Chain of Unit-Physics: A Primitive-Centric Approach to Scientific Code Synthesis
📝 Original Info
- Title: Chain of Unit-Physics: A Primitive-Centric Approach to Scientific Code Synthesis
- ArXiv ID: 2512.01010
- Date: 2025-11-30
- Authors: Vansh Sharma, Venkat Raman
📝 Abstract
Agentic large language models are proposed as autonomous code generators for scientific computing, yet their reliability in high-stakes problems remains unclear. Developing computational scientific software from natural-language queries remains challenging broadly due to (a) sparse representation of domain codes during training and (b) the limited feasibility of RLHF with a small expert community. To address these limitations, this work conceptualizes an inverse approach to code design, embodied in the Chain of Unit-Physics framework: a first-principles (or primitives)-centric, multi-agent system in which human expert knowledge is encoded as unit-physics tests that explicitly constrain code generation. The framework is evaluated on a nontrivial combustion task (12 degrees-of-freedom), used here as a representative benchmark for scientific problem with realistic physical constraints. Closed-weight systems and code-focused agentic variants fail to produce correct end-to-end solvers, despite tool and web access, exhibiting four recurrent error classes: interface (syntax/API) hallucinations, overconfident assumptions, numerical/physical incoherence, and configuration fragility. Open-weight models with chain-of-thought (CoT) decoding reduce interface errors but still yield incorrect solutions. On the benchmark task, the proposed framework converges within 5-6 iterations, matches the human-expert implementation (mean error of 3.1ˆ10 ´3%), with a "33.4% faster runtime and a "30% efficient memory usage at a cost comparable to mid-sized commercial APIs, yielding a practical template for physics-grounded scientific code generation. As datasets and models evolve, zero-shot code accuracy will improve; however, the Chain of Unit-Physics framework goes further by embedding first-principles analysis that is foundational to scientific codes, thereby guiding more reliable and interpretable human-AI collaboration.📄 Full Content
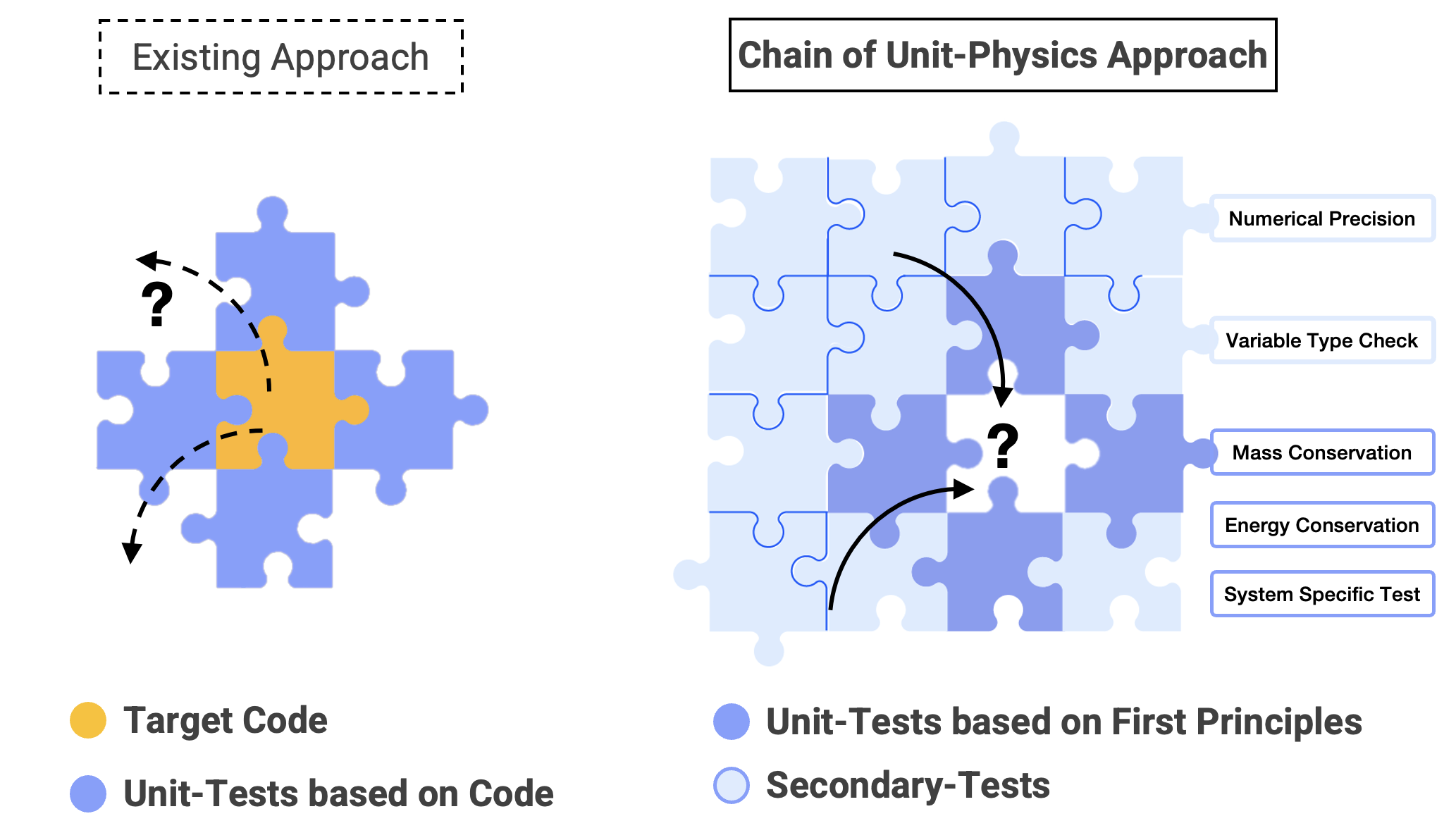
From an engineering perspective, scientific code generation tasks diverge fundamentally from traditional software development. General purpose applications, such as mobile apps or utility libraries, prioritize rapid iteration, user experience, and flexibility, often tolerating minor glitches and relying on integration tests. In contrast, scientific software demands mathematically rigorous algorithms, bit-for-bit reproducibility, and exhaustive validation against analytical or reference benchmarks [10]. Moreover, it must be optimized for large-scale numerical workloads on high-performance computing platforms without sacrificing stability [11], leveraging precision-oriented languages and parallel libraries (e.g. MPI [12]) to ensure both performance and accuracy. Given these divergent workflows and the pivotal role of testing in ensuring correctness, current research on LLM-driven code generation emphasizes on developing test cases from existing codebases [13,14,15] and transforming them into formal, verifiable unit-test specifications [16]. This also highlights that validation currently re-Figure 1: Conceptual difference between Chain of Unit-Physics approach and existing methods. Left: the existing “code-first” approach, where unit tests are written after implementation, merely exposing latent errors and forcing rework. Right: the proposed approach, in which a human expert specifies first-principles unit tests (e.g., conservation laws) that guide code generation.
