VLASH: Real-Time VLAs via Future-State-Aware Asynchronous Inference
📝 Original Info
- Title: VLASH: Real-Time VLAs via Future-State-Aware Asynchronous Inference
- ArXiv ID: 2512.01031
- Date: 2025-11-30
- Authors: Jiaming Tang, Yufei Sun, Yilong Zhao, Shang Yang, Yujun Lin, Zhuoyang Zhang, James Hou, Yao Lu, Zhijian Liu, Song Han
📝 Abstract
https://github.com/mit-han-lab/vlash Figure 1. VLASH enables VLA to play ping-pong rallies with humans. Snapshots showing 𝜋 0.5 [16] with VLASH successfully tracking and striking a fast-moving ping-pong ball during a rally. The robot initiates its reaction by the third frame, demonstrating low-latency perception-to-action response. The task requires both fast reaction and smooth continuous motion, which are enabled by our asynchronous inference with future-state-awareness. Under synchronous inference, the robot fails to achieve this dynamic interaction.📄 Full Content
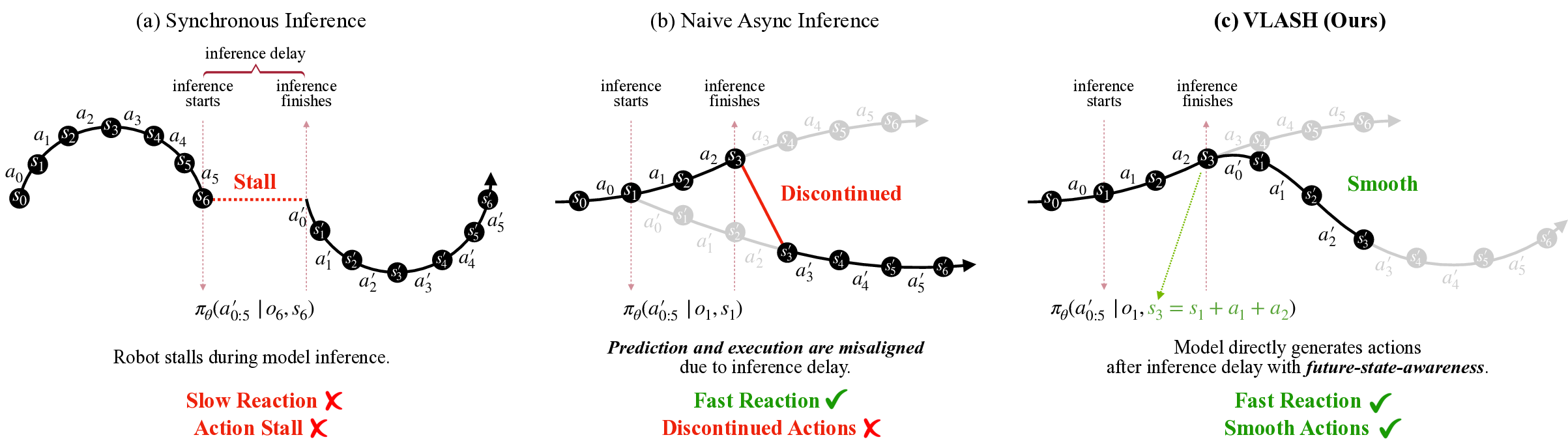
To prevent this stop-and-go behavior, researchers have proposed asynchronous inference [4,24,29,31]. In a nutshell, asynchronous inference allows the robot to execute the current action chunk while simultaneously performing n Models (VLAs) inference for the next one. Because the execution duration of an action chunk is typically longer than the model inference time, the robot can immediately switch to the next chunk once the inference completes, avoiding idle period between chunks [4,24,29,31]. This design eliminates action stalls and allows the robot to perform smooth, continuous motion. Moreover, since inference is performed continuously, the robot can maintain real-time perception and thus react to environmental changes more promptly and accurately [4,24]. In summary, asynchronous inference provides a promising way to achieve smooth, accurate, and fast reaction control for VLAs.
