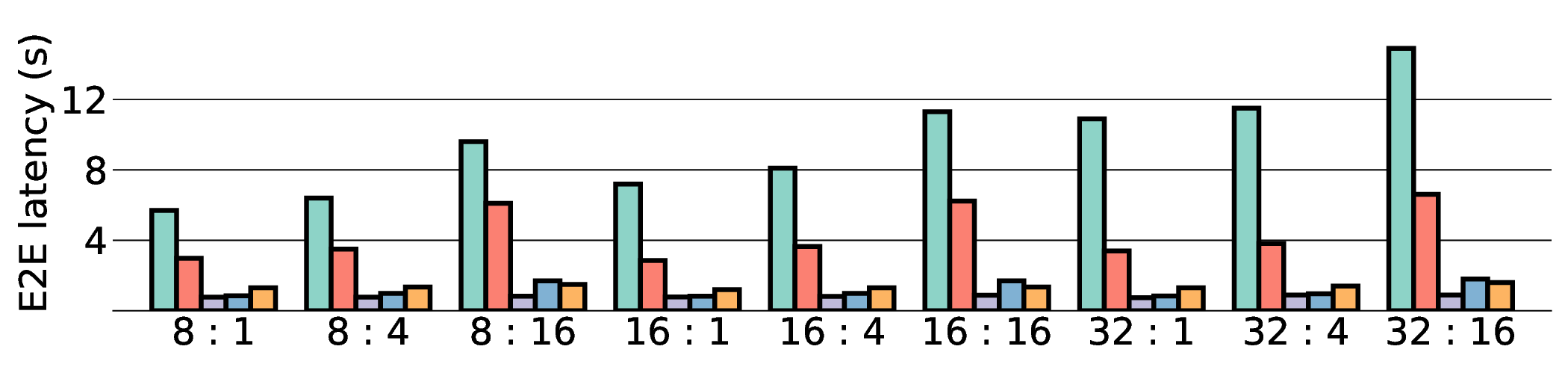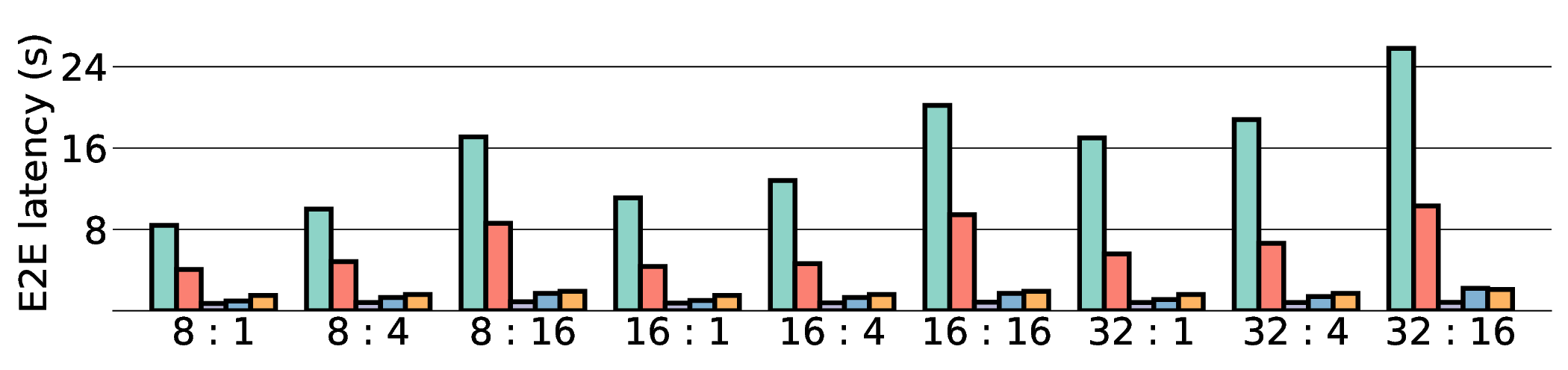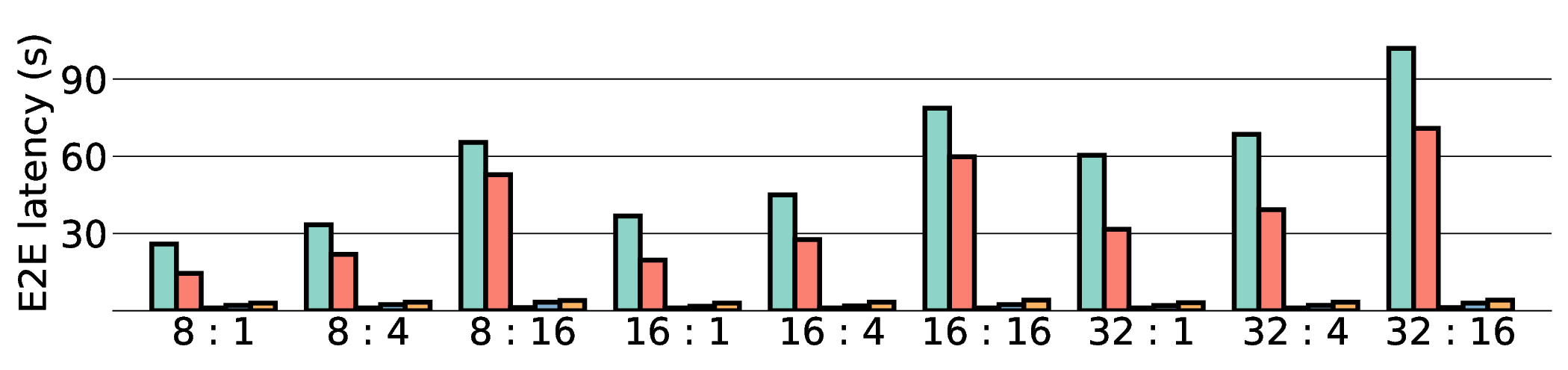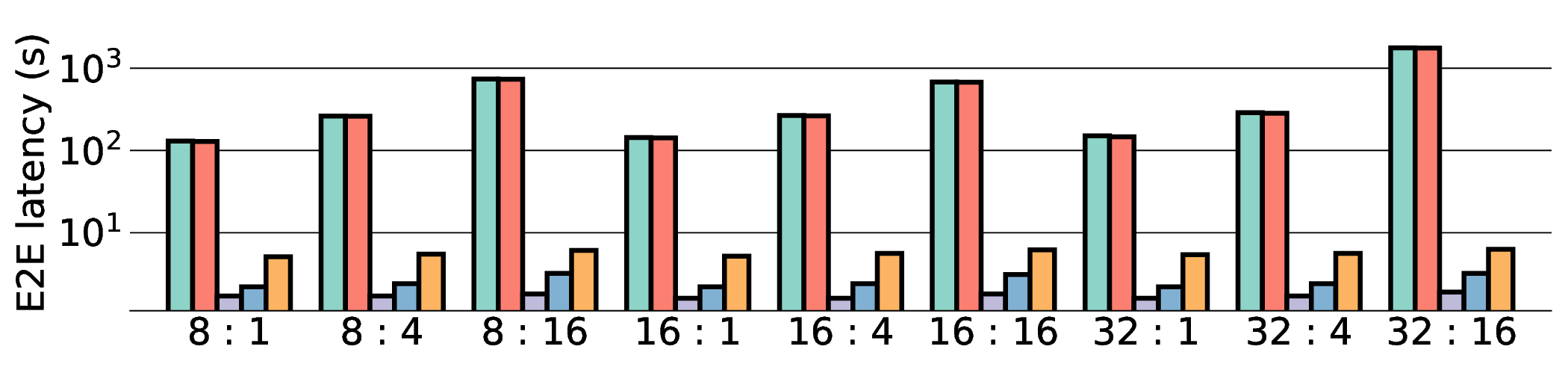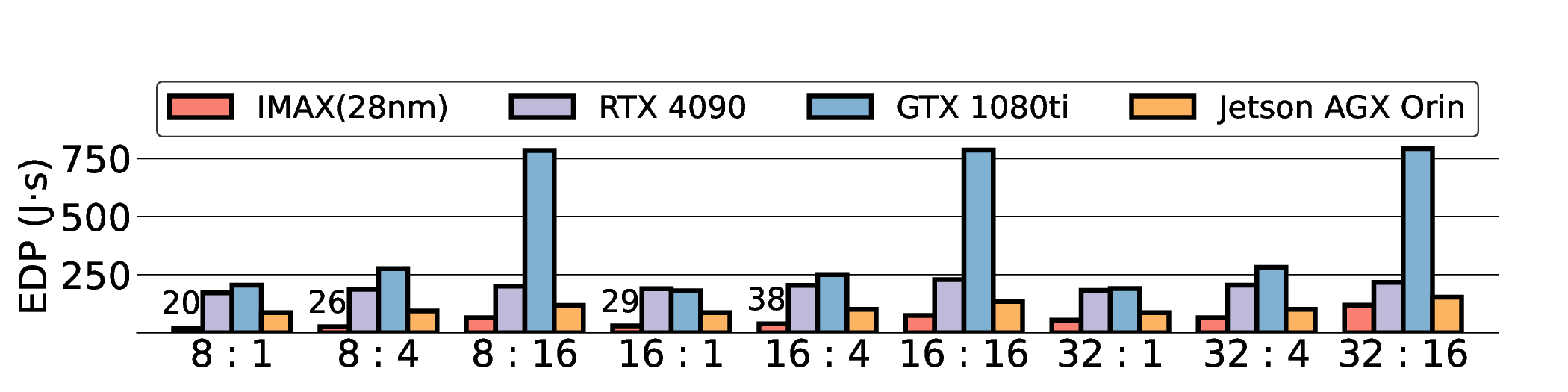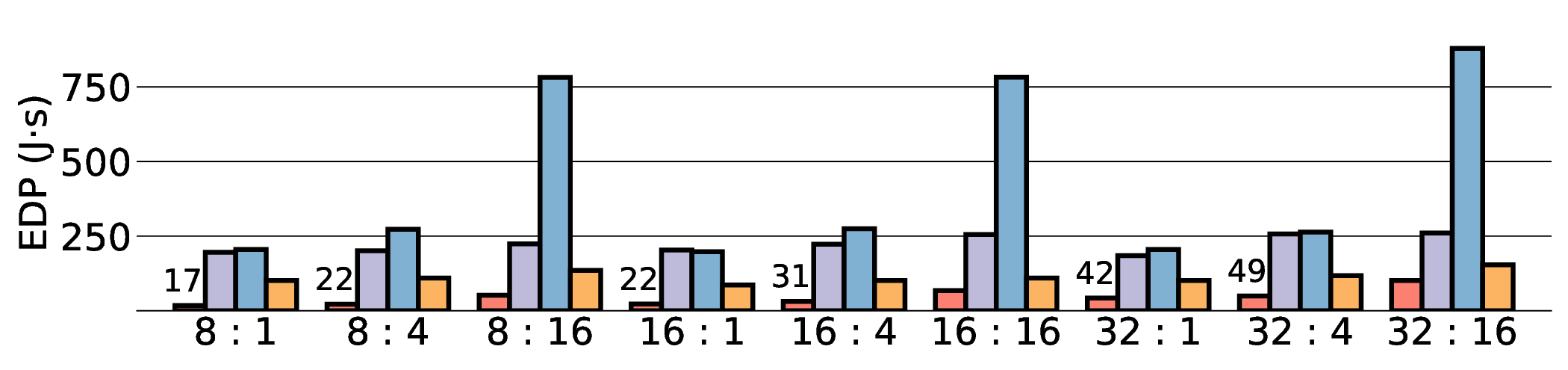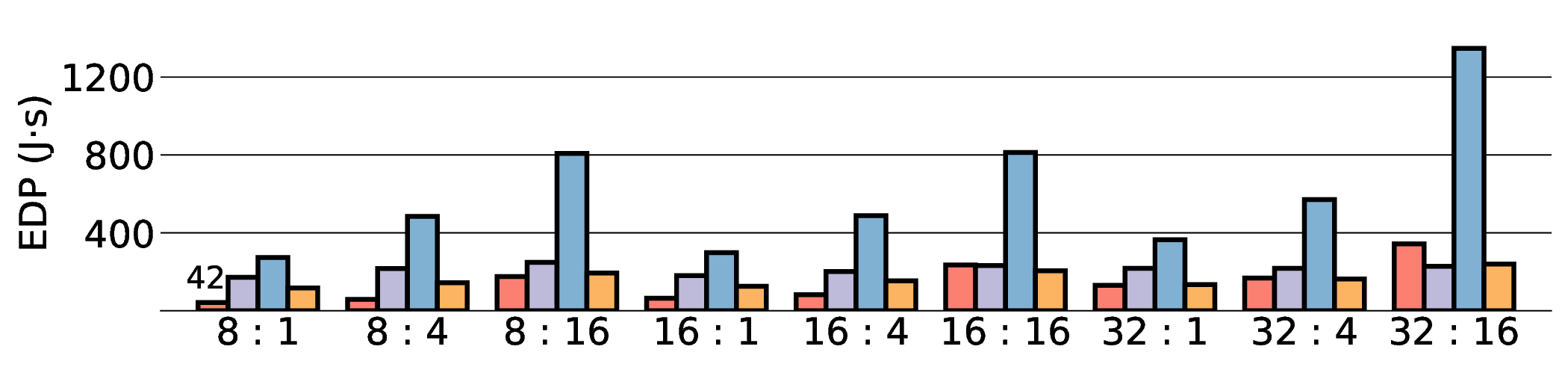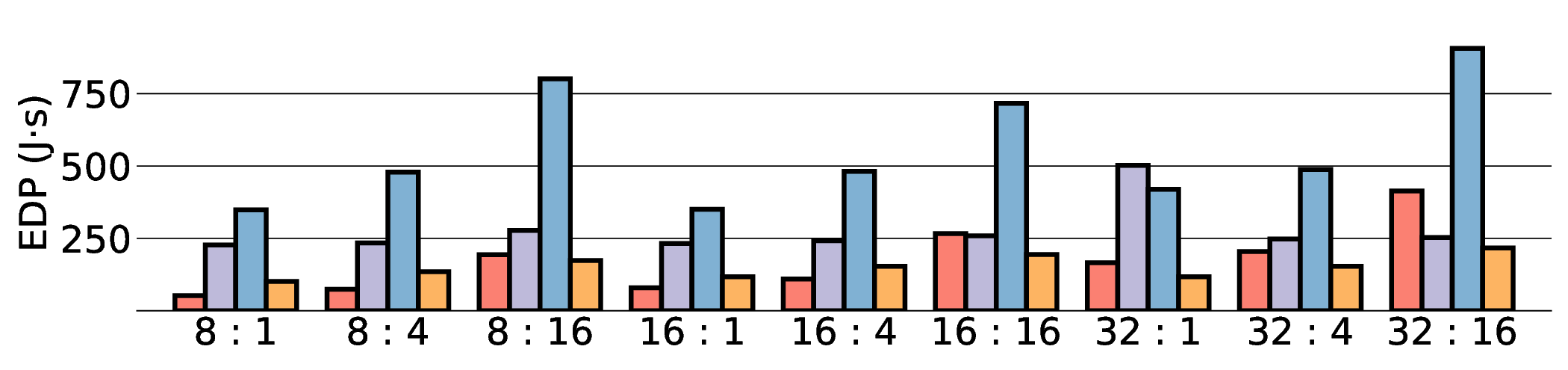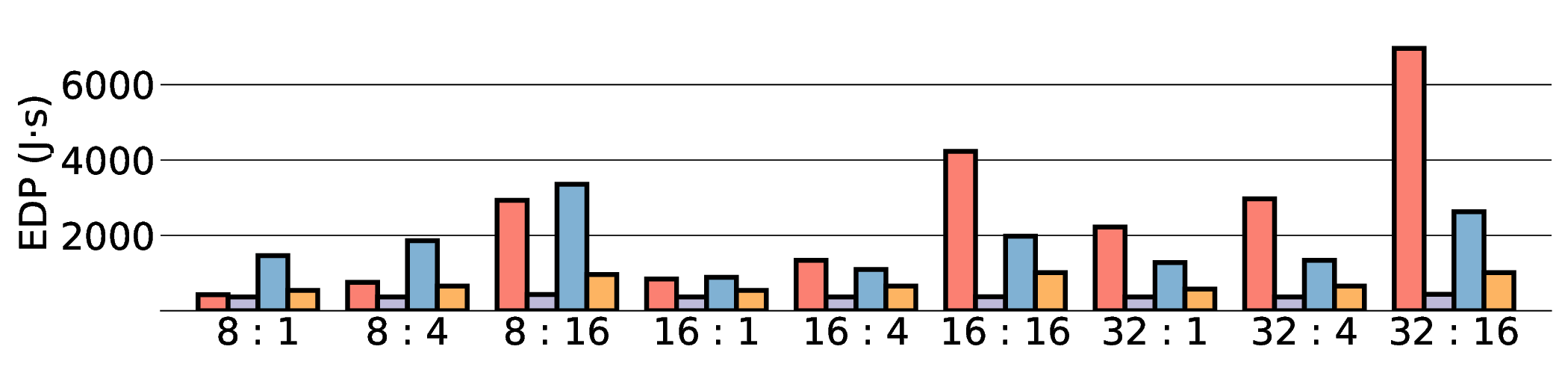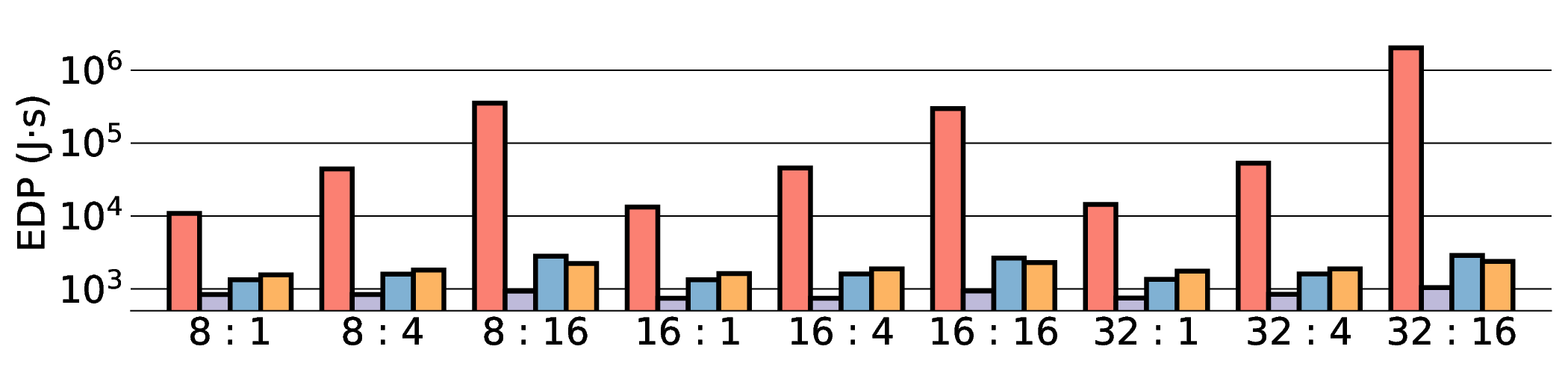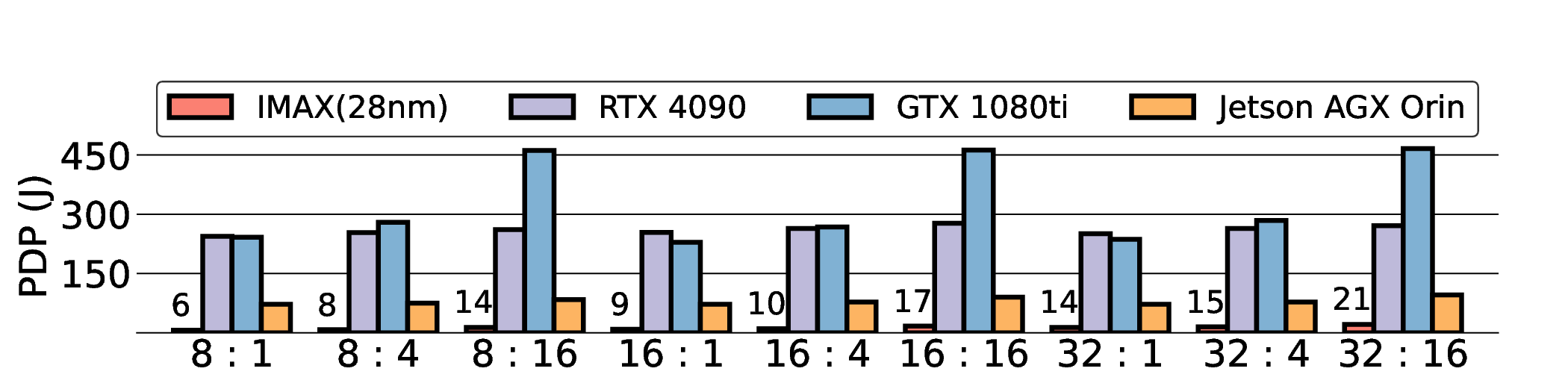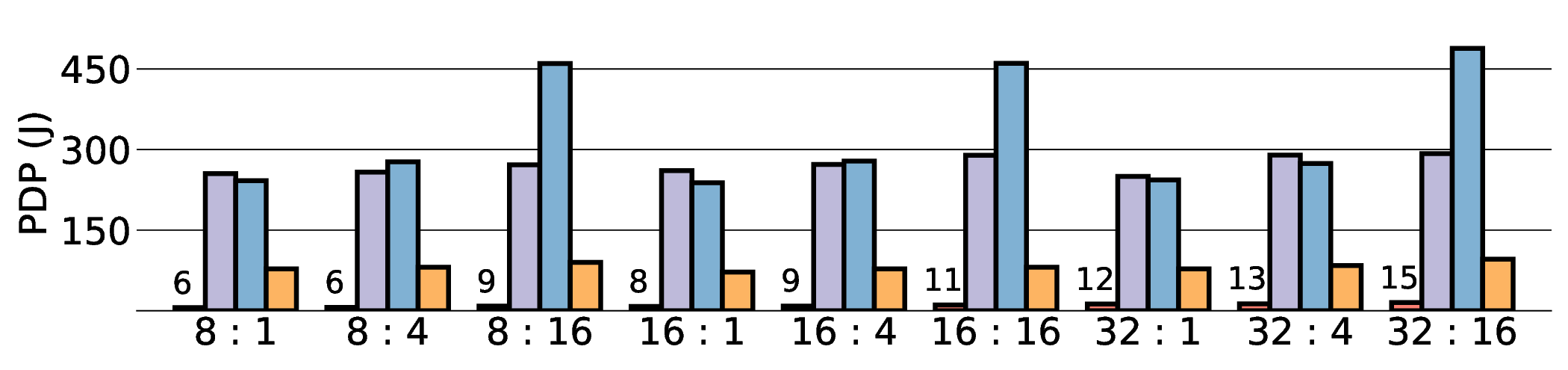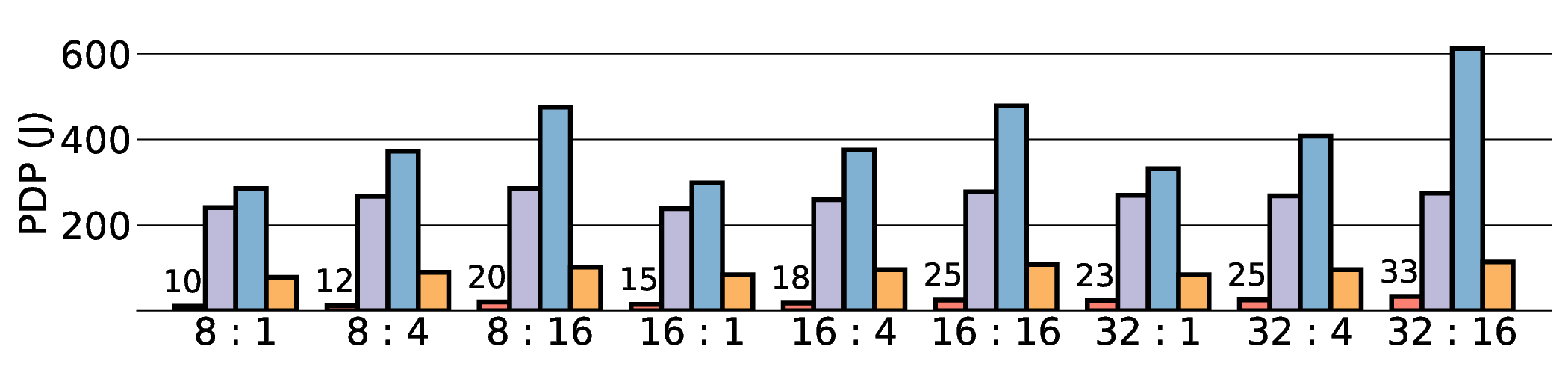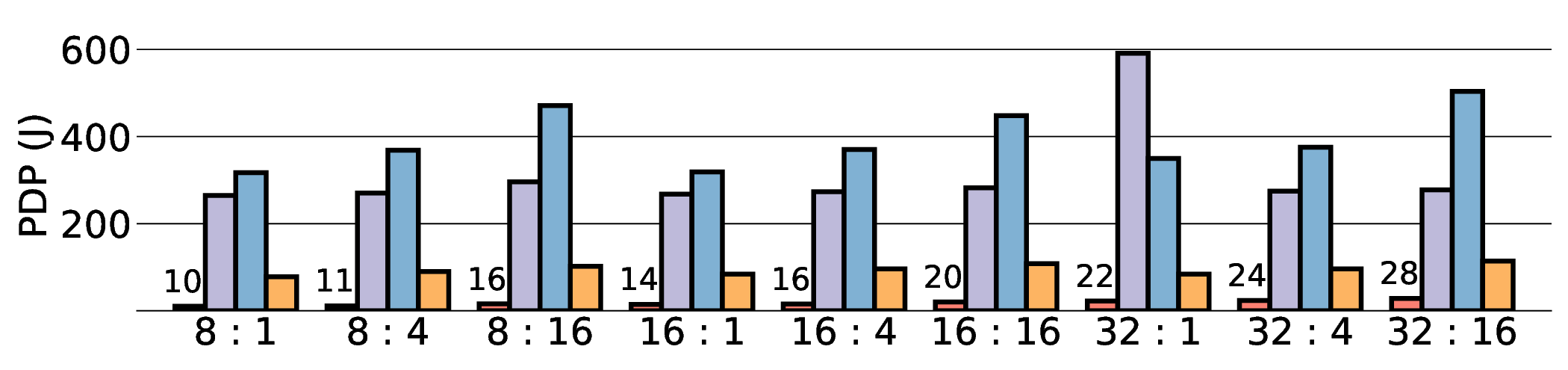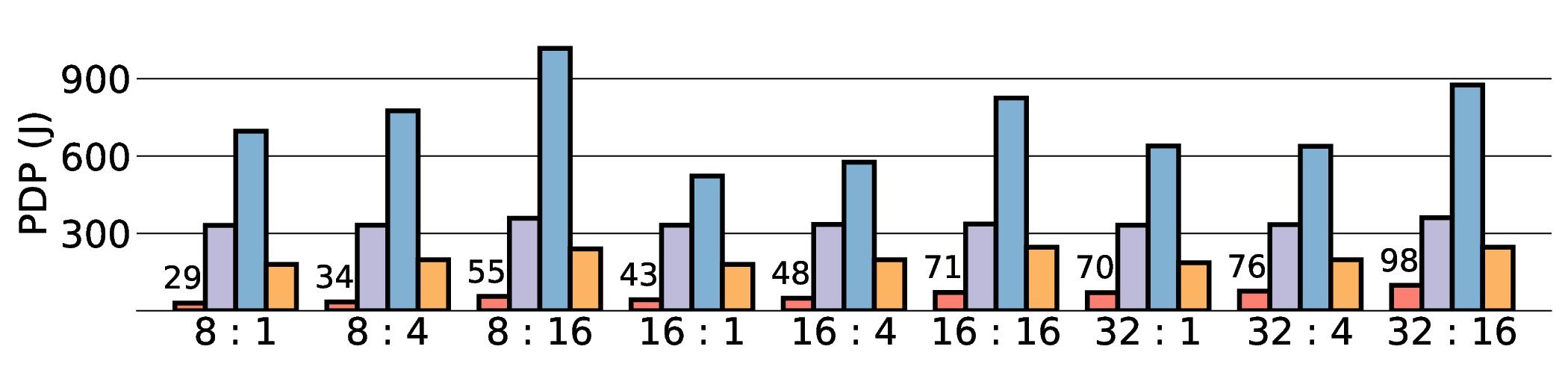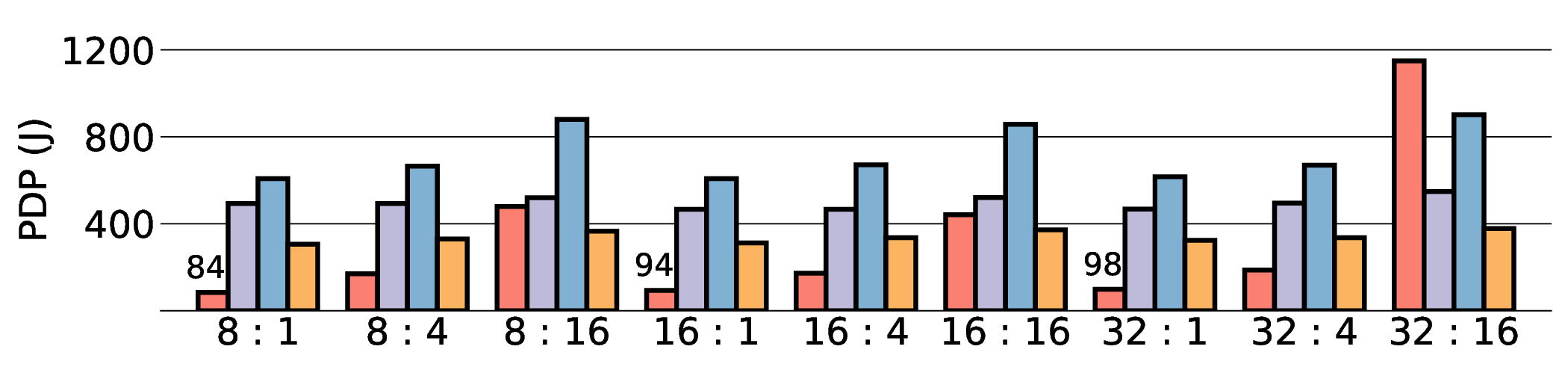Efficient Kernel Mapping and Comprehensive System Evaluation of LLM Acceleration on a CGLA
📝 Original Info
- Title: Efficient Kernel Mapping and Comprehensive System Evaluation of LLM Acceleration on a CGLA
- ArXiv ID: 2512.00335
- Date: 2025-11-29
- Authors: Takuto Ando, Yu Eto, Ayumu Takeuchi, Yasuhiko Nakashima
📝 Abstract
Large Language Models (LLMs) demand substantial computational resources, resulting in high energy consumption on GPUs. To address this challenge, we focus on Coarse-Grained Reconfigurable Arrays (CGRAs) as an effective alternative that provides a trade-off between energy efficiency and programmability. This paper presents the first comprehensive, end-to-end evaluation of a non-AI-specialized Coarse-Grained Linear Array (CGLA) accelerator for the state-of-the-art Qwen3 LLM family. The architecture has a general-purpose, task-agnostic design, yet its flexible instruction set allows for domain-specific adaptations. This flexibility enables the architecture to achieve high efficiency for sustainable LLM inference. We assess the performance of our architecture on an FPGA prototype using the widely adopted llama.cpp framework. We then project its potential as a 28 nm ASIC and compare it against a high-performance GPU (NVIDIA RTX 4090) and an edge AI device (NVIDIA Jetson AGX Orin). While GPUs exhibit lower latency, our non-AI-specific accelerator achieves higher energy efficiency, improving the Power-Delay Product (PDP) by up to 44.4× and 13.6× compared with the RTX 4090 and Jetson, respectively. Similarly, it reduces the Energy-Delay Product (EDP) by up to 11.5× compared to the high-performance GPU, demonstrating a favorable performance-energy trade-off. Critically, our system-level analysis identifies host-accelerator data transfer as the primary performance bottleneck, a factor often overlooked in kernel-level studies. These findings provide design guidance for next-generation LLM accelerators. This work validates CGRAs as a suitable platform for LLM inference in power-constrained environments, without being confined to specific algorithms.📄 Full Content
To address this challenge, specialized hardware such as Application-Specific Integrated Circuits (ASICs) and Field-Programmable Gate Arrays (FPGAs) have been widely investigated. While edge GPUs, such as the NVIDIA Jetson series, demonstrate progress in reducing power consumption, their general-purpose graphics pipelines inherently constrain substantial gains in power efficiency. In contrast, ASICs can potentially achieve orders of magnitude higher power efficiency. ASICs specialize their circuits for the core computational patterns of LLM inference, such as dot-product operations. This allows them to remove all unnecessary functionality and achieve maximum performance for a specific task. However, this high efficiency is intrinsically coupled with a lack of flexibility, rendering these designs unable to adapt to evolving algorithms. Therefore, we consider Coarse-Grained Reconfigurable Arrays (CGRAs) as an architectural paradigm that addresses the fundamental trade-off between efficiency and flexibility. CGRAs achieve power efficiency approaching that of an ASIC by mapping dataflow graphs directly onto an array of processing elements (PEs), while preserving programmability through their reconfigurable fabric. This work focuses on IMAX [20], a general-purpose accelerator based on Coarse-Grained Linear Arrays (CGLAs), a type of CGRA architecture. IMAX features a linear arrangement of PEs and Local Memory Modules (LMMs), a design specifically intended to efficiently handle the irregular memory access patterns of LLM inference.