lies on comparing code outputs with predefined input-output datasets, an approach that is infeasible when problems are complex or due to limited number of experts in the field. In such domains, agents often generate erroneous codes that require extensive human debugging. In addition, for a given problem, there could be multiple correct code implementations, complicating validation based solely on output matching. While it may seem intuitive that providing unit tests alongside problem specifications would automatically improve the accuracy of LLMgenerated code, this assumption has not been rigorously validated [17]. The true effect of such test suites on the fidelity and robustness of model output remains largely unexplored [18], and, in particular, the mechanisms by which LLMs interpret, apply, and iteratively refine their code based on these tests [19] have yet to be systematically investigated. Generating unit tests from existing code can inadvertently perpetuate latent errors [20], particularly when those tests are not limited to generic checks, such as data type or format tests, rather emphasize algorithmic correctness [21]. This issue is especially acute in the development of custom computational fluid dynamics (CFD) solvers [22,23] built on libraries such as OpenFOAM [24] and AMReX [25]. To overcome these limitations, this work systematically applies an inverse code design methodology (see Fig. 1), formally known as test-driven development (TDD) [26], to scientific software in combustion science, one such domain where TDD approaches have not been thoroughly evaluated. This work proposes Chain of Unit-Physics, an approach that embeds human expert knowledge directly into distinct reasoning chains of the agentic system via “unit-physics”-formalized, testable constraints that encode fundamental physics (e.g., energy conservation laws) and practitioner experience (e.g., dimensional / bound checks, and floating-point diagnostics). This inverse-design method provides two key advantages in scientific software. First, humanauthored tests embed deep domain expertise (first principles or primitives) into targeted validation checks, ensuring that each algorithmic component faithfully represents the underlying physics. Second, because these verification suites are au-thored by specialists, they impose stringent quality criteriaany failure of the LLM generated code then clearly indicates a gap in the expert’s test specification itself, thereby shifting the source of error away from the model and onto the test suite or expert’s own knowledge. This discussion naturally prompts the question:“If we can so precisely formalize our requirements, why not use a single numerical solver across all combustion applications, simply adapting for different fuel phases?”. While a universal solver for all combustion problems in this context might seem appealing, it is neither practical nor conducive to the advancement of scientific discovery. There are a myriad of approaches to solving complex set of equations, including the choice of models, the choice of numerical schemes, their implementation as well as the specific regime of validity for all these choices. Instead, designing targeted “unit-physics” tests or “primitives”, each grounded in first principles, provides a more direct, transparent, and reliable framework for developing and verifying solver components for specific physical processes. Beyond the framework, a key contribution of this study is the systematic evaluation of human-authored unit tests to recast fundamental physics checks as stringent formal specifications for AI-driven code generation, thus reducing model ambiguity and minimizing error propagation. The following sections describe the proposed framework in detail ( § 2) and evaluate it on a benchmark scientific task ( § 3).
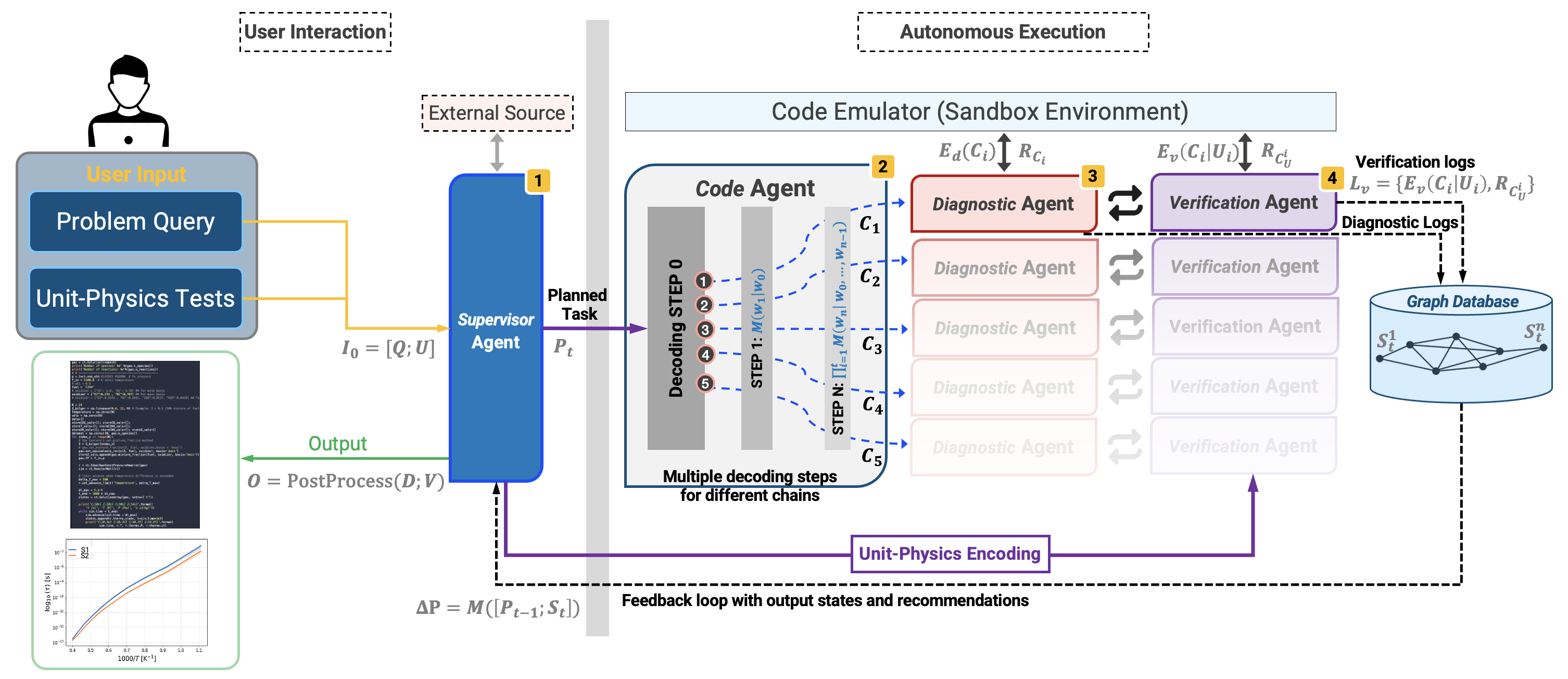
AI systems with higher degree of autonomy and goaldirected behavior, with a notion of planning and reasoning [27], embedded during model training, are termed as “agents” in this framework. While this definition is evolving, current work uses open-weight instruction-tuned decoder-only LLMs as the base for agents: Llama 3.3 70B Instruct [28] and GPT-OSS-20B model with o200k_harmony tokenizer [29]. Based on additional experiments (not shown), the framework adheres to established guidelines for the selection of model parameters (e.g. sampling temperature), specified in the respective reference articles [28,29]. The models are accessed using the Transformers library [30] and vLLM library [31] while the agents are orchestrated through custom code within a Python 3.11 environment. Inference is performed with PyTorch [32] (GPU-accelerated where available), while task decomposition and prompt management use custom code abstractions. The framework runs inside a dedicated Python virtual sandbox environment that is not pre-configured with metadata on all available libraries. The agent is granted isolated code execution privileges within