Escaping Barren Plateaus in Variational Quantum Algorithms Using Negative Learning Rate in Quantum Internet of Things
📝 Original Info
- Title: Escaping Barren Plateaus in Variational Quantum Algorithms Using Negative Learning Rate in Quantum Internet of Things
- ArXiv ID: 2511.22861
- Date: 2025-11-28
- Authors: Ratun Rahman, Dinh C. Nguyen
📝 Abstract
Variational Quantum Algorithms (VQAs) are becoming the primary computational primitive for next-generation quantum computers, particularly those embedded as resourceconstrained accelerators in the emerging Quantum Internet of Things (QIoT). However, under such device-constrained execution conditions, the scalability of learning is severely limited by barren plateaus, where gradients collapse to zero and training stalls. This poses a practical challenge to delivering VQA-enabled intelligence on QIoT endpoints, which often have few qubits, constrained shot budgets, and strict latency requirements. In this paper, we present a novel approach for escaping barren plateaus by including negative learning rates into the optimization process in QIoT devices. Our method introduces controlled instability into model training by switching between positive and negative learning phases, allowing recovery of significant gradients and exploring flatter areas in the loss landscape. We theoretically evaluate the effect of negative learning on gradient variance and propose conditions under which it helps escape from barren zones. The experimental findings on typical VQA benchmarks show consistent improvements in both convergence and simulation results over traditional optimizers. By escaping barren plateaus, our approach leads to a novel pathway for robust optimization in quantum-classical hybrid models.📄 Full Content
estimation, and adaptive sensing on low-resource hardware. Importantly, this workflow takes use of the fact that only scalar measurement information or model parameters must be shared externally, rather than entire quantum states, reducing quantum communication cost and making VQA-style processing compatible with edge-level QIoT designs.
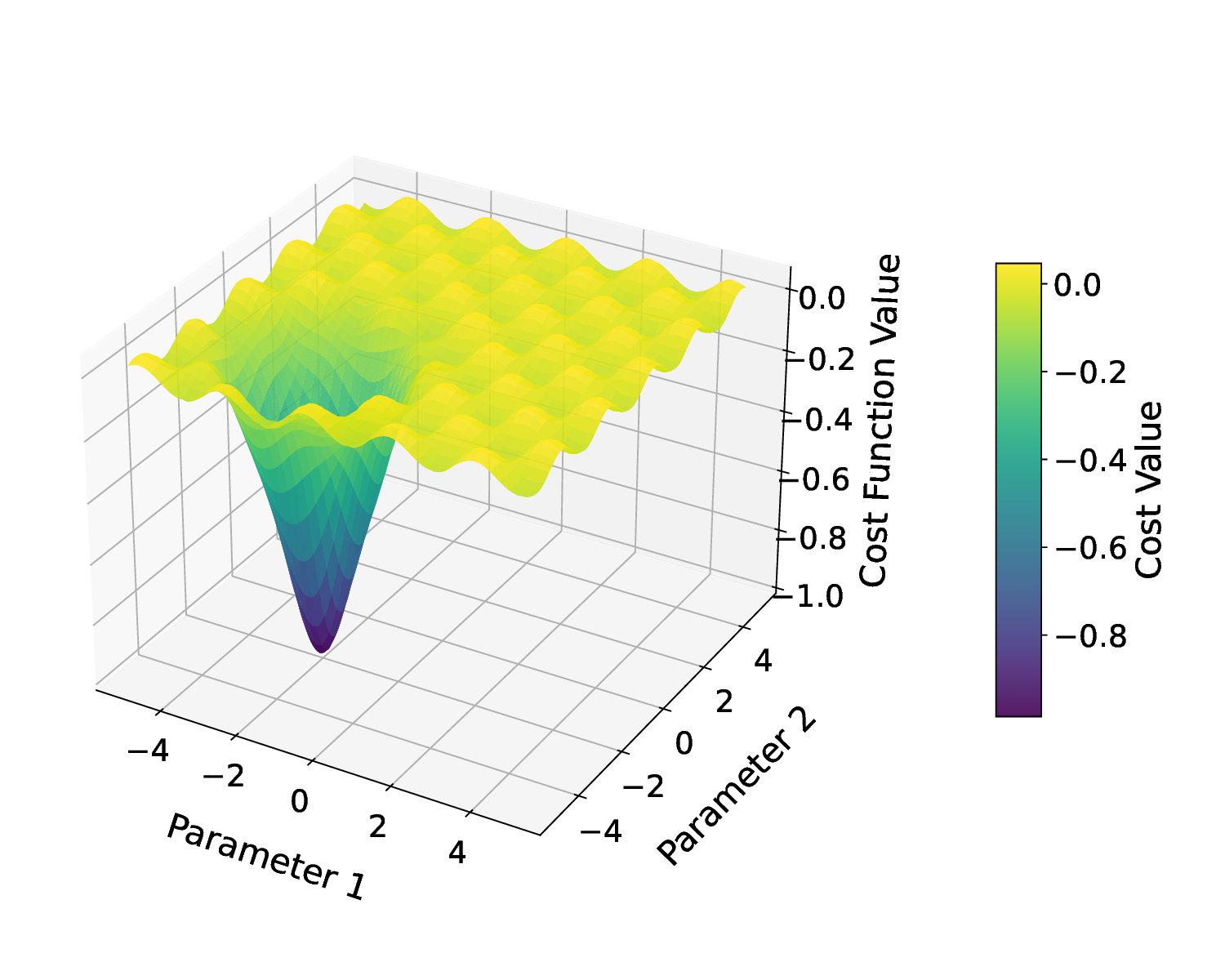
Despite their potential, VQAs suffer from obstacles, particularly the phenomenon of barren plateaus, in which the gradients of the optimization landscape disappear rapidly as the number of qubits grows [4], [5]. In a barren plateau, the cost function becomes almost flat in large areas of the parameter space, making it exceedingly difficult for gradientbased optimization methods to determine a meaningful direction for parameter updates [6]. As a result, the training process stalls out and may require exponentially many observations to properly predict gradients, making optimization essentially impossible for large-scale systems [7]. This problem arises from the high-dimensional geometry of quantum states and the concentration of measurement phenomena encountered in random quantum circuits [8]. Basic QML approaches, such as standard gradient descent or heuristic optimization, cannot overcome barren plateaus because they rely on the existence of relevant gradient data [9]. Without structural modifications to the algorithm or parameterized circuit design, these techniques have inherent limitations in their ability to escape barren zones and perform scalable quantum learning [10], [11]. To overcome the limitations imposed by barren plateaus in VQA in QIoT devices, we present a novel approach that employs negative learning rates during VQA training. We can summarize the contribution as follows.
