PEOAT: Personalization-Guided Evolutionary Question Assembly for One-Shot Adaptive Testing
📝 Original Info
- Title: PEOAT: Personalization-Guided Evolutionary Question Assembly for One-Shot Adaptive Testing
- ArXiv ID: 2512.00439
- Date: 2025-11-29
- Authors: Xiaoshan Yu, Ziwei Huang, Shangshang Yang, Ziwen Wang, Haiping Ma, Xingyi Zhang
📝 Abstract
With the rapid advancement of intelligent education, Computerized Adaptive Testing (CAT) has attracted increasing attention by integrating educational psychology with deep learning technologies. Unlike traditional paper-and-pencil testing, CAT aims to efficiently and accurately assess examinee abilities by adaptively selecting the most suitable items during the assessment process. However, its real-time and sequential nature presents limitations in practical scenarios, particularly in large-scale assessments where interaction costs are high, or in sensitive domains such as psychological evaluations where minimizing noise and interference is essential. These challenges constrain the applicability of conventional CAT methods in time-sensitive or resourceconstrained environments. To this end, we first introduce a novel task called one-shot adaptive testing (OAT), which aims to select a fixed set of optimal items for each test-taker in a one-time selection. Meanwhile, we propose PEOAT, a Personalization-guided Evolutionary question assembly framework for One-shot Adaptive Testing from the perspective of combinatorial optimization. Specifically, we began by designing a personalization-aware initialization strategy that integrates differences between examinee ability and exercise difficulty, using multi-strategy sampling to construct a diverse and informative initial population. Building on this, we proposed a cognitive-enhanced evolutionary framework incorporating schema-preserving crossover and cognitively guided mutation to enable efficient exploration through informative signals. To maintain diversity without compromising fitness, we further introduced a diversity-aware environmental selection mechanism. The effectiveness of PEOAT is validated through extensive experiments on two datasets, complemented by case studies that uncovered valuable insights.📄 Full Content
Existing research on CAT (Liu et al. 2024) primarily focuses on enhancing the question selection algorithm, which are widely regarded as key determinants of assessment adaptability and effectiveness. These approaches can be broadly categorized into heuristic methods and datadriven learning methods. Heuristic approaches (Bi et al. 2020;Zhuang et al. 2023) rely on explicitly defined, interpretable rules to select items that align question characteristics with the test taker’s estimated ability. For instance, BECAT (Zhuang et al. 2023) approximates full-response gradients to guide item selection, enabling accurate ability estimation with fewer questions and offering theoretical guarantees on estimation error. In contrast, data-driven methods (Ghosh and Lan 2021;Zhuang et al. 2022) seek to improve performance by learning personalized item selection policies directly from data. A representative example is NCAT (Zhuang et al. 2022), which views CAT as a bilevel reinforcement learning problem, where an attentive policy is trained to select items by modeling learning behavior.
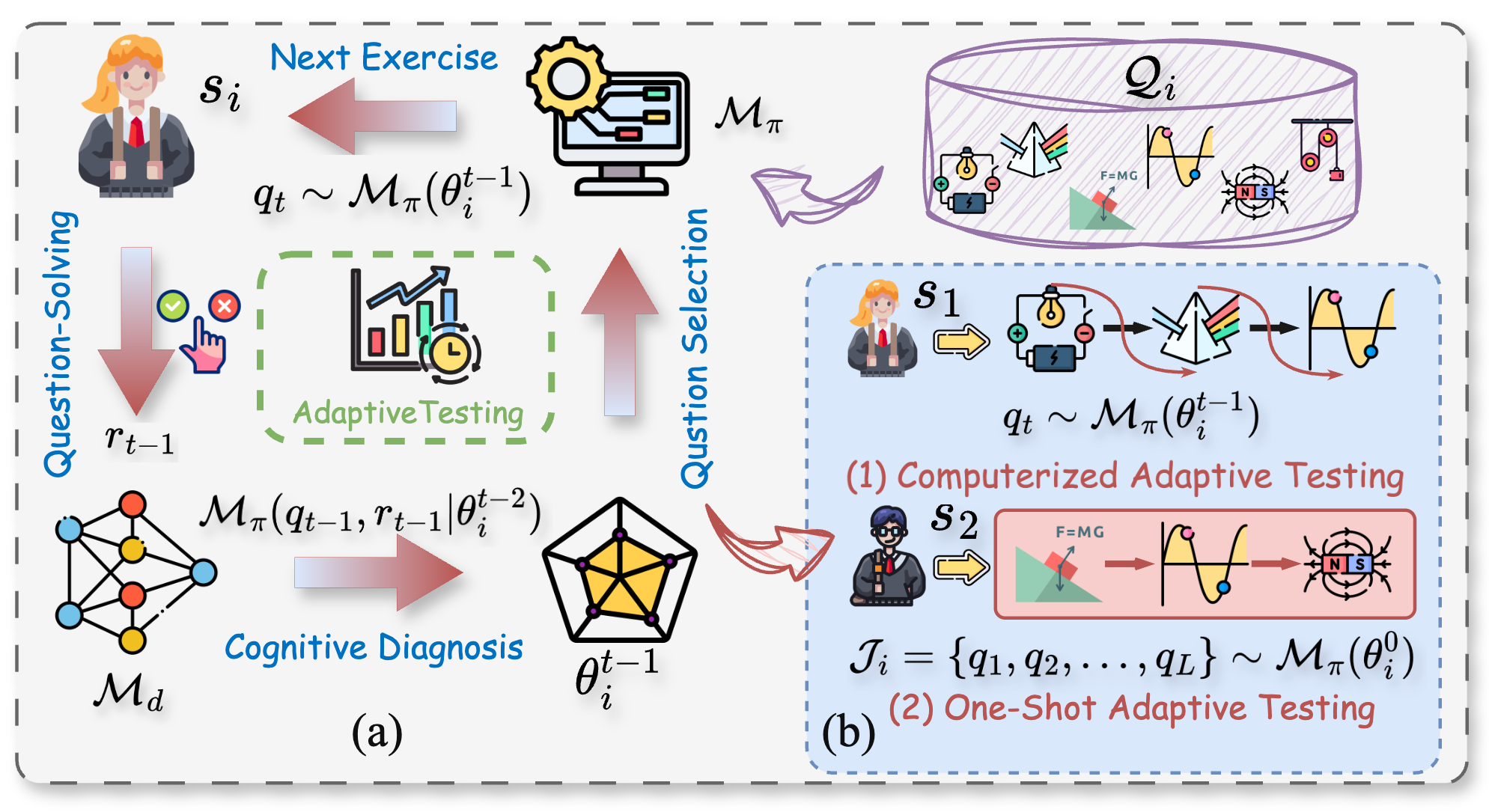