this sandbox, ensuring that any dependency installs or script executions cannot affect the system root directory or global files. During code execution, any missing dependencies are detected using builtin the subprocess library. Configuration and runtime states are managed with the logging library, and human-expert guidance can be integrated via command line interface (CLI). Figure 2 illustrates a multi-agent LLM-driven scientific workflow that transforms a domain-specific user query into actionable code and visual results. In the input, the user’s scientific question is paired with ‘basis prompts’ that establish execution permissions, tool availability, coding language settings, and transfer protocols. Additional input scopes the unitphysics tests that concatenated with the scientific query to form the complete input to the framework. The Supervisor Agent is the only part of the framework that interacts with the User. This agent identifies the objective by extracting critical parameters (e.g., thermodynamic variables, software/language requirements) and generates a structured plan that sequences the necessary steps and tool invocations and then sets up an autonomous iterative loop: each task is passed to Code Agent, which uses a custom decoding algorithm [33] that elicits intermediate reasoning traces. The modified decoding algorithm branches only at the first generated token: instead of taking the greedy top-1 token, it spawns multiple paths by taking each of the top-k candidates, then continues each path with standard greedy or beam search decoding. This procedure generates multiple code candidates per task similar to Chain-of-Thought (CoT) [34], without relying on explicit “think step by step” instructions. For every completed path, the algorithm identifies the answer span and computes a “confidence” score as the average margin between the probabilities of the top-1 and the top-2 tokens over those answer tokens. These chains can be evaluated in parallel, either on separate GPUs or, depending on model memory requirements, jointly on a single GPU. While these self-assigned confidence scores enable chain selection via a user-specified confidence threshold, they are not a substitute for validation against first-principles physical constraints and numerical consistency checks.
The pruned candidate chains are then asynchronously routed to two downstream agents, a Diagnostic agent and a Verifica-tion agent, which together constitute “chain of unit-physics”. The Diagnostic Agent first performs preliminary checks (e.g. dependency installation) by automatically running code in the emulator, analyzing any errors, and applying targeted corrections. Subsequently, the Verification Agent applies formalized unit-physics tests to assess physical and numerical consistency. These primitives yield physics-grounded verification even without reference datasets. At each stage of the framework, the agent states and logs for different interactions persist in a graphbased database. The database stores the summarized execution and diagnostic logs for each code candidate on nodes, to avoid context-window limitations [5], while the edges define the logic route and transitions. If any candidate code cannot be corrected within a user-specified number of attempts, the complete error log and the candidate implementation are returned to the Supervisor Agent for updating the plan as needed, optionally incorporating human feedback. Finally, the agent consolidates the output into domain-relevant visualizations (for example, line graphs and contour graphs of key quantities of interest), closing the loop between natural-language inquiry and quantitative scientific insight.
The proposed framework is formally described as follows: let M be the decoder-only Transformer model with Q " TokenizepUserQueryq and U " TokenizepUnitPhysicsTestsq concatenated into the initial supervisor input I 0 " r Q; U s. The sandboxed execution operator Execp¨q returns a pair pR, Eq where R is the runtime output (or ∅ on failure or no valid output) and E is the error message (or ∅ if successful or no error message). Then the workflow is:
• Supervisor Initialization.
• Multi-Chain Code Decoding (Code Agent). For iter-ations t " 1, 2, . . . the supervisor produces a decoding prompt P t´1 and the code agent generates K candidate programs via multi-chain decoding:
where each chain k branches at the first token.
• Code Execution. For each candidate chain k:
• Diagnostics (Diagnostic Agent).
• Testing Against Unit-Physics (Verification Agent).
• Supervisor Plan Update. With optional external guidance H t :
• Termination & Final Output. If some chain k ‹ satisfies diagnostic and verification criteria:
otherwise, continue with iteration t `1.
• CoTDecode K pM, Pq: multi-chain decoding that branches on the first token and greedily completes K candidate programs under prompt P.
• Diag: diagnostic analysis of runtime behavior and errors.
• Verify: execution of candidate code against unit-physics tests U.
