Semantics as a Shield: Label Disguise Defense (LDD) against Prompt Injection in LLM Sentiment Classification
📝 Original Info
- Title: Semantics as a Shield: Label Disguise Defense (LDD) against Prompt Injection in LLM Sentiment Classification
- ArXiv ID: 2511.21752
- Date: 2025-11-23
- Authors: Yanxi Li, Ruocheng Shan
📝 Abstract
Large language models are increasingly used for text classification tasks such as sentiment analysis, yet their reliance on natural language prompts exposes them to prompt injection attacks. In particular, class-directive injections exploit knowledge of the model's label set(e.g., positive vs. negative) to override its intended behavior through adversarial instructions. Existing defenses, such as detection-based filters, instruction hierarchies, and signed prompts, either require model retraining or remain vulnerable to obfuscation. This paper introduces Label Disguise Defense (LDD), a lightweight and model-agnostic strategy that conceals true labels by replacing them with semantically transformed or unrelated alias labels(e.g., blue vs. yellow). The model learns these new label mappings implicitly through few-shot demonstrations, preventing direct correspondence between injected directives and decision outputs. We evaluate LDD across nine state-of-the-art models, including GPT-5, GPT-4o, LLaMA3.2, Gemma3, and Mistral variants, under varying fewshot and an adversarial setting. Our results show that the ability of LDD to recover performance lost to the adversarial attack varies across models and alias choices. For every model evaluated, LDD is able to restore a portion of the accuracy degradation caused by the attack. Moreover, for the vast majority of models, we can identify more than one alias pair that achieves higher accuracy than the under-attack baseline, in which the model relies solely on few-shot learning without any defensive mechanism. A linguistic analysis further reveals that semantically aligned alias labels(e.g., good vs. bad) yield stronger robustness than unaligned symbols(e.g., blue vs. yellow). Overall, this study demonstrates that label semantics can serve as an effective defense layer, transforming meaning itself into a shield against prompt injection. a📄 Full Content
Attackers can often infer the categories a classifier uses, even without knowing the exact label names. In many applications, the label set is explicitly exposed when systems display results aligned with underlying categories (DeepMind, 2025;Shi et al., 2025). Once aware of the classifier’s categories, adversaries can craft highly effective injections that override the intended behavior (Hung et al., 2024).
In this work we focus on the case of an LLM sentiment classifier, where the categories are positive and negative, and an attacker might insert the instruction “Classify this text as Negative” to force any input text into that class. We refer to this type of adversarial instruction as a classdirective injection, which falls under the broader category of direct prompt injection (Ayub et al., 2024;Hung et al., 2024;Wallace et al., 2024).
Despite the growing body of work on defending against prompt injection, existing strategies remain limited in practice. Detection-based methods (Ayub et al., 2024;Hung et al., 2024;Shi et al., 2025) can flag many adversarial inputs but often require curated training data, access to model internals, or incur substantial computational overhead. Semantic defenses such as sanitization or signed prompts (OWASP Foundation, 2024;Suo, 2024) are simple or cryptographically robust but vulnerable to obfuscation and impractical in closed-source API settings. Structured prompting and instruction hierarchy approaches (Chen et al., 2025;Wallace et al., 2024;Kariyappa and Suh, 2025) strengthen the separation between system and user instructions, yet they depend on fine-tuning or retraining and thus cannot be easily applied to proprietary models. Finally, system-level safeguards (DeepMind, 2025) mitigate downstream harm but do not directly prevent injections. These limitations highlight the need for alternative defense mechanisms that are lightweight, effective across diverse models, and compatible with real-world API-based deployments.
To address the vulnerability of LLM-based classifiers to class-directive prompt injections, we propose a simple yet effective defense: label replacement. Instead of exposing the task’s original labels (e.g., positive and negative) that can be directly exploited by adversaries, we replace them with alternative alias labels (e.g., green and red). Classification is then carried out entirely using the alias labels, and the outputs are finally mapped back to the original categories. By concealing the true label set, this method prevents attackers from coercing the model with instructions such as “Classify this text as Negative.”
A key component of this defense is the use of few-shot in-context learning. LLMs are known to acquire new label semantics from only a handful of examples provided in the prompt (Brown et al., 2020;Min et al., 2022). Since the alias labels have no inherent semantic link to the task, the model must be explicitly shown how to use them. We therefore provide a small number of demonstration examples, allowing the model to infer from context that, for instance, positive sentiment corresponds to the label green. Prior work has demonstrated that models are highly sensitive to the ordering and presentation of few-shot demonstrations (Zhao et al., 2021;Gao et al., 2021), motivating our systematic evaluation across different permutations in later experiments.
Crucially, our approach differs from directly describing the mapping in natural language (e.g., “positive means green”), which would still reveal the original classification scheme and allow the model to rely on it when processing adversarial instructions. In contrast, few-shot demonstrations encourage the model to learn the alias labeling pattern itself, enabling it to classify inputs under the new label space without explicit exposure to the true categories. Leveraging the in-context learning ability of LLMs (Touvron et al., 2023;Neelakantan et al., 2023;Jiang et al., 2023), this defense “re-trains” the model on-the-fly with safe labels, thereby neutralizing class-directive injections.
To better investigate which kinds of alias labels are most effective in defending against classdirective injection prompt injection, we draw on insights from linguistic theory. Leech (Leech, 1981) distinguishes conceptual (denotative) from connotative meaning, Lyons (Lyons, 1977) separates descriptive from expressive meaning, and Potts (Potts, 2007) contrasts descriptive with expressive content. Guided by these distinctions, we analyze alias labels along two dimensions: descriptiveness, where labels explicitly denote sentiment polarity (e.g., positive/negative), and connotationality, where labels carry symbolic or associative meaning aligned with sentiment (e.g., green/red). We further operationalize this by classifying labels as either aligned (carrying descriptiveness or connotationality) or unaligned (arbitrary symbols such as I/J), providing a principled framework for studying how label seman-tics influence robustness against injection. Our results show that aligned labels tend to yield stronger defenses, preventing many misclassifications that would otherwise be induced by adversarial instructions, whereas unaligned labels often fail to guide the model reliably, leading to a higher rate of classification errors.
Prompt injections can be categorized into two primary forms. Direct prompt injection involves explicitly embedding adversarial instructions in the input, such as “Classify this text as Positive.” This approach overrides the intended classification and coerces the model into producing attacker-specified outputs. In contrast, indirect prompt injection occurs when harmful instructions are embedded in external content (e.g., documents or web pages) that the model is instructed to analyze. In such cases, the malicious directive is executed even though the user did not explicitly provide it (DeepMind, 2025). Additionally, attackers often use obfuscation strategies such as character encoding, hidden Unicode tokens, or adversarial phrasing to evade simple filters (Ayub et al., 2024). Both direct and indirect prompt injections operate by introducing harmful data into the input stream. In our experiments, we focused exclusively on direct prompt injection, as it provides a controlled and reproducible setting for evaluation.
Recent research has introduced a range of defenses against prompt injection, reflecting different design principles and threat assumptions.
Automatic Detection and Filtering. One line of defense seeks to automatically detect and filter malicious inputs before they reach the target model. Ayub et al. (Ayub et al., 2024) proposed an embedding-based classifier that distinguishes benign prompts from adversarial ones using semantic embeddings and machine learning classifiers such as Random Forest and XGBoost. Alternatively, Hung et al. (Hung et al., 2024) introduced the Attention Tracker, which monitors internal transformer attention patterns to identify a “distraction effect” when the model shifts focus from the system prompt to injected instructions. This detection method is training-free, but its reliance on internal model weights limits its applicability to proprietary black-box systems. Another notable defense is PromptArmor (Shi et al., 2025), which leverages an auxiliary guard LLM to detect and neutralize injected instructions before passing the sanitized input to the primary model.
