From Passive Perception to Active Memory: A Weakly Supervised Image Manipulation Localization Framework Driven by Coarse-Grained Annotations
📝 Original Info
- Title: From Passive Perception to Active Memory: A Weakly Supervised Image Manipulation Localization Framework Driven by Coarse-Grained Annotations
- ArXiv ID: 2511.20359
- Date: 2025-11-25
- Authors: Zhiqing Guo, Dongdong Xi, Songlin Li, Gaobo Yang
📝 Abstract
Image manipulation localization (IML) faces a fundamental trade-off between minimizing annotation cost and achieving fine-grained localization accuracy. Existing fully-supervised IML methods depend heavily on dense pixel-level mask annotations, which limits scalability to large datasets or real-world deployment. In contrast, the majority of existing weakly-supervised IML approaches are based on image-level labels, which greatly reduce annotation effort but typically lack precise spatial localization. To address this dilemma, we propose BoxPromptIML, a novel weakly-supervised IML framework that effectively balances annotation cost and localization performance. Specifically, we propose a coarse region annotation strategy, which can generate relatively accurate manipulation masks at lower cost. To improve model efficiency and facilitate deployment, we further design an efficient lightweight student model, which learns to perform fine-grained localization through knowledge distillation from a fixed teacher model based on the Segment Anything Model (SAM). Moreover, inspired by the human subconscious memory mechanism, our feature fusion module employs a dualguidance strategy that actively contextualizes recalled prototypical patterns with real-time observational cues derived from the input. Instead of passive feature extraction, this strategy enables a dynamic process of knowledge recollection, where long-term memory is adapted to the specific context of the current image, significantly enhancing localization accuracy and robustness. Extensive experiments across both indistribution and out-of-distribution datasets show that Box-PromptIML outperforms or rivals fully-supervised models, while maintaining strong generalization, low annotation cost, and efficient deployment characteristics.📄 Full Content
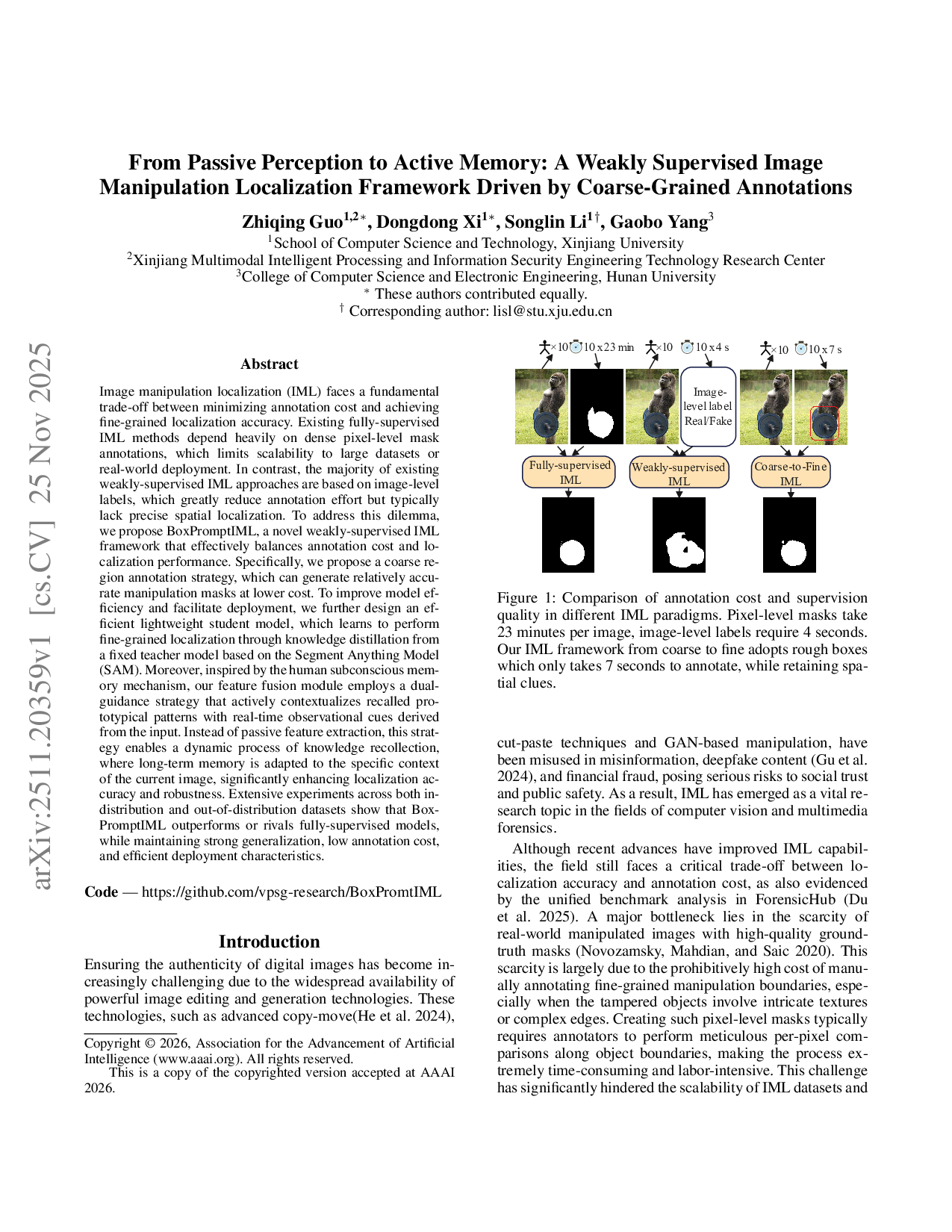
Copyright © 2026, Association for the Advancement of Artificial Intelligence (www.aaai.org ). All rights reserved. This is a copy of the copyrighted version accepted at AAAI 2026. Our IML framework from coarse to fine adopts rough boxes which only takes 7 seconds to annotate, while retaining spatial clues.