Despite existing CAT methods have demonstrated notable success, their inherent interactivity, requiring iterative item selection and ability estimation, poses significant limitations in scenarios with high interaction costs or constrained response conditions. In many real-world scenarios, such as psychological assessments (Meyer et al. 2001), post-instruction diagnostic evaluations (Holman 2000), or remote/offline testing (Haq et al. 2021), the feasibility of interactive testing is often hindered by factors such as response latency, user anxiety, or device limitations. To address this gap, this paper proposes a novel task called One-Shot Adaptive Testing (OAT), in which a fixed set of candidate items is adaptively selected beforehand and presented to the testtaker all at once, as illustrated in Figure 1(b). Considering the characteristics of this problem, we attempt to model it from a combinatorial optimization perspective.
However, this task is challenging mainly due to three issues: (1) ensuring student adaptability during optimization;
(2) searching effectively in a vast solution space; (3) mitigating encoding sparsity given a candidate pool much larger than the test length. To this end, in this paper, we propose PEOAT, a Personalization-guided Evolutionary question assembly framework for One-hot Adaptive Testing. Specifically, we first propose a personalization aware-based population initialization strategy that accounts for individual student ability differences and exercise difficulty, employing multi-strategy sampling to generate a diverse initial question population and effectively construct the initial search space. Next, we develop a cognitive-enhanced evolutionary search framework, featuring the schema-preserving uniform crossover and the cognitive information-guided mutation operators that leverage informative cues throughout population evolution for efficient exploration. Finally, we design a diversity-preserving environmental selection strategy that balances diversity maintenance with fitness during offspring selection. Extensive experiments on two realworld educational datasets validate the effectiveness of the proposed PEOAT model. Additionally, we conduct insightful case studies that reveal valuable findings.
As a core assessment paradigm in personalized education, computerized adaptive testing (CAT) (Wainer et al. 2000) originated from educational psychology and has evolved through the incorporation of deep learning techniques (Ma et al. 2024b(Ma et al. , 2025b;;Li et al. 2025). It aims to achieve accurate ability diagnosis by interactively selecting suitable exercises in response to test-taker performance. Recent advances in CAT have predominantly focused on improving item selection strategies, generally falling into two categories (Chang 2015;Liu et al. 2024;Yu et al. 2024c): heuristic methods and data-driven approaches. The former (Chang and Ying 1996;Chang 2015;Zhuang et al. 2023;Bi et al. 2020;Ma et al. 2025a;Yang, Qin, and Yu 2024) selects questions based on explicitly defined and interpretable rules, aiming to match question characteristics with the test-taker’s estimated ability. For example, Maximum Fisher Information (MFI) (Lord 2012) minimizes ability estimation variance via local item information, whereas KLI (Chang and Ying 1996) improves robustness by incorporating global Kullback-Leibler divergence. Moreover, MAAT (Bi et al. 2020) defines the informativeness of exercises based on the expected maximum change criterion from active learning. In contrast, data-driven methods (Ghosh and Lan 2021;Zhuang et al. 2022;Wang et al. 2023;Yu et al. 2024a) aim to enhance performance by learning personalized selection policies directly from learner-exercise interaction data. Representatively, NCAT (Zhuang et al. 2022) casts CAT as a bilevel reinforcement learning problem, where an attentive neural policy is trained to select items by directly modeling student behaviors (Gao et al. 2025(Gao et al. , 2024a;;Yu et al. 2024d). Although these methods have achieved notable success, they are often impractical in resource-constrained ability assessment scenarios, highlighting the need for one-shot adaptive testing, which serves as the primary motivation for this study.
