Structured Prompting Enables More Robust Evaluation of Language Models
📝 Original Info
- Title: Structured Prompting Enables More Robust Evaluation of Language Models
- ArXiv ID: 2511.20836
- Date: 2025-11-25
- Authors: Asad Aali, Muhammad Ahmed Mohsin, Vasiliki Bikia, Arnav Singhvi, Richard Gaus, Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Yifan Mai, Jordan Cahoon, Michael Pfeffer, Roxana Daneshjou, Sanmi Koyejo, Emily Alsentzer, Christopher Potts, Nigam H. Shah, Akshay S. Chaudhari
📝 Abstract
As language models (LMs) are increasingly adopted across domains, high-quality benchmarking frameworks that accurately estimate performance are essential for guiding deployment decisions. While frameworks such as Holistic Evaluation of Language Models (HELM) enable broad evaluation across tasks, they often rely on fixed prompts that fail to generalize across LMs, yielding unrepresentative performance estimates. Unless we approximate each LM's ceiling (maximum achievable via changes to the prompt), we risk underestimating performance. Declarative prompting frameworks, such as DSPy, offer a scalable alternative to manual prompt engineering by crafting structured prompts that can be optimized per task. However, such frameworks have not been systematically evaluated across established benchmarks. We present a reproducible DSPy+HELM framework that introduces structured prompting methods which elicit reasoning, enabling more accurate LM benchmarking. Using four prompting methods, we evaluate four frontier LMs across seven benchmarks (general/medical domain) against existing HELM baseline scores. We find that without structured prompting: (i) HELM underestimates LM performance (by 4% average), (ii) performance estimates vary more across benchmarks (+2% standard deviation), (iii) performance gaps are misrepresented (leaderboard rankings flip on 3/7 benchmarks), and (iv) introducing reasoning (chain-of-thought) reduces LM sensitivity to prompt design (smaller performance ∆ across prompting methods). To our knowledge, this is the first benchmarking study to systematically integrate structured prompting into an established evaluation framework, demonstrating how scalable performance-ceiling approximation yields more robust, decision-useful benchmarks. We open-source (i) DSPy+HELM Integration 1 and (ii) Prompt Optimization Pipeline 2 .📄 Full Content
While benchmarking frameworks such as Holistic Evaluation of Language Models (HELM) (Liang et al., 2022;Bedi et al., 2025) enable holistic evaluation via a comprehensive suite covering diverse tasks, public leaderboards typically evaluate multiple LMs under a fixed prompt per benchmark. However, fixed prompts rarely generalize well across LMs, leading to unrepresentative performance estimates that obscure underlying strengths and weaknesses of LMs. Hence, broader LM adoption necessitates scalable approximation of performance ceilings (i.e., the maximum achievable via prompt-only changes), thereby allowing practitioners to weigh cost-benefit tradeoffs and choose the right model for each downstream task. Prompt engineering has emerged as a practical alternative to fine-tuning. Well-designed prompts improve performance, as demonstrated by Nori et al. (2024); Maharjan et al. (2024), combining few-shot selection, chain-of-thought (CoT) (Wei et al., 2022), and ensembling. However, these methods rely on hand-engineered prompts, demanding domain expertise and iterative experimentation, making them labor-intensive and often non-robust to new model rollouts (Wang et al., 2025). Consequently, researchers have explored automatic prompt optimization (APO) (Li et al., 2025), which treats prompt design as an optimization problem.
DSPy (Khattab et al., 2023) is a widely used declarative framework that represents prompts as modular, parameterized components with an intuitive structure that allows moving from zero-shot prompts to more adaptive prompting styles all within a single unified system supporting reproducible, structured prompting. Moreover, DSPy supports automatic prompt optimizers (APOs) such as MIPROv2 (Opsahl-Ong et al., 2024), which can convert high-level task specifications into optimized instructions and few-shot examples.
