RecToM: A Benchmark for Evaluating Machine Theory of Mind in LLM-based Conversational Recommender Systems
📝 Original Info
- Title: RecToM: A Benchmark for Evaluating Machine Theory of Mind in LLM-based Conversational Recommender Systems
- ArXiv ID: 2511.22275
- Date: 2025-11-27
- Authors: Mengfan Li, Xuanhua Shi, Yang Deng
📝 Abstract
Large Language models (LLMs) are revolutionizing the conversational recommender systems (CRS) through their impressive capabilities in instruction comprehension, reasoning, and human interaction. A core factor underlying effective recommendation dialogue is the ability to infer and reason about users' mental states (such as desire, intention, and belief), a cognitive capacity commonly referred to as Theory of Mind (ToM). Despite growing interest in evaluating ToM in LLMs, current benchmarks predominantly rely on synthetic narratives inspired by Sally-Anne test, which emphasize physical perception and fail to capture the complexity of mental state inference in realistic conversational settings. Moreover, existing benchmarks often overlook a critical component of human ToM: behavioral prediction, the ability to use inferred mental states to guide strategic decision-making and select appropriate conversational actions for future interactions. To better align LLM-based ToM evaluation with human-like social reasoning, we propose RECTOM, a novel benchmark for evaluating ToM abilities in recommendation dialogues. RECTOM focuses on two complementary dimensions: Cognitive Inference and Behavioral Prediction. The former focus on understanding what has been communicated by inferring the underlying mental states. The latter emphasizes what should be done next, evaluating whether LLMs can leverage these inferred mental states to predict, select, and assess appropriate dialogue strategies. Together, these dimensions enable a comprehensive assessment of ToM reasoning in CRS. Extensive experiments on state-of-the-art LLMs demonstrate that RECTOM poses a significant challenge. While the models exhibit partial competence in recognizing mental states, they struggle to maintain coherent, strategic ToM reasoning throughout dynamic recommendation dialogues, particularly in tracking evolving intentions and aligning conversational strategies with inferred mental states.📄 Full Content
Recent advancements in LLMs have fueled growing interest in evaluating their capacity for ToM reasoning (de Carvalho et al. 2025;Friedman et al. 2023). While several benchmarks (Gandhi et al. 2023;Xu et al. 2024;Wu et al. 2023;Jin et al. 2024) have been proposed to evaluate ToM in LLMs, they exhibit significant limitations for assessing conversational recommender systems. One limitation is that many existing works (Jin et al. 2024;Xu et al. 2024;Shi et al. 2025) rely on the Sally-Anne test and similar paradigms, which typically involve simplified scenarios, such as individuals entering a space, moving objects, and others arriving afterward. These setups lack engaging and naturalistic interactions, rendering them ill-suited for complex conversational recommendation systems. A further limitation lies in the predominant focus of current benchmarks (Chan et al. 2024;Jung et al. 2024) on retrospective reasoning about mental states (e.g., beliefs, intentions, desires), based on dialogues that have already transpired. Such benchmarks fail to capture a core aspect of human ToM: the ability to use inferred mental states to guide strategic decisionmaking for future interactions.
To bridge this gap, we introduce RECTOM, a benchmark for evaluating the ToM capabilities of LLMs specifically within conversational recommender systems as shown in Figure 1. RECTOM situates LLMs in realistic social in-Figure 1: An example dialogue in RECTOM.
teractions featuring asymmetrical conversational roles (i.e., recommender and seeker), enabling assessment of complex psychological reasoning. Specifically, the benchmark highlights two core reasoning types: (1) Cognitive Inference, which assesses the LLMs’ capability to accurately infer and explain the true mental states of the recommender and seeker, such as their desires, beliefs, and intentions, treating these mental states as theoretical constructs supporting observable behaviors, and (2) Behavioral Prediction, which evaluates the LLMs’ ability to apply inferred mental states to effectively anticipate conversational actions, such as predicting appropriate dialogue strategies or evaluating the effectiveness of proposed conversational strategies based on dialogue history.
Following existing ToM benchmarks (Chan et al. 2024;Yu et al. 2025), we also adopt the question answering (QA) data format for constructing our RECTOM benchmark, while there are several distinctive features specifically designed for conversational recommendation:
• Multi-choice Strategy. An utterance from either the rec-ommender or seeker may express multiple distinct intentions within a single sentence. Table 1 presents the distribution of different question types and an analysis of their corresponding answer options.