cut-paste techniques and GAN-based manipulation, have been misused in misinformation, deepfake content (Gu et al. 2024), and financial fraud, posing serious risks to social trust and public safety. As a result, IML has emerged as a vital research topic in the fields of computer vision and multimedia forensics.
Although recent advances have improved IML capabilities, the field still faces a critical trade-off between localization accuracy and annotation cost, as also evidenced by the unified benchmark analysis in ForensicHub (Du et al. 2025). A major bottleneck lies in the scarcity of real-world manipulated images with high-quality groundtruth masks (Novozamsky, Mahdian, and Saic 2020). This scarcity is largely due to the prohibitively high cost of manually annotating fine-grained manipulation boundaries, especially when the tampered objects involve intricate textures or complex edges. Creating such pixel-level masks typically requires annotators to perform meticulous per-pixel comparisons along object boundaries, making the process extremely time-consuming and labor-intensive. This challenge has significantly hindered the scalability of IML datasets and the broader development of the field. To mitigate this issue, some weakly supervised IML methods have been proposed, typically leveraging image-level labels to minimize annotation effort, though they generally lack precise spatial supervision.
To the best of our knowledge, there is currently no quantitative analysis of how long it takes humans to annotate different types of supervision for real-world manipulated images. To address this gap, we conducted a controlled user study involving 10 volunteers, who were asked to annotate 100 tampered images along with their corresponding authentic versions. These image pairs were selected from realworld manipulation examples in the IMD2020 (Novozamsky, Mahdian, and Saic 2020) and In-the-Wild (Huh et al. 2018) datasets. During annotation, participants were allowed to refer to both the tampered and original images to assist in identifying manipulated regions. The labeling tasks included generating pixel-level manipulation masks, imagelevel real/fake labels, and coarse bounding boxes. The time required for each annotation type was carefully recorded, and cross-validation was performed among participants to ensure annotation quality and consistency. All annotations were conducted using the CVAT platform.
