CoreEval: Automatically Building Contamination-Resilient Datasets with Real-World Knowledge toward Reliable LLM Evaluation
📝 Original Info
- Title: CoreEval: Automatically Building Contamination-Resilient Datasets with Real-World Knowledge toward Reliable LLM Evaluation
- ArXiv ID: 2511.18889
- Date: 2025-11-24
- Authors: Jingqian Zhao, Bingbing Wang, Geng Tu, Yice Zhang, Qianlong Wang, Bin Liang, Jing Li, Ruifeng Xu
📝 Abstract
Data contamination poses a significant challenge to the fairness of LLM evaluations in natural language processing tasks by inadvertently exposing models to test data during training. Current studies attempt to mitigate this issue by modifying existing datasets or generating new ones from freshly collected information. However, these methods fall short of ensuring contamination-resilient evaluation, as they fail to fully eliminate pre-existing knowledge from models or preserve the semantic complexity of the original datasets. To address these limitations, we propose CoreEval, a Contaminationresilient Evaluation strategy for automatically updating data with real-world knowledge. This approach begins by extracting entity relationships from the original data and leveraging the GDELT database to retrieve relevant, up-todate knowledge. The retrieved knowledge is then recontextualized and integrated with the original data, which is refined and restructured to ensure semantic coherence and enhanced task relevance. Ultimately, a robust data reflection mechanism is employed to iteratively verify and refine labels, ensuring consistency between the updated and original datasets. Extensive experiments on updated datasets validate the robustness of CoreEval, demonstrating its effectiveness in mitigating performance overestimation caused by data contamination.📄 Full Content
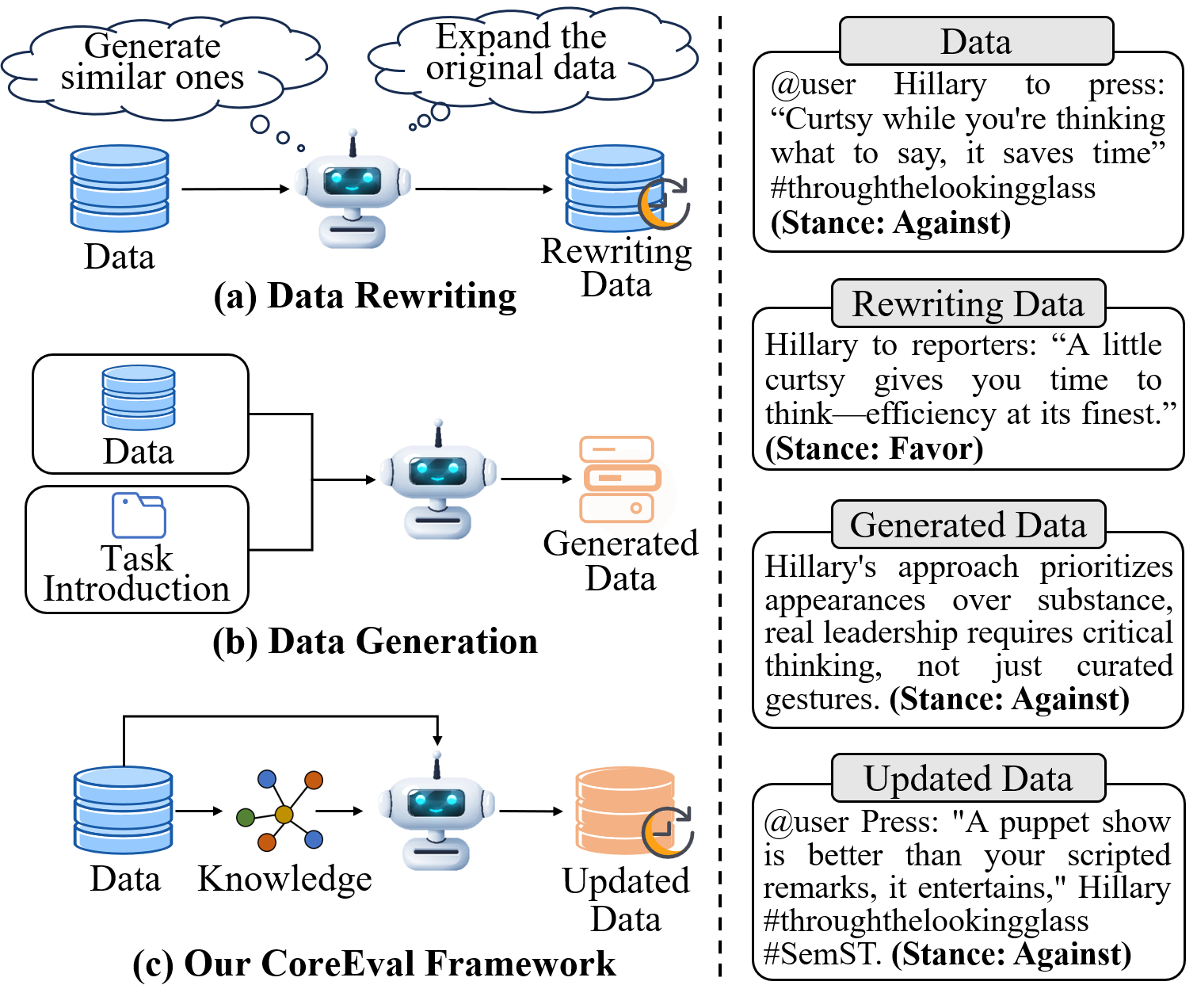
To mitigate data contamination, curating new datasets has become a widely adopted approach. Recently, researchers have explored automated dataset construction methods to reduce the time and labor costs associated with manual curation (Ying et al., 2024). These approaches using LLMs can be broadly categorized into two types: data rewriting, which modifies existing data while preserving its original structure, and data generation, which leverages newly collected data to create taskspecific datasets (Li et al., 2024b;Wu et al., 2024).