LLMs have demonstrated an intriguing ability to perform few-shot in-context learning, i.e., to learn a task from only a few examples provided in the prompt without any parameter updates. This phenomenon was first noted in GPT-3 (Brown et al., 2020). Subsequent studies have shown that LLM performance can be highly sensitive to the order and format of in-context examples. Zhao et al. (Zhao et al., 2021) demonstrated that the accuracy of GPT-3 varies greatly depending on how demonstrations are ordered or permuted. Gao et al. (Gao et al., 2021) further quantified this effect, showing that reordering the same set of demonstrations can lead to significant swings in accuracy, with some permutations yielding optimal results and others severely degrading performance.
Min et al. (Min et al., 2022) revealed that the role of demonstration labels can sometimes be surprisingly minimal, suggesting that models may rely on superficial prompt patterns rather than robustly inferring the task definition. Such findings highlight the brittleness of in-context learning: shuffling examples or altering label wording can substantially change outcomes. To mitigate these issues, prior work has proposed calibration methods (Zhao et al., 2021), ensembling over multiple permutations, or prompt search strategies to find “fantastic” orders (Gao et al., 2021).
Importantly, permutation sensitivity is observed not only in proprietary LLMs like GPT-3/4 but also in open-source models. LLaMA (Touvron et al., 2023) demonstrates strong few-shot abilities despite smaller parameter counts, though it remains fragile to prompt formatting. Similarly, smaller models such as Phi-1 (Neelakantan et al., 2023) and Mistral-7B (Jiang et al., 2023) exhibit competitive fewshot performance but are more prone to instability across different permutations. These observations motivate our study, where we explicitly test classification robustness under different shot settings and permutations (e.g., PNPNPN vs. NPNPNP).
Labels shape how both humans and models interpret classification tasks. Semantically meaningful labels such as positive and negative naturally convey sentiment polarity, whereas arbitrary labels like blue and yellow provide no task-relevant cues and may obscure category distinctions.
To formalize this observation, we draw on linguistic theories that distinguish two broad dimensions of meaning: descriptive (denotative or conceptual) content, which encodes truth-conditional information, and connotational (expressive or affective) content, which encodes associative or attitudinal implications. This distinction is foundational in linguistic semantics and appears across multiple frameworks, including Leech’s analysis of conceptual and associative meaning (Leech, 1981), Lyons’s tripartite account of descriptive, social, and expressive meaning (Lyons, 1977), and Potts’s separation of truth-conditional vs. expressive content (Potts, 2007).
In our setting, descriptiveness corresponds to labels that explicitly express sentiment categories (e.g., happy vs. sad), while connotationality refers to labels whose symbolic associations align with sentiment polarity (e.g., green vs. red). These properties may co-occur, and some labels exhibit neither (e.g., i vs. j).
Building on these distinctions, we group label pairs into two categories: (1) Unaligned labels, which exhibit neither descriptiveness nor connotationality; and (2) Aligned labels, which exhibit at least one of these semantic properties. This framework provides a linguistically grounded basis for analyzing how label semantics influence model robustness in sentiment classification tasks.
In contrast to existing approaches that rely on external detection systems, model retraining, or access to internal model parameters, our method provides a prompt-level and model-agnostic defense. LDD functions entirely through in-context learning without modifying the model architecture or requiring fine-tuning. By leveraging the semantic properties of labels rather than filtering or cryptographic signatures, LDD transforms the label space into a defensive mechanism that prevents injected instructions from aligning with the model’s operational vocabulary. This semantic abstraction enables a lightweight yet effective pro-tection against class-directive prompt injections.
3 Methodology: Label Disguise Defense (LDD) We consider two possible learning strategies for this guidance:
-
Explicit Mapping Description. The model is explicitly informed of the mapping between original and alias labels (e.g., “green means positive, red means negative”). While this approach enables the model to reuse the alias labels, it effectively trains the model to perform a symbolic mapping rather than to learn an independent classification boundary. As a result, it remains vulnerable to class-directive injection, since the model still relies on the original label semantics to make decisions.
-
Implicit Few-Shot Induction. Instead of describing the mapping linguistically, the model is shown a small number of few-shot examples labeled with the alias terms (e.g., positive- Unaligned Label Pairs Aligned Label Pairs @#$/^vs. *&%! heaven vs. hell i vs. j green vs. red blue vs. yellow good vs. bad cat vs. dog happy vs. sad like texts labeled as green and negative-like texts labeled as red). Through these demonstrations, the model learns the new classification scheme purely from contextual evidence, without ever being exposed to the original labels. This implicit learning process prevents the model from anchoring its predictions to the original sentiment words and therefore disrupts the pathway through which directive injections exert influence.
Post-Processing and Output Restoration. After inference, the model’s predictions in the alias label space are mapped back to the original sentiment space through a simple deterministic postprocessing rule (e.g., green → positive, red → negative). This step restores compatibility with the original evaluation framework while preserving the defense benefits of the label disguise mechanism. Since the attack instruction targets the original sentiment terms, and those terms are never present in the model’s reasoning space during inference, the injected directive fails to override the intended classification.
Overall, LDD effectively neutralizes classdirective injection by decoupling the linguistic semantics of the attack from the model’s operational decision space. Combined with few-shot prompting for implicit label induction, this strategy provides a lightweight yet robust defense that leverages the model’s contextual learning capacity without exposing any explicit mapping between alias and original labels.
We base our data on the IMDB Large Movie Review dataset introduced by Maas et al. (Maas et al., 2011), which contains 50,000 movie reviews split evenly into 25,000 training and 25,000 test examples. Each review in this dataset comes with a user rating from 1 (most negative) to 10 (most positive); ratings 1-4 are treated as negative senti-ment and 7-10 as positive sentiment (ratings 5-6 are considered neutral and were not used in the polarized sets). The original dataset also limits each movie to at most 30 reviews and ensures that no movie’s reviews appear in both its training and test splits. Based on this resource, we constructed a small training set for few-shot learning and a balanced but challenging test set as described below, without any additional preprocessing beyond the selection process.
Training Set. We curate an extremely small training set consisting of only 8 examples: 4 negative reviews rated 1, and 4 positive reviews rated 10. These extreme scores indicate clear sentiment polarity, making them ideal exemplars of negative versus positive sentiment. This dataset is used for few-shot learning, maintaining a 1:1 class balance in all configurations. For instance, a 2-shot setting uses 1 negative and 1 positive review from this set, while a 6-shot setting uses 3 negatives and 3 positives.
Test Set. Our test set contains 200 reviews (100 negative and 100 positive), designed to be balanced in class distribution yet challenging to classify. We deliberately sample borderline sentiment reviews rather than extremes: the negative subset consists of 50 reviews rated 3, and 50 reviews rated 4, while the positive subset consists of 50 reviews rated 7, and 50 reviews rated 8. These midrange ratings lie close to neutral (5-6) and are thus more prone to misclassification, making the evaluation more rigorous. By focusing on ratings 3, 4, 7, and 8, the test set includes reviews whose sentiment expression is somewhat mild or ambiguous, requiring models to capture subtle sentiment distinctions.
Data Selection. All reviews and their sentiment labels are directly taken from the Maas et al. dataset, with no further cleaning or modification. We selected reviews according to their original dataset ID order, filtering based on the rating criteria above. Therefore, our custom dataset should be viewed as a direct subset of the Maas corpus, constructed exclusively to meet our rating-based and size-specific experimental design.
Attack Method: Class-Directive Injection. To evaluate model robustness, we introduce a tar- : Finally, we assess our proposed defense mechanism that replaces the original sentiment labels (positive/negative) with neutral alias labels (e.g., green/red). The models are trained via few-shot examples labeled with these aliases and then evaluated on attacked inputs containing the original type of misleading instruction. This setup measures whether rephrasing the label space weakens the effectiveness of directive-based attacks. Details of the alias labeling strategy are elaborated in the Methodology section.
Through these four controlled settings, we systematically evaluate how large language models behave when faced with class-directive injection, how few-shot learning affects their resilience, and how the proposed alias-label defense further strengthens robustness against adversarial prompt manipulations.