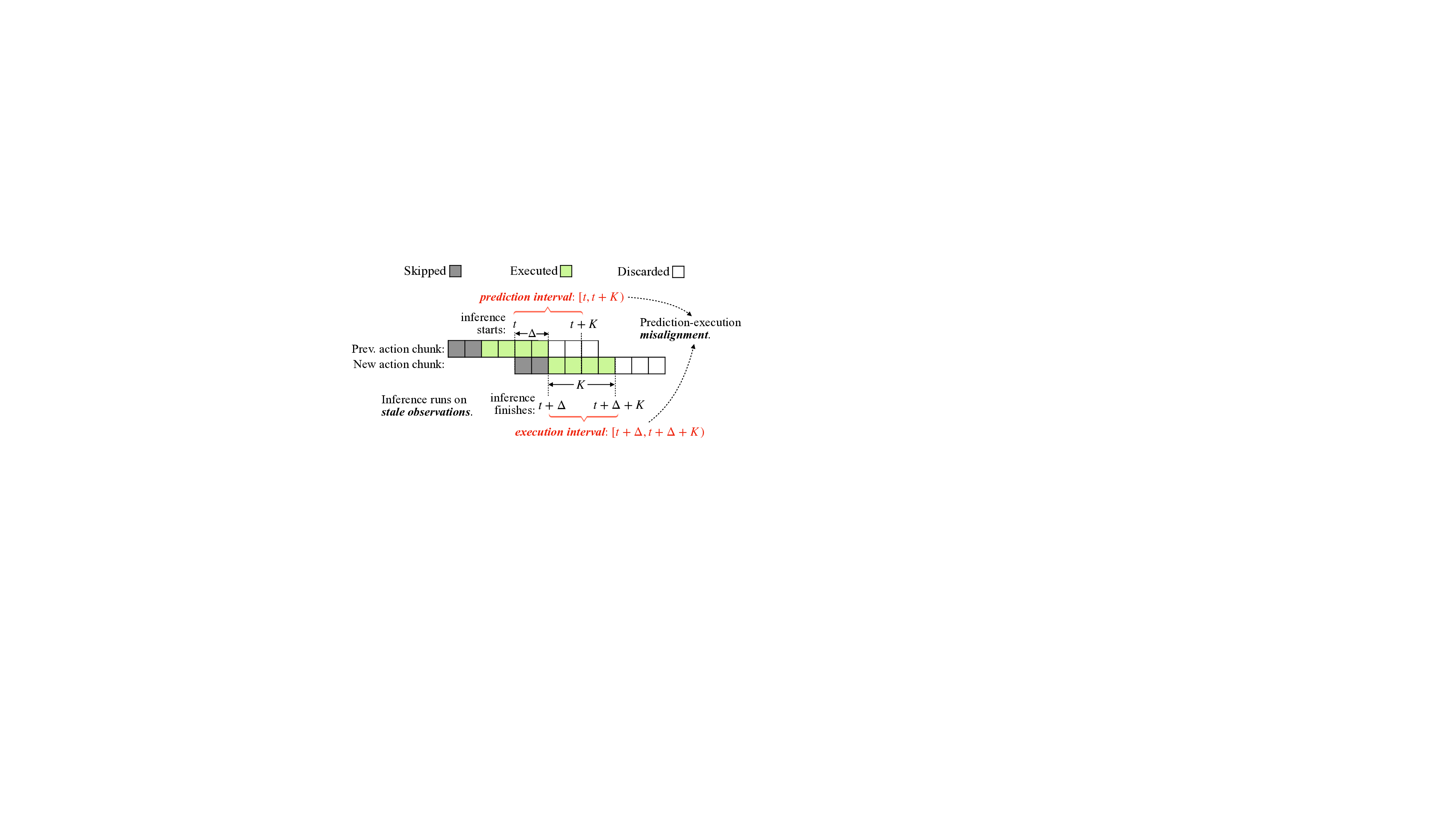
However, asynchronous inference faces a fundamental challenge that makes it unstable and inaccurate in practice. Since both the robot and the environment continue to evolve during inference, a temporal misalignment arises between the prediction interval starting when inference begins and the execution interval starting when inference finishes [4,29]. As a result, the newly generated action misaligns with the robot’s execution-time state and environment, leading to severe instability and degraded control accuracy. For example, naive asynchronous inference reduces reaction latency but exhibits unstable and laggy control performance [4]. RTC [4] mitigates this by freezing the actions guaranteed to execute and inpainting the rest, but it introduces additional runtime overhead and complicates the deployment. In addition, current implementations [24,29,31] often require multi-threaded redesign of the inference framework to support asynchronous inference efficiently. Together, these create a significant barrier for the adoption of asynchronous inference for VLAs.
To address these challenges, we propose VLASH, a general asynchronous inference framework for VLAs that achieves smooth, accurate, and fast reaction control without additional overhead or architectural changes. In a nutshell, VLASH makes the model future-state-aware by accurately estimating the execution-time robot state using the previously issued action chunk, effectively bridging the gap be-tween prediction and execution. VLASH integrates seamlessly into existing fine-tuning pipelines and introduces no additional cost or latency. With a clean and lightweight implementation, VLASH provides a full-stack asynchronous inference framework from fine-tuning to inference at deployment, making asynchronous control practical and easy to adopt for real-time VLA systems.
We build and evaluate VLASH across various VLA models, including 𝜋 0.5 [16] and SmolVLA [31]. On simulation benchmarks [25], VLASH achieves up to 30.5% accuracy improvement compared to naive asynchronous inference and consistently outperforms all baselines. On real-world benchmarks [31], VLASH achieves up to 2.03× speedup and reduces reaction latency by up to 17.4× compared to synchronous inference while fully preserving the original accuracy. Beyond quantitative gains, VLASH demonstrates that large VLA models can handle fast-reaction, high-precision tasks such as playing ping-pong and playing whack-a-mole, which were previously infeasible under synchronous inference. We hope these results will inspire future research toward extending VLAs to more dynamic and physically interactive robotics.
