Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models
📝 Original Info
- Title: Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models
- ArXiv ID: 2511.18890
- Date: 2025-11-24
- Authors: Yonggan Fu, Xin Dong, Shizhe Diao, Matthijs Van keirsbilck, Hanrong Ye, Wonmin Byeon, Yashaswi Karnati, Lucas Liebenwein, Hannah Zhang, Nikolaus Binder, Maksim Khadkevich, Alexander Keller, Jan Kautz, Yingyan Celine Lin, Pavlo Molchanov
📝 Abstract
Efficient deployment of small language models (SLMs) is essential for numerous real-world applications with stringent latency constraints. While previous work on SLM design has primarily focused on reducing the number of parameters to achieve parameter-optimal SLMs, parameter efficiency does not necessarily translate into proportional real-device speed-ups. This work aims to identify the key determinants of SLMs' real-device latency and offer generalizable principles and methodologies for SLM design and training when real-device latency is the primary consideration. Specifically, we identify two central architectural factors: depth-width ratios and operator choices. The former is crucial for small-batch-size latency, while the latter affects both latency and large-batch-size throughput. In light of this, we first study latency-optimal depth-width ratios, with the key finding that although deep-thin models generally achieve better accuracy under the same parameter budget, they may not lie on the accuracy-latency trade-off frontier. Next, we explore emerging efficient attention alternatives to evaluate their potential as candidate building operators. Using the identified promising operators, we construct an evolutionary search framework to automatically discover latency-optimal combinations of these operators within hybrid SLMs, thereby advancing the accuracy-latency frontier. In addition to architectural improvements, we further enhance SLM training using a weight normalization technique that enables more effective weight updates and improves final convergence. This technique can serve as a generalizable component for future SLMs. Combining these methods, we introduce a new family of hybrid SLMs, called Nemotron-Flash, which significantly advances the accuracy-efficiency frontier of state-of-the-art SLMs, e.g., achieving over +5.5% average accuracy, 1.3×/1.9× lower latency, and 18.7×/45.6× higher throughput compared to Qwen3-1.7B/0.6B, respectively.📄 Full Content
Most existing SLM designs prioritize parameter reduction to achieve efficiency; however, parameterefficient models do not necessarily yield proportional latency reductions, especially on hardware AI accelerators like GPUs and TPUs. Additionally, current SLM development processes rely heavily on empirical trial-and-error rather than systematic and principled methodologies. For instance, deep-thin architectures -such as those employed in MobileLLM [1] and SmolLM [2] -often result in suboptimal accuracylatency trade-offs. Furthermore, with the rapid advent of efficient attention operators [3,4], the potential synergies of combining these operators in hybrid models have not been thoroughly explored [5,6,7,8], leading to manual, heuristic-driven architecture decisions that are increasingly costly and less scalable.
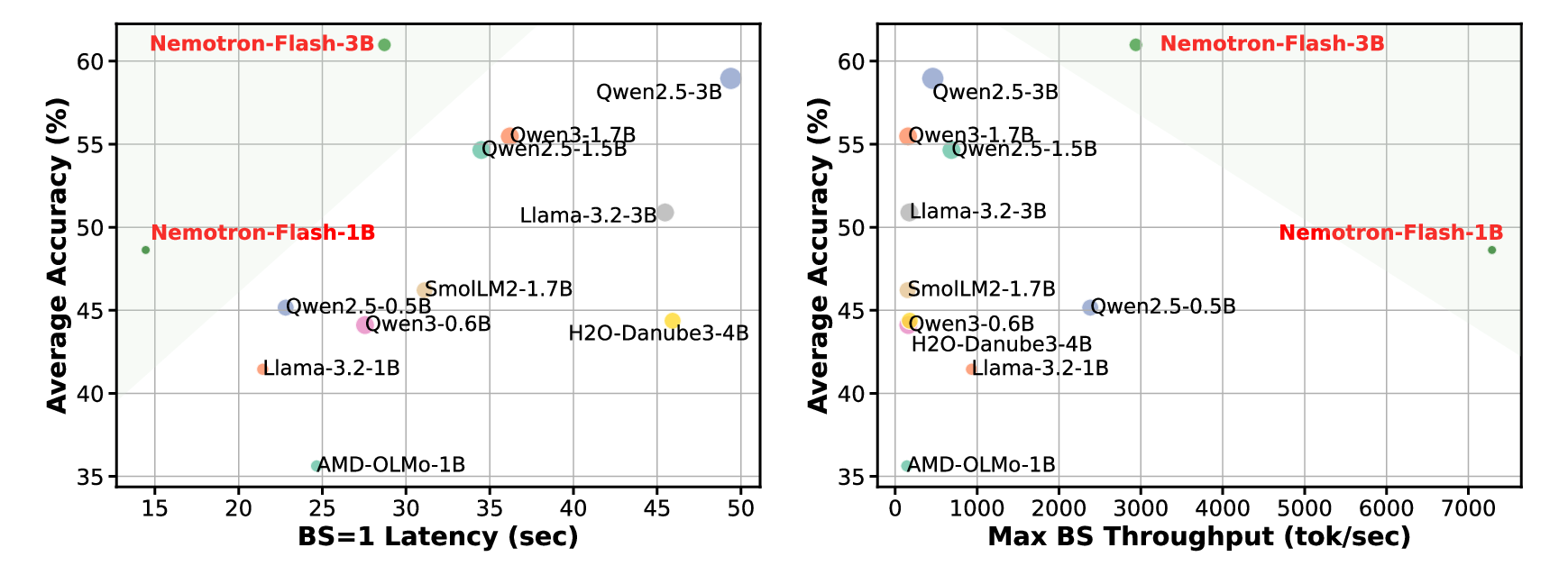
To address these gaps, this paper introduces generalizable principles and automated methodologies for latency-optimal SLM design and training. We perform a comprehensive study of both architectural choices and training strategies to understand their impact on efficiency and accuracy. Based on these insights, we propose a series of techniques for constructing latency-optimal SLMs and analyze their general applicability and effectiveness. These advancements are integrated into a new family of SLMs, which we refer to as Nemotron-Flash. Specifically, our architectural exploration focuses on two key factors: depth-width ratios and operator selection, where the former is crucial for smallbatch-size latency and the latter affects both latency and large-batch-size throughput. Through extensive training and profiling, we show that (1) deep-Figure 1 | Visualizing (a) the accuracy-latency trade-off and (b) the accuracy-throughput trade-off of our Nemotron-Flash and SOTA SLMs, where the average accuracy is computed across 16 tasks spanning commonsense reasoning, math, coding, and recall tasks. Latency is measured on an NVIDIA H100 GPU for decoding 8k tokens with a batch size of 1 using CUDA Graph. Decoding throughput is measured with a 32k-token input length using the maximum batch size that does not cause out-of-memory (OOM) errors for each model. The marker size represents the model depth.
thin models, while parameter-efficient, yield suboptimal latency-accuracy trade-offs, and (2) the optimal depth-width ratio scales with the target latency constraints. Guided by this general principle, we also extend existing scaling laws [9] to relate model loss to both depth and width. This allows the sweet-spot depth-width ratio to be determined by profiling a range of configurations and selecting the one that meets the latency constraint while minimizing loss, as predicted by the scaling law.
