GED-Consistent Disentanglement of Aligned and Unaligned Substructures for Graph Similarity Learning
📝 Original Info
- Title: GED-Consistent Disentanglement of Aligned and Unaligned Substructures for Graph Similarity Learning
- ArXiv ID: 2511.19837
- Date: 2025-11-25
- Authors: Zhentao Zhan, Xiaoliang Xu, Jingjing Wang, Junmei Wang
📝 Abstract
Graph Similarity Computation (GSC) is a fundamental graph-related task where Graph Edit Distance (GED) serves as a prevalent metric. GED is determined by an optimal alignment between a pair of graphs that partitions each into aligned (zero-cost) and unaligned (cost-incurring) substructures. However, the solution for optimal alignment is intractable, motivating Graph Neural Network (GNN)-based GED approximations. Existing GNN-based GED approaches typically learn node embeddings for each graph and then aggregate pairwise node similarities to estimate the final similarity. Despite their effectiveness, we identify a fundamental mismatch between this prevalent node-centric matching paradigm and the core principles of GED. This discrepancy leads to two critical limitations: (1) a failure to capture the global structural correspondence for optimal alignment, and (2) a misattribution of edit costs by learning from spurious node-level signals. To address these limitations, we propose GCGSim, a GEDconsistent graph similarity learning framework that reformulates the GSC task from the perspective of graph-level matching and substructure-level edit costs. Specifically, we make three core technical contributions. First, we design a Graph-Node Cross Matching (GNCM) mechanism to learn pair-aware contextualized graph representations. Second, we introduce a principled Prior Similarity-Guided Disentanglement (PSGD) mechanism, justified by variational inference, to unsupervisedly separate graph representations into their aligned and unaligned substructures. Finally, we employ an Intra-Instance Replicate (IIR) consistency regularization to learn a canonical representation for the aligned substructures. Extensive experiments on four benchmark datasets show that GCGSim achieves state-of-the-art performance. Our comprehensive analyses further validate that the framework successfully learns disentangled and semantically meaningful substructure representations.📄 Full Content
A prevalent and theoretically grounded metric for GSC is the Graph Edit Distance (GED) [1]. GED quantifies the dissimilarity between two graphs, G i and G j , as the minimum cost of edit operations (node/edge insertions, deletions, and relabel) required to transform G i into G j . The computation of GED can be formulated as an optimal alignment problem, which partitions each graph into two disjoint sets: an aligned substructure and an unaligned substructure, as illustrated in Fig. 1a. The aligned substructures represent the structurally identical portions identified by the optimal alignment, thereby incurring zero edit cost. The final GED value is derived exclusively from the cumulative cost of editing the unaligned substructures. The NP-hard nature of exact GED computation has catalyzed the development of efficient, learning-based approximation methods.
Recently, Graph Neural Networks (GNN) have become the dominant approach for GED approximation, achieving remarkable performance [2]- [6]. A prevalent paradigm of existing GNN-based methods follows a three-stage, end-to-end paradigm (illustrated in upper part of Fig. 1b): (1) Embedding Learning: GNN independently encode nodes of each graph into feature vectors. (2) Matching: A similarity matrix is computed via pairwise node-node interactions across the two graphs, capturing node-level correspondence (3) Alignment Learning: A final regression head maps the alignment (or cost) signals within the similarity matrix to a predicted similarity score. While this node-centric paradigm has proven highly effective, we identify a fundamental mismatch between such approaches and the core principles of GED. This discrepancy leads to two critical limitations:
Limitation I: Neglect of Global Structural Correspondence. Existing methods, by focusing on local node-to-node matching, fail to capture the global alignment perspective to GED. The optimal GED alignment is a graph-level property that maximizes the isomorphism between aligned substructures. In contrast, local matching can erroneously align nodes with similar local neighborhoods but starkly different global roles (e.g., aligning a central hub in G i with a peripheral node in Fig. 1: (a) A graph edit path for an input graph pair (G i , G j ). The graph is partitioned into aligned substructures (as i , as j ) and unaligned substructures (us i , us j ). GED is derived from the cost of transforming us i to us j . The number within each node denotes its ID, and the color indicates its label. (b) Comparison of the conventional node-centric framework with our proposed GED-consistent framework (GCGSim).
Limitation II: Misattribution of Edit Costs. GED is sourced only from operations on unaligned substructures. However, existing methods learn from a dense matrix of all nodelevel similarities (or costs) [7], [8]. They cannot distinguish between the “true” dissimilarity that contributes to GED (i.e., between unaligned parts) and other “irrelevant” dissimilarities (e.g., between an aligned part of G i and an unaligned part of G j ). This conflation leads to the model learning from spurious signals and misattributing the sources of the final graph similarity.
