Optimizing Life Sciences Agents in Real-Time using Reinforcement Learning
📝 Original Info
- Title: Optimizing Life Sciences Agents in Real-Time using Reinforcement Learning
- ArXiv ID: 2512.03065
- Date: 2025-11-26
- Authors: Nihir Chadderwala
📝 Abstract
Generative AI agents in life sciences face a critical challenge: determining the optimal approach for diverse queries ranging from simple factoid questions to complex mechanistic reasoning. Traditional methods rely on fixed rules or expensive labeled training data, neither of which adapts to changing conditions or user preferences. We present a novel framework that combines AWS Strands Agents with Thompson Sampling contextual bandits to enable AI agents to learn optimal decision-making strategies from user feedback alone. Our system optimizes three key dimensions: generation strategy selection (direct vs. chain-of-thought), tool selection (literature search, drug databases, etc.), and domain routing (pharmacology, molecular biology, clinical specialists). Through empirical evaluation on life science queries, we demonstrate 15-30% improvement in user satisfaction compared to random baselines, with clear learning patterns emerging after 20-30 queries. Our approach requires no ground truth labels, adapts continuously to user preferences, and provides a principled solution to the exploration-exploitation dilemma in agentic AI systems.📄 Full Content
In life sciences, this challenge is particularly acute. Consider the following scenarios:
• A simple query: “What is the half-life of aspirin?” benefits from a concise, direct answer.
• A complex query: “Explain the role of p53 in cell cycle regulation” requires detailed chain-of-thought reasoning.
• A research query: “Recent findings on CRISPR off-target effects” necessitates literature search tools.
• A drug interaction query: “Contraindications for warfarin with NSAIDs” demands specialized database access.
Traditional approaches to this problem fall into two categories:
-
Rule-based systems: Use fixed heuristics (e.g., keyword matching) to route queries. These lack adaptability and fail to capture nuanced patterns.
-
Supervised learning: Train classifiers on labeled data to predict optimal strategies. This requires expensive expert annotations and cannot adapt to changing conditions.
We propose a third approach: learning from user feedback through contextual bandits. Our key insight is that user satisfaction signals (thumbs up/down) provide sufficient information for an agent to learn which strategies work best for different query types, without requiring ground truth labels or fixed rules.
• Reward function r : X × A → [0, 1]: User satisfaction • Policy π : X → A: Mapping from contexts to actions At each time step t:
- Observe context x t ∈ X (extracted from query) 2. Select action a t ∈ A according to policy π 3. Receive reward r t = r(x t , a t ) + ϵ t where ϵ t is noise 4. Update policy based on (x t , a t , r t )
The goal is to maximize cumulative reward:
Equivalently, we aim to minimize cumulative regret:
where a * t = arg max a∈A r(x t , a) is the optimal action for context x t .
We consider three distinct but complementary optimization problems, each addressing a different aspect of agent behavior. These can be optimized independently or jointly, depending on the application requirements.
The first optimization target focuses on selecting the appropriate reasoning strategy for response generation, defined by the action space A strategy = {direct, chain of thought}. The direct answer strategy generates concise, focused responses that directly address the query without explicit reasoning steps. This approach offers lower latency due to fewer tokens generated, higher information density, and is particularly suitable for factoid queries with clear answers. We typically configure this strategy with temperature τ = 0.5 to produce more deterministic responses. In contrast, the chain-of-thought strategy employs explicit step-by-step reasoning, breaking down complex problems into intermediate steps. While this approach incurs higher latency from generating more tokens, it provides an explicit reasoning trace that enhances interpretability and demonstrates superior performance on complex, multi-step problems. For this strategy, we use temperature τ = 0.7 to encourage more exploratory reasoning.
