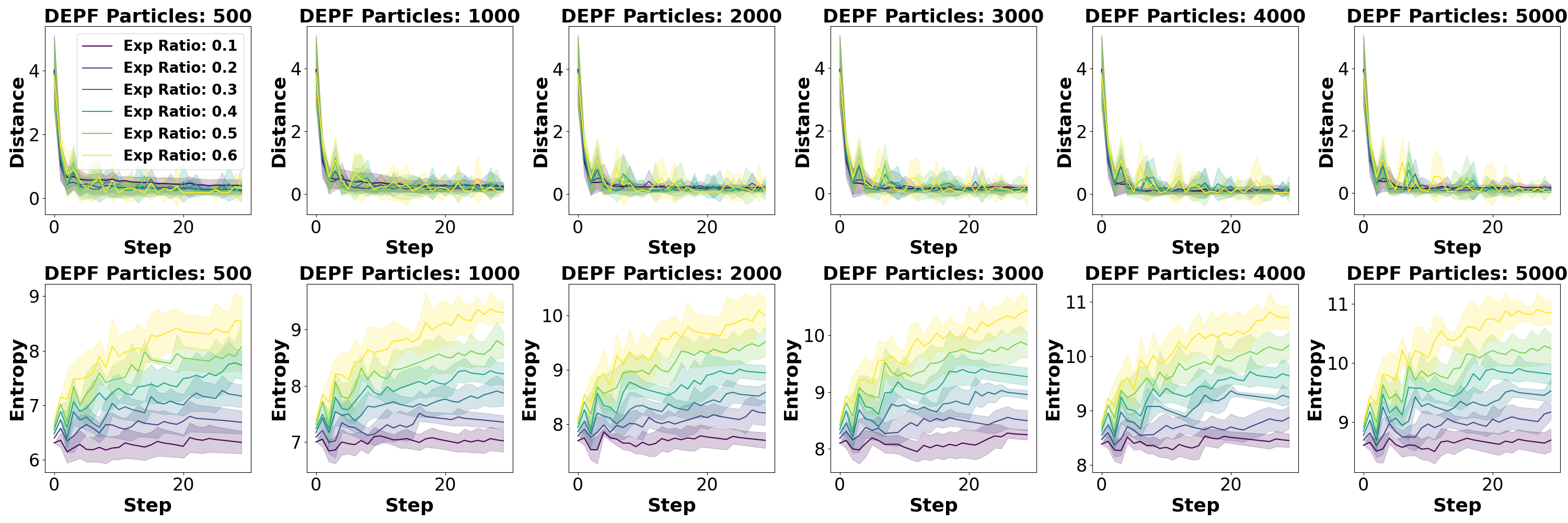
Figure 4: Impact of the number of particles and δ on DEPF performance under Severe Error.
Sensitivity to particle number and margin parameter δ. We first analyze how DEPF’s performance is affected by the number of particles and the support margin ratio δ, which determines the proportion by which the posterior support region is expanded beyond the initial prior boundary at each step. As shown in Figure 4, increasing δ generally allows the model to converge more quickly-reflected in lower belief-to-goal distances-because particles are better able to explore outside the constrained prior region. However, this broader support also leads to higher posterior entropy, as particles become more dispersed and the belief distribution less concentrated. This trade-off is particularly pronounced at low particle counts (e.g., N = 500-2000), where large δ causes belief imprecision. When using larger particle sets (N ≥ 3000), DEPF maintains both fast convergence and acceptable entropy levels even at higher δ, indicating that sufficient particle resolution can stabilize exploration-induced uncertainty. Overall, a moderate support ratio (δ ∈ [0.2, 0.4]) paired with adequate particle numbers achieves a good balance between exploration and localization precision. These results reinforce DEPF’s ability to recover from severely misaligned initial state estimates by dynamically expanding support and refining the belief. Bayesian consistency. These outcomes highlight that DEPF’s gains do not stem from ad-hoc noise, but from a calibrated, evidence-triggered expansion pipeline.
Hyperparameter sensitivity: λ and A. We then study the kernel stability parameter λ, which controls the diagonal regularization added to the empirical covariance, and the KDE bandwidth constant A. The two tables below summarize the effect of these hyperparameters. Mid-range values of λ (10 -3 -10 -2 ) strike the best balance between numerical stability and diffusion accuracy, yielding the lowest ADE and competitive OCE. Too large a λ overdamps useful moves and slows convergence; too small a λ induces numerical instability and degraded metrics. For the bandwidth constant A, an intermediate value A ≈ 0.5 minimizes belief-to-goal distance, posterior entropy, and convergence steps, whereas either under-or over-diffusion (very small or very large A) harms recovery. This confirms the need for bandwidth matching to the evolving posterior covariance, as encoded by DEPF’s covariance-scaled perturbations.
