Optimizing Generative Ranking Relevance via Reinforcement Learning in Xiaohongshu Search
📝 Original Info
- Title: Optimizing Generative Ranking Relevance via Reinforcement Learning in Xiaohongshu Search
- ArXiv ID: 2512.00968
- Date: 2025-11-30
- Authors: Ziyang Zeng, Heming Jing, Jindong Chen, Xiangli Li, Hongyu Liu, Yixuan He, Zhengyu Li, Yige Sun, Zheyong Xie, Yuqing Yang, Shaosheng Cao, Jun Fan, Yi Wu, Yao Hu
📝 Abstract
Ranking relevance is a fundamental task in search engines, aiming to identify the items most relevant to a given user query. Traditional relevance models typically produce scalar scores or directly predict relevance labels, limiting both interpretability and the modeling of complex relevance signals. Inspired by recent advances in Chain-of-Thought (CoT) reasoning for complex tasks, we investigate whether explicit reasoning can enhance both interpretability and performance in relevance modeling. However, existing reasoning-based Generative Relevance Models (GRMs) primarily rely on supervised fine-tuning on large amounts of human-annotated or synthetic CoT data, which often leads to limited generalization. Moreover, domain-agnostic, free-form reasoning tends to be overly generic and insufficiently grounded, limiting its potential to handle the diverse and ambiguous cases prevalent in open-domain search. In this work, we formulate relevance modeling in Xiaohongshu search as a reasoning task and introduce a Reinforcement Learning (RL)-based training framework to enhance the grounded reasoning capabilities of GRMs. Specifically, we incorporate practical business-specific relevance criteria into the multi-step reasoning prompt design and * This work was conducted during Ziyang's internship at Xiaohongshu.📄 Full Content
The rapid progress of Large Language Models (LLMs) in industrial applications [12,27] has sparked the development of Generative Relevance Models (GRMs) [37]. By keeping LLMs’ output head and leveraging their generative capabilities, GRMs enable more flexible and interpretable relevance assessments. Existing GRMs fall into two main categories: (1) Vanilla GRMs, which generate a single token (e.g., “Yes” or “No”) to indicate relevance [11]. However, such single-token decisions impose a strict token budget that limits semantic elaboration, leading to suboptimal performance in complex relevance scenarios. (2) Reasoning-based GRMs, which incorporate Chain-of-Thought (CoT) reasoning [24] before producing relevance judgments [13,25], and have demonstrated promising results in vertical domains such as e-commerce search [23,36]. Despite their success, these reasoning-based models predominantly rely on Supervised Fine-Tuning (SFT) using costly human-annotated or synthetic CoT data distilled from advanced LLMs [23,36], which are data-intensive and exhibit limited generalization [3]. Moreover, relevance modeling in open-domain search remains particularly challenging due to the diversity of user queries and the prevalence of ambiguous search cases for which domain-agnostic, free-form reasoning fails to yield clear relevance judgments. Additionally, unlike vertical search domains enriched with structured signals (e.g., product brands and categories), open-domain search must operate over unstructured content, which significantly increases the difficulty of CoT reasoning and undermines its consistency and reliability in the absence of domain-specific guidance [6].
In this work, we formulate relevance modeling in Xiaohongshu search as a reasoning task and introduce a new Reinforcement Learning (RL)-based training paradigm that enhances the grounded reasoning capabilities of GRMs, yielding substantial improvements in both interpretability and performance (see Figure 1). To overcome the limitations of domain-agnostic reasoning in opendomain search, we incorporate domain-specific relevance criteria-accumulated through years of Xiaohongshu search system development-directly into the multi-step reasoning prompt design. By injecting these well-established decision rules, particularly those tailored for challenging or ambiguous cases, we guide the model’s reasoning process with critical prior knowledge, thereby aligning its relevance judgments more closely with real-world user expectations. To ensure that the model effectively internalizes these criteria, we further propose Stepwise Advantage Masking (SAM), a lightweight process supervision strategy that improves credit assignment in RL2 (see Figure 2). SAM employs a rule-based verifier over intermediate reasoning steps to provide targeted supervision and distribute rewards more accurately along the reasoning trajectory. This efficient approach eliminates the need for expensive full-trajectory human annotations [10] or highly computational Monte Carlo-based online value estimation [8], making it a practical process-supervised RL solution for industrial systems.