Our previous work has demonstrated the versatility and effectiveness of the IMAX architecture across a diverse range of workloads, including Sparse General Matrix Multiplication (SpGEMM), Fast Fourier Transform (FFT), and Convolutional Neural Networks (CNNs) [20], [21], [22]. We have also extended this versatility to LLMs, showing the feasibility of implementing key kernels from the Llama2based model on IMAX [23], [24]. Based on this foundation, this work provides the first comprehensive evaluation of IMAX as an LLM accelerator. Specifically, we expand our analysis to the state-of-the-art Qwen3 model [25], [26]. We adopt the widely used C/C++ inference engine llama.cpp [27] to assess performance in practical scenarios. This approach allows our evaluation to encompass the entire system from end-to-end (E2E), rather than being limited to single-kernel performance. This evaluation accounts for host-CPU interaction, data transfer overheads, and complex control flows.
The main contributions of this paper are as follows:
• We present the first comprehensive, E2E evaluation of a general-purpose CGRA for modern LLM inference. Our work demonstrates that a non-AI-specialized architecture can achieve superior energy efficiency, improving the Power-Delay Product (PDP) by up to 44.4× and the Energy-Delay Product (EDP) by up to 11.5× compared to a high-performance GPU. This finding validates a sustainable hardware approach that avoids the risk of rapid obsolescence associated with task-specific ASICs.
• We identify a critical performance bottleneck shift from computation to host-accelerator data transfer. Our system-level analysis using the llama.cpp framework reveals that the decode phase is data-transfer-bound, a finding obscured in kernel-centric evaluations that provides crucial guidance for latency optimization. • We validate CGRAs as a viable architectural solution that balances efficiency and programmability for sustainable LLM inference. Our work establishes that general-purpose reconfigurable hardware can effectively adapt to rapid algorithmic evolution, making it a practical choice for power-constrained deployment.
The remainder of this paper is organized as follows. Section II surveys related work in LLM acceleration and introduces the IMAX architecture. Section III details our implementation methodology, including the execution framework and kernel mapping strategies. Section IV presents the experimental results, comparing our accelerator against GPUs on E2E latency and energy-efficiency metrics. Section V analyzes performance bottlenecks by examining onchip memory impact, execution phase breakdowns, and host system limitations, and discusses directions for future work. Finally, Section VI concludes the paper.
This work relates to both hardware acceleration for LLMs and CGRA implementation. In this section, we survey the key trends in both domains to contextualize our work and clarify its unique position and contributions.
Research on hardware acceleration for LLM inference falls into three main streams. The primary stream centers on the use of GPGPUs. Innovations such as Tensor Cores and the Hopper architecture [28] have substantially increased the throughput of LLM inference. The high programmability and well-developed ecosystem of GPGPUs facilitate rapid prototyping and application development [29]. However, this approach consumes substantial power, posing a significant sustainability challenge [30].
The second stream involves the development of ASICs specifically tailored for LLM inference. Architectures such as Google’s TPU [31] and Meta’s MTIA [32] achieve performance and power efficiency that far surpass GPGPUs by concentrating computational resources on the large-scale dotproduct operations at the core of LLMs. However, this high efficiency often results in over-specialization to particular algorithms or quantization methods, limiting adaptability. Consequently, these designs inherently risk rapid obsolescence due to the difficulty in adapting to fast-evolving LLM algorithms such as Mixture of Experts (MoE) [33] and Activation-aware Weight Quantization (AWQ) [34].
The third stream, positioned between the efficiency of ASICs and the flexibility of GPGPUs, explores the use of reconfigurable hardware, such as FPGAs and CGRAs. These architectures have already proven effective for general AI acceleration, with numerous research demonstrating their advantages in balancing performance and power consumption [35], [36], [37], [38]. Based on this success, they are now emerging as a suitable solution for LLM inference. The reconfigurability of these devices can potentially address the inflexibility inherent in ASICs, offering a suitable approach for the rapid evolution of LLMs.