Hyperparameter sensitivity: β and exploratory ratio. Finally, we study the entropy regularization strength β and the ratio of exploratory particles per step, summarized in Table 5 and Table 6. As β increases from 0.1 to 0.4, the task OCE steadily improves from 0.88±0.04 to 0.91±0.02, while the path cost (ADE) decreases from 22±1.2 to 18±0.7 and the localization error (LPS) drops from 0.25 ± 0.03 to 0.19 ± 0.01. Execution latency (REV) remains around 0.10 ± 0.05, indicating that entropy regularization primarily enhances convergence efficiency and localization accuracy without introducing additional delays. When β is further increased to 0.5, all metrics remain essentially unchanged, suggesting that performance enters a plateau and becomes robust within the range β ∈ [0.3, 0.5]. For the exploratory-particle ratio, there is a clear interior optimum around 5% (Table 6). Too few exploratory particles slow support expansion and delay recovery; too many inject excess randomness, raising entropy and slightly reducing stability. Together with the diffusion-related ablations, these results yield a practical recipe: pair a moderate exploratory ratio (about 5%) with a mid-range bandwidth (A ≈ 0.5), moderate smoothing (β ≈ 0.3-0.4), and a stability parameter λ in [10 -3 , 10 -2 ] to reliably break S-PSI while maintaining efficient convergence.
In this work, we identified and formalized S-PSI, a baseline-specific limitation of bootstrap particle filters that arises under zero transition and no rejuvenation. To address this issue, we proposed the DEPF framework, which dynamically expands posterior support through exploratory particle injection, entropy-driven diffusion, and kernel-based perturbations validated by Metropolis-Hastings.
Experiments on hazardous-gas localization tasks demonstrated that DEPF consistently corrects severe prior misalignment, substantially outperforming both classical perturbation strategies and RL-based baselines. By resolving bootstrap-specific lock-in while maintaining Bayesian rigor, DEPF offers a robust and practical solution for decision-support systems in emergency management.
The particle filtering process recursively approximates the posterior distribution P (Θ k | z 1:k ) through four main steps: sampling, weight update, normalization, and resampling. These steps iteratively adapt particle sets to new observations, enabling sequential Bayesian inference.
Step 1. Sampling (Prediction): Gordon et al. (1993b) Particles are sampled from an importance distribution q(Θ k | Θ k-1 , z k ), typically approximated by the state transition model
The propagation of particles is expressed as:
where
k denotes the i-th particle at time k.
Step 2. Weight Update: Doucet et al. (2001a) Particle weights are updated to reflect their likelihood given the new observation. The unnormalized weights are calculated as:
k ) is the observation likelihood, and q(Θ k | Θ k-1 , z k ) is the importance distribution used in sampling.
Step 3. Normalization of Weights: Liu & Chen (1998) Weights are normalized to maintain their probabilistic interpretation:
Step 4. Resampling: Doucet et al. (2000) To mitigate weight degeneracy (domination by a few particles), resampling occurs when the effective particle number N eff falls below a threshold:
.
Particles are then resampled based on current weights, and weights are reset uniformly:
These recursive steps approximate the posterior P (Θ k | z 1:k ). However, under the stationary bootstrap baseline with zero transition and no rejuvenation, particle trajectories remain confined to the initial prior support. We formalize this diagnostic effect as Stationarity-Induced Posterior Support Invariance (S-PSI): the posterior cannot expand beyond the prior support in this baseline setting. Importantly, S-PSI is not an inherent property of particle filtering-classical perturbation strategies such as jittering, roughening, or resample-move can, in principle, relax this constraint, and are included as baselines in our experiments.
Let the prior p 0 (Θ) have support S 0 := supp p 0 (Θ) = {θ | p 0 (θ) > 0} ⊂ R 7 . If particles are initialized exclusively within S 0 , then under a stationary bootstrap baseline with zero transition and no rejuvenation, the posterior distributions at all subsequent time steps will satisfy:
We refer to this diagnostic baseline effect as Stationarity-Induced Posterior Support Invariance (S-PSI). It indicates that:
Even if observations strongly suggest a source location outside the prior support, the particle filter cannot estimate it-not due to insufficient likelihood, but because no particles exist in that region under the baseline assumptions.
Consequently, estimation fails if the true source Θ * lies outside the initial prior support:
Proposition B.1 (S-PSI under the stationary bootstrap baseline). Given particles initialized exclusively within the prior support S 0 , the particle support range S k at any time k satisfies:
with the base case: S 0 = S prior .
Thus, under the baseline assumptions, the posterior support remains invariant over time:
Proof. By definition, the particle support S k at step k is:
For the base case at k = 0, by construction:
Assume inductively that S k-1 ⊆ S prior . Particle propagation at time k depends entirely on particles from step k -1, and under the stationary baseline assumption (no transition noise, no rejuvenation), we have:
Combining this with the inductive hypothesis:
Thus, particles cannot move beyond the initial support boundary under this baseline, making the posterior support invariant over time.
Remarks. S-PSI is not an inherent property of particle filtering but a consequence of the stationary bootstrap baseline. Classical perturbation strategies such as jittering, roughening, or resamplemove rejuvenation can, in principle, relax this invariance and are included as baselines in §5. Our proposed method DEPF builds upon this insight by introducing belief-triggered exploratory injection, covariance-scaled diffusion, and MH validation, enabling adaptive support expansion only when data contradict the current belief.