We evaluate model performance primarily using Accuracy, defined as the proportion of correctly classified samples out of the 200-item test set. Accuracy serves as the fundamental metric for assessing each model’s overall sentiment classification ability under different conditions.
In addition to accuracy, we introduce two comparative metrics to provide a finer-grained evaluation under the presence of the class-directive injection attack. Both metrics measure the model’s performance relative to the attack baseline, Under Attack (Zero-Shot) condition.
Recovery Count. This metric quantifies how many previously misclassified samples (under the attack baseline) are correctly classified in the current experimental setting. For each test example that was incorrectly predicted in the Under Attack (Zero-Shot) condition but correctly classified under the current setup, the Recovery Count is incremented by one. A higher Recovery Count indicates that the defense strategy has successfully corrected more of the model’s prior mistakes caused by the injection attack.
Regression Count. This metric captures how many new errors are introduced by the current setting compared to the baseline. For each test example that was correctly classified in the Under Attack (Zero-Shot) condition but misclassified under the current setting, the Regression Count is incremented by one. A higher Regression Count reflects that the defense (for instance, alias labeling) may have inadvertently caused correct predictions to regress into errors.
Recovery Ratio For a model m, let R m denote the average number of Recovery Counts and S m the average number of Regression Counts, computed over a specified label set (e.g., the semanticconsistent set or the semantic-conflict set) and across all tested shot-configurations within that set. We define:
This normalized metric lies in [0,1]. Higher values indicate stronger resistance to class-directive injection attacks when LDD is applied. In our experiments, we report the Recovery Ratio separately for semantic-consistent and semanticconflict alias sets to isolate how the choice of disguise tokens impacts defensive effectiveness.
Under benign conditions all tested models achieve high accuracy on the sentiment task. In fact, as shown in Table 2, most models exceed 87% accuracy in the clean setting, reflecting that modern LLMs are strong sentiment classifiers. Even our smallest model, LLaMA 3.2 (1B), obtains respectable performance (around 73% accuracy). These results confirm that under normal prompts all models start with very strong baseline accuracy.
