NNGPT: Rethinking AutoML with Large Language Models
📝 Original Info
- Title: NNGPT: Rethinking AutoML with Large Language Models
- ArXiv ID: 2511.20333
- Date: 2025-11-25
- Authors: Roman Kochnev, Waleed Khalid, Tolgay Atinc Uzun, Xi Zhang, Yashkumar Sanjaybhai Dhameliya, Furui Qin, Chandini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Dmitry Ignatov, Radu Timofte
📝 Abstract
Building self-improving AI systems remains a fundamental challenge in the AI domain. We present NNGPT, an open-source framework that turns a large language model (LLM) into a self-improving AutoML engine for neural network development, primarily for computer vision. Unlike previous frameworks, NNGPT extends the dataset of neural networks by generating new models, enabling continuous fine-tuning of LLMs based on closed-loop system of generation, assessment, and self-improvement. It integrates within one unified workflow five synergistic LLM-based pipelines: zero-shot architecture synthesis, hyperparameter optimization (HPO), code-aware accuracy/early-stop prediction, retrieval-augmented synthesis of scope-closed Py-Torch blocks (NN-RAG), and reinforcement learning. Built on the LEMUR dataset as an audited corpus with reproducible metrics, NNGPT emits from a single prompt and validates network architecture, preprocessing code, and hyperparameters, executes them end-to-end, and learns from result. The PyTorch adapter makes NNGPT frameworkagnostic, enabling strong performance: NN-RAG achieves 73% executability on 1,289 targets, 3-shot prompting boosts accuracy on common datasets, and hash-based deduplication saves hundreds of runs. One-shot prediction matches search-based AutoML, reducing the need for numerous trials. HPO on LEMUR achieves RMSE 0.60, outperforming Optuna (0.64), while the code-aware predictor reaches RMSE 0.14 with Pearson r = 0.78. The system has already generated over 5K validated models, proving NNGPT as an autonomous AutoML engine. Upon acceptance, the code, prompts, and checkpoints will be released for public access to enable reproducibility and facilitate community usage.📄 Full Content
Large language models (LLMs) such as GPT-4 [42], Code Llama [47], and DeepSeek [11] excel at code generation, which has motivated attempts to let them propose architectures, hyperparameters, or training scripts. Most prior work, however, remains at design time: the LLM emits fragments or templates that are only loosely tied to execution, logging, or learning from outcomes, so the feedback loop from generation to training to improved generation is rarely closed.
We ask whether a single LLM, embedded in an online loop with executable code and training feedback, can serve as the core of a self-improving AutoML engine for neural networks. Answering this requires representing full training pipelines as executable specifications, validating and running them at scale, predicting performance early, and using logs to continuously improve the LLM.
We introduce NNGPT, an open-source framework that, to our knowledge, is the first to unify zero-shot model generation and editing, hyperparameter recommendation, accuracy and early-stop prediction, retrieval-augmented code synthesis, and an reinforcement learning (RL)-based improvement loop into a single closed AutoML cycle driven by prompt-based LLM inference. From one high-level prompt, NNGPT produces an executable training specification (model, transforms, metrics, optimizer, schedule), executes it, logs code and metrics, and uses these logs to finetune and reinforce the underlying LLMs.
NNGPT is built on LEMUR [16], which we treat as a corpus of executable neural programs with audited implementations, unified preprocessing, and reproducible metrics. This grounds one-shot generation in runnable Py-Torch [44] code rather than abstract templates. The framework remains PyTorch-agnostic via a thin adapter that exposes model factories, data transforms, and metric bindings. In practice, NNGPT has generated and trained over 10,000 distinct models (over 5,000 through its self-improving loop Method LLM Arch. HPO Full train One-shot Closed loop Acc. pred. Open source with LLMs), with training statistics, all incorporated into LEMUR as verified outcomes.
The closed-loop view is as follows. A fine-tuned LLM emits network architectures, preprocessing code, and hyperparameters; an execution engine compiles, trains, and logs; a code-aware predictor forecasts final accuracy and a stopping epoch from model code plus early metrics; a retrieval module patches or synthesizes PyTorch blocks; and an RL layer updates LoRA adapters [22] using rewards derived from executability and downstream performance.
Our experiments demonstrate that LLMs can function as autonomous AutoML systems: they generate complete pipelines, predict performance, and refine themselves based on real-time feedback within a continuous selfimprovement loop.
Prior work falls into two strands: (i) search-based AutoM-L/NAS and (ii) LLM-driven generation.
Search-based AutoML and NAS. Classical HPO frameworks such as Optuna [2], Hyperopt [6], and Google Vizier [15] rely on Bayesian optimization or TPE to iteratively probe the space of hyperparameters. These tools are strong baselines but typically require hundreds of trials, treat training code as an opaque black box, and do not synthesize complete train specs (data, metrics, optimizer). NAS systems, including ENAS [46], DARTS [32], and Au-toKeras [24], extend search to architectures (with many stabilized variants), yet remain compute-intensive and slow to adapt to new tasks and codebases.
LLM-driven generation and closed loops. Recent methods integrate LLMs into design loops: EvoPrompting [7] uses an LLM as a mutation operator in evolutionary search; LLAMBO [34] couples LLM suggestions with Bayesian optimization; LLMatic [40], GPT-NAS [56], and Self-Programming AI [50] generate code or fill templates. Grammar/schema prompting [52] and retrieval help with validity. However, most systems either require repeated LLM queries, cover only fragments of the pipeline (e.g., mutations without training integration), or lack an online mechanism to learn from executed runs.
Performance prediction. Predicting final accuracy and early stopping has been studied via curve fitting from early learning curves [1,14], architecture-or text-based surrogates [36,53], and graph-level representations [13]. These approaches often abstract away implementation details (losses, custom layers, metric code) that strongly affect convergence, and they rarely integrate with executable pipelines.