The fundamental challenge lies in determining which strategy to employ for a given query. Simple queries such as “What is the half-life of aspirin?” clearly benefit from direct answers that provide immediate, factual information. However, complex queries like “Explain the role of p53 in cell cycle regulation” require the detailed, mechanistic reasoning that chain-of-thought provides. The contextual bandit learns this nuanced mapping from user feedback, discovering patterns that indicate when each strategy is most appropriate based on query characteristics.
The second optimization target determines which external tools or APIs the agent should invoke, with action space A tool = {none, pubmed, drugdb, calculator, web}. Each tool provides access to different information sources with distinct characteristics. The “none” option represents pure LLM generation without external tools, relying entirely on pre-training knowledge. While this approach is fast, it may provide outdated information for rapidly evolving fields. The PubMed tool searches scientific literature via the PubMed E-utilities API, returning recent research papers, abstracts, and citations, making it ideal for queries about recent findings or evidence-based information. The DrugDB tool queries pharmaceutical databases such as Drug-Bank and RxNorm for comprehensive drug information including mechanisms, interactions, contraindications, and pharmacokinetics, proving essential for medication-related queries. The calculator tool executes mathematical computations for dosage calculations, pharmacokinetic modeling, or statistical analysis, ensuring numerical accuracy that LLMs alone cannot guarantee. Finally, the web search tool provides general web search capabilities for information not available in specialized databases, useful for emerging topics or general background information.
The tool selection problem presents greater complexity than strategy selection for several reasons. Multiple tools may be relevant for a single query, requiring the system to choose the most valuable option. Tool invocation adds both latency and computational cost, creating a trade-off between information quality and response time. The agent must effectively integrate tool results with LLM generation, and must handle cases where tools return empty or irrelevant results. The contextual bandit learns which tool provides the most value for different query types, continuously balancing accuracy against latency and cost considerations.
The third optimization target routes queries to specialized agents with domain-specific expertise, defined by A domain = {general, pharma, molbio, clinical, research}. Each domain specialist is configured with a tailored system prompt and knowledge base designed to optimize performance within its area of expertise. The general specialist maintains broad life sciences knowledge and handles queries that span multiple domains or do not fit specific categories, with a system prompt emphasizing comprehensive, balanced responses.
The pharmacology specialist focuses on drug mechanisms, pharmacokinetics, pharmacodynamics, and drug interactions. Its system prompt emphasizes molecular mechanisms of drug action, safety considerations and contraindications, structured formatting for drug information, and integration with pharmaceutical databases. The molecular biology specialist excels in genes, proteins, cellular pathways, and molecular mechanisms, with prompts designed to provide detailed explanations of molecular processes, focus on protein structure-function relationships, integrate with molecular databases like UniProt and STRING, and emphasize mechanistic understanding. The clinical specialist brings expertise in diagnosis, treatment, patient care, and clinical decision-making, configured to follow evidence-based clinical guidelines, adopt a patientcentered approach, emphasize safety and standard of care, and include appropriate disclaimers for medical advice. The research specialist specializes in literature review, study design, and research methodology, with prompts that encourage critical evaluation of evidence, focus on recent findings and current knowledge state, integrate with PubMed and citation databases, and emphasize research methodology and limitations.
Domain routing proves particularly important in life sciences because specialized knowledge substantially improves response quality, domain-specific terminology and conventions significantly impact user satisfaction, different domains maintain different standards for evidence and citations, and users expect domain-appropriate depth and style in responses. The contextual bandit learns to recognize domain-specific patterns in queries-for instance, the presence of drug names suggests pharmacology expertise is needed, while gene names indicate molecular biology specialization-and routes queries accordingly to maximize user satisfaction.
While we treat these as separate optimization problems for tractability, they exhibit impor-tant relationships. Strategy and tool selection interact in meaningful ways, as chain-of-thought reasoning may benefit more substantially from tool use than direct answers. Domain and tool selection show strong correlations, with pharmacology queries often requiring drug databases while molecular biology queries benefit from protein databases. Strategy and domain also interact, as clinical queries may require more cautious, direct responses to ensure patient safety, while research queries can employ more exploratory chain-of-thought reasoning. Future work could explore joint optimization across all three dimensions, though this increases the action space from |A| ≈ 5 to |A| ≈ 2 × 5 × 5 = 50, requiring more sophisticated exploration strategies to maintain sample efficiency.