To address these limitations, we propose a novel framework, GCGSim (GED Consistent Graph Similarity Learning), illustrated in lower part of Fig. 1b, designed to align the learning process with the core principles of GED. GCGSim reformulates the task from the perspective of graph-level matching and substructure-level edit costs. Our work addresses three core challenges:
Challenge I: How to learn a graph representation that is aware of the alignment context? To overcome the locality of node-level matching, we must learn graph embeddings that are contextualized for a specific graph pair. We propose GNCM (Graph-Node Cross Matching), a cross-attention mechanism that computes a pair-aware embedding for each graph. It explicitly models the alignment between the local structures of one graph and the global structure of the other, allowing the model to dynamically highlight structurally congruent substructures.
Challenge II: How to disentangle representations for aligned and unaligned substructures without direct supervision? The aligned/unaligned partition is a latent property of the optimal alignment and is not available as a label during training. To solve this, we introduce PSGD (Prior Similarity-Guided Disentanglement). PSGD is a principled mechanism that disentangles the pair-aware graph embedding into distinct representations for the aligned and unaligned substructures. Crucially, we provide a theoretical justification for PSGD from a variational inference perspective, showing that it uses the model’s own graph similarity estimate as a dynamic signal to guide the disentanglement process.
Challenge III: How to learn a canonical representation for aligned substructures and predict GED-consistent costs? Following disentanglement, the resulting aligned embeddings are not guaranteed to be semantically identical, as they originate from different graphs. To resolve this, we introduce IIR (Intra-Instance Replicate), a novel consistency regularization method that encourages the aligned embeddings to learn into a canonical representation. With this canonical representation established, our framework then interacts the substructure pairs to learn the edit costs in a GED-consistent manner, predicting a zero cost for the aligned parts and the true GED for the unaligned parts, thereby eliminating spurious signals.
Our contributions are summarized as follows:
• We identify a mismatch between existing GNN-based GSC methods and the core principle of GED, highlighting limitations in global alignment and cost attribution. • We propose GCGSim, a novel end-to-end framework that is consistent with the GED mechanism by learning from the perspective of graph-level matching and substructurelevel edit costs. • We design three core technical modules: GNCM to learn pair-aware graph representations, PSGD to perform principled disentanglement of substructures, and IIR to enforce semantic consistency for aligned embeddings • We conduct extensive experiments on four real-world datasets, demonstrating that GCGSim achieves state-of-the-art performance and validating the effectiveness of principled disentangled representation learning.
Given a graph G = (V, E, X, A), where V = {v (k) } N k=1 is the set of nodes with number N , E ⊆ V × V is the set of edges, X ∈ R N ×d is the node features (e.g., labels or attribute vectors) with dimension d, and A ∈ R N ×N is the adjacency matrix, where A [k, l] = 1 if and only if edge e (k,l) ∈ E, otherwise A [k, l] = 0. Given a graph database D and a set of query graphs Q, the aim of GSC is to produce a similarity score S ∈ R (0,1] between ∀G i ∈ D and ∀G j ∈ Q, i.e., ŝij = S (G i , G j ). ŝij is the predicted graph similarity score, S : D × Q → S is a trainable estimation model. We train the model based on a set of training triplet (G i , G j , s ij ) ∈ D × Q × S consisting of the input graph pairs and the ground-truth similarities s ij . s ij is computed as follows:
where GED (G i , G j ) is ground-truth GED of G i and G j .
Definition 1 (Graph Edit Distance). Given a graph pair (G i , G j ), the minimum cost of edit operations that transform G i to G j is called the graph edit distance and denoted by GED (G i , G j ). Specifically, there are three types of edit operations: adding or removing an edge; adding or removing a node; and relabeling a node.
The computation of GED is formulated as a minimization problem over all possible mappings π:
where ged (G i , G j , π) denotes the cost of edit operations that transform G i to G j under π, π is an orthogonal permutation matrix that delineates the injective mapping between entities (nodes, edges) of G i and G j . ged V and ged E respectively denote the cost of editing operations acting on nodes and edges, calculated as follows:
where I (•) is the indicator function that returns 1 if the condition holds and 0 otherwise, ∥•∥ p denotes p-norm, πX j is the row-permuted transformation of X j , πA j π T is the rowand column-permuted transformation of A j . Note that if G i and G j have different numbers of nodes, pad the smaller X and A with zeros to make the two graphs equal in size.
Definition 2 (Optimal Alignment). Given a graph pair (G i , G j ), π * denotes the optimal alignment between G i and
Definition 3 (Aligned and Unaligned substructure). Given a graph pair (G i , G j ), the aligned substructure of G i with respect to G j is defined as a 2-tuple as i = (V as i , E as i ), where
and
the unaligned substructure of G i with respect to G j is defined as
and
For a graph pair (G i , G j ), where 1a examples a graph edit path that transform G i to G j with minimum cost and visualizes the partition of aligned substructures and unaligned substructures. Specifically, the aligned substructures of G i and G j are defined as
, respectively. The unaligned substructures are us i = v
. The optimal alignment π * reflects a node mapping v
Research on the GED approximation can be divided into two main streams: heuristic algorithms and learning-based methods
Traditional approaches for approximating GED in polynomial time often rely on combinatorial heuristics. For instance, A*-Beam [9] prunes the search space of the exact A* algorithm [10] with a user-defined beam width to balance accuracy and efficiency. A more prevalent family of methods models GED computation as a Linear Sum Assignment Problem (LSAP). The Hungarian method [11], a cornerstone of this approach, first constructs a cost matrix where each entry estimates the cost of matching two nodes. The problem is then solved using the Hungarian algorithm [12] to find a minimum-cost node assignment, which serves as the GED approximation. Subsequent works, such as VJ [13], have focused on improving the computational efficiency of solving this assignment problem. While effective, the performance of these heuristic methods is fundamentally limited by their reliance on hand-crafted rules for defining the cost matrix, which may struggle to capture complex structural patterns.
