Minimal neuron ablation triggers catastrophic collapse in the language core of Large Vision-Language Models
📝 Original Info
- Title: Minimal neuron ablation triggers catastrophic collapse in the language core of Large Vision-Language Models
- ArXiv ID: 2512.00918
- Date: 2025-11-30
- Authors: Cen Lu, Yung-Chen Tang, Andrea Cavallaro
📝 Abstract
Large Vision-Language Models (LVLMs) have shown impressive multimodal understanding capabilities, yet their robustness is poorly understood. In this paper, we investigate the structural vulnerabilities of LVLMs to identify any critical neurons whose removal triggers catastrophic collapse. In this context, we propose CAN, a method to detect Consistently Activated Neurons and to locate critical neurons by progressive masking. Experiments on LLaVA-1.5-7b-hf and InstructBLIP-Vicuna-7b reveal that masking only a tiny portion of the language model's feed-forward networks (just as few as four neurons in extreme cases) suffices to trigger catastrophic collapse. Notably, critical neurons are predominantly localized in the language model rather than in the vision components, and the down-projection layer is a particularly vulnerable structure. We also observe a consistent two-stage collapse pattern: initial expressive degradation followed by sudden, complete collapse. Our findings provide important insights for safety research in LVLMs.📄 Full Content
Neuron-level analyses revealed that transformer models contain task-specific or language-specific neurons: certain neurons activate predominantly when processing syntax-related tasks, while others respond more strongly to specific languages [2,29]. Recent work has extended mechanistic understanding to multimodal settings, such as identifying domain-specific neurons specialized for medical images or document understanding [10]. Manipulating these domain-specific neurons causes only modest performance changes on these domains (at most 10% accuracy degradation) [10]. Recent research on LLMs has also found super weights that are decisive for model’s functionality [23,31]. A tiny fraction of neurons can be crucial for safety mechanisms in LLMs: safety neurons have been Fig. 1: Catastrophic collapse modes induced by masking critical neurons in the language model feed-forward network (FFN) of LLaVA-1.5-7b-hf. The original model generates correct outputs (green box), but masking only 4-5 neurons in the language model causes catastrophic failure (red boxes). identified that are responsible for model alignment and refusal behaviors, such as rejecting malicious prompts [5,33]. Inspired by neuroscience, researchers have developed interventional methods, such as neuron ablation [2], that introduce virtual lesions to identify critical components [14,22]. However, existing works have overlooked the robustness limits of LVLMs, for example the identification of subsets of neural units whose ablation triggers complete catastrophic collapse. This problem is important given the deployment of LVLMs in safety-critical applications such as autonomous driving [34] and medical diagnosis [15]. A natural question arises: which neurons should be removed for an LVLM to completely fail? If this number is small, adversarial attacks targeting these critical neurons could lead to catastrophic consequences.
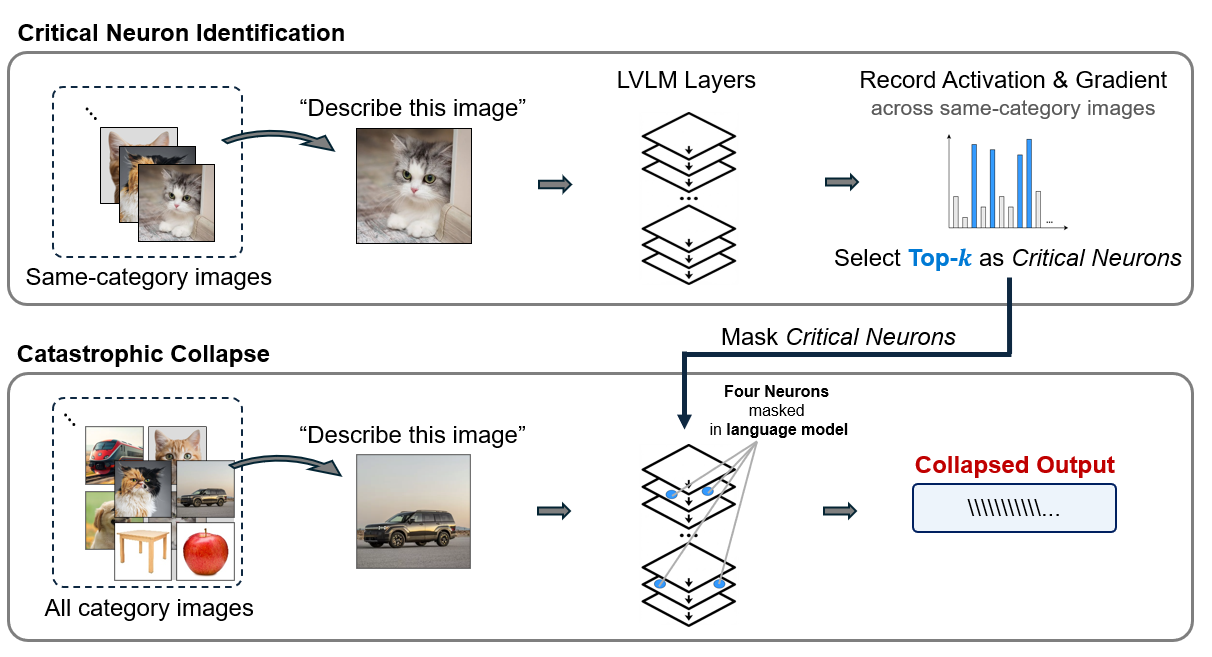
To this end, we explore how LVLMs respond to neuron deactivation, and the conditions under which their performance completely fails. We define catastrophic collapse as a failure state characterized by a severe corruption of the model’s internal output distribution over its vocabulary (the logits). This internal breakdown prevents the model from generating coherent text across any valid input. Such a collapse can be triggered by masking only four or five critical neurons in the language model, leading to repetitive character sequences or empty outputs. We show that using images of different object categories for critical neuron identification and masking can trigger distinct collapse thresholds in LVLMs, yet the underlying cause is consistent: removing only a tiny fraction of neurons is enough to collapse the model (Fig. 1).