To enable practical deployment, we adopt a distillation-based approach to adapt our large-scale RL-tuned model for Xiaohongshu’s search production environment. Extensive offline experiments on industrial datasets, along with online A/B tests, demonstrate that our approach consistently outperforms strong baselines and offers a practical design paradigm for RL-based relevance modeling.
Our key contributions are summarized as follows:
• We formulate relevance modeling as a reasoning task and introduce a novel RL-based training paradigm that achieves stronger generalization than the data-intensive SFT baseline. Step 1: … \boxed{1}
Step 2: … \boxed{2}
Step 3: … \boxed{2} 1 O
Step 1: … \boxed{2}
Step 2: … \boxed{1}
Step 3: … \boxed{1}
Step 1: … \boxed{2}
Step 2: … \boxed{2}
Step 3: … \boxed{2}
Stepwise Advantage Masking A 1 (step 2) < 0 A 1 (step 3) < 0 A 2 (step 1) > 0 A 2 (step 2) > 0 A 2 (step 3) > 0
A n (step 1) = 0 A n (step 2) > 0 A n (step 3) > 0 . . . The rapid advancement of LLMs has shifted relevance modeling from traditional discriminative classification [14,28,39] to generative paradigms (i.e., GRMs) [21,38]. GRMs exploit the text generation capabilities of LLMs to assess query-item relevance in a more flexible and interpretable manner. Early GRMs follow a pointwise scoring strategy, deriving relevance from the likelihood of specific token outputs (e.g., “Yes” or “No”) [9,38]. Recent progress introduces ranking-oriented prompting strategies that support pairwise [15] and listwise [21] comparisons, benefiting from LLMs’ instruction-following abilities. To further enhance relevance assessment, CoT prompting has been incorporated into GRMs [13,25], enabling multi-step reasoning akin to human judgment. However, existing reasoning-based approaches either depend on SFT with costly collected reasoning paths [23,25,36], which may generalize poorly to long-tail queries, or adopt outcome-based RL [34,40] without fine-grained supervision of intermediate reasoning steps, leading to suboptimal reasoning chains. In contrast, we introduce a process-supervised RL framework that performs step-level credit assignment, yielding more grounded reasoning trajectories and significantly improving robustness in ambiguous search scenarios.
Recent advances in relevance modeling highlight the importance of incorporating explicit criteria to guide ranking decisions. Early relevance criteria are often formulated as information retrieval axioms, which define desirable ranking properties through formal mathematical constraints to guide the design of ranking models. Prior work demonstrates the benefits of augmenting neural rankers with axiomatic regularization during fine-tuning [17], while ARES [1] further embeds these constraints into the pre-training phase to enhance ad hoc retrieval performance. Other efforts leverage axiomatic perturbations to synthesize training data that improves neural ranking [2]. With the emergence of LLM-based ranking, the notion of relevance criteria has evolved from rigid symbolic axioms to natural-language formulations. MCRanker [6] introduces automatically generated multi-perspective criteria to guide zero-shot pointwise LLM rankers during inference. In the medical domain, Zeng et al. [32] constructs disease-specific synthetic criteria to enhance the consistency and interpretability of LLM-based doctor ranking. However, automatically induced criteria often suffer from semantic drift, limited domain reliability, and insufficient alignment with real-world user intent. Unlike prior work, our approach leverages high-precision, expert-curated relevance criteria accumulated through years of industrial development at Xiaohongshu search. These criteria inherently reflect authentic intent patterns and ambiguity-resolution strategies observed in real search scenarios, providing stronger practical grounding and reliability than synthetic alternatives. To operationalize such criteria within LLMs, we further employ process-supervised RL training, enabling the model not only to memorize the rules but also to apply them coherently during step-by-step reasoning.