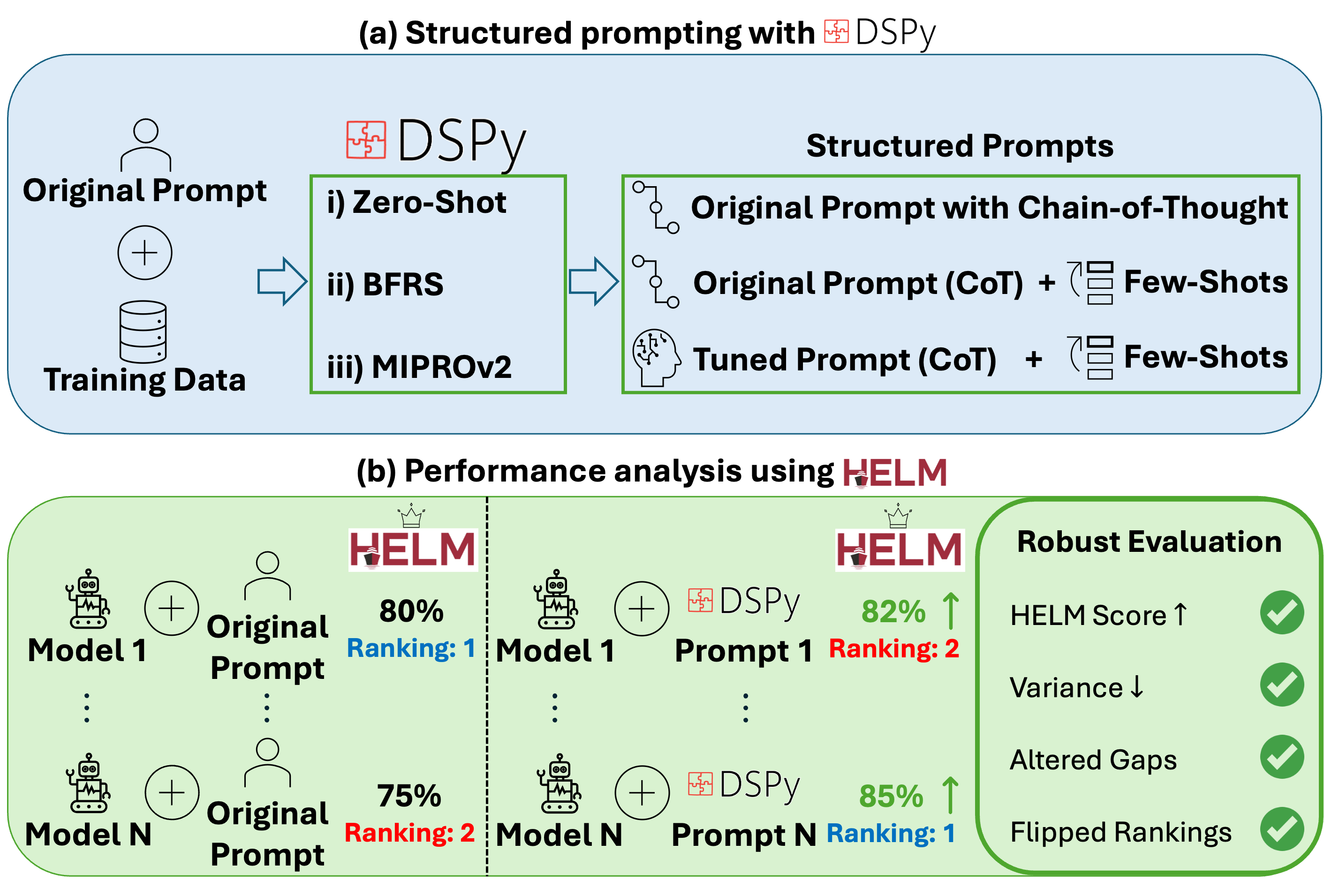
However, despite the growing use of structured prompting, we lack a systematic evaluation of how these approaches affect benchmark robustness and performance estimates across established evaluation suites. We use DSPy as an instantiation of structured prompting and integrate it with HELM (Figure 1), presenting:
-
A reproducible DSPy+HELM framework that introduces structured prompting methods which elicit reasoning, enabling more robust evaluation of LMs across HELM benchmarks.
-
An evaluation of prompting methods (Zero-Shot, Bootstrap Few-Shot with Random Search, MIPROv2) against HELM’s baseline across four LMs and seven HELM benchmarks that span general and medical domains (reasoning, knowledge QA, problem-solving, error-classification), where each prompting method leverages a distinct mechanism for refining prompts to approximate LM performance ceilings.