In summary, our main contributions are:
-We propose the Consistently Activated Neurons (CAN) method for identifying critical neurons in LVLMs across different images. Analyzing LLaVA-1.5-7b-hf and InstructBLIP-vicuna-7b, we generate component-specific rankings across vision encoder, cross-modal alignment module, and language model, and object-specific rankings, revealing neurons with the strongest activation patterns.
-Leveraging CAN, we identify a very small subset of neurons that are disproportionately important for the model’s output. For example, masking only four neurons in LLaVA-1.5-7b-hf suffices to collapse the model, showing an extreme vulnerability. -We identify that critical neurons reside predominantly in the language model rather than in the vision components. Unlike vision-neuron ablations that degrade visual understanding, masking language-model neurons causes catastrophic collapse, disabling both comprehension and generation capabilities.
Neuron ablation is a powerful technique for understanding the internal mechanisms and functional specialization within neural networks [2]. For example, the neural erosion method [1] applies synaptic pruning and neuron deactivation in LLMs, showing that LLMs lose cognitive abilities in a hierarchical manner: mathematical reasoning first, followed by linguistic capabilities. By replacing neuron activations with their mean values across samples, researchers have identified specialized entropy neurons and token frequency neurons that impact model confidence rather than direct predictions, revealing calibration circuits across architectures [28]. Additionally, recent work applies neuron ablation to evaluate role-playing prompts in medical LLMs, showing that different role assignments activate similar groups of neurons and affect only linguistic features rather than core reasoning [17]. These studies focus on identifying functional neurons and overlook the ablation thresholds that may lead to catastrophic collapse. While traditional neuron ablation identifies neurons critical for general model performance, safety neuron identification targets neurons responsible for safety alignment, ensuring models reject malicious prompts and generate safe responses. Contrastive methods used to identify safety neurons in LLMs showed that these neurons are both sparse and effective, with only 5% of neurons responsible for 90% of safety performance [5]. Safety neurons constitute fewer than 1% of all parameters and predominantly reside in self-attention layers [33]. Complementing neuron-level analyses, Zhou et al. [35] showed that ablating safety-related attention heads degrades safety capabilities. While these safety-focused methods rely on contrastive activation patterns between aligned and unaligned models, we develop a neuroscience-inspired approach to identify critical neurons in LVLMs through activation-gradient ranking to investigate catastrophic failure risks.
Let M be an LVLM that processes a visual input, v, and a textual prompt, t, to generate M(v, t), the output response. Let N = {n ℓ,j | ℓ ∈ L, j ∈ J ℓ } denote the set of neurons across all layers L and all positions J ℓ , where ℓ is the layer index and j is the position within layer ℓ. Let a ℓ,j (v, t) be the activation on input (v, t) for a neuron at layer ℓ and position j.
Given a dataset D = {(v i , t)} M i=1 containing M vision-language pairs with a fixed textual prompt, our objective is to identify a critical neuron subset, C * ⊂ N , with |C * | ≪ |N | that satisfies:
where ∆ perf (M|C, v i , t) quantifies performance degradation of model M when neurons in C are ablated on input (v i , t), and τ is a threshold indicating catastrophic failure. We define τ through joint criteria based on perplexity and CLIP score information, as described in Section 5.
To identify critical neurons in LVLMs, we draw inspiration from lesion-function analyses in neuroscience [4]. Lesion-symptom mapping establishes functional specificity by associating selective cognitive impairments with localized brain damage [11,21]. Translating this principle to neural networks, we hypothesize that LVLMs contain sparse subsets of neurons that are disproportionately critical for all types of tasks [23,31]. Specifically, we employ neuron ablation techniques to validate the importance of identified neurons, aligning with neuroscience practices such as virtual lesioning (e.g., Transcranial Magnetic Stimulation [8]). Furthermore, we use random neuron ablation as a control to mimic the practice of comparing targeted lesions to random ones in neuroscience experiments [25].
Inspired by previous works [12,18,27], we propose the Consistently Activated Neurons (CAN) method to identify candidate critical neurons (Fig. 2). CAN quantifies neuron importance through activation magnitude and gradient sensitivity. The activation-based importance contribution focuses on how strongly neurons respond to inputs (forward pass). The gradient-based importance contribution focuses on how changes to neurons would affect the loss, revealing their impact on model predictions (backward pass).
To initiate the activation localization protocol, we extract activation profiles across all layers during forward propagation. For each neuron at layer ℓ and index j, we record its activation values across all samples in D:
To quantify the importance of each neuron, we introduce an importance scoring mechanism that combines activation magnitude with gradient weighting. For each neuron at layer ℓ and index j, we compute:
where ∂L ∂a ℓ,j represents the gradient sensitivity of the loss with respect to neuron activation, and the hyperparameter α ∈ [0, 1] controls the balance between the Next, we rank all neurons by their importance scores in descending order. The top-k neurons are then selected as critical neurons:
where the hyperparameter k is determined adaptively through iterative masking by incrementally increasing k until a catastrophic performance degradation occurs. This identifies the number of critical neurons k * that suffices to trigger catastrophic collapse for each specific model and component.
We evaluate performance degradation using perplexity [3], to assess the language modeling capability, and CLIP Score [9], to verify image-text alignment. Perplexity measures a model’s ability to maintain probability distribution over the original model’s output, evaluating whether the masked model can still follow the base model’s linguistic patterns. The CLIP score measures semantic alignment between generated text and visual content. A low CLIP score with stable perplexity can arise from two distinct failure modes, namely perceptual failure and expressive degradation. With a perceptual failure the model generates fluent but irrelevant descriptions (e.g., describing a cat when shown a car), indicating damage of vision neurons and loss of visual grounding, while preserving linguistic capabilities. With an expressive degradation the model outputs malformed text, suggesting damage to the language generation component.
