Fine-tuning of lightweight large language models for sentiment classification on heterogeneous financial textual data
📝 Original Info
- Title: Fine-tuning of lightweight large language models for sentiment classification on heterogeneous financial textual data
- ArXiv ID: 2512.00946
- Date: 2025-11-30
- Authors: Alvaro Paredes Amorin, Andre Python, Christoph Weisser
📝 Abstract
Large language models (LLMs) play an increasingly important role in financial markets analysis by capturing signals from complex and heterogeneous textual data sources, such as tweets, news articles, reports, and microblogs. However, their performance is dependent on large computational resources and proprietary datasets, which are costly, restricted, and therefore inaccessible to many researchers and practitioners. To reflect realistic situations we investigate the ability of lightweight open-source LLMs -smaller and publicly available models designed to operate with limited computational resources -to generalize sentiment understanding from financial datasets of varying sizes, sources, formats, and languages. We compare the benchmark finance natural language processing (NLP) model, FinBERT, and three open-source lightweight LLMs, DeepSeek-LLM 7B, Llama3 8B Instruct, and Qwen3 8B on five publicly available datasets: FinancialPhraseBank, Financial Question Answering, Gold News Sentiment, Twitter Sentiment and Chinese Finance Sentiment. We find that LLMs, specially Qwen3 8B and Llama3 8B, perform best in most scenarios, even from using only 5% of the available training data. These results hold in zero-shot and few-shot learning scenarios. Our findings📄 Full Content
Natural language processing (NLP) models have been commonly applied to analyze emotions in various contexts and languages [5,20,24,25,26,27]. Large language models (LLMs) have systematically outperformed NLP models in sentiment analysis tasks by enhancing contextual comprehension through the use of deep learning techniques [4,5,7,8,9]. However, the training process of LLMs is computationally expensive, as it requires very large datasets and computational power, and specialized processors such as graphics processing units (GPUs) for massive parallel processing, which are often costly. Furthermore, high-performing LLMs, such as OpenAI GPT4 or Google Gemini, are limited to inference via APIs. Although multilingual LLMs such as XLM-R and mBERT support cross-lingual generalization, they usually require extensive fine-tuning to perform well in low-resource or domain-specific tasks such as financial sentiment analysis. To account for real-life scenarios where data and computational resources are limited, we consider light-weight versions of LLMs (between 7 and 8 billion parameters), as they offer a favorable balance between capability and resource demands, achieving high performances and enabling fine-tuning on devices with limited GPU power.
We compared FinBERT, DeepSeek-LLM 7B, Llama3 8B and Qwen3 8B in their ability to generalize understanding of sentiment in financial domains from different sources, including financial news, social media content, and forum discussion. Since FinBERT is a transformer-based model previously fine-tuned on the FinancialPhraseBank and Financial Question Answering (FiQA) datasets, we include those datasets for comparison, alongside two distinct labeled sentiment datasets: the Gold Sentiment dataset, which exclusively contains financial news about gold, and the Twitter Financial News Sentiment dataset, which is a dataset containing an English-language annotated corpus of finance-related tweets. We extend these commonly used financial datasets with a sentiment data set in Chinese-language. This allows us to assess the ability of models to operate in so-called analytic languages such as Chinese, where word order and particles are used to express grammatical relationships. This contrasts with inflectional languages, such as English, where words change form to convey grammar (e.g., tense, number, or case). We applied a Role-Playing (RP) format to design prompts used to train and evaluate the LLMs. This approach, introduced by [16] appears more effective than vanilla prompts in various research works that applied LLMs in sentiment analysis [1,17].