-
Empirical evidence that without structured prompting: (i) HELM underestimates LM performance (by 4% average), (ii) performance estimates vary more across benchmarks (+2% standard deviation), (iii) performance gaps are misrepresented (leaderboard rankings flip on 3/7 benchmarks), and (iv) introducing reasoning (CoT) reduces LM sensitivity to prompt design (smaller ∆ across prompts).
Respond with the corresponding output fields, starting with “REASONING”, then “OUTPUT”.
Prompt 4: MIPROv2 (Instruction + Few-Shot Optimized)
Your input fields are: “INPUTS” Your output fields are: “REASONING” and “OUTPUT” Your objective is: You are a highly skilled medical expert working in a busy emergency room. A patient presents with a complex medical history and concerning symptoms. The attending physician needs your immediate assistance in calculating a critical risk score to guide treatment decisions. The patient’s life may depend on your accuracy.
INPUTS: → REASONING:
Given a patient note and a clinical question, compute the requested medical value.
Respond with the corresponding output fields, starting with “REASONING”, then “OUTPUT”. to denote running program Φ under a particular prompt assignment. Given a dataset D = (x, y) of inputs x with ground-truth y and an evaluation metric µ that compares the program’s output Φ(x) against y, the optimization maximizes µ over all instructions and demonstrations:
(1)
As a baseline, we evaluate LMs using the following prompting methods:
-
HELM Baseline. HELM supports multiple prompting configurations; we adopt the commonly reported fixed, zero-shot (hand-crafted) prompt configuration without CoT as the baseline for comparison.
-
Zero-Shot Predict. DSPy’s Zero-Shot Predict configuration is an unoptimized non-adaptive baseline, which we instantiate with the dspy.Predict module. Each module’s instruction prompt is initialized with the same HELM baseline instruction, without in-context demonstrations (i.e. K = 0).
In addition, we evaluate LMs using the following structured prompting methods (Figure 2):
- Zero-Shot CoT. DSPy’s Zero-Shot CoT configuration utilizes the same prompting structure as Zero-Shot Predict, but instead instantiates the dspy.ChainOfThought module, which elicits step-by-step rationales, instructing the LM to generate an explicit reasoning trace with the output.
We choose seven benchmarks (Table 2) based on (i) public availability, (ii) task diversity (reasoning, knowledge QA, problem-solving, error classification), and (iii) domain coverage (general/medical).
MMLU-Pro. MMLU-Pro (Wang et al., 2024b) is an enhanced version of MMLU that focuses on more challenging, reasoning-intensive questions. It expands answer choices from four to ten and removes trivial items, providing a more discriminative measure of higher-order reasoning. The metric µ is exact match.
GPQA. GPQA (Rein et al., 2024) is a graduate-level multiple-choice benchmark covering biology, physics, and chemistry to test advanced reasoning. The metric µ is the fraction of correct answers (exact match).
GSM8K. GSM8K (Cobbe et al., 2021) consists of grade school math word problems designed to evaluate reasoning. The task requires computing a final numeric answer, and the metric µ is exact match.
MedCalc-Bench. MedCalc-Bench (Khandekar et al., 2024) is a medical calculation benchmark, where the input is a patient note and a question asking for a numerical/categorical value. The evaluation metric µ is exact match for the risk, severity, and diagnosis categories, and a within-range correctness check for others.
Medec. Medec (Abacha et al., 2024) is an error detection and correction benchmark, where each input contains a narrative that may contain factual errors, and the task is to identify/correct these errors. The evaluation metric µ involves checking how accurately LMs identify whether a note contains an error (binary).
HeadQA. HeadQA (Vilares & Gómez-Rodríguez, 2019) is a collection of biomedical multiple-choice questions for testing medical knowledge, where questions cover medical knowledge and often resemble medical board exams. The performance metric µ is exact match between the prediction and the correct option.
MedBullets. MedBullets (Medbullets, 2025) is a benchmark of USMLE-style medical questions with multiple-choice answers. MedBullets covers broad topics and is designed to reflect the difficulty of medical licensing exams. Like HeadQA, the primary metric µ is exact match accuracy on the correct answer.
seed (u i (x)) to B i . 2: Search: For r = 1:R:
6: r) ) by equation 15. Fit/update TPE from H t-1 to obtain ℓ, g in equation 16.