In this appendix, we provide a theoretical analysis of the Diffusion-Enhanced Particle Filtering (DEPF) framework proposed in Section 4, focusing particularly on the rationality, correctness, and asymptotic unbiasedness of its mechanisms: exploratory particle injection, entropy-based weight smoothing, kernel-induced stochastic perturbation, and Metropolis-Hastings (MH) validation.
By injecting exploratory particles uniformly drawn from an expanded region B k beyond the initial prior support S 0 , DEPF implicitly modifies the initial prior distribution p 0 (Θ) as:
where U (B k ) denotes the uniform distribution on B k . This is equivalent to relaxing the diagnostic Stationarity-Induced Posterior Support Invariance (S-PSI) baseline, which arises under a stationary bootstrap PF with zero transition and no rejuvenation ( §3.4). Since ϵ is small, this injection introduces minimal bias while enabling posterior support expansion outside S 0 .
To preserve particle diversity, DEPF smooths weights toward higher entropy. One implementation is:
which can be viewed as Bayesian smoothing (Doucet et al., 2001b;Liu & Chen, 1998). In practice, we also adopt a standard tempering scheme
with T k ≥ 1 adapted from entropy gaps, ensuring theoretical coherence with standard SMC while mitigating degeneracy.
Particles are further perturbed by a Gaussian kernel:
where LL ⊤ = Σ is the Cholesky factorization of the weighted covariance. This is equivalent to a kernel density approximation (Silverman, 2018), and ensures that as N → ∞ the perturbed empirical measure converges to the true posterior.
To maintain Bayesian coherence, proposals are validated by a standard MH acceptance step:
with π(Θ) ∝ p(z k | Θ) p(Θ | z 1:k-1 ). For symmetric Gaussian q, this reduces to
This guarantees detailed balance and convergence to the true posterior distribution (Hastings, 1970).
Combining these mechanisms, DEPF ensures:
-
Minimal bias from exploratory injection, expanding support beyond S 0 only when warranted.
-
Stability of particle diversity due to entropy-based weight smoothing.
-
Asymptotic convergence via kernel-induced diffusion validated by MH acceptance.
Therefore, DEPF is asymptotically unbiased:
Under the stationary bootstrap baseline with zero transition and no rejuvenation, particle filters exhibit the diagnostic phenomenon we term Stationarity-Induced Posterior Support Invariance (S-PSI): the posterior support remains confined to the prior support set S prior . This is not an inherent limitation of PF but a consequence of the baseline assumptions ( §3.4). Classical remedies such as jittering, roughening, or resample-move can, in principle, expand support, but they do so in an always-on and often inefficient manner. Here, we formally prove that with DEPF’s enhancements-exploratory injection, entropy-based regularisation, and kernel-induced stochastic diffusion validated by MH-the support set S k can expand beyond S prior . Proposition D.1 (Expansion of Support Range Beyond S-PSI). With the proposed enhancements, the support range S k satisfies the recursion Proof.
Step 1: Base case. At k = 0, S 0 = S prior .
Step 2: Exploratory injection. At step k > 0, particles sampled from U(B) enlarge the predictive support:
Step 3: Weight-based survival. Exploratory particles obtain weights proportional to their likelihood:
k ). Particles consistent with observations survive resampling, ensuring that regions supported by data persist.
Step 4: Kernel-induced diffusion. Surviving particles are further perturbed:
Step 5: Induction. Iterating steps 2-4, if Θ * ∈ B, then with positive probability it survives weighting and resampling, and by induction there exists finite k such that Θ * ∈ S k .
Remarks. This result shows that DEPF breaks the S-PSI constraint by combining: (i) exploratory injection to seed new regions, (ii) likelihood-driven survival so only data-supported regions expand, and (iii) kernel diffusion to propagate local coverage. Together with MH validation ( §3.1), these steps ensure support expansion is both data-triggered and statistically coherent.
The three policy error scenarios are defined as follows: (1) No Error (Ideal Scenario) in Figure 2(a) represents an ideal policy scenario in which the initial government decision on the disaster source location is completely accurate. Specifically, the initial particle distribution (gray region: (0, 20) × (0, 20)) accurately covers the true source region (green region: (10, 20) × (10, 20)). This scenario serves as a baseline, assessing the best-case performance without initial decision uncertainty.
