LegalWebAgent: Empowering Access to Justice via LLM-Based Web Agents
Reading time: 17 minute
...
📝 Original Info
Title: LegalWebAgent: Empowering Access to Justice via LLM-Based Web Agents
ArXiv ID: 2512.04105
Date: 2025-11-28
Authors: Jinzhe Tan, Karim Benyekhlef
📝 Abstract
Access to justice remains a global challenge, with many citizens still finding it difficult to seek help from the justice system when facing legal issues. Although the internet provides abundant legal information and services, navigating complex websites, understanding legal terminology, and filling out procedural forms continue to pose barriers to accessing justice. This paper introduces the LegalWebAgent framework that employs a web agent powered by multimodal large language models to bridge the gap in access to justice for ordinary citizens. The framework combines the natural language understanding capabilities of large language models with multimodal perception, enabling a complete process from user query to concrete action. It operates in three stages: the Ask Module understands user needs through natural language processing; the Browse Module autonomously navigates webpages, interacts with page elements (including forms and calendars), and extracts information from HTML structures and webpage screenshots; the Act Module synthesizes information for users or performs direct actions like form completion and schedule booking. To evaluate its effectiveness, we designed a benchmark test covering 15 real-world tasks, simulating typical legal service processes relevant to Québec civil law users, from problem identification to procedural operations. Evaluation results show LegalWebAgent achieved a peak success rate of 86.7%, with an average of 84.4% across all tested models, demonstrating high autonomy in complex real-world scenarios.
📄 Full Content
The significant gap between the public's legal needs and their ability to find legal information and solutions has created a "justice gap" in countries worldwide [1]. For ordinary citizens, the cost of hiring a lawyer is prohibitively expensive [2], forcing them to spend a great deal of time navigating a maze of government websites, legal statutes, and procedural forms on their own. Even so, they often find it difficult to search using correct legal terminology, locate relevant information on cluttered websites, or make critical errors when filling out online forms.
Existing legal tech tools, such as static frequently asked questions (FAQ) portals and simple ruledriven chatbots, seek to address this issue. They typically provide information in plain language 1 , or offer simplified legal pathways and relevant cases [3,4] to help reduce the user’s cognitive load. However, as the legal domains covered by these websites and the volume of information they contain increase, the cognitive burden on users increases correspondingly. Furthermore, these tools still lack the ability to interact with the broader web ecosystem or perform actions on behalf of the user. This means that the most difficult and error-prone practical “operational” steps, such as submitting forms or scheduling appointments, are still left to the user.
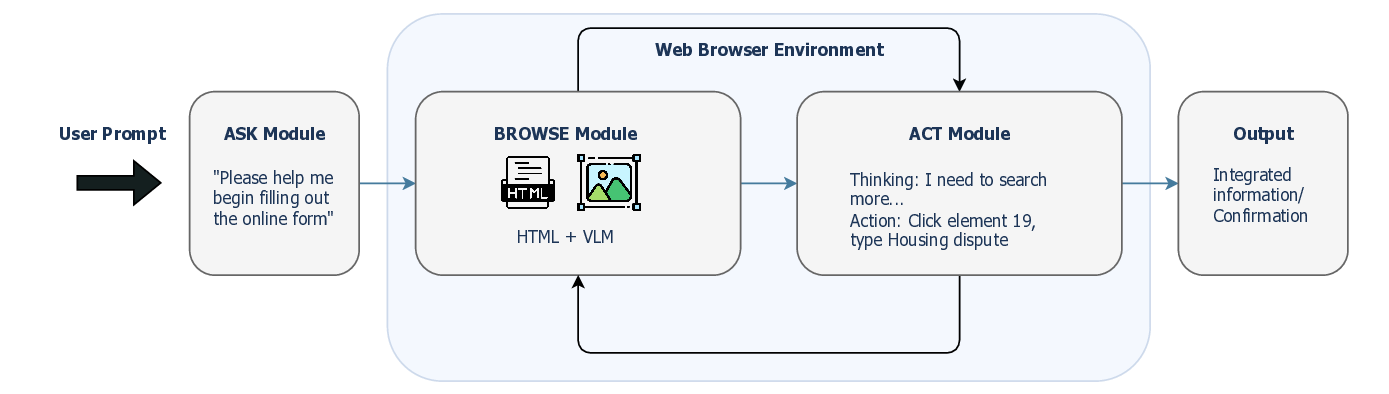
The recent development in the field of multimodal large language models (MLLMs) has advanced the role of AI in building a general-purpose tool to enhance access to justice. The improved reasoning capabilities of LLMs have made it possible to build autonomous agents [5,6]. GPT-4o-vision and more advanced LLMs demonstrate strong capabilities in natural language understanding and generation. Moreover, their multimodal understanding abilities allow for the simultaneous processing of inputs other than text, such as images [7], making it feasible to build web agents that can comprehend both the text and visual elements of webpages [8]. In this study, we introduce the LegalWebAgent (see Figure 1) framework, a multimodal web agent designed to autonomously create plans based on a user’s query to perform tasks such as web browsing, information gathering, and web interaction.