• Summarize: compression of execution and verification logs into a state S t .
• RefinepP, ∆Pq: update of the supervisor plan.
• Score: ranking function combining diagnostic and verification signals.
• PostProcesspRq: formatting, data manipulation, and visualization of the selected result.
Unit-physics primitives encode the first-principles constraints that a combustion expert would impose on any admissible thermochemical state. These constraints may be problemspecific (e.g., detonations vs. constant-pressure reactors) or generic to reacting mixtures, and are designed to be portable across mechanisms and numerical implementations (primitives are domain-portable). In contrast to conventional unit tests, which mostly compare implementation details against reference outputs, primitives enforce conservation, thermodynamic consistency, and physical consistency, and thus provide partial verification even when no ground-truth solution is available.
For example, in a problem consisting of a spatially homogeneous (zero-dimensional) reactor that integrates species mass fractions Y i , temperature T , pressure p, and density ρ, typical primitives include:
• Species mass conservation:
• Equation-of-state residual for an ideal mixture: ˇˇp ρRT { W ˇˇď ϵ, where W is the molecular weight of the mixture.
• Physical bounds:
ˇˇď ϵ between two states of the same closed system.
• Dimensional consistency of thermochemical quantities: h i in J kg ´1, ωi in kg m ´3 s ´1 for species enthalpy and mass production rate.
Similarly, for a one-dimensional Zeldovich-von Neumann-Döring (ZND) detonation structure [35,36,37], additional process-specific primitives supplement these generic checks. Denoting pre-and post-shock states by superscripts p1q and p2q and v " 1{ρ as specific volume, we impose:
• Rankine-Hugoniot energy closure:
ˇˇh 2 ´h1 1 2 pp 2 p1 qpv 2 ´v1 q ˇˇď ϵ.
• Chapman-Jouguet (CJ) condition at the equilibrium product state: Mach CJ " 1.
• Consistency of product states between ZND and equilibrium (HP) calculations: ˇˇˇT ZND ´T HP T HP ˇˇˇď ϵ and ˇˇχ ZND i χHP i ˇˇď ϵ for major species mass or mole fractions χ i . These primitives can be enforced during both synthesis and evaluation of agent-generated codes, providing thermochemically grounded verification signals even in the absence of curated reference datasets. Within the AI framework, they may be supplied either as natural-language descriptions or as a structured JSON specification that is parsed into executable checks.
This study will consider a canonical reactor-design problem (prompt shown below) to calculate the ignition delay time (IDT) for two different types of systems: 1. Closed-weight models and 2. Open-weight models. Although the Cantera library [38] provides built-in routines to perform this calculation, the system is deliberately prompted to implement the time integrators directly for the full N `1 degree-of-freedom (dof) problem (12 dofs for H 2 ), rather than calling these high-level functions. The fundamental nature of this task makes it well suited to illustrate why unit-physics must be explicitly encoded in the system, and the same lesson extends to analogous problems in other scientific domains. Since this is a domain-specific realistic problem with nontrivial numerical constraints and the available benchmarks do not resolve such fine-grained combustion physics or numerical aspects, there is limited information on the model behavior here. The present case therefore serves as a proxy for real engineering problems that fall outside standard benchmark coverage. The closed-weight models are evaluated using their APIs, and open-weight models are distributed on 4 NVIDIA H100 GPUs based on workload.
You need to develop an ignition delay calculator for different fuels. They key here is to provide an explicit Euler or RK scheme to integrate states and using Cantera lib in python. STRICT: You cannot use Cantera’s reactor functions. You can only obtain gas object related properties from Cantera. For starters you can use fuel as hydrogen at temperature of 1300 Kelvin at pressure of 101325 Pa for stoichiometric composition.
First, closed-weight models such as ChatGPT [39], Claude Sonnet 4.5 [40] and Gemini 2.5 Pro [41] are tested for the given reactor prompt. All models have CoT, have access to local Python emulator to verify the codes 1 and can access the Web during script generation. The results in the upper half of Table 1 show that none of the evaluated models produced the target code, and detailed analysis highlights an incorrect understanding of ignition delay time, however, which does not impede code execution.
OpenAI ChatGPT: The function derivatives() that computes derivatives of state variables with time fails on execution. The code shown in the snippet exemplifies an API hallucination: it calls a nonexistent gas-object method (reported as int_enegries_mass), which is a clear syntax/API error based on Cantera documentation. An additional fundamental error lies in the process assumption: the model treats the evolution as a constant-pressure process rather than the intended constant-volume process. Furthermore, the model confidently suggests using gri30.yaml mechanism (CH 4 focused) for H 2 combustion as it will contain relevant reactions. 1 Codes to be released after paper is accepted.