Relevance modeling in Xiaohongshu search is defined as a multiclass classification task, whose objective is to assign a discrete relevance label 𝑦 ∈ {-1, 0, 1, 2, 3} to each query-note pair (𝑞, 𝑛).
Each label corresponds to a distinct level of semantic relevance, ranging from strongly irrelevant (-1), irrelevant (0), weakly relevant (1), partially relevant (2), to perfectly relevant (3). The annotation scheme is derived from human judgments made by trained evaluators, following detailed guidelines that account for search intent alignment, topical consistency, expected user engagement, and other relevance-related dimensions.
This section outlines our RL-based training paradigm. Section 4.1 reformulates relevance modeling from a generative perspective, enabling the model to jointly produce reasoning traces and final assessments. Section 4.2 introduces our criteria-augmented prompt design, while Section 4.3 presents a distillation-driven cold-start initialization that stabilizes subsequent RL training. Finally, Section 4.4 details our process-supervised RL framework and its Stepwise Advantage Masking (SAM) mechanism, which further improves reasoning fidelity and quality.
In this work, we formulate relevance modeling in Xiaohongshu search as a reasoning task rather than a direct prediction problem. To achieve deeper semantic understanding and provide interpretable decision paths, we introduce a generative relevance model 𝜋 𝜃 that first performs structured reasoning to produce a reasoning trace o = (𝑜 1 , 𝑜 2 , . . . , 𝑜 𝑇 ), and then derives the final relevance label l based on this reasoning process. Given a dataset D = {(𝑝 (𝑖 ) , 𝑞 (𝑖 ) , 𝑛 (𝑖 ) , 𝑙 (𝑖 ) )} 𝑁 𝑖=1 , where 𝑝 is the task prompt (instruction), 𝑞 is the query, 𝑛 is the note, and 𝑙 is the golden relevance label, the reasoning trace o is generated in an autoregressive manner as:
Here, 𝜋 𝜃 (𝑜 𝑡 | 𝑝, 𝑞, 𝑛, 𝑜 <𝑡 ) denotes the probability of generating the 𝑡-th token in the reasoning trace, conditioned on the input (𝑝, 𝑞, 𝑛) and all previously generated tokens 𝑜 <𝑡 . The output o includes both the reasoning process and the predicted label l ∈ o. Our objective is to maximize the probability that the generated label matches the ground-truth label: max
where I(•) is the indicator function, and 𝑓 (o) extracts the final predicted label l from the generated reasoning trace o.
While recent advances in RL with verified rewards have demonstrated strong capabilities in mathematical reasoning [5], extending this paradigm to search relevance assessment remains fundamentally challenging. Mathematical and coding tasks are inherently objective, governed by universal axioms and formal logic. Since LLMs already acquire the foundational knowledge for such tasks during pretraining, RL can further enhance performance by promoting unconstrained reasoning grounded in this prior [31]. In contrast, relevance assessment is intrinsically subjective and domain-specific.
The relevance criteria are tightly coupled with the specific business context and user ecosystem of platforms like Xiaohongshu, especially in ambiguous search cases. Without specific guidance, You are a search relevance assessment assistant. You need to provide a relevance score among {-1,0,1,2,3} for the query and note. Your reasoning process will be divided into the following three steps:
Step 1: General Semantic Analysis query analysis, taxonomy matching, keyword matching, content proportion analysis, etc.
Step 2: Rule-based Upper Bound Analysis -Comparative queries: The query presents multiple comparison items.
-[Incomplete comparison information]: The query contains multiple comparison items, but the note only provides detailed information about one of the items. In this case, assign at most 1 point for relevance; -…
Step 3: Final Reflection and Judgment After synthesizing the above analysis process, reflect and make the final relevance judgment.