Combinatorial optimization (Papadimitriou and Steiglitz 1998;Blum and Roli 2003) refers to the process of searching for an optimal object from a finite but often exponentially large solution space, and it plays a central role in various complex decision-making tasks (Yu et al. 2025b;Yang et al. 2025b;Ma et al. 2024a). When the solution space lacks closed-form structure or involves complex constraints, gradient-based methods (Lezcano Casado 2019) often fail, making heuristic strategies, particularly evolutionary algorithms (EAs), a compelling alternative (Yang et al. 2023b;Yu et al. 2024b). Over the past decades, a wide variety of evolutionary algorithms ( Črepinšek, Liu, and Mernik 2013) have been proposed and refined. Classical examples include the Genetic Algorithm (GA) (Lambora, Gupta, and Chopra 2019), which mimics natural selection through genetic operators, and Differential Evolution (DE) (Das and Suganthan 2010), which leverages vector-based mutations for continuous and combinatorial tasks. These methods have proven effective in various domains and are gaining increasing traction in education (Yang et al. 2023a;Bu et al. 2022;Sun et al. 2022;Bu et al. 2023), where they are used to tackle complex decision-making problems. For example, PEGA (Yang et al. 2023a) employs a constrained multi-objective framework with dual co-evolution to assemble personalized exercise groups (Liu et al. 2023;Yu et al. 2024b). In the cognitive diagnosis (Yang et al. 2025a;Dong, Chen, and Wu 2025), HGA-CDM (Bu et al. 2022) applies a memetic algorithm combining genetic and adaptive local search to the DINA model, mitigating its exponential computational complexity. However, how to effectively model the OAT task from an evolutionary optimization perspective remains unexplored and presents a valuable research direction.
In this section, we formally define the One-Shot Adaptive Testing (OAT) task. In an intelligent education system, let S = {s 1 , s 2 , . . . , s N } be the set of N students, Q = {q 1 , q 2 , . . . , q M } be the candidate pool of M questions, and C = {c 1 , c 2 , . . . , c K } be the set of K knowledge concepts. The mapping between questions and knowledge concepts is commonly represented by a Q-matrix, denoted as Q = {m ij } M ×K . In this matrix, an entry m ij = 1 signifies that question e i is linked to concept c j , while m ij = 0 indicates no such association. For each student s i ∈ S with historical assessment records, their interactions can be represented as
, where r ij = 1 denotes a correct response to question q j , and r ij = 0 otherwise. The complete One-Shot Adaptive Testing (OAT) system is composed of two fundamental components: (1) the cognitive diagnosis module M d that models the examinee’s knowledge proficiency by predicting the probability of correctly answering each question q (Gao et al. 2024b;Yu et al. 2025a), denoted as M d (q | θ) ∈ [0, 1]; and (2) the question selection module M π that selects a subset of L questions J ⊂ Q in a one-shot manner, based on an initial ability θ 0 . More specifically, given the initial ability estimate θ 0 i of examinee s i , the OAT selects a fixed-length question set J i = {q 1 , q 2 , . . . , q L } ∼ M π (θ 0 i ) without any intermediate feedback during the test process. After the examinee finishes all L questions and their responses r = {r i1 , r i2 , . . . , r iL } are collected, the diagnostic model M d conducts a singlestep ability update to produce the final proficiency estimate θ final i . In contrast to conventional CAT, where questions are selected sequentially as q t ∼ M π (θ t-1 i ) and ability estimates θ t i are updated iteratively after each response, OAT aims to estimate the true knowledge proficiency θi as accurately and efficiently as possible using only a single batch of adaptively selected questions, i.e., θ final i → θi .
Unlike CAT, which selects questions in a sequential and feedback-driven manner (Yu et al. 2024a), OAT poses a distinct challenge: selecting an optimal fixed-length question set in a single round without any intermediate feedback. This constraint requires the selection policy to holistically consider the test-taker’s prior ability and question characteristics to maximize the diagnostic utility of the selected items. From a modeling perspective, this task can be naturally viewed as a bi-level combinatorial optimization problem, where the outer layer selects a subset of questions, and the inner layer estimates student ability based on simulated response data. The optimization objective is to ensure that the final ability estimation is as close as possible to the student’s true proficiency. Formally, from the perspective of discrete combinatorial optimization, the OAT task for each student s i ∈ S can be characterized as follows:
where
(1)
In this section, we present the PEOAT framework in detail.