We measure the perplexity degradation on a validation set D val = {(v i , t)} M val i=1 , which consists of validation image-prompt pairs. For each input pair (v i , t) ∈ D val and masking configuration C k , the model generates a token sequence y (i) = (y
. The perplexity is computed as:
We measure the incremental log-ratio of perplexities to quantify the sudden deviation when masking additional neurons:
where
is the perplexity at the previous masking step, and ∆k is the masking step size. We use log-scale to capture order-of-magnitude changes in perplexity. This metric evaluates the incremental degradation in language modeling capability: larger values indicate a sudden collapse when masking the current set of neurons compared to the previous step. The CLIP score [9] measures semantic coherence between visual inputs and generated descriptions. We compute the CLIP score on the validation set:
where CLIP(v i , (M|C k , v i , t)) is the cosine similarity between the CLIP embedding of image v i and the text generated by model M with neurons in C k masked on input (v i , t). The lower the CLIP score, the worse the semantic alignment between the visual input and the generated text. We determine the critical neuron set size k in a data-driven manner by greedy search with step size ∆k. We increase k until catastrophic failure occurs:
where τ PPL and τ CLIP are failure thresholds. A complete collapse occurs when ∆ PPL ≥ τ PPL and CLIP ≤ τ CLIP , illustrating catastrophic collapse of core model capabilities. We set τ PPL = 1 (indicating one order of magnitude degradation) and τ CLIP = 22 based on empirical failure patterns (see details in Section 6.4).
Architecture-Specific Neuron Localization. We adapt the neuron identification to the specific components of LLaVA [19] and InstructBLIP [6], as CAN Experimental setup. We conduct experiments with InstructBLIP-vicuna-7b and LLaVA-1.5-7b-hf on a dataset of 300 images for each of 10 object categories from the ILSVRC2013 dataset [7]. All experiments were executed on