Further, we comprehensively evaluate emerging attention operators for their accuracy-latency trade-offs and potential as SLM building blocks. With these findings, we introduce an evolutionary search framework that efficiently identifies optimal combinations of hybrid attention operators. Our search strategy exploits the early stabilization of performance rankings among LM architectures, using short training runs as reliable proxies for final performance, thereby enabling fast and reliable search.
In addition to architectural modifications, based on observations of structural patterns in the weight matrices of trained LMs, we further enhance SLM training by constraining weight norms to increase the effective learning rate. This consistently improves final convergence and downstream accuracy across model families. We also employ learnable meta tokens [7] for cache initialization.
By combining these architectural and training innovations, we develop the Nemotron-Flash model family, which significantly advances the accuracy-latency trade-offs for SLMs. As shown in Fig. 1, Nemotron-Flash markedly pushes forward the accuracy-efficiency frontier compared to state-of-the-art (SOTA) SLMs. For example, with all models accelerated using TensorRT-LLM’s AutoDeploy kernels [10] and CUDA Graph, Nemotron-Flash-3B achieves +2.0%/+5.5% higher average accuracy, 1.7×/1.3× lower latency, and 6.4×/18.7× higher throughput compared to Qwen2.5-3B/Qwen3-1.7B, respectively. Similarly, Nemotron-Flash-1B achieves +5.5% higher average accuracy, 1.9× lower latency, and 45.6× higher throughput than Qwen3-0.6B.
Small language models. The large model size and computational demands of LLMs [11,12,13,14,15,16,17,18] hinder their efficient deployment on resource-constrained platforms. This has motivated the development of SLMs, such as MobileLLM [1], MiniCPM [9], PanGu-𝜋 Pro [19], and TinyLlama [20]. These works aim to deliver parameter-efficient SLMs within a given parameter budget. However, parameter efficiency alone often does not translate into proportional latency reductions on real devices. For example, previous SLMs [1,19] often adopt deep-thin model structures, which may result in suboptimal latency-accuracy trade-offs. Our work targets realdevice efficiency and aims to provide insights and methodologies for developing latency-optimal SLMs.
Efficient attention alternatives. To address the quadratic computation and linearly increasing memory of attention modules, efficient attention alternatives with sub-quadratic complexity in sequence length have been proposed [21,22,23,24,25,4,26,27]. Notable examples include RWKV [21], RetNet [22], Mamba [23], Mamba2 [24], GLA [25],
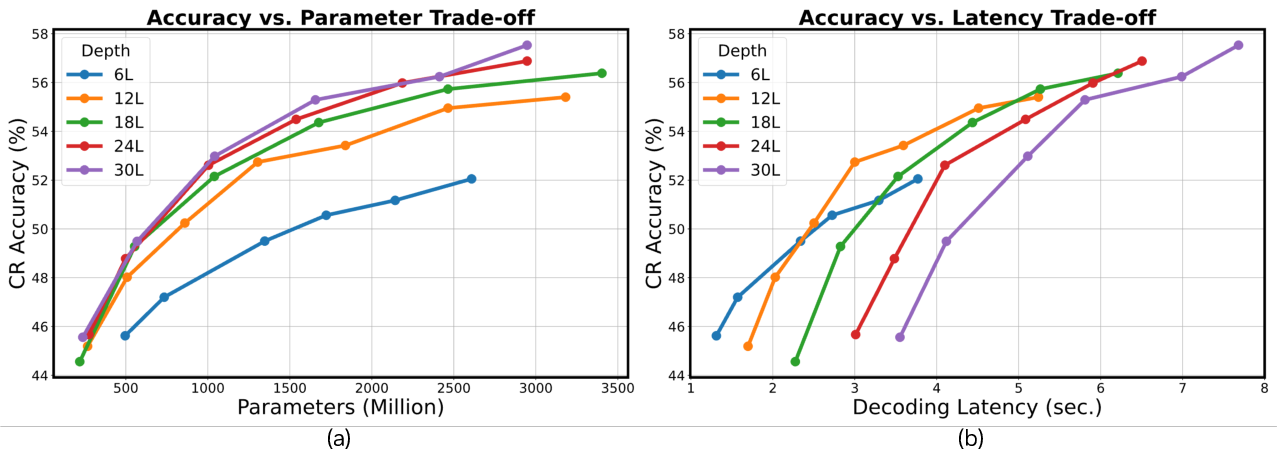
Figure 2 | The accuracy-parameter/latency trade-offs when varying depth and width. While deeper models generally achieve a better accuracy-parameter trade-off, they may not perform as well in the accuracy-latency trade-off and there exists an optimal depth-width ratio for a latency budget.
DeltaNet [26], Gated DeltaNet [27], and JetBlock [28], each featuring different memory update rules. However, despite their potential, linear attention mechanisms have been found to exhibit limited recall capabilities [6] and to underperform standard attention mechanisms on in-context learning tasks [29].
Hybrid language models. To combine the efficiency of linear attention with the recall capabilities of quadratic attention, hybrid models that incorporate both types of operators have emerged. Specifically, [29,6,5,30,31] sequentially stack Mamba and attention layers in hybrid models and show enhanced commonsense reasoning and long-context capabilities. [7] proposes a hybrid-head structure that stacks attention and Mamba in parallel. Other recent works have also explored hybrid models that mix linear RNNs or convolutions with attention [8,32,33,26]. However, existing hybrid models still rely on manual operator combinations, requiring tedious trial-anderror processes. Our work aims to automate operator combination in hybrid models, enabling more scalable hybrid model development.
Previous SLMs [1,19] find that deep-thin models generally achieve better task accuracy than wide-shallow ones under the same parameter budget. However, when targeting real-device latency, this may not hold, as partially noted by [19]. Our key question is: Do deeper or wider models better optimize the accuracylatency trade-off? To answer this, we provide a systematic exploration to understand the impact of depth and width on the accuracy-latency trade-off.
