Tourism Question Answer System in Indian Language using Domain-Adapted Foundation Models
📝 Original Info
- Title: Tourism Question Answer System in Indian Language using Domain-Adapted Foundation Models
- ArXiv ID: 2511.23235
- Date: 2025-11-28
- Authors: Praveen Gatla, Anushka, Nikita Kanwar, Gouri Sahoo, Rajesh Kumar Mundotiya
📝 Abstract
This article presents the first comprehensive study on designing a baseline extractive questionanswering (QA) system for the Hindi tourism domain, with a specialized focus on the Varanasi-a cultural and spiritual hub renowned for its Bhakti-Bhaav (devotional ethos). Targeting ten tourismcentric subdomains-Ganga Aarti, Cruise, Food Court, Public Toilet, Kund, Museum, General, Ashram, Temple and Travel, the work addresses the absence of language-specific QA resources in Hindi for culturally nuanced applications. In this paper, a dataset comprising 7,715 Hindi QA pairs pertaining to Varanasi tourism was constructed and subsequently augmented with 27,455 pairs generated via Llama zero-shot prompting. We propose a framework leveraging foundation models-BERT and RoBERTa, fine-tuned using Supervised Fine-Tuning (SFT) and Low-Rank Adaptation (LoRA), to optimize parameter efficiency and task performance. Multiple variants of BERT, including pre-trained languages (e.g., Hindi-BERT), are evaluated to assess their suitability for low-resource domainspecific QA. Evaluation metrics -F1, BLEU, and ROUGE-L -highlight trade-offs between answer precision and linguistic fluency. Experiments demonstrate that LoRA-based fine-tuning achieves competitive performance (85.3% F1) while reducing trainable parameters by 98% compared to SFT, striking a balance between efficiency and accuracy. Comparative analysis across models reveals that RoBERTa with SFT outperforms BERT variants in capturing contextual nuances, particularly for culturally embedded terms (e.g., Aarti, Kund). This work establishes a foundational baseline for Hindi tourism QA systems, emphasizing the role of LORA in low-resource settings and underscoring the need for culturally contextualized NLP frameworks in the tourism domain. Keywords SFT • LORA • Tourism Domain • Hindi Language • QA System • BERT • RoBERTa * The work has done during her internship at IIT Bhilai📄 Full Content
The QA systems offer efficiency, convenience, and enhanced user experience by providing domain-specific expertise with continuous 24/7 availability. Baseball Green et al. [1961] and Lunar Woods [1973] were among the initial QA systems, developed to address specific domains. The Baseball system was designed to answer queries related to the U.S. baseball league over a one-year period, while the Lunar system focused on responding to questions concerning the geological analysis of rock samples retrieved during the Apollo moon mission. Traditional QA paradigms established foundational frameworks through rule-based approaches, incorporating template-based Fabbri et al. [2020], Sammut and Banerji [1986], Liu et al. [2018], syntax-based Straach and Truemper [1999], Harabagiu et al. [2005], Heilman and Smith [2010], and semantic-based Levy and Andrew [2006], Dhole and Manning [2020], Yao and Zhang [2010] methodologies. These early implementations laid the crucial foundation through dependency parsing and the identification of semantic relationships within textual contexts Cao et al. [2017]. QA systems have undergone substantial advancements through the development of extractive and abstractive methodologies Chen et al. [2017]. Abstractive QA systems generate free-form answers by mimicking human summarization, enabled by advances in sequence-to-sequence architectures like AG Lewis et al. [2020a], Llama3 Tran et al. [2024], Yadav et al. [2024]. The T5 model Raffel et al. [2020] unified diverse NLP tasks into a text-to-text framework, facilitating flexible answer generation, while BART Lewis et al. [2020b] combined bidirectional and autoregressive pretraining to excel in generative benchmarks. Extractive QA systems identify and retrieve answer spans from provided contexts, evolved from rule-based approaches to transformer-based architectures Farea and Emmert-Streib [2024], Pandey and Roy [2024], Sengupta et al. [2025]. The introduction of BERT by Devlin et al. (2018) Devlin et al. [2019] marked a paradigm shift, leveraging bidirectional attention to contextualize tokens dynamically, thereby achieving state-of-the-art performance on benchmarks such as SQuAD Rajpurkar et al. [2016a]. Subsequent models like RoBERTa Liu et al. [2019] and ELECTRA Clark et al. [2020] refined pre-training strategies, optimizing span prediction accuracy and computational efficiency. Authors have also explored retrieval methods for extractive QA Kruit et al. [2024]. Despite progress, extractive systems remain constrained by their inability to synthesize answers for less explored domains, such as tourism in low-resource languages.
According to the statistics released by the Uttar Pradesh Government on 30 March 2023, the number of tourists in 2022 in the Varanasi region was 71,701,816 2 , which increased to 129,405,720 in 2023, according to data released on 29 March 2024 3 . This significant growth in tourism, combined with Hindi’s status as the most widely spoken language in the region, highlights the necessity for language-accessible resources to cater to the needs of visitors. According to the 2011 Census of India, Hindi has 528 million speakers 4 , constituting 43.63% of the total population.
Given the confluence of the rising tourist influx and Hindi’s dominance, we have developed a dedicated Hindi QA system for Varanasi Tourism to enhance accessibility and user engagement. Here is the key contribution of the article:
• We have developed a comprehensive Hindi QA dataset for Varanasi tourism, initially comprising 7,715 manually curated question-answer pairs, which was subsequently augmented to 27,455 pairs using a Llamabased approach. This dataset spans diverse subdomains, including Temples, Ashrams, Kunds, Museums, Ganga Aarti, Cruise, Travel Agencies, Food Court, Public Toilets, and General Enquiry.