To overcome the limitations of hand-crafted heuristics, recent work has shifted towards learning-based approaches, which can be broadly categorized into two main paradigms.
a) Graph-level Embedding Regression: This paradigm first maps each graph into a single, fixed-size vector representation. The final similarity score is then computed directly from these two graph embeddings, typically using a simple regressor. Representative works include SimGNN [2], EGSC [4], N2AGim [6], and GraSP [14]. While computationally efficient, this paradigm tends to lose fine-grained structural details, as the entire graph’s information is compressed into a single vector, thereby limiting its expressive power for the correspondence-rich task of GED calculation.
b) Node-level Interaction Matching: To capture more detailed structural alignments, another powerful paradigm is based on node-level interaction. These methods also begin by learning node embeddings for each graph but then introduce an interaction module. The core idea is to learn a pairwise interaction matrix that explicitly encodes the alignment information or edit costs between nodes , which is then aggregated to predict the final score. Prominent examples include Graph-Sim [5], NA-GSL [6], GraphOTSim [7], GEDGNN [8] and GEDIOT [15]. These approaches employ diverse mechanisms, such as applying CNNs to the similarity matrix or using optimal transport and attention to learn soft correspondences.
Our work is situated within this node-level interaction paradigm. Nevertheless, we argue that even these methods often exhibit a subtle mismatch with the combinatorial nature of GED. First, they tend to rely on local neighborhood information when computing node similarities, struggling to capture the optimal alignment that GED seeks. Second, by learning from a dense similarity (or cost) matrix, they conflate the true edit costs derived from unaligned substructures with irrelevant signals from aligned parts. Our proposed framework addresses these specific limitations by reformulating the interaction process to be more consistent with the principles of global matching and edit cost attribution inherent to GED.
The architecture of GCGSim is illustrated in Fig. 2. The entire process is composed of three stages: (1) Embedding Learning, where we generate multi-scale representations for each graph in the pair; (2) Matching, where a graph-level matching module creates pair-aware contextualized graph embeddings; and (3) Alignment Learning, the core of our method, which first disentangles the embeddings into representations for aligned and unaligned substructures and then jointly predicts the final similarity and edit costs. We will elaborate on each of these stages in the subsequent sections.
The initial stage of our framework is dedicated to generating rich, multi-scale representations for each graph in an input pair (G i , G j ). By leveraging the hierarchical outputs of a deep GNN, we capture structural information across varying receptive fields. We employ a Siamese architecture, where an identical encoder with shared parameters processes each graph.
- Node Embedding Learning: Our node encoder is built upon an L-layer GNN to iteratively refine node features. As the GNN layers deepen, each node’s receptive field expands, allowing the model to capture progressively largerscale structural patterns. We select the Residual Gated Graph Convolutional Network (RGGC) [16] as our backbone for its enhanced expressive power, which uses gating mechanisms and residual connections to effectively capture complex patterns. The update rule for a node k’s representation at the l-th layer is:
where H l V denotes the matrix of node embeddings at the lth layer, W S and W N are learnable matrices, N (k) is the neighborhood of node k, ⊙ is the Hadamard product, and η k,u is the learned gate that modulates the message from node u to k. This RGGC encoder, with its weights shared, is applied independently to both G i and G j . The process yields a full sequence of layer-wise node representations {H 0 Vi , . . . , H L Vi } for G i and {H 0 Vj , . . . , H L Vj } for G j , where each matrix H l V captures structural patterns at a distinct scale.
- Graph Embedding Learning: Following the generation of multi-scale node embeddings, we derive a corresponding set of graph-level representations. It is crucial that features from different scales are aggregated consistently. Therefore, at each layer l, we apply a shared, permutation-invariant readout function to the node embeddings H l Vi and H l Vj respectively. We employ DeepSets [17] for this purpose:
The DeepSets module, specifically its MLP l DS , shares parameters for both graphs, ensuring a uniform mapping from node sets to graph embeddings. This layer-wise aggregation results in a sequence of graph embeddings {H 0 Gi , . . . , H L Gi } for G i and a corresponding sequence {H 0 Gj , . . . , H L Gj } for G j .