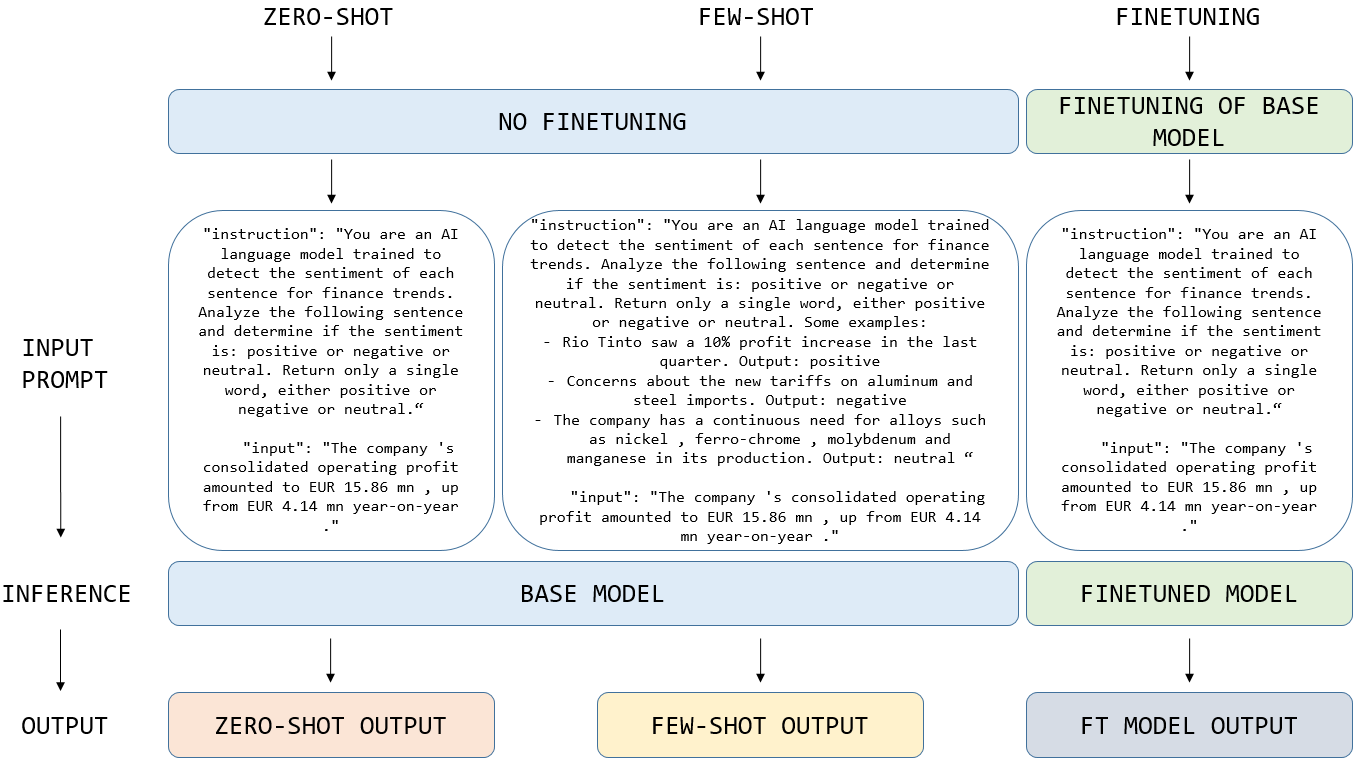
LLMs can improve their performance by further training on a specific dataset or task (supervised fine-tuning, SFT) or from additional prompt examples. In real-case scenarios, often only very limited or unspecialized training data may be available. Common methods to mitigate the problem of sparse training data include zero shot learning (ZSL) and few shot learning (FSL) [2,5] (Figure 1). FSL consists of adding some examples inside the prompt of how the model should behave. For example, a 3-shot case refers to a prompt that includes 3 examples of input-output pairs. Both FSL and ZSL are computationally efficient as they do not require extensive datasets or resources for fine-tuning.
To achieve effective training with varied datasets, we designed a pipeline that integrates financial sentiment datasets from different sources and media support, such as tweets, news headlines, or microblogs. We fine-tuned the models using the training splits of all available labeled datasets: Fi-nancialPhraseBank, FiQA, Twitter Sentiment, and Gold Sentiment. The evaluation is then conducted on the respective test splits of each dataset.