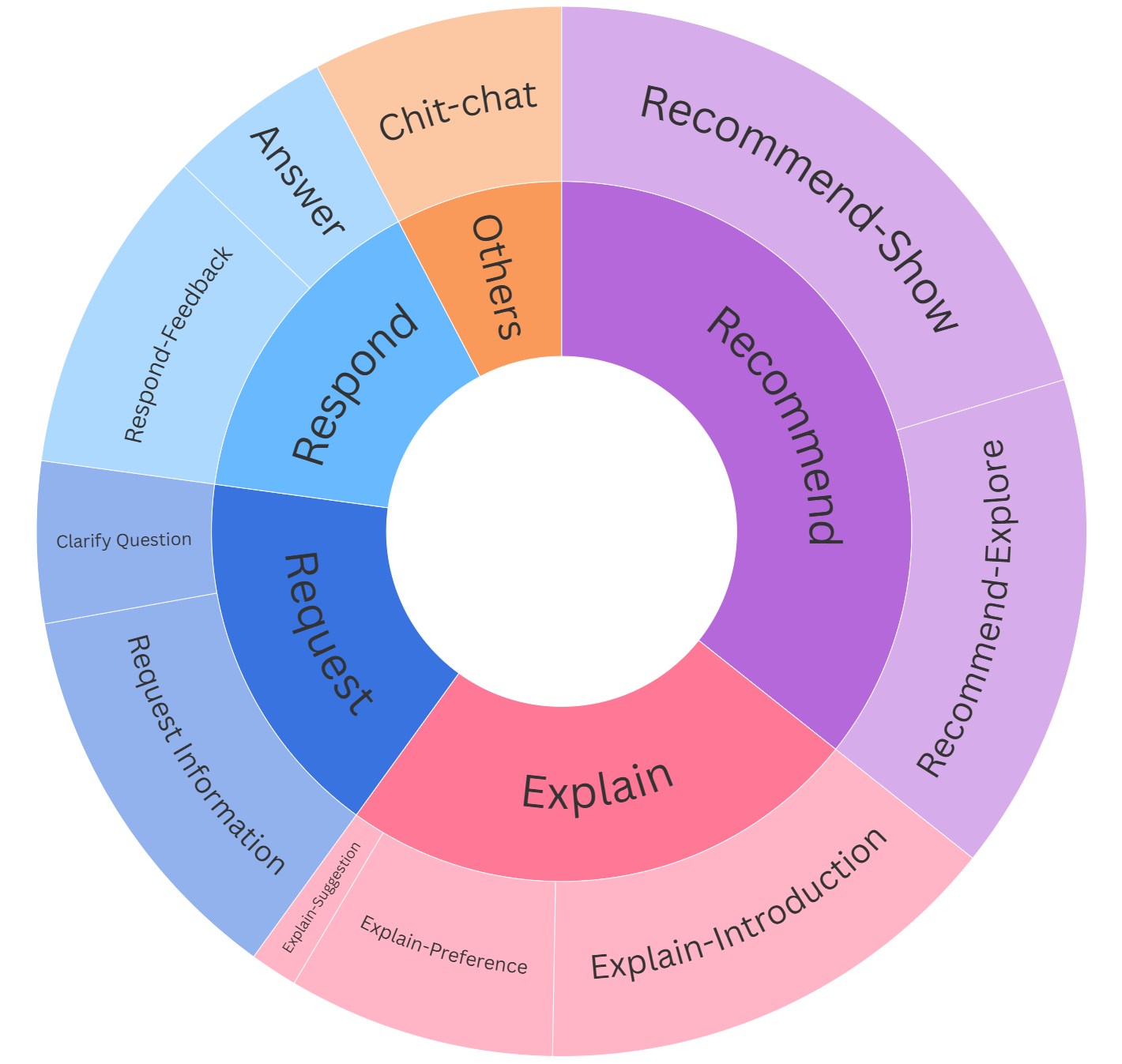
• Multi-granular Intention. Intentions in dialogue are inherently hierarchical: a single utterance can convey both a high-level purpose and nuanced, context-dependent sub-intentions. Figure 2 illustrates the categorization of intentions into coarse-grained and fine-grained levels. • Multi-dimensional Belief. In conversational recommendation systems, beliefs about an item (e.g., a film) are not uni-dimensional, but rather involve multiple interrelated aspects, such as who introduces the film (seeker or recommender), whether the seeker has viewed it, and their level of preference or acceptance, all contribute to a more nuanced mental reasoning. • Multi-concurrent Desire. Recommendation dialogues often involve the simultaneous pursuit of multiple goals, such as exploring diverse film options and comparing alternatives. RECTOM captures this complexity by modeling the seeker’s concurrent inclinations toward each recommended item, reflecting coexisting preferences that require independent evaluation.