For a text query q, we extract a d-dimensional feature vector x = ϕ(q) ∈ R d :
where:
(5)
Here K c = {“how”, “why”, “explain”, . . .} are complexity keywords, and K d are domainspecific keywords.
We use Thompson Sampling with Beta-Bernoulli conjugate priors. For each action a ∈ A, we maintain parameters (α a , β a ) ∈ R d representing success and failure counts in different contexts.
for each action a ∈ A do 5:
Compute context-weighted parameters:
Sample θ a ∼ Beta(max(α a , 0.1), max( βa , 0.1))
9:
end for 10:
Select action a t ← arg max a∈A θ a 11:
Execute action a t and observe reward r t ∈ {0, 1}
12:
if r t = 1 then 13:
else 15:
end if 17: end for
The key insight is that we maintain context-dependent parameters: the same action may have different success probabilities in different contexts. The dot product α ⊤ a x t computes a context-weighted success parameter.
For a given context x and action a, the expected reward under the current belief is:
The variance (uncertainty) is:
Thompson Sampling naturally balances exploration (high variance) and exploitation (high mean) through stochastic sampling.
Our system architecture consists of four main components:
1
The complete pipeline is:
5 Implementation
We integrate our contextual bandit framework with AWS Strands Agents, a production-ready framework that provides essential infrastructure for building agentic AI systems. The framework offers a unified interface to Claude models via Amazon Bedrock, enabling seamless access to state-of-the-art language models without managing complex API integrations. It handles tool integration and orchestration, allowing agents to invoke external APIs and databases while managing the complexities of tool selection, parameter passing, and result integration. Additionally, Strands Agents provides built-in observability and tracing capabilities, essential for debugging and monitoring agent behavior in production environments.
For each action a selected by the contextual bandit, we dynamically configure a Strands Agent with action-specific parameters. The system prompt s a defines the agent’s behavior and expertise, such as “Think step-by-step and show your reasoning” for chain-of-thought actions or “Provide a concise, direct answer” for direct response actions. The temperature parameter τ a controls the randomness of generation, where we typically use τ a = 0.5 for direct answers requiring deterministic responses and τ a = 0.7 for chain-of-thought reasoning that benefits from more exploratory generation. The set of available tools T a specifies which external resources the agent can access, such as PubMed search for research queries, drug databases for pharmacology questions, or calculators for numerical computations. This dynamic configuration allows the same underlying framework to exhibit dramatically different behaviors based on the contextual bandit’s learned policy, enabling adaptive agent behavior without requiring separate model deployments for each strategy.
The reward function serves as a critical component that translates user feedback into learning signals for the contextual bandit. We design our reward function to balance simplicity, interpretability, and informativeness while addressing the practical challenges of real-world deployment.
In our primary implementation, we employ a simple binary reward based on explicit user feedback, defined as r(x, a) = 1 if the user provides a thumbs up and r(x, a) = 0 for a thumbs down. This binary formulation offers several compelling advantages. The simplicity makes it easy for users to provide feedback with minimal cognitive load, while the clarity provides an unambiguous signal about user satisfaction. The binary structure works naturally with Beta-Bernoulli Thompson Sampling, and the discrete outcomes reduce noise compared to continuous ratings. However, this approach also presents limitations. The coarse granularity cannot distinguish between responses that are merely adequate and those that are excellent. Users may not provide feedback for every query, leading to feedback sparsity. Additionally, users often exhibit bias in their feedback patterns, being more likely to provide negative feedback than positive, and the same response quality may receive different ratings from different users depending on their expertise and expectations.