In the following sections, we review related work (Section 2), introduce the LegalWebAgent framework (Section 3), outline our experiment design (Section 4), and present results (Section 5). We then discuss key insights and current limitations (Section 6), and conclude. Given a user’s query, LegalWebAgent formulates a plan, analyzes the webpage’s HTML elements and screenshots, and determines the appropriate actions (such as clicks, scrolls, or inputs). After gathering the necessary information or completing the requested task, it generates a concise summary of the process and presents the results to the user.
The access to justice gap is a global issue that not only incurs monetary, temporal, and psychological costs [9,10,11,12,13] but also erodes public confidence in the justice system. AI technology has been widely applied to bridge this gap [14], with efforts ranging from providing legal information [15,16] and assisting with form completion [17,18] to online dispute resolution [19,20,21]. In addition to these primarily text-focused efforts, Vision-Large Language Models (VLLMs) have also undergone preliminary exploration in the legal domain in recent years [22]. Researchers have also explored integrating AI with information portals to help users map natural language descriptions to relevant legal issues [16,23]. However, these systems are often built for specific contexts and thus lack generalizability. Furthermore, they are largely passive, requiring users to independently read, comprehend, and act upon the information provided.
The internet has long been one of the primary channels for users to obtain information. It can be viewed as a continuously updated real-time database. In the legal field, modifications to legal information, promulgation of new laws, and introduction of new cases are all published on the internet in a very timely manner. When needed, people can readily find the information they require online. Furthermore, tasks such as booking meetings, filling out online forms, and completing online questionnaires offer users the possibility of handling tasks remotely, saving them valuable time.
In practice, however, this process is far from straightforward: (1) users may encounter websites containing outdated or misleading information; (2) retrieving legal information often requires extensive cross-verification and synthesizing information from numerous web pages; (3) users may be unaware of the existence of certain authoritative resources; and (4) human cognitive limitations, along with states such as distraction and fatigue, can significantly hinder users’ ability to navigate the web effectively [24].
The internet is designed for humans, enabling them to interact with the digital world through operations such as clicking, scrolling, and typing [25]. Creating web agents capable of simulating these operations is expected to significantly help reduce the sense of disorientation and inefficiency experienced during the aforementioned web browsing process.
Such web agents or web automation have been extensively explored for decades. Early research typically relied on structured data sources or site-specific wrappers to perform tasks such as flight booking or information scraping [26,27,28]. These methods required significant manual configuration for each website and were highly brittle, often breaking when sites changed [29,30].
With the development of deep learning and reinforcement learning, more generalized web agents have become possible. Depending on the architecture, they range from agents trained purely on HTML files [31,32,33], to models that combine HTML and visual screenshots [34,35], and even to agents that rely solely on visual input from screenshots [36]. These modern web agents are capable of helping users interact with real-world websites and perform everyday tasks [37].