• We propose a novel approach of negative learning rates in the context of VQA training for QIoT devices, laying the theoretical groundwork for their effectiveness in overcoming barren plateaus by implementing an effective training method that alternates between positive and negative learning phases to promote gradient amplification and improve landscape exploration. • We investigate the behavior of negative learning phases and explain when and why negative learning might successfully decrease barren plateau problems. • We perform extensive experiments in VQAs and show that our approach consistently and reliably improves the convergence and performance of the model compared to traditional optimization approaches, reducing the classification loss by up to 8.2% across both synthetic and Pa ra m e te r 1 publicly available datasets.
The phenomenon of barren plateaus is widely acknowledged as a critical barrier to scalable VQA training. McClean et al. [4] demonstrated that in deep unstructured parameterized quantum circuits, the gradients of the cost function vanish exponentially with the number of qubits. This makes gradient-based optimization ineffective as system size grows, which is particularly restrictive for low-resource QIoT devices where circuits cannot be made arbitrarily deep and repeated re-initialization cycles are impractical. Beyond optimization-level studies, recent work has explored how quantum technologies integrate with IoT architectures, leading to the emergence of QIoT. Adil et al. [1] examined the effect of quantum computing on healthcare IoT, showing how quantum-enhanced communication and learning can strengthen trust and privacy. Panahi [2] introduced an energy-efficient and decoherence-aware entanglement generation architecture for resource-limited QIoT endpoints running VQA-based workloads. These results collectively highlight the growing importance of lightweight, trainable quantum learning pipelines in IoT settings, motivating our work toward optimizer-level stabilization of variational models for QIoT devices.
Several subsequent studies have helped to learn the reasons for barren plateaus. By differentiating between global and local cost functions, Cerezo et al. [5] showed that the selection of the cost function has a substantial impact on the formation of barren plateaus. Global cost functions, which need measurements throughout the whole system, are more likely to produce barren plateaus, but local cost functions, which focus on particular subsystems, can reduce gradient vanishing. According to Grant et al. [10], initialization techniques are also important; although well-planned layerwise or identitypreserving initializations might enhance trainability, random parameter initialization often results in barren plateaus. The entanglement architecture of the parameterized circuits also determines the appearance of barren plateaus. Marrero et al. [12] showed that excessive entanglement causes the concentra-tion of measurement phenomena, increasing the disappearance of the gradient. Similarly, Pesah et al. [8] investigated how organized, shallow circuits could prevent barren plateaus by restricting entanglement development. Noise and hardware imperfections can also result in barren plateaus. Wang et al. [9] investigated how noise contributes to the problem of vanishing gradient, resulting in “noise-induced barren plateaus.” Their findings indicate that even professionally planned ansätze can suffer from barren plateaus in realistic noise situations [13].
Several mitigation strategies have been proposed to address the problems of barren plateaus. Designing shallow, problem-inspired approaches [14], using hardware-efficient circuits [15], and the implementation of local cost functions [5] have shown promising results. Adaptive techniques, including dynamic circuit growth [11] and symmetry-informed pruning [16], have been developed. Skolik et al. [17] proposed a layer-wise learning strategy for quantum neural networks, gradually increasing the depth of the circuit during training to maintain training capacity and prevent gradient vanishing in deeper networks. More recent research has looked into various approaches to addressing barren plateaus. Zhang et al. [18] suggested Gaussian-based initializations to decrease gradient decay in deeper circuits, whereas Yao and Hasegawa [19] studied the role of entanglement structure in avoiding plateaus entirely. Liu et al. [20] found that well-specific perturbations can enhance optimization-level techniques, including negative learning phases. In addition, a few studies have investigated random restarts / random re-initialization procedures as a means of avoiding flat sections in VQA [21]. The main concept is to continually re-sample parameters and re-run optimization until a non-plateau zone is located. This can assist in shallow instances, but it does not preserve curvature information throughout training [6]. In contrast, our NLR method adds gradient-aligned reversals within the same local area instead of discarding accumulated structure. This allows for more systematic escape dynamics than re-initializationbased sampling.
Despite these developments, a widely applicable optimization-based strategy for systematically escaping barren plateaus remains elusive. Most current mitigation strategies focus on architectural changes or initialization schemes rather than substantially affecting optimization dynamics. This gap encourages the investigation of alternative optimization techniques, such as the integration of negative learning phases, in order to improve trainability without needing significant modifications to the circuit or problem structure.
III. METHODS A. Quantum Machine Learning Each client constructs a local quantum model using a VQA applied to an encoded quantum state. A VQA consists of L layers, each comprising parameterized single-qubit rotation gates (e.g., R x , R y , R z ) that act on individual qubits, together with entangling gates (e.g., CNOT) that generate correlations between qubits. The overall unitary transformation at round t is written as
where θ t is the parameter vector at round t, and U ℓ (θ t,ℓ ) denotes the unitary operation in layer ℓ, parameterized by θ t,ℓ . If G ℓ is the Hermitian generator (e.g., a Pauli operator) associated with a rotation gate, then the unitary operator for layer ℓ is
After applying the VQA, the output quantum state is obtained as
where |ψ enc (θ)⟩ denotes the encoded input state. To produce a prediction, the state is measured with respect to a Hermitian observable O (e.g., Pauli-Z), yielding the expectation value
In practice, measurements are repeated M times (shots) to obtain an empirical estimate
where H j denotes the observed measurement outcome of the j-th shot. For a given data point (x, y), the prediction ft (θ, θ t ) is compared against the label y through a loss function ℓ(y, ft (θ, θ t )). For each local epoch t, a mini-batch d t ⊆ D t of size |d t | is sampled from the client dataset, and the mini-batch loss is defined as
Gradients of the expectation value with respect to circuit parameters are computed using the parameter-shift rule. For the d-th parameter,
where e d is the unit vector along the d-th coordinate of the parameter space.