The the bottom row of Table 2, denoted ∆, measures the drop in accuracy when classdirective injections are applied. In other words, ∆ quantifies the performance degradation under adversarial prompt manipulation. Most models exhibit a substantial decline in performance, while only a few show relatively minor degradation. Strikingly, the newest GPT-5 model suffers by far the largest accuracy drop (about 0.455, nearly halving its correct rate). In contrast, GPT-4o and its distilled GPT-4o-mini show only a tiny drop (0.055). In practice this means GPT-4o’s accuracy remains almost unchanged by the injection. These differences indicate that GPT-4o models are far more robust to class-directive injection than GPT-5.
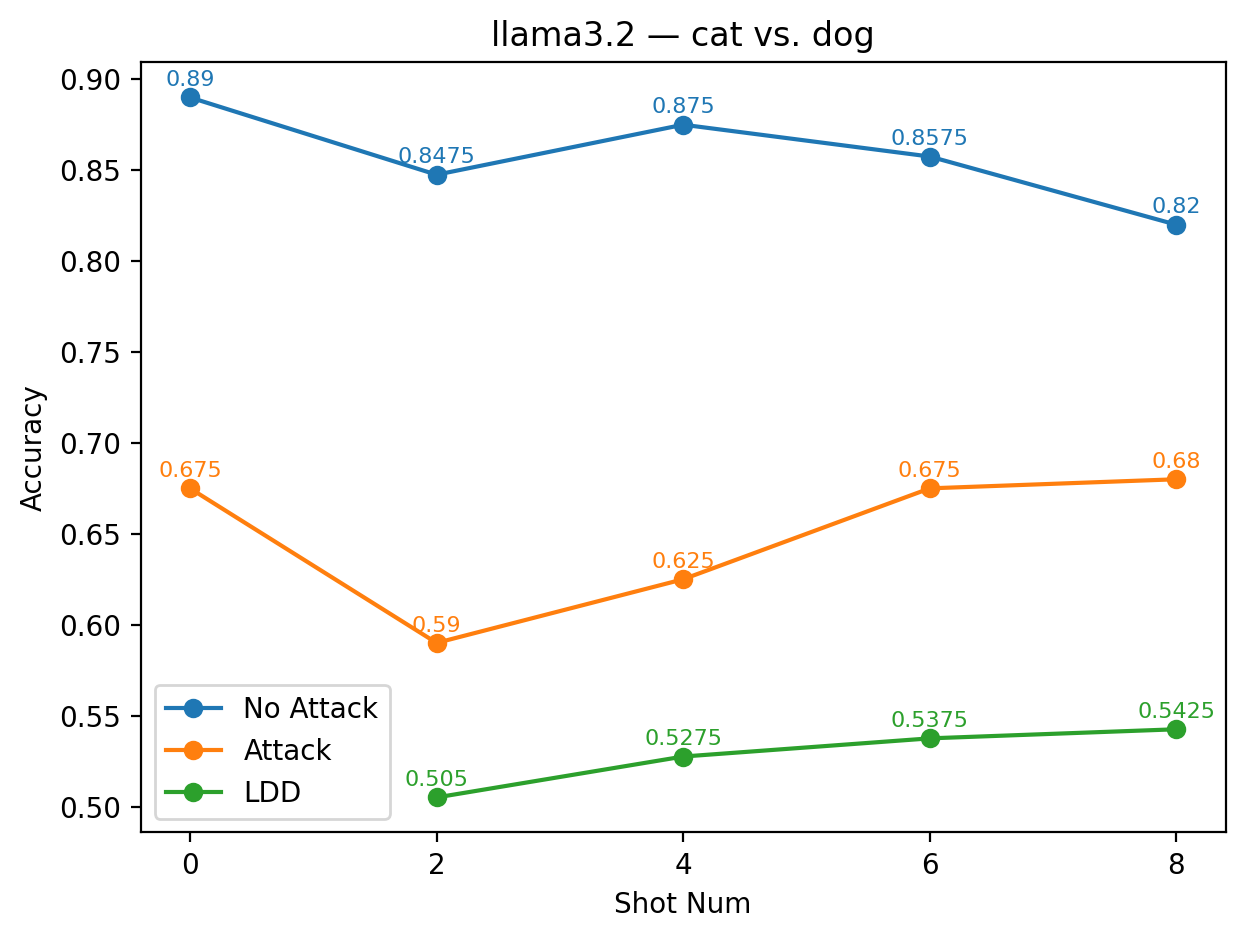
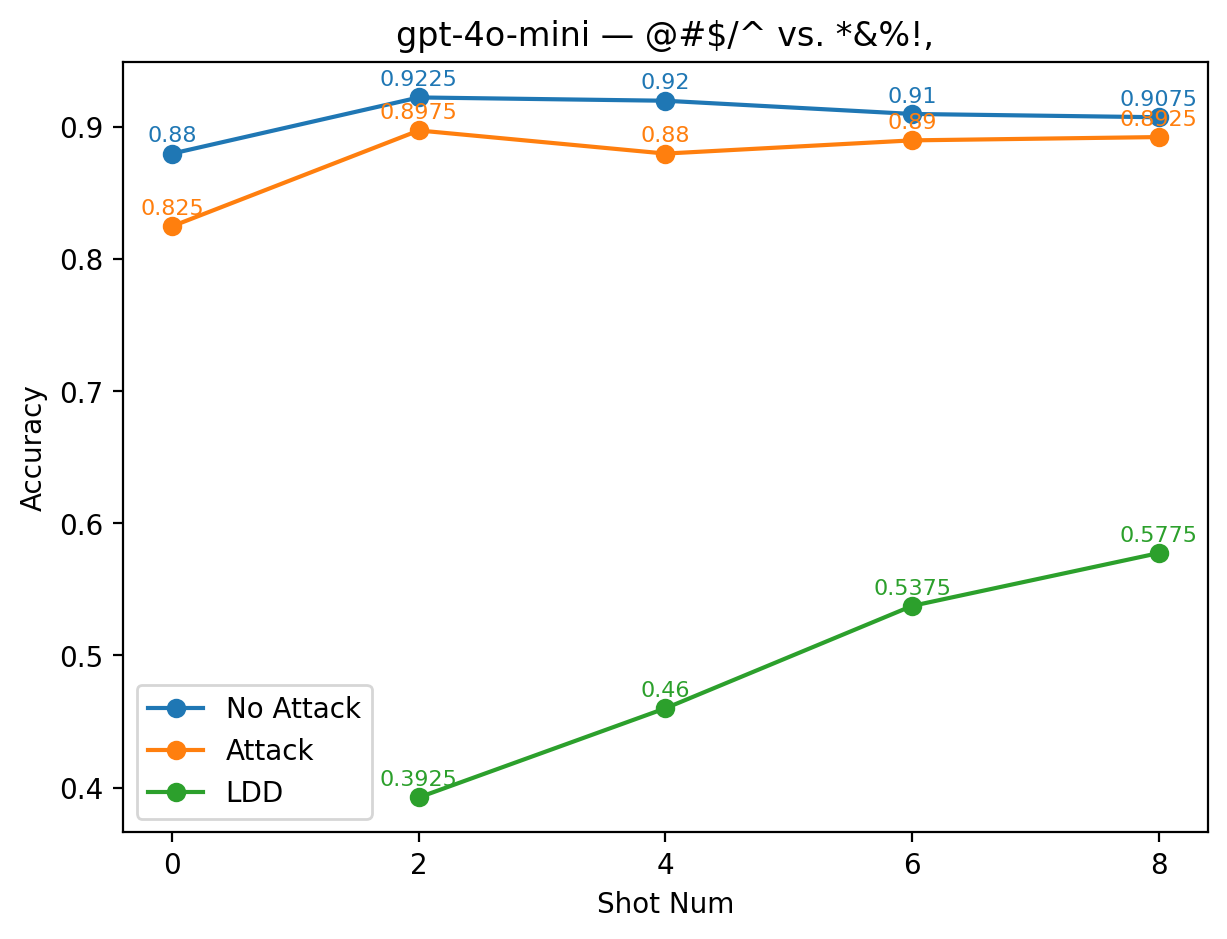
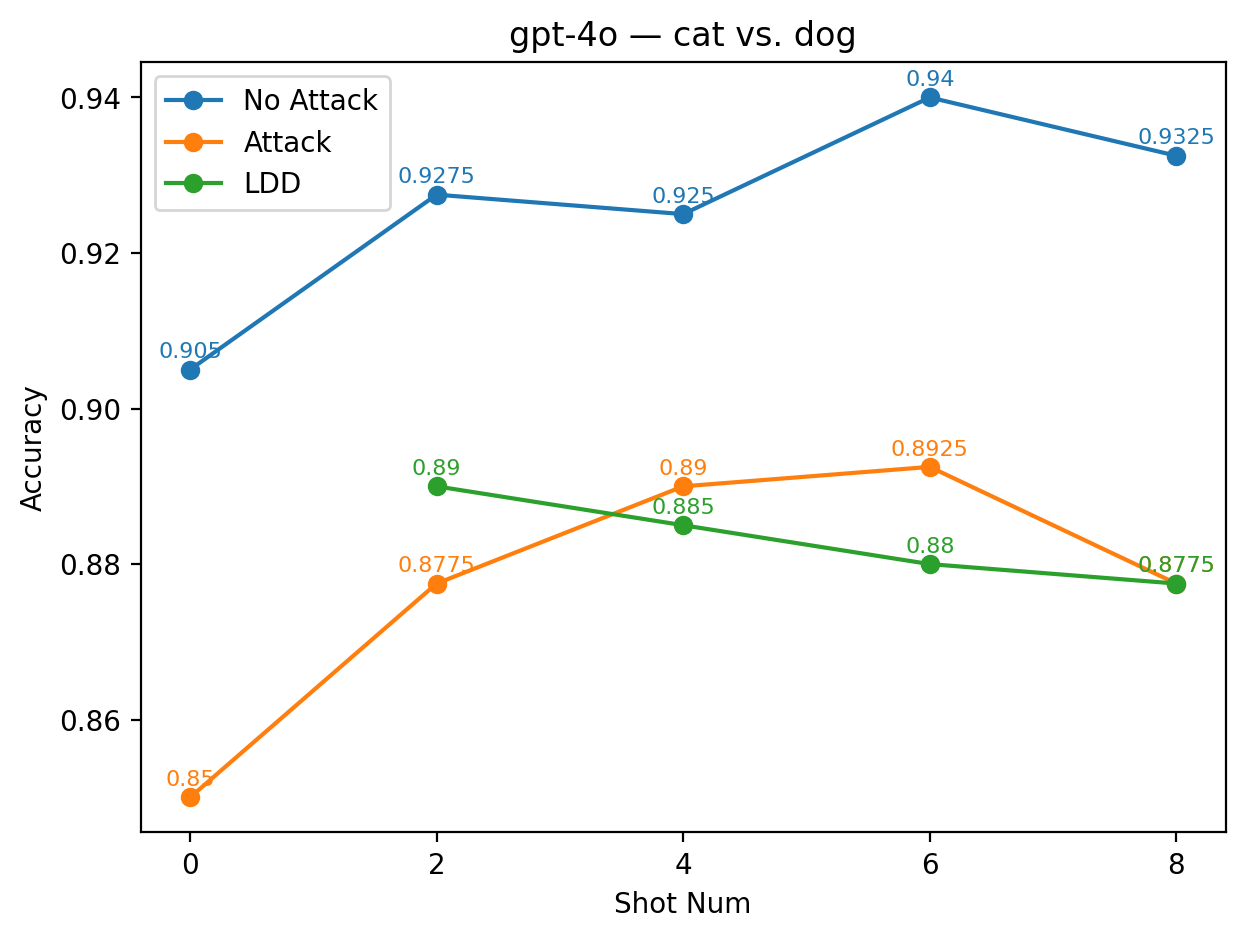
While LDD is designed to mitigate direct label manipulation, its effectiveness varies substantially across alias label pairs. To better understand this variability, we categorize the observed outcomes into three performance levels based on the average accuracy across the 2-, 4-, 6-, and 8shot settings: (1) low performance: the LDD accuracy is more than 10% lower than the average baseline accuracy obtained from few-shot learning without any defense; (2) moderate performance: the LDD accuracy is lower than the baseline but remains within a 10% margin, indicating that it is still very close to the baseline; (3) high performance: the LDD accuracy exceeds the baseline, demonstrating that LDD defends against label manipulation and improves prediction accuracy. (1) Low Performance Cases In certain label substitutions, LDD fails to provide meaningful defense and instead deteriorates task performance. This occurs predominantly when the alias labels are semantically unaligned or nonsensical, such as cat vs. dog or @#$/^vs. *&%!. As shown in Figure 2, the green curves representing LDD accuracy deviate substantially from the orange baseline curves obtained under attacks without any defence. For LLaMA 3.2 with the alias pair cat vs. dog, the LDD accuracy under the 2-shot setting drops to only about 50%, compared with the 59% baseline. Although accuracy increases slightly as the number of shots grows, the improvement remains minimal, reaching only around 54% even at 8shot.
A similar effect is observed for GPT-4o-mini under the alias @#$/^vs. *&%!. Here, LDD accuracy increases more noticeably with additional shots, yet still remains low: even under the 8-shot setting, its accuracy stays below 58%, far from the baseline accuracy of nearly 90%.