LegalWebAgent is composed of three modules (Ask Module / Browse Module / Act Module) and works in concert with a web browsing environment. LegalWebAgent builds on top of the open-source Browse-Use framework [38], the core of which is Playwright [39], which enables reliable and fast web automation by providing a unified API for Chromium, Firefox, and WebKit. When a user command is received, LegalWebAgent launches a Chromium browser and then provides context to the LLM by collecting the webpage’s HTML elements and a screenshot (see Figure 2). Based on the current state, LegalWebAgent analyzes the completion status of the previous objective, updates its memory, and formulates the next objective. According to the objective, LegalWebAgent proposes an action to be executed and performs the operation within the browser environment.
When the user provides a prompt (e.g., “Find the rental dispute department closest to H3A0G4. “), the Ask module performs the following steps: (1) It uses an LLM to parse the user’s intent. In this example, the module may recognize that the user needs legal information on landlord-tenant disputes in Québec, as well as the address and phone number of the relevant tribunal. (2) Based on the parsed intent, the Ask module generates a web navigation plan. For instance, the plan might be:
Search for rental dispute resolution services; 2. The user’s postal code is H3A0G4, focus the search on Montreal.
The Browse module receives the current state of the webpage at each execution step and decides the next action to take. Because modern webpages often contain a large number of elements and complex layouts, we adopt a multimodal perception mechanism to improve the robustness of the Browse module.
HTML Analysis. The module parses the HTML Document Object Model (DOM) of the page, identifies candidate interactive elements (e.g., links,
Visual Analysis. At the same time, the tagged page screenshot is passed to a VLLM. Since relying solely on DOM information can be misleading or incomplete (for instance, menus that appear only on hover), the visual input helps the LLM better handle different types of web pages.
After extracting webpage information, the Browse module must choose an action from a predefined action library. We define a set of primitive actions inspired by human browser interactions: click(element), input(text, field), scroll(direction), wait(seconds), etc.
The Act module executes the actions provided by the Browse module in a real browser environment. If the action involves a click or text input, it performs the corresponding operation on the page and then returns control, along with the updated page state, back to the Browse module. This loop continues until either the predefined goal is achieved or the maximum number of execution steps is reached.
If the user requests an explanation or information, once the browsing stage has collected the relevant text, the Act module calls the LLM to generate a concise and user-friendly answer.
If the task objective involves performing an operation, the Act module verifies the completion of each sub-operation (e.g., filling in forms, uploading files, booking an appointment) and proceeds until the final submission. Upon completion, it outputs a confirmation message to the user (see Figure 3), such as: Form submitted successfully. Your confirmation number is 123-456.
To evaluate the performance of LegalWebAgent on legal web tasks, we designed a preliminary benchmark suite comprising 15 tasks (described in Table 1). These tasks were selected from the domain of Québec Civil Law and are designed to simulate real user queries or goals. The tasks are structured around three key stages of an ordinary citizen’s legal journey:
Information Gathering. In this stage, the user is just starting to understand their legal problem. The tasks involve obtaining basic explanations of legal rights or concepts. For example, the user inquires
Step 1 Goal: Click on the “Submit Online Form” button. Action: Click element by index: 6
Step 2 Goal: Select the ‘Housing Rights’ form to proceed with the application. Action: Click element by index: 6
Step 3 Goal: Begin filling out the form by entering the first name ‘Jack’ and last name ‘Soul’. Step 5 Goal: Select ‘Repairs/Maintenance’ as the housing issue type for the form. Action: Click element by index: 21
Step 6 Goal: Select the urgency level for the housing issue. Action: Click element by index: 1
Step 7 Goal: Check if any fields remain unfilled.
Action: Scroll down by: 50 pixels
Step 8 Goal: Fill in the financial information, agree to the terms, and submit the form. Action: Click element by index: 18 about “my landlord raised the rent without prior notice, saying I have to move out next month if I don’t pay the new rent. Can he do that?” This type of query primarily involves information retrieval and comprehension. LegalWebAgent must locate authoritative sources (such as government websites or legal information platforms) to find relevant resources and explain them to users in plain English.