To the best of our knowledge, RECTOM is the first human-annotated conversational recommendation benchmark to introduce ToM evaluation for LLMs in realistic recommendation scenarios. Experiments on the state-of-the-art LLMs reveal several key findings regarding the modeling of ToM in CRS:
(1) Increased option complexity hinders ToM reasoning in CRS. LLMs exhibit the significantly lower accuracy on multiple choice questions compared to single choice ones, indicating that their ability to infer the intentions of dialogue participants deteriorates as the choice space becomes more complex. This limitation highlights a fundamental challenge in CRS: capturing the nuanced mental states in dynamic and multi-faceted interactions.
(2) Fine-Grained intent discrimination remains a key bottleneck. While LLMs perform well on coarse-grained intention classification, their performance drops notably on finegrained tasks. This gap reflects a critical limitation in current CRS: the inability to effectively model the subtle and evolving preferences of participants during conversation, essential for accurate and context-aware recommendation.
(3) LLMs exhibit early potential for multi-dimensional mental state reasoning. Despite performance limitations, LLMs show some capacity to integrate multiple contextual cues into a coherent reasoning process. This indicates early potential for modeling complex seeker states in CRS, such as belief attribution, which are essential for generating contextually appropriate and personalized recommendations.
(4) LLMs exhibit a systematic bias towards sycophantic or “pleasing” responses. In open-ended scenarios, LLMs frequently produce responses that align with perceived participants preferences or expectations, even when such responses are not factually or logically sound. This tendency, consistent with the “Answer Sycophancy” phenomenon (Sharma et al. 2024), poses a serious risk in CRS, where overly agree- (5) Chain-of-thought (CoT) prompting yield limited benefits in complex recommendation tasks. Contrary to expectations, CoT provides only marginal gains in ToM reasoning within CRS, and in some cases leads to performance degradation. This indicates that current prompting strategies may fail to effectively scaffold coherent, multi-step reasoning about mental states in realistic, context-rich CRS.
Recent advances in LLMs have significantly influenced the development of CRS (An et al. 2025;He et al. 2025;Huang et al. 2025). Thanks to their strong language understanding and generation capabilities (Naveed et al. 2023), LLMs demonstrate promising performance in several key aspects of CRS, including response quality, natural language understanding, and personalized recommendation generation (Bao et al. 2023;Karanikolas et al. 2023;Deng et al. 2023).
While LLMs excel at generating fluent and seemingly intelligent responses, it remains unclear whether they can accurately model the underlying mental states (e.g., intentions, beliefs and desires) of both the recommender and the seeker throughout the conversation, or whether they truly engage in socially aware and contextually appropriate decisionmaking is still an open question.
ToM, the ability to attribute and reason about mental states, has gained increasing attention in both cognitive science and artificial intelligence (Kosinski 2023;Zhang et al. 2025;Gandhi et al. 2023). In recent years, several benchmarks have been proposed to evaluate ToM reasoning in LLMs. Notable examples include Hi-ToM, FANTOM, Persuasive-ToM, OpenToM, AutoToM, NegotiationToM, MumA-ToM, and MMToM-QA (Wu et al. 2023;Kim et al. 2023;Yu et al. 2025;Xu et al. 2024;Zhang et al. 2025;Chan et al. 2024;Shi et al. 2025;Jin et al. 2024), which assess the model’s ability to understand beliefs, intentions, and desires through narrative comprehension or dialogue reasoning tasks.