• We have conducted an extensive experimental study comparing the performance of two state-of-the-art foundation models-mBERT and RoBERTa, fine-tuned using supervised fine-tuning on this dataset.
• Since the individual subdomains are very small, they are treated as low-resource settings that necessitate careful optimization to extract maximum performance from limited data. To address this, we integrate Low-Rank Adaptation (LoRA) with mBERT, systematically exploring various configurations with ranks of 2, 4, 8, 16, and 32 to optimize parameter efficiency and achieve the best trade-off between performance and model complexity.
Roy et al. ( 2022) [Roy et al., 2022] explored a generative approach models like OAAG (using BiLSTM) & Chime (using XL-Net transformer), for analysis, the BM25 algorithm for answering customer queries in e-commerce. An Amazon product review dataset was utilized, comprising 1.4 million user reviews along with corresponding product evaluations.
The models are evaluated on two product categories: Home & Kitchen and Sports & Outdoors, using the ROUGE metric. Al-Laith (2025) Al-Laith [2025] explored multilingual LLMs for financial QA, demonstrating fine-tuned XLM-RoBERTa-Large’s superiority (SAS: 0.96-0.98, EM: 0.76-0.81) over GPT-4o, which improved via few-shot learning (EM: 0.48-0.52). The study highlighted trade-offs between precision in fine-tuned models for extractive tasks and generative LLMs’ flexibility in low-resource scenarios. These insights reinforce context-driven model selection for domain-specific NLP, balancing accuracy and adaptability. Kasai et al. (2023) Kasai et al. [2023] proposed a real-time QA framework that implements six baseline approaches, leveraging a robust pre-trained model. These include four open-book methods based on Dense Passage Retrieval (DPR) and two closed-book models-Retrieval-Augmented Generation (RAG) and a prompting-based approach utilizing GPT-3.
Ali Al-Laith (2025) Al-Laith [2025] worked on the Exploring the Effectiveness of Multilingual and Generative Large Language Models for Question Answering in Financial Texts, provided a comprehensive analysis of large language models (LLMs) for financial causality detection using the FinCausal 2025 shared task dataset. This dataset consisted of 3,999 training samples and 999 test samples from financial disclosures in English and Spanish, structured for a hybrid question-answering task. The study employed both generative and discriminative techniques, utilizing four pre-trained language models: GPT-4o for generative QA and fine-tuned versions of XLM-RoBERTa (base and large) and BERT-base-multilingual-cased for multilingual QA. The evaluation was based on two key accuracy metrics: Semantic Answer Similarity (SAS) and Exact Match (EM). The results revealed that the fine-tuned XLM-RoBERTa-Large model outperformed others, achieving SAS scores of 0.96 (English) and 0.98 (Spanish), and EM scores of 0.762 and 0.808, respectively. While GPT-4o initially underperformed in a zero-shot setting (SAS: 0.77, EM: 0.002), it showed significant improvement with few-shot prompting, reaching SAS scores of 0.94 and EM scores of 0.515 (English) and 0.487 (Spanish). The paper effectively highlighted the strengths of fine-tuned PLMs in extractive question answering while showcasing GPT-4o’s adaptability in scenarios where extensive fine-tuning was not feasible. The study’s detailed comparative analysis and experimental techniques provided valuable insights into financial NLP, reinforcing the importance of model selection in domain-specific tasks. Kasai et al. (2024) Kasai et al. [2023] developed an framework and a benchmarking timeline for real-time QA system submission. For the evaluation of the system, they used 1,470 QA pairs and further, they provided 2,886 QA pairs and they included nearly 30 multiple choice questions at 3 am GMT on every Saturday and they used API search for these questions. REALTIME QA executed six baselines in real time that are based on a strong pre-trained model: four open-book and two closed-book models. Open-book QA model retrieved the documents from DPR, and for answer prediction, they used two methods: retrieval-augmented generation (RAG) and a prompting method with GPT-3. They used the BART-based RAG-sequence model for the RAG baseline, again finetuned on Natural Questions from the Transformers library. Two methods were used for closed-book QA: the finetuning method and the prompting method.
In the Finetuning Method, they used the T5 model finetuned on the Natural Questions data again from the Transformers library. They applied a prompting method to GPT-3 similar to the open-book baselines. GPT-3 with retrieval achieves the best performance; EM scores were 34.6, and F1 scores were 45.3.