Vision-Language-Action Models (VLAs). Recent advances in Vision-Language-Action models have demonstrated remarkable capabilities in robotic manipulation by leveraging large-scale pretraining on diverse and internetscale vision-language data. Models such as 𝜋 0.5 [16], RT-2 [43], and Gr00t [26], etc. [3,19] combine visual encoders with large language models to enable generalist robotic policies that can follow natural language instructions and generalize across tasks and embodiments. These models are typically deployed under synchronous inference, where the robot waits for model inference to complete before executing actions, resulting in action stall and slow reaction to environmental changes [4,29]. Our work addresses this limitation by enabling efficient asynchronous inference for VLAs.
Asynchronous VLA Inference. Asynchronous inference offers a promising way to eliminate action stalls and improve reaction speed of VLAs, but existing approaches still face significant barriers to adoption in VLA community. SmolVLA [31] implements naive asynchronous inference by directly switching to new action chunks, but this causes severe prediction-execution misalignment and unstable control. Real-time Chunking (RTC) [4] mitigates this by freezing actions guaranteed to execute and inpainting the remaining actions, but this introduces additional runtime overhead for the inpainting process and complicates deployment. A concurrent work A2C2 [29] adds an additonal correction heads to the model to mitigate the prediction-execution misalignment, but this also introduces runtime overhead and Robot stalls during model inference.
Fast Reaction Smooth Actions requires architecture changes to the model. In contrast, our method achieves asynchronous inference through futurestate-awareness without additional overhead.
Action chunking policy. We consider an action chunking policy 𝜋 𝜃 ( 𝐴 𝑡 | 𝑜 𝑡 , 𝑠 𝑡 ) [16,31,42], where 𝑜 𝑡 is the environment observation (e.g., image, multi-view visual input), 𝑠 𝑡 is the robot state (e.g., joint positions, gripper state), and 𝑡 is the controller timestep. At each timestep 𝑡, the policy generates a chunk of future actions
where 𝐻 is the number of actions in the chunk. We refer to 𝐻 as the prediction horizon.
Prediction and execution intervals. In practice, only the first 𝐾 ≤ 𝐻 actions from each chunk are executed before the next inference to ensure control accuracy. We denote 𝐾 as the execution horizon. For a chunk 𝐴 𝑡 predicted at timestep 𝑡, we define the prediction interval
as the time interval where the first 𝐾 actions from the action chunk 𝐴 𝑡 are planned to be executed. During actual execution, however, the 𝐾 actions from 𝐴 𝑡 will start being applied later due to inference latency [4,31].
Let Δ > 0 be the inference latency measured in control steps. Then the 𝐾 actions from 𝐴 𝑡 are actually executed on the robot over the execution interval
With asynchronous inference, the robot continues executing the previous action chunk while 𝜋 𝜃 computes 𝐴 𝑡 in the background. As illustrated in Fig. 2, when Δ > 0, the action chunk 𝐴 𝑡 is planned for the prediction interval
Intuitively, the actions in 𝐴 𝑡 are not wrong for the original prediction interval [𝑡, 𝑡 + 𝐾). However, under asynchronous inference, by the time they are executed, the environment and robot state have changed, so the same action sequence is applied to a different state and scene, leading to unstable and discontinuous behavior [4,29].
In asynchronous inference, the robot keeps moving while the VLA performs a forward pass, so the state at inference start generally differs from the state at which the new actions actually begin execution. Our key idea is to make the policy future-state-aware: instead of conditioning on the current robot state 𝑠 𝑡 , we condition on the robot state at the beginning of the next execution interval 𝑠 𝑡+Δ .
Although the future environment observation is unknown, the robot state at the beginning of the execution interval 𝑠 𝑡+Δ is determined by the current robot state 𝑠 𝑡 and the actions executed during the inference delay 𝑎 𝑡:𝑡+Δ-1 . As shown in Fig. 3(c), when inference for the new chunk starts at state 𝑠 1 , the robot will still execute the remaining actions 𝑎 1 , 𝑎 2 from the previous chunk before the new chunk is ready to take over. Since the actions 𝑎 1 , 𝑎 2 are already known, we can roll the state forward under them to obtain the execution-time state. In the Fig. 3(c at the start of the execution interval.
During the forward pass, VLASH feeds both the current environment observation 𝑜 1 and this rolled-forward future state 𝑠 3 into the VLA. In this way, the model generates actions for the state at the execution-time rather than for the stale state at inference start, bridging the gap between prediction and execution in terms of robot state. While the future environment is still unknown, this mechanism mirrors how humans act under reaction delays: we react to the world with slightly outdated visual input, but use our internal body state to anticipate what we will do when the action actually takes effect. Thus, humans inherently have the ability to compensate for such reaction delay, and we expect VLAs to possess the same capability.