a H100 GPU using fp32 precision. To generate ranked neuron lists, we use images from the 10 categories with Describe the object in this image as prompt t. We found this simple prompt to be effective for critical neuron identification after testing different prompts, including more detailed instructions. We record the activation magnitude of each neuron across all model components after generating the first token, then rank neurons using CAN across all image categories. For each object category, we evaluate the progressively masked model using the corresponding 100 test images from the same category.
In the following we address these questions:
-What is the minimum number of critical neurons (i.e. ablated neurons that cause catastrophic collapse)? -Is the number of critical neurons stable across inputs? -Does the masking position impact the number of critical neurons? -Where are critical neurons located in the architecture of the LVLM?
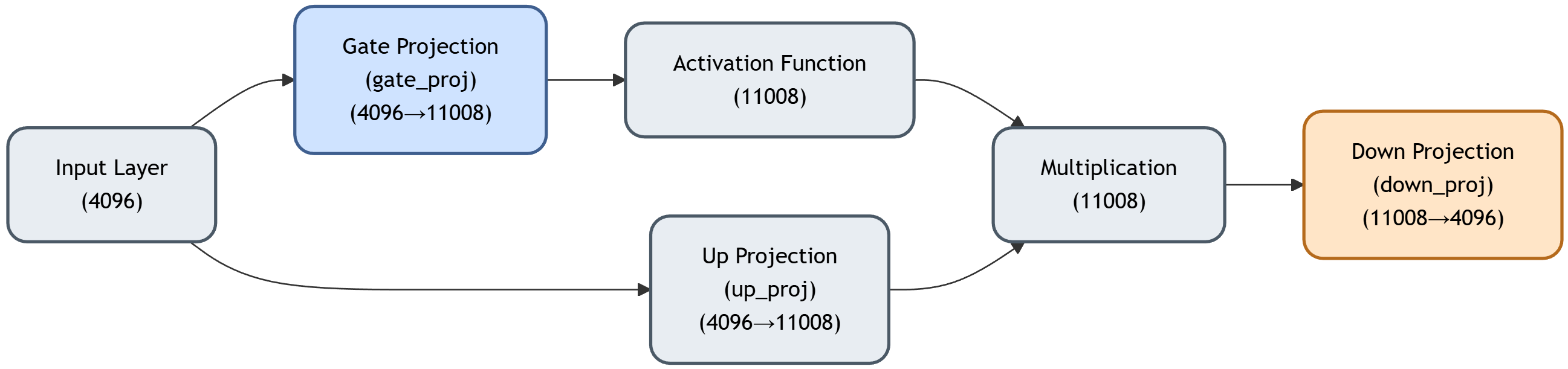
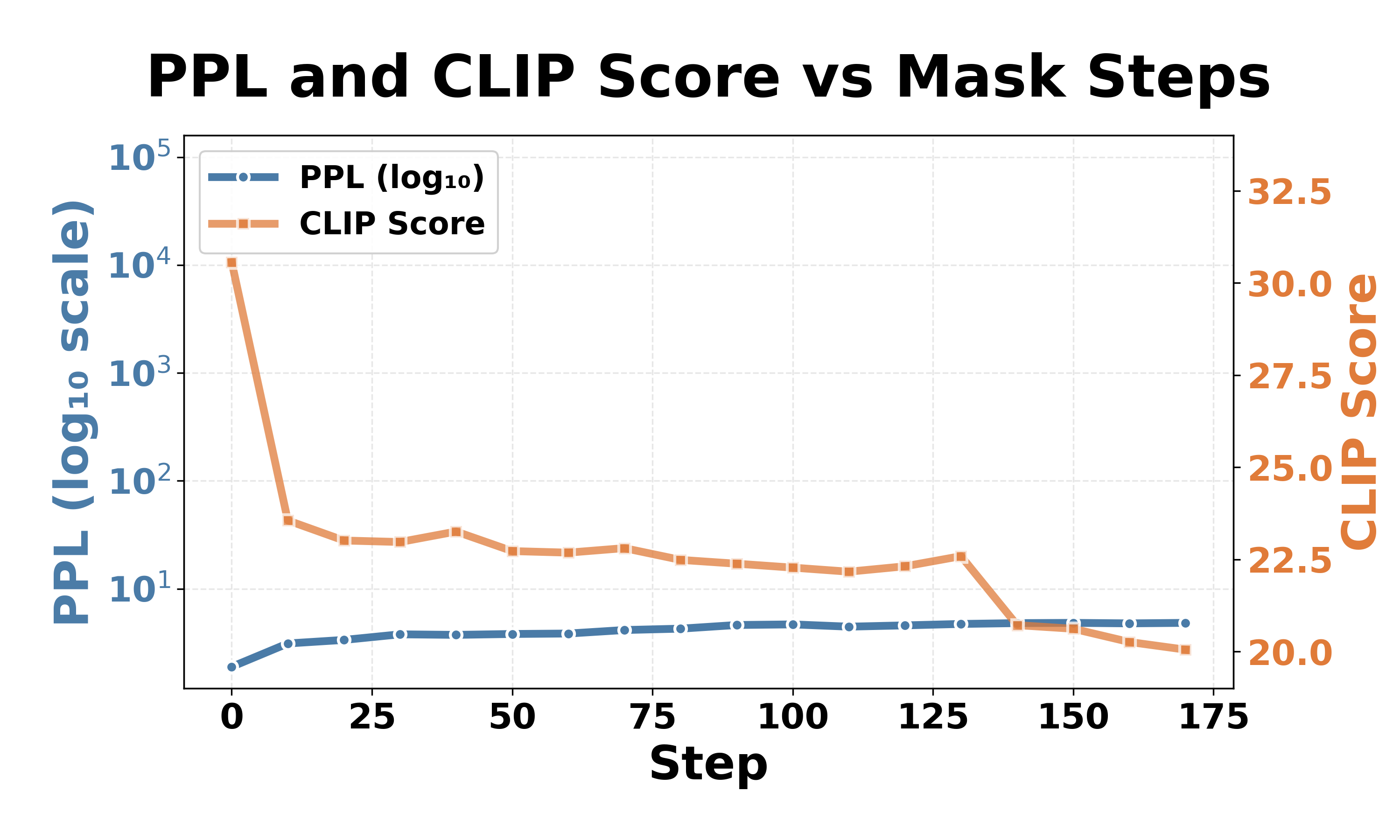
We progressively masked critical parts in gate_proj (see Fig. 3) from the FFN module in the language model of LVLMs. Our results on LLaVA-1.5-7b-hf show Table 1: Comparison of catastrophic collapse thresholds between LLaVA-1.5-7b-hf and InstructBLIP-vicuna-7b across different object categories. Each row shows results averaged over 100 test images. Progressive steps of 100 are used for the latter to find an approximate collapse threshold.
LLaVA-1. a consistent pattern of catastrophic collapse across different object categories. As shown in Table 1, LLaVA-1.5-7b-hf requires only five neurons to trigger catastrophic failure across all 10 object categories, with perplexity increases exceeding three orders of magnitude and CLIP scores becoming undefined (NaN) as the model outputs only end-of-sentence tokens, rendering the CLIP score computation infeasible. Remarkably, these five neurons remain consistent regardless of the object category, with three neurons located in layer 1 and two neurons in