Exploration settings. We train a series of Llama models with five depth settings: 6, 12, 18, 24, and 30 blocks, where each block contains one attention and one feed-forward network (FFN), on 100B tokens from the Smollm-corpus [34]. For each depth setting, we also vary the model width (i.e. hidden size) to create models with different sizes and latencies. We visualize the resulting accuracy-parameter and accuracy-latency trade-offs in Fig. 2 (a) and (b), respectively. Accuracy is averaged over eight commonsense reasoning (CR) tasks, and latency is measured as the decoding time for a 1k token generation under a batch size of 1 on an NVIDIA A100 GPU.
Observations and analysis. We observe that: ❶ Deeper models generally achieve a better accuracyparameter trade-off over a wide depth range, although the benefit gradually saturates; ❷ For the accuracylatency trade-off, the advantage of deep-thin models may not hold, and there exists an optimal depth setting for a given latency budget. For example, when the latency budget is 3 seconds, a depth of 12 achieves the best accuracy among the evaluated settings; ❸ The optimal depth-width ratio generally increases with the latency budget. These observations highlight the necessity of deliberate depth/width selection based on deployment constraints, rather than defaulting to deep-thin models. Augmented scaling laws for determining sweet-spot depth-width ratios. Although the general trend in the above analysis holds, detailed curves may shift across devices and generation lengths, complicating the selection of model depth and width. As such, in addition to the above insights, we also explore principled methods to identify the sweet-spot depth-width ratio within a model family.
In light of this, we augment existing scaling laws [35,9] by parameterizing model loss with model depth and width. Specifically, existing LM scaling laws [35,9] parameterize language modeling loss ℒ(𝑃, 𝑁 ) = ℒ 0 + 𝐶1 • 𝑃 -𝛼 + 𝐶2 • 𝑁 -𝛾 , with 𝑃 and 𝑁 as model size and data size, respectively, and 𝐶1, 𝐶2, 𝛼, 𝛾 as fitting parameters. We decouple the model size 𝑃 into two factors, model depth 𝐷 and width 𝑊 , and reformulate the scaling law:
where the fitting parameters 𝑎, 𝑏, and 𝑐 control the contributions from each dimension, and the exponents 𝛼, 𝛽, and 𝛾 govern the diminishing returns from increasing each respective dimension. Since the impact of data size is additive and decoupled from depth and width, we can study the effect of depth and width on LM loss under a fixed data size, i.e., by neglecting the data size term.
As such, in practice, given a target latency budget and deployment setting, the sweet-spot depth-width ratio can be obtained by profiling a range of depthwidth configurations and selecting the one that meets the latency constraint while achieving the lowest loss.
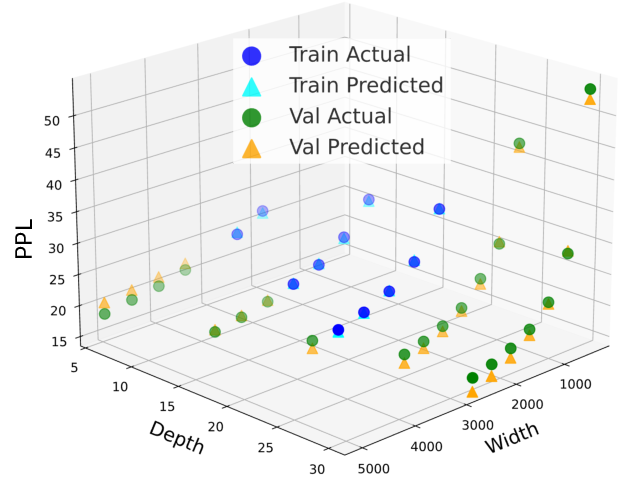
Fitting and extrapolation. To validate the effectiveness of this augmented scaling law, we fit it using the above Llama models with varying depth 𝐷 and width 𝑊 . Specifically, we use perplexity (PPL) as the loss metric, fit the scaling law on a subset of depth/width settings, and validate it on models with larger width/depth settings to assess extrapolation. As shown in Fig. 3, we find that the model extrapolates reasonably well to unseen depth/width settings, staying within 5.3% of the ground-truth PPL, demonstrating that the fitted function generalizes beyond the observed training configurations.
Lesson learned: SLM depth-width ratios. Deep-thin models may not be latency-optimal, and the optimal depth-width ratio generally increases with the target latency budget. Fitting a scaling law with depth and width provides a more principled approach to identifying the sweet-spot ratios.
Beyond model depth and width, the operator used in each layer is another critical dimension. We first train existing LM architectures in a fully controlled setting to identify the most promising operators on the accuracy-latency frontier. We then develop an evolutionary search pipeline to automatically and efficiently discover hybrid combinations of these operators for constructing hybrid SLMs.
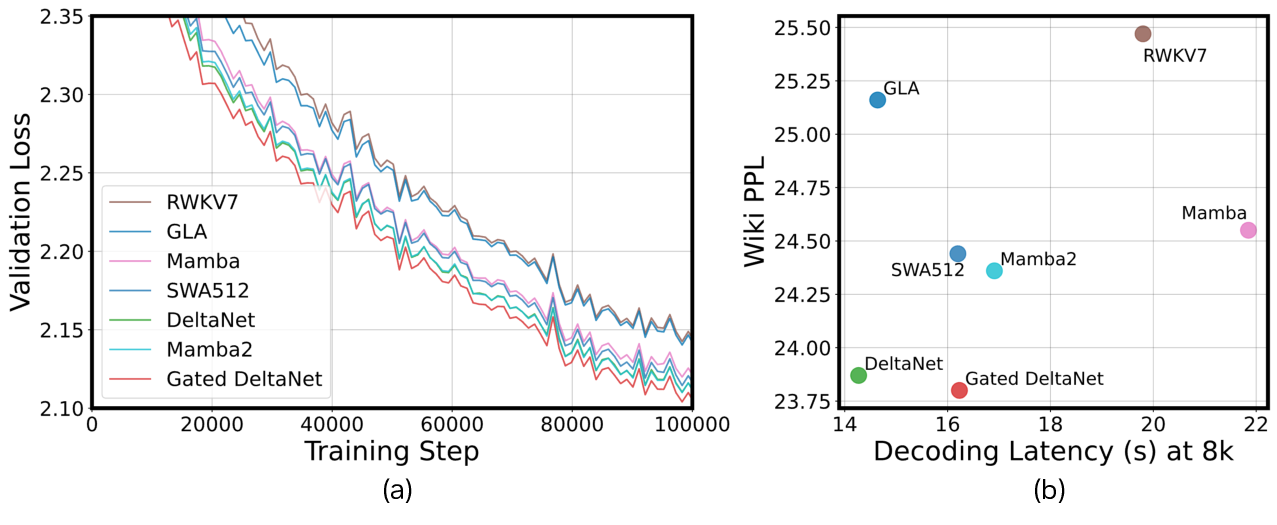
Exploration settings. We train a series of 500M LMs built using emerging efficient attention alternatives, including Mamba [23], Mamba2 [24], GLA [25], DeltaNet [26], Gated DeltaNet [27], RWKV7 [36], and sliding window attention (SWA) with a window size of 512. We use the official implementation for Mamba/Mamba2, FlashAttention [37] for SWA, and FlashLinearAttention [38] for all other linear attention variants. All models follow the designs specified in their original papers (e.g., one FFN after each attention operator, except for Mamba/Mamba2), use the same number of blocks, and are trained on 100B tokens from the Smollm-corpus. We present the validation loss in Fig. 4 (a) and the Wikitext PPL-latency trade-off in Fig. 4 (b), measured by decoding 8k tokens with a batch size of 1 on an NVIDIA A100 GPU with CUDA Graph enabled.