Acquire candidate:
).
Append to history: t) , y (t) )}.
if t mod E = 0 then 10:
Select top-K by running mean; evaluate each on full D val to get J(•).
11:
12: Return v † and Φ v † . Ceiling -Baseline (∆) +4.99% +4.80% +4.83% +2.31%
Table 3: HELM leaderboard (macro-averaged over seven benchmarks) across four language models and five prompting methods. Green marks the “ceiling” performance for a model (best value across prompting methods). Entries are reported as the macro-average ± standard deviation σ over seven benchmarks. At each model’s ceiling, structured prompting on average leads to +4% in accuracy and -2% in σ across benchmarks.
Implementation details. We evaluate four frontier LMs (Table 1). We initialize each DSPy program with HELM’s baseline instruction for comparability. DSPy then applies its own standardized prompting modules, treating the full HELM prompt as input. For BFRS and MIPROv2 optimizers, we follow DSPy’s data separation: the demonstration pool is bootstrapped exclusively from the training split, while candidate prompts are evaluated on a disjoint held-out validation split from the original training partition; neither optimizer ever sees the HELM leaderboard test set. Each benchmark’s loader creates a fixed train/val partition (default 90/10 with the same seed), and we cap both bootstrapped and labeled demonstrations at K ≤ 3 per module. All final scoring is performed via HELM, so outputs are judged identically regardless of how they were produced. All results reflect single, deterministic runs (temperature = 0), matching HELM’s experimental setup. For HELM baselines, we report HELM’s public leaderboard scores when the setup matches ours: (i) identical LM API version, (ii) zero-shot prompting, and (iii) no CoT reasoning. For benchmarks where the leaderboard setup does not match, we reproduce them with single, deterministic runs.
To summarize gains, we take the mean of the three structured prompting methods (Zero-Shot CoT, BFRS, MIPROv2); for each LM, we first macro-average across benchmarks, and then average the ∆ (absolute % change over baseline) across LMs. The change in variability (σ) is reported analogously.
Improved performance over HELM baseline. Structured prompting methods (Zero-Shot CoT, BFRS, MIPROv2) consistently improve over the HELM baseline (Table 3). On average, LMs gain +4% in absolute accuracy. Non-reasoning models benefit most (+5%), while o3 Mini sees smaller but consistent gains (+2%).
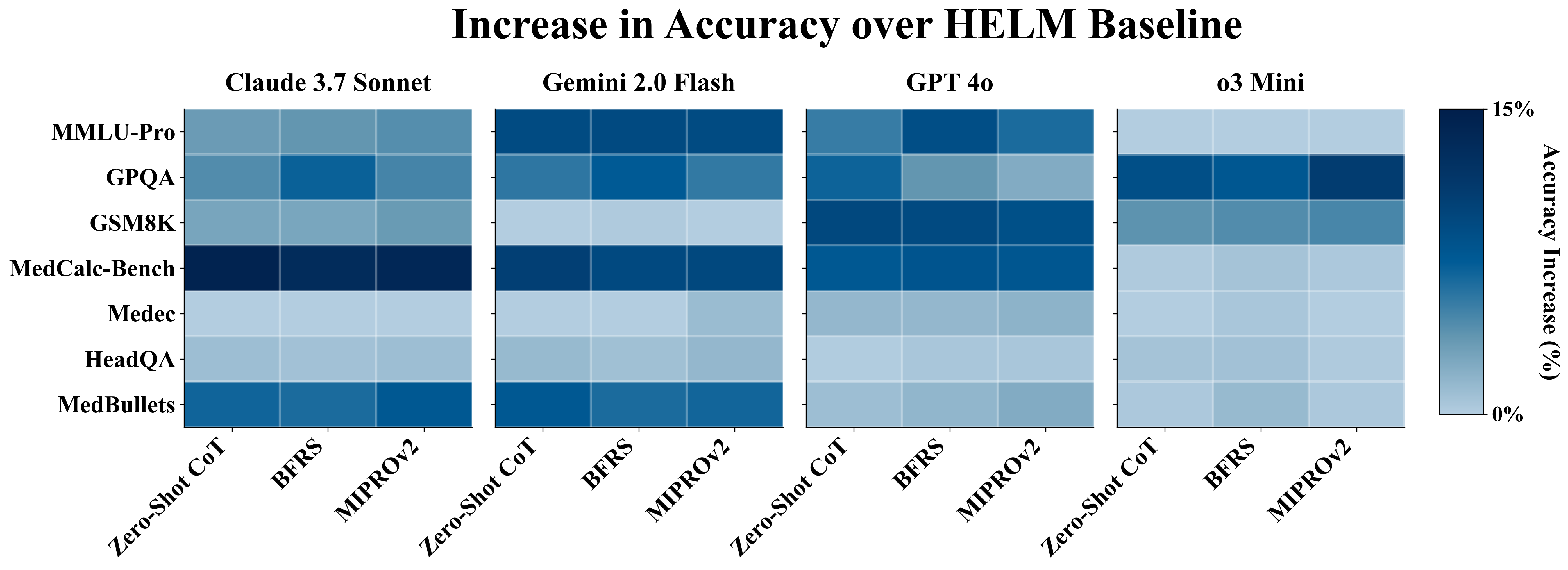
Flipped leaderboard rankings. At ceiling, three leaderboard rankings flip. On MMLU-Pro ( Benchmark-dependent sensitivity. Performance gains vary across benchmarks (Figure 3). Tasks requiring reasoning, such as MMLU-Pro, GPQA, GSM8K, MedCalc-Bench, and MedBullets, show the largest gains (average +5.5% absolute across models). In contrast, HeadQA and Medec exhibit smaller improvements (average +0.4% absolute across models). We hypothesize that HeadQA is bottlenecked by high baseline scores (∼90%), while Medec likely reflects fundamental limits in the LM’s knowledge base.