(2) Moderate Error (Partial Misalignment Scenario) in Figure 2(b) simulates a realistic and moderate error scenario where the government’s initial policy assumptions about the disaster location (gray region: (0, 20) × (0, 20)) are partially misaligned, overlapping only partially with the true disaster source region (green region: (10, 25) × (10, 25)). This setup tests the ability of our method and baseline algorithms to adaptively correct moderate inaccuracies in initial policy assumptions, reflecting realistic emergency management conditions. (3) Severe Error (Complete Misalignment, PSI Scenario) in Figure 2(c) represents the most challenging and realistic scenario, termed the Posterior Support Invariance scenario, in which the initial policy completely excludes the true disaster location. Here, the initial policy region (gray region: (0, 20) × (0, 20)) and the true disaster source regions (green regions: (15, 30) × (20, 30) ∪ (20, 30) × (15, 20)) are entirely disjoint, creating a strict zero-prior barrier. This scenario explicitly tests each algorithm’s robustness and ability to dynamically correct severe initial policy errors-situations where bootstrap particle filtering methods typically fail due to their inherent inability to extend beyond the initial support.
where q s is the pollutant release rate, u is the wind speed, ϕ is the wind direction, d s represents dispersion coefficients, dist denotes the Euclidean distance between the agent’s position and the pollutant source.
At each time step, the RL agent observes:
• Its current two-dimensional coordinates (x, y).
• The pollutant concentration z measured at that location.
Based on these observations, the agent selects its next position within the spatial boundary constraints. The agent’s action space consists of discrete movements within predefined distances, typically in increments of 1 meter in either the x or y direction.
Crucially, the environment itself does not provide any explicit reward signals. The agent must indirectly infer useful positional information solely from the sequence of measured pollutant concentrations. Consequently, the agent’s learning process depends entirely on interpreting these indirect observations, making it a suitable scenario to investigate methods dealing with sparse or implicit rewards, as discussed extensively in Section §3.
We provide detailed definitions and interpretations for each evaluation metric used in the experiments, accompanied by illustrative examples:
• Operational Completion Efficacy (OCE): This metric quantifies the proportion of emergency response missions successfully completed. For instance, if an algorithm successfully completes 90 out of 100 missions, it achieves an OCE of 0.90, indicating high reliability and effectiveness in operational scenarios.
• Average Deployment Efficiency (ADE): ADE measures the average total distance traveled by response units during their missions. For example, if algorithm A requires units to travel an average of 15 kilometers per mission, while algorithm B achieves the same objectives in only 10 kilometers, algorithm B demonstrates a better (lower) ADE, suggesting superior efficiency in routing and resource usage.
• Response Execution Velocity (REV): REV assesses the total time from initial deployment to mission completion. As an example, consider two algorithms where one completes missions in an average of 20 minutes, while the other requires 30 minutes on average. The first algorithm, with its shorter completion times (higher REV), is preferable for urgent, time-sensitive scenarios.
• Localization Precision Score (LPS): LPS evaluates localization accuracy by measuring the average spatial difference between estimated and actual source positions. For instance, if algorithm A consistently estimates the source within an average of 2 meters from its actual location, whereas algorithm B averages a 5-meter error, algorithm A demonstrates a superior (lower) LPS, reflecting more precise and reliable source localization.
These metrics collectively offer a comprehensive evaluation framework, enabling thorough assessments of both algorithmic efficiency and practical effectiveness in complex operational environments.
Below, all baseline methods are described using the unified notation from this paper (Θ for the hidden source vector, p k for robot position, z 1:k for observations, b k (Θ) for the belief, a k for actions, r k for rewards, and discount factor γ).
A self-terminating RL framework that uses the particle-filter posterior’s uncertainty to decide when the source has been located, thus avoiding handcrafted sparse rewards. Belief approximation:
AGDC-KLD: Uses the Kullback-Leibler divergence between successive beliefs as reward,
driving actions that yield maximal information gain.
PC-DQN. The first source-search DRL method combining DQN with PF. It compresses particles into a compact 6-D feature vector using DBSCAN, then trains a vanilla DQN for discrete moves.
Reward: -1 per step until the source is declared (then +20).
A continuous-action RL approach using DDPG with GRU memory. The PF posterior is approximated by a Gaussian mixture model,
with mixture parameters used as state input. This method handles continuous moves and outperforms information-theoretic baselines.
Infotaxis. A POMDP planner minimizing expected posterior variance:
Entrotaxis. A simplified Infotaxis variant using entropy of the predictive distribution as reward,
DCEE. Dual-control exploration-exploitation planning:
Under the stationary bootstrap baseline with zero transition and no rejuvenation, PF exhibits Stationarity-Induced Posterior Support Invariance (S-PSI): the posterior cannot escape the initial prior support ( §3.4). This is not an inherent PF limitation; classical perturbation methods can relax S-PSI by injecting noise, albeit in an always-on and uncontrolled manner. We include three such baselines:
PF+Jittering. Each particle receives a small Gaussian perturbation after resampling:
Ensures support expansion but without control over when/where to perturb.
PF+Roughening. Similar to jittering but with covariance scaled to N and state dimension, encouraging broader diffusion:
More exploratory, but risks over-dispersion.
PF+Rejuvenation (Resample-Move). After resampling, particles undergo MH moves with Gaussian proposals:
Provides stronger correction but increases cost.
Comparison to DEPF. While these baselines demonstrate that S-PSI is not universal, they lack principled triggers and validation. In contrast, DEPF expands support only when observations contradict the belief, scales diffusion with posterior covariance, and validates proposals via MH acceptance, ensuring minimal-bias and Bayesian coherence.