In addition, inspired by recent hybrid LMs [6,30,5,31,7], which combine attention and Mamba/Mamba2 within the same model, we also integrate the promising operators identified in Fig. 4 with Mamba2 or SWA to construct hybrid models in a layer-wise interleaved manner, aiming to gain insights into which operator combinations are well-matched and complementary, as shown in Tab. 1. Note that, for fair comparison, we control the number of blocks in the hybrid models to be the same as in the pure models, based on the insights from Sec. 3.1. More details of the ablation settings are provided in Appendix A.
Observations and analysis. We observe that: ❶ In terms of language modeling, DeltaNet and Gated DeltaNet generally emerge as promising candidates, lying on the PPL-latency Pareto frontier; ❷ When integrated into hybrid models with attention or Mamba2, pairing DeltaNet or Gated DeltaNet with Mamba2 typically results in lower PPL and higher accuracy, consistently outperforming the corresponding pure models. In contrast, improvements from pairing with attention are less stable. This indicates both the advantages of hybrid models and the importance of selecting complementary operator combinations; ❸ When used in hybrid models, the performance gap between individual operators may narrow, likely due to the complementary and diverse memory mechanisms introduced by hybrid layers. For example, although Gated DeltaNet outperforms DeltaNet in language modeling, their task performance becomes comparable when integrated with Mamba2, making DeltaNet the preferable operator in hybrid models due to its greater efficiency.
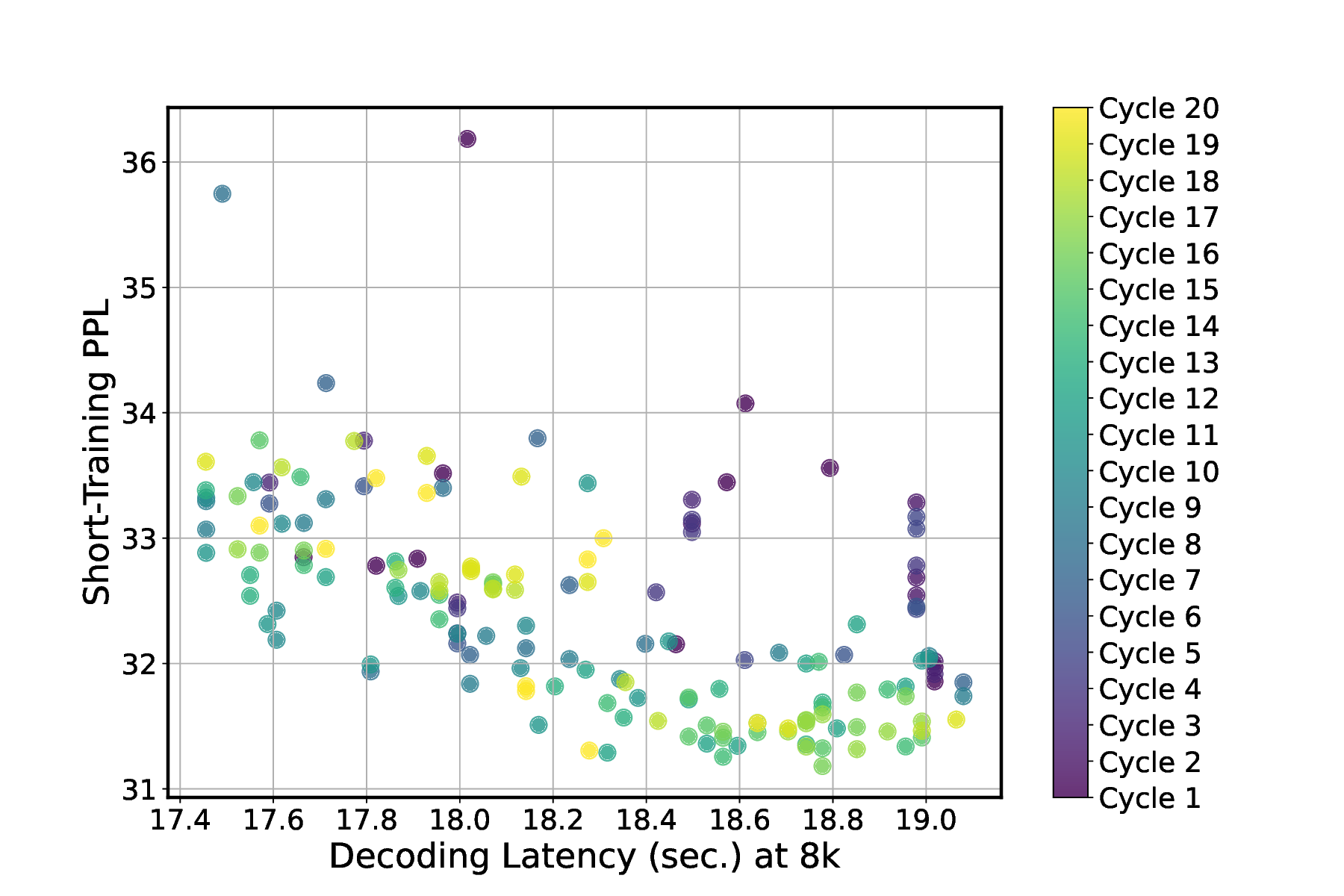
Evolutionary search for operator combinations. The emergence of various efficient attention mechanisms and their complex synergy in hybrid models motivate an automated framework to identify their efficient and complementary combination in hybrid SLMs. To achieve this, we built an evolutionary search engine to efficiently navigate a complex combinatorial design space. Short-training PPL as a search proxy. A crucial observation underpinning our method is that the relative performance rankings of different LM architectures stabilize early during training, which can also be observed from the validation loss curves in Fig. 4 (a). Using this insight, we demonstrate that short-training PPL provides a reliable proxy metric to predict final task performance, substantially reducing training cost for assessing each candidate. We compute the Spearman correlation [39], a measure of rank correlation that is crucial for architecture ranking in our case, between short-training PPL and full-training PPL across multiple LM architectures. We find an 88.8% Spearman correlation, which is sufficient to identify strong architectures within our search space.