Ranking stability analysis. Table 5: MedHELM leaderboard (medical domain) across four language models and five prompting methods. Green marks the “ceiling” performance for a model (best value across prompting methods). ↑ and ↓ indicate a one-step increase or decrease in leaderboard rank, respectively. Entries are reported as mean ± 95% bootstrap confidence interval. Overall, structured prompting consistently improves the robustness of benchmarks.
We first formalize the effect of CoT on prompt sensitivity. Consider a LM with parameters θ, input x, and two prompts p and p ′ that share the same CoT interface but differ in instructions and/or demonstrations3 . Under prompt p, the model samples a full reasoning path τ (CoT) and then produces a final answer y; i.e.,
The predictive answer distribution under p is obtained by marginalizing over reasoning paths (self-consistency):
Once a full reasoning path τ has been generated, the residual dependence of y on the prompt is negligible:
Because all structured prompt variants instruct the LM to output a reasoning trace, once τ is fixed, small changes in the instructions/demonstrations do not systematically change the conditional distribution over y: p → τ → y forms a Markov chain given x, (
Applying Pinsker’s inequality to the right-hand side gives We now state a pointwise decision-stability result. Fix x and prompts p, p ′ . If
then the prediction is invariant:
Moreover, a sufficient condition is
Condition 9 implies that the probability mass on the top-class y ⋆ cannot be reduced by more than 1 2 m(x; p), while the mass on any competitor cannot be increased by more than the same amount. Hence no competitor can overtake y ⋆ , giving 10. Inequality 11 combines the TV bound in 7 with the margin condition 9.
In CoT decoding, P θ (y | x, p) can be viewed as a marginalization over possible reasoning paths, which typically enlarges the margin m(x; p) compared to direct (non-CoT) decoding. At the same time, structured prompting methods mainly alter instructions and few-shot examples while preserving the CoT interface, so they primarily act by reweighting P θ (τ | x, p) rather than changing the conditional channel P θ (y | x, τ ). Once CoT is enabled, the effective KL divergence between path distributions under different structured prompts is small enough that equation 11 holds for most items, and further optimization rarely flips decisions except on near-tied examples. Empirically, this is reflected in our results: moving from non-CoT to Zero-Shot CoT yields majority gains, while more aggressive optimizers (BFRS, MIPROv2) produce marginal improvements.
