Energy-Efficient Federated Learning via Adaptive Encoder Freezing for MRI-to-CT Conversion: A Green AI-Guided Research
📝 Original Info
- Title: Energy-Efficient Federated Learning via Adaptive Encoder Freezing for MRI-to-CT Conversion: A Green AI-Guided Research
- ArXiv ID: 2512.03054
- Date: 2025-11-25
- Authors: Ciro Benito Raggio, Lucia Migliorelli, Nils Skupien, Mathias Krohmer Zabaleta, Oliver Blanck, Francesco Cicone, Giuseppe Lucio Cascini, Paolo Zaffino, Maria Francesca Spadea
📝 Abstract
Background and Objective: Federated Learning (FL) holds the potential to advance equality in health by enabling diverse institutions to collaboratively train deep learning (DL) models, even with limited data. However, the significant resource requirements of FL often exclude centres with limited computational infrastructure, further widening existing healthcare disparities. To address this issue, we propose a Green AI-oriented adaptive layer-freezing strategy designed to reduce energy consumption and computational load while maintaining model performance. Methods: We tested📄 Full Content
Although Artificial Intelligence (AI) and particularly Deep Learning (DL) have shown great promise for supporting and improving diagnostic accuracy and patient’s outcomes, their training and integration into routine care may require considerable computing power [3]. DL models with an increasing number of parameters and operations require large amounts of energy, in addition to water for cooling the data centres [4,5]. Such resource-intensive approaches -termed red AI [6] -prioritise ever-higher performance at the cost of substantial computational and energy usage. This dynamic can reinforce barriers to access, restricting digital health to those who can afford it and undermining health equity. On the other side, green AI (or, more recently, green-in AI [3]) emphasises the integration of sustainable practices and techniques by design, to train and deploy DL models in clinics while reducing the environmental costs and the financial burden [6]. This paradigm advocates for assessing DL models not only on their quantitative performance, but also for their efficiency -both in training and testing -and therefore sustainability [7]. Consequently, in response to growing ethical and environmental concerns, the literature calls for more sustainable and socially responsible DL practices, requiring a reorientation of current research towards environmental and social sustainability as well as equity [8,9,10].
Complementing this, Federated Learning (FL) enables multiple institutions to collaboratively train DL models without centralizing data, preserving patient’s privacy and broadening access to DL-based algorithms by potentially allowing even smaller centres to advance their diagnostic and research capabilities [11]. Indeed, by participating in a federation, these centres can contribute with their data, thereby increasing data diversity and benefiting from a DL model that is potentially less prone to bias and designed to foster the development of more robust and generalisable models.
However, the effectiveness of FL is contingent upon the participating institutions’ computational resources and infrastructure [11]. Centers with limited computational capabilities may struggle to engage in FL initiatives, potentially leading to a concentration of AI benefits among better-equipped institutions. This could result in a scenario where only well-resourced centers can fully leverage FL [12].
Ensuring that FL does not exacerbate existing disparities or concentrate decision-making power within a few wellresourced institutions or countries, calls for a focus on equity, which entails actively reducing barriers that prevent resource-constrained institutions from fully participating [13]. In response, inspired by recent contributions in the literature [14], this work aims to lower FL’s computational demand by proposing an adaptive layers freezing method, to dynamically freeze the layers involved in training and aggregation, thereby mitigating computational overhead and making FL more accessible to resource-limited institutions.
While prior research has explored layer freezing strategies to address heterogeneity in FL, existing works have primarily focused on communication efficiency and memory usage. For instance, [15,16] proposed a methodology for freezing parameters to reduce communication costs, and [17] introduced SmartFreeze to improve memory efficiency. However, these studies do not fully align their approaches with the principles of Green AI, particularly in the context of clinical applications and their social implications. By explicitly focusing on sustainability, this work contributes to making FL more energy-efficient and inclusive, facilitating wider participation without compromising the federated model’s performance.
For our purposes, we elected as our case study the federated inter-modality medical Image-to-Image (I2I) translation task. Inter-modality I2I translation converts data between different image modalities (e.g., Magnetic Resonance Imaging (MRI) to Computed Tomography (CT)), offering benefits in areas like radiotherapy planning, by enhancing treatment accuracy and reducing additional radiation [18].