Our search space. Based on the identified promising operator candidates and their synergy in hybrid models, we adopt DeltaNet, Attention, and Mamba2 as candidate operators. We search over a maximum of three types of building blocks, each assigned to the early, middle, or late stages of the LM architecture. This three-stage strategy balances operator heterogeneity with architectural regularity. The search explores the ratios of each operator and the number of FFNs per block type, and the repetition count of each block type. More details are provided in Appendix C.1.
Evolutionary search algorithm. We adopt the aging evolution search [40] with the following steps: ① Initialization: Seed and short-train an initial population of architectures, either from known designs or randomly sampled ones; ② Selection: In each evolutionary cycle, we use tournament selection [41] to identify parent architectures that are high-performing based on short-training PPL and meet a predefined target latency budget; ③ Mutation: Selected par- Search with decoding latency. To evaluate the efficacy of our search framework, we conduct a search using decoding latency as the efficiency metric (measured by generating 8k tokens with a batch size of 1 on an NVIDIA A100 GPU). For demonstration purposes, we use a window size of 512 for attention, as this length is sufficient for general CR tasks and for the search proxy. We visualize our search process in Fig. 5, where 10 new architectures are sampled and evaluated in each cycle. Our search process progressively improves toward better models with lower PPL under the target latency.
The searched architecture is visualized in Tab. 2. Interestingly, we find that the latency-friendly architecture discovered by the search adopts DeltaNet-FFN-Mamba2-FFN and Attention-FFN-Mamba2-FFN as basic building blocks, stacking them in an interleaved manner. This finding echoes both our earlier observations-that DeltaNet and Mamba2 are strong candidates-and prior work that interleaves attention and state-space models [6,30,5,31,7].
We benchmark against baseline architectures that have the same model depth and a scaled hidden size to match the decoding latency of our searched architecture. All models are trained on 100B tokens from the Smollm-corpus, and we evaluate them using Wikitext PPL and CR accuracy, averaged over eight tasks.
As shown in Tab. 3, the searched hybrid architectures outperform their pure-model counterparts in both PPL and accuracy. This improvement is attributed to: (1) efficient operator combinations that allow for larger parameter counts under the same decoding latency, and (2) the complementary roles played by the hybrid operators.
Search with number of parameters. We also conduct a new round of search using the number of parameters (500M) as the efficiency metric. We find that: ❶ The searched architecture achieves over 1.21% higher CR accuracy and a reduction of more than 0.74 in PPL compared to all 500M baselines (detailed results are provided in Appendix C.3); and ❷ as shown in Tab. 2, when comparing the parameter-efficient architecture with the decoding-efficient one, the former generally includes more attention modules, which are parameter-efficient but decoding-unfriendly, and fewer Mamba2/DeltaNet modules, and has greater model depth, which is a parameter-efficient design choice according to Sec. 3.1. This set of experiments validates our search scheme’s efficacy in identifying operator combinations that align with the target efficiency metric.
Hybrid models show great promise, but the synergy among different operators is complex, necessitating the identification and combination of complementary operators. The relatively stable ranking of architectures in the early training phases serves as a useful signal for iterating over different designs, and this process can be strategically accelerated using appropriate search algorithms.
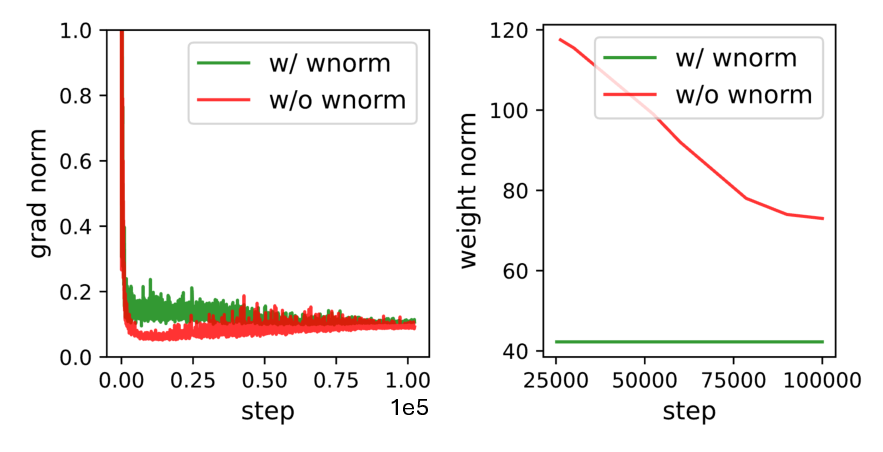
The potential of SLMs can be better realized when they are properly trained. We observe that model weights trained under a standard scheme exhibit non- smoothness, with large weight magnitudes along certain dimensions, as shown in the first row of Fig. 6.
As suggested by [42,43], larger weight magnitudes can lead to smaller relative weight updates under comparable gradient magnitudes, potentially resulting in ineffective learning during later training stages when the learning rate is low.