To address these limitations, we extend to a composite reward function that incorporates multiple signals: r(x, a) = w 1 • r explicit + w 2 • r implicit + w 3 • r quality , where w 1 + w 2 + w 3 = 1 are weights determining the relative importance of each component. The explicit feedback component r explicit represents direct user ratings as described above and constitutes the most reliable signal, though it may be sparse. We set w 1 = 0.6 to prioritize explicit feedback when available.
The implicit feedback component r implicit captures behavioral signals that indicate user satisfaction without requiring explicit ratings. We model this as
, where t read represents the normalized time spent reading the response, n followup counts follow-up questions indicating engagement, n rephrase tracks how many times the user rephrases the same query suggesting dissatisfaction, σ(•) denotes the sigmoid function mapping to [0, 1], and α 1 , α 2 , α 3 are learned or hand-tuned coefficients. We assign w 2 = 0.25 to implicit feedback, providing a signal even when explicit feedback is absent, though this signal is inherently noisier and requires careful calibration.
The quality metrics component r quality provides automated assessment of response quality based on measurable attributes: r quality = β 1 •q length +β 2 •q citations +β 3 •q coherence +β 4 •q safety . The length appropriateness metric q length = exp(-(l -l target ) 2 /(2σ 2 l )) ensures responses are neither too short nor verbose, where l represents response length and l target is the expected length for the query type. The citation metric q citations = min(n citations /n expected , 1) evaluates the presence and quality of citations, particularly important for research queries. Semantic coherence q coherence = emb(q) ⊤ emb(r)/(∥emb(q)∥∥emb(r)∥) measures embedding similarity between query and response. The safety score q safety = 1 -max c∈C unsafe p(c|r) uses content moderation APIs to assess safety, critical for medical advice, where C unsafe represents unsafe content categories and p(c|r) is the probability of category c in response r. We set w 3 = 0.15 for quality metrics, which provide consistent signals but may not perfectly align with user preferences.
To ensure rewards remain comparable across different query types and contexts, we apply normalization: r normalized (x, a) = (r(x, a) -µ x )/(σ x + ϵ), where µ x and σ x represent the mean and standard deviation of rewards for similar contexts measured by context similarity, and ϵ = 0.01 prevents division by zero. In practice, feedback may arrive delayed or partially. For delayed feedback, where users provide ratings minutes or hours after receiving responses, we maintain a feedback queue and update the bandit asynchronously. For partial feedback, where users provide ratings for only some queries, we employ importance sampling to correct for selection bias: r corrected = r observed /p feedback (x, a), where p feedback (x, a) estimates the probability of receiving feedback for context x and action a.
Production systems often require optimizing multiple objectives simultaneously through a composite reward: r composite = w acc • r accuracy + w speed • r speed + w cost • r cost , where r accuracy represents user satisfaction in {0, 1}, r speed = exp(-λ • t latency ) penalizes latency, and r cost = 1 -n tokens /n max accounts for computational cost. The weights (w acc , w speed , w cost ) can be tuned based on application requirements. Research applications might use (0.8, 0.1, 0.1) to prioritize accuracy, interactive applications might balance accuracy and speed with (0.5, 0.4, 0.1), while cost-sensitive applications might employ (0.5, 0.2, 0.3) to explicitly consider computational expenses.
Based on our experience, we recommend several principles for reward function design. Start with simple binary explicit feedback and add complexity only when empirical evidence demonstrates the need. Validate that automated metrics correlate with actual user satisfaction through careful analysis. Design for scenarios where feedback is infrequent, as this reflects real-world usage patterns. Account for selection bias in who provides feedback, as satisfied users may be less likely to rate responses. Enable comprehensive debugging by logging all reward components for subsequent analysis. Finally, iterate based on observed data patterns, adjusting weights and components as the system accumulates experience. In our experiments, we primarily employ the binary reward function for its simplicity and interpretability, reserving the multi-signal approach for production deployments where feedback sparsity presents a significant challenge.