The future-state-awareness assumes that the VLA is able to leverage the rolled-forward robot state. However, we find that existing VLAs often fail to exploit this future state properly. Even more, current VLAs appear to largely rely on visual input and under-utilize the robot state. In our experiments with 𝜋 0.5 (Table 1), fine-tuning without state input (visual only) consistently outperforms fine-tuning with state input on LIBERO [23]. Therefore, simply feeding a future robot state at test time is insufficient to achieve accurate and stable asynchronous control.
Since large VLAs are almost always fine-tuned on downstream data before deployment, we design a training augmentation that can be seamlessly integrated into the standard fine-tuning stage with no additional overhead. We keep the architecture and fine-tuning pipeline unchanged, and only from the pair (𝑜 𝑡 , 𝑠 𝑡+ 𝛿 ). Under this scheme, the same image 𝑜 𝑡 can correspond to different ground-truth actions depending on the offset robot state 𝑠 𝑡+ 𝛿 . To fit the data, the VLA is forced to attend to the state input rather than overfitting purely to visual features. In particular, it learns to interpret 𝑠 𝑡+ 𝛿 as a meaningful future state for action selection.
We randomly sample 𝛿 during training because, in practice, the same VLA may be deployed on hardware with different compute budgets, leading to different inference delays Δ, and sometimes even in synchronous settings where there is no gap between prediction and execution. By training over a range of offsets, our augmentation makes the model compatible with different inference delays while preserving performance in the synchronous case. At deployment with asynchronous inference, we can then feed the rolled-forward execution-time state together with the current observation, and the fine-tuned VLA naturally leverages this future state to produce actions that are aligned and stable over the execution interval.
The temporal-offset augmentation creates multiple stateaction pairs for the same observation 𝑜 𝑡 . A naive implementation would treat each offset 𝛿 as a separate training ex-ample, i.e., run the VLA independently on (𝑜 𝑡 , 𝑠 𝑡+ 𝛿 , 𝐴 𝑡+ 𝛿 ) for each sampled 𝛿. This implementation is completely plug-and-play and can be seamlessly integrated into existing VLA fine-tuning pipeline. However, it repeatedly encodes the same observation 𝑜 𝑡 for every offset, leaving substantial room for further efficiency gains.
Instead, we exploit the fact that all offsets share the same observation 𝑜 𝑡 and design an efficient attention pattern that reuses the observation tokens across offsets in a single pass (Fig. 4). Concretely, we pack one observation and multiple offset branches into a single sequence:
where each (𝑠 𝑡+ 𝛿 , 𝐴 𝑡+ 𝛿 ) corresponds to one temporal offset. We then apply a block-sparse self-attention mask with the following structure:
• All observation tokens (e.g., image tokens from two views and language prompt, about ∼700 tokens for 𝜋 0.5 ) can attend to each other, as in standard VLA fine-tuning. • For each offset branch, the state-action tokens (𝑠 𝑡+ 𝛿 , 𝐴 𝑡+ 𝛿 ) can attend to all observation tokens and to tokens within the same offset, but cannot attend to tokens from other offsets. This attention map, illustrated in Fig. 4, makes different offsets condition on a shared observation while remaining independent of each other. For each offset branch, the positional encodings of (𝑠 𝑡+ 𝛿 , 𝐴 𝑡+ 𝛿 ) are assigned to start at the same index, equal to the length of observation tokens. From the model’s perspective, this is equivalent to training on multiple (𝑜 𝑡 , 𝑠 𝑡+ 𝛿 , 𝐴 𝑡+ 𝛿 ) examples that share the same 𝑜 𝑡 , but we only encode 𝑜 𝑡 once.
For 𝜋 0.5 , an observation with two images and language prompt corresponds to ∼ 700 tokens, while one state and action chunk are about ∼ 50 tokens [16]. Therefore, packing 𝑁 𝛿 = 5 offsets into a single sequence therefore increases the token length by only ∼ 20%, while the number of effective training trajectories becomes 5× larger. In practice, under the same effective batch size as standard fine-tuning, this method can significantly improve training efficiency by reusing each observation across multiple offset targets in a single pass.
With asynchronous inference and future-state-awareness, the model inference time is effectively hidden behind execution. Once this inference latency is removed, the overall speed of the system is primarily limited by how fast the robot can physically execute the action sequence. To push the execution speed further, we need to accelerate the motion itself.