As illustrated in Figure 1, we compare three representative supervision strategies in IML:
• Fully-supervised IML, which relies on pixel-level manipulation masks and offers the highest localization accuracy, but suffers from prohibitively high annotation cost-up to 23 minutes per image in our user study. • Weakly-supervised IML methods that rely on imagelevel real/fake labels significantly reduce annotation effort (4 seconds per image), but fails to provide any spatial guidance, often resulting in poor localization. • The proposed Coarse-to-Fine IML, which uses rough bounding box annotations and reduces annotation time to about 7 seconds per image, while still preserving essential spatial information.
The results above clearly show that rough bounding box annotation offers a compelling cost-performance trade-off, reducing labeling effort by over 98% compared to full supervision, while preserving essential spatial cues for learning. This motivates the need for a middle-ground solution that preserves spatial localization signals without incurring the high cost of pixel-level annotations. Thus, we design a coarse-to-fine localization approach in which simple bounding boxes act as inexpensive yet informative prompts to guide the model training. A frozen SAM (Kirillov et al. 2023) is then used to transform these coarse prompts into fine-grained pseudo masks. These pseudo masks serve as soft supervision signals to train a lightweight student model, which can independently localize manipulation during inference. Inspired by theories of collective memory and selective attention, we design a Memory-Guided Gated Fusion Module (MGFM) to further enhance the localization performance of the student model. This module maintains a learnable memory bank that stores prototypical manipulation patterns, and employs a gating mechanism to selectively fuse multi-scale features based on their relevance. Memory bank is structurally advantageous as it decouples knowledge aggregation from the network’s weights. By storing and averaging feature activations from past iterations, it creates a more stable and diverse global prior of manipulation archetypes than what can be implicitly learned by standard attention mechanisms. This acts as a strong regularizer that forces the model to reconcile real-time evidence with this robust prior, which is critical for preventing overfitting and improving OOD generalization.
Our main contributions are summarized as follows:
•
As image manipulations grew more sophisticated, fully supervised IML approaches empowered by large-scale pixellevel annotations showed remarkable capabilities in localizing tampered regions. TruFor (Guillaro et al. 2023) leveraged contrastive learning to extract noise fingerprints and refined anomaly localization by correcting confidence maps, thereby reducing false positives. PIM (Kong et al. 2025) enhanced generalization by modeling pixel-level inconsistencies caused by disruptions to natural image signal processing pipelines. Mesorch (Zhu et al. 2025) addressed the limitation of relying solely on low-level visual traces by integrating both micro-and macro-level features into a unified mesoscopic representation, offering a more holistic approach to manipulation detection.
To reduce reliance on costly pixel-level annotations, the WSCL framework (Zhai et al. 2023) fully-supervised methods on both in-domain and out-ofdomain datasets.
Fully-supervised IML methods offer accurate localization but rely heavily on dense annotations, limiting scalability. Weakly-supervised methods that rely solely on imagelevel labels reduce annotation cost but generally struggle to achieve precise localization. The SCAF sets a new performance benchmark for IML by outperforming fully supervised counterparts through the use of scribble-based annotations. However, its relatively high annotation cost (around 20 seconds per image), slower convergence, and large model size and computational overhead limit its practicality for resource-constrained scenarios. To address these limitations, we propose a lightweight, efficient, and fast-converging weakly-supervised IML framework that further reduces annotation effort, offering a practical solution for real-world image forensics.
