This study introduces PEFT-DML, a parameter-efficient deep metric learning framework for robust multi-modal 3D object detection in autonomous driving. Unlike conventional models that assume fixed sensor availability, PEFT-DML maps diverse modalities (LiDAR, radar, camera, IMU, GNSS) into a shared latent space, enabling reliable detection even under sensor dropout or unseen modality-class combinations. By integrating Low-Rank Adaptation (LoRA) and adapter layers, PEFT-DML achieves significant training efficiency while enhancing robustness to fast motion, weather variability, and domain shifts. Experiments on benchmarks nuScenes demonstrate superior accuracy.
Reliable detection of moving 3D objects is fundamental for autonomous driving but remains challenged by fast motion, environmental variability, and sensor limitations. To overcome these issues, we propose PEFT-DML, which unifies LiDAR, radar, camera, IMU, and GNSS into a shared latent space. Using LoRA and adapters, PEFT-DML achieves robust, modality-agnostic detection with reduced training cost.
The proposed PEFT-DML framework surpasses recent studies in multi-modal 3D object detection and cooperative perception. Unlike 3ML-DML framework (Dullerud et al. 2022), which requires fixed modality availability, PEFT-DML generalizes across unseen modality-class combinations through a unified latent space, enabling zero-shot cross-modal detection. In addition, CRKD (Zhao, Song, and Skinner 2024) focuses on distillation between camera and radar but it is fragile when one sensor fails. PEFT-DML instead supports any subset of sensors which ensures robustness under partial sensor dropout.
RoboFusion (Song et al. 2024) leverages computationally heavy Visual Foundation Models which limits efficiency. In contrast, PEFT-DML achieves comparable robustness via lightweight LoRA-based fine-tuning. The authors in (Chae, Kim, and Yoon 2024) introduce weather-aware gating but still requires both modalities at inference whereas PEFT-DML performs robust detection even when one or more modalities are missing.
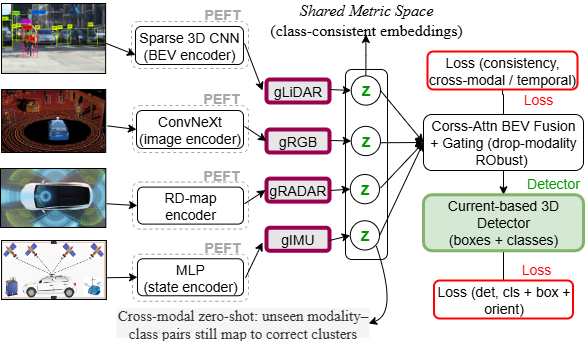
We propose PEFT-DML, a framework for robust 3D object detection in autonomous driving (Figure 1). The model unifies heterogeneous modalities where backbone encoders remain frozen to preserve pretrained features, while lightweight LoRA and adapter layers enable efficient finetuning. Each modality is mapped by a projection head into a normalized d-dimensional embedding, where intra-class features cluster closely and inter-class features remain distinct. Cross-attention and gating modules fuse embeddings, ensuring flexibility under sensor dropout. A detection head then predicts 3D bounding boxes and class labels.
Training is guided by a joint multi-objective loss L = λ det L det +λ met L metric +λ cons L consistency where Detection Loss is L det = L cls +L reg = FocalCE(y, ŷ)+IoU(b, b)+∥o-ô∥ 1 . This combines focal classification loss, IoU-based bounding box regression, and orientation regression.
Metric Alignment Loss, is L metric = max 0, d(z i , z j )d(z i , z k ) + α . A triplet loss encourages embeddings z i and z j from the same class to be closer than z i and z k from different classes.
In addition, Consistency Loss is L consistency = ∥z tz t+1 ∥ 2 2 which enforces temporal stability across adjacent frames and consistency across modalities. Together, these objectives enable cross-modal zero-shot generalization by mapping them into the shared latent space
Experiments on nuScenes dataset demonstrate that PEFT-DML achieves superior accuracy, robustness, and parameter efficiency compared to state-of-the-art baselines.
Figure 2: PEFT-DML consistently achieves the highest AP3D scores across all weather conditions, demonstrating superior robustness compared to RoboFusion and 3D-LRF. Furthermore, PEFT-DML in Figure 3 achieves higher accuracy than full fine-tuning while requiring far fewer trainable parameters, demonstrating superior parameter efficiency. Table 1 compares PEFT-DML with six recent methods across the nuScenes benchmark using detection and error metrics. The results demonstrate that PEFT-DML consistently outperforms all baselines. It achieves the highest mAP (62.2) and NDS (71.7), reflecting superior detection accuracy and overall performance. In terms of localization and geometry, PEFT-DML attains the lowest mATE (0.316) and mASE (0.206), indicating more precise and stable bounding boxes. It also outperforms others in orientation and velocity estimation, with the lowest mAOE (0.346), mAVE (0.339), and mAAE (0.993). Full FT PEFT-DML (r={4, 8, 16})
Figure 3: PEFT-DML achieves nearly the same or slightly higher accuracy than Full Fine-Tuning (Full-FT) while updating less than 10% of the parameters.
In conclusion, the proposed PEFT-DML framework delivers a modality-agnostic 3D object detection for autonomous driving. By unifying heterogeneous sensors in a shared latent space and employing parameter-efficient fine-tuning, it outperforms other models.
This content is AI-processed based on open access ArXiv data.