Recent developments in large language models (LLMs) have exerted a substantial influence on methodologies for sentiment analysis applied to financial textual data. Kumar et al. [2] fine-tuned LLaMA3 using only the FinancialPhraseBank (FPB) training dataset and achieved better predictive performance than with BERT-based models. Zhang et al. [7] adopted an instruction tuning method to fine-tune LLaMA 7B in various financial sentiment datasets. Zhang et al. [4] fine-tuned an LLaMA 7B model and implemented a retrieval augmented generation (RAG) module. Fatemi et al. [9] tested Flan-T5 Base, Large and XL models as well as ChatGPT turbo 3.5 in zero and few-shot learning settings. They further fine-tuned the Flan-T5 models using some of the previously introduced financial sentiment datasets, achieving better results than in zero-shot and few-shot learning scenarios. They also found that in zero and few-shot learning contexts, finetuned LLaMA3 8B, Mistral 7B, and Phi 3 mini-instruct models achieved better results than the baseline models BloombergGPT, AdaptLLM-7B and FinMA-7B, which are trained on financial data. Wang et al. [8] fine-tuned several open-source models such as Llama2 7B, Falcon 7B, BLOOM 7.1B, MPT 7B, ChatGLM2 6B and Qwen 7B with the FPB and FiQA datasets, where LLaMA2 7B and MPT 7B obtained the best results. These studies are summarized in Table A. 4.
Since they rely on explicit instructions to capture sentiments, NLP models may encounter difficulties in extracting sentiments from some non-English languages such as Chinese. Stemming procedures to obtain the root, also called the stem, of words can be applied in English by removing suffixes. For example, one may extract the stem ’look’ by removing ‘ing’ in ’looking’ or ’ed’ in ’looked’. However, in Chinese, there is no concept of stem. Separating building blocks of Chinese characters would completely change their meaning. Without the need for explicit rules, LLMs can capture sentiments from Chinese LLMs by learning contextual representations via pretraining on massive corpora. Lan et al. ( 2023) [3] fine-tuned several LLMs, including Longformer, LLaMA, BLOOM and ChatGLM, on a Chinese sentiment dataset. Their results showed that Chinese LLaMA Plus outperformed other models in sentiment analysis, especially in a zero-shot learning scenario. However, no study considered addressing financial sentiment in both English and Chinese fine-tuning a single model.
This study aims to evaluate and compare the performance of four models, FinBERT, Llama3 8B, DeepSeek LLM 7B and Qwen3 8B, on financial data from multiple sources and language types. We adapt the training pipelines to align with the inherent constraints that vary among the investigated models. However, to ensure fair comparison, the training parameters remain the same, except for batch sizes due to memory limitations. We evaluated the models in a low-resource efficiency setting by varying training and test data ratios and asses how the LLMs perform with ZSL, FSL and SFT. The examples given in the prompt during the few-shot learning were randomly selected.
Without claiming to offer a comprehensive benchmark analysis of LLMs applied in sentiment analysis of financial data, our study attempts to offer a fair and transparent comparison of recent lightweight LLMs available publicly. The LLMs chosen have a similar number of parameters (7-8B) and were released between 2024 and 2025, their characteristics are summarized in Table B.5.
• FinancialPhraseBank (FBP): A dataset of financial sentences labeled with sentiment categories, specifically designed for sentiment analysis in the financial domain [11].
• Financial Question Answering (FiQA): A dataset containing financial question-answer pairs, labeled with sentiment annotations. It focuses on financial documents and provides essential data for training models to analyze sentiment in finance-related texts [12].
• Gold News Sentiment (GSD): A sentiment-labeled dataset that focuses on news related to gold commodities [13].
• Twitter Sentiment (TSD): A dataset consisting of tweets related to financial news, providing sentiment annotations. It allows analysis of sentiments expressed on social networks, offering a unique perspective compared to traditional news datasets [14].
• Chinese Finance Sentiment (CSD): A dataset consisting of financial news articles labeled with sentiment annotations, specifically focused on Chinese financial news, which allows sentiment classification tasks based on text in Chinese language [15].