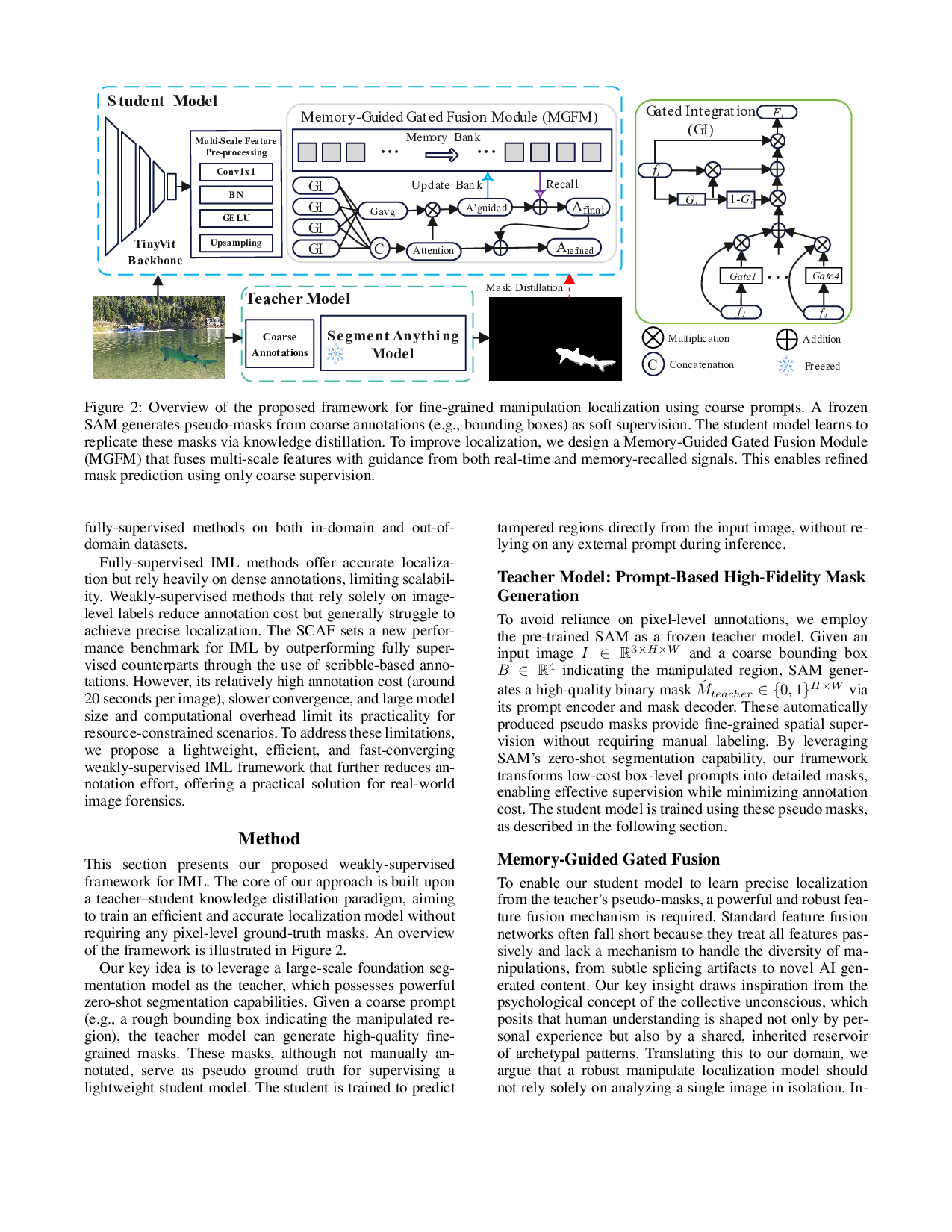
This section presents our proposed weakly-supervised framework for IML. The core of our approach is built upon a teacher-student knowledge distillation paradigm, aiming to train an efficient and accurate localization model without requiring any pixel-level ground-truth masks. An overview of the framework is illustrated in Figure 2.
Our key idea is to leverage a large-scale foundation segmentation model as the teacher, which possesses powerful zero-shot segmentation capabilities. Given a coarse prompt (e.g., a rough bounding box indicating the manipulated region), the teacher model can generate high-quality finegrained masks. These masks, although not manually annotated, serve as pseudo ground truth for supervising a lightweight student model. The student is trained to predict tampered regions directly from the input image, without relying on any external prompt during inference.