While these efforts have advanced our understanding of ToM capabilities in language models, existing benchmarks primarily focus on general purpose (Xu et al. 2024;Zhang et al. 2025;Shi et al. 2025;Jin et al. 2024) or task-oriented settings (Chan et al. 2024;Yu et al. 2025), and often abstract away from the nuanced, domain specific of real world conversational systems. To date, RECTOM is the first and only benchmark that systematically evaluates ToM reasoning in the context of CRS, where effective interaction relies on understanding the underlying mental states of both participants. Furthermore, our benchmark further captures more complex psychological dynamics, such as asymmetric roles, hierarchical intention structures, and evolving preferences.
Overview By constructing the RECTOM benchmark, we aim to assess the theory of mind capabilities of LLMs by answering following questions: (1) Can LLMs reason about mental states within a multiple choice context? For instance, a single utterance may encode multiple intentions, e.g., a seeker’s statement might simultaneously convey a request for recommendations and a preference for horror genres.
(2) How consistent is their performance across different granularity levels of mental state inference? For example, can models equally identify both coarse-grained intentions (e.g., “request”) and fine-grained nuances (e.g., requesting preferences, seeking feedback, or asking clarifying questions)? (3) Can they integrate multi-dimensional reasoning to understand the mental state comprehensively? This question examines whether LLMs can synthesize diverse and interrelated factors that collectively shape an agent’s internal state. For instance, in assessing the seeker’s attitude toward a movie, the model must jointly consider who proposed the movie, whether the seeker has seen it, and whether they ultimately accepted or rejected it. (4) Do LLMs exhibit a tendency to ingratiate through overly affirmative responses? For instance, when evaluating the effectiveness of a proposed conversational strategy, do models provide reasoned and objective judgments based on deliberation, rather than merely catering with reflexive positive responses?
The multi-turn conversational recommendation data used in this work is derived from the REDIAL dataset (Li et al. 2018), a publicly available corpus centered on movie recommendation dialogues. In REDIAL, each dialogue involves two participants: seeker and recommender. Moreover, to ensure dialogue quality and meaningful interaction, we follow the selection protocol established by IARD (Cai and Chen 2020), and selects 253 satisfactory recommendation dialogues, those in which the seeker initially rejects a recommended movie but later accepts a subsequent suggestion, and 83 unsatisfactory dialogues, where no recommendation is accepted by the seeker.
We further process the selected dialogues through two manual refinement steps: (1) Belief: identifying the final ac-Type RECTOM Questions
Is the
What is the intention expressed by the <Recommender/Seeker> in the
Belief Reasoning How does the
Prediction Reasoning What strategy will <Recommender/Seeker> use next?
Judgement Reasoning <Recommender/Seeker> will adopt