Please note that at each step, you must output a relevance score, which should be enclosed in \boxed{}. a model cannot reliably infer such nuanced criteria through unguided exploration, often leading to suboptimal performance. To bridge this gap, we leverage Xiaohongshu’s relevance criteria, a structured body of operational knowledge developed over years of search optimization. These criteria include general relevance principles defined by human experts, as well as specialized rules for handling edge cases, which together serve as pseudo-axioms to guide the model’s reasoning process. Building on these, we design a structured prompt (see Figure 3) that internally decomposes the relevance assessment into three interpretable reasoning steps:
(1) General Semantic Analysis: Following general relevance principles, the model conducts a high-level semantic comparison between the query 𝑞 and the note 𝑛, including query analysis, taxonomy and keyword matching, content proportion analysis, and more. This step produces an initial relevance score from a broad perspective. Notably, both Step 1 and Step 2 are capable of generating independent relevance estimates. However, these two estimates serve different purposes: the first provides an initial relevance assessment, while the second supplies an upper bound on the achievable relevance. In practice, the final relevance judgment is derived by combining the general assessment with the upper bound constraint obtained in the second step. See Appendix A for empirical validation of the proposed criteria-augmented prompt.
Preliminary experiments reveal that directly applying RL from a cold start leads to unstable reasoning behaviors: the model often fails to follow the multi-step instructions specified in our prompt. To mitigate this cold-start issue, we bootstrap the reasoning ability of GRMs through a SFT stage using synthesized reasoning traces. This warm-up step serves as actor initialization for the subsequent RL phase. Given each example (𝑝 ( 𝑗 ) , 𝑞 ( 𝑗 ) , 𝑛 ( 𝑗 ) , 𝑙 ( 𝑗 ) ) ∈ D distill , we prompt advanced LLMs to generate a structured reasoning trace ô(𝑗 ) using the multi-step prompt introduced in Section 4.2. This prompt enforces a three-step reasoning format, with intermediate boxed scores \boxed{} at the end of each step. To ensure highquality imitation learning, we employ rejection sampling: a reasoning trace is accepted only if the final predicted relevance label l (extracted from the third step of ô) matches the ground-truth label 𝑙. After filtering, the final distillation dataset is defined as
. We train the model by minimizing the Negative Log-Likelihood (NLL) loss:
This objective guides the model to accurately reproduce the reference reasoning traces under a teacher-forcing regime.
To overcome the data-intensive nature and limited generalization of SFT, we introduce RL to enhance the model’s grounded reasoning capabilities. Specifically, we treat the GRM 𝜋 𝜃 (• | 𝑝, 𝑞, 𝑛) as a policy model, and optimize the following objective: max
where 𝜋 ref is the reference model (i.e., the model before RL finetuning), R (o, 𝑙) is the reward function, D KL is the KL divergence, and 𝛽 is a hyperparameter balancing the task-specific objective with the KL regularization. (5)
4.4.2 Group Relative Policy Optimization. Group Relative Policy Optimization (GRPO) [19] is a variant of Proximal Policy Optimization (PPO) [18]. Instead of relying on a learned value function, GRPO normalizes rewards at the group level, leveraging the mean and standard deviation of multiple sampled outputs for each prompt. Recent studies have shown that GRPO achieves superior performance on verifiable tasks such as mathematical reasoning [5].