Thirumala and Ferracane (2022) Thirumala and Ferracane [2022] explored extractive question answering for Hindi and Tamil using Wikipedia articles as context, with questions prepared by native speakers. They evaluated XLM-RoBERTa, XLM-RoBERTa+fine-tuning, and RoBERTa+Hindi/Tamil fine-tuning. The models achieved word-level Jaccard scores of 0.656 (XLM-RoBERTa), 0.749 (XLM-RoBERTa+fine-tune), 0.958 (RoBERTa+Hindi fine-tune), and 0.829 (RoBERTa+Tamil fine-tune). They concluded that RoBERTa + Hindi/Tamil fine-tuning outperformed the other models. 2.2 QA systems for Tourism Domain Sui (2021) Sui [2021] developed a tourism QA system using a knowledge graph. The system converts natural language questions into Cypher queries, enabling efficient retrieval of tourism-related information. Data was sourced from popular travel platforms such as Horse Beehive Travel and Baidu Travel, ensuring a rich knowledge base for query execution. Similarly, Li et al. (2022) Li et al. [2022] also proposed a knowledge-based tourism QA system specifically for Zhejiang, China. The researchers collected data from Baidu keywords and surveys to identify key scenic spot attributes. Kang et al. (2024) Kang et al. [2024] developed a Machine Reading Comprehension (MRC)-based tourism QA system using BERT series pre-trained models. The system, implemented as a smart tourism chatbot, processes input sentences up to 512 tokens in standard Transformer models, while the BigBird model handles 4096 tokens using block sparse attention for efficiency. The tourism QA dataset contains 1,000+ contexts and 10,000+ questions. The KoBigBird model achieved EM 96.85 and F1 98.84, demonstrating high accuracy in tourism-related QA tasks. Kırtıl et al. (2024) Kırtıl et al. [2024] focused on developing an AI chatbot for tourism and viniculture in Türkiye using OpenAI’s GPT-3.5-turbo, fine-tuned with QA and plaintext formats. The resulting model, WineBot, demonstrated superior performance over base ChatGPT models by reducing misleading or incomplete responses, highlighting the efficacy of domain-specific fine-tuning. Wei This highlights that the tourism domain remains underexplored in the Indian context in Indian languages, with limited datasets available to support the development of QA systems in this field.
In this study, we present a comprehensive Hindi QA dataset tailored to Varanasi tourism. The dataset comprises 7,755 manually created QA pairs, which were subsequently augmented using LLMs to address a wide range of tourist queries.
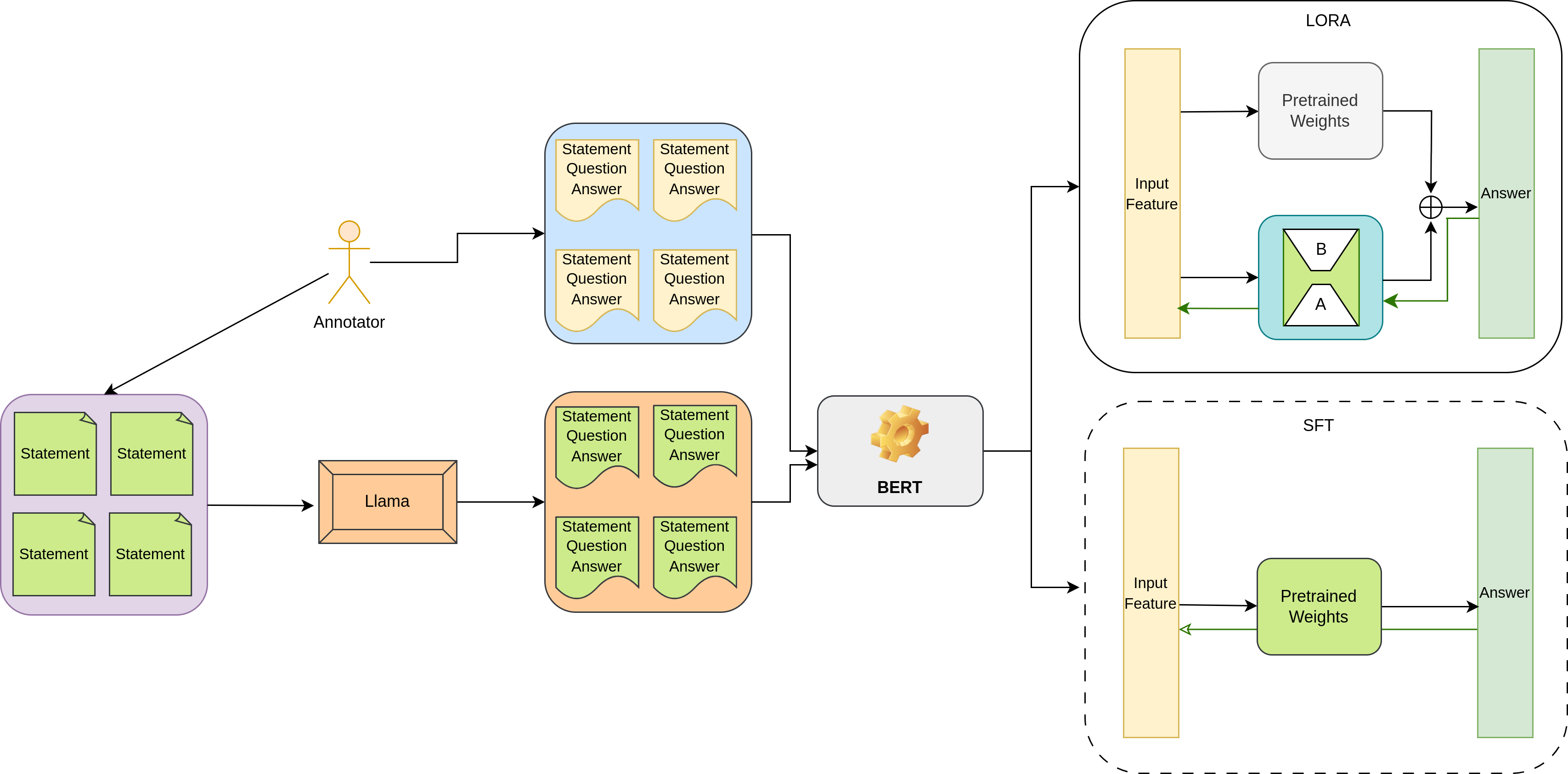
A detailed questionnaire was first developed to capture all necessary information related to Varanasi tourism. Data were collected from both secondary sources (as mentioned in Table 14) and primary sources (official temple websites 567 , pamphlets, visiting cards, etc) during the project tenure (February to August 2024). Primary data were gathered during 10 field visits8 to key sites including temples, travel agencies, museums, ashrams, and kunds. The primary data served to validate and refine the information obtained from secondary sources, with rigorous proofreading ensuring accuracy. After the initial manual creation, the dataset was augmented by using the Llama model to generate additional similar Hindi questions. These Llama-generated questions were cross-checked at the syntactic and semantic levels by the annotators, validated using the agreement between the annotators, measured by Cohen’s Kappa score, which was 0.9. The example of semantically repeated pairs, removed by the annotators shown in Appendix ??.