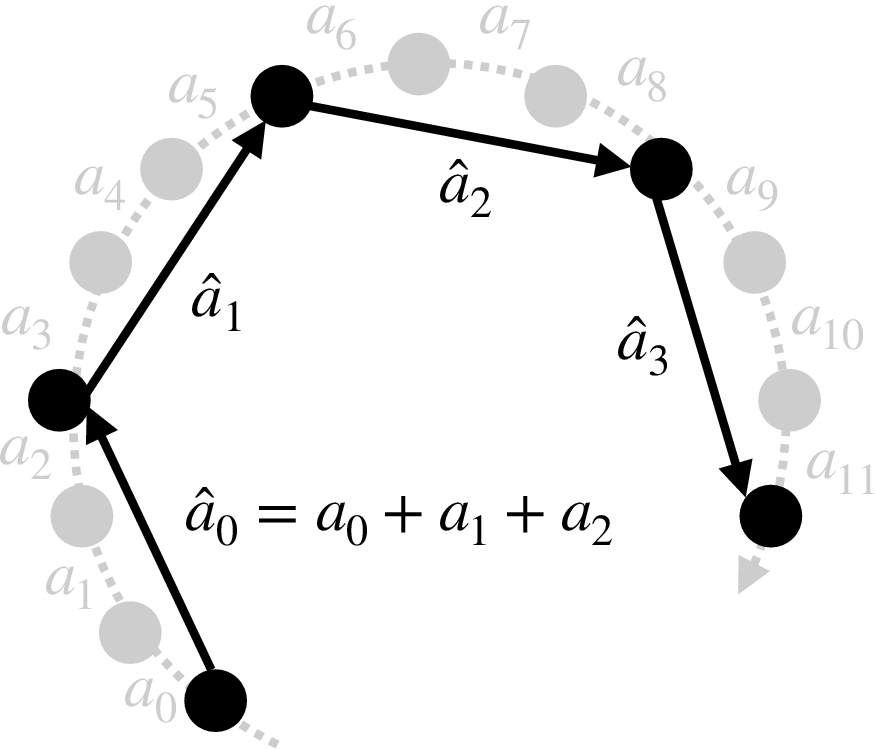
Our approach is to quantize actions, in analogy to weight quantization for LLMs [11,22,37]. State-of-the-art VLAs are typically trained on fine-grained teleoperation data (e.g., ∼50 Hz control with small deltas at each step) [3,16], which leads to action sequences with high granularity. However, many short micro-movements are more precise than what is actually required to solve the tasks. In LLMs, 16-bit weights provide high numerical precision, but quantizing them to 8bit or 4-bit can substantially accelerate inference with only a mild drop in accuracy [11,22,37]. We apply the same philosophy to robot control. Given a fine-grained action sequence {𝑎 0 , 𝑎 1 , . . . , 𝑎 𝑇 }, we group consecutive actions into coarser macro-actions. For a chosen quantization factor 𝑞, we construct a new sequence { â0 , â1 , . . . } where each macro-action summarizes a block of 𝑞 fine-grained actions. For delta actions, this can be implemented as
so that â𝑖 takes the robot approximately from the start state of 𝑎 𝑖𝑞 to the end state of 𝑎 (𝑖+1)𝑞-1 in a single, longer step. Fig. 5 illustrates this process: the original fine-grained trajectory (gray) is replaced by a shorter, quantized trajectory (black) with macro-actions â0 , â1 , â2 , â3 , where â0 = 𝑎 0 + 𝑎 1 + 𝑎 2 .
Executing macro-actions instead of all micro-actions increases the distance moved per control step, effectively speeding up the robot’s motion. The temporal granularity of control becomes coarser, but in many tasks the robot does not need to visit every intermediate waypoint explicitly; moving directly between sparser waypoints is sufficient to achieve the goal. As a result, action quantization offers a tunable speed-accuracy trade-off: small quantization factors behave like the original fine-grained policy, while larger factors yield progressively faster but less fine-grained motion. In practice, we select task-dependent quantization factors that maintain success rates close to the unquantized policy while substantially reducing the number of executed steps. Table 1. Performance on LIBERO benchmarks with different inference delays. We evaluate 𝜋 0.5 [16] across four LIBERO subbenchmarks (Spatial, Object, Goal, LIBERO-10) under various inference delays (0 to 4 steps). SR: average success rate; Steps: average execution steps to task completion; Time: completion time on a laptop RTX 4090 GPU (inference latency: 103ms for 2 images). Sync (w/o state): fine-tuned and evaluated with synchronous inference without robot state input.
We design experiments to investigate the following questions:
- Performance. How does our method compare to synchronous control, naive asynchronous and baselines in terms of accuracy and latency? (Sec. 5.1.1, Sec. 5.2) 2. Generalization. How well does our method generalize across different inference delays? Does it hurt the original model performance? How well does our method generalize across different VLAs? (Sec. 5.1.2) 3. Speed-accuracy trade-off. What is the speed-accuracy trade-off of action quantization at deployment? (Sec. 5.2) 4. Fine-tuning efficiency. How does our method compare to the standard fine-tuning in terms of training cost and data efficiency? How much the shared observation finetuning can reduce the training cost? (Sec. 5.3)
We evaluate VLASH on simulated robotic manipulation benchmarks including Kinetix [25] and LIBERO [23].