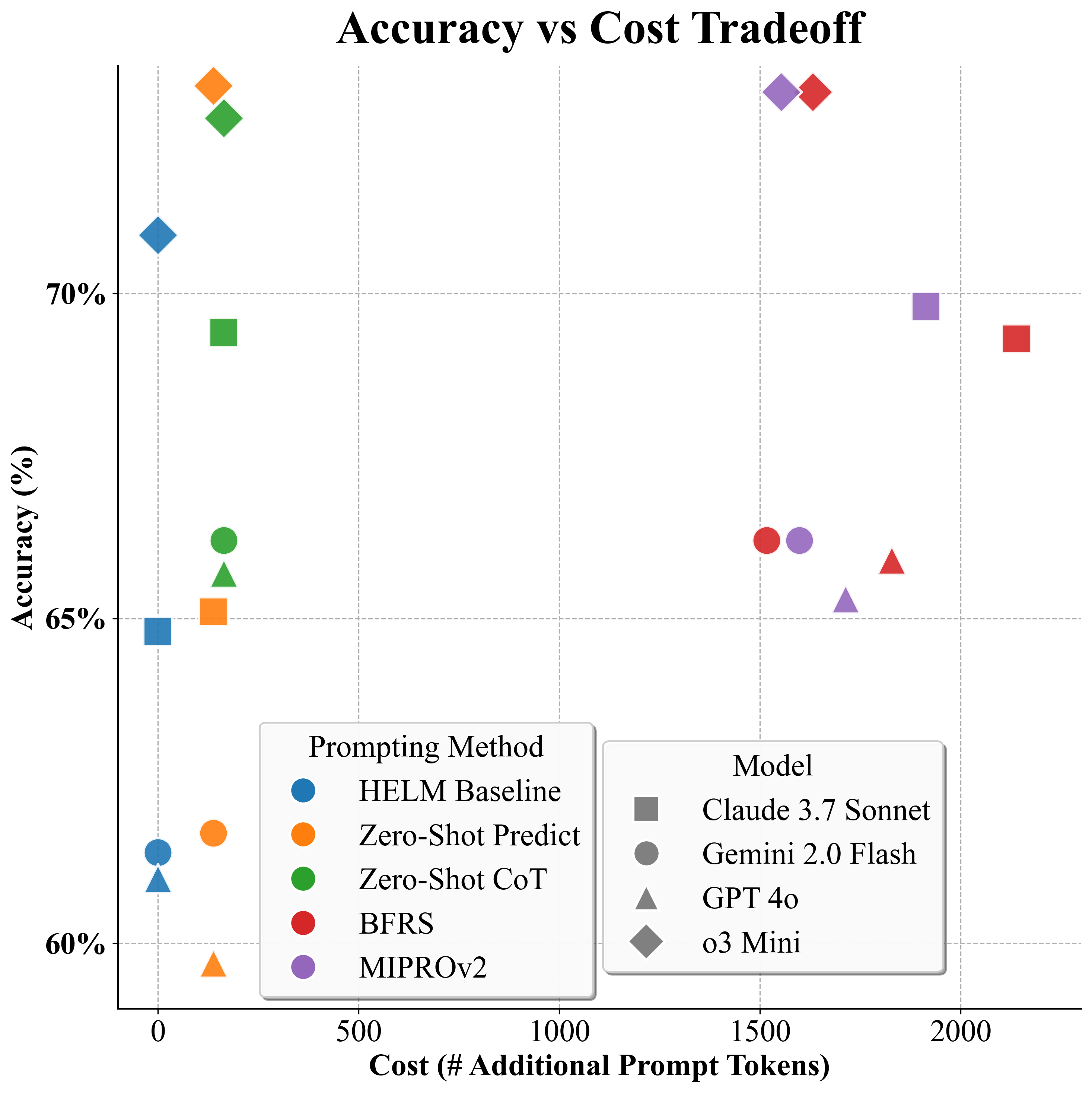
We evaluate the inference-time computational cost across prompting methods by examining token usage. BFRS and MIPROv2 optimizations are one-time expenses amortized over future runs: DSPy’s documentation reports that optimization runs range from a few cents to tens of dollars depending on the configuration,4 . Our optimization costs match DSPy’s reported range. We therefore focus our analysis on inference-time tokens.