Code snippet from ChatGPT: derivatives() . . . # mass fractions Y = s_massdens / rho # update gas state so Cantera returns consistent properties gas.TPY = T, P, Y # T [K], P [Pa], mass fractions Y # molar net production rates [kmol/m3/s], shape (n_species,) omega_dot = gas.net_production_rates # kmol / m3 / s # molecular weights [kg/kmol] W = gas.molecular_weights # kg / kmol # mass production rates [kg/m3/s] mdot = W * omega_dot # elementwise, kg/m3/s # specific internal energies of species [J/kg] u_species = gas.int_energies_mass Ð Error # mixture constant-volume specific heat [J/kg/K] cv_mix = gas.cv_mass # dT/dt from internal energy balance (closed homogeneous system) numerator = np.dot(u_species, mdot) # J/m3/s dTdt = -numerator / (rho * cv_mix) . . . Ð Error Anthropic Claude Sonnet: The model yields the most elaborate deliverables: an algorithmic data-flow outline, a report, and an instructions file, even though such artifacts were not requested in the prompt. This likely reflects internal prompt expansion or meta-scaffolding [42], where a smaller model expands the query with detailed problem specifications to reduce hallucinations. The model selects the correct reaction mechanism (h2o2.yaml), but the final code implementation was incorrect: during RK time integration, it produces a negative temperature, indicating numerical/physical instability. After an expert review of the code and additional tests with smaller time steps, a second issue (similar to ChatGPT’s code) was identified: the gas state was being set using an incompatible combination of thermodynamic formulation. The code snippet shows a function that is formulate by the model to update states for a constant volume system, but it currently applies a constantpressure energy formulation which is highly incorrect. Instead of using species enthalpies (h k ) and c p , it should use species internal energies and mixture c v . Thus, even if the RK step had succeeded, the incorrect state-setting logic would have caused a subsequent failure. Google Gemini: In comparison to other models, Gemini did capture the correct process (constant-volume) assumption but fails at input initialization, requesting a mechanism file, h2_gri30.yaml, that does not exist. Upon manually fix- Since the focus is on AI systems, we also evaluate agentic deployments of these models (see Table 1). The agentic variants: Codex [6] and Claude Code [43] exhibit the same failure patterns observed in their base models -given that the agent orchestrations are layered on the same underlying models despite having access to Web. The Claude Code agent ignores the instruction to implement an Euler integrator, instead providing only an RK4 scheme with faulty adaptive time-stepping logic and the same thermodynamic inconsistency observed for Sonnet 4.5. Additionally, the Codex agent repeats the same syntactic mistake as the GPT model. The agents systems are able to navigate and work with files in local directories, creating requested files in the correct locations, but still end up generating erroneous code. Essentially, workflow or agentic system does not remediate core model/API errors as observed previously. Furthermore, across models and systems, we observe a systematic mechanism mis-specification: the code tends to default to gri30.yaml even for H 2 fuel, which undermines fidelity from the outset. Despite being trained by different companies, the models select mechanisms based on what is most documented and frequently co-occurs with terms such as “Cantera” and “ignition,” not on physical fidelity, so they all tend to converge on the same overrepresented mechanism in their training data distribution.
Collectively, these outcomes illustrate four recurring error classes in agentic code synthesis for scientific workflows: (i) interface hallucinations (nonexistent methods/attributes), (ii) over-assumption about scientific process (hard assumptions that do not translate to correct codes), (iii) numerical and physical incoherence (instabilities such as negative T and misuse of thermodynamic state variables), and (iv) configuration fragility (missing files and unsuitable default mechanisms).
