From Illusion to Intention: Visual Rationale Learning for Vision-Language Reasoning
📝 Original Info
- Title: From Illusion to Intention: Visual Rationale Learning for Vision-Language Reasoning
- ArXiv ID: 2511.23031
- Date: 2025-11-28
- Authors: Changpeng Wang, Haozhe Wang, Xi Chen, Junhan Liu, Taofeng Xue, Chong Peng, Donglian Qi, Fangzhen Lin, Yunfeng Yan
📝 Abstract
Recent advances in vision-language reasoning underscore the importance of thinking with images, where models actively ground their reasoning in visual evidence. Yet, prevailing frameworks treat visual actions as optional tools, boosting metrics but leaving reasoning ungrounded and crops ineffective. This gap gives rise to the illusion of thinking with images: models seem visually grounded but rely on context-agnostic actions that neither refine perception nor guide reasoning toward correct answers. We address this problem by reframing visual actions as core reasoning primitives rather than optional tools, which we term visual rationalization, the visual analogue of textual Chain-of-Thought. Building on this insight, we propose Visual Rationale Learning (ViRL), an end-to-end paradigm that grounds training in the visual rationale itself. ViRL integrates (1) Process Supervision with ground-truth rationales, (2) Objective Alignment via step-level reward shaping, and (3) Fine-Grained Credit Assignment to distinguish correct, redundant, and erroneous actions. By ensuring each action contributes meaningfully to the reasoning chain, ViRL enables models to "get the right answer for the right visual reason". Trained purely with end-to-end RL, ViRL achieves state-of-the-art results across benchmarks spanning perception, hallucination, and reasoning. This work establishes visual rationalization as a taskagnostic, process-grounded paradigm for building transparent, verifiable, and trustworthy vision-language models.📄 Full Content
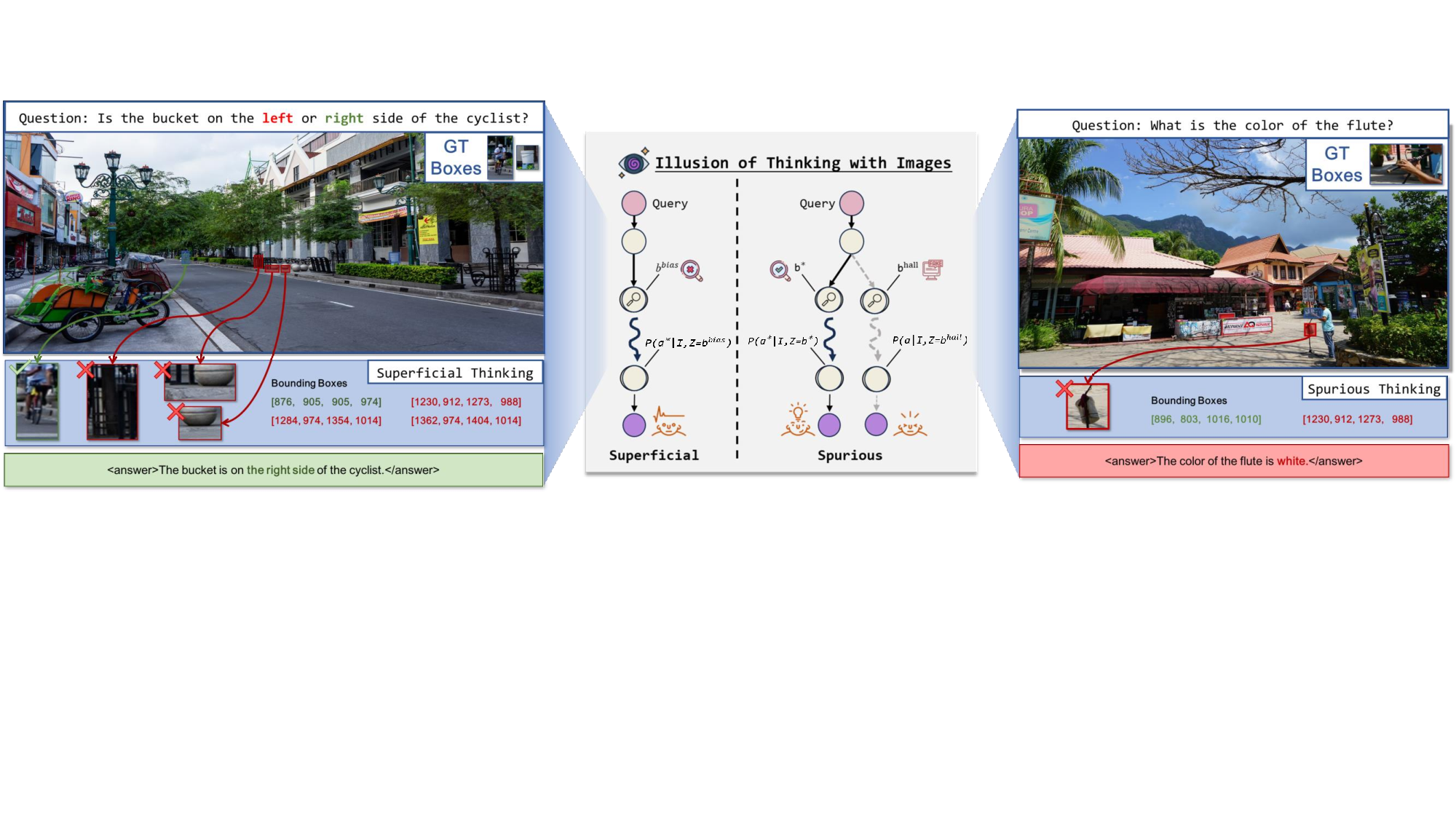
The true potential of “thinking with images” lies in its ability to transform a model from a passive observer into an active participant [44,47]. By performing zoom-in operations, a model can decompose a complex visual scene into a series of focused inquiries, mimicking the human ability to scrutinize details and gather evidence. This active perception promises to yield models that are: (a) more robust, grounding each step of their reasoning in specific visual evidence rather than relying on spurious correlations; (b) more efficient, by concentrating computational resources on relevant details; and (c) more trustworthy, by producing a transparent and verifiable visual audit trail for their decisions. In this ideal vision, a simple zoom-in is not merely an action but a Figure 2. Examples illustrating the illusion of “thinking with images”. Even when models execute visual actions, they often zoom into irrelevant regions (superficial) or select misleading cues (spurious), creating the false impression of grounded reasoning while contributing little to answering the question. deliberate, structured component of a causal reasoning chain.
However, a significant gap exists between this ideal and the current reality. As illustrated in Fig. 2, we identify a fundamental, underexplored problem we term the illusion of “thinking with images”. This illusion arises when models appear to engage in image-grounded reasoning, yet their visual actions are, in practice, superficial or even spurious, contributing little to the final decision. This issue stems not merely from a choice of learning algorithm, but from a deeper conceptual misunderstanding. The prevailing approach treats visual actions as a form of “tool use”, where they are considered as an auxiliary mechanism to inspect visual details. This perspective naturally leads to outcomebased supervision, as the zoom-in “tool” is only optional for maximizing task success.