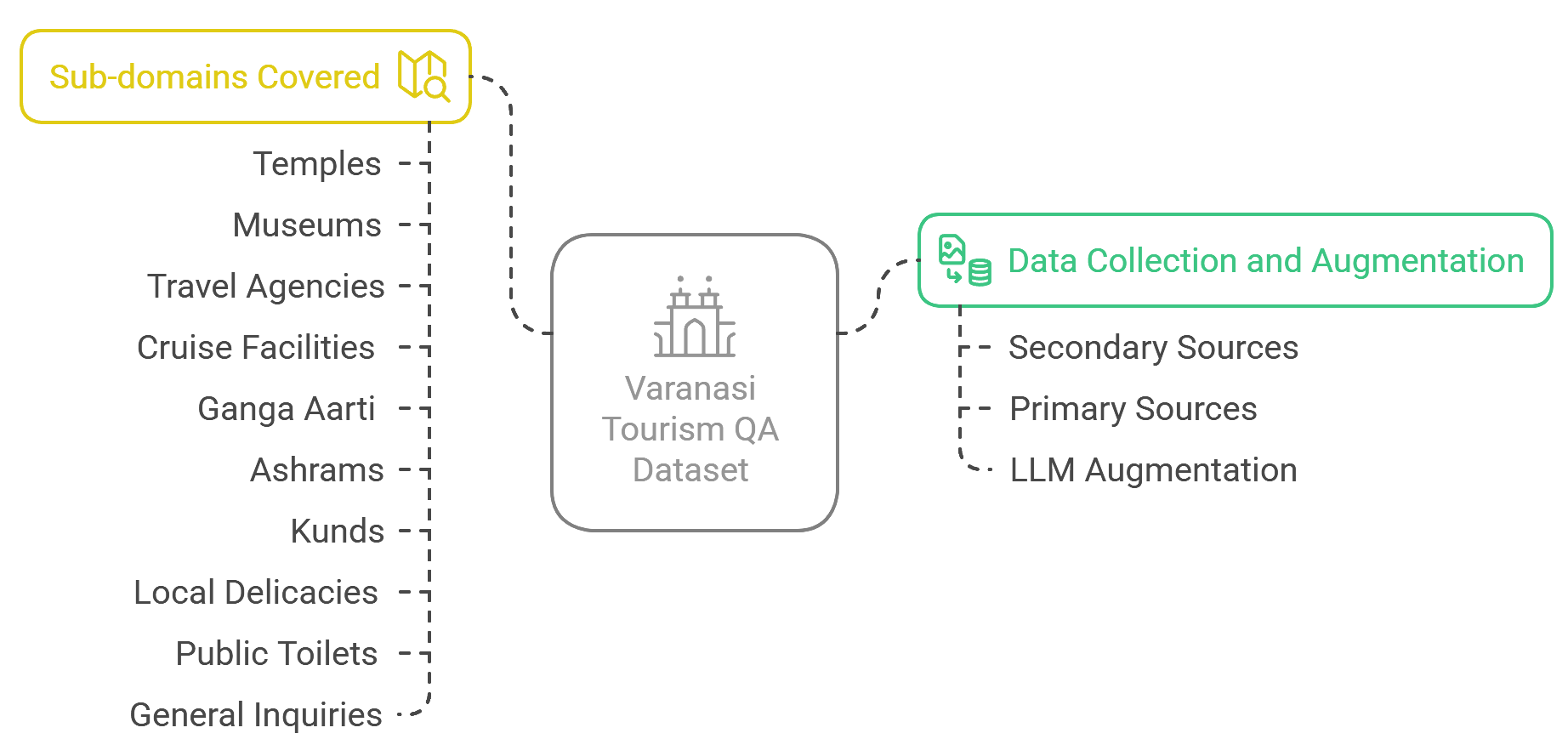
The Hindi QA dataset addresses multiple sub-domains pertinent to Varanasi tourism, ensuring that visitors receive well-rounded and reliable information. The key domains include:
• Temples: Details on timings, rituals, special events, and facilities at major temples such as Shri Kashi Vishwanath Mandir, Sankat Mochan Mandir, and Durga Mandir. • Museums: Information regarding operating hours, entry fees, and facilities available at museums like Bharat Kala Bhavan, Ramnagar Fort Museum, and Man Singh Observatory. • Public Toilets: Details about well-maintained public toilet facilities (e.g., the Sulabh complex) in key tourist areas. • General Inquiries: A broad category addressing common questions about weather, best travel seasons, local transportation, accommodation, selfie spots, and boating facilities.
To curate this dataset, both purposive and convenience sampling techniques were employed. The outline of data collection, domains, and augmentation is represented in Figure 1.