Open-weight models include the Llama (sampling temperature of 0.6) and OSS models (sampling temperature of 0.3 and reasoning effort set to medium), and are accessed using the framework described in §2. Two types of tests are performed here: first with the standard model and second with model coupled to CoT decoding algorithm to improve program search efficiency. During both these tests, the models do not have access to the Web or a python emulator. From top row of Table 2, across all models, the synthesized codes2 fail on basic physics/API checks. Llama-3.3-70B produces NaN states during the RK4 step, indicating numerical/physical instability during the integration process. Adding CoT does not fully resolve such errors; while output code executes, but the model instead misdefines IDT (defined by the model as the time when TěT+100), a conceptual or semantic error that runs the code but produces the wrong output. OSS-20B without CoT already fails at input handling and state initialization: it invokes an invalid Cantera call and overwrites the gas state in two incorrect ways: (i) treating mole fractions as mass fractions and (ii) calling the wrong function for setting for mass fractions. With CoT enabled, the failure mode shifts to inconsistent thermodynamics: the model implicitly treats the scalar gas.enthalpy_mass as a species-resolved vector, producing a temperature derivative of the wrong shape (see code snippet). Overall, CoT shifts the dominant failure mode from calling nonexistent functions to misusing valid APIs-an improvement, but still insufficient. Hence, one CoT-based model is marked ‘partially successful’: the codes executed without any API errors, but the IDT compute logic was incorrect. We also note the same mechanism mis-specification (use of gri30.yaml for H 2 fuel) in these tests as well.
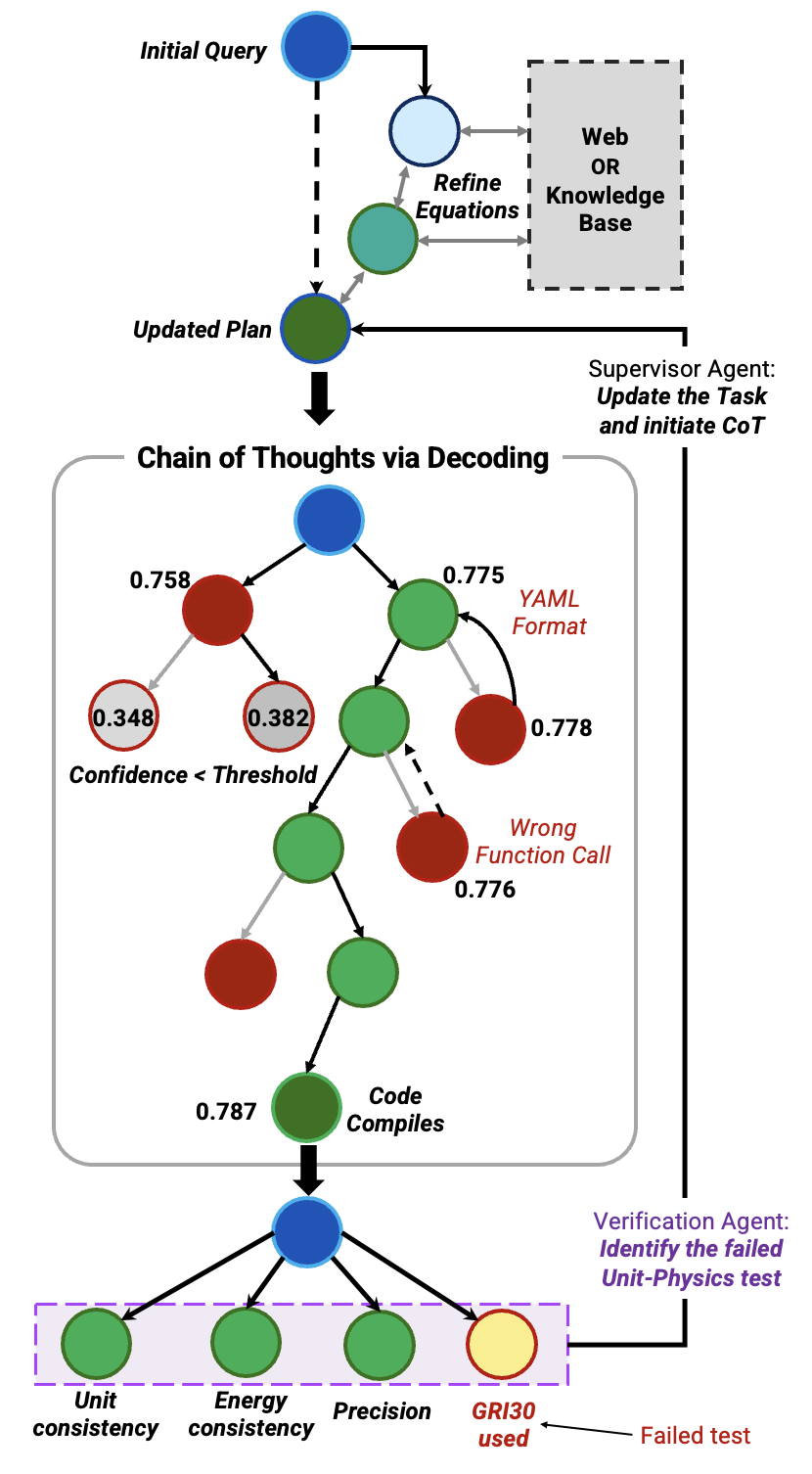
The primitives-based AI system successfully synthesized the correct solution. Llama-3.3-70B model (sampling temperature of 0.6) supervised planning and tool use, while task-specific coding agents were instantiated with OSS-20B (sampling temperature of 0.3 and reasoning effort set to medium) for its codegeneration proficiency. The system operated on a retrieval budget (at most two web queries), limiting dependence on external search and consistent with other evaluations in this study. Figure 3 summarizes the workflow as a state graph focusing on the solution and not agent blocks, where each node (colored circle) is a state or CoT step annotated with its confidence score (if available). Following the method in §2, the initial query is passed to the supervisor agent that performs targeted fact/equation checks, formulates a plan, and communicates specific coding instructions to a code agent that explores four parallel candidates (one per GPU). The CoT states (in Fig. 3) record progressive fixes across candidates-for example, correcting the Cantera mechanism format from .cti to .yaml. Candidates with confidence below 0.4 (user-defined) are pruned (gray states) and remaining candidates are passed to the Diagnostic agent. This agent performs an initial sanity check by executing the code and resolving issues relating to dependencies before proceeding, if needed. In our setup, the Python environment intentionally did not include Cantera. On execution, the agent correctly captured the traceback ModuleNotFoundError: No module named ‘cantera’. As a diagnostic repair, it issued a single command, !pip install cantera, to resolve the error 3 . Once the Diagnostic agent checks a candidate, the Verification Agent enforces the human-defined unit-physics tests. One primitive initially failed due to a mis-specified reaction mechanism (as shown). This failure is logged and stored in the graph database, and then fed back to the Supervisor Agent, which updates the plan and triggers another iteration. The system requires roughly 5-6 iterations to synthesize code that satisfies all checks. After these corrections, the primitive-grounded code runs successfully, yielding an IDT of 1.13179e-05 s. For statistical insights, this test case is repeated five times, obtaining four successful runs and one case where the system exhausts its iteration budget before converging.
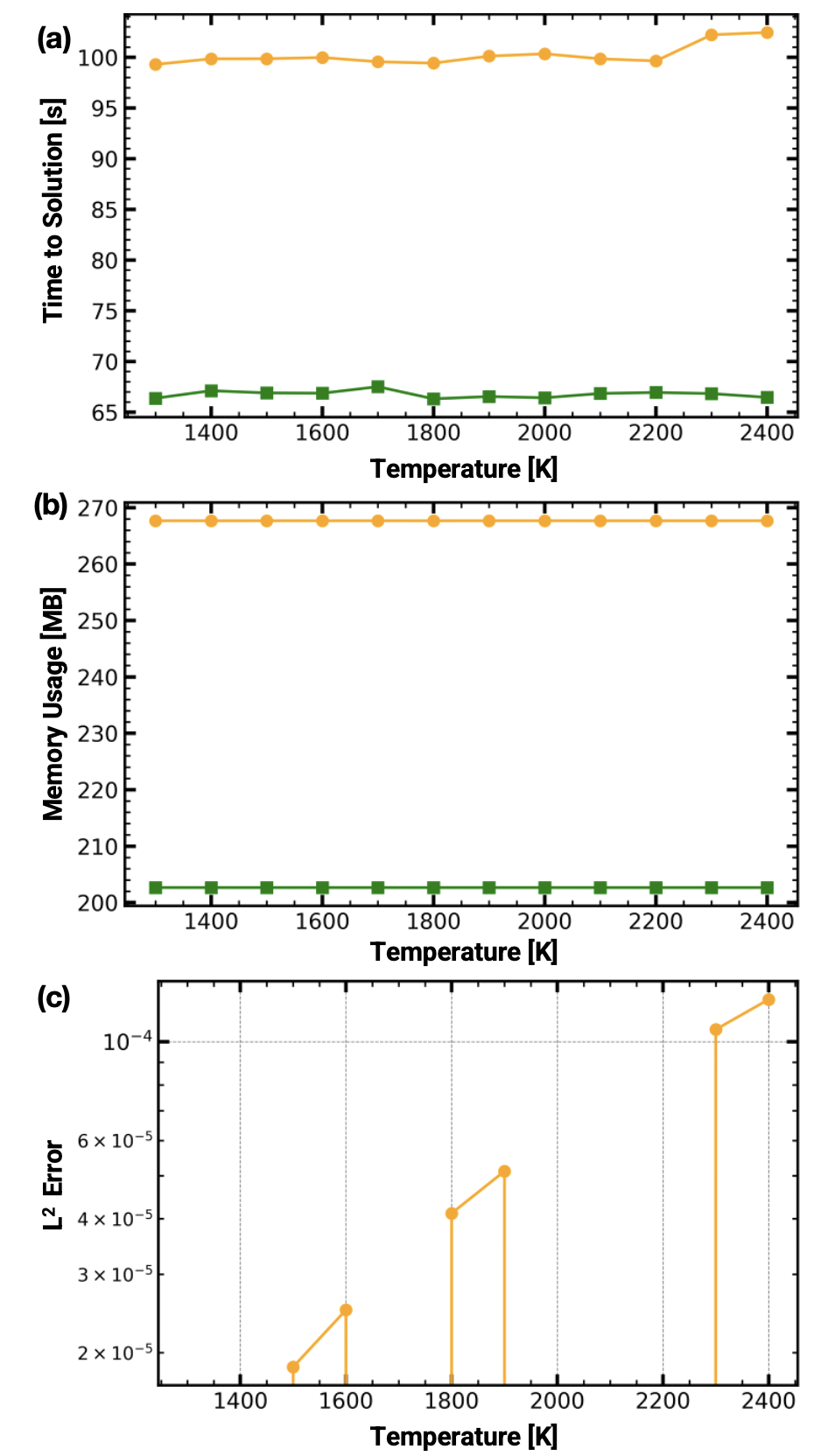
The code produced by the framework is evaluated against a reference implementation developed by a human expert and compared in three dimensions: (1) execution time, (2) memory usage, and (3) L 2 error. The representative chemical conditions with ϕ " 1 and p " 1 atm with H 2 -O 2 combustion and numerical conditions of dt " 1e ´10 with RK4 integrator are fixed and only the input temperature is varied from 1300 to 2400 K.