Resource Finding. In this stage, the user is already aware of their general problem and is seeking specific resources or contact information. Task S2-LSA-01 asks, “Where is the nearest rental dispute office to my postal code H3A0G4?” This requires not only finding information about rental dispute offices but also locating the nearest one based on the user’s location in Québec. Task S2-CS-01 is, “Search CanLii for a judgment date between August 19, 2023, and August 31, 2023, and a judgment length of exactly 23 pages. " This task tests the agent’s database retrieval capabilities. These tasks involve complex, multi-page information retrieval but do not include form submission.
Action Taking. This stage contains the most complex, multi-step tasks, requiring the agent to perform concrete actions on web pages. Task S3-OFC-01 is, “Fill out the online form on legal-agent-sandbox.” This simulates the scenario of a user submitting a claim or application through an official court web form. The agent must navigate a multi-page form interface, input predefined user information, interact with complex components (such as a calendar), and finally submit the application. These tasks significantly challenge the agent’s autonomous navigation and form-handling capabilities, especially when dealing with dynamic elements such as date pickers or multi-step processes.
All tasks were executed on live or staged websites. For the first two stages, we require the agent to interact with actual public websites. For the third stage, which involves web form filling and online appointment scheduling, we built a legal-agent-sandbox2 to avoid wasting public resources. This sandbox is deployed on a public domain and mimics the design of real websites, allowing us to test the agent’s action-taking capabilities in a controlled environment.