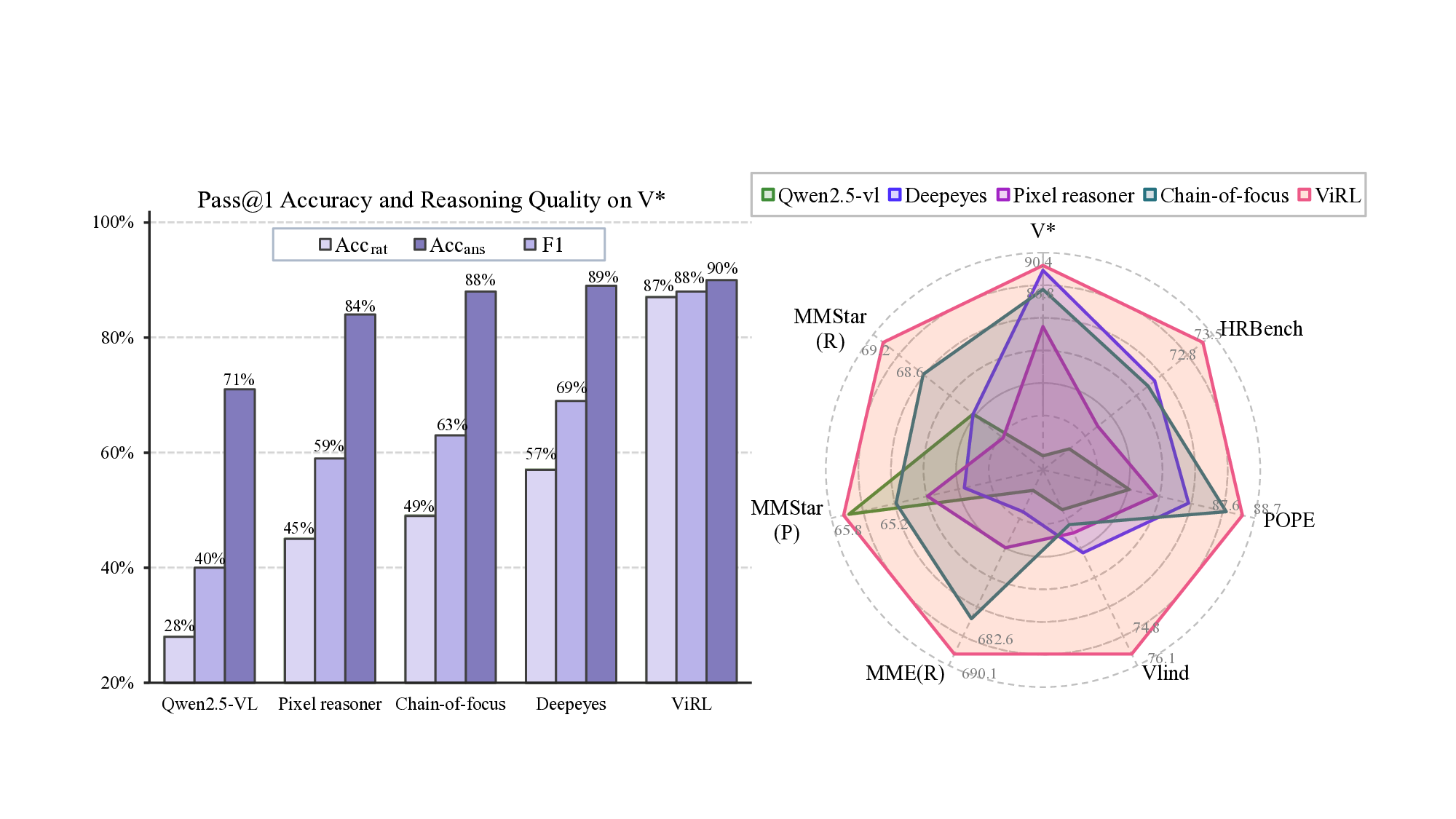
The consequence of this view is a stark disconnect between actions and outcomes. As shown in Figure 1, some models achieve high final-answer accuracy (e.g., Deepeyes [61] at 89.1%) while exhibiting low accuracy in their visual actions (57%) and performing an excessive number of operations. Such high performance on a benchmark belies a fragile and inefficient process. As shown in our analyses, this illusion results in models that are: (1) brittle, as their shortcut behaviors collapse under distribution shifts; (2) inefficient, inflating inference costs with redundant actions; and (3) untrustworthy, as their spurious reasoning traces undermine interpretability in high-stakes applications.
To break this illusion, we must move beyond the “tooluse” metaphor. The sequence of zoom-in operations is not an auxiliary procedure but the reasoning process itself. We clarify and formalize this concept as Visual Rationalization-the visual analogue of textual CoT. In this framework, the reasoning unfolds through an explicit sequence of zoom-in operations that progressively highlight the evidence underlying each conclusion. This reframing elevates zoom-in operations from simple tools to the core components of transparent and verifiable rationales, shifting the learning paradigm from outcome-centric to process-grounded learning and ensuring that models “get the right answer for the right reason”.
To realize this, we introduce Visual Rationale Learning (ViRL), an end-to-end learning paradigm that explicitly optimizes the fidelity and utility of the visual reasoning process. A primary obstacle to learning such rationales has been the absence of process-level supervision. Our first key contribution is a process-grounded dataset, which provides ground-truth visual rationales that serve as the evidence foundation for each task. Beyond supervision, this dataset also employs a reasoning-centric filtering strategy to retain tasks that genuinely require image-grounded reasoning. With this data, ViRL implements two novel learning mechanisms:
• Rationale Fidelity Reward, which measures the fidelity of the visual rationale by directly evaluating how closely the model’s sequence of visual foci (i.e., zoom-in coordinates) matches the ground-truth evidence; • Rationale Utility Shaping, a mechanism that shapes the model’s policy by defining the utility of each zoom-in action (e.g., correct, redundant, or erroneous), teaching the model to make more deliberate and efficient choices. By directly optimizing the reasoning process, ViRL not only sets a new state-of-the-art on key benchmarks but also produces models with demonstrably superior accuracy and efficiency in their visual rationales. This work establishes a new path for building verifiable and trustworthy visionlanguage models, demonstrating that to truly think with images, an agent must ground its reasoning in coherent and causally meaningful visual evidence.
Large Visual Reasoning Models. Recently, many reasoning models have been proposed to handle more complex tasks due to their strong ability to decompose these difficult questions into simple, small queries. Early methods rely only on text to decompose these complex tasks and do not
Cropped Image 1 Cropped Image 2 analyze the full inputs [24][25][26]59]. Like Visual cot [37], VPD [14], V* [52], Inght-V [10], and Llava-cot [56]. These methods decompose the visual questions into sample queries in Chain-of-Thoughts(CoTs). However, they tend to ignore the visual clues when thinking in deep chains. In the latter, many methods introduce visual tools to think with images rather than text only. Visual Sketchpad [15], DetToolChain [53], Cropper [19], toolformer [35], AutoCode [44], and react [57] understand complex tasks and call visual tools like zoom-in, drawing line, and depth perception [7] as additional auxiliary tips through in-context learning without training. However, these methods are mainly made up of visual workflows and cannot truly understand the tools. Later, Models like o3 [32], Pixel Reasoner [47], Deepeyes [61], Chain-of-focus [60], and OpenThinkIMG [41] demonstrate the ability by dynamically applying visual tools to reasoning in multimodal chains of thoughts [12,42,54]. While these methods improve visual reasoning, their outcome-supervised rewards make the visual thinking process error-prone and susceptible to hallucination.