Our recent study introduced FedSynthCT-Brain [19], a FL framework built upon encoder-decoder architectures, such as U-Net variants. The work dealt with a benchmark analysis aimed at identifying architectures that are both effective and computationally efficient for the MRI-to-CT synthesis task. It emphasized the need to further optimize computational efficiency as a natural direction for future research. Thus, this study builds on our FedSynthCT-Brain [19] and is guided by research paradigms that advocate for DL-based clinical decision support systems (CDSS) that, by design, meet clinical requirements while upholding a commitment to optimization, sustainability and equity [9].
We specifically introduce a patience-based mechanism, also inspired by early stopping strategies commonly used in DL [20], combined with the overall distance between consecutive encoder weights update. The patience mechanism is crucial in ensuring that freezing occurs exclusively when the designated network components (i.e., the encoder) achieved the stability. This facilitates the comprehension of the client consensus, as the aggregated model weights’ distance undergoes a natural reduction over successive rounds, culminating in a synchronised approach across all participants.
The application of FL to medical I2I translation is a recent development, with only a few studies specifically addressing this task [21,22]. Among them is our recent FedSynthCT-Brain framework [19], which tackles MRI-to-CT translation in a federated setting using a cross-silo horizontal FL approach. In this previous work, we observed that the task’s complexity and the high resolution of medical images pose a significant computational burden on individual clients, leading to extended training times.
A common initial optimisation strategy to address the aforementioned issue is to reduce communication overhead, which primarily arises from frequent synchronisation between the central server and clients during weight exchanges. A typical solution is to increase the number of local training epochs, thereby reducing synchronisation frequency. While this reduces communication costs, it may come at the expense of model accuracy, as more frequent synchronisations have been shown to improve knowledge sharing among clients and thus model performance [23]. The trade-off analysis in [23] suggests that a moderate increase in local epochs can reduce communication costs with only marginal accuracy degradation.
The implementation of alternative optimisation strategies is focused on the objective of reducing bandwidth usage, through the application of model compression techniques, such as pruning, quantisation and their combinations, such as FedWSOcomp [24,25,26]. However, these approaches result in a substantial increase in resource consumption, due to the additional computational load associated with the model compression and decompression on both client and server sides [16].
Several studies have also focused on developing customised aggregation functions to mitigate the adverse effects of non-IID and imbalanced data, thereby improving convergence and reducing the number of required communication rounds. One potential solution is the incorporation of a regularisation term within FedProx [27], which serves to penalise local updates that deviate from the global model. In our previous study, we demonstrate that the employment of FedAvg in combination with FedProx achieves optimal performance, with FedProx typically requiring fewer federated rounds when compared with other strategies such as FedAvg, FedAvgM, FedBN and FedYogi [19]. However, this optimisation proved insufficient to reduce the local computational burden or training time to a noteworthy extent, indicating that further optimisation of local training is still necessary.
In the context of federated I2I translation tasks, where encoder-decoder networks (such as U-Net, residual U-Net, or as generators in GAN architectures) are frequently employed [28,29,30], the methodology of freezing layers emerged as a particularly relevant area of interest. This approach demonstrates to be an effective training optimisation technique, both in centralised and federated settings [31,32,33,16]. In the context of centralised training, layer freezing demonstrates to accelerate the training process by circumventing the back-propagation procedure for the frozen layers. In federated settings, the use of freezing may reduce communication costs and the computational load on individual clients.
The most common freezing strategies involve “layer-wise” freezing, where specific layers are held constant throughout training. Over time, this reduces the computational load by skipping updates for the frozen parameters.
Both adaptive and permanent layer freezing approaches have been explored. In adaptive freezing, layers may be frozen or unfrozen at different training iterations, based either on random selection or guided by proxies, such as the magnitude of weight updates across epochs or classification accuracy on a calibration set. In permanent freezing, once a layer is frozen, it remains unchanged until training concludes [16].
Several studies have applied adaptive layer freezing to reduce local computational costs and encourage client participation [31,32,33,16]. FedPT [34] proposes reducing communication costs by statically selecting a subset of layers to train throughout the entire learning process, while keeping the remaining layers fixed with randomly initialised weights. However, this manual selection of trainable layers cannot guarantee optimality and may lead to substantial accuracy losses [16]. Furthermore, other works propose incremental freezing schedules based on the topological order of network layers, following predefined manual schedules or introduce an automated procedure for selecting layers to freeze by monitoring the evolution of client-model updates [33,16].
The method proposed in this paper leverages the benefits of freezing in federated training, while adapting it to different encoder-decoder architectures used in I2I translation tasks [28,29,30].