layer 30 (out of 32 layers, zero-indexed), suggesting that neurons at the beginning and end of LLaVA-1.5-7b-hf may play critical roles in maintaining model stability. In contrast, InstructBLIP-Vicuna-7b is more robust as it requires at least 1200 neurons (still representing an extremely small fraction of 0.17 × 10 -6 of the model parameters), depending on the object category.
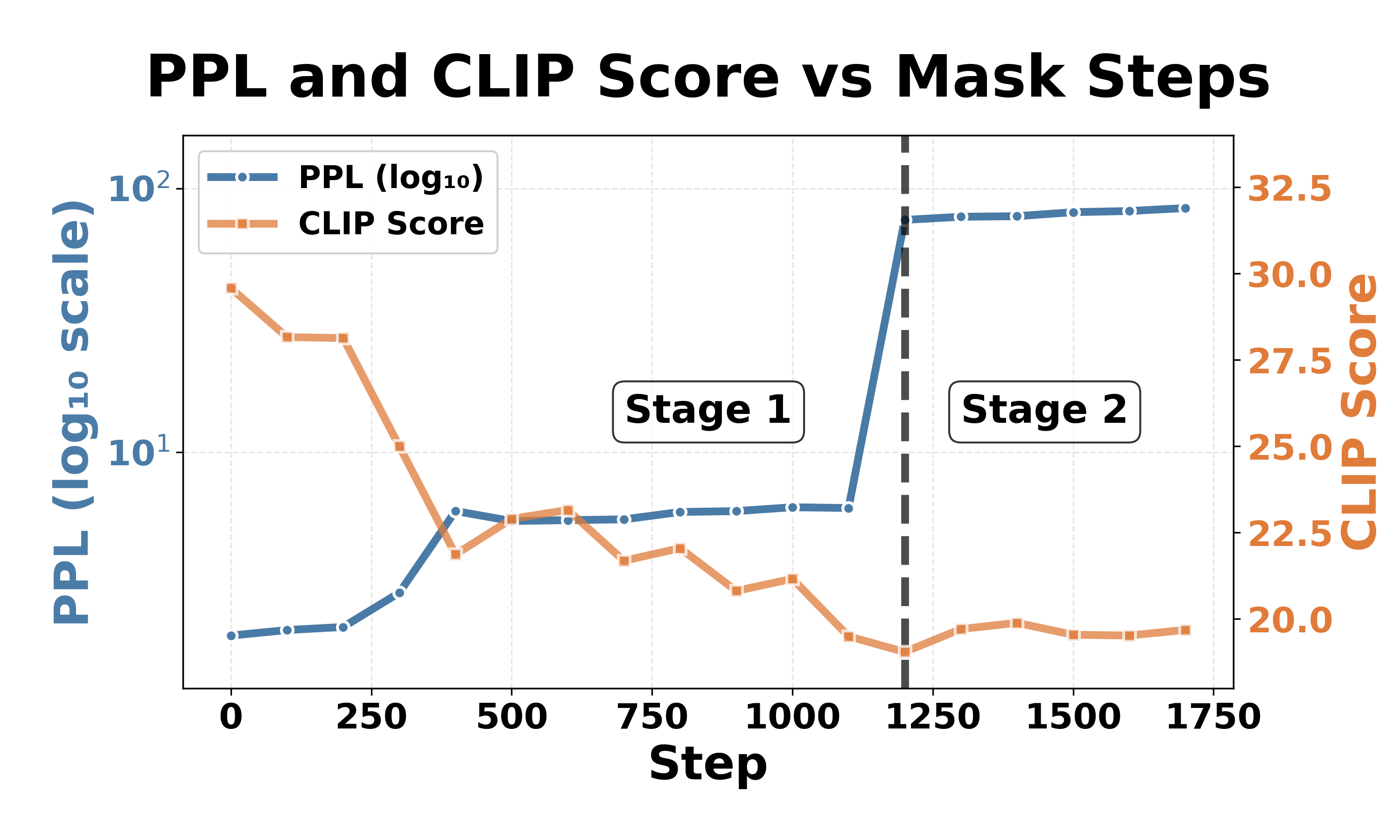
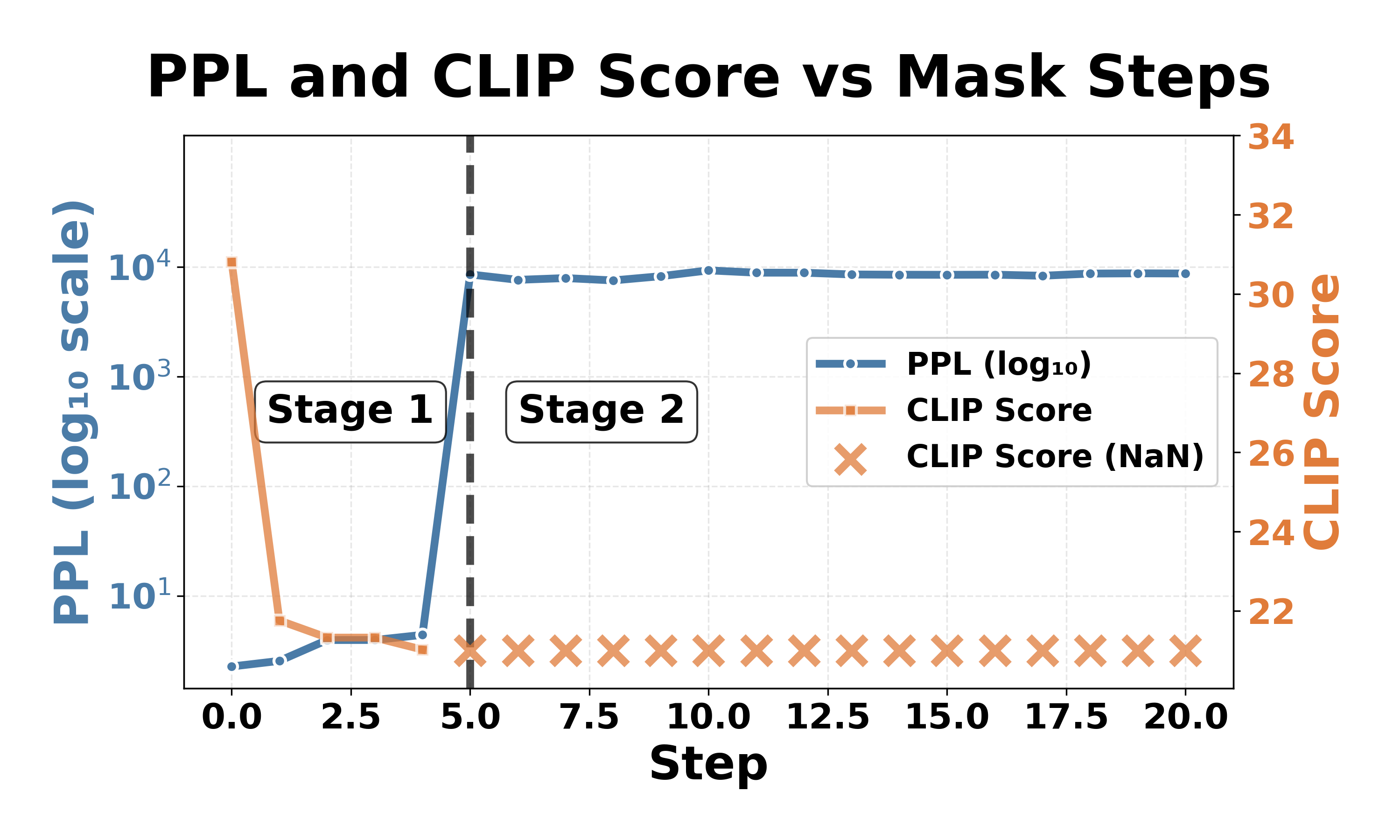
Fig. 4 illustrates the collapse progression for both models on the car category. Despite different thresholds, both models exhibit similar two-stage patterns, with an expressive degradation followed by a complete collapse. Stage 1: expressive degradation. For LLaVA-1.5-7b-hf (Fig. 4a, Steps 0-4), CLIP scores gradually decrease from 31 to 21 while perplexity remains stable, indicating declining output quality with preserved comprehension, similar to expressive aphasia [26] in human cognition. For InstructBLIP-Vicuna-7b (Fig. 4b, Steps 0-1100), CLIP scores drop from 30 to 20 with modest perplexity increases, showing a similar degradation pattern in generation capability.
Although the outputs at this stage have already degenerated and contain unintelligible specific tokens (e.g., “archivi”, “sierp 2013”), the model still retains most of its original comprehension ability. increases dramatically while CLIP scores either become NaN or drop to around 19, meaning that the models fail to produce meaningful output (e.g., “and, and …”, “ÄÄÄÄÄÄ…”). Continued masking beyond this threshold produces minimal additional change: both models stabilize in a permanent collapsed state and the models cannot recover their functionality the models cannot recover their functionality once collapsed. 1 . The observation that both models show similar collapse patterns but the number of critical neurons varies across architectures aligns with prior robustness studies: LLaVA achieves 89% attack success rates under jailbreak attacks, while InstructBLIP is more resilient at 33% [13].