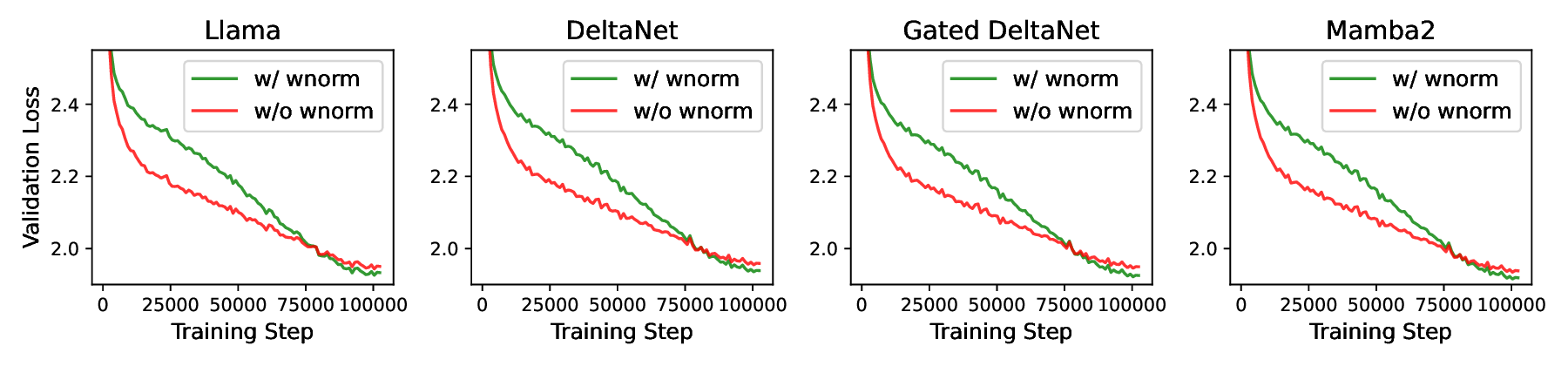
Motivated by this and following [43], we constrain weight magnitudes by projecting model weights onto a unit norm sphere after each training iteration. This normalization step eliminates the radial component and emphasizes angular updates, leading to larger relative weight changes under comparable gradient magnitudes. Specifically, based on the patterns shown in Fig. 6, where weight matrices applied to hidden features (noted as Case-1 ) and those whose outputs are added back to hidden features (noted as Case-2 ) exhibit horizontal and vertical patterns, respectively, we perform weight normalization along the corresponding dimensions. Formally, for each weight matrix W ∈ R 𝐶𝑜𝑢𝑡×𝐶𝑖𝑛 , after each training step, we project it onto a unit norm sphere: W 𝑖,: ← Evaluation across models. We apply weight normalization to different models and visualize the validation loss curves in Fig. 7, along with the average element-wise gradient norm and L2 norm of the weight matrices in Fig. 8. We can observe that ❶ although in the early training stage, the baseline w/o weight normalization has steeper convergence due to unconstrained weights updates (with radical weight updates), the convergence speed will gradually diminish. With weight normalization, the convergence speed is more constant and the convergence will surpass the baseline in later training stages, leading to consistent better final convergence across model families; ❷ Weight normalization leads to much reduced L2 norm of model weights while slightly increasing the gradient norm compared to the baseline, ensuring We also report the corresponding improvements in language modeling and CR accuracy in Tab. 4. We observe that weight normalization consistently improves CR accuracy by +1.20% and reduces PPL by 0.66 on average across model families, indicating its general effectiveness as an add-on component.
Our weight normalization technique can be viewed as a simplified and efficient variant of nGPT [43], which enforces all computations in LMs to operate on a unit sphere by introducing multiple activation normalization layers in addition to weight normalization. We find that: ❶ Weight normalization, along with the resulting more effective weight updates, is key to improved convergence. When applied alone, weight normalization achieves final task performance comparable to the full nGPT solution, as demonstrated in Appendix D.1; ❷ More importantly, the additional activation normalization layers in nGPT introduce significant training overhead-i.e., increasing SLM training time by more than 20%-which reduces the number of training tokens given a fixed training duration. Thus, our contribution lies in identifying the primary contributing component and delivering a more efficient alternative.
Previous work [7] has shown that prepending a set of learnable tokens to regular tokens can alleviate attention sinks [44], which are caused by the forceto-attend phenomenon on semantically unimportant tokens. We find that these meta tokens can also ben-efit non-softmax linear attention mechanisms, as they serve as learned cache initialization when reformulating linear attention in a recurrent format during decoding. As shown in Tab. 5, prepending 256 meta tokens can consistently improve both language modeling and reasoning accuracy (+0.45% on average) with negligible overhead.
Combining all the above architectural improvements and training techniques, we develop and train a new hybrid SLM family called Nemotron-Flash with two different model sizes.
Model configuration. We adopt the decodingfriendly model structure searched in Sec. 3.2, which interleaves DeltaNet-FFN-Mamba2-FFN (Block-1) and Attention-FFN-Mamba2-FFN (Block-2) as basic building blocks. We build two models Nemotron-Flash-1B/3B with 0.96B/2.7B parameters, respectively, with depth and width configured based on the scaling laws in Sec. 3.1. Specifically, Nemotron-Flash-1B has the same configuration as in Tab. 2, where the larger parameter count comes from a new tokenizer mentioned below. It has a hidden size of 2048 and contains 12 blocks, each with one token-mixing module and one FFN, or 24 operators if counting DeltaNet, Mamba2, Attention, and FFN as separate operators. Nemotron-Flash-3B has a hidden size of 3072 and contains 36 operators, with two additional Block-1 and one additional Block-2.
Tokenizer. Different from previous parameterefficient SLMs [1] that adopt a tokenizer with a small vocabulary size to save parameters, we adopt a tokenizer with a larger vocabulary size [45]. We find that the latency overhead of the enlarged embedding layer/LM head is small, while the more coarse-grained token representations reduce the token count when encoding the same sentence, resulting in more significant latency reduction (see Appendix E for details).
Training settings. Both models are trained using the Adam optimizer (without weight decay, due to the use of weight normalization) and a cosine learning rate schedule with an initial learning rate of 1e-3. We first train the models on Zyda2 [46], then switch to higherquality datasets, including commonsense reasoning datasets (Climb-Mix [47] and Smollm-corpus [34]), a proprietary high-quality dataset with high proportions of math and code, and MegaMath [48]. Both models are trained for 4.5T tokens using 256 NVIDIA H100 GPUs, with a batch size of 2M tokens and a context length of 4096, except for the final 25B tokens, where we extend the context length to 29000. Table 6 | We benchmark our Nemotron-Flash-1B/3B against SOTA SLMs across 16 tasks, including MMLU, commonsense reasoning (CR), math, coding, and recall tasks. Latency is measured on an NVIDIA H100 GPU for decoding 8k tokens with a batch size of 1 using CUDA Graph. Throughput (Thr.) is measured with a 32k-token input length using the maximum batch size w/o OOM. Nemotron-Flash-3B-TP is a throughputoptimized variant configured with the 1FA+2SWA setting in Sec. 4 Deployment settings for latency measurement. To fairly benchmark against baseline models dominated by full attention layers, we adopt TensorRT-LLM’s AutoDeploy kernels [10] with efficient KV cache management for full attention and use CUDA Graph for further acceleration. For other operators, we use the official implementation of Mamba2 [24] and FlashLinearAttention [38] for linear attention layers such as DeltaNet, and we always wrap the entire model in a CUDA Graph.
Baselines and tasks. We benchmark against SOTA SLMs, including Qwen3 [49], Qwen2.5 [50], Llama3.2 [51], SmolLM2 [2], h2o-Danube [52], and AMD-OLMo [53] series. Accuracy is evaluated using lm-evaluation-harness [54] across 16 tasks including MMLU, commonsense reasoning (PIQA, ARCC, ARCE, Hellaswag, Winogrande, OBQA), math (GSM8k, MathQA), coding (HumanEval, HumanEval-Plus, MBPP, MBPP-Plus), and recall (FDA, SWDE, Squad). We use 5-shot evaluation for GSM8K and MMLU, 3-shot for MBPP and MBPP-Plus, and 0shot for all remaining tasks. We report the average accuracy on each domain in Tab. 6 and provide taskwise accuracy in Appendix B.