Figure 4 compares the performance of the proposed framework (green) with a reference code developed by a human expert (orange). In terms of runtime [plot (a)], the human-expert code consistently achieves a longer time to solution-on the order of 32-34s (33.4% on average) slower across the temperature range-indicating that the framework implementation is more optimized for wall-clock performance. The performance of the AI code can be attributed to using vectorized energy evaluations instead of explicitly looping over each species. Additionally, the proposed framework is more memory efficient [plot (b)], reducing peak memory usage from roughly 270 MB for the human code to about 200 MB (reduction of nearly 30%), with only weak dependence on temperature. The accuracy of the generated solver is quantified by the L 2 error between the two solutions [plot (c)]. The error remains below 10 ´4 for all tested temperatures (mean relative error of 3.1 ˆ10 ´3%), with absolute match for some temperatures and a modest increase at higher temperatures, demonstrating that Chain of Unit-Physics closely reproduces the human-expert solution while trading a small increase in runtime for a substantial reduction in memory usage. Upon additional code review, the improved memory footprint of Chain of Unit-Physics arises from the way the AIgenerated code organizes data: state variables are packed into a single contiguous structure rather than being split across multiple arrays and objects, which reduces overhead and allocator fragmentation. The slight slowdown in runtime was expected due to additional safeguard introduced by the model, an internal high temperature-bounds check (T ě 4000 K) that is frequently evaluated during the integration, however the vectorized approach offsets the time lost in checks. This extra validation step improves robustness, but adds a small computational penalty (“5s) relative to human-optimized implementation.
The economic competitiveness and cost profile of the proposed framework are summarized in Table 3. For the reference reactor task, Codex v0.44.0 consumes 352297 input and 16098 output tokens at a total API cost of $0.25, while Claude Code v2.0.5 uses substantially fewer tokens (32110 / 2796) and therefore incurs a lower absolute cost of $0.07. Normalizing by token count, however, reveals that Claude Code is actually more expensive on a per-token basis than Codex, so its apparent advantage is due primarily to greater token efficiency rather than cheaper pricing. In contrast, the proposed Chainof-Unit-Physics framework processes 225502 input and 25382 output tokens on local GPUs, yielding a comparable or larger token budget than the commercial systems. The agent-level average token usage further indicates that most of this budget is concentrated in the Supervisor, Code, and Verification agents, with the Diagnostic agent contributing relatively less to the usage. These trends are consistent with the intended roles of the agents: the Supervisor oversees the entire process and therefore consumes the largest share of tokens, while the Code and Verification agents repeatedly iterate over the code once the Diagnostic agent has resolved dependency issues during the initial iterations.
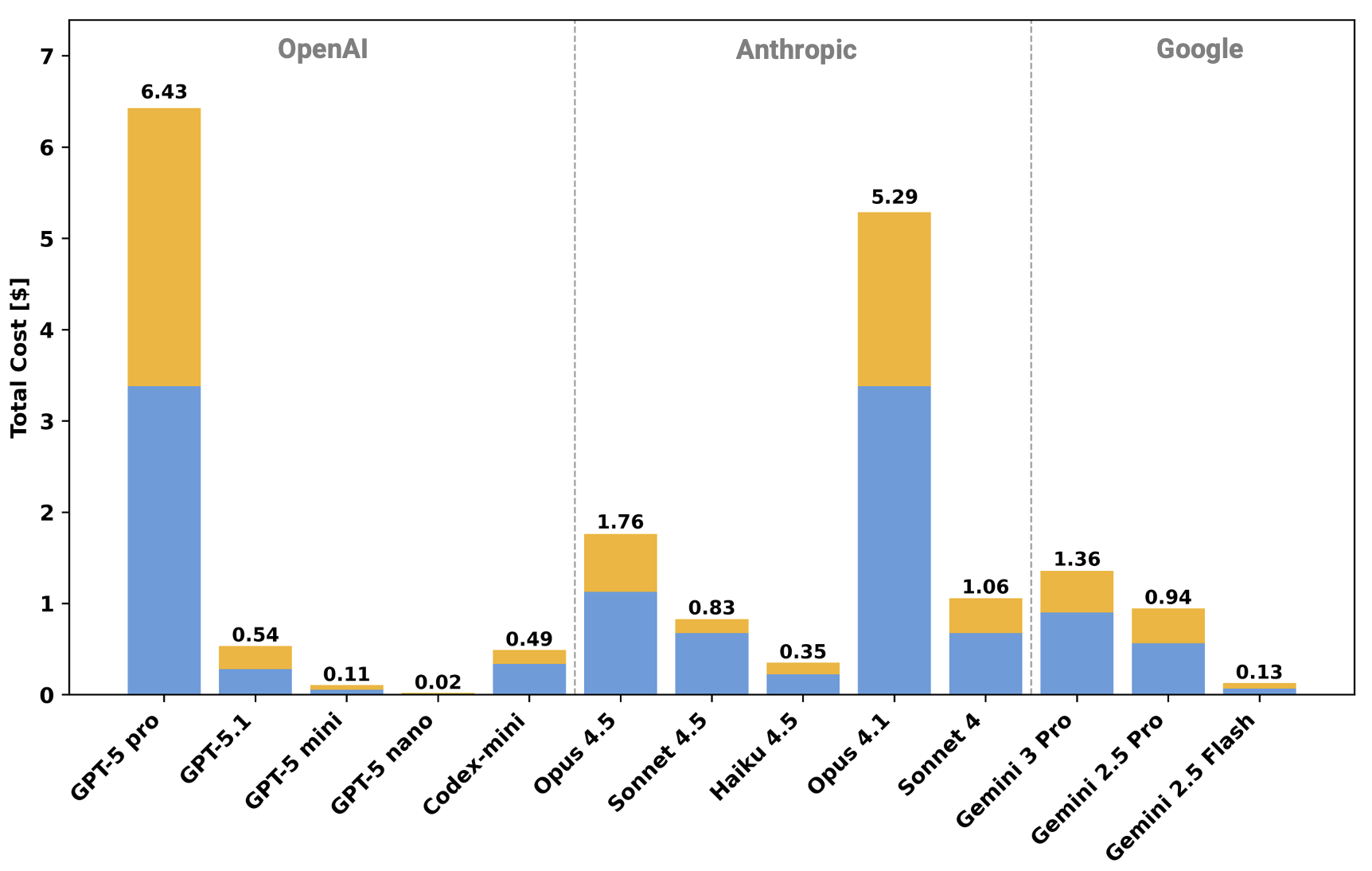
To further contextualize the API cost of the proposed framework relative to commercial providers, Fig. 5 breaks down the projected cost for different model variants. For the fixed Chainof-Unit-Physics workload, the resulting API cost spans more than two orders of magnitude across providers. Among Ope- nAI and Google models, lightweight variants such as GPT-5 nano and Gemini 2.5 Flash are the most economical, at approximately $0.02 and $0.13 per run, respectively, while mid-sized models (GPT-5 mini, Codex-mini, Sonnet 4.5, Haiku 4.5, Gemini 2.5 Pro) fall in the $0.1-$1 range. In contrast, frontier chat models such as GPT-5 pro and Anthropic Opus are substantially more expensive, at $6.43 and $5.29 for the same token budget. Since Chain-of-Unit-Physics is implemented with midsized models, its effective cost is in the same regime as the midsize hosted APIs, while remaining up to two to three