Given that our relevance task also falls into the category of verifiable problems, GRPO is a natural and well-suited choice for our setting. To optimize 𝜋 𝜃 with the objective Eq. ( 4), GRPO maximizes the following surrogate objective3 :
where Â𝑖,𝑡 is the advantage function estimated via group-based normalization:
with R = {𝑟 1 , 𝑟 2). Since the correctness of each reasoning step (𝑐 1 , 𝑐 2 , 𝑐 3 ) can be determined, we refine the application of the final advantage 𝐴 𝑡 , which is based on the outcome of 𝑐 3 , by selectively attributing it only to the reasoning steps responsible for the final outcome. Specifically: (1) If the final CoT prediction is correct ( l = 𝑙), we reinforce only the correct reasoning steps (i.e., those with 𝑐 𝑖 = True), while ignoring incorrect ones to avoid reinforcing spurious reasoning; (2) If the final CoT prediction is incorrect ( l ≠ 𝑙), we penalize only the incorrect steps (i.e., those with 𝑐 𝑖 = False), masking out correct steps to avoid punishing valid reasoning segments. Formally, we define a stepwise advantage mask 𝑚 𝑡 for each token 𝑡 in the reasoning chain as:
Here, step(𝑜 𝑡 ) denotes the reasoning step index to which token 𝑜 𝑡 belongs, determined by the boxed token positions. The final policy objective of SAM-augmented GRPO is given by:
where Â𝑖,𝑡 denotes the advantage computed from the reward at the third step of the CoT path, and m 𝑖,𝑡 is a binary mask that selectively modulates this advantage according to the correctness of step(𝑡). We provide a pseudo-code describing our proposed SAMaugmented GRPO, as shown in Algorithm 1. 1. We provide a detailed description of each dataset below:
• RANDOM: The queries are randomly sampled from a largescale online search system, and for each query, notes are selected from candidate note lists at various ranking positions. This design ensures that the dataset closely reflects the naturally occurring data distribution observed in practical deployments. Each query-note pair is manually annotated and has undergone multiple rounds of quality inspection. • LONGTAIL: This dataset adopts the same configuration and sampling strategy for note selection as RANDOM, but differs in the query selection process: the queries are sampled based on their page view (PV) statistics, focusing on those that receive fewer than five PVs within a single day. These longtail queries are inherently more challenging, demanding stronger semantic understanding for effective processing.
We use accuracy (ACC), macro F1, and weighted F1 as our evaluation metrics. In particular, we report both 5-class ACC and 2-class ACC. The 2-class ACC is included to better align with our practical application needs, where labels -1 and 0 are grouped into one category, and labels 1, 2, and 3 are grouped into the other. Reporting both metrics allows us to evaluate the model’s fine-grained classification capability while also reflecting its practical decision-making behavior in real-world search applications.
To construct the training dataset for our framework, we adopt the same query and note sampling strategy as used in the RANDOM benchmark. In total, we sampled 50K queries, each paired with 20 notes. 25 professionally trained annotators labeled 1M query-note pairs over three months. The overall label distribution is consistent with that of the RANDOM dataset. To obtain the initial CoT reasoning data, we employ DeepSeek-R1 [5] to generate reasoning traces using the proposed criteria-augmented reasoning prompt. Given that the raw reasoning outputs may be unreliable, we apply rejection sampling to retain only those traces whose final predictions are consistent with human annotations. Since the rejection sampling step inevitably alters the original label distribution, we slightly over-sample or down-sample certain instances to restore it to match the original dataset. This process yields 500K validated reasoning trajectories. To further enhance data quality in RL training, we introduce an offline difficulty estimation strategy based on avg@k. For each query-note instance, we compute avg@k as the average prediction accuracy obtained by sampling the initial policy reasoning path 𝑘 times:
Intuitively, avg@k serves as a proxy for decision-boundary stability, reflecting the intrinsic difficulty of an instance. We set 𝑘 = 64 in all experiments. Based on their avg@64 scores, we prune the training samples as follows:
• High-confidence samples: those with avg@64 > 0.97 (under the 5-class ACC setting) are discarded; • Low-confidence samples: those with avg@64 < 0.04 (under the 2-class ACC setting) are removed. This asymmetric pruning strategy is not heuristic but essential: high-confidence samples contribute negligible gradient signals in RL optimization, while extremely low-confidence instances often originate from annotation errors or semantically insufficient notes that destabilize training. By removing both extremes, we retain a dataset that preserves the original distribution while emphasizing informative, yet non-trivial reasoning samples. 5.1.3 Models. Our base model, RedOne [35], is an in-house posttrained version of Qwen2.5-32B-Instruct [16], further adapted to Xiaohongshu’s domain-specific search data. To enable systematic comparison, we evaluate RedOne across different SFT and RL training methods, as well as across different scales of training data.