Vi and H l Gi , derived in the previous stage, encapsulate multi-scale structural information. However, they are context-agnostic, as the representation of each graph is learned in isolation, without any information from the other graph in the pair. This intrinsic limitation hinders the model from directly reasoning about the alignment between the two graphs.
To address this, we introduce the Graph-Node Cross Matching (GNCM), a mechanism designed to generate pair-aware contextualized graph representations. The core rationale is that while a node embedding H properties of its local substructure, its contribution to the final similarity score is not absolute. Instead, its significance must be modulated by the global context of the graph it is being compared to G j . For instance, a complex substructure in G i may contribute little to the similarity if no analogous structure exists within G j .
Conceptually, GNCM functions as a cross-graph attention mechanism. It learns to dynamically re-weight the importance of each local substructure in one graph based on its relevance to the global context of the other. This allows the model to emphasize structurally congruent substructures and de-emphasize dissimilar ones, thereby calibrating the representations for the specific comparison task.
Formally, we first compute the node-wise relevance scores ω l i,j by measuring the correspondence between each node embedding in G i and the global graph embedding of G j :
where ω l i,j [k] is the attention score for the k-th node, and Θ(•, •) is the cosine similarity function. Subsequently, these scores are used to produce a pair-aware graph embedding Hl Gi via a weighted aggregation of the node embeddings:
The resulting embedding, Hl Gi , represents a contextualized view of graph G i , re-weighted according to the structure of G j . A symmetric operation is performed to compute Hl Gj . C. Alignment Learning 1) Prior Similarity-Guided Disentanglement: After obtaining the pair-aware graph embeddings for both graphs in the pair, Hl Gi and Hl Gj , which encapsulate holistic information about their relationship, our next crucial step is to disentangle these representations. To this end, each embedding is separately processed to yield representations for its respective aligned and unaligned substructures, using two distinct modules: an Aligned Encoder and an Unaligned Encoder.
A core challenge lies in determining the relative contribution of each substructure type to the overall graph representation. Intuitively, if two graphs are highly similar, their aligned substructures should dominate the final similarity score. Conversely, for dissimilar graphs, the unaligned substructures and their associated edit costs are more informative. To operationalize this intuition, we propose using the similarity of the graph embeddings themselves, which serves as a taskaware prior, to dynamically estimate the influence weights for disentanglement. This prior, denoted as α, is computed as:
where Θ(•, •) is the cosine similarity function. This choice is not merely a heuristic. In Section V, we provide a rigorous theoretical justification from a variational inference perspective, demonstrating that using graph embedding similarity as the prior is a principled approach to optimize the evidence lower bound (ELBO).
With this principled weight α l , we can now guide the disentanglement process. The Aligned Encoder and Unaligned Encoder, both parameterized as MLPs, generate the aligned embedding H l asi and unaligned embedding H l usi at layer l as follows:
where MLP l as and MLP l us are the respective encoders. The embeddings for the graph G j (H l asj and H l usj ) are obtained through a symmetric operation.
- Semantic Alignment and Substructure Interaction: Having disentangled the representations, the next step is to interact them to learn their correspondence and fuse the multi-layer information.
a) Semantic Alignment via Intra-Instance Replicate (IIR): A prerequisite for a meaningful interaction between H l asi and H l asj is that they must share the same canonical semantics of “aligned-ness”. Directly enforcing this with typical regularization constraints can interfere with the primary GSC task [18], [19]. We therefore introduce a novel consistencybased method, Intra-Instance Replicate (IIR).
The intuition is to treat this as a data augmentation task in the embedding space. During training, for a given pair (G i , G j ), we randomly replace the original H l asi with a convex combination of itself and its counterpart H l asj :
where τ ∼ Bernoulli(β) with β ∈ [0, 1] being a hyperparameter. The model is then tasked with making a prediction using this augmented embedding Ĥl asi . Since the groundtruth label remains unchanged regardless of whether this augmentation occurs, the model is implicitly forced to be robust to this replication.
To minimize the long-term training objective, the optimal strategy for the encoders is to learn representations H l asi and H l asj that are semantically interchangeable. By making the representations nearly identical, the model effectively learns that the useful signal is the structural pattern that is common to both.
b) Substructure-level Interaction: With semantically aligned representations, we now perform interaction using the Neural Tensor Network (NTN) [2], chosen for its efficacy in modeling complex relationships between embeddings [20]. Two distinct NTN modules function as the Aligned Discriminator and Unaligned Discriminator. For each layer l, we compute interaction embeddings for both aligned and unaligned substructures:
where Ĥl asi is the potentially augmented aligned embedding from (17) (if no augmentation is applied, Ĥl asi = H l asi ). To leverage the structural information captured across all L layers, we concatenate the layer-wise interaction embeddings to form final, comprehensive representations for the aligned and unaligned substructures:
where ∥ denotes the concatenation operator. These fused representations, I as and I us , now serve as the input for the final predictors.