Given the high intelligence requirements of the web agent applications, we selected and evaluated three leading large language models: two vision-language models and one text-only model (to assess performance in an HTML-based plain-text context). We include one text-only model to measure how much performance depends on visual perception. Specifically, we tested OpenAI’s GPT-4o, Anthropic’s Claude-Sonnet-4-20250514, and DeepSeek’s DeepSeek-v3.1.
In the experiment, each model was given the same prompt and run at a temperature of 0.6. Once the prompt was sent to the model, no further intervention was made. After task completion, we scored whether the task was successful. A task was marked as successful if the model correctly fulfilled the request (e.g., providing accurate legal information, finding the correct institutions and locations, or submitting a form as instructed). It was marked as a failure if the model provided incorrect information, failed to retrieve useful information, or was unable to complete the required web interactions. We recorded the success/failure status, the number of reasoning/interaction steps, the time to completion, and the tokens consumed for each model on every task. User needs to identify the correct government department for a rental dispute and find the location and phone number of the nearest office based on their postal code. Legal Aid
User is looking for free or low-cost community legal services specializing in family law near downtown Montreal.
Form Completion 1 User requests assistance in filling out an online legal application form with their personal details (name, address) and case description (landlord-tenant issue). Appointment Booking 2 User instructs the system to schedule a legal consultation for them on a specific website for a given date.
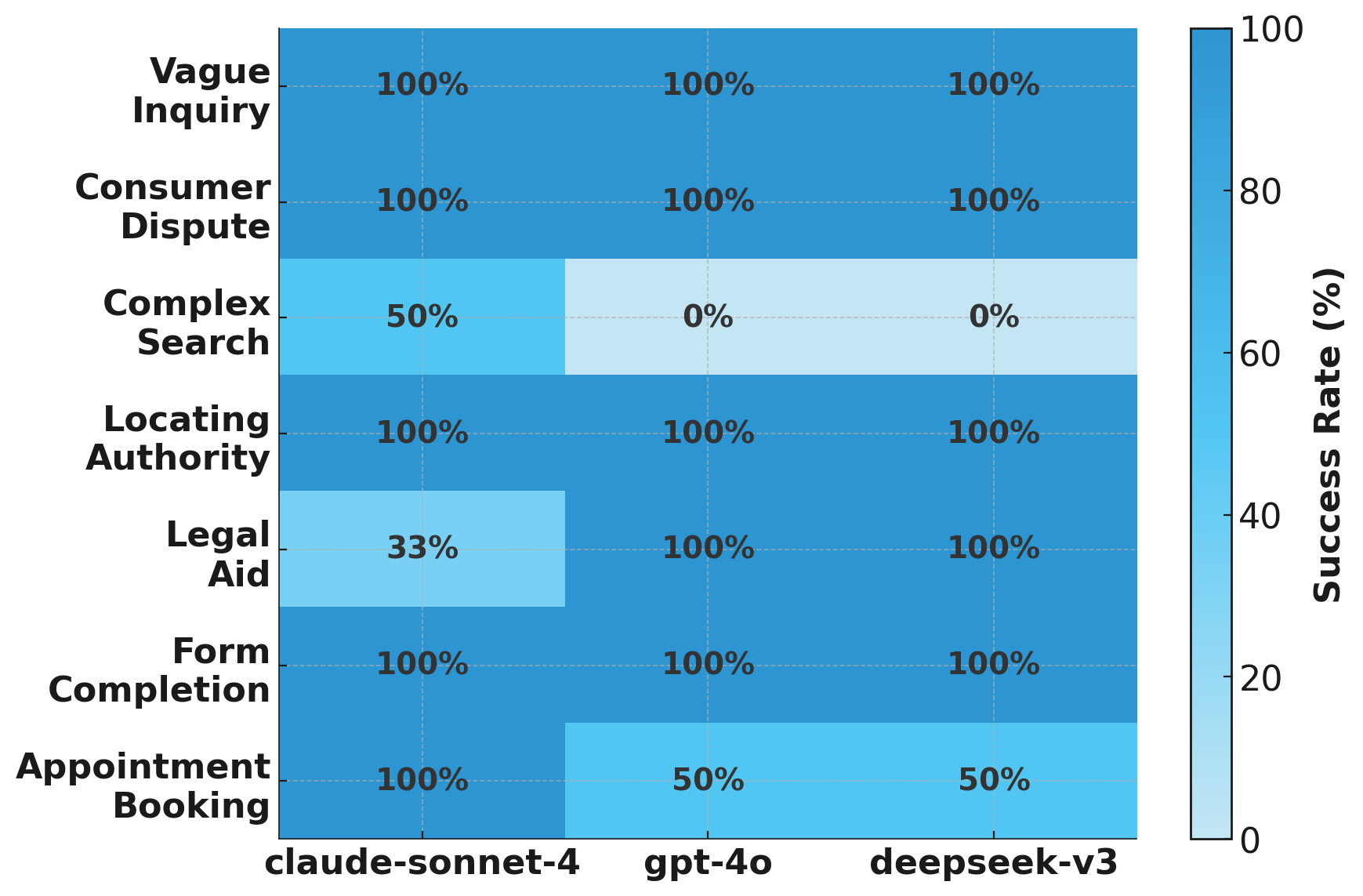
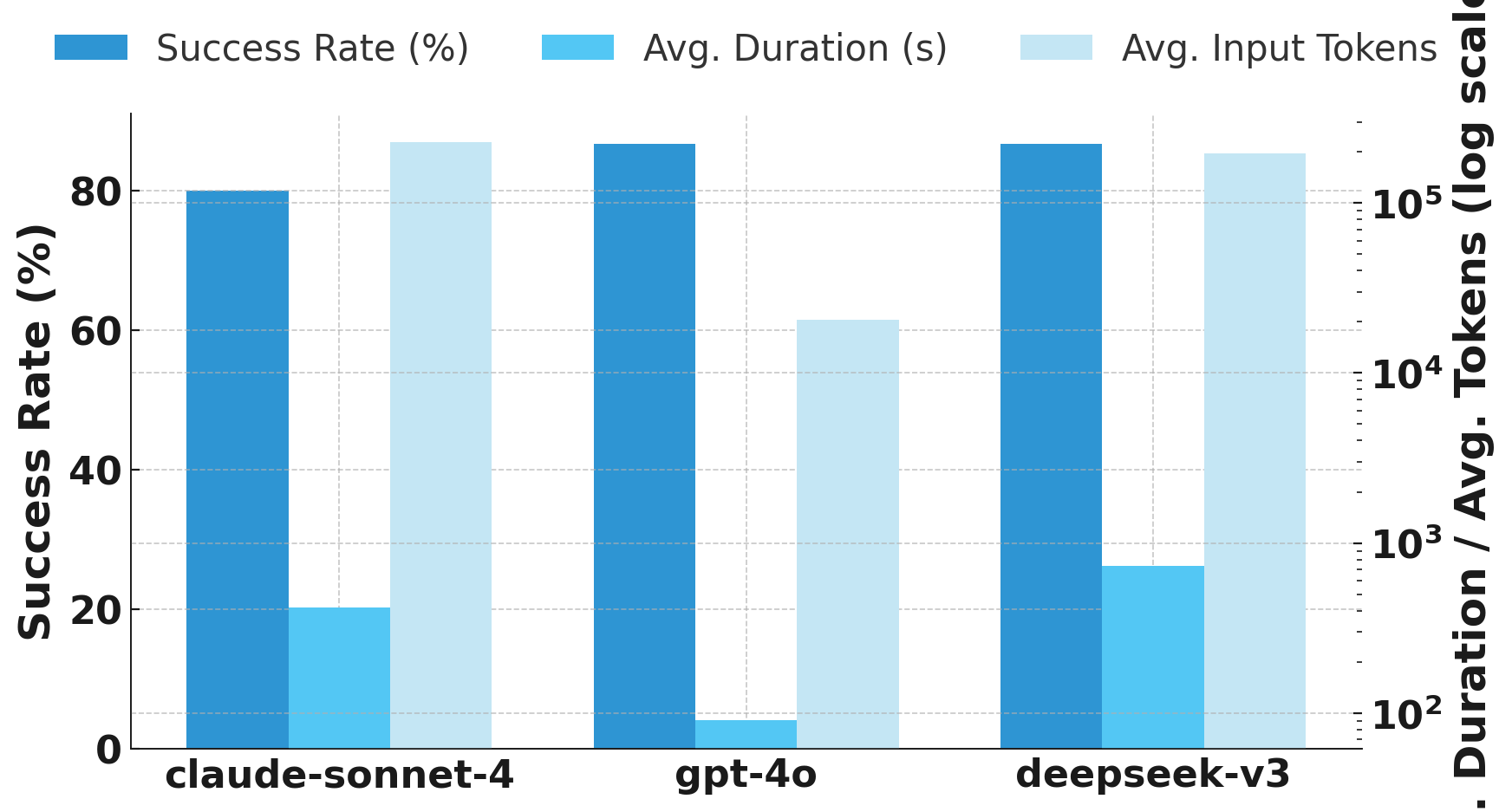