As shown in Tab. 6, our Nemotron-Flash family achieves the lowest decoding latency and the best accuracy among models of comparable size. For ex-ample, Nemotron-Flash-1B delivers 5.5% higher accuracy than Qwen3-0.6B with 1.9× latency reduction and 46× higher throughput. Similarly, Nemotron-Flash-3B achieves +2.0%/+5.5% higher average accuracy, 1.7×/1.3× latency reduction, and 6.4×/18.7× higher throughput than Qwen2.5-3B/Qwen3-1.7B, respectively. In addition, with further optimization of the attention configuration, Nemotron-Flash-3B-TP achieves 10.1× and 29.7× higher throughput compared to Qwen2.5-3B and Qwen3-1.7B, respectively.
It is worth noting that (1) in addition to achieving the most competitive latency and throughput, Nemotron-Flash-3B attains the highest accuracy in commonsense reasoning, math, coding, and recall tasks among models larger than 1.5B parameters; and (2) although Nemotron-Flash-1B and Nemotron-Flash-3B contain only 2 and 3 full-attention layers, respectively, both achieve the most competitive recall accuracy, suggesting that maintaining full KV cache across all layers is unnecessary, which is consistent with observations from existing hybrid LMs [45,55].
We instruction-tune the Nemotron-Flash-3B model using a two-stage supervised fine-tuning (SFT) strategy on two proprietary datasets. The learning rates for the first and second stages are set to 8e-6 and 5e-6, respectively. Each stage is trained for one epoch
Figure 9 | Visualizing the NIAH scores of different attention configurations on the Ruler benchmark [56]. We benchmark Nemotron-Flash-3B-Instruct against Qwen2.5-1.5B and Qwen3-1.7B across MMLU (5-shot), GPQA (0-shot), GSM8K (5-shot), and IFEval. As shown in Table 7, Nemotron-Flash-3B-Instruct demonstrates strong reasoning and instruction-following capabilities, achieving the best average accuracy and efficiency, e.g., over +4.7% average accuracy and 4.3×/18.7× higher throughput compared to Qwen2.5-1.5B and Qwen3-1.7B, respectively. Despite having over 1.6× more parameters, which contribute to enhanced intelligence, Nemotron-Flash maintains superior real-device efficiency, owing to its architectural improvements.
Full attention (FA) operators are essential for longcontext retrieval; however, they also become the primary bottleneck for large-batch-size long-context throughput. To better understand this trade-off, we conduct an ablation study on the attention configurations of Nemotron-Flash-3B. Starting from the pretrained Nemotron-Flash-3B base model with three FA layers, we perform continuous pretraining with a 29k context length for 25B tokens under three configurations: (1) three FA layers, (2) two FA layers plus one SWA layer with an 8k window size, and (3) one FA layer and two SWA layers.
We report the accuracy on both general bench-marks and three needle-in-a-haystack (NIAH) tasks from Ruler [56] in Tab. 8 and Fig. 9, respectively. The results show that (1) replacing more FA layers with SWA substantially improves throughput, e.g., the 1FA+2SWA configuration achieves 1.6× higher throughput than the 3FA setting; (2) general benchmark accuracy, including recall performance, remains largely unaffected when more SWA layers with 8k window size are used; and (3) NIAH performance, however, drops significantly at longer context lengths when the number of FA layers is reduced to one, highlighting the importance of FA operators for longcontext capability. Therefore, we recommend maintaining at least two full attention layers even in SLMs.
Rather than merely offering a smaller LLM, this work re-imagines small models from the perspective of realworld latency and throughput, systematically exploring the key architectural and training factors essential for developing latency-optimal SLMs. By analyzing optimal depth-width ratios, strategically combining efficient attention operators through an evolutionary search framework, and enhancing training with weight normalization and meta tokens, we establish a comprehensive framework that significantly improves both real-device latency and accuracy, and deliver the Nemotron-Flash model family that advances the SOTA accuracy-latency frontier. Beyond the framework, we hope the actionable insights and guidelines provided here will inform future research and development of low-latency, high-throughput SLMs tailored to diverse, latency-sensitive real-world applications.
Depth-width scaling in Sec. 3.1. We train a series of Llama models with five depth settings: 6, 12, 18, 24, and 30 blocks, where each block contains one attention and one FFN. For each depth setting, we further vary the model width, i.e., hidden size, to create different models, ensuring that the resulting models across different depths have relatively comparable parameter ranges. We train each model on 100B tokens from the Smollm-corpus [34] using the AdamW optimizer and a cosine learning rate schedule with an initial learning rate of 5e-4.
Architecture explorations in Sec. 3.2. For vanilla Mamba and Mamba2 models, we do not insert FFNs, following their original papers. For all other pure models we explored, we add one FFN after each token mixing operator. For hybrid models, we adopt the building block of Operator1-Operator2-FFN. For example, when building a hybrid model with DeltaNet and Mamba2, we use the building block DeltaNet-Mamba2-FFN. All models have 500M parameters and consist of 24 operators, where each token mixing operator and each FFN is counted as one operator.
We train each model on 100B tokens from the Smollmcorpus [34] using the AdamW optimizer and a cosine learning rate schedule with an initial learning rate of 5e-4. The same training settings are used for training the searched architectures, as well as for the meta token experiments in Sec. 3.4.
Weight normalization experiments in Sec. 3.3. For all models with and without weight normalization, we train them on 100B tokens from the Smollm-corpus [34] using the AdamW optimizer and a cosine learning rate schedule with an initial learning rate of 1e-3. This learning rate is the tuned learning rate that achieves the best convergence for models without weight normalization. We then apply weight normalization on top of this setting to demonstrate that our method can further boost task performance beyond the best baseline.
Tasks for computing average commonsense reasoning (CR) accuracy. Unless otherwise specified, in the above exploration experiments, we adopt eight tasks to compute the average CR accuracy: Lambda, PIQA, ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, TruthfulQA, and SIQA, all from the lm-evaluation-harness [54].
As a complement to the domain-averaged accuracies reported in Sec. 4.1 and Tab. 6, we present the detailed per-task accuracies within each domain in Tab. 9. We search for both the number of blocks in each stage and the structure of each block, including the involved operators, their ratios, and the ratio of FFNs.
Operators and their ratios. Based on the exploration of pure and hybrid models in Sec. 3.2, we include attention, Mamba2, and DeltaNet in our search space, considering both operator efficiency and their complementary roles. To ensure regularity and avoid overly complex blocks, we allow at most two types of operators (excluding FFNs) in each stage. We support different ratios between two hybrid operators: 0:1 (i.e., only one operator), 1:1, 1:2, and 1:3. FFN ratios. We allow for 0, 1, or 2 FFNs after each token mixing operator in each building block.