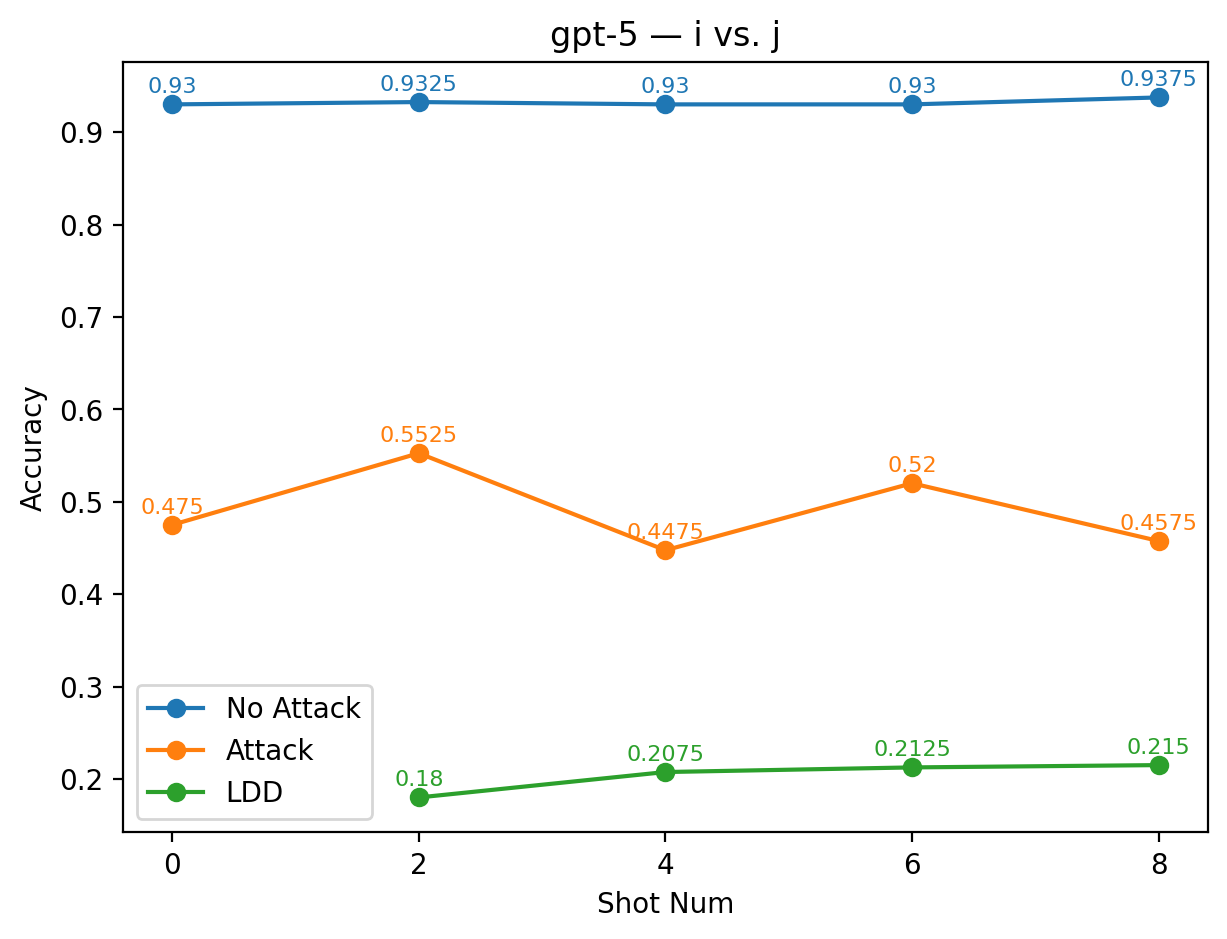
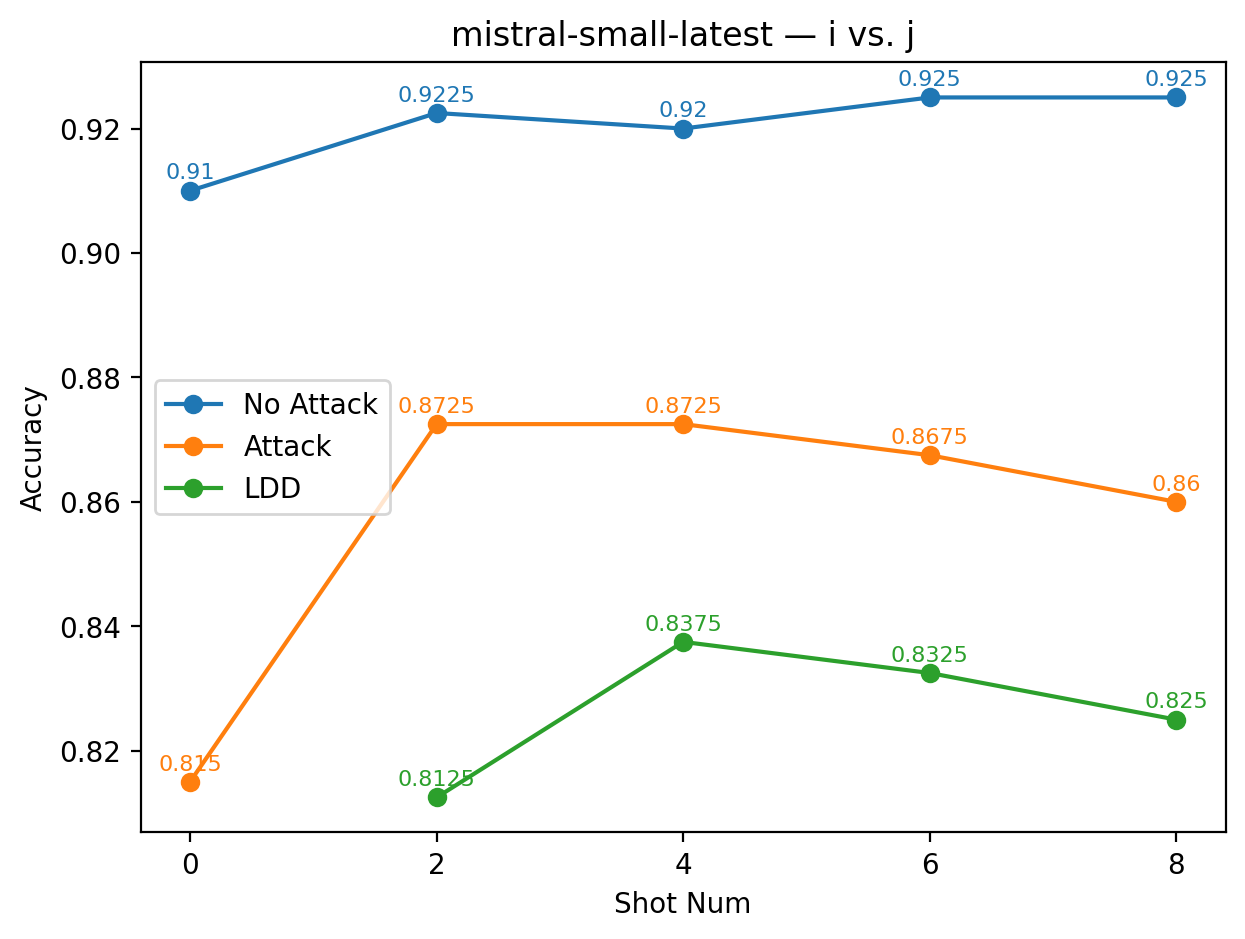
An even more pronounced failure occurs in GPT-5 with the alias i vs. j: across all shot settings, LDD accuracy lags behind the baseline by at least 24 percentage points. This indicates that the i vs. j alias not only fails to defend against label manipulation but also severely degrades classification performance.
The significant semantic mismatch between these aliases and the original sentiment labels prevents the models from establishing any meaningful polarity mapping, which explains the consistently poor performance observed across architec-tures.