Research on FPGA-based LLM acceleration is an important focus of current research in algorithm-hardware codesign [39], [40], [41], [42]. For instance, UltraFormer [43] exemplifies this approach by redesigning the Transformer architecture itself for FPGAs. It pursues algorithmic-level optimization by integrating a linear-complexity attention mechanism with 1.58-bit quantization derived from BitNet [44].
Similarly, research like BitMoD [45] and AccLLM [46] have demonstrated a method for improving performance and efficiency while maintaining model accuracy. They achieve this by proposing custom low-bit data types, such as 2-bit and 3-bit formats, and implementing specialized arithmetic units on FPGAs to process them efficiently.
Furthermore, FPGAs provide a suitable platform for experimenting with innovative architectures to address the memory bandwidth bottleneck. For example, FlexCiM [47] leverages fully digital compute-in-memory (DCiM) technology to support flexible structured sparsity, while MECLA [48] substantially reduces off-chip data transfers through a novel on-chip weight reorganization technique. The research area is also expanding beyond single-accelerator designs to establish development ecosystems. A notable example is SECDA-LLM [49], which proposes a framework for rapidly integrating FPGA accelerators within llama.cpp. Although FPGAs are an active area of research for LLM acceleration, they still encounter challenges such as high development complexity and inherent limitations in operating frequency and power efficiency compared to ASICs.
CGRAs have recently been investigated as an architectural solution to overcome the performance and programmability trade-offs of FPGAs. By spatially mapping dataflow graphs (DFGs) onto an array of PEs, CGRAs achieve power efficiency approaching that of ASICs while retaining programmability through reconfiguration. Research on CGRAs for LLM acceleration is an emerging field, with several distinct approaches recently introduced.
Other research focuses on optimizing linear operations like Matrix-Vector Multiplication (MVM), which represent a major computational component in LLMs. The CORO algorithm [50], for instance, exemplifies a data-centric optimization strategy, combining non-uniform quantization with variable-length data encoding. This technique leverages the clustering of weight values to reduce the memory footprint by encoding them in pairs. CORO’s contribution lies in improving algorithmic memory efficiency for kernel-level performance on flexible accelerators. However, it does not extend to broader architectural and system-level challenges.
Another research direction focuses on the optimization of non-linear operations. While these operations account for a smaller portion of the total computation compared to MVM, they often become significant latency bottlenecks. A representative work in this area is PICACHU [51], a plugin CGRA accelerator designed to efficiently handle diverse non-linear functions such as Softmax and normalization. It is designed to complement existing LLM accelerators by offloading only non-linear computations to the CGRA.
Our work differs from these works in two key aspects: its architectural philosophy and its evaluation methodology. First, regarding our architectural philosophy, we emphasize architectural versatility. Similar to CORO, our work focuses on offloading dot-product operations, which account for the majority of the computational load in LLMs. In contrast to CORO, which is designed specifically for dot-product operations in LLMs, our IMAX architecture is a generalpurpose CGRA that is not limited to a single task or model. We have already demonstrated its capability on diverse workloads such as FFT [20] and CNNs [21], [22]. This research shows that the same architecture can achieve high energy efficiency on modern LLM inference tasks without modification, demonstrating a design principle for sustainable hardware that avoids task-specific specialization. A second key difference is our evaluation methodology. We assess E2E system performance using the widely used llama.cpp framework. This approach enables the assessment of E2E system performance under realistic conditions. Our analysis incorporates important factors such as host-CPU interaction, DMA transfer overheads, and complex software control. In the emerging field of LLM acceleration on CGRAs, this paper provides a comprehensive characterization of the performance and challenges of a versatile architecture at a fullsystem level.