Despite recent advancements, none of the state-of-the-art works have explored freezing strategies in the context of federated medical I2I translation (such as the MRI-to-CT task tackled in FedSynthCT-Brain [19]). Furthermore, our method addresses key limitations highlighted in previous works, including the study by Malan et al. [16]. Although their approach has shown promising results in cross-device federated classification using shallow CNNs, applying it to deeper models poses scalability challenges.
In contrast, our method introduces a patience-based adaptive freezing strategy that dynamically determines when to freeze encoder layers based on a quantitative measure of inter-round convergence in aggregated encoder weights. The mechanism incorporates user-controlled stability criteria -such as the patience rounds-to distinguish between transient fluctuations and stable convergence, ensuring robustness and scalability to complex encoder-decoder architectures. Our methodology is designed in line with the principles of Green AI [6], prioritizing computational efficiency as a way to reach federated sustainability. By reducing client-side training loads via selective freezing, we aim to limit energy consumption and promote more responsible AI practices.
We designed a FL environment to simulate a realistic collaboration among four distinct clinical centres, in accordance with the setup employed in the original study [19]. Each centre trained a local DL model on its own data, while a central server coordinated the federated model by aggregating key parameters (e.g., weights, biases, batch normalization) from all clients after each training round. Following the the findings outlined in [19], we used as DL models for our FL framework:
• The original U-Net [35], referred to as Simple U-Net, featuring an encoder-decoder structure with concatenation-based long skip connections;
• The architecture proposed by Li et al. [36], designed specifically for the MRI-to-CT translation task, characterised by an encoder-decoder structure with residual connections instead of traditional skip connections, and identified as the best trade-off between effectiveness and efficiency according to [19];
• A deep encoder-decoder network inspired by U-Net, proposed by Spadea, Pileggi et al. [37], which is distinguished by its increased depth, extensive use of multi-layer convolutional blocks at each level, and regularisation via dropout;
• The architecture introduced by Fu et al. [38] for synthetic CT generation from MRI in the male pelvic region, which adopts a U-Net-like structure, but differs in its deep bottleneck, the use of instance normalisation, residual additions instead of concatenations, and the exclusive reliance on transposed convolutions for upsampling;
• A lightweight U-Net variant proposed by Li et al. [39] for the MRI-to-CT translation task, characterised by the use of Leaky ReLU activations and concatenation-based skip connections.
As for the original study [19], the experiments were conducted using the aforementioned FL setup with 4 clients (Centre A, B, C, and D) and 1 server (Centre E) on brain images.
Centres A, B, and C contained private datasets from US, Italy and Germany respectively, acquired in compliance with the ethical standards of the 1964 Declaration of Helsinki and its later amendments, with written informed consent obtained from all patients. Centres D and E were single institutions selected from the SynthRAD Grand Challenge 2023 [40]. Image dimensions and number of the samples in each dataset are detailed in Table 1. Further details on the scanners used for image acquisition for each centre were reported in the previous study [19].
Each client represented a distinct hospital (or silo) with unique and non-overlapping datasets. The federated model was further validated on the unseen dataset of the server (Centre E), which was not included in any client’s training and validation process. This setup ensured that the server-side evaluation process tested the generalisation capabilities of the federated model on an unseen dataset with different characteristics.
Following recent findings [19], [41] a pre-preprocessing pipeline was applied to harmonize the datasets without exchanging data. Firstly, N4 bias field correction was applied with different parameters for each client. All MRIs were then rescaled and normalised to the [0,1] range. To ensure uniform input dimensions for the networks, all images were resized to 256×256×256 using a combination of cropping, resizing, and padding techniques. Additionally, each client applied data augmentation using spatial transformations, such as rotations, translations, and flipping.
The concept of the proposed method is to selectively freeze the encoder weights of encoder-decoder architectures. This strategy aims to lessen the computational requirements within the FL framework, while preserving the performance akin to those of the unfrozen architectures (i.e., encoder-decoder based models without layer freezing).
As presented in Figure 1, the proposed method quantified the alignment of clients’ models during federated training by tracking incremental changes in encoder weights across consecutive training rounds. The key metric of the proposed method was the relative percentage difference (ρ % ) of encoder weights, computed as:
Where: W R represented the mean encoder weights at the current training round, W R-1 represented the mean encoder weights from the previous training round and f (•) computed the Mean Absolute Error (MAE) between corresponding encoder layers.
The MAE is defined as: Where
R-1 denote the weights of the i-th encoder layer for the current and previous training rounds, respectively, and n was the total number of layers. The average MAE across layers provided a measure of weight divergence.