Under the stationary bootstrap baseline with zero transition and no rejuvenation, particle filters exhibit Stationarity-Induced Posterior Support Invariance (S-PSI): particle support remains confined to the initial prior region S prior . If the true state Θ * lies outside this support, then
so Bayesian updates cannot recover it. This baseline pathology motivates explicit support-expansion mechanisms. Classical perturbations (jittering, roughening, resample-move) can in principle relax S-PSI but do so in an always-on and uncontrolled manner.
To overcome S-PSI in a principled way, DEPF augments filtering with four components:
- Belief-Triggered Exploratory Particles: At each step, a small fraction E of particles is redrawn from an extended box B ⊇ S prior :
These particles seed new regions but survive only if supported by likelihood.
To prevent weight collapse, we smooth weights toward higher entropy, e.g. via tempering:
-
Covariance-Scaled Stochastic Diffusion: Surviving particles are perturbed by a Gaussian kernel aligned with the weighted covariance:
-
MH Validation: Each perturbed particle Θ ′ is accepted with standard Metropolis-Hastings probability
, since the Gaussian proposal is symmetric. Accepted proposals expand support consistently with Bayesian updates.
These steps yield the recursion
allowing support expansion beyond S prior only when justified by data.
Algorithm 1 Diffusion-Enhanced Particle Filter (DEPF)
Require: prior support S prior , extended box B, particle count N , thresholds η, ϵ, smoothing parameter β, kernel parameters A, λ, horizon K 1: Initialize {(Θ
0 ∼ S prior and w
Select an exploratory index set E ⊆ {1, . . . , N } 4:
end for 7:
end for 10:
(ii) Bayesian weight update & smoothing (lines 8-12): all particles, including the exploratory ones, are reweighted by the likelihood p(z k | Θ (i) k ). Optional tempering (T k ≥ 1) smooths overly peaky weights to prevent premature collapse; weights are then normalized. If ESS falls below η, resampling is performed and weights are reset.
(iii) Covariance-scaled diffusion (lines 13-16): from the weighted cloud, the posterior mean µ and covariance Σ are computed, with a small ridge λI for stability. A Cholesky factor L aligns a Gaussian step to the posterior geometry, and the bandwidth h opt = A N -1/(n+4) sets the step size (KDE-style, shrinking with N and growing with dimension n). Each particle proposes Θ ′ = Θ (i) k + h opt Lδ, δ ∼ N (0, I), which locally dilates the support along high-uncertainty directions.
(iv) MH validation (lines 17-21): because the proposal q is symmetric, the Metropolis-Hastings acceptance reduces to a likelihood ratio,
.
If u ∼ U(0, 1) is below α, the move is accepted. This step enforces Bayesian coherence and filters out spurious expansion.
End-to-end picture with the reward. Together, lines 3-21 implement the belief update b k → b k+1 in a way that is dormant when data agree with the current belief (few injections, small accepted moves) and active when they disagree (more accepted moves toward informative regions). The controller in the figure then evaluates the change in belief via D KL (b k+1 ∥b k ) and learns actions that maximize its expectation. Thus, the figure’s reward explains how actions are chosen, while Algorithm 1 explains how beliefs are updated so that informative actions actually lead to recoveries from mis-specified priors.
Table 1 provides a systematic comparison across three levels of prior error and two spatial scales. We analyze the results by scenario, scale, and method family, and then link the observed outcomes to the underlying mechanisms of DEPF and the baselines.
In the No Error scenario, where the initial prior fully covers the true source, most methods succeed. DEPF reaches OCE of 0.90 with LPS fixed at 0.20, ADE of 19 in small-scale and 167 in large-scale, and REV of 0.10. AGDC closely matches these values, confirming that when no structural correction is required both methods perform optimally. PC-DQN and GMM-PFRL attain OCE around 0.80 but with higher ADE. Information-theoretic planners such as Infotaxis show partial success in the small-scale environment (OCE 0.85) but collapse to near zero success in large-scale. Perturbation baselines (Jittering, Roughening, Rejuvenation) remain close to DEPF under this easy condition, with OCE between 0.88 and 0.89, but their always-on diffusion leads to slightly larger LPS values (0.23-0.26) and longer ADE compared to DEPF’s minimal-bias behavior. This shows that DEPF does not overshoot when the prior is already correct.
The Moderate Error condition exposes sharper differences. DEPF sustains OCE of 0.90, LPS of 0.20, and ADE of 22 in small-scale and 200 in large-scale, maintaining REV at 0.10. AGDC drops dramatically, with OCE of 0.45/0.42, LPS climbing to 2.6, ADE lengthening to 59/235, and REV inflating to 0.40 with frequent timeouts in large-scale. Other RL baselines degrade to OCE around 0.40 with high ADE and LPS, while information-theoretic planners almost entirely fail in the larger environment. Perturbation baselines partly alleviate this condition: PF+Rejuvenation performs best (OCE 0.52/0.48, LPS 2.7/2.9, ADE 50/225), followed by Roughening (OCE 0.48/0.44, LPS 2.9/3.1, ADE 55/235) and Jittering (OCE 0.40/0.36, LPS 3.2/3.4, ADE 65/250). However, these remain far below DEPF’s near-ideal accuracy and efficiency. The contrast reflects the difference between always-on perturbations, which add diversity without discrimination, and DEPF’s belieftriggered expansion guided by covariance and validated by MH acceptance.