While a direct quantitative comparison with other FPGA and ASIC-based LLM accelerators is valuable, achieving a fair comparison is challenging. This is due to discrepancies in target models, quantization schemes, process technologies, and evaluation methodologies. For instance, some studies use isolated kernel benchmarks, whereas others perform E2E system-level measurements. Many papers report per- formance in TOPS or TOPS/W based on peak theoretical throughput, figures that often omit significant system-level overheads. Therefore, this work provides a detailed performance analysis of a general-purpose, non-specialized CGRA architecture, using the industry-standard llama.cpp. The C++ framework is used unmodified, and we compare our results against those of GPU platforms. Our evaluation inherently incorporates host-accelerator interactions and data transfer overheads, thereby offering a realistic assessment of systemlevel performance and energy efficiency.
The IMAX architecture is based on a different design approach from those previously mentioned. The architecture is designed for task-agnostic versatility, providing both linear scalability and high programmability through direct compilation from C/C++. IMAX employs a CGLA structure, arranges PEs and LMMs in an alternating pattern in a onedimensional array. This design addresses the complex routing and compilation challenges of conventional 2D meshbased CGRAs. The combination of this simple structure with multi-functional, CISC-based PEs allow IMAX to efficiently execute diverse workloads. These include not only linear operations like General Matrix Multiplication (GEMM) but also those involving irregular memory accesses and complex control flows. This linear topology is particularly well-suited for the dot-product operations that dominate LLM inference, providing a theoretical basis for its high energy efficiency. Specifically, weights and activations can be streamed through the one-dimensional array of PEs, creating a deep, deterministic pipeline. This structure improves spatial data locality and reuse. Data passed from one PE is immediately consumed by its neighbor, which eliminates the need for complex routing or access to a higher-level memory hierarchy. The highly regular and predictable memory access patterns inherent in this dataflow execution minimize the energy overhead associated with data movement and address calculation. These factors contribute significantly to reducing power consumption in conventional architectures.
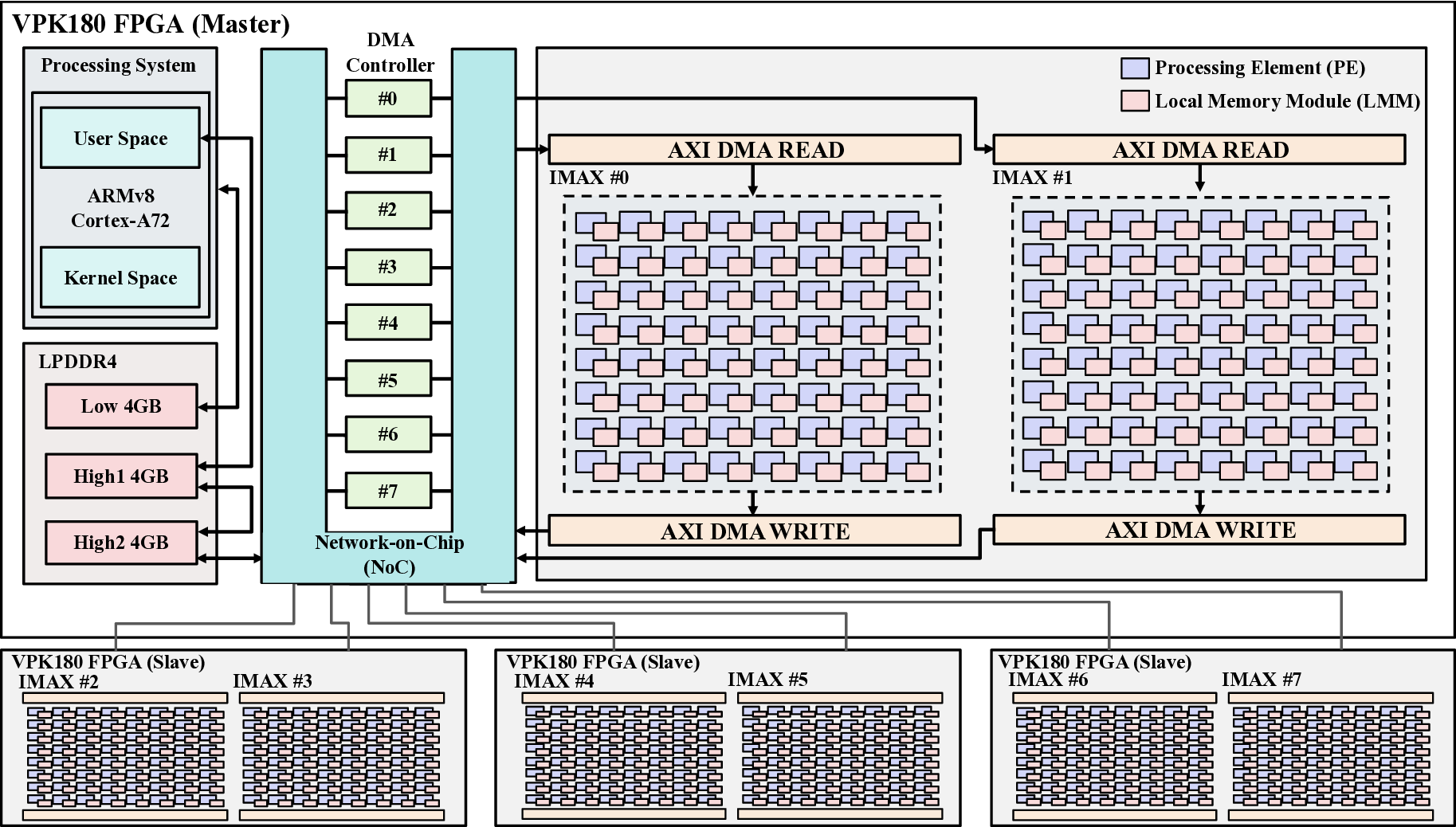
Fig. 1 provides a high-level overview of the IMAX3 system architecture. Implemented on an AMD Versal VPK180 FPGA, IMAX3 is a System-on-Chip (SoC) consisting of a Processing System (PS) and Programmable Logic (PL). The PS serves as the host, featuring a dual-core Arm Cortex-A72 processor running Linux. It manages the entire workflow, from application compilation to execution control. A high-bandwidth Network-on-Chip (NoC) facilitates communication between the PS and PL, while a dedicated DMA controller efficiently transfers data between system memory and the accelerator. The accelerator core itself resides within the PL. It consists of eight independent compute lanes. This multi-lane design is central to the architecture’s scalability, as performance can be tailored by allocating a variable number of lanes to match an application’s degree of parallelism.
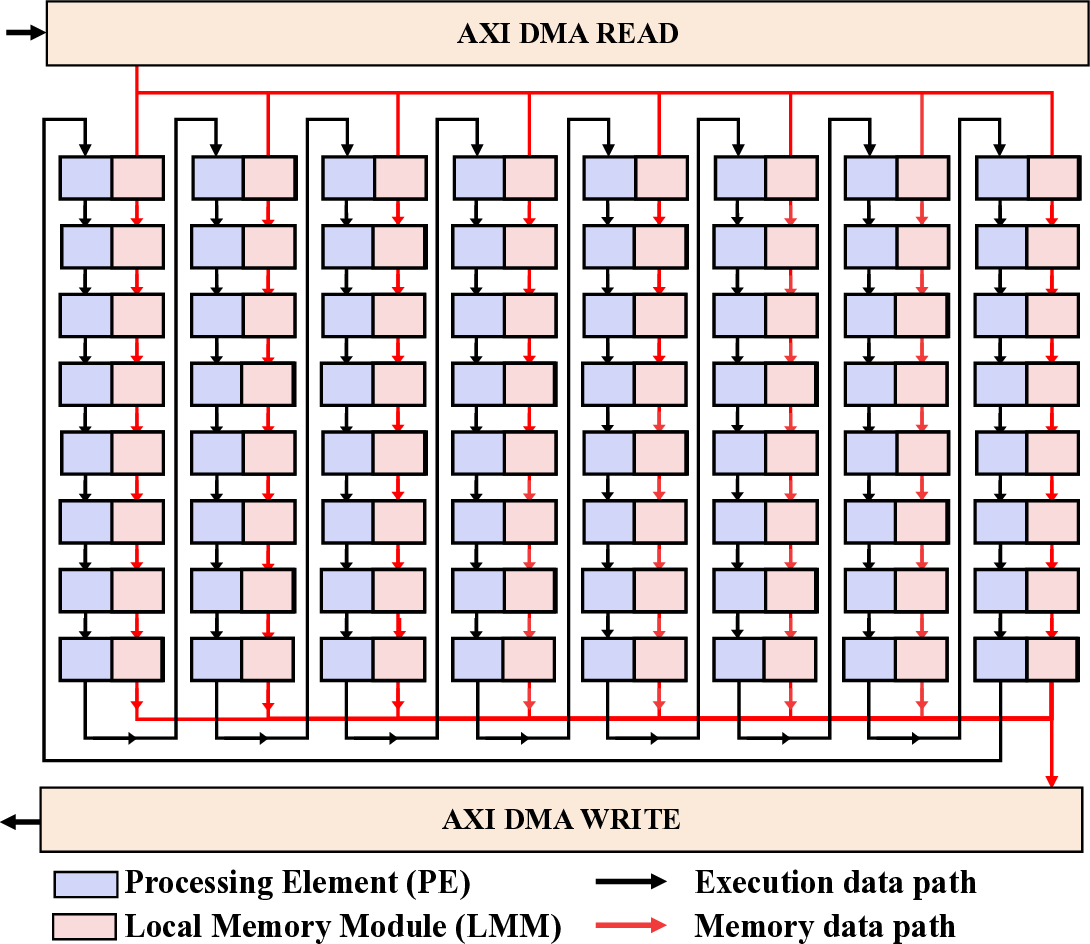
The internal structure of each compute lane is depicted in Fig. 2. This illustrates the core CGLA structure of IMAX, where PEs and LMMs are arranged alternately in a one- dimensional array. This linear topology simplifies the data paths between PEs, facilitating easier compilation while also enabling low-latency access to adjacent LMMs. Data is loaded into the LMMs via DMA and then forms a pipelined dataflow across the PEs, which is essential for maintaining high utilization of the arithmetic units. Each PE features a heterogeneous design, comprising multiple arithmetic units, address generation units, and LMMs. The arithmetic component consists of three ALUs (ALU1, ALU2, and ALU3), dedicated to integer, logical, and shift operations, respectively, which enables the parallel execution of diverse instructions. The Address Generation Units (AG1, AG2) operate independently of the ALUs to calculate memory addresses. This design decouples the computation and memory access pipelines, thereby improving execution efficiency. The LMM is implemented with a hardware-managed double-buffered configuration, a key feature designed to enable the concurrent execution of computation and data transfers. While one buffer is being used by the PEs for active computation, the DMA controller can simultaneously load the next set of data into the other buffer. This mechanism is intended to mask memory access latency by overlapping communication with computation, thereby maximizing data throughput. The integration of these components allows each PE to efficiently process the large volumes of data demanded by high-performance computing tasks.
Previous work has established IMAX3 as a general-purpose computing platform. Its effectiveness has been demonstrated across a wide spectrum of workloads. These range from traditional kernels, such as SpGEMM, FFT [20], light-field image processing [52] to modern AI applications such as CNNs [21], [22], Graph Convolutional Networks (GCNs) [53], and Retrieval-Augmented Generation (RAG) systems [54]. This work applies these findings to the domain of LLMs. Our previous works [23], [24] presented the implementation of a Llama2-based model on IMAX, confirming its feasibility. Based on that success, this work aims to validate the performance and robustness of IMAX as an LLM accelerator using a wider range of models and workloads. To validate the generalizability of the architecture, we evaluate its robustness against the Qwen3 family, which features diverse model structures. Therefore, we expand our evaluation to the state-of-the-art Qwen3 family to assess its practical performance.
This section details our methodology for implementing a recent LLM family, Qwen3, on IMAX, our general-purpose CGLA accelerator. We constructed a hybrid execution model built upon the widely adopted llama.cpp framework, which offloads computationally intensive kernels to the IMAX accelerator. We first provide an overview of the overall execution framework, followed by a detailed description of the dataflow design and mapping strategies for the various quantized kernels we implemented in this work.
For a realistic system-level evaluation, we implement a hybrid execution model based on the llama.cpp framework. For our target models, we selected the state-of-the-art Qwen3. We selected the Qwen3 for its high performance at smaller scales and its wide range of model sizes (e.g., 0.6B, 1.7B, 8B). This allows us to test our accelerator’s capabilities on workloads ranging from edge to high-performance scenarios. In our model, the host CPU and the IMAX accelerator collaborate on LLM inference. Fig. 4 presents a high-level view of the target LLM architecture and delineates our proposed task partitioning. This partitioning is guided by the principle of assigning tasks to the most suitable processing unit: utilizing the CPU for complex, sequential control flow and the IMAX accelerator for parallel, computationally intensive operations. The host CPU handles tasks that demand complex control and sequential logic. These responsibilities include prompt tokenization, embedding layer computations, KV cache management, and the final Softmax operation. Conversely, we offload the most computationally demanding kernels, which constitute the majority of the inference latency, to the IMAX accelerator. As highlighted in pink in Fig. 4, IMAX executes the dot-product operations within all linear projections, the Grouped Multi-Query Attention mechanism, and the linear transformations of the SwiGLU network. We retain nonlinear operations, such as RMS Normalization and the application of Rotary Position Encodings, on the host CPU.