Position of NNGPT. Table 1 situates NNGPT among these lines. Unlike prior art, NNGPT (1) one-shot generates schema-validated full training specifications (architecture & HPO) that run immediately; (2) replaces costly search for many tasks with LLM-based hyperparameter recommendation; (3) includes a code-aware predictor that consumes executable code and early metrics to forecast final accuracy and a stopping epoch; and (4) closes the loop via LoRA/RL updates using execution logs -within a single open-source framework. A comprehensive literature review with extended comparisons is provided in the Supplementary Material, Sec. 6.
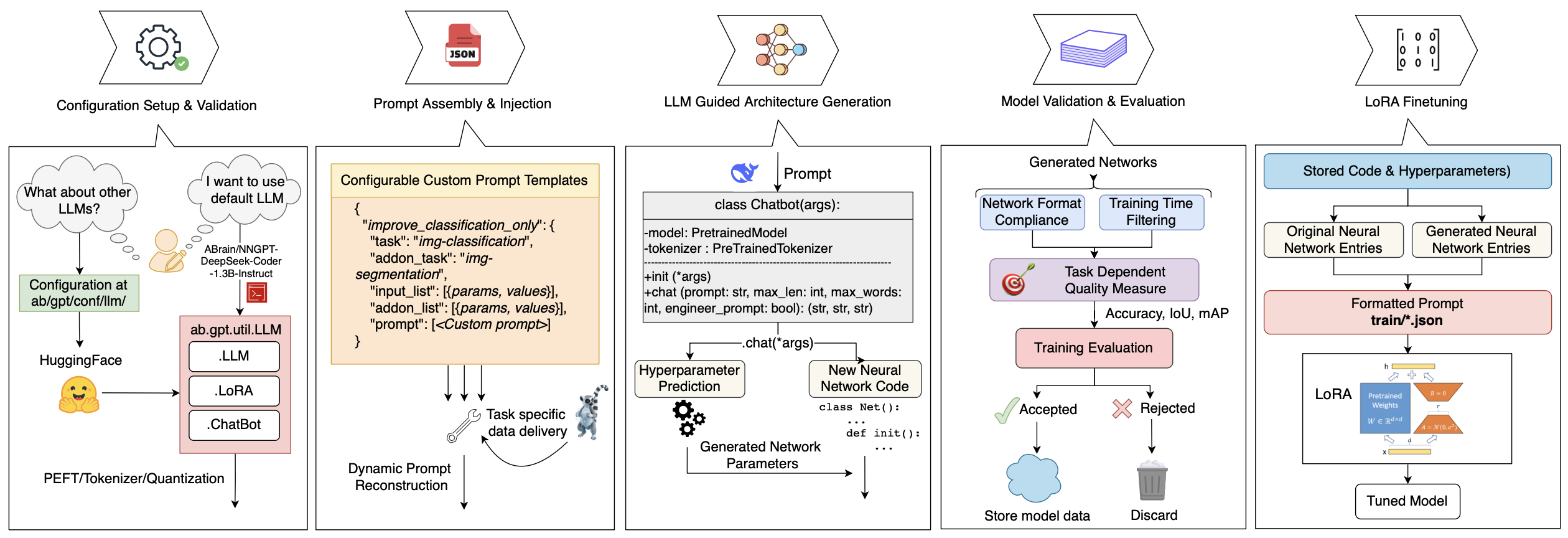
NNGPT exposes LLMs as end to end configuration agents for neural networks. Given a high level task description, the system constructs a structured prompt, calls an LLM once, validates the structured output, executes the resulting training pipeline, logs all artefacts, and feeds the trace back into its training data.
At the core of NNGPT is a shared execution substrate built on the LEMUR dataset framework, which provides executable PyTorch models, standardized training loops, and Figure 1. Overview of the NNGPT Pipeline: starting with a query to the LEMUR API to retrieve a neural network entry and its metadata, the system constructs a prompt, using an LLM generates the code of neural network model, and trains it. Artifacts are logged in a structured database, while LoRA fine-tuning continuously updates the LLM based on training results, creating a self-improving AutoML loop.
reproducible evaluation metrics. To avoid hard coupling to LEMUR, the framework defines a thin adapter interface for arbitrary PyTorch codebases that maps a configuration object to a model constructor, data transforms, and metric definitions. Any model that implements this interface can be driven by the same LLM generated specification.
A typical pass through the system proceeds as follows. First, the configuration module aggregates task level information such as dataset, objective, resource limits, and optional seed architectures. Next, a prompt builder converts this state into a JSON like instruction block that encodes the desired output schema. The LLM backend then emits a structured, machine readable specification with explicit fields for architecture, hyperparameters, and training procedure. A schema layer based on Pydantic validates the output and either autocorrects minor issues or requests a single regeneration in case of structural violations. Valid configurations are handed off to a distributed training engine, which runs the experiment, logs metrics and metadata in an SQLite store, and optionally exports models back into the LEMUR corpus. Finally, dedicated modules use these traces to fine tune the LLM with LoRA, to train an accuracy and early stopping predictor, or to update a RL signal. This shared infrastructure underpins all pipelines described below.
We cast NNGPT as closed-loop neural pipeline synthesis problem. Given a task prompt P (task, dataset, metric, optional budget) and an optional retrieval set R (code and metadata from LEMUR or external projects), the goal is to produce an executable training specification C and a horizon T that maximize downstream performance under a compute budget.
An LLM generator G θ maps
where C is a YAML/JSON spec that defines the model, data transforms, optimization schedule, loss, and nominal epochs. A validator V (schema + type/shape checks) enforces structural constraints, auto-fixes minor issues or triggers a single re-prompt; only V ( C) = pass is promoted to C.
Given C and T , the trainer E executes the pipeline,
producing validation metrics over epochs m and auxiliary logs u (loss curves, learning rate, runtime, hardware). Code and traces are persisted in a structured log.
To cut wasted compute, a code-aware predictor H ϕ estimates
where acc * approximates the final accuracy and t * proposes an early-stopping epoch from the first t 0 epochs. This induces an adaptive horizon T ′ = t * and enables early termination and priority scheduling.
Over time the log
updates θ and ϕ: G θ is refined with LoRA fine-tuning and lightweight policy-gradient updates using rewards from executability and downstream performance, while H ϕ is trained to minimize prediction error on final accuracy and stopping epoch. This closes the loop: generate, validate, execute, log, update, under an explicit compute budget.