Reinforcement Learning for MLLM Reasoning. Reinforcement Learning, as a technique in the post-training of MLLMs [8,29,43,45], has been shown to effectively enhance reasoning ability in visual reasoning tasks. In particular, Proximal Policy Optimization (PPO) [36] has become the most widely adopted algorithm for aligning multimodal reasoning behaviors with reward signals and has been extensively applied in recent vision-language alignment frameworks [33]. More recently, GRPO [8] has been introduced as an efficient alternative, offering faster convergence and improved sample efficiency in complex multimodal reasoning scenarios. Later, to alleviate the vanishing advantages problem [45] during RL training, SSR [45] and DAPO [58] was proposed. Several works have further refined the optimization process by either redesigning the reward function or adjusting the advantage estimation. VLM-R1 [39] incorporates multi-component rewards, such as accuracy, format, and REC, to stabilize training. HICRA [48] discovered emergent reasoning hierarchy in reasoning LLMs and propose to modulate the advantages on critical planning tokens, leading to better strategic exploration and training results. In this paper, we focus on shaping reward and credit assignment to ensure that models not only reach correct answers but also ground their reasoning in coherent visual rationales.
We first formalize the challenge of “thinking with images” by identifying the core constraint of standard Vision-Language Models (VLMs): inherent partial observability. When a VLM first processes an image, its visual encoder creates an information bottleneck. Constrained by finite resolution, this encoding obscures or loses the fine-grained details crucial for complex reasoning. The model, therefore, operates on an incomplete belief state, not the full image.
To overcome this, the model must transform from a passive observer into an active reasoner that sequentially gathers new evidence to resolve uncertainty. This transforms the task into a sequential decision-making problem. We define an action space that allows the model to interleave internal logic with active perception. At any step, the policy π θ can choose from two distinct actions: • Textual Rationalization. The model generates text to construct hypotheses, devise next-step strategies, and integrate multimodal evidence into coherent reasoning. • Visual Rationalization. The model executes a visual operation (such as zoom-in on region b k ) to actively probe the image and acquire new, high-fidelity information. As noted in our introduction, this is the visual analogue of textual Chain-of-Thought. Our goal is to learn a policy π θ that generates an optimal sequence of these textual and visual rationales. A naive solution would employ reinforcement learning (RL) using an outcome-only reward, to activate reasoning ability. The core deficiency of this signal is that it is fundamentally indiscriminate. It cannot distinguish between a correct answer achieved via a lucky guess and one derived from a faithful, step-bystep visual grounding process. Worse, it often creates a pathological local optimum: a policy may discover that exploiting spurious correlations or “hallucinating” a plausible-sounding answer is a lower-cost, more facile strategy for obtaining a reward than undertaking a complex, multi-step visual rationalization process that carries a higher risk of failure. The outcome-only signal, therefore, can perversely discourage the very reasoning we aim to elicit.
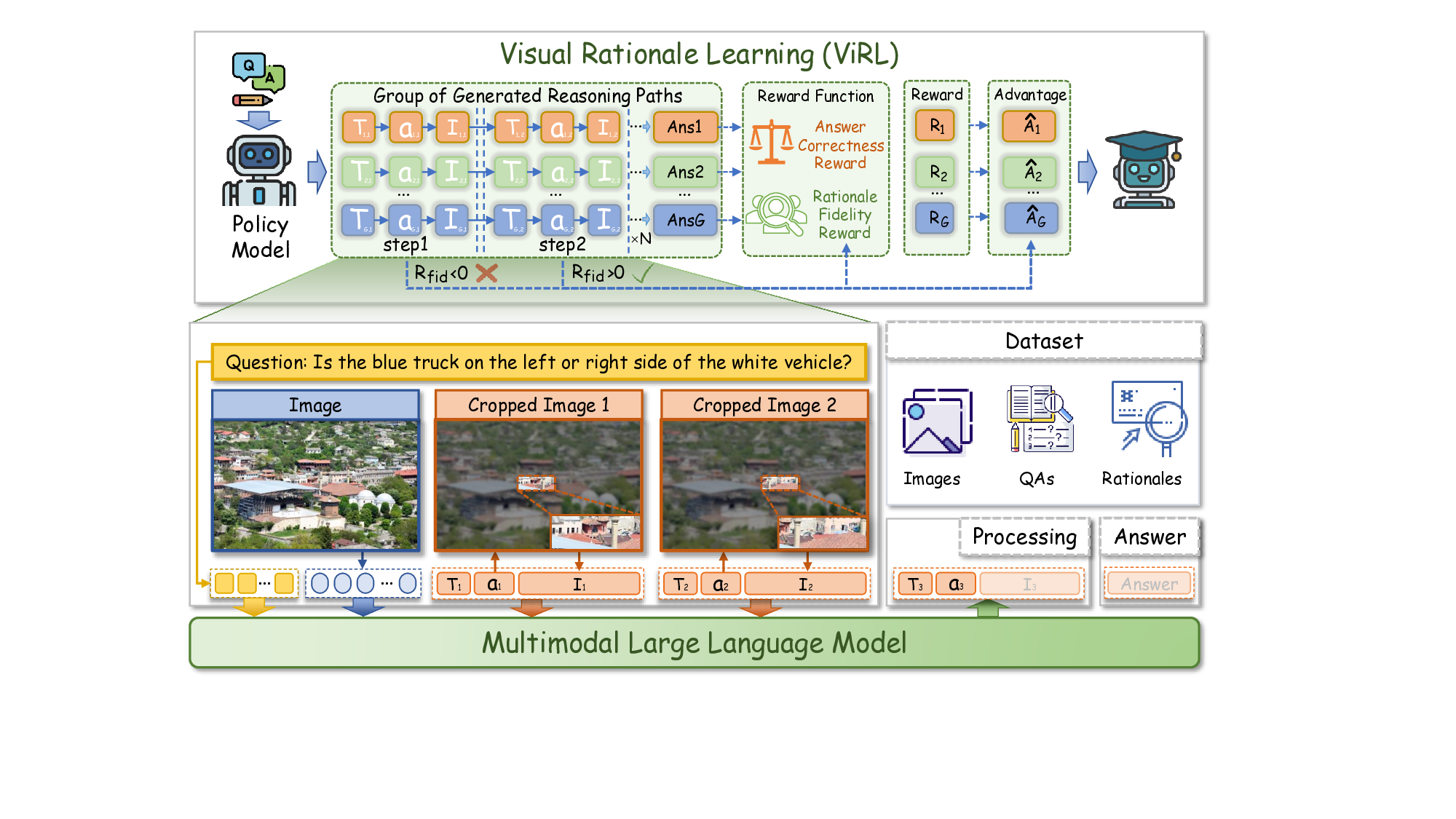
To break this illusion, we shift the training objective from outcome accuracy to process-level fidelity and utility, ensuring that each zoom-in action contributes meaningfully to the reasoning trajectory. We introduce Visual Rationale Learning (ViRL), a principled framework that learns a policy by explicitly rewarding the reasoning process. ViRL is built on two insightful components designed to solve the challenges of hallucinated rationales and coarse credit assignment: • Rationale Fidelity Reward that inextricably links the quality of the reasoning process to its ultimate goal.
• Fine-Grained Credit Assignment that identifies the precise contribution of each heterogeneous rationale.