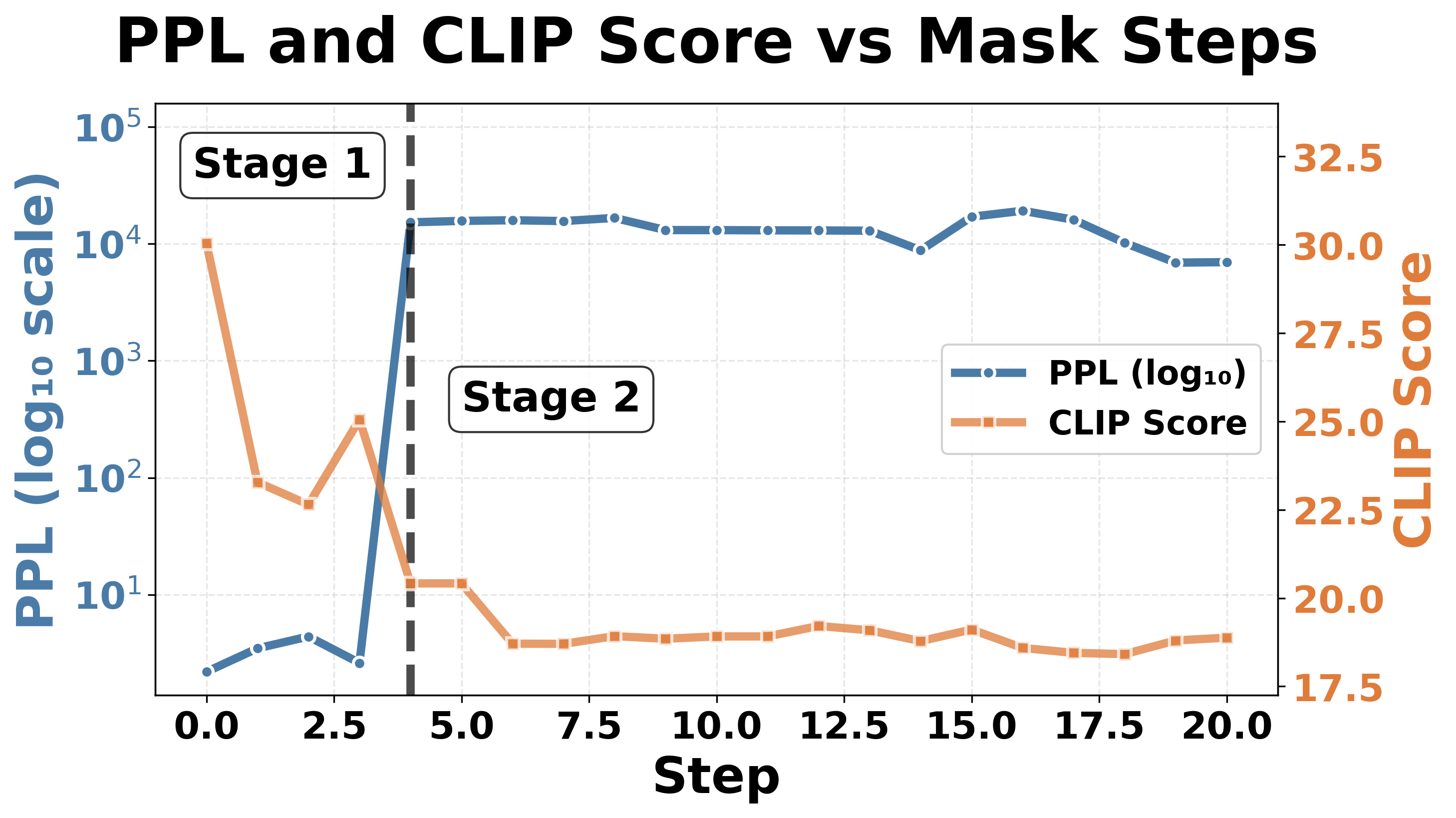
To assess how neuron position influences the number of critical neurons required to trigger catastrophic collapse, we conducted a comparative analysis across two distinct positions in the FFN architecture. In Section 6.1, we examined gate_proj (blue component in Fig. 3, 11,008 dimensions), which operates on the expanded intermediate representation before activation function, and down_proj (orange component in Fig. 3,4,096 dimensions), which performs dimensionality reduction at the network output. In general, masking neurons in down_proj requires fewer critical neurons to induce collapse compared to gate_proj (see Table 2). For LLaVA-1.5-7b-hf, only four neurons in down_proj (compared to five in gate_proj) are sufficient to trigger catastrophic failure, with perplexity increases reaching up to four orders of magnitude. These four neurons also remain consistent regardless of object category, with two neurons located in layer 1 and two neurons in layer 30 (out of 32 layers, zero-indexed), further confirming the Table 2: Collapse induced by masking neurons in the down_proj component of LLaVA-1.5-7b-hf and InstructBLIP-vicuna-7b. Progressive steps of 100 are used for the latter to find an approximate collapse threshold. The collapse manifests as perplexity increases of at least three orders of magnitude and a significant drop in CLIP Score to below 22.
LLaVA-1.5-7b-hf InstructBLIP-vicuna-7b
importance of neurons at the language model’s boundaries. Notably, the perplexity values after collapse in down_proj are consistently higher than those observed in gate_proj masking (Table 1), suggesting that down_proj represents a more critical bottleneck in the information flow. This sensitivity can be attributed to the dimensionality reduction performed by down_proj, which projects the expanded intermediate representation back to the original dimensionality. This process creates a critical bottleneck, making it a particularly vulnerable component in the network architecture. Similarly, InstructBLIP-Vicuna-7b shows the same pattern of increased vulnerability in down_proj. The model requires fewer neurons for collapse in down_proj across 9 object categories, and also achieves higher perplexity values after collapse.
Masking critical neurons in down_proj for both models results in severe output corruption. For LLaVA-1.5-7b-hf, masking down_proj produces empty outputs with only end-of-sentence tokens, while masking gate_proj generates repetitive character strings, as shown in Fig. 1. In contrast, Instruct-BLIP-Vicuna-7b outputs repetitive token after masking both positions, suggesting model-specific vulnerability patterns to neuron masking in FFN components.