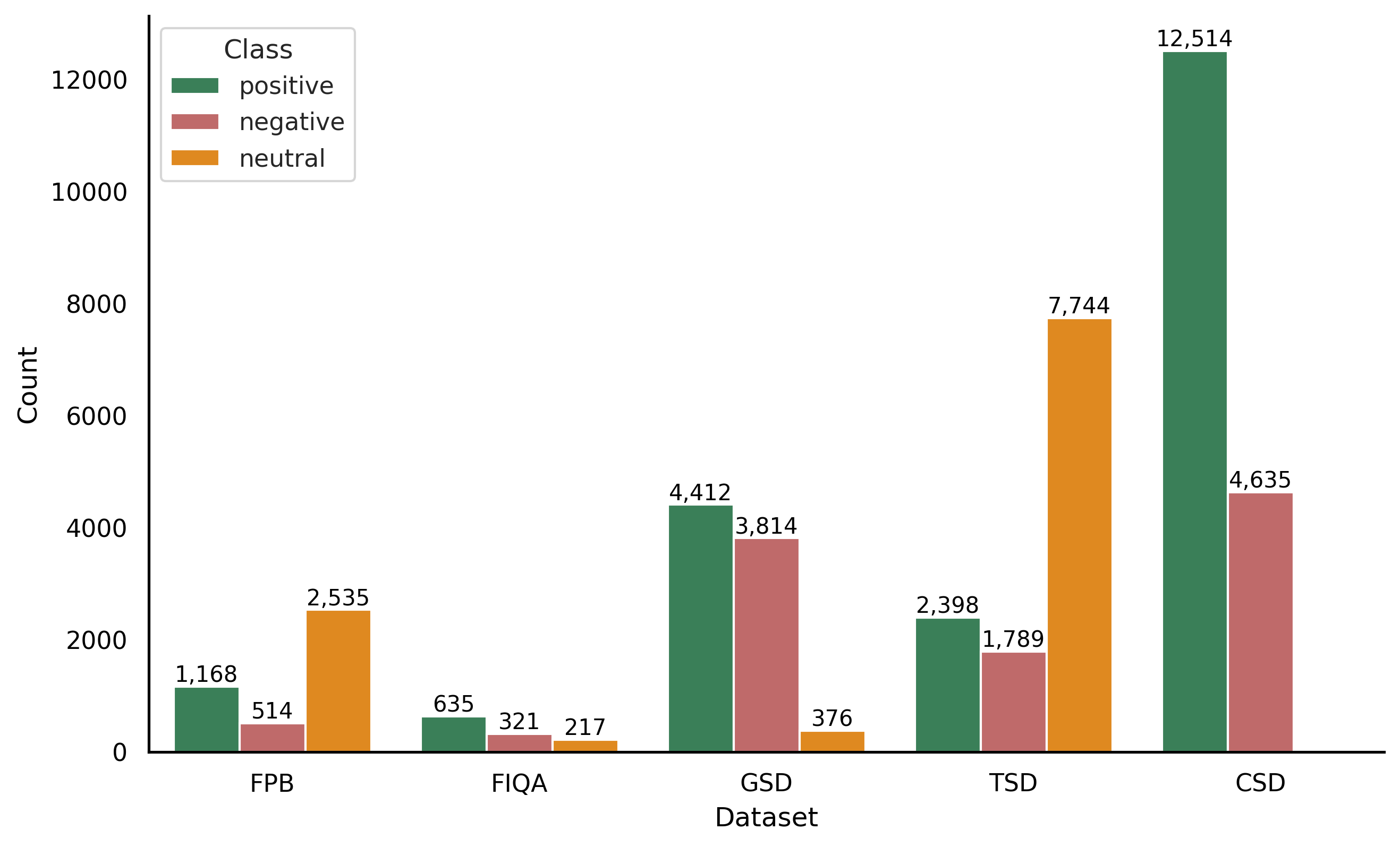
FinancialPhraseBank, FiQA, Gold News Sentiment, Twitter Sentiment are available on Huggingface, and Chinese Finance Sentiment is available in [15]. All labels in the datasets are unbalanced (Fig. 2), which means that the proportion of observations between the sentiment classes (positive, negative, and neutral) differs substantially. Unbalanced data are common in the financial sector, such as bankruptcy prediction, credit card fraud, and credit approval, and therefore require care in analyzing them [22]. The choice of predictive scores is particularly important in this context. Accuracy, which refers to the proportion of correct predictions made by a model out of all predictions, may be misleading. A trivial classifier that would always predict the majority class consisting of, for example, 90% of the labels would reach the accuracy of 90%. To address this issue, we will complement the accuracy with the macro F1 score, which accounts for the class imbalance in assessing the predictive performance of the models.