Table 2: ToM questions from RECTOM benchmark ceptance status of the recommended item. For each dialogue, we locate the exact utterance where the seeker explicitly expresses their opinion on a recommended movie.
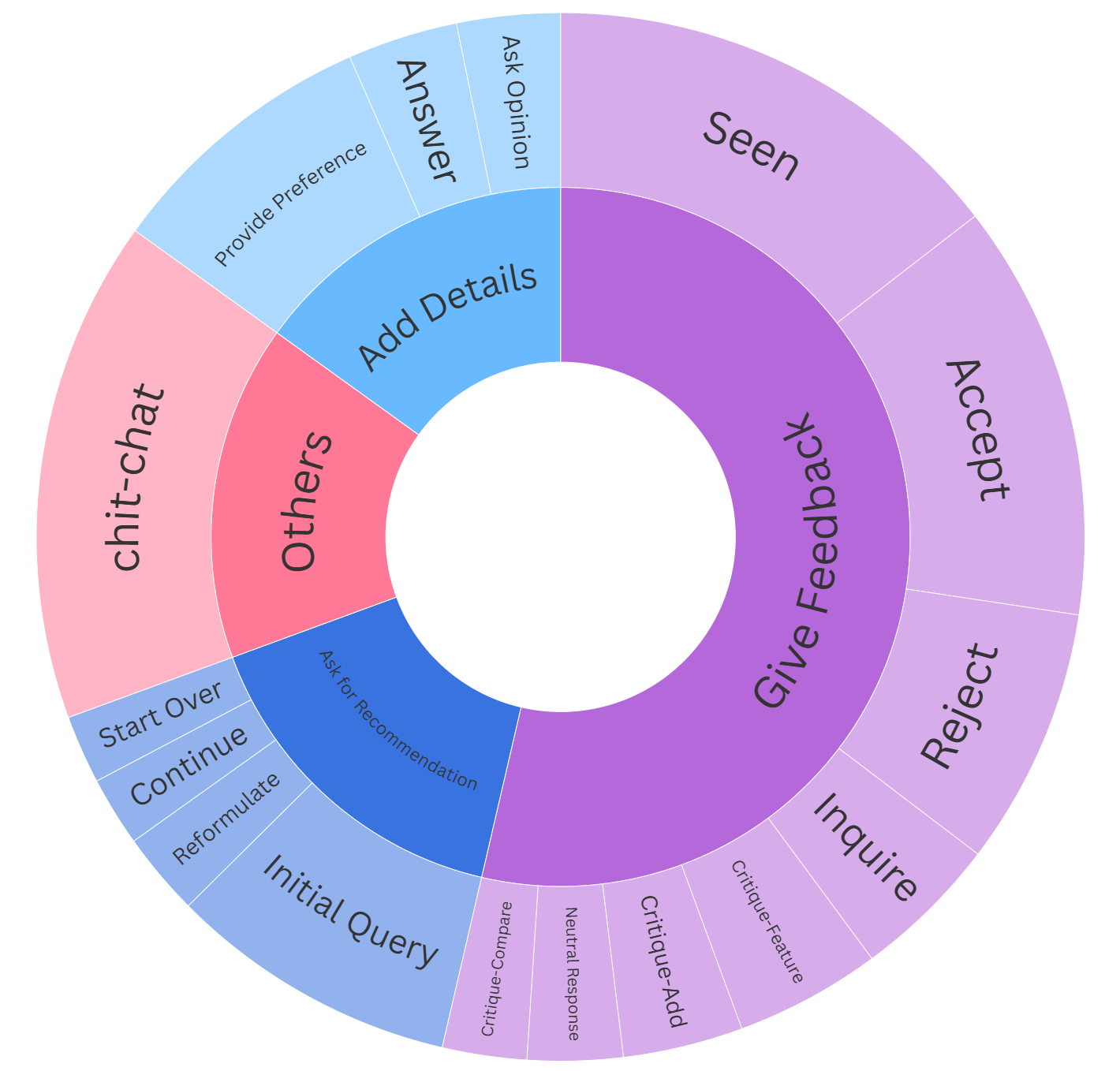
(2) Desire: annotating multi-dimensional desires. We re-annotate three core dimensions for each movie mentioned, including suggestion (whether the movie was suggested by the recommender or initiated by the seeker), seen (whether the seeker has seen the movie), and liked (whether the seeker liked the movie or the recommendation). Specificlly, three PhD students (trained in ToM knowledge and prior psychology projects) annotated the data. Two annotators labeled initially, conflicts resolved by a third. The IAA score (Fleiss’s K) (Fleiss 1971) is 0.79. The former targets mental-state attribution, encompassing questions about desires, intentions, and beliefs. The latter involves strategic prediction and effectiveness judgment, reflecting the application of inferred mental states to guide conversational actions. Notably, the recommender and seeker characterize asymmetrical social status in complex psychological activities. (e.g., recommender is expected to infer the seeker’s belief about the movies and while the reverse is not required). This reflects the realistic dynamics of recommendation dialogues, where the recommender, as the proactive agent initiating the interaction, must primarily evaluate the seeker’s attitude and desires to guide effective communication. Examples of all 10 question types can be found in Appendix A.2.
In RECTOM, cognitive inference is decomposed into three core components: desire, intention, and belief reasoning, corresponding to the Belief-Desire-Intention (BDI) model (Bratman 1987) of mental-state attribution.
Desire Reasoning Desire represents a motivational state that drives behaviors thought it does not imply a firm commitment (Kavanagh, Andrade, and May 2005;Malle and Knobe 2001). In the context of CRS, desire reflects a seeker’s latent interest or inclination toward specific items, such as movies, which may evolve dynamically through the interaction. In RECTOM we evaluate whether LLMs can infer and track the evolving motivational state through questions of the form “Is the seeker likely to watch the
Belief Reasoning Belief refers to a cognitive state in which an agent holds a specific understanding or assumption about another agent’s perspective or attitude toward a proposition. In CRS, belief reasoning involves understanding how the recommender infers the seeker’s attitude toward a suggested item. In RECTOM, we evaluate whether LLMs can infer the recommender’s belief about the seeker’s stance toward a recommended movie through belief reasoning questions. Inspired by the multi-dimensional annotation schema in REDIAL (Li et al. 2018), we decompose belief into three key dimensions: Suggestion:whether the movie was suggested by the recommender or initiated by the seeker, Seen: whether the seeker has seen the movie and liked: whether the seeker liked the movie or the recommendation. This design require models to interpret contextual cues, such as explicit preferences, indirect feedback, and prior statements, and to dynamically update beliefs as the conversation progresses.