The final stage of our framework involves two predictors that jointly learn from the fused interaction embeddings. a) Edit Cost Prediction (ECP): The Edit Cost Predictor computes the edit costs directly from the fused substructure representations. The aligned substructures should, by definition, have an edit cost of zero, while the unaligned substructures are responsible for the total GED. This is formalized as:
The corresponding Mean Squared Error (MSE) loss function is:
(24) b) Similarity Prediction: The Similarity Predictor computes the final graph similarity score. It takes the concatenated aligned and unaligned interaction embeddings as input, allowing it to consider information from both sources:
This is trained using a standard MSE loss against the groundtruth similarity s ij :
c) Final Objective: The model is trained end-to-end by minimizing a weighted sum of the two loss components:
where λ is a hyper-parameter that balances the contribution of the edit cost prediction task.
In this section, we provide a formal theoretical justification for our Prior Similarity-Guided Disentanglement (PSGD) mechanism. We frame the task from the perspective of variational inference on a probabilistic latent variable model. This rigorous approach demonstrates that our design-which employs the similarity of graph embeddings as a dynamic, data-dependent prior-is a principled strategy to optimize the evidence lower bound (ELBO), rather than a mere heuristic.
We formulate the graph similarity prediction task as a probabilistic generative model. Given a pair of graphs (G i , G j ), our objective is to learn a model, parameterized by θ, that captures the conditional probability p θ (s ij |G i , G j ) of the true similarity score s ij . We introduce a discrete latent variable k ∈ {as, us}, which represents the underlying structural source contributing to the final similarity, where as denotes the aligned substructure and us denotes the unaligned substructure.
Under our generative assumption, the marginal likelihood of the similarity score s ij is obtained by marginalizing out the latent variable k:
Here, p θ (k|G i , G j ) is the prior distribution over the substructure types, modeled as a Bernoulli distribution over the set {as, us}. The conditional likelihood p θ (s ij |G i , G j , k) dictates the contribution of each substructure type. The learning objective is to maximize the log-marginal likelihood, log p θ (s ij |G i , G j ).
Directly optimizing the objective in (28) is intractable. We therefore employ variational inference to maximize its ELBO.
Lemma 1 (The Evidence Lower Bound Objective). The logmarginal likelihood admits the following ELBO,
where for brevity, q ϕ (k) ≜ q ϕ (k|G i , G j , s ij ) and p θ (k) ≜ p θ (k|G i , G j ), q ϕ (k|G i , G j , s ij ) is a variational distribution, parameterized by ϕ, that approximates the true posterior p θ (k|G i , G j , s ij ).
Proof.
(by Jensen’s Inequality)
The optimization of the ELBO (Equation. (29)) comprises two objectives: 1) Maximizing the reconstruction term, which is directly handled by our model’s MSE loss functions. 2) Minimizing the KL-divergence. Our theoretical argument centers on a principled design of the prior p θ (k|G i , G j ) to effectively minimize this term.
Lemma 2 (Monotonicity of the Ideal Posterior). The ideal posterior probability p θ (k = as|G i , G j , s ij ), which represents the probability of the substructure being aligned given knowledge of the true similarity s ij , is a monotonically increasing function of s ij .
Proof. This lemma follows from the definition of graph similarity. As s ij → 1, the graphs approach isomorphism, implying that the vast majority of their structure is aligned; hence, p θ (k = as|•) must approach 1. Conversely, as s ij → 0, the graphs are structurally disparate, dominated by unaligned components, causing p θ (k = as|•) to approach 0. The posterior probability is therefore monotonically correlated with s ij .
Theorem 1 (Optimizing the ELBO via an Informed Prior Design). The KL-divergence term in the ELBO is effectively minimized by designing a prior distribution p θ (k|G i , G j ) that aligns with the target behavior of the variational posterior q ϕ (k). The similarity of graph embeddings, Θ(H Gi , H Gj ), serves as a principled function for such a prior.
Proof. The core of variational inference is to optimize the variational distribution q ϕ (k) to be the closest possible approximation of the ideal posterior p θ (k|G i , G j , s ij ). Consequently, the variational objective compels an optimized q ϕ (k) to learn and exhibit the properties of this ideal posterior. From Lemma 2, we know a key property of the ideal posterior is its monotonic dependence on the true similarity score s ij . Therefore, the learning target for q ϕ (k) is to acquire this same monotonic behavior.
Our strategy is to design a prior p θ (k) that preemptively matches this learning target of q ϕ (k). This requires a function that mimics the behavior of s ij but adheres to a critical constraint: the prior must not be a direct function of the label s ij to prevent information leakage.
This challenge motivates the use of a proxy. Within our GNN framework, the graph embeddings H Gi and H Gj are representations learned specifically to capture the structural information relevant for similarity prediction. Thus, their similarity, Θ(H Gi , H Gj ), constitutes the model’s own best, labelindependent estimate of s ij and, by extension, the behavior of the ideal posterior.