As clients optimised the global objective rather than their local objectives round after round, the ρ % decreased over successive training rounds (see Figure 1), serving as an indicator of clients’ consensus in the federated task.
A patience mechanism was then introduced to manage encoder freezing based on ρ % . A minimum threshold τ was established to distinguish values of ρ % from minor fluctuations. The patience parameter N was defined to specify the number of consecutive rounds during which ρ % must remain below τ to trigger the mechanism. The patience mechanism is formalised as:
Where, R is the current round, N is the patience parameter, defining the number of consecutive rounds where ρ % < τ , I(•) is the indicator function, returning 1 if the condition is true, and 0 otherwise, ρ
% is the percentage difference at round t, τ is the minimum threshold for ρ % to be considered converged. The t was defined as R -N + 1. Thus, the condition was only satisfied in the last N consecutive rounds. Once ρ % was below the threshold τ for the defined N consecutive rounds, the encoder was frozen, which indicates sufficient convergence for the encoder.
For our purposes, we used the experimental setup proposed in [19], which used PyTorch [42] and MONAI [43] for the DL implementation, and the Flower framework [44] for the FL implementation.
All experiments were conducted in a containerised environment equipped with 32GB of RAM, 1 NVIDIA A100 80GB GPU, and 16 CPU cores. These computational resources were required to support the load of the entire federation (see Section 3.1) within a single physical node. Each client was nevertheless treated as an independent remote centre, and no individual client would require comparable resources in an actual distributed deployment.
The data augmentation process was implemented using the AugmentedDataLoader library2 . The CodeCarbon3 [45] library was used to track the emissions and the consumption of each federated training [6].
To ensure reproducibility, each experiment was repeated five times using an identical setup for each client: a batch size of 8, a learning rate of 10 -4 , 1 epoch of training for each local client for each round and the Adam optimizer. Following the experimental protocol and findings of our previous work [19], models were trained using the Random Multi-2D approach, and a voting strategy to reach a consensus on the predictions made for each anatomical plane was applied before the test; the best performing aggregation strategy, FedAvg combined with FedProx (with a proximal term of 3), was used for each experiment. Finally, as convergence and stability were consistently achieved within 25 communication rounds and no substantial performance improvements were observed beyond this [19], a fixed number of 25 rounds was used in all experiments. Therefore, a fixed number of 25 rounds was used in all experiments.
To validate our approach, we computed a set of metrics, including time, emissions, and energy consumption, both with and without the proposed methodology, in an isolated environment.
To assess the impact of the methodology on image similarity, we employed four datasets (Centres A, B, C, and D) during the federation phase and an additional external dataset (Centre E) to evaluate the federated model’s generalisation performance on previously unseen data. Image similarity was assessed using well-established metrics for the MRI-to-CT translation task [28,29,19], such as: (i) the Mean Absolute Error (MAE); (ii) the Peak Signal-to-Noise Ratio (PSNR); and (iii) the Structural Similarity Index Measure (SSIM), computed between the ground truth CT and the predicted CT.
In the first set of experiments, a preliminary study was performed. Models were trained without the encoder freezing in the FL setup. The goal was to observe the update trend of the encoder weights across training rounds and establish baseline patterns for subsequent studies.
Two percentage difference thresholds were selected for the observational study, specifically τ = 5% and τ = 10%. Both values were tested using a fixed number of patience rounds (N = 3).
Analysis of the encoder weight relative difference trends indicated that the 10% threshold was consistently reached after approximately 5-6 rounds, whereas the 5% threshold was typically reached after 7-10 rounds.
It was observed that, although the activation of the freezing mechanism was delayed when using the more conservative τ = 5%, model performance remained unchanged while the time needed to complete the rounds was considerably reduced.
Nevertheless, employing the higher threshold (τ = 10%) could have yielded further gains in terms of training time, energy consumption, and emissions. However, this configuration resulted in performance degradation across different models, due to the anticipation of encoder freezing, thereby undermining the reliability of the approach.