The first pipeline turns LLMs into generators of complete architectures and training specifications. Given a task
The second pipeline treats hyperparameter tuning as conditional text generation over a fixed schema. Training data are drawn from LEMUR runs that link each model to its dataset, transforms, target accuracy, epoch budget, and the hyperparameters that achieved this performance. Prompts expose the model name, nn code, transform code, task, dataset, and either a target accuracy or a “maximize accuracy” instruction; the LLM is asked to output only the values for a predefined set of hyperparameters (learning rate, momentum, weight decay, batch size, etc.) in a strict order. We fine-tune several DeepSeek and CodeLlama variants with LoRA on this corpus and integrate the best checkpoints (DeepSeek-Coder-1.3B-Base and DeepSeek-R1-Distill-Qwen-7B) as plug-and-play recommenders inside NNGPT. At inference time, the hyperparameter pipeline runs as a one-shot replacement for search-based HPO: a single LLM call produces a configuration that is executed by the same backend as Optuna, and outcomes are logged back to LEMUR. Section 3.2 shows that these oneshot recommendations reach accuracy comparable to TPEbased Optuna on LEMUR, while eliminating thousands of optimization trials.
The third pipeline uses an LLM as a multi-task predictor of training dynamics. Each training run in LEMUR is converted into a structured prompt that fuses three modalities: (i) structured metadata (task, dataset, maximum epochs), (ii) executable code snippets for the model, metric, and data transforms, and (iii) early-epoch validation accuracies (typically at epochs 1 and 2). A DeepSeek-Coder-1.3B backbone is adapted with 4-bit QLoRA, reducing memory by ∼4× while keeping full context, and fine-tuned to regress both the final best validation accuracy and the epoch at which it occurs under a constrained JSON/YAML output schema. Stratified group splitting by (task, dataset, architecture) prevents leakage between similar models and enforces out-ofarchitecture generalization.
Within NNGPT, the predictor runs alongside training: after a few epochs, it estimates ( acc * , t * ) and can trigger early stopping when predicted accuracy is low, or prioritize promising runs in the job scheduler. As shown in Sec. 3.3, the baseline model achieves RMSE ≈ 0.145 and Pearson r ≈ 0.78 over 1,200+ runs, making it practical for computeaware filtering and scheduling.
The fourth pipeline augments generation with a retrieval system for reusable PyTorch blocks. NN-RAG scans cu-rated repositories for non-abstract nn.Module subclasses that implement forward(), round-trips their source through LibCST [30] to preserve concrete syntax, and indexes parse trees and import relations in an SQLite-backed store with SHA-1 content addressing. Given a target architecture and a textual or code query (e.g., “multi-head attention block”), NNGPT retrieves candidate blocks and uses a scope-sensitive resolver to compute the minimal transitive closure of dependencies that respects Python’s LEGB and import semantics. Definitions are reordered via topological sort to satisfy definition-before-use constraints, and the resulting scope-closed module is passed through AST parsing, bytecode compilation, and sandboxed import. On a corpus of 1,289 target blocks, this validator admits 941 modules (73% executability), covering attention, convolutions, transformer blocks [51], losses, and higherlevel architectures. These validated blocks form a library that NNGPT can splice into generated models, enabling retrieval-augmented patching while preserving executability guarantees.
We add an RL layer on top of supervised fine-tuning, treating the LLM as a policy over architecture code and configurations. From LEMUR we build a masked-architecture corpus where layer definitions (e.g., self.conv1 = nn.Conv2d(…)) are replaced by placeholders; the model learns to reconstruct these blocks, acquiring realistic priors. At RL time it proposes full architectures that are executed via check nn, which tests compilation, forward correctness, and a short CIFAR-10 [26] run. A scalar reward mixes syntactic validity, runtime feasibility, and validation accuracy, and a GRPO-style policy-gradient update (inspired by DeepSeek-R1 [10]) is applied to LoRA adapters.
In parallel, a channel-mutation engine performs deterministic width edits through five steps: torch.fx tracing, mapping graph nodes to source, planning shape-preserving changes, AST rewriting, and re-validation. Both RLgenerated and mutated models pass through the same validation and training stack, and successful configurations are added to LEMUR, closing a performance-aware loop that explores and reinforces architectures that train well in practice.
Across all five pipelines, accepted configurations, logs, and artifacts are exported back into LEMUR dataset or external repositories, turning raw LLM generations into a continually expanding corpus of executable neural programs that subsequent NNGPT runs can query, modify, and build upon.
Experiments are conducted on a single 24GB GPU (Geforce RTX 3090/4090) at a time, using PyTorch and 8-bit or 4-bit LoRA adapters on top of code-capable LLMs within the AI Linux1 environment on the Kubernetes cluster. NNGPT interacts with the LEMUR corpus through a fixed API that exposes model factories, transformation pipelines, and metric definitions, but any PyTorch codebase can be integrated via the same adapter interface. For each pipeline we report results on mid-scale vision benchmarks (e.g. CIFARlike classification and COCO-style detection/segmentation tasks), using standardized training and evaluation protocols from LEMUR. Further engineering details, CLI tools, and prompts are provided in the Supplementary Material, Sec. 7.
To quantify NNGPT’s ability to expand LEMUR via zeroshot generation, we instantiate a Few-Shot Architecture Prompting (FSAP) pipeline. For each base model and dataset, the LLM receives a natural-language task description, one reference implementation, and n ∈ {1, . . . , 6} supporting architectures sampled from strong LEMUR entries, and is asked to synthesize a new PyTorch model that follows the required API. We denote the resulting variants alt-nn1-alt-nn6. Generated code passes through schema validation and a whitespace-normalized MD5 hash check to remove duplicates before training.