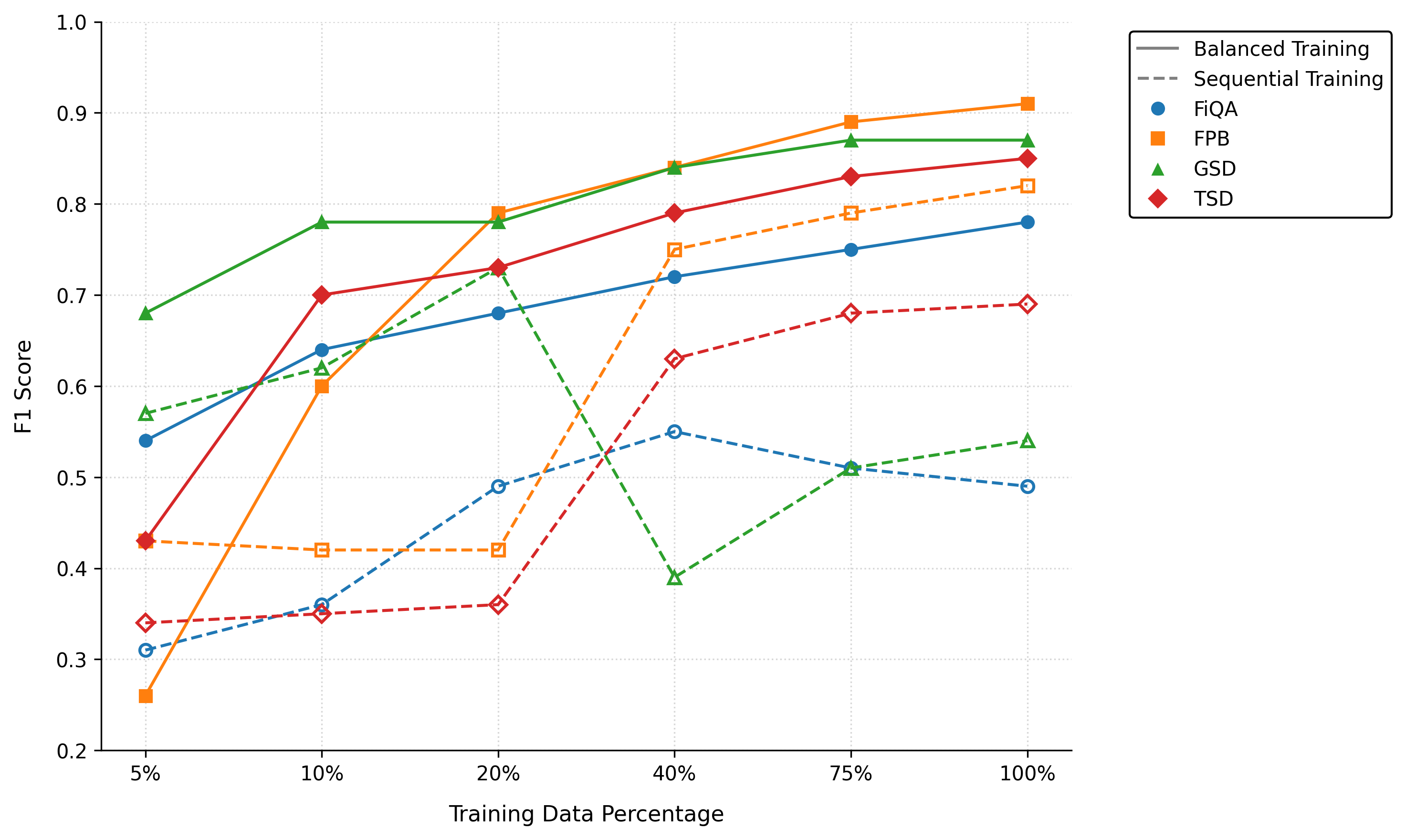
We designed a pipeline to carry out the sentiment analysis on financial multi-domain datasets, such as tweets, headlines, and microblogs, which vary by their language style and format. The pipeline allows models to train on multiple datasets simultaneously and fine-tune the five investigated financial sentiment datasets, combining English and Chinese data. Based on an empirical analysis on similar datasets (see details in Appendix A.3), we opted for a balanced learning across datasets and domains. This procedure automatically sub-samples or up-samples when needed to maintain equal representation and prevents bias towards more frequent domains. Here, we iteratively varied the proportions of the training data, from 5% to a fully 100% fine-tuned model.
The training process follows three phases. During the initialization phase (20% of the steps), the model prioritizes underrepresented domains (e.g., FiQA) with learning rate warm-up, which is a technique that gradually increases the learning rate at the beginning of training to stabilize and improve model convergence. In the balanced phase (60% of the steps), the training data is split into small subsets of data (called batches) to ensure that each type of data (or domain) is equally represented by applying weights. These weights control the sampling probability of each dataset, so that smaller domains with fewer examples are oversampled (their samples appear more frequently), while larger domains are undersampled (a smaller fraction of their samples is drawn per epoch). This weighted sampling guaranties that on average