Rationale Fidelity Reward. Our objective is to learn a rational policy that maximizes task utility while maintaining faithful and concise visual reasoning. Given a query Q and trajectory τ , we optimize
where the total reward jointly evaluates answer correctness, format compliance, and process fidelity:
This formulation emphasizes process-level supervision, where each visual rationale directly supports the model’s perceptual and inferential steps. Each rationalization step a k receives a fidelity reward based on its spatial alignment
with the reference rationale b * k . Specifically, it comprises a signed correctness term that directly reinforces plausible reasoning while penalizing misaligned ones, and a discrete refinement bonus activated beyond a soft threshold h 0 , which further encourages precise spatial alignment as IoU increases. Formally,
where sign(u k -h 0 ) provides the signed correctness signal, η controls the magnitude of the refinement bonus, and ⌊•⌋ denotes the discretization operator that introduces stepwise gains. Specifically, ⌊(u k -h 0 )/∆h⌋ increases by one for every ∆h improvement in IoU, thereby modeling progressive alignment refinements beyond the soft threshold h 0 . If no visual action is taken, R fid (a k ) = 0.
Aggregating the step-level rewards across the reasoning trajectory yields the overall fidelity score:
where averaging ensures fair credit assignment across variable-length trajectories. A smooth redundancy penalty ρ(C k ) grows beyond a soft budget, discouraging repetitive or overlapping rationales and promoting concise reasoning.
Fine-Grained Credit Assignment. With the trajectory reward R(τ ), we confront the second challenge-the credit assignment problem, which is further exacerbated by the heterogeneous nature of our action space. A single trajectorylevel advantage is too coarse, indiscriminately crediting or blaming all steps and encouraging erroneous visual rationales within successful trajectories. We solve this with a bi-level credit assignment strategy that modulates the advantage signal based on rationale-specific quality.
• Trajectory-Level Advantage: First, we compute a coarse advantage signal for the entire trajectory τ i by comparing its reward to the average of a group of G trajectories [38]:
This indicates whether the trajectory is globally advantageous (A i > 0) or disadvantageous (A i < 0). • Rationale-Level Adjustment: To obtain fine-grained credit assignment, we differentiate the coarse advantage signal. Textual rationales preserve the original advantage A i , whereas visual rationales are adaptively modulated by their fidelity (Eq. 3). The resulting adjusted advantage for each action a t is denoted as Âi,t :
where h(a t ) is a simple modulator based on the rationale:
This logic provides a highly principled teaching signal:
• In an advantageous Trajectory (A i > 0): the model amplifies credit for high-fidelity visual rationales (h good > 1) while attenuating it for low-fidelity ones (h bad < 1). This guides the policy to attribute success to its precise and faithful visual reasoning. • In a disadvantageous Trajectory (A i < 0): the model amplifies blame for bad visual rationales (h bad > 1) and mitigate blame for any good ones (h good < 1). This guides the policy to recognize that failure stems from inaccurate or misleading visual reasoning.
Policy Optimization. This fine-grained advantage Âi,t is then used to update the policy π θ via a standard PPO-style objective. This bi-level ViRL framework compels the policy to learn the true contribution of each visual rationale, moving the model from illusion to intention by ensuring it generates reasoning that is not just faithful, but also utility-enhancing.
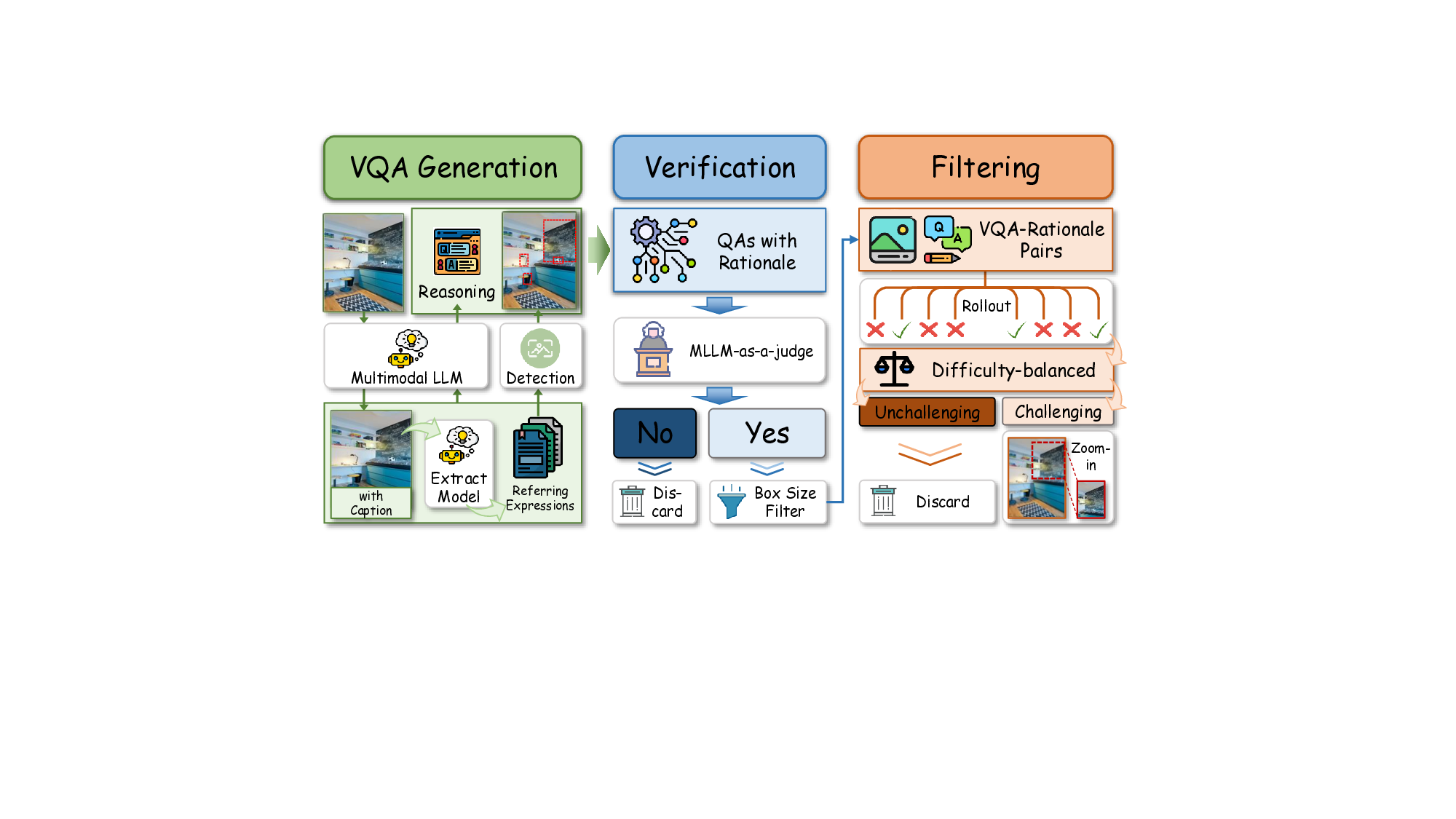
As illustrated in Figure 4, the dataset is constructed through a three-stage pipeline comprising generation, verification, and filtering. The pipeline ensures both high-quality reasoning data and explicit process-level supervision, forming the foundation of the visual rationale learning paradigm.
(1) Generation. We construct reasoning-oriented VQA supervision by leveraging region captions from GRIT [51]. For each region, the model extracts referring expressions and generates questions that require implicit visual reasoning rather than explicit object naming. The corresponding visual rationale is obtained by localizing the referring expression with a detector and padding the predicted box to capture necessary context. To maintain region diversity, we apply NMS to filter overlapping candidates. This process yields question, answer, rationale region triplets that serve as supervision for training visual reasoning behaviors.