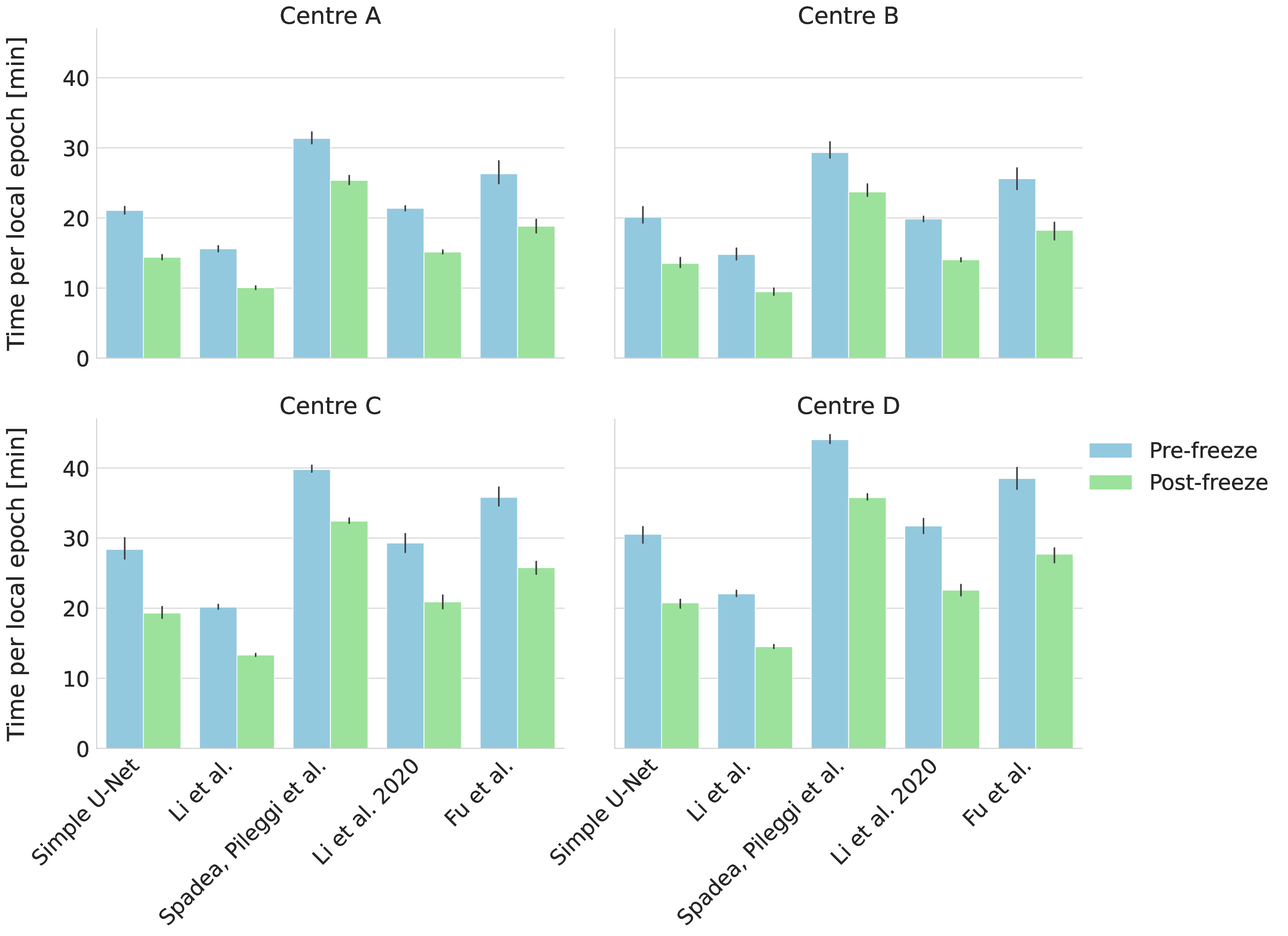
Following this findings, using the same setup, the models were trained for 25 rounds across 5 repetitions, with the patience parameter (N ) set to 3 rounds to ensure that the threshold (τ = 5%) was consistently exceeded. A consistent reduction in the number of trainable parameters was observed following the activation of the encoder freezing controlled using the proposed methodology. Therefore, a reduction in training time per local epoch was observed on all clients (see Figure 2 and Table 3), leading to a global decrease in the total training time across all architectures, with improvements ranging from 9.4% (Spadea, Pileggi et al. [37]) to 22.0% (Li et al. [36]).
These temporal gains translated into proportional decreases in total energy consumption and CO 2 eq emissions, with reductions between 9.1% and 23.2%. The Li et al. [36] model showed the largest benefits, while the Simple U-Net [35], Fu et al. [38], and Li et al. 2020 [39] achieved consistent improvements around 16-17%.