each domain contributes a similar number of updates to the model during training and prevents the learning process from being dominated by one type over another. The learning rate follows the decay of the cosine learning rate. This is a scheduling technique where the learning rate decreases over time following a cosine curve. In other words, it starts higher and gradually slows down. This helps the model learn quickly at first, and after the model has learned a lot, it slows down, allowing it to make smaller adjustments. The finalization phase (20% of the steps) consists of a reduction in the learning rate per layer and the application of early stopping per domain.
To fine-tune the LLMs, we applied Low-Rank Adaptation (LoRA [28]) and quantization. The LoRA method is facilitated by the Parameter Efficient Fine-Tuning (PEFT) module, which enables fine-tuning large language models by updating only a small subset of parameters, such as adapters or LoRA layers, making training faster, cheaper, and more memory efficient. Quantification is done via the BitsAndBytes [29] library, which enables efficient model training and inference by providing low-bit (e.g., 4-bit, 8-bit) quantization and optimized CUDA kernels to reduce memory usage and accelerate performance. The chosen quantization setup was 4-bit for weight storage and bfloat16 for the computation dtype for fine-tuning and inference. In this way, we can achieve a higher accuracy using bfloat16 during the operations calculation but with a reduced GPU memory usage from the model loading. A single NVIDIA A100 40GB GPU is used for fine-tuning and inference.