(2) Verification. The generated VQA-rationale pairs are subsequently verified via MLLM-based consistency checks, evaluating (i) whether the answer is correct with respect to the visual input, and (ii) whether the annotated rationale aligns with the reasoning target implied by the question. Each sample is re-evaluated using the hinted rationale region and corresponding QA pair, and only those satisfying both semantic correctness and rationale consistency are preserved.
(3) Reasoning-Centric Filtering. Finally, we apply a reasoning-centric filtering stage to ensure that the remaining samples genuinely require image-grounded reasoning. First, samples with overly large rationale regions are removed, as such tasks can typically be solved without localized visual evidence. Second, we conduct an offline difficulty balancing by rolling out multiple reasoning attempts: questions solvable without visual grounding are down-weighted, while those that critically depend on localized cues are retained. This process yields a dataset that encourages models to think with images, providing reliable step-level visual rationales for process-grounded learning.
We construct a 200k-scale dataset by collecting samples from Visual-Cot [37], GQA [17], TextVQA [40], Visual7W [62], InfographicsVQA [31], and GRIT [51], covering general understanding, visual grounding, reasoning, and OCR tasks. After processing within the data generation pipeline (Sec . 3.2), 8k high-quality samples are retained. Since all data have open-vocabulary answers that are difficult to evaluate, we repackage them as multiple-choice questions by synthesizing 3-7 plausible distractors from the VQA and
We conduct comprehensive evaluations against a wide range of competitive baselines. For closed-source models, including GPT-4o [34] and GPT4o-mini [33]. For open-source models, we benchmark against state-of-theart visual language models such as Qwen2.5-VL [5] and LLaVA-OneVision [20]. We also compare with workflowbased methods like Visual Sketchpad [15], SEAL [52],
and DyFo [21], which design explicit multi-step reasoning pipelines. In addition, we evaluate against recent “thinking with images” approaches, including Deepeyes [61], Chainof-focus [60], and Pixel Reasoner [47]. For evaluation, we adopt a comprehensive benchmark suite spanning three complementary dimensions of vision-language reasoning: (i) Perception-Oriented benchmarks, including fine-grained perception (V*) [52] and high-resolution perception (HRBench) [49]; (ii) Reliability-Oriented benchmarks, covering hallucination tendency (POPE) [23] and language-prior reliance (VLind) [18]; and (iii) Reasoning-Oriented benchmarks, as-sessing general multimodal reasoning capabilities (MME(R) [11] and MMStar [6]). This comprehensive design ensures a fair and multi-dimensional comparison. In addition to external benchmarks, we further report two internal diagnostics that quantify how models engage in image-grounded reasoning: Rationale Accuracy, which measures whether visual zoom-ins successfully hit the ground-truth evidence, and Rationale Count, which captures the frequency of visualthinking steps. We also provide a joint F 1 score that summarizes answer correctness and rationale fidelity. Complete definitions of these metrics are included in Appendix A.
Perception-Oriented Results. As shown in the Perception-Oriented results of Table 1, fine-grained and high-resolution perception remain core challenges for vision-language models. Model scaling offers limited benefits (Qwen2. score, indicating strong resistance to hallucination. Notably, ViRL also attains the best performance on VLind, reflecting its reduced reliance on language priors. This is not merely a byproduct of lower hallucination rates: VLind explicitly probes whether models actively ground their predictions in visual evidence. Higher VLind scores reflect that the model actively relies on image-grounded cues to override textual regularities based on language priors. ViRL’s superior performance (+8.7 compared to baseline) demonstrates that its active visual reasoning effectively mitigates languageprior-induced hallucinations, confirming that the model genuinely leverages visual evidence to guide its predictions.
Reasoning-Oriented Results. As shown in the Reasoning-Oriented results of Table 1, ViRL achieves the highest performance (691.0 on MME(R) and 67.5 on MMStar † ), outperforming both proprietary and open-source models. Unlike prior methods that employ tools as auxiliary aids with limited gains (e.g., Deepeyes reports reductions of 10 on MME(R) and 1.2 on MMStar † ), ViRL instead elevates the zoom-in operation into a core reasoning primitive, ensuring that each visual action contributes meaningfully to the inference trajectory and remains both informative and image-grounded. This process-level supervision yields more stable perception, coherent multi-step inference, and superior performance on complex reasoning tasks, demonstrating that faithful and interpretable reasoning naturally emerges when perception and reasoning are trained as a unified, evidence-driven system.
Does process supervision matter? As shown in Table 2, removing the rationale fidelity reward (answer-only supervision) collapses the model’s ability to think with images. Although answer accuracy remains superficially strong (87.6%), the absence of explicit visual rationale signals leads to the disappearance of intermediate visual reasoning traces. This reveals that under pure outcome supervision, the model simply learns to “answer in context” by exploiting latent correlations in the prompt and visual content, bypassing the need for actual visual rationale invocation. To probe this effect, we analyze how different reward designs shape be-
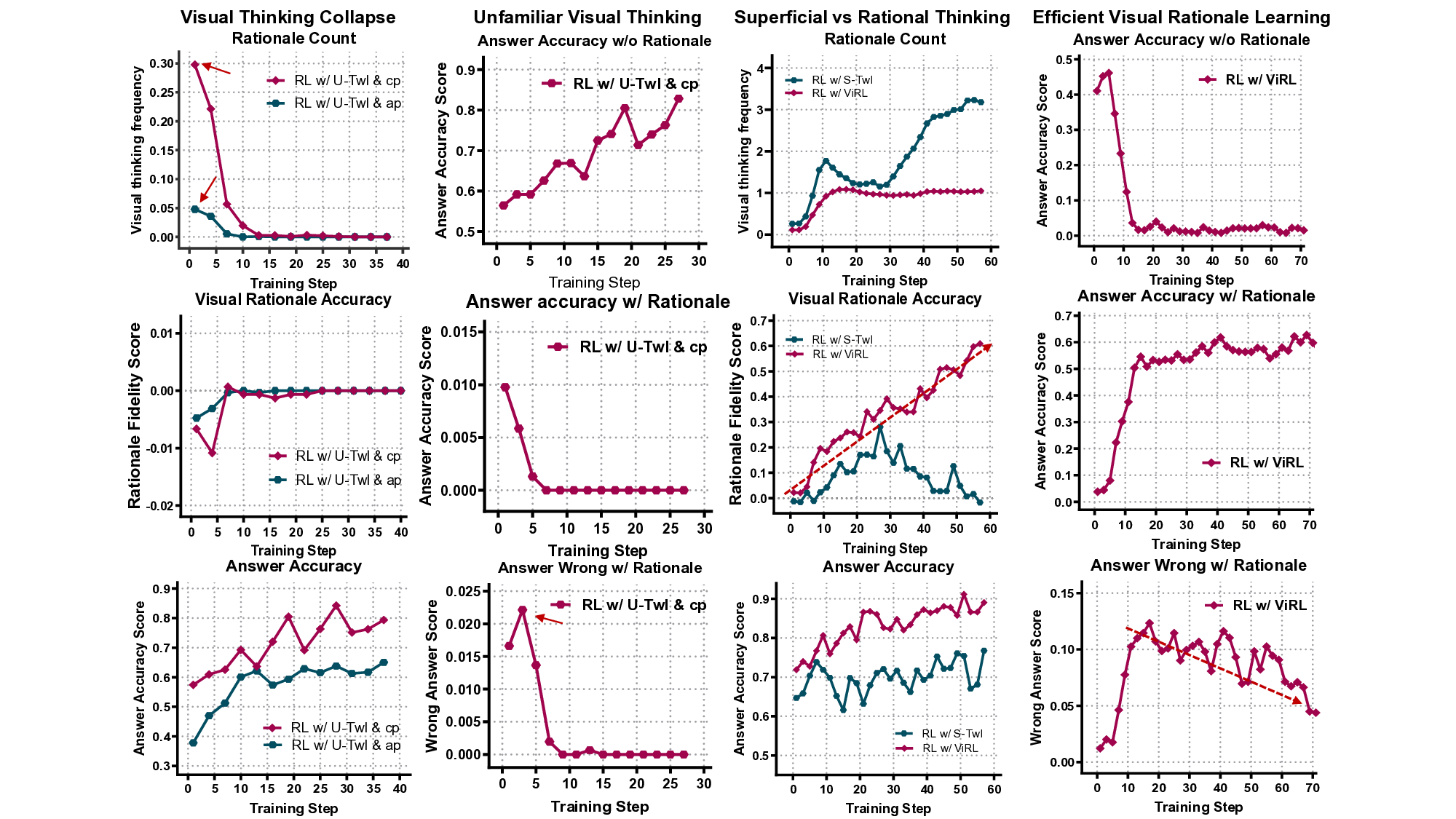
From Latent Ability to Structured Reasoning. As shown in Fig. 5a, we observed a characteristic: an initial spike in zoom-in invocations followed by a steep decay to near-zero invocation frequency, even as answer accuracy remains non-trivial. We term this behavior visual thinking collapse. Our empirical study points to three mechanistic contributors:
• Prompt Effects. As shown by the “Rationale Count” in Fig. 5a, Clear prompts more strongly tie zoom-ins to reasoning, fostering stronger early exploration, whereas prior designs treat visual thinking as a vague action and yield weak early engagement. (Appendix C) • Unfamiliarity with Visual Thinking. Early zoom-ins often inject misleading regional evidence, yielding lowutility explorations and increasing “Answer Wrong w/ Rationale” errors (Fig. 5b). • Outcome-only Supervision. Outcome-only rewards encourage avoiding rationales: accuracy improves without zoom-ins but degrades with them, reinforcing risk-averse, answer-first behavior (Fig. 5b).