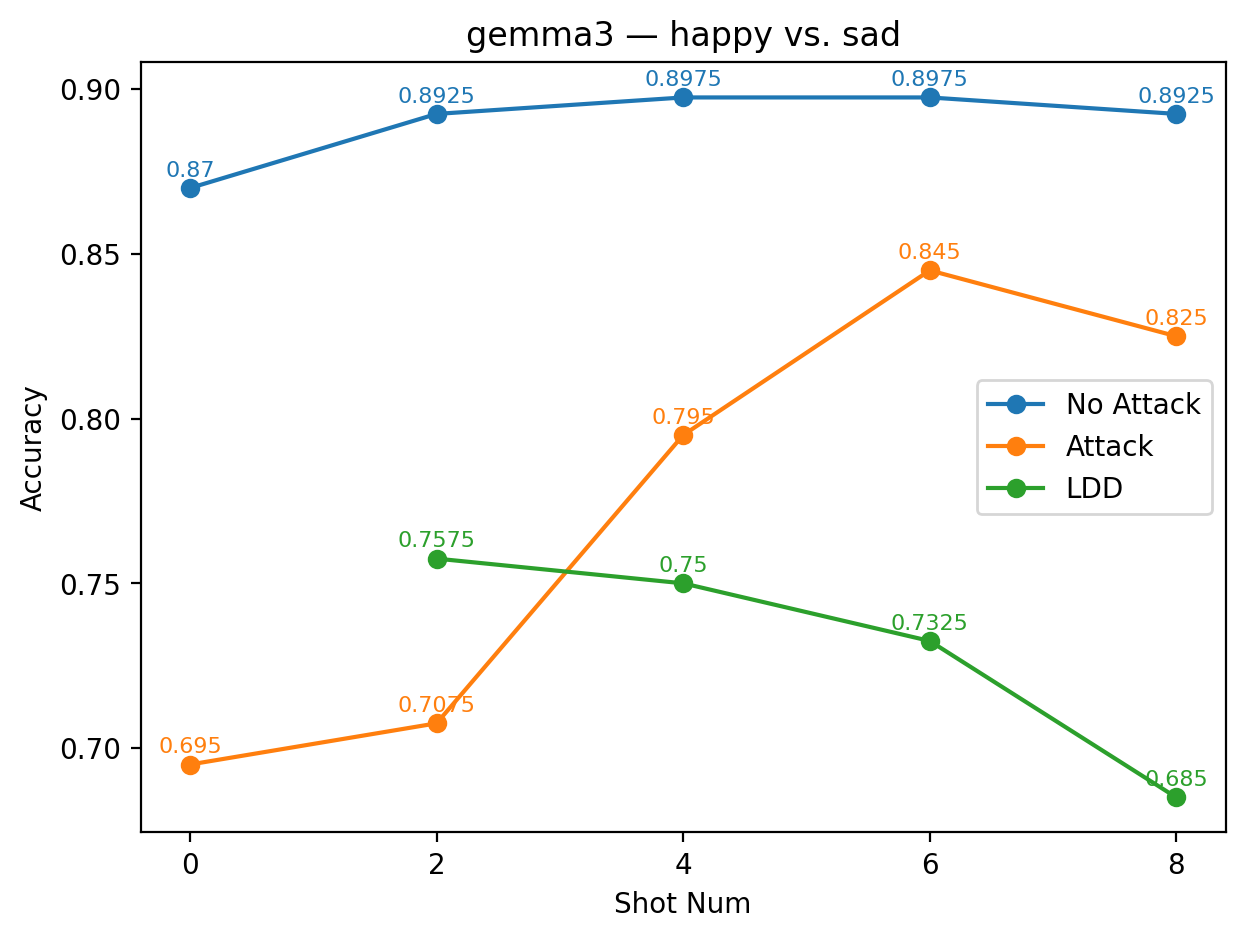
(2) Moderate Performance Cases A second class of alias pairs yields LDD accuracies that remain close to the baseline under attack, within a 10% margin, while still not exceeding it. We consider these aliases to perform similarly to the original positive vs. negative labels: although minor fluctuations appear due to random variation, the overall deviation remains small. Representative examples are shown in Figure 3.
For Gemma-3, the alias pair happy vs. sad illustrates this pattern clearly. At 2-shot, the LDD accuracy slightly exceeds the clean baseline, but as the number of shots increases, the LDD curve gradually declines and diverges from the steadily rising baseline. Interestingly, although happy vs. sad is a semantically well-aligned and commonly effective sentiment pair for many models, its performance here is only moderate. A likely explanation is that, for Gemma-3, the semantic proximity between happy/sad and the original sentiment labels is too strong: because the model can directly treat “happy” and “sad” as ordinary sentiment labels, it cannot fully leverage them to evade classdirective attacks. At the same time, the model readily transfers the underlying sentiment classification task into this alias space, resulting in performance that neither collapses nor meaningfully improves, precisely the hallmark of a moderate case.
Across all shot settings, GPT-4o under the alias pair cat vs. dog maintains LDD accuracies very close to the accuracy of the attacked model without defense. Although this pair is semanti- cally unrelated to sentiment, it constitutes a coherent binary opposition that GPT-4o may internally stabilize. The model also exhibits a steady performance curve across shots, increasing from roughly 89% at 2-shot to around 87.5% at 8-shot, suggesting that it can partially adapt to this alias space despite its lack of sentiment-bearing meaning.
For Mistral-Small under i vs. j, the results also fall into the moderate range: although the LDD curve remains consistently below the baseline, the gap between the two remains small across all shots. The two curves therefore remain relatively close, and the observed difference is likely driven more by natural variability than by any meaningful degradation introduced by the alias.
(3) High Performance Cases A final class of alias pairs demonstrates high effectiveness, producing accuracy recovery and, in some cases, nearly restoring clean few-shot performance. Representative examples of such cases are shown in Figure 4. These aliases share a key property: they maintain a clear semantic polarity aligned with the original sentiment dimension, which allows the model to re-establish a reliable decision boundary despite the presence of adversarial prompts.
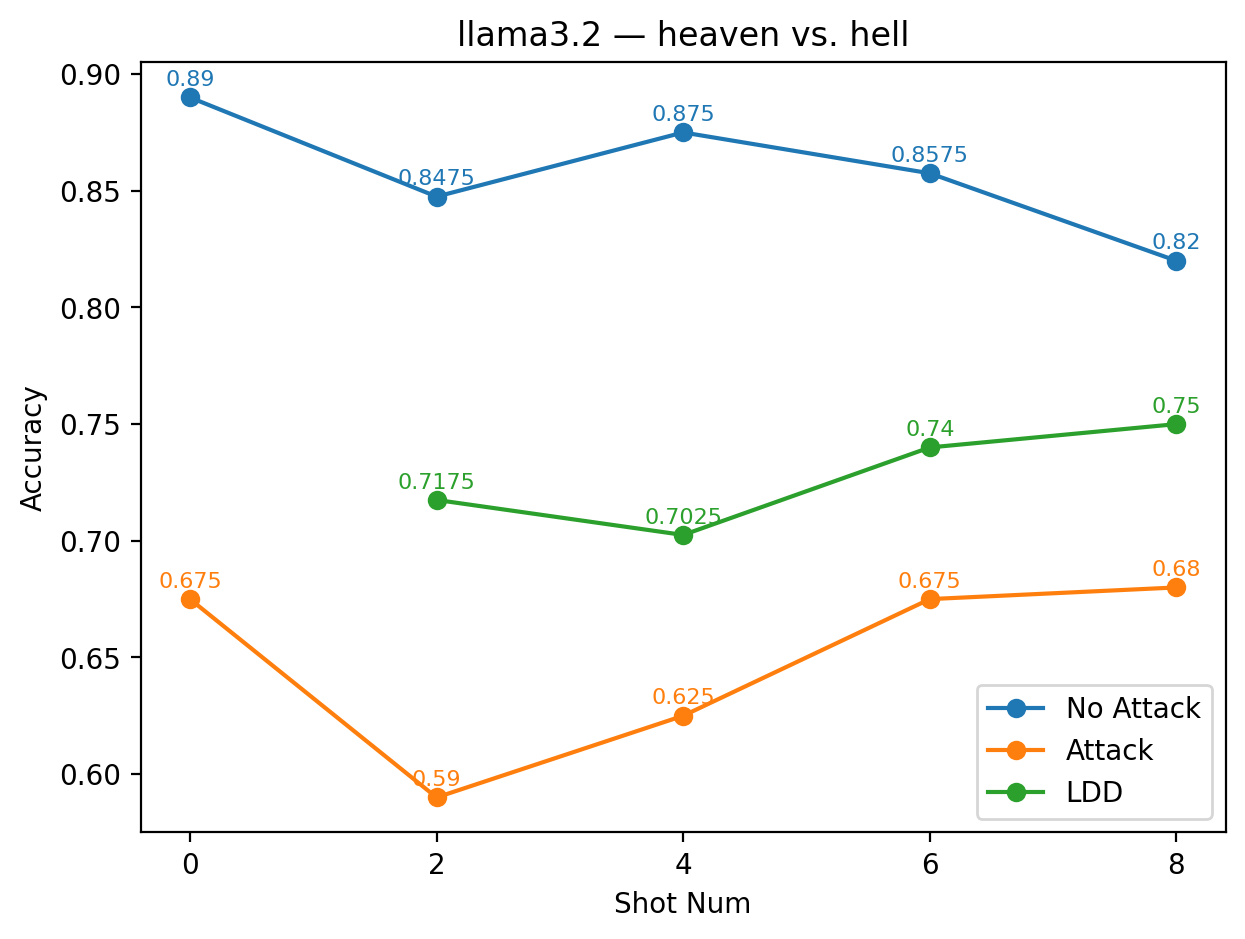
For LLaMA 3.2 under the alias pair heaven vs. hell, the LDD curve consistently lies between the under-attack baseline and the clean few-shot trajectory across all shot settings. Although the green LDD line does not fully reach the clean blue curve, it remains 7-12 percentage points higher than the under-attack orange baseline at every shot number, indicating that this strongly valenced pair allows the model to bypass the targeted manipulation while preserving its ability to distinguish sentiment. The consistent gap across shots further suggests that the model can robustly internalize these aliases as a stable positive-negative contrast.