We selectively targeted prominent and high-demand locations such as:
• Temples: Including Shri Kashi Vishwanath Mandir, Annapurna Mandir, Sankat Mochan Mandir, Vishalakshi Mandir, etc. • Ashrams: Such as Annapurna Ashram, Kumarswami Ashram, and Jangamwadi Mutt.
• Travel Agencies: Including Shreenath Ji Tours and Travels, Endeman Tour, and Ganga Travels.
• Kunds: Like Lolark Kund, Durga Kund, Krim Kund, and Manikarnika Kund.
• Major Activities: Such as Ganga Aarti and cruise services.
Due to constraints such as high location density, limited access to some informants, and time restrictions, convenience sampling was applied to include accessible locations like Mani Mandir, Rudra Kund, and Udupi 2 Mumbai Food Court. This ensured that the dataset remained diverse yet practical.
The statistics of the data set for various subdomains related to Varanasi tourism are presented, with a focus on the Manually Created Hindi Question Answer Dataset (MCHQAD) and the Llama Generated Hindi Question Answer Dataset (LGHQAD), which was augmented by zero-shot prompting Scius-Bertrand et al. [2025]. Among the covered domains, Temples constitute the largest category, comprising 2,686 MCHQAD and 9,496 LGHQAD. The Kunds subdomain includes 470 MCHQAD and 2,398 LGHQAD, while the Ashram category consists of 1,555 MCHQAD and 5,284 LGHQAD. The Museum domain includes 484 MCHQAD but does not contain any LGHQAD. The Travel The agency domain represents the second largest category in the dataset, with 2,413 MCHQAD and 6,828 LGHQAD. This highlights the significant focus on tourism-related services and infrastructure.
Additionally, several smaller yet essential subdomains have been included to enhance the comprehensiveness of the dataset. The Ganga Aarti category comprises 15 MCHQAD and 46 LGHQAD, reflecting the importance of this spiritual event for visitors. Cruise Services, which cater to river tourism experiences, contain 19 MCHQAD and 60
LGHQAD. The Food Courts sub-domain, which provides insights into local dining options, includes 11 MCHQAD and 15 LGHQAD. In addition, the public infrastructure is also addressed within the data set. The Public Toilets domain includes 9 MCHQAD and 13 LGHQAD, ensuring that accessibility-related queries are covered. The General Enquiries category, with 53 MCHQAD and 81 LGHQAD, serves as a broad repository for common tourist questions and essential information. An example QA pair from the dataset is shown in Figure 2. The English translation of the example is given below: “Yes, Shri Kashi Vishwanath Temple is located in Godowlia, Varanasi. Godowlia is the main religious area of Varanasi. Devotees can walk on foot or use a rickshaw from Godowlia to reach the temple, where they can experience spiritual peace. Godowlia is a unique place with the confluence of antiquity and modernity, which reflects the historical and religious importance of Varanasi. Que. -1. Where is Shri Kashi Vishwanath Temple located? Ans. -Shri Kashi Vishwanath Temple is located in Godaulia, Varanasi. Que. -2. In which area the Shri Kashi Vishwanath Temple is located in Varanasi? Ans. -Shri Kashi Vishwanath Temple is located in Godowlia, Varanasi. Que. -3. How to reach Shri Kashi Vishwanath Temple from Godaulia Chowk? Ans. -To reach Shri Kashi Vishwanath Temple from Godowlia Chowk, one can go by foot, or a rickshaw facility is also available.”
These diverse categories collectively contribute to the building of a well-rounded QA system for Varanasi tourism, ensuring coverage of both the main and minor aspects of the tourist experience. The total numbers of MCHQAD and LGHQAD are 7715 and 27455, respectively, as shown in Table 2. A detailed questionnaire was first developed to capture all necessary information related to Varanasi tourism. Data were collected from both secondary sources (as mentioned in Table 14) and primary sources (official temple websites, pamphlets, visiting cards, etc). Primary data were gathered during 10 field visits to key sites, including temples, travel agencies, museums, ashrams, and kunds. The primary data served to validate and refine the information obtained from secondary sources, with rigorous proofreading ensuring accuracy. A total of six annotators were involved in the creation of the dataset. Two annotators created the initial manual dataset, and four were involved in the data augmentation process. Initially, two Hindi language experts validated the manually created dataset, which was revised and proofread multiple times during its development. After the manual creation, the dataset was augmented using the LLaMA model to generate additional similar Hindi questions, which were then cross-checked and manually validated.
Extractive QA is a fundamental task in NLP that requires models to extract relevant information from a given context to answer a question. Formally, a QA system can be defined as a function:
where Q represents the question, C denotes the context or passage containing the answer, and A is the extracted answer span. In this article, we relied on Transformer-based modern approaches, such as BERT (Bidirectional Encoder Representations from Transformers), RoBERTa (Robustly Optimized BERT Pretraining Approach), along with associated fine-tuning techniques like LoRA (Low-Rank Adaptation) to achieve high accuracy while maintaining efficiency. The overview of the complete architecture is shown in Figure 3.