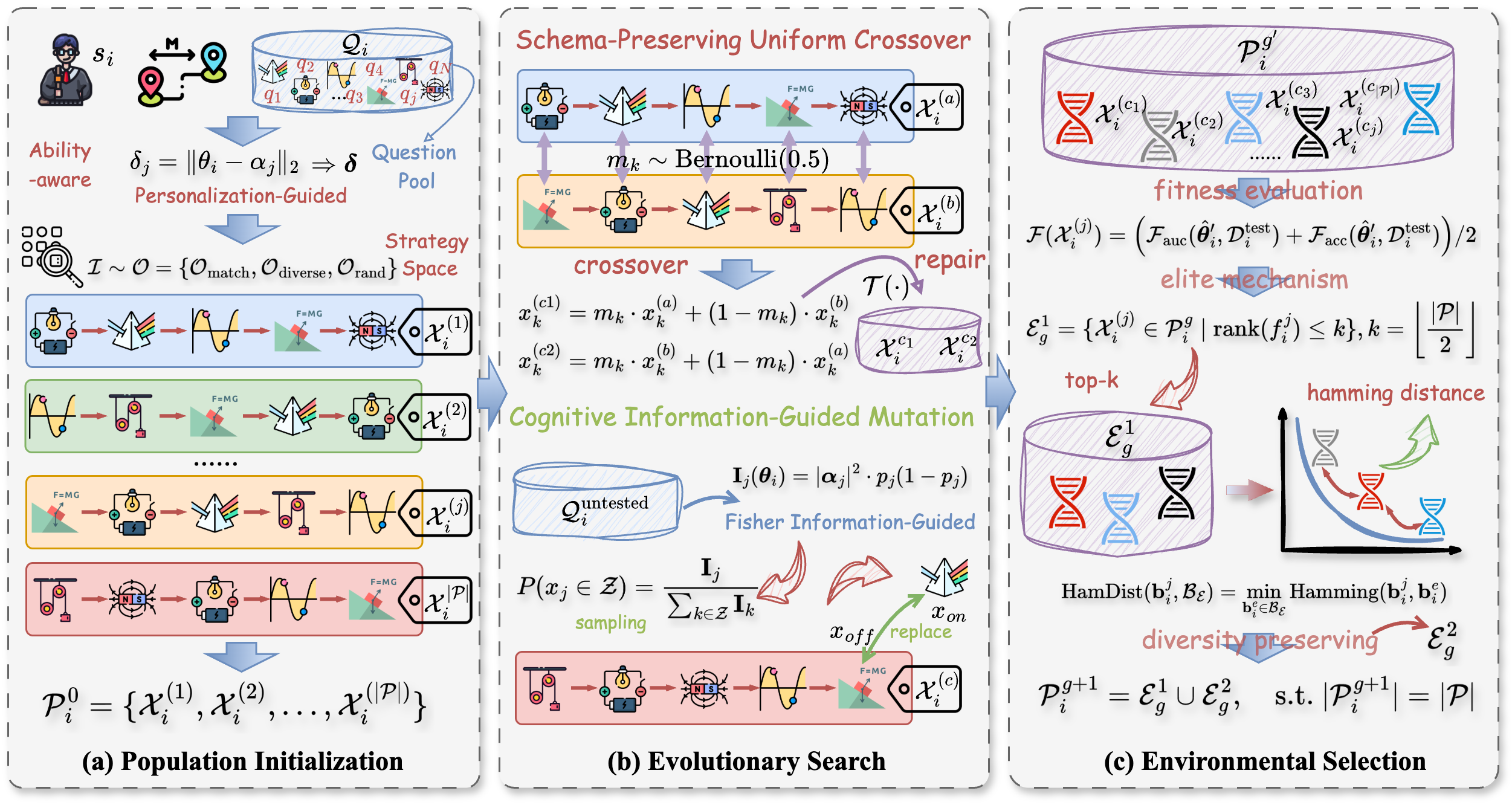
As depicted in Figure 2, the PEOAT is composed of three key components: the personalization-aware population initialization, the cognitive-enhanced evolutionary search, and the diversity-preserving environmental selection.
To effectively guide the evolutionary search in OAT, we design a personalization-aware population initialization mechanism that adaptively generates an informative and diverse initial population based on students’ personal abilities and the characteristics of the candidate exercises. As mentioned earlier, the one-shot item selection process for each student can be modeled as a population-based evolutionary optimization procedure. Accordingly, for each student s i ∈ S, every individual in the population represents a candidate test form consisting L questions, encoded as follows:
where X
(j) i denotes the j-th individual in the candidate population of student s i , and x k represents the k-th gene in the chromosome, which indexes a question from the student’s remaining question pool, i.e., x k → q k ∈ Q untested i , and Q untested i denotes the set of untested questions for student s i . We assume that all selected indices are unique-i.e., q k1 ̸ = q k2 for k 1 ̸ = k 2 -thereby satisfying the fixed-length constraint |X | = L. This subset-based encoding not only defines the structure of each individual but also serves as a retrieval mechanism for latent features (e.g., question embeddings or difficulty parameters). Compared to sparse one-hot encodings, it offers a more compact and efficient representation, particularly suited for large-scale optimization.