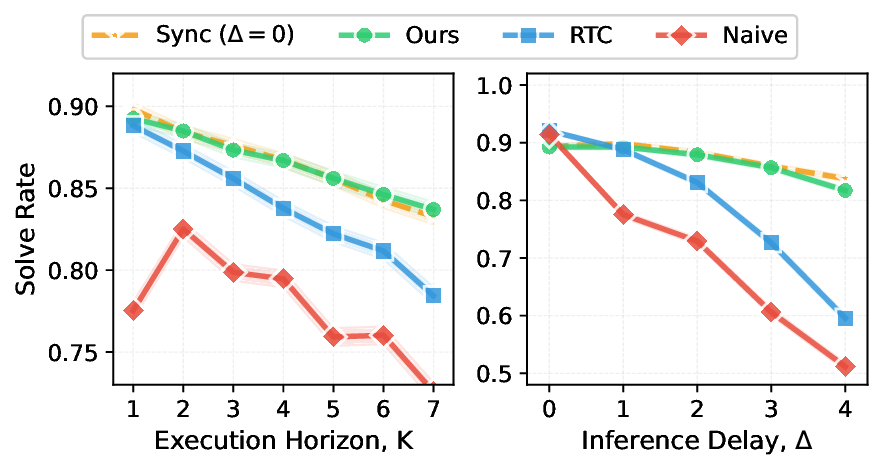
Experimental Setup. Kinetix [25] is a highly dynamic simulated robotic manipulation benchmark that demands asynchronous execution to handle rapidly changing environments. The tasks are designed to test dynamic reaction capabilities, including throwing, catching, and balancing. Following the setup in RTC [4], we train action chunking flow policies with a prediction horizon of 𝐻 = 8 and a 4-layer MLP-Mixer [35] architecture for 32 epochs. We report average success rates across 12 tasks, each evaluated with 1,024 rollouts per data point, under simulated delays ranging from 0 to 4 steps. We compare against the following baselines:
• Sync. This baseline serves as an optimal baseline for all tasks. The inference delay is explicitly set to 0 at all times.
• Naive async. This baseline is the naive asynchronous inference baseline, which simply switches chunks as soon as the new one is ready [31]. • RTC. This baseline is the Real-time Chunking [4], which freezes the actions guaranteed to execute and inpaints the rest. This introduces additional overhead at runtime.
As shown in Fig. 6, VLASH tracks the synchronous upper bound closely across execution horizons, while other baselines drop more noticeably as the execution horizon increases. When the inference delay increases, VLASH remains robust and consistently achieves high success rates, while RTC degrades rapidly and the Naive Async baseline collapses under larger delays. Notably, at inference delay of 4 steps, VLASH achieves 81.7% success rate compared to only 51.2% for Naive Async, which is a substantial 30.5% accuracy improvement. Overall, VLASH effectively mitigates prediction-execution misalignment, delivering high success rates under asynchronous operation.
Experimental Setup. We evalute on LIBERO benchmark [23], one of the popular benchmarks for evaluating VLA, which includes 4 different sub-benchmarks (Spatial, Object, Goal, and LIBERO-10) that contain 10 tasks each. We evaluate on 2 state-of-the-art VLAs: 𝜋 0.5 [16] and SmolVLA [31]. We report the performance by fine-tuning all models on the training dataset for 30K iterations with a batch size of 32. Following the setup in 𝜋 0.5 [16], we set the execution horizon to 𝐾 = 5 [10]. Since LIBERO tasks involve slowly changing environments with mild state transitions, different asynchronous methods behave similarly. Therefore, we focus our comparisons on synchronous inference to evaluate the effectiveness of VLASH under various inference delays. For time measurement, we use a laptop RTX 4090 GPU where the inference latency with 2 input images is 103ms. For synchronous inference, the time per action chunk is the sum of execution duration (166ms for 1.76× 1.82×
Sync Naive Async Vlash Vlash (q=2) Vlash (q=3)
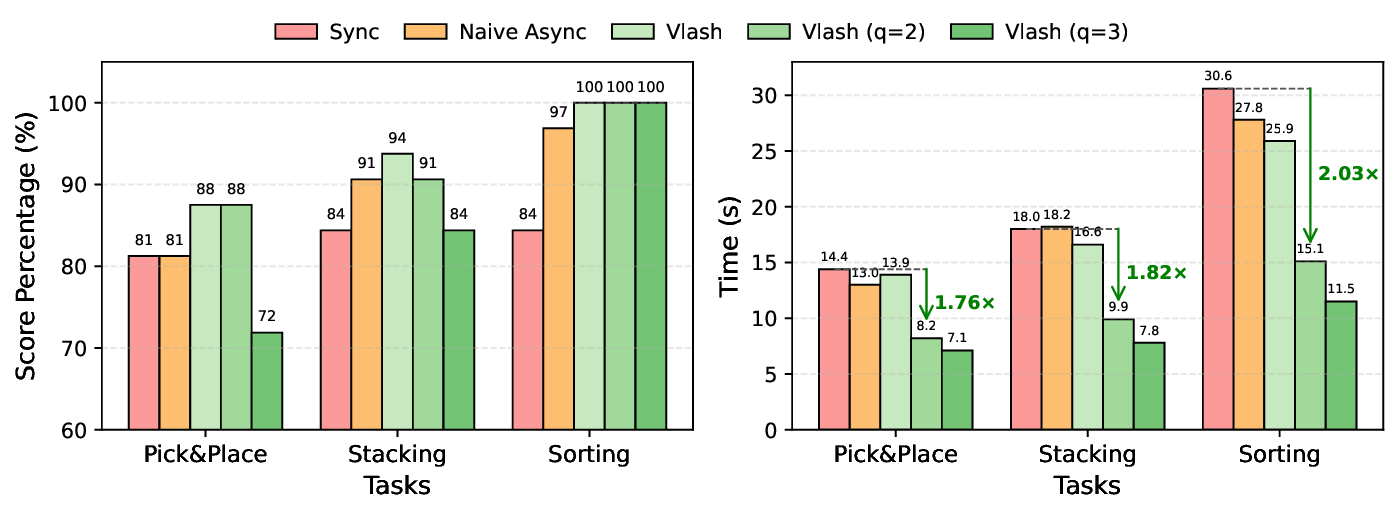
Figure 7. Real-world evaluation results on manipulation tasks. We evaluate 𝜋 0.5 [16] on three tasks with different inference methods.