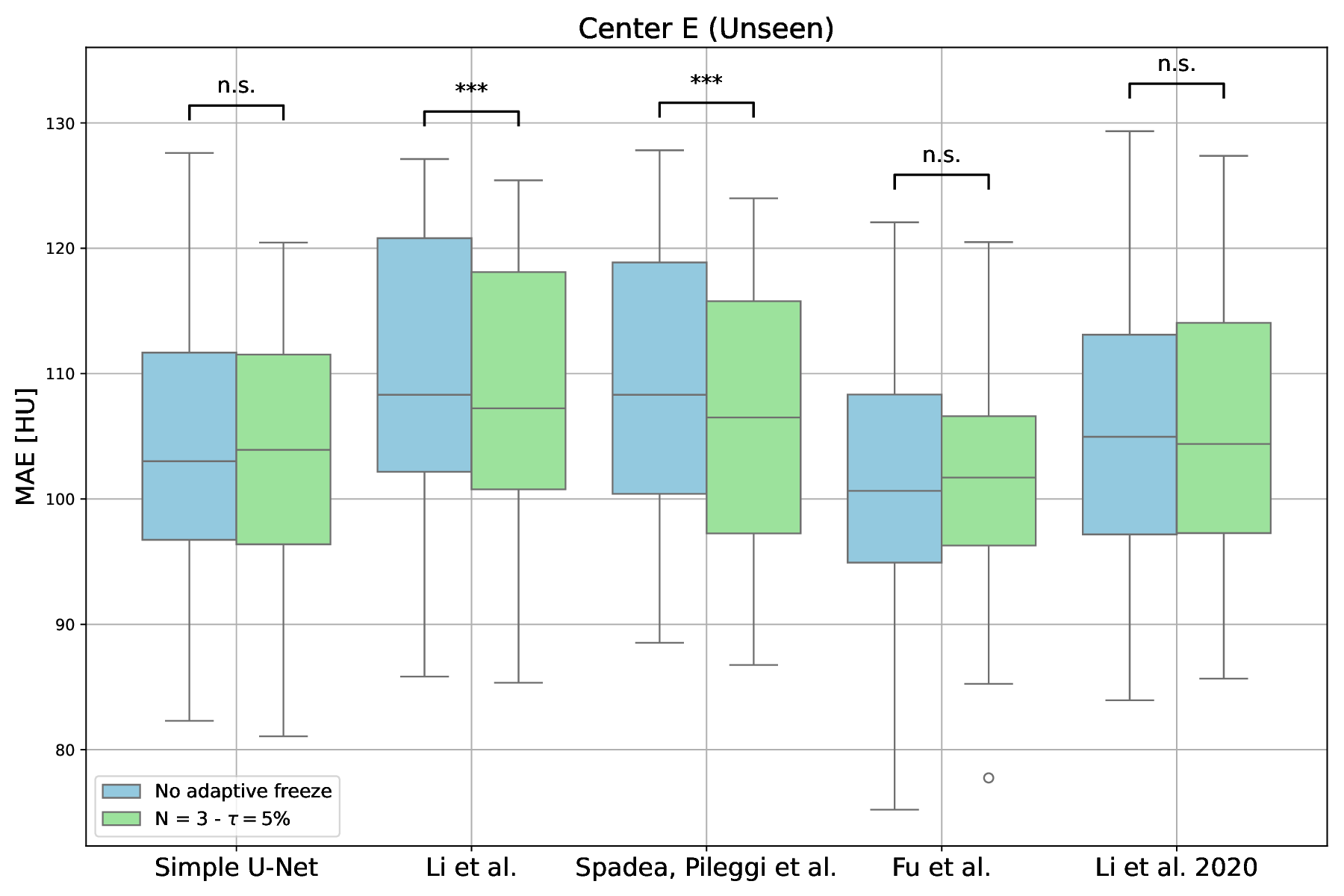
Nevertheless, the box-plot comparison of the MAE results obtained on the unseen Center E, for each model, is presented in Figure 3. The statistical analysis indicated that for three of the five architectures (Simple U-Net [35], Fu et al. [38], and Li et al. [39]) no statistically significant difference in MAE was found (p > 0.05). In contrast, Li et al. [36] and Spadea, Pileggi et al. [37] demonstrated statistically significant improvements (p < 0.001) in terms of MAE.
The PSNR and SSIM metrics are reported in Table 4. No systematic differences between the two training strategies were observed, with only minor stochastic fluctuations across the evaluated architectures.
This study introduces an adaptive encoder layer freezing strategy within federated encoder-decoder architectures for MRI-to-CT translation, operationalising the principle of equity through a Green AI by design approach.