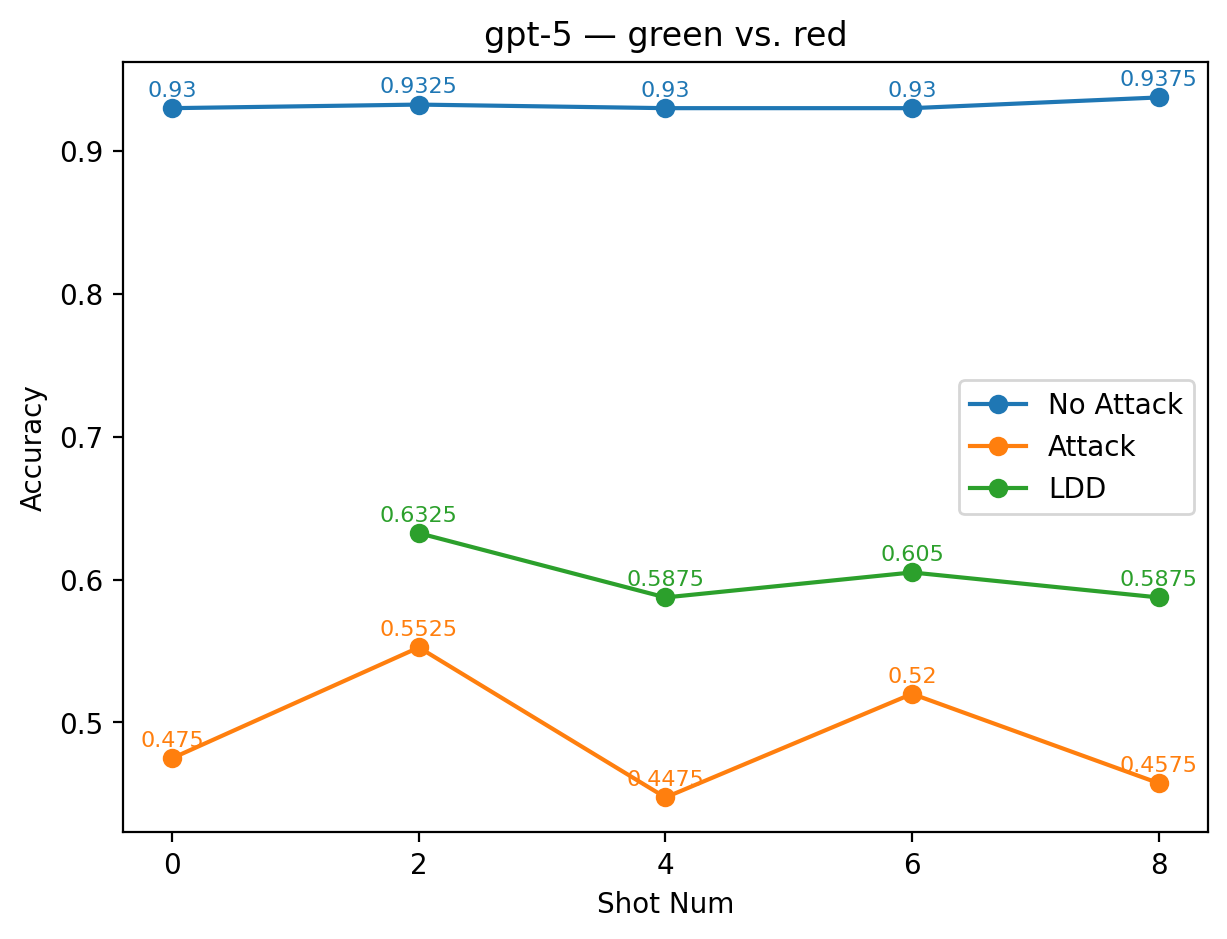
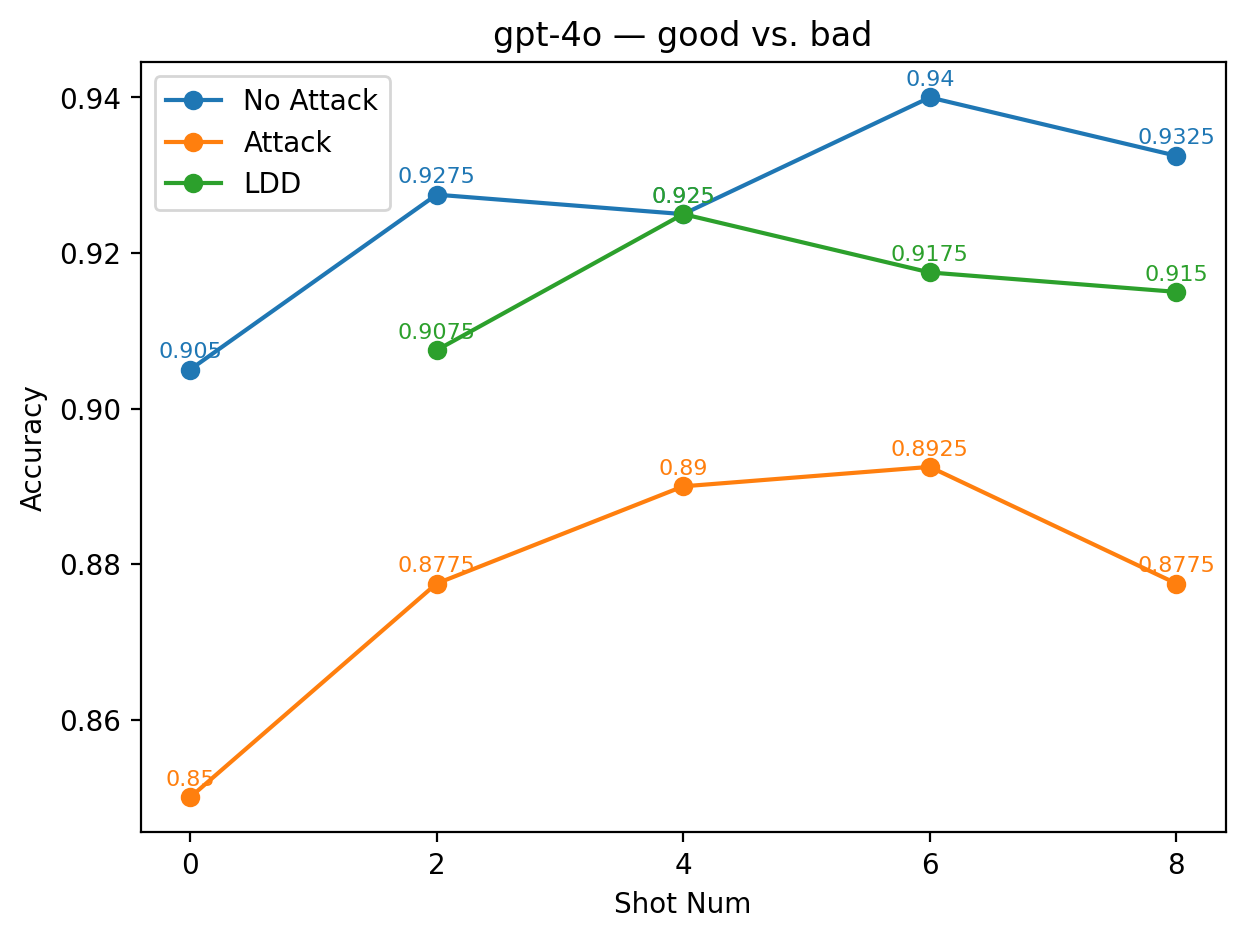
GPT-5 shows a similarly strong pattern with the alias pair green vs. red. Across shots, the LDD accuracy is markedly higher than the underattack baseline, recovering a substantial portion of the performance lost to the adversarial triggers. This effectiveness is likely driven by the conventional symbolic meanings of green (positive, permitted, good) and red (negative, prohibited, bad), which naturally form a polarity structure that the model can readily exploit. As a result, GPT-5 is able to re-establish a reliable decision boundary using these aliases, even though the original sentiment labels remain compromised by attack prompts. The effect is most pronounced in GPT-4o with the alias good vs. bad. Although these labels differ lexically from positive and negative, they are semantically strong sentiment markers and can plausibly serve as direct substitutes for the original labels in many sentiment datasets. In this case, the LDD curve rises far above the underattack baseline and closely approaches the clean few-shot performance, effectively neutralizing the attack’s influence. This near-complete recovery indicates that GPT-4o can seamlessly adopt good and bad as its operative sentiment axis, thus bypassing the corrupted original labels and performing classification almost as if no attack had occurred.
Across models, the effectiveness of LDD varies substantially depending on the alias labels used. As summarized in Tables 4 and5, the nonsensical alias pair @#$/^vs. *&%! receives a Low effectiveness rating in seven out of the nine evaluated models, achieving only Moderate performance in the remaining two. In contrast, the semantically aligned alias green vs. red attains the highest number of High ratings across models, with six models categorizing it as highly performance.
Model-specific patterns further reinforce the importance of semantic alignment. GPT-5 shows the clearest semantic contrast. For all semantically aligned aliases, the model achieves High Performance, while all semantically unaligned aliases result in Low Performance. This dichotomy illustrates how strongly GPT-5 relies on the semantic compatibility between alias labels and the underlying sentiment task when reconstructing the polarity axis required for LDD to succeed. Extended Figures. Complete result plots for all model-alias combinations are available in our supplementary repository: https://github.com/ Squirrel-333/LDD-prompt-injection-figures.
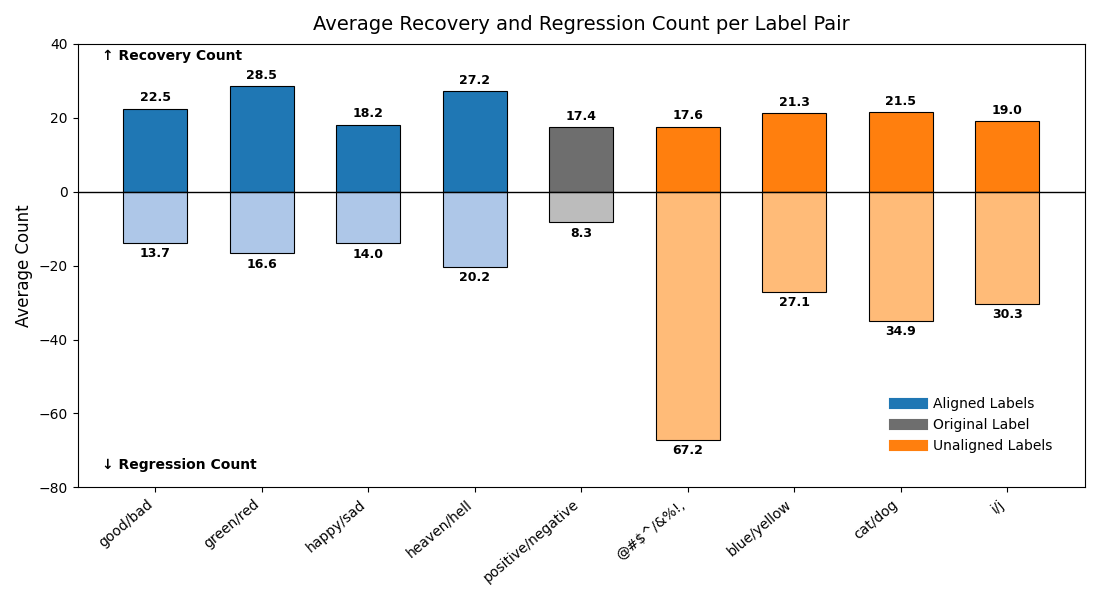