Table 2 summarizes generation statistics. With n = 1 (alt-nn1), NNGPT produces 3,394 valid architectures; increasing the number of supporting examples sharply reduces success, down to 306 models for n = 2 and ≈ 100 models for n = 3-5. At n = 6 (alt-nn6) the system generates only 7 models (99.8% failure), indicating severe context overflow. Across all settings, we obtain 4,033 candidates, of which about 1,900 are unique after hashbased deduplication; the hash validator rejects ∼100 nearduplicate programs and saves an estimated 200-300 GPU hours of redundant training.
To compare quality across datasets with different sample sizes, we report dataset-balanced means (Table 3). The balanced mean accuracy peaks at n = 3 (alt-nn3, 53.1%) compared to 51.5% for the n = 1 baseline, while larger contexts (n = 4, 5) degrade performance to 47.3% and 43.0%. Gains are most pronounced on harder tasks such as CIFAR-100, where alt-nn3 improves over alt-nn1 by +11.6 percentage points after a single epoch. In aggregate, this pipeline contributes roughly 1.9k new architectures (and over 3k trained runs) to LEMUR, demonstrating that NNGPT can continuously grow its own training corpus through LLM-driven zero-shot generation.
We evaluate how well fine-tuned DeepSeek and CodeLlama models generate valid hyperparameter sets from structured Accuracy of generated architectures (datasetbalanced mean). For each variant alt-nnk we train every accepted model for one epoch with SGD+momentum and report top-1 accuracy. To avoid bias from uneven per-dataset sample counts, we first average within each (variant, dataset) pair and then macroaverage across datasets (equal weight per dataset). alt-nn6 is omitted due to insufficient sample size (n=7). Bold marks the best overall balanced mean.
prompts. Given a specification describing model architecture, dataset, task, transform pipeline, and desired accuracy, the LLM must output a complete hyperparameter configuration (names and values) that conforms to the expected schema (Listing 5). Evaluation is carried out on 500 heldout neural configurations sampled from LEMUR; a generation is counted as correct if it passes schema and value-type checks.
Table 4 reports the number of correct generations. The best overall result is obtained by DeepSeek-R1-Distill-Qwen-7B [10] (20 epochs), with 465 valid outputs (93.00%), slightly outperforming our fine-tuned CodeLlama-7b-Python-hf [47] (460/500, 92.00%), which has previously been used as a strong baseline for this task [25]. Smaller and domain-specialized DeepSeek variants also perform well: DeepSeek-Coder-1.3b-base [17] reaches 88.40% after 15 epochs, and DeepSeek-Coder-7b-Instruct-v1.5 [17] longed fine-tuning collapse to near-zero valid generations (e.g., 25-35 epochs for DeepSeek-Coder-1.3b-base and DeepSeek-Math-7b-base [49]), highlighting the sensitivity of structured generation tasks to overfitting and overtraining.
To assess downstream effectiveness, we use the generated hyperparameters to train models on two evaluation sets: (i) the 17-model CV benchmark from [25] and (ii) the LEMUR dataset. For each configuration, we compute an error term ϵ i = 1 -a i , where a i is the observed accuracy under the predicted hyperparameters, and report RMSE over ϵ i along with standard errors and 95% confidence intervals (Table 5).
On the 17-model benchmark, prior results for CodeLlama-7b-Python-hf [25] achieve an RMSE of 0.563, statistically outperforming Optuna [3] (0.589). Our DeepSeek-based models yield higher RMSEs and wider intervals on this heterogeneous testbed, consistent with their sensitivity to overfitting. On the LEMUR distribution, where schemas and transforms align more closely with training, DeepSeek-Coder-1.3b-base and DeepSeek-R1-Distill-Qwen-7B obtain RMSEs of 0.649 and 0.652, close to Optuna’s 0.636, while our fine-tuned CodeLlama-7b-Python-hf achieves the best RMSE of 0.603. Although LLM-based methods show wider confidence intervals (partly because each model is evaluated on only 35-50 one-shot predictions compared with over 20 000 trials for Optuna), they approach or exceed Optuna’s accuracy while avoiding iterative search, demonstrating that one-shot LLM hyperparameter generation can serve as a competitive, low-cost alternative in the NNGPT loop.
We instantiate the predictor H ϕ as a code-aware LLM fine-tuned with 4-bit QLoRA on 1,200+ NNGPT/LE-MUR runs spanning CNNs and Transformers [51] on CelebA-Gender [33], CIFAR-10/100 [26], ImageNette [21], MNIST [28], Places365 [59], SVHN [41], and COCO [31]. Each run is converted into a structured prompt with nn code, transform code, metric code, hyperpa- rameters, dataset/task metadata, max epochs, and validation accuracies at epochs 1-2; the model predicts the final best validation accuracy and its epoch. To prevent leakage, we use stratified group splits by (task, dataset, architecture). Per-dataset outcomes are summarized in Tab. 6.
We report two variants. The baseline (Exp. 1) is a QLoRA-tuned code LLM without additional balancing/strong regularization; it achieves RMSE = 0.1449, r = 0.7766, and R 2 ≈ 0.55 globally (see Tab. 8). Correlation varies by dataset, ranging from moderate on CIFAR-10/SVHN to strong on COCO, while roughly 50% and 75% of predictions fall within 5% and 10% of the true final accuracy, respectively. The dataset-wise heterogeneity is visible in Tab. 6. We use the predictions both as a proxy for final performance and to propose an early-stop epoch T ′ = t * for low-potential runs.
An experiment 2 applies inverse-frequency balancing and stronger regularization (higher dropout/weight decay, fewer epochs). It underperforms: RMSE rises to 0.2567, R 2 drops to 0.2885, r to 0.6409, and only 12.3%/45.0% of predictions fall within 5%/10% tolerance (Tab. 7; also compared side-by-side in Tab. 8). We therefore adopt the baseline predictor in the full NNGPT loop.
The baseline is already useful for early-stop and priority scheduling, but (i) correlation varies across datasets; (ii) aggressive balancing/regularization can suppress adaptation in LoRA-tuned LLMs; and (iii) adding uncertainty estimates is a promising next step for safer automated stopping.