orders of magnitude cheaper than the highest-end commercial offerings. Moreover, the Codex and Claude Code systems did not produce fully correct solutions for this task, so any practical deployment of those systems would likely require multiple retries or additional verification steps, further increasing their effective cost. Collectively, these observations suggest that the proposed framework is cost-competitive with commercial baselines for this workload, and that further gains in cost-effectiveness might come from techniques such as KV-cache compression [44] or batch prompting [45] than from fundamental changes to the overall concept.
This work examined ignition-delay computation for hydrogen combustion as a representative, high-stakes scientific task for agentic code generation. Closed-weight systems equipped with web access failed to produce a correct end-to-end solution. The experiments reveal four recurring error classes in agentic scientific coding: (i) interface hallucinations (nonexistent methods or attributes), (ii) overconfident assumptions about the scientific process (hard-wired logic that does not implement the correct algorithm), (iii) numerical and physical incoherence (e.g. invalid thermodynamic states), and (iv) configuration fragility (missing files or unsuitable default mechanisms). Across providers, models tended to select the same reaction mechanism, driven by its prominence in online documentation and frequent co-occurrence with “Cantera” and “ignition,” rather than any explicit consideration of physical fidelity. Openweight models display the same pattern: CoT decoding reduces interface hallucinations, but mainly shifts errors toward misuse of valid APIs.
The proposed Chain of Unit-Physics framework attains a correct solution in 5 to 6 iterations for the same ignition-delay problem; measured across five independent runs, four converged, and the remaining failure was attributable to an externally imposed token budget rather than to a modeling error. Performance analysis shows that the generated code closely matches the human-expert reference (L 2 error below 10 ´4), with approximately 33.4% faster runtime and using about 30% less memory, a gain attributable to more compact data handling. When the same token budget is priced under different provider tariffs, the framework places in the cost band of midsized hosted models (on the order of $0.1-$1 per run), while avoiding excessive retries and verification passes that might be necessary for closed-model-based agents.
Overall, the results indicate that current agentic systems, even with tools and web access, are not yet reliable for this class of scientific workflow, and that embedding expert-designed unit-physics primitives as constraints is an effective way to improve reliability without sacrificing economic plausibility. The central idea is the use of portable physics and numerical primitives as an organizing scaffold for code search, rather than any specific underlying model family. This primitives-centric design offers a new horizon for human-AI collaboration in scientific computing: expert constraints define the admissible solution space, models search within that space, and resulting failures remain interpretable enough to train subsequent models. Future research should quantify how unit-test relaxation affects search and incorporate iterative refinement of the unit-physics tests in situ, allowing the tests themselves to evolve within the code-generation cycle as new failure modes are discovered. Another direction for future work is to systematically evaluate influence of sampling temperature, an aspect not explored in the present study.
Code snippet from Gemini: calculate_derivatives() . . . try: gas.TPY = T, P, Y except Exception as e: # Handle cases where the state is invalid (e.g., T < 0) print(f"Error setting Cantera state: {e}”) # Return zeros to avoid crashing the solver return np.zeros_like(y_state) . . . Ð Error
a Agent token count is averaged over successful runs.
Codes to be released after paper is accepted.
Execution privileges are explicitly granted for these runs; such commands should be used with caution.
📸 Image Gallery