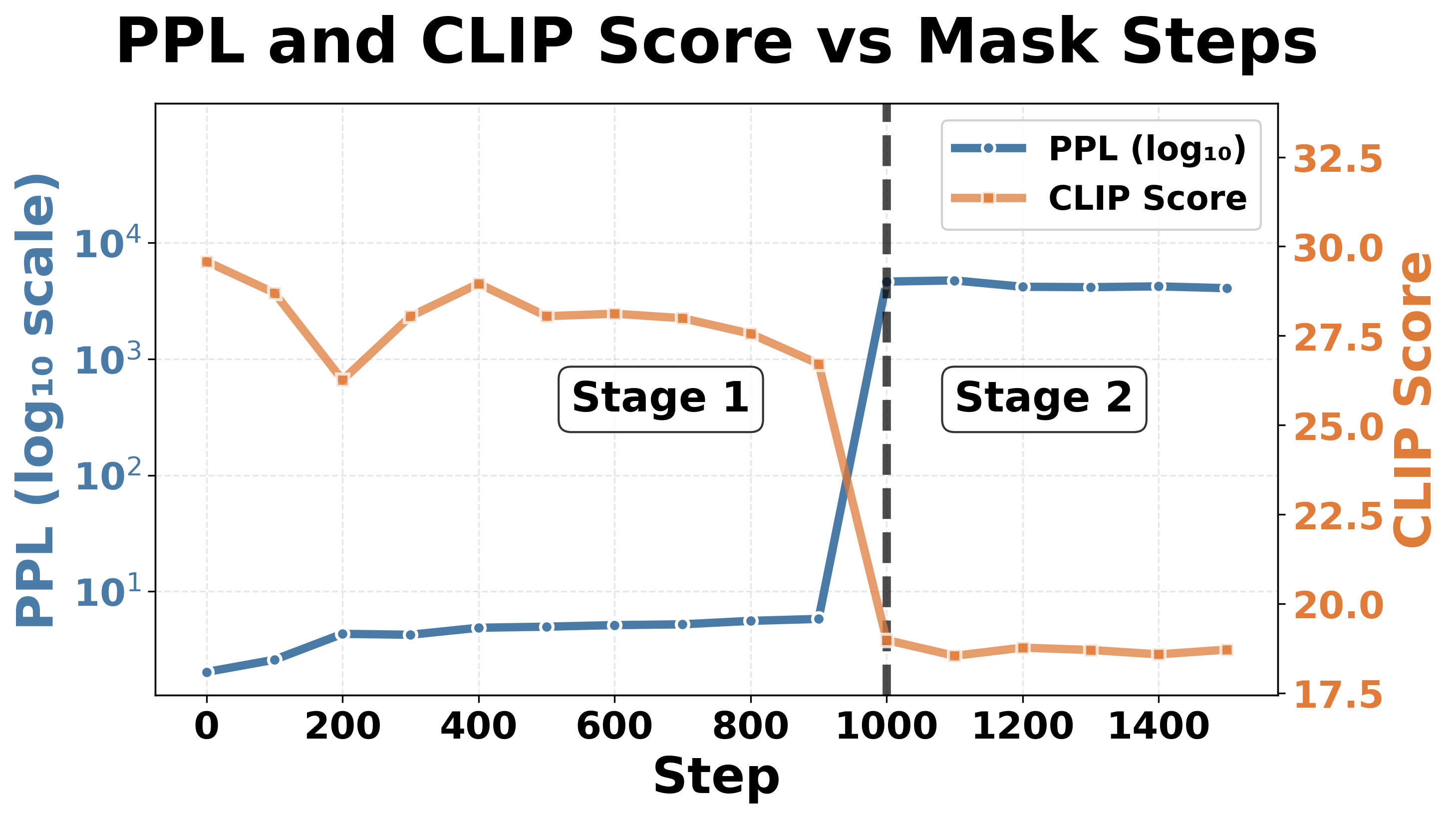
The collapse progression in down_proj shown in Fig. 5 follows the same twostage pattern observed for collapse in gate_proj in Fig. 4. Both models still follow the two-stage collapse pattern: Stage 1 (expressive degradation) shows gradual CLIP score degradation with relatively stable perplexity; Stage 2 (complete collapse) exhibits an abrupt “phase transition” at the threshold where perplexity spikes and CLIP scores become extremely low, with minimal further change upon continued masking. 2 . This pattern across masking positions reinforces our hypothesis that LVLMs contain fragile bottlenecks, and that down_proj is more vulnerable than gate_proj due to its role in information synthesis.