We evaluate NN-RAG as a retrieval-augmented system for extracting reusable, scope-closed PyTorch blocks. The pipeline scans repositories for non-abstract nn.Module classes with forward(), round-trips sources through LibCST to preserve syntax, and indexes parse artifacts and import relations in an SQLite store with content hashing.
For each target name, a scope-aware resolver computes the minimal transitive closure of dependencies (respecting Python’s LEGB and import rules), orders definitions topologically, and emits a self-contained module that preserves original imports and aliases. Candidates then pass AST parsing, compilation, and sandboxed import to catch unresolved symbols and import-time failures. We test on 1,289 target blocks from widely used PyTorch projects -attention, convolutions, transformer components, pooling, normalization, losses, architectures, and utilities (Tab. 9). NN-RAG reconstructs 941 blocks as executable scope-closed modules, a 73.0% executability rate without manual intervention. Major libraries (torchvision [38], timm [54], transformers [55], OpenMMLab [43]) contribute many targets, while a long tail of smaller repos supplies the rest. This yields a large, validated library of importcomplete building blocks that NNGPT can safely retrieve and assemble during LLM-driven synthesis.
We evaluate the RL loop by generating 32 executable AirNet models and training each for a single epoch on MNIST [28], SVHN [41], and CIFAR-100 [26]. As a non-RL baseline we use one-epoch averages and best scores from the LEMUR AlexNet [27] (ast-dimension) family; the baseline values are embedded in Tab. 10. RLgenerated models match or exceed the baseline on the simpler datasets: on MNIST the average and best accuracies are 0.9876 and 0.9921, and on SVHN they are 0.8148 and Limitations. Our deployment on a single 24 GB GPU limits prompt length, context window, and schema complexity. Experiments focus on mid-scale vision; large-scale datasets such as ImageNet-1k [12] and LVIS [19] are left for future work. We also do not yet enforce architectural novelty or optimize explicitly for hardware efficiency.
We introduced NNGPT, a self-improving AutoML framework that turns an LLM into an online engine for neural network development. From a single prompt, NNGPT emits a full executable specification, validates and trains it, logs code and metrics, and improves its generators and predictors from these traces. The framework unifies five pipelines in one loop: zero-shot model generation and editing, hyperparameter recommendation, accuracy and early-stop prediction, retrieval-augmented code synthesis, and reinforcement learning updates. Experiments show practical effectiveness. Zero-shot generation added over 5,000 trained models and about 1.9k unique architectures to LEMUR. NN-RAG reconstructs 941 of 1,289 target blocks (73% executability). One-shot hyperparameter prediction reaches 93% schema-valid outputs and RMSE close to Optuna. The code-aware predictor achieves RMSE 0.1449 with Pearson r = 0.7766 across more than 1,200 runs and supports early termination and scheduling. The RL loop reliably generates executable models and attains strong one-epoch accuracy on MNIST and SVHN.
NNGPT reduces AutoML cost and latency by replacing many-trial search with one-shot, schema-validated generation while maintaining transparent, reproducible logs. Code, prompts, and checkpoints are released to support replication and extension.
We include a time-lapse screen recording that demonstrates the end-to-end workflow of TuneNNGen.py: prompt assembly, one-shot YAML/code generation, schema validation, training and logging, and LoRA updates. It also shows typical failure modes (e.g., schema violations, missing functions) and how NNGPT surfaces them through the validator and executor stack. Refer to the supplementary video for the full run, including intermediate console outputs and per-model evaluation messages.
Automated neural network configuration has long been a focus of research, with prior work falling broadly into two categories: classical search-based optimization and recent LLM-driven generative approaches. Below we review key methods from both domains, focusing on the limitations addressed by NNGPT.
Search-Based Hyperparameter Optimization. Frameworks like Optuna [2], Hyperopt [6], and Google Vizier [15] use Bayesian optimization and Tree-structured Parzen Estimators (TPE) [5] to iteratively tune hyperparameters. Though effective, these methods demand significant compute, often requiring hundreds of training runs, and act as black-box optimizers, offering limited transparency into the configuration semantics or model behavior beyond their final scores.
AutoML and Neural Architecture Search (NAS). Au-toML systems such as Optuna [3] and Hyperopt treat tuning as black-box optimization, while NAS frameworks like ENAS [46], AutoKeras [24], and DARTS [32] (plus variants like CDARTS, SDARTS, iDARTS) expand this to architecture generation via reinforcement learning or differentiable search. These methods, however, remain resource-intensive and adapt slowly to new tasks.
Efforts to stabilize NAS, such as RC-DARTS [57], NDARTS [9], and MSR-DARTS [37], still rely on costly infrastructure. NNGPT bypasses iterative search entirely: a single LLM call produces a complete, schema-valid configuration that is directly executable and logged for traceability. This design reduces computational cost while maintaining competitive accuracy, as shown by our DeepSeek-based results.
LLMs for Code and Configuration Generation. Recent advances in code-oriented LLMs such as Codex [8], Code Llama [48], and DeepSeek-Coder [18] enable automatic generation of hyperparameters, architectures, and training scripts. Tools like GitHub Copilot [45] and Alpha-Code [29] further highlight their utility for programming tasks.
Most existing systems, however, lack integration with execution pipelines. Outputs are rarely validated empirically or tested for reproducibility. EvoPrompting [7] embeds LLMs into evolutionary search but requires repeated inference and lacks schema control.
NNGPT employs a one-shot generation strategy: a finetuned LLM produces a schema-compliant YAML configuration that is immediately validated and executed. Structured output enforcement (via Pydantic) and empirical feedback support reliable AutoML automation.
Prediction of Neural Network Accuracy. Despite advances in LLMs, many methods rely on high-level descriptions that miss implementation-specific patterns, or predict isolated metrics instead of full training dynamics. Yet performance prediction is vital for tuning efficiency and resource use in AutoML.
We address this via a multi-modal predictor that processes both structured metadata (e.g., task, dataset) and executable code (e.g., nn code, metric code). Key contributions include: (1) joint modeling of code and metadata, (2) efficient 4-bit QLoRA fine-tuning [23] to predict accuracy and stopping points, and (3) stratified data splits that prevent leakage while preserving balance.