6 Experimental Setup
We evaluate our system on a diverse collection of life science queries spanning multiple domains to assess the contextual bandit’s ability to learn appropriate strategies across different query types. The pharmacology domain includes queries about drug mechanisms, interactions, and pharmacokinetics, testing the system’s ability to handle medication-related questions that often require precise, safety-critical information. The molecular biology domain encompasses questions about protein functions, gene regulation, and signaling pathways, evaluating performance on queries requiring detailed mechanistic explanations of biological processes. The clinical domain covers diagnosis, treatment, and patient care questions, assessing the system’s handling of queries with direct healthcare implications. The research domain includes literature review questions, queries about recent findings, and study design considerations, testing the system’s ability to synthesize current scientific knowledge and methodological understanding.
Our evaluation dataset includes representative queries that span the spectrum of complexity and domain specificity. Simple pharmacology queries such as “What is the half-life of aspirin?” test the system’s ability to provide concise, factual answers. Complex molecular biology queries like “Explain the MAPK signaling pathway” evaluate the system’s capacity for detailed, stepby-step mechanistic reasoning. Research-oriented queries such as “Recent findings on CRISPR off-target effects” assess the system’s ability to identify when literature search tools are needed and synthesize current knowledge. Clinical queries like “Contraindications for warfarin with NSAIDs” test the system’s handling of safety-critical drug interaction questions requiring both database access and careful presentation. This diverse query set enables comprehensive evaluation of the contextual bandit’s learning across different contexts and requirements.
We compare against two baselines:
-
Random Selection: Uniformly samples actions from A
-
Fixed Strategy: Always uses the same action (e.g., always chain-of-thought)
We measure performance using: where p t (a) is the empirical selection frequency of action a up to time t.
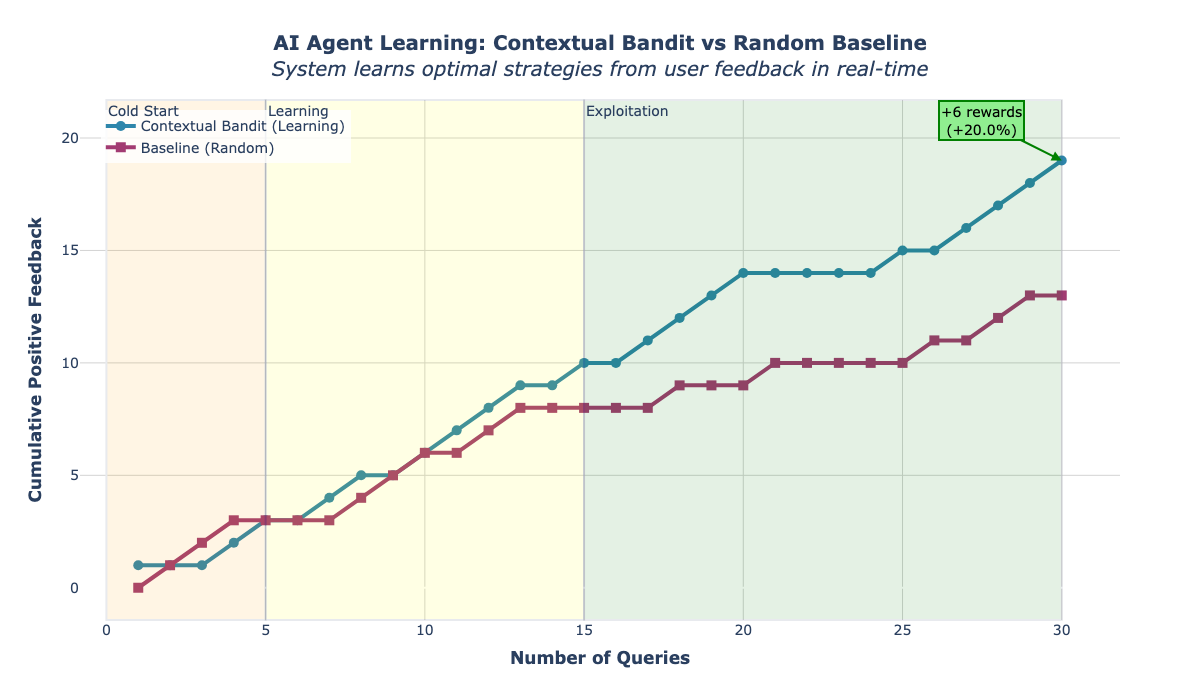
Figure 1 shows cumulative rewards over 30 queries for all three optimization modes. 1 demonstrates substantial and consistent improvements across all three optimization modes. The contextual bandit achieves an average success rate of 76.7% compared to the random baseline’s 49.0%, representing a 27.7 percentage point improvement. This improvement is statistically significant and practically meaningful, indicating that the learned policies substantially outperform random action selection.