Despite their widespread adoption, these methods have significant limitations. As illustrated in Figure 1 (a), data rewriting employs prompt-based instructions to guide LLMs in modifying existing data. While this approach is straightforward, it often risks generating data with labels that deviate from the original annotations. Additionally, the rewriting process may inadvertently introduce contaminated data, as models could rely on preexisting information from their training corpus. On the other hand, data generation, which directly produces new datasets based on data and task introduction, shown in Figure 1 (b), fails to preserve the semantic richness and complexity of the original dataset, leading to information loss. These limitations undermine the reliability and effectiveness of existing approaches for contamination-resilient evaluation.
Therefore, this paper introduces CoreEval, a framework designed to mitigate data contamination and enable reliable, up-to-date LLM evaluation. As illustrated in Figure 1, CoreEval goes beyond simple data rewriting and generation. Instead, it systematically integrates newly acquired knowledge, preserving data quality, enhancing robustness, and maintaining semantic richness while ensuring alignment with task objectives. Specifically, CoreEval first extracts entity relationships from the original data and utilizes the Global Database of Events, Language, and Tone (GDELT) Project to retrieve up-to-date, real-world knowledge. This knowledge is then recontextualized with original data to refine and restructure the dataset, ensuring semantic coherence and alignment with task objectives. Finally, a rigorous data reflection mechanism enforces label consistency and preserves dataset integrity. We systematically evaluate CoreEval on multiple NLP datasets across different LLMs. Extensive experiments on these updated datasets validate the stability of our framework, demonstrating that CoreEval not only upholds high data quality but also effectively mitigates performance overestimation caused by data contamination. The contributions of this paper can be summarized as follows:
• We propose CoreEval, an automatic contamination-resilient evaluation strategy that integrates real-world knowledge to update datasets.
• We design a structured workflow inspired by cognitive learning theory to ensure reliable and timely LLM evaluation.
• Extensive experiments across multiple tasks and a series of LLMs demonstrate the effectiveness of CoreEval in mitigating data contamination.