LLM-Driven Neural Network Generation. LLMs are increasingly integrated into NAS pipelines. EvoPrompting uses a pretrained LLM as a mutation operator, requiring multiple inference calls and soft prompt-tuning [7]. LLMatic replaces hand-written mutations with CodeGengenerated code [40]. GPT-NAS [56] completes partial architectures, and Self-Programming AI [50] revises its own configs.
While effective, these methods rely on expensive iterative queries. In contrast, NN-GPT performs one-shot generation: a single LoRA-tuned LLM call yields an executable, schema-compliant configuration with no further iteration required.
Schema-Constrained Generation. LLMs frequently generate syntactically invalid code in structured tasks. Grammar Prompting mitigates this by embedding formal grammars (e.g., Backus-Naur Form) into prompts [52], while RAG methods reduce errors by referencing external examples [4]. NN-GPT adopts a different approach: it employs a strict Pydantic schema tailored to YAML configurations. Minor issues are auto-corrected; major ones trigger a single re-prompt, ensuring valid, executable outputs without relying on grammars or retrieval.
LLMs have also been explored for broader pipeline automation. LLAMBO [34] frames Bayesian optimization as an LLMdriven dialogue, where the model proposes new candidates based on previous evaluations, outperforming classical BO in sparse regimes. Prompt-based HPO uses GPT-4 to refine hyperparameters from task descriptions [58], and NADA [20] generates full control algorithms, filtering them through simulation. In contrast, NN-GPT focuses on endto-end generation: a single LLM call outputs complete, runnable training recipes -data loaders, models, and optimization logic, without requiring iterative refinement.
Training Performance Prediction. Efforts to predict training outcomes fall into three main groups, each with key limitations. Statistical curve fitting [1,14] extrapolates final metrics from early trends but ignores architecture and implementation, reducing generalizability. These approaches treat training as a numeric process, overlooking structural factors that influence convergence behavior.
Architecture-Based Performance Predictors. Methods like [36,53] use textual summaries or engineered features to estimate model performance. However, such abstractions overlook critical implementation-level details, limiting their ability to capture the nuanced behaviors encoded in executable code.
Graph-Based Approaches. Techniques such as [13] represent models via explicit computational graphs, sometimes enhanced with differential modeling. Although more expressive than text, these methods require costly manual graph construction and still miss fine-grained code-level patterns such as custom regularization or dynamic scheduling, which strongly affect training outcomes.
Multimodal Prediction via Executable Code. While prior approaches either discard architectural context [1,14] or rely on lossy text abstractions [36,53], our method directly processes executable code snippets (nn code, metric code, transform code) within the LLM prompt. This enables the model to learn implementationspecific patterns, e.g., custom regularization, branching, or metric logic, that strongly influence convergence but are inaccessible via abstract representations.
In contrast to graph-based methods [13] requiring manual topology construction, we combine three complementary inputs: (i) structured metadata, (ii) raw executable code, and (iii) early training dynamics. This multimodal context allows the model to align syntactic code patterns with numerical trends, revealing complex interactions that are missed by unimodal models.
Moreover, our LLM jointly predicts final accuracy and optimal stopping points within a shared latent space, capturing their intrinsic correlation -unlike prior works that treat them separately. This unified structure enhances generalization across tasks and architectures. Table 1 situates NNGPT among classical AutoML toolkits and recent LLM-driven approaches. Bayesian HPO and NAS frameworks provide strong baselines for search over hyperparameters and architectures but rely on iterative evaluation and do not synthesize full training programs. Recent LLM-based methods introduce generation and closed-loop ideas, yet typically cover only parts of the pipeline or lack robust execution and prediction components. In contrast, NNGPT combines one-shot generation of executable specifications, code-aware accuracy prediction, and a closed feedback loop inside a single open-source framework.
The NNGPT framework is implemented in pure Python and provided as a pip-installable package. It requires Python 3.10 or higher and CUDA for GPU-based training. The core components are accessible via top-level commandline interfaces such as NNAlter * .py, NNEval.py, TuneNNGen * .py, TuneAccPrediction.py, TuneHyperparameters.py or TuneRAG.py. These tools together compose the full pipeline introduced in Section 8.
The codebase is organized into modular subdirectories. The ab/gpt directory contains the main scripts. Prompt templates, training configurations, and YAML schema definitions are defined in ab/gpt/conf, while LoRA fine-tuning utilities and other helper functions reside in ab/gpt/util.
The script NNAlter.py performs seed model alteration using architectures from the LEMUR corpus. Each modified model is trained for a small number of epochs (default: 8, configurable via the -e flag). This utility relies on the ab.gpt.util.AlterNN.alter method and defaults to the deepseek/ai/DeepSeek-R1-Distill-Qwen-7B model.
The TuneNNGen * .py scripts handle one-shot LLMbased generation, YAML schema validation, full model training, and optional LoRA fine-tuning. A fast iteration mode can be enabled by passing the -s flag, which skips the alteration phase.
Additionally, NNEval.py offers standalone evaluation of generated architectures without invoking LoRA, enabling targeted testing of LLM outputs.
All required CUDA and MPI dependencies are prepackaged in the public Docker image.
Prompt assembly begins with encoding task specifications, dataset, metric, and compute constraints into a structured JSON block. This prompt is then transformed into strict YAML by the LLM. The DeepSeek 7B model is loaded via transformers.AutoModelForCausalLM in 8bit precision, with LoRA adapters applied as needed.
Model training is executed using PyTorch [44] and torch.distributed. MPI support is configured at install time using system-level dependencies. During training, per-epoch statistics such as loss, accuracy, mAP/IoU, GPU utilization, and Git SHA are recorded in a local SQLite database via SQLAlchemy. If an optional statistics module is available, the database can be exported to Excelcompatible dashboards using a single API call.
LoRA adapters are fine-tuned after every 50 new model training runs. The fine-tuning procedure consists of three epochs using a linear warm-up and cosine decay schedule. The resulting adapter checkpoints are published to the framework’s Hugging Face namespace, making them available for the next generation cycle.