To avoid reliance on pixel-level annotations, we employ the pre-trained SAM as a frozen teacher model. Given an input image I ∈ R 3×H×W and a coarse bounding box B ∈ R 4 indicating the manipulated region, SAM generates a high-quality binary mask Mteacher ∈ {0, 1} H×W via its prompt encoder and mask decoder. These automatically produced pseudo masks provide fine-grained spatial supervision without requiring manual labeling. By leveraging SAM’s zero-shot segmentation capability, our framework transforms low-cost box-level prompts into detailed masks, enabling effective supervision while minimizing annotation cost. The student model is trained using these pseudo masks, as described in the following section.
To enable our student model to learn precise localization from the teacher’s pseudo-masks, a powerful and robust feature fusion mechanism is required. Standard feature fusion networks often fall short because they treat all features passively and lack a mechanism to handle the diversity of manipulations, from subtle splicing artifacts to novel AI generated content. Our key insight draws inspiration from the psychological concept of the collective unconscious, which posits that human understanding is shaped not only by personal experience but also by a shared, inherited reservoir of archetypal patterns. Translating this to our domain, we argue that a robust manipulate localization model should not rely solely on analyzing a single image in isolation. In-stead, it must emulate this dual cognitive process. It needs to combine the the meticulous analysis of immediate evidence within the current image and the recall of prototypical manipulation patterns which learned collectively from a vast corpus of examples. To realize this, we designed the Memory-Guided Gated Fusion Module (MGFM), as illustrated in Figure 2. The MGFM operationalizes this dualpronged approach. Its Gated Integration mechanism dynamically assesses multi-scale features to identify immediate contextual anomalies, while its Memory Bank recalls prototypical tampering patterns to provide historical context. This entire cognitive process is predicated on the module’s ability to effectively interpret the initial evidence, which is provided by the backbone network in the form of multi-scale features.
Multi-Scale Feature Pre-Processing. We adopt Tiny-ViT (Wu et al. 2022) as the backbone to extract four multiscale features F 1 , F 2 , F 3 , F 4 . To enable effective fusion, we unify their dimensions and resolutions to obtain aligned features
Gated Integration and Memory-Guided Refinement. The workflow within the MGFM begins at the Gated Integration (GI) stage. This stage is responsible for intelligently merging the multi-scale features {F ′ 1 , …, F ′ 4 }. For each feature map F ′ i , a corresponding gate map G i is generated to learn its spatial importance:
These gates then steer a dynamic fusion strategy. For each feature F ′ i , a preliminary fused feature F ′′ i is computed, which combines the feature with a weighted aggregation of all other features:
where ⊙ denotes the element-wise Hadamard product. This result is further modulated to enhance the original feature’s contribution:
Finally, all modulated features { F1 , F2 , F3 , F4 } are concatenated and passed through a convolutional block to produce a single, richly integrated feature map, F f used . Simultaneously, this stage yields an average gate map,
With F f used and G avg available, the module proceeds to its core memory-guided refinement stage. This stage is driven by a dual-guidance mechanism. First, an efficient attention mechanism computes a base attention map, A ′ base , from F f used . The refinement of this attention is then guided by two synergistic sources of information:
• Real-time Gate Prior: The average gate map, G avg , provides a direct spatial saliency prior derived from the current input. • Long-term Memory Prior: Prototypical tampering patterns are recalled from a Memory Bank, which provides a historical knowledge prior, Āmem .
These two priors work in concert to produce the final, memory-informed attention map, A f inal , which embodies both immediate analysis and long-term experience:
where α is a balancing factor. This final attention map A f inal is then used to re-weight the feature representations, generating a refined output, A ref ined , through a residual connection, which ultimately forms the model’s final prediction.