2 Related Works
Many datasets are widely used to evaluate models in NLP tasks like sentiment analysis (Saif et al., 2013;Rogers et al., 2018), stance detection (Li et al., 2021;Glandt et al., 2021), and emotion classification (Chen et al., 2017). With LLMs, it is often assumed that a more advanced base model yields superior performance (Pathak and Rana, 2024). However, despite their critical role in benchmarking, the lack of transparency regarding the training data of these models makes it challenging for researchers to verify whether a given model has been contaminated by specific datasets.
Recent studies have explored data contamination in the evaluation of LLM. Aiyappa et al. (2023) analyzed ChatGPT’s stance detection, highlighting risks associated with its closed nature and updates. Li et al. (2024c) reported contamination rates from 1% to 45% across six Question Answering (QA) benchmarks. To tackle these challenges, researchers have explored methods for detecting contamination, revealing the limitations of stringmatching techniques like n-gram overlap (Yang et al., 2023;Jiang et al., 2024a;Ippolito et al., 2023). Simple test variations, such as paraphrasing, can bypass these methods, allowing even a 13B model to overfit benchmarks and perform comparably to GPT-4. Dekoninck et al. (2024a) further emphasized these issues with the introduction of Evasive Augmentation Learning (EAL).
To achieve contamination-resilient evaluation, updating datasets by collecting new data is an intuitive solution. However, due to the time-consuming and labor-intensive nature of this process, automatic update methods have emerged (Wu et al., 2024). These methods primarily fall into two categories: data rewriting and data generation.
Data rewriting modifies existing data to generate updated versions. Ying et al. (2024) proposed two strategies: mimicking, which preserves style and context, ensuring consistency, and extending, which introduces varied difficulty to broaden the dataset’s cognitive scope. Data generation relies on newly collected data to build task-specific datasets. LatestEval (Li et al., 2024b) ensures integrity by using texts from recent sources, avoiding overlaps with pre-trained corpora. Similarly, LiveBench (White et al., 2024) creates novel datasets by extracting challenges from up-to-date sources like math competitions, arXiv papers, news articles, and transforming them into more challenging, contamination-free versions. Despite their innovations, these methods have limitations. Data rewriting may produce inconsistent labels and introduce contamination from model biases, while data generation often fails to fully capture the semantic depth of the original dataset, leading to information loss. These challenges reduce the reliability and practicality of datasets for contamination-resilient evaluations. Unlike these studies, CoreEval combines structured knowledge retrieval, semantic recontextualization, and iterative label verification to ensure dataset quality and robustness. By utilizing real-world updates and a reflection mechanism, CoreEval mitigates contamination while preserving semantic complexity.
3 CoreEval Framework
In this section, we introduce our novel CoreEval framework, inspired by Bruner’s cognitive theory, for constructing contamination-resilient datasets that integrate real-world knowledge. Building upon Bruner’s cognitive learning theory (Bruner, 2009), we assert that the essence of learning lies in the active formation of cognitive structures rather than the passive absorption of information. Learners actively construct their own knowledge systems by synthesizing newly acquired knowledge with their existing cognitive frameworks. Learning is conceptualized as involving three nearly simultaneous processes: the acquisition of information, the transformation of information, and its subsequent evaluation. As shown in Figure 2, we organize these processes into three components to better align with LLM evaluation. 1) Real-World Knowledge Attainment corresponds to information acquisition, collecting real-time knowledge from the GDELT database. 2) Knowledge Recontextualization component handles information transformation, updating the dataset by incorporating new knowledge. 3) Data Reflection component addresses the evaluation process by refining and assessing the data. This structure ensures that all learning processes are effectively integrated into a cohesive framework.