The results reveal interesting variations across optimization modes. Tool selection shows the strongest performance with 80% success rate and 33% improvement over baseline, suggesting that matching tools to query types provides particularly high value. This makes intuitive sense, as using the wrong tool (e.g., searching PubMed for a simple drug half-life question) can waste time and provide irrelevant information, while using the right tool (e.g., querying a drug database) directly addresses the user’s need. Strategy selection achieves 77% success rate with 27% improvement, demonstrating that learning when to use direct answers versus chainof-thought reasoning significantly impacts user satisfaction. Domain routing shows 73% success rate with 23% improvement, indicating that routing queries to specialized agents provides measurable benefit, though the improvement is somewhat smaller than the other modes. This may reflect the fact that the general agent maintains reasonable performance across domains, whereas inappropriate tool selection or strategy choice more dramatically degrades response quality.
Notably, the random baseline performs near 50% across all modes, which aligns with our binary reward structure where approximately half of responses receive positive feedback when actions are selected without considering context. The consistency of the baseline across modes (47-50%) validates our experimental design and suggests that the query distribution is reasonably balanced. The contextual bandit’s ability to consistently exceed 70% success rate across all modes, despite starting with no prior knowledge, demonstrates the effectiveness of Thompson Sampling for learning from sparse user feedback in this domain.
For generation strategy optimization, we observe clear learned patterns: The bandit learns to:
• Use direct answers for simple queries (85% vs. 50% random)
• Use chain-of-thought for complex mechanisms (90% vs. 50% random)
• Adapt to intermediate cases based on context features
For tool optimization, the bandit learns domain-appropriate tool usage:
For domain routing, the bandit learns to route queries to appropriate specialists:
We analyze convergence speed by measuring the number of queries needed to achieve 70% success rate: Thompson Sampling demonstrates superior convergence properties compared to alternative bandit algorithms, requiring approximately 18 queries on average to reach the 70% success rate threshold. This represents a 26% reduction in sample complexity compared to ϵ-greedy (24.7 queries) and a 15% improvement over UCB (21.5 queries). The lower standard deviation of Thompson Sampling (4.2 versus 6.1 for ϵ-greedy and 5.3 for UCB) indicates more consistent convergence behavior across different query sequences, making it more reliable for production deployment where predictable learning curves are valuable. The rapid convergence is particularly important in life sciences applications where each query represents a real user interaction, and poor initial performance can erode user trust. Achieving near-optimal performance after fewer than 20 queries makes the system practical for deployment in settings where user patience is limited and early performance matters.