Throughout this paper, we refer to the client-level minibatch loss in Eq. ( 6) as the local loss function L(θ t ), while the term global cost function C(θ t ) denotes the aggregated objective across all participating clients.
Classical optimization of VQA typically relies on gradient descent, where parameters are updated in the opposite direction of the gradient. This assumes that the gradient consistently points toward lower-cost regions. However, in barren plateau regimes, gradients vanish exponentially with system size [4], leaving the optimizer with almost no information about how to adjust parameters. As a result, standard gradient descent often stalls. To address this issue, we introduce negative learningrate (NLR) training, an optimization strategy that incorporates controlled gradient reversals to encourage exploration. Instead of exclusively following the negative gradient, NLR permits occasional updates in the positive gradient direction, thereby implementing a form of cost-conditioned ascent. The intuition is that when gradients are extremely small, reversing the update direction perturbs the parameter trajectory, enabling the model to escape flat regions and reach neighborhoods with more informative gradients.
The procedure operates as follows. At each step, a tentative gradient descent update is performed and its cost is evaluated:
• If ∆C ≤ 0 (the cost decreases or remains the same), the update is accepted:
• If ∆C > 0 (the cost increases), the update is reversed with a negative learning rate:
where η ′ > 0 controls the magnitude of the ascent step. Thus, NLR training alternates between standard descent steps and occasional controlled ascent steps triggered by failed descent attempts. This mechanism transforms the optimization trajectory into a stochastic exploration process that performs a random walk in barren plateau regions.
Guideline for Selecting the Negative Learning Rate. Choosing a suitable negative learning rate η ′ is crucial for achieving stable yet exploratory optimization. η defines the conventional descent scale, but η ′ specifies how strongly the model reacts as the cost increases. A useful heuristic is to set η ′ = κη, while κ ∈ [1.5, 3.0] depends on the circuit depth L, Hamiltonian variance σ 2 H , and hardware noise rate ν as
Smaller numbers (η ′ ≈ 1.5η) are appropriate for shallow, lownoise circuits, but bigger ratios (η ′ ≈ 3η) are advantageous for deeper or noisier settings. In practice, an initial η ′ = 2η gives a reliable starting point that can be changed based on loss oscillations or divergence behavior. This adaptive algorithm provides a reproducible mechanism for tuning η ′ based on the Hamiltonian, ansatz structure, circuit depth, and noise profile. Compute mini-batch loss Lt(θt)
Estimate gradient gt ← ∇ θ Lt(θt) (e.g., by parameter-shift rule)
6:
Tentative descent step: θtemp ← θt -η • gt 7:
Evaluate mini-batch loss: Ltemp ← Lt(θtemp)
if Ltemp > Lt(θt) then Update cost estimate: C(θt+1) ← aggregate loss evaluated at θt+1 14: end for
To avoid barren plateaus, we investigate training a single quantum variational model using mini-batch stochastic gradient optimization and loss-driven negative learning rate steps. Algorithm 1 explains the suggested negative learning rate training approach. Initially (Line 1), the cost function is assessed at the initial parameters θ 0 . Each training step involves sampling a mini-batch from the dataset (Line 3) and computing the related mini-batch loss. The gradient for the mini-batch is calculated (Line 5), followed by a preliminary standard gradient descent update (Line 6). The loss after the tentative update is measured (Line 7). If the tentative update produces a worse loss than the previous model (Line 8), a negative learning phase is initiated, and the update is reversed in the gradient direction (Line 9). Otherwise, tentative updates are accepted (Line 11). The revised cost function of the model is then calculated for future comparison (Line 13). This dynamic alternating between positive and negative learning stages allows the model to go beyond barren plateaus and seek more effective optimization routes.
IV. THEORETICAL ANALYSIS VQAs suffer severe training challenges due to barren plateaus, where gradient magnitudes drop exponentially with the number of qubits, leading to near-zero updates in gradientbased optimization [4]. The strong expressivity of deep circuits results in the cost function’s variance decaying as O(2 -d ) for d dimensions of qubit [5]. We present a comprehensive theoretical explanation of how NLR training mitigates these challenges by producing loss-conditioned non-monotone steps, increasing exploration in flat landscapes, and lowering prediction time to escape barren plateaus. Unlike techniques that combine two positive step sizes, NLR uses sign flips to sample opposite directions, reducing noise-induced errors and improving diffusion.
We use the following requirements, which are conventional in non-convex optimization and suited to quantum situations with noisy gradients Assumption 1 (Smoothness). The cost function C : R d → R is twice continuously differentiable, with L-Lipschitz gradients (i.e., ∥∇C(θ) -∇C(θ ′ )∥ ≤ L∥θ -θ ′ ∥) and bounded Hessian
Assumption 2 (Barren Plateau Region). A barren plateau area B = {θ : ∥∇C(θ)∥ ≤ ε, ∥∇ 2 C(θ)∥ ≤ L} exists, where ε = O(exp(-αd)) for dimentions d and constant α > 0.
Assumption 3 (Stochastic Gradients). The observed gradient is g t = ∇C(θ t ) + ξ t , where ξ t is noise with E[ξ t |θ t ] = 0 and covariance Cov(ξ t |θ t ) = Σ t ⪯ σ 2 I, with σ 2 = O(exp(-αd)) representing finite-shot measurement noise in VQAs.
Assumption 4 (Small Step Sizes). For learning rates η, η ′ > 0, max(η, η ′ ) ≤ η max , where η max is small enough that Taylor remainders are o(η 2 ∥g t ∥ 2 ).
For simplicity, it is assumed that cost assessments are accurate; noisy evaluations raise the likelihood of a violation.
These assumptions capture the flat, noisy landscapes of barren plateaus while maintaining analytical tractability.
We first describe the conditions under which the attempted descent fails, connect them to local curvature and noise.
Lemma 1 (Acceptance Test via Curvature). For θ t ∈ B and a small η, the change of cost is:
In plateau areas, where ∥∇C(θ t )∥ ≤ ε ≪ σ, the firstorder gradient signal is severely weak. The apparent cost variation may be impacted by both curvature and stochastic noise, depending on the local size of ∥H t ∥. If the curvature is considerable or combined with noise fluctuations, these effects may dominate the step outcome, resulting in a failure descent. When both the gradient and the Hessian are minimal, updates are practically neutral, with little change in cost.