To incorporate real-world knowledge, we leverage GDELT (Leetaru and Schrodt, 2013), a comprehensive CAMEO-coded database containing over 200 million geolocated events spanning global coverage from 1979 to the present. Given a dataset D = {(d 1 , y 1 ), (d 2 , y 2 ), …, (d n , y n )} consisting of n samples, where each sample d i is paired with a corresponding label y i from the label set Y = {y 1 , y 2 , …, y n }. The knowledge extraction process begins by identifying relevant entities from the data using LLM M, where the input d i acts as information cues for entity extraction.
where E i = {e i,1 , e i,2 , …, e i,j i } and j i represents the set and number of entities extracted from d i . These extracted entities form the foundation for subsequent knowledge retrieval. To efficiently query large-scale data, we utilize Google Big-Query1 and the GDELT. BigQuery enables fast, scalable processing of vast datasets like GDELT, while the API facilitates seamless real-time data retrieval. A list of extracted entities is used to query GDELT databases G for data points within a specific time period to retrieve the most relevant and up-to-date knowledge. Then we employ LLM to summarize the knowledge to obtain. The overall retrieval process can be formalized as:
where K i indicates the knowledge retrieved from the GDELT database. Ki represents the knowledge after being summarized by the LLM. t start and t end represent the start and end times for the query2 .
The knowledge recontextualization phase involves integrating new knowledge with existing cognitive structures, transforming it into a form suited for new tasks. During this phase, learners process and reorganize newly acquired knowledge to enhance both understanding and application. We begin by extracting relational triples from the original sentence d i . These relational triples are represented as
, where e i,j and e ′ i,j are entities, and r i,j denotes the relation between them. l i is the number of relational triples extracted from d i . Next, using new knowledge Ki and an LLM M, we update the original triples T i by generating replacement triples Ti . The updated sentence d u i is then derived by substituting the original triples with Ti , as shown by: Ti ← M(T i , Ki )
where f is the replacement operation. Furthermore, semantic rewriting is performed while preserving the T i , resulting in:
We leverage the semantic style of d s i combined with the label y i to construct a semantic dataset D s .
The updated text di adopts the semantic style of d s i , preserving its linguistic characteristics while incorporating the triples of Ti . Additionally, to maintain classification coherence, the label of di is kept consistent with that of the original sentence d i . Formally, this process is represented as:
The updated dataset D is then formed by combining di with the corresponding label. This process ensures the systematic integration of new knowledge while maintaining the coherence and adaptability of the transformed content.
To evaluate the quality of the generated text, we design an agent to reflect and perform evaluations. This evaluation process employs prompting (Wei et al., 2022) to facilitate step-by-step reasoning. The assessment focuses on two key criteria:
Incorrect Information: Evaluating whether the generated text accurately reflects the facts derived from the provided knowledge. Any discrepancies or inconsistencies are flagged for re-generation.
Label Alignment: Measuring the degree of alignment between the generated text and the corresponding ground truth label, ensuring consistency and relevance to the intended output.
The prompting allows the agent to iteratively reflect on these criteria, providing a rationale for its evaluation. Based on this reflection, the agent determines whether the text required to be regenerated to improve accuracy or alignment. Detailed prompts can be found in Appendix A.1.
We selected five representative Natural Language Understanding (NLU) tasks from the TweetEval Benchmark (Barbieri et al., 2020) and GLUE Benchmark (Wang, 2018), including Emotion Recognition (Mohammad et al., 2018), Irony Detection (Van Hee et al., 2018), Stance Detection (Mohammad et al., 2016), Microsoft Research Paraphrase Corpus (MRPC) (Dolan and Brockett, 2005), and Recognizing Textual Entailment (RTE) (Wang, 2018), to apply our method for automatic updating and evaluation. Table 1 presents the statistical characteristics of these datasets. Notably, for the MRPC and RTE datasets, we refine the provided sentence pairs during the data reflection phase and ensure the supervision of label accuracy for improved consistency and correctness.
To ensure the reliability of our proposed strategy, we conduct a comprehensive human evaluation with five experienced computational linguistics researchers. All evaluators underwent prior training to ensure consistency in their assessments. The evaluators analyze 50 randomly selected samples based on four key criteria: Fluency, Coherence, Factuality, and Accuracy. Following the approach of Ying et al. (2024), Fluency and Coherence are rated on a 3-point scale: 2 (Good), 1 (Acceptable), and 0 (Unsatisfactory). Factuality and Accuracy are rated as 1 (Yes) or 0 (No). Detailed evaluation guidelines can be found in Appendix D.