To embed personalized prior knowledge into the search space while effectively balancing exploitation and exploration, we propose a multi-strategy population initialization mechanism. Specifically, we define a strategy space O = {O match , O diverse , O rand }, representing three initialization strategies that select candidate exercises based on students’ initial abilities: matching, diverse, and random, respectively-each encouraging a distinct form of exploration.
For each individual, one strategy is randomly sampled from O, and the process of constructing question index geneencoded candidates can be formalized as follows:
where |I| = L, and δ ↑ i and δ ↓ i denote the ascending and descending sorted indices of δ i , respectively. The vector δ i = [δ 1 , δ 2 , . . . , δ |Qi| ] represents a personalized distance vector that quantifies the matching quality between student s i and the questions in Q i , where each δ j is computed as:
where θ i and α j represents the ability vector of student s i and the difficulty vector of question q j , respectively. Each resulting index set I i is subsequently transformed into the corresponding individual encoding, i.e., I i → X i . The final initialized population of predefined size |P| is given by:
i , . . . , X (|P|) i }.
(5)
To evolve high-quality question subsets tailored to individual examinees, we propose a cognitive-enhanced evolutionary search framework comprising two key operators: the schema-preserving uniform crossover operator and the cognitive information-guided mutation operator. Both operators maintain the fixed-length structure of individuals while being guided by the cognitive relevance signals.
Schema-Preserving Uniform Crossover Let two parent individuals be denoted as
2 , . . . , x
L ] and
L ], each representing a candidate question list. To generate two offspring X (c1) i and X (c2) i , we sample a binary mask vector m ∈ {0, 1} L with m k ∼ Bernoulli(0.5), and perform crossover as follows:
where 1 ≤ k ≤ L denotes the crossover index, and the operator preserves individual structure while enabling finegrained recombination, outperforming one-point or multipoint crossover in maintaining feasibility and diversity. To ensure that both offspring preserve uniqueness and validity (i.e., no duplicate questions and
), we apply a repair operator T (•) that resolves duplicates by replacing them with randomly sampled non-overlapping items from the untested pool. The final offspring are given by:
Cognitive Information-Guided Mutation To introduce adaptive perturbation, we propose a mutation strategy that leverages personalized item information gain. For a given individual X i = [x 1 , . . . , x L ], we randomly select a gene x off to remove, and then sample a replacement x on from the unselected pool based on an information-based distribution. Specifically, let θ i ∈ R d denote the ability vector of examinee s i , and let α j ∈ R d be the difficulty vector of item q j . According to the item response theory (IRT) (Reckase 2009), the probability that s i correctly answers q j is computed as:
denotes the sigmoid function. To quantify how informative item q j is for estimating θ i , we refer to the Fisher information matrix (Rissanen 1996), which characterizes the expected curvature of the log-likelihood with respect to θ i , and is defined as:
However, directly manipulating this matrix in the mutation operator is computationally inefficient, especially when comparing information across many candidate items. To address this, we approximate the information matrix using its Frobenius norm (Peng et al. 2018) as a scalar proxy, yielding the scalar information gain for item q j as follows:
Let Z = Q untested i \X i denote the pool of unselected candidate questions. We define a categorical sampling distribution over Z based on normalized information gain:
where the new gene x on is then sampled from this distribution to replace the removed gene x off , introducing a personalized, cognitively-informed mutation step that promotes high-information test composition. This mutation operator ensures that inserted genes are both personalized and cognitively informative, leading to more effective evolution.
To ensure robust convergence and mitigate premature stagnation, we adopt a diversity-preserving environmental selection strategy. This mechanism balances fitness-oriented exploitation with diversity-aware exploration, ultimately forming the next-generation population with both high-quality and semantically diverse candidate question lists.
For each individual X
its fitness is assessed by simulating the one-shot assessment process. Specifically, student s i first completes the selected set of questions, after which the cognitive diagnosis model M d performs a virtual parameter update to estimate the personalized knowledge ability vector, following the trajectory θ0 i update —→ θ′ i . The updated ability θ′ i is then evaluated on the reserved test set D test i , and the prediction quality is measured using a hybrid metric that combines AUC and accuracy:
where F auc (•) and F acc (•) are computed between the predicted responses (based on θ′ i and the true labels in D test i ). During this process, the model parameters are restored after evaluation to preserve consistency across candidates.