• SFT-Label: • PPO-Reasoning: We apply the standard PPO algorithm to optimize SFT-Reasoning-v1 using learned value heads for token-level advantage estimation. This setup enables more fine-grained optimization than outcome-based RL but may introduce potential bias in value estimation [30]. • OutcomeRL-Reasoning: We adopt the standard GRPO algorithm to optimize SFT-Reasoning-v1 in an outcome-based manner. The accuracy of the final relevance prediction serves as the reward for group computation, which results in uniform credit assignment and prevents differentiation across different steps of the reasoning process. • ProcessRL-Reasoning (ours): We apply SAM-augmented GRPO to optimize SFT-Reasoning-v1, using partial advantage masking to enable step-level credit assignment and mitigate spurious reward propagation.
All RL-based methods are trained on the same 50k sampled training set, pruned using the avg@k-based offline difficulty estimation described in Section 5.1.2. The resulting dataset maintains a label distribution closely aligned with the RANDOM benchmark, ensuring fair and controlled comparisons across all RL variants. Additional implementation details can be found in Appendix B. 2, our proposed ProcessRL-Reasoning approach achieves the best overall performance across both benchmarks and all evaluation metrics. RQ1: Does reasoning hurt or help with SFT? We first compare the purely supervised baselines. The SFT-Label (trained on 200k label-only instances) provides a strong reference point, reaching 90.26/78.64 (2-ACC/5-ACC) on RANDOM and 89.11/77.66 on LONGTAIL. In contrast, the two supervised reasoning variants, SFT-Reasoning-v1 (150k CoT traces) and SFT-Reasoning-v2 (500k CoT traces), perform notably worse: even with more data, SFT-Reasoning-v2 only attains 83.04/63.06 on RANDOM and 81.15/63.55 on LONG-TAIL. This gap indicates that naively adding multi-step reasoning and training it with SFT alone does not automatically translate into better relevance modeling. Instead, it introduces additional optimization difficulty and error modes in the reasoning trajectory, which SFT alone cannot effectively correct. This observation challenges the implicit assumption held by recent GRM studies-that incorporating multi-step reasoning naturally improves ranking quality-highlighting instead that reasoning without proper optimization can be detrimental, which motivates us to introduce RL-based optimization to better harness multi-step reasoning.
RQ2: Can process-supervised RL truly enhance relevance reasoning? We compare three RL variants grounded on the same SFT-initialized reasoning model. All variants use identical data, prompts, and reward definitions, ensuring that performance differences stem solely from how each method attributes credit during optimization. PPO-Reasoning delivers substantial improvements over SFT-Reasoning-v1, but its reliance on value-function estimation introduces bias and unstable credit assignment, preventing it from fully exploiting the reasoning structure and leaving its performance close to the label-only baseline. In contrast, OutcomeRL-Reasoning removes the value head entirely and normalizes rewards at the group level, thereby avoiding value estimation errors and stabilizing policy optimization. As a result, it further boosts performance to 80.90 5-ACC on RANDOM and 77.03 5-ACC on LONGTAIL, mostly outperforming PPO across all metrics. However, outcomebased RL provides uniformly distributed advantages across all tokens within a trajectory, regardless of each step’s contribution to the final decision. Our ProcessRL-Reasoning addresses this limitation by introducing stepwise credit assignment via the proposed SAM mechanism, mitigating spurious reward propagation. The ProcessRL-Reasoning achieves the best overall performance-81.23 5-ACC and 73.55 Macro F1 on RANDOM, and 77.72 5-ACC and 66.39 Macro F1 on LONGTAIL-consistently surpassing both SFT and RL variants. These results confirm that step-level credit assignment via SAM provides consistent gains over outcome-only RL, especially on Macro F1, demonstrating improved robustness and generalization in realistic search scenarios.