To assess inter-annotator agreement, we use Fleiss ’ Kappa Statistic (Fleiss, 1971). As shown in Table 2, the results demonstrates that our method generates high-quality data through proper demonstration and structured workflow. Moreover, the values of κ falling within the range 0.70 < κ < 0.85 indicate substantial agreement among annotators. 2024), we adopted the macro F1-score as the unified evaluation metric across all tasks to ensure consistency in performance assessment. Following Ying et al. (2024), we evaluate the model’s performance P using the macro F1-score and subsequently employ performance gain as a metric to assess its resilience to data contamination. This metric quantifies the improvement from test set fine-tuning, with a smaller boost indicating greater resistance to contamination. In the contamination test experiment, we implement two simulation settings. The first involves training solely on the test set and measuring the performance gain δ 1 = P test -P zero against zero-shot performance where P test denotes performance after fine-tuning on the test set only, and P zero represents the zero-shot performance. The second setting incorporates both training and test sets, comparing the performance gain δ 2 = P train+test -P train . where P train indicates performance after fine-tuning on the training set alone, and P train+test represents performance after finetuning with both training and test sets. Detailed information about metric δ can be found in Appendix B.
We first evaluate the zero-shot performance of LLMs on both the original and our updated datasets, using zero-shot evaluation as a standard configuration for assessing LLMs capabilities. We analyze how LLMs performance varies across different tasks after data updates. Refer to Appendix C.1 for the inference configurations. To mitigate prompt bias, we average results across multiple prompt templates, with detailed prompts provided in Appendix A.2.
The experimental results, illustrated in Figure 3, reveal the following: 1) While proprietary models generally outperform most open-source models, the Qwen2.5 series achieves comparable or even superior performance among open-source models. 2) Emotion recognition and stance detection tasks substantially decline in performance on our updated dataset relative to the original one. This decline can be attributed to two factors. First, these tasks may already be contaminated in existing LLMs, leading to decreased performance on our updated dataset, which aligns with prior studies (Aiyappa et al., 2023;Sainz et al., 2024). Second, emotion and stance tasks inherently involve more subjective interpretations and contextual nuances, requiring an understanding of complex, evolving social and cultural contexts. The injection of new knowledge can alter textual patterns, including time-dependent emotional and stance expressions, thereby affecting LLM judgments. This underscores the importance of timely LLM iterations. 3) Proprietary models exhibit a more significant performance drop of 5.42%, compared to 3.62% for open-source models, suggesting that proprietary models may suffer from more severe data contamination. The lack of transparency in their training data and model parameters makes detecting and mitigating data contamination in proprietary systems a critical challenge.
To assess the effectiveness of our method in mitigating the overestimation problem caused by data contamination, we follow prior studies (Zhou et al., 2023;Ying et al., 2024) and simulate data contamination scenarios. Specifically, we introduce test prompts and the test set with ground truth labels, during the training phase to simulate data contami-nation conditions, enabling a rigorous assessment of our approach’s resistance to data leakage.
We conduct contamination simulations on eight open-source models, comparing results across three types of datasets: the original dataset D, semantic dataset D s , and our updated dataset D. Detailed training configurations are provided in Appendix C.2. The results are presented in Table 3, where δ 1 captures both the model’s ability to improve task comprehension and its potential to memorize test set information due to contamination. In contrast, δ 2 isolates the effect of training data, making it a more reliable indicator of contamination by attributing performance gains solely to test set exposure. This distinction ensures that δ 2 provides a precise measure of an LLM’s resistance to data contamination. Our observations reveal several critical trends regarding data contamination in LLMs:
Performance overestimation intensifies with increasing model size in contaminated settings. For instance, in our simulation using the original dataset, Qwen2.5-7B shows δ 1 and δ 2 values of 12.01 and 4.74, respectively, whereas the larger Qwen2.5-14B model exhibits higher values of 17.45 and 7.19. This trend is consistent across different model series. However, when tested on our updated dataset, these parameter-scale-induced discrepancies are significantly reduced.