5 Question Answering with BERT
BERT pretraining involves Masked Language Modeling (MLM) and Next Sentence Prediction (NSP), where MLM randomly masks tokens X m ⊂ X and predicts them using adjacent words:
Similarly, NSP tells the consecutiveness of two sentences (S 1 , S 2 ) by using: Since both MLM and NSP are performed during pretraining, the objective is to minimize the total loss:
As specified in Section 4 for QA input and output, the input sequence to BERT consists of the given question Q and context C, represented as:
where [CLS] is a special classification token and [SEP] marks boundaries between the question and the context. The model applies multiple layers of a Transformer-based encoder Enc θ (parameterized by θ) to generate contextualized token embeddings using equation 26 Question Answering With RoBERTa
RoBERTa Liu et al. [2019] builds upon BERT but introduces modifications to the pretraining and fine-tuning mechanisms, leading to superior performance on QA tasks. Let X be a sequence of tokens designed using equation 6 and let M (X) denote a random masked version of X. In BERT, static masking is applied once, whereas RoBERTa uses dynamic masking, where each token x i is masked with a probability p m in each batch:
The MLM loss is computed as:
where P ϕ is the probability assigned by RoBERTa’s encoder Enc ϕ (as shown in equation 2 parameterized by ϕ).
7 Supervised Fine-Tuning with Task-Specific Layers Supervised fine-tuning the pretrained BERT or RoBERTa involves modifying their architecture by adding task-specific layers and optimizing the model on a downstream task loss function. In the context of extractive QA, this requires training the model to predict the start and end indices of the answer span within a given context.
For span prediction, both models employ two linear classifiers to determine the start and end positions of the answer:
where W s , W e ∈ R d are learned weight vectors for predicting start and end positions, and softmax ensures probabilities sum to 1 across possible token positions. H is the pretrained weights of the models. The model is fine-tuned by minimizing the negative log-likelihood loss for the correct start and end indices (s * , e * ):
where s * and e * are the starting and end positions of the ground truth, while s and e are respective positions obtained from prediction. The model maximizes the probability of selecting the correct answer span.
Fine-tuning BERT or RoBERTa on large QA datasets requires updating all parameters θ, leading to high computational costs. The standard parameter updation expression is represented by:
where η is the learning rate. This full fine-tuning is expensive. To address this, LoRA (Low-Rank Adaptation) Shen et al. freezes the original model parameters and injects low-rank updates into weight matrices. Instead of modifying a full weight matrix W ∈ R d×k , LoRA decomposes updates as:
where B ∈ R d×r , A ∈ R k×r are low-rank matrices and r ≪ min(d, k) ensures a small number of trainable parameters.
The adapted representation for layer l becomes:
To maintain stability, the loss function for LoRA fine-tuning regularizes low-rank updates:
where ∥ • ∥ F is the Frobenius norm, and λ is a hyperparameter controlling regularization. The algorithm 1 describes the SFT and LORA-based fine-tuning.
For preprocessing, the input Hindi QA data was tokenized with a maximum sequence length of 384 tokens and a stride of 128 tokens to effectively capture overlapping contexts; additionally, both overflowing tokens and offset mappings were returned, and all sequences were padded to the maximum length to ensure uniformity. We conduct an extensive evaluation of two transformer-based language models, multilingual foundation Models-BERT and RoBERTa, employing SFT on a multi-domain dataset comprising diverse sub-domains such as temples, museums, travel agencies, cruise facilities, and other culturally significant areas. We have used bert-base-multilingual-cased Devlin et al. [2019], ai4bharat/indic-bert Kakwani et al. [2020], l3cube-pune/hindi -bert-v2 Joshi [2022] and l3cube-pune/hindi-roberta Joshi [2022], referred as mBERT, IndicBERT, HindiB-ERT and Hindi-RoBERTa, respectively. The dataset has been split into 80 and 20 rations for training and testing, respectively. Both models were fine-tuned under a consistent hyperparameter regime, using a learning rate of 3e-5, a batch size of 48, and training for upto 3 epochs with early stopping based on validation loss, while optimization was
// Update adapters end return θLORA ← {A l , B l } carried out using the AdamW optimizer. To further promote regularization, a weight decay of 0.01 was also employed. We targeted the model’s query and value modules for adaptation, applying a dropout rate of 0.1 to the LoRA layers and opting for no bias adaptation, thereby ensuring parameter efficiency and robust model adjustment. The LoRA exclusively used with mBERT by introducing trainable low-rank matrices. We have explored LoRA configurations with rank values of 2, 4, 8, 16, and 32. For data augmentation, the Llama model has explored with zero-shot propmpting Scius-Bertrand et al. [2025] where the prompt was Statement: Generate questions in Hindi along with their answers from Context .