Invocation Frequency ̸ = Invocation Quality. A naive fix is to reward zoom-ins, but Fig. 5c shows that this boosts activity without improving, and often harming task accuracy. The model learns to invoke for the sake of invoking: rationale counts rise while per-invocation fidelity stagnates. This reveals the illusion of “thinking with images”: the model appears to be actively engaging tools, yet the underlying reasoning quality stagnates or deteriorates. Thus, genuine “thinking with images” emerges not from more invocations, but from learning to strategically ground reasoning in the right visual evidence. Efficient visual reasoning requires sparse yet precise grounding. As shown in “Visual Rationale Accuracy” and “Answer Wrong w/ Rationale” (Fig. 5c,d), highperforming agents exhibit an early increase in invocation frequency during exploration, followed by convergence to a stable regime with markedly higher per-invocation accuracy and fewer illusion-induced errors. This transition reflects a shift from noisy trial-and-error to targeted, high-value visual reasoning. In contrast, naive invocation-level incentives lead to persistent over-activation, inflating tool use without improving reasoning quality.
In this work, we addressed the illusion of “thinking with images” by reframing visual actions from auxiliary tools into core reasoning primitives. We introduced ViRL, a processsupervised reinforcement learning framework that explicitly optimizes the fidelity and utility of visual reasoning chains.
By grounding supervision at the process level rather than solely on final outcomes, ViRL enables models to strategically attend to the right visual evidence at the right time. This shift not only yields state-of-the-art performance across perception, hallucination resistance, and visual reasoning benchmarks, but also establishes a verifiable and interpretable foundation for building trustworthy vision-language agents. Future work will further generalize this paradigm to more complex reasoning modalities and interactive settings.
To comprehensively evaluate both the accuracy of answers and the quality of visual reasoning behaviors, we introduce three metrics: Rationale Accuracy, Rationale Count, and F1 Score. These metrics are designed to disentangle what the model answers from how it reasons, enabling a more fine-grained understanding of visual thinking performance.
Rationale Accuracy. Rationale Acc measures whether the visual rationale invoked during reasoning effectively hits the ground-truth evidence. Formally, let R denote the invoked (predicted) rationale region and G the ground-truth bounding box. We define Rationale Accuracy as the fraction of the ground-truth area covered by the invoked region:
We adopt this coverage-based formulation instead of a conventional IoU for two main reasons. First, visual thinking (zoom-in) is a reasoning behavior rather than a strict localization task: effective zoom-ins often include contextual regions around the target to capture supporting cues, and such evidence-inclusive regions should not be penalized. Second, our objective is to evaluate whether the model accesses the critical evidence needed for inference, not how tightly it localizes the target. Measuring coverage relative to the ground-truth region more faithfully reflects this grounding quality.
Rationale Count. Rationale Count reflects the average number of visual thinking steps taken per reasoning trajectory. It provides insight into how frequently the model engages in image-grounded reasoning when answering questions. An excessively low count suggests shortcut behaviors with insufficient visual exploration, while an excessively high count often indicates inefficient or unstable reasoning with redundant visual operations. F 1 Score. To jointly evaluate perception and reasoning quality, we compute the F 1 score as the harmonic mean of Answer Accuracy (Acc ans ) and Rationale Accuracy(Acc rat ). This formulation emphasizes that strong performance requires both correct answers and correct evidence grounding, rather than excelling in only one aspect:
Acc ans × Acc rat Acc ans + Acc rat .
A high F 1 indicates not only good answer quality but also faithful visual grounding, reflecting more reliable multimodal reasoning. Expected output format:
You are a visual question answering and grounding evaluation expert.
Given a question, its answer, and the corresponding image (with a red bounding box corresponding to the reference area for question-answer pairs), your task is to determine: 1. Whether the answer is correct based on the image and question. 2. Whether the red bounding box matches the question-answer pair, i.e., whether this region contains all the necessary visual evidence to support answering the question correctly.
-Think step by step, carefully analyzing the question, answer, image, and red bounding box.
-ONLY output the final judgment in the exact format: \boxed{1} if both conditions are true, else \boxed{0}.
Question: {question} Given Answer: {answer} Bounding Box Coordinates (padded 10%): {padded bbox} This box has been marked with a red rectangle in the original image.
Please pay attention to this area and determine whether it contains the key evidence for answering the question, and whether the given answer is correct.
In this appendix, we provide a brief explanation of the data used for VQA generation and evaluation. Compared with traditional datasets that mainly rely on large bounding boxes and direct object localization, our dataset focuses on reasoning-centric question construction. Specifically, the designed prompts guide the model to generate questions that require implicit reasoning based on both the local region and the global scene context. This shifts the focus from merely identifying visual objects to understanding their relations, attributes, or roles in the broader scene.
The verification is conducted after generating the VQAs. With the VQA and Grounding Evaluation Prompt, we judge the generated VQA from two aspects: (1) Answer Correctness: Based on the Question and the Visual input, is the provided answer correct? (2) Rationale consistency: Consider whether the visual rationale annotations fully cover the relevant object or region required for the reasoning trajec-tory.