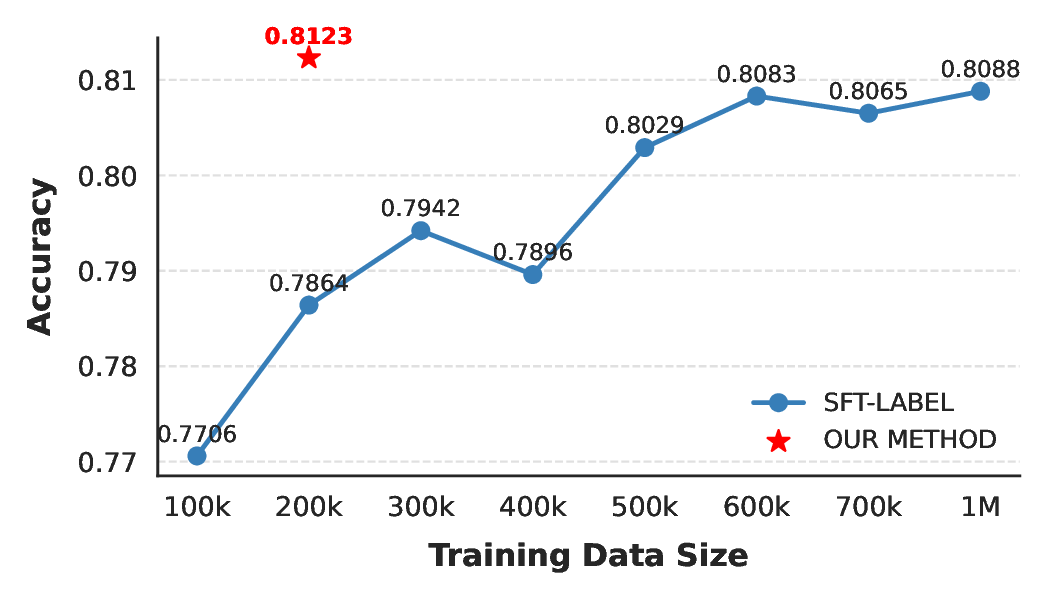
To assess the training efficiency of our proposed approach, we conduct an ablation study comparing the performance of ProcessRL-Reasoning against the SFT-Label method using varying amounts of supervised training data. Specifically, we sample subsets of the labeled training data, ranging from 100K to 1M examples, and evaluate the resulting 5-class ACC of the SFT model on the RANDOM benchmark. As shown in Figure 4, the SFT-Label baseline exhibits steady performance improvements as the training data size increases; however, its accuracy gains begin to plateau beyond 500K samples. In contrast, ProcessRL-Reasoning achieves superior accuracy with far fewer samples. Remarkably, ProcessRL-Reasoning outperforms the SFT-Label model trained on 1M samples, using only 150K SFT CoT samples and 50K RL samples in total. This improvement can be attributed to the enhanced reasoning capabilities incentivized by process-supervised RL, which enables better generalization by leveraging stepwise reasoning rather than relying solely on rigid pattern matching, as seen in traditional SFT. In practical terms, our method requires far less labeled data to achieve competitive performance, highlighting its superior data efficiency. However, it still benefits from high-quality, accurately labeled training data to ensure effective optimization during the RL phase, underscoring the importance of robust data annotation and filtering strategies-such as our use of avg@k-based difficulty estimation. From the perspective of the 5-class setting, the recall for the “1*” category improves through a general enhancement across labels 1/2/3, with only a slight sacrifice in precision for labels 2 and 3. Furthermore, ProcessRL-Reasoning shows significant improvements in both precision and recall for the minority classes (labels -1 and 1), demonstrating its strong ability to handle long-tail cases. This improvement in both precision and recall indicates that our method refines the decision boundary by optimizing the reasoning process itself, rather than simply learning input-output mappings. These results suggest that incorporating grounded reasoning-where the model relies on domain-specific relevance criteria-enables the model to capture subtle distinctions between fine-grained categories, leading to improved classification performance.