The proposed strategy was deliberately confined to the encoder layers. As demonstrated and discussed in our previous study [19], although federated models tend to generalise to unseen data, they exhibit reduced specificity at the client level. adaptation. This design therefore achieves a balance between computational efficiency, convergence stability, and personalization.
To demonstrate its effectiveness, we evaluated the method on multiple encoder-decoder architectures.
In consideration of the results presented in Table 2, on the Simple U-Net architecture by Ronneberger et al. [35], the adaptive freezing configuration (with parameters N = 3 and τ = 5%) resulted in a global reduction in training time of 16.8% (from 13.40 ± 0.76 hours to 11.15 ± 0.64 hours). This temporal efficiency translated directly into proportional reductions in energy consumption and environmental impact, with total energy decreasing from 5.32 ± 0.23 kWh to 4.45 ± 0.23 kWh (16.4% reduction) and kgCO 2 eq emissions decreasing from 2.03 ± 0.09 kg to 1.69 ± 0.09 kg (16.7% reduction). S p a d e a , P i l e g g i e t a l .
L i e t a l . 2 0 2 0 F u e t a l .
Pre-freeze Post-freeze Improvements were observed with the Li et al. [36] architecture, where the adaptive freezing mechanism achieved a remarkable 22.0% reduction in training time (from 10.11 ± 0.38 hours to 7.89 ± 0.22 hours). Correspondingly, this architecture exhibited the most substantial environmental benefits, with kgCO 2 eq emissions reduced by 23.2% (from 1.51 ± 0.04 kg to 1.16 ± 0.03 kg) and energy consumption decreased by 23.0% (from 3.96 ± 0.10 kWh to 3.05 ± 0.07 kWh).
The positive trend was confirmed for the Fu et al. [38] architecture, which exhibited substantial efficiency improvements, with training time reduced by 16.2% (from 16.49±0.57 hours to 13.81±0.64 hours). This architecture also demonstrated notable environmental benefits, with kgCO 2 eq emissions decreasing by 17.1% (from 2.17 ± 0.07 kg to 1.80 ± 0.07 kg) and energy consumption reduced by 16.7% (from 5.69 ± 0.17 kWh to 4.74 ± 0.20 kWh).
Similarly, the Li et al. 2020 [39] architecture showed consistent improvements with a 16.6% reduction in training time (from 14.10 ± 0.28 hours to 11.76 ± 0.59 hours), as well as corresponding decreases in emissions (16.8%, from 1.85 ± 0.03 kg to 1.54 ± 0.07 kg) and energy consumption (16.7%, from 4.85 ± 0.09 kWh to 4.04 ± 0.19 kWh).
Notably, the Spadea, Pileggi et al. [37]
No adaptive freeze N = 3 -= 5% These per-epoch reductions scaled across the full federated training process, leading to proportional decreases in total energy consumption and CO 2 emissions observed in Table 2, highlighting that adaptive freezing not only accelerates training but also improves the environmental efficiency of the federated learning workflow, without adversely affecting model performance across heterogeneous client datasets.
This findings demonstrated the efficacy of the patience-based adaptive freezing approach in a federated environment, with consistent improvements observed across various architectures, ranging from fundamental designs to more complex variants.
The statistical analysis of the models’ performance -in terms of MAE -on the unseen Centre E dataset (Figure 3) revealed that the proposed adaptive freezing mechanism preserved generalisation performance and occasionally marginally enhanced it.
For three of the five evaluated architectures (Simple U-Net [35], Fu et al. [38], and Li et al. [39]), no statistically significant difference in MAE was found (p > 0.05, t-test) on 23 unseen patients, indicating that computational efficiency gains were achieved without compromising model performance. The conduction of statistical testing across single clients was precluded by the limited number of test cases available per site.
Notably, the results for the Li et al. [36] and Spadea, Pileggi et al. [37] architectures, demonstrated statistically significant improvements in terms of MAE (p < 0.001, t-test). However, the absolute MAE reduction (≈2-3 HU) remains well below radiologically and clinically meaningful thresholds for image contrast and radiotherapy, where deviations greater than 20-50 HU are typically required to discriminate biological tissues and affect dose distributions [46,47]. Hence, these results indicated that the proposed adaptive freezing mechanism preserved model fidelity, with potential minor regularisation effects, but without producing relevant performance changes.
Indeed, no performance improvement or deterioration was observed in terms of PSNR and SSIM -metrics that are less sensitive than MAE -with only minor stochastic fluctuations resulting from the independent repetitions of the experiments. Comparable or identical findings across the different architectures and methodologies was also reported in the FedSynthCT-Brain study [19], particularly with regard to SSIM, further emphasising that MAE remains the pivotal metric for performance evaluation in this type of task.