Let
} denote the population of student s i at generation g, with corresponding fitness values
We sort the individuals in descending order of fitness and retain the top-k elites as:
To preserve diversity, the remaining individuals are selected by filtering the rest of the population based on Hamming distance. Specifically, each candidate is encoded as a binary bit-string b j i = Pack(X (j)
i ) and compared against the elite pool B E via batch Hamming distance: where only those candidates satisfying HamDist > τ are admitted to the survivor set, and τ is a threshold (e.g., τ = 0.15L). This filtering is repeated until the survivor set reaches the desired size, or a maximum number of attempts is reached. The final population is formed as:
where E g i contains the diversity-preserved candidates sampled under the Hamming constraints.
Datasets. We conducted experiments on two real-world educational datasets of different scales and characteristics, JUNYI (Chang et al. 2015) and PTADisc (Hu et al. 2023), to evaluate the effectiveness of the proposed PEOAT on the one-shot adaptive testing (OAT) task. The statistical overview of both datasets is presented in Table 1.
Baseline Approaches. To demonstrate the effectiveness of the proposed model, we compare it with a comprehensive set of computerized adaptive testing approaches, including both heuristic and data-driven methods. In total, eight CAT algorithms are considered: RAND, MKLI (Chang 2015), MAAT (Bi et al. 2020), BECAT (Zhuang et al. 2023), BOB-CAT (Ghosh and Lan 2021), NCAT (Zhuang et al. 2022), GMOCAT (Wang et al. 2023), and UATS (Yu et al. 2024a).
Evaluation Metrics. The goal of the OAT task is to maximize the quality of ability assessment. Following the evaluation protocol commonly used in traditional CAT settings, we adopt two standard metrics to assess model performance: the area under the ROC curve (AUC) and accuracy (ACC).
Experimental Settings. In our experiment, we adopt MIRT (Reckase 2009) and NCD (Wang et al. 2020) as the backbone diagnosis models of the ability estimation module. During the pre-training of M d , the student and item embeddings are initialized with dimensions equal to the number of knowledge concepts. In the OAT evaluation phase, the question selection model M π adopts consistent settings, where the learning rates for MIRT and NCD updates are set to 0.02 and 0.005, respectively, with 5 * √
L epochs. The one-shot selection lengths L are set {5, 10, 15, 20}. We used a population size of 20, 15 evolutionary generations, a crossover rate of 0.8, a mutation rate of 0.2, and search the distance threshold τ in {0.5, 0.75, 1, 1.25, 1.5}. All models are Xavierinitialized and optimized using Adam in PyTorch, with experiments conducted on two NVIDIA RTX 4090 GPUs. Bold highlights the best performance (statistically significant at p < 0.05), and underline marks the second-best performance.
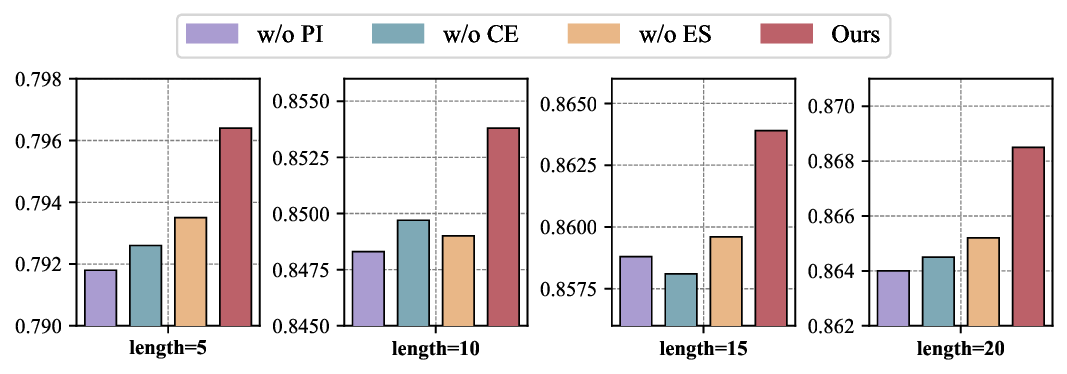
We conducted a comprehensive ablation study to investigate the contribution of each module in the PEOAT framework by defining the following variants: 1) w/o PI: removing the personalization-aware population initialization and replacing it with random initialization only; 2) w/o CE: removing the cognitive-enhanced evolutionary search strategy and replacing it with basic crossover and mutation operations; 3) w/o ES: removing the diversity-preserving environmental selection. To conserve space, we provide the accuracy results of MIRT as a basic dianosis model on the JUNYI dataset. As illustrated in Figure 3, the results reveal insightful observations: (1) Compared to PEOAT, all variants exhibit relative performance degradation, highlighting the contribution of the designed sub-modules to our proposed model. (2) The most significant performance drop occurs when the population initialization strategy is removed, indicating that the incorporation of personalized information substantially enhances the quality of the initial population.