Intention Reasoning Intention refers to an agent’s deliberate commitment to perform an action, typically grounded in their beliefs and desires, and directed toward achieving a specific goal (Phillips, Wellman, and Spelke 2002). In conversational systems, modeling intention is essential for understanding the purpose behind each utterance, especially in goal oriented interactions such as recommendation dialogues. In RecToM, we evaluate whether LLMs can identify the intentions underlying the utterances of both the recommender and the seeker, using the questions of the form “What is the intention expressed by the Recommender/seeker in the
While cognitive inference plays the crucial role in understanding the mental states of recommender and seeker, it is equally important to leverage these inferred states to inform action. specifically, to guide the selection of effective recommendation strategies and evaluate the effectiveness on the dialogue outcomes.
Prediction Reasoning Prediction reasoning involves anticipating the dialogue strategies that the recommender or seeker is likely to employ in the next turn. This is operationalized through questions of the form: “What strategy will recommender/seeker use next?”. Given the diversity of possible dialogue strategies and the potential for multiple strategies to be expressed within a single utterance, this task is framed as a multiple choice problem. Successfully answering these questions require LLMs to infer the current conversational state and generate plausible predictions about future interactions. This, in turn, influences the dynamic evolution of the recommender’s and seeker’s beliefs, desires and intentions, making prediction reasoning a key component of effective and proactive dialogue modeling.
Judgment Reasoning Judgment Reasoning assesses the model’s ability to evaluate the effectiveness of a given dialogue strategy in advancing the conversation. In this task, a strategy is randomly specified, and models are asked to judge its likely impact using questions of the form: using the form of: “The recommender/seeker will adopt
By integrating both cognitive and behavioral inference, RECTOM offers a comprehensive evaluation of ToM capabilities in conversational recommendation settings. It bridges the gap between cognitive theory and real world applications in conversational artificial intelligence, moving beyond mere comprehension of mental states to modeling their role in strategic interaction.
We evaluate RECTOM on five state-of-the-art LLMs from diverse sources with varying levels of reasoning abilities. Deepseek-V3 (Liu et al. 2024): a robust Mixture-of-Experts (MoE) language model featuring a total 671 billion total parameters, with 37 billion activated for each token processing. GPT-4o-mini (OpenAI 2024b) and GPT-4o (OpenAI 2024a): both are multimodal, multilingual generative pretrained transformer models developed by OpenAI (Abacha et al. 2024). Gemini 2.5 Flash-Lite (Comanici et al. 2025): developed by Google and designed to provide ultra-lowlatency performance and high throughput per dollar. Claude 3.5 Haiku (Anthropic 2024): a fast and cost-effective language model from Anthropic.
Following established practices in the theory of mind literature (Sabour et al. 2024;Kim et al. 2023) we evaluate these models with two types of prompting strategies: (1) vanilla zero-shot prompting directly asks LLMs to select the answer (single or multiple options) without providing any explanation.
(2) Chain-of-thought (CoT) prompting, adapted from (Kojima et al. 2022;Wei et al. 2022), in which the model is instructed with the prompt “Let’s think step by step.” to encourage explicit reasoning. The final answer is then extracted via string matching from a fixed output format. the temperature for all model generations is set to 0.7 to balance creativity and determinism.
LLMs demonstrate notable yet uneven performance across cognitive inference and behavioral prediction tasks in the CRS. While most models significantly outperform random guessing, indicating a basic capacity to extract and reason about mental states such as beliefs and intentions from dialogue context, substantial gaps remain compared to humanlevel performance. Even with the zero-shot CoT prompting, improvements are marginal and inconsistent. The comprehensive evaluation on RECTOM, summarized in Table 4, reveals critical insights into the capabilities and challenges of LLMs in ToM reasoning within CRS. First, cognitive load from multiple choice formats impairs decision accuracy. On multi-choice tasks requiring discrimination among numerous plausible mental state attributions, LLMs’ performance is markedly low (see Table 4 results in italics), averaging only 27.74% of fine-grained intention reasoning for the recommender role. In contrast, performance on single choice tasks, such as belief reasoning (68.72%) and desire reasoning (86.35%), is substantially higher. This pronounced performance gap highlights the difficulty LLMs face in managing increased cognitive load when distinguishing between nuanced and plausible alternatives, particularly in complex, multiple choice inference scenarios.