In our setup, the input (e.g., question, patient note) is identical across prompting methods, and outputs are capped at <200 tokens. As a result, differences in inference cost arise almost entirely from the prompt prefix (the instructions and demonstrations prepended to the input). Hence, we quantify the number of additional prompt tokens relative to the HELM baseline instruction, capturing each prompting method’s overhead.
DSPy introduces a lightweight structured prompt template across all methods, resulting in 138 additional tokens for Zero-Shot Predict and 164 tokens for Zero-Shot CoT, which further includes a brief reasoning header. In contrast, BFRS and MIPROv2 insert task-specific demonstrations, producing much larger prompts: averaged across LMs and benchmarks, BFRS adds 1,779 tokens per query and MIPROv2 adds 1,694.
Figure 4 shows the resulting tradeoff. Few-shot optimizers reach high ceilings but require the largest token budgets. Zero-Shot CoT captures most of these gains while using minimal additional prompt tokens, making Zero-Shot CoT the most cost-effective structured prompting method in our study.
Holistic benchmarking. The General Language Understanding Evaluation (GLUE) (Wang et al., 2018) benchmark was one of the first multi-task evaluation frameworks, aggregating nine distinct language understanding tasks. Benchmarks of increasing scale followed: (i) Measuring Massive Multitask Language Understanding (MMLU) (Hendrycks et al., 2020), including 57 tasks spanning STEM, humanities, social sciences, and (ii) Beyond the Imitation Game (BIG-Bench) (Srivastava et al., 2023), with 204 diverse tasks. The HELM framework is an established standard, designed for transparent, reproducible, and multi-metric evaluation of model capabilities (Liang et al., 2022). However, these benchmarks are typically evaluated using static prompts. Liang et al. (2022) note they opt for simple, generic prompts to orient development “towards generic language interfaces” that do not require “model-specific incantations”. This reliance on fixed prompts, however, risks the underestimation of the true capabilities of LMs. Srivastava et al. (2023); Suzgun et al. (2023) conclude that standard few-shot prompting substantially underestimates the capabilities of LMs.
Prompting methods. The discovery of in-context learning (Brown et al., 2020), where models learn from n-shot demonstrations, and the breakthrough of chain-of-thought (CoT) prompting (Wei et al., 2022) established the important role of prompt design in model performance. Complex, manually-composed strategies like Medprompt (Nori et al., 2023), which combine few-shot selection, CoT, and ensembling, demonstrate that a LM’s performance ceiling often lies higher than with the use of static prompts. Because manual prompt engineering is impractical for systematically approximating this ceiling, researchers often frame prompt design as a formal “optimization problem”, leading to the field of APO. Early APO methods include generation-and-selection, such as Automatic Prompt Engineer (APE) (Zhou et al., 2022), which uses an LM to propose candidate instructions and a separate scoring function to select the best one. Subsequent systems expanded this search paradigm (Wang et al., 2023;Yang et al., 2023;Singla et al., 2024). These methods often outperform zero-shot or manually engineered prompts on a variety of general tasks. In the LM-as-Optimizer paradigm, an LM is instructed to iteratively refine prompts by showing it a trajectory of previously evaluated candidates and their scores. Other approaches have employed evolutionary search, like Promptbreeder (Fernando et al., 2024), which treats prompts as “genes” and evolves a population of instructions over generations using a LM to perform mutation. The DSPy framework (Khattab et al., 2023) generalizes these methods, providing a programming model that compiles declarative, multi-stage pipelines.
First, we focus on widely used frontier LMs rather than open-source models. While this choice highlights that even strong models remain sensitive to prompt design, it limits the generality of our findings because frontier LMs differ in training data transparency, accessibility, and reproducibility compared to open-source models. Second, our benchmarks primarily involve multiple-choice and short-form reasoning tasks, and results may not generalize to open-ended generation tasks. Third, we evaluate a subset of structured prompting methods from the DSPy family; alternative frameworks could yield higher ceilings. However, our goal is not to identify the optimal prompting method, but to demonstrate that fixed-prompt (without CoT) leaderboard evaluations can systematically underestimate LM performance and often distort model comparisons and rankings.