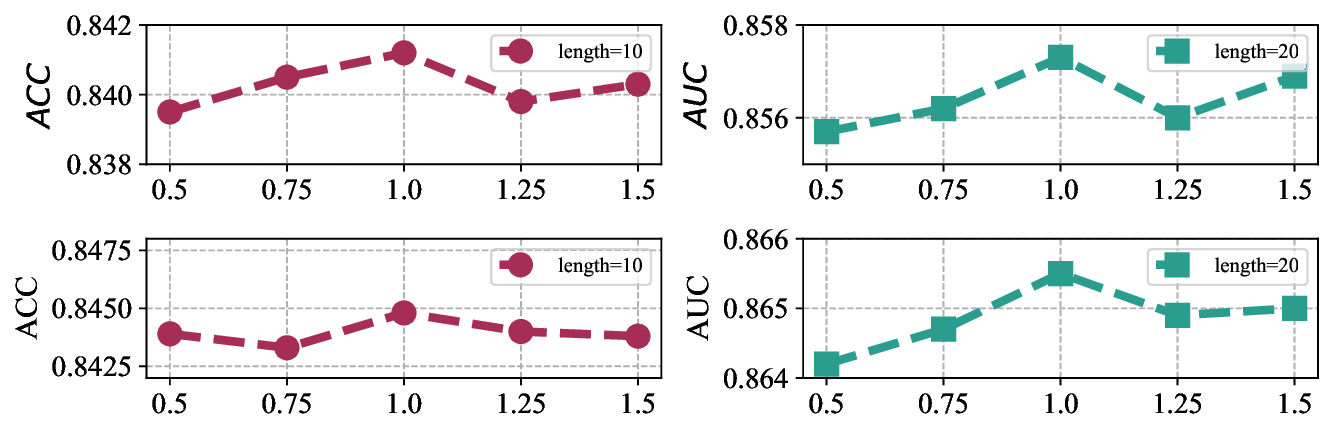
In this section, we conducted a parameter sensitivity analysis to examine the impact of key hyper-parameters, with a primary focus on the distance threshold τ used in the diversitypreserving environmental selection. Specifically, we set τ to {0.5, 0.75, 1.0, 1.25, 1.5}, and primarily report the experimental results on the JUNYI dataset. As shown in Figure 4, the model achieves its best performance when τ is set to 1.0, under testing lengths of 10 and 20. Notably, as the threshold varies, the model’s performance does not exhibit a strictly consistent pattern or a clear linear trend. Nevertheless, the overall tendency roughly follows an initial increase followed by a decrease, which may be impacted by the testing length.
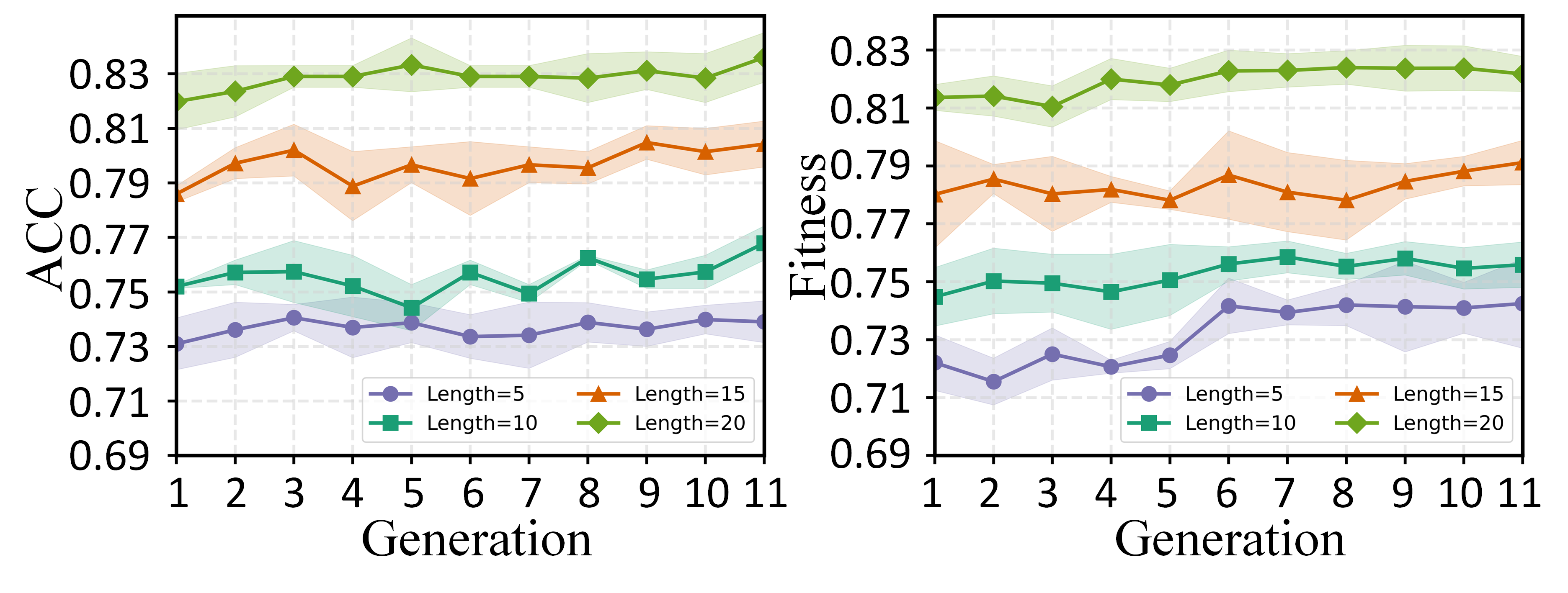
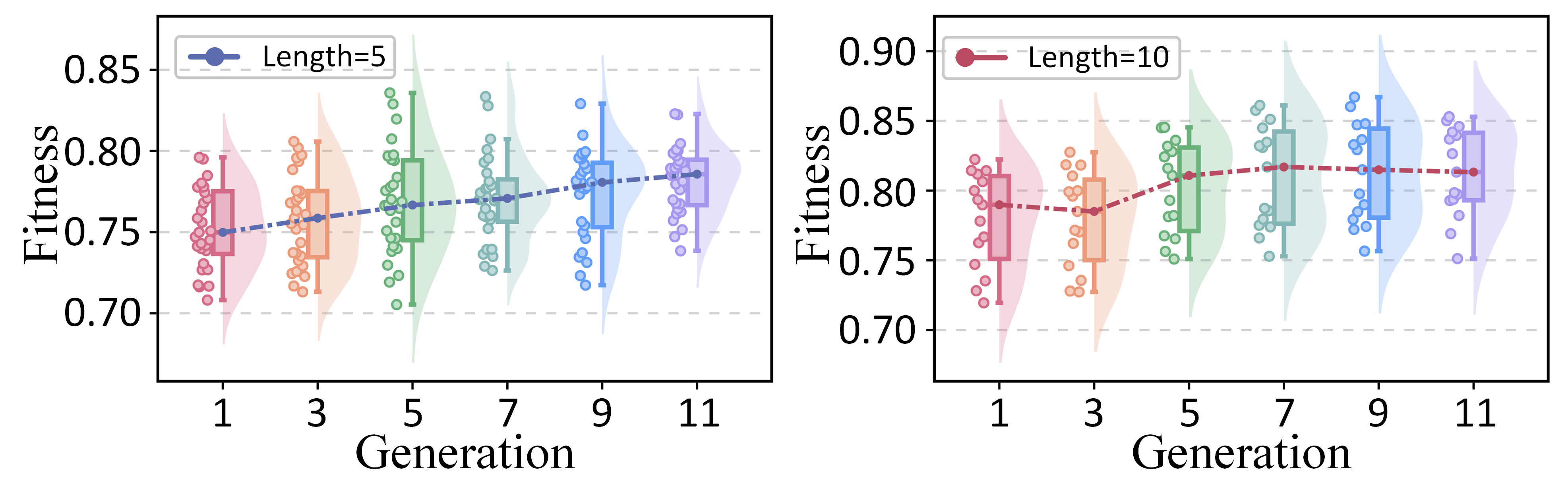
To further investigate the evolution of question populations and the convergence of search strategies in PEOAT’s question selection, we conduct two case studies in this section. Specifically, 20 students with similar ability levels from the JUNYI dataset are selected, and their ability estimation performance (accuracy and fitness) is tracked during population evolution under varying test lengths, using MIRT as the base model. Figure 5 presents the performance evolution with error bands under two metrics. It can be observed that the assessment performance of individual students improves significantly as the population evolves across different test lengths, particularly in terms of fitness, highlighting the effectiveness of PEOA in evolutionary search. Meanwhile, we also sampled two student groups and visualized the evolution of their overall assessment performance us- ing cloud-rain plots. As shown in Figure 6, both groups exhibit an upward performance trend under test lengths of 5 and 10, gradually converging as the number of generations increases. This indicates that student performance not only improved but also became more consistent over time.
In this paper, we first proposed a novel task called One-Shot Adaptive Testing (OAT). This task posed three major challenges: ensuring student adaptability during optimization, effectively searching an enormous solution space, and alleviating encoding sparsity due to a candidate pool far exceeding test length. To address these, we introduced PEOAT, a Personalization-guided Evolutionary question assembly framework for One-shot Adaptive Testing. We first designed a personalization-aware population initialization method that incorporated individual ability and exercise difficulty, using multi-strategy sampling to build a diverse and effective initial search space. Then, we developed a cognitive-enhanced evolutionary search incorporating schema-preserving crossover and cognitive informationguided mutation operators to enable efficient exploration. Finally, a diversity-preserving environmental selection strategy was implemented to maintain population diversity while considering fitness. Extensive experiments on two real educational datasets demonstrated the model’s effectiveness, and additional case studies provided valuable insights.
📸 Image Gallery