To evaluate the student model online, we deployed it on the Xiaohongshu A/B testing platform. We randomly sampled 5% of the online traffic as the test group and applied our proposed approach to this group. Another 5% of the traffic was used as the baseline group, which continued to rely on the previous BERT-based model. For a fair comparison, we continuously monitored the experimental results on the platform. To mitigate the impact of traffic fluctuations, we set a minimum testing period of seven days. Notably, we adopt the following two business metrics to evaluate online user experience:
• CES: CES is a core metric used to quantify user engagement on the platform. It aggregates user actions such as likes, favorites, comments, shares, and follows. A higher CES value indicates stronger user engagement and thus a better user experience. • DCG 0/1: DCG 0/1 is a key metric for evaluating ranking quality in search systems. In practice, a professional annotator manually reviews the top eight results from A/B experiments across 2,000 randomly sampled queries and labels each result as relevant or irrelevant. The metric counts the number of irrelevant results on the search result page, where a lower value indicates higher ranking quality and improved user experience. According to the results in Table 4, our approach achieves a 0.72% improvement in the CES metric, reflecting increased user engagement and an enhanced user experience. In addition, the DCG 0/1 metric shows a cumulative reduction of 0.36%, indicating fewer irrelevant results and improved ranking quality. Overall, these findings demonstrate that our approach significantly enhances both user experience and ranking relevance.
Over-Association and Reasoning Errors. We have identified overthinking as a key failure mode, especially when handling ambiguous user queries about TV shows or movie characters. For example, if a query refers to Drama A but the note actually concerns Character C from Drama B (played by Actor D), the model might incorrectly associate the query with Drama B, since Actor D is also the lead in Drama A according to its internal knowledge. This kind of spurious associative reasoning can sometimes lead to correct results in open-domain search, but it also risks generating false positives. To address this, we plan to implement reasoning confidence modeling and introduce a refusal mechanism, aiming to minimize false inferences and improve the accuracy and stability of the reasoning process.
Challenges in Criteria Adaptation. Our long-term goal is to train the model once and enable the business team to dynamically update criteria within the prompts, allowing the model to adapt to evolving business logic. We refer to this concept as Relevance LLM. This model would be capable of adjusting to changing business requirements by leveraging a set of continuously updated rules. However, our experiments show that the current RL-tuned model is overfitted to the fixed rule set used during training. When the rules are modified during inference, the model still tends to reason based on the original logic learned during training. We hypothesize this happens because the criteria system was static during RL training, without exposure to dynamic rule changes. Future work will focus on introducing dynamic criteria variations during training to improve robustness and reduce overfitting, ensuring the model can handle criteria modifications more effectively during inference.
Combining SAM with LLM-as-Verifier. In this work, we propose SAM, an intuitive process-supervised strategy that enhances outcome-based RL by enabling step-level credit assignment. The success of SAM relies on unbiased stepwise correctness judgments, achieved through exact matching in our scenario. However, such rule-based verification may not be feasible for more general reasoning tasks. With the rise of LLMs as generative verifiers [33], LLMs offer a powerful, domain-agnostic approach to verifying each reasoning step in a more flexible and generalizable manner. Combining SAM with LLMs as verifiers could present a promising direction for future research, allowing for more robust verification and credit assignment in general RL tasks. Xie et al. [26] has already conducted preliminary studies in this area.
In this paper, we introduce a reinforcement learning paradigm that formulates relevance modeling in Xiaohongshu search as a multi-step reasoning task. By integrating domain-specific relevance criteria into structured prompts and proposing Stepwise Advantage Masking (SAM) for step-level credit assignment, our method delivers grounded and interpretable relevance reasoning, especially in complex and ambiguous search scenarios. Extensive offline evaluations and online A/B tests demonstrate that our approach achieves significant improvements across key metrics, providing a practical solution for industrial relevance modeling.
GRPO (𝜃 ) using Eq. (9); Update policy parameters 𝜃 ← 𝜃 + 𝜂∇ 𝜃 J 𝑆𝐴𝑀 GRPO (𝜃 ); end return 𝜋 𝜃 ;
GRPO (𝜃 ) using Eq. (9
GRPO (𝜃 ) using Eq. (
Credit assignment refers to the problem of accurately attributing success or failure to individual actions within a sequential decision process, particularly when rewards are sparse or delayed[22].
Note that this is the on-policy version of the GRPO objective.
𝑠 3 is exactly l.
📸 Image Gallery