We designed this functional partitioning to maximize overall system throughput by utilizing the architectural strengths of each processing unit.
Quantization is an essential technique in LLM inference. It reduces both the memory footprint and the required memory bandwidth, while also enabling faster computation through integer arithmetic. In resource-constrained environments, model compression via quantization is often a prerequisite for execution. The llama.cpp framework supports a diverse range of quantization schemes, offering flexibility to balance the trade-off between model accuracy and performance.
To demonstrate the versatility and robustness of the IMAX architecture, we implemented and evaluated the following four distinct computational kernels, each with varying characteristics:
• FP16: A 16-bit floating-point format. This serves not only as a baseline but is also an essential data type used for specific high-precision operations within all quantized models. • Q8_0: A standard 8-bit integer quantization scheme.
This kernel constitutes the majority of the operations performed in the Q8_0 models. • Q3_K: A highly compressed mixed-precision scheme by combining 1-bit, 2-bit, 4-bit, and 6-bit quantization blocks. It represents the majority of the computations in the highly compressed Q3_K_S models. • Q6_K: A 6-bit integer format that is also utilized for specific layers within the Q3_K_S models, complementing the Q3_K kernel.
These data types are strategically employed across different layers of the models. The large weight matrices of the linear layers contain the majority of model parameters in the attention and feed-forward networks. These matrices are quantized to low-bit integer formats such as Q8_0, Q3_K, and Q6_K. This approach substantially reduces the overall model file size and memory bandwidth requirements. In contrast, we preserve the weights of the normalization layers in highprecision FP16 to avoid the risk of performance degradation, as these layers are necessary to maintain computational stability. Since the parameter count in normalization layers is negligible compared to that of linear layers, retaining their precision has a minimal impact on the total model size. Our evaluation adopts a common strategy used in modern LLMs. We quantize only the large linear layers, while the smaller normalization layers remain in high precision to maintain model stability.
The selection of these specific quantization formats is intended to cover a realistic spectrum of quality-efficiency trade-offs. Empirical studies on the Qwen3 model family have demonstrated that 8-bit quantization (Q8_0) maintains performance nearly identical to the FP16 baseline, with negligible degradation on standard benchmarks such as MMLU [55]. Conversely, quantization formats with extremely low bit-widths, such as Q3_K, result in a measurable degradation in accuracy. However, their reduced memory footprint, a 4.5× reduction compared to FP16, makes them an enabling technology for deploying LLMs on severely memoryconstrained edge devices. Our evaluation includes this range to demonstrate the architecture’s flexibility across this entire spectrum.
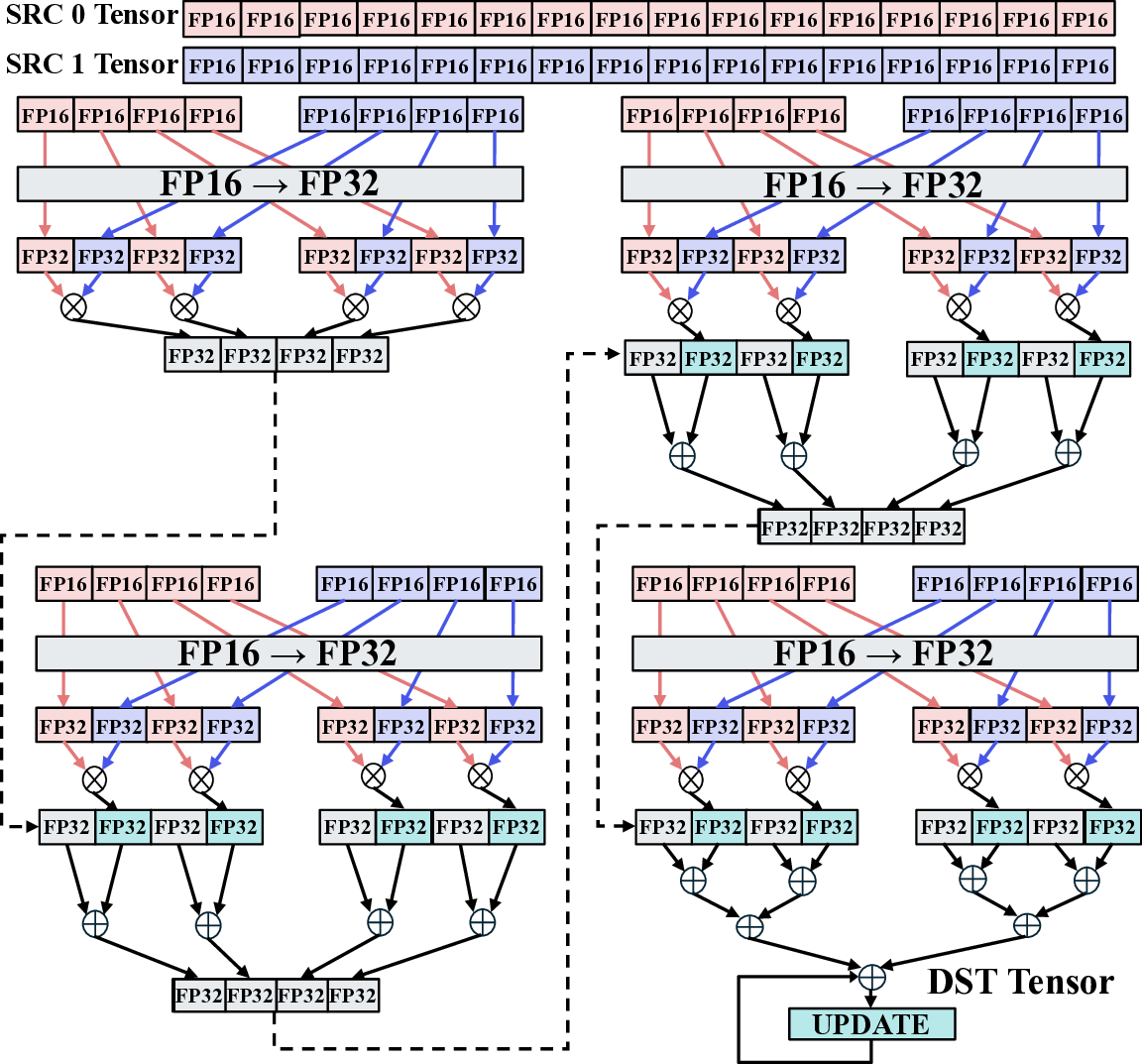
This section details how high-level dot-product operations from llama.cpp are compiled and mapped onto the IMAX CGLA architecture. The mapping process leverages IMAX’s compiler-friendly design and a rich set of custom instructions to maximize pipelining and data-level parallelism. First, the compiler analyzes the high-level C++ code, focusing on performance-critical loops such as the dot-product operation. Then, it maps the dataflow of the operation onto IMAX’s one-dimensional PE array. This linear topology, unlike 2D mesh architectures, allows for a deterministic mapping without complex routing heuristics, enabling predictable performance. Second, the compiler translates the low-level arithmetic within the dataflow into IMAX’s custom instructions, which are designed to exploit fine-grained data parallelism as shown in Fig. 5. The following subsections describe the specific dataflows and custom instructions used for each implemented kernel, serving as concrete examples of this mapping process.
Fig. 6 illustrates the dataflow for the FP16 dot-product kernel, which we designed to use the full programmability of IMAX. We first employ a lookup table (LUT) implemented within each PE to efficiently convert incoming FP16 data to an inter-nal FP32 representation in-line, thus bypassing the need for dedicated conversion hardware. To enhance throughput, we then exploit two key parallelization features of IMAX. First, we apply SIMD instructions to execute two 32-bit operations concurrently on a single 64-bit datapath, maximizing the utilization of the Fused Multiply-Add (FMA) units. Second, we use column-wise multithreading to effectively mask the arithmetic pipeline latency. This technique time-multiplexes multiple logical FMA operations on a single physical FPU. This kernel utilizes 22 arithmetic units to efficiently process a 16-element multiplication in a single operational burst.
The dataflow for the Q8_0 dot-product operation, shown in Fig. 5, serves as the architectural foundation for all our quantized kernels. The IMAX dataflow efficiently integrates multiplication, addition, and data type conversion. We accelerate the core multiply-accumulate operation using the custom instructions conceptually illustrated in Fig. 7. The OP_SML8 instruction performs a two-way SIMD signed 8-bit multiply-accumulate, independently multiplying each 8-bit segment of the input operands and summing the results into a sign-extended 24-bit output. We then use the OP_AD24 instruction, a two-way 24-bit integer addition, to aggregate these intermediate results along the pipeline. Data is pipelined across twelve PEs and accumulated as 24-bit integers before being multiplied by a single-precision 32-bit floating-point scaling factor in the final stage. This entire process is replicated four times to run in parallel across the PE array, and two such parallel executions complete the processing of a full 32-element vector segment. The Q8_0 kernel utilizes a total of 46 arithmetic units.
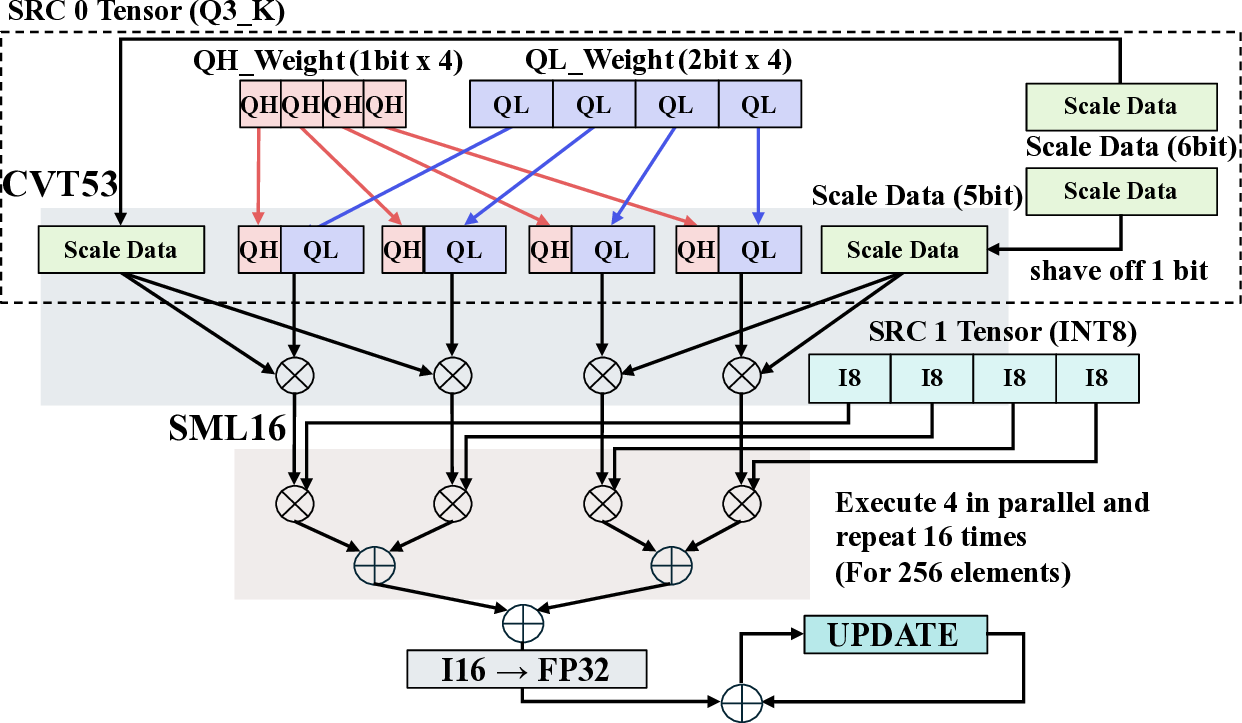
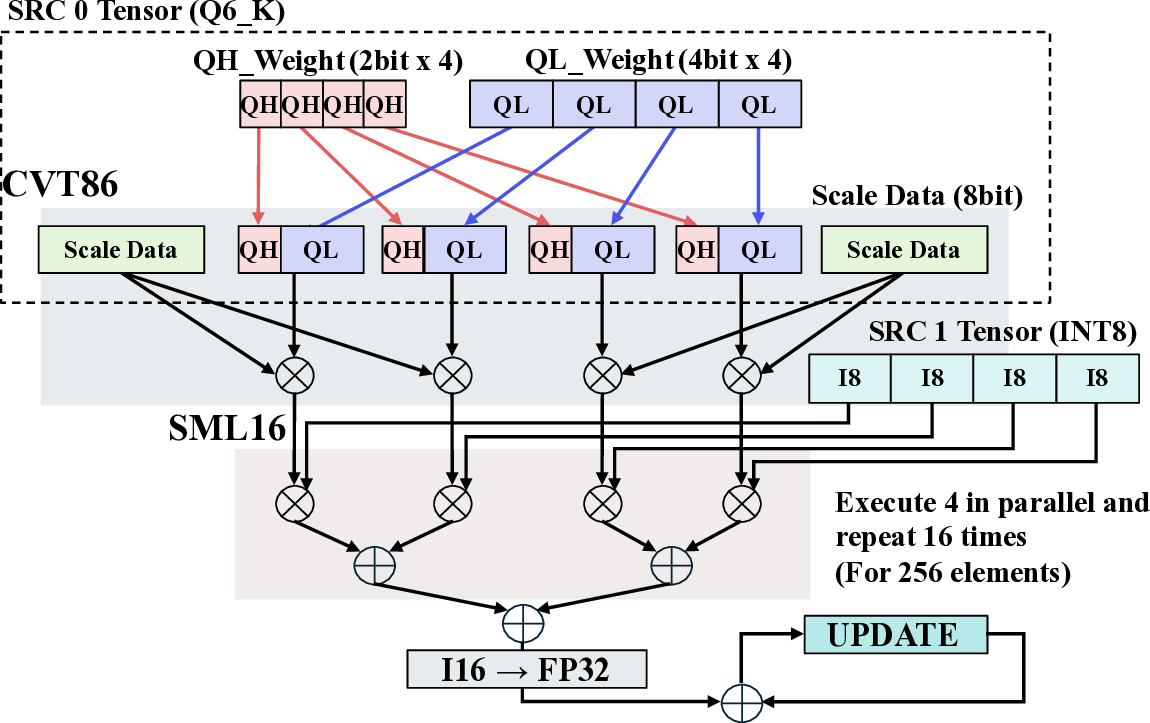
The dataflows for the Q6_K and Q3_K dot-product kernels, shown in Fig. 8 and Fig. 9, respectively, build upon this Q8_0 foundation. Although these low-bit mixed-precision kernels involve more complex data structures, they adopt a unified processing flow to maintain architectural versatility. The core strategy is to decompress and reconfigure the diverse low-bit formats into a common 8-bit integer (INT8) representation at the front-end, allowing the standardized back-end multiplyaccumulate pipeline to be reused without modification. The Q6_K kernel utilizes 64 arithmetic units. For this kernel, a custom CVT86 instruction decodes incoming 2-bit and 4-bit quantized weights and their corresponding 8-bit scales in a single cycle, producing 16-bit intermediate data. Another This kernel handles the Q3_K format, which packs 1-bit (QH) and 2-bit (QL) quantized weights. custom instruction, SML16, then performs the dot-product operation between this decoded data and the 8-bit integer inputs. This sequential execution of decompression followed by computation is a methodical approach to managing complex, packed data formats within the CGLA architecture. The Q3_K kernel, which uses 51 arithmetic units, requires even more intricate data manipulation. This format natively uses 6-bit scales with 2-bit and 1-bit quantized weights. To process this data efficiently on IMAX’s SIMD architecture, we designed a custom data reconfiguration method. A dedicated instruction, OP_CVT53, performs an approximate conversion of the 6-bit scales to 5-bit and packs the 2-bit and 1-bit segments into a unified 3-bit format. This reconfiguration enables the combination of 8-bit input data with 5-bit and 3-bit weight data, allowing us to implement a processing flow similar to that of the Q8_0 kernel. We empirically confirmed that this approximation of the scale data, which carries less information than the weights, has a negligible impact on the final computational accuracy. This front-end conversion approach allows us to achieve high performance without architectural versatility, processing 256 elements per burst by running four parallel dataflows for sixteen iterations.