Proof Sketch. Use the noisy gradient from Assumption 3 to apply the Taylor expansion under Assumption 1. The violation occurs when the quadratic component exceeds the weak linear decline term, which is affected by noise in the positive curvature directions. This does not imply significant curvature everywhere, but rather emphasizes that modest curvature or noise may momentarily dominate in flat areas. Full proof in Appendix A. This updated explanation shows that tentative descents may fail not because curvature is inherently enormous, but because very small gradients mixed with curvature or noise unpredictability can obscure descent directions, a phenomenon common in barren plateaus.
Lemma 2 (Backtracking Cap under Violation). Assuming E t occurs, C(θ t -ηt g t ) ≤ C(θ t ) -cη t ∥g t ∥ 2 (e.g., Armijo condition, c > 0) is a descent-only backtracking rule that requires:
In plateaus,
Proof Sketch. Derive the Armijo inequality by solving for the maximum ηt using the Taylor expansion from Lemma 1. The constrained curvature and small gradients enable the bound to diminish in B. Full proof in Appendix A.
This lemma emphasizes that in violation scenarios, backtracking drastically reduces steps, which inhibits exploration in noisy plateaus.
Next, we contrast the diffusive behavior of NLR with a backtracking technique that relies solely on descent.
Theorem 1 (Diffusion Ordering in Barren Plateaus). Suppose that p t = P(E t |θ t ). For B, the NLR update is expressed as
while the backtracking update is formulated as
The diffusion coefficients, assuming isotropic noise (Σ t = σ 2 I/d), are described as
for both approaches, estimating conditional expectations in plateaus with almost isotropic g t . While NLR’s constant η ′ preserves greater variance, backtracking’s reduced ηt (from Lemma 2) decreases D BT . Full proof in Appendix A.
This theorem demonstrates that, in contrast to the conservative shrinking of backtracking, NLR’s sign flip permits longer steps in violation directions, improving exploration.
Remark 1 (Exit-Time Scaling). In barren plateau areas, parameter updates with small step sizes η max behave like a discrete random walk accompanied by stochastic gradient noise. As η max → 0, this trajectory is approximated by a continuous diffusion process with effective coefficient D. With this approximation, the predicted time to depart a plateau region of radius R grows approximately.
2D ,s corresponds to the average first-passage time of Brownian motion in d-dimensional space [22]. This interpretation, while not a precise limit theorem, provides an intuitive notion that a higher diffusion coefficient-achieved through negative learning phases-leads to faster escape from flat loss landscapes.
NLR operates similarly to regular SGD after gradients are no longer on the plateau, where they become informative.
Theorem 2 (Post-Escape Stability). Assume G ε = {θ : ∥∇C(θ)∥ ≥ ε}. For θ t ∈ G ε , the violation probability p t → 0. The approach approximates stochastic gradient descent using infrequent disturbances. Using a Robbins-Monro schedule ( t η t = ∞, t η 2 t < ∞), the iterates nearly certainly reach stationary positions {θ :
Proof Sketch. In informative regions, linear descent dominates (Lemma 1), which reduces p t . Convergence follows traditional SGD results with bounded variance, and rare ascents do not interrupt the process. Full proof in Appendix A.
Remark 2. NLR’s sign flip provides directional diversity, reducing noise-induced inaccuracies in barren plateaus, as opposed to two positive rates that remain in the same direction (scaled). This is consistent with observations that stochastic perturbations aid escape in quantum environments [20]. However, for deep PQCs, exponential scaling remains [23], restricting NLR to shallow circuits unless supplemented with additional mitigations, such as structured initializations [10].
The quantum model used in our research is a PQC with six qubits. Amplitude encoding maps classical input vectors to quantum states. The PQC has L = 5 levels, with each layer using a series of trainable single-qubit rotation gates (R x , R y , and R z ) followed by a set of CNOT gates to entangle neighboring qubits. Each rotation gate is defined by a learnable angle. The entanglement structure is linear, with each qubit connected to its nearest neighbor to optimize the circuit depth efficiency. Following unitary evolution, the final quantum state is measured using a Hermitian observable, especially the Pauli-Z operator, and the expectation value is utilized as the model’s prediction output. The entire design achieves an appropriate balance between expressibility and trainability while limiting circuit depth to prevent excessive noise amplification.
Experimental Environment. Training employs mini-batch stochastic gradient descent with the proposed negative learning rate scheme. Each iteration samples a batch of size B = 32, conducts a forward update with η = 0.01, then reverses direction with η ′ = 0.02 when the loss grows. Measurements employ M = 1000 shots, and training lasts T = 500 steps with dynamic switching between positive and negative phases. The model parameters are evenly initialized from [-π, π]; classical layers adopt Xavier initialization; and noise and switching thresholds are controlled by constants σ = 0.05 and τ = 0.1. The simulations are run on an NVIDIA RTX 4090 GPU with 64GB RAM running Ubuntu 22.04.
In our primary experiments, we create a customized synthetic dataset with properties important to investigating barren plateaus in variational quantum optimization. Two multivariate Gaussian distributions are constructed in R d , each representing a different class. Samples are taken at random, normalized to the unit norm, and then mapped to quantum states using amplitude encoding. This encoding guarantees that the data fully leverage the Hilbert space structure, resulting in complicated cost landscapes. The categorization labels are assigned according to the original Gaussian distribution. The created dataset is partitioned into a training set (80%) and a test set (20%), with no data augmentation techniques performed. This is an ideal condition for barren plateaus because: i) High dimensionality and non-linearity are introduced by amplitude encoding. ii) The Hilbert space is filled with normalized vectors sampled at random. iii) Optimization becomes difficult, resembling the behavior of plateaus. This controlled synthetic setting enables us to carefully study the optimization behavior at different levels of barren plateau severity.
In addition to synthetic data, we have also used some publicly available datasets. The Quantum Data Set (QDataSet) [24] labels synthetic quantum states for supervised learning tasks and has been used to assess variational algorithms. The MNIST dataset [25], initially classical, has been extensively utilized in quantum investigations after preprocessing (e.g., by lowering image dimensionality and encoding quantum states). The Fashion-MNIST [26] and QSVM Toy Dataset from IBM’s Qiskit library are also used, offering a systematic examination of barren plateau effects in realistic settings beyond fully synthetic distributions.