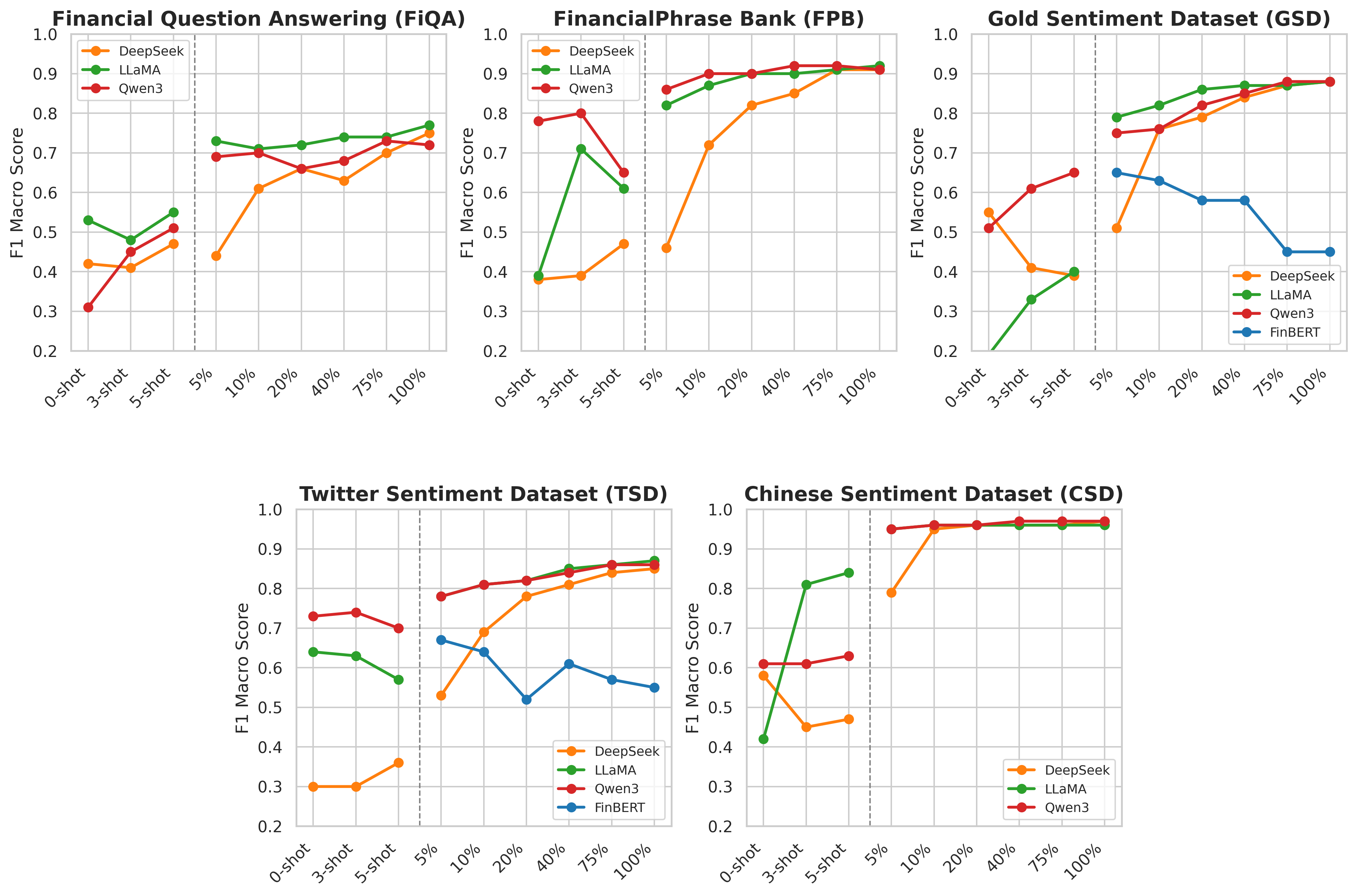
We present a comprehensive evaluation of the performance of FinBERT, DeepSeek LLM 7B, Llama3 8B Instruct, and Qwen3 8B in predicting sentiments based on four financial datasets in English. Table 1 shows the predic-tive performance (accuracy and macro F1 score) of a first evaluation, which includes only the LLM in 0 shot, 3 shot and 5-shot settings. Both results of 3-shot and 5-shot settings are averaged because of the randomness when choosing examples provided in the prompt, which come from the test data.