Although the LMMs are configurable up to 512 KB, we selected a size of 64 KB for all evaluations in this work. We found this configuration to be a favorable compromise between power consumption and performance, as it is sufficient to accommodate the tensor sizes involved in the dotproduct operations of the Qwen3 models we evaluated. We will provide a quantitative justification for this choice in the discussion in Section V. Data transfers between the host and IMAX via DMA can become a significant performance bottleneck, particularly for large-scale models. To mitigate this, we implemented a transfer coalescing strategy to maximize DMA efficiency. A naive implementation would issue separate DMA transactions for each input tensor (e.g., activations, weights, and scaling factors), incurring substantial overhead from multiple transaction setups. Although these tensors may reside in non-contiguous memory locations, our approach aggregates them into a single, contiguous block in the host-side DMA buffer before initiating the transfer. For instance, the Q8_0 kernel requires four distinct input arrays. By arranging them contiguously, the IMAX DMA engine, which utilizes a shared address space, can load the entire data block into the LMMs with a single burst-transfer instruction. A similar coalescing strategy is applied when writing results back to the host. This method significantly improves data transfer efficiency by minimizing the overhead associated with issuing multiple DMA transactions. A preliminary evaluation of this optimization confirmed its effectiveness, accelerating the LOAD phase by a factor of 1.2 and the DRAIN phase by a factor of 4.8 compared to the naive implementation, which is a non-coalesced approach. All results reported in Section IV utilize this optimized data transfer method, demonstrating the critical importance of such low-level optimizations in memory-bound LLM workloads.
In this section, we present a comprehensive, E2E evaluation of the LLM inference performance on our IMAX accelerator. We compare the measured performance of our FPGA prototype and the projected performance of a potential 28 nm ASIC implementation against a state-of-theart high-performance GPU, a general-purpose GPU with a comparable process node, and a dedicated edge AI GPU. The primary objective of these experiments is to quantitatively evaluate the performance and energy efficiency of the IMAX architecture. This analysis focuses on the fundamental tradeoff between performance and power consumption.
We compare the performance of our IMAX accelerator against several commercial platforms. As shown in Fig. 10, we implemented the IMAX prototype on an AMD Versal Premium VPK180 evaluation kit using Vivado 2024.1. This prototype consists of an eight-lane IMAX operating at 145 MHz and uses an Arm Cortex-A72 PS as the host. Although the FPGA supports up to eight IMAX lanes, our main evaluation uses a two-lane configuration. A preliminary analysis revealed that the dual-core ARM host becomes a performance bottleneck beyond two lanes, limiting the accelerator’s utilization. This two-lane setup was therefore chosen to isolate the accelerator’s performance from the host system. The architecture’s scalability and the impact of host performance are further analyzed in Section V. To evaluate the future potential of the architecture, we projected its performance as a 28 nm ASIC. This projection is based on the established methodology from our previous work [20], where we performed a detailed static timing and power analysis using Synopsys Design Compiler [60]. The analysis utilized the TSMC 28 nm process technology, including its standard cell libraries and wireload models, and assumed 10% average switching activity for power estimation. From this analysis, we determined that a maximum operating frequency of 840 MHz is achievable, which represents an approximately 6× speedup over the FPGA implementation. For the 64 KB LMM configuration adopted in our evaluation, the power was calculated to be 2.16 W for the FP16 kernel, 4.41 W for Q8_0, 4.88 W for Q3_K, and 6.1 W for Q6_K. Our commercial comparison platforms include a modern highperformance GPU system (NVIDIA RTX 4090), a previousgeneration GPU system (NVIDIA GTX 1080 Ti), and an edge AI device (NVIDIA Jetson AGX Orin). The GTX 1080 Ti was selected to provide a comparison against a widely adopted GPU manufactured on a 16 nm process, which is closer to our 28 nm ASIC projection. Detailed hardware specifications are summarized in Table 1. The software and operating system configurations for each platform were standardized to ensure a fair comparison:
• The IMAX FPGA prototype runs a PetaLinux distribution, cross-compiled for the 64-bit ARM (aarch64) architecture. c For IMAX3 (28 nm), the power consumption is estimated and varies depending on the kernels (FP16: 2.16 W, Q8_0: 4.41 W, Q3_K: 4.88 W, Q6_K: 6.1 W), references for other devices are from Cortex-A72 [56], Jetson AGX Orin 32 GB (most high performance mode) [57], NVIDIA GTX 1080 Ti [58], NVIDIA RTX 4090 [59].
• The NVIDIA Jetson AGX Orin uses the JetPack R36.4.4 software stack.
All platforms were benchmarked using an identical version of the llama.cpp framework and the exact same quantized model files. This rigorous setup eliminates variations from the software stack and model data, allowing for a direct comparison of the underlying hardware architectures.
To establish a consistent baseline for comparing energy efficiency, our power model utilizes nominal specifications.
For the IMAX (28 nm) ASIC projection, the total power during offloaded phases is calculated based on synthesis results. Specifically, the active power is determined by multiplying the power estimated from synthesis by the number of active lanes (two in our primary evaluation). The total system power is then calculated by adding the measured idle power of the host CPU to this active power value. This model distinguishes between host-primary processing and phases where the IMAX cores are active. For the commercial GPU/CPU platforms, we model active power using their official Thermal Design Power (TDP) values applying either the host CPU’s base or peak TDP [61] depending on which component is primarily active. This approach enables us to assess the potential energy efficiency of each architecture operating within its specified maximum power budget. While TDP does not represent average power consumption, it provides a standardized metric for comparing performance under peak load conditions. The NVIDIA Jetson AGX Orin was evaluated in its nominal 60 W maximum performance mode.
We acknowledge this methodological choice as a limitation and discuss its implications in Section V.
We executed a diverse set of LLM inference workloads on these platforms. We selected three models with varying parameter counts (0.6B, 1.7B, and 8B) from the state-of-theart Qwen3 LLM family. We then combined these models with the multiple quantized kernels implemented in Section III, resulting in 54 distinct workloads to test the architecture’s versatility and robustness. For these experiments, we varied the combination of input and output tokens from [8:1] to [32:16]. This range is intended to cover various practical scenarios. For instance, short input-output pairs mimic latencysensitive Q&A in conversational AI, whereas long inputs with short outputs represent tasks such as document summarization. Combinations requiring longer outputs correspond to throughput-dependent scenarios such as code generation or lengthy text translation. All reported performance metrics (E2E latency, PDP, and EDP) are the average of 10 independent runs for each workload configuration. A fixed seed was used for all experiments to ensure reproducibility. The standard deviation for all measurements was consistently below 3% of the mean value, indicating high stability and minimal run-to-run variation.
We assess the performance of each platform using three primary metrics. The first metric is E2E latency, defined as the total time from prompt input to the generation of the first token, which indicates system responsiveness. The second is the PDP, which, as shown in (1), directly measures energy efficiency as the total energy consumed to complete a task.
The third metric is the EDP, calculated as the product of power and the square of the latency (2). The EDP offers a comprehensive view of the performance-energy trade-off.
EDP is a key metric for power-constrained systems. We note that our PDP and EDP calculations are based on the nominal TDP values. Our analysis uses TDP, which reflects peak rather than average power consumption. Therefore, the results indicate the potential energy efficiency of each architecture, not its performance in typical application scenarios.
In this subsection, we conduct an E2E performance evaluation of the IMAX architecture. We first analyze the E2E latency to assess pure processing speed, then shift our focus to energy efficiency, the primary emphasis of this work, by quantifying the PDP and EDP.
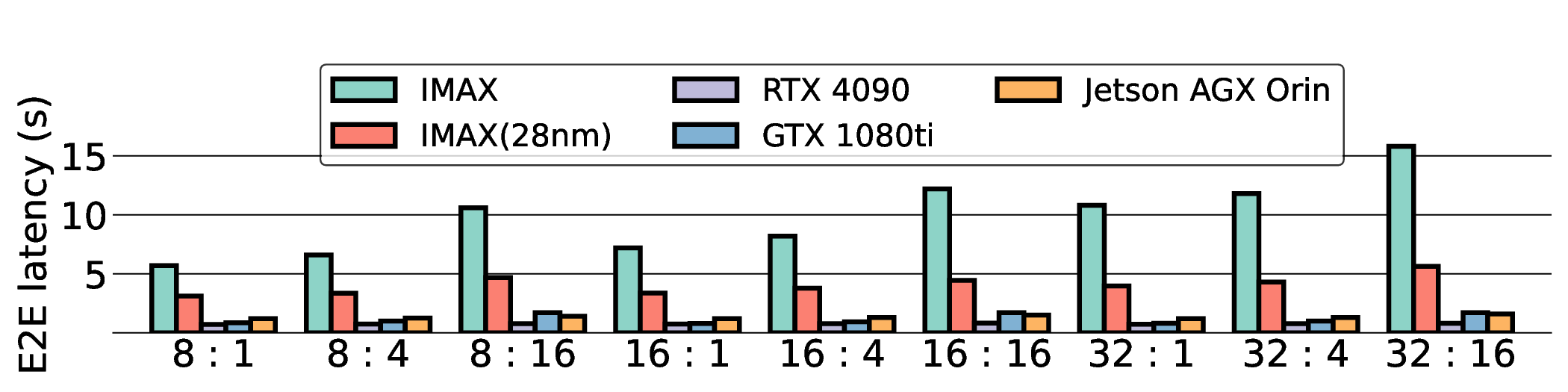
E2E latency comparison in Fig. 11 shows that data transfer has become the primary system bottleneck for our architecture. As expected, the NVIDIA RTX 4090 demonstrated the lowest latency in all scenarios due to its substantial resources. For instance, on a representative workload, the RTX 4090 achieved a latency of approximately 0.8 s, whereas our projected IMAX (28 nm) latency was 5.63 s. Critically, this performance gap scales with model size, particularly for memory-bound models such as Qwen3-8B Q8_0. This scaling behavior strongly indicates that the system’s performance is not compute-bound by the IMAX core but is instead bottlenecked by data transfer overhead.
As shown in Fig. 12 and Fig. 13, the advantages of our design become clear from the energy-centric metrics. These results indicate that the IMAX architecture, particularly the 28 nm ASIC projection, has the potential to achieve energy efficiency far superior to existing platforms. In terms of PDP, the IMAX (28 nm) projection demonstrates significant The EDP evaluation, which squares the impact of execution time, exposes the latency trade-offs of the architecture. In compute-bound workloads, the advantage of IMAX (28 nm) is particularly significant. For example, on the Qwen3-0.6B Q3_K_S [32:16] workload, IMAX (28 nm) recorded an EDP of 118.9 J s, outperforming both the RTX 4090 (216.8 J s) and the Jetson AGX Orin (153.6 J s). It maintained a substantial efficiency lead in many scenarios over high-power GPUs, outperforming the RTX 4090 by up to 11.5× and the GTX 1080 Ti by 15×. However, as workloads become more memory-bound with larger data transfers, the impact of latency becomes the primary factor. For the Qwen3-1.7B Q8_0 [32:16] workload, the shorter latency of the Jetson (1.9 s) gave it an advantage in EDP, resulting in a score of 216.6 J s that surpassed IMAX (413.6 J s) with 14.7 s latency. This result indicates the trade-off where low latency is prioritized in EDP, even though IMAX held the advantage in pure energy efficiency (PDP). This trend was most significant in the memory-bottlenecked Qwen3-8B Q8_0 model, where the EDP of IMAX (28 nm) was substantially higher than that of the other platforms. These results suggest that, under the current system configuration, the EDP advantages of the IMAX (28 nm) architecture are most apparent in computebound workloads.