By integrating DSPy with HELM, we empirically approximate LM performance ceilings, obtaining more representative estimates. Our results show that structured prompting can materially alter benchmark conclusions, shifting relative LM ordering and improving robustness by reducing sensitivity to arbitrary prompt choices. Sensitivity is heterogeneous: reasoning LMs show marginal gains, whereas some benchmarks for non-reasoning LMs benefit more, and gains are largely agnostic to the particular structured prompting method. The key driver of improvement is the transition from the baseline prompt to any CoT variant, with Zero-Shot CoT providing the most cost-efficient instantiation. Future public leaderboards should report performance under multiple structured prompting methods, enabling practitioners to assess achievable performance across prompting styles and make more informed deployment decisions. Together, we show that scalable and automated performance-ceiling approximation enables more robust, decision-useful benchmarks.
). Each box corresponds to one method, showing how instructions and context differ across methods. For BFRS and MIPROv2, K denotes the number of in-context demonstrations (Inputs → Reasoning, Output).
- MIPROv2. MIPROv2 (Algorithm 2) is an optimizer that jointly selects instructions and K few-shot demonstrations via: (i) bootstrapping demos, (ii) grounded instruction proposals from a proposer LM conditioned on dataset summaries, program structure, exemplar demos, and trial history, and (iii) Bayesian search over instruction-demo pairs. It treats each configuration v as hyperparameters, learns p(y | v) from trial outcomes, and steers toward high-scoring regions. For efficiency, candidates are scored on mini-batches of size B, with periodic full-dataset D evaluations of top contenders; the best full-data configuration is returned (with hyperparameters instruction text, demo-set, and K).
Algorithm 1 BFRS: Bootstrap Few-Shot with Random Search Require: Seed program Φ seed ; train/val sets D tr , D val ; threshold τ ; demos per module K i ; trials R; minibatch size B. 1: Bootstrap: i (x), Φ
Altered inter-model performance gaps. When evaluated at ceiling performance, models can either narrow or widen their relative performance gaps, providing a more accurate view of true capability differences. Averaging across benchmarks, the gap between the top two models (o3 Mini and Claude 3.7 Sonnet) shrinks from 6% at baseline (70.9 vs. 64.8) to 3% (73.2 vs. 69.8). However, this trend is not uniform: on GPQA, the gap widens substantially, from 0.6% at baseline (57.6 vs. 57.0) to 4.3% at ceiling (68.4 vs. 64.1).
HELM leaderboard (general domain) across four language models and five prompting methods. Green marks the “ceiling” performance for a model (best value across prompting methods). ↑ and ↓ indicate a one-step increase or decrease in leaderboard rank, respectively. Entries are reported as mean ± 95% bootstrap confidence interval. Overall, structured prompting consistently improves the robustness of benchmarks.Reduced across-benchmark variance. Structured prompting methods reduce dispersion. Acrossbenchmark σ drops for Claude 3.7 Sonnet (22.6% → 18.8%), Gemini 2.0 Flash (23.8% → 20.9%), and GPT 4o (23.9% → 22.5%), while o3 Mini is unchanged (19.7%), indicating lower sensitivity.
HELM leaderboard (general domain) across four language models and five prompting methods. Green marks the “ceiling” performance for a model (best value across prompting methods). ↑ and ↓ indicate a one-step increase or decrease in leaderboard rank, respectively. Entries are reported as mean ± 95% bootstrap confidence interval. Overall, structured prompting consistently improves the robustness of benchmarks.
CoT reduces sensitivity to prompt design. We study the impact of each prompting method on the leaderboard by averaging results across LMs and benchmarks. Moving from HELM’s baseline to Zero-Shot Predict yields minimal improvement (64.6% → 64.9%). In contrast, introducing CoT reasoning and moving from Zero-Shot Predict to Zero-Shot CoT results in substantial gains (64.9% → 68.5%). Interestingly, moving from Zero-Shot CoT to more sophisticated optimizers, such as BFRS and MIPROv2, does not lead to a meaningful additional improvement (68.5% → 68.6%), indicating that once CoT is introduced, LMs become less sensitive to further optimization.
DSPy+HELM Integration: https://github.com/stanford-crfm/helm/pull/3893
Prompt Optimization Pipeline: https://github.com/StanfordMIMI/dspy-helm
Throughout, we fix the decoding temperature and sampling strategy, so that changing p only affects the textual prefix.
DSPy Optimizer Costs: https://dspy.ai/learn/optimization/optimizers/ .
📸 Image Gallery