Table 2 and Figure 4 (a) show the models’ overall task success and efficiency. OpenAI GPT-4o and DeepSeek-v3 achieved the highest success rate at 86.7% (13 out of 15 tasks each), while Claude-Sonnet-4, known for higher reasoning ability, completed 80.0% (12/15 tasks). Notably, GPT-4o was by far the most efficient, with an average run time of only about 90 seconds per task and approximately 20k tokens consumed, compared to Claude’s 416 seconds and 227k tokens. DeepSeek-v3’s runtime and token consumption are also an order of magnitude higher than GPT-4o’s (averaging 730 seconds and consuming 195k tokens). Claude-Sonnet-4 tends to generate extremely detailed and lengthy outputs while exploring more pages (resulting in high token consumption), yet this does not translate into higher success rates. In fact, Claude’s comprehensive approach sometimes leads to diminishing returns, as it fails on tasks other models accomplish with fewer steps. Figure 4 (b) provides a heatmap of success rates across the seven task categories (see Table 1 for task breakdown). We observe 100% success across all models for most information-seeking tasks, including vague rights inquiries (S1-VRI) and consumer disputes (S1-CDD). All models also succeeded in locating authorities (S2-LSA) and completing the complex online form (S3-OFC) on our sandbox site. This suggests that current LLM agents are highly capable in straightforward information retrieval and form-filling scenarios in the legal domain.
The Complex Search (S2-CS) tasks had the lowest success rates: one CanLII case query (S2-CS-01), inspired by [24], that is very difficult to search for but very easy to verify, was not solved by any model (0% success). The other, a statistical query (S2-CS-02), was solved only by Claude (50% success vs. 0% for GPT-4o and DeepSeek-v3 in this category). These complex searches require combining multiple filters or conditions on the website and involve extensive browsing to find the correct answer. Most failures were due to the models failing to correctly apply multiple filters simultaneously or abandoning the search prematurely.