The most demanding case is the Severe Error scenario, corresponding to the S-PSI baseline where the prior and true state are completely disjoint. Here, DEPF achieves OCE of 0.89/0.88, LPS of 0.20, ADE of 27/255, and REV of 0.10, well within the 100/300-step timeout thresholds. All RL and information-theoretic baselines collapse (OCE < 0.05, LPS > 12.5, ADE and REV exceeding timeouts), confirming their inability to cross strict prior boundaries. Perturbation baselines show small but non-zero recovery in small-scale (Rejuvenation OCE 0.16, Roughening 0.10, Jittering 0.06) but degrade severely in large-scale, with OCE dropping to 0.12/0.08/ < 0.05 and ADE approaching or exceeding 285 steps. Their LPS values remain an order of magnitude higher than DEPF. This contrast highlights that while naive diffusion can occasionally escape narrow priors in limited domains, only DEPF provides consistent, data-driven support expansion at scale. Across all metrics, DEPF exhibits stable LPS at 0.20 irrespective of scale or error severity, indicating precise localization. In comparison, perturbation methods and RL baselines experience a tenfold increase in LPS under moderate and severe errors. ADE and REV patterns reinforce the efficiency of DEPF: its paths remain short and consistent, while baselines often exceed timeout thresholds in large domains. The cross-scale comparison further shows that only DEPF resists degradation when moving from 1:30 to 1:300 environments; all other methods experience steep drops in OCE and sharp increases in ADE and REV.
These results align directly with DEPF’s design. The belief-triggered exploratory injection ensures that expansion is dormant in the No Error case but activates under misalignment. Covariance-scaled diffusion guides exploration along directions of highest uncertainty, avoiding the excessive spread of jittering or roughening. MH validation rejects unsupported moves, preserving Bayesian coherence. Together, these mechanisms yield minimal bias and high efficiency, enabling DEPF to overcome S-PSI conditions and consistently outperform baselines under prior misalignment while remaining competitive under ideal conditions.
Table 1 compares eight methods across three prior-error severities (No, Moderate, Severe) and two spatial scales (1:30 and 1:300), using four metrics: success (OCE↑), efficiency (ADE↓), time-tocompletion (REV↓), and localization accuracy (LPS↓). The patterns are consistent with the theoretical picture established in the main text: under the stationary bootstrap baseline with zero transition and no rejuvenation (the S-PSI diagnostic), methods that do not explicitly expand support struggle as prior misalignment worsens, especially in large domains; DEPF maintains performance by triggering expansion only when data contradict the belief, scaling diffusion with the posterior covariance, and validating proposals via an MH step.
In the No Error condition, where the prior fully covers the truth, most algorithms perform well and DEPF does not seek to outperform them but to match the upper bound without incurring unnecessary exploration cost. DEPF attains OCE 0.90 ± 0.03 at both scales, LPS 0.20 ± 0.01, ADE 19 ± 0.8 (1:30) and 167 ± 15 (1:300), and REV 0.10 ± 0.05. AGDC closely tracks these values (OCE 0.90/0.87, LPS 0.20, ADE 18/168, REV 0.10-0.12). RL baselines PC-DQN and GMM-PFRL also succeed (OCE around 0.80 in small scale and 0.77-0.79 in large scale). Information-theoretic planners are more fragile with scale: Infotaxis achieves OCE 0.85 at 1:30 but collapses below 0.05 at 1:300. The three SMC perturbation baselines stay close to DEPF in this easy regime (e.g., PF+Rejuvenation OCE 0.89/0.86, LPS 0.23-0.24), but their always-on diffusion slightly increases ADE and LPS relative to DEPF, reflecting superfluous spread when expansion is not required.
When priors are moderately misaligned, differences sharpen in both success and precision. DEPF maintains high, scale-stable performance with OCE 0.90 ± 0.03, LPS 0.20 ± 0.01, ADE 22 ± 1.2 (1:30) and 200 ± 10 (1:300), and REV fixed at 0.10 ± 0.05. By contrast, AGDC’s OCE drops to 0.45 (1:30) and 0.42 (1:300), LPS rises to 2.60, ADE increases to 59 and 235, and large-scale REV inflates to 0.40 ± 0.15 with frequent timeouts. PC-DQN and GMM-PFRL show similar degradation, and planners (Infotaxis/Entrotaxis/DCEE) nearly fail at 1:300. The perturbation baselines do recover part of the gap, with a consistent ordering that mirrors their expansion strength: PF+Rejuvenation (OCE 0.52/0.48, LPS 2.70/2.90, ADE 50/225) > PF+Roughening (OCE 0.48/0.44, LPS 2.90/3.10, ADE 55/235) > PF+Jittering (OCE 0.40/0.36, LPS 3.20/3.40, ADE 65/250). Nevertheless, all three remain substantially behind DEPF in both success and accuracy. The gap in LPS is especially telling: DEPF holds 0.20 across scales, whereas perturbations remain an order of magnitude larger (2.7-3.4), indicating uncontrolled dispersion.