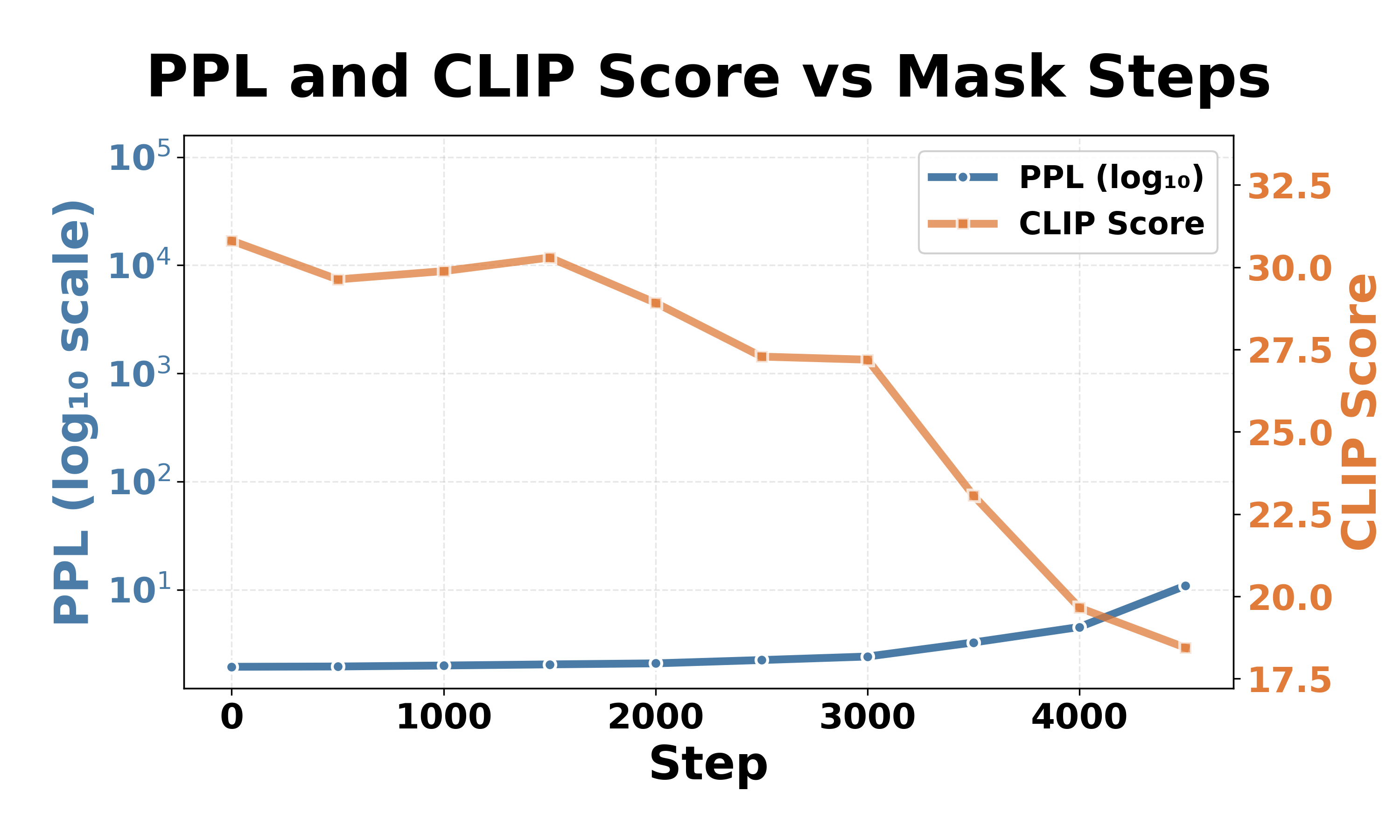
We now mask neurons in vision-related components: the multimodal_projector and vision encoder MLP in LLaVA-1.5-7b-hf, and the Q-Former and vision encoder MLP in InstructBLIP-vicuna-7b. Tables 3 and4 show a distinct failure mode compared to language model components (Tables 1 and2). Masking vision components causes CLIP scores to drop dramatically while perplexity remains stable. Instead, masking the language model’s FFN neurons leads to complete collapse: simultaneous perplexity explosion and CLIP score degradation. This dissociation suggests that vision component failures result in perceptual failure: the model loses visual grounding while retaining its linguistic ability. According to previous research on compositional reasoning and object hallucination, CLIP scores in the 15-22 range represent a “chance-level” baseline where outputs become semantically indistinguishable from random image-text pairings [9,24,32]. This threshold is supported by our language model results, where all masked outputs converge to this range despite generating non-meaningful text. We therefore adopt 22 as the CLIP score threshold for perceptual failure.
For LLaVA-1.5-7b-hf, perceptual failure requires masking 61-97% of the multimodal projector and 17-30% of the vision encoder, far exceeding the sparse critical neuron rates in language model FFN components. As Fig. 6a shows, even when CLIP scores drop below 22, perplexity remains stable. The vision encoder of InstructBLIP-Vicuna-7b shows similar patterns, requiring 8-26% masking. However, the Q-Former behaves distinctly: only 0.33-1.63% of neurons trigger perceptual failure, yet perplexity changes remain minimal (Fig. 6b). This suggests that vision-related components function as perceptual pathways rather than core reasoning components: the masking causes visual impairment while preserving the model’s fundamental capabilities. In contrast, masking critical neurons in the language model’s FFN components causes complete collapse (Tables 1 and2): simultaneous perplexity explosion and severe CLIP score degradation indicate catastrophic failure in both comprehension and generation.
We investigated the vulnerabilities of LVLMs through neuron-level ablation studies. To this end, we proposed CAN, a neuron identification method that combines activation magnitude with gradient sensitivity, and we used it for critical neuron identification. We revealed that masking only four neurons can collapse a billion-parameter model like LLaVA. We also identified a consistent two-stage collapse pattern: from expressive degradation to complete collapse. Moreover, we identified the language model as the vulnerability bottleneck, since critical neurons are localized predominantly in language model feed-forward networks. This finding challenges the intuition that failures in multimodal tasks should stem from vision-language alignment components [16], revealing instead that the language backbone constitutes the primary structural vulnerability in LVLMs. Our results show a critical vulnerability: the small number of neurons required for catastrophic collapse makes LVLMs highly susceptible to targeted attacks. These findings provide insights for LVLM safety research, as adversaries could exploit these weaknesses through precision perturbations on critical neurons. Future work will extend our analysis to larger models and diverse architectures, and design defense strategies such as redundant neuron pathways.
†
‡
§ , Change) (Orig. → Masked § , % Change) (Orig. → Masked § , Change) (Orig. → Masked § , % Change) † Total neuron candidates in each component.‡ Percentages are calculated relative to the total candidates. § Orig. and Masked denote metrics before and after masking critical neurons.
§ , Change) (Orig. → Masked § , % Change) (Orig. → Masked § , Change) (Orig. → Masked § , % Change) † Total neuron candidates in each component.
Notably, multiple ablation trials of the same number of randomly selected noncritical neurons in both models consistently produce negligible impact on model performance, confirming the specificity of these critical neurons.
Repeated ablations of the same number of randomly selected non-critical neurons in both down_proj in both models consistently produce negligible impact on model performance, further confirming the specificity of these critical neurons across FFN components in language model.
📸 Image Gallery