Number of building blocks. We allow flexible numbers of building blocks in each stage, as long as the total number of operators does not exceed a predefined limit (i.e., 30). If the total exceeds this limit, we reduce the number of building blocks in the last stage to meet the depth limit.
After determining all the above design factors for a new architecture, we select a hidden size from [1024,1280,1536,1792,2048,2304,2560], choosing the largest size that satisfies the target latency. This strategy allows us to use the short-training PPL solely to rank the searched architectures.
As a complement to the search algorithm described in Sec. 3.2, we present our adopted aging evolutionary search in Alg. 1, which iteratively refines a population of hybrid language model architectures by selectively sampling and mutating architectures over multiple cycles.
Search process. After initializing a population of architectures from a set of seeded and randomly initialized architectures, a set of candidate architectures (we use 10) is sampled, mutated, and evaluated concurrently in each cycle. Mutations are performed by altering one of the searchable factors: (1) changing one operator in a building block type, (2) varying the hybrid operator ratio in a building block type, (3) adjusting the FFN ratio in a building block type, or (4) modifying the number of building blocks across stages. The sampled architectures are evaluated using short-training perplexity as an efficient proxy for final performance, and latency is quickly estimated using a pre-measured lookup table (LUT). This parallel, proxy-driven strategy effectively balances the exploration of novel designs and the exploitation of known strong performers, facilitating rapid convergence to high-quality architectures.
We train each model on 10B tokens from the Smollm-corpus [34] using the AdamW optimizer and a cosine learning rate schedule with an initial learning rate of 5e-4. Training and evaluating a sampled architecture takes approximately 2 hours using 32 NVIDIA A100 GPUs.
As a complement to the searched architecture optimized for parameter efficiency, presented in Sec. 3.2 and Tab. 3, we provide a benchmark against other baseline architectures, all with 500M parameters, in terms of Wikitext PPL and CR accuracy averaged over eight tasks. All models are trained on 100B tokens from the Smollm-corpus [34] using the AdamW optimizer and a cosine learning rate schedule with an initial learning rate of 5e-4. As shown in Tab. 10, the searched architecture achieves over 1.21% higher CR accuracy and a reduction of more than 0.74 in PPL compared to all 500M baselines.
We provide the detailed configurations of our final Nemotron-Flash models in Tab. 11.
As discussed in Sec. 3.3, our weight normalization technique can be viewed as a simplified and efficient variant of nGPT [43], which enforces all computations in LMs to operate on a unit sphere by introducing multiple activation normalization layers in addition to weight normalization. To analyze the performance breakdown achieved by nGPT, we evaluate our weight normalization, nGPT without weight normalization As shown in Tab. 12, we observe that: (1) Using only our weight normalization achieves strong task performance, with higher CR accuracy than nGPT and slightly worse language modeling PPL; (2) Weight normalization is essential to nGPT, as removing it leads to a notable drop in accuracy; (3) Additional activation normalization layers in nGPT introduce over 30% training overhead, reducing the number of training tokens in a fixed training budget. Thus, our weight normalization offers a more efficient alternative to nGPT while maintaining comparable accuracy.
As a complement to Sec. 3.3, we further visualize the gradient norm evolution during training with and without weight normalization for four models in Fig. 10. We observe that weight normalization results in a slightly increased gradient norm, leading to larger relative weight updates, considering the smaller weight norm. This effect is particularly beneficial in the later stages of training and leads to consistent final accuracy improvements across model families.
Previous parameter-efficient SLMs [1] adopt a tokenizer with a small vocabulary size, such as Llama2 [13], to reduce the number of parameters.
In contrast, we use a tokenizer with a larger vocabulary size, i.e., Mistral-NeMo-Minitron [45]. The rationale is that a larger vocabulary often results in more concise token representations and fewer tokens when encoding the same sentence. For example, the phrase by the way" can be tokenized into a single by-the-way" token.
Table 13 | Tokens per sample on AG News / Wikitext datasets using LLaMA2 [13] and Mistral-NeMo-Minitron [45] As shown in Tab. 13, when averaging the number of tokens per sample over two datasets, the Mistral-NeMo-Minitron tokenizer achieves a 9.3% and 13.5% reduction in token count. At the same time, the decoding latency for generating 8k tokens using models with embedding dimensions corresponding to the two tokenizers shows only a 5.8% latency gap (38.93 seconds vs. 41.31 seconds). This suggests that overall efficiency could be higher when using tokenizers with larger vocabularies. Furthermore, given that larger vocabulary sizes often improve task performance, we adopt the Mistral-NeMo-Minitron tokenizer [45] over smaller alternatives.
Existing deployment frameworks such as TensorRT-LLM [60] and vLLM [61] support Attention and [38]. Hybrid LMs involve diverse operators and require a deployment flow that can efficiently accelerate each operator type. To this end, we integrate TensorRT-LLM’s AutoDeploy kernels [10] with efficient KV cache management for full Attention, the official implementation of Mamba2 [24], and DeltaNet via FlashLinearAttention [38] to deploy our Nemotron-Flash. The entire model is wrapped with CUDA Graph to mitigate kernel launch overhead, which is critical for edge applications with a batch size of 1.
To demonstrate the effectiveness of our deployment flow, we benchmark the decoding speed of a Llama model (12 blocks, hidden size of 1536, 550M parameters) using PyTorch, vLLM, TensorRT-LLM, and our deployment flow. As shown in Tab. 14, our deployment flow outperforms vLLM in decoding speed at longer sequence lengths and achieves a latency gap within 15% of TensorRT-LLM for full-attention models. This gap could be further reduced with improved full-attention kernel optimization on top of [10]. Additionally, our deployment supports linear attention variants, which are not supported by vLLM or TensorRT-LLM. This set of comparisons validates the effectiveness of our deployment flow.
In our architecture search for SLMs, we primarily use language modeling as the search proxy, which may not fully capture other capabilities such as long-context understanding. Additionally, our search focuses on macro-architecture, leaving room to explore more finegrained factors. We will extend our search framework to optimize for these aspects in future work.
Operator1Operator2 ↓ Wiki PPL ↑ CR Acc (%)
Operator1
ModelParams (M) ↓ Wiki PPL ↑ CR Acc (%) ↓ Latency
Model
[d, f, m2, f, a, f, m2, f, d, f, m2, f, a, f, m2, f, d, f, m2, f, d, f, m2, f] [m2, f, a, f, a, f, d, m2, f, a, f, a, f, d, m2, f, a, f, a, f, d, m2, f, a, f, d, f, f]
📸 Image Gallery