The Severe condition is the strict S-PSI test in which the prior support is disjoint from the true region. DEPF is the only method that preserves high success and low error across scales, achieving OCE 0.89 (1:30) and 0.88 (1:300), LPS 0.20-0.20, ADE 27 and 255, and REV 0.10, all well within the 100/300-step time limits. AGDC, the RL baselines, and planners collapse, with OCE < 0.05, LPS > 12.5, and ADE/REV exceeding the timeout thresholds in both scales-consistent with the inability to leave the initial support under the S-PSI baseline. Perturbation baselines show a small non-zero recovery only in the small-scale domain: PF+Rejuvenation reaches OCE 0.16 with LPS 9.0 and ADE 90 ± 12 (no timeout), PF+Roughening achieves OCE 0.10 with LPS 10.5 but times out, and PF+Jittering barely registers OCE 0.06 and also times out. At 1:300 these partial gains largely vanish: PF+Rejuvenation drops to OCE 0.12 with ADE 285 ± 35 (near the 300-step limit), while Roughening and Jittering fall below 0.10 OCE with timeouts. These numbers show that always-on noise can occasionally bridge small gaps but scales poorly, whereas DEPF’s data-triggered expansion remains effective even when the prior and truth are fully disjoint.
A cross-metric reading clarifies where efficiency and precision come from. Under Moderate/Severe misalignment, DEPF simultaneously sustains high OCE and bounded path/time (e.g., ADE 22/200 and 27/255, REV 0.10 in both scales), while baselines either fail outright or succeed late with longer paths and higher REV, especially at 1:300. LPS for DEPF remains near 0.20 across all conditions-an unusually stable accuracy profile-whereas perturbation baselines exhibit an order-of-magnitude larger LPS in Moderate and Severe settings. Scaling from 1:30 to 1:300 amplifies these contrasts: AGDC and the perturbation baselines lose additional OCE points, ADE/REV inflate, and timeouts become common; DEPF’s OCE stays within 0.88-0.90 with controlled ADE and fixed REV.
These empirical patterns align with the design. Because DEPF expands only when belief-data inconsistency is detected, it remains dormant in the No Error regime and avoids needless spread. When misalignment is present, diffusion is covariance-scaled with bandwidth h opt = AN -1/(n+4) , steering exploration along the current posterior geometry rather than isotropically; and MH validation filters proposals, preserving Bayesian coherence and avoiding the over-diffusion that inflates ADE and LPS for always-on perturbations. Altogether, the table demonstrates that DEPF is competitive at the ideal upper bound and uniquely robust under partial or complete prior failure, with consistent gains in success, efficiency, and accuracy that persist under scaling. Proof sketch. By (i)-(ii) exploratory particles near Θ ⋆ receive non-negligible weight; tempering avoids collapse; covariance-scaled perturbations propagate local coverage; MH acceptance enforces consistency. Iterating over time expands S k to include a neighborhood of Θ ⋆ with probability one. :contentReference[oaicite:6]index=6 :contentReference[oaicite:7]index=7 Corollary L.4 (Finite-step support-recovery bound). Let δ be the per-step probability that an exploratory particle lands in the η-ball around Θ ⋆ , and let γ ∈ (0, 1] be the probability that such a particle both passes MH and survives weighting/resampling. Then, after k steps,
This quantifies the rate at which DEPF breaks the zero-prior barrier under S-PSI. :contentReference[oaicite:8]index=8
DEPF is an inference module and is orthogonal to the controller. In our experiments the policy receives the belief b k and the immediate reward is the one-step information gain
which encourages actions that maximally reduce posterior uncertainty. The specific RL algorithm (e.g., PPO) is chosen for stability and does not alter the analysis above. :contentReference[oaicite:9]index=9 L.3 POSITIONING W.R.T. CLASSICAL AND TEMPERED/BRIDGE SMC Always-on perturbation baselines (jittering, roughening, resample-move) can leak mass across boundaries and sometimes escape S-PSI on small domains, but they lack principled triggers and acceptance control; as a result they tend to over-diffuse and degrade efficiency/accuracy under severe misalignment or at larger scales. By contrast, DEPF expands support only when belief-data inconsistency is detected, scales moves with the posterior covariance, and validates proposals via MH. Moreover, tempered/annealed (“bridge”) SMC improves adaptation within the original support by annealing between prior/transition and likelihood, but it still requires nonzero overlap; where the prior assigns zero mass to Θ ⋆ , all intermediate bridge distributions remain zero there, so no sequence of local MCMC mutations can create support in the excluded region. This is precisely the barrier that DEPF’s exploratory injection and MH-validated diffusion are designed to overcome. :contentReference[oaicite:10]index=10 L.4 EMPIRICAL EVIDENCE IN SUPPORT OF THE THEORY Across three prior-error severities (No/Moderate/Severe) and two map scales (1:30, 1:300), DEPF matches strong baselines when the prior is correct, and it uniquely maintains high success, low localization error, and bounded path/time under severe misalignment. For example, in the strict S-PSI (Severe) setting, DEPF attains OCE ≈ 0.88-0.89 and LPS ≈ 0.20 at both scales, while RL/planning baselines collapse and classical perturbations succeed only sporadically with much larger errors and frequent timeouts. Component-wise ablations confirm that entropy smoothing, covariance-scaled diffusion, and MH validation are jointly necessary for robust recovery, and sensitivity studies identify moderate settings (e.g., β ∈ [0.3, 0.5], A ≈ 0.5, λ ∈ [10 -3 , 10 -2 ], ∼5% exploratory ratio) as consistently effective.