Our training objective is designed to enable the student model to accurately localize manipulated regions without any human-annotated pixel-level masks. To achieve this, we adopt a pseudo-supervised distillation strategy, where the high-fidelity masks generated by the teacher model serve as soft supervision signals. The student model, which takes only the raw image I as input, predicts a manipulation localization map
H×W . This prediction is supervised by the pseudo mask from the teacher using a standard binary cross-entropy loss:
where BCE is computed element-wise across all pixels. This loss encourages the student model to replicate the teacher’s mask quality, even though it receives no prompt or bounding box during inference.
Detailed Our method shows strong performance on multiple benchmarks using only 20 epochs. The results also serve as a baseline to analyze overfitting and convergence speed across models.
CocoGlide (Nichol et al. 2021), DSO (De Carvalho et al. 2013), IMD2020, Korus (Korus and Huang 2016), and In-the-Wild.
While pixel-level F1 and AUC are widely used metrics in IML, recent research indicates that pixel-level AUC often overestimates confidence in these tasks (Ma et al. 2024).
Consequently, we have opted to evaluate all our experiments using the F1-score with a fixed threshold of 0.5. To comprehensively evaluate model efficiency, we also report the number of parameters and FLOPs for each method.
To fairly assess the generalization dynamics of different models, we evaluate their performance at 10, 20, and 70 training epochs. This setting enables a direct comparison of how quickly each model learns and how well it generalizes, especially to OOD scenarios. All methods are trained on our unified mixed training set for consistent comparison. Results are summarized in Table 1. Among all evaluated models, some full-supervised methods like Mesorch and MFI-Net (Ren et al. 2023) show strong IND performance when given sufficient training. For example, Mesorch achieves an average F1 of 0.754 at 70 epochs, and MFI-Net reaches 0.694. These results demonstrate the effectiveness of their sophisticated architectures in modeling fine-grained manipulation traces. Despite not having access to groundtruth masks, our method achieves a competitive F1 score of 0.619 at only 20 epochs. This surpasses several strong baselines including Trufor, PSCC-Net (Liu et al. 2022), and SparseViT (Su et al. 2025), demonstrating the effectiveness of our pseudo-supervision strategy. Generalization to unseen domains remains a significant challenge for IML models. While several full-supervised methods perform well in the IND setting, their robustness in OOD scenarios is often limited. For example, TruFor and PSCC-Net demonstrate a concerning trend: their average F1 scores on OOD datasets decrease as training epochs increase. Specifically, TruFor drops from 0.303 (10 epochs) to 0.267 (70 epochs), and PSCC-Net degrades from 0.360 to 0.323 over the same range. This indicates that these models are prone to overfitting and may struggle to generalize beyond the training distribution. Similarly, Mesorch, though highly effective on IND datasets, shows limited OOD performance even after extended training, improving only marginally from 0.228 to 0.241. In contrast, methods like PIM and SparseViT exhibit more stable improvements across training epochs. PIM steadily increases its average OOD F1 from 0.330 to 0.357 between 10 and 20 epochs, while SparseViT grows from 0.250 to 0.297 over 70 epochs, reflecting better generalization potential. Our method also demonstrates consistent gains in OOD performance, increasing from 0.253 to 0.285 between 10 and 20 epochs, despite being trained without real masks.
Overall, these results highlight the trade-offs between different design choices in IML models. Fully-supervised methods such as Mesorch, TruFor and PSCC-Net exhibit high performance on IND datasets but suffer from poor generalization to unseen domains. This degradation with more training epochs suggests overfitting to dataset-specific patterns, possibly due to their reliance on finely annotated pixel-level masks, which can induce semantic bias during training. On the other hand, models like PIM and SparseViT demonstrate relatively better OOD consistency, indicating that stronger architectural priors or training regularizations can improve cross-domain robustness. However, their reliance on full supervision and complex backbones still limits scalability. In contrast, our method achieves a favorable balance across multiple dimensions: it performs competitively on IND benchmarks, maintains stable improvements on OOD datasets, and requires no ground-truth masks. The consistent upward trend in OOD performance, even under limited supervision, highlights the generalization capability of our coarse-to-fine pseudo-labeling framework.