Second, a significant granularity gap in intention infer-ence reveals fundamental representational deficits. While LLMs achieve moderate accuracy in coarse-grained intention classification (e.g., GPT-4o: 64.22% for seeker), performance sharply declines in fine-grained tasks (e.g., GPT-4o: 28.84% for seeker), exposing their limited capacity to capture the subtle, context-dependent evolution of participant preferences. This deficit hinders the delivery of truly adaptive and personalized recommendations in CRS.
Third, LLMs exhibits a non-trivial yet limited capacity for multi-dimensional belief inference in CRS. The topperforming model (Deepseek-v3 + cot) achieves 79.46% accuracy, substantially exceeding the random baseline (14.29%) and outperforming smaller models such as GPT-4o-mini (52.50%). This indicates that, under favorable conditions, sufficient model scale and structured prompting, LLMs can integrate conversational history and social cues to form coherent, albeit imperfect, inferences about the recommender’s beliefs regarding seeker’s attitudes.
Fourth, the efficacy of CoT prompting in realistic conversational reasoning workflows is limited and inconsistent. Despite its success in other domains, CoT yields only marginal improvements in this CRS context, such as a +1.95 percentage point (pp) gain for DeepSeek-v3 in coarse grained intention inference of recommender, and +0.46% pp for GPT-4o in belief reasoning, and no improvement or even degradation in many cases (e.g., GPT-4o in coarse grained intention of seeker: 64.22% → 54.10%). This variability suggests that CoT does not reliably enhance multi-step reasoning in complex, context-sensitive dialogues and may introduce noise or redundant reasoning that disrupts decision accuracy.
These results highlight the gap between surface-level language understanding and the deeper, inference-driven reasoning necessary for effective ToM in CRS.
Judgement Reasoning Bias. As shown in Table 4, in the binary classification of judgement reasoning task, LLMs perform below random guess, indicating a systematic distortion driven by preference-conforming bias. To further assess the LLMs’ tendency toward generating overly positive “Yes” responses (a “pleasing” bias), we analysis the confusion matrix using three metrics: Prediction Bias (lower is better), defined as (T P + F P )/(T P + F P + T N + F N ), measures the proportion of “Yes” predictions; False Positive Rate (FPR, lower is better), calculated as F P/(F P + T N ), quantifies the misclassification of actual “No” instances as “Yes”; and Recall for “No” (higher is better), computed as T N/(F P + T N ), reflects the model’s accuracy in identifying correct “No” responses. As shown in Table 5, the LLMs exhibits a high Prediction Rate of “Yes” (∼93.37%) indicating a strong default toward affirmative responses regardless of ground truth. This is further evidenced by an extremely high FPR of ∼93.28%, meaning nearly all true"No” instances are incorrectly classified as “Yes”. Complementing this, the recall for “No” is only ∼7.22%, confirming the LLMs’ near inability to correctly identify and respond with “No” when required. Together, these results reveal a severe affirmative bias, consistent with “answer sycophancy” (Sharma et al. 2024), where the LLMs prioritizes favoring agreement over accuracy, undermining its reliability in judgment tasks.