Another challenging area was the online appointment booking system. In this task category, Claude-Sonnet-4 successfully completed both scheduling tasks (100%), whereas GPT-4o and DeepSeek-v3 each completed only one. Specifically, in task S3-OAB-02, which involves booking via an external Microsoft Forms page, both GPT-4o and DeepSeek-v3 struggled. DeepSeek-v3 failed after 50 repetitive steps on the booking interface, while Claude completed the form and secured the appointment in just 15 steps. This discrepancy suggests that despite its slower execution and higher cost, Claude’s more comprehensive planning strategy yields superior performance in handling highly complex, multi-step interactions.
(a) Overall performance comparison across models.
The left y-axis shows the success rate (%) for each model, while the right y-axis (log-scale) compares average duration (s) and average input tokens. GPT-4o achieves the highest efficiency (shortest duration, lowest token use), while Claude-Sonnet-4 produces the most thorough outputs but at a higher computational cost.
Our initial evaluation suggests that web agents powered by large language models can autonomously perform information gathering, resource discovery, and take action to promote access to justice.
LegalWebAgent demonstrated strong performance on our tasks, achieving high success rates in answering legal questions, locating government agencies, and even completing online form submissions. However, we also observed challenges during experimentation that would arise when deploying such agents in real-world scenarios.
We observed that tasks requiring deep website navigation (many clicks or layers of pages) had a higher failure probability. Advanced models like Claude-Sonnet-4 tended to “dig deeper” into sites, which sometimes helped but often led to getting sidetracked or timing out. Excessive exploration can cause the agent to lose context or encounter dead ends (e.g., endlessly following related links). An effective agent must balance thoroughness with focus. Future agents might benefit from adaptive search depth control, stopping when sufficient information is found rather than exhaustively clicking every link.
Our findings suggest that today’s websites, designed for human users, can inadvertently confuse or hinder AI agents. For example, pop-ups like cookie consent or privacy policy notices are easy for humans to handle but can disrupt an agent’s understanding. Similarly, information hidden within complex menus or behind interactive components is difficult for web agents to extract. To improve agent performance (and perhaps human usability too), web developers could consider offering “AI-friendly” design, such as simplified HTML views, Markdown or JSON endpoints, or well-labeled content, tailored for autonomous agents.
The difference in token consumption across different models for the same task highlights the importance of optimizing how agents process web content. Claude-Sonnet-4 tends to load entire pages or even multiple pages in detail, leading to an exceptionally large context window. This not only impacts agent execution speed but may also trigger LLM context-length limitations. We can reduce token consumption by optimizing the content extracted by agents, which is important for cost reduction and efficiency improvement in web agents as well as their real-world deployment.
This research is a preliminary exploration of web agents for promoting access to justice, tested on a limited dataset (15 tasks) focused on Québec’s legal context. While our dataset was designed to reflect genuine user needs, broader evaluation is required for more accurate results. Future work should expand the testing scope to include more diverse legal scenarios, such as different jurisdictions, various legal websites, and a wider array of legal problem types. A further limitation is the framework’s dependence on large proprietary language models, which may incur excessive operational costs. Investigating smaller or open-source models and enhancing agent efficiency are therefore worthwhile research avenues. Agent safety is another important concern. For instance, [41] suggests web agents might be more vulnerable to jailbreaking, and [42] discusses how developers could add a “toxic” page, visible only to agents, to manipulate their behavior. This indicates that the present study is experimental in nature and requires critical robustness testing and security reviews before practical deployment.
The LegalWebAgent framework showcases the potential of multimodal LLM-based agents in bridging the “justice gap.” By combining MLLMs with web navigation and action execution, such agents can empower individuals to find legal information and complete online procedures with minimal manual effort. Our model comparison results indicate that while current state-of-the-art LLMs can reliably handle most tasks, they still require fine-tuning to effectively manage complex searches and intricate web forms. There remains significant room for improvement in agent response speed, reliability, and web content parsing. We believe that by automating web browsing processes, web agents based on MLLMs have strong potential to enhance access to justice.