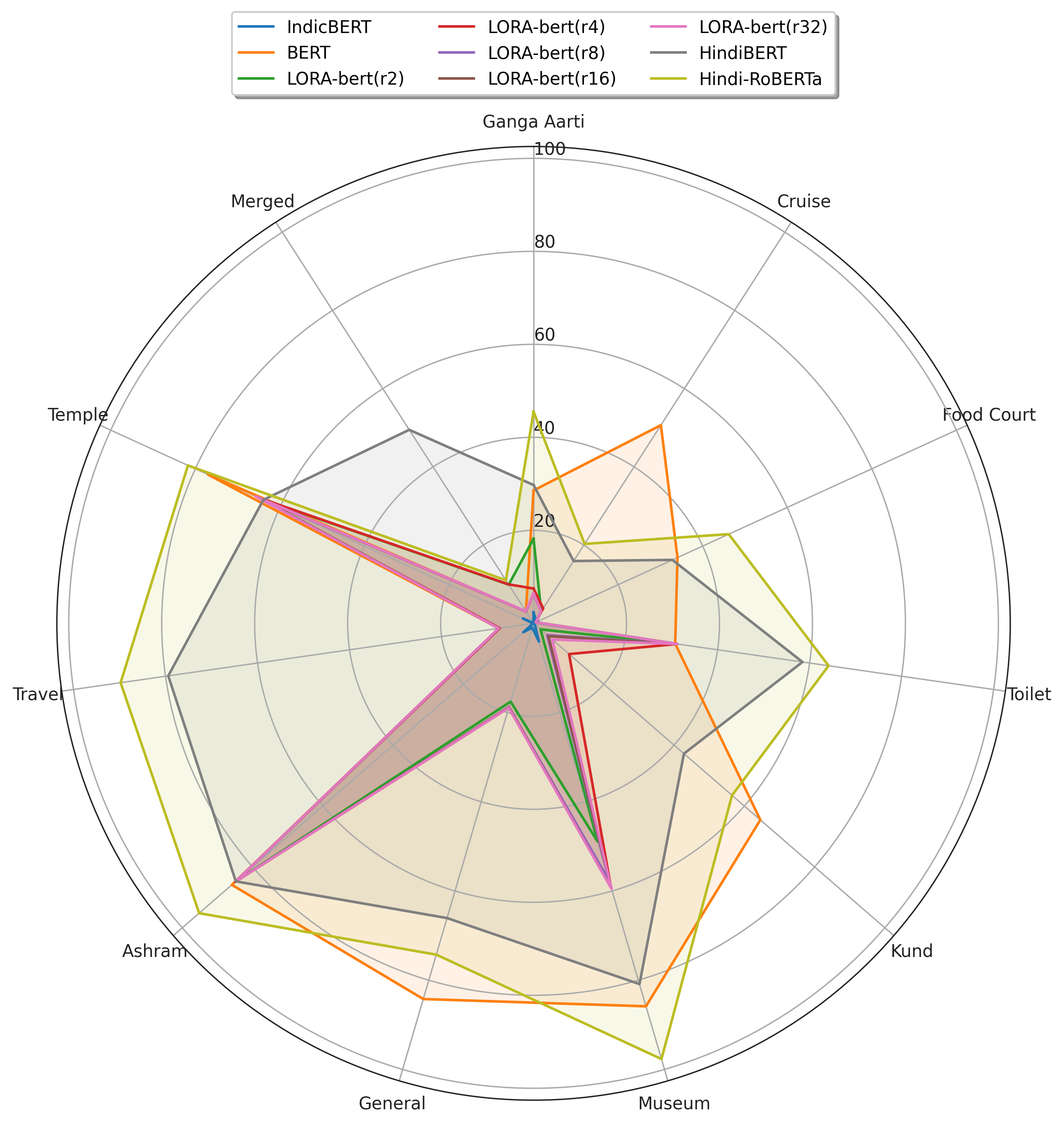
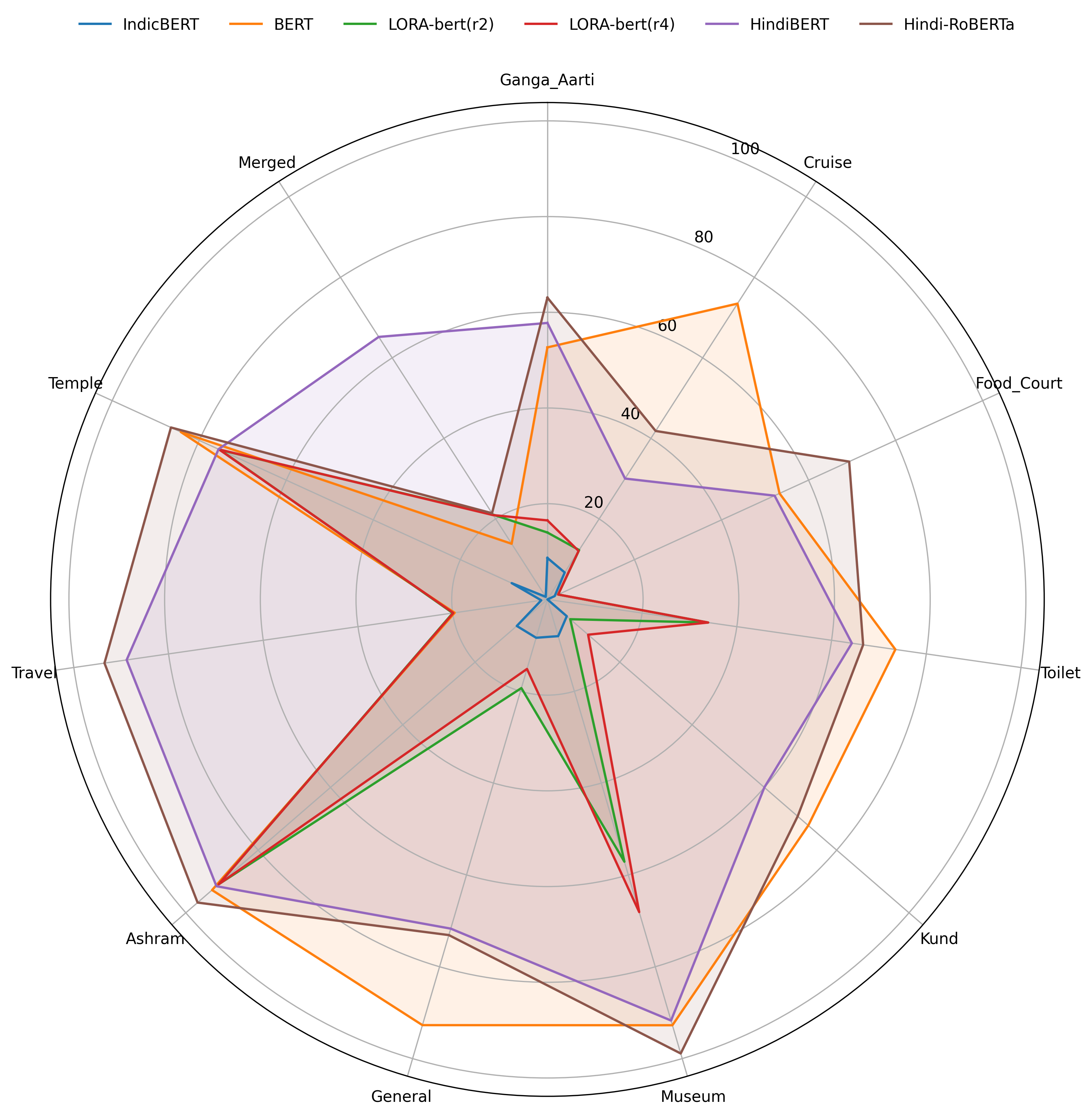
Table 3, for the Aarti domain, the F1, BLEU, and RougeL scores for the IndicBERT model were found to be 8.67, 2.361, and 20 respectively. The BERT model had an F1 Score of 52.664, a BLEU score of & 28.578, and RougeL score of 20. In the case of the LORA-bert(r2) model, the F1 Score was 13.979, BLEU score was 8.203, and RougeL score was 0. The LORA-bert(r4) model had an F1 Score of 16.512, BLEU score of 7.477, and RougeL score was found to be 0. The LORA-bert(r8) model had an F1 Score of 15.569, BLEU score of 6.409, and RougeL score was found to be 0. The LORA-bert(r16) model had an F1 Score of 15.569, BLEU score of 6.409, and RougeL score was 0. The LORA-bert(r32) model had an F1 Score of 15.569, BLEU score of 6.409, and RougeL score was 0. For the HindiBERT Developing extractive QA systems for low-resource languages is particularly challenging in domain-specific settings. In this study, we manually prepared a Hindi QA dataset focused on Varanasi tourism¯a cultural and spiritual hub renowned for its Bhakti-Bhaav¯comprising 7,715 question-answer pairs obtained through extensive fieldwork using purposive and convenience sampling, and covering ten tourism-centric subdomains: Ganga Aarti, Cruise, Food Court, Public Toilet, Kund, Museum, General, Ashram, Travel, and Temple. Which was subsequently augmented to 27,455 pairs using a Llama-based zero-shot prompting technique. We propose a framework leveraging foundation models-BERT and RoBERTa, fine-tuned using SFT and LORA, to optimize parameter efficiency and task performance. Multiple variants of BERT, including mBERT, Hindi-BERT, IndicBERT, etc., are evaluated to assess their suitability for low-resource domain-specific QA. In the Ganga Aarti, General, and Toilet sub-domains, the BERT model achieved the highest F1 scores, registering 51.223,76.216,and 73.469,respectively,while in the Cruise,Kund,Museum,Ashram,Travel,Temple,and Food Court domains,66.639,95.532,96.575,90.91,86.493,and 66.987 respectively; as the