The results show that Qwen and Llama models benefit most from fewshot learning, with performance improving markedly from 0-shot to 3-shot settings for the datasets FPB, GSD and CSD. Changes from 3-shot to 5shot learning do not appear to substantially change the model performance. Deepseek shows worse results in 3 and 5-shot settings across all datasets except for TSD, where they increase slightly. The small standard deviations of accuracy and macro f1 suggest that using different examples inside the prompt does not have such a big impact on the model prediction performance. Overall, Qwen achieves the best results on 0-shot with an average accuracy and macro f1 of 0.67 and 0.59 respectively, while Deepseek achieves 0.67 and 0.55 and Llama 0.55 and 0.43. For 3-shot, Qwen gets the best results again, 0.74 accuracy and 0.64 macro f1 score, and for 5-shot, Qwen is still the best performer with 0.73 and 0.63 average accuracy and macro f1 scores.
Following this initial assessment, we fine-tuned the models on varying data proportions (5, 10, 20, 40, 75 and 100%). FinBERT’s prior pre-training with FiQA and FPB datasets forbids its re-evaluation on those to avoid data leakage. Table 2 shows the predictive performance (accuracy and macro F1 score) of this second evaluation, which includes all models with various proportions of training data.
FinBERT consistently underperformed, with accuracy and macro F1 scores decreasing for GSD (up to a -30% accuracy and macro F1 score) and TSD (-18% macro F1 score) as it is fine-tuned. This is most likely the result of overfitting during training or catastrophic interference. In contrast, LLMs show great performance with a bare minimum of data used to fine-tune (5%), except for DeepSeek evaluated in FPB and TSD datasets; however, its performance jumps quickly with training data of 10%. Qwen exhibited robust performance across all datasets, maintaining high accuracy and macro F1 scores even at low data proportions, suggesting efficient learning and generalization. In the fully fine-tuned stage, Llama slightly surpassed the Qwen and Deepseek models, achieving the highest overall performance across most datasets and training sizes. These findings suggest that, while FinBERT is limited in its generalization beyond its pretraining domain, LLMs offer superior scalability and sentiment classification capabilities, making them ideal for both low-and high-data resource applications. The three LLMs show the worst performance when tested on the FiQA dataset, most likely due to the small size of this dataset. It has only around 1200 sentences, in contrast with the total size of the dataset used to fine-tune these models formed by the 4 datasets together, adding to a total of almost 26000 sentences. This can cause interference in the models’ weights, which happens when models forget previously learned information while training with a new one. Furthermore, they all achieve up to 0.97 F1 Score when tested on the Chinese Sentiment Dataset. These results are higher likely because this dataset only contains two classes, positive and negative, instead of three as the rest. The results with balanced training (ZSL and FSL) and fine-tuned evaluations are shown in Fig. 3.
We compare the results of the best prediction model (and an alternative specification that used only 10% of the data for training) with benchmark models from previous studies on the same datasets (Table 3). The best model shows more consistent results across different financial sentiment datasets in English language, even having been fine-tuned in a large proportion with Chinese language data. In addition, Llama3 model fine-tuned with only 10% of the data still performed competitively or even outperformed the models in previous works.
We perform a comparative analysis between FinBERT, a domain-specific natural language processing model for financial sentiment analysis, and parameter efficient large language models, with the objective of predicting sentiment in financial text corpora. We assess the low-resource capabilities of LLMs by fine-tuning with different proportions of the training data as well as evaluating the base models in 0, 3 and 5 shot learning in English and Chinese languages. We find that large language models (LLMs) can surpass the performance of FinBERT while relying on only a minimal proportion of training data, or even in the complete absence of task-specific training data under a zero-shot evaluation setting.
Secondly, we design a domain-balanced training pipeline to improve the fine-tuning process by considering the training data as a corpus of datasets from various sources and sizes. The results suggest that fine-tuning the models in such a way may improve predictive performance compared to a sequential training strategy.
Future work may explore incorporating additional financial datasets, finetuning of LLMs on multilingual sentiment datasets, extending to sentiment tasks outside of finance, or integrating RAG for more contextual predictions. We hope that the tools, methods, and findings presented here will support researchers and practitioners in building robust sentiment analysis models tailored to the financial domain, particularly in data-scarce and low-resource environments.
📸 Image Gallery