While Section IV demonstrated the significant energy efficiency advantages of the CGLA-based approach, it also highlighted performance bottlenecks under specific conditions. To provide architectural insight and guide future work, this section analyzes these limitations from three perspectives: the impact of internal memory size, a granular breakdown of execution phase timings, and the inherent scalability limits imposed by the host system.
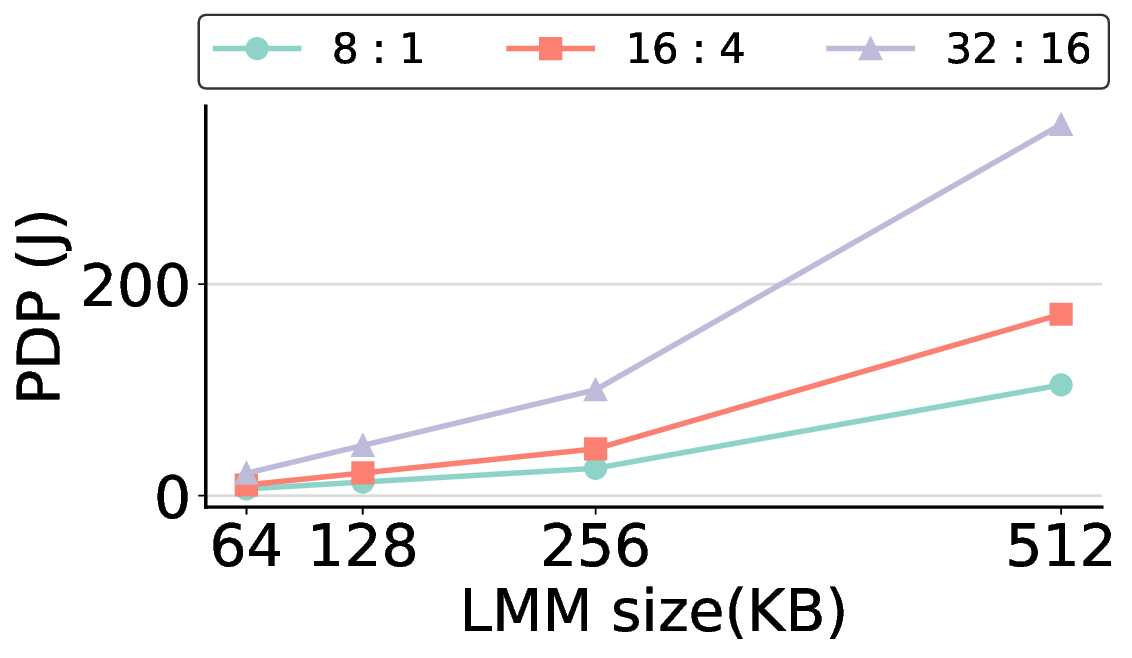
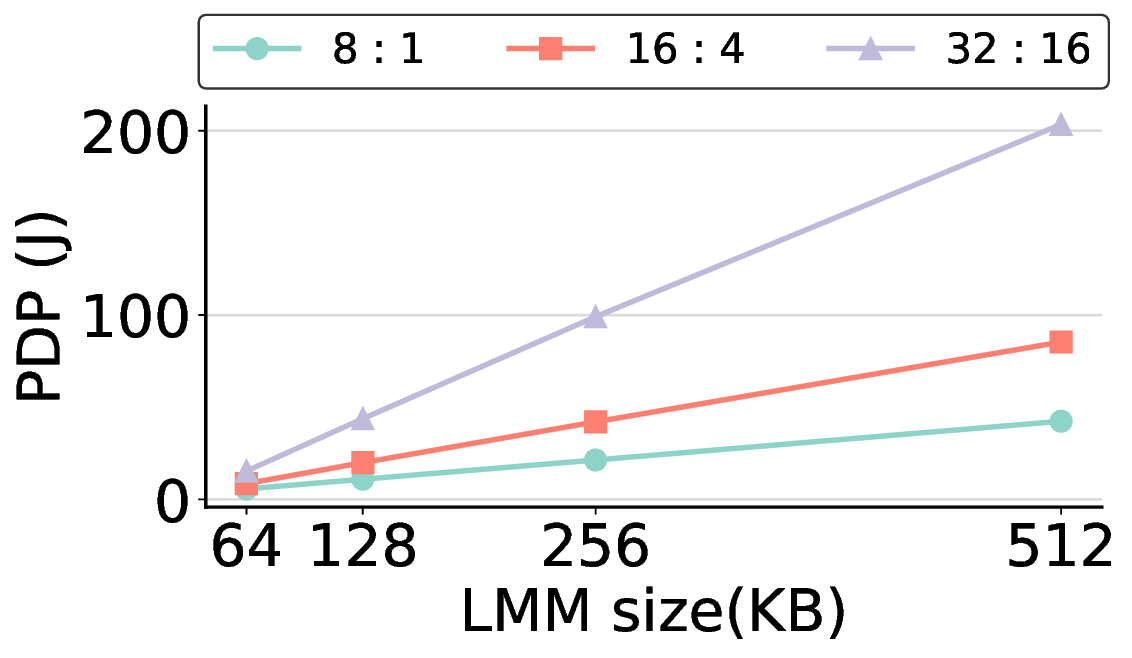
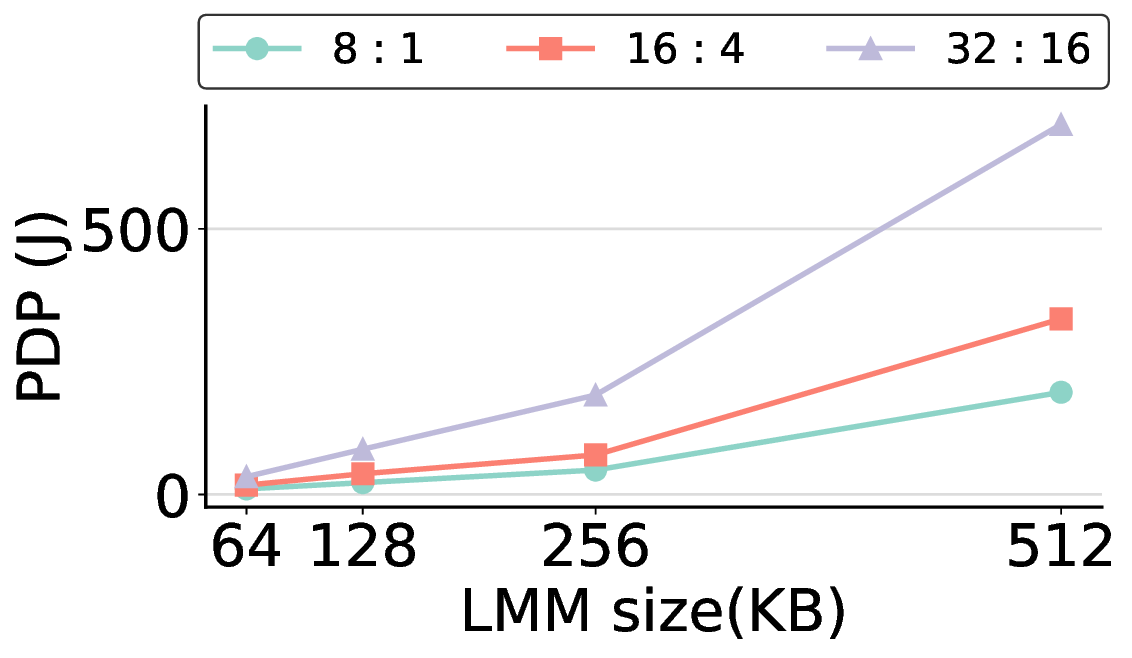
The size of the LMM in each PE is a key architectural design parameter. This choice directly impacts overall system efficiency, as the LMM capacity governs the fundamental trade-off between performance and power consumption. In this subsection, we quantitatively validate our selection of a size of 64 KB for the LMM, demonstrating that it provides a suitable balance between offload ratio and power efficiency for our target workloads.
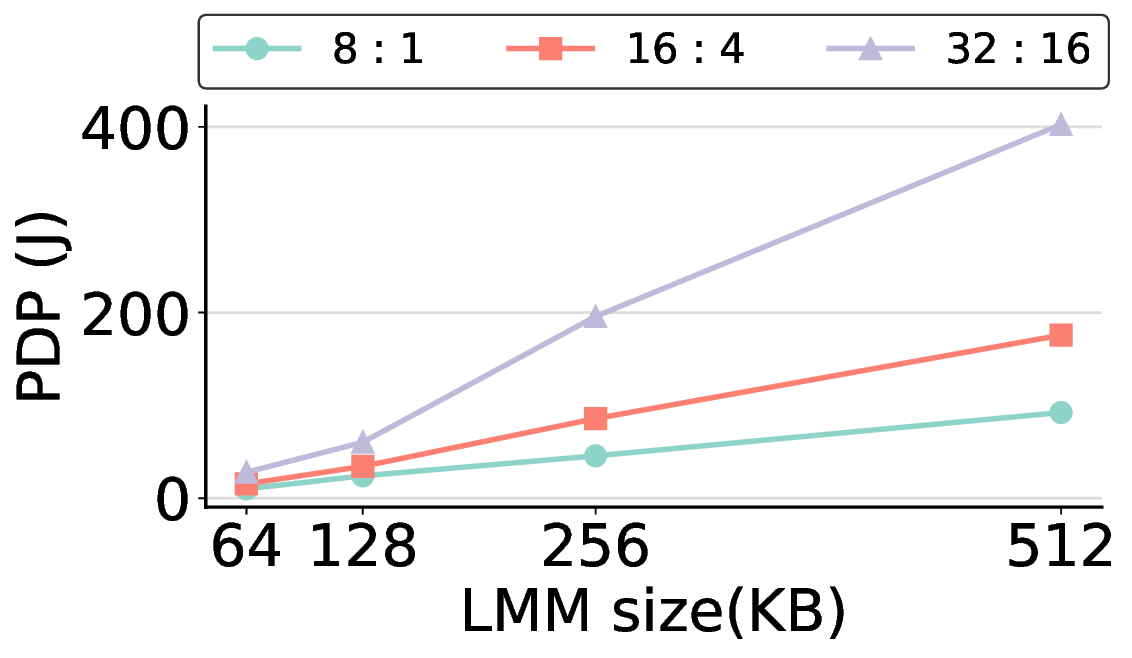
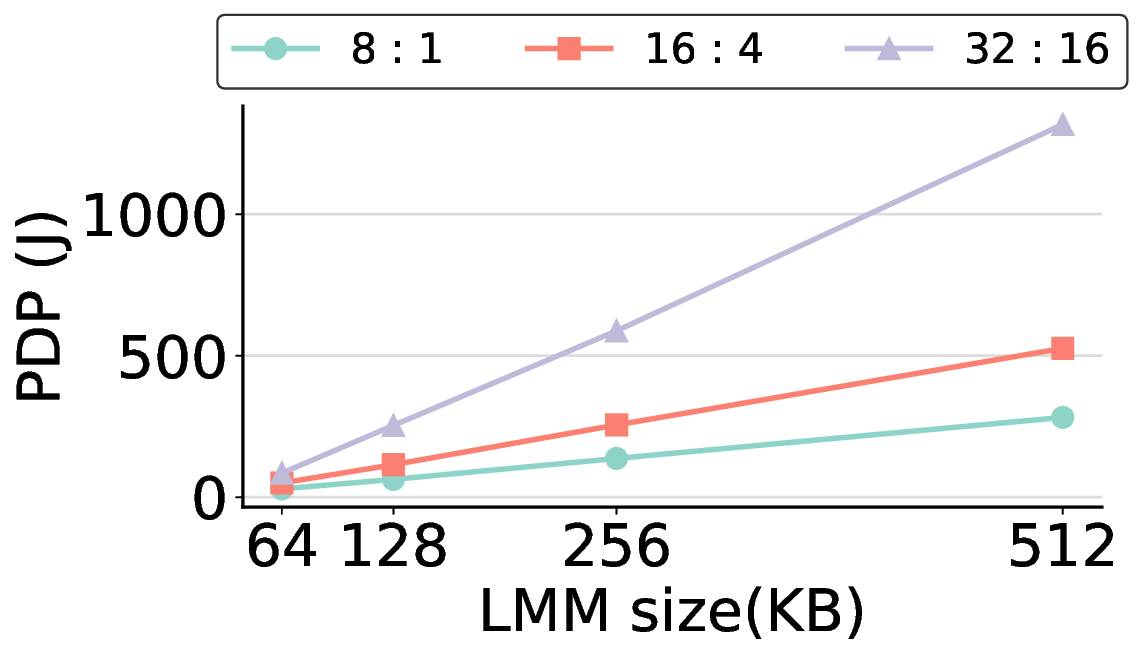
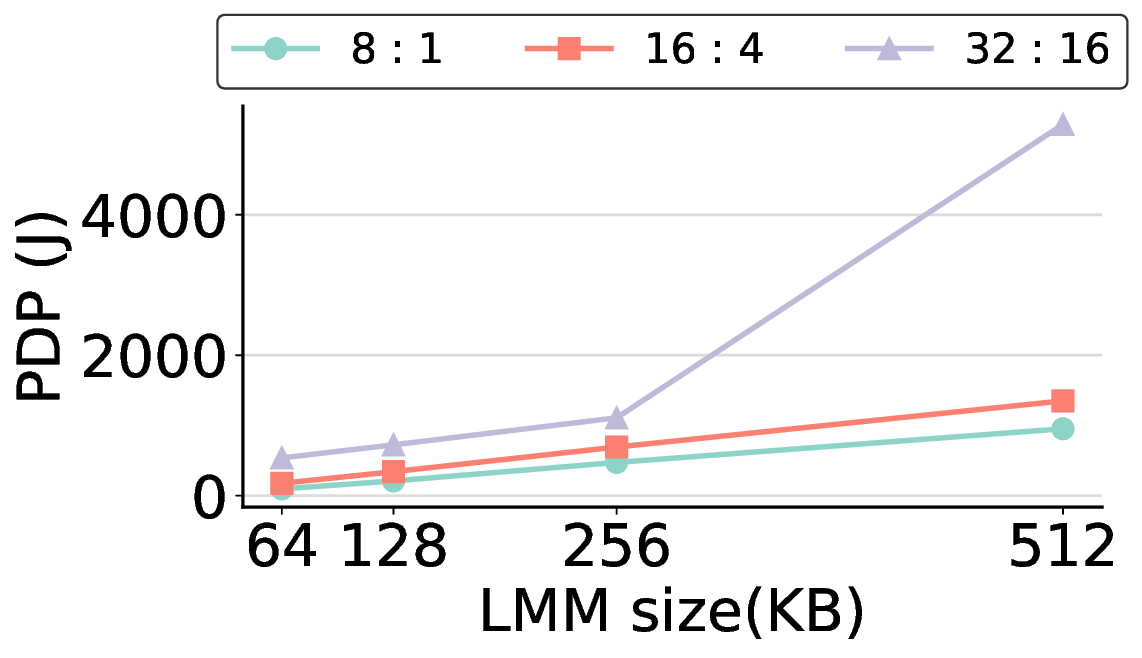
In general, increasing the LMM size allows more computational kernels to reside entirely within on-chip memory. This strategy tends to improve the offload ratio, which is the proportion of operations executed on the IMAX accelerator rather than the host CPU, thereby reducing overall processing time. However, a larger LMM also linearly increases static power consumption, meaning that it does not automatically translate to better energy efficiency. Fig. 14 clearly illustrates this trade-off. For most workloads, increasing the LMM size beyond 64 KB results in a higher PDP, as the penalty from increased power consumption outweighs the benefit of reduced execution time. The offload ratios in Table 2 explain this phenomenon. For most models, a 64 KB LMM is sufficient to achieve high offload ratios exceeding 85%, with the common FP16 kernel fitting entirely within this memory. This indicates that at 64 KB, most targeted computations are already on-chip, offering limited potential for further improvement. Consequently, the marginal performance improvement from larger LMMs fails to offset their increased power draw, leading to a degradation in PDP, making it more energy-efficient to execute it on the host. The Qwen3-8B Q8_0 model, while initially appearing to be an exception, reinforces this conclusion because the substantial size of its Q8_0 kernel leads to excessive DMA transfer latency. Note: “0%” indicates that offloading is possible but was not performed; “-” indicates that there is no computation to be offloaded for that kernel.