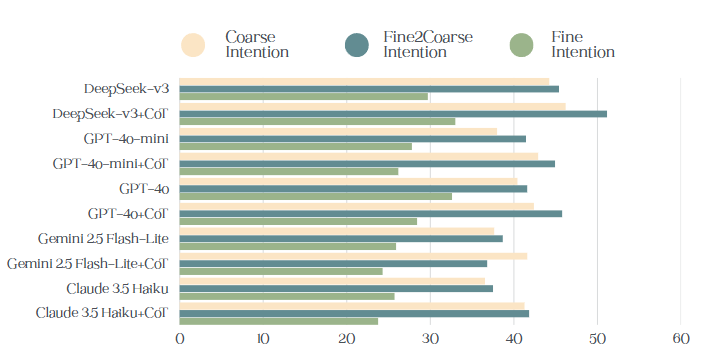
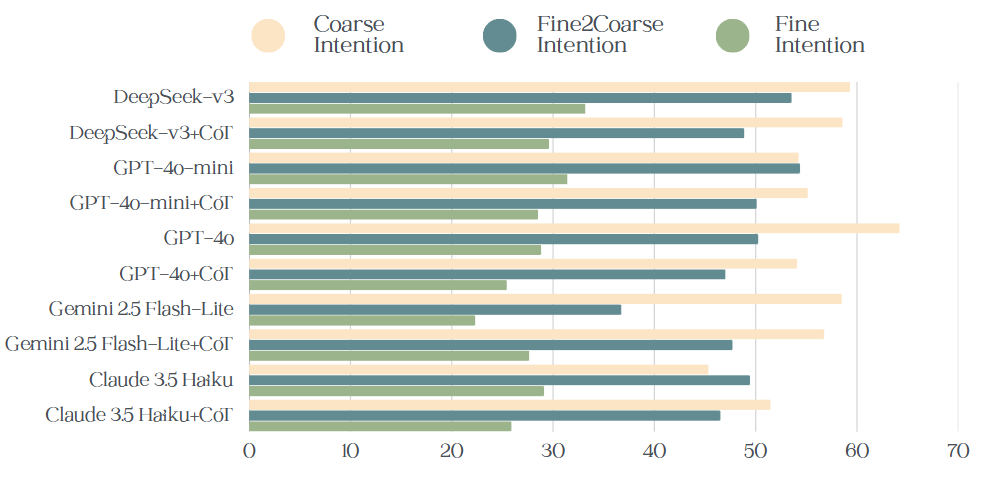
Fine-grained Intention Error Analysis. As shown in Figure 3, the Fine2Coarse task involves a human-annotated Figure 3: Intention reasoning compared across 10 models (accuracy in %), Fine2Coarse intention reflect the accuracy of mapping fine-grained intentions to their predefined coarse-grained categories. The upper section reports results for the recommender; the lower section for the seeker.
mapping: given the LLMs’ fine-grained intention outputs, we manually map them to their corresponding coarsegrained categories using predefined rules, thereby eliminating potential model-induced mapping errors. Empirical analysis reveals fine-grained accuracy is consistently lower than Fine2Coarse accuracy across all models (e.g., DeepSeek-v3: 29.71% vs. 45.40% for Recommender; GPT-4o: 28.84% vs. 50.25% for Seeker). Fine2Coarse accuracy approximates or is close to coarse-grained accuracy (e.g., DeepSeek-v3+CoT: 51.16% vs. 46.21% for Recommender), indicating most fine-grained outputs, though imprecise, still fall within the correct coarse-grained category. The poor performance in fine-grained intention classification stems not from misalignment with the coarse-grained direction (as evidenced by robust Fine2Coarse results) but from weak ability to discriminate between fine-grained options within the same coarse category. Models struggle to pinpoint the exact fine-grained intent, despite correctly identifying the broader coarse-grained scope.
This work introduces RECTOM, a benchmark designed to evaluate the Machine Theory of Mind in LLMs within conversational recommendation systems. The core of RECTOM lies in its structured assessment of cognitive inference and behavioral prediction, characterized by four key dimensions: multi-choice strategy reasoning, multi-granular intentions, multi-dimensional beliefs, and multi-concurrent desires. Through comprehensive experiments, we evaluate state-of-the-art LLMs on this benchmark, revealing critical insights into their strengths and limitations in modeling human-like mental state reasoning in realistic CRS.
We define 10 questions for our benchmark. Below is a snippet illustrating the structure. Specifically, “utterance pos” indicates the utterance turn within the current dialogue. The tasks for Coarse-grained Intention Reasoning, Fine-grained Intention Reasoning, and Prediction Reasoning, for both the recommender and the seeker, are formulated as multiplechoice questions.
Performance of judgement reasoning task. Results are reported in percentage (%). Claude 3.5 denotes the Claude 3.5 Haiku; Gemini 2.5 refers to Gemini 2.5 Flash-Lite. The upper section presents results for the Recommender; the lower section for the Seeker. Best results are highlighted in bold; second-best in italics.
📸 Image Gallery