As illustrated in the Figure 6 and Figure 7, traditional data encourages straightforward localization-based answering, while our reasoning-driven data embeds inference cues in the question itself, stimulating deeper visual thinking. This design better aligns with real-world scenarios where answers often depend on implicit reasoning rather than direct perception.
In this section, we provide the prompt designs used for visual reasoning. We compare the Clear Prompt with the Ambiguous Prompt commonly adopted in existing works. Unlike traditional designs that treat zoom-in merely as an optional tool invocation, our prompt explicitly integrates zoom-in as part of the reasoning trajectory. This encourages the model to actively gather visual evidence before producing an answer, rather than passively attaching tool calls to the end of reasoning.
The ambiguous prompt design gives a brief instruction about zoom-in usage, but does not emphasize its role in reasoning. As a result, models may ignore zoom-in actions or invoke them superficially without integrating them into their decision-making process.
Think first, call image zoom in tool if needed, then answer. Format strictly as:
What is on the man’s lap?
Who is wearing shorts? What are three bananas sitting on? What kind of animal is there?
The prompt explicitly instructs the model to treat zoom-in as a core step in the reasoning process rather than a post-hoc attachment. It also constrains the timing of output: if visual evidence is insufficient, the model must zoom in and cannot answer in the same step. This structured reasoning format improves both the quality and faithfulness of intermediate steps.
This design ensures that visual inspection is not an afterthought but a structured reasoning action, promoting faithful intermediate steps and robust reasoning under ambiguity.
To further illustrate the reasoning challenges and the necessity of visual rationale learning, we present several representative illusion cases observed during inference. These cases highlight different types of failures in the visual reasoning process that cannot be captured by answer accuracy alone. By examining the intermediate thinking steps and invoked visual regions, we can better understand how reasoning illusions emerge and why they undermine trustworthiness.
Specifically, we categorize illusion cases into these types: Overall, these cases reveal that visual thinking quality is not strictly coupled with answer accuracy: models can exhibit reasoning illusions that degrade interpretability, efficiency, and safety. Therefore, evaluating and improving the faithfulness of visual reasoning trajectories is essential for building trustworthy multimodal systems.
To further illustrate how visual rationale learning enables genuine integration of perception into reasoning, we provide an additional qualitative example in Fig. 10. Rather than merely triggering a tool call, the model learns to iteratively refine its visual inspection based on previous feedback. When an initial visual attempt yields ambiguous or incorrect cues, the model performs a second round of targeted visual reasoning, progressively converging toward stable and reliable evidence that grounds the final answer. This adaptive refinement highlights a fundamental shift from shallow tool invocation to feedback-driven visual cognition.
Question: Is the red balloon above or below the white balloon? While our main experiments focus on perception-centric tasks, ViRL also demonstrates strong generalization to broader reasoning scenarios. As shown in Fig. 11, 12, 13, the model leverages visual rationale not only for fine-grained perceptual inspection but also as an integral part of general reasoning. In these cases, visual thinking serves a similar role to textual chain-of-thought-enabling the model to extract and verify visual evidence step by step to support its reasoning trajectory. This grounding process enhances the len(a) > 2is true, and the code will print ’the list has more than 2 numbers’. The question asks if the output is ’the list has less than 2 numbers’, which is not correct based on the code’s logic. logical soundness and trustworthiness of the model’s outputs, reduces hallucinations, and makes intermediate reasoning
"image_zoom_in_tool", "arguments": {"bbox_2d": [402, 221, 558, 306], "label": "road section"}} <\tool_call>
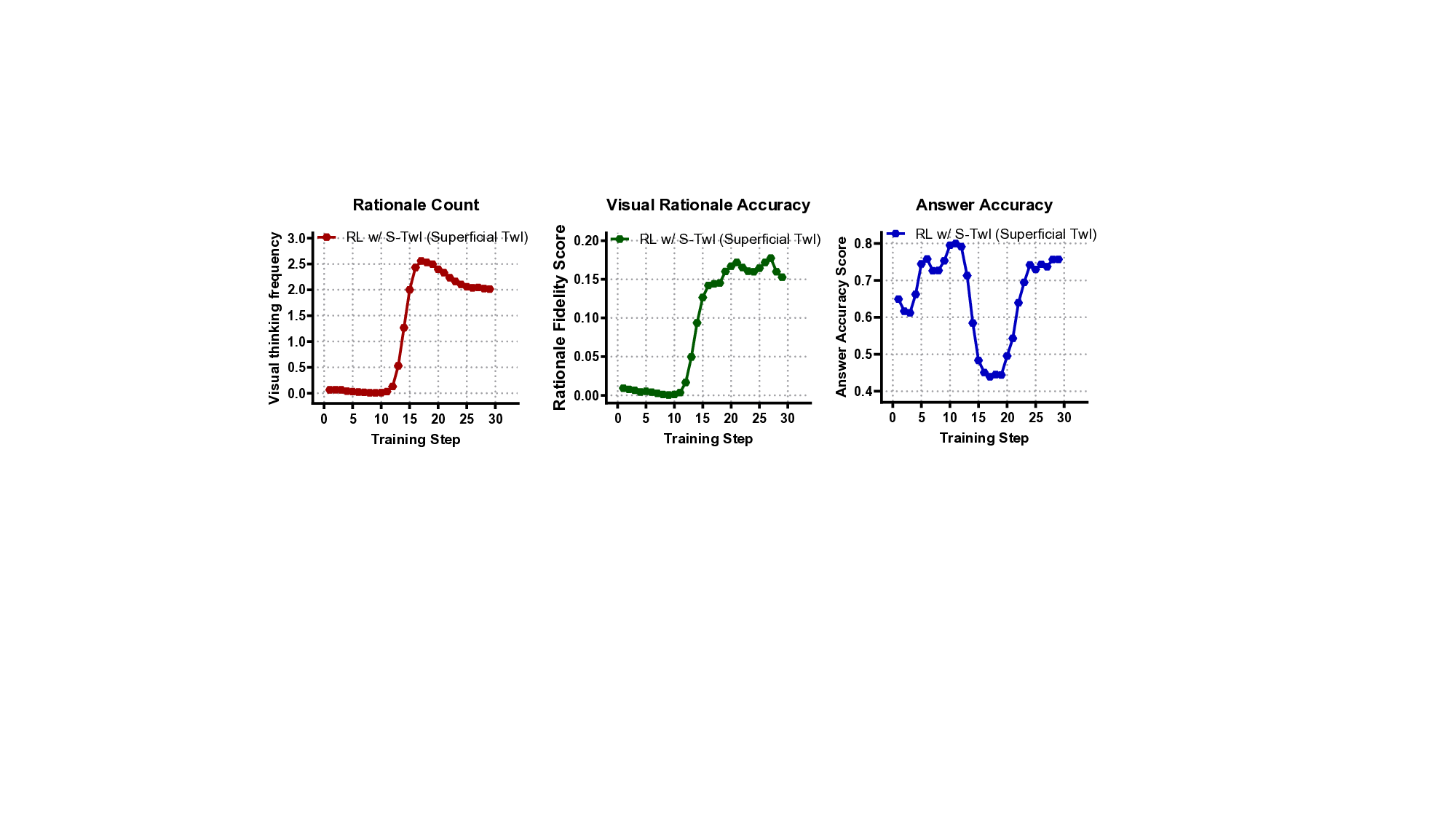
Reward Hacking. As shown in Figures 14,a sual thinking activity, where the frequency of zoom-in calls rapidly increases within a short interval. However, this surge is not accompanied by improved reasoning quality. On the contrary, due to immature visual reasoning skills, the model introduces a large amount of irrelevant or noisy visual evidence, causing a steep drop in answer accuracy. This phenomenon reveals a critical negative side effect of naively rewarding zoom-in behavior: the model overuses the tool without meaningful grounding, amplifying reasoning illusions and destabilizing early learning. Although answer accuracy eventually recovers as the model learns to selfregulate its zoom-in usage, this explosion phase reflects a deeper issue closely tied to the illusion of thinking with images: the model learns to perform visual reasoning behaviorally without genuinely integrating visual evidence into its decision process. Such outcome-driven dynamics encourage superficial exploration rather than structured reasoning, leading to suboptimal convergence and unstable training-ultimately exposing the gap between apparent tool usage and truly grounded reasoning.