NNGPT ensures consistency and reproducibility through a pre-built Docker image and a pinned requirements.txt file that specifies fixed versions of key libraries such as torch [44], transformers [55], and peft [39].
Prompt generation is template-driven. A JSON file defines the structure of the prompt, including optional insertion points for code samples. This enables dynamic construction of prompts containing one or two models sampled from the database, under a given task. For training data generation, prompts may be further constrained to ensure shared or divergent characteristics between samples, improving task alignment while maintaining flexibility.
During early experiments, the raw DeepSeek-Coder-1.3B model frequently refused to modify input code, either claiming sufficiency or producing rule-violating changes. Introducing stricter task constraints often led to outputs that ignored parts of the prompt or simply returned unmodified code. These observations motivated the need for a bootstrapped training set.
To address this, the larger DeepSeek-R1-Distill-Qwen-7B model was used to generate initial examples. During 20 offline epochs, this model produced modified architectures by applying simple transformations, such as changing channel widths or digits in Conv2d layers, without requiring accuracy improvements. The first prompt template is shown in Listing 1. To diversify the training set, additional prompts requested the model to modify 2 to 4 digits randomly. Since DeepSeek-R1 7B reliably introduced at least one valid change, its outputs served as the initial training corpus for fine-tuning the smaller model.
During prompt engineering, both one-shot and fewshot examples were evaluated. However, neither significantly improved task fidelity on the raw models. In fact, DeepSeek-Coder-1.3B and DeepSeek-R1-Distill-Qwen-7B often lost track of task requirements or confused multiple examples. Zero-shot prompting consistently yielded more predictable behavior and was therefore adopted. -Randomly change 2 digits in the code to new values. 6. Do not make any changes beyond the rules above.
Here is the input code for you to modify: ‘’’\n{nn_code}\n’’'
Listing 1. Prompt instructing the LLM to modify neighboring nn.Conv2d() layers under strict rules, ensuring in-place edits and structural preservation of PyTorch code.
The extended dataset was generated using prompt templates similar to those used during fine-tuning (e.g., Listing 2). Generated samples were stored alongside their originating code and task context to ensure proper evaluation. Certain datasets such as COCO required specific preprocessing (e.g., fixed Resize operations), and segmentation tasks mandated the use of IoU rather than accuracy.
- Change the layers in the following implementation to improve accuracy on image classification tasks.
-Modify ONLY the layers in the code.
-DO NOT introduce new methods or parameters.
-Include the full code (including unchanged classes or functions). -Indicate the modified class explicitly.
-Actually make at least one layer modification.
-Not worry about decreasing accuracy -it’ s acceptable
Input code: ‘’’\n{nn_code}\n’’'
Listing 2. Prompt directing the LLM to modify existing layers in a neural network implementation under strict constraints, requiring full-code output and explicit identification of edits.
To extract generated code, regular expressions were used to match code blocks wrapped in triple backticks. To avoid infinite loops in parsing, the number of backticks was counted before applying regex-based extraction. Evaluation was performed via the LEMUR API. If parsing or execution errors occurred, the failing code and exception trace were returned to the LLM for repair. Each sample was given up to two correction attempts. Validated models were saved in structured directories compatible with the LEMUR dataset format and integrated into the local repository for downstream use.
The model Deepseek-coder-1.3b-Instruct was fine-tuned via supervised learning to enable the prediction of validation accuracy changes resulting from architectural modifications. To align with the offline generation procedure described earlier, the fine-tuning objective was formulated as a code-to-code transformation task, where the model is presented with an original implementation, its evaluated accuracy, and the accuracy of a known improved variant. The expected output is the modified architecture that corresponds to the target accuracy, drawn from the LEMUR dataset.
The prompt, shown in Listing 3, encodes this training setup explicitly. It instructs the model to alter only layer definitions in order to achieve the desired accuracy gain, without introducing new methods or structural components. The fields {accuracy} and {addon accuracy} represent the original and improved accuracy, respectively, and {nn code} contains the complete source code of the base model. The expected output is the full code of the improved model, including unchanged components, so the model also learns to preserve contextually irrelevant structures. After eight epochs of supervised fine-tuning, the model consistently produced syntactically valid outputs that adhered to the required formatting and structural constraints. It successfully learned to apply targeted architectural modifications that align with observed changes in validation accuracy, and reliably preserved all components mandated by the LEMUR API specification.
In addition to replicating transformations observed during training, the model demonstrated the ability to compose valid variants across different architecture families. It consistently selected effective transformation strategies for given task-model pairs, producing high-quality outputs with minimal prompt engineering. This behavior reflects an emerging structural prior that favors stable and empirically grounded edits.
Moreover, the model preserved functional integrity even in cases where only subtle changes were required, maintaining coherence across unchanged code regions. These results confirm that the fine-tuned model captures not only the mapping between code edits and accuracy shifts, but also the appropriate output syntax and modular consistency necessary for downstream execution and evaluation.
In addition to accuracy prediction, NNGPT also supports automated generation of numeric hyperparameter values tailored to a given neural network, task, and dataset. To enable this capability, we fine-tuned a diverse collection of DeepSeek models using supervised learning on entries from the LEMUR dataset. The selected set spans a wide range of model scales and pretraining strategies, including both lightweight and instruction-tuned architectures. This diversity allowed us to examine how model size and initialization influence hyperparameter reasoning ability.
Each model was fine-tuned using the LoRA method to reduce memory overhead while preserving gradient flow across transformer layers. LoRA rank and alpha were selected from 16, 32, 64, with a dropout of 0.05. All experiments employed a consistent setup that included the AdamW optimizer, a cosine learning rate scheduler, a fixed learning rate of 3 × 10 During evaluation, a modified version of the prompt (Listing 5) asked the model to produce hyperparameters aimed at maximizing accuracy, thereby testing generalization to unseen combinations. All fine-tuned models were subsequently integrated into the NNGPT pipeline. Specifically, two of the best performing checkpoints, DeepSeek-Coder-1.3b-Base and DeepSeek-R1-Distill-Qwen-7B, were published to Hugging Face and are now directly accessible within the framework. These models can be used as plug-and-play components for automated hyperparameter suggestion in both evaluation and generation modes.