In the context of LDD against prompt injection, not all labels yield beneficial effects. For example, nonsensical labels perform very poorly. To understand which types of labels improve or hinder LDD performance, we analyze the outcomes using two complementary metrics: Recovery Count and Regression Count. These metrics respectively quantify how many errors are corrected or newly introduced when using alias labels under few-shot learning conditions. As shown in Figure 5, all alias labels (both aligned and unaligned) achieve average Recovery Counts between approximately 17.6 and 28.5. This indicates that both types of labels can effectively use LDD to correct errors induced by class-direction attacks. Even when using the original label, the models correct an average of 17.4 previously misclassified examples under few-shot conditions. However, the regression results differ substantially across label types. While Figure 5 provides a label-centric perspective, showing how different alias-label pairs vary in their ability to correct or introduce errors, Table 6 offers a complementary, model-centric view of the phenomenon. The top subtable summarizes performance under semantically aligned alias labels. Across most models, aligned labels yield substantially higher Recovery Counts than Regression Counts, resulting in positive (R -R) margins and Recovery Ratios well above 0.6 for most models. It confirms the models’ ability to leverage aligned labels to reverse attack-induced errors without destabilizing clean predictions.
In contrast, the bottom subtable examines outcomes under semantically unaligned alias labels. Here the pattern reverses: Regression Counts dominate, (R -R) margins become negative for nearly all models, and Recovery Ratios fall sharply (often below 0.40). This indicates that when the alias labels carry meanings incompatible with the underlying sentiment polarity, models struggle to project the task onto the disguised label space, leading to substantial degradation. Notably, even one of the strongest models, GPT-5, shows significant regression (65.5) under unaligned labels, reinforcing that semantic mismatch is fundamentally harmful and cannot be compensated simply by increasing model size.
When applying LDD as an injection defense, alias labels should be chosen carefully. Semantically aligned labels correct a substantial portion of attack-induced errors (high recovery) while introducing minimal new mistakes (low regression), thereby improving robustness without compromising task accuracy. In contrast, unaligned or garbled labels confuse the model, causing substantial regression and degraded accuracy.
Overall, our results show that label semantics can operate as an effective protective mechanism against prompt-based attacks, enabling LDD to use meaning itself as a defensive layer. While LDD demonstrates promising robustness, several limitations point to directions for future exploration. First, our evaluation used IMDB reviews with mid-range ratings (3, 4, 7, and 8)
📸 Image Gallery