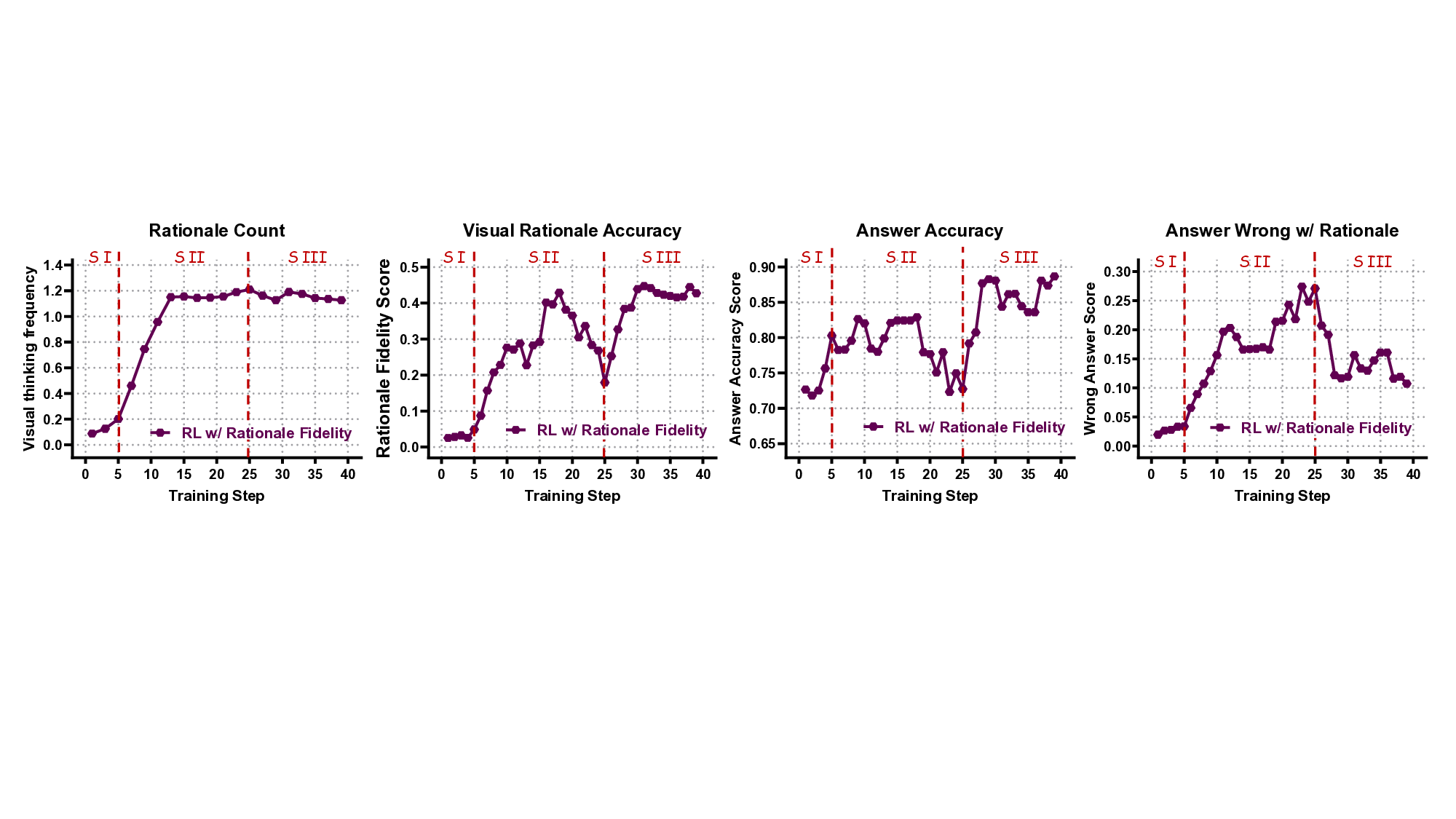
The staged dynamics of Visual Rationale Learning. Our experiments reveal that robust “thinking with images” is not an automatic by-product of answer learning but a staged process (Fig. 15):
• Stage I -Answer-first learning. The agent initially optimizes for surface correlations to produce correct answers; zoom-in attempts are noisy and yield little benefit, so the model learns to avoid them.
Dip. The agent begins to explore the tool at a high frequency, but its actions are often erroneous or misaligned. This injects spurious evidence and creates a strong interference, paradoxically causing a significant dip in answer accuracy and a spike in tool-related errors. Crucially, the agent does not become tool-avoidant but persists through this period of intense but inefficient exploration. per-action feedback and appropriate priors, useful invocations are reinforced and stabilized; thereafter, zoom-ins and answer learning enter a mutually reinforcing regime where visual actions meaningfully improve performance. This staged view explains why answer competence alone does not imply image-grounded reasoning: learners must be guided through exploration and selective reinforcement before visual actions become net-positive.
Although our approach demonstrates clear benefits in activating structured visual reasoning, it still faces several limitations. First, the dataset remains relatively small and primarily focuses on perception-driven reasoning tasks, limiting its coverage of more complex, multi-hop reasoning scenarios. Second, current supervision mainly targets short reasoning chains; extending it to deeper, longer-horizon reasoning remains an open challenge.
In future work, we plan to expand the dataset to support richer and more diverse reasoning patterns, including multistep causal inference and math reasoning. We also aim to develop more scalable supervision strategies to broaden the applicability of process-grounded training without sacrificing data quality.
global descriptions to preserve task difficulty. We fine-tune Qwen2.5-VL-7B[5] on 8 A100 GPUs for 80 iterations. Following DAPO[58], we adopt clip-higher, dynamic sampling, and token-level policy loss to enhance data utilization. Training uses a batch size of 64 with 16 rollouts per prompt, allowing up to 6 rounds of cropping. The learning rate is 1 × 10 -6 , the maximum response length is 20,480 tokens, and neither KL nor entropy regularization is applied.
global descriptions to preserve task difficulty. We fine-tune Qwen2.5-VL-7B[5] on 8 A100 GPUs for 80 iterations. Following DAPO[58]
global descriptions to preserve task difficulty. We fine-tune Qwen2.5-VL-7B[5] on 8 A100 GPUs for 80 iterations. Following DAPO
global descriptions to preserve task difficulty. We fine-tune Qwen2.5-VL-7B[5]
global descriptions to preserve task difficulty. We fine-tune Qwen2.5-VL-7B
📸 Image Gallery