Cognitively complex tasks are more sensitive to data contamination. Tasks such as irony detection, stance detection, and RTE, consistently yield higher δ values, suggesting a positive correlation between task cognitive complexity contamination sensitivity. These cognitively demanding tasks may prompt models to rely more on shortcuts like memorization, making them more vulnerable to data contamination compared to simpler tasks like emotion recognition and MPRC.
Our real-world knowledge integration method significantly improves contamination mitigation. While simple data rewriting techniques provide some resistance to data contamination, our method, incorporating real-world real-time knowledge, demonstrates superior performance mitigating overestimation and counteracting the effects of contamination. Notably, it outperforms conventional approaches such as semt, highlighting the importance of dynamic knowledge updates in ensuring model robustness.
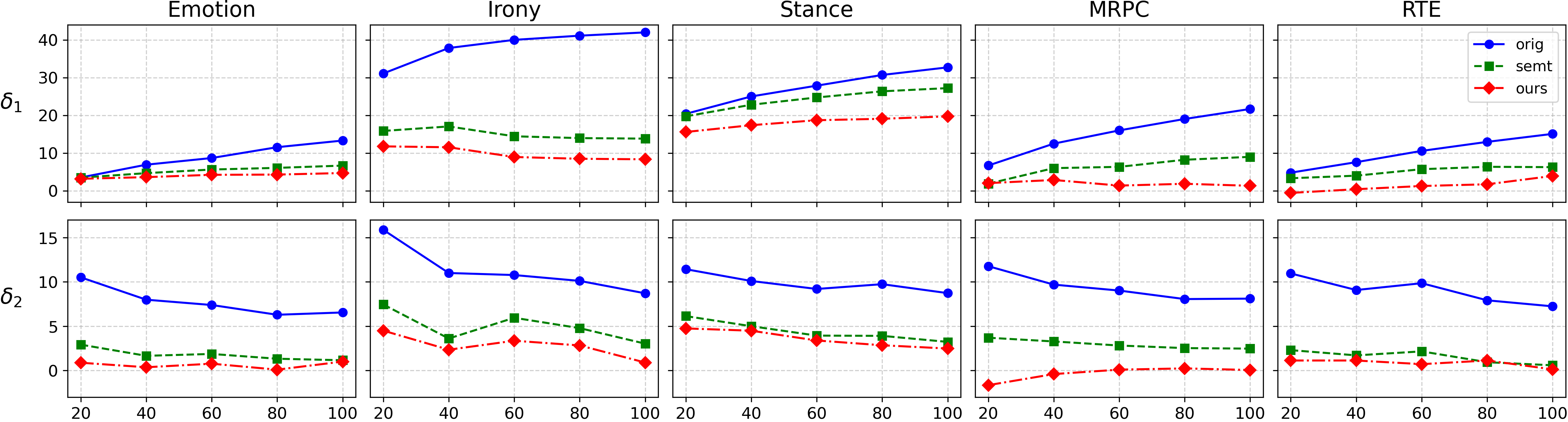
In this section, we examine how varying data proportions influence the effects of data contamination. For the ’test set only’ simulated scenario, we sample different proportions of the test set to compute δ 1 and analyze how varying ratios of the test data contamination impact performance overestimation. For the ’training set and test set’ simulated scenario, we vary the proportion of the training set and compute δ 2 by incorporating it with the test set. All training configurations remain consistent with those detailed in Section 4.3. The results are visualized in Figure 4.
δ 1 exhibits an upward trend, reflecting increasing performance overestimation as more test set data is exposed. This is expected, as greater test set contamination amplifies the model’s memorization effect, artificially inflating performance.
δ 2 demonstrates a downward trend, aligning with the explanation in Section 4.3. This metric isolates and quantifies performance improvements resulting from test set contamination, inde-pendent of enhanced task understanding. When incorporating the training set during the training process, models develop task understanding primarily through training data rather than test data. Therefore, as the proportion of the training set increases, δ 2 effectively filters out the performance gains attributed to task understanding from test data, leading to a more precise measurement of performance overestimation due to contamination by the test data.