Based on this, we set the prior probability for the aligned substructure as:
Correspondingly, as the latent space for k is binary and its distribution must sum to unity, the prior probability for the unaligned substructure is complementarily defined as:
This formulation is not an ad-hoc choice. It establishes a data-dependent prior, a standard technique in Amortized Variational Inference. This informed prior is therefore constructed to match the learning target of the variational posterior q ϕ (k). Such a design preemptively satisfies the objective of minimizing the KL-divergence, which permits the model to dedicate its capacity to the reconstruction task.
To demonstrate the effectiveness of GCGSim, we perform extensive experiments on four real-world benchmark datasets. We first compare our model against a wide range of state-ofthe-art GNN-based methods for graph similarity computation. Then, through a series of ablation studies and qualitative analyses, we systematically investigate the impact of our core technical modules and validate the design principles of our framework.
We evaluate GCGSim on LINUX [21], AIDS700nef [21], IMDBMulti [22], and PTC [23]. The statistical information of the dataset is presented in Table I. We adopt the same data splits as [2]: 60%, 20%, and 20% of all graphs are used as the training, validation, and testing sets, respectively. The groundtruth GEDs of graph pairs in AIDS700nef and LINUX are computed by the A* algorithm [10]. For IMDBMulti and PTC, we use the minimum of the results of approximate algorithms, Beam [9], Hungarian [11], and VJ [24] as ground-truth GEDs, following the way in [2].
GCGSim uses PyTorchGeometric for evaluation. We employ the Adam optimizer with a learning rate of 0.001 and set the batch size to 64. We adopt 4 layers of RGGC, with the number of feature channels defined as 64, 64, 32, and 16. We set β = 0.05 and λ = 0.05. We run 50 epochs on each dataset, performing validation after each epoch. Finally, the parameters that result in the smallest validation loss are selected to evaluate the test data. All experiments were conducted on a Linux server equipped with an Intel(R) Core(TM) i9-10900X CPU @ 3.70GHz and a single NVIDIA GeForce RTX 3090.
To comprehensively evaluate our model on the GSC task, the following five metrics are adopted to evaluate results for fair comparisons: Mean Squared Error (MSE) (in the format of 10 -3 ), which measures the average squared differences between the predicted and the ground-truth similarity scores. Spearman’s Rank Correlation Coefficient (ρ) and Kendall’s Rank Correlation Coefficient (τ ) evaluate the ranking correlations between the predicted and the true ranking results. Precision at k (p@k) where k = 10, 20, which is the intersection of the top k results of the prediction and the ground-truth. The smaller the MSE, the better the performance of models; for ρ, τ , and p@k, the larger the better.
To validate our approach, we compare GCGSim against nine competitive baselines: SimGNN [2], GraphSim [5], GMN [25], MGMN [26], ERIC [20], NA-GSL [6], GEDGNN [8], GEDIOT [15], and GraSP [14]. We reimplement all methods, tuning their hyperparameters for optimal performance. To ensure a fair comparison, the output similarity scores of all models are unified to the definition used in this paper.
The results, summarized in Table II, show that GCGSim consistently achieves state-of-the-art (SOTA) performance across the majority of metrics and datasets, demonstrating its effectiveness and robustness. On AIDS700nef and LINUX, our model achieves the lowest Mean Squared Error (MSE), reducing the error by 13.8% and 32.0% respectively over the strongest competitor, indicating superior prediction accuracy. On IMDBMulti, GCGSim excels in ranking-based metrics, securing the top scores for ρ (0.949) and τ (0.848), crucial for graph retrieval tasks. Similarly, on PTC, it obtains the best performance on most metrics, including MSE and ρ, while some baselines face Out-of-Memory (OOM) issues.
In summary, the superior performance across diverse graph types demonstrates that learning from a GED-consistent perspective enables GCGSim to capture more accurate and robust similarity patterns than previous approaches.
We conducted an ablation study by individually removing four key components: GNCM, PSGD, IIR, and ECP. As presented in Table V, removing any module degrades performance, confirming that all are integral and contribute synergistically to our framework.
The results reveal that PSGD is the cornerstone of our model. Its removal causes the most drastic performance drop, with the MSE on IMDBMulti more than doubling (from 0.568 to 1.196). This strongly validates that our theoreticallygrounded disentanglement is fundamental to the model’s success. Crucially, the removal of ECP also leads to a substantial performance degradation across all datasets (e.g., MSE on PTC increases by 25.8%). This empirically validates our core motivation: that explicitly supervising the model with substructurelevel edit costs is vital for learning a meaningful and accurate similarity function. Similarly, removing GNCM results in a significant decline, confirming the necessity of generating pairaware contextual representations. Finally, the absence of IIR causes the mildest drop, demonstrating its role as a beneficial regularizer for learning canonical representations. Collectively, these results verify our design choices and the contribution of each component.
While the ablation study (Section VI-E) demonstrates the performance contribution of the PSGD module, we seek to more directly and quantitatively verify its core function: the disentanglement of aligned and unaligned representations. We hypothesize that if PSGD is effective, it should enforce informational orthogonality between the two representation types. In other words, the mutual information (MI) between the aligned embedding (H as ) and the unaligned embedding (H us ) should be minimized, signifying that they capture distinct and non-overlapping semantic features.