By extending the NNGPT workflow with fine-tuned LLMs for hyperparameter prediction, we close the loop be-tween architecture generation and training configuration, offering a unified and fully automated AutoML solution. Experimental results evaluating the quality and effectiveness of these generated hyperparameters are presented in Section 3.2.
NNGPT reconceptualizes LLMs as fully automated configuration agents for neural networks. Given a high-level task specification, the system follows the eight-stage pipeline depicted in Figure 1, encompassing architecture retrieval, prompt generation, model evaluation, and iterative selfimprovement. Below, we detail each stage.
NNGPT starts by querying the LEMUR Dataset API for executable architectures and metadata with standardized training and evaluation. LEMUR provides full implementations, uniform preprocessing, and reproducible metrics, so oneshot generation targets runnable code and uses LEMUR as a reliable metric oracle. Unlike torchvision [38], it adds reproducible benchmarking, native metric logging, and direct access to architecture code, making it well suited for generative AutoML.
Following the API query, candidate architectures and associated metadata are retrieved from the LEMUR corpus. A dedicated script, NNAlter * .py, then applies a controlled set of architectural perturbations -including insertion/removal of layers, changes to channel widths, and alterations to residual connections. Each altered model undergoes a lightweight convergence check via a short warm-up training run (with the -e flag), ensuring that the resulting design remains viable. The resulting population of diverse, trainingvalidated models is archived in an SQLite-backed repository, which serves as training data for LLM fine-tuning and architecture prediction.
After retrieval, a configuration scaffold is constructed that encapsulates the task, dataset, desired metric, and (optionally) a compute budget. This configuration is used to parameterize the prompt generator, enabling reproducible and deterministic experiment assembly. The prompt generation code is modular and extensible, supporting dynamic reconfiguration and alternate LLM backbones through Hugging Face-compatible interfaces.
The core input to the LLM is a structured prompt, assembled from the configuration data. This includes a JSON object describing the task, dataset, metric, and resource con-straints. The prompt is formatted with system-level instructions that force the model to emit a strict YAML block beginning with -yaml and following a predefined schema.
The generative pass itself is carried out using a DeepSeek-V2 16B model equipped with 8-bit LoRA adapters fine-tuned on the altered-model corpus. Sampling is configured using T = 0.2, p = 0.9, and top-1 selection to minimize unnecessary exploration. Output is parsed with ruamel.yaml and validated using pydantic. Minor schema violations are auto-corrected, while major issues trigger a re-prompt with an embedded diagnostic message. Only configurations that pass validation proceed to execution.
Once validated, the YAML output is interpreted as an experiment specification that includes a full architecture graph, optimizer parameters, loss functions, and data transformations. This file serves as the input to the training engine. Generated architectures may differ from their seed counterparts not only in topology but also in auxiliary properties such as normalization strategies or metric implementations. This stage integrates architectural creativity with empirical feasibility, ensuring that every configuration is both novel and executable.
Training is conducted using a distributed PyTorch engine (ab/gpt/TuneNNGen * .py), which uses mpi4py and torch.distributed for multi-GPU support. All datasets are accessed through the LEMUR API to ensure consistent preprocessing and evaluation. During training, metrics such as loss, accuracy, mAP, and IoU are logged per epoch alongside GPU utilization and configuration hashes. These logs are persisted in the same SQLite database as the architecture graph, enabling traceability and post-hoc analysis via an internal visualization suite designed for model benchmarking.
In parallel, a lightweight accuracy prediction module is used to estimate final model performance based on early training signals and static features. The predictor processes three input modalities: (i) structured metadata, (ii) executable code (model, transform, metric), and (iii) early accuracy values. A stratified split strategy ensures robust generalization and prevents data leakage across similar architectures.
After k = 50 successful training runs, a new fine-tuning iteration is triggered. LoRA adapters are retrained on the extended dataset of architecture-performance pairs using three epochs of linear warm-up and cosine decay. This up-dates the LLM’s internal representation of the architecture space, biasing future generations toward successful configurations. The updated checkpoints are immediately used in subsequent pipeline passes.
All artifacts, including trained weights, YAML specifications, metric logs, and architectural source code, are stored in a structured SQLite-based repository designed for long-term reproducibility. This supports future reanalysis, dataset expansion, and model distillation. The continuous accumulation of structured training data reinforces the NNGPT pipeline, transforming raw LLM generations into a curated and executable AutoML knowledge base.
Once all eight stages complete, the pipeline automatically restarts using updated model checkpoints, prompt templates, and database entries. This iterative process enables NNGPT to function as a self-improving AutoML cycle, where each generation, validation, and fine-tuning pass enhances the quality and diversity of future outputs.
training with LLM-generated hyperparameters vs. Optuna. We compare one-shot LLM recommendations (no iterative search; 35-50 predictions per model) against Optuna (>20k trials) on two evaluation sets. Metric: RMSE↓ of ϵi=1-ai, where ai is the observed validation accuracy when trained with predicted HPs. We report SE and normal-approx. 95% CI. Rows * reproduced from[25].
training with LLM-generated hyperparameters vs. Optuna. We compare one-shot LLM recommendations (no iterative search; 35-50 predictions per model) against Optuna (>20k trials) on two evaluation sets. Metric: RMSE↓ of ϵi=1-ai, where ai is the observed validation accuracy when trained with predicted HPs. We report SE and normal-approx. 95% CI. Rows * reproduced from[25]
training with LLM-generated hyperparameters vs. Optuna. We compare one-shot LLM recommendations (no iterative search; 35-50 predictions per model) against Optuna (>20k trials) on two evaluation sets. Metric: RMSE↓ of ϵi=1-ai, where ai is the observed validation accuracy when trained with predicted HPs. We report SE and normal-approx. 95% CI. Rows * reproduced from
" Listing 4. Prompt template used for fine-tuning LLMs to generate hyperparameter values based on model code, task, dataset, transformations, target accuracy, and training duration.
📸 Image Gallery