Our updated dataset demonstrates stronger resistance to data contamination across both scenarios, significantly reducing performance overestimation regardless of task complexity or the ratio between test and training sets. Further analysis of the mean and variance of δ 1 and δ 2 across different proportions for the original, semantic, and our datasets (outlined in Appendix C.4) reveals that our CoreEval provides more stable metrics across various data proportions compared to both the original and semantic datasets. These findings underscore the critical role of incorporating real-world and real-time knowledge into dataset design to enhance model robustness against data contamination. Table 3: Data contamination resistance (%) of eight open-source models across simulated scenarios. orig denotes using original dataset, semt denotes using semantic dataset, which involves restating the text while preserving its original meaning, and ours denotes using our updated dataset. Following Section 4.2, we use multiple prompt templates to mitigate prompt biases, reporting averaged performance. Best performances are in bold. and δ 2 values, when measured on the original datasets under these text-only contamination conditions, are predominantly negative across eight distinct open-source models. This observation suggests that text-only contamination, without label leakage, does not contribute to performance overestimation, consistent with the prior research by Li et al. (2024c). Conversely, the substantial performance improvements observed in Table 3, where test sets including ground truth labels and test prompts are contaminated, highlight the critical need for targeted mitigation strategies to address this type of data contamination.
In this paper, we introduce CoreEval, an automatic contamination-resilient evaluation framework incorporating real-time real-world knowledge. We further propose a structured workflow engineered to guarantee the timeliness and reliability of LLM evaluations. Extensive experiments across various NLP tasks demonstrate CoreEval’s robust effectiveness in mitigating data contamination. CoreEval is developed to be broadly applicable across NLP tasks, delivering efficient contamination-resilient evaluation while ensuring high data quality with minimal human intervention, thus facilitating fairer and more timely LLM assessment.
Our proposed CoreEval framework updates text based on up-to-date and real-world knowledge. Although we have implemented data reflection and iteration processes to minimize inaccuracies, there is a possibility of generating a minimal amount of hallucinated data. Given our manual evaluation scores for the quality of updated data, the impact of such minimal hallucinated data on the evaluation of LLMs for most NLP tasks is negligible. Furthermore, in this study, CoreEval is applied only to classification tasks. In the future, we plan to extend its application to more complex tasks such as question answering and summarization.
A.1 Prompt of CoreEval Framework
To address potential result bias stemming from task sensitivity to prompts, we employed three prompt templates for each task. The performance metrics were then averaged across these prompt variations to obtain the final results. The comprehensive set of prompt templates utilized for all five tasks is detailed in Table 5, 6, 7, 8, and9, which present the complete prompt formulations for each taskspecific evaluation.
Data contamination, which refers to the inflated performance of a model on a specific dataset or benchmark due to the leakage of test data, can distort the true evaluation and assessment of a LLM’s capabilities. (Zhou et al., 2023;Dekoninck et al., 2024b) Therefore, mitigating the overestimation of performance caused by data contamination is key to addressing this issue. The degree of spurious performance growth following data contamination becomes the primary metric for evaluating data contamination mitigation efforts. However, precisely determining whether a model has been contaminated by certain datasets remains challenging in practice. Previous studies have simulated data contamination by directly training models on test sets of specific datasets (Ying et al., 2024;Li et al., 2024c;Jiang et al., 2024b;Zhou et al., 2023). The mitigation effectiveness is then quantified by measuring the performance gap between the contaminated model before and after data updates. In our work, we similarly introduce δ 1 , which measures the performance difference between the model’s evaluation results after training solely on the test set and its zero-shot performance (i.e., performance without any training) as one of the indicators for evaluating data contamination mitigation.
Furthermore, we argue that the performance improvements of LLMs directly exposed to test set data may stem from two sources: enhanced task understanding through exposure to task-specific data, and direct memorization effects from test set contamination. To isolate the latter effect, we propose δ 2 , which compares the performance difference between models trained on both train and test sets versus those trained exclusively on the train set. δ 2 effectively eliminates the task-understanding gains from the train set while capturing the additional benefits derived from test set inclusion in training (i.e., the primary impact of data contamination), thereby providing a more accurate reflection of data contamination’s contribution to model performance.