RoBERTa model was pretrained on a large dataset, fine-tuning on the merged sub-domains enabled the Hindi-RoBERTa model to achieve an overall best F1 score of 89.75. As future work, we will leverage the existing multilingual LLM with RAG to enhance model robustness and effectively handle real-time diversified queries. Additionally, a similar Hindi QA dataset can be developed for other domains, such as education, agriculture, and health sciences.
A Appendix-Sources
Mamba, Falcon Mamba, Jamba, Zamba, Samba, Scarcity of High-Quality, Large-Scale QA Datasets for Indic Languages, Limited Applicability to Underrepresented Indic Languages, Weak Performance on Multi-Sentence or Ambiguous QuestionsVats et al. [2025]
Mamba, Falcon Mamba, Jamba, Zamba, Samba, Scarcity of High-Quality, Large-Scale QA Datasets for Indic Languages, Limited Applicability to Underrepresented Indic Languages, Weak Performance on Multi-Sentence or Ambiguous Questions
Mamba, Falcon Mamba, Jamba, Zamba, Samba,
1.437. Whereas in case of the LORA-bert(r2) model, the F1 Score was 19.983, BLEU score was 7.432, and RougeL score was 1.437. The LORA-bert(r4) model had an F1 Score of 19.865, BLEU score was 7.342, and RougeL score was 1.437. The LORA-bert(r8) model had an F1 Score of 19.989, BLEU score was 7.534, and RougeL score was 1.437. The LORA-bert(r16) model had an F1 Score of 19.999, BLEU score was 7.547, and RougeL score was 1.437. The LORA-bert(r32) model had an F1 Score of 19.982, BLEU score was 7.546, and RougeL score was 1.437. HindiBERT
https://uptourism.gov.in/en/article/year-wise-tourist-statistics
https://uptourism.gov.in/en/post/Year-wise-Tourist-Statistics
https://language.census.gov.in/eLanguageDivision_VirtualPath/eArchive/pdf/C-16_2011.pdf
https://www.shrikashivishwanath.org/
https://kashiannapurnaannakshetratrust.org/
https://sankatmochanmandirvaranasi.com/
Researchers physically visited majoritiy of the tourists sites to get the authentic and reliable information from the tourist places in Varanasi.
The[] comprising translation of Hindi text
📸 Image Gallery