M.4 MAIN GUARANTEE: DEPF RESOLVES S-PSI Theorem M.4 (Asymptotic coverage under S-PSI). Assume S-PSI holds for the baseline (Def. M.2) and Θ ⋆ / ∈ S prior . Under (C1)-(C2) and standard SMC regularity (bounded likelihood; stable tempering/entropy regularisation; KDE bandwidth h opt = A N -1/(n+4) ), as N → ∞ the DEPF support covers the true state with probability one: Proof sketch. (C1) gives a strictly positive chance to seed particles in an η-ball of Θ ⋆ at each step. By (C2), accepted proposals satisfy detailed balance and thus preserve the posterior target. Within the η-ball, the likelihood is bounded away from zero, so exploratory particles near Θ ⋆ obtain nonvanishing weights and survive resampling with positive probability. Covariance-scaled perturbations with h opt (KDE rate) ensure that as N → ∞ the empirical measure converges to the true posterior. Combining the seeding, survival and diffusion with the recursion (7) yields the claim.
Finite-step guarantee. Let δ be the per-step probability of injecting (at least) one particle into the η-ball of Θ ⋆ and let γ be the probability that such a particle survives the MH/weighting/resampling pipeline at that step. Under (C3) and the mechanisms above, P at least one survivor near Θ ⋆ within k steps ≥ 1 -(1 -δγ) k .
(8)
This lower bound quantifies the speed at which DEPF probabilistically covers previously excluded regions.
To mitigate weight collapse and preserve exploratory mass, we use an entropy-aware smoothing (or tempering) step:
with T k ≥ 1 adapted from the entropy gap to a target level (see Appendix H). This raises the posterior weight entropy when it becomes overly concentrated, helping exploratory particles retain influence long enough for data to validate (or reject) them.
M.6 MH ACCEPTANCE WITH SYMMETRIC GAUSSIAN PROPOSALS Let q(Θ ′ | Θ) = N (Θ ′ ; Θ, Σ ′ ) with Σ ′ aligned to the weighted covariance (Appendix H). Then q(Θ ′ | Θ) = q(Θ | Θ ′ ) and the MH acceptance is
In particular, when the prior factor p(Θ | z 1:k-1 ) is locally flat at the proposal scale, α reduces to a likelihood ratio min 1, p(z k | Θ ′ )/p(z k | Θ) . This ensures detailed balance and convergence to the intended posterior.
M.7 DISCUSSION: WHY DEPF BREAKS S-PSI RELIABLY Compared with always-on perturbations (jittering/roughening/resample-move), DEPF: (i) triggers support expansion only when belief-data inconsistency is detected, (ii) scales diffusion with the current covariance and a KDE bandwidth that vanishes at the right rate, and (iii) validates proposals by MH to preserve Bayesian coherence. These elements together provide both the asymptotic guarantee (Theorem M.4) and the finite-step bound (8). As shown in Table ??, DEPF consistently outperforms all baselines across every field and evaluation metric. In particular, DEPF maintains high posterior coverage and low estimation error even when the true source lies outside the prior support, whereas all baselines suffer substantial performance degradation. These findings provide strong empirical evidence that DEPF is robust to prior misspecification and generalizes effectively to multi-dimensional, complex inference tasks.
O.1 DYNAMIC FIELDS AND GOVERNING EQUATIONS Table 9 summarizes the dynamic fields used in our additional experiments: Temperature (Temp.), Concentration (Conc.), Magnetic (Mag.), Electric (Elec.), Energy (En.), and Noise. Each governing equation is a generalized convection-diffusion or potential-distribution formulation that can incorporate diffusion, advection, reactions, turbulence, external fields, and dissipation.
ization, covariance-scaled stochastic diffusion, and MH-based acceptance-are jointly necessary for robust recovery. Removing stochastic diffusion collapses performance under Severe Error, yielding timeouts and large residual errors despite correct behavior in the No Error setting. Disabling entropy regularization substantially lowers OCE and increases LPS (e.g., 0.62 OCE and ∼ 3.0 LPS), indicating premature weight concentration and insufficient posterior spread. Absent MH validation, the algorithm becomes ill-posed (not work), confirming the role of acceptance control in maintaining
📸 Image Gallery