The substantial difference between these two indicators, as demonstrated in Table 3, effectively validates this observation. Moreover, the declining trend of δ 2 with increasing train set proportions, as illustrated in Figure 4, confirms that this indicator successfully isolates the impact of data contamination by removing the contribution of improved task understanding.
For proprietary models, we set the temperature to 1.0, top-p to 1.0, max tokens to 1024, and fixed the seed to ensure experimental reproducibility. For open-source models, we load model weights in bf16 format, set the temperature to 1.0, top-p to 1.0, max tokens to 512, and apply greedy decoding to guarantee reproducibility.
Due to computational resource constraints, we applied LoRA fine-tuning (Hu et al., 2021) to eight open-source models. The LoRA hyperparameters were configured with a rank of 16, alpha of 32, dropout of 0.1, learning rate of 1e-4, and 3 epochs.
For the RTE task, we set the training batch size to 2 and maximum sequence length to 512. For all other tasks, the maximum sequence length was set to 400, while the training batch size was adjusted according to model size. Specifically, Llama3-8B, Qwen2.5-7B, Mistral-8B, and Yi1.5-6B were trained with a batch size of 8; Yi1.5-9B, Llama2-13B, and Mistral-12B with a batch size of 3; and Qwen2.5-14B with a batch size of 2. For text-only contamination simulated scenarios, we configured the LoRA hyperparameters with a rank of 16, alpha of 32, dropout of 0.1, training batch size of 1, maximum sequence length of 1024, and 3 epochs. The learning rate was set to 1e-3 for the RTE task and 1e-5 for other tasks.
During inference, we employed a greedy decoding strategy by setting do_sample to False and num_sample to 1, thereby ensuring the reproducibility of our experimental results.
We employed a greedy decoding strategy by setting do_sample to False and num_sample to 1, thereby ensuring the reproducibility of our experimental results. The detailed results of the original dataset and our updated dataset are presented in Table 10.
Table 11 presents the detailed experimental results of our data proportion analysis, encompassing the performance of eight open-source models across five tasks. The evaluation was conducted using varying proportions (20%, 40%, 60%, 80%, and 100%) of both test and training sets, along with the average performance across all five tasks. Table 12 illustrates the standard deviations in data contamination resistance performance under varying data proportions for three datasets: the original, semantic, and our proposed updated dataset. The analysis reveals that our updated dataset consistently achieves lower variance compared to its counterparts. This reduced variability substantiates that our dataset yields more stable and robust evaluation metrics across different degrees of data contamination.
Table 13 outlines the guidelines for human evaluation. Before presenting annotators with the final evaluation materials, we conduct a training session, providing them with this form and comprehensive instructions. This helps ensure they fully grasp the evaluation process, the significance of each metric, and the corresponding scoring standards.
The statistics of the updated datasets are presented. κ denotes Fleiss’ Kappa(Fleiss, 1971).3 . The experimental evaluation also included three prominent proprietary LLMs: ChatGPT, Gemini1.5, and Claude3.5 4 . Evaluation Metrics. Inspired by Opitz (
The statistics of the updated datasets are presented. κ denotes Fleiss’ Kappa(Fleiss, 1971).3
The statistics of the updated datasets are presented. κ denotes Fleiss’ Kappa(Fleiss, 1971).
The statistics of the updated datasets are presented. κ denotes Fleiss’ Kappa(Fleiss, 1971)
The statistics of the updated datasets are presented. κ denotes Fleiss’ Kappa
https://cloud.google.com/bigquery
We chose the release date of the latest open-source model as the starting point for retrieval to prevent overlap with the model’s training data.
For all aforementioned open-source models, we utilized instruction-tuned versions of the model weights.
In our experiments, we utilized the following model versions: gpt-3.5-turbo-0125 for ChatGPT, gemini-1.5-flash for Gemini1.5, and claude-3-5-haiku-20241022 for Claude3.5.
📸 Image Gallery