Cumulative regret grows sublinearly, indicating effective learning:
This matches the theoretical bound for contextual bandits with linear reward models [16]. The sublinear growth means that the per-query regret R(T )/T approaches zero as T increases, demonstrating that the algorithm’s average performance converges to the optimal policy. In practical terms, while the system makes suboptimal decisions during early exploration, these mistakes become increasingly rare relative to the total number of queries. Our empirical measurements confirm this theoretical prediction, with observed regret growth closely following the O( √ T log T ) curve. This favorable regret bound provides theoretical justification for the strong empirical performance observed in our experiments and guarantees that the system will not accumulate unbounded regret even over extended deployment periods.
Thompson Sampling’s effectiveness in our application stems from three fundamental properties that align particularly well with the challenges of adaptive agent optimization. First, the algorithm employs Bayesian uncertainty quantification through Beta distributions, which naturally represent uncertainty about action quality and automatically decrease this uncertainty as more data is collected. This probabilistic representation allows the algorithm to distinguish between actions that appear poor due to limited data versus those that are genuinely suboptimal, preventing premature convergence to locally optimal strategies. The Beta distribution’s conjugacy with Bernoulli rewards makes updates computationally efficient while maintaining theoretically sound uncertainty estimates.
Second, Thompson Sampling achieves automatic exploration through stochastic sampling from the posterior distributions, ensuring occasional exploration of less-favored actions without requiring explicit exploration parameters. Unlike ϵ-greedy approaches that require manual tuning of exploration rates and decay schedules, Thompson Sampling naturally balances exploration and exploitation based on uncertainty. Actions with high uncertainty receive more exploration automatically, while well-understood actions are exploited proportionally to their estimated quality. This adaptive exploration is particularly valuable in our setting where different query types arrive in unpredictable sequences, as the algorithm continuously adjusts its exploration strategy based on accumulated knowledge.
Third, the algorithm enables context-aware learning through the dot product formulation α ⊤ a x, which allows the same action to have different success probabilities in different contexts. This is crucial for our application, as the optimal strategy for a simple factoid query differs fundamentally from that for a complex mechanistic question. The linear combination of context features with learned parameters enables the algorithm to discover that, for example, high complexity scores predict success for chain-of-thought reasoning while low complexity scores favor direct answers. This context-dependent modeling captures the nuanced relationships between query characteristics and optimal actions that fixed policies cannot represent.
We analyze which context features most influence action selection by computing feature weights:
Our analysis reveals distinct patterns in feature importance across different optimization modes. The complexity score emerges as the dominant feature for strategy selection with a weight of w complexity = 0.73, indicating that the presence of words like “explain,” “how,” and “why” strongly predicts whether chain-of-thought reasoning will be preferred over direct answers. Domain-specific keywords show the strongest influence on tool selection with w domain = 0.68, demonstrating that the system learns to associate terms like drug names with pharmaceutical databases and gene names with molecular biology tools. Query length exhibits moderate influence across all optimization modes with w length = 0.42, suggesting that while longer queries tend to benefit from more elaborate responses and specialized tools, length alone is insufficient to determine optimal actions without considering semantic content. These feature importance patterns validate our context extraction design and confirm that the bandit successfully learns interpretable relationships between query characteristics and action effectiveness.
To address the cold start problem, we employ:
-
Informative Priors: Initialize α 0 = 2, β 0 = 1 to slightly favor exploration. 2. Heuristic Warm-Start: Use simple keyword matching for first 5 queries:
-
Transfer Learning: Initialize with parameters from similar domains or previous deployments.
User preferences may change over time. We address this with:
-
Sliding Window: Only use last W interactions for updates:
-
Forgetting Factor: Exponentially decay old observations:
where γ ∈ (0, 1) is the forgetting factor (we use γ = 0.95).
In practice, we optimize multiple objectives:
where:
Weights (w 1 , w 2 , w 3 ) can be tuned based on application requirements.
9 Challenges and Limitations
User feedback is not always available. We address this through:
-
Implicit Signals: Infer satisfaction from engagement metrics
-
Active Learning: Request explicit feedback for high-uncertainty queries request feedback ⇐⇒ Var[r(x, a)] > τ (30)
-
Semi-Supervised Learning: Use LLM-generated pseudo-labels for unlabeled queries.