To measure this, we devise an experiment on the AIDS700nef and LINUX datasets. For a single anchor graph G i from the test set, we form a series of graph pairs by matching it with every other graph {G j } j̸ =i in the set. This process generates two corresponding sets of representations for the anchor graph G i : a set of its aligned embeddings {H as i|j } j̸ =i conditioned on each G j , and a set of its unaligned embeddings {H us i|j } j̸ =i . These two sets effectively form the empirical distributions for the random variables H asi and H usi . We then employ the Mutual Information Neural Estimator (MINE) [27], a robust method for estimating MI in high-dimensional settings, to compute I(H asi ; H usi ). This analysis is performed on the output of each of the four GNN layers for both our full GCGSim model and the GCGSim (w/o PSGD) variant to observe how disentanglement evolves with network depth. The results, presented in Table IV. Across both datasets and all network layers, the full GCGSim model exhibits substantially lower mutual information between its aligned and unaligned representations compared to the variant without PSGD. On AIDS700nef, the MI plummets by nearly 90% at Layer 1 (from 3.46 to 0.37), and a similarly dramatic reduction of over 82% is observed on LINUX (from 3.11 to 0.54). This powerful initial separation is then effectively maintained throughout the subsequent layers. This substantial reduction in MI confirms that PSGD successfully learns semantically independent features for aligned and unaligned substructures.
A core objective of our work is to learn disentangled representations, H as and H us , that meaningfully correspond to aligned and unaligned substructures. However, the absence of ground-truth substructure labels makes direct validation challenging. To circumvent this, we design a set of embedding swapping experiments to probe the semantic properties of the learned representations. Our central hypothesis is that if the disentanglement is successful, these embeddings should exhibit specific, predictable behaviors when swapped within or across graph pairs. We introduce two probing tasks: Intra-Instance Swap (IIS) and Extra-Instance Swap (EIS). We use the Mean Squared Error (MSE) difference relative to the standard GCGSim model (without swapping) as the primary evaluation metric.
A larger MSE difference indicates a greater performance degradation caused by the swap. The results from EISA (Fig. 3b, ‘All’ model) robustly refute the first trivial solution. Swapping aligned embeddings from a completely independent graph pair causes only a minor increase in MSE. If H as were vacuous, the model would be relying on the now-mismatched unaligned embeddings (H us from pair 1 with H us from pair 2), which would have led to a catastrophic performance collapse. The observed stability strongly implies that H as captures context-invariant, semantically meaningful features of the aligned substructures. Symmetrically, the EISU results (Fig. 3c) challenge the second trivial solution. The moderate MSE increase indicates that H us also captures essential predictive information.
The IIS results (Fig. 3a) highlight the effectiveness of our full model. While swapping aligned embeddings significantly degrades the performance of a model without our proposed components (‘None’), the complete GCGSim (‘All’) is remarkably robust to this swap. This demonstrates that our framework successfully enforces the learning of canonical and Collectively, these experiments provide compelling evidence against trivial solutions and affirm that GCGSim learns to disentangle representations in a semantically meaningful way. The model successfully separates features corresponding to aligned and unaligned substructures into their respective representations. While the moderate performance drop in EISU suggests that learning perfectly clean, context-free unaligned representations remains challenging, our overall framework demonstrably achieves its goal of structured and semantically valid representation disentanglement, providing a solid foundation for its superior performance.
To gain deeper insight into the inner workings of our Graph-Node Cross Matching (GNCM) module, we visualize the learned similarities between the local representations of one graph and the global representation of the other. As illustrated in Fig. 4, we generate a heatmap of these similarity scores for each node across all GNN layers. A primary observation from the heatmaps is that the GNCM module successfully learns to differentiate between nodes belonging to aligned versus unaligned substructures. Across all layers, nodes within aligned substructures consistently exhibit higher similarity scores (indicated by red and pink hues). Conversely, nodes from unaligned parts of the graph, such as the distinct node within the annular substructure in Layer 3, show markedly lower similarity values (cooler, blueish colors).
The visualization also reveals a compelling dynamic of how the basis for similarity assessment evolves with network depth, a phenomenon directly tied to the expanding receptive field of the GNN.
• In shallow layers (e.g., Layers 1-2), where a node’s representation is dominated by its immediate neighbors and its own features, the similarity scores are heavily influenced by intrinsic node attributes (e.g., labels). The model primarily performs local, feature-based matching. • In deeper layers (e.g., Layers 3), as the receptive field grows to encompass larger topological patterns, the structural context begins to dominate the similarity computation. The model shifts from local feature matching to a more holistic, topology-aware comparison. Interestingly, in the final layer, the similarities tend to become more uniform across all nodes. This is a well-known characteristic of deep GNNs, where node representations can converge due to over-smoothing. This observation highlights the importance of using multi-layer information and reinforces the motivation for our approach, which does not rely solely on the output of the final layer for its decision.