Table 2 presents a comparison between our method and existing weakly supervised IML approaches on the IND benchmark. Due to code availability, only WSCL and SCAF are retrained on our benchmark using the same 20 epoch training schedule. Results for other methods are taken directly from their respective papers. While direct comparisons may be influenced by differences in training settings, they still offer a meaningful indication of relative performance under weak supervision.
Our method achieves a substantial performance gain over most existing weakly supervised methods. It reaches an average F1 score of 0.619, markedly outperforming WSCL (0.239), EdgeCAM (Zhou et al. 2024) (0.3218), SOWCL (Zhu, Li, and Wen 2025) (0.312), and WSCCL (Bai 2025) (0.356). These results validate the effectiveness of our coarse-to-fine pseudo-mask supervision strategy, which utilizes spatial prompts to guide learning while keeping annotation cost minimal. Notably, the recently proposed SCAF method which based on scribble annotations has shown strong localization performance and is capable of surpassing fully supervised methods when trained to full convergence. However, SCAF relies on a more intensive form of supervision, with higher annotation time and introduces a larger model size and computational cost. In our controlled 20epoch setting, SCAF does not reach its optimal performance, highlighting a trade-off between supervision strength and training efficiency. In summary, while scribble-based supervision enhances localization quality, our method offers a
We evaluate model efficiency in terms of parameter count and FLOPs. As shown in Table 3, our model achieves the lowest FLOPs (1.4G) and the second-smallest number of parameters (5.5M) among all methods. Despite its lightweight design and lower resolution input, it maintains competitive localization performance.
Figure 3 presents a qualitative comparison of our method against several baselines on both IND and OOD samples, highlighting its effectiveness and generalization capability. Performance on IND Data: On IND samples (Row 1), our method generates masks that are highly consistent with the ground truth in terms of accuracy and compactness. Its performance is visually indistinguishable from top fullysupervised methods like Trufor and PIM, while clearly surpassing the broad and inaccurate masks produced by the weakly-supervised baseline (WSCL).
Robustness on OOD Data: The key advantage of our method is its robustness on challenging OOD samples (Rows 3-5). For example, in the butterfly case (Row 5), our result is the most complete. Even in a highly ambiguous scene (Row 4), our method captures the manipulated region more clearly than the alternatives. In contrast, while fullysupervised methods perform well on some OOD instances (e.g., Trufor in Row 3), they often struggle with incomplete detection or weak activations in others (Rows 4, 5).
We conduct ablation studies to validate the effectiveness of each key component within our proposed MGFM, with results presented in Table 5. Our Baseline model consists of the backbone network followed by a simple FPN-style decoder. As shown in the table, our full model significantly outperforms the Baseline, confirming the overall superiority of the MGFM architecture. We analyze the contribution of each core component below. In conclusion, all ablated components are proven to be effective and essential. They synergistically form our proposed dual-guidance mechanism (real-time gate prior + long-term memory prior), which is key to achieving robust and accurate manipulation localization.
In this paper, we propose a novel weakly supervised framework for IML that eliminates the need for pixel-level mask annotations. By leveraging a powerful segmentation foundation model (SAM) with coarse prompts, we generate finegrained pseudo masks at minimal annotation cost, which in turn guide the training of a lightweight student model.
To further boost localization performance, we propose a memory-guided gated fusion module that stores prototypical tampering patterns, improving the model’s generalization and localization accuracy for complex manipulations.
- Extensive experiments on both in-distribution and out-ofdistribution datasets demonstrate that our method achieves competitive or superior localization performance compared to fully supervised methods, while offering strong generalization, faster convergence, and deployment efficiency. In summary, our approach provides a practical and scalable solution for IML with minimal supervision.
-
Full (pixel-level masks), Weak (bounding boxes).
📸 Image Gallery