To further investigate the impact of the adaptive freezing mechanism on the generated sCTs, additional qualitative comparisons are provided in the supplementary material (see Section S.1, Figure S1-S10). Specifically, for each evaluated model, two representative cases are presented: (i) the case with the smallest difference and (ii) the case with the largest difference in MAE between the sCTs generated by the models trained with and without adaptive freezing, across the test set.
The visual comparisons confirmed that no systematic degradations are associated with the proposed methodology, and the observed differences were attributable to the inherent stochastic nature of the training process and the independent experiments.
The standard deviations reported for each metric across five repetitions indicate stable and reproducible results, with the adaptive freezing methodology consistently reducing variability in training time and resource consumption. The emissions reductions ranged from 9.1% to 23.2%, with an average reduction of ≈ 19.9% across all models. These improvements are particularly important given the increasing emphasis on sustainable machine learning practices and the growing concern regarding the carbon footprint of DL model training [48]. Furthermore, this efficiency gain is especially valuable in clinical settings where computational resources may be limited and cost considerations are essential.
The parameters N = 3 and τ = 5% were found to provide an optimal balance between computational efficiency and performance preservation in the evaluated architectures, and for the MRI-to-CT translation task. While these values proved to be flexible and effective across the five encoder-decoder architectures considered, they may not be optimal for other encoder-decoder architectures. Establishing suitable values requires initially observing the evolution of the relative percentage difference in the aggregated encoder (ρ % ) without freezing across training rounds, as represented in Figure 1. This procedure offers a principled methodology for selecting hyperparameters that balance client-specific adaptability, convergence stability and computational efficiency.
Consequently, the presented configuration should be regarded as a reasonable baseline, while systematic tuning would be necessary for other encoder-decoder-based architectures, such as GAN generators.
In this study we laid the foundation for operationalising the principle of equity in FL by applying the Green AI’s theory by design. We achieved this by introducing a patience-based adaptive freezing strategy for encoder layers in federated encoder-decoder-based architectures for MRI-to-CT translation. By leveraging relative percentage differences in encoder weights, our approach effectively reduced computational demands, emissions, and total energy consumption across rounds. Unlike conventional layer freezing techniques, which primarily focus on communication and memory efficiency, our method integrates environmental, economic, and social considerations as well, with the aim of making the federated strategy more accessible to a wider range of users in the medical field. The required manual tuning required for the τ and patience parameters might represent a limitation of this methodology, because it may necessitate some preliminary investigation of the specific model in use, in order to observe the dynamics of weight variations and to select appropriate values. As a direction for future work, it would be valuable to explore automated strategies for determining the correct τ threshold or to develop a systematic protocol to guide the selection of both τ and patience parameters, thereby enhancing the practicality and generalisability of the approach.
To qualitatively assess the potential impact of the adaptive freezing strategy on the generated synthetic CTs (sCTs), we conducted a visual comparison between the sCTs obtained with and without the proposed methodology. For each model employed in the study, we selected two representative test cases based on the following criteria:
• The case with the minimum difference in terms of MAE, thus the lowest difference between the sCTs MAE generated with and without adaptive freezing.
• The case with the maximum difference in terms of MAE, thus the highest difference between the sCTs MAE generated with and without adaptive freezing.
Each figure presents the following for the axial, coronal and sagittal plane of the central slice:
-
Input MR image;
-
Ground-truth CT image;
-
sCT generated without adaptive freezing;
-
sCT generated with the proposed adaptive freezing, using N = 3 and τ = 5%;
-
Absolute difference map between the two sCTs. Across all models and both selected cases, no relevant and systematic structural differences were observed. The differences highlighted in the absolute difference maps and the variation in MAE are attributable to the stochastic
All the architectures predicted 256 × 256 synthetic CT (sCT) slices from 256 × 256 MRI inputs. C.B. Raggio et al. -Energy-Efficient Federated Learning via Adaptive Encoder Freezing for MRI-to-CT Conversion A PREPRINT -DECEMBER 4, 2025
A
Extending the freezing strategy to the decoder would exacerbate this limitation, further restricting the capacity of the global model to accommodate local data heterogeneity. By focusing on the encoder, the federated model can instead exploit inter-client consensus to enhance stability and efficiency, while preserving decoder flexibility for client-specific C.B.
📸 Image Gallery