Consequently, offloading this kernel results in a higher PDP, as the overhead from data transfer outweighs the computational gains. The most energy-efficient strategy, therefore, is to avoid offloading this specific kernel. This is precisely the behavior that a 64 KB LMM enforces, making it an effective choice even for this challenging case.
To identify performance bottlenecks, we conducted a multilevel breakdown of the IMAX execution time. We first analyze the E2E latency from a system-level (macro) perspective, and then analyze the internal (micro) execution phases within the IMAX accelerator.
A detailed breakdown of the E2E latency for a representative workload (Qwen3-0.6B Q3_K_S with a [32:16] token I/O) reveals that system-level overheads are the dominant performance bottleneck. Out of a total latency of 16.3 s, is substantial, exceeding even the net kernel execution time (4.47 s). While a degree of host CPU overhead (33.3%) is expected in a heterogeneous system for tasks such as scheduling and data preparation, the significant latency from the DMA load points to the host-accelerator data path constitutes a definitive system-level bottleneck.
This system-level bottleneck is a direct reflection of the accelerator’s internal behavior. To understand this relationship, we now analyze the breakdown of the time spent within the offloaded tasks on IMAX. LLM inference is characterized by two distinct phases: the prefill phase, which processes the input prompt in parallel, and the decode phase, which generates tokens sequentially. As shown in Fig. 15, we categorize the The prefill phase is generally compute-bound. For most workloads, excluding the Qwen3-8B Q8_0 model, the net computation time (EXEC) accounts for over 50% of the total execution time. This indicates that the computational resources of IMAX are being utilized efficiently. However, we also observe a trend where the proportion of time spent on data transfer (LOAD) increases with the number of input tokens, a direct consequence of the larger data sizes associated with longer prompts. This suggests that even in the prefill phase, data transfer can become a significant bottleneck for large-scale models. Furthermore, we note that the proportion of time spent on result data transfer (DRAIN) is larger in the decode phase compared to the prefill phase. This difference in DRAIN ratio reflects the distinct data characteristics of each phase, specifically KV cache generation in prefill versus single token output in decode. This observation confirms that the behavior of the CGLA architecture aligns with the inherent workload duality. While our experiments cover typical interactive scenarios, the performance implications for workloads with much longer token sequences, such as large document summarization, also warrant consideration. The trends observed suggest that data transfer would become an even more significant bottleneck in such scenarios. In the prefill phase, a longer prompt linearly increases the LOAD duration, while in the decode phase, a longer context length requires loading an ever-larger KV cache. These factors can lead to memory bandwidth saturation, indicating that the increasing data transfer overhead is a critical bottleneck for scaling to very long contexts. This observation suggests that enhancing the host-accelerator interconnect will be a key consideration for improving scalability in future architectural designs.
In contrast, the decode phase exhibits a clear memorybound characteristic and is specifically LOAD-bound. This behavior stems from the algorithmic nature of the decode phase. The computational workload is relatively small, as only a single token is generated per step. However, the entire large KV cache, generated from all previous tokens, must loaded from memory in each iteration. The LOAD time is the primary component of the overall execution. Its proportional share grows with longer context lengths because of the corresponding expansion of the KV cache. Finally, a notable observation in the prefill breakdown for the Q3_K_S models is the significant proportion of register initialization overhead (REGV). This is primarily attributed to the Q6_K kernel, which utilizes all 64 PEs of the IMAX architecture and thus requires a substantial amount of register configuration. The prefill phase’s higher utilization of the Q6_K kernel results in this increased REGV overhead. These measurements were taken with IMAX’s doublebuffered LMMs actively overlapping computation and DMA transfers. That data transfer remains the dominant bottleneck, even with this hardware optimization, highlights the severity of the memory bandwidth challenge in LLM inference. While architectural overlap is essential, it is insufficient, indicating that further optimizations at both the system and algorithmic levels are required.
This work demonstrates the potential of a general-purpose CGRA for energy-efficient LLM inference, but it is equally important to discuss the limitations of our approach, which in turn define critical directions for future work.
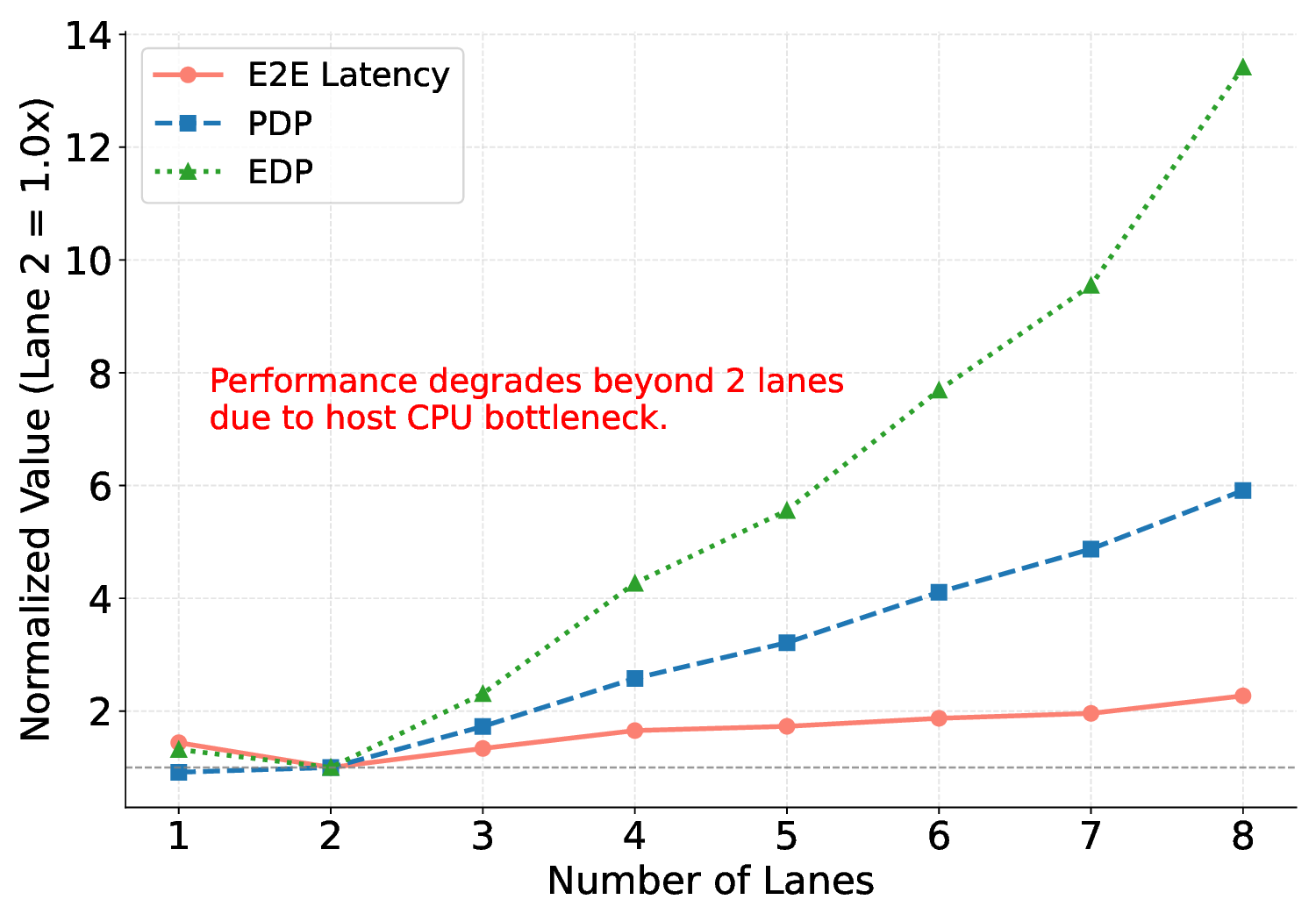
A primary limitation, as revealed by our scalability analysis, is the architecture’s dependence on the host system’s performance. As shown in Fig. 16, performance saturates and then degrades beyond a two-lane configuration. This bottleneck is not inherent to the IMAX architecture itself but is a direct consequence of the dual-core ARM host’s limited capability to manage data transfers and control flow for multiple parallel lanes. This finding highlights a fundamental challenge in heterogeneous computing, where an accelerator’s performance is often constrained by its host system. Therefore, a crucial next step is to integrate the IMAX architecture with a higher-performance host (e.g., an eight-core CPU), ideally via a high-bandwidth PCIe interconnect, to experimentally validate its true scalability potential.
Further limitations relate to the scope of our evaluation. First, the performance and power figures for the 28 nm ASIC are projections derived from synthesis tools. While based on standard industry practice, these estimates are subject to variations in the final physical implementation and manufacturing process. Second, our experiments were conducted on a specific embedded platform (AMD Versal VPK180 FPGA). System dynamics, particularly data transfer overhead, may differ significantly in other environments, such as a server with a PCIe-based interconnect. Finally, our analysis focused on the Qwen3 model family. Although our approach theoretically supports larger model sizes, the prototype’s limited DMA buffer size restricted our experiments to the current configurations. While representative, future work should extend this evaluation to models with diverse architectures, such as MoE, to ensure broader applicability.
Addressing these limitations forms a clear approach for future research. Beyond scaling the host system, optimizing the host-accelerator interface through software co-design and exploring hardware support for emerging low-bit quantization formats remain promising approaches to further enhance performance and efficiency.
In this paper, we investigated the effectiveness of the generalpurpose CGLA accelerator, IMAX, in addressing the fundamental challenge of high energy consumption in LLM inference. We presented the first implementation of the stateof-the-art Qwen3 LLM family, along with a diverse set of quantized kernels, on IMAX using the practical llama.cpp framework. We then conducted a comprehensive E2E performance evaluation based on an FPGA prototype and a projected 28 nm ASIC implementation. Although the proposed approach does not match the E2E latency of GPGPUs, the experimental results demonstrate its superior energy efficiency. The projected IMAX ASIC achieves up to a 44.4× improvement in PDP and a 11.5× improvement in EDP compared to the NVIDIA RTX 4090. These results demonstrate that a general-purpose architecture can attain high energy efficiency on modern LLM inference tasks.
The analysis of the primary bottlenecks identified in this work provides clear architectural guidance for future designs. Our findings highlight the critical need to redesign the hostaccelerator interface for data-center-scale performance and to explore co-design opportunities with emerging low-bit quantization formats. These promising approaches represent key directions for future research.
a The number of cores for IMAX3 refers to the number of PEs per lane. b 8 GB DDR4 for OS buffer and 4 GB DDR4 for DMA buffer.
VOLUME 13, 2025
VOLUME 13, 2025
VOLUME 13, 2025
VOLUME 13, 2025
VOLUME 13, 2025
VOLUME 13, 2025
VOLUME
13, 2025
VOLUME 13, 2025
VOLUME 13, 2025
📸 Image Gallery