Effect of Negative Learning Rate. However, as d increases, the final loss continues to decrease until it reaches its minimum at d = 12. Increasing d grows the Hilbert space’s representational capacity, improving separability and solution accuracy until plateau effects take over, and with significant resources. We decided on d=8 as the best dimensionality for training because it strikes a nice balance between gradient norm and model complexity, allowing for rapid exploration while minimizing computing cost.
Effect of Quantum Layer Depth on Model Performance. Table IV demonstrates that increasing the number of quantum layers improves optimization by improving circuit expressibility, with a peak at L = 5. In this experiment, we employed d = 8 input dimensionality and the identical hyperparameter setup as Table III. However, deeper configurations eventually reduce gradient magnitudes and somewhat increase loss, implying the beginning of barren plateaus due to greater entanglement and parameter correlations. These findings show that moderatedepth circuits are sufficient for effective training in the negative learning-rate regime, but complex deep circuits may require hybrid mitigation methods to maintain performance.
Effect of Quantum Noise on Model Performance. In actual QIoT technology, decoherence, gate infidelity, and readout
, where ν is the average hardware noise rate and L is the circuit depth. This modification avoids overascent in high-noise environments while allowing exploration in moderate-noise environments. Empirically, ν ≤ 0.05 maintains NLR effective. Standard error-mitigation procedures, like as zero-noise extrapolation and readout calibration, can further stabilize convergence under actual device settings.
Comparison with Momentum-Based Optimizers. To ensure that the benefits of NLR training are not only related to using a basic SGD baseline, we conducted tests using other optimizers often used in machine learning and quantum learning. We specifically compared SGD with momentum (momentum=0.9), Adam, and RMSProp, all with identical learning rate parameters. Table VI shows that momentum and adaptive optimizers increased convergence over vanilla SGD, but still experienced significant gradient erosion in barren plateau regimes. NLR training outperforms all baselines in terms of final loss and gradient norm, indicating that the sign-flip mechanism provides exploratory dynamics beyond momentum-based updates. 100% across all sample sizes, training loss lowers dramatically when more data is supplied. The gradient norm grows with increasing n, indicating more robust and informative updates. These findings emphasize the relevance of data availability in quantum-inspired models: greater datasets improve convergence while also increasing gradient signal intensity, which is crucial for avoiding barren plateaus.
Comparison with Random Noise Perturbations. To determine whether NLR’s gain is due to structured exploration or random noise, we replaced the negative learning step with additive perturbations from (i) a Gaussian N (0, σ 2 I) or (ii) a uniform U[-σ, σ] distribution, both with variance matched to η ′ = 0.02. We additionally provide a baseline that uses repeated random re-initialization, a standard strategy for escaping barren plateaus. As seen in Table VIII, NLR clearly outperforms both random perturbations, demonstrating that its benefit comes from sign-consistent, gradient-aligned reversals that exploit curvature knowledge instead of uninformed stochastic exploration.
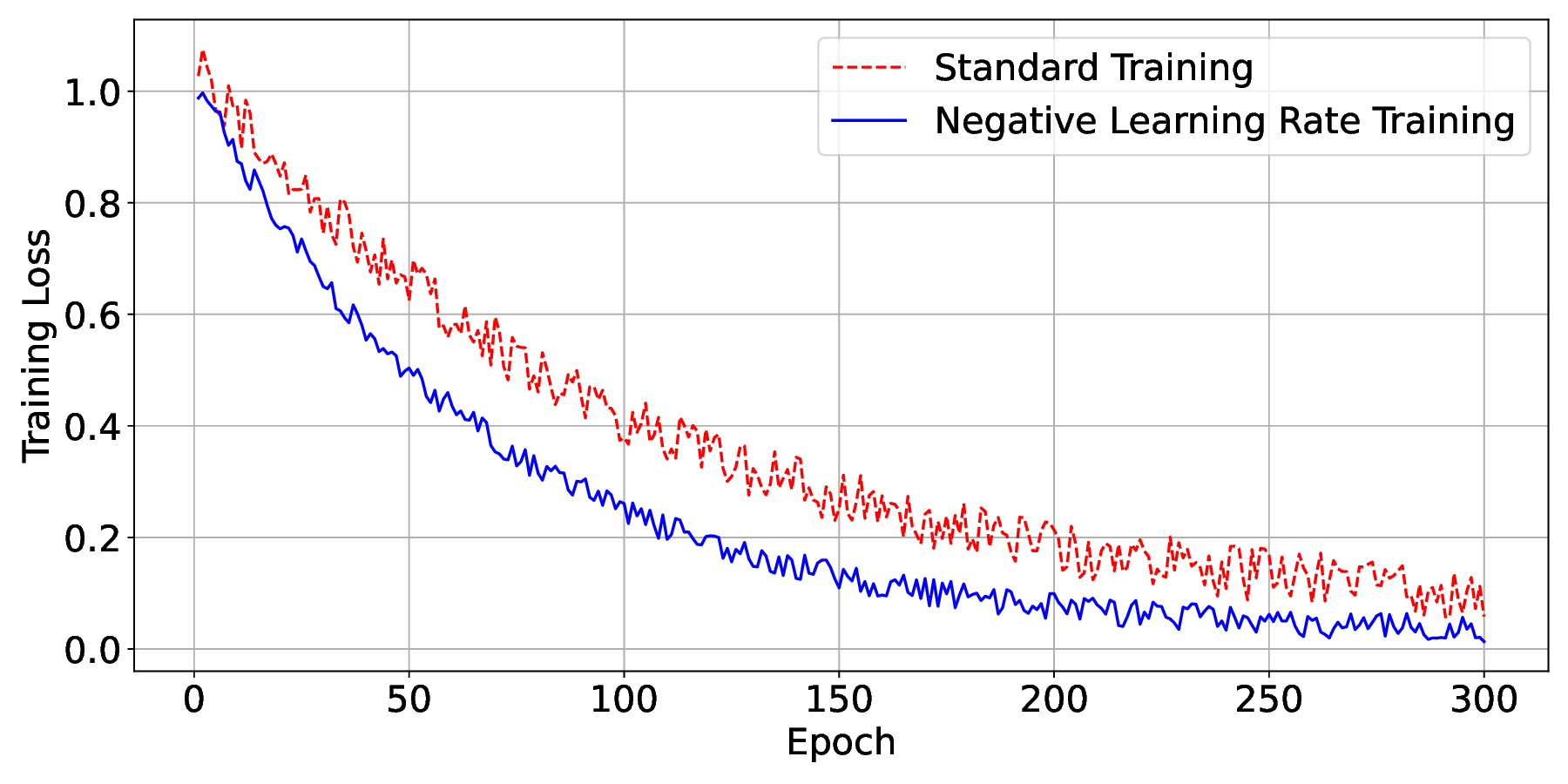
Convergence Behavior on Synthetic Data. In Figure 2, the training loss was tracked throughout all rounds of both the regular gradient descent and our proposed negative learning rate method. In the early stages of training, both approaches showed a cost reduction; however, conventional optimization rapidly plateaued, failing to make progress. The figure also illustrates that the transient increase in loss during negative learning phases is due to active exploration, rather than slower convergence. These brief reversals assist the optimizer in escaping flat barren zones by restoring gradient variety, resulting in a faster overall descent to minima. Thus, occasional loss spikes are a necessary trade-off for greater global convergence stability. After exiting the first barren plateau area, the gradient signal in NLR becomes more stable than in standard descent; therefore, the fluctuation amplitude decreases in the subsequent stages of training, even if the exploration effect was greater in the early stages. When the cost grew, the model used negative gradient ascent steps to explore alternative trajectories that led to more favorable optimization routes. The summary of the convergence results is shown in Table IX.