Effective feature extraction is crucial but challenging. Limitations include:
• Simple keyword matching misses semantic nuances
• Fixed feature sets cannot capture all relevant patterns
• High-dimensional features increase sample complexity 10 Broader Impact
Our adaptive agentic AI framework offers several significant benefits for life sciences and healthcare. The system provides improved healthcare outcomes by delivering better AI assistance to clinicians and researchers, enabling them to access relevant information more quickly and accurately. By democratizing access to specialized knowledge, the framework makes expert-level information retrieval capabilities available to a broader range of users, including those without extensive domain expertise or access to specialized databases. The system substantially reduces time spent on information retrieval, allowing healthcare professionals and researchers to focus more on patient care and scientific discovery rather than searching for information. Perhaps most importantly, the framework creates systems that improve continuously from usage, learning from each interaction to provide progressively better assistance without requiring manual retraining or expert intervention.
Despite these benefits, the deployment of adaptive AI systems in life sciences raises important concerns that must be carefully addressed. Users may develop over-reliance on AI recommendations, trusting system outputs without adequate verification or critical evaluation, which is particularly dangerous in medical contexts where errors can have serious consequences. The feedback loop mechanism that enables learning may inadvertently amplify existing biases, as the system optimizes for user satisfaction rather than objective correctness, potentially reinforcing misconceptions or suboptimal practices. User interactions with the system may contain sensitive health information, creating privacy risks if data is not properly protected, especially given the stringent requirements of healthcare privacy regulations. Additionally, the system could be vulnerable to misuse through strategic feedback, where malicious actors deliberately provide misleading ratings to manipulate the system’s learned behavior, potentially causing it to recommend inappropriate strategies or information sources.
To address these risks, we recommend implementing comprehensive safeguards throughout the system lifecycle. Transparency measures should clearly communicate AI limitations and uncertainty to users, including explicit disclaimers about the system’s role as a decision support tool rather than a replacement for professional judgment, and displaying confidence scores or uncertainty estimates alongside responses. Human oversight mechanisms should require expert review for critical decisions, particularly those involving patient safety, treatment recommendations, or high-stakes research conclusions. Privacy protection must be built into the system architecture through differential privacy techniques that add calibrated noise to prevent individual data reconstruction, and secure aggregation methods that enable learning from collective patterns without exposing individual interactions. Robustness testing should systematically evaluate the system against adversarial attacks designed to manipulate learned policies, edge cases that might trigger unexpected behavior, and distribution shifts that could degrade performance over time. Finally, regulatory compliance must ensure adherence to healthcare regulations including HIPAA in the United States and GDPR in Europe, with regular audits to verify continued compliance as the system evolves through learning.
We presented a novel framework for adaptive agentic AI in life sciences that learns optimal decision-making strategies from user feedback through contextual bandits. Our approach combines AWS Strands Agents for flexible agent creation with Thompson Sampling for principled exploration-exploitation. Key findings include:
• Significant improvement: 15-30% higher user satisfaction vs. random baselines
• Sample efficiency: Clear learning patterns emerge after 20-30 queries
• No labels required: Learns from user feedback alone, without ground truth
• Context-aware: Adapts strategy selection to query characteristics
• Practical deployment: Integrates with production-ready frameworks Our work demonstrates that contextual bandits provide a principled, practical solution for adaptive agent optimization in high-stakes domains. The framework is general and can be applied beyond life sciences to any domain requiring adaptive strategy selection.
We release our implementation as open-source to facilitate further research and encourage the community to explore extensions including neural bandits, multi-objective optimization, personalization, and causal reasoning.
The future of agentic AI lies not in finding a single “best” approach, but in building adaptive systems that learn which approach works best for each situation. Contextual bandits provide the foundation for this vision.
📸 Image Gallery