Left: Score percentages (based on 2-point scoring: 1 for success of picking up the object, 1 for task completion) of VLASH and baselines across three tasks. Right: Task completion times with green arrows indicating speedup of VLASH (𝑞=2) relative to synchronous baseline. VLASH (𝑞) applies action quantization with quantization ratio 𝑞. 𝐾 = 5 steps at 30Hz) and inference time. For asynchronous inference, larger delays are needed to overlap with the inference latency, so the time per action chunk is: execution duration + max(0, inference time -execution duration 𝐾 × delay).
Results. As shown in Table 1, VLASH demonstrates strong performance across all LIBERO benchmarks under various inference delays. With small inference delays, VLASH maintains comparable accuracy to synchronous inference while achieving speedups of 1.17× and 1.31×, respectively. As the inference delay increases, the time advantages become more pronounced, achieving up to 1.47× speedup at delay 3. Although accuracy decreases slightly at higher delays, VLASH still achieves strong performance across all tasks, demonstrating an effective accuracy-latency trade-off. We also evaluate on SmolVLA [31], with detailed results provided in supplementary materials.
To evaluate VLASH in real-world settings, we deploy 𝜋 0.5 [16] on two robotic platforms: the Galaxea R1 Lite [13] and the LeRobot SO-101 [15]. The R1 Lite is a dual-arm robot equipped with two 7-DOF arms from Galaxea [12]. The SO-101 is a 6-DOF collaborative robotic arm from LeRobot [5]. For 𝜋 0.5 , we apply a projection layer to map the robot state into an embedding, bypassing the tokenizer instead of incorporating it into the language prompt in the original implementation. We design our real-world experiments to evaluate three key aspects: (1) Accuracy: the success rate of completing manipulation tasks; (2) Efficiency: the task completion time and motion smoothness; and (3) Reaction speed: the latency to react to dynamic changes in the environment.
Setup. Following the setup in SmolVLA [31], we evaluate 𝜋 0.5 (𝐻 = 50) on three manipulation tasks that test different aspects of robotic control. We set the execution horizon to 𝐾 = 24 steps at 30Hz. All experiments are conducted on a laptop with NVIDIA RTX 4090 GPU, with an inference delay of 4 steps. On our robotic platforms, we evaluate three tasks:
• Pick and Place: pick up a cube from varying starting positions and place it into a fixed box; • Stacking: pick up a blue cube and stack it on top of an orange cube, where both cubes’ initial positions vary across episodes; • Sorting: sort cubes by color, placing the orange cube in the left box and the blue cube in the right box, with cube positions varying across episodes. For each task, we conduct 16 rollouts per method and report both the score percentage and the task completion time. The score percentage is calculated based on a 2-point scoring system per rollout: 1 point for successfully picking up the object, and 1 point for completing the task. We compare synchronous inference, naive asynchronous inference, and VLASH across these tasks.
Results. As shown in Fig. 7, VLASH delivers better or comparable score percentage to synchronous inference while significantly reducing task completion time across all tasks. Specifically, VLASH maintains an 94% average score percentage, outperforming synchronous baseline (83%) and naive asynchronous inference (89.7%), while completing tasks in 18.8 seconds on average compared to 21 seconds for synchronous inference, which is a 1.12× speedup.
Furthermore, by applying action quantization, we can
Experimental Setup. To evaluate the reaction speed improvement of asynchronous inference, we compare the maximum reaction latency between synchronous and asynchronous inference across different hardware configurations. Following the setup in 𝜋 0.5 [16], we set the execution horizon to 𝐾 = 25 for synchronous inference and a control frequency of 50Hz [4,16], resulting in an execution duration of approximately 0.5 seconds per action chunk. We measure the model inference latency of 𝜋 0.5 on three different GPUs: RTX 5090, RTX 4090, and RTX 5070, using torch.compile to enable CUDAGraph optimization and kernel fusion for minimal latency [2].
Results. As shown in Table 2, asynchronous inference significantly reduces the maximum reaction latency compared to synchronous inference, achieving up to 17.4× speedup.