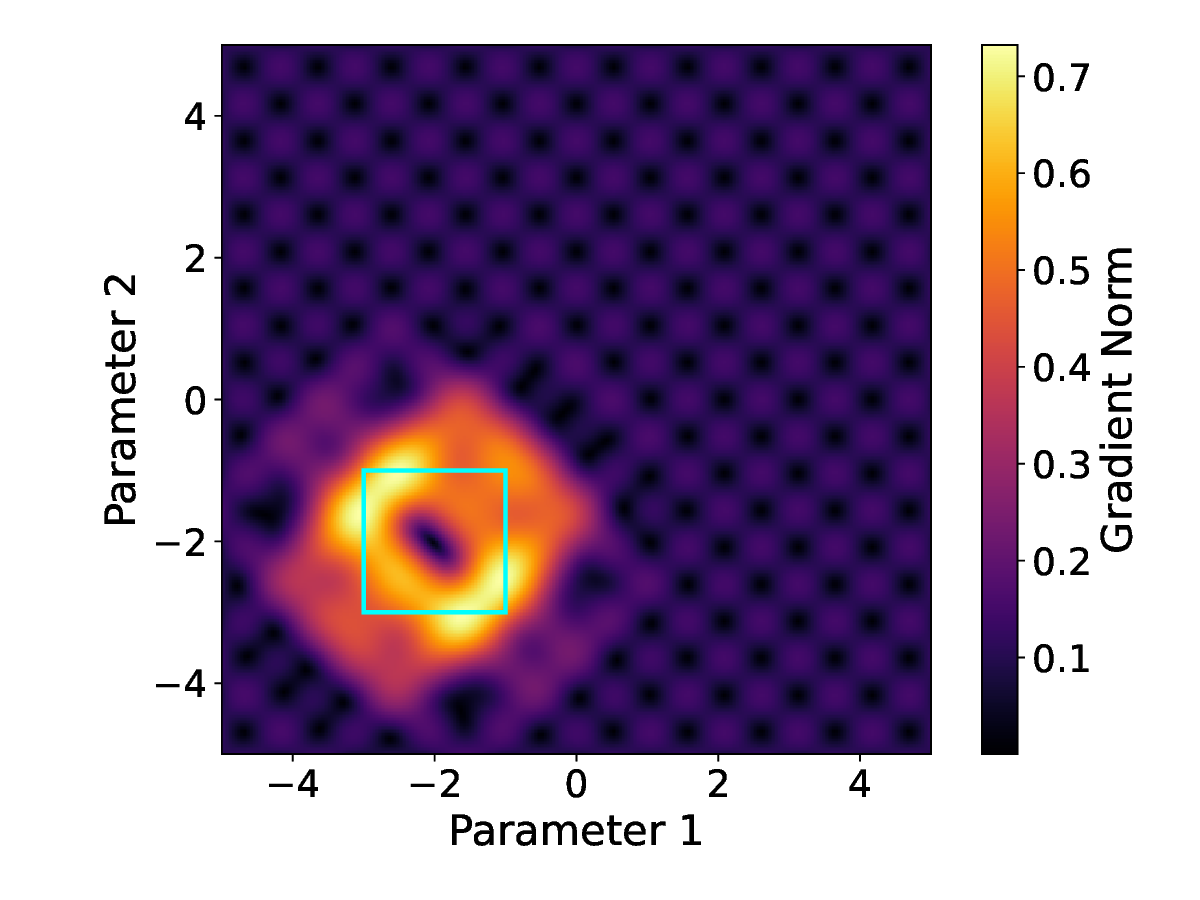
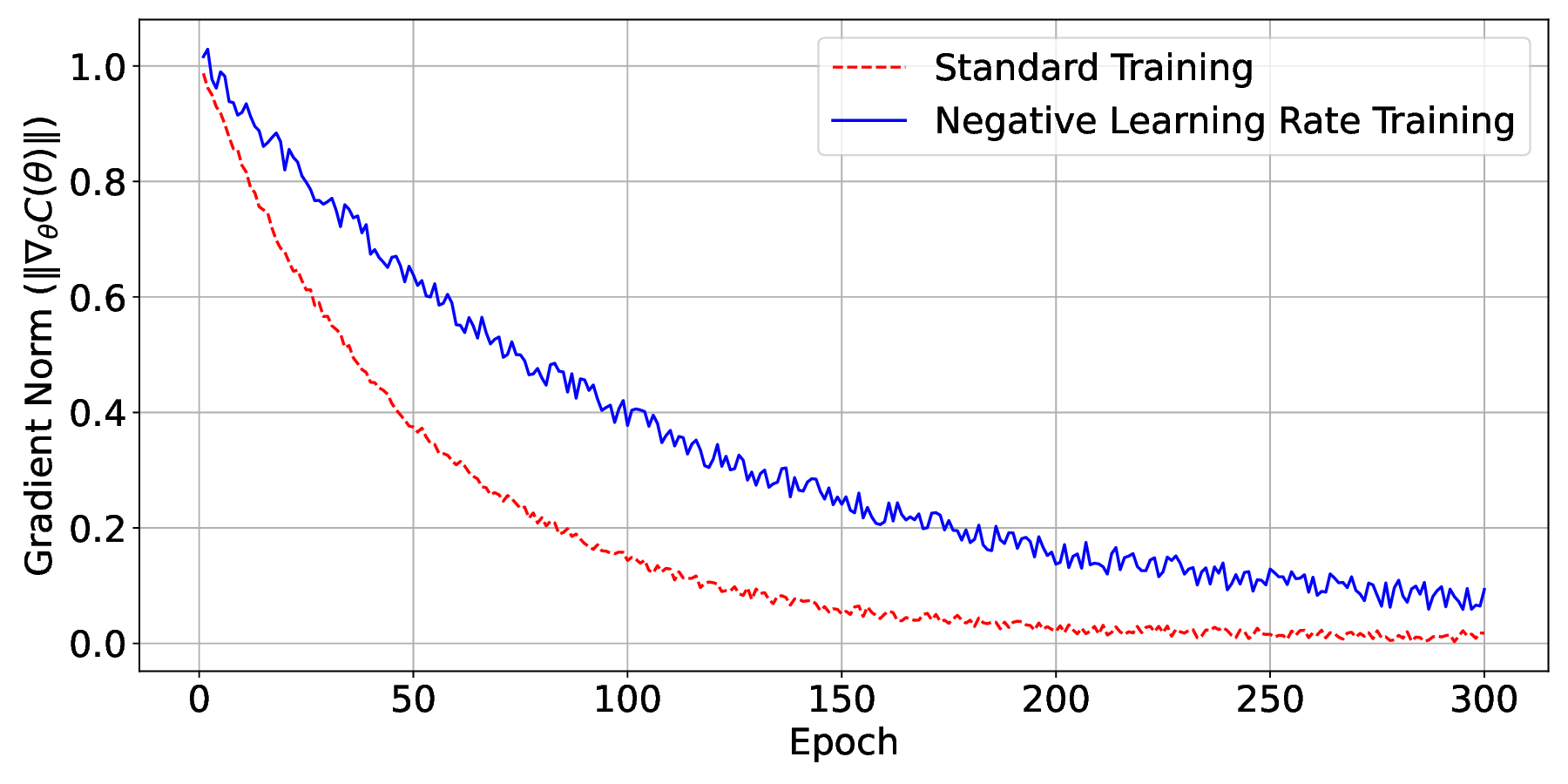
Gradient Norm Analysis. To better understand the structure of barren plateaus in variational quantum optimization, we track the ℓ 2 -norm of the gradient ∥∇ θ C(θ t )∥ while training in Figure 3 . This statistic represents the magnitude of the signal accessible for optimization. In conventional training, we found that the gradient norms continuously decreased with time, achieving near-zero values within the first few hundred steps. This behavior is typical of barren plateaus, in which the optimization landscape becomes flat and non-informative, forcing the optimizer to stall because of diminishing gradients.
On the other hand, models that were trained using negative learning rate phases behaved quite differently. Gradient norms continued to decline in the early phase; they demonstrated occasional recovery spikes in gradient magnitude caused by the reversed update direction as the loss increased. These recoveries show that the negative learning steps helped shift the parameter trajectory away from flat regions and toward locations where the gradient is more informative. During training, this resulted in a more dynamic and exploratory optimization route with higher average gradient norms, allowing the model to escape potentially inescapable plateaus. This difference is evident in the simulated gradient norm curves, where the negative learning-rate curve swings with more amplitude and lasts longer than the standard training curve, which flattens rapidly. This suggests that selective gradient ascent enhances gradient flow and prevents stagnation in barren areas.
Classification Accuracy. We evaluate our approach’s classification accuracy against both the custom synthetic dataset and numerous publicly accessible datasets Quantum Data Set (QDataSet) [24], the MNIST dataset [25], the Fashion-MNIST dataset [26], and the QSVM Toy Dataset from IBM’s Qiskit library in Table X. For each dataset, we use the standard method of preprocessing to decrease dimensionality and translate classical data into quantum states using amplitude or angle encoding.
Across these datasets, negative learning rate training consistently outperforms standard training in terms of convergence speed and classification precision. Notably, on MNIST and Fashion-MNIST, we observe up to a 5-10% lower loss values relative to the baseline, with greater gradient norms and a continuous loss reduction over training. These findings show that, while both models may achieve equivalent accuracy in basic datasets, the advantages of negative learning become more evident in complex or high-dimensional data environments. The strategy improves the capacity of the model to negotiate challenging cost landscapes, avoid barren plateaus, and achieve superior generalization performance in real-world scenarios.