To assess the practical applicability of our model, we compare its inference time against the baselines, with results presented in Table III. The comparison reveals that GCGSim is highly efficient, consistently ranking as the second-fastest method across all datasets and closely following the state-ofthe-art model ERIC.
Notably, GCGSim is significantly faster than many established methods like GraphSim and MGMN, which often employ more computationally intensive node-level interaction modules. The marginal difference in speed compared to ERIC is a direct trade-off for our more principled architecture, which includes disentanglement encoders and an auxiliary prediction task. This minor computational overhead is justifiable, as it enables the superior predictive accuracy demonstrated in Section VI-D. In conclusion, GCGSim strikes an excellent balance between state-of-the-art accuracy and high computational efficiency, making it a practical solution for real-world applications.
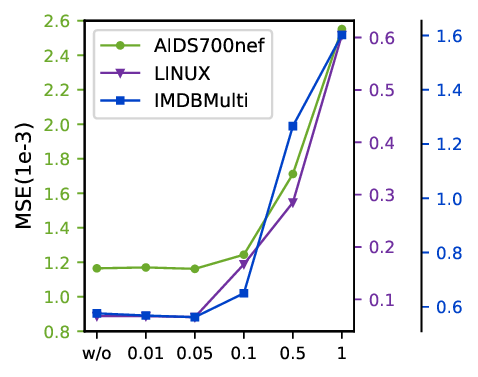
We analyze the sensitivity of the ECP weight λ and the IIR parameter β, with results shown in Fig 5 . Both hyperparameters exhibit a similar U-shaped impact on performance. As observed, the model achieves optimal performance across all datasets when both λ and β are set to approximately 0.05. Performance degrades when the components are removed (‘w/o’ case), consistent with our ablation study. Conversely, performance also deteriorates sharply with excessively large values. This is because an overly large λ compromises the primary similarity task, while a large β can introduce disruptive noise to the representations. Therefore, we set λ = 0.05 and β = 0.05 in our main experiments.
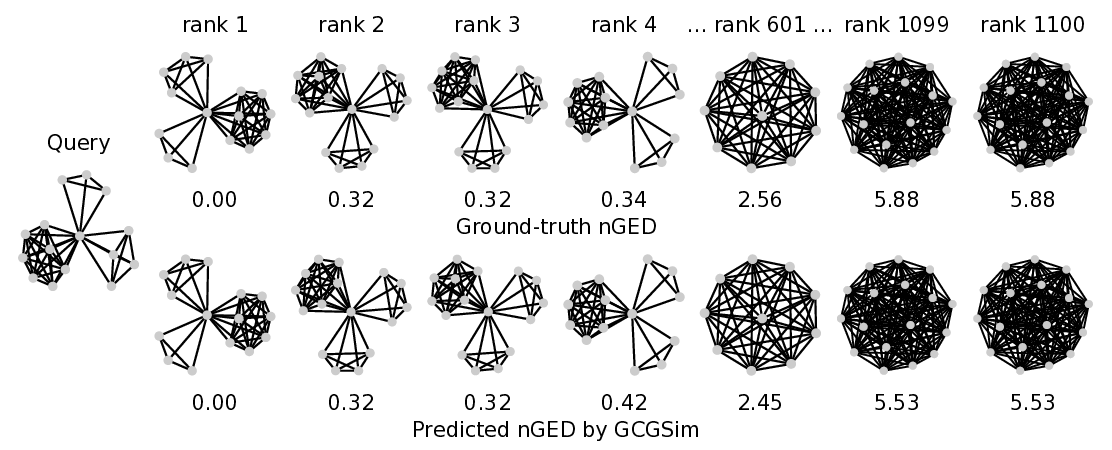
We conduct graph search experiments on AIDS700nef, LINUX, and IMDBMulti to retrieve k graphs from the dataset that are most similar to the given query graph. As shown in Fig. 6, in each example, we demonstrate the predicted similarity ranking result computed by GCGSim compared with ground-truth ranking. The top-ranked graph has a high degree of isomorphism with the query. It indicates that GCGSim possesses the capability to retrieve graphs that are similar to the query graph.
In this paper, we addressed the fundamental mismatch between prevalent GNN-based methods and the core principles of GED. We proposed GCGSim that reformulates the GSC task from a GED-consistent perspective of graph-level matching and substructure-level edit costs. This is achieved through a synergy of three components designed to tackle distinct conceptual challenges: GNCM, to overcome the contextagnostic limitations of conventional graph embeddings; the theoretically-grounded PSGD, to operationalize the core GED concept of partitioning graphs into aligned (similar) and unaligned (dissimilar) substructures within the representation space; and IIR,to enforce canonicity upon the representations of aligned substructures. Extensive experiments show GCGSim achieves state-of-the-art performance, confirming that embedding these combinatorial principles directly into the learning objective yields a more effective and robust model for graph similarity.
📸 Image Gallery