To showcase the fast reaction and smooth control capabilities of VLASH, we train 𝜋 0.5 to perform highly dynamic interactive tasks: playing ping-pong with a human and playing whack-a-mole. These tasks demand both rapid reaction to dynamic changes and smooth continuous motion to maintain control accuracy. To the best of our knowledge, we are the first to demonstrate a VLA successfully playing pingpong rallies with a human. Under synchronous inference, the robot’s reaction is too slow to track the fast-moving ball, while VLASH enables real-time response and stable rallies. We encourage readers to view the demo videos in the supplementary materials to see the dynamic performance of VLASH in action.
Experimental Setup. We evaluate the training efficiency gains from our efficient fine-tuning with shared observation approach. A key consideration is that training with multiple temporal offsets using shared observation effectively increases the effective batch size by a factor equal to the number of offsets. Therefore, we compare our method against standard fine-tuning under the same effective batch size to ensure a fair comparison. Specifically, we conduct experiments on the LIBERO benchmark using 𝜋 0.5 [16] trained on 4×H100 GPUs with DDP [21]. For our method, we use Δ max = 3 with a physical batch size of 4 per GPU, resulting in an effective batch size of 16 per GPU and 64 in global.
The standard baseline uses a physical batch size of 16 per GPU to match this effective batch size. Both methods are trained for 10K, 20K, and 30K iterations, and we report the average success rate across all LIBERO tasks. We also measure the training time per forward-backward pass to quantify the speedup.
Results. As shown in Table 3, VLASH converges more slowly in the early stages but ultimately achieves comparable accuracy to standard fine-tuning. Although more training steps are needed for convergence, each step is significantly faster, achieving a 3.26× speedup per step. This efficiency gain comes from encoding the shared observation only once and reusing it across all temporal offsets. Furthermore, since both methods are evaluated under synchronous inference, these results also demonstrate that VLASH does not hurt the original synchronous performance of the model.
We present VLASH, a general and efficient framework for enabling asynchronous inference in Vision-Language-Action models. By making the policy future-state-aware through simple state rollforward, VLASH effectively bridges the prediction-execution gap that has hindered asynchronous control. Experiments on both simulated and real-world benchmarks demonstrate that VLASH achieves smooth, accurate, and fast-reaction control, consistently matching or surpassing the accuracy of synchronous inference while providing substantial speedups. Moreover, we demonstrate that VLAs can perform highly dynamic tasks such as playing ping-pong rallies with humans. We hope these results will inspire future research toward extending VLAs to more dynamic and physically interactive domains.
• Folding clothes: Complex manipulation requiring coordinated movements. We compare three inference modes: synchronous inference, naive asynchronous inference, and VLASH. Additionally, we demonstrate the effects of action quantization, showing how our method can achieve further speedups while maintaining task performance.
The video demonstrations clearly show that VLASH produces noticeably smoother motions and faster task completion compared to both synchronous and naive asynchronous baselines. The synchronous baseline often exhibits stuttering behavior due to action stalls, while naive asynchronous inference suffers from prediction-execution misalignment that leads to erratic movements. In contrast, VLASH maintains fluid motion throughout task execution while achieving significant speedup. We encourage readers to view the video to appreciate the dynamic performance improvements of our approach.
A key advantage of VLASH is that it requires no architectural modifications to achieve effective performance across diverse VLA models. Since all current VLA models accept robot state inputs, VLASH can be applied directly by simply offsetting the state information during fine-tuning to account for inference delay. This straightforward approach enables the model to learn the temporal alignment between delayed observations and corresponding actions without any changes to the model architecture.
For standard VLA architectures like 𝜋 0 [3] and SmolVLA [31], which incorporate a state projection layer to embed proprioceptive state vectors into continuous representations before feeding them into the transformer backbone, VLASH integrates seamlessly and achieves excellent results out of the box.
We further note that VLASH also works directly with 𝜋 0.5 [16] without modifications, as demonstrated in our experiments in Table 1. However, 𝜋 0.5 employs a unique design that converts numerical state values into text tokens and appends them to the language prompt. This text-based encoding forces numerical state values through tokenization and one-hot encoding, disrupting their inherent numerical structure and making it more challenging for the model to learn from state information. For such architectures, we find that adding a lightweight state projection like the design of 𝜋 0 and injecting the resulting embeddings back into their original positions can further enhance smoothness and stability. A simpler alternative is to incorporate the projected state embeddings into the AdaRMSNorm layers as conditioning signals alongside timestep embeddings. While entirely optional (and VLASH already performs well without it), this small architectural enhancement consistently improves control smoothness for 𝜋 0.5 . Importantly, the ad-ditional parameters introduced by this state projection layer are negligible: it consists only of a linear mapping from the state dimension to the hidden dimension. Moreover, because it is zero-initialized, it completely preserves the pretrained model’s performance during the initial stages of fine-tuning.
t , A t s t+1 , A t+1 s t+′ ma x , A t+′ ma x No cross-offset attention
📸 Image Gallery