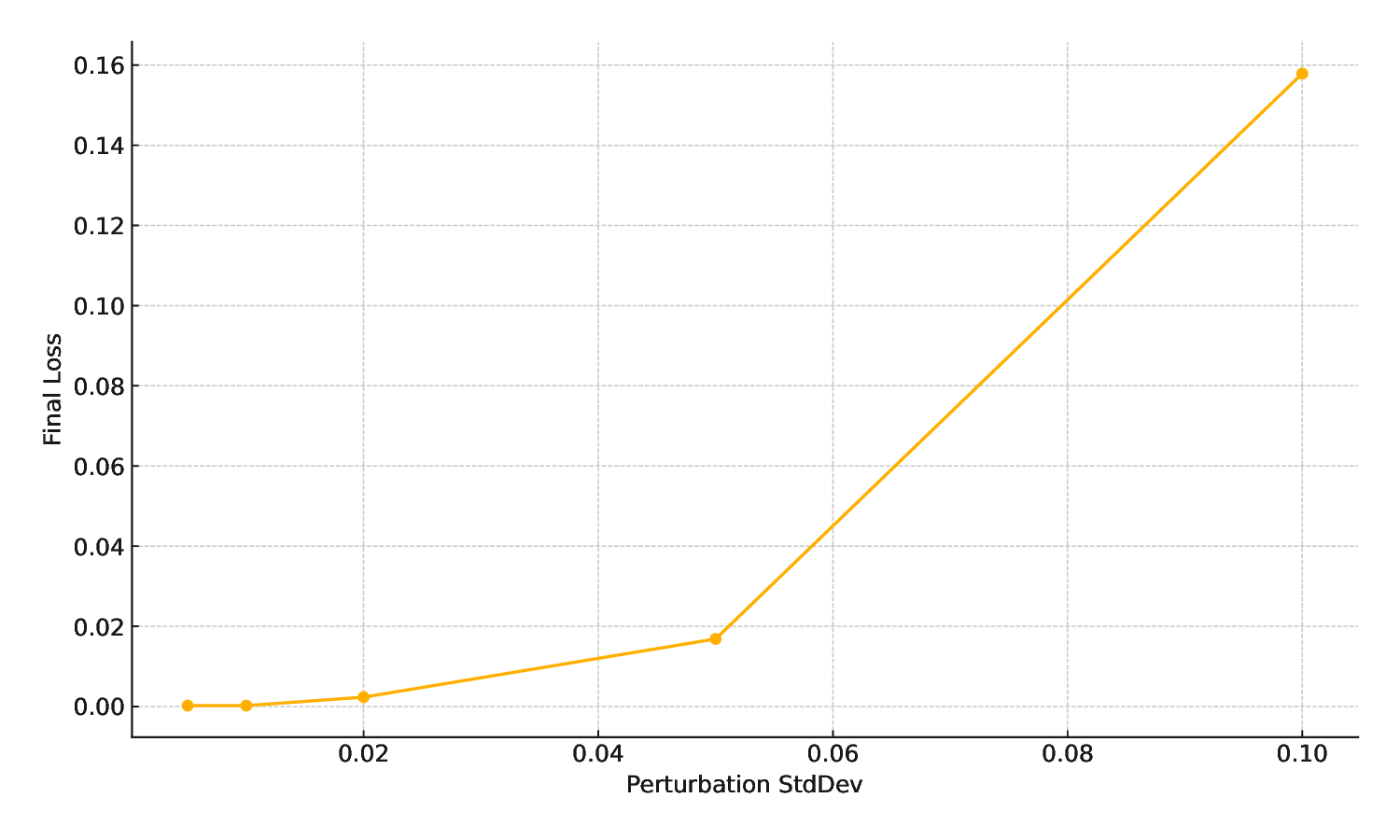
Final Loss vs. Perturbation StdDev. Figure 4 compares the influence of noise size (perturbation standard deviation) during corrective stages to the final training loss. As predicted, small perturbations (e.g., 0.005-0.02) aid in the avoidance of local traps, while without disturbing training. Higher noise levels (greater than 0.05) decrease efficiency, causing the [17], (iii) identity-based initialization [10], and (iv) negative learning rate updates (this work). To achieve comparable results, all simulations employ the same variational quantum model, training cost, and the same synthetic dataset.
Our findings show that, while shallow circuits and creative initialization provide an escape from barren plateaus, they diminish model expressibility or lose effectiveness as training advances. Layer-wise training increases convergence robustness, but adds substantial computational cost. In contrast, negative learning rate training provides optimal balance of accuracy, loss reduction, and training duration while not requiring architectural changes. This makes it an excellent choice for lightweight mitigation of barren plateau at the optimizer level in both simulated and hardware-constrained scenarios.
VI. LIMITATIONS Although negative learning rate training shows promising results in escaping barren plateaus, there are a few limitations to consider. To avoid overshooting and destabilizing training, the approach introduces a new hyperparameter: the negative learning rate η ′ , which must be carefully set relative to the regular learning rate η. Poorly selected values might cause divergent behavior or unsatisfactory convergence. Additionally, while the technique helps avoid flat regions, it is not certain that the optimizer will identify globally optimum solutions. Importantly, when the system is toward a true minimum, the tentative descent step does not increase the loss (i.e., ∆C ≤ 0), and so the negative learning condition is not activated. This means that NLR does not mistakenly “jump out” of a true minimum even though the gradient is small. However, it may reach severe local minima or fluctuate around saddle points, especially in high-dimensional parameter spaces. Although this work focuses on the proposed negative learning-rate technique in a QML classification environment, the underlying process is directly applicable to other VQA like VQE and QAOA for future studies. Finally, in hardware imple-mentations, particularly on QIoT devices, additional gradient assessments and backtracking steps can increase execution time and resource overhead, limiting their effectiveness in lowlatency or resource-constrained environments.
In this research, we introduced negative learning rate training, a unique optimizer-level strategy to escape barren plateaus in VQAs for the QIoT devices. Unlike prior strategies that rely on architectural constraints, circuit redesign, or complex initialization schemes, our method works dynamically by reversing the gradient direction as the cost increases, allowing for exploration in flat optimization landscapes where traditional training fails. We theoretically showed that this approach leads to random walk-like behavior in parameter space, allowing the model to avoid regions with vanishing gradients. Simulations 2D , as derived from the radial Bessel process or mean-field approximations [18]. Since our update steps are small (η max ≪ 1), the discrete process is well-approximated by this continuous limit.
Proof of Theorem 2. In the informative region G ε = {θ : ∥∇C(θ)∥ ≥ ε}, we have g ⊤ t ∇C(θ t ) ≥ ε 2 . By Lemma 1, the violation probability satisfies Pr(E t ) ≤ O ηLσ 2 d ε 2 → 0 as η → 0.
Thus, almost all updates are standard descent steps ∆θ t = -ηg t . Classical stochastic approximation results [22] then guarantee convergence: with a Robbins-Monro step schedule, iterates converge almost surely to stationary points; with constant η, we converge to an O(η) neighborhood in expectation. Rare ascent steps do not alter this behavior since p t is vanishingly small.
Effect of Training Epochs on Model Performance. Table II shows that increasing the number of training epochs continuously improves both the final loss and the gradient
noise are inevitable disturbances that arbitrarily skew cost and gradient estimations. Unlike controlled perturbations in simulation, such noise can both resemble and negate the desired impact of negative learning. To ensure stable optimization, the negative learning rate is scaled by the effective noise level:
t H t g t + O(η 2 t ∥g t ∥ 3 ) ≤ -c∥g t ∥ 2 . Hence, ηt ≤ 2 g ⊤ t ∇C(θ t ) -c∥g t ∥ 2 g ⊤ t H t g t